i
PENCARIAN KARAKTERISTIK CALON MAHASISWA
BARU UNIVERSITAS SANATA DHARMA YANG TIDAK
MENDAFTAR ULANG DENGAN MENGGUNAKAN
ALGORITMA POHON KEPUTUSAN
Skripsi
Diajukan untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Sains
Program Studi Ilmu Komputer
Oleh: Lilik Haryanto NIM: 033124010
PROGRAM STUDI ILMU KOMPUTER
JURUSAN MATEMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
i
FINDING CHARACTERISTICS OF SANATA DHARMA
UNIVERSITY NOT-ENROLLING-APPLICANTS USING
DECISION TREE ALGORITHM
A Final Thesis
Presented as Partial Fulfillment of The Requirements for the Degree of Sarjana Sains
in Computer Science
By: Lilik Haryanto
Student Number: 033124010
COMPUTER SCIENCE STUDY PROGRAM
DEPARTMENT OF MATHEMATICS
FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY
YOGYAKARTA
iv
“ Akirametakunai, Fuan ni naru to te wo nigiri, Issho ni ayunde kita “ -Kiroro-
Kupersembahkan untuk:
Jesus Christ
Ibu, Bapak (Alm), Budhe, mas Hari, Pam-Pam
vi
ABSTRAK
Penambangan data merupakan suatu teknik untuk mengestraksi pola yang penting atau informasi yang menarik dari basis data yang berukuran besar. Penambangan data memberikan informasi yang digunakan sebagai penunjang dalam melakukan pengambilan keputusan. Teknik yang digunakan dalam melakukan penambangan data diantaranya adalah klasifikasi, yaitu teknik yang menentukan kelas-kelas ataupun kategori dari suatu objek berdasarkan sifat/atribut yang dimilikinya. Salah satu metode klasifikasi adalah algoritma pohon keputusan.
vii
ABSTRACT
Data mining is a way to extract important pattern or interesting information from large databases. Data mining gives information that is used to make a decision. Classification is one of technique that can be applied on data mining. The technique will define classes or categories of an object based on its characteristics. One of classification technique is decision tree algorithm.
ix
KATA PENGANTAR
Dalam nama Bapa Putera dan Roh Kudus, penulis selalu diberi kekuatan untuk berkembang dan menjadi lebih. Puji dan syukur penulis panjatkan kepada-Nya atas segala kesehatan, keselamatan, keberuntungan, berkat, rahmat, kasih dan bimbingan-Nya sehingga dapat menyelesaikan penyusunan skripsi yang berjudul “ Penambangan Data Penerimaan Mahasiswa Baru Universitas Sanata Dharma untuk Mencari Pola Karakteristik Calon Mahasiswa yang tidak Mendaftar Ulang dengan Menggunakan Algoritma Pohon Keputusan”.
Dalam kesempatan ini, penulis ingin mengucapkan terima kasih yang sebesar-besarnya kepada semua pihak yang turut memberikan dukungan, semangat dan bantuan hingga selesainya skripsi ini :
1. Jesus Christ….Makasih untuk selalu mendampingi dan menuntunku di saat apapun….Engkau selalu ada di saat tak seorangpun menemani setiap langkahku….Bersama-Mu segalanya menjadi lebih mudah dan begitu indah….
2. Keluargaku….Ibu Th. Kasyati, Bpk. Marjuki (Alm), Budhe, Masku Hari, adikku Pam-Pam. Terima kasih atas semua cinta, kasih dan semangat yang diberikan sehingga aku dapat lebih baik….Bu… akhirnya lulus…
3. Ibu P.H Prima Rosa, S.Si., M.Sc. selaku dosen pembimbing dan Kaprodi, atas segala kesabaran, waktu, bimbingan dan saran yang diberikan.
x
7. Bapak Drs. H. Haris Sriwindono, M.Kom selaku dosen pembimbing akademik atas bimbingannya selama kuliah.
8. Pak Tukijo dan mbak Linda, maaf telah banyak merepotkan 9. Mas Susilo selaku pegawai laboran
10.Anak-anak program studi Ilmu Komputer: Oneng, Ina, Teguh, Iin, Toto, Elis, Frans, Citra, Josephine, Vika, Ika, Kelik, Gondez, Suryo, Rey, Vitri, Kadek, Henry, Doni, Teteh, Dimas, Andi, Anjar, Clara, Hendro, Beni Aji, Iyus, Guritno, Wiwid, Rano, Aris, Wawan, Kornel, Beni, Ferry, Puguh, Bayu, Fatso, Fani, Prity
11.Teman-teman, yang selalu ada dan tidak dapat penulis sebutkan satu persatu, yang telah memberikan semangat dalam penulisan skripsi ini. Penulis menyadari bahwa penyusunan skripsi ini masih jauh dari sempurna karena keterbatasan kemampuan dan pengetahuan yang dimiliki serta terbatasnya waktu yang ada. Oleh karena itu, dengan kerendahan hati, penulis mengharapkan segala kritik maupun saran yang berguna dan membangun bagi perbaikan skripsi ini.
Akhir kata, penulis berharap semoga skripsi ini dapat bermanfaat bagi pembaca dan pihak lain yang membutuhkannya.
Penulis
xi
DAFTAR ISI
HALAMAN JUDUL ... i
HALAMAN PERSETUJUAN PEMBIMBING ... ii
HALAMAN PENGESAHAN ... iii
HALAMAN PERSEMBAHAN iv PERNYATAAN KEASLIAN KARYA ... v
ABSTRAK ... vi
ABSTRACT ... vii
LEMBAR PERNYATAAN PERSETUJUAN viii KATA PENGANTAR ... ix
DAFTAR ISI ... xi
DAFTAR TABEL ... xiii
DAFTAR GAMBAR ... xiv
BAB I PENDAHULUAN ... 1
A. Latar Belakang ... 1
B. Perumusan Masalah ... 3
C. Batasan Masalah ... 3
D. Tujuan ... 4
E. Manfaat ... 4
F. Metodologi ... 4
G. Sistematika Pembahasan ... 5
xii
A. Penambangan Data ... 6
B. Proses Penambangan Data ... 6
C. Teknik Klasifikasi ... 10
D. Pohon Keputusan ... 11
E. Contoh Penerapan Algoritma Pohon Keputusan …... 20
BAB III PERANCANGAN SISTEM ... 40
A. Identifikasi Sistem ... 40
B. Pembersihan Data ... 41
C. Integrasi Data ... 41
D. Transformasi Data ... 42
E. Perancangan Umum Sistem ... 42
1. Masukan Sistem ... 42
2. Proses Sistem ... 44
3. Keluaran Sistem ... 48
4. Perancangan Struktur Data ... 50
5. Perancangan Antarmuka ... 51
BAB IV IMPLEMENTASI SISTEM ... 63
A. Jalannya Program dan Pembahasannya ... 63
B. Analisa Hasil Program... 84
BAB V KESIMPULAN DAN SARAN ... 89
A. Kesimpulan ... 89
B. Saran ... 89
DAFTAR PUSTAKA ... 91
xiii
DAFTAR TABEL
Tabel 2.1 Tabel Kontingensi 2 x 2... 16
Tabel 2.2 Data Nasabah... 20
Tabel 2.3 Nilai information gain data nasabah 1... 27
Tabel 2.4 Nilai information gain data nasabah 2... 31
Tabel 2.5 Aturan Klasifikasi yang diperoleh... 32
Tabel 2.6 Tabel Kotingensi Untuk Kekayaan... 33
Tabel 2.7 Tabel Nilai Frekuensi Harapan Untuk Kekayaan... 34
Tabel 2.8 Tabel Kotingensi Untuk abungan... 36
Tabel 2.9 Tabel Nilai Frekuensi Harapan Untuk Tabungan... 37
Tabel 2.10 Aturan Yang Paling Sederhana... 38
Tabel 2.11 Hasil Prediksi... 39
Tabel 3.1 Deskripsi Atribut-Atribut Tabel Data Pelatihan... 34
Tabel 3.2 Deskripsi Atribut-Atribut Tabel Data Tes... 34
Tabel 3.3 Keluaran Contoh ArrayList………... 51
Tabel 4.1 Confusion Matrix Pengujian I…... 85
Tabel 4.2 Confusion Matrix Pengujian II... 85
Tabel 4.3 Confusion Matrix Pengujian III... 86
Tabel 4.4 Confusion Matrix Pengujian IV... 86
Tabel 4.5 Confusion Matrix Pengujian V... 86
xiv
DAFTAR GAMBAR
Gambar 2.1 Langkah-langkah dalam Penambangan Data... 8
Gambar 2.2 Penambangan datadan teknologi database lainnya... 9
Gambar 2.3 Pohon Keputusan... 11
Gambar 2.4 Contoh Pohon Keputusan... 12
Gambar 2.5 Nilai positif dan negatif kejadian atribut tabungan... 22
Gambar 2.6 Nilai positif dan negatif kejadian atribut kekayaan... 23
Gambar 2.7 Nilai positif dan negatif kejadian atribut pendapatan... 25
Gambar 2.8 Pohon Awal... 27
Gambar 2.9 Nilai positif dan negatif kejadian atribut tabungan... 28
Gambar 2.10 Nilai positif dan negatif kejadian atribut pendapatan... 30
Gambar 2.11 Pohon Percabangan... 32
Gambar 3.1 Desain Antarmuka FormInput Data Tabel... 51
Gambar 3.2 Desain Antarmuka Form Detail Tabel... 52
Gambar 3.3 Desain Antarmuka Form Penentuan Node Awal... 53
Gambar 3.4 Desain Antarmuka Form Pembuatan Pohon... 54
Gambar 3.5 Desain Antarmuka FormUnpruned Aturan... 55
Gambar 3.6 Desain Antarmuka Form Aturan Default... 56
Gambar 3.7 Desain Antarmuka Form Simulasi... 57
Gambar 3.8 Desain Antarmuka Form Pengujian Aturan... 58
xv
Gambar 3.10 Desain Antarmuka Form Aturan-Aturan... 60
Gambar 3.11 Desain Antarmuka Form Aturan-Aturan Sederhana... 61
Gambar 3.12 Desain Antarmuka Form Prediksi Sampel... 61
Gambar 4.1 Form Menu dan Form Input Data Tabel... 63
Gambar 4.2 Form Aturan Himpunan Tabel Pelatihan dan Tes... 64
Gambar 4.3 Form Tentang Program Penambangan Data... 64
Gambar 4.4 Kotak Peringatan 1... 65
Gambar 4.5 Kotak Peringatan 2... 65
Gambar 4.6 Form Data Tabel (Tabel Pelatihan) ... 66
Gambar 4.7 Form Data Tabel (Tabel Tes) ... 66
Gambar 4.8 Form Penentuan Node Awal... 67
Gambar 4.9 Form Pembuatan Pohon... 70
Gambar 4.10 Progress Bar Proses Pembuatan Pohon... 71
Gambar 4.11 Gambar 4.11 Kotak Pesan 1... 72
Gambar 4.12 Form Unpruned Aturan... 72
Gambar 4.13 Status Progress Bar Unpruned Aturan... 75
Gambar 4.14 Form Aturan Default... 75
Gambar 4.15 Kotak Pesan 2... 76
Gambar 4.16 Kotak Pesan 3... 76
Gambar 4.17 Form Simulasi... 77
Gambar 4.18 Form Simulasi Setelah Tombol Buat Simulasi diklik... 78
Gambar 4.19 Form Detail Sampel... 78
xvi
Gambar 4.21 Form Pengujian Aturan... 79
Gambar 4.22 Form Pengujian Aturan Setelah Tombol Uji Aturan diklik... 80
Gambar 4.23 Form Detail Simulasi Aturan... 81
Gambar 4.24 Kotak Pesan 5... 81
Gambar 4.25 Kotak Pesan 6... 82
Gambar 4.26 Form Aturan-Aturan Sederhana... 82
Gambar 4.27 Form Prediksi Sampel... 83
1
BAB I
PENDAHULUAN
A. Latar Belakang
Dalam proses Penerimaan Mahasiswa Baru (PMB), calon mahasiswa harus menjalani serangkaian tes tertulis terlebih dahulu sebelum mereka dinyatakan diterima sebagai mahasiswa Universitas Sanata Dharma. Setelah mengikuti tes dan dinyatakan lulus, maka data calon mahasiswa yang bersangkutan disimpan dalam suatu basis data tersendiri. Untuk melengkapi persyaratan dan bukti bahwa calon mahasiswa yang telah dinyatakan lulus tes tersebut benar-benar terdaftar sebagai mahasiswa Universitas Sanata Dharma, maka calon mahasiswa diwajibkan untuk melakukan daftar ulang. Setelah melakukan daftar ulang, seorang mahasiswa secara resmi menjadi civitas academica di Universitas Sanata Dharma. Yang menjadi masalah disini adalah bagaimana jika mahasiswa yang telah dinyatakan lulus tersebut tidak melakukan daftar ulang. Hal ini akan sangat merugikan bagi Universitas Sanata Dharma.
seluruh mahasiswa yang diterima, mendaftar ulang kembali sehingga kuota tidak terpenuhi. Namun, ketika ditetapkan jumlah mahasiswa yang diterima lebih dari kuota agar mahasiswa yang tidak mendaftar ulang dapat terantisipasi, ada akibat jumlah pendaftar ulang melebihi kuota. Masalah yang muncul adalah bagaimana menetapkan jumlah mahasiswa yang diterima agar kuota yang ditetapkan bisa terpenuhi secara relatif tetap.
Sebenarnya ada banyak solusi untuk mengatasi hal tersebut. Salah satu caranya dengan penambangan data (data mining). Penambangan data merupakan teknik untuk mengekstraksi informasi atau menemukan pola yang penting atau menarik dari data yang ada dalam basis data yang besar. Pendekatannya memakai algoritma pohon keputusan (decision trees). Algoritma ini merupakan salah satu pendekatan klasifikasi, yaitu proses pengelompokan data yang dipergunakan sebagai tujuan penambangan data.
B. Perumusan Masalah
Berangkat dari latar belakang masalah yang telah dikemukakan di atas, maka perumusan masalah dalam penelitian ini adalah bagaimana mengimplementasikan penambangan data pada basis data PMB Universitas Sanata Dharma untuk mengenali karakteristik calon mahasiswa yang tidak melakukan daftar ulang dengan mempergunakan algoritma pohon keputusan ?
C. Batasan Masalah
Berdasarkan rumusan masalah yang akan diteliti, diperlukan adanya pembatasan masalah. Hal ini dilakukan supaya penelitian lebih terfokus pada inti dari permasalah yang akan diteliti. Oleh karena itu, penulis memberi batasan penelitian sebagai berikut:
1. Pendekatan yang digunakan berupa pendekatan klasifikasi dengan hanya memakai algoritma pohon keputusan (ID3 Quinland).
2. Input adalah data PMB yang diperoleh dari Biro Administrasi dan Perencanaan Sistem Informasi (BAPSI). Universitas Sanata Dharma dari tahun 2005 sampai 2006.
3. Program diimplementasikan menggunakan bahasa Visual Basic.net dan MySQL
D. Tujuan
Dapat mengenali karakteristik calon mahasiswa yang tidak melakukan daftar ulang.
E. Manfaat
Hasil klasifikasi dari penambangan data dapat digunakan oleh Kaprodi untuk memprediksi kuota secara lebih tepat dengan memperhitungkan mahasiswa-mahasiswa yang diperkirakan tidak akan melakukan daftar ulang.
F. Metodologi
1. Mencari data PMB Universitas Sanata Dharma dari tahun 2005 sampai 2006.
2. Melakukan pembersihan data terhadap data yang tidak konsisten ataupun data yang kosong.
3. Implementasi teknik pohon keputusan pada data PMB dengan cara: a. Mengubah bentuk data menjadi model pohon.
b. Mengubah node pohon menjadi aturan. c. Menyederhanakan aturan.
G. Sistematika Pembahasan
BAB I. PENDAHULUAN
Pada bab ini akan dibahas mengenai latar belakang masalah, rumusan masalah, batasan masalah, tujuan, manfaat, metodologi, dan sistematika laporan.
BAB II. LANDASAN TEORI
Pada bab ini disajikan landasan teori yang berisi konsep/teori/temuan penelitian terdahulu/yang direplikasi yang berkaitan dengan implementasi penambangan data. Secara khusus akan dibahas algoritma pohon keputusan.
BAB III. PERANCANGAN SISTEM
Bab ini berisi tentang identifikasi sistem, pembersihan data, integrasi data, transformasi data dan perancangan sistem secara umum. BAB IV. IMPLEMENTASI PROGRAM
Bab ini berisi implementasi program penambangan data dan analisis terhadap hasil penelitian yang telah dilakukan.
BAB V. KESIMPULAN DAN SARAN
6
BAB II
LANDASAN TEORI
A. Penambangan Data
Beberapa pengertian penambangan data menurut sejumlah penulis adalah sebagai berikut :
1. Definisi sederhana dari penambangan data adalah ekstraksi informasi atau pola yang penting atau menarik dari data yang berada di basis data yang besar (Yudho, 2003:1).
2. Penambangan data adalah suatu percobaan untuk memperoleh informasi yang berguna yang tersimpan di dalam basis data yang sangat besar (Mitra & Acharya, 2003:1).
3. Suatu proses yang mengidentifikasi hubungan dan pola-pola tersembunyi dalam suatu data (Groth, 1998:4).
Dari pengertian-pengertian diatas, penambangan data dapat diartikan sebagai suatu proses untuk mencari pola-pola yang tersembunyi dari basis data yang besar sehingga didapatkan informasi yang menarik.
B. Proses Penambangan Data
khusus dalam basis data yang besar (Fayyad, Piatetsky-shapiro & Smyth, 1996: 40).
Berikut ini merupakan langkah-langkah dalam membangun penambangan data :
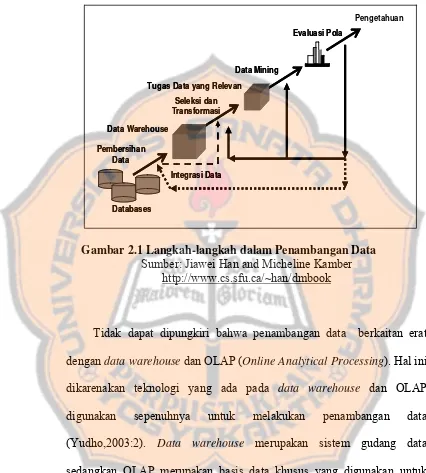
1. Pembersihan Data. Proses ini dilakukan untuk membuang data yang tidak konsisten dan derau yang ada dalam data tersebut, seperti data yang tidak relevan, data yang salah ketik maupun data kosong yang tidak diperlukan.
2. Integrasi data merupakan penggabungan tabel dari beberapa sumber agar seluruh data terangkum dalam satu tabel utuh (denormalisasi).
3. Seleksi dan transformasi data. Pada proses ini data yang ada dipilih untuk selanjutnya diubah menjadi bentuk yang sesuai untuk ditambang.
4. Penerapan teknik penambangan data adalah menerapkan algoritma untuk mencari pola yang menarik
Tahap-tahap tersebut diilustrasikan ke dalam gambar berikut ini :
Gambar 2.1 Langkah-langkah dalam Penambangan Data Sumber: Jiawei Han and Micheline Kamber
http://www.cs.sfu.ca/~han/dmbook
Tidak dapat dipungkiri bahwa penambangan data berkaitan erat dengan data warehouse dan OLAP (Online Analytical Processing). Hal ini dikarenakan teknologi yang ada pada data warehouse dan OLAP digunakan sepenuhnya untuk melakukan penambangan data (Yudho,2003:2). Data warehouse merupakan sistem gudang data sedangkan OLAP merupakan basis data khusus yang digunakan untuk menunjang proses pengambilan keputusan. Berikut ini merupakan gambar yang menunjukkan posisi masing-masing teknologi :
Pembersihan Data
Integrasi Data
Databases Data Warehouse
Tugas Data yang Relevan Seleksi dan Transformasi
Data Mining
Evaluasi Pola
Pengetahuan
Pembersihan Data
Integrasi Data
Databases Data Warehouse
Tugas Data yang Relevan Seleksi dan Transformasi
Data Mining
Evaluasi Pola
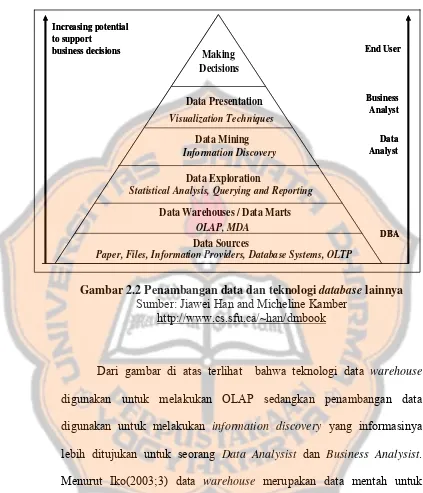
Gambar 2.2 Penambangan data dan teknologi database lainnya Sumber: Jiawei Han and Micheline Kamber
http://www.cs.sfu.ca/~han/dmbook
Dari gambar di atas terlihat bahwa teknologi data warehouse digunakan untuk melakukan OLAP sedangkan penambangan data digunakan untuk melakukan information discovery yang informasinya lebih ditujukan untuk seorang Data Analysist dan Business Analysist. Menurut Iko(2003;3) data warehouse merupakan data mentah untuk penambangan data. Data warehouse sendiri secara periodik diisi data dari OLTP(Online Transaction Processing) setelah menjalani pembersihan dan integrasi data. OLTP merupakan basis data yang dipakai perusahaan-perusahaan dalam melakukan operasi sehari-harinya seperti pencatatan
Increasing potential to support
business decisions End User
Business Analyst Data Analyst DBA Making Decisions Data Presentation Visualization Techniques Data Mining Information Discovery Data Exploration OLAP, MDA
Statistical Analysis, Querying and Reporting
Data Warehouses / Data Marts Data Sources
Paper, Files, Information Providers, Database Systems, OLTP
Increasing potential to support
business decisions End User
Business Analyst Data Analyst DBA Making Decisions Data Presentation Visualization Techniques Data Mining Information Discovery Data Exploration OLAP, MDA
Statistical Analysis, Querying and Reporting
Data Warehouses / Data Marts Data Sources
transaksi jual-beli, administrasi pengiriman barang, inventori, penggajian, dan lain sebagainya.
C. Teknik Klasifikasi
Salah satu metode yang digunakan dalam membangun penambangan data adalah teknik klasifikasi. Klasifikasi merupakan suatu teknik yang menentukan kelas-kelas ataupun kategori dari suatu objek berdasarkan sifat/atribut yang dimilikinya.
Algoritma teknik klasifikasi terdiri dari dua langkah, yaitu : 1. Membangun model
Tahap ini menggambarkan satu himpunan data dari kelas-kelas yang telah ditentukan sebelumnya. Masing-masing sampel diasumsikan sebagai kepunyaan suatu kelas yang sudah diketahui berdasarkan nilai-nilai atributnya. Sampel-sampel data yang digunakan untuk membangun model disebut himpunan data pelatihan. Model direpresentasikan sebagai clasification rules, pohon keputusan, atau formula matematis.
2. Penggunaan model
contoh himpunan data tes yang diklasifikasikan secara benar oleh model.
D. Pohon Keputusan
Ada beberapa model yang dapat dibangun pada teknik klasifikasi, salah satunya adalah pohon keputusan. Pohon keputusan adalah suatu diagram alir seperti struktur pohon, yang mana setiap titik (node) bagian dalam merupakan sebuah atribut, setiap cabang (branch) menggambarkan keluaran dari suatu logikal tes dan daun-daun (leaf node) menggambarkan kelas-kelas atau suatu kelas distribusi. Node yang paling atas disebut akar (root node). Untuk lebih jelasnya dapat dilihat pada gambar di bawah ini.
Gambar 2.3 Pohon Keputusan
Di bawah ini merupakan contoh dari suatu pohon keputusan yang mempunyai konsep tentang pembelian komputer dari suatu toko elektronik, yang mengindikasikan kemungkinan seorang pelanggan membeli komputer atau tidak.
Gambar 2.4 Contoh Pohon Keputusan Sumber: Jiawei Han and Micheline Kamber
http://www.cs.sfu.ca/~han/dmbook
Ada banyak algoritma yang dapat digunakan dalam membuat pohon keputusan. Salah satu algoritma yang dapat digunakan untuk membuat pohon keputusan adalah algoritma ID3 Quinland (Hamilton,2000). Langkah–langkah untuk melakukan prediksi dalam pohon keputusan dengan menggunakan algoritma ID3 Quinland adalah sebagai berikut : 1. Mengubah bentuk data menjadi bentuk model pohon
Langkah-langkah dalam mengubah model data menjadi model pohon adalah sebagai berikut :
umur?
mahasiswa? credit_rating?
ya tidak
ya
ya tidak
baik sekali cukup
ya tidak
a. Menentukan node terpilih/node awal
Atribut mana yang harus dipilih sebagai node awal adalah atribut yang memungkinkan untuk mendapatkan pohon keputusan yang paling kecil ukurannya atau atribut yang bisa memisahkan objek menurut kelasnya. Secara heuristik dipilih atribut yang menghasilkan node yang paling ”purest” (paling bersih). Jika dalam satu cabang anggotanya berasal dari satu kelas maka cabang ini disebut pure. Semakin pure suatu cabang semakin baik. Ukuran purity dinyatakan dengan tingkat impurity. Salah satu kriteria impurity adalah information gain. Jadi dalam memilih atribut untuk memecah objek dalam beberapa kelas harus dipilih atribut yang menghasilkan information gain paling besar.
Untuk menghitung information gain perlu dihitung dahulu nilai informasi dalam satuan bits dari suatu kumpulan obyek. Cara penghitungan dilakukan dengan menggunakan konsep entropi. Entropi menyatakan impurity suatu kumpulan obyek. Berikut ini merupakan definisi dari entropi suatu ruang sampel data (S) :
entropi(S) = − P+log2 P+−P- log2 P- ...2.1
dimana :
S = ruang sampel data yang digunakan untuk data pelatihan P+ = jumlah yang bersolusi positif (mendukung) pada sampel data P- = jumlah yang bersolusi negatif (tidak mendukung) pada sampel
Nilai rata-rata terbobot entropi suatu atribut dapat dirumuskan sebagai berikut :
E(A)=
∑
= ⎟⎟⎠
⎞ ⎜⎜
⎝
⎛ ×
⎟ ⎠ ⎞ ⎜ ⎝ ⎛ inst
i t
i
e n n
1
i ...2.2
dimana :
inst = jumlah kejadian
ni = jumlah data kejadian ke-i nt = jumlah total data keseluruhan ei = nilai entropi kejadian ke-i
Sehingga information gain dapat di hitung dengan rumus:
Gain(A) = entropi(S) – E(A)...2.3 dimana :
entropi(S) = nilai entropi total dari atribut keputusan dalam ruang sampel data S.
E(A) = nilai rata-rata terbobot entropi suatu atribut b. Menyusun Pohon
Penyusunan pohon dimulai dari node yang terpilih. Node yang terpilih tersebut menjadi akar (root leaf) dari pohon yang akan disusun. Langkah selanjutnya adalah memilih node daun (leaf node) selanjutnya. Langkah yang dilakukan adalah :
1) Memilih node dari sampel data yang tidak homogen
3) Pilih atribut yang mempunyai nilai gain paling besar sebagai node daun selanjutnya.
Proses ini dilakukan secara terus menerus sampai setiap node daun mempunyai sampel data yang homogen atau sampel data yang ada kosong atau jika sampel masih tidak homogen (heterogen) tetapi tidak ada lagi atribut yang tersisa.
2. Mengubah node pohon menjadi aturan
Pada tahap ini pohon yang telah selesai dibangun diubah menjadi aturan if...then. Menurut Han dan Kamber (1998), node-node yang ada merupakan anteseden pada suatu aturan, sedangkan nilai anteseden merupakan cabang-cabang yang terbentuk pada node. Nilai konsekuennya adalah :
Jika sampel sudah homogen, maka nilai konsekuennya adalah kejadian atribut target/keputusan pada sampel data tersebut.
Jika sampel kosong, maka nilai konsekuennya merupakan kejadian paling banyak dari atribut target pada keseluruhan sampel.
Jika sampel masih heterogen tetapi atribut kondisi sudah habis, maka nilai konsekuennya adalah kejadian pada atribut target yang mempunyai jumlah kejadian paling banyak pada sampel yang tersisa (Han dan Kamber, 1998)
3. Menyederhanakan aturan (pruning)
meningkatkan akurasi klasifikasi. Aturan yang terbentuk menjadi lebih sederhana dan lebih akurat. Menurut Hamilton (2000), langkah-langkah dalam penyederhanaan aturan adalah :
a. Menyederhanakan aturan dengan menghilangkan anteseden yang tidak perlu. Langkah-langkah untuk menghilangkan anteseden adalah sebagai berikut :
1) Membangun tabel kontingensi untuk setiap aturan yang mengandung lebih dari satu anteseden. Aturan yang hanya memiliki satu anteseden tidak dapat disederhanakan lebih lanjut, jadi hanya aturan yang terdiri dari dua atau lebih anteseden yang dapat disederhanakan. Tabel kontingensi merupakan nilai frekuensi yang teramati. Tabel kontingensi terdiri dari r baris dan c kolom. Total r baris dan c kolom dalam tabel kontingensi disebut frekuensi marjinal. Untuk lebih jelasnya, dapat dilihat pada tabel berikut ini :
Tabel 2.1 Tabel Kontingensi 2 x 2
C1 C2 Jumlah Marjinal
R1 x11 x12 R1T = x11 + x12 R2 x21 x22 R2T = x21 + x22 Jumlah
Marjinal
CT1 = x11+ x21 CT2 = x1+x22 T = x11+x12+x21+x22
Keterangan :
x11, x12, x21, x22 : merepresentasikan frekuensi dari setiap pasangan anteseden dengan konsekuen R1T, R2T : jumlah marjinal dari baris
CT1, CT2 : jumlah marjinal dari kolom
T : jumlah keseluruhan frekuensi marjinal
2) Menguji data-data dari kriteria tertentu dengan menggunakan uji kebaikan suai. Uji kebaikan suai ini berguna untuk menentukan tingkat independensi pada suatu kriteria. Uji ini didasarkan pada seberapa baik kesesuaian antara frekuensi yang teramati dalam data dengan frekuensi harapan yang didasarkan pada sebaran yang dihipotesiskan. Berikut ini merupakan rumus untuk menghitung frekuensi harapan bagi sembarang sel :
eij = T
C RiT• Tj
...2.4
dimana :
eij = nilai frekuensi harapan baris ke-i kolom ke-j RiT = total baris ke-i
CTj = total kolom ke-j
Uji kebaikan suai yang teramati dengan frekuensi harapan didasarkan pada besaran :
2
χ =
2
) (
∑ ∑
−baris
i kolom
j ij
ij ij
e e o
...2.5
dimana :
2
χ = nilai bagi peubah acak χ2 yang sebaran penarikan
contohnya sangat menghampiri sebaran chi-square i = baris
j = kolom
ij
o = nilai frekuensi teramati baris ke-i kolom ke-j
ij
e = nilai frekuensi harapan baris ke-i kolom ke-j
buruk akan membawa pada penolakan Ho. Penolakan Ho mengakibatkan penerimaan hipotesis alternatif, yang dilambangkan dengan H1 (Walpole, 1995).
3) Menghitung derajat kebebasan
Untuk menghitung derajat kebebasan digunakan rumus : dk = (baris - 1)(kolom - 1)...2.6 4) Gunakan tabel chi-square dengan χ2 dan derajat kebebasan
untuk menentukan apakah anteseden secara individual independen dengan konsekuennya. Untuk kepercayaan sebesar
α , jika :
χ2 >χ2α
dengan derajat kebebasan dk : tolak hipotesis nol dan menerima alternatif hipotesis yaitu anteseden secara individual dependen dengan konsekuen.
χ2 ≤χ2α
dengan derajat kebebasan dk : terima hipotesis nol yaitu anteseden yang secara individual independen dengan konsekuen. χ2α dapat diperoleh pada tabel chi-square.
b. Menyederhanakan aturan dengan membuang aturan-aturan yang tidak perlu
contoh penyederhanaan aturan adalah dengan membuat aturan default. Aturan default ini dibentuk dengan mencari konsekuen paling banyak pada aturan tersebut. Aturan-aturan yang memiliki konsekuen inilah yang nanti dijadikan aturan default.
E. Contoh Penerapan Algoritma Pohon Keputusan
Berikut ini merupakan contoh penyelesaian suatu kasus dengan menggunakan algoritma pohon keputusan. Pada kasus ini data yang digunakan adalah data nasabah (Daniel, 2005). Permasalahan yang ada disini adalah bagaimana mengklasifikasi resiko kredit seorang nasabah. Data nasabah ini terdiri dari empat kategori atribut, yaitu tabungan, kekayaan, pendapatan dan atribut resiko kredit sebagai atribut keputusannya. Di bawah ini adalah data nasabah tersebut :
Tabel 2.2 Data Nasabah
Nasabah Tabungan Kekayaan Pendapatan ($ 1000s)
Resiko kredit
1 Sedang Tinggi 75 Baik
2 Rendah Rendah 50 Buruk
3 Tinggi Sedang 25 Buruk
4 Sedang Sedang 50 Baik
5 Rendah Sedang 100 Baik
6 Tinggi Tinggi 25 Baik
7 Rendah Rendah 25 Buruk
8 Sedang Sedang 75 Baik
Langkah 1 : mengubah bentuk data menjadi bentuk model pohon
1. Menentukan node terpilih
Hal yang harus dilakukan pada tahap ini adalah menghitung nilai entropi atribut keputusan yaitu atribut resiko kredit dan nilai entropi setiap kejadian dengan rumus 2.1, selanjutnya menghitung nilai rata-rata terbobot entropi setiap atribut menggunakan rumus 2.2 dan selanjutnya menghitung nilai information gain dengan rumus 2.3. Pilihlah atribut yang mempunyai nilai information gain paling besar, atribut inilah yang akan menjadi node awal. Berikut ini merupakan penghitungan information gain dari setiap atribut.
Langkah awal adalah menghitung nilai entropi total dari atribut keputusan, yaitu :
Pada data nasabah terdapat dua keputusan yaitu baik atau buruk. Ada 5 keputusan resiko kredit baik dan ada 3 keputusan resiko kredit buruk. Dimisalkan bahwa keputusan resiko kredit baik adalah positif sedangkan keputusan resiko kredit buruk adalah negatif, maka dapat dihitung entropinya :
entropi(S) = − P+log2 P+−P- log2 P-
=
8 3 log 8 3 8 5 log 8 5
2 2 −
−
a. Atribut tabungan
1) Cari jumlah nilai positif dan negatif dari setiap kejadian pada atribut tabungan, berikut ini penggambarannya :
Gambar 2.5 Nilai positif dan negatif kejadian atribut tabungan
2) Hitung nilai entropi dari setiap kejadian, yaitu:
Tabungan = Tinggi (e1) e1 = − P+log2 P+−P- log2 P
-e1 = 2 1 log 2 1 2 1 log 2 1 2 2 − −
e1 = 0.5 + 0.5 e1 = 1
Tabungan = Sedang (e2) e2 = − P+log2 P+−P- log2 P
-e2 = 0
3 3 log 3 3 2 − −
e2 = 0
Tabungan = Rendah (e3) e3 = − P+log2 P+−P- log2 P
-Tabungan 3 positif
e3 = 3 2 log 3 2 3 1 log 3 1 2 2 − −
e3 = 0.528321 + 0.389975 e3 = 0.918
3) Hitung nilai rata-rata terbobot entropi atribut tabungan, yaitu:
E =
∑
= ⎟⎟⎠ ⎞ ⎜⎜ ⎝ ⎛ × ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ inst i t i e n n 1 i
E = ⎟
⎠ ⎞ ⎜ ⎝ ⎛ × + ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ × + ⎟ ⎠ ⎞ ⎜ ⎝
⎛ × 3
8 3 2 8 3 1 8 2 e e e
E = 0.25 + 0 + 0.3444 E = 0.594
4) Hitung information gain dari atribut tabungan, yaitu: Gain(A) = entropi(S) – E(A)
= 0.954 – 0.594 = 0.36
b. Atribut kekayaan
1) Cari jumlah nilai positif dan negatif dari setiap kejadian pada atribut kekayaan, berikut ini penggambarannya :
Gambar 2.6 Nilai positif dan negatif kejadian atribut kekayaan
Kekayaan 3 positif
2) Hitung nilai entropi dari setiap kejadian, yaitu:
Kekayaan = Tinggi (e1) e1 = − P+log2 P+−P- log2 P
-e1 = 0
2 2 log 2 2 2 − −
e1 = 0
Kekayaan = Sedang (e2) e2 = − P+log2 P+−P- log2 P
-e2 = 4 1 log 4 1 4 3 log 4 3 2 2 − −
e2 = 0.311278 + 0.5 e2 = 0.811
Kekayaan = Rendah (e3) e3 = − P+log2 P+−P- log2 P
-e3 = 2 2 log 2 2
0− 2
e3 = 0
3) Hitung nilai rata-rata terbobot entropi atribut kekayaan, yaitu:
E =
∑
= ⎟⎟⎠ ⎞ ⎜⎜ ⎝ ⎛ × ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ inst i t i e n n 1 i
E = ⎟
⎠ ⎞ ⎜ ⎝ ⎛ × + ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ × + ⎟ ⎠ ⎞ ⎜ ⎝
⎛ × 3
8 2 2 8 4 1 8 2 e e e
4) Hitung information gain dari atribut kekayaan, yaitu: Gain(A) = entropi(S) – E(A)
= 0.954 – 0.406 = 0.548
c. Atribut pendapatan
1) Cari jumlah nilai positif dan negatif dari setiap kejadian pada atribut pendapatan, berikut ini penggambarannya :
Gambar 2.7 Nilai positif dan negatif kejadian atribut pendapatan
2) Hitung nilai entropi dari setiap kejadian, yaitu:
Pendapatan = 25 (e1) e1 = − P+log2 P+−P- log2 P
-e1 = 3 2 log 3 2 3 1 log 3 1 2 2 − −
e1 = 0.528321 + 0.389975 e1 = 0.918
Pendapatan = 50 (e2) e2 = − P+log2 P+−P- log2 P
e2 = 0.5 + 0.5 e2 = 1
Pendapatan = 75 (e3) e3 = − P+log2 P+−P- log2 P
-e3 = 0
2 2 log 2 2 2 − −
e3 = 0
Pendapatan = 100 (e4) e4 = − P+log2 P+−P- log2 P
-e4 = 0
1 1 log 1 1 2 − −
e4 = 0
3) Hitung nilai rata-rata terbobot entropi atribut pendapatan, yaitu:
E =
∑
= ⎟⎟⎠ ⎞ ⎜⎜ ⎝ ⎛ × ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ inst i t i e n n 1 i
E = ⎟
⎠ ⎞ ⎜ ⎝ ⎛ × + ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ × + ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ × + ⎟ ⎠ ⎞ ⎜ ⎝
⎛ × 4
8 1 3 8 2 2 8 2 1 8 3 e e e e
E = 0.34425 + 0.25 + 0 + 0 E = 0.594
4) Hitung information gain dari atribut pendapatan, yaitu: Gain(A) = entropi(S) – E(A)
Dari penghitungan nilai information gain setiap atribut tersebut, didapatkan tabel information gain sebagai berikut :
Tabel 2.3 Nilai information gain data nasabah 1
Atribut Nilai information gain Tabungan 0.360
Kekayaan 0.548 Pendapatan 0.360
Pada tabel tersebut terlihat bahwa nilai information gain paling besar dimiliki oleh atribut kekayaan sebesar 0.548. Atribut kekayaan inilah yang menjadi node awal dalam penyusunan pohon keputusan.
2. Menyusun pohon
Untuk menyusun suatu pohon ditentukan suatu atribut sebagai node awal. Dalam kasus ini, didapatkan node awal yaitu atribut kekayaan. Berikut ini merupakan pohon awal yang terbentuk :
Gambar 2.8 Pohon Awal
Tinggi Sedang Rendah
Kekayaan
baik baik
baik baik baik buruk
Langkah selanjutnya adalah mencari atribut lain untuk menjadi node selanjutnya. Dari pohon awal tersebut, terdapat sampel data yang tidak homogen yaitu atribut kekayaan dengan kejadian sedang. Maka yang menjadi node percabangan adalah node pada kejadian ini. Untuk mencari node selanjutnya, dilakukan penghitungan untuk mencari nilai information gain setiap atribut kecuali atribut yang menjadi node diatasnya.
Berikut ini penghitungannya : a. Atribut tabungan
1) Cari jumlah nilai positif dan negatif dari setiap kejadian pada atribut tabungan, berikut ini penggambarannya :
Gambar 2.9 Nilai positif dan negatif kejadian atribut tabungan
2) Hitung nilai entropi dari setiap kejadian, yaitu:
Tabungan = Tinggi (e1) e1 = − P+log2 P+−P- log2 P
-e1 =
1 1 log 1 1
0− 2
e1 = 0
Tabungan 2 positif
1 positif
Tinggi
Sedang Rendah
Tabungan = Sedang (e2) e2 = − P+log2 P+−P- log2 P
-e2 = 0
2 2 log 2 2 2 − −
e2 = 0
Tabungan = Rendah (e3) e3 = − P+log2 P+−P- log2 P
-e3 = 0
1 1 log 1 1 2 − −
e3 = 0
3) Hitung nilai rata-rata terbobot entropi atribut tabungan, yaitu:
E =
∑
= ⎟⎟⎠ ⎞ ⎜⎜ ⎝ ⎛ × ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ inst i t i e n n 1 i
E = ⎟
⎠ ⎞ ⎜ ⎝ ⎛ × + ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ × + ⎟ ⎠ ⎞ ⎜ ⎝
⎛ × 3
4 1 2 4 2 1 4 1 e e e
E = 0 + 0 + 0 E = 0
4) Hitung information gain dari atribut tabungan, yaitu: Gain(A) = entropi(S) – E(A)
= 0.954 – 0 = 0.954 b. Atribut pendapatan
Gambar 2.10 Nilai positif dan negatif kejadian atribut pendapatan
2) Hitung nilai entropi dari setiap kejadian, yaitu:
Pendapatan = 25 (e1) e1 = − P+log2 P+−P- log2 P
-e1 = 1 1 log 1 1
0− 2
e1 = 0
Pendapatan = 50 (e2) e2 = − P+log2 P+−P- log2 P
-e2 = 0
1 1 log 1 1 2 − −
e2 = 0
Pendapatan = 75 (e3) e3 = − P+log2 P+−P- log2 P
-e3 = 0
1 1 log 1 1 2 − −
e3 = 0
e4 = − P+log2 P+−P- log2 P
-e4 = 0
1 1 log 1 1 2 − −
e4 = 0
3) Hitung nilai rata-rata terbobot entropi atribut pendapatan, yaitu:
E =
∑
= ⎟⎟⎠ ⎞ ⎜⎜ ⎝ ⎛ × ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ inst i t i e n n 1 i
E = ⎟
⎠ ⎞ ⎜ ⎝ ⎛ × + ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ × + ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ × + ⎟ ⎠ ⎞ ⎜ ⎝
⎛ × 4
4 1 3 4 1 2 4 1 1 4 1 e e e e
E = 0 + 0 + 0 + 0 E = 0
4) Hitung information gain dari atribut pendapatan, yaitu: Gain(A) = entropi(S) – E(A)
= 0.954 – 0 = 0.954
Dari penghitungan nilai information gain tersebut didapat suatu tabel sebagai berikut :
Tabel 2.4 Nilai information gain data nasabah 2
Atribut Nilai information gain Tabungan 0.954
Pendapatan 0.954
Gambar 2.11 Pohon Percabangan
Langkah 2 : mengubah node pohon menjadi aturan
Pada tahap ini, node pohon yang terbentuk di ubah ke dalam aturan if...then, yaitu :
Tabel 2.5 Aturan Klasifikasi yang diperoleh
Aturan If Then
1 Kekayaan = Tinggi Baik
2 Kekayaan = Rendah Buruk
3 Kekayaan = Sedang ^ Tabungan = Tinggi Buruk 4 Kekayaan = Sedang ^ Tabungan = Sedang Baik 5 Kekayaan = Sedang ^ Tabungan = Rendah Baik
Tinggi Rendah Kekayaan
baik baik
buruk buruk Sedang
Tinggi Sedang Rendah Tabungan
buruk baik baik
Langkah 3 : menyederhanakan aturan
1. Menyederhanakan aturan dengan menghilangkan anteseden yang tidak perlu
Aturan yang perlu disederhanakan adalah aturan yang memiliki anteseden lebih dari satu yaitu aturan nomor 3 sampai dengan nomor 5 yang melibatkan anteseden kekayaan dan tabungan. Pada tahap ini, tabel Chi-Square digunakan untuk melakukan uji hipotesis. Data yang ada telah dikalikan dengan nilai lima (5) agar data dapat digunakan pada uji tabel Chi-Square dan diasumsikan nilai tingkat kepercayaannya (α) sebesar 0.05.
a. Hipotesis Ho : kekayaan dan resiko kredit independen
1) Membuat tabel kotingensi
Tabel 2.6 Tabel Kotingensi Untuk Kekayaan
Resiko kredit
(Baik)
Resiko kredit (Buruk)
Jumlah Marjinal
Tinggi 10 0 10
Sedang 15 5 20
Rendah 0 10 10
Jumlah Marjinal 25 15 40
2) Nilai Frekuensi Harapan (eij)
Selanjutnya menggunakan rumus 2.4.3 untuk menghitung nilai frekuensi harapan tiap sel, yaitu :
Frekuensi harapan pada sel X11 : e11 =
40 25 10×
Frekuensi harapan pada sel X12 : e12 =
40 15 10×
= 3.75
Frekuensi harapan pada sel X21 : e21 =
40 25 20×
= 12.5
Frekuensi harapan pada sel X22 :
e22 = 40
15 20×
= 7.5
Frekuensi harapan pada sel X31 : e31 =
40 25 10×
= 6.25
Frekuensi harapan pada sel X32 : e32 =
40 15 10×
= 3.75
Berikut ini merupakan tabel nilai frekuensi harapan dari penghitungan di atas :
Tabel 2.7 Tabel Nilai Frekuensi Harapan Untuk Kekayaan
Resiko kredit
(Baik)
Resiko kredit (Buruk)
Tinggi 6.25 3.75
Sedang 12.5 7.5
3) Nilai χ2
Untuk menghitung nilai χ2 digunakan rumus 2.4.4, berikut penghitunggannya : 2 χ = 2 ) (
∑ ∑
− baris i kolom j ij ij ij e e o 2 χ =(
) (
) (
)
(
) (
) (
)
75 . 3 75 . 3 10 25 . 6 25 . 6 0 5 . 7 5 . 7 5 5 . 12 5 . 12 15 75 . 3 75 . 3 0 25 . 6 25 . 6 10 2 2 2 2 2 2 − + − + − + − + − + − 2χ = 2.25 + 3.75 + 0.5 + 0.833 + 6.25 + 10.417
2
χ = 23.99967
4) Nilai derajat kebebasan
Nilai ini dihitung dengan menggunakan rumus 2.4.5, yaitu : dk = (baris - 1)(kolom - 1) = (3 - 1)(2 - 1) = 2
5) Nilai χ2α
Nilai χ2α pada tabel Chi-Square dengan derajat kebebasan 2 adalah 5.991.
6) Kesimpulan :
b. Hipotesis Ho : tabungan dan resiko kredit independen
1) Membuat tabel kotingensi
Tabel 2.8 Tabel Kotingensi Untuk Tabungan
Resiko kredit
(Baik)
Resiko kredit (Buruk)
Jumlah Marjinal
Tinggi 5 5 10
Sedang 15 0 15
Rendah 5 10 15
Jumlah Marjinal 25 15 40
2) Nilai Frekuensi Harapan (eij)
Selanjutnya menggunakan rumus 2.4.3 untuk menghitung nilai frekuensi harapan tiap sel, yaitu :
Frekuensi harapan pada sel X11 : e11 =
40 25 10×
= 6.25
Frekuensi harapan pada sel X12 : e12 =
40 15 10×
= 3.75
Frekuensi harapan pada sel X21 : e21 =
40 25 15×
= 9.75
Frekuensi harapan pada sel X22 :
e22 = 40
15 15×
= 5.625
Frekuensi harapan pada sel X31 : e31 =
40 25 15×
Frekuensi harapan pada sel X32 : e32 =
40 15 15×
= 5.625
Berikut ini merupakan tabel nilai frekuensi harapan dari penghitungan di atas :
Tabel 2.9 Tabel Nilai Frekuensi Harapan Untuk Tabungan
Resiko kredit
(Baik)
Resiko kredit (Buruk)
Tinggi 6.25 3.75
Sedang 9.75 5.625
Rendah 9.75 5.625
3) Nilai χ2
Untuk menghitung nilai χ2 digunakan rumus 2.4.4, berikut penghitunggannya : 2 χ = 2 ) (
∑ ∑
− baris i kolom j ij ij ij e e o 2 χ =(
) (
) (
)
(
) (
) (
)
625 . 5 625 . 5 10 75 . 9 75 . 9 5 625 . 5 625 . 5 0 75 . 9 75 . 9 15 75 . 3 75 . 3 5 25 . 6 25 . 6 5 2 2 2 2 2 2 − + − + − + − + − + − 2χ = 0.25 + 0.4167 + 2.827 + 5.625 + 2.314 + 3.403
2
χ = 14.835
4) Nilai derajat kebebasan
5) Nilai χ2α
Nilai χ2α pada tabel Chi-Square dengan derajat kebebasan 2 adalah 5.991.
6) Kesimpulan :
Karena nilai χ2 > χ2α, maka hipotesis nol independensi Hoditolak dan H1 diterima yang berarti tabungan dan resiko kredit tidak independen. Maka anteseden tabungan tidak dapat dieliminasi dan aturan klasifikasi masih tetap seperti pada tabel 2.7.
2. Menyederhanakan aturan dengan membuang aturan
Setelah menyederhanakan aturan dengan menggunakan langkah pertama, maka dilanjutkan dengan mencari konsekuen yang paling banyak. Pada aturan diatas konsekuen yang paling banyak berjumlah 3, yaitu Baik. Ketiga aturan ini dijadikan default aturan, sehingga aturan-aturan tersebut menjadi :
Tabel 2.10 Aturan Yang Paling Sederhana
Aturan If Then
1 Kekayaan = Rendah Buruk
2 Kekayaan = Sedang ^ Tabungan = Tinggi Buruk
Langkah 4 : hasil prediksi himpunan data pelatihan
Tabel 2.11 Hasil Prediksi
Nasabah Tabungan Kekayaan Pendapatan ($ 1000s)
Resiko kredit
Prediksi
1 Sedang Tinggi 75 Baik Baik
2 Rendah Rendah 50 Buruk Buruk
3 Tinggi Sedang 25 Buruk Buruk
4 Sedang Sedang 50 Baik Baik
5 Rendah Sedang 100 Baik Baik
6 Tinggi Tinggi 25 Baik Baik
7 Rendah Rendah 25 Buruk Buruk
8 Sedang Sedang 75 Baik Baik
40
BAB III
PERANCANGAN SISTEM
A. Identifikasi Sistem
Setiap pergantian tahun akademik baru, Universitas Sanata Dharma selalu melakukan Penerimaan Mahasiswa Baru (PMB). Calon mahasiswa baru ini harus melakukan serangkaian tes tertulis terlebih dahulu. Setiap tahun pula program studi menyediakan kuota untuk mahasiswa baru yang diterima. Calon mahasiswa yang diterima belum tentu melakukan daftar ulang, untuk itulah Ketua Program Studi (Kaprodi) harus benar-benar selektif dalam memilih mahasiswa mana yang pasti melakukan daftar ulang, sehingga kuota yang ditetapkan dapat terisi relatif tepat. Masalah tersebut dapat diatasi dengan menggunakan metode penambangan data, karena penambangan data ini dapat digunakan untuk mengenali karakteristik mahasiswa yang tidak melakukan daftar ulang.
finalnya. Data yang didapat akan dibagi dua secara acak, kemudian digunakan sebagai himpunan data pelatihan dan himpunan data tes dengan proporsi yang bervariasi.
B. Pembersihan Data
Data calon penerimaan mahasiswa baru yang didapat dari BAPSI, dibersihkan terlebih dahulu sebelum data tersebut ditambang. Proses pembersihan data ini berfungsi untuk menghilangkan data yang tidak konsisten dan derau seperti data tidak relevan, data yang salah ketik maupun data kosong yang tidak diperlukan. Data yang tidak konsisten ini dapat berupa jenis SMA yang mempunyai arti sama, tapi penulisannya berbeda-beda. Misalnya IPA ada yang menuliskan SMA IPA ataupun IPA, jadi dalam proses ini dilakukan penyeragaman nama terhadap data yang tidak konsisten.
C. Integrasi Data
D. Transformasi Data
Dalam proses ini dilakukan klasifikasi data nilai final yang bertipe numerik dan berkisar dalam rentang 0 sampai 10. Berikut ini klasifikasinya :
o N ≤ 3
o 3 < N ≤ 4
o 4 < N ≤ 5
o 5 < N ≤ 6
o 6 < N ≤ 7
o 7 < N ≤ 8
o N > 8
E. Perancangan Umum Sistem
1. Masukan Sistem
Masukan sistem yang akan dibuat adalah tabel himpunan data pelatihandan tabel himpunan data tes. Pada tabel himpunan data pelatihan, yang menjadi atribut keputusan adalah atribut status yang terdiri dari dua kondisi yaitu daftar ulang dan tidak daftar ulang.
Tabel 3.1 Deskripsi Atribut-Atribut Tabel Data Pelatihan
No Nama Atribut Deskripsi Nilai Kejadian 1 gelombang Gelombang masuk 1, 2, 3
2 pilihan Prioritas pilihan pada program studi tempat calon
mahasiswa tersebut diterima
1, 2 ,3
3 prodi Program studi tempat
mahasiswa diterima
AKT, BK, FAR, FIS, IND, IPAK, MAN, MAT, MEKA, PAK, PBI, PBI, PBSID, PEK, PFIS, PGSD, PMAT, PSEJ, PSI, SEJ, SING, TE, TI, TM
4 jenis_kelamin Jenis kelamin mahasiswa L, P
5 jenis_sma Jenis SMA mahasiswa IPA, IPS, Bahasa, SMK, STM, SMF, SPG/SGO,
LAIN-LAIN 6 final Nilai final tes masuk
berdasarkan program studi dimana mahasiswa tersebut diterima
N ≤ 3, 3 < N ≤ 4, 4 < N ≤ 5, 5 < N ≤ 6, 6 < N ≤ 7, 7 < N ≤ 8, N > 8 7 status Status mahasiswa yang
melakukan daftar ulang atau tidak
Daftar Ulang, tidak DU
Berikut ini merupakan deskripsi dari atribut-atribut pada tabel data tes beserta nilai kejadian dari atribut-atribut tersebut :
Tabel 3.2 Deskripsi Atribut-Atribut Tabel Data Tes
No Nama Atribut Deskripsi Nilai Kejadian 1 gelombang Gelombang masuk 1, 2, 3
2 pilihan Prioritas pilihan pada program studi tempat calon
mahasiswa tersebut diterima
1, 2, 3
mahasiswa diterima FIS, IND, IPAK, MAN, MAT, MEKA, PAK, PBI, PBI, PBSID, PEK, PFIS, PGSD, PMAT, PSEJ, PSI, SEJ, SING, TE, TI, TM
4 jenis_kelamin Jenis kelamin mahasiswa L, P
5 jenis_sma Jenis SMA mahasiswa IPA, IPS, Bahasa, SMK, STM, SMF, SPG/SGO,
LAIN-LAIN 6 final Nilai keseluruhan tes
berdasarkan program studi dimana mahasiswa tersebut diterima
N ≤ 3, 3 < N ≤ 4, 4 < N ≤ 5, 5 < N ≤ 6, 6 < N ≤ 7, 7 < N ≤ 8, N > 8 7 status Status mahasiswa yang
melakukan daftar ulang atau tidak
Daftar Ulang, tidak DU 8 prediksi Nilai awalnya kosong,
nantinya akan berisi prediksi status mahasiswa yang melakukan daftar ulang atau tidak
Daftar Ulang, tidak DU
2. Proses Sistem
Proses-proses yang dilakukan pada sistem yang dibangun adalah : a. Mengubah bentuk data menjadi bentuk pohon
1) Menentukan node awal
Langkah yang dilakukan untuk menentukan node awal adalah menghitung nilai gain tiap atribut kecuali atribut keputusan. Berikut merupakan langkah-langkah penghitungannya :
a) Hitung jumlah baris pada sampel data
c) Cari atribut-atribut dan hitung jumlah atribut yang akan dihitung nilai gainnya
d) Hitung jumlah kejadian untuk atribut ke-i e) Untuk atribut ke-i, kejadian ke-j
• Hitung jumlah sampel yang memenuhi syarat kejadian dengan atribut ke-i = kejadian ke-j dan status = Daftar Ulang.
• Hitung jumlah sampel yang memenuhi syarat kejadian dengan atribut ke-i = kejadian ke-j dan status = tidak DU. f) Kemudian hitung nilai entropi pada kejadian ke-j dengan rumus
2.1
g) Lakukan langkah e dan f untuk keseluruhan atribut ke-i
h) Hitung rata-rata terbobot entropi atribut ke-i dengan rumus 2.2 i) Hitung nilai gain atribut ke-i dengan mengurangkan entropi
atribut keputusan dengan rata-rata terbobot entropi atribut ke-i. j) Cari nilai gain atribut paling besar. Atribut inilah yang akan
menjadi node awal. 2) Menyusun pohon
dimana harus memenuhi nilai dari cabang tersebut dan nilai dari cabang-cabang di atasnya (jika ada). Proses dibawah ini dilakukan pada setiap cabang-cabang tersebut. Hitung jumlah sampel yang memenuhi syarat di atas dan setiap kejadian pada atribut keputusan yaitu dalam hal ini adalah atribut status. Selanjutnya dilakukan proses pengecekan untuk menentukan ada atau tidaknya percabangan, proses tersebut berupa :
Jika sampel tidak ada, maka cari kejadian paling banyak pada atribut keputusan untuk keseluruhan sampel. Kejadian paling banyak inilah yang menjadi nilai hasil.
Jika sampel sudah homogen, maka hasilnya berupa kejadian atribut keputusan pada sampel ini, dan tidak dilakukan percabangan lagi.
hasil dengan melakukan pencarian terhadap kejadian paling banyak pada atibut keputusan pada sampel yang tersisa. b. Mengubah node pohon menjadi aturan
Langkah-langkah untuk mengubah node pohon menjadi aturan yang dimulai dari node pertama adalah sebagai berikut :
1) Pada node tersebut, cari cabang-cabang (kejadian-kejadian) dari pohon. Setiap cabang akan menjadi aturan dengan anteseden berupa node = cabang ke-j.
2) Selanjutnya untuk setiap cabang dilakukan pengecekan apakah ada node lagi (hasil kosong) atau tidak (hasil berupa Daftar Ulang atau tidak DU).
Jika tidak, maka nilai hasil akan menjadi konsekuen
Jika ada, maka cari anteseden selanjutnya dengan melakukan langkah 1 dan seterusnya.
c. Menyederhanakan aturan-aturan
1) Menyederhanakan aturan dengan menghilangkan anteseden-anteseden yang tidak perlu
tabel chi-square untuk menguji suatu hipotesis, nilai derajat kebebasan yang terbentuk melebihi batas maksimal nilai derajat kebebasan pada tabel chi-square, sehingga dibutuhkan dasar-dasar teori teknik uji independensi tingkat lanjut.
2) Menyederhanakan aturan dengan membuang aturan-aturan yang tidak perlu
Langkah ini mencari jumlah konsekuen yang paling banyak dan selanjutnya aturan-aturan dengan konsekuen ini diubah menjadi aturan default.
d. Menguji aturan-aturan pada himpunan data tes
Aturan–aturan yang sudah terbentuk diujikan pada himpunan data tes. Nilai prediksi setiap data sampel yang dihasilkan dibandingkan dengan nilai atribut keputusannya. Sesudah itu dihitung persentase keberhasilan prediksi. Hasil penghitungan dari keberhasilan prediksi ini akan disimpan sehingga pemakai program dapat membandingkan hasilnya dengan hasil dari simulasi aturan yang akan dibuat selanjutnya.
3. Keluaran Sistem
Sistem yang dibuat akan menampilkan keluaran sebagai berikut :
b. Keluaran pada penentuan node awal adalah nilai gain pada tiap atribut beserta atribut yang dipilih sebagai node awal.
c. Pada proses pembuatan pohon, keluarannya adalah tabel pohon yang di dalamnya berisi informasi nomor, tingkat pohon, nomor akar atasnya, atribut-atribut yang menjadi node, cabang-cabang berupa nama kejadian-kejadian dan hasilnya.
d. Pada proses unpruned aturan yaitu proses mengubah pohon menjadi aturan, keluarannya ada dua tabel yaitu tabel pertama yang berisi nomor aturan, konsekuen, banyaknya anteseden dan total sampel sedangkan tabel kedua berupa anteseden-anteseden beserta nomor aturannya.
e. Pada proses penyederhanaan aturan
Proses penyederhanaan aturan dengan membuang aturan-aturan yang tidak perlu, keluarannya adalah konsekuen dengan jumlah paling banyak dan mengeliminasi aturan-aturan dengan konsekuen tersebut serta aturan yang telah disederhanakan.
f. Keluaran pada pengujian aturan adalah himpunan data tes beserta hasil pengujian aturan dan informasi yang berisi persentase keberhasilan prediksi, hasil simulasi berupa jumlah benar, jumlah salah dan jumlah yang tidak dapat diprediksi
4. Perancangan Struktur Data
Dalam proses pembuatan pohon, data pohon disimpan dalam 6 ArrayList. ArrayList merupakan versi array yang berbentuk list. Jumlah data pohon yang disimpan tidak dapat diperkirakan sebelumnya dalam proses pembuatan pohon. ArrayList menjadi solusi karena tidak diperlukan pendeklarasian seberapa banyak kuota yang harus disediakan untuk menampung data. Kapasitas ArrayList akan bertambah secara otomatis sesuai dengan jumlah data yang disimpan.
ArrayList pertama menyimpan nomor akar pohon, ArrayList kedua menyimpan tingkat pohon, ArrayList ketiga menyimpan nomor akar atasnya, ArrayList keempat menyimpan node, ArrayList kelima menyimpan cabang, ArrayList keenam menyimpan hasil. Tipe data yang dapat digunakan dalam ArrayList hanya tipe data objek. Tipe data objek dapat berupa tipe data lain, misalnya string, numeric, booelan, char, date dan sebagainya. Berikut ini contoh penggunaan ArrayList :
Public Class ContohArrayList
Public Shared Sub Main() 'deklarasi ArrayList
Dim tingkat, noAkar, node, cabang, _ hasil As New ArrayList
'Menyimpan data ke ArrayList tingkat.Insert(0, 1)
tingkat.Insert(1, 1) noAkar.Insert(0, 0) noAkar.Insert(1, 0) node.Insert(0, "prodi") node.Insert(1, "prodi") cabang.Insert(0, "IKOM") cabang.Insert(1, "PSI")
'menampilkan dalam DataGridView Dim i As Integer
For i = 0 To 1
DataGridView1.Rows.Add()
DataGridView1.Rows(i).Cells(0).Value = i + 1 DataGridView1.Rows(i).Cells(1).Value = tingkat(i) DataGridView1.Rows(i).Cells(2).Value = noAkar(i) DataGridView1.Rows(i).Cells(3).Value = node(i) DataGridView1.Rows(i).Cells(4).Value = cabang(i) DataGridView1.Rows(i).Cells(5).Value = hasil(i) Next
End Sub End Class
Keluarannya :
Tabel 3.3 Keluaran Contoh ArrayList
No Tingkat No Akar Atasnya Node Cabang Hasil
1 1 0 prodi IKOM Daftar Ulang
2 1 0 prodi PSI Tidak DU
5. Perancangan Antarmuka
Perancangan antarmuka sistem adalah sebagai berikut : a. Form Input Data Tabel
Form di atas merupakan form awal dimana tabel data pelatihan dan tabel data tes digunakan sebagai masukan untuk sistem. Ada dua tombol dalam form ini yaitu :
Reset, digunakan untuk menghapus tabel data pelatihan dan tabel data tes yang telah dimasukan sebelumnya
Ok, digunakan untuk melanjutkan ke form berikutnya yaitu form detail tabel.
b. Form Detail Tabel
Gambar 3.2 Desain Antarmuka Form Detail Tabel
Tampil tabel, digunakan untuk menampilkan himpunan data sampel, beserta informasi detail tabel tersebut yang telah dijelaskan di atas.
Proses ID3, untuk melanjutkan ke proses atau form selanjutnya yaitu form penentuan node awal.
c. Form Penentuan Node Awal
Gambar 3.3 Desain Antarmuka Form Penentuan Node Awal
Form di atas untuk menampilkan nama atribut serta nilai gain masing-masing atribut dan menampilkan atribut yang dipilih menjadi node awal beserta nilai gainnya. Ada dua tombol dalam form ini yaitu:
Cari Node Awal, tombol ini digunakan untuk mencari atribut yang dipilih menjadi node awal beserta nilai gainnya, serta mencari nilai gain atribut yang lain.
d. Form Pembuatan Pohon
Gambar 3.4 Desain Antarmuka Form Pembuatan Pohon
Form di atas digunakan untuk melakukan proses pembentukan pohon dan menampilkan tabel pohon yang sudah terbentuk yang berisi informasi tentang tingkat pohon, nomor akar atasnya, atribut-atribut yang menjadi node, cabang-cabang berupa nama kejadian-kejadiannya dan hasilnya. Ada dua tombol yaitu :
Buat Pohon, digunakan untuk melakukan proses pembentukan pohon dan menampilkan tabel pohon yang terbentuk.
e. Form Unpruned Aturan
Gambar 3.5 Desain Antarmuka Form Unpruned Aturan
Form di atas digunakan untuk proses penentuan aturan dan menampilkan aturan tersebut serta jumlahnya. Dalam form tersebut terdapat combo box klasifikasi yang digunakan untuk menampilkan aturan-aturan berdasarkan klasifikasi yang dipilih. Informasi ditampilkan dalam dua tabel, tabel pertama menampilkan informasi tentang nomor aturan, konsekuen, total anteseden dan total sampel, sedangkan tabel kedua menampilkan informasi anteseden yang berisi nomor aturan dan anteseden. Ada dua tombol yaitu :
Lanjut, untuk melanjutkan ke proses atau form selanjutnya yaitu form Aturan Default
f. Form Aturan Default
Gambar 3.6 Desain Antarmuka Form Aturan Default
Form di atas digunakan untuk membuat aturan default. Dalam form tersebut terdapat combo box klasifikasi yang digunakan untuk menampilkan aturan-aturan berdasarkan klasifikasi yang dipilih. Ada dua tombol dalam form ini yaitu
Aturan Default, digunakan untuk membuat aturan default.
g. Form Simulasi dan Pengujian Aturan
o Form Simulasi
Gambar 3.7 Desain Antarmuka Form Simulasi
Form simulasi ini digunakan untuk membuat simulasi aturan, menghapus aturan-aturan yang diinginkan dan menampilkan informasi tentang aturan beserta anteseden yang dihapus. Informasi tersebut berisi tentang nomor aturan, konsekuen, total anteseden dan nama antesedennya. Dalam form tersebut terdapat combo box klasifikasi yang digunakan untuk menampilkan aturan-aturan berdasarkan klasifikasi yang dipilih dan jumlah aturan. Tombol-tombol yang ada yaitu :
Pengujian Aturan, digunakan untuk melanjutkan ke form pengujian aturan.
Lihat Sampel, tombol ini digunakan untuk menjalankan form detail sampel.
Hapus Aturan, tombol ini digunakan untuk menghapus aturan yang telah dipilih
Selesai, tombol ini digunakan untuk menyelesaikan pembuatan simulasi dan menyimpan aturan-aturan yang termasuk dalam simulasi ini.
Batal, digunakan untuk membatalkan aturan yang telah dihapus.
o Form Pengujian Aturan
Gambar 3.8 Desain Antarmuka Form Pengujian Aturan
informasi yang berupa persentase keberhasilan prediksi dan detail hasil simulasi yang berisi nomor simulasi, jumlah benar, jumlah salah dan jumlah yang tidak dapat diprediksi. Tombol-tombol yang ada dalam form ini yaitu :
Data Tes, digunakan untuk menampilkan tabel tes dan detail atribut keputusan pada tabel tes
Uji Aturan, tombol ini digunakan untuk menampilkan hasil uji yang terdapat pada atribut prediksi dan persentase keberhasilan prediksi serta menampilkan detail hasil simulasi yang dibuat.
Aturan-Aturan, digunakan untuk menampilkan aturan-aturan pada simulasi yang telah dibuat dengan menjalankan form aturan-aturan.
Pilih Simulasi, digunakan untuk memilih salah satu simulasi dimana aturan-aturan yang ada pada simulasi tersebut merupakan aturan-aturan yang paling sederhana dan akan melanjutkan ke Form aturan-aturan sederhana dan prediksi sampel.
Hapus Simulasi, digunakan untuk menhapus simulasi yang telah dibuat.
o Form Detail Sampel
Gambar 3.9 Desain Antarmuka Form Detail Sampel
Form di atas digunakan untuk menampilkan informasi yang berisi tentang jumlah sampel masing-masing kejadian pada atribut keputusan dan detail sampelnya.
o Form Aturan-Aturan
Gambar 3.10 Desain Antarmuka Form Aturan-Aturan
h. Form Aturan-Aturan Sederhana dan Prediksi Sampel
o Form Aturan-Aturan Sederhana
Gambar 3.11 Desain Antarmuka Form Aturan-Aturan Sederhana
Form di atas digunakan untuk menampilkan aturan-aturan yang merupakan aturan paling sederhana.
o Form Prediksi Sampel
Form di atas digunakan untuk melakukan prediksi terhadap suatu sampel yaitu dengan memasukkan data yang ada pada kedua combo box dan menampilkan hasil prediksi. Tombol-tombol yang ada pada form ini yaitu :
Prediksi, digunakan untuk memprediksi suatu sampel
Hasil Prediksi, tombol ini digunakan untuk memprediksi sampel berdasarkan data yang telah dimasukkan dari kedua combo box dan menampilkan hasil prediksi berupa nomor aturan dan prediksinya.
Reset, tombol ini digunakan untuk mengganti keseluruhan nilai-nilai kejadian yang telah dipilih
63
BAB IV
IMPLEMENTASI PROGRAM
A. Jalannya Program dan Pembahasannya
Program ini meminta masukan berupa himpunan data pelatihan yang digunakan untuk membuat pohon keputusan dan aturan-aturan serta himpunan data tes yang digunakan untuk menguji aturan-aturan yang telah dibuat. Dari pengujian tersebut dapat diketahui seberapa besar ketepatan prediksi dari aturan-aturan yang telah dibuat. Berikut ini merupakan penjabaran proses jalannya program. Pada saat program dijalankan, form yang pertama kali ditampilkan adalah form berikut ini :
Gambar 4.1 Form Menu dan Form Input Data Tabel
submenu-submenu yaitu Program Penambangan Data (menu untuk melakukan proses penentuan data) dan Keluar (menu untuk keluar dari program). Menu Window untuk menampilkan form yang aktif atau yang sudah ditampilkan. Menu Bantuan terdiri dari submenu Aturan yaitu menu untuk menampilkan aturan-aturan tentang himpunan data pelatihan dan himpunan data tes dan submenu Tentang Program Penambangan Data yaitu menu untuk menampilkan informasi tentang program ini. Untuk lebih jelasnya, lihat gambar berikut ini :
Gambar 4.2 Form Aturan Himpunan Tabel Pelatihan dan Tes
Gambar 4.3 Form Tentang Program Penambangan Data
Jika pemakai program belum memilih kedua tabel, maka program akan menampilkan kotak peringatan :
Gambar 4.4 Kotak Peringatan 1
Jika tabel data tes belum dipilih, maka program akan menampilkan kotak peringatan :
Gambar 4.5 Kotak Peringatan 2
Gambar 4.6 Form Data Tabel (Tabel Pelatihan)
Berikut ini merupakan form data tabel (Tabel Tes) :
Gambar 4.7 Form Data Tabel (Tabel Tes)
keputusan dan informasi tentang detail atribut yang lain beserta jumlah sampel setiap kejadian suatu atribut. Untuk menampilkan informasi tentang detail atribut yang lain, pemakai program dapat memilih nama atribut yang sudah ditampilkan di combo box. Informasi yang ada pada tabel tes sebagian besar sama dengan informasi yang ada pada tabel pelatihan. Yang membedakan adalah penambahan informasi tentang nama atribut hasil. Tombol Tampil Tabel juga akan mengaktifkan tombol Proses ID3 yang berguna untuk menampilkan form penentuan node awal. Berikut ini adalah form Penentuan Node Awal :
Gambar 4.8 Form Penentuan Node Awal
yang berfungsi untuk menunjukkan bahwa proses penentuan node awal sedang berlangsung. Konstruksi programnya adalah sebagai berikut :
entropi_awal = 0
For i = 0 To MDI_utama.temp_sq1_akhir.Rows.Count - 1
q1 = "select count(" & MDI_utama.field_akhir & ") from " & _ MDI_utama.tbl_training & " where " &
MDI_utama.field_akhir & _ "='" &
MDI_utama.temp_sq1_akhir.Rows(i).Item(0) & "'" Dim ambil_p As New MySqlDataAdapter(q1, konek) Dim temp As New DataTable
ambil_p.Fill(temp)
PA = temp.Rows(0).Item(0) / objDt.Rows.Co