SINOPSIS BUKU MENGGUNAKAN
AGGLOMERATIVE
HIERARCHICAL CLUSTERING
SKRIPSI
Diajukan Untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Komputer
Program Studi Teknik Informatika
Oleh
Johannes Agus Subagio 145314026
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI UNIVERSITAS SANATA DHARMA
ii
SYNOPSIS OF THE BOOKS USING AGGLOMERATIVE
HIERARCHICAL CLUSTERING
A THESIS
Presented as Partial Fulfillment of The Requirements to Obtain Sarjana Komputer Degree
In Informatics Engineering Study Program
Writen by: Johannes Agus Subagio
145314026
INFORMATICS ENGINEERING STUDY PROGRAM
DEPARTMENT OF INFORMATICS ENGINEERING FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY YOGYAKARTA
iii SKRIPSI
PENGELOMPOKAN DAN REKOMENDASI BUKU BERDASARKAN
SINOPSIS BUKU MENGGUNAKAN
AGGLOMERATIVE
HIERARCHICAL CLUSTERING
Oleh
Johannes Agus Subagio 145314026
Telah disetujui oleh :
Pembimbing
iv
PENGELOMPOKAN DAN REKOMENDASI BUKU BERDASARKAN SINOPSIS BUKU
MENGGUNAKAN AGGLOMERATIVE HIERARCHICAL CLUSTERING
Dipersiapkan dan ditulis oleh : JOHANNES AGUS SUBAGIO
NIM : 145314026
Telah dipertahankan di depan Penguji pada tanggal …………..
Susunan Panitia Penguji
Nama Lengkap Tanda Tangan
Ketua : Robertus Adi Nugroho, S.T., M.Eng. ………
Sekretaris : Drs. Haris Sriwindono, M.Kom ………
Anggota : Dr. C. Kuntoro Adi, S.J., M.A., M.Sc. ………
Yogyakarta, ………
Fakultas Sains dan Teknologi
Universitas Sanata Dharma
Dekan,
v
“Be humble in this life, that God may raise you up in the next”
St. Stephen of Hungary
“DON’T GIVE UP”
When your faith is being tested
For God has prepared something for those who have faith in Him.
vi
Saya menyatakan dengan sesungguhnya bahwa skripsi yang saya tulis ini tidak memuat karya atau bagian karya orang lain, kecuali yang telah disebutkan dalam kutipan dan daftar pustaka sebagaimana layaknya karya ilmiah.
Yogyakarta, 08 Februari 2019
Penulis
vii
UNTUK KEPENTINGAN AKADEMIS
Yang bertanda tangan dibawah ini, saya mahasiswa Univeristas Sanata Dharma : Nama : Johannes Agus Subagio
NIM : 145314026
Demi pengembangan ilmu pengetahuan, saya memberikan kepada perpustakaan Universitas Sanata Dharma karya ilmiah yang berjudul
PENGELOMPOKAN DAN REKOMENDASI BUKU BERDASARKAN SINOPSIS BUKU
MENGGUNAKAN AGGLOMERATIVE HIERARCHICAL CLUSTERING
Beserta perangkat yang diperlukan (bila ada). Dengan demikian saya memberikan kepada perpustakaan Universitas Sanata Dharma hak untuk menyimpan, mengaktikan dalam bentuk media lain, mengelolahnya dalam bentuk pangkalan data, mendistribusikan secara terbatas dan mempublikasikan di internet atau media lain untuk kepentiangan akademis tanpa perlu meminta izin dari saya maupun memberikan royalty kepada saya selama tetap mencamtukan nama saya sebagai penulis.
Demikian pernyataan ini saya buat dengan sebenarnya.
Yogyakarta, 08 Februari 2019 Yang menyatakan
viii
ABSTRAK
Penjualan berbasis online (e-commerce) kian banyak digunakan di bidang usaha. PT. Kanisius menggunakan aplikasi web untuk memudahkan para customer
mereka untuk mencari, memilih dan membeli. Namun, web mereka belum dilengkapi dengan fitur rekomendasi kepada customer. Penelitian ini bertujuan untuk membangun sistem yang secara otomatis mampu mengelompokkan dan merekomendasikan buku berdasarkan sinopsis dan mengetahui tingkat akurasinya. Tahapan dimulai dari
preprocessing, yaitu pemilihan data yang berdasarkan sinopsis buku, tokenizing, stopword, stemming, pembobotan kata, principal component analysis, normalisasi min-max, normalisasi z-score dan menghitung jarak antar data menggunakan euclidean distance dan cosine similarity. Proses selanjutnya adalah mengelompokkan data dengan menggunakan agglomerative hierarchical clustering yang memiliki 3 metode yaitu single, average dan complete linkage. Dilakukan 96 kali percobaan pengelompokan dan setiap percobaan dihitung nilai sum of square error.
Dari hasil percobaan tersebut, ditemukan hasil percobaa yang paling optimal pada percobaan ke-14 dengan error terkecil yaitu 3.0103. Percobaan tersebut menggunakan metode normalisai min-max, penghitungan jarak menggunakan
euclidean distance serta metode AHC complete linkage.
ix
ABSTRACT
More businesses are using e-commerce nowadays. PT.Kanisius uses
web to help the customers in searching, choosing, and buying online
effortlessly. However, their web is not completed with recommendation
feature yet. This research aims to build a system which can automatically
cluster and present the book recommendation and figure out the accuracy
using the agglomerative hierarchical clustering. The stages were started
from preprocessing, tokenizing, stop word, stemming, word weighting,
principal component analysis, normalization min-max, normalization
score, and distance counting using Euclidean distance and cosine
similarity. Data were collected by using the agglomerative hierarchical
clustering which has 3 methods; they are single, average and complete
linkage. 96 times of clustering trials were done and sum of square error
value of each trial were counted.
From the trials, it was found that the 14th trial is the most optimum
trial with the minimum error value 3.0103. The trial was presented by
using the method of min-max normalization, distance counting based on
euclidean distance, and AHC complete linkage.
x
KATA PENGANTAR
Puji dan syukur penulis ucapkan kehadirat Tuhan Yang Maha Esa oleh karena berkat dan kasih-Nya penulis dapat menyelesaikan skripsi yang berjudul
“Pengelompokan dan Rekomendasi Buku Berdasarkan Sinopsis Buku Menggunakan Agglomerative Hierarchical Clustering” dengan baik dan tepat waktu. Skripsi ini merupakan salah satu syarat mahasiswa untuk mendapatkan gelar S-1 pada Program Studi Teknik Informatika di Universitas Sanata Dharma.
Pada kesempatan ini, penulis ingin mengucapkan terimakasih kepada pihak-pihak yang telah membantu dan mendukung penulis selama mengerjakan skripsi ini. Ucapan terimakasih saya sampaikan kepada :
1. Tuhan Yang Maha Esa, karena senantiasa melindungi dari segala marabahaya dan memberikan kesehatan selama penyelesaian skripsi ini.
2. Sudi Mungkasi, S.Si., M.Math.Sc., Ph.D, selaku Dekan Fakultas Sains dan Teknologi Universitas Sanata Dharma Yogyakarta.
3. Dr. C. Kuntoro Adi, S.J., M.A., M.Sc., selaku dosen pembimbing saya, yang selalu mau memberikan waktu, saran, kritik dan pelajaran buat saya.
4. Dr. Anastasia Rita Widiarti, M.Kom., selaku dosen metopen dan sekaligus sebagai kaprodi Teknik Informatika yang selalu memberikan arahan, kritikan, saran dan membimbing kami selama mata kuliah metopen sehingga saya memiliki gambaran kedepannya untuk menyelesaikan skripsi ini.
5. Orangtua saya Thomas Dwi Purwanto dan Endang Sri Wahyuni saya yang jauh di pulau seberang serta keluarga saya (VENA) yang selalu memberikan dukungan dan doanya.
xi
7. Keluarga Sweet Home, yaitu Ike, Elfrida dan Rio yang selalu membuat penulis semangat, marah, bahagia dan perasaan yang bercampur aduk. Keluarga kecil yang gila dan tidak tau dimana sweet nya.
8. Keluarga BSS Transport yang selalu mengerti keadaanku ketika mengejar deadline skripsi dan mau membantu untuk mencarikan penggantiku.
9. Dana, Galih, yang selalu mengajari, mendukung, berbagi ilmu dan saling memberikan semangat dan motivasi untuk menyelesaikan Skripsi.
10.Mas Surya, Kak Tommy dan Wiliam Sianturi yang telah membantu, mendukung, membagi ilmu, mengajari jika terdapat kesulitan, dan selalu memberikan semangat untuk menyelesaikan Skripsi.
11.Budhi, Joni, Jefry, Andre, Kingkin, Nata, Asto, Al, Dian, Sam dan teman-teman Teknik Informatika Sanata Dharma tahun 2014 dan teman penulis lainnya yang tidak dapat disebutkan satu per satu yang selalu memberikan semangat untuk menyelesaikan Skripsi.
12.Para pegawai Fakultas Sains & Teknologi yang selalu memberikan waktu dan hati untuk melayani permintaan kami dalam mendukung penyelesaian Skripsis ini.
Penulis menyadari bahwa masih banyak kekurangan dari penulisan Skripsi ini, sehingga penulis mengharapkan kritik dan saran yang bersifat membangun untuk penyempurnaan dikemudian hari. Akhir kata, penulis berharap semoga skripsi ini dapat bermanfaat bagi banyak pihak.
Yogyakarta, 08 Februari 2019
xii
DAFTAR ISI
PENGELOMPOKAN DAN REKOMENDASI BUKU BERDASARAKAN SINOPSIS BUKU MENGGUNAKAN AGGLOMERTATIVE HIERARCHICAL
CLUSTERING . ... i
CLUSTERING AND BOOK RECOMMENDATION BASED ON THE SYNOPSIS OF THE BOOKS USING AGGLOMERTATIVE HIERARCHICAL CLUSTERING ………. ii
HALAMAN PERSETUJUAN PEMBIMBING……….. iii
HALAMAN PENGESAHAN ... iv
MOTTO ... v
PERNYATAAN KEASLIAN KARYA ... vi
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS ... vii
ABSTRAK ... viii
ABSTRACT ... ix
KATA PENGANTAR ... x
DAFTAR ISI ... xii
DAFTAR GAMBAR ... xvi
DAFTAR TABEL ... xviii
BAB I PENDAHULUAN ... 1
1.1.Latar Belakang ... 1
xiii
1.3.Tujuan ... 4
1.4.Manfaat Penelitian ... 4
1.5.Luaran ... 5
1.6.Batasan Masalah ... 5
1.7.Sistematika Penulisan ... 5
BAB II LANDASAN TEORI ... 7
2.1Information Retrieval ... 7
2.1.1 Tokenizing ... 7
2.1.2 Stopword ... 8
2.1.3 Stemming ... 9
2.1.4 Pembobotan Kata ... 13
2.2Principal Component Analysis ... 14
2.3Normalisasi ... 20
2.3.1 Z-Score ... 20
2.3.2 Min-Max ... 21
2.4Penghitungan Jarak ... 21
2.4.1 Euclidean Distance ... 21
2.4.2 Cosine Similarity ... 22
2.5Uji Data ... 23
2.5.1 Agglomerative Hierarchical Clustering ... 23
2.5.1.1Single Linkage (Jarak Terdekat) ... 24
2.5.1.2Complete Linkage (Jarak Terjauh) ... 24
2.5.1.3Average Linkage (Jarak Rerata) ... 25
2.5.2 Uji Akurasi Data ... 32
2.5.2.1Internal Evaluation ... 32
xiv
BAB III METODOLOGI PENELITIAN ... 35
3.1. Data ... 35
3.2. Spesifikasi Kebutuhan Sistem ... 38
3.3. Tahap-Tahap Penelitian ... 38
3.1.1 Studi Pustaka ... 38
3.3.2. Pengumpulan Data ... 38
3.3.3. Pembuatan Alat Uji ... 38
3.3.4. Pengujian ... 39
3.4.Desain Graphical User Interface (GUI) ... 39
3.5.Skenario Sistem ... 40
3.5.1. Gambaran Umum Sistem ... 40
3.5.1.1 Tahap Preprocessing ... 41
3.5.1.2 Tahap Pembobotan ... 43
3.5.1.3 Principal Component Analysis ... 51
3.5.1.4 Tahap Normalisasi ... 51
3.5.1.5 Penghitungan Jarak ... 54
3.5.1.6 Agglomerative Hierarchical Clustering ... 57
3.5.1.7 Uji Data ... 60
3.5.1.8 Uji Data Tunggal ... 60
3.6. Desain Pengujian ... 60
BAB IV IMPLEMENTASI DAN ANALISA ... 61
4.1. Implementasi ... 61
4.1.1 Data ... 61
4.1.2 Preprocessing ... 63
4.1.3 Pengujian Sistem ... 74
xv
4.1.3.2 Output ... 76
4.1.3.3 Error ... 76
4.1.4 Uji Data Tunggal ... 77
4.2. Hasil dan Analisa ... 78
4.2.1 Hasil Percobaan ... 80
4.3. User Interface ... 88
BAB V IMPLEMENTASI DAN ANALISA ... 93
5.1. Kesimpulan ... 93
5.2. Saran ... 94
DAFTAR PUSTAKA ... 95
xvi
DAFTAR GAMBAR
Gambar 2.1 Hasil eigenvector dan eigenvalue dengan matlab ... 18
Gambar 2.2 Hasil dendogram single linkage ... 28
Gambar 2.3 Hasil dendogram complate linkage ... 30
Gambar 2.4 Hasil dendogram average linkage ... 31
Gambar 3.1 Judul buku, sinopsis dari pengarang Donny Kurniawan ... 35
Gambar 3.2 Judul buku, sinopsis dari pengarang Janine Amos ... 36
Gambar 3.3 Judul buku, sinopsis dari pengarang Sharon Jennings ... 36
Gambar 3.4 Judul buku, sinopsis dari pengarang Paulette Bourgeois, Brenda Clark ... 37
Gambar 3.5 Judul buku, sinopsis dari pengarang Eddy Supangkat ... 37
Gambar 3.6 Desain graphical user interface ... 39
Gambar 3.7 Diagram blok ... 40
Gambar 3.8 Dendogram data min-maxsinglelinkage ... 57
Gambar 3.9 Dendogram data min-maxcomplatelinkage ... 58
Gambar 3.10 Dendogram data min-maxaveragelinkage ... 59
Gambar 4.1 Data ... 62
Gambar 4.2 Contoh database unik ... 67
Gambar 4.3 Contoh hasil term frequency ... 68
Gambar 4.4 Contoh hasil menghitung weight ... 69
Gambar 4.5 Contoh hasil principal component analysis 150x50 ... 70
Gambar 4.6 Contoh hasil implementasi normalisasi min-max ... 71
Gambar 4.7 Contoh hasil implementasi normalisasi z-score ... 72
Gambar 4.8 Contoh hasil implementasi dari jarak euclidean distance ... 73
Gambar 4.9 Contoh hasil implementasi dari jarak cosine similarity ... 73
Gambar 4.10 Output hasil cluster setiap metode ... 76
Gambar 4.11 Hasil potongan data baru untuk uji data ... 77
xvii
Gambar 4.13 Hasil Rekomendasi ... 77
Gambar 4.14 Grafik percobaan single linkage ... 80
Gambar 4.15 Grafik percobaan average linkage ... 81
Gambar 4.16 Grafik percobaan complete linkage ... 82
Gambar 4.17 Dendrogram PCA 150x100 normalisasi z-score jarak euclidean cluster complete ... 83
Gambar 4.18 Dendrogram PCA 150x50 normalisasi min-max jarak euclidean cluster complete ... 84
Gambar 4.19 Dendrogram PCA 150x150 normalisasi z-score jarak cosine cluster complete ... 86
Gambar 4.20 Tampilan sebelum melakukan pengujian ... 88
Gambar 4.21 Tampilan setelah melakukan pengujian ... 89
Gambar 4.22 Input data ... 90
Gambar 4.23 Memilih data ... 90
Gambar 4.24 Proses pengambilan data sudah selesai ... 90
Gambar 4.25 Hasil kata unik dan bobot ... 90
Gambar 4.26 Proses tidak memillih PCA ... 91
Gambar 4.27 Proses memillih PCA dan memasukan jumlah PCA ... 91
Gambar 4.28 Proses memillih normalisasi, penghitungan jarak dan AHC ... 91
Gambar 4.29 Hasil proses setelah memilih normalisasi, penghitungan jarak dan AHC .... 91
Gambar 4.30 Tabel 5 data uji ... 92
Gambar 4.31 Uji data tunggal ... 92
xviii
DAFTAR TABEL
Tabel 2.1 Kombinasi awalan akhiran yang tidak diijinkan ... 10
Tabel 2.2 Cara menentukan tipe awalan untuk kata yang diawali dengan “te-” ... 11
Tabel 2.3 Jenis awalan berdasarkan tipe awalannya ... 11
Tabel 2.4 Contoh data PCA ... 14
Tabel 2.5 Hasil penghitungan rata-rata ... 15
Tabel 2.6 Proses penghitungan covariance ... 16
Tabel 2.7 Hasil penghitungan covariance ... 16
Tabel 2.8 Hasil data set baru PCA ... 19
Tabel 2.9 Contoh data AHC ... 25
Tabel 2.10 Hasil penghitungan euclidean distance ... 26
Tabel 2.11 Matriks jarak dari hasil perhitungan euclidean distance ... 26
Tabel 2.12 Matriks jarak pertama untuk single lingkage ... 27
Tabel 2.13 Matriks jarak kedua untuk single lingkage ... 28
Tabel 2.14 Matriks jarak pertama untuk complate lingkage ... 29
Tabel 2.15 Matriks jarak kedua untuk complate lingkage ... 29
Tabel 2.16 Matriks jarak pertama untuk average lingkage ... 30
Tabel 2.17 Matriks jarak kedua untuk average lingkage ... 31
Tabel 2.18 Contoh data SSE ... 33
Tabel 2.19 Rata-rata data SSE ... 34
Tabel 2.20 Hasil pengurangan data dengan rata-rata ... 34
Tabel 2.21 Hasil pangkat dari hasil pengurangan ... 34
Tabel 2.22 Hasil sum dari pangkat 2 ... 34
xix
Tabel 3.2 TF sinopsis precil tetap tinggal di danau ... 44
Tabel 3.3 TF sinopsis franklin bermain sepak bola ... 44
Tabel 3.4 TF sinopsis si manis yang banyak tingkah ... 44
Tabel 3.5 TF sinopsis detektif franklin ... 45
Tabel 3.6 Penghitungan document frequency(df) ... 45
Tabel 3.7 Penghitungan inverse document frequency(idf) ... 47
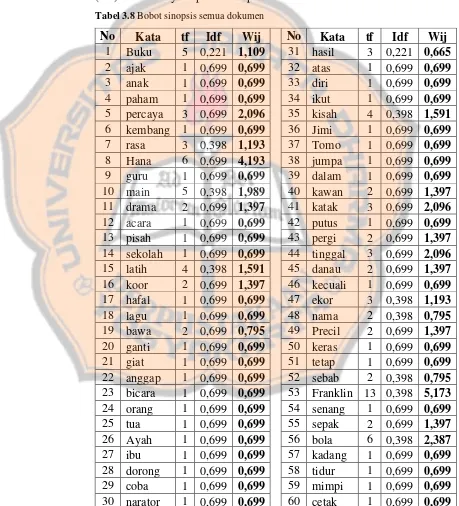
Tabel 3.8 Bobot sinopsis semua dokumen ... 49
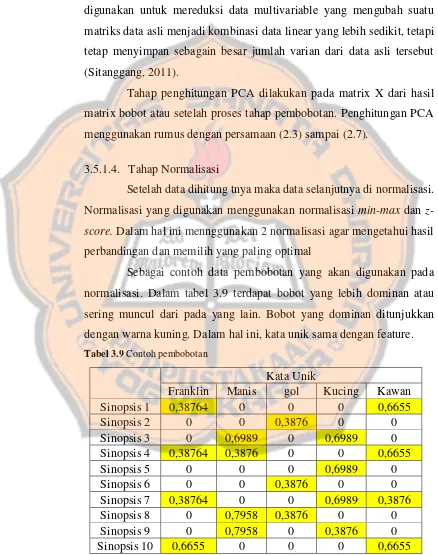
Tabel 3.9 Contoh pembobotan ... 51
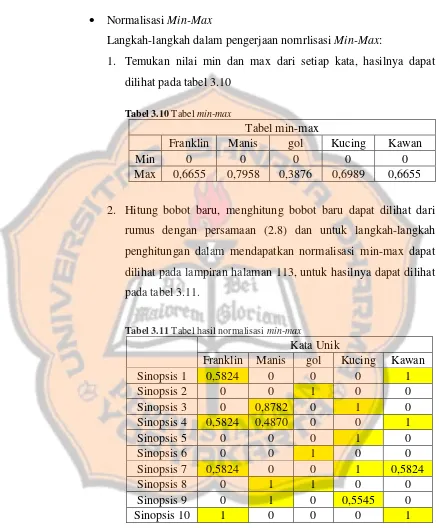
Tabel 3.10 Tabel min-max ... 52
Tabel 3.11 Tabel hasil normalisasi min-max ... 52
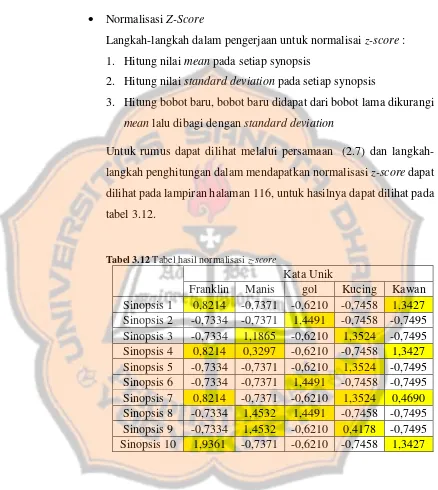
Tabel 3.12 Tabel hasil normalisasi z-score ... 53
Tabel 3.13 Hasil matriks jarak euclideandistancedengan normalisasi min-max ... 54
Tabel 3.14 Hasil matriks jarak euclidean distancedengan normalisasi z-score ... 55
Tabel 3.15 Hasil matriks jarak cosinesimilaritydengan normalisasi min-max ... 55
Tabel 3.16 Hasil matriks jarak cosinesimilaritydengan normalisasi z-score ... 56
Tabel 3.17 Cluster data min-maxsinglelinkage ... 58
Tabel 3.18 Cluster data min-maxcomplatelinkage ... 58
Tabel 3.19 Cluster data min-maxaveragelinkage ... 59
Tabel 4.1 Tabel percobaan single linkage ... 80
Tabel 4.2 Tabel percobaan complete linkage ... 81
Tabel 4.3 Tabel percobaan average linkage ... 82
Tabel 4.4 Tabel hasil pengelompokan error terkecil pertama ... 83
Tabel 4.5 Tabel hasil pengelompokan error terkecil kedua ... 85
1
BAB I
PENDAHULUAN
1.1. LATAR BELAKANG
Teknologi informasi saat ini terus berkembang secara pesat. Hal ini menuntut kita untuk terus mengikuti perkembangannya, misalnya di bidang penjualan berbasis online.
Penjualan berbasis online merupakan layanan yang dapat memudahkan para customer dalam mencari, memilih dan membeli barang secara online dari suatu website tertentu. Layanan ini kini semakin popular di kalangan pengguna
e-commerce.
Menurut data yang dirilis oleh tekno.liputan6.com dan biro riset Frost & Sullivan (2013) bersama China, Indonesia menjadi negara dengan pertumbuhan pasar e-commerce terbesar dengan rata-rata pertumbuhan 17 persen tiap tahun. Tentu hal ini memiliki dampak yang besar terhadap persaingan diantara penyedia layanan penjualan berbasis online.
Penjualan berbasis online tidak hanya menjual 1 kategori barang tertentu saja, melainkan lebih dari 1 kategori, misalnya kategori buku, aksesoris, pakaian wanita/pria, sepatu wanita/pria, dll. Penjualan berbasis online juga tidak hanya menjual barang yang digunakan oleh orang secara umum melainkan ada yang menjual barang-barang rohani, salah satunya adalah PT.Kanisius.
Kitab Suci, Katekese, Doa, Bacaan Rohani, Kelompok Bermain, Pelajaran TK, Pelajaran SD, Pelajaran SMP, Pelajaran SMA/K, Filsafat, Psikologi, Ilmu Sosial, Hukum, Ekonomi, Manajemen Organisasi, Pendidikan, Bahasa, Kedokteran, Kesehatan, Pertanian (Perkebunan, Tanaman), Peternakan (Perikanan, Hewan), Sains Teknik, Seni, Keterampilan/Hobi, Referensi, Sejarah dan Fiksi.
Dalam upaya mendongkrak dan mengembangkan hasil penjualan penerbitan yang mereka olah sendiri tersebut, maka mereka menggunakan aplikasi web yang memungkinkan customer dapat melihat dan membeli produk PT.Kanisius. Namun, saat ini sistem mereka belum dilengkapi dengan fitur pemberian rekomendasi buku kepada pelanggan. Padahal, fitur tersebut akan sangat bermanfaat bagi customer karena berupa presentasi perbandingan beberapa buku sejenis sehingga memudahkan customer untuk memilih buku yang paling sesuai dengan kebutuhannya.
Penulis melihat hal ini sebagai kebutuhan yang sebenarnya dapat diciptakan solusinya. Maka dari itu, penulis ingin membuat sistem yang dapat membantu PT Kanisius dalam menangani kekurangan pada WEB mereka yakni fitur rekomendasi buku dengan menggunakan metode agglomerative hierarchical clustering.
Analisa mengenai sistem rekomendasi yang telah dilakukan oleh Abdul Rokhim dan Akhmad Saikhu (2016) yang menggunakan metode Collaborative Filtering dalam sistem rekomendasi buku pada aplikasi perpustakaan SMKN 1 Bangil memberikan hasil yang dapat membantu dalam mengolah data di rekomendasi buku sehingga dapat menjadi inovasi di dalam percepatan layanan dan membantu dalam mencari informasi mengenai data yang dibutuhkan.
Teguh Budianto dan Galih Hermawan (2013) memberikan hasil pada implementasi dan hasil uji mereka bahwa metode user based collaborative filtering mampu untuk mengatasi kekosongan data dengan tingkat sparsity
sebanyak 70%, namun hasil akhir dari perhitungan MAE (Mean Absolute Error) memiliki rentang 0 – 1, yang menghasilkan nilai lebih dari 0.5. Jadi, metode ini masih kurang akurat.
1.2. RUMUSAN MASALAH
Berdasarkan latar belakang yang telah dikemukakan diatas, maka permasalahan yang akan dibahas dalam penelitian ini, yaitu:
1. Apakah agglomerative hierarchical clustering dapat mengelompokkan dan merekomendasikan buku secara baik? 2. Berapakah error yang didapat dalam mengelompokkan dan
merekomendasikan buku menggunakan agglomerative hierarchical clustering?
1.3. TUJUAN
Tujuan dari penelitian ini , yaitu :
1. Membangun sistem yang secara otomatis untuk mengelompokan dan merekomendasikan buku secara baik menggunakan
agglomerative hierarchical clustering.
2. Mengetahui error yang didapat dari mengelompokkan dan merekomendasikan buku menggunakan agglomerative hierarchical clustering.
3. Mengetahui metode yang paling optimal dalam mengelompokkan dan merekomendasikan buku menggunakan agglomerative hierarchical clustering
1.4. MANFAAT PENELITIAN
Manfaat yang diberikan pada penelitian ini, yaitu:
1. Mengetahui error yang didapat dari mengelompokkan dan merekomendasikan buku menggunakan agglomerative hierarchical clustering.
2. Mengetahui metode yang paling optimal dalam mengelompokkan dan merekomendasikan buku menggunakan agglomerative hierarchical clustering.
3. Menjadi referensi bagi para peneliti lainnya yang sesuai dengan kasus pengelompokan dan merekomendasikan buku menggunakan
1.5. LUARAN
Luaran yang diharapkan pada penelitian ini berupa sistem pengelompokan dan rekomendasi yang cerdas.
1.6. BATASAN MASALAH
Batasan masalah yang penulis akan pakai dalam penelitian ini sebagai berikut:
1. Penulis menggunakan data judul, pengarang dan sinopsis buku. 2. Penulis mengambil data dari PT.Kanisius
3. Data yang digunakan hanya kategori fiksi dengan 5 pengarang yang dimiliki oleh PT. Kanisius
4. Data yang diolah hanya data yang menggunakan bahasa Indonesia. 5. Perangkat lunak dibangun dengan menggunakan aplikasi Matlab
1.7. SISTEMATIKA PENULISAN
Sistematika penulisan dalam penelitian ini dibagi menjadi beberapa bab dengan susunan sebagai berikut:
BAB I : Pendahuluan
BAB II : Landasan Teori
Berisi tentang penjelasan dan uraian dari teori-teori yang akan berkaitan dengan pengelompokan dan rekomendasi buku, dengan menggunakan teori information retrieval, principal component analysis, min-max, z-score, cosine similarity, euclidean distance, agglomerative hierarchical clustering dan sum of square error.
BAB III : Metodologi Penelitian
Berisi tentang analisa dan design yang merupakan detail dari teknis sistem yang akan dibangun kemudian membahas alur dari penelitian.
BAB IV : Implementasi dan Analisa Hasil
Berisi tentang implementasi dari perancangan yang telah dibuat pada bab sebelumnya dan membuat analisa dari hasil program yang telah dibuat.
BAB V : Kesimpulan
7
BAB II
LANDASAN TEORI
Bab ini berisi penjabaran dari teori-teori yang akan digunakan. Teori yang mencakup, yaitu: information retrieval, principal component analysis, min-max, z-score, euclidean distance, cosine similarity, agglomerative hierarchical clustering dan
sum of square error.
2.1.Information Retrieval
Information retrieval adalah proses untuk menemukan dokumen (biasanya teks) yang sifatnya tidak terstruktur untuk memenuhi kebutuhan informasi dari koleksi atau dari data yang besar (Manning, dkk, 2009).
Berikut beberapa proses yang dimiliki oleh information retrieval :
2.1.1 Tokenizing
Tokenizing adalah proses untuk memotong kalimat menjadi beberapa bagian-bagian kecil (kata), yang disebut dengan token. Walaupun terkadang pada saat bersamaan membuang beberapa karakter tertentu, seperti tanda baca (Manning, dkk, 2009).
Contoh proses tokenizing Kalimat asli:
Franklin meminjam buku dari perpustakaan, tapi ia menghilangkannya. Lalu Franklin mencoba mengingat kembali kegiatannya sebelum buku itu hilang.
Hasil tokenizing :
Franklin tapi mencoba buku
meminjam ia mengingat itu
buku menghilangkannya kembali hilang
dari lalu kegiatannya
2.1.2 Stopword
Stopword adalah suatu kata yang sangat sering muncul dalam berbagai dokumen yang tidak berguna dalam information retrieval.
Contoh stopword dalam bahasa Indonesia, yaitu : - kata ganti orang (“aku”, “kamu”, “kita”, dsb.),
- konjungsi (“dan”, “atau”, dsb.), dan beberapa kata lainnya (Ardyan, dkk, 2016).
Sebelum proses stopword dilakukan maka harus membuat daftar stoplist
terlebih dahulu, yang berisikan kata-kata umum, kata-kata penghubung, kata ganti orang dan bukan kata unik. Jika sebuah kata terdapat dalam
stoplist maka kata tersebut dihapus. Untuk daftar stoplist bersumber dari Tala (2003).
Contoh untuk stopword Hasil dari tokenizing :
Franklin tapi mencoba buku
meminjam ia mengingat itu
buku menghilangkannya kembali hilang
dari lalu kegiatannya
perpustakaan Franklin sebelum
Hasil stopword :
Franklin menghilangkannya hilang meminjam Franklin
buku kegiatannya
2.1.3 Stemming
Stemming merupakan suatu proses yang terdapat dalam sistem
information retrieval yang menghilangkan kata berimbuhan menjadi kata dasar yang berasal dari proses stopword dengan menggunakan aturan yang sudah ditentukan (Agusta, 2009).
Contoh proses stemming Hasil dari stopword :
Franklin menghilangkannya hilang meminjam Franklin
buku kegiatannya
perpustakaan buku
Hasil stemming :
Franklin hilang hilang minjam Franklin
buku kegiatan
perpustakaan buku
Algortima untuk melakukan proses stemming pada teks berbahasa Indonesia menggunakan algoritma Nazief & Adriani (2007), yaitu:
1. Cari kata yang akan distem ke dalam kamus. Jika ditemukan maka diasumsikan bahwa kata tesebut adalah root word. Maka algoritma berhenti tetapi jika tidak ditemukan dilanjutkan ke langkah 2.
2. Inflection suffixes (“-lah”, “-kah”, “-ku”, “-mu”, atau “-nya”) dibuang. Jika berupa particles (“-lah”, “-kah”, “-tah”atau “-pun”) maka langkah ini diulangi lagi untuk menghapus possesive pronouns (“-ku”, “-mu”,
atau “-nya”), jika ada.
Jika tidak maka ke langkah 3a, yaitu:
a. Jika “-an” telah dihapus dan huruf terakhir dari kata tersebut adalah
“-k”, maka “-k” juga ikut dihapus.
Jika kata tersebut ditemukan dalam kamus maka algoritma berhenti. Jika tidak ditemukan maka lakukan langkah 3b.
b. Akhiran yang dihapus (“-i”, “-an” atau “-kan”) dikembalikan, lanjut ke langkah 4
4. Hapus derivation prefix. Jika pada langkah 3 ada sufiks yang dihapus maka pergi ke langkah 4a, jika tidak pergi ke langkah 4b.
a. Periksa tabel 2.1 untuk kombinasi awalan-akhiran yang tidak diijinkan.
Tabel 2.1 Kombinasi awalan akhiran yang tidak diijinkan Awalan Akhiran yang tidak diijinkan be- -i
di- -an
ke- -i, -kan
me- -an
se- -i, -kan
Jika ditemukan maka algoritma berhenti, jika tidak maka lanjut ke langkah 4b.
b. For i = 1 to 3, tentukan tipe awalan kemudian hapus awalan. Jika root word belum juga ditemukan lakukan langkah 5, jika sudah maka algoritma berhenti.
Catatan: jika awalan kedua sama dengan awalan pertama algoritma berhenti.
5. Melakukan Recoding.
Tipe awalan ditentukan melalui langkah-langkah berikut:
1. Jika awalannya adalah: “di-”, “ke-”, atau “se-” maka tipe awalannya secara berturut-turut adalah “di-”, “ke-”, atau“se-”. 2. Jika awalannya adalah “te-”, “me-”, “be-”, atau “pe-” maka
dibutuhkan sebuah proses tambahan untuk menentukan tipe awalannya.
3. Jika dua karakter pertama bukan “di-”, “ke-”, “se-”, “te-”, “be-”,
“me-”, atau “pe-” maka berhenti.
4. Jika tipe awalan adalah “none” maka berhenti. Jika tipe awalan
adalah bukan “none” maka awalan dapat dilihat pada tabel 2.2
Tabel 2.2 Cara menentukan tipe awalan untuk kata yang diawali dengan “te-”
Following charcters Tipe Awalan
Set 1 Set 2 Set 3 Set 4
“-r-” “-r-” - - None
“-r-” vowel - - Ter- luluh
“-r-” Not(vowel
or “-r-”)
“-er-” Vowel Ter
“-r-” Not(vowel
or “-r-”)
“-er-” Not vowel Ter-
“-r-” Not(vowel
or “-r-”)
Not “-er-” - Ter
Not(vowel
or “-r-”)
“-er-” Vowel - None
Not(vowel
or “-r-”)
Tabel 2.3. Jenis awalan berdasarkan tipe awalannya Tipe Awalan Awalan yang harus dihapus
di- di
ke- ke
se- se
te- te
ter- ter
ter-luluh ter
Untuk mengatasi keterbatasan pada algoritma di atas, maka ditambahkan aturan-aturan dibawah ini:
1. Aturan untuk reduplikasi.
• Jika kedua kata yang dihubungkan oleh kata penghubung adalah kata yang sama maka root word adalah bentuk
tunggalnya, contoh : “buku-buku” root word-nya adalah
“buku”.
• Kata lain, misalnya “bolak-balik”, “berbalas-balasan, dan
”seolah-olah”. Untuk mendapatkan root word-nya, kedua kata diartikan secara terpisah.
Jika keduanya memiliki root word yang sama maka diubah menjadi bentuk tunggal, contoh: kata “berbalas-balasan”,
“berbalas” dan “balasan” memiliki root word yang sama
yaitu “balas”, maka root word “berbalas-balasan” adalah
“balas”.
Sebaliknya, pada kata “bolak-balik”, “bolak” dan “balik” memiliki root word yang berbeda, maka root word-nya
2. Tambahan bentuk awalan dan akhiran serta aturannya.
• Untuk tipe awalan “mem-“, kata yang diawali dengan
awalan “memp-” memiliki tipe awalan “mem-”.
• Tipe awalan “meng-“, kata yang diawali dengan awalan
“mengk-” memiliki tipe awalan “meng-” (Agusta, 2009).
2.1.4 Pembobotan Kata
Pembobotan dilakukan untuk mendapatkan term dari hasil information retrieval. Metode yang digunakan dalam pembobotan ini adalah TF-IDF.
Metode TF-IDF ini merupakan metode pembobotan dalam bentuk sebuah integrasi antar term frequency (TF) dan inverse document frequency (IDF) (Putri, 2013).
Berikut rumus yang digunakan untuk mencari bobot kata dengan Term Frequency (TF) –Inverse Document Frequency (IDF), (Tresnawati, 2017):
idf = log (D/df) (2.1)
Keterangan:
D : Jumlah semua dokumen dalam koleksi df : Jumlah dokumen yang mengandung term t
Wij = tfij * idf
Wij = tfij * log (D/dfj) (2.2)
Keterangan :
Wij : bobot term tj terhadap dokumen di
tfij : jumlah kemunculan term tj dalam dokumen di
2.2. Principal Component Analysis
Principal component analysis (PCA) merupakan teknik yang digunakan untuk mereduksi data multivariable yang mengubah suatu matriks data asli menjadi kombinasi data linear yang lebih sedikit, tetapi tetap menyimpan sebagain besar jumlah varian dari data asli tersebut. Secara singkat dapat dijelaskan tujuan dari PCA adalah, menunjukan sebanyak mungkin dari jumlah varian data asli yang menggunakan komponen utama atau menggunakan vektor sesedikit mungkin (Situmorang, 2015).
Berikut algoritma dalam penggunaan PCA (Smith,2002) :
1. Matrix X adalah hasil pengurangan rata-rata dari setiap dimensi data pada matrix data.
2. Matrix Cx merupakan covaiance matrix dari matrix X.
3. Hitung eigenvector dan eigenvalue dari Cx.
4. Memilih komponen dan bentuk vector feature dan principal component
dari eigenvector yang memiliki eigenvalue paling besar diambil. 5. Menurunkan data set baru.
Sebagai contoh data teks yang akan diproses menggunakan PCA, dapat dilihat pada tabel 2.4
Tabel 2.4 Contoh data PCA
Data X Y
a 2.19 3.77
b 5.13 0
c 0 0.79
d 3.52 8.21
dengan dimensi MxN, dimana M adalah jumlah kolom sedangkan N adalah jumlah baris pada data.
𝑋 = [
𝑥11 𝑥12 𝑥𝑖𝑗 𝑥𝑗𝑁
𝑥21 ⋯ ⋯ 𝑥2𝑁
𝑥𝑖1 ⋯ ⋯ 𝑥𝑖𝑁
𝑥𝑀1 𝑥𝑀2 𝑥𝑀𝑗 𝑥𝑀𝑛
]
Untuk fitur ke-j, semua nilai pada kolom dikurangi rata-ratanya. Rumus yang digunakan adalah sebagai berikut (Prasetyo,2012):
𝑥′𝑖𝑗 = 𝑥𝑖𝑗 − 𝑥̅𝑗 (2.3)
Keterangan :
i = 1,2,…,M dan j adalah kolom ke-j
Rumus tersebut menerangkan bahwa 𝑥 pada 𝑖𝑗 merupakan hasil pengurangan dari data 𝑥𝑖𝑗 dengan rata-rata data 𝑥 di setiap kolom 𝑗 (𝑥̅𝑗).
Tabel 2.5 Hasil penghitungan rata-rata
Data X Y Rata-rata 2.71 3.1925
a -0.52 0.5775 b 2.42 -3.1925 c -2.71 -2.402 d 0.81 5.0175
Data dari hasil perhitungan rata-rata diatas dihitung untuk mendapatkan
covariance, yaitu 𝐶𝑥. Rumus yang digunakan adalah (Prasetyo,2012):
𝐶𝑥= 𝑀1 𝑋𝑇𝑋 (2.4)
Keterangan :
𝐶𝑥 : covariance matrix
𝑀 : jumlah data
Apabila contoh diatas pada tabel 2.5 dihitung covariance matrix-nya maka hasilnya sebagai dapat dilihat pada tabel 2.6 dan tabel 2.7
M = 4;
Tabel 2.6 Proses penghitungan covariance
Tabel 2.7 Hasil penghitungan covariance
X Y
X 3.77 0.63 Y 0.63 10.36
Matrix 𝐶𝑥 mempunyai ciri-ciri sebagai berikut (Prasetyo,2012) :
1. 𝐶𝑥 merupakan matrix simetris yang bersifat bujur sangkar dengan ukuran NxN.
2. Pada bagian diagonal dari kiri atas ke kanan bawah merupakan nilai varian dari masing-masing fitur sesuai dengan indeks kolom.
3. Selain itu, bagian diagonal juga merupakan kovarian di antara dua pasangan yang bersesuaian.
Matriks 𝐶𝑥 mengandung kovarian di antara semua pasangan yang mungkin dari fitur data matrix 𝑋. Nilai kovarian dapat meredakan noise dan redundansi pada fitur (Prasetyo,2012):
1. Diasumsikan bahwa dalam diagonal utama memiliki nilai tinggi yang berkorelasi dengan struktur data yang sangat penting.
Perlu diingat kembali, tujuan PCA adalah :
1. Meminimalkan redundansi pengukuran nilai jarak dari kovarian. 2. Memaksimalkan hasil pemetaan yang diukur dengan varian.
Jadi, PCA adalah matrix dari hasil pemetaan dan 𝐶𝑥 adalah matrix kovarian dari 𝑋, yang diharapkan dari PCA adalah (Prasetyo, 2012) :
1. Semua elemen selain diagonal utama dalam 𝐶𝑥 harus nol dan 𝐶𝑥 harus berbentuk matrix diagonal.
2. Peletakan dimensi dalam PCA, diurutkan secara descending dari kiri ke kanan.
Harapan PCA dapat dicapai dengan menghitung eigenvector dan eigenvalue
dari covariance matix 𝐶𝑥. Eigenvector adalah sebuah bilangan scalar dan
eigenvector adalah sebuah matix yang keduanya dapat mendefinisikan matrix A. Jika matrix A adalah 𝑚 𝑥 𝑚, maka setiap scalar 𝜆 memenuhi persamaan:
A𝑥 = 𝜆𝑥 (2.5)
Setiap nilai eigenvalue 𝜆harus memenuhi persamaan determinan,
|𝐴 − 𝜆| = 0 (2.6)
yang dikenal sebagai persamaan karateristik 𝐴.
Hasil covariance pada tabel 2.6 dapat dicari eigenvalue-nya yang dianggap sebagai matrik A.
𝐴 = [3.77 0.630.63 10.36]
Karakteristik dari determinan
Karena persamaan karatersitik |𝐴 − 𝜆| = 0, maka :
∴ (3.77 − 𝜆)(10.36 − 𝜆) − (0.63 ∗ 0.63) = 0 ∴ 39.05 − 3.77𝜆 − 10.36𝜆 + 𝜆2− 0.3969 = 0
∴ 39.05 − 14.13𝜆 + 𝜆2− 0.3969 = 0
∴ 𝜆2− 14.13𝜆 + 38.65 = 0
Sampai hasil tersebut sudah dapat dicari nilai eigenvalue-nya. Tetapi, untuk melanjutkannya dengan hitungan manual akan mengalami kesulitan. Maka dari itu, penulis menggunakan program matlab untuk menentukan eigenvector dan
eigenvalue dari tabel 2.6.
Gambar 2.1 Hasil eigenvector dan eigenvalue dengan matlab
Dari hasil perhitungan menggunakan matlab diketahui sebagai berikut : 𝑒𝑖𝑔𝑒𝑛𝑣𝑒𝑐𝑡𝑜𝑟 = [−0.9955 0.09430.0943 0.9955]
Pada tahap ini, eigenvalue dan eigenvector telah ditemukan. Proses selanjutnya yaitu membentuk feature vector. Feature vector adalah mengambil diagonal utama dari eigenvalue dengan diurutkan secara descending atau urutan besar ke terkecil. Mengambil nilai eigenvector disusun berdasarkan indeks yang telah di urutkan secara descending pada proses eigenvalue.Hasilnya akan seperti ini :
diagonal 𝑒𝑖𝑔𝑒𝑛𝑣𝑎𝑙𝑢𝑒 = [ 3.710310.4197]
𝑖𝑛𝑑𝑒𝑥 𝑠𝑜𝑟𝑡𝑖𝑛𝑔 𝑑𝑖𝑎𝑔𝑜𝑛𝑎𝑙 = [21]
𝑓𝑒𝑎𝑡𝑢𝑟𝑒 𝑣𝑒𝑐𝑡𝑜𝑟 = [0.09430.9955]
Proses selanjutnya yaitu menurunkan data set baru, yakni feature vector
dikalikan dengan data matrix 𝑋 pada table 2.5.
𝑃𝐶𝐴 = 𝑋 ∗ 𝑓𝑒𝑎𝑡𝑢𝑟𝑒 𝑣𝑒𝑐𝑡𝑜𝑟 (2.7)
Hasil data set baru dapat dilihat pada tabel 2.8
Tabel 2.8 Hasil data set baru PCA
Data X
2.3. Normalisasi
Normalisasi adalah teknik scaling yang digunakan untuk range baru dari range yang sudah ada. Metode normalisasi sangat membantu, karena dapat memperkecil data khususnya untuk range yang dihasilkan terlalu luas. Normalisasi yang digunakan untuk penelitian ini adalah metode normalisasi z-score dan metode normalisasi min-max.
2.3.1. Z-Score
Normalisasi z-score digunakan jika nilai minimum dan maximum pada sebuah atribut tidak diketahui (Mustaffa, 2010). Normalisasi z-score
dilakukan berdasarkan rata-rata dan standard deviation. Normalisai z-score dirumusukan sebagai berikut :
v’ = ( (v-𝐴̅) / 𝜎A ) (2.8)
Keterangan:
v’ : nilai baru v : nilai lama
𝐴̅ : rata-rata dari atribut A
𝜎 : nilai standard deviasi dari atribut A
Untuk rumus standard deviasi sebagai berikut :
𝑠 = √𝑛 ∑𝑛𝑖=1𝑥𝑖2−(∑𝑛𝑖=1𝑥𝑖)2
𝑛(𝑛−1) (2.9)
Keterangan:
s : standar deviasi 𝑥𝑖 : Nilai x ke-i
2.3.2. Min-Max
Normalisasi min-max merupakan metode normalisasi dengan melakukan transformasi liniear terhadap data asli. Normalisasi min-max dirumusakan sebagai berikut (Mustaffa, 2010) :
𝑋
𝑛=
𝑋𝑋0− 𝑋𝑚𝑖𝑛𝑚𝑎𝑥−𝑋𝑚𝑖𝑛 (2.10)
Keterangan:
𝑋𝑛 : nilai baru untuk variable X
𝑋0 : nilai lama untuk variable X
𝑋𝑚𝑖𝑛 : nilai minimum dalam data set
𝑋𝑚𝑎𝑥 : nilai maximum dalam data set
2.4. Penghitungan Jarak
2.4.1 Euclidean Distance
Euclidean distance digunakan untuk menghitung nilai kedekatan antara dua dokumen. Perhitungan Euclidean distance dapat dirumuskan sebagai berikut (Prasetyo, 2014) :
𝑑(𝐴, 𝐵) = √|𝐴1− 𝐵1|2+ |𝐴2− 𝐵2|2+ … … + |𝐴𝑖 − 𝐵𝑖|2 (2.11)
atau
𝑑(𝐴, 𝐵) = √∑ (𝐵𝑖 − 𝐴𝑖)𝑛 2
𝑖=1 (2.12)
Keterangan :
2.4.2 Cosine Similarity
Cosine Similarity digunakan untuk mengukur kemiripan dari dua dokumen x dan y. Kemiripan yang sama antara x dan y akan diberikan nilai 1 dan sebaliknya akan diberikan 0 jika x dan y tidak sama atau berbeda. Nilai 1 yang dibentuk oleh veckor x dan y akan menyatakan sudut 00, yang diartikan antara vektor x dan y adalah sama jaraknya. Perhitungan untuk
Cosini Similarity dapat dirumuskan sebagai berikut (Prasetyo, 2014) :
𝑠 (𝑥, 𝑦) = cos(𝑥, 𝑦) = ||𝑥||‖𝑦‖𝑥 .𝑦 (2.13)
Tanda titik (.) = inner product
𝑥 . 𝑦 = ∑𝑟𝑖=1𝑥𝑖 𝑦𝑖 (2.14)
Tanda ||x|| adalah panjang dari vector x, dimana
2.5. Uji Data
2.5.1 Agglomerative Hierarchical Clustering
Agglomerative Hierarchical Clustering adalah metode analisis kelompok yang berusaha untuk membangun sebuah hirarki kelompok data. Strategi
pengelompokannya umumnya ada 2 jenis yaitu
Agglomerative (Bottom-Up) dan Devisive (Top-Down). Namun pada bagian ini peneliti akan menggunakan konsep Agglomerative (Suppianto, 2014).
Agglomerative Hierarchical Clustering (AHC) dengan menggunakan
bottom-up, dimana proses pengelompokannya dimulai dari masing-masing data sebagai satu buah cluster, kemudian secara rekursif mencari cluster terdekat sebagai pasangan untuk bergabung sebagai satu cluster yang lebih besar. Proses tersebut diulang terus sehingga tampak bergerak keatas membentuk hirarki (Prasetyo, 2014).
Pengelompokan berbasis hirarki sering ditampilkan dalam bentuk grafis menggunakan diagram yang mirip pohon (tree) yang disebut dengan dendogram. Dendogram merupakan diagram yang menampilkan hubungan cluster dan subclusternya dalam urutan yang mana cluster yang digabung (agglomerative view) atau dipecah (divisive view) (Prasetyo, 2014).
Algoritma AgglomerativeHierarchicalClustering (AHC) sebagai berikut (Prasetyo, 2014) :
1. Hitung matriks kedekatan berdasarkan jenis jarak yang digunakan 2. Ulangi langkah 3 sampai 4, hingga hanya 1 cluster yang tersisa
3. Gabungkan kedua cluster terdekat berdasarkan parameter kedekatan yang ditentukan
4. Perbarui matriks kedekatan untuk merefleksikan kedekatan diantar cluster baru dan cluser yang tersisa.
Ada 3 teknik kedekatan yang dapat digunakan untuk menghitung kedekatan diantara 2 cluster di metode AgglomerativeHierarchical Clustering
(AHC), yaitu (Prasetyo, 2014) :
2.5.1.1 Single Linkage (Jarak Terdekat)
Single Linkage atau MIN, kedekatan diantara 2 cluster ditentukan dari jarak terdekat (terkecil) antar 2 data dari cluster yang berbeda atau sering disebut dengan nilai kemiripan yang paling maksimal. Metode ini bagus untuk menangani set data yang bentuk distribusi datanya non-elips (non-elliptical shapes), tapi sangat sensitive terhadap noise dan outlier. Rumus untuk single linkage, yaitu (Prasetyo, 2014) :
𝑑(𝑈, 𝑉) = min{𝑑(𝑈, 𝑉)} ; 𝑑(𝑈, 𝑉)𝜖𝐷 (2.16) Keterangan :
d(U,V) : jarak antar-cluster U dan V
min{d(U,V)} : nilai minimum dari cluster U dan V
2.5.1.2 Complete Linkage (Jarak Terjauh)
Complete Linkage atau MAX, kedekatan diantara dua cluster ditentukan dari jarak terjauh (terbesar) di antara 2 data dari 2 cluster berbeda atau sering disebut dengan nilai kemiripan yang paling minimal. Metode ini kurang peka terhadap noise dan outlier, tetapi bagus untuk data yang mempunyai distribusi bentuk bulat. Rumus untuk
complete linkage, yaitu (Prasetyo, 2014) :
𝑑(𝑈, 𝑉) = max{𝑑(𝑈, 𝑉)} ; 𝑑(𝑈, 𝑉)𝜖𝐷 (2.17) Keterangan :
d(U,V) : jarak antar-cluster U dan V
2.5.1.3 Average Linkage (Jarak Rerata)
Average Linkage atau AVERAGE, kedekatan di antara 2 cluster ditentukan dari jarak rata-rata di antara 2 data dari 2 cluster berbeda atau disebut juga nilai rata-rata di antara single linkage dan complete linkage. Metode ini merupakan pendekatan yang mengambil pertengahan di antara single linkage dan complete linkage. Rumus untuk average linkage, yaitu (Prasetyo, 2014) :
𝑑(𝑈, 𝑉) = 𝑛1
𝑢 𝑛𝑣 {𝑑(𝑈, 𝑉)}; 𝑑(𝑈, 𝑉)𝜖 𝐷 (2.18)
Keterangan :
𝑛𝑢 : jumlah data pada cluster U
𝑛𝑣 : jumlah data pada cluster V
d(U,V) : jarak antar-cluster U dan V
Sebagai contoh, terdapat 4 data dengan jumlah 2 dimensi. Pengelompokkan dilakukan dengan metode Algomerative Hierarchical Clustering dengan menggunakan jarak euclidean distance, metode single linkage, average linkage dan complete linkage. Untuk contoh data dapat dilihat pada tabel 2.9
Tabel 2.9 Contoh data AHC
Data X Y
1 1 1
2 4 1
3 1 2
• Hitung jarak euclidean distance, untuk setiap pasangan data 𝑑(1,2) = √(|4 − 1|2+ |1 − 1|2) = 3
𝑑(1,3) = √(|1 − 1|2+ |2 − 1|2) = 1
𝑑(1,4) = √(|3 − 1|2+ |4 − 1|2) = 3.60
𝑑(2,3) = √(|1 − 4|2+ |2 − 1|2) = 3.16
𝑑(2,4) = √(|3 − 4|2+ |4 − 1|2) = 3.16
𝑑(3,4) = √(|3 − 1|2+ |4 − 2|2) = 2.82
• Similarity Matriks
Tabel 2.10 Hasil penghitungan euclidean distance
1 2 3 4
1 0 3 1 3,60
2 3 0 3.16 3.16
3 1 3.16 0 2.82
4 3.60 3.16 2.82 0
• Matriks Jarak
Karena similarity matriks bersifat simetris maka dapat dirubah menjadi matriks jarak
Tabel 2.11 Matriks jarak dari hasil penghitungan euclidean distance
1 2 3 4
1 0 3 1 3.60
2 0 3.16 3.16
3 0 2.82
• Mengggunakan metode single linkage
Dari tabel 2.11 jarak yang paling dekat atau terkecil. min(𝑑𝑢𝑣) = 𝑑13 = 1
Cluster 1 dan 3 terpilih, maka cluster 1 dan 3 digabungkan. Selanjutnya, menghitung kembali jarak antara cluster (13) dengan cluster yang tersisa 2 dan 4.
𝑑(13)2min(𝑑12𝑑32) = min{3, 3.16} = 3
𝑑(13)4min(𝑑14𝑑34) = min{3.60, 2.82} = 2,82
Setelah mendapat cluster 13, baris dan kolom matriks jarak yang bersesuaian dengan cluster 1 dan 3 dihapus, kemudian ditambahkan baris dan kolom untuk custer 13, maka hasil matriksnya dapat dilihat pada tabel 2.12.
Tabel 2.12 Matriks jarak pertama untuk single lingkage 13 2 4
13 0 3 2.82
2 0 3.16
4 0
Selanjutnya dipilih jarak dua cluster terkecil/terdekat min(𝑑𝑢𝑣) = 𝑑134 = 2.82
Cluster 13 dan 4 terpilih, maka cluster 13 dan 4 digabungkan. Selanjutnya, menghitung kembali jarak antara cluster (134) dengan cluster
yang tersisa 2.
𝑑(134)2min(𝑑12𝑑32𝑑42) = min{3, 3.16,3.16} = 3
Tabel 2.13 Matriks jarak kedua untuk single lingkage 134 2
134 0 3
2 0
Ketika jarak cluster tersisa 1 maka proses iterasi perhitungan untuk pembentukan cluster berhenti. Jadi, cluster (134) dan 2 digabung agar membentuk 1 cluster yaitu, 1234 dengan jarak terdekat 3. Maka, untuk hasil dendrogramnya dapat dilihat pada gambar 2.2.
Gambar 2.2 Hasildendogram singlelinkage
• Mengggunakan metode complete linkage
Dengan metode ini akan di cari setiap jarak cluster yang paling jauh Data yang digunakan tetap berasal dari tabel 2.6.
min(𝑑𝑢𝑣) = 𝑑13 = 1
Untuk awal cluster 1 dan 3 terpilih, maka cluster 1 dan 3 digabungkan. Selanjutnya, menghitung kembali jarak antara cluster (13) dengan cluster
yang tersisa 2 dan 4.
𝑑(13)2max(𝑑12𝑑32) = max{3, 3.16} = 3.16
𝑑(13)4max(𝑑14𝑑34) = max{3.60, 2.82} = 3.60
Tabel 2.14 Matriks jarak pertama untuk complate lingkage
13 2 4
13 0 3.16 3.60
2 0 3.16
4 0
Selanjutnya dipilih jarak dua cluster terkecil/terdekat min(𝑑𝑢𝑣) = 𝑑132 = 3.16
dan
min(𝑑𝑢𝑣) = 𝑑24= 3.16
Karena hasilnya didapatkan 2 cluster yang sama maka penulis memilih Cluster 2 dan 4, maka cluster 2 dan 4 digabungkan. Selanjutnya, menghitung kembali jarak antara cluster (24) dengan cluster yang tersisa 13.
𝑑(24)13max(𝑑21𝑑23𝑑41𝑑43) = max{3, 3.16,3.60,2.82} = 3.60
Setelah mendapat cluster 132, baris dan kolom matriks jarak yang bersesuaian dengan cluster 13 dan 2 dihapus, kemudian ditambahkan baris dan kolom untuk cluster 132, maka hasil matriksnya dapat dilihat pada tabel 2.15.
Tabel 2.15 Matriks jarak kedua untuk average lingkage 13 24
134 0 3.60
2 0
Ketika jarak cluster tersisa 1 maka proses iterasi perhitungan untuk pembentukan cluster berhenti. Jadi, cluster (13) dan (24) digabung agar membentuk 1 cluster yaitu, 1234 dengan jarak terdekat 3.60. Maka, untuk hasil
Gambar 2.3 Hasil dendogram complete linkage
• Mengggunakan metode average linkage
Dengan metode ini akan di cari setiap jarak cluster yang akan dihitung dengan nilai rata-rata. Data yang digunakan tetap berasal dari tabel 2.6.
min(𝑑𝑢𝑣) = 𝑑13 = 1
Untuk awal cluster 1 dan 3 terpilih, maka cluster 1 dan 3 digabungkan. Selanjutnya, menghitung kembali jarak antara cluster (13) dengan cluster
yang tersisa 2 dan 4.
𝑑(13)2average(𝑑12𝑑32) = average{3, 3.16} = 3 + 3.162 = 3.08
𝑑(13)4average(𝑑14𝑑34) = average{3.60, 2.82} = 3.60 + 2.822 = 3.21
Setelah mendapat cluster 13, baris dan kolom matriks jarak yang bersesuaian dengan cluster 1 dan 3 dihapus, kemudian ditambahkan baris dan kolom untuk custer 13, maka hasil matriksnya dapat dilihat pada tabel 2.16.
Tabel 2.16 Matriks jarak pertama untuk average lingkage
13 2 4
13 0 3.08 3.21
2 0 3.16
Selanjutnya dipilih jarak dua cluster terkecil/terdekat min(𝑑𝑢𝑣) = 𝑑132 = 3.08
Cluster 13 dan 2 terpilih, maka cluster 13 dan 2 digabungkan. Selanjutnya, menghitung kembali jarak antara cluster (132) dengan cluster
yang tersisa 4.
𝑑(132)4average(𝑑14𝑑34𝑑24) = average{3.60, 2.82,3.16}
=3.60 + 2.82 + 3.163 = 3.19
Setelah mendapat cluster 132, baris dan kolom matriks jarak yang bersesuaian dengan cluster 13 dan 2 dihapus, kemudian ditambahkan baris dan kolom untuk cluster 132, maka hasil matriksnya dapat dilihat pada tabel 2.17.
Tabel 2.17 Matriks jarak kedua untuk average lingkage 132 4
134 0 3.19
2 0
Ketika jarak cluster tersisa 1 maka proses iterasi perhitungan untuk pembentukan cluster berhenti. Jadi, cluster (132) dan 4 digabung agar membentuk 1 cluster yaitu, 1234 dengan jarak terdekat 3.19. Maka, untuk hasil
dendrogramnya dapat dilihat pada gambar 2.4.
2.5.2 Uji Akurasi Data
Data sinopsis yang sudah di preprocessing dan di uji menggunakan agglomerative hierarchical clustering diperlukan adanya uji akurasi. Fungsi uji akurasi ini berfungsi untuk mengetahui validitas dari pengujian tersebut. Dalam penulisan ini karena menggunakan clustering terdapat 2 jenis akurasi dalam menguji data dengan menggunakan metode clustering, yaitu internal evaluation dan external evaluation.
2.5.2.1 Internal Evaluation
Internal evaluation atau unsupervised validation merupakan pengujian tanpa informasi dari luar. Contoh internal evaluation adalah
cohesion, separation, silhouette coefficient dan sum of square error
(SSE).
2.5.2.2 External evaluation
External evaluation atau supervised validation merupakan pengujian antara label pada cluster yang sudah terbentuk dengan hasil cluster pada sistem. Contoh external evaluation adalah confusion matrix, entropy dan purity.
Dalam penulisan ini, penulis menggunakan uji akurasi data menggunakan internal evaluation dengan metode sum of square error (SSE). Setiap percobaan dalam pembentukan cluster akan dihitung nilai
Rumus SSE yang akan digunakan adalah sebagai berikut (Rokach, 2010) : 𝑆𝑆𝐸 = ∑ ∑ ||𝑥𝑖 − 𝜇𝑘||2
∀𝑥𝑖∈∁𝑘
𝐾
𝑘=1
Keterangan :
𝑥𝑖 : jarak data 𝑥 di indeks 𝑖
𝜇𝑘 : rata-rata semua jarak pada data 𝑥𝑖di cluster 𝑘
Untuk algoritma SSE sebagai berikut :
1. Tentukan matrix 𝐾 untuk dihitung menggunakan SSE 2. Jika k=1, maka
3. Hitunglah rata-rata cluster 𝑘 (𝜇𝑘)… 𝑎 4. Lakukan langkah 5 dan 7 untuk setiap data 𝑥
5. Kurangkan 𝑎 dengan data 𝑥 pada indeks 𝑖(||𝑥𝑖 − 𝜇𝑘||)…b 6. Hitung 𝑏2…c
7. 𝑐 dijumlahkan untuk setiap cluster 𝑘… d 8. Jumlah total d di matrix 𝐾
9. Selesai
Contoh dapat dilihat pada tabel 2.18 sampai dengan tabel 2.22
Tabel 2.18 Contoh data SSE
Data
Tabel 2.19 Rata-rata data SSE Data
A 1.3914
B 1.7465
C 2.0911
D 0.1184
Rata - rata 1.33685
Tabel 2.20 Hasil pengurangan data dengan rata-rata Data Rata-rata ||𝒙𝒊− 𝝁𝒌|| a 1.3914
1.33685
0.05455
b 1.7465 1.7465
c 2.0911 2.0911
d 0.1184 0.1184
Tabel 2.21 Hasil pangkat dari hasil pengurangan
Data Hasil Pengurangan Pangkat ^ 2
a 1.3914 0.05455 0.002976
b 1.7465 1.7465 3.050262
c 2.0911 2.0911 4.372699
d 0.1184 0.1184 0.014019
Tabel 2.22 Hasil sum dari pangkat 2 Pangkat ^ 2
a 0.002976 b 3.050262 c 4.372699 d 0.014019 Jumlah 7.439956
35
BAB III
METODOLOGI PENELITIAN
Dalam metodologi penelitian akan dijelaskan hal-hal terkait data, spesifikasi kebutuhan sistem, tahap-tahap penelitian, desain graphical user interface, skenario sistem dan desain pengujian.
3.1. Data
Data yang akan digunakan dalam penelitian ini diperoleh dari PT. Kanisius, penulis menggunakan kategori fiksi sebagai data yang akan diolah. Terdapat 5 pengarang dalam kategori fiksi yakni: Janine Amos, Donny Kurniawan, Paulette Bourgeois & Brenda Clark, Eddy Supangkat dan Sharon Jennings. Dari setiap pengarang tersebut, penulis mengambil data minimal 20 judul buku per pengarang dengan total data sebanyak 155 judul buku.
Data yang digunakan pada penelitian ini hanya menggunakan bahasa Indondesia. Buku yang sudah terpilih kemudian disimpan dalam bentuk file excel. File ini akan berguna sebagai inputan pada sistem untuk diolah lebih lanjut.
Berikut contoh sinopsis dari pengarang Donny Kurniawan yang sudah dipilih pada Gambar 3.1 :
Gambar 3.1 Judul buku, sinopsis dari pengarang Donny Kurniawan
PRECIL, TETAP TINGGAL DI DANAU
Berikut contoh sinopsis dari pengarang Janine Amos yang sudah dipilih pada Gambar 3.2 :
Gambar 3.2 Judul buku, sinopsis dari pengarang Janine Amos
Berikut contoh sinopsis dari pengarang Sharon Jennings yang sudah dipilih pada Gambar 3.3 :
Gambar 3.3 Judul buku, sinopsis dari pengarang Sharon Jennings
CONFIDENT - PERCAYA DIRI
Buku ini mengajak anak memahami rasa percaya diri dan bagaimana cara mengembangkan perasaan tersebut. ;Hana diminta gurunya untuk bermain drama dalam acara perpisahan di sekolah. Padahal selama ini, dia sudah berlatih koor dan merasa sudah hafal dengan semua lagu yang akan dibawakan. Ia menjadi tidak percaya diri karena harus berganti kegiatan. Ia merasa dianggap tidak mampu dalam koor. Hana kemudian membicarakan hal ini dengan kedua orang tuanya. Ayah dan ibu Hana mendorong Hana untuk mencoba dan mau berlatih menjadi narator dalam drama. Berhasilkah Hana mengatasi rasa percaya dirinya? Ikuti kisahnya dalam buku ini. Tidak hanya kisah Hana, namun juga kisah Jimi dan Tomi bisa dijumpai di dalamnya.
DETEKTIF FRANKLIN
Berikut contoh sinopsis dari pengarang Paulette Bourgeois & Brenda Clark yang sudah dipilih pada Gambar 3.4 :
Gambar 3.4 Judul Buku, Sinopsis dari pengarang Paulette Bourgeois, Brenda Clark
Berikut contoh sinopsis dari pengarang Eddy Supangkat yang sudah dipilih pada Gambar 3.5 :
Gambar 3.5 Judul buku, sinopsis dari pengarang Eddy Supangkat
FRANKLIN BERMAIN SEPAK BOLA
Franklin sangat senang bermain sepak bola. Kadang-kadang Franklin tidur sambil membawa bolanya. Bahkan, Franklin sering bermimpi mencetak gol. Kenyataannya Franklin belum bisa menendang bola dengan baik. Franklin juga belum pernah membuat gol. Begitu juga dengan tim sepak bolanya, sehingga mereka selalu kalah dalam pertandingan. Tim Bearlah yang selalu menjadi pemenang. Akhirnya Franklin bisa menemukan penyebab kekalahan mereka. Setiap sore sampai hari pertandingan tiba, Franklin dan timnya berlatih di taman. Pelatih mengajari mereka bermain dalam suatu permainan istimewa. Hari pertandingan tiba. Tim Franklin menunjukkan permainan istimewa mereka di lapangan. Mereka berhasil menahan gol lawan dan membuat gol ke gawang lawan. Meskipun pada akhirnya tim Bear yang menjadi pemenang, tim Franklin tetap merasa gembira. Mengapa demikian? Rahasianya ada dalam buku ini.
SI MANIS YANG BANYAK TINGKAH
Ini kisah tentang seekor kucing bernama si Manis. Selama ini dia sangat
disayangi oleh keluarga majikannya. Ia satu-satunya hewan peliharaan dalam
rumah itu. Perasaan disayang itu menjadi berubah dengan kehadiran hewan
peliharaan yang lain. Mula-mula si Beo, kemudian si Pusi. Manis merasa keluarga
Johan tidak menyayanginya lagi. Banyak hal dia lakukan untuk merebut rasa
3.2. Spesifikasi Kebutuhan Sistem
Dalam proses pembuatan sistem ini digunakan software dan hardware
pendukung sebagai berikut : 1. Software :
a. Sistem Operasi : Windows 10 64-bit b. Bahasa Pemrograman : Matlab 2015a
2. Hardware
a. Processor : Intel (R) Core(TM) i5-4200M CPU @2.50Ghz
b. Memory : 4 Gb
c. Harddisk : 500 Gb
3.3. Tahap-Tahap Penelitian 3.3.1. Studi Pustaka
Pada tahap ini penulis mencantumkan dan menggunakan teori yang terkait dengan penelitian yang akan dilakukan, seperti teori information retrieval, pembobotan kata, principal component analysis, min-max, z-score,
euclidean distance, agglomerative hierarchical clustering dan sum of square error.
3.3.2. Pengumpulan Data
Data yang akan digunakan pada penelitian ini yaitu sinopsi buku berkategori fiksi.
3.3.3. Pembuatan Alat Uji
3.3.4. Pengujian
Pada tahap pengujian, data akan di pre-processing terlebih dahulu, kemudian data di kelompokkan, kemudian hasil pengelompokan tersebut di uji dengan sum of square error.
3.4. Desain Graphical User Interface (GUI)
3.5. Skenario Sistem
3.5.1 Gambaran Umum Sistem
Gambar 3.7 Diagram blok
Gambar 3.7 menjelaskan pengelompokan dan rekomendasi buku dengan metode agglomerative hierarchical clustering. Proses pertama data sinopsis buku dibuat dalam 1 file yang ekstensi filenya .xls dan dibaca satu per satu. Apabila data sudah dibaca, maka data di
preprocessing, proses preprocessing terdiri dari tokenizing, stopword,
stemming, pembobotan kata (TF-IDF), principal component analysis
(PCA), kemudian hasil PCA di normalisasi. Tahapan normalisasi menggunakan dua metode yaitu, normalisasi min-max dan z-score. Hasil normalisasi akan dihitung jaraknya dengan euclidean distance dan cosine similarity. Proses normalisasi dan penghitungan jarak menggunakan dua metode bertujuan untuk
Apabila sudah selesai dalam menghitung jarak maka data siap diuji untuk
menentukan clustering dengan menggunakan agglomerative hierarchical clustering yang memiliki tiga metode, yaitu single linkage, complete linkage dan average linkage. Setiap hasil cluster yang terbentuk akan menghitung error, apabila error semakin kecil maka hasilnya akan menunjukan cluster yang stabil. Tahap akhir dari penulisan ini yaitu uji data tunggal, yang akan menghasilkan pengelompokan data baru dan hasil rekomendasi.
3.5.1.1. Tahap Preprocessing
Tahap preprocessing terdapat beberapa bagian yaitu, tokenizing,
stopword, stemming, term frequency, weight, principal component analysis, normalisasi (min-max dan z-score) dan penghitungan jarak (euclidean distance dan cosine similarity). Penjelasan untuk tahap
preprocessing adalah sebagai berikut : a. Tokenizing
Tokenizing adalah proses untuk memotong kalimat menjadi beberapa bagian-bagian kecil (kata), yang disebut dengan token. Walaupun terkadang pada saat bersamaan membuang beberapa karakter tertentu, seperti tanda baca (Manning, dkk, 2009).
Langkah-langkah tokenizing : 1. Baca setiap kalimat pada file excel.
2. Potong setiap token pada sinopsi dengan menggunakan jarak spasi sebagai pemisah antara satu token dengan token lain dan hilangkan tanda baca yang ada pada sinopsis tersebut.
b. Stopword
Stopword adalah suatu kata yang sangat sering muncul dalam berbagai dokumen dan tidak berguna dalam pemerolehan informasi. Dalam proses stopword akan menghilangkan kata tidak penting, seperti kata sambung. Dalam hal ini, stopword memiliki kamus sendiri yang sudah tersedia dan dapat digunakan. Sistem akan mengecek dari kata sinopsis ke kamus stopword, jika ada kata yang terkandung di kamus maka kata yang ada di sinopsis akan dihapus.
Langkah-langkah stopword: 1. Baca data hasil dari tokenizing
2. Cocokkan setiap kata dari tokenizing dengan kata yang berada di stoplist
3. Jika kata tersebut sama dengan stoplist, maka kata tersebut dihapus. Jika tidak maka disimpan
Untuk contoh stopword dapat dilihat pada bab 2 halaman 8 dan pada lampiran halaman 109
c. Stemming
Setelah data diubah dari proses tokenizing dan stopword selesai, maka proses selanjutnya menghilangkan kata berimbuhan dan membuat menjadi kata dasar.
Langkah-langkah proses stemming :
1. Baca setiap kata kemudian cek dengan kata dasar yang terdapat pada kamus.
2. Jika kata tersebut sama dengan kamus maka kata tersebut adalah kata dasar
4. Lakukan pengecekan dari hasil langkah ke 3 ke kamus, jika tidak ada yang sama atau berbeda maka anggap kata tersebut sebagai kata dasar
Untuk contoh stemming dapat dilihat pada bab 2 halaman 9 dan pada lampiran halaman 111
3.5.1.2. Tahap Pembobotan
Tahap ini bertujuan unutk mendapatkan term atau nilai dari kata yang sudah melalui beberapa tahap sebelumnya. Bagian ini memiliki beberapa langkah agar data tersebut bisa memiliki bobot, yaitu: menghitung term frequency (tf), menghitung document frequency (df), menghitung inverse document frequency (idf) dan menghitung weight
(bobot). Berikut contoh proses dalam pembobotan kata yang sudah di
stemming,dapatdilihat pada tabel 3.1 sampai dengan tabel 3.5.
• Menghitung term frequency (tf)
Tabel 3.1 TF sinopsis confident – percaya diri
Tabel 3.2 TF sinopsis precil tetap tinggal di danau
Tabel 3.3 TF sinopsis franklin bermain sepak bola
Tabel 3.5 TF sinopsis detektif franklin
• Menghitung document frequency (df)
Contoh penghitungan document frequency (df) merupakan banyaknya frekuensi yang terdapat dalam seluruh data sinopsis, dan hasilnya dapat dilihat pada tabel 3.6.
Tabel 3.6 Penghitungan document frequency (df)
• Menghitung inverse document frequency (idf)
Pada bagian ini, untuk total seluruh document (D) sebanyak 5
document. Berikut contoh penghitungan idf, dengan menggunakan rumus pada persamaan (2.1) dan hasilnya dapat dilihat pada tabel 3.7.
Tabel 3.7 Penghitungan inverse document frequency (idf)