SUPPORT VECTOR MACHINE UNTUK IMAGE RETRIEVAL
Muhammad Athoillah1, M. Isa Irawan2 dan Elly Matul Imah31Jurusan Matematika, FMIPA, Institut Teknologi Sepuluh Nopember, Jl. Arief Rahman Hakim, Surabaya, 60111,
2Jurusan Matematika, FMIPA, Institut Teknologi Sepuluh Nopember, Jl. Arief Rahman Hakim, Surabaya, 60111,
3Jurusan Matematika, FMIPA, Universitas Negeri Surabaya, Jl. Ketintang, Surabaya, 60231,
Abstrak. Gerbang Tol Otomatis (GTO) mulai diberlakukan di beberapa pintu masuk jalan tol di
Indonesia, dengan sistem seperti ini tentunya diperlukan sebuah alat yang dapat memilah atau membedakan jenis kendaraan apa yang ada didepan gerbang karena tidak semua jenis kendaraan boleh masuk jalan tol, permasalahan membedakan objek tersebut pada dasarnya adalah masalah klasifikasi. Salah satu algoritma yang baik dalam memecahkan masalah pengklasifikasian adalah Support Vector Machine (SVM), Penelitian yang diusulkan dalam paper ini adalah untuk membangun sebuah metode klasifikasi dengan algoritma SVM yang di ujicobakan dalam image retrieval. Dari hasil yang diperoleh, menunjukkan bahwa metode yang diajukan memiliki rata-rata akurasi sebesar 82,22%, presisi 82,82% dan recall 82,22% untuk dataset citra sebanyak 1000 dengan 2 kategori kelas citra dengan objek roda dua dan roda empat, hasil penelitian juga menunjukkan bahwa rata-rata waktu komputasi selama proses training 19,50 detik sedangkan proses testing rata-rata membutuhkan waktu 9,47 detik.
Kata kunci:Pengenalan Objek, Klasifikasi, Support Vector Machine, Image Retrieval
Pendahuluan
Klasifikasi merupakan salah satu metode yang sangat fundamental dalam memecahkan berbagai permasalahan khususnya yang berhubungan dengan big data. Klasifikasi sendiri dapat diartikan sebagai metode untuk menyusun data secara sistematis menurut aturan-aturan yang telah ditetapkan sebelumnya. Sampai saat ini metode klasifikasi telah terbukti banyak membantu pekerjaan manusia khususnya dengan algoritma Support Vector Machine (SVM), misalnya untuk klasifikasi audio [1], dokumen [2], biologi medis [3], lampu lalu lintas [4], dll.
Banyaknya penggunaan SVM untuk memecahkan persoalan klasifikasi oleh para peneliti dikarenakan kemampuan SVM itu sendiri yang dapat mengklasifikasikan objek dengan baik [1][2][3][4]. Hal ini dikarenakan pada SVM, untuk memisahkan kelas, algoritma ini akan berusaha menemukan hyperplane yang terbaik pada input space, hyperplane pemisah terbaik antara kedua kelas dapat ditemukan dengan mengukur margin hyperplane tsb. dan mencari titik maksimalnya. Penjelasan lebih lanjut akan di sajikan pada bab berikutnya.
Baru-baru ini penggunaan Gerbang Tol Otomatis (GTO) mulai diberlakukan di beberapa pintu masuk jalan tol di Indonesia, dan kedepan rencananya semua gerbang tol yang ada akan diberlakukan secara otomatis. Dengan Gebang Tol Otomatis ini pengguna jalan tidak lagi harus membayar uang tol pada petugas, namun cukup dengan menggesekkan kartu yang biasa disebut dengan E-tol maka akan secara otomatis pintu masuk akan terbuka. Dengan sistem pembayaran seperti ini tentunya diperlukan sebuah alat yang dapat memilah atau membedakan jenis
kendaraan apa yang ada didepan gerbang, hal ini berkaitan dengan ketentuan dari jalan tol itu sendiri, dimana hanya jenis kendaraan beroda empat atau lebih yang boleh melewati jalan tol.
Didasari oleh permasalahan tersebut, penelitian ini bertujuan untuk membangun sebuah metode klasifikasi dengan algoritma Support Vector Machine (SVM) untuk dapat membedakan atau mengklasifikasikan citra dengan objek alat transportasi beroda dua dengan alat transportasi beroda empat atau lebih, yang selanjutnya akan diujicobakan pada aplikasi image retrieval.
image retrieval sendiri merupakan teknik yang digunakan untuk mencari citra-citra yang
memiliki kemiripan karakter dari citra acuan (input). Dalam hal ini, image retrieval dapat diimplementasikan dengan membandingkan fitur-fitur hasil dari ekstraksi citra atau dengan cara yang lain.
Pemilihan Image retrieval sebagai objek dari ujicoba dalam penelitian ini, dikarenakan objek penelitian ini memang menarik dan banyak diminati oleh para peneliti, bahkan Datta dkk [5] mencatat bahwa pertumbuhan publikasi penelitian tentang image retrieval pada ACM, IEEE dan Springer mengalami kenaikan yang sangat signifikan dari tahun ke tahun.
Dasar Teori
2.1 Support Vector Machine (SVM)
Support Vector Machine merupakan algoritma yang baik dalam menyelesaikan masalah
klasifikasi [1][2][3][4][6], sehingga sampai saat ini pun algoritma ini masih banyak digunakan oleh peneliti-peneliti untuk menyelesaikan masalah penelitiannya khususnya dalam hal klasifikasi, misalnya yang dilakukan Shuiping dkk [1] yang menggunakan SVM untuk mengklasifikasikan audio, atau oleh Wang dkk [2] yang digunakan untuk mengklasifikasin dokumen serta, xian dkk [7] yang mencoba untuk memodifikasi SVM dalam masalah
multi-tasking.
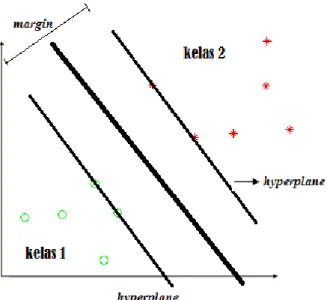
Pada SVM, untuk memisahkan kelas algoritma ini akan berusaha menemukan hyperplane yang terbaik pada input space, Hyperplane pemisah terbaik antara kedua kelas dapat ditemukan dengan mengukur margin hyperplane tsb. dan mencari titik maksimalnya. Margin adalah jarak antara hyperplane tersebut dengan pattern terdekat dari masing-masing class. Pattern yang paling dekat ini disebut sebagai support vector. Berikut adalah ilustrasi dari pemisahan kelas pada SVM.
Misalkan terdapat {𝑥1, … , 𝑥𝑛} adalah data set dan 𝑦𝑖 ∈ {+1, −1} adalah label kelas dari data 𝑥𝑖 maka kelas dari data pengujian 𝑥 dapat ditentukan berdasarkan nilai dari fungsi keputusan:
𝑓(𝑥𝑑) = ∑ 𝛼𝑖𝑦𝑖𝑥𝑖𝑥𝑑 + 𝑏, (1)
𝑛𝑠
𝑖=1
𝑥𝑖 adalah support vector, ns = jumlah support vector dan 𝑥𝑑 adalah data yang akan diklasifikasikan.
Pada kenyataannya tidak semua data dapat dipisahkan secara linier, untuk mengatasi permasalahan tersebut SVM dapat dimodifikasi dengan menambahkan fungsi kernel didalamnya. ide dasar dari metode kernel ini adalah dengan memetakan data 𝑥 ke ruang vektor yang berdimensi lebih tinggi dengan fungsi Φ(𝑥) sehingga pada ruang vektor yang baru ini,
hyperplane dapat dikonstruksikan. Selanjutnya, perhitungan untuk menemukan titik-titik support
vectornya bergantung pada dot product dari data yang sudah ditransformasikan pada ruang baru dimensi yang baru. Karena sulitnya menemukan fungsi transformasi dari Φ, maka menurut Mercer, perhitungan dot product tersebut dapat digantikan dengan fungsi kernel 𝐾(𝑥𝑖,𝑥𝑗) dimana fungsi tersebut mendefinisikan transformasi Φ secara implisit. Inilah yang disebut dengan
“kernel trick”. Yang dirumuskan dengan :
𝐾(𝑥𝑖,𝑥𝑗) = Φ(𝑥𝑖). Φ(𝑥𝑗) (2)
Sehingga hasil klasifikasi dari data 𝑥 ini dapat dituliskan dengan persamaan berikut: 𝑓(Φ(𝑥)) = ∑ 𝛼𝑖𝑦𝑖 𝑛 𝑖=1,𝑥𝑖 𝜖𝑆𝑉 Φ(𝑥). Φ(𝑥𝑖) = ∑ 𝛼𝑖𝑦𝑖 𝑛 𝑖=1,𝑥𝑖 𝜖𝑆𝑉 𝐾(𝑥, 𝑥𝑗) + 𝑏 (3)
Beberapa fungsi kernel yang biasa digunakan diantaranya adalah [8]: Kernel Polynomial yang didefinisikan sebagai berikut :
𝐾(𝑥𝑖,𝑥𝑗) = (𝑥𝑖𝑥𝑗+ 1) p (4) Kernel Gaussian : 𝐾(𝑥𝑖,𝑥𝑗) = exp (−‖𝑥𝑖−𝑥𝑗 ‖ 2 2σ2 ) (5) Kernel Sigmoid : 𝐾(𝑥𝑖,𝑥𝑗) = tanh (𝛼𝑥𝑖𝑥𝑗+ β) (6) 2.2 Image Retrieval
Sampai saat ini image retrieval merupakan objek penelitian yang menarik dan banyak diminati oleh peneliti, bahkan Datta dkk [5] mencatat bahwa pertumbuhan publikasi penelitian tentang
image retrieval pada ACM, IEEE dan Springer mengalami kenaikan yang sangat signifikan dari
tahun ke tahun. Selain karena trend citra digital baik foto maupun video yang semakin lekat dengan gaya hidup masyarakat saat ini, Menurut Datta [5], banyaknya penelitian atas image
retrieval ini juga dikarenakan oleh banyaknya aspek yang dapat diteliti pada image retrieval itu
sendiri diantaranya perhitungan kemiripannya, cakupan datanya, query modalities and
processing, visual signature dll.
Image retrieval sendiri dapat didefinisikan sebagai teknik yang digunakan untuk mencari
citra-citra yang memiliki kemiripan karakter dari citra acuan (input). Dalam hal ini, image
retrieval dapat diimplementasikan dengan membandingkan fitur-fitur hasil dari ekstraksi citra
atau dengan cara yang lain. Berdasarkan teknik pembelajarannya, ada tiga cara untuk mengaplikasikan image retrieval diantaranya dengan cara
Clustering, jika konsentrasi utama dari penelitiannya adalah kecepatan dan kebutuhan memori dari aplikasi yang dibangun, cara ini dapat dilakukan dengan algoritma K-Means,
Kernel mapping dll,
Classification, jika penelitiannya menitikberatkan pada keakuratan hasilnya, serta pemilihan teknik pre-prosesingnya, dapat dilakukan dengan SVM, Klasifikasi Bayes, K-Nearest Neighbor dll
Relevance Feedback, jika penelitian berfokus pada hubungan user dan aplikasi, metode yang digunakan biasanya adalah feature re-weighting, active learning, memory/mental
retrieval dll [5].
Metodologi Penelitian
3.1 Implementasi
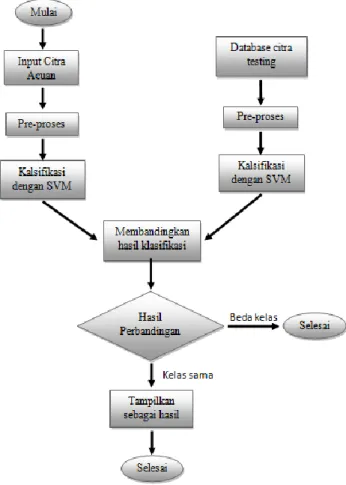
Penelitian ini dilakukan dalam beberapa tahap, diantaranya adalah tahap pre-processing, pada tahapan ini dataset berupa citra akan diproses untuk didapatkan histogramnya, karena feature dan warna setiap citra yang membedakan antara citra satu dengan yang lainnya direpresentasikan oleh histogram tersebut[9]. Setelah histogram didapatkan, tahap selanjutnya adalah mengklasifikasikannya (training) dengan algoritma SVM. Pada proses klasifikasi dengan SVM ini parameter yang perlu diperhatikan adalah fungsi kernelnya, dalam hal ini fungsi kernel yang digunakan adalah kernel polynomial dengan order 3, kernel tersebut dipilih karena mampu memberikan hasil yang terbaik dalam masalah pengklasifikasian daripada kernel lainnya[6]. Untuk proses testing data (citra) input akan diproses dengan model klasifikasi yang telah dibangun sebelumnya kemudian hasil testing akan dibandingkan dengan hasil testing dari dataset
testing, citra yang memiliki hasil yang sama dengan citra input akan muncul sebagai output dari
proses aplikasi pencarian.
Gambar 2 Diagram Proses Image Retrieval
dan berikut adalah user interface dari image retrieval yang telah dibangun :
Gambar 3 User interface Image Retrieval
Pada penelitian ini dataset yang digunakan terdiri dari 1000 citra berwarna dengan 2 kategori kelas yaitu objek roda dua dan roda empat, Sedangkan untuk validasi model akan digunakan metode cross-validation dengan k-fold validation dimana data dibagi menjadi sepuluh bagian (𝑘 = 10), dengan pembagian data 𝑥 berjumlah(𝑘 − 1) kelompok untuk training dan y berjumlah 1 kelompok untuk testing. Kemudian proses akan diulang sebanyak 𝑘 kali dengan data training dan testing yang selalu berbeda dengan skema untuk percobaan sebagai berikut: percoabaan yang pertama data 𝑥 = (𝑘1, 𝑘2, … , 𝑘9) sedangkan data 𝑦 = 𝑘10 kemudian percobaan kedua data 𝑥 = (𝑘10, 𝑘1, 𝑘2 … , 𝑘8) sedangkan data 𝑦 = 𝑘9 dan begitu seterusnya.
Hasil dan Pembahasan
Untuk mengukur kemampuan hasil klasifikasi pada aplikasi image retrieval yang dibangun, maka dalam penelitian ini akan dihitung akurasi, presisi dan recall serta waktu komputasi yang dibutuhkan. Untuk nilai akurasi, presisi dan recall dihitung dengan rumusan sebagai berikut :
Misalnya nilai luaran dan nilai sebenarnya dari image retrieval adalah sebagai berikut :
TABEL I Nilai Luaran dan Sebenarnya Nilai Sebenarnya
True False
Nilai Luaran
True True True True False
False False True False False
Presisi = 𝑇𝑟𝑢𝑒 𝑇𝑟𝑢𝑒
True True+True False 𝑥 100% (7) Recall = 𝑇𝑟𝑢𝑒 𝑇𝑟𝑢𝑒
𝑇𝑟𝑢𝑒 𝑇𝑟𝑢𝑒+False True𝑥 100% (8)
Akurasi = 𝑇𝑟𝑢𝑒 𝑇𝑟𝑢𝑒+ False False
𝑇𝑜𝑡𝑎𝑙 𝑑𝑎𝑡𝑎 𝑠𝑎𝑚𝑝𝑙𝑒 𝑥 100% (9)
Untuk hasil perhitungan rata-rata nilai akurasi, presisi dan recall serta waktu komputasi yang dibutuhkan pada saat pencarian gambar (testing), akan disajikan dalam table berikut :
TABLE2Rata-rata hasil percobaan Kelas Waktu
testing Presisi Recall Akurasi Roda dua 10,911 80,14 85,55 82,22 Roda empat 8,039 85,51 78,88 82,22 Rata-rata 9,475 82,82 82,22 82,22 Keterangan :
nilai precision, recall, akurasi dalam %, waktu komputasi dalam detik
Terlihat dalam tabel bahwa secara umum aplikasi yang dibangun dapat membedakan dengan baik antara objek beroda dua dan objek beroda empat, dibuktikan dengan rata-rata tingkat akurasi yang baik yaitu sekitar 82,22%, presisi 80,14% untuk kelas roda dua dan 85,51 untuk kelas roda empat, sedangkan nilai recall mencapai 85,55% untuk kelas roda dua dan 78,88% untuk kelas roda empat dengan waktu komputasi yang cepat yaitu sekitar 9.475 detik untuk setiap proses
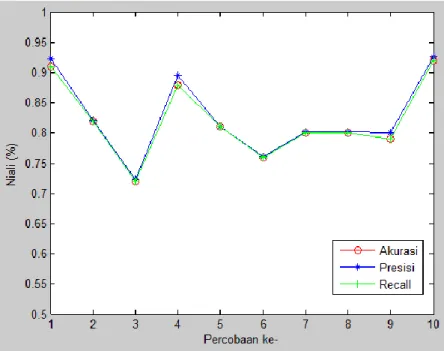
pencarian gambar sedangkan untuk proses training aplikasi tersebut membutuhkan waktu sekitar 19,508 detik. Berikut kurva untuk seluruh percobaan yang telah dilakukan.
Gambar 4 Grafik hasil percobaan
Gambar 5 Grafik waktu komputasi
Terlihat dalam tabel bahwa untuk secara keseluruhan percobaan nilai dari presisi, recall dan akurasi selalu memiliki nilai yang baik dengan nilai lebih dari 70% hal ini berarti bahwa model klasifikasi yang dibangun dengan metode SVM ini memiliki performa yang baik dan stabil untuk semua dataset coba, serta membutuhkan waktu komputasi yang relatif cepat yaitu berada disekitar 10 detik pada proses testing dan 18 detik pada proses training untuk semua percobaan.
Pada paper ini dilakukan penelitian yaitu membangun model klasifikasi dengan algoritma SVM yang diaplikasikan pada image retrieval dengan dataset berupa citra dengan dua kategori yaitu objek roda dua dan objek roda empat. Hasilnya, aplikasi yang dibangun dapat membedakan dengan baik antara objek beroda dua dan objek beroda empat, dibuktikan dengan rata-rata tingkat akurasi yang mencapai nilai 82,22 % dengan waktu komputasi yang cepat pula dengan rata-rata waktu mencapai 9.475 detik untuk setiap proses pencarian gambar sedangkan untuk proses training aplikasi tersebut membutuhkan rata-rata waktu sekitar 19,508 detik.
Penelitian Selanjutnya
Pada dasarnya SVM merupakan algoritma klasifikasi biner, dimana hanya mampu mengklasifikasikan suatu objek kedalam dua kelas, sedangkan dalam konteks masalah klasifikasi pada umumnya seringkali kita menemui permasalahan klasifikasi yang melibatkan banyak kelas, untuk itu ke depan penelitian selanjutnya diharapkan mampu membuat metode klasifikasi khususnya dengan SVM yang dapat digunakan untuk mengklasifikasikan obyek dengan banyak kelas.
Daftar Pustaka
[1] Shuiping, W., Zhenming, T., dan Shiqiang, Li., 2011.Design and implementation of an audio classification system based on SVM, Prosedia Engineering, School of Computer Science & Technology, Nanjing University of Science & Technology, Nanjing, China.
[2] Wang, Z, dan Sun, X., 2011.Document Classification Algorithm Based on MMP and
LS-SVM, Prosedia Engineering, Henan University of Technology, School of Information
Science and Engineering, Zhengzhou, China.
[3] Benerjee, A.K., Ravi, V., Murty, U.S.N., Shanbhag, A.P., dan Prasanna, A.L., 2013. Keratin
protein property based classification of mammals and non-mammals using machine learning techniques, Jurnal Computers in Biology and Medicine, Institute of Chemical Technology,
India,
[4] Castellano, J.M., Jimenez, I.M., Pozuelo, C.F., dan Alvarez, J.L.R 2014, Traffic sign
segmentation and classification using statistical learning methods, Jurnal Neurocomputing,
Rey Juan Carlos University, Madrid, Spanyol.
[5] Datta, R., Joshi, D.J., Li, J., dan Wang, J.Z., 2008. Image Retrieval: Ideas, Influences, and Trends of the New Age, ACM Computing Surveys, Vol. 40, No. 2, Article 5, The
Pennsylvania State University, Amerika Serikat.
[6] Hussain, M., Wajid, S.K., Elzaart, A., dan Berbar, M., 2011. A Comparison of SVM Kernel
Function for Breast Cancer Detection, Computer Graphics, Imaging and Visualization
(CGIV), Eighth International Conference, pp. 145-150,
[7] He, X.,Mourot, G., Maquin, G.,Ragot, J., Beauseroy, P., Smolarz, A., dan Grall-Maës, E., 2014“Muti-task learning with One-class SVM ”, Jurnal Neurocomputing, Nancy University, Prancis.
[8] Scholkopf, B., dan Smola, A.J., 2002 “Learning With Kernels ”, Buku Adaptive Computation and Machine Learning, Massachusetts Institute of Technology, Amerika Serikat.
[9] Lei, B,. Tan, E., C, S., Ni, D., dan Wang, T., 2015. Saliency-driven image classification
method based on histogram mining and image score, Jurnal Pattern Recognition, Nanyang Technological University, Singapore.