Izgradnja podatkovnega skladišča v NKBM d.d. : diplomsko delo
Bebas
68
0
0
Teks penuh
(2) 2. PREDGOVOR Banke so med poslovanjem izpostavljene različnim finančnim tveganjem. Vzrok zakaj prihaja do sprejetja napačnih poslovnih odločitev, je v veliki meri odvisen od nepopolne slike komitenta oziroma pomanjkljivih poslovnih podatkov. V Novi KBM d.d. se zavedamo, da pri upravljanju informacij banke ločimo dve vrsti računalniških sistemov, to so sistemi za sprotno obdelavo transakcij in sistemi za analiziranje. Za uspešno poslovanje banke morata oba računalniška sistema delovati brezhibno, kar pomeni, komitentom omogočiti realizacijo želenega posla oziroma transakcije, ter zaposlenim nuditi pravilne informacije o komitentih in osnovo za sprejemanje pravilnih poslovnih odločitev. Po celoviti prenovi transakcijskega računalniškega sistema, ki se je začel leta 2003 z uvedbo transakcijskega računa in sedaj prehaja že v zaključno fazo, je potrebno zagotoviti ustrezno informacijsko podporo, ki bo osnova za sprejemanje poslovnih odločitev. To pomeni izgradnjo računalniškega sistema za analiziranje in podporo odločanju. Namen smiselnega upravljanja banke je doseganje njenih ciljev, kot je finančna uspešnost, kakovost storitev, izpolnjevanje časovnih rokov ter fleksibilnost v smislu prilagajanja banke novo nastalim situacijam na finančnem trgu. Kompleksno upravljanje, ki zahteva številne odgovorne odločitve, lahko izvaja samo človek, vendar si lahko pri tem bistveno pomaga z ustreznimi informacijami. Informacijski sistem zajema podatke iz lastnega poslovnega sistema in širšega okolja. Podatkovno skladišče je vez med informacijskim sistemom in uporabniki – upravljavci, saj podatke, ki jih zagotavlja informacijski sistem približa miselnim procesom človeka, ki jih nato pretvori v potrebne informacije za upravljavsko odločanje. Začetna oznaka za podatkovna skladišča je bila ‘sistem za podporo odločanju’. Ta opis je še danes med najboljšimi, saj podatkovno skladišče dejansko predstavlja gonilno silo za uspešno odločanje. Glavno vodilo pri izgradnji podatkovnega skladišča je osnovno prepričanje, da ‘če lahko svoje podatke bolje vidim, lahko bolje upravljam svoje poslovanje’, kar pomeni, da je osrednji dejavnik podatkovnega skladišča dostop ‘do pravih podatkov’. V zadnjih letih smo priča zahtevam, da podatkovna skladišča čim bolje podpirajo odločitveni proces in ne predstavljajo samo veliko knjižnico podatkov..
(3) 3 PREDGOVOR .....................................................................................................................1 1. UVOD ...........................................................................................................................5 1.1 Opredelitev problema ................................................................................................5 1.2 Namen in cilji diplomskega dela ................................................................................5 1.3 Predpostavke.............................................................................................................6 1.4 Uporabljene metode raziskovanja .............................................................................6 2. PODATKOVNO SKLADIŠČE .......................................................................................7 2.1 Opredelitev podatkovnega skladišča .........................................................................7 2.2 Uporabnik in managerji podatkovnega skladišča ......................................................8 2.3 Razlike med podatkovnim skladiščem in transakcijskim............................................8 informacijskim sistemom......................................................................................................8 2.3.1 Predmet osredotočanja..............................................................................................9 2.3.2 Vzorec izkoriščanja strojne opreme.........................................................................10 2.3.3 Odzivni čas in število uporabnikov...........................................................................10 2.3.4 Značilnosti podatkov ................................................................................................10 2.3.5 Način dela uporabnika .............................................................................................10 2.3.6 Vzroki izgradnje podatkovnih skladišč .....................................................................11 3. ARHITEKTURA PODATKOVNEGA SKLADIŠČA .....................................................12 3.1 Centralizirana arhitektura.........................................................................................13 3.1.1 Podatkovni model v centralizirani arhitekturi podatkovnega skladišča ....................14 3.1.2 Področno skladišče v centralizirani arhitekturi podatkovnega .................................14 skladišča ............................................................................................................................14 3.2 Federativna arhitektura podatkovnega skladišča ....................................................14 3.2.1 Gradnja federativnega podatkovnega skladišča......................................................15 3.2.2 Skupni informacijski model v federativnem podatkovnem skladišču .......................16 3.2.3 Področja priprave informacij v federativnem podatkovnem skladišču .....................16 3.3 Distribuirana arhitektura podatkovnega skladišča ...................................................17 3.3.1 Podatkovni model v distribuirani arhitekturi podatkovnega skladišča......................18 3.3.2 Posebnosti v distribuirani arhitekturi podatkovnega skladišča................................18 4. PODATKOVNI MODEL PODATKOVNEGA SKLADIŠČA ..........................................19 4.1 Zvezdna oblika.........................................................................................................19 4.1.1 Tabele dejstev .........................................................................................................20 4.1.2 Dimenzijske tabele...................................................................................................21 4.1.3 Področna skladišča..................................................................................................22 4.1 Struktura podatkov v podatkovnem skladišču .........................................................24 4.1.1 Referenčni detajlni podatki ......................................................................................24 4.2.2 Sumarizirani podatki ................................................................................................25 4.2.3 Zgodovinski podatki .................................................................................................26 4.2.4 Meta podatki ............................................................................................................26 5. PRENOS PODATKOV V PODATKOVNO SKLADIŠČE.............................................27 5.1 Proces ETL10 ...........................................................................................................27 5.1.1 Ekstrakcija podatkov................................................................................................28 5.1.2 Čiščenje podatkov in transformacija ........................................................................29 5.1.3 Nalaganje podatkov .................................................................................................30 5.1.4 Časovnost postopkov ETL13 ....................................................................................30 5.1.5 Vmesniki za podporo procesa ETL14 .......................................................................31 5.1.6 Kakovost izvornih podatkov16 ..................................................................................32 6. IZGRADNJA PODATKOVNEGA SKLADIŠČA V NKBM d.d. ...................................34 6.1 Izbira tehnologije......................................................................................................35 6.2 Analiza in definicija podatkovnih virov .....................................................................36 6.2.1 Določitev izvorne baze podatkov .............................................................................36 6.2.2 Ustvarjanje shrambe................................................................................................36.
(4) 4 6.3 Arhitektura in struktura podatkov v podatkovnem skladišču NKBM d.d. ................37 6.3.1 Hierarhije v dimenzijah ...........................................................................................39 6.4 Struktura kadrov pri izgradnji podatkovnega skladišča v NKBM d.d. ......................40 6.5 Faze izgradnje podatkovnega skladišča v NKBM d.d..............................................41 6.5.1 Seznam podfaz podatkovnega skladišča za pravne osebe v NKBM d.d.................42 6.6 Uporabniška aplikacija.............................................................................................46 6.6.1 Tehnične značilnosti ................................................................................................47 6.7 Varnostni vidik .........................................................................................................47 6.7.1 Zanesljivost podatkov v PS......................................................................................48 7. ZAKLJUČEK ...............................................................................................................49 8. POVZETEK.................................................................................................................51 ZUSAMMENFASSUNG..............................................................................................52 SEZNAM VIROV................................................................................................................53 PRILOGA...........................................................................................................................55.
(5) 5. 1. UVOD 1.1. Opredelitev problema. Glede na potrebe v današnjem poslovnem življenju, ki zahteva veliko prilagodljivost in predvidljivosti, hiter časovni odziv na dobljene informacije ter pravilno odločanje, je za banko nujno potrebno, da ima poleg visoko izobraženega kadrovskega potenciala tudi informacijski sistem, s pomočjo katerega lahko vsak trenutek izbere poslovno odločitev, s katero si bo ustvarila prednost pred konkurenco. Dejstva, ki sem jih navedla so dovolj prepričljiva, da izgradnja podatkovnega skladišča ni le ‘modna muha’, temveč potreba in pogoj za eksistenco v sodobnem poslovnem življenju. V Novi KBM d.d. smo se po prenovi transakcijskega informacijskega sistema znašli v točki, ko moramo prenoviti oz. izgraditi nov informacijski sistem namenjen analizi podatkov in podpori odločanju. Odločitev za izgradnjo podatkovnega skladišča je zagotovo pravilna. 1.2. Namen in cilji diplomskega dela. Namen diplomskega dela je predstaviti faze projekta izgradnje podatkovnega skladišča, katerega cilj je popolna slika komitenta na dnevni osnovi. To pomeni zbrati in ustrezno prikazati osnovne podatke o komitentu, boniteto komitenta, povezane osebe in poslovno sodelovanje, ki vsebuje postavke pasivnih, aktivnih in nevtralnih poslov na določen dan. Naloga je razdeljena na teoretični del, v katerem bom na osnovi domače in tuje literature predstavila in razložila pojem podatkovno skladišče. V drugem delu naloge bom konkretno opisala projekt izgradnje podatkovnega skladišča v NKBM d.d.. Sklopi in cilji prvega dela naloge, ki se nanašajo na podatkovno skladišče so: -. raziskati namen in tehnologijo podatkovnih skladišč,. -. predstaviti zgradbo podatkovnega skladišča,. -. opisati podatkovni model podatkovnega skladišča,. -. proučiti namen in proces podatkovnega izkopavanja.. V drugem delu naloge bom zajela opis izgradnje podatkovnega skladišča v NKBM d.d., z opisom načrtovanih in doseženih ciljev projekta: -. opredeliti obseg projekta izgradnje podatkovnega skladišča,. -. načrtovanje in opis konkretnega podatkovnega modela,.
(6) 6. 1.3. izdelati in predstaviti prototip spletne aplikacije. Predpostavke. Na podlagi analize obstoječega stanja na področju pridobivanja informacij o komitentu banke, bom skušala prikazati, kako pomembne so kvalitetne in točne informacije, ki jih lahko uporabnik dobi na enem mestu za poslovanje banke. Področje izgradnje podatkovnih skladišč, ki ga nameravam obdelati v diplomskem delu je obsežno predstavljeno v tuji in domači literaturi. Dostop in razpoložljivost literature je dobra, zato bom izbrala tisto literaturo, ki je najbližja izbrani temi in katero smo tudi v NKBM d.d. uporabljali pri projektu izgradnje podatkovnega skladišča. Vse analize in predpostavke za izgradnjo podatkovnega skladišča se bodo izključno navezovale na NKBM d.d. 1.4 Uporabljene metode raziskovanja V nalogi bom uporabila znane metode sestavljanja in pisanja strokovnih člankov. Glavni pristop raziskovanja bo temeljil na deskriptivnem pristopu, s prednostjo opisovanja. Uporabila bom naslednje metode v okviru deskriptivnega pristopa: -. metodo deskripcije – opis dejstev,. -. metodo kompilacije – povzemanje opazovanj, spoznanj, stališč, sklepov in rezultatov drugih avtorjev,. metodo komparacije – postopek primerjave enakih ali podobnih dejstev..
(7) 7. 2.. PODATKOVNO SKLADIŠČE. 2.1. Opredelitev podatkovnega skladišča. Podatkovno skladišče je predmetno naravnana, povezana, časovno opredeljena in nespremenljiva zbirka podatkov namenjena za odločitve vodilnih delavcev v podjetju (Cabena in drugi 1997, 19-21). Predmetno naravnana zato, ker se v podatkovnem skladišču osredotočimo na poslovne subjekte oziroma na glavne enitete podjetja (komitent, produkt, dobavitelj itd.) in ne k posameznim dogodkom (prodaja, kredit, depozit), kot je to v klasičnih transakcijah. Povezanost ali integriranost predstavlja najpomembnejši vidik podatkovnega skladišča. Vsi podatki v podatkovnem skladišču so integrirani, kar se kaže v obliki konsistentnih poimenovanj, konsistentnosti fizičnih atributov podatkov, itd. in so shranjeni v vnaprej dogovorjeni obliki. V transakcijskih sistemih lahko obstaja več različnih šifrantov za isto entiteto, v podatkovnem skladišču se uporablja le eden. Časovna opredeljenost se kaže v treh pogledih: -. v podatkovnem skladišču so podatki shranjeni 5-10 let,. -. podatki vsebujejo zaznamek časa, ko so bili aktualni (leto, mesec, poslovno leto),. -. prisotna je časovna razsežnost , kar pomeni, da so podatki v podatkovnem skladišču uvrščeni v časovni okvir, kar nam je v pomoč kasneje pri časovnih analizah.. Nespremenljiva, ker se podatki preneseni v podatkovno skladišče ne spreminjajo več. Služijo kot stabilen vir za konsistentno poročanje in primerjalne analize. Naslednja definicija pravi, da je podatkovno skladišče kopija transakcijskih podatkov, posebej strukturiranih za namene poizvedb in analiz (Kimball 1998, 310). Podatkovno skladišče je integrirana zbirka podatkov, ki združuje podatke iz različnih virov in omogoča enostavno realizacijo poizvedovanj, potrebnih za izvajanje analiz in sprejemanje poslovnih odločitev (Inmon, 1992, 3). Zadnja definicija, ki jo bom omenila pravi, da podatkovno skladišče lahko razumemo kot vez med informacijskim sistemom in uporabniki – upravljavci. Podatke, ki jih zagotavlja informacijski sistem, približa miselnim procesom človeka, ki jih laže pretvori v potrebne informacije za upravljavsko odločanje (Rajkovič, 1998, 2)..
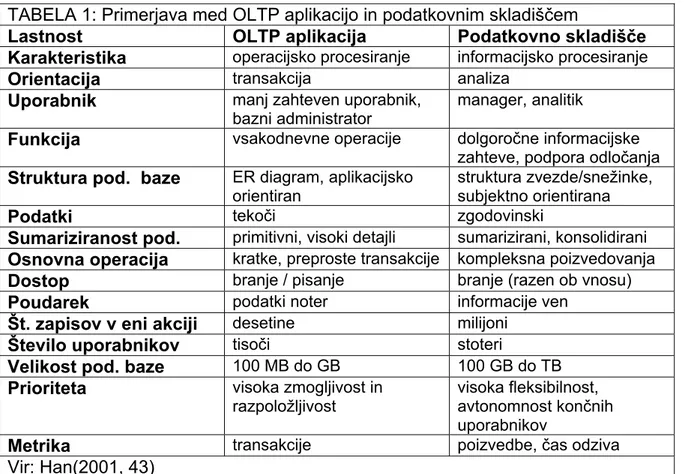
(8) 8. Podatkovna skladišča so najbolj primerna za podjetja, kjer (Turban in Aronson, 1998, 125):. 2.2. -. so podatki shranjeni v različnih sistemih,. -. je v uporabi informacijski pristop do vodenja,. -. obstaja velika in raznolika baza strank,. -. so isti podatki v različnih sistemih prikazani različno. Uporabnik in managerji podatkovnega skladišča. Analitik podatkovnega skladišča: - izdelava poročil, ki zahtevajo pregledovanje velikega števila zapisov, ni vnosa podatkov, aktivnosti se spreminjajo. Managerji podatkovnega skladišča: - pomembna je skrb za kakovost podatkov. Uporabnik podatkovnega skladišča: - koristi informacije podatkovnega skladišča, ki jih prejme v obliki poročil ali izdelane aplikacije, ter na njihovi osnovi sprejema poslovne odločitve. 2.3. Razlike med podatkovnim skladiščem in transakcijskim informacijskim sistemom. Podjetja gradijo podatkovna skladišča z namenom pridobiti nevtralno zbirko podatkov za kvalitetno podporo odločanju. Mnoga podjetja imajo več aktivnih aplikacij, ki služijo podpori poslovnih procesov. Imenujemo jih OLTP1 aplikacije. Kot je razvidno iz imena so predvsem namenjene transakcijam, lahko pa njihove baze podatkov, imenujemo jih transakcijske baze, služijo tudi za razna vpogledovanja v podatke in pomoč pri podpori odločanju. Kadar ima podjetje več takšnih OLTP2 aplikacij in potrebuje poročila oziroma analize z več področij delovanja podjetja, pa se pojavijo težave, ker se podatki po aplikacijah razlikujejo po vsebini, obliki in stopnji pravilnosti. V takšnih primerih je pametno zgraditi podatkovno skladišče in v njem zbrati, poenotiti, preveriti in pripraviti podatke za analizo celotnega poslovanja podjetja. V podatkovno skladišče pa se lahko vključijo tudi podatki iz poslovnega okolja, kot so npr. registri transakcijskih računov, ki ga vodi Banka Slovenije, register davčnih številk iz Davčne uprave in podobno. ____________________________________________________ 1 OLTP – On Line Transaction Processing. 2 Več OLTP aplikacij predstavlja tki. Poslovni informacijski sitem..
(9) 9. TABELA 1: Primerjava med OLTP aplikacijo in podatkovnim skladiščem Lastnost OLTP aplikacija Podatkovno skladišče operacijsko procesiranje informacijsko procesiranje Karakteristika transakcija analiza Orientacija manj zahteven uporabnik, manager, analitik Uporabnik Funkcija Struktura pod. baze Podatki Sumariziranost pod. Osnovna operacija Dostop Poudarek Št. zapisov v eni akciji Število uporabnikov Velikost pod. baze Prioriteta Metrika Vir: Han(2001, 43). bazni administrator vsakodnevne operacije. ER diagram, aplikacijsko orientiran tekoči primitivni, visoki detajli kratke, preproste transakcije branje / pisanje podatki noter desetine tisoči 100 MB do GB visoka zmogljivost in razpoložljivost transakcije. dolgoročne informacijske zahteve, podpora odločanja struktura zvezde/snežinke, subjektno orientirana zgodovinski sumarizirani, konsolidirani kompleksna poizvedovanja branje (razen ob vnosu) informacije ven milijoni stoteri 100 GB do TB visoka fleksibilnost, avtonomnost končnih uporabnikov poizvedbe, čas odziva. 2.3.1. Predmet osredotočanja Podatkovno skladišče je osredotočeno na predmete. Predmet podatkovnega skladišča je lahko komitent ali storitev. Informacije o komitentu se zbirajo z vnosom podatkov v različne OLTP aplikacije, kot je na primer otvoritev transakcijskega računa, najem kredita, prenos denarja iz računa na račun in številnimi drugimi OLTP aplikacijami. Z izgradnjo podatkovnega skladišča težimo k temu, da vse podatke o izbranem predmetu (v mojem primeru govorim o komitentu), prenesemo na eno mesto, kjer bo mogoče skozi eno samo aplikacijo spremljati vse naštete informacije. Za izgradnjo podatkovnega skladišča so hkrati z živimi podatki, ki se vnašajo v podatkovno bazo dnevno, pomembni tudi starejši, arhivski podatki. Trdimo lahko, da je za podatkovna skladišča pomembna globalna konsistentnost podatkov. Na konsistentnost podatkov gledamo s stališča kakovosti podatkov (Inmon, 1998, 4). Transakcijski informacijski sistem je osredotočen na posamezne transakcije. Primeri transakcij so otvoritev transakcijskega računa, najem kredita, prenos denarja z računa na račun. Za vsako transakcijo je izdelan poseben računalniški program ali za zahtevnejše transakcije celo aplikacija. Vsaka transakcija mora biti v celoti izvršena, nobena se ne sme izgubiti. Govorimo o konsistentnosti na podrobnem (mikroskopskem) nivoju (Inmon, 1998, 4)..
(10) 10. 2.3.2 Vzorec izkoriščanja strojne opreme Iz vzorca izkoristka strojne opreme pri podatkovnem skladišču je možno razbrati, da je le ta popolnoma izkoriščena ponoči, ko se posodabljajo podatki. Podnevi se računalnik obremeni le v primeru, če uporabniki posegajo po globini podatkovne kocke. Kadar uporabniki posegajo samo po vrhnjem delu kocke, obremenitve računalnika praktično ni čutiti. V podatkovnem skladišču torej obstaja veliko nihanje v izkoristku strojne opreme. To dejstvo je osnovni razlog, zakaj ni priporočljivo imeti transakcijskega informacijskega sistema in podatkovnega skladišča na isti strojni opremi. V vzorcu izkoristka strojne opreme transakcijskega informacijskega sistema sicer obstajajo vzponi in padci, vendar je sistem skozi ves dan enakomerno obremenjen. 2.3.3 Odzivni čas in število uporabnikov Podatkovno skladišče ima le nekaj uporabnikov. Tudi v velikih podjetjih je manj kot sto uporabnikov. Povpraševanje po podatkih lahko zahteva branje iz tabel z več milijoni zapisov. Da bi prišel do uspešnega izida, mora računalnik opraviti branje z več tabel, ki imajo med seboj vzpostavljene relacije. V transakcijskem informacijskem sistemu lahko več sto uporabnikov sočasno opravlja svoje delo in s tem povzroča na stotine transakcij. Vsaka izmed transakcij pa se bo izvršila v zelo kratkem času, saj posega po malo zapisih iz podatkovne baze. Sprejemljiv odzivni čas v transakcijskem informacijskem sistemu je do dve sekundi. V primeru, da se odzivni čas podaljša, povzročijo zastoji škodo v poslovnem procesu. 2.3.4 Značilnosti podatkov V podatkovnem skladišču se podatki osvežujejo dnevno, lahko celo tedensko, odvisno od potrebe. Vsekakor se podatki ne osvežujejo več kot enkrat dnevno. Postopek osveževanja ponavadi poteka ponoči, tako da ima uporabnik zjutraj že sveže podatke. Podatki v podatkovnem skladišču se načeloma ne izbrišejo in ne posodabljajo, ampak se samo dodajajo. V transakcijskem informacijskem sistemu nastajajo podatki neprestano. Iz sekunde v sekundo se podatki dodajajo in osvežujejo. Stari podatki so v transakcijskem sistemu odveč, zato se brišejo ali arhivirajo. 2.3.5 Način dela uporabnika Uporabnik podatkovnega skladišča raziskuje. Rezultati trenutne raziskave mnogokrat služijo kot osnova za nadaljnje raziskovanje. Z različnimi pogledi na.
(11) 11. skladiščene podatke skuša uporabnik ugotoviti, ali se v podatkih pojavljajo zakonitosti. V transakcijskem informacijskem sistemu uporabnik v naprej ve, kaj bo z računalnikom delal. Opravila so standardizirana in za ta opravila so napisani programi, ki vedno delujejo po istem principu. 2.3.6 Vzroki izgradnje podatkovnih skladišč Vzroki, zakaj se podjetja lotevajo gradnje podatkovnega skladišča, so v vedno hitrejših potrebah po celovitih poslovnih informacijah. Obstoječe OLTP aplikacije tega ne omogočajo, ker (Singh 1998, 16): -. ne vsebujejo on-line3 starih podatkov,. -. podatki za analize se nahajajo na različnih operacijskih sistemih,. -. zmogljivost poizvedovanja podatkov je zelo slaba,. -. strukture podatkovnih baz teh aplikacij niso primerne za sisteme za podporo odločanju.. V primeru bank potreba po podatkovnem skladišču izhaja iz sklepa o zagotavljanju integralnih podatkov, ki ga je izdala Banka Slovenije. Ta od bank zahteva integralni informacijski sistem, ki omogoča spremljanje posameznega komitenta po vseh njegovih poslih (Černe in Bratuša 1999, 173). Podatkovna skladišča sinergijsko delujejo v kombinaciji z OLAP4 orodji. Tehnologija OLAP omogoča dinamično, večrazsežno analizo zgoščenih podatkov, pridobljenih iz podatkovnega skladišča, ki nudi končnemu uporabniku podporo, pri analizi in odločanju. Podpora pri analiziranju vključuje naslednje aktivnosti: -. analize trendov v različnih časovnih obdobjih,. -. modeliranje in kalkulacije preko več dimenzij ali pri fiksirani določeni dimenziji,. -. prikaz poljubnega dela podatkov,. -. možnosti '' IF – THEN '' analiz. 3 On line podatki – podatki dostopni v realnem času. 4 OLAP – On-Line Analytic Processing (sprotna obdelava podatkov)..
(12) 12. 3.. ARHITEKTURA PODATKOVNEGA SKLADIŠČA. Način gradnje arhitekture podatkovnega skladišča se razlikuje od podatkovnih baz OLTP aplikacij. Pri slednjih je pomembno, da so baze grajene in optimizirane za hitro hranjenje, ažuriranje in vsakodnevno poročanje poslovnih transakcij, To je doseženo z normalizirano strukturo entitetno relacijskih diagramov. V takšni bazi podatkov je podvojenih podatkov malo oz. samo tista polja, ki služijo za logično povezavo z ostalimi tabelami. To izboljšuje hitrost procesiranja in zmanjšuje stroške hranjenja podatkov. SLIKA 1: Osnovni elementi podatkovnega skladišča. Prirejeno po Kimball (1998, 15). Podatkovna skladišča služijo za hranjenje velikih količin podatkov, ki nastanejo v podjetju. Imajo denormalizirano strukturo, kar pomeni, da se določni podatki podvajajo, vendar se to izraža v večji hitrosti pri poizvedovanju po podatkih. Denormalizirane strukture je tudi lažje načrtovati kot normalizirane, vendar gre to na račun večjih količin podatkov. Ko podatke enkrat shranimo v podatkovno skladišče, se ti ne spreminjajo, ponavadi pa dnevno (tedensko, mesečno) dodajamo nove. Poznamo tri vrste arhitekture podatkovnih skladišč: -. centralizirana,.
(13) 13. -. distribuirana in. -. federativna.. V naslednjih poglavjih bom na kratko opisala vse arhitekture podatkovnih skladišč. Najnatančnejše bom opisala distribuirano arhitekturo, katere zagovornik je Ralph Kimball in ki smo jo izbrali pri izgradnji podatkovnega skladišča v NKBM d.d. 3.1. Centralizirana arhitektura. V središču arhitekture podatkovnega skladišča je podatkovno skladišče zaključenega organiziranega sistema, ki ''hrani'' področna skladišča, polni pa se iz operativnih podatkovnih baz ter operativnega podatkovnega skladišča. Največji zagovornik take arhitekture je Inmon. Strogo rečeno so v taki arhitekturi področna skladišča odvisna struktura, saj so podatki pridobljeni oziroma naloženi izključno iz podatkovnega skladišča organizacije (Golob in Welzer, 2001, 3). Izhajajoč iz arhitekture centraliziranega podatkovnega skladišča je osrednje podatkovno skladišče edini vir podatkov za področno skladišče. Področna skladišča ne ločuje med podatki, ki so prišli v podatkovno skladišče neposredno iz operativnega sveta ali preko operativne podatkovne hrambe. SLIKA 2: Arhitektura centraliziranega podatkovnega skladišča. Prirejeno po Golob – Welzer (2001, 3).
(14) 14. 3.1.1 Podatkovni model v centralizirani arhitekturi podatkovnega skladišča Struktura podatkovnega skladišča je normalizirana. V maloštevilnih primerih je struktura le delno denormalizirana. Delno denormaliziranost lahko uvedemo v naslednjih primerih (Golob in Welzer, 2001, 4): -. kjer je znano, da se bodo redundantni podatki redno uporabljali skupaj z drugimi podatki in zato dopuščamo redundantnost.. -. kjer so enkrat izračunani podatki večkrat uporabljeni (npr. shranimo letno bruto plačo, čeprav je to izpeljan, izračunljiv podatek).. -. če sklepamo, da bodo skupine podatkov normalno in pogosto uporabljene skupaj, formiramo zanje nov skupen prostor.. -. če sklepamo, da se verjetnost dostopa, do posameznih podatkovnih elementov (atributov) pri uporabi bistveno razlikuje in zato izvedemo ločitev podatkov.. 3.1.2 Področno skladišče v centralizirani arhitekturi podatkovnega skladišča Osrednje podatkovno skladišče je edini vir podatkov za področno skladišče. Področno skladišče ne ločuje med podatki, ki so prišli v podatkovno skladišče neposredno iz operativnega sveta ali preko operativne podatkovne hrambe. Osnovne značilnosti, ki ločijo področno skladišče in podatkovno skladišče so naslednje: -. podatkovno skladišče vsebuje veliko količino zelo podrobnih podatkov iz daljšega obdobja (npr. 10 let) v enostavnih strukturah, področno skladišče pa le agregirane in sumarizirane podatke omejene zgodovine (npr. mesec dni) v veliko bolj zapletenih strukturah,. -. strukture podatkovnega skladišča so namenjene neznani uporabi, strukture področnega skladišča so načrtovane za specifične, znane namene,. -. področna skladišča so manjša,. -. podatkovno skladišče ne vsebuje samo granularnih podatkov, temveč tudi sumarne podatke poslovanja celotne organizacije.. 3.2 Federativna arhitektura podatkovnega skladišča Federativno podatkovno skladišče je hibridna rešitev, temelječa na skupnem poslovnem modelu in področjih priprave informacij, ki so v skupni rabi. Takšna arhitektura zagotavlja nizke stroške in hitro povrnitev vloženih sredstev z uporabo.
(15) 15. neodvisnih področnih skladišč, pri čemer kasnejša podatkovna integracija ni potrebna. SLIKA 3: Arhitektura federativnega podatkovnega skladišča. Prirejeno po Golob – Welzer (2001, 6) 3.2.1 Gradnja federativnega podatkovnega skladišča Gradnjo federativnega podatkovnega skladišča bi lahko strnili v šest korakov: -. Dokumentiranje obstoječih sistemov podatkovnih in področnih skladišč rezultira v entitetnem diagramu, ki prikazuje sisteme in vse podatkovne tokove med njimi, vključno s tokom meta podatkov. Dokumentiranje obstoječih sistemov na nivoju toka podatkov vključuje podatkovni tok, pripadajoče korake transformacije in integracije ter repozitorije meta podatkov. Vsak podatkovni element mora biti ocenjen v smislu kakovosti, razpoložljivosti in enostavnosti dostopa..
(16) 16. -. Določitev podatkov, ki prinašajo dodano vrednost in imajo dovolj visok pomen oziroma vpliv v celotnem sistemu. V tem koraku se išče posebna, najbolj pomembna podatkovna integracija.. -. Zbiranje kandidatov iz prejšnjega koraka in analiziranje njihovega vpliva in možnosti za implementacijo. V tem koraku se tudi izbere ustrezne kandidate, ki najbolj prispevajo k strateškemu načrtu organizacije in so hkrati najmanj tvegani.. -. Implementacija orodja za zajem transformacij in polnjenje podatkov, ki podpira skupen, globalni repozitorij meta podatkov sistemov podatkovnih in področnih skladišč.. -. Gradnja manjše, strogo namenske in usmerjene iteracije federativne arhitekture, ki temelji na izbranem kandidatu iz četrtega koraka. Sledi dokumentiranje in objava doseženega z namenom pridobiti ali obdržati politično voljo, potrebno za nadaljnje iteracije.. 3.2.2 Skupni informacijski model v federativnem podatkovnem skladišču Opisan pristop podpira iterativni razvoj podatkovnega skladišča, ki vsebuje neodvisna področna skladišča. Ključni element podatkovne integracije je skupni poslovni model poslovnih informacij, hranjen in upravljan s strani podatkovnega skladišča. Izdelava skupnega poslovnega modela zagotavlja konsistenco pri uporabi imen podatkov in poslovnih definicij v vseh procesih podatkovnega skladišča. Skupni poslovni model se ažurira vsakič, ko se zgradi novo področno skladišče. Kadar obstoječi podatki v operativnih sistemih narekujejo načrtovanje področnih skladišč, uporabimo skupni poslovni model, v zaporedno z razvojem podatkovnih modelov podrejenih področnih skladiščih. V okoljih, kjer so vodilo poslovne zahteve uporabnikov iz poslovnega sveta, najprej razvijemo skupni poslovni model in ga nato uporabimo za razvoj podatkovnih modelov podrejenih področnih skladišč. 3.2.3 Področja priprave informacij v federativnem podatkovnem skladišču Vsakič, ko je zgrajeno novo področno skladišče, se praviloma ustvari nova garnitura aplikacij za zajem in transformacijo, ki pa so le redko integrirana z aplikacijami za gradnjo ostalih področnih skladišč. Uporaba neodvisnih področnih skladišč pa poveča tudi število programskih rutin za zajem in transformacijo. Vzdrževanje takih rutin je izjemno kompleksno in zahtevno do virov, najtežje pa je zagotoviti njihovo izvajanje v času, ko je operativna baza obremenjena z rednim procesom. Rešitev omenjenega problema je razbitje procesiranja v več korakov,.
(17) 17. kar vključuje množice rutin, ki zajemajo podatke in z njimi polnijo področja priprave. Ob dodajanju novih področnih skladišč v sistem podatkovnega skladišča se obstoječe rutine za zajem in podatki v področjih priprave po potrebi ponovno uporabijo oziroma izboljšajo. Tak način še posebej dobro deluje v federativnem podatkovnem skladišču, kjer lahko skupni poslovni model uporabimo pri načrtovanju področij priprave in programskih rutin za zajem podatkov. 3.3. Distribuirana arhitektura podatkovnega skladišča. Največji zagovornik tipične distribuirane arhitekture je R. Kimball. V distribuirani arhitekturi je podatkovno skladišče unija vseh področnih skladišč. Področno skladišče igra ponavadi vlogo oddelčnega, krajevnega ali funkcionalnega podatkovnega skladišča in podpira eno ali več specifičnih področij. Organizacija kot del iterativnega procesa gradnje podatkovnega skladišča zgradi vrsto distribuiranih področnih skladišč in jih na koncu poveže v logično podatkovno skladišče celotne organizacije. Ta pristop se imenuje “od spodaj navzgor” (angl. bottom-up). Slika 4: Arhitektura distribuiranega podatkovnega skladišča. Vir: Kimball(1998);.
(18) 18. Vsako področno skladišče mora biti predstavljeno z dimenzijskim modelom, ki mora biti znotraj enotnega podatkovnega skladišča skladen. Skladna dimenzija (angl. conformed dimension) je dimenzija, za katero je značilno, da ima enoličen pomen, ne glede na to, s katero tabelo dejstev jo povežemo. Zagotavlja tudi, da je podatek predstavljen le enkrat. Glavna skupina načrtovalcev podatkovnega skladišča pri načrtovanju distribuirane arhitekture podatkovnega skladišča je vzpostavitev, objava in vzdrževanje skladnih dimenzij, kot tudi zagotavljanje njihove dosledne uporabe. Brez upoštevanja koncepta skladnih dimenzij podatkovno skladišče ne more delovati kot integrirana celota. 3.3.1 Podatkovni model v distribuirani arhitekturi podatkovnega skladišča Struktura področnih skladišč je denormalizirana, v določenih primerih le delno normalizirana. Osnovni podatkovni model je dimenzijski, za osnovno modelirno tehniko pa uporabljamo dimenzijsko modeliranje. Dimenzije, še posebej skladne, imajo navadne atomarne podatke5, kar pomeni, da morajo biti tudi tabele dejstev na najnižjem nivoju, ki obstaja med pripadajočimi dimenzijami. To dejstvo olajšuje prehod podatkov iz operativnih podatkovnih baz v tabele dejstev. 3.3.2 Posebnosti v distribuirani arhitekturi podatkovnega skladišča Arhitektura distribuiranega podatkovnega skladišča omogoča razmeroma hitro gradnjo prvega področnega skladišča, ki ima visok poslovni pomen, hkrati pa jo je razmeroma enostavno implementirati. Potrebe organizacije po analizah so razvidne iz poslovnih zahtev, od tod izvira določanje prioritet. Tak pristop omogoča, da v najkrajšem času pridobimo delujočo podatkovno skladišče, s tem pa tudi podporo zagovornikov s strani vodstva in uporabnikov, kar posledično predstavlja novo iteracijo, to je gradnjo novega področnega skladišča.. _________________________________ 5 Atomarni podatki – podatki z nizko granulacijo.
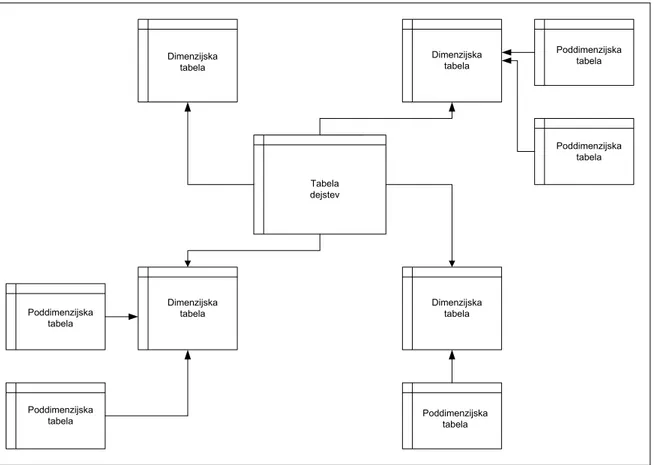
(19) 19. 4.. PODATKOVNI MODEL PODATKOVNEGA SKLADIŠČA. 4.1. Zvezdna oblika. Zvezdna oblika je specifični tip oblike podatkovnega skladišča za podporo analitičnega procesiranja. Sestavljena je iz dveh vrst tabel, tabel dejstev in dimenzijskih tabel. Na sredini je velika tabela dejstev, ki nima redundantnih vrednosti, okrog nje pa so denormalizirane dimenzijske tabele. Če dimenzijam dodamo poddimenzije dobimo obliko snežinke. Slika 5: Primer zvezdne oblike strukture podatkovnega skladišča. Dimenzijska tabela. Dimenzijska tabela. Poddimenzijska tabela. Poddimenzijska tabela Tabela dejstev. Poddimenzijska tabela. Poddimenzijska tabela. Dimenzijska tabela. Dimenzijska tabela. Poddimenzijska tabela. Na sredini je tabela dejstev, ki jo obkrožajo razsežnostne tabele. Vsaka razsežnostna tabela ima primarni ključ, ki določa izključno en stolpec. Razsežnostne tabele imajo številne stolpce, ki podrobneje opisujejo razsežnost. Tabela dejstev je sestavljena iz primarnega ključa, ki je vedno sestavjen iz več stolpcev primarnih ključev razsežnostnih tabel. Poleg primarnega ključa tabela dejstev vsebuje izključno stolpce z vrednostmi. Razlika v podatkih med tabelo dejstev in razsežnostnimi tabelami je ta, da so podatki v razsežnostnih tabelah opisni, podatki v tabeli dejstev pa povsem številčni. Podatki v tabeli dejstev so lahko izključno številčni, če uporabljamo umetne ključe. Pri določanju ključev lahko razpolagamo tudi z naravnimi ključi. Naravni ključi so podatki, ki sami zase nekaj povedo. Umetni ključi so popolnoma.
(20) 20. umetno ustvarjeni in sami po sebi ne povedo ničesar. Odločitev med uporabo umetnega ali naravnega ključa je odvisna od spreminjanja podatkov v primarnem ključu v razsežnostnih tabelah. V primeru, da izberemo naravni ključ in obstaja možnost, da se bodo ti podatki čez čas spremenili, je pravilneje izbrati umetni ključ, sicer lahko pride do nepravilnosti pri povezovanju podatkov. Preprostost zvezdne oblike podatkovnega skladišča ima naslednje prednosti (Singh 1998, 143-144): -. dopušča kompleksno, multidimenzionalno podatkovno strukturo, ki je definirana s preprostim podatkovnim modelom.. -. poenostavlja definiranje relacij med posameznimi dimenzijskimi tabelami.. -. zmanjšuje število fizičnih relacij v poizvedbi, kar izboljša hitrost poizvedbe.. -. zaradi preprostega podatkovnega modela se zmanjša možnost takšnih poizvedb uporabnika, ki časovno in performančno zelo obremenijo bazo ali vrnejo napačne informacije.. -. Dopušča enostavno rast in širitev podatkovnega skladišča, z relativno majhnimi posegi.. Pri sestavljanju poizvedb je dobro upoštevati dejstvo, da so tabele dejstev veliko večje kot dimenzijske tabele, zato se po zahtevanih pogojih najprej preiščejo manjše dimenzijske tabele, potem pa se z dobljenim rezultatom poiščejo še tabele dejstev. Tako se znatno zmanjša število vrstic v tabelah, ki se preberejo, s tem pa se poveča hitrost poizvedbe. TABELA 2: Karakteristike podatkov v tabeli dejstev in dimenzijski tabeli Tabela dejstev Dimenzijska tabela Milijoni ali milijarde vrstic Deset do nekaj milijonov vrstic Več tujih ključev Eden primarni ključ Numerični podatki Tekstovni in numerični podatki Se ne spreminjajo Se spreminjajo Vir: Anahory in Murray (1997, 42) 4.1.1 Tabele dejstev Podatki v tabeli dejstev predstavljajo približno 70 % vseh podatkov v podatkovnem skladišču, zato je pomembno, da se struktura te tabele pazljivo definira. To se ponavadi stori skupaj z uporabniki, saj so narobe razumljene uporabniške zahteve lahko vzrok za kasnejše popravke strukture tabele dejstev. Kakršnikoli popravki struktur tako velikih tabel pa so časovno zahtevni in zahtevajo velike stroške..
(21) 21. V tabelah dejstev ločimo dva tipa podatkov. Prvi so merljivi podatki, ki jih kasneje uporabniki obdelujejo v svojih analizah in so pogosto uporabljeni v funkcijah (vsota, povprečje ipd.) Primeri merljivih podatkov so znesek kredita, stanje na računu, znesek obresti itd. Drugi tip podatkov, ki se nahajajo v teh tabelah so atributi podatka. Ti služijo kot povezave (tuji ključi6) med posameznim zapisom – vrstico v tabeli dejstev in ključem v dimenzijski tabeli. 4.1.2. Dimenzijske tabele. V primerjavi s tabelami dejstev, se dimenzijske tabele skozi čas večkrat spreminjajo. Vzroki za spremembe so lahko reorganizacija podjetja, spremenjene šifre produktov, spremenjeni poslovni proces. Že pri definiranju dimenzijske tabele se moramo zato zavedati možnih prihodnjih uporabniških zahtev in strukturo tabele definirati tako, da jo bo kasneje mogoče zelo hitro in brez velikih stroškov spremeniti. Pri tem velja pravilo počasi-se-spreminjajočih-se-dimenzij, ki ga je razrešil Kimball (Kimbal 1996). Pravilo podaja tri predloge: -. Tip 1: staro vrednost prepišemo.. -. Tip 2: dodaj nov zapis v dimenzijsko tabelo.. -. Tip 3: dodaj nov atribut v dimenzijsko tabelo.. Posamezne dimenzije lahko preprosto opišemo tudi kot okna, skozi katera uporabniki vidijo podatke. Dimenzije vsebujejo opise in lastnosti, ki jih lahko podatki vsebujejo. Klasičen primer dimenzije je dimenzija komitent. V tabeli dejstev je zapisan le ključ komitenta, v dimenzijski tabeli pa se nahajajo podatki kot so ime, naslov, spol, izobrazba, davčna številka itd. Uporabnik ima možnost podatke združevati in analizirati po lastnostih, zapisanih v dimenzijskih tabelah. Na primer, lahko preveri koliko kreditov je odprla enota banke v Ljubljani. Dimenzijske tabele so praviloma denormalizirane in v nekaterih primerih vsebujejo vse kombinacije možnih lastnosti povezane dimenzije. Če velja to, ima struktura podatkovnega skladišča klasično zvezdno obliko. Če dimenzijske tabele normaliziramo, dobimo naslednji nivo tabel, strukturo pa imenujemo snežinka. Prednost tega je, da se zmanjša velikost podatkovnega skladišča, slabost pa, da se povečata kompleksnost strukture in časi poizvedovanja, ker je potrebno med sabo povezati več tabel. Ponavadi so slabosti večje kot prednosti, zato se oblike snežink izogibamo. Dimenzijske tabele normaliziramo tako, da jim dodamo pod dimenzije, ki imajo svoje primarne ključe povezane s tujimi ključi v dimenzijskih tabelah. ________________________________ 6 S tujimi ključi se v podatkovnih bazah vzdržujejo povezave med tabelami..
(22) 22. 4.1.3 Področna skladišča Področna skladišča7 so podmnožica podatkov podatkovnega skladišča. V njih se hranijo izbrani podatki, oblikovani posebej zato, da se odzovejo poslovnim zahtevam določenih uporabnikov. Podatki lahko v področna skladišča pridejo iz podatkovnega skladišča ali pa iz originalnega izvora, podatkovnih baz OLTP aplikacij. Področna skladišča so lahko samostoječa, kar pomeni, da imajo svojo zvezdno strukturo in poleg vsebine tudi svojo obliko podatkov, lahko pa so povezana in sicer tako, da je struktura podatkov v področnih skladiščih identična in da uporabljajo skladne dimenzije. V primeru, da so posamezna področna skladišča povezana in usklajena, so primerna tudi za iskanje globalnih podatkov oziroma podatkov na nivoju podjetja, ki izvirajo iz različnih področnih skladišč. Ta pristop zagovarja tudi Ralph Kimball v svojem predlogu distribuirane arhitekture podatkovnega skladišča (glej točko 3.3). Za izdelavo področnega skladišča je v primerjavi z izdelavo podatkovnega skladišča, potrebno občutno manj časa, prav tako so nižji tudi stroški. Ker z njim izpolnjujemo zahteve ožjega kroga uporabnikov, ga je lažje specificirati, kot celotno skladišče. Količina shranjenih podatkov je navadno toliko manjša, da za uspešno uporabo podatkov lahko uporabimo mnogo cenejšo strojno opremo, kot bi jo potrebovali za izdelavo celovitega podatkovnega skladišča. TABELA 3: Razlika med podatkovnim in področnim skladiščem Podatkovno skladišče Področno skladišče Poslovanje celotne banke Poslovanje sektorja Obseg Mnogo Malo Število podatkovnih virov 100 GB – 1TB + < 100 GB Velikost Meseci, leta Meseci Čas trajanja projekta Veliki sistemi Manjši sistemi Platforme Vir: Černe in Bratuša (2000, 175); Prednosti področnih skladišč v primerjavi s celovitim podatkovnim skladiščem so naslednje: hitrejši in cenejši razvoj, zaradi njihove majhnosti so lažje obvladljiva in bolje prilagojena specifičnim uporabniškim zahtevam. Slabosti področnih skladišč pa se kažejo v dejstvu, da bi za vzpostavitev pregleda nad celotnim podjetjem potrebovali izgrajena in med seboj usklajena področna skladišča, ki bi pokrivala vsa področja poslovanja. Za to bi potrebovali občutno več resursov, kot pri izgradnji celovitega podatkovnega skladišča. Zaradi fizične razdrobljenosti pa bi bila manjša tudi hitrost pregleda celovitih, združenih podatkov. _____________________________________________ 7 Področno skladišče imenujemo tudi namensko podatkovno skladišče – angl. Data mart..
(23) 23. Ali je primernejše v podjetju zgraditi sistem povezanih področnih skladišč ali celovito podatkovno skladišče, je odvisno od stanja v posameznem podjetju. Včasih najprej kot pilotski projekt zgradimo področno skladišče in pridobimo potrebne izkušnje za izgradnjo celovitega podatkovnega skladišča. Pri odločitvi se moramo ozirati tudi na stopnjo urejenosti trenutnega informacijskega sistema. Lastnosti visoke stopnje urejenosti so (Černe in Bratuša 1999, 180-182): -. urejeni in enotni registri in šifranti,. -. nepodvojeni podatki,. -. hiter in enostaven dostop do podatkov,. -. visoka stopnja zanesljivosti delovanja informacijskega sistema,. -. možnost hitre ponovne postavitve sistema ob padcu, brez izgub podatkov in transakcij.. Visoka stopnja urejenosti je predpogoj za uspešno izgradnjo centralnega podatkovnega skladišča. V primeru nižje stopnje urejenosti, moramo oceniti koliko sredstev in naporov je potrebno vložiti v urejanje obstoječega informacijskega sistema in se na osnovi tega odločiti ali je izgradnja centralnega podatkovnega skladišča smiselna ali se moramo zadovoljiti s področnimi (Černe in Bratuša 1999, 182)..
(24) 24. 4.1. Struktura podatkov v podatkovnem skladišču. Podatkovno skladišče vsebuje detajlne in sumarizirane podatke. Struktura teh podatkov je prikazana na naslednji sliki. Slika 6: Struktura podatkov v podatkovnem skladišču. Visoko sumarizirani podatki. Nizko sumarizirani podatki. Meta podatki. Referenčni detajlni podatki. Zgodovinski podatki. Vir: Singh(1998, 19); 4.1.1. Referenčni detajlni podatki. To so tisti podatki, ki prihajajo neposredno iz operativnega nivoja. Predstavljajo jedro podatkov in s tem največjo skrb za upravljanje in interes po njih. Najpomembnejši vzroki za to so:.
(25) 25. -. ti podatki odsevajo nedavno ali pravkar nastalo dogajanje, ki je vedno predmet največjega zanimanja.. -. količina teh podatkov je daleč največja, saj se nahajajo na najnižjem nivoju granulacije8.. -. shranjeni morajo biti na načine, ki omogočajo zelo hiter dostop, kar pa je lahko zelo drago in kompleksno za upravljanje.. 4.2.2 Sumarizirani podatki V tabelah podatkovnega skladišča se sčasoma pojavi velika količina podatkov, kar vpliva na hitrost poizvedovanja. Eden izmed načinov pospeševanja iskanja podatkov je s pomočjo sumariziranih tabel. Podatke v podatkovnem skladišču lahko združimo po eni ali več dimenzijah, ki jih podatki vsebujejo in tako dobimo sumarizirano tabelo, v kateri je občutno manj podatkov kot v originalni tabeli. Po kateri dimenziji se naj združijo podatki ponavadi določijo uporabniki. Izberejo tiste poizvedbe, ki jih ponavadi potrebujejo za dnevna poročila, na primer spisek vseh kreditov z dnevom zapadlosti na dan poizvedbe. Z vsako sumarizirano tabelo se v podatkovnem skladišču rezervira določen prostor, poveča pa se hitrost pridobivanja podatkov, saj se sumarizirane tabele dnevno ažurirajo in so vedno na voljo sveži podatki. Nizko sumarizirani podatki predstavljajo destilirane podatke iz nižjega nivoja referenčnih detajlnih podatkov in njihova kakovost predstavlja kakovost podatkovnega skladišča. Ker vsi poslovni elementi (oddelki, sektorji, poslovne funkcije...) nimajo enakih informacijskih zahtev, morajo učinkovita podatkovna skladišča oskrbovati posamezne poslovne elemente s prilagojenimi in sumariziranimi podatki, ki jih potrebujejo. Pri načrtovanju strukture teh podatkov je potrebno upoštevati: -. Kakšen naj bo čas sumarizacije?. -. Kakšno vsebino oz. atribute naj ti podatki imajo?. Zaradi pogostosti uporabe so nizko sumarizirani podatki skoraj vedno shranjeni na diskih. Visoko sumarizirane podatke pridobimo iz referenčnih detajlnih podatkov na zelo kompleksen način. Te podatke uporabljajo predvsem nosilci poslovnih odločitev (managerji). Količina podatkov na tem nivoju je veliko manjša, kot na predhodnih nivojih. Zaradi manjše pogostosti uporabe, se lahko nahajajo znotraj skladišča ali zunaj nekih meja, ki omejujejo podatkovno skladišče. V vsakem primeru pa so ti podatki del podatkovnega skladišča, ne glede na to, kje se fizično nahajajo. ______________________________________________ 8 Večja kot je granulacija, manjša je podrobnost podatkov in obratno.
(26) 26. 4.2.3 Zgodovinski podatki Lahko jih poimenujemo tudi arhivski podatki. So podatki iz starejših časovnih obdobij. Ohranjamo jih zato, ker predstavljajo neke značilne in pomembne informacije, ki jih lahko uporabljamo za napovedovanje in analize trendov9. Poleg starih podatkov se tukaj nahajajo tudi meta podatki od teh starih podatkov. Ker se ti podatki uporabljajo relativno poredko, jih ne hranimo na diskih, temveč na npr. magnetnih trakovih. 4.2.4 Meta podatki Najpomembnejša komponenta podatkovnega skladišča so meta podatki, ki so namenjeni razlagi vsebine podatkov in procesov v skladišču. Lahko jih primerjamo s kazalom v knjigi, vendar so še več. Meta podatki ne vsebujejo podatkov iz OLTP aplikacij, ampak vsebujejo informacije o tem, kdaj so določeni podatki prišli v skladišče, iz katerega sistema in s katerim orodjem. V njih so tudi informacije o tem, kdo je odgovoren za podatke, kdo je lastnik in kdo z njimi upravlja. Zaradi visoke stopnje normalizacije tabel dejstev, so v meta podatkih tudi opisi posameznih polj in zapisov in pa opisi ključev v posameznih tabelah. Meta podatki predstavljajo posebno skupino podatkov, ker ne vsebujejo informacij dobljenih direktno iz operacijskega okolja. Uporabljajo se kot: -. usmerjevalci, za pomoč analitikom pri pregledovanju vsebine skladišča,. -. vodiči, za pravilno pozicioniranje podatkov pri transformaciji le-teh iz operacijskega okolja v okolje skladišča podatkov,. -. vodilo za algoritme, ki se uporabljajo za sumarizacijo nizko sumariziranih podatkov iz referenčnih detajlnih podatkov sumarizacijo visoko sumariziranih podatkov iz nizko sumariziranih.. ______________________________________________________________ 9 Ti podatki so osnova za izkopavanje podatkov (več v naslednjih poglavjih)..
(27) 27. 5. PRENOS PODATKOV V PODATKOVNO SKLADIŠČE. V aplikacija OLTP se podatki vpisujejo večinoma ročno, včasih tudi z avtomatiziranimi procesi. S tem se doseže namen, da so poslovni procesi informacijsko podprti in da o vsakem poslovnem dogodku obstaja urejena, elektronska dokumentacija. Ker se v podatkovna skladišča vnaša velika količina podatkov, iz različnih virov in včasih tudi za nazaj, jih je nemogoče vnašati ročno. Virov je lahko več, na primer podatkovne baze raznih OLTP aplikacij, preglednice, kupljene podatkovne baze in podobno. Za prenos podatkov iz določenega vira je potrebno izdelati poseben programski vmesnik, ki pravilno zajema podatke, jih obdela, preveri in popravi njihovo pravilnost ter shrani v podatkovnem skladišču, v naprej predpisani obliki. Seveda je potrebno vzpostaviti tudi avtomatsko proženje teh vmesnikov v določenih časovnih intervalih. Osnovni procesi, ki oblikujejo podatkovno skladišče so naslednji (Singh 1998,22): -. Ekstrakcija podatkov in nalaganje v začasne tabele.. -. Čiščenje in transformacija podatkov v obliko, ki je primerna za velike količine podatkov in omogoča kratke čase pri poizvedovanju.. -. Nalaganje podatkov v podatkovno skladišče.. -. Arhiviranje podatkov in njihova zaščita.. -. Kreiranje poizvedb. Proces ETL10. 5.1. Proces ETL se sestoji iz treh postopkov: -. ekstrakcije podatkov iz izvornih sistemov (OLTP aplikacije, zunanji podatki),. -. čiščenja podatkov in transformacije ter. -. nalaganja podatkov v podatkovno skladišče.. ____________________________________________________________________________ 10 angl. ETL – Extraction, Transformation, Load (Izločitev, transformacija, nalaganje podatkov).
(28) 28. Slika 15: Osnovni procesi, ki oblikujejo podatkovno skladišče. Vir: Anahory in Murray (1997, 22); Ti procesi predstavljajo največ časa in truda v celotnem projektu gradnje podatkovnega skladišča, tudi do 80 %. Na trgu obstajajo namenska orodja, ki olajšajo te procese, lahko pa se jih lotimo programirati sami (PL/SQL11 procedure, programsko jezik C…). 5.1.1. Ekstrakcija podatkov. Namen faze ekstrakcije podatkov je ustvarjanje ločene zbirke podatkov, ki so iz izvornega okolja preneseni v nekem časovnem preseku, v katerem se njihova slika v izvornem okolju ne spreminja. Podatki predstavljajo točen posnetek stanja v trenutku prenosa. Prenos podatkov se vrši iz izvornega okolja v vmesne, začasne tabele, znotraj podatkovnega skladišča, ob tem pa se struktura in oblika podatkov ohrani in ostane ista kot v viru podatkov. Podatki se morajo prenesti znotraj skladišča čim hitreje, tako da je časovno okno prenosa čim krajše. To postaja kritično, ko se število izvornih podatkovnih virov veča in časovno okno manjša. V okviru ekstrakcije podatkov poteka tudi nalaganje podatkov v začasne tabele znotraj skladišča, v katerih se kasneje vrši čiščenje podatkov in transformacija. V okviru tega nalaganja lahko opravimo tudi preproste transformacije podatkov kot so:. ________________________________________________________________________ 11 angl. PL/SQL – Procedural Language / Structured Query Language (proceduralni jezik / strukturiran poizvedovalni jezik).
(29) 29. -. Iz tabel izločimo stolpce podatkov, ki jih sigurno ne bomo potrebovali.. -. Poenotimo podatkovne tipe istih podatkov (npr. vse datume v osemmestno obliko LLLLMMDD).. S tem si olajšamo delo v naslednji fazi kompleksnih transformacij. 5.1.2 Čiščenje podatkov in transformacija Pri čiščenju podatkov moramo paziti, da so podatki (Singh 1998, 25): -. Konsistentni sami s sabo. Če vzamemo posamezno vrstico podatkov v tabeli, mora njena vsebina imeti smisel. Te napake so pogosto povzročene z napakami v izvornih sistemih, npr. napačne telefonske številke, naslovi…. -. Konsistentni z ostalimi podatki v istem izvoru podatkov. Na primer, vse vrednosti vrste prometa v tabeli Promet morajo biti tudi v veljavnem šifrantu Vrsta prometa.. -. Konsistentni s podatki v ostalih izvorih podatkov. Na primer, primerjati je potrebno zapis o komitentu z zapisom o komitentovih dogodkih v drugi podatkovni bazi. V primeru razlikovanja morajo uporabniki odločiti, kateri zapis je bolj pravilen. Ta preverjanja so med najzahtevnejšimi.. -. Konsistentni s podatki, ki so že v podatkovnem skladišču. Zagotoviti moramo, da podatki, ki jih vnašamo v skladišče ne nasprotujejo že obstoječim podatkom.. Ta preverjanja so zakodirana in se morajo avtomatsko izvesti v okviru procesa ETL pri vsakem polnjenju podatkovnega skladišča. To pomeni brez intervencij operaterjev. Če kateri test konsistentnosti ''pade'' ga moramo ponoviti. V nobenem primeru pa podatkov, ki ne zadostijo temu testu, ne smemo naložiti v podatkovno skladišče, ker bi se s tem zmanjšala kvaliteta podatkov. Ko so podatki očiščeni jih moramo preoblikovati v strukturo, primerno za podatkovna skladišča. S tem imamo v mislih, da se doseže čim boljše razmerje med zmogljivostjo oziroma hitrostjo poizvedovanj (čim večja) in operacijskimi stroški delovanja (čim manjši). Kot sem že omenila, je najprimernejša struktura za podatkovna skladišča oblika zvezde. V to obliko pretvorimo očiščene podatke že v začasnem prostoru skladišča. V središče te strukture postavimo eno ali več tabel dejstev, katerim pridružimo potrebne dimenzijske tabele. V tej fazi določimo tudi ključe, po katerih se podatki v teh dveh vrstah tabel združujejo..
(30) 30. Po zaključku transformacije so podatki izvornih virov podatkov prečiščeni in se nahajajo v začasnih tabelah, ki imajo enako (zvezdno) strukturo, kot je v podatkovnem skladišču. 5.1.3 Nalaganje podatkov V tej fazi se transformirani podatki iz začasnih tabel naložijo v podatkovno skladišče. Ob tem se seveda postavijo vsi indeksi, ki so potrebni za čim hitrejše poizvedovanje. Vnos podatkov moramo narediti v čim krajšem času, kar vedno ne gre, ker so predvsem tabele dejstev zelo velike. Ob vsakem vnosu zapisa pa se kreira tudi indeks. Zato velja pravilo, da se pred vnosom podatkov v skladišče vsi indeksi v tabeli dejstev pobrišejo, nato se podatki naložijo in na koncu se zopet postavijo indeksi, tokrat na dopolnjeni tabeli dejstev. Ta način se je izkazal za najhitrejšega. Pri nalaganju dimenzijskih tabel se tega postopka običajno ne poslužujemo, ker je njihova velikost veliko manjša. S tem procesom je ETL zaključen, lahko pa v smislu olajšanja uporabnikovega dostopa do podatkov naredimo še dve akciji in sicer: -. kreiranje pogledov12 in. -. sumariziranih podatkov.. Čeprav so poizvedovanja po pogledih malo zamudnejša od poizvedovanja po tabelah (pogled se mora izvesti) je včasih priporočljivo, da imamo na voljo pogled za npr. vrsto prometa v zadnjem četrtletju. Določene poizvedbe se v podatkovnih skladiščih pogosteje izvajajo in za te je priporočljivo, da se pripravijo sumarizirani podatki. Takšni podatki so vsi statistični podatki. Pravila za sumarizirane podatke so znana v naprej (v meta podatkih) zato se sumarizirani podatki kreirajo avtomatsko ob vsakem novem vnosu v podatkovno skladišče. Sumarizirane podatke dejansko skreirajo SQL stavki v okviru PL/SQL procedur ali v na primer v programskem jeziku C. 5.1.4 Časovnost postopkov ETL13 Kot sem že omenila, se podatki, ki so enkrat v skladišču, ne spreminjajo in so ves čas na razpolago za poizvedovanje in analize, razen takrat, ko se skladišče polni oziroma poteka proces ETL. Postopki v procesu ETL so ponavadi dolgotrajni, zato je potrebno te postopke opraviti takrat, da to ne moti poslovnega procesa podjetja. ____________________________________________________________________________ 12 V pogledu (angl. View) iz več tabel združimo določene atribute, ki nas v določenem trenutku najbolj zanimajo. 13 Povzeto po (Perko 2002,22)..
(31) 31. Že pri načrtovanju podatkovnega skladišča je potrebno določiti pogostost uvažanja novih podatkov (kvartalno, mesečno, tedensko, dnevno) in določiti časovno okno, znotraj katerega se morajo postopki ETL končati. Paziti moramo na dvoje: -. Da so podatki v izvornem sistemu v celotnem trajanju ETL postopka ne spreminjajo (zato je potrebno počakati, da se vsi poslovni proces za tisti čas, npr. dan, končajo).. -. Da se v celotnem trajanju ETL postopka v podatkovnem skladišču ne vršijo analize in poizvedovanja podatkov.. Težavo lahko predstavljajo podatkovna skladišča, ki morajo biti na razpolago 24 ur na dan (na primer za potrebe internet bančništva). V tem primeru se uporabljata dve podatkovni skladišči, ki sta organizirani tako, da se eno polni s podatki, medtem ko je drugo na voljo uporabnikom in obratno. 5.1.5 Vmesniki za podporo procesa ETL14 V podporo procesu ETL je potrebno izdelati programe, ki se avtomatizirano prožijo v določenih intervalih in napolnijo podatkovno skladišče s svežimi podatki. Tem programom pravimo vmesniki. Napišejo se lahko ročno ali pa se za njihovo izgradnjo uporabi orodje za generiranje kode. Če se odločimo za prvi način, lahko vmesnike napišemo v programskem jeziku (na primer C) ali kot PL/SQL proceduro. Prednost tega načina je v prilagodljivosti obstoječemu sistemu in v začetku njihove implementacije tudi v hitrosti prvih rezultatov. Slabosti pa se kažejo v relativno slabi dokumentiranosti, nizkem nivoju standardiziranosti in visokih stroških vzdrževanja. Prednost generiranih vmesnikov je avtomatska izdelava meta podatkov o prenosu in o podatkih, prenesenih v podatkovno skladišče ter možnosti izdelave popolnoma standardiziranih vmesnikov z možnostjo dostopa do podatkov, shranjenih v različnih oblikah ter podatkovnih strukturah. Primer orodja za avtomatizirano prenašanje podatkov med različnimi viri podatkov in podatkovnim skladiščem je MS DTS15.. __________________________________________________________________________ 14 Povzeto po (Perko 2002, 22). 15 MS DTS – Microsoftovo orodje za prenos podatkov, ki je del podatkovnega strežnika MS SQL server..
(32) 32. 5.1.6 Kakovost izvornih podatkov16 Podatki se v podatkovno skladišče prenašajo iz dveh razlogov: -. Da zagotovimo lažje iskanje in analiziranje združenih podatkov iz različnih virov.. -. Da zagotovimo kvalitetne rezultate povpraševanj in poročil.. Ker podatki ne nastajajo v samem podatkovnem skladišču, ampak so vanj preneseni iz zunanjih virov, je večina težav povezana z nizko kakovostjo podatkov v virih, iz katerih se podatki črpajo. Obstaja pa tudi možnost, da se kakovost podatkov zmanjša pri prenosu v podatkovno skladišče. Poseben problem predstavljajo podvojeni podatki, ki so shranjeni na različnih lokacijah in neodvisnih sistemih. Ti predstavljajo določeno tveganje, saj se lahko isti podatek na prvi lokaciji spremeni, na drugi(h) pa ne, kar povzroči nekonsistentnost podatkov. Razrešiti je potrebno dilemo, kateri vir je točen (Černe in Bratuša 1999, 182). V primerih nizke kakovosti podatkov že v izvornih aplikacijah, velja pravilo GIGO17. V teh primerih je potrebno preveriti ali je smiselno razmišljati o alternativnih virih, o posegih v izvorne aplikacije ali pa v vmesnike do podatkovnega skladišča vgraditi tako imenovane ''čistilce podatkov''. Vsaka od navedenih treh možnosti ima prednosti in slabosti: -. Alternativnih virov v organiziranem poslovnem okolju ponavadi ni na voljo, saj so podatki zaradi optimizacije poslovnega procesa načeloma zajeti le v eni poslovni aplikaciji.. -. Posegi v izvorne aplikacije so lahko finančno in časovno izredno zahtevni, saj je potrebno posegati v podatke poslovnih aplikacij, spreminjati delujoče postopke ter včasih korigirati tudi ustaljeno organizacijo delovnih procesov.. -. S tako imenovanimi čistilci podatkov je v procesu ETL mogoče popraviti nekatere ugotovljene pomanjkljivosti podatkov. Vendar je popravljanje podatkov v vmesnikih bolj primerno za rešitev v sili, manj pa za trajno rešitev, saj je pravilnost delovanja ''čistilcev podatkov'' zelo težko nadzorovati in tako zagotavljati visoko kakovost podatkov.. Pri ocenjevanju kakovosti podatkov se ocenjujejo predvsem verjetnosti napak, njihova resnost ter stroški popravila. V začetku delovanja podatkovnega skladišča se v podatkovnem skladišču nahajajo tudi podatki, ki ne dosegajo želenega nivoja kakovosti, zaradi česar je pred uporabo podatkov iz skladišča potrebno izvesti postopek višanja kvalitete podatkov. V tem postopku se sprva odkrivajo napake, 16 Povzeto po (Perko 2002, 18-20). 17 GIGO – angl. Garbage In, Garbage out (smeti noter, smeti ven)..
(33) 33. oziroma podatki z nezadovoljivo kakovostjo. V nadaljevanju postopka se določi resnost posledic ob napaki in identificirajo posegi, ki napake odpravljajo. Po preučitvi napak in stroškov za odpravo le-teh, se določi zaporedje dejanj za izboljšanje kakovosti podatkov v podatkovnem skladišču..
(34) 34. 6. IZGRADNJA PODATKOVNEGA SKLADIŠČA V NKBM d.d.. Z večanjem konkurence na področju finančnih institucij so se le-te zavedle, da morajo svoje storitve bolj prilagoditi in usmeriti proti komitentu, če hočejo zagotoviti njegovo zadovoljstvo in lojalnost. Bistveno je postalo dobro poznavanje komitenta, njegovega poslovanja in povezav s finančno institucijo kot celoto. Produktno usmerjeno trženje sta začela nadomeščati bolj direkten pristop do komitenta in komitentu prilagojena ponudba storitev. Banke so začele ugotavljati kdo so njihovi komitenti, kako se obnašajo in kateri od njih so najbolj dobičkonosni, ter usmerjati svoje napore v to, da slednje zadržijo. S spoznavanjem vzorcev obnašanja svojih komitentov so vzporedno lahko bolj usmerjeno in učinkovito iskale poslovne priložnosti na trgu. Večina bank se danes utaplja v podatkih. Managerji so se začeli zavedati, da podatki o komitentih in podatkovne baze o poslovanju predstavljajo neprecenljivo bogastvo. Slika 8: Poslovanje banke. Prvi napori drugačnega načina poslovanja bank so bili vloženi v iskanje povezav med produktnimi sistemi na ravni komitenta in ustvarjanju centralnega pogleda na komitenta in njegovo poslovanje. Ob veliki konkurenci na trgu pa je postalo jasno, da samo spremljanje komitenta ne bo dovolj – da bo potrebno komitenta razumeti – njegove navade, uporabe produktov, uporabe kanalov za poslovanje (enote banke, elektronsko plačevanje, klicni center, mobilno plačevanje in ostalo) ter razumeti tudi dobičkonosnost in tveganost njegovega poslovanja za banko. V podatkovnih bazah bank se skrivajo še druge pomembne informacije. Informacije, na podlagi katerih je mogoče identificirati potencialne komitente, predvideti obnašanje in preference komitentov, oceniti potrebe trga po finančnih.
(35) 35. storitvah in spremljati razvoj trga ali pa spremljati poslovanje banke in analizirati njeno uspešnost, pomenijo veliko konkurenčno prednost. Tak pogled na poslovanje banke s komitentom je povzročil, da so začeli v bankah razmišljati o podatkovnih skladiščih. Vzroke, zakaj smo se v NKBM d.d. odločili za izgradnjo podatkovnega skladišča, lahko strnemo v naslednje predpostavke: -. hitrejše, lažje in kakovostnejše pridobivanje podatkov,. -. boljša odzivnost do komitentov s poudarkom na svetovanju,. -. pristop k celovitemu trženju vseh bančnih storitev na enem mestu,. -. podlaga za tržno orientirano organizacijo poslovnih procesov,. -. hitra izdelava poročil, analiz za potrebe banke in zunaj nje s kakovostnimi podatki,. -. povezava s projektom CRM-ja18.. 6.1. Izbira tehnologije. V NKBM d.d. smo se odločili, da podatkovno skladišče zgradimo na Oraclovi tehnologiji. Podatki so shranjeni v obliki dimenzijskih podatkovnih modelov v relacijski zbirki podatkov Oracle, pri čemer se v praksi uporabljajo najsodobnejše zmogljivosti zbirke podatkov pri delu z zelo velikimi količinami podatkov: -. fizično deljenje tabel (partitoning),. -. materializirani pogledi (materialized views),. -. mehanizem prepisa poizvedb (query rewrite),. -. uporaba analitičnih funkcij ter. -. druge tovrstne možnosti, ki omogočajo kar najbolj učinkovito delovanje zbirke podatkov.. Zaradi različnih virov podatkov je prenos podatkov v skladišče realiziran s pomočjo izdelanih procedur v jeziku PL/SQL. Aplikacija preko katere bodo uporabniki lahko dostopali do podatkov v podatkovnem skladišču, bo spletna aplikacija, programirana v javi. ___________________________________________________________________________ 16 CRM – angl. Customer Relationship Management (upravljanje odnosov s strankami)..
(36) 36. 6.2. Analiza in definicija podatkovnih virov. 6.2.1 Določitev izvorne baze podatkov Izvorna baza podatkov je tista, iz katere gradimo podatkovno skladišče. V večini primerov je to baza podatkov transakcijskega informacijskega sistema. V našem primeru je izvorih baz podatkov več, saj podatke črpamo iz več različnih transakcijskih aplikacij, ki delujejo na različnih platformah. Vire od koder prenašamo podatke v podatkovno skladišče predstavljajo naslednje aplikacije, s svojimi podatkovnimi modeli: -. aplikacija za vodenje Kreditov/Depozitov Krede, za področje Maribora, baza podatkov je v Supra,. -. aplikacija za vodenje Kreditov Depozitov Kart, za področje Nove Gorice, baza podatkov je Supra,. -. aplikacija Tolarskega plačilnega prometa TIS, baza podatkov je Supra,. -. aplikacija NOBIS, baza podatkov je Oracle,. -. aplikacija plačilnega prometa Devize podjetij, baza podatkov so VSAM datoteke,. -. podporna aplikacija vodenja vrednostnih papirjev in kapitalskih naložb, podatke smo pridobili v tekstovni ''txt'' obliki.. Pred prenosom podatkov smo najprej opredelili tabele, ki smo jih želeli prenesti v podatkovno skladišče ter v posamezni tabeli definirali vrste podatkov, ki jih bomo prenesli v shrambo in kasneje v podatkovno skladišče. Tabele z izbranimi tipi podatkov predstavljajo izvorne tabele iz katerih črpamo podatke za izgradnjo shrambe. Za prenos podatkov iz posameznega vira je potrebno izdelati poseben programski vmesnik, ki pravilno zajema podatke in jih v naprej predpisani tabeli shrani v shrambo. 6.2.2 Ustvarjanje shrambe Namen shrambe je, kot že pove ime samo, shranjevanju podatkov. Vse podatke izvornih tabel smo transformirali v Oracle-ve tabele. Preneseni podatki predstavljajo točen posnetek stanja v trenutku prenosa. Glede na to, da smo prenašali podatke iz toliko različnih virov, je sledila faza ekstrakcije, ki zajema čiščenje in transformacijo podatkov:.
(37) 37. 6.3. -. iz šifrantov poiskati in brisati dvojnike,. -. poenotenje podatkovnih tipov,. -. preveriti smiselnost vsebine prenesenih podatkov,. -. preveriti konsistenost z ostalimi podatki,. -. primerjati zapise o istem komitentu iz dveh različnih virov, ter odločiti kateri zapis je bolj pravilen. Arhitektura in struktura podatkov v podatkovnem skladišču NKBM d.d.. Prednosti zvezdne strukture podatkovnega skladišča sem že naštela v poglavju 4.1, Ker dopušča enostavno rast in širitev podatkovnega skladišča z relativno majhnimi posegi smo se za zvezdno obliko podatkovnega skladišča odločili tudi v naši banki. Ne nazadnje je na to izbiro vplivala tudi federativna arhitektura podatkovnega skladišča. Slika 9 – grafični prikaz Podatkovnega skladišča za pravne osebe v NKBM d.d..
(38) 38. Podatkovni model ima dve tabeli dejstev: -. Prva tabela dejstev je tabela z nazivom Promet, preko katere bomo lahko dostopali do vseh transakcij po vrstah prometa in storitvah, za posameznega komitenta.. -. Druga tabela dejstev ima naziv Stanje, v njej bodo sumarizirani podatki o prometu. Vsebovala bo podatek o dnevnem, tedenskem, mesečnem, kvartalnem, letnem stanju, po vrstah prometa in storitvah.. Ostale tabele v podatkovnem modelu so dimenzijske tabele in vsebujejo naslednje dimenzije: -. Komitent, vsebuje podatke o komitentu.. -. Račun, vsebuje matične podatke o transakcijskih računih.. -. Stroškovno mesto, vsebuje podatke os stroškovnih mestih.. -. Valuta, vsebuje podatke o valuti.. -. Časovna dimenzija, vsebuje podatke o datumu.. -. Storitev, vsebuje podatke o analitiki.. -. Tip prometa, vsebuje podatke o vrsti prometa.. -. Obrestna mera, vsebuje podatke o obrestni meri.. -. Plačilni instrument, vsebuje podatke o plačilnih instrumentih.. -. Kanal, vsebuje podatke o kanalu preko katerega so bila realizirana plačila.. Podatkovno skladišče v NKBM d.d. gradimo postopoma. V podatkovno skladišče smo najprej prenesli podatke, ki zajemajo integrirano sliko komitenta pravne osebe z naslednjimi glavnimi sklopi: -. splošnimi podatki o komitentu (naslov, telefonska številka, številka TRR, davčna številka in podobno),. -. mehke informacije (beležke o sestankih, sklenjeni dogovori, opombe, izpolnjevanje pogojev ),. -. povezane osebe povezanosti),. -. boniteta,. (spisek. celotne. skupine. povezanih. oseb,. način.
(39) 39. -. poslovno sodelovanje (prikaz stanja, po vrstah prometa za določen dan),. -. tolarski in devizni plačilni promet,. -. vrednostni papirji.. 6.3.1 Hierarhije v dimenzijah Hierarhije v dimenziji komitent so: -. Geografska hierarhija • Regija • Skupina občin • Občina. -. Hierarhija vrste komitenta • Tip komitenta • Vrsta komitenta. Hierarhije v dimenziji storitev so : - Hierarhija v poslu • tip posla (aktivni, pasivni) • Storitev (kreditiranje, varčevanje) • Tip storitve • Vrsta vloge • Analitika -. Hierarhija po ročnosti • Tip posla (aktivni pasivni) • Storitev (kreditiranje, varčevanje) • Tip storitve • Ročnost • Analitika. Hierarhije v časovni dimenziji so: - Hierarhija 1 • Dan • Mesec • Kvartal • Polletje • Leto -. Hierarhija 2 • Dan • Teden.
(40) 40. 6.4. Struktura kadrov pri izgradnji podatkovnega skladišča v NKBM d.d.. Pri projektu izgradnje podatkovnega skladišča so sodelovali bodoči uporabniki podatkovnega skladišča, tehnologi, ki poznajo poslovne tokove v banki ter informatiki. Iz naslednje preglednice je mogoče razbrati koliko ljudi iz posameznega področja je sodelovalo v projekti in katere so bile njihove glavne naloge: Tabela 4: Struktura kadra na projektu izgradnje podatkovnega skladišča Št. ljudi Področje Naloge 2 Informatika Nova Gorica Prenosi šifrantov in izdelava procedur za prenos podatkov na področju Nove Gorice 4 Informatika Maribor Prenosi šifrantov, izdelava procedur za prenos podatkov, izdelava prototipa spletne aplikacija, programiranje spletne aplikacije, izdelava izpisov poročil 1 Sektor trženja in razvoja Specifikacija za programiranje storitev uporabniške aplikacije, oblikovanje navodil za uporabnike 3 Sektor naložb in sredstev Definiranje šifrantov in podatkov, ki jih je potrebno prenesti in preverjanje pravilnosti podatkov v testni verziji aplikacije za področje naložb in sredstev 1 Sektor plana in analiz Definiranje šifrantov in podatkov, ki jih je potrebno prenesti in preverjanje pravilnosti podatkov v testni verziji aplikacije za področje plana in analiz 1 Sektor poslovanja s tujino Definiranje šifrantov in podatkov, ki jih je potrebno prenesti in preverjanje pravilnosti podatkov v testni verziji aplikacije za področje poslovanja s tujino 1 Sektor merjenje kreditnega Definiranje šifrantov in podatkov, ki jih portfelja je potrebno prenesti in preverjanje pravilnosti podatkov v testni verziji aplikacije za področje merjenja kreditnega portfelja.
Gambar

Dokumen terkait
Pri pregledu in primerjavi izračunanih podatkov kriminalitetno število kaznivih dejanj v zvezi z drogami na 10.000 prebivalcev, sem za povprečje vzel podatek za Slovenijo, je
Tabela 4: ŠTEVILO UPORABNIKOV ELEKTRONSKEGA BANČNIŠTVA V SLOVENIJI Banka Nova Ljubljanska banka NKBM SKB banka Banka Koper Gorenjska banka Banka Celje Poštna banka Slovenije
12.2 KAZALO TABEL Tabela 1: Pregled delovnih mest po zasedbi in spolu delavcev za leto 2004, stran 26, Tabela 2: Pregled delovnih mest po zasedbi in spolu delavcev za leto 2005,
KAZALO TABEL Tabela 1: Sestava prebivalstva po formalnem statusu – registriranih virih Tabela 2: Medobčinske delovne migracije v občini Gorenja vas - Poljane Tabela 3: Temeljni
Tako sta v Sloveniji največja ponudnika zunanjega oglaševanja prav podjetje Proreklam in podjetje Metropolis Media, ki imata skupaj že več kot 6000 površin panojev oziroma
Zaradi skromnih donosov domačih vrednostnih papirjev se še naprej močno krepijo naložbe v tujino, saj je obseg sredstev skladov, ki imajo več kot polovico naložb v tujih
Zaradi omejenega dostopa do podatkov trgovinskega sodelovanja EU z Afriko bomo na tem mestu pojmovali Afriko v okviru sodelovanja EU s skupino AKP, katera zajema večino držav
Tabela 7: Število samozaposlitev po občinah v obdobju 2001 – 2004 Oddelek za prestrukturiranje RTH, 2006 Tabela 8: Število prezaposlitev in samozaposlitev skupaj po občinah v
