BAB 2
LANDASAN TEORI
Bab ini membahas tentang teori penunjang dan penelitian sebelumnya yang berhubungan
dengan penerapan metode Radial Basis Function (RBF) untuk mengklasifikasikan
kualitas biji kopi berdasarkan bentuk.
2.1 Kopi (Coffee)
Kopi merupakan salah satu komoditas unggulan dalam subsektor perkebunan di Indonesia
karena memiliki peluang pasar yang besar baik di dalam negeri maupun luar negeri.
Indonesia merupakan negara pengekspor kopi nomor empat terbesar dan produsen kopi
terbesar ketiga setelah Negara Brazil dan Vietnam. Proses distribusi kopi dimulai dari
petani, kemudian petani menjual ke pengepul, pengepul menjual kopi ke eksportir dan
eksportir yang mendistribusikan kedalam negeri maupun luar negeri. Sebelum kopi
diekspor atau dipasarkan, eksportir memberikan sampel kopi ke petugas (Balai Pengujian
dan Sertifikasi Mutu Barang) untuk diuji, dan petugas menguji sampel kopi yang
diberikan ekportir berdasarkan Standart Nasional Indonesia (SNI) untuk mendapatkan
sertifikat (Kemenperin, 2013).
Standart yang digunakan untuk mengetahui kualitas kopi adalah standart yang telah
ditetapkan oleh Kementerian Perindustrian melalui penerbitan SNI No.01-2907-2008.
Berdasarkan ketetapan tersebut, kualitas kopi arabika dibagi menjadi 6 bagian
berdasarkan kriteria nilai cacat pada sampel biji kopi. Pengawasan dan pengujian mutu /
Barang yang dibawah pengawasan Kementrian Perindustrian (Kemenperin, 2013).
Pengujian mutu yang diterapkan dalam BPSMB masih manual sehingga ada
kemungkinan besar petugas melakukan kesalahan akibat tidak konsentrasi karena sampel
yang diteliti sangat banyak. Selain itu petugas juga memerlukan waktu yang relatif lama
untuk memisahkan sampel yang tidak cacat dengan sampel yang cacat untuk mengetahui
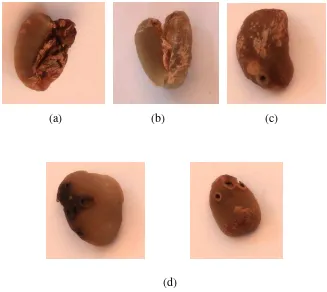
kelas kualitasnya. Gambar jenis cacat biji kopi berdasarkan bentuk dapat dilihat pada
Gambar 2.1.
(a) (b) (c)
(d)
Tabel 2.1. Penentuan Besarnya nilai cacat biji kopi (Badan Standarisasi Nasional, 2008)
No Jenis Cacat Nilai cacat
1 1 (satu) biji hitam 1(satu)
2 1 (satu) biji hitam sebagian ½ (setengah)
3 1 (satu) biji hitam pecah ½ (setengah)
4 1 (satu) kopi gelondong 1(satu)
5 1 (satu) biji coklat ¼ (seperempat)
6 1 (satu) kulit kopi ukuran besar 1 (satu)
7 1 (satu) kulit kopi ukuran sedang ½ (setengah)
8 1 (satu) kulit kopi ukuran kecil 1/5 (seperlima)
9 1 (satu) biji berkulit tanduk ½ (setengah)
10 1 (satu) kulit tanduk ukuran besar ½ (setengah)
11 1 (satu) kulit tanduk ukuran sedang 1/5 (seperlima)
12 1 (satu) kulit tanduk ukuran besar 1/10 (sepersepuluh)
13 1 (satu) biji pecah 1/5 (seperlima)
14 1 (satu) biji muda 1/5 (seperlima)
15 1 (satu) biji berlobang satu 1/10 (sepersepuluh)
16 1 (satu) biji berlobang lebih dari satu 1/5 (seperlima)
17 1 (satu) biji bertutul-tutul 1/10 (sepersepuluh)
18 1 (satu) ranting, tanah atau batu berukuran besar
5 (lima)
19 1 (satu) ranting, tanah atau batu berukuran sedang
2(dua)
20 1 ranting, tanah atau batu berukuran kecil 1(satu)
Tabel 2.1 menunjukkan bahwa jumlah nilai cacat dihitung dari contoh uji seberat 300
gram, untuk mewakili per kualitas. Jika satu biji kopi mempunyai lebih dari satu nilai
2.2 Pengolahan Citra
Citra (image) merupakan salah satu komponen multimedia memegang peranan sangat
penting sebagai bentuk informasi visual (Hartono, 2007). Citra mempunyai karakteristik
yang tidak dimiliki data teks, meskipun suatu citra memiliki informasi, seringkali citra
mengalami penurunan mutu, misalnya : citra tersebut rusak (cacat), warnanya pudar
(terlalu kontras), dan kabur (blurring). Citra yang seperti itu akan sulit memberikan
informasi.
Agar citra yang mengalami gangguan tersebut menjadi lebih mudah memberikan
informasi kepada manusia ataupun komputer maka citra tersebut perlu diolah menjadi
citra yang kualitasnya baik atau sering disebut pengolahan citra (image processing).
Berikut adalah operasi pengolahan citra berdasarkan klasifikasinya :
Peningkatan kualitas citra
Bertujuan untuk memperbaiki kualitas citra dengan cara memanipulasi
parameter-parameter citra. Contohnya : penajaman citra, deteksi tepi citra, memperbaiki kontras
citra, dan mengurangi derau citra.
Perbaikan citra
Bertujuan untuk meminimumkan cacactnya suatu citra atau pemugaran citra.
Contohnya : Menghilangkan kesamaran (blurring), menghilangkan derau (noise), dll.
Segmentasi citra
Bertujuan untuk membagi suatu citra kedalam beberapa segmen kedalam kriteria
tertentu, biasanya berkaitan dengan pola.
Analisis citra
Bertujuan untuk menghitung nilai dari citra untuk mendapatkan hasil deskripsinya.
Analisis citra ini juga membantu mengidentifikasi citra untuk mengalokasikan objek
yang diinginkan. Contohnya deteksi tepi (edge detection), ekstraksi batas (boundary),
Rekonstruksi citra
Bertujuan untuk membentuk ulang objek dari beberapa citra hasil proyeksi, paling
banyak digunakan dibidang media. Contohnya rontgen dengan sinar X dimana
membentuk ulang gambar organ tubuh (Hartono, 2007).
Pada penelitian ini akan dilakukan beberapa proses preprocessing yang akan
digunakan untuk mendapatkan nilai fitur pada proses ekstraksi fitur yaitu:
1. Grayscale
Proses grayscale adalah proses merubah nilai-nilai piksel dari warna RGB menjadi
graylevel. Proses ini dapat digunakan untuk memisahkan bayangan dengan warna asli
pada citra. Proses perhitungan grayscale dapat dilakukan dengan persamaan
Gray = (R + G + B) / 3
2. Threshold
Proses thresholding adalah proses untuk mengelompokkan semua piksel pada citra
dengan nilai tertentu menjadi dua bagian dengan nilai gray level yang telah
ditentukan. Pembuatan citra biner adalah salah satu bentuk thresholding dengan nilai
0 dan 1, yaitu melakukan perubahan semua nilai piksel yang lebih besar atau sama
dengan nilai ambang menjadi 1 dan semua nilai piksel yang lebih kecil dari nilai
ambang menjadi 0.
3. Sobel
Sobel merupakan salah satu pengembangan dari teknik edge detection sebelumnya
(metode Robert) dengan menggunakan HPF (High Pass Filter) yang diberi satu angka
nol penyangga. Algoritma ini berfungsi sebagai filter image yaitu filter yang
mendeteksi keseluruhan edge yang ada (Munandar Imam dkk, 2014).
Kelebihan dari metode ini adalah mengurangi noise sebelum melakukan
perhitungan deteksi tepi. Proses pengurangan noise merupakan proses konvolusi dari
matriks yang ditetapkan terhadap citra yang dideteksi dengan menggunakan 5 x 5
piksel untuk perhitungan gradient sehingga perkiraan gradient berada tepat ditengah
matriks. Besar gradient yang dihitung menggunakan operator Sobel pada persamaan :
� = �2 + �2
Dimana : G = besar gradient operator sobel
Gx = gradient sobel arah vertical
Gy = gradient sobel arah horizontal
Dengan konstanta = 2 maka Gx dan Gy dapat diimplementasikan menjadimatriks
berikut :
Hasil akhir dari operator sobel ini adalah ditemukannya beberapa piksel dengan
intensitas yang lebih besar atau tajam dan juga ukuran tepi objek yang jauh lebih
besar dari ukuran sebelumnya. Keadaan ini dikarenakan titik-titik yang lebih dekat
dengan titik tengah diberi harga yang lebih dominan dalam perhitungan.
2.3 Ekstraksi Fitur
Ekstraksi Fitur merupakan suatu pengambilan ciri dari suatu bentuk yang nantinya nilai
yang didapatkan akan dianalisis untuk proses selanjutnya. Ekstraksi fitur memiliki tujuan
yaitu :
Memperkecil jumlah data
Mengambil informasi yang penting dari data yang diolah
Mempertinggi presisi pengolahan
(2.2)
Ekstraksi fitur terbagi menjadi 3 yaitu: ekstraksi fitur warna, ekstraksi fitur
tekstur,dan ekstraksi fitur bentuk.
a) Ekstraksi Fitur berdasarkan warna
Fitur warna merupakan salah satu fitur yang sering digunakan dalam pengolahan
citra. Beberapa model warna yang digunakan dalam pengolahan citra yaitu : RGB
(Red, Green, Blue), HSV (Hue, Saturation, Value), dan Y, Cb, Cr (Luminance dan
Chrominance).Ada beberapa keuntungan fitur warna :
Kebutuhan kapasitas rendah
Secara signifikan, ukuran histogram warna lebih kecil dari pada citra itu sendiri.
Kesederhanaan Komputasi
Perhitungan histogram mempunyai kompleksitas A(X,Y) untuk citra yang berukuran
X x Y. Kompleksitas untuk kesesuaian citra tunggan adalah linear, A(n), dimana n
adalah jumlah warna yang berbeda.
Ketahanan
Histogram warna tidak sensitive terhadap perubahan dari resolusi gambar, histogram
dan oklusi. Histogram warna tidak berubah juga terhadap rotasi gambar dan
perubahan yg kecil jika diskalakan.
Kesederhanaan Implementasi
Pembentukan histogram adalah pemindai citra, membentuk histogram menggunakan
komponen warna sebagai indeks, dan nilai warna sebagai resolusi histogram.
Efektivitas
Adanya relevansi yang tinggi antara citra query dan citra ekstrak.
Ekstraksi fitur warna dilakukan dengan mengekstraksi karakteristik dari salah satu
elemen warna pada proses fitur warna. Pada proses ini, hasil citra setelah di-rezise
(hue, saturation, value) dari citra asli yang di resize. Setelah elemen-elemen
dipisahkan maka akan dihasilkan elemen pertama adalah hue, elemen kedua
saturation dan elemen ketiga adalah value ( Praida, 2008).
b) Ekstraksi Fitur berdasarkan tekstur
Tekstur merupakan karakteristik dari suatu citra yang terkait dengan tingkat kekasaran
(roughness), granularitas (granulation), dan keteraturan (regularity) susunan
struktural piksel. Tekstur tidak memiliki kemampuan untuk menemukan bersamaan
citra namun dapat digunakan untuk mengklasifikasikan citra bertekstur dan
non-tekstur dan dapat dikombinasikan dengan fitur lainnya. Seperti warna untuk
menghasilkan informasi yang lebih efektif (Murinto, 2014).
Tekstur dapat didefenisikan sebagai fungsi dari variasi spasial intensitas piksel
(nilai keabuan) dalam citra. Berdasarkan strukturnya, tektur dapat diklasifikasikan
dalam dua golongan yaitu :
Makrostruktur
Tekstur makrostruktur memiliki perulangan pola lokal secara periodik pada suatu
daerah citra, biasanya terdapat pada pola-pola buatan manusia dan cenderung mudah
untuk direpresentasikan secara matematis.
Mikrostruktur
Pola-pola lokal dan perulangan tidak terjadi begitu jelas, sehingga tidak mudah untuk
Gambar 2.2 Contoh tekstur visual dari Album Tekstur Brodatz . Atas: makrostruktur Bawah: mikrostruktur ( Crouse et al, 1998)
Secara intuitif tekstur menyatakan ciri dari permukaan objek yang
menggambarkan pola visual. Ciri ini berisi informasi tentang komposisi struktur
permukaan, seperti misalnya awan, daun, batu bata dan kain. Selain itu juga
menjelaskan hubungan antara permukaan untuk lingkungan sekitarnya (Crouse et al,
1998). Sehingga tekstur menjadi salah satu fitur yang penting.
Ciri tekstur antara lain meliputi kehalusan (smoothness), kekasaran (coarseness),
dan keteraturan (regularity). Penggunaan fitur tekstur telah banyak digunakan secara
luas oleh peneliti dalam menyelesaikan masalah pengenalan pola (pattern
recognition) dan computer vision. Secara umum, representasi tekstur dapat
diklasifikasikan menjadi dua, yaitu : struktural dan statistik.
c) Ekstraksi fitur berdasarkan bentuk
Bentuk merupakan salah satu fitur citra yang dapat digunakan untuk mendeteksi objek
atau batas wilayah. Untuk mendapatkan nilai fitur bentuk dapat menggunakan
konversi citra RGB menjadi grayscale untuk mendapatkan nilai warna yang lebih
sederhana. Warna grayscale memiliki intensitas warna 0 – 255 untuk setiap
pikselnya. Ekstraksi fitur berdasarkan bentuk dikategorikan pada teknik yang
digunakan yaitu:
Berdasarkan batas (Boundary-based)
Berdasarkan Daerah (Region-based)
Menggunakan karakteristik Internal
Setelah ekstraksi fitur selesai, maka dilakukan deteksi tepi. Deteksi tepi pada
pengolahan citra adalah suatu proses yang menghasilkan tepi dari objek citra yang
membatasi dua wilayah homogen yang memiliki tingkat kecerahan yang berbeda.
Proses ini dilakukan sebelum proses ekstraksi fitur bentuk untuk meningkatkan
penampakan garis batas suatu daerah atau objek didalam citra dan mendapatkan
bentuk dasar citra (Febriani, 2008). Dalam penelitian ini, metode untuk deteksi tepi
adalah menggunakan operator sobel.
2.4 Radial Basis Function
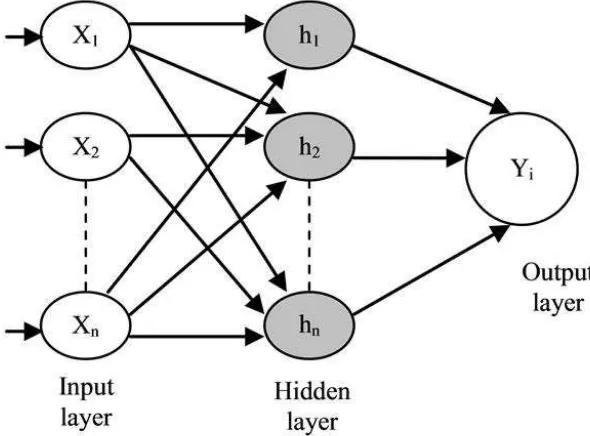
Radial basis function adalah suatu jenis arsitektur jaringan saraf tiruan, yaitu jaringan
yang cara kerjanya meniru jaringan saraf manusia dan terdiri dari berlapis-lapis neuron
yang bekerja untuk memecahkan suatu permasalahan (Tahir et al, 2012). RBF memiliki 3
lapisan yaitu lapisan masukan (input layer), lapisan tersembunyi (hidden layer), dan
lapisan keluaran (output layer). Struktur jaringan RBF dapat dilihat pada Gambar 2.3.
Pada jaringan RBF, hidden layer menggunakan fungsi Gaussian sebagai radial
basis function. Fungsi Gaussian dinyatakan dengan :
�
= exp
(
−| � −� |²
2�²
)
Dimana :
� = fungsi gaussian
� =� = 1
r = data kesekian
j,k = indeks
Nilai Spread menentukan bagaimana data tersebar. Jika nilai spread
makin besar, sensitivitas antar data semakin berkurang.
Nilai spread makin besar maka sensitivitas antar data semakin berkurang.
Centers adalah pusat cluster data
Setelah nilai Gaussian nya diketahui maka nilai RBF nya sudah bisa dicari
dengan menggunakan fungsi berikut :
Y(X) = �= � G(|| X - tt ||) + b
a) Input Layer (Lapisan Masukan)
Input Layer adalah bagian dari jaringan saraf tiruan radial basis function
yang melakukan proses pertama. Input Layer berfungsi untuk membaca
data dari keluaran plant (unit sensor) dan nilai yang kita kehendaki.
b) Hidden Layer (Lapisan Tersembunyi)
Hidden Layer adalah lapisan tersembunyi dari dimensi yang lebih tinggi
untuk melayani suatu tujuan pada fungsi basis dan bobotnya dengan nilai
yang berbeda.
c) Output Layer ( Lapisan Keluaran)
Output Layer merupakan hasil dari penjumlahan dari perkalian antara
bobot dengan fungsi basis akan menghasilkan keluaran. Output Layer ini
merespon dari jaringan sesuai pola yang diterangkan pada input layer
(Bhowmik et al , 2009).
Menurut Haryono (2005), hal yang penting pada RBF adalah sebagai
berikut :
Pemrosesan sinyal dari input layer ke hidden layer , sifatnya
nonlinear , sedangkan dari hidden layer ke output layer sifatnya
linear.
Pada hidden layer digunakan sebuah fungsi aktivasi yang berbasis
radial, misalnya fungsi Gaussian.
Pada Output Layer, sinyal dijumlahkan seperti biasa
Sifat jaringannya adalah feef-forward.
2.5 Algoritma K-Means
Untuk mengetahui nilai dari jaringan RBF, maka dibutuhkan suatu metode untuk
menghitung nilai parameter dari Gaussian yang akan diperlukan di hidden layer, oleh
karena itu diperlukan algoritma K-Means. Algoritma k-means merupakan salah satu
model centroid yang melakukan clustering. Centroid adalah ‘titik tengah’ suatu cluster
yang berupa nilai untuk mengitung jarak suatu objek data terhadap centroid .
Suatu objek data termasuk dalam suatu cluster apabila memiliki jarak terpendek
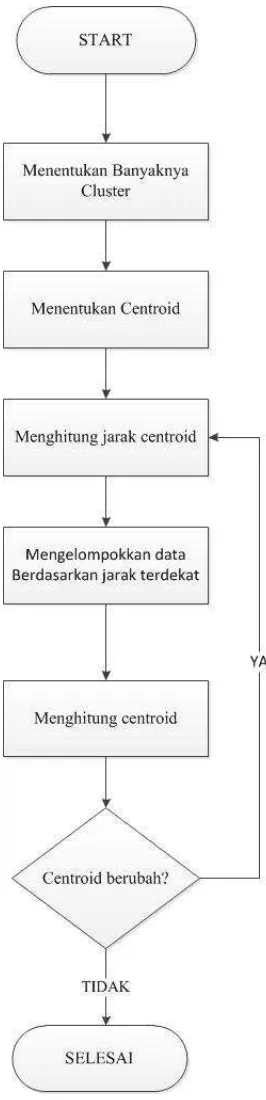
terhadap centroid cluster. Tahapan algoritma K-Means clustering dapat dilakukan
sebagai berikut :
Menentukan banyaknya cluster atau kelompok,
Banyaknya cluster yang akan dibuat harus lebih kecil dari jumlah data yang
digunakan.
Menentukan centroid atau center secara acak
Apakah centroid berubah?
Jika Tidak, selesai
Mengelompokkan data berdasarkan jarak terdekat (Dhanachandra et al , 2015)
Untuk menghitung jarak data dengan centroid maka digunakan persamaan Euclidean
distance. Berikut adalah persamaan Euclidean distance :
d( Xy,Cy) = �= − �
dimana :
d = jarak
j = jarak data
j = banyak data
x = data
c = centroid
2.6 Penelitian Terdahulu
Penentuan mutu bisa dilakukan oleh manusia tetapi manusia mempunyai kelemahan dari
sisi subjektivitas yang mengakibatkan kesalahan akibat kelelahan mata. Masalah ini dapat
diatasi dengan teknologi pengolahan citra (image processing). Pada penelitian ini
dilakukan perbandingan antara pemeriksaan manual dengan pemeriksaan yang
memenfaatkan algoritma image processing dalam proses pemutuan biji kopi dan
penentuan kelas mutu kopi (Madi, 2010).
Dalam menentukan kualitas biji kopi berdasarkan populasi biji kopi, bukan biji
kopi tunggal yang menjadi sampel. Hal ini dapat dikembangkan melalui sistem visi
komputer. Selain penyimpangan di warna, bentuk dan ukuran kopi sebagai sampel biji
yang terkait dengan nomor cacatnya, pantulan cahaya juga mempengaruhi penampilan
warna dan tekstur pada permukaan sampel biji kopi. Sehingga kualitas biji kopi bisa
ditandai dengan parameter warna dan tekstur seluruh sampel. Dengan menggunakan
metode back-propagation jaringan saraf maka masalah tersebut dapat diselesaikan
sehingga dapat meningkatkan tingkat recognition untuk biji kopi penentuan kelas
otomatis. (Faridah, et al., 2011).
Secara komersial mendeteksi cacat dari biji kopi dapat dilakukan oleh manusia
sesuai dengan ukuran biji kopi (penuh, setengah atau rusak). Jenis biji kopi dan kualitas
dapat dinilai dengan inspeksi visual. Tetapi manusia juga mengalami kesalahan dalam
menentukan kualitas yang mungkin dipengaruhi oleh faktor internal dan ekternal. Dengan
bantuan dari pengolahan citra (gambar) maka dapat diidentifikasi kualitas biji kopi.
Teknik pengolahan gambar biji kopi, dapat dianalisis dan dinilai berdasarkan parameter
seperti nilai metric tergantung pada parameter biji kopi (Ayitenfsu, 2014).
Untuk mengklasifikan suatu data dibutuhkan suatu metode yaitu metode RBF
(Radial Basis Function). Metode ini sudah pernah dipakai untuk mengklasifikasikan 60
lembar daun teh. Daun teh tersebut diklasifikasikan menjadi 6 kelas, masing-masing 10
lembar per kelas. RBF membutuhkan waktu sekitar 2.02 detik untuk mengolah data dan
tingkat keakuratan data 86,2%. Didalam penelitian tersebut RBF dibandingkan dengan
metode K-Nearest Neighbour yang memiliki keakuratan data 78% dan membutuhkan 3,6
detik (Arunpriya & Thanamani, 2014).
RBF pernah juga dipakai untuk mengklasifikasikan morfologi sel darah merah.
Proses yang mereka lakukan adalah mengakusisis citra, grayscale, deteksi tepi dan
ekstraksi ciri untuk menghasilkan input bagi RBF. Dalam penelitian ini RBF
dibandingkan dengan metode Back-Propagation. Dari penelitian mereka memperoleh
perbedaan yang signifikan yaitu RBF memiliki tingkat akurasi 100% dengan waktu
sekitar 0.849087114 detik sedangkan BP hanya 92,85% dan membutuhkan waktu sekitar
8.868 detik. RBF memiliki kemampuan yang sangat baik dalam memproses data yang
jumlahnya besar (Tahir et al., 2012). Berikut adalah rangkuman dari penelitian terdahulu