7.5. MEMILIH UKURAN SAMPEL 7.5. MEMILIH UKURAN SAMPEL
Ukuran sampel untuk estimasi µ dengan B batas error estimasiUkuran sampel untuk estimasi µ dengan B batas error estimasi
̅̅
……….(7.12)……….(7.12)Untuk mendapatkan nilai dari ukuran sampel kita bisa menguraikan persamaan 7.12 Untuk mendapatkan nilai dari ukuran sampel kita bisa menguraikan persamaan 7.12 dengan menggunakan rumus sampel acak sederhana.Rumus tersebut digunakan pada dengan menggunakan rumus sampel acak sederhana.Rumus tersebut digunakan pada saat:
saat: 1.
1. Populasinya acak sehinggaPopulasinya acak sehingga
̅̅
dandan̅̅
ekuivalenekuivalen 2.2. Sampel yang sangat besar Sampel yang sangat besar untuk populasi tersusun (ordered population)untuk populasi tersusun (ordered population) 3.
3. Sampel yang sangat kecil untuk populasi periodik (periodic population).Sampel yang sangat kecil untuk populasi periodik (periodic population). Ukuran sampel untuk estimasi µ
Ukuran sampel untuk estimasi µ dengan B batas error estimasi:dengan B batas error estimasi:
DimanaDimana
(halaman 210 persamaan 7.4 buku Elementary Survey Sampling ) (halaman 210 persamaan 7.4 buku Elementary Survey Sampling ) Contoh 7.4
Contoh 7.4..
Manajemen suatu perusahaan listrik besar tertarik pada jumlah rata-rata tagihan yang Manajemen suatu perusahaan listrik besar tertarik pada jumlah rata-rata tagihan yang telah lewat jatuh tempo.Suatu sampel sistematik akan diambil dari daftar abjad dari telah lewat jatuh tempo.Suatu sampel sistematik akan diambil dari daftar abjad dari N=2500 rekening nasabah yang jatuh tempo.Berdasarkan survey yang sama tahun lalu N=2500 rekening nasabah yang jatuh tempo.Berdasarkan survey yang sama tahun lalu didapatkan varians sampel
didapatkan varians sampel
hari. Tentukan ukuran sampel untuk estimasi µ,hari. Tentukan ukuran sampel untuk estimasi µ, jumlahjumlah rata-rata rata-rata tagihan tagihan listrik listrik yang yang telah telah lewat lewat jatuh jatuh tempo tempo dengan dengan batas batas error error B= B= 22 hari.
hari.
Penyelesaian: Penyelesaian:
Dengan asumsi populasi adalah acak,sehingga
Dengan asumsi populasi adalah acak,sehingga ρ ≈ρ ≈ 0.Kemudian kita gunakan0.Kemudian kita gunakan persamaan 7.13 untuk menemukan aproximasi ukuran sampel. Mengganti
persamaan 7.13 untuk menemukan aproximasi ukuran sampel. Mengganti
dengandengan
dan dan
Kita dapatkan Kita dapatkan
Dengan demikian manajemen harus memiliki sampel sekitar 97 rekening untuk Dengan demikian manajemen harus memiliki sampel sekitar 97 rekening untuk mengestimasi jumlah rata-rata tagihan yang telah jatuh
Ukuran sampel untuk estimasi τ dengan B batas error estimasi
Untuk mendapatkan rumus ukuran sampel yang diperlukan untuk estimasi
dengan batas error estimasi B kita mengggunakan metode di bagian 4.4. sampel acak sederhana yaitu
dimana
(halaman 70 persamaan 4.14 buku Elementary Survey Sampling )
Ukuran sampel untuk estimasi p dengan B batas error estimasi
Ukuran sampel yang dibutuhkan untuk mengestimasi p dalam unit B bisa ditemukan dengan menggunakan rumus unkuran sampel untuk memperkirakan p dengan sampel acak sederhana.
dimana
and
(halaman 74 persamaan 4.19 buku Elementary Survey Sampling )
Jika p tidak diketahui kita bisa menggunakan nilai estimasi sebagai pengantinya atau p=0.5 untuk mendapatkan ukuran sampel yang konservatif.
Contoh 7.5
Untuk menghilangkan beberapa biaya yang terkait dengan wawancara pribadi, para peneliti memutuskan untuk menggunakan sampel sistematik dari N = 5000, nama-nama yang tercantum dalam daftar masyarakat dan mengumpulkan data melalui wawancara telepon. Tentukan ukuran sampel yang diperlukan untuk mengestimasi p, proporsi orang-orang yang menganggap produk "diterima", dengan batas error estimasi besarnya B = 0,03 (yaitu 3%)
Penyelesaian:
Ukuran sampel yang dibutuhkan dapat ditemukan dengan menggunakan persamaan (7.14). Meskipun tidak ada data sebelumnya yang tersedia di produk baru ini, kita masih dapat menemukan ukuran sampel perkiraan. Dengan menetapkan p = 0,5 dalam persamaan (7.14) dan
Maka ukuran sampel yang diperlukan adalah
Oleh karena itu perusahaan harus mewawancarai 910 orang untuk menentukan pelanggan yang menerima produk dengan batas error 3%.
7.6. SAMPEL SISTEMATIK BERULANG
Sampel sistematik berulang digunakan pada saat kita tidak bisa mengestimasi
̅
karena sampel sistematik memberikan sedikit informasi untuk biaya per unit daripada sampel acak sederhana. Sampel sistematis berulang membutuhkan pemilihan lebih dari satu sampel sistematik.Perhitungan sampel sistematik berulang didasarkan pada sampel sistematik.Misalkan ada suatu populasi N, dengan ukuran sampel n dan kita dapatkan k= N/n. Dari k yang didapatkan dari sampel sistematik kita akan mendapatkan k’ sampel sistematik berulang,dengan cara mengalikan ns sampel sistematik berulang dengan k. Jadi k’= k .ns.
Kita akan menghitung sampel sampai ukuran sampel sistematik berulang yang diinginkan tercapai ,dapat diperoleh dengan menambahkan titik awal (starting point) dengan k’ yang hasilnya akan menjadi titik berikutnya(titik kedua).Selanjutnya kita menambahkan titik kedua dengan k’ yang kemudian menjadi titik ketiga.Penambahan titik selanjutnya dengan k’ dilakukan sampai ukuran sampel yang diminta terpenuhi. Ada juga cara lain yaitu dengan menambahkan titik awal(starting point) dengan k’ untuk
mendapatkan titik k edua , 2k’ untuk mendapatkan titik ketiga. Penambahan titik awal(starting point) dilakukan dengan urutan k’,2k’,3k’ sampai nk’ dengan n adalah ukuran sampel yang diinginkan.
Contoh:
Suatu populasi terdiri dari N=960 unsur dengan nomor urut, dengan ukuran sampel sistematik n=60,berapa nilai sampel sistematis berulang
= 10 dari ukuran 6?Penyelesaian:
Ambil 10 sampel sistematik secara acak antara 1 dan 160 dari populasi sebanyak N=960, Didapatkan angka: 73,42,81,145,6,21,86,17,112,102
Angka tersebut diurutkan dan dijadikan titik awal(starting point) , kemudian setiap titik awal ditambahkan dengan 160 yang kemudian akan menjadi sampel unsur kedua dan selanjutnya sampai 6 kali.
Cara pertama:
Pengambilan ke Hasil No Random starting point
1 73 1 6 2 42 diurutkan 2 17 3 81 3 21 4 145 4 42 5 6 5 73 6 21 6 81 7 86 7 86 8 17 8 102 9 112 9 112 10 102 10 145 Random starting point
Start point+k’ Unsur kedua dalam sampel Unsure kedua +k’ Unsur ketiga dalam sampel Unsur ketiga+k’ 6 6+160 = 166 166+160= 326 326+160= 17 17+160 = 177 177+160= 337 337+160= 21 21+160 = 181 181+160= 341 341+160= 42 42+160 = 202 202+160= 362 362+160= 73 73+160 = 233 233+160= 393 393+160= 81 81+160 = 241 241+160= 401 401+160= 86 86+160 = 246 246+160= 406 406+160= 102 102+160= 262 262+160= 422 422+160= 112 112+160= 272 272+160= 432 432+160= 145 145+160= 305 305+160= 465 465+160= Unsur keempat dalam sampel
Unsur keempat +k’ Unsur kelima dalam sampel
Unsur kelima +k’ Unsur keenam
486 486+160= 646 646+160= 806 497 497+160= 657 657+160= 817 501 501+160= 661 661+160= 821 522 522+160= 682 682+160= 842 553 553+160= 713 713+160= 873 561 561+160= 721 721+160= 881 566 566+160= 726 726+160= 886 582 582+160= 742 742+160= 902 592 592+160= 752 752+160= 912 625 625+160= 785 785+160= 945
Cara pertama: Random Starting Point RSP+k’ RSP+2k’ RSP+3k’ RSP+4k’ RSP+5k’ Unsur kedua dalam sampel Unsur ketiga dalam sampel Unsur keempat dalam sampel Unsur kelima dalam sampel Unsur keenam dalam sampel 6 6+160= 166 6+2(160)=326 6+3(160)=486 6+4(160)=646 6+5(160)=806 17 17+160= 177 17+2(160)=337 17+3(160)=497 17+4(160)=657 17+5(160)=817 21 21+160= 181 21+2(160)=341 21+3(160)=501 21+4(160)=661 21+5(160)=821 42 42+160= 202 42+2(160)=362 42+3(160)=522 42+4(160)=682 42+5(160)=842 73 73+160= 233 73+2(160)=393 73+3(160)=553 73+4(160)=713 73+5(160)=873 81 81+160= 241 81+2(160)=401 81+3(160)=561 81+4(160)=721 81+5(160)=881 86 86+160= 246 86+2(160)=406 86+3(160)=566 86+4(160)=726 86+5(160)=886 102 102+160=262 102+2(160)=422 102+3(160)=582 102+4(160)=742 102+5(160)=902 112 112+160=272 112+2(160)=432 112+3(160)=592 112+4(160)=752 112+5(160)=912 145 145+160=305 145+2(160)=465 145+3(160)=625 145+4(160)=785 145+5(160)=945
Jadi untuk mendapatkan unsur ke n yaitu ukuran sampel kita bosa langsung mencarinya dengan cara , starting point+(ukuran sampel systematik berulang -1)k’
Random starting point
Starting point+(ukuran sampels-1)k’
Starting point+(6-1)k’=starting point+5k’
6 6+5(160)=806 17 17+5(160)=817 21 21+5(160)=821 42 42+5(160)=842 73 73+5(160)=873 81 81+5(160)=881 86 86+5(160)=886 102 102+5(160)=902 112 112+5(160)=912 145 145+5(160)=945
Rumus untuk memperkirakanμ dari sampel sistematis ns ditunjukkan pada
persamaan (7.15), (7.16), (7.17).
Estimator dari mean populasi μmenggunakan ns1-di-k’sampel sistematik :
Dimana
merupakan rata-rata sampel sistematik.Estimasi varians dariμ:
̂()∑
̂
batas error dari estimasi:
()∑
̂
Kita juga bisa menggunakan sampling sistematik berulang untuk memperkirakan total populasiτ, jika N diketahui. Rumus yang diperlukan diberikan dalam persamaan (7.18), (7.19), dan (7.20).
Estimasi dari total populasiτmenggunakan ns 1-di-k sampel sistematik ':
̂̂
Estimasi varians dariτ:
()∑
̂
Batas error dari estimasi:
̂
()∑
̂
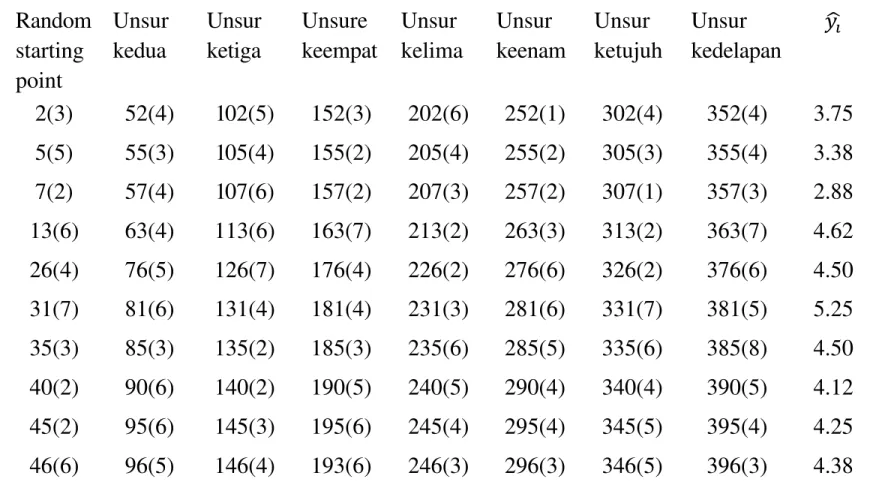
Contoh 7.6.Sebuah Taman kota,biaya masuk dengan mobil yang penuh berisi orang, dan seorang petugas taman ingin memperkirakan rata-rata jumlah orang per mobil untuk liburan musim panas tertentu. Dia mengetahui dari pengalaman sebelumnya bahwa seharusnya ada sekitar 400 mobil yang memasuki taman,dan ia ingin mengambil sampel 80 mobil. Untuk memperoleh estimasi varians,ia menggunakan sample sistematik berulang dengan 10 sampel dari 8 mobil masing-masing. Dengan menggunakan data yang diberikan pada Tabel7.2.Estimate rata-rata jumlah orang per mobil, dan tentukan batas error estimasi.
Tabel 7.2 Data jumlah orang per mobil (the responses
are in parenthese) Random starting point Unsur kedua Unsur ketiga Unsure keempat Unsur kelima Unsur keenam Unsur ketujuh Unsur kedelapan
2(3) 52(4) 102(5) 152(3) 202(6) 252(1) 302(4) 352(4) 3.75 5(5) 55(3) 105(4) 155(2) 205(4) 255(2) 305(3) 355(4) 3.38 7(2) 57(4) 107(6) 157(2) 207(3) 257(2) 307(1) 357(3) 2.88 13(6) 63(4) 113(6) 163(7) 213(2) 263(3) 313(2) 363(7) 4.62 26(4) 76(5) 126(7) 176(4) 226(2) 276(6) 326(2) 376(6) 4.50 31(7) 81(6) 131(4) 181(4) 231(3) 281(6) 331(7) 381(5) 5.25 35(3) 85(3) 135(2) 185(3) 235(6) 285(5) 335(6) 385(8) 4.50 40(2) 90(6) 140(2) 190(5) 240(5) 290(4) 340(4) 390(5) 4.12 45(2) 95(6) 145(3) 195(6) 245(4) 295(4) 345(5) 395(4) 4.25 46(6) 96(5) 146(4) 193(6) 246(3) 296(3) 346(5) 396(3) 4.38 Penyelesaian:Untuk satu sampel sistematik
Oleh karena itu untuk ns = 10 sampel,
Kesepuluh angka berikut ini adalah angka acak antara 1 dan 50 yang diambil: 13, 35, 2, 40, 26, 7, 31, 45,, 5, 46
Mobil dengan angka-angka ini membentuk titik awal untuk sampel acak sistematis. Untuk Tabel 7.2 kuantitas
̅
adalah rata-rata untuk barispertama
̅
adalah rata-rata untuk baris kedua, dan selanjutnya .Estimasi dari μ adalaĥ
∑
Identitas berikut dapat ditetapkan:
̂
Subtitusikan, memperoleh
Dengan demikian varians estimasi μ adalah
̂()∑
̂
(
)[
]
Estimasiμ dengan batas error estimasi adalaĥ ̂ √
Oleh karena itu perkiraan terbaik dari rata-rata orang per mobil