1
Penerapan Algoritma Genetika Untuk Permasalahan Distribusi Rantai
Pasok Dua Tingkat Yang Dipengaruhi Oleh Biaya Tetap
Novita M Mayasari1, Mahendrawathi Er, S.T, M.Sc, Ph.D1, Rully Soelaiman, S.Kom, M.Kom2 1Jurusan Sistem Informasi, Institut Teknologi Sepuluh Nopember, Surabaya, Indonesia 2
Jurusan Teknik Informatika, Institut Teknologi Sepuluh Nopember, Surabaya, Indonesia
Abstrak
Permasalahan distribusi merupakan hal penting yang harus dipertimbangkan oleh perusahaan-perusahaan dalam sebuah jaringan rantai pasok. Hal ini dikarenakan sekitar 30% biaya produk ditimbulkan oleh biaya distribusi.Selain itu biaya distribusi juga memiliki peran yang penting dalam menentukan harga. Banyak permasalahan transportasi dan distribusi dapat dimodelkan sebagai permasalahan transportasi dengan biaya tetap. Permasalahan transportasi dengan biaya tetap merupakan perluasan dari permasalahan transportasi klasik dimana biaya tetapnya terjadi untuk setiap pasokan yang digunakan sebagai solusi
Pada tugas akhir ini diajukan penggunaan algoritma genetika untuk menyelesaikan permasalahan distribusi rantai pasok dua tingkat yang dipengaruhi oleh biaya tetap. Dua jenis biaya yang dipertimbangkan dalam permasalahan transportasi dengan biaya tetap adalah (i) variable cost yaitu biaya yang meningkat seiring dengan jumlah produk yang diantarkan dari sumber ke tujuan, (ii) fixed cost yaitu biaya yang timbul setiap terjadi proses transportasi untuk sejumlah barang dari sumber ke tujuan. Tujuan yang ingin dicapai adalah untuk meminimalkan total biaya distribusi.
Hasil yang diharapkan dapat diperoleh dari tugas akhir ini adalah sebuah implementasi dari algoritma genetika untuk menyelesaikan permasalahan distribusi rantai pasok dua tingkat yang dipengaruhi oleh biaya tetap. Hasil dari algoritma genetika ini akan dibandingkan dengan solusi yang dihasilkan menggunakan software TORA sehingga dapat diketahui bahwa algoritma ini mampu menyelesaikan persoalan distribusi dengan baik. Hal ini untuk kedepannya diharapkan dapat menjadi masukan untuk manajemen rantai pasok perusahaan dalam menghadapi permasalahan distribusi dan transportasi.
Kata Kunci : Permasalahan distribusi,Rantai pasok,Algoritma genetika,Biaya tetap ransportasi
1. PENDAHULUAN
anajemen rantai pasok telah menjadi konsep penting di dunia bisnis dewasa ini [4]. Inti utama dari manajemen rantai pasok adalah proses distribusi. Distribusi adalah proses untuk memindahkan dan menyimpan barang mulai dari tingkat pemasok sampai ke tingkat pelanggan dalam rantai pasok [9]. Distribusi yang optimal akan menjadi kunci dari keberhasilan perusahaan dalam menjalankan bisnis, karena secara langsung proses distribusi akan berdampak pada biaya rantai pasok
Salah satu permasalahan distribusi adalah strategi keputusan dalam menentukan rute pengiriman dan pengalokasian banyaknya produk yang harus dipindahkan mulai dari tingkat produksi hingga ke tingkat pelanggan. Banyak permasalahan transportasi dan distribusi dapat dimodelkan sebagai permasalahan transportasi dengan biaya tetap. Pada persoalan distribusi ini terdapat dua macam macam biaya yang berpengaruh (i) variable cost
yaitu biaya yang meningkat seiring dengan jumlah produk yang diantarkan dari sumber ke tujuan, (ii) fixed cost yaitu biaya yang timbul setiap terjadi proses transportasi untuk sejumlah barang dari sumber ke tujuan.
.Permasalahan distribusi banyak tingkat merupakan permasalahan umum dalam konteks jaringan rantai pasok, sedangkan sebagian besar dari penelitian yang telah dilakukan sebelumnya diarahkan pada permasalahan distribusi satu tingkat . Dengan pertimbangan diatas, tugas akhir ini memusatkan pada permasalahan distribusi dari tiga elemen rantai pasok yang melibatkan distribusi dua tingkat dan biaya tetap, dengan tujuan meminimumkan biaya total distribusi. Oleh karena itu digunakan algoritma genetika untuk menentukan total biaya distribusi yang paling optimal. Algoritma genetika ini sangat tepat digunakan untuk penyelesaian masalah optimasi yang kompleks dan sukar diselesaikan dengan metode konvensional.
2. DASAR TEORI 2.1 Persoalan Distribusi
Persoalan transportasi membahas masalah pendistribusian suatu komoditas atau produk dari sejumlah sumber (supply) kepada sejumlah tujuan (destination, demand) dengan tujuan meminimumkan ongkos pengangkutan. Ciri-ciri khusus persoalan transportasi [11] adalah :
Terdapat sejumlah sumber dan sejumlah tujuan tertentu.
Kuantitas komoditas atau produk yang didistribusikan dari setiap sumber dan yang diminta oleh setiap tujuan, besarnya tertentu.
Komoditas yang dikirim atau yang diangkut dari suatu sumber ke suatu tujuan, besarnya sesuai dengan permintaan dan atau kapasitas sumber.
Ongkos pengangkutan komoditas dari suatu sumber ke suatu tujuan, besarnya tertentu.
2.2 Algoritma Genetika
GA sebagai salah satu cabang dari algoritma evolusi merupakan metode adaptive yang biasa digunakan untuk memecahkan suatu pencarian nilai dalam sebuah masalah optimasi [8]. Peletak prinsip dasar sekaligus pencipta GA adalah John Holland. Algoritma ini didasarkan pada proses genetik yang ada dalam makhluk hidup yaitu perkembangan generasi dalam sebuah populasi yang alami, secara lambat laun mengikuti prinsip seleksi alam atau “siapa yang kuat, dia yang bertahan (survive)”. Dengan meniru proses ini, GA dapat digunakan untuk mencari solusi permasalahan-permasalahan dalam dunia nyata.
2 Algoritma ini bekerja dengan sebuah populasi yang terdiri dari individu-individu, yang masing-masing individu merepresentasikan sebuah solusi yang mungkin bagi persoalan yang ada. Dalam kaitan ini, individu dilambangkan dengan sebuah nilai fitness yang akan digunakan untuk mencari solusi terbaik dari persoalan yang ada.
Algoritma genetika banyak digunakan untuk memecahkan masalah yang rumit dimana fungsi objektifnya tidak memiliki sifat-sifat yang ramah seperti sifat tidak kontinyu, tidak dapat di differensialkan ataupun saat pengetahuan tentang daerah asal (domain) sangat jarang atau bahkan tidak ada sehingga menyulitkan baik desain maupun analisis, pada saat itulah algoritma genetika akan terlihat keunggulannya.
Pada umumnya GA akan melalui suatu siklus yang terdiri dari 4 fase [10], di antaranya:
1. Membangun sebuah populasi yang terdiri dari kromosom kromosom.
2. Mengevaluasi masing-masing kromosom. 3. Proses seleksi agar didapat kromosom yang
terbaik.
Manipulasi genetik untuk menciptakan populasi baru dari kromosom-kromosom
2.3 Mekanisme Kerja Algoritma Genetika
Mekanisme yang ada dalam GA sangat sederhana, yaitu hanya melibatkan penyalinan string dan pertukaran bagian string. Siklus perkembangbiakan GA diawali dengan pembuatan himpunan solusi secara random dinamakan populasi, dimana di dalamnya terdapat individu-individu yang dinamakan kromosom. Kromosom ini secara lambat laun mengalami iterasi pemilihan dalam sebuah generasi. Selama dalam sebuah generasi, kromosom-kromosom ini dievaluasi, dengan menggunakan rumus-rumus yang ada dalam fungsi fitness. Untuk menciptakan generasi berikutnya dengan kromosom yang baru (dinamakan keturunan/offspring) dapat dilakukan dengan menggabungkan dua kromosom yang telah didapat sebelumnya dengan menggunakan operator pindah silang (crossover) ataupun dengan memodifikasi sebuah kromosom dengan menggunakan operator mutasi. Sebuah generasi baru sebelum dievaluasi lagi, maka dia melalui proses seleksi berdasarkan fungsi fitness-nya. Dari seleksi ini, kromosom-kromosom yang paling bagus mempunyai kemungkinan besar untuk terseleksi. Setelah beberapa generasi, algoritma akan mengalami konvergen pada sejumlah kromosom terbaik, yang memiliki nilai optimum dari permasalahan yang diselesaikan.
3. METODOLOGI
Pada Bagian metodologi ini dibahas mengenai perancangan dan pembuatan siatem perangkat lunak. Perancangan yang dilakukan meliputi dua bagian penting, yaitu perancangan persoalan distribusi dan perancangan algoritma genetika.
3.1 Desain Persoalan Distribusi
Pada bagian ini akan dijelaskan terlebih dahulu model persoalan distribusi rantai pasok, asumsi-asumsi yang digunakan dan model matematika pada persoalan distribusi rantai pasok.
Model Persoalan Distribusi Rantai Pasok
Model permasalahan distribusi rantai pasok disini dinyatakan sebagai permasalahan distribusi dua tingkat yang dipengaruhi biaya tetap. Dengan permodelan demikian maka akan terdapat dua tingkatan distribusi dimana tingkatan pertama dimulai dari pabrik (pemasok) ke pusat distribusi dan yang kedua dari pusat distribusi ke pelanggan. Demikian pula untuk biaya yang diperhitungkan, juga terdapat dua jenis biaya, yaitu
variabel cost, biaya yang berubah-ubah tergantung pada jumlah yang ditransportasikan, dan yang kedua adalah
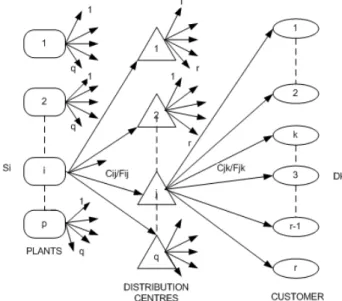
fixed cost yaitu biaya tetap yang tidak akan berubah meskipun jumlah yang ditransportasikan bertambah atau berkurang. Model distribusi rantai pasok ini dapat dilihat pada gambar 3.1.
Gambar 3.1 Model Distribusi Rantai Pasok
Berdasarkan gambar 3.1 dapat dijelaskan bahwa terdapat sejumlah p pabrik (pemasok atau gudang), sejumlah q pusat distribusi (gudang atau ritel) dan sejumlah r pelanggan (ritel atau pengguna akhir). Setiap pabrik dapat mengirimkan ke pusat distribusi yang mana pun dengan sejumlah Cij biaya transportasi (untuk setiap unit yang dikirim) ditambah dengan Fij biaya tetap. Setiap pusat distribusi dapat mengirimkan ke pelanggan yang mana pun dengan sejumlah Cjk biaya transportasi (untuk setiap unit yang dikirimkan) dan ditambah dengan Fjk biaya tetap. Setiap pabrik i=1,2,...p memiliki batasan pasokan Si dan setiap pelanggan k=1,2,...r memiliki jumlah permintaan Dk . Setiap pusat distribusi j memiliki kapasitas penyipanan SCj .
Asumsi
Asumsi-asumsi yang digunakan pada persoalan ini adalah sebagai berikut:
- Jumlah kapasitas sumber ≥ dari jumlah
permintaan.
p i r k iD
S
1 k 1(1)
- Kapasitas stok pada distribution center ≥ jumlah
permintaan. j
SC
r k kD
1
j
,
j
1
to
q
(2)
3
Model Matematika
Model matematika pada persoalan distribusi rantai pasok yang dipengaruhi oleh biaya tetap ini adalah : Minimum Z =
q j r k jk jk jk jk p i q j ij ij ij ijX F C X F C 1 1 1 1 (3) Dengan Batasan :
q j ijX
1
S
i(
i
,
i
1
sampai p) (4)
q j k jkD
X
1 (
k
,
k
1
sampai r) (5)0
ijX
, dan integer (6)0
jkX
, dan integer (7)0
ij
jikaX
ij
0
, = 1 jikaX
ij
0
,0
jk
jikaX
jk
0
, = 1 jikaX
jk
0
.Dari persamaan 3 hingga 7 telah dijabarkan mengenai fungsi tujuan serta batasan yang menjadi model matematis dari persoalan distribusi rantai pasok yang dipengaruhi oleh biaya tetap. Dari model matematis yang telah dijabarkan tersebut, diperoleh model matematis yang dapat digunakan pada algoritma genetika untuk menyelesaikan permasalahan yang sama. Hal tersebut dilakukan dengan merubah persamaan 3 menjadi model transportasi linier dengan cara mengabaikan nilai variable biner (
ij
) dan (
jk
) (Palekar et al., 1990;King, 1975) sehingga model matematika yang dihasilkan menjadi : Minimum Z =
p i q j q j r k jk jk ij ijX
CF
X
CF
1 1 1 1 (8) Dimana
ij i j ij ijC
F
Min
S
A
CF
/
,
(9)
jk j k jk jkC
F
Min
A
D
CF
/
,
(10)
r k k jD
A
1 (
j
,
j
1
sampai q ) (11) Berdasarkan pada persamaan 8 ini persoalan distribusi dua tingkat dapat diubah menjadi suatu bentuk ekuivalent persoalan distribusi satu tingkat. Sehingga persoalan distribusi satu tingkat ini juga memiliki ekuivalent matriks biaya distribusi. Ekuivalent matriks biaya distribusi ini dapat dilihat pada Tabel 3.1. Persamaan 8 inilah yang akan digunakan sebagai fungsi tujuan pada implementasi penyelesaian persoalan distribusi rantai pasok dua tingkat dengan biaya tetap dengan menggunakan algoritma genetika.3.2 Desain Algoritma Genetika
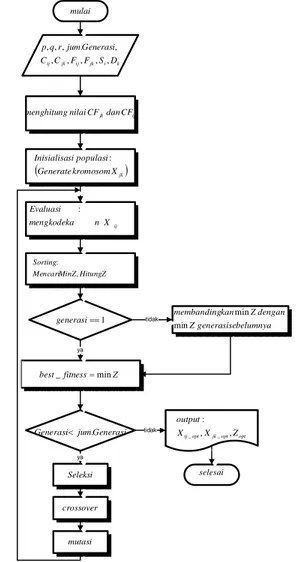
Desain algoritma genetika dapat dijelaskan dengan diagram alir pada Gambar 3..2. Langkah-langkah pada diagram alir ini adalah sebagai berikut :
k i jk ij jk ijC F F S D C Generasi jum r q p , , , , , , . , , , GeneratekromosomXjk populasi si Inisialisa : mulai ij X n mengkodeka Evaluasi : Z Hitung Z Min Mencari Sorting , : Z fitness best_ min Generasi jum Generasi . Seleksi crossover mutasi tidak ya tidak ya selesai ij jkdanCF CF nilai menghitung opt opt jk opt ij X Z X output , , : _ _ belumnya generasise Z dengan Z kan membanding min min 1 generasi
Gambar 3.2 Diagram Alir Algoritma Genetika
1. Modul Input
Data input yang digunakan untuk penerapan algoritma genetika pada persoalan distribusi ini dapat dilihat pada Tabel 3.2.
2. Inisialisasi Kromosom
Representasi kromosom merupakan salah satu bagian terpenting dalam proses GA yang memberikan dampak pada hasil akhir dari metode GA tersebut. Dengan kata lain apabila representasi kromosom tidak tepat, maka hasil akhir yang diperoleh bisa jadi tidak sesuai dengan apa yang diharapkan. Proses untuk merepresentasikan permasalahan ke dalam kromosom biasa disebut sebagai proses encoding.
Dalam permasalahan optimasi biaya pada permasalahan distribusi rantai pasok dua tingkat kromosom direpresentasikan sebagai matrix perencanaan distribusi. Perencanaan distribusi yang mungkin adalah yang memenuhi kebutuhan pelanggan dari pusat distribusi . Jadi kromosom akan berupa matrik ukuran j*k, dimana setiap elemennya merupakan gen. Pada sebuah gen baris ke-j dan kolom ke-k dari kromosom mengindikasikan jumlah unit Xjk yang didistribusikan kepada pelanggan k melalui pusat distribusi j.
Populasi awal biasanya dibangkitkan secara acak. Namun beberapa studi menunjukkan bahwa pembangkitan populasi awal yang menyertakan beberapa
4 solusi yang bagus, dapat meningkatkan konvergensi dari GA.
Untuk meningkatkan keanekaragaman dari kromosom awal yang dibangkitkan, maka tiga kromosom dibangun dengan menerapkan prosedur alokasi biaya terendah dengan menggunakan aturan dan data diawah ini:
Kromosom 1, di-generate dengan mengaplikasikan aturan biaya terkecil pada CFjk
Kromosom 2, di-generate dengan mengaplikasikan aturan biaya terkecil pada Cjk
Kromosom 3, di-generate dengan mengaplikasikan aturan biaya terkecil pada Fjk
Kromosom 4-10, digenerate secara random. Kesepuluh kromosom yang dibangun merupakan populasi awal. Pengalokasian selesai dilakukan apabila permintaan pelanggan Dk terpenuhi.
Tabel 3.2 Data Input
No Nama Data Keterangan
1. p Jumlah pabrik
2. q Jumlah pusat distribusi
3. r Jumlah pelanggan
4. Si kapasitas pabrik ke-i
5. Dk Permintaan dari pelanggan
k
6. Cij Biaya satuan distribusi
produk dari pabrik i ke pusat distribusi j
7. Fij Biaya tetap yang
mempengaruhi dengan setiap pengiriman dari pabrik i ke pusat distribusi
j.
8. Cjk Biaya satuan distribusi
produk dari pusat distribusi j ke pelanggan
k
9. Fjk Biaya tetap yang
mempengaruhi dengan setiap pengiriman dari pusat distribusi j ke pelanggan k.
10. JumlahGenerasi Jumlah Generasi 11. pop_size Ukuran Populasi 12. p_cross Probabilitas crossover 13. p_mut Probabilitas mutasi 3. Evaluasi Kromosom
Pada tahap evaluasi ini adalah menentukan nilai
fitness masing-masing kromosom. Nilai fitness adalah total biaya distribusi (Z) dari pabrik ke pelanggan melalui pusat distribusi. Nilai Z diperoleh dengan menjumlahkan total biaya distribusi dari pabrik ke pusat distribusi (TC1) dan total biaya distribusi dari pusat distribusi ke pelanggan (TC2). Langkah pertama proses evaluasi ini adalah menghitung nilai TC2, yaitu dengan mensubstitusikan nilai Xjk pada masing-masing kromosom ke dalam persamaan 8. Langkah selanjutnya adalah menghitung nilai TC1,dalam rangka menemukan nilai TC1, perencanaan distribusi Xij dibutuhkan. Prosedur dibawah ini diambil untuk mendapatkan tabel Xij :
Langkah 1: Menemukan jumlah unit yang dikirimkan dari setiap pusat distribusi.
)
1
,
(
1q
sampai
j
X
A
j r k jk j
Langkah 2: Menemukan empat kemungkinan perencanaan distribusi dari pabrik ke pusat distribusi yang memenuhi kebutuhan dari Aj dengan menerapkan metode alokasi biaya berikut ini:
Biaya terkecil pada CFij
Biaya terkecil pada Cij
Biaya terkecil pada Fij dan
Random.
Langkah 3:Evaluasi semua empat rencana distribusi dengan TC1 dan rencana distribusi terbaik Xij.
Langkah 4:Menyimpan Xij terbaik.
Setelah Xij ditentukan, maka nilai TC1 dapat dihitung dengan mensustitusikan nilai Xij kedalam persamaan 8, maka nilai fitness atau nilai Z dari kromosom tersebut dapat ditemukan.
4. Sorting
Pada tahap ini, nilai fitness yang telah didapatkan dari proses evaluasi dipilih yang paling minimum. Nilai Z yang minimum disebut dengan best_fitness.Best_fitness
ini akan dibandingkan dengan best_fitness generasi berikutnya sehingga akan menghasilkan best_fitness yang paling optimal.
5. Seleksi
Tujuan utama proses seleksi ini adalah mempertahankan kromosom yang memiliki nilai fitness
terbaik dan mengeliminasi kromosom yang memiliki nilai fitness buruk. Langkah-langkah proses seleksi ini adalah:
- Mengkonversi nilai fitness masing-masing kromosom. Fungsi konversi yang digunakan adalah :
new_fit(c) =
e
v*fit(c) (12) Keterangan :e
: eksponensialv
: nilai pembeda antara kromosom terbaik dari yang buruk dalam persoalan minimasi.Dalam persoalan ini ditetapkan v = 0.00005 sebagai pembeda terbaik.
- Menghitung probabilitas kromosom.
Pada langkah ini, new_fit (c) yang dihasilkan digunakan untuk menemukan frekuensi yang diharapkan atau probabilitas seleksi p(c) tiap kromosom. Probabilitas seleksi pada tiap kromosom ini dapat dihitung dengan persamaan 13.
size pop cc
fit
new
c
fit
new
c
p
_ 1_
/
_
(13)- Memilih kromosom baru
Pada langkah ketiga ini bertujuan untuk memilih kromosom baru pada generasi berikutnya. Metode pemilihan yang digunakan adalah Roulette Wheel. Sehingga langkah selanjutnya adalah menghitung probabilitas kumulatif dengan persamaan 14
c cc
p
c
cp
1 (14)5 Kemudian tentukan bilangan R secara acak untuk tiap kromosom. Selanjutnya kromosom yang terpilih adalah kromosom yang memiliki nilai R sesuai dengan bentuk persamaan 15.
c
1
R
cp
(
c
)
cp
(15)Pada proses ini kromosom yang memiliki nilai fitness baik akan terpilih dan kromosom yang memiliki nilai fitness buruk akan ditolak.
6. Crossover
Modul seleksi tidak dapat membuat solusi baru pada populasi tetapi hanya membuat banyak salinan dari solusi bagus dengan mengorbankan solusi yang tidak terlalu bagus. Untuk membuat solusi baru dilakukan modul crossover dan mutasi. Kemungkinan dari crossover
(p_cross) merupakan parameter yang penting pada operasi crossover. Pada tugas akhir ini nilai dari p_cross
diasumsikan 0.3, sehingga setidaknya 30% kromosom yang terpilih oleh modul seleksi akan menjalani crossover dan menghasilkan offspring. Operasi crossover akan menghasilkan anak baru dari orang tua. Gen baru untuk anak (offspring) memiliki karakteristik kombinasi dari ortu (parent). Modul crossover terdiri dari dua tahapan:
Pemilihan kromosom yang akan di-crossover , dengan cara :
1. Tentukan angka secara acak R_cross untuk semua kromosom.
2. Bandingkan R_cross masing-masing kromosom dengan p_cross. Jika R_cross < p_cross maka kromosom tersebut terpilih untuk di-crossover.
3. Jika jumlah kromosom yang terpilih ganjil, ulangi langkah1 sampai jumlah kromosom genap.
Operasi crossover
operator crossover yang digunakan pada tugas akhir ini adalah operator PMX (partially mapped crossover) dengan dua titik potong. Dua titik potong ini ditentukan dengan men-generate secara random jumlah customer
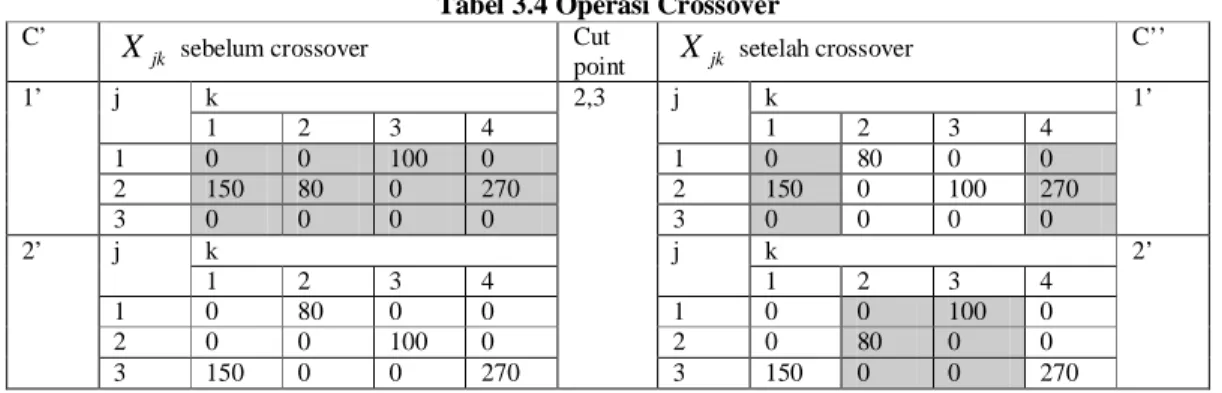
(k). sehingga gen yang berada pada dua titik potong tersebut dipindah silang sehingga menghasilkan kromosom anak. Proses operasi crossover dapat lebih jelas dilihat pada tabel 3.4.
7. Mutasi
Tujuan dari mutasi adalah menjaga keanekaragaman dan menghindari terjadinya solusi lokal seperti mengenalkan gen baru atau menciptakan ulang dari gen yang bagus. Parameter utama yaitu probabilitas mutasi (p_mut). Untuk melakukan mutasi secara efektif, efek dari mutasi haruslah besar dengan begitu kemungkinan p_mut
haruslah tinggi. Pada tugas akhir ini nilai p_mut
diasumsikan 0.5. langkah-langkah melakukan proses mutasi adalah:
Tentukan bilangan random R_mut untuk tiap gen.
Bandingkan R_mut tiap gen dengan p_mut.
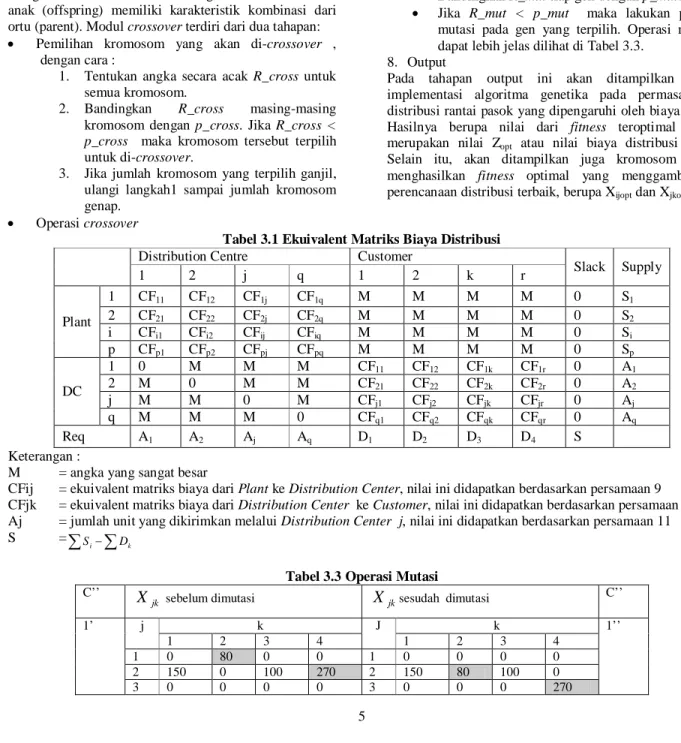
Jika R_mut < p_mut maka lakukan proses mutasi pada gen yang terpilih. Operasi mutasi dapat lebih jelas dilihat di Tabel 3.3.
8. Output
Pada tahapan output ini akan ditampilkan hasil implementasi algoritma genetika pada permasalahan distribusi rantai pasok yang dipengaruhi oleh biaya tetap. Hasilnya berupa nilai dari fitness teroptimal yang merupakan nilai Zopt atau nilai biaya distribusi total. Selain itu, akan ditampilkan juga kromosom yang menghasilkan fitness optimal yang menggambarkan perencanaan distribusi terbaik, berupa XijoptdanXjkopt .
Tabel 3.1 Ekuivalent Matriks Biaya Distribusi
Distribution Centre Customer
Slack Supply 1 2 j q 1 2 k r Plant 1 CF11 CF12 CF1j CF1q M M M M 0 S1 2 CF21 CF22 CF2j CF2q M M M M 0 S2 i CFi1 CFi2 CFij CFiq M M M M 0 Si p CFp1 CFp2 CFpj CFpq M M M M 0 Sp DC 1 0 M M M CF11 CF12 CF1k CF1r 0 A1 2 M 0 M M CF21 CF22 CF2k CF2r 0 A2 j M M 0 M CFj1 CFj2 CFjk CFjr 0 Aj q M M M 0 CFq1 CFq2 CFqk CFqr 0 Aq Req A1 A2 Aj Aq D1 D2 D3 D4 S Keterangan :
M = angka yang sangat besar
CFij = ekuivalent matriks biaya dari Plant ke Distribution Center, nilai ini didapatkan berdasarkan persamaan 9 CFjk = ekuivalent matriks biaya dari Distribution Center ke Customer, nilai ini didapatkan berdasarkan persamaan 10 Aj = jumlah unit yang dikirimkan melalui Distribution Center j, nilai ini didapatkan berdasarkan persamaan 11
S =
k
i D
S
Tabel 3.3 Operasi Mutasi C’’
jk
X
sebelum dimutasiX
jksesudah dimutasi C’’1’ j k J k 1’’
1 2 3 4 1 2 3 4
1 0 80 0 0 1 0 0 0 0
2 150 0 100 270 2 150 80 100 0
6
Tabel 3.4 Operasi Crossover C’
jk
X
sebelum crossover Cutpoint
X
jk setelah crossoverC’’ 1’ j k 2,3 j k 1’ 1 2 3 4 1 2 3 4 1 0 0 100 0 1 0 80 0 0 2 150 80 0 270 2 150 0 100 270 3 0 0 0 0 3 0 0 0 0 2’ j k j k 2’ 1 2 3 4 1 2 3 4 1 0 80 0 0 1 0 0 100 0 2 0 0 100 0 2 0 80 0 0 3 150 0 0 270 3 150 0 0 270
4. HASIL UJI COBA DAN EVALUASI
Tahap uji coba dilakukan pada prosesor Intel(R) Core(TM) Duo CPU T5450 @ 1.66 GHz, memory sebesar 1.00 GB dan perangkat lunak berupa Sistem Operasi Windows XP Professional dan Matlab 7.0.4. Uji coba dapat dilakukan pada data yang terdapat pada Tabel 4.I. Data uji coba ini adalah berupa tabel biaya distribusi dan biaya tetap dari plant ke customer melalui
Distribution Center. Tujuan dari pelaksanaan ujicoba ini dimaksudkan untuk melihat tingkat keakurasian solusi yang dihasilkan oleh aplikasi . Sedangkan untuk mengetahui pengaruh parameter algoritma genetika terhadap solusi yang dihasilkan serta waktu komputasi yang dibutuhkan, akan dilakukan ujicoba parameter.
Tabel 4.1 Data Uji Coba
i j Si 1 2 3 1 Fij = 1000 Cij = 10 400 25 1150 30 250 2 900 5 200 35 1300 14 350 k j Dk 1 2 3 1 Fjk = 500 Cjk = 43 2250 20 400 60 150 2 1200 25 1500 5 1800 32 80 3 800 10 0 0 2300 50 100 4 2000 50 2000 30 1000 40 270 Keterangan :
i = identifikasi dari plants/pabrik (i = 1 sampai p) j = identifikasi dari distribution center (j =1 sampai q) k = identifikasi dari customer (k = 1 sampai r) Si = persediaan pada plant i
Dk = permintaan pada customer k
4.1 Skenario Uji Coba Parameter
Pada tahap ini akan dilakukan uji coba dan evaluasi terhadap aplikasi dengan tujuan untuk melihat pengaruh parameter-parameter algoritma genetika, yaitu ukuran populasi, maksimal generasi, probabilitas pindah silang (p_cross), dan probabilitas mutasi (p_mut) dalam membantu mendapatkan solusi yang optimal serta pengaruhnya terhadap waktu komputasi.
Pada ujicoba parameter ini akan digunakan 3 data uji untuk mewakili permasalahan ukuran kecil, sedang, dan besar. Sedangkan untuk skenario ujicoba, terdapat 4 skenario yang akan menguji masing-masing parameter. Setiap uji coba pada tiap-tiap skenario akan dijalankan sebanyak 10 kali untuk setiap ujicoba . Hasil keluaran dari tiap uji coba akan dievaluasi dengan cara melihat grafik nilai minimum serta rata-rata nilai dari tiap uji coba, berikut empat skenario tersebut.
1. Ujicoba Ukuran Populasi.
Uji coba dilakukan untuk melihat pengaruh ukuran populasi dalam membantu untuk mendapatkan solusi yang optimal. Nilai untuk ukuran populasi dibuat berbeda dimulai dari yang paling kecil, 10, hingga yang paling besar, 200. Dari uji coba ini dapat dianalisa bahwa pengaruh ukuran populasi pada semua jenis data terhadap nilai terbaik stabil dari ukuran populasi terkecil hingga terbesar. Sedangkan rata-rata nilai pada data besar akan cenderung lebih minimum seiring bertambahnya ukuran populasi. Waktu komputasi berbanding lurus dengan ukuran populasi. Langkah ujicoba skenario 1 beserta hasilnya dapat dilihat pada tabel 4.2, 4.3 dan 4.4.
Tabel 4.2 Hasil Ujicoba Parameter Ukuran Populasi Permasalahan kecil
Parameter Uji1 Uji2 Uji3 Uji4 Uji5
Ukuran populasi 10 50 100 150 200 Maksimal generasi 250 250 250 250 250 Pc 0.5 0.5 0.5 0.5 0.5 Pm 0.5 0.5 0.5 0.5 0.5 MinZ 112600 112600 112600 112600 112600 Waktu(s) 2.9973 12.8422 25.3251 37.9734 50.7807
Tabel 4.3 Hasil Ujicoba Parameter Ukuran Populasi Permasalahan sedang
Parameter Uji1 Uji2 Uji3 Uji4 Uji5
Ukuran populasi 10 50 100 150 200 Maksimal generasi 250 250 250 250 250 Pc 0.5 0.5 0.5 0.5 0.5 Pm 0.5 0.5 0.5 0.5 0.5 MinZ 64743 64743 64743 64743 64743 Waktu(s) 3.5688 15.8886 31.5596 47.8484 63.965
7
Tabel 4.4 Hasil Ujicoba Parameter Ukuran Populasi Permasalahan besar
Parameter Uji1 Uji2 Uji3 Uji4 Uji5
Ukuran populasi 10 50 100 150 200 Maksimal generasi 250 250 250 250 250 Pc 0.5 0.5 0.5 0.5 0.5 Pm 0.5 0.5 0.5 0.5 0.5 MinZ 73195 73195 73195 73195 73195 Waktu(s) 5.0967 23.5773 46.5218 70.7649 91.9901
2. Ujicoba Maksimal Generasi
Uji coba dilakukan untuk melihat pengaruh maksimal generasi dalam membantu untuk mendapatkan solusi yang optimal. Nilai untuk maksimal generasi dibuat berbeda dimulai dari yang paling kecil, 50, hingga yang paling besar, 500. Pada ujicoba skenario 2 dapat dianalisa pengaruh maksimal Generasi pada semua jenis data nilai terbaik stabil dari maksimal generasi terkecil hingga terbesar. Rata-rata nilai pada data besar akan cenderung lebih minimum seiring bertambahnya maksimal generasi. Waktu komputasi berbanding lurus dengan ukuran maksimal generasi. Langkah ujicoba skenario 2 beserta hasilnya dapat dilihat pada tabel 4.5, 4.6 dan 4.7.
Tabel 4.5 Hasil Ujicoba Parameter Maksimal Generasi Permasalahan kecil
Parameter Uji1 Uji2 Uji3 Uji4 Uji5
Ukuran populasi 100 100 100 100 100 Maksimal generasi 50 150 250 350 500 Pc 0.5 0.5 0.5 0.5 0.5 Pm 0.5 0.5 0.5 0.5 0.5 MinZ 112600 112600 112600 112600 112600 Waktu(s) 5.3728 15.3497 25.3376 35.2962 50.3103
Tabel 4.6 Hasil Ujicoba Parameter Maksimal Generasi Permasalahan sedang
Parameter Uji1 Uji2 Uji3 Uji4 Uji5
Ukuran populasi 100 100 100 100 100 Maksimal generasi 50 150 250 350 500 Pc 0.5 0.5 0.5 0.5 0.5 Pm 0.5 0.5 0.5 0.5 0.5 MinZ 64743 64743 64743 64743 64743 Waktu(s) 6.5367 18.6918 30.8619 43.1208 61.2158
Tabel 4.7 Hasil Ujicoba Parameter Maksimal Generasi Permasalahan besar
Parameter Uji1 Uji2 Uji3 Uji4 Uji5
Ukuran populasi 100 100 100 100 100 Maksimal generasi 50 150 250 350 500 Pc 0.5 0.5 0.5 0.5 0.5 Pm 0.5 0.5 0.5 0.5 0.5 MinZ 73195 73195 73195 73195 73195 Waktu(s) 9.7382 27.8216 45.3624 63.4823 90.4868
3. Ujicoba Probabilitas Pindah Silang.
Uji coba dilakukan untuk melihat pengaruh probabilitas pindah silang dalam membantu untuk mendapatkan solusi yang optimal. Nilai untuk probabilitas pindah silang dibuat berbeda dimulai dari yang paling kecil, 0.1, hingga yang paling besar, 0.9. Pada ujicoba skenario 3 dapat dianalisa pengaruh probabilitas crossover yang semakin tinggi akan mempengaruhi besarnya ruang explorasi yang lebih luas karena kemungkinan kromosom yang terpilih lebih banyak. Nilai terbaik stabil dari Pc terkecil hingga terbesar, rata rata nilai cenderung turun seiring bertambahnya nilai Pc. Waktu komputasi cenderung naik dengan bertambahnya nialai Pc. Langkah ujicoba skenario 3 beserta hasilnya dapat dilihat pada tabel 4.8, 4.9 dan 4.10.
Tabel 4.8 Hasil Ujicoba Parameter Probabilitas Pindah Silang Permasalahan kecil
Parameter Uji1 Uji2 Uji3 Uji4 Uji5
Ukuran populasi 100 100 100 100 100 Maksimal generasi 250 250 250 250 250 Pc 0.1 0.3 0.5 0.7 0.9 Pm 0.5 0.5 0.5 0.5 0.5 MinZ 112600 112600 112600 112600 112600 Waktu(s) 25.1411 25.129 25.2814 25.358 25.4095
Tabel 4.9 Hasil Ujicoba Parameter Probabilitas Pindah Silang Permasalahan sedang Parameter
Uji1 Uji2 Uji3 Uji4 Uji5
Ukuran populasi 100 100 100 100 100 Maksimal generasi 250 250 250 250 250 Pc 0.1 0.3 0.5 0.7 0.9 Pm 0.5 0.5 0.5 0.5 0.5 MinZ 64743 64 6474 64743 64743 Waktu(s) 30.7726 30.6419 30.8067 30.9988 31.2038
Tabel 4.10 Hasil Ujicoba Parameter Probabilitas Pindah Silang Permasalahan besar
Parameter Uji1 Uji2 Uji3 Uji4 Uji5
Ukuran populasi 100 100 100 100 100 Maksimal generasi 250 250 250 250 250 Pc 0.1 0.3 0.5 0.7 0.9 Pm 0.5 0.5 0.5 0.5 0.5 MinZ 73195 73195 73195 73195 73195 Waktu(s) 46.8601 47.1583 46.1526 46.8344 47.162
4. Ujicoba Probabilitas Mutasi.
Uji coba dilakukan untuk melihat pengaruh probabilitas mutasi dalam membantu untuk mendapatkan solusi yang optimal. Nilai untuk probabilitas mutasi dibuat berbeda dimulai dari yang paling kecil, 0.1, hingga yang paling besar, 0.9. Pada ujicoba skenario 4 dapat dianalisa probabilitas mutasi yang semakin besar akan menyebabkan kemungkinan gen yang terpilih untuk dimutasi semakin banyak. Nilai terbaik stabil dari Pm terkecil
8 hingga terbesar, rata-rata nilai cenderung stabil hingga Pm 0.5, kemudia akan mengalami peningkatan. Waktu komputasi cenderung naik dengan bertambahnya nilai Pm. Langkah ujicoba skenario 3 beserta hasilnya dapat dilihat pada tabel 4.11, 4.12 dan 4.13
.
Tabel 4.11 Hasil Ujicoba Parameter Probabilitas Mutasi Permasalahan kecil
Parameter Uji1 Uji2 Uji3 Uji4 Uji5
Ukuran populasi 100 100 100 100 100 Maksimal generasi 250 250 250 250 250 Pc 0.5 0.5 0.5 0.5 0.5 Pm 0.1 0.3 0.5 0.7 0.9 MinZ 112600 112600 112600 112600 112600 Waktu(s) 23.0966 25.0982 25.2811 25.2013 25.4193
Tabel 4.12 Hasil Ujicoba Parameter Probabilitas Mutasi Permasalahan sedang
Parameter
Uji1 Uji2 Uji3 Uji4 Uji5
Ukuran populasi 100 100 100 100 100 Maksimal generasi 250 250 250 250 250 Pc 0.5 0.5 0.5 0.5 0.5 Pm 0.1 0.3 0.5 0.7 0.9 MinZ 64743 64743 64743 64743 64743 Waktu(s) 30.6387 30.6802 30.7785 31.0685 31.2798
Tabel 4.13 Hasil Ujicoba Parameter Probabilitas Mutasi Permasalahan besar.
Parameter Uji1 Uji2 Uji3 Uji4 Uji5
Ukuran populasi 100 100 100 100 100 Maksimal generasi 250 250 250 250 250 Pc 0.5 0.5 0.5 0.5 0.5 Pm 0.1 0.3 0.5 0.7 0.9 MinZ 73195 73195 73195 73195 73195 Waktu(s) 35.5287 43.9123 45.5875 45.9305 45.4832
4.2 Skenario Uji Coba Akurasi
GA termasuk salah satu metode heuristik untuk menyelesaikan permasalahan optimasi. Hasil yang diperoleh melalui metode ini tidak selalu tepat sama dengan hasil dari metode konvensional. Namun bisa didapatkan hasil yang mendekati nilai optimal.
Pada bagian ini akan dipaparkan mengenai ujicoba tingkat akurasi solusi yang dihasilkan oleh aplikasi dengan menggunakan metode genetic algoritma. Untuk mengetahui tingkat akurasi dari aplikasi yang dihasilkan dengan menggunakan GA, maka solusi-solusi yang diperoleh dari aplikasi dibandingkan dengan solusi yang dihasilkan menggunakan TORA. Oleh karena hal tersebut maka pada tahapan ini akan terdapat dua skenario ujicoba yang akan dilakukan :
1. Skenario uji coba menggunakan TORA. 2. Skenario uji coba menggunakan input parameter
algoritma genetika, yaitu jumlah kromosom = 10, probabilitas crossover = 0.3, probabilitas mutasi = 0.5 dan maksimal generasi = pq+qr.
Solusi yang dihasilkan dihitung presentase selisih dari keduanya dengan menggunakan persamaan 5.1 .
100
)
(
%
TORA
TORA
GA
Deviation
Berdasarkan hasil uji coba yang telah dilakukan telah dibuktikan bahwa implementasi dari algoritma genetika mampu menghasilkan solusi yang optimal untuk menyelesaikan persoalan distribusi rantai pasok dua tingkat dengan biaya teteap. Hasil uji coba ini dibandingkan dengan solusi optimal yang telah dijalankan dengan TORA.
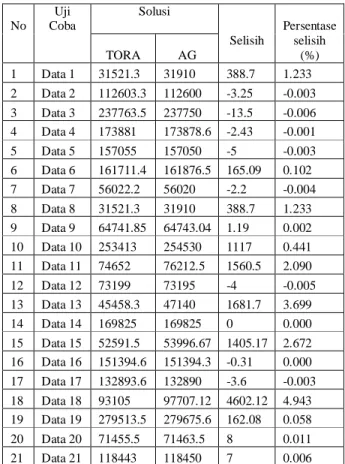
Tabel 5.1 dan Gambar 5.1 akan menunjukkan perbandingan hasil solusi yang didapatkan dari algoritma genetika dan TORA. Berdasarkan pada Tabel 5.1 diatas dapat dilihat bahwa dari 21 data yang ada, 8 data hasil yang diperoleh GA lebih bagus dari TORA dengan presentase selisih 0.003%, dan 12 data tidak lebih baik dari TORA dengan presentase selisih 1.37%, serta satu data memberikan hasil yang sama antara TORA dengan GA. Hasil GA yang lebih minimum ini dimungkinkan terjadi dikarenakan implementasi pada TORA dan GA menggunakan fungsi tujuan yang berbeda. Pada Tora digunakan persamaan 3, sedangkan pada GA digunakan persamaan 8.
Tabel 5.1 Perbandingan Hasil No Uji Coba Solusi Selisih Persentase selisih (%) TORA AG 1 Data 1 31521.3 31910 388.7 1.233 2 Data 2 112603.3 112600 -3.25 -0.003 3 Data 3 237763.5 237750 -13.5 -0.006 4 Data 4 173881 173878.6 -2.43 -0.001 5 Data 5 157055 157050 -5 -0.003 6 Data 6 161711.4 161876.5 165.09 0.102 7 Data 7 56022.2 56020 -2.2 -0.004 8 Data 8 31521.3 31910 388.7 1.233 9 Data 9 64741.85 64743.04 1.19 0.002 10 Data 10 253413 254530 1117 0.441 11 Data 11 74652 76212.5 1560.5 2.090 12 Data 12 73199 73195 -4 -0.005 13 Data 13 45458.3 47140 1681.7 3.699 14 Data 14 169825 169825 0 0.000 15 Data 15 52591.5 53996.67 1405.17 2.672 16 Data 16 151394.6 151394.3 -0.31 0.000 17 Data 17 132893.6 132890 -3.6 -0.003 18 Data 18 93105 97707.12 4602.12 4.943 19 Data 19 279513.5 279675.6 162.08 0.058 20 Data 20 71455.5 71463.5 8 0.011 21 Data 21 118443 118450 7 0.006
Dapat dilihat pada Tabel 5.1, pada beberapa data selisih antara GA dan TORA memiliki prosentase yang lebih besar dibandingkan lainnya, apabila ditinjau dengan data yang digunakan, selisih yang besar tersebut tidak dipengaruhi oleh ukuran persoalan maupun jumlah entitas pada setiap level. Hal ini dapat diartikan bahwa baik data
9 berukuran kecil, sedang maupun besar, memungkinkan hasil dengan selisih yang besar maupun kecil.
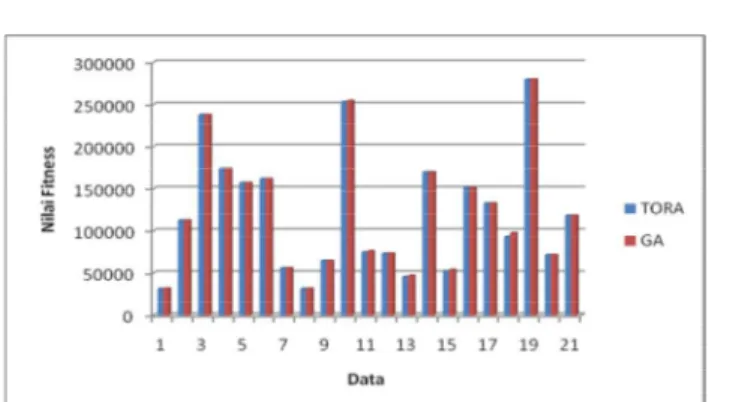
Gambar 5.1 Grafik Perbandingan Hasil TORA-GA
Apabila dilihat secara keseluruhan, selisih antara GA dan TORA tidak terlampau jauh. Gambar 5.1 menunjukkan grafik perbandingan hasil memperlihatkan bahwa hasil perhitungan persoalan distribusi di TORA dan AG hampir sama.
5. KESIMPULAN
Kesimpulan yang dapat diambil dari pengerjaan Tugas Akhir ini adalah:
1. Algoritma Genetika ini dapat menyelesaikan persoalan distribusi dengan menghasilkan solusi yang mendekati akurat jika dibandingkan TORA yang terlihat dari nilai rata-rata prosentase selisihnya sebesar 1.37% tidak lebih baik dari TORA
2. Performansi Algoritma Genetika dipengaruhi oleh beberapa parameter yaitu:
Ukuran populasi : pada semua jenis data nilai terbaik stabil dari ukuran populasi terkecil hingga terbesar. Rata-rata nilai pada data besar akan cenderung lebih minimum seiring bertambahnya ukuran populasi. Waktu komputasi berbanding lurus dengan ukuran populasi.
Maksimal Generasi : pada semua jenis data nilai terbaik stabil dari maksimal generasi terkecil hingga terbesar. Rata-rata nilai pada data besar akan cenderung lebih minimum seiring bertambahnya maksimal generasi. Waktu komputasi berbanding lurus dengan ukuran maksimal generasi.
Probabilitas crossover : probabilitas crossover yang semakin tinggi akan mempengaruhi besarnya ruang explorasi yang lebih luas karena kemungkinan kromosom yang terpilih lebih banyak. Nilai terbaik stabil dari Pc terkecil hingga terbesar, rata rata nilai cenderung turun seiring bertambahnya nilai Pc. Waktu komputasi cenderung naik dengan bertambahnya nialai Pc.
Probabilitas mutasi : probabilitas mutasi yang semakin besar akan menyebabkan kemungkinan gen yang terpilih untuk dimutasi semakin banyak. Nilai terbaik stabil dari Pm terkecil hingga terbesar, rata-rata nilai cenderung stabil hingga Pm 0.5, kemudia akan mengalami peningkatan. Waktu komputasi cenderung naik dengan bertambahnya nilai Pm.
6. DAFTAR PUSTAKA
[1]
Adlakha, V., dan Kowalski, K.,1999. “On The Fixed Charge Transportation Problem”. OMEGA 27, 381-388.
[2] Arhami, Muhammad., dan Desiani, Anita.2005.
Pemrograman MATLAB. Yogyakarta: ANDI. [3] Busetti,Franco. Genetic Algorithm Overview.
Italia
[4] Chopra, Sunil, dan Meindl, Peter. 2001. Supply Chain Management: Strategy, Planning, and Operation. New Jersey: Prentice-Hall.
[5] Gen, M. dan Cheng, R. 1997. Genetic Algorithm and Engineering Design. New York : John Wiley & Sons, Inc.
[6] Jawahar, N., dan Balaji, A.N., 15 Desember 2007. “A genetic algorithm for two-stage supply chain distribution problem associated with a fixed charge ”. European journal of Operational Research 194, 496-537.
[7] Markos, Sibel. 2008. Crossover Operators.
URL:http://www.google.com
[8] Melanie, Mitchell. 1999. An Introduction to Genetic Algorithms. Massachusetts: MIT Press. [9] Pujawan, I Nyoman. 2005. Supply Chain
Management. Surabaya : ITS.
[10] Suyanto. 2005. GA dalam Matlab. Yogyakarta: ANDI.
[11] Taha, Hamdi A. 1982. Operation Research : An Introduction,edisi ke-3.Macmillan Publishing Co.Inc. .New York.