Jom F.TEKNIK Volume 1 NO. 2 Oktober 2014 1
ANALISA PREDIKSI DATA DEBIT RUNTUN WAKTU MENGGUNAKAN
JARINGAN SYARAF TIRUAN
ALGORITMA BACKPROPAGATION
(STUDI KASUS DAS INDRAGIRI)
Gian Habriandi Tarigan1, Manyuk Fauzi2, Imam Suprayogi2
1
Jurusan Teknik Sipil Program S-1, Fakultas Teknik Universitas Riau
2
Staff Pengajar Jurusan Teknik Sipil Fakultas Teknik Universitas Riau Pekan baru Kampus Bina Widya JL. HR Soebrantas KM 12,5 Pekanbaru Pos 28293
E-mail : [email protected]
ABSTRAK
Peramalan data debit runtun waktu Qn untuk Qn+1 mengunakan pendekatan model Jaringan
Syaraf tiruan Algoritma Backpropagation menghasilkan nilai korelasi yang baik antara Debit prediksi dan Debit aktualnya, hal ini juga dipengaruhi oleh Pola data yang tersedia cukup baik, dapat dilihat dari proses pelatihan, pengujian dan validasi pada Jaringan syaraf tiruan yang menghasilkan nilai korelasi pembelajaran yang cukup tinggi.
Pada proses membangun model jaringan syaraf tiruan Algoritma Backpropagation menggunakan MATLAB, didapat nilai-nilai parameter yang memberikan hasil korelasi pembelajaran yang baik, adapun parameter tersebut yaitu Epoch =2000, lr = 0,1 , mc = 0,9, parameter tersebut telah melalui percobaan yang berulang-ulang terhadap masing-masing variasi parameter yang mempengaruhi. Variasi data 80 (pelatihan) dan 20 ( pengujian) memberikan hasil korelasi yang sedikit lebih baik dibandingkan dengan variasi data 70-30 dan 75-25, hal ini dibuktikan Pada proses pengujian model Jaringan syaraf tiruan yang diaplikasikan dalam memprediksi debit tahun 2009.
Dari hasil penelitian ini dalam memprediksi debit dapat Qn+1 dikembangkan dengan melakukan
penelitian yang lebih mendalam, sehingga dapat menjadi suatu rekomendasi sistem peringatan dini banjir untuk daerah sekitar stasiun AWLR Pulau Berhala.
Kata kunci : Jaringan syaraf tiruan, Algoritma backpropagation, Peramalan data Debit Runtun waktu
Jom F.TEKNIK Volume 1 NO. 2 Oktober 2014 2
ABSTRACT
Series data forecasting discharge Qn to Qn+1 using artificial neural network modeling approach
backpropagation algorithm produces a good correlation between the value of the discharge predictions and actual discharge, it is also influenced by the pattern of the data available is quite good, it can be seen from the training process , testing and validation in MATLAB value that produces a fairly high correlation learning.
In the process of building a model of artificial neural networks using matlab backpropagation algorithm, obtained parameter values that provide a good learning outcome correlation, while the parameters that epoch = 2000, lr = 0.1, mc = 0.9, the parameters have been experimentally repeated on each of the various parameters that affect. variation in the data 80 (training) and 20 (test) results are slightly better correlation than the data variation 70-30 and 75-25, this is evidenced in the testing process neural network model is applied to predict discharge in 2009. The results of this study in predicting discharge Qn+1 be developed by conducting in-depth
research, so it may be a recommendation for a flood early warning system around the station AWLR locations berhala island.
Key word : Artificial neural network, Algoritm Backpropagation, forecasting 1. Pendahuluan
Dalam rangka kegiatan serta perencanaan di Daerah aliran sungai Indragiri dibutuhkan adanya analisis untuk tujuan-tujan tertentu, guna implementasi praktis terkadang dibutuhkan suatu metode yang sederhana tanpa penjelasan proses yang terjadi dalam suatu sistem. Dalam kegiatan perencanaan seringkali antara kesadaran terjadinya suatu peristiwa dimasa depan dan kejadian nyata peristiwa itu dipisahkan oleh rentang waktu yang cukup lama. Beda waktu inilah yang merupakan alasan utama diperlukannya suatu perencanaan (planning) dan peramalan
(forecasting). Jika beda waktu itu sama dengan nol atau cukup kecil, maka tidak diperlukan perencanaan. Sebaliknya jika beda waktu itu besar dan kejadian peristiwa dimasa depan dipengaruhi oleh faktor-faktor yang terkontrol, maka dalam hal ini suatu perencanaan sangat berperan penting (Dewi 2008). Salah satu unsur yang sangat penting dalam pengambilan keputusan adalah dengan peramalan, sebab efektif atau tidaknya suatu keputusan tergantung pada beberapa faktor yang tidak dapat kita lihat pada waktu keputusan itu sendiri diambil. Berbagai bidang baik itu Sipil, hidrologi, curah hujan, debit, banjir dan berbagai
Jom F.TEKNIK Volume 1 NO.2 Oktober 2014 3
bidang riset selalu membutuhkan peranan peramalan. Peramalan sangat diperlukan untuk mengetahui kapan suatu peristiwa akan terjadi sehingga tindakan yang tepat dapat dilakukan guna pencegahan hal-hal yang dapat merugikan.
Debit merupakan salah satu parameter penting yang biasa digunakan dalam bidang Teknik Sipil khususnya dalam bidang pengolahan sumber daya air seperti pada pembangunan waduk, irigasi pertanian, irigasi perikanan dan lain sebagainya. Menurut Joko Windarto (2008) Metode yang digunakan dalam prakiraan debit banjir dapat di kelompokkan menjadi dua yaitu model matematis/konseptual dan model black-box. Prakiraan debit secara konseptual adalah dengan memperhitungkan semua aspek siklus hidrologi yang ada dalam satu Daerah aliran sungai. Metode ini mempunyai banyak kendala di antaranya sulitnya mendapatkan data di lapangan, seperti tata guna lahan, evapotranspirasi, infiltrasi, perkolasi, interflow, dll. Sedangkan sistem prediksi banjir model black-box hanya dengan menggunakan data curah hujan dan debit yang didapat dari alat pengukur otomatis.
Dalam analisis proses hidrologi terutama prediksi Debit pada suatu Daerah aliran sungai dapat didekati menggunakan
teknik pemodelan, pemodelan jaringan saraf tiruan (JST) algoritma backpropagation merupakan salah satunya. Teknik jaringan Syaraf tiruan adalah teknik pengolahan informasi yang cara kerjanya menirukan cara kerja jaringan syaraf manusia. Salah satu penelitian JST ini dilakukan oleh Mahyudin (2013) dengan mengeksplorasi potensi JST dalam memprediksi liku kalibrasi dengan menggunakan data dari Stasiun pengukuran pantai cermin Sungai Siak menggunakan pendekatan JST algoritma backpropagation. Kinerja algoritma backpropagation pemodelan JST pada Sungai siak ini sangat baik dimana menghasilkan tingkat korelasi sangat kuat dengan nilai koefisien korelasi, R=0,9975 sehingga penelitian ini bisa dikembangkan dengan meneliti sungai-sungai lainnya yang ada di Provinsi Riau termasuk Daerah aliran Sungai Indragiri.
Dalam penelitian ini akan dikembangkan metode jaringan syaraf tiruan Backpropagation dalam peramalan/prediksi debit data runtun waktu dengan menganalisa data Automatic Water Level Recorder (AWLR) yang sudah ada.
1.1 Perumusan Masalah
Berdasarkan latar belakang diatas, maka rumusan masalah dalam penelitian ini adalah menentukan konfigurasi model
Jom F.TEKNIK Volume 1 NO.2 Oktober 2014 4
jaringan syaraf tiruan dan menilai keandalannya guna prediksi debit runtun waktu dengan memanfaatkan ketersediaan data automatic water level recorder (AWLR) pada Daerah aliran sungai Indragiri pada Stasiun Pulau Berhalo.
1.2 Tujuan dan Manfaat
Tujuan dari penelitian ini adalah memprediksi Debit pada DAS Indragiri Stasiun AWLR (automatic water level recorder) Pulau Berhalo Tahun 2010 dengan menggunakan metode jaringan saraf tiruan. Sedangkan manfaat dari penelitian ini yaitu dapat dijadikan metode alternatif dalam menentukan Debit yang lebih cepat dan akurat. Kemudian pihak pemerintah dapat menjadikan pertimbangan dalam pengambilan keputusan.
1.3 Batasan Masalah
Adapun batasan masalah pada penelitian ini adalah :
1. Data yang digunakan dalam penelitian ini adalah data AWLR (Automatic Water Level Recorder) dari DAS Indragiri 2003 s/d 2010 stasiun pulau berhalo. 2. Data 2003 s/d 2009 digunakan sebagai
data pelatihan, pengujian dan validasi dengan pembagian variasi data.
3. Jumlah data yang digunakan bervariasi :
a. Untuk proses pelatihan yaitu 70%, sedangkan untuk proses pengujian yaitu 30 % dari total data yang digunakan.
b. Untuk proses pelatihan yaitu 75%, sedangkan untuk proses pengujian yaitu 25% dari total data yang digunakan.
c. Untuk proses pelatihan yaitu 80%, sedangkan untuk proses pengujian yaitu 20 % dari total data yang digunakan.
4. Metode yang digunakan untuk mendapatkan output berupa prediksi debit adalah jaringan saraf tiruan menggunakan bahasa pemrograman Matlab 7.7.0.471 (R2008b).
5. Metode pembelajaran jaringan saraf tiruan yang digunakan yaitu algoritma backpropagation.
6. Arsitektur jaringan terdiri dari single input, multi hidden layer dan single output.
2. Metodelogi Penelitian
Secara sederhana, skema penelitian ini adalah sebagai berikut.
Gambar 1. Sistem Prediksi Debit Menggunakan JST
Qn Algoritma
JST
Jom F.TEKNIK Volume 1 NO.2 Oktober 2014 5
Dari gambar di atas, Qn sebagai data
input, merupakan debit yang mengalir pada Sungai Indragiri pada hari ke-n dan Qn+1
sebagai data target, merupakan debit yang mengalir pada hari ke-n+1. Dengan menggunakan JST yang terdapat pada software MATLAB, dibuatlah model untuk mensimulasikan sistem di atas dengan Qn
sebagai data input dan Qn+1 sebagai data
target sehingga dihasilkan suatu model. Adapun tahapan-tahapan membangun model tersebut yaitu pelatihan (training), pengujian (testing). Proses prediksi dilakukan dengan
menggunakan model hasil
pengujian(testing) kemudian debit hasil prediksi diplot ke dalam excel dalam bentuk grafik hubungan debit prediksi dan Debit Observasi yang diperoleh dari data existing yang tersedia dari data AWLR.
2.1 Pelatihan JST
Pada kegiatan pelatihan jaringan syaraf tiruan digunakan jumlah data 70%, 75% dan 80 % dari total seluruh data yang ada. Proses pelatihan menggunakan MATLAB dapat dilihat pada BAB II (sub bab 2.9 hal 21-27).
2.2 Pengujian JST
Model JST hasil pelatihan (training) perlu dilakukan pengujian untuk mengetahui apakah model JST yang telah dibangun bisa diaplikasikan untuk data yang lain atau
hanya terbatas untuk data pelatihan. Data pengujian menggunakan 20%, 25% dan 30% dari total data. Tahapan-tahapan dari proses pengujian sama dengan tahapan-tahapan pada proses pelatihan yang telah dijelaskan sebelumnya hanya berbeda pada data masukan yang digunakan.
2.3 Validasi JST
Validasi dilakukan setelah pelatihan dan pengujian selesai. Validasi ini dilakukan untuk mengaplikasikan model JST yang telah dibangun pada proses pelatihan sehingga model JST tersebut bisa digunakan untuk memprediksi Debit pada tahun 2010. 2.4 Prediksi Debit
Model JST yang telah dibangun pada proses pelatihan, lalu diuji serta dilakukan validasi digunakan untuk memprediksi Debit pada tahun 2010 data Debit tahun 2003-2009 (Q) yang diperoleh dari BWS Sumatera III Provinsi Riau.
2.5 Kriteria Pembelajaran
Pada penelitian ini digunakan 3 kriteria pembelajaran sebagai berikut:
1. Correlation Coefficient (R)
Correlation Coefficient (R) merupakan perbandingan antara hasil prediksi dengan nilai yang sebenarnya, dimana jika hasil perhitungan nilai R semakin mendekati 1, maka hasil prediksi akan
Jom F.TEKNIK Volume 1 NO.2 Oktober 2014 6
mendekati hasil yang sebenarnya. Nilai R dapat dihitung dengan persamaan berikut.
2 2 y x xy R dengan: x = X – X’, y = Y – Y’ X = Nilai pengamatan/Observasi X’ = Rata-rata nilai X Y = Nilai Prediksi Y’ = Rata-rata nilai YMenurut Suwarno (2008), koefisien korelasi adalah pengukuran statistik kovarian atau asosiasi antara dua variabel. Besarnya koefisien korelasi berkisar antara -1 sampai dengan +1. Koefisien korelasi menunjukkan kekuatan (strenght) hubungan linear dan arah hubungan dua variabel acak. Jika koefisien korelasi positif, maka kedua variabel mempunyai hubungan searah. Artinya jika nilai variabel X tinggi, maka nilai variabel Y akan tinggi pula. Sebaliknya, jika koefisien korelasi negatif, maka kedua variabel mempunyai hubungan terbalik. Artinya jika nilai variabel X tinggi, maka nilai variabel Y akan menjadi rendah. Untuk memudahkan melakukan interpretasi mengenai kekuatan hubungan antara dua variabel dibuat kriteria sebagai berikut.
a. R = 0 : Tidak ada korelasi antara dua variabel,
b. 0 < R ≤ 0,25 : Korelasi sangat lemah, c. 0,25 < R ≤ 0,50 : Korelasi cukup, d. 0,50 < R ≤ 0,75 : Korelasi kuat, e. 0,75 < R ≤ 0,99 : Korelasi sangat kuat, dan f. R = 1,00 : Korelasi sempurna. 2. Root Mean Square Error (RMSE)
Root Mean Square Error (RMSE)
merupakan besarnya tingkat kesalahan hasil prediksi, dimana semakin kecil (mendekati 0) nilai RMSE maka hasil prediksi akan semakin akurat. Nilai RMSE dapat dihitung dengan persamaan sebagai berikut.
n Y X RMSE
2 dengan: n = Jumlah data.3. Nash-Sutcliffe Efficiency (NSE)
Kriteria pembelajaran model NSE tidak jauh berbeda dengan kriteria pembelajaran yang lainnya, adapun persamaan Nash-sutchliffe efficiency (NSE) sebagai berikut :
dengan :
2 2 ) ( ) ( 1 X X Y X NSEJom F.TEKNIK Volume 1 NO.2 Oktober 2014 7
O = nilai observasi, P = nilai prediksi, dan Ō = rerata observasi.
NSE memiliki range antara – ∞ sampai dengan 1. Berdasarkan penelitian yang dilakukan oleh motovilov et al (1999), NSE memiliki beberapa kriteria seperti yang diperlihatkan pada tabel 1 berikut.. Tabel 1. kriteria Nilai Nash-Sutcliffe efficiency (NSE) Nilai Nash-sutcliffe efficiency(NSE) Interpretasi NSE > 0,75 Baik 0,36 < NSE < 0,75 Memenuhi NSE < 0,36 Tidak Memenuhi Sumber : Motovilov, et al (1999)
1. Pelatihan 1 (data 70 %)
Percobaan dilakukan dengan menggunakan 70% dari jumlah data. lalu data yang telah dibangun pada Excel diinput pada program JST, adapun proses penginputan data dapat dilihat pada gambar 4.1 berikut ini.
Gambar 2.`Pemasukan data input dan data target
Sebelum menentukan Parameter-parameter JST kita harus menentukan fungsi-fungsi yang berpengaruh pada pemodelan jaringan syaraf tiruan,adapun Fungsi-fungsi tersebut yaitu;
1) Fungsi Training, Learning dan Kinerja. Dalam peneltian ini Fungsi traning dan Learning dibatasi dengan menggunakan Fungsi TRAINGDX dan LEARNGDM, fungsi ini sudah dibuktikan dalam penelitian sebelumnya oleh Mahyudin 2013, dimana menghasilkan nilai korelasi yang optimum.
Fungsi pelatihan yang digunakan yaitu epoch, gradient descent dengan momentum dan adaptive learning rate (TRAINGDX), fungsi ini akan memperbaiki bobot-bobot berdasarkan gradient descent dengan learning rate yang bersifat adaptive dan menggunakan momentum. Dimana perubahan Learning rate mempengaruhi model JST yang kita bangun dalam menghasil Korelasi yang diharapkan. Apabila learning rate terlalu tinggi, maka algoritma menjadi tidak stabil. Sangat sulit untuk menentukan berapa nilai learning rate yang optimal sebelum proses pelatihan berlangsung. Pada kenyataannya, nilai learning rate yang optimal ini akan terus berubah selama proses pelatihan seiring dengan berubahnya nilai fungsi kinerja.
Jom F.TEKNIK Volume 1 NO.2 Oktober 2014 8
Pada fungsi TRAINGDX, nilai learning rate akan diubah selama proses pelatihan untuk menjaga agar algoritma ini senantiasa stabil selama proses pelatihan. Fungsi pelatihan TRAINGDX, pada dasarnya sama dengan fungsi pelatihan standar dengan beberapa perubahan. Pertama dihitung terlebih dahulu nilai output jaringan dan error pelatihan. Pada setiap epoch, bobot-bobot baru dihitung dengan menggunakan learning rate yang ada. Kemudian dihitung kembali output jaringan dan error pelatihan. Jika perbandingan antara error pelatihan yang baru dengan error pelatihan yang lama melebihi maksimum kenaikan kinerja (max_perf_inc), maka bobot-bobot baru tersebut akan diabaikan, sekaligus nilai learning rate akan dikurangi dengan cara mengalikannya dengan lr_dec. sebaliknya, apabila perbandingan antara error pelatihan baru dengan error pelatihan lama kurang dari maksimum kenaikan kinerja, maka nilai bobot-bobot akan dipertahankan, sekaligus nilai learning rate akan dinaikkan dengan cara mengalikannya dengan lr_inc. Dengan cara ini, apabila learning rate terlalu tinggi dan mengarah ke ketidakstabilan, maka learning rate akan diturunkan. Sebaliknya, jika learning rate terlalu kecil untuk menuju konvergen, maka learning rate akan
dinaikkan. Dengan demikian, maka algoritma pemberlajaran akan tetap terjaga pada kondisi stabil.
fungsi pembelajaran LEARNGDM. Perbedaan fungsi LEARNGDM ini dengan fungsi LEARNGD yaitu fungsi ini tidak hanya merespon gradien lokal saja, namun juga mempertimbangkan kecenderungan yang baru saja terjadi pada permukaan error. Besarnya perubahan bobot ini dipengaruhi oleh suatu konstanta yang dikenal dengan nama momentum, mc yang bernilai antara 0 sampai 1. Dengan demikian, apabila nilai mc = 0, maka perubahan bobot hanya akan dipengaruhi oleh gradiennya. Namun, apabila nilai mc = 1, maka perubahan bobot akan sama dengan perubahan bobot sebelumnya.
Fungsi kinerja yang digunakan yaitu Mean Square Error (MSE), fungsi ini adalah fungsi kinerja yang paling sering digunakan untuk backpropagation. Fungsi ini akan mengambil rata-rata kuadrat error yang terjadi antara output jaringan dan target. 2. Fungsi Aktifasi
Seperti yang Sudah dijelaskan pada Bab 2, dimana ada 3 Fungsi aktifasi pada algoritma Backpropagation yaitu LOGSIG, TANSIG, PURLINE. Fungsi aktifasi sangat mempengaruhi kinerja model JST yang dibangun dalam menghasilkan nilai korelasi
Jom F.TEKNIK Volume 1 NO.2 Oktober 2014 9
yang optimum, dimana Fungsi aktifasi merespon kinerja Jaringan pada tiap lapisan (layer). Pada penelitian ini digunakan Fungsi aktifasi LOGSIG dan PURLINE, penggunaan fungsi ini sudah dibuktikan sebelumnya pada penelitian Mahyudin 2013 dengan menghasilkan nilai korelasi yang tinggi atau optimum. Adapun fungsi aktifasi ini dibagi, pada Lapisan input (1 dan 2) menggunakan LOGSIG dan pada Lapisan output (3) PURLINE.
Fungsi aktifasi yang digunakan yaitu LOGSIG pada lapisan 1 dan 2, serta PURELIN pada lapisan 3. LOGSIG atau fungsi sigmoid biner adalah fungsi yang digunakan untuk JST yang dilatih menggunakan metode backpropagation. Fungsi ini memiliki nilai pada range 0 sampai 1. Oleh karena itu, fungsi ini sering digunakan JST yang membutuhkan nilai output yang terletak pada interval 0 sampai 1. Fungsi ini memiliki sifat non-linier sehingga sangat baik untuk menyelesaikan permasalahan dunia nyata yang kompleks. Sedangkan PURELIN atau fungsi linier adalah fungsi identitas yang mempunyai nilai keluaran sama dengan nilai masukannya. Pemilihan fungsi aktifasi disesuaikan dengan permasalahan yang diamati serta algoritma pelatihan yang digunakan.
Gambar 3. Propertis Jaringan Pelatihan 1 Berdasarkan Gambar 3 digunakan algoritma
feed-forward backpropagation yaitu
perhitungan maju untuk menghitung error antara keluaran aktual dan target; dan perhitungan mundur untuk yang mempropagasikan balik error tersebut untuk memperbaiki bobot-bobot sinaptik pada semua neuron yang ada. Perhitungan maju dan mundur tersebut dilakukan berulang-ulang sebanyak epoch (iterasi) yang kita tetapkan hingga mencapai nilai error yang kita inginkan. Kemudian jumlah Layer yang digunakan telah ditetapkan sebanyak 3 lapisan dengan 10 neuron yang telah ditetapkan pada awal penelitian.
Dengan tahapan-tahapan pelatihan ini dilakukan percobaan dengan beberapa Jumlah epoch yang berbeda-beda, yaitu
Jom F.TEKNIK Volume 1 NO.2 Oktober 2014 10
1200, 1400, 1600, 1800, 2000, sama seperti proses pelatihan jaringan pada sub bab 3.4.1 di atas, maka pada pelatihan ini digunakan propertis jaringan untuk membangun model. Berikut ini proses dan hasil pelatihan yang menghasilkan nilai korelasi optimum. Yaitu epoch 2000 dengan menggunakan nilai lr dan Mc default seperti yang disajikan pada Gambar 4 seperti di bawah ini. Berdasarkan aturan yang berlaku pada JST bahwa semakin banyak epoch yang dilakukan maka tingkat kesalahan output akan semakin kecil. Namun, jika epoch yang digunakan terlalu banyak maka proses pembelajaran akan membutuhkan waktu lama sehingga akan mengurangi efisiensi dari JST itu sendiri.
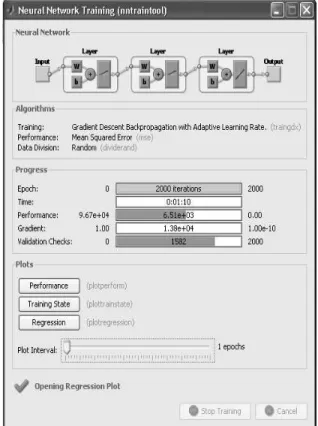
Gambar 4. Parameter-parameter Pelatihan 1 Adapun proses pembelajaran dengan parameter-parameter di atas disajikan pada Gambar 5 seperti di bawah ini.
Gambar 5. Proses Pembelajaran Pelatihan 1 Dari gambar di atas didapatkan informasi sbb:
a. Jumlah epoch (perulangan) = 2000 iterasi
b. Lama proses pembelajaran = 1 menit 10detik
c. Nilai error yang terjadi/MSE = 6.51 x 10 ^3
d. Gradien = 1.38 x 104
e. Maksimum kegagalan = 1582/2000 Hasil pembelajaran yang telah dilakukan berupa koefisien korelasi dan MSE disajikan pada Gambar 6 dan Gambar 7 seperti berikut ini.
Jom F.TEKNIK Volume 1 NO.2 Oktober 2014 11
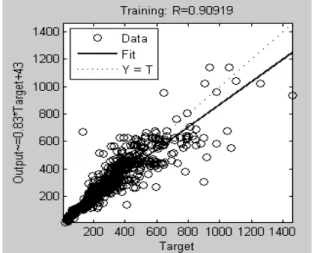
Gambar 6 Nilai Korelasi Output dan Target Pelatihan 1
Gambar 7 Nilai MSE Pelatihan 1 Dari Gambar 6 dan Gambar 7 sebelumnya dapat dilihat bahwa hasil korelasi pelatihan dengan melakukan epoch sebanyak 2000 kali merupakan hasil yang paling optimum dari beberapa percobaan yang telah dilakukan. Adapun hasil percobaan menggunakan beberapa variasi epoch yang telah dilakukan dapat dilihat pada tabel 4.1.
Tabel 2 Hasil Korelasi R dan MSE pada Matlab tiap variasi data
Ep och Waktu Dtk) M SE Grad ient Kegag alan Korela si( R) 120 0 46 65 10 4250 0 782 0.9083 140 0 53 65 10 284 982 0.9085 160 0 59 65 10 2430 1182 0.9088 180 0 66 65 10 218 1382 0.9090 200 0 74 65 10 1380 0 1582 0.9091 Sumber: analisa perhitungan MATLAB.
Berikut ini adalah tabulasi hasil pelatihan yang dilakukan dengan parameter learningrate (lr) yang berbeda.
Tabel 3 Hasil korelasi R dan MSE terhadap perubahan Learningrate Learn ingrat e Wakt u(Dtk ) M S E Gra dien t kega gala n korel asi( R) 0.1 38 64 90 780 552 0.907 5 0.2 37 64 90 526 0 547 0.907 5 0.3 37 64 80 270 00 529 0.907 5 0.4 37 64 80 276 00 544 0.907 5 0.5 37 64 90 769 0 552 0.907 5 Sumber:analisa perhitungan MATLAB
Dari tabel 4.2 dapat dilihat tidak ada perbedaan signifikan pada perubahan MSE dan nilai R model jaringan syaraf tiruan dengan perbedaan waktu pembelajaran yang tidak jauh berbeda, jadi dipilih nilai learningrate 0.1 untuk dilakukan ketahap selanjutnya dengan lama pembelajaran selama 38 detik hanya terpaut 1 detik dari
Jom F.TEKNIK Volume 1 NO.2 Oktober 2014 12
nilai lr yang lainnya. Hasil dari beberapa percobaan terhadap beberapa nilai Mc yang berbeda dapat dilihat pada tabel 4.3 berikut ini.
Tabel 4. Hasil korelasi R dan MSE terhadap perubahan Learningrate Mome ntum (Mc) Time( Dtk) MS E Gra dien t Kega galan Korel asi( R) 0.5 36 649 0 1270 291 0.9058 0.6 35 649 0 1710 0 364 0.9063 0.7 35 647 0 4000 381 0.9067 0.8 35 649 0 2140 458 0.9069 0.9 35 649 0 780 552 0.9075
Tabel 5. Perbandingan hasil pelatihan menggunakan Matlab Data pelat ihan Fungsi aktivasi Fungsi pelatihan Fungsi pembel ajaran R 70 Logsig- logsig-purline Traingdx Learng dm 0.90 91 75 Logsig- logsig-purline Traingdx learngd m 0.91 43 80 Logsig- logsig- pureline Traingdx Learng dm 0,91 53
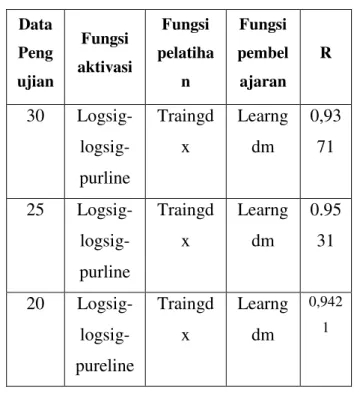
Tabel 6. Perbandingan hasil pengujian menggunakan Matlab Data Peng ujian Fungsi aktivasi Fungsi pelatiha n Fungsi pembel ajaran R 30 Logsig- logsig-purline Traingd x Learng dm 0,93 71 25 Logsig- logsig-purline Traingd x Learng dm 0.95 31 20 Logsig- logsig- pureline Traingd x Learng dm 0,942 1
Tabel 4.6 perbandingan hasil korelasi, RMSE dan NSE pada analisa perhitungan Data test Jumla h data % kesala han (Max) R RM SE NSE 20% 437 31.88 0.99 78 18.9 970 0.99 48 25% 547 47.93 0.98 76 42.3 700 0.97 43 30% 657 51.75 0.98 55 46.9 436 0.96 85 Sumber : Analisa perhitungan
3. Validasi dan prediksi debit
X (Observasi) = data Debit 2010 (sebagai Debit Observasi/target) network1 = model JST hasil Validasi
Jom F.TEKNIK Volume 1 NO.2 Oktober 2014 13
Y(Output) = sim(network1,X)
= hasil prediksi debit bulan Januari tahun 2010
analisa perhitungan dilakukan menggunakan EXCEL.
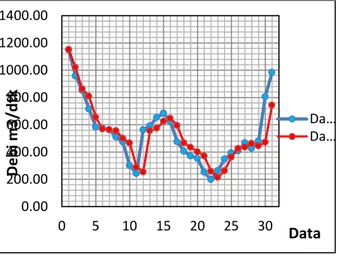
Dengan hasil R= 0.8751, RMSE = 111.064 , NSE = 0.7618.
Gambar 4.43 Perbandingan Antara Data Observasi dan Prediksi bulan Januari tahun
2010 4. Kesimpulan
Proses kalibrasi model JST pada pelatihan/training dengan data debit
2003-2009 pada MATLAB,
menunjukkan bahwa parameter-parameter kalibrasi epoch = 2000, Lr = 0.1 , dan mc = 0.9, merupakan parameter yang memberikan nilai korelasi optimum dan error terkecil dengan memperhitungan efisien durasi pelatihan. 2. Proses kalibrasi dan verifikasi model JST
dengan variasi data pada MATLAB menghasilkan nilai koefisien korelasi (R)
dan MSE sebagai berikut : Pelatihan 7= 0.9091 , Pelatihan 75% = 0.9143, Pelatihan 80% = 0,91533 , Pengujian 30% = 0,9371, Pengujian 25% = 0.9531, Pengujian 20% = 0,9421
3 Maka berdasarkan klasifikasi R, model JST yang dibangun mempunyai tingkat korelasi sangat kuat dengan nilai koefisien korelasi berada pada 0,75 < R ≤ 0,99. Proses pelatihan, menunjukkan bahwa pelatihan menggunakan data 80% menghasilkan nilai R yang lebih baik serta pada proses pengujian menunjukkan pengujian 25% menghasilkan korelasi yang lebih baik. 4. Proses prediksi debit menghasilkan nilai
koefisien korelasi (R), RMSE dan NSE. Dengan hasil Variasi data 80-20 lebih baik dari variasi data 75-25 dan 70-30 . Dengan R20>R25>R30 (0.9978 > 0.9876 > 0.9855); RMSE20 < RMSE25 < RMSE 30 (18.9970 < 42.3700 < 46.9436 );dan NSE20 > NSE25 > NSE 30 ( 0.9948 > 0.9743 > 0.9685). Berdasarkan klasifikasi nilai R, model tersebut mempunyai tingkat korelasi sangat kuat dengan nilai koefisien korelasi berada pada 0,75 < (R dan NSE) ≤ 0,99.
5. Pada proses validasi pada matlab dengan data 2003 s/d 2009 didapat nilai korelasi yang cukup kuat dengan R = 0.93356,
0.00 200.00 400.00 600.00 800.00 1000.00 1200.00 1400.00 0 5 10 15 20 25 30 Da… Da… Deb i m3 /d tk Data
Jom F.TEKNIK Volume 1 NO.2 Oktober 2014 14
6. Hasil perbandingan antara Debit prediksi 2010 dengan Debit Observasi (Aktual), memiliki tingkat korelasi yang sangat tinggi dengan nilai R = 0,8751, RMSE = 111,064 dan NSE = 0,7618
5. Daftar Pustaka
Agustin, M 2012. Penggunaan jaringan syaraf tiruan Backpropagation untuk seleksi penerimaan mahasiswa baru
pada jurusan teknik computer
dipoliteknik negeri sriwijaya. Tesis Program Pascasarjana magister Sistem informasi, Semarang ; Universitas Diponegoro
Amriana. 2010. Pembuatan aplikasi jaringan saraf tiruan. Jurnal SMARtek, vol.8 No.4. November 2010 : 301-306
Asdak, C. 1995. Hidrologi dan Pengelolaan Daerah Aliran Sungai. Yogyakarta: Gadjah Mada University Press. Arliansyah, J., Model tarikan perjalanan
dengan menggunakan Back Propagation Neural Network, Jurnal Transportasi FSTPT, Vol.8, 2008 Goel, A. 2011.ANN-Based Approach for
Predicting Rating Curve of an Indian
River.International Scholarly
Research Network ISRN Civil Engineering, Volume 2011, Article
ID 291370, 4 pages
doi:10.5402/2011/291370. Kusumadewi, Sri. 2003. Artificial
Intelligence.( Teknik dan Aplikasinya ) Yogyakarta: Graha Ilmu.
Mahyudin. 2013. Model Prediki Liku Kalibrasi Menggunakan Pendekatan Jaringan Saraf Tiruan (JST). Tugas akhir jurusan Teknik Sipil. Pekanbaru : Universitas Riau
Siang, Jong Jek. Jaringan saraf tiruan dan
pemrogramannya menggunakan