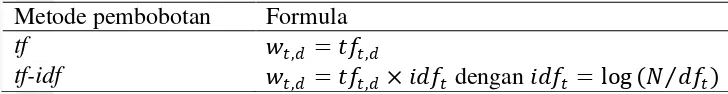ABSTRAK
ADYATMA BHASKARA HUTOMO. Klasifikasi Dokumen Berita Menggunakan Metode Support Vector Machine dengan Kernel Radial Basis Function. Dibimbing oleh JULIO ADISANTOSO.
Setiap hari jumlah dokumen teks, khususnya dokumen berita online di internet terus meningkat. Akibatnya, para pencari informasi mengalami kesulitan dalam memperoleh informasi yang diinginkan, sehingga diperlukan sebuah teknik pengolahan dokumen yang mampu mengelompokkan dokumen teks berdasarkan kategori yang telah ditentukan secara otomatis. Teknik ini adalah klasifikasi dokumen. Salah satu metode klasifikasi yang sangat baik dan populer yaitu support vector machine (SVM). Konsep SVM adalah untuk menemukan bidang pemisah terbaik antara 2 kelas data pada ruang vektor. Dengan kernel trick, SVM mampu menyelesaikan klasifikasi pada kasus taklinear. Tujuan penelitian ini adalah menerapkan kernel radial basis function pada SVM untuk melakukan klasifikasi dokumen berita berbahasa Inggris Reuters-21578, dengan membandingkan metode pembobotan term frequency (tf) dan term frequency-inverse document frequency ( tf-idf). Seleksi ciri dilakukan dengan metode chi-square, menghasilkan 1716 kata penciri dari 7279 kata hasil tokenisasi dan pembuangan stopword. Hasil akhir menunjukkan bahwa klasifikasi SVM menghasilkan akurasi sebesar 93.21% menggunakan pembobotan tf dan 92.97% menggunakan pembobotan tf-idf.
Kata kunci: chi-square, klasifikasi dokumen, radial basis function, seleksi ciri, support vector machine
ABSTRACT
ADYATMA BHASKARA HUTOMO. News Document Classification Using Support Vector Machine Method with Radial Basis Function Kernel. Supervised by JULIO ADISANTOSO.
Every day the number of text documents, especially online news documents increase. As a result, it is more difficult for information seekers in obtaining the desired information. This problem requires a text processing technique that is able to automatically classify text documents based on predetermined categories. This technique is document classification. A very good and popular classification method is support vector machine (SVM). SVM tries to find the best hyperplane which separates 2 classes of data in a vector space. By applying kernel trick, SVM can implement classification in non-linear case. The goals of this research are applying the radial basis function kernel of SVM to classify Reuters-21578 news documents, and comparing the weighting method term frequency (tf) and term frequency-inverse document frequency (tf-idf). The research uses chi-square in feature selection, producing 1716 features out of 7279 terms from tokenization and stopwords removal. The final result shows that the SVM classification produces an accuracy of 93.21% using tf weighting and 92.97% using tf-idf weighting.
KLASIFIKASI DOKUMEN BERITA MENGGUNAKAN
METODE
SUPPORT VECTOR MACHINE
DENGAN
KERNEL
RADIAL BASIS FUNCTION
ADYATMA BHASKARA HUTOMO
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
15 Hal lain yang mempengaruhi kinerja klasifikasi SVM yaitu pemilihan fitur ciri dari kedua kelas dan pemilihan parameter terbaik dalam pembangunan model SVM. Proses pemilihan fitur terbukti dapat meminimalkan jumlah kata penciri yang akan digunakan pada proses selanjutnya. Proses pemilihan parameter yang menghasilkan akurasi paling tinggi dapat memberikan akurasi yang tinggi juga pada proses pengujian. Ketepatan dalam menggunakan metode-metode tersebut di atas dapat membuat metode SVM semakin baik dalam mengklasifikasikan dokumen ke dalam 2 kelas.
SIMPULAN DAN SARAN
Simpulan
Setelah melakukan penelitian ini, diperoleh simpulan bahwa metode SVM mampu melakukan klasifikasi dokumen berita berbahasa Inggris dengan jumlah data yang besar (3110 × 1716 data latih dan 1252 × 1716 data uji). Kernel RBF dapat diterapkan pada SVM untuk melakukan klasifikasi. Metode ini menghasilkan akurasi yang baik yaitu sebesar 93.21% dengan menggunakan chi-square sebagai metode pemilihan fitur serta tf sebagai metode pembobotan. Hasil tersebut menjadi pembanding penggunaan metode pemilihan fitur chi-square dan pembobotan tf-idf yang menghasilkan akurasi sebesar 92.97%. Dengan demikian, pembobotan tf lebih baik daripada pembobotan tf-idf dalam melakukan klasifikasi dokumen.
Saran
Pengembangan lebih lanjut dari penelitian ini adalah klasifikasi dokumen multikelas dengan menggunakan dokumen yang sama dengan yang digunakan pada penelitian ini. Dapat pula dicobakan metode pembobotan lain yang memperbaiki pembobotan tf, misalnya dengan menggunakan pembobotan system for the mechanical analysis and retrieval of text (SMART) atau yang lebih sering disebut SMART notation. Dengan demikian, dapat diketahui metode pembobotan mana yang lebih baik dalam melakukan klasifikasi dokumen.
DAFTAR PUSTAKA
Borovikov EA. 2005. An Evaluation of Support Vector Machines as a Pattern Recognition Tool. Maryland (US): University of Maryland Pr.
16
Gijsberts A. 2007. Evolutionary optimization of kernel [tesis]. Delft (NL): Delft University of Technology.
Hsu CW, Chang CC, Lin CJ. 2003. A Practical Guide to Support Vector Classification. Department of Computer Science and Information Engineering (TW): National Taiwan University.
Joachims T. 1998. Text categorization with support vector machines: learning with many relevant features. Machine Learning: ECML-98. 1398:137-142.doi: 10.1007/BFb0026683.
Manning CD, Raghavan P, Schütze H. 2008. An Introduction to Information Retrieval. Cambridge (GB): Cambridge Univ Pr.
Putri AD. 2013. Klasifikasi dokumen teks menggunakan metode support vector machine dengan pemilihan fitur chi-square [skripsi]. Bogor (ID): Institut Pertanian Bogor.
Santosa B. 2000. Data Mining Teknik Pemanfaatan Data untuk Keperluan Bisnis. Yogyakarta (ID): Graha Ilmu.
Tan P, Steinbach M, Kumar V. 2006. Introduction to Data Mining. Minneapolis (US): Addison Wesley.
KLASIFIKASI DOKUMEN BERITA MENGGUNAKAN
METODE
SUPPORT VECTOR MACHINE
DENGAN
KERNEL
RADIAL BASIS FUNCTION
ADYATMA BHASKARA HUTOMO
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Klasifikasi Dokumen Berita Menggunakan Metode Support Vector Machine dengan Kernel Radial Basis Function adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
ABSTRAK
ADYATMA BHASKARA HUTOMO. Klasifikasi Dokumen Berita Menggunakan Metode Support Vector Machine dengan Kernel Radial Basis Function. Dibimbing oleh JULIO ADISANTOSO.
Setiap hari jumlah dokumen teks, khususnya dokumen berita online di internet terus meningkat. Akibatnya, para pencari informasi mengalami kesulitan dalam memperoleh informasi yang diinginkan, sehingga diperlukan sebuah teknik pengolahan dokumen yang mampu mengelompokkan dokumen teks berdasarkan kategori yang telah ditentukan secara otomatis. Teknik ini adalah klasifikasi dokumen. Salah satu metode klasifikasi yang sangat baik dan populer yaitu support vector machine (SVM). Konsep SVM adalah untuk menemukan bidang pemisah terbaik antara 2 kelas data pada ruang vektor. Dengan kernel trick, SVM mampu menyelesaikan klasifikasi pada kasus taklinear. Tujuan penelitian ini adalah menerapkan kernel radial basis function pada SVM untuk melakukan klasifikasi dokumen berita berbahasa Inggris Reuters-21578, dengan membandingkan metode pembobotan term frequency (tf) dan term frequency-inverse document frequency ( tf-idf). Seleksi ciri dilakukan dengan metode chi-square, menghasilkan 1716 kata penciri dari 7279 kata hasil tokenisasi dan pembuangan stopword. Hasil akhir menunjukkan bahwa klasifikasi SVM menghasilkan akurasi sebesar 93.21% menggunakan pembobotan tf dan 92.97% menggunakan pembobotan tf-idf.
Kata kunci: chi-square, klasifikasi dokumen, radial basis function, seleksi ciri, support vector machine
ABSTRACT
ADYATMA BHASKARA HUTOMO. News Document Classification Using Support Vector Machine Method with Radial Basis Function Kernel. Supervised by JULIO ADISANTOSO.
Every day the number of text documents, especially online news documents increase. As a result, it is more difficult for information seekers in obtaining the desired information. This problem requires a text processing technique that is able to automatically classify text documents based on predetermined categories. This technique is document classification. A very good and popular classification method is support vector machine (SVM). SVM tries to find the best hyperplane which separates 2 classes of data in a vector space. By applying kernel trick, SVM can implement classification in non-linear case. The goals of this research are applying the radial basis function kernel of SVM to classify Reuters-21578 news documents, and comparing the weighting method term frequency (tf) and term frequency-inverse document frequency (tf-idf). The research uses chi-square in feature selection, producing 1716 features out of 7279 terms from tokenization and stopwords removal. The final result shows that the SVM classification produces an accuracy of 93.21% using tf weighting and 92.97% using tf-idf weighting.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
KLASIFIKASI DOKUMEN BERITA MENGGUNAKAN
METODE
SUPPORT VECTOR MACHINE
DENGAN
KERNEL
RADIAL BASIS FUNCTION
ADYATMA BHASKARA HUTOMO
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Penguji:
1 Ahmad Ridha, SKom,
Judul Skripsi : Klasifikasi Dokumen Berita Menggunakan Metode Support Vector Machine dengan Kernel Radial Basis Function
Nama : Adyatma Bhaskara Hutomo NIM : G64100018
Disetujui oleh
Ir Julio Adisantoso, MKom Pembimbing I
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Segala puji dan syukur penulis naikkan kepada Tuhan yang Maha Esa, yang telah memelihara, menyelamatkan, dan memimpin. Karena hanya oleh anugerah-Nya semata, tugas akhir ini berhasil diselesaikan. Penelitian yang dilaksanakan sejak bulan Februari 2014 ini bertema temu kembali teks, dengan judul Klasifikasi Dokumen Berita Menggunakan Metode Support Vector Machine dengan Kernel Radial Basis Function.
Penulis juga mengucapkan terima kasih kepada seluruh pihak yang terlibat dalam membantu diselesaikannya tugas akhir ini, yaitu:
1 Ayahanda, Ibunda, dan Kakak yang dengan tekun berdoa, memberi nasihat dan semangat, serta kasih sayang yang luar biasa kepada penulis.
2 Bapak Ir Julio Adisantoso, MKom selaku dosen pembimbing dan pengajar mata kuliah Temu Kembali Informasi yang memberikan bimbingan dan pengajaran, ide, dukungan, serta kesabaran dalam pengerjaan tugas akhir ini. 3 Bapak Ahmad Ridha, SKom, MS dan Ibu Dr Imas Sukaesih Sitanggang, SSi,
MKom selaku dosen penguji yang telah memberikan masukan dan saran guna semakin memperbaik tugas akhir ini.
4 Teman-teman terdekat, Christyne dan Richardson yang telah menemani, memberi dukungan dan semangat, bersama-sama berjuang demi menyelesaikan tugas akhir masing-masing.
5 Segenap mahasiswa Persekutuan Mahasiswa Kristen (asistensi Listra, Bethel, dan El Emet, asisten mata kuliah Pendidikan Agama Kristen Protestan, kelompok kecil, kelompok PA matrikulasi, Komisi Pembinaan Pemuridan, Kepanitiaan KATA dan MSP, serta rekan PA MRII Bogor) yang senantiasa menguatkan dan memberikan sukacita kepada penulis selama di IPB.
6 Rekan-rekan Wisma Pakis dan OMDA Manggolo Putro. Semoga perjuangan kita selama ini membuahkan kesuksesan.
7 Rekan-rekan satu bimbingan (Damayanti Elisabeth dan Ahmad Baskoro) yang telah berjuang bersama dan melaksanakan bimbingan bersama.
8 Rekan-rekan Pixels (Ilmu Komputer angkatan 47) atas segala kebersamaan dan kenangan selama masa studi. Semoga kita kelak dapat berjumpa kembali sebagai orang-orang sukses.
9 Dosen dan staf Departemen Ilmu Komputer atas pengajaran selama kegiatan perkuliahan dan bantuan dalam hal akademik maupun non akademik. Semoga Departemen Ilmu Komputer menjadi semakin lebih baik ke depannya.
Semoga karya ilmiah ini bermanfaat. Soli deo Gloria.
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 2
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 2
METODE 2
Pengumpulan Dokumen 3
Tokenisasi dan Pembuangan Stopword 3
Pemilihan Fitur Ciri 4
Pembobotan Kata 5
Klasifikasi Dokumen 6
Pengujian 9
Lingkungan Pengembangan Sistem 9
HASIL DAN PEMBAHASAN 10
Pengumpulan Dokumen 10
Tokenisasi dan Pembuangan Stopword 11
Pemilihan Fitur Ciri 11
Pembobotan 12
Klasifikasi Dokumen 12
Pengujian 13
SIMPULAN DAN SARAN 15
Simpulan 15
Saran 15
DAFTAR PUSTAKA 15
LAMPIRAN 17
DAFTAR TABEL
1 Tabel kontingensi antara kata terhadap kelas 5
2 Nilai kritis �2untuk taraf nyata α dan derajat bebas 1 5
3 Contoh metode pembobotan 6
4 Confusion matrix 9
5 Informasi data penelitian 10
6 Struktur tabel dokumen latih dan dokumen uji 11
7 Hasil tahap pemilihan fitur ciri dengan taraf nyata 0.001 12
8 Hasil akurasi parameter terbaik 13
9 Confusion matrix klasifikasi SVM dengan pembobotan tf 14 10 Confusion matrix klasifikasi SVM dengan pembobotan tf-idf 14
DAFTAR GAMBAR
1 Tahapan penelitian 3
2 SVM berusaha menemukan bidang pemisah terbaik 7
3 Penerapan kernel pada SVM dalam transformasi ke dimensi lebih tinggi 8
DAFTAR LAMPIRAN
1 Contoh dokumen Reuter-21578 17
2 Daftar stopword 18
1
PENDAHULUAN
Latar Belakang
Semakin pesatnya perkembangan teknologi informasi, disertai dengan semakin meningkatnya jumlah dokumen teks, menyebabkan semakin sulitnya memperoleh informasi yang diinginkan. Jumlah dokumen teks, khususnya dokumen berita online di internet meningkat per harinya. Hal ini juga terjadi sebagai akibat dari kecenderungan masyarakat umum yang lebih gemar membaca berita online daripada berita tercetak. Oleh karena itu, diperlukan teknik pengolahan dokumen yang mampu mengelompokkan dokumen teks berdasarkan kategori yang telah ditentukan. Dokumen berita yang telah dikelompokkan berdasarkan kesamaan topik bahasan akan mempermudah akses pencari informasi dalam menemukan informasi yang akan dicari. Teknik ini dinamakan klasifikasi dokumen. Dengan klasifikasi dokumen, dokumen dikelompokkan sesuai dengan kategorinya sehingga pencari informasi hanya perlu mencari pada kategori yang berhubungan dengan informasi yang ingin dicari (Joachims 1998).
Ada 2 kasus dalam melakukan klasifikasi, yaitu linear dan taklinear. Pada kasus linear, data terpisah secara sempurna sehingga pengklasifikasi hanya perlu mencari garis linear sebagai pemisah antarkelas. Akan tetapi, permasalahan klasifikasi yang sering dijumpai bersifat taklinear, yakni data tidak dapat dipisahkan secara linear. Untuk itu diperlukan metode yang dapat meningkatkan dimensi data agar pengklasifikasi bisa memisahkan data secara sempurna. Support vector machine (SVM) adalah metode yang dapat melakukan klasifikasi yang bersifat taklinear. SVM merupakan salah satu metode berbasis pembelajaran mesin (machine learning) yang tergolong baru (Manning et al. 2008). Kemampuannya dapat disandingkan dengan neural network, keduanya masuk dalam kelas supervised learning (Santosa 2000). SVM telah digunakan dalam mengatasi permasalahan temu kembali informasi, terutama klasifikasi dokumen.
Permasalahan klasifikasi taklinear dapat diatasi dengan menerapkan fungsi kernel pada SVM, untuk mentransformasikan data ke ruang vektor berdimensi lebih tinggi. Penelitian Putri (2013) menerapkan kernel linear, polinomial dan RBF (radial basis function) dan mampu melakukan klasifikasi dokumen dengan akurasi yang diperoleh berturut-turut sebesar 70.80%, 70.80%, dan 73.72%. Borovikov (2005) mengemukakan bahwa penggunaan kernel RBF pada SVM memberikan akurasi yang paling baik di antara ketiganya. Pemilihan kernel yang digunakan sangat mempengaruhi nilai akurasi yang dihasilkan.
2
Perumusan Masalah
Perumusan masalah pada penelitian ini adalah:
1 Apakah SVM dengan kernel RBF mampu melakukan klasifikasi dokumen berita berbahasa Inggris?
2 Apakah pembobotan tf cukup baik dalam klasifikasi dokumen?
Tujuan Penelitian
Tujuan penelitian ini adalah:
1 Melakukan klasifikasi dokumen berita berbahasa Inggris menggunakan metode SVM dengan kernel RBF.
2 Membandingkan pembobotan tf dan tf-idf dalam klasifikasi dokumen.
Manfaat Penelitian
Penelitian ini diharapkan dapat membantu dalam mengelompokkan dokumen berita berdasarkan kategori yang telah ditentukan secara otomatis.
Ruang Lingkup Penelitian
Ruang lingkup penelitian ini meliputi:
1 Penelitian difokuskan kepada klasifikasi dokumen berbahasa Inggris dalam 2 kelas menggunakan metode SVM dengan kernel RBF.
2 Penelitian juga berfokus pada pembandingan metode pembobotan tf dan tf-idf dalam klasifikasi dokumen.
3 Penelitian dibatasi pada percobaan metode dalam klasifikasi, tanpa membangun sebuah sistem pengklasifikasi otomatis.
METODE
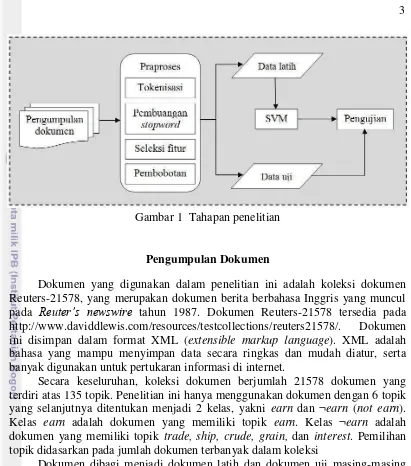
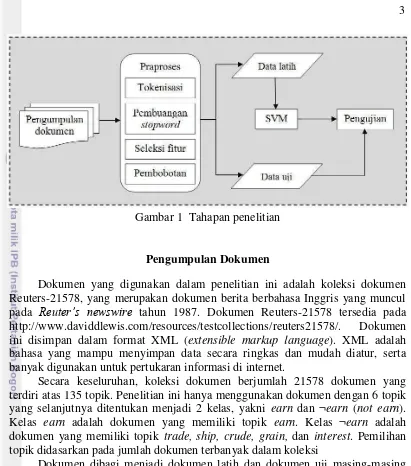
Garis besar alur pengerjaan penelitian ini disajikan dalam Gambar 1. Beberapa tahapan dari sistem meliputi pengumpulan dokumen, praproses, pembagian data, pemodelan, dan pengujian.
3 .
Gambar 1 Tahapan penelitian
Pengumpulan Dokumen
Dokumen yang digunakan dalam penelitian ini adalah koleksi dokumen Reuters-21578, yang merupakan dokumen berita berbahasa Inggris yang muncul pada Reuter’s newswire tahun 1987. Dokumen Reuters-21578 tersedia pada http://www.daviddlewis.com/resources/testcollections/reuters21578/. Dokumen ini disimpan dalam format XML (extensible markup language). XML adalah bahasa yang mampu menyimpan data secara ringkas dan mudah diatur, serta banyak digunakan untuk pertukaran informasi di internet.
Secara keseluruhan, koleksi dokumen berjumlah 21578 dokumen yang terdiri atas 135 topik. Penelitian ini hanya menggunakan dokumen dengan 6 topik yang selanjutnya ditentukan menjadi 2 kelas, yakni earn dan ¬earn (not earn). Kelas earn adalah dokumen yang memiliki topik earn. Kelas ¬earn adalah dokumen yang memiliki topik trade, ship, crude, grain, dan interest. Pemilihan topik didasarkan pada jumlah dokumen terbanyak dalam koleksi
Dokumen dibagi menjadi dokumen latih dan dokumen uji masing-masing dengan proporsi 70% dan 30%. Data latih akan digunakan untuk melatih sistem sehingga dihasilkan model klasifikasi SVM. Data uji digunakan untuk pengujian hasil klasifikasi.
Tokenisasi dan Pembuangan Stopword
4
Tahap selanjutnya adalah pembuangan kata yang dianggap tidak penting, biasa disebut stopword. Pada umumnya, kata-kata yang sering muncul di banyak dokumen juga dibuang. Kata ini tidak sesuai untuk dijadikan penciri suatu dokumen. Kata-kata yang termasuk dalam stopword ini kemudian dibuang dan tidak diikutsertakan dalam proses selanjutnya.
Pemilihan Fitur Ciri
Menurut Manning et al. (2008), pemilihan fitur merupakan suatu proses memilih subset dari setiap kata unik yang ada di dalam himpunan dokumen latih yang akan digunakan sebagai fitur di dalam klasifikasi dokumen. Pemilihan fitur memiliki 2 tujuan utama. Pertama, membuat proses pelatihan dan penggunaan fungsi klasifikasi lebih efisien dengan mengurangi jumlah kata yang digunakan. Kedua, hal ini dapat meningkatkan akurasi hasil klasifikasi.
Ada beberapa metode pemilihan fitur yang baik untuk diterapkan dalam masalah klasifikasi dokumen, yaitu pemilihan fitur berbasis frekuensi, information gain, dan chi-square (�2). Pemilihan fitur berbasis frekuensi dapat bekerja dengan baik ketika fitur yang dipilih berjumlah ribuan. Metode lainnya, yaitu mutual information (MI) yang mengukur berapa banyak informasi kemunculan sebuah term berpengaruh dalam mengklasifikasi ke kelas tertentu. Namun, MI memberikan nilai peluang yang tidak signifikan dan tidak ada batas pasti nilai MI yang baik, sehingga harus memperkirakannya. Chi-square memperbaiki kedua metode tersebut. Penelitian ini menggunakan metode chi-square sebagai pemilihan fitur.
Chi-square merupakan pengujian hipotesis mengenai perbandingan antara frekuensi contoh yang benar-benar terjadi dengan frekuensi harapan yang didasarkan atas hipotesis tertentu pada setiap kasus atau data. Secara umum, perhitungan nilai chi-square ditunjukkan pada persamaan (Walpole 1982):
2
=
( − )2=1 (1)
= ×
� (2)
dengan oi adalah frekuensi observasi, dan ei adalah frekuensi harapan. Perhitungan nilai ei ditunjukkan pada Persamaan 2, dengan adalah jumlah
frekuensi pada kolom, adalah jumlah frekuensi pada baris, dan � adalah jumlah total frekuensi pengamatan. Berdasarkan nilai chi-square (�2) tersebut dapat diambil suatu keputusan statistik apakah terjadi perbedaan antara pola frekuensi observasi dengan frekuensi harapan. Hipotesis nol (H0) diterima jika nilai perhitungan �2 < nilai kritis pada taraf nyata tertentu. Hipotesis nol (H0) ditolak jika nilai perhitungan �2 > nilai kritis pada taraf nyata tertentu.
5 Nilai yang terdapat pada tabel kontingensi merupakan nilai frekuensi observasi dari suatu kata terhadap kelas.
Tabel 1 Tabel kontingensi antara kata terhadap kelas
Kata Kelas
c ¬ c
t N11 N10
¬ t N01 N00
Perhitungan nilai chi-square berdasarkan Tabel 1, menurut Manning et al. (2008) dapat disederhanakan menjadi:
2
( , ) =
�(�11�00−�10�01)2�11+�01 �11+�10 �10+�00 (�01+�00)
(3) dengan t merupakan kata yang sedang diujikan terhadap suatu kelas c, N merupakan jumlah dokumen latih, N11 merupakan banyaknya dokumen kelas c yang memuat kata t, N10 merupakan banyaknya dokumen yang bukan kelas c namun memuat kata t, N01 merupakan banyaknya dokumen kelas c namun tidak memiliki kata t di dalamnya, serta N00 merupakan banyaknya dokumen yang bukan merupakan kelas c dan tidak memuat kata t.
Pengambilan keputusan dilakukan berdasarkan nilai �2 dari masing-masing kata. Kata yang memiliki nilai �2 di atas nilai kritis pada taraf nyata α adalah kata yang akan dipilih sebagai penciri dokumen. Kata yang dipilih sebagai penciri merupakan kata yang memiliki pengaruh terhadap kelas c. Nilai kritis �2 untuk
taraf nyata α ditunjukkan pada Tabel 2 (Walpole 1982). Penelitian ini
menggunakan taraf nyata α yaitu 0.001 dan derajat bebas yaitu 1 yang diartikan bahwa kriteria kata yang dipilih sebagai penciri dokumen adalah kata yang memiliki nilai �2 lebih besar atau sama dengan 10.83.
Tabel 2 Nilai kritis �2untuk taraf nyata α dan derajat bebas 1
α Nilai kritis
0.100 2.71
0.050 3.84
0.010 6.63
0.005 7.83
0.001 10.83
Pembobotan Kata
6
Tabel 3 Contoh metode pembobotan Metode pembobotan Formula
tf , = ,
tf-idf , = , × dengan = log (� )
Semakin sering suatu kata muncul pada suatu dokumen, diduga semakin penting kata itu untuk dokumen tersebut. Angka kemunculan suatu kata pada suatu dokumen menyatakan tingkat kepentingan kata tersebut. Hal inilah yang menjadi dasar pemikiran dari pembobotan tf. Metode ini tergolong sederhana. Jika dibandingkan dengan pembobotan boolean, yang paling sederhana karena hanya memperhitungkan hadir atau tidaknya suatu kata dalam dokumen, pembobotan tf memberikan nilai bobot yang lebih nyata. Nilai bobot term t pada dokumen d (wt,d) diperoleh dari frekuensi kemunculan term t pada dokumen d (tft,d).
Pembobotan ini dapat disebut sebagai pembobotan lokal, karena hanya memerhatikan kemunculan kata pada dokumen tunggal.
Menyambung ide dari pembobotan tf, terdapat kata yang memiliki frekuensi kemunculan tinggi pada dokumen tunggal, namun frekuensi kemunculan kata tersebut juga tinggi di setiap dokumen. Artinya, kata tersebut sebenarnya tidak signifikan. Oleh karena itu, pembobotan tf kadang kala menimbulkan persoalan. Metode pembobotan yang sangat populer yang mampu mengatasi persoalan ini yaitu tf-idf. Nilai idf menyatakan ukuran kepentingan suatu kata. Artinya, semakin besar nilai idf suatu kata, semakin penting kata tersebut. Nilai bobot term t pada dokumen d (wt,d) diperoleh dari hasil perkalian frekuensi kemunculan term t pada
dokumen d (tft,d) dan nilai idf term t (idft). Nilai diperoleh dari hasil logaritma
perbandingan jumlah keseluruhan dokumen (N) dan frekuensi dokumen yang mengandung term t ( ). Maka, nilai bobotnya cenderung berbanding lurus dengan nilai tf dan berbanding terbalik dengan nilai df. Berbeda dengan pembobotan tf, pembobotan tf-idf memerhatikan aspek lokal yaitu kemunculan kata pada dokumen tunggal dan aspek global kemunculan kata pada keseluruhan dokumen.
Penelitian ini mencoba membandingkan kinerja metode pembobotan tf yang sederhana dan diduga cukup untuk memberikan nilai bobot dari setiap fitur terpilih, serta tf-idf sebagai metode pembobotan yang sangat populer dan telah digunakan pada penelitian Putri (2013). Proses pembobotan dilakukan untuk semua kata yang diperoleh dari proses pemilihan fitur. Setiap kata diberi bobot pada setiap dokumen, hal ini berlaku pada semua dokumen latih dan dokumen uji. Dalam hal ini, setiap dokumen akan diwujudkan sebagai sebuah vektor dengan elemen bobot dari setiap fitur terpilih.
Klasifikasi Dokumen
7
Margin terbesar
Support vector
Hyperplane
terbaik
Hyperplane
alternatif
rule memerlukan biaya yang mahal. Pada supervised learning, sistem disupervisi untuk bisa belajar (learning) menggunakan data latih.
SVM merupakan metode pembelajaran yang tergolong baru, diperkenalkan oleh Vapnik, Boser dan Guyon pada tahun 1992. Dewasa ini SVM telah berhasil diaplikasikan dalam problema dunia nyata (real-world problems), dan secara umum memberikan solusi yang lebih baik dibandingkan metode konvensional.
Konsep dasar SVM dapat dijelaskan sebagai usaha mencari hyperplane terbaik yang berfungsi sebagai pemisah 2 kelas pada input space (Joachims 1998). Secara sederhana, SVM mampu menyelesaikan permasalahan klasifikasi 2 kelas. Pembuatan model berdasarkan masukan dari data latih dari masing-masing kelas dilakukan oleh SVM. Model inilah yang kemudian dapat dipakai untuk mengelompokkan data baru.
Usaha untuk mencari lokasi hyperplane merupakan inti dari proses pembelajaran pada SVM. Gambar 2 mengilustrasikan bidang pemisah terbaik ialah bidang pemisah yang menghasilkan nilai margin terbesar. Nilai margin merupakan jarak antara bidang pemisah dengan elemen terluar dari kedua kelas.
Gambar 2 SVM berusaha menemukan bidang pemisah terbaik (Manning et al. 2008)
Menurut Manning et al. (2008), fungsi pemisah yang dicari adalah fungsi linear sebagai berikut:
= ( � + ) (4)
dengan adalah bobot yang merepresentasikan posisi hyperplane pada bidang normal, adalah vektor data masukan, dan adalah bias yang merepresentasikan posisi bidang relatif terhadap pusat koordinat.
Teknik ini berusaha menemukan fungsi pemisah (hyperplane) terbaik di antara fungsi yang tidak terbatas jumlahnya untuk memisahkan 2 macam obyek. Mencari hyperplane terbaik ekuivalen dengan memaksimalkan margin antara 2 kelas yang dapat diperoleh dari formula 2 . Hal ini sama dengan meminimalkan fungsi 1
2
8
diselesaikan dengan Lagrange multiplier sehingga fungsi klasifikasinya menjadi seperti pada Persamaan 5.
= � � + (5)
dengan � adalah Lagrange multiplier yang berkorespondensi dengan (Manning et al. 2008).
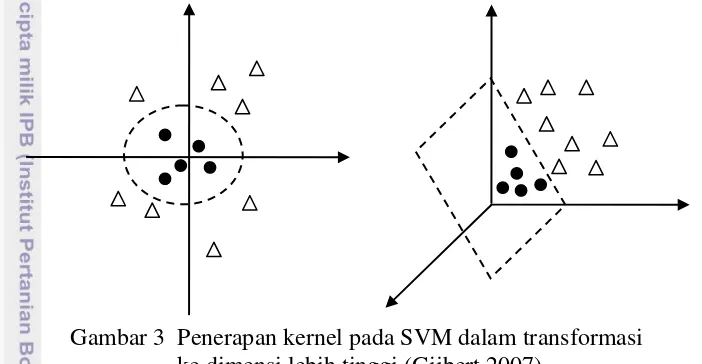
Dengan fungsi kernel, data akan ditransformasikan ke ruang vektor berdimensi lebih tinggi. Usaha mencari bidang pemisah antara kedua kelas pada ruang vektor baru adalah langkah selanjutnya. Pada Gambar 3 diilustrasikan modifikasi SVM dengan kernel.
Gambar 3 Penerapan kernel pada SVM dalam transformasi ke dimensi lebih tinggi (Gijbert 2007)
Ada beberapa bentuk fungsi kernel, yang paling umum digunakan di antaranya linear, polinomial, radial basis function (RBF), dan sigmoid. Menurut Hsu et al. (2003) fungsi kernel yang direkomendasikan untuk diuji pertama kali ialah fungsi kernel RBF karena memiliki performa yang sama dengan SVM linear pada parameter tertentu, memiliki perilaku seperti fungsi kernel sigmoid dengan parameter tentu dan rentang nilainya kecil [0,1]. Penelitian ini menggunakan kernel RBF. Menurut Manning et al.(2008), fungsi kernel untuk RBF ditunjukkan pada Persamaan 6.
� , = exp −� − 2 (6) dengan adalah vektor data latih dan adalah vektor data uji. Setelah menerapkan fungsi kernel, fungsi keputusannya (decision surface) ditulis dalam:
= � � , + (7)
dengan � adalah Lagrange multiplier yang berkorespondensi dengan (Manning et al. 2008).
9 classification. LIBSVM tersedia pada http//www.csie.ntu.edu.tw/~cjlin/libsvm. Penggunaan LIBSVM meliputi pemodelan SVM terhadap data latih dan pengujian data uji terhadap model SVM. Penggunaan kernel dalam support vector classification juga telah dikembangkan, serta mendukung penerapan kernel RBF pada SVM. Dengan demikian, LIBSVM dapat diterapkan pada penelitian ini untuk melakukan klasifikasi SVM 2 kelas dengan kernel RBF.
Pengujian
Proses pelatihan akan menghasilkan model SVM, lalu data uji yang sudah diketahui kelasnya ini akan diujikan terhadap fungsi klasifikasi SVM. Proses pengujian hasil klasifikasi dokumen tersebut dilakukan untuk mengetahui tingkat akurasi klasifikasi SVM dengan kernel RBF terhadap suatu data uji. Penelitian ini menggunakan metode confusion matrix dalam penghitungan tingkat akurasi. Confusion matrix merupakan matriks yang menyatakan jumlah kasus yang diklasifikasikan dengan benar dan salah (Tan et al. 2006), disajikan pada Tabel 4.
Tabel 4 Confusion matrix
Prediksi Observasi
Benar Salah
Benar TP FP
Salah FN TN
Dari perhitungan confusion matrix, diperoleh formula untuk menghitung akurasi sebagai berikut:
� = ��+��
��+��+��+�� (8)
Lingkungan Pengembangan Sistem
Lingkungan pengembangan sistem pada penelitian ini meliputi perangkat keras dan perangkat lunak dengan spesifikasi sebagai berikut:
1 Perangkat keras
Intel Pentium Core 2 Duo @2.00 GHz
Memori 2048 MB RAM
Harddisk 250 GB
2 Perangkat Lunak
Sistem operasi Microsoft Windows 7
LIBSVM 3.18
Matlab R2008b
PHP MySQL sebagai bahasa pemrograman
Notepad++ sebagai code editor
10
HASIL DAN PEMBAHASAN
Pengumpulan Dokumen
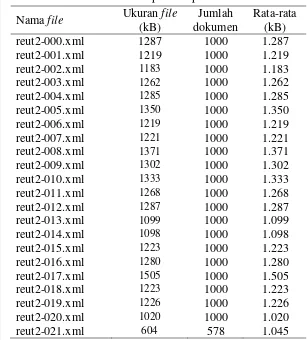
Tahapan awal yang dilakukan dalam penelitian adalah mengolah dokumen XML yang akan menjadi korpus. Terdapat 21578 dokumen berita yang terdiri atas 135 topik. Seluruh dokumen tersimpan dalam 22 file berformat XML dengan rincian terdapat pada Tabel 5.
Tabel 5 Deskripsi data penelitian Nama file Ukuran file
(kB)
Jumlah dokumen
Rata-rata (kB)
reut2-000.xml 1287 1000 1.287
reut2-001.xml 1219 1000 1.219
reut2-002.xml 1183 1000 1.183
reut2-003.xml 1262 1000 1.262
reut2-004.xml 1285 1000 1.285
reut2-005.xml 1350 1000 1.350
reut2-006.xml 1219 1000 1.219
reut2-007.xml 1221 1000 1.221
reut2-008.xml 1371 1000 1.371
reut2-009.xml 1302 1000 1.302
reut2-010.xml 1333 1000 1.333
reut2-011.xml 1268 1000 1.268
reut2-012.xml 1287 1000 1.287
reut2-013.xml 1099 1000 1.099
reut2-014.xml 1098 1000 1.098
reut2-015.xml 1223 1000 1.223
reut2-016.xml 1280 1000 1.280
reut2-017.xml 1505 1000 1.505
reut2-018.xml 1223 1000 1.223
reut2-019.xml 1226 1000 1.226
reut2-020.xml 1020 1000 1.020
reut2-021.xml 604 578 1.045
Contoh dokumen Reuters-21578 dapat dilihat pada Lampiran 1. Ada beberapa tag di dalam setiap dokumen, namun beberapa tag yang penting untuk diperhatikan untuk proses selanjutnya yaitu:
<TOPICS></TOPICS>, tag ini menunjukkan topik bahasan dari dokumen, yang akan dijadikan nama kelas dari setiap dokumen.
<TITLE></TITLE>, menunjukkan judul dari dokumen berita.
<BODY></BODY>, merupakan isi berita dari dokumen.
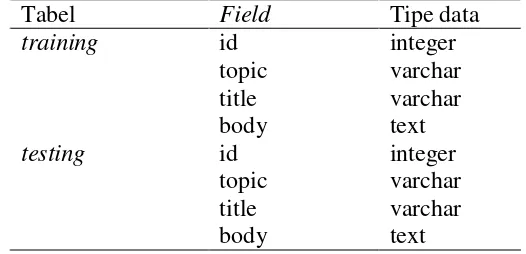
11 dilakukan dengan membuat program menggunakan bahasa pemrograman PHP dan MySQL. Secara sederhana, yang dilakukan program ini yaitu membaca setiap file, dan mengambil string yang diapit oleh tag <TOPICS></TOPICS> disimpan sebagai topik dokumen, tag <TITLE></TITLE> disimpan sebagai judul dokumen, serta tag <BODY></BODY> disimpan sebagai isi dokumen untuk setiap dokumen. Struktur tabel pada basis data disajikan dalam Tabel 6.
Tabel 6 Struktur tabel dokumen latih dan dokumen uji
Tabel Field Tipe data
training
testing
id topic title body id topic title body
integer varchar varchar text integer varchar varchar text
Tokenisasi dan Pembuangan Stopword
Tokenisasi dan pembuangan stopword dilakukan dengan membuat program menggunakan bahasa pemrograman PHP dan MySQL. Proses diawali dengan mengambil dokumen latih pada basis data. Lalu dilanjutkan dengan penghapusan tanda baca dan karakter numerik serta pengubahan huruf kapital menjadi huruf kecil. Token yang didefinisikan sebagai suatu kata didapatkan dengan memisahkan dokumen berdasarkan karakter spasi putih (white space) kemudian dihitung frekuensinya. Dalam tahap ini diperoleh 160320 kata hasil tokenisasi terhadap dokumen latih.
Seluruh kata tersebut disaring dengan membuang kata-kata tidak penting atau stopword, seperti “the”, “and”, “but”, dan lain-lain. Pendefinisian stopword dilakukan berdasarkan kata hasil tokenisasi dengan frekuensi kemunculan sangat tinggi dan sangat rendah, dari sini dipilih kata-kata yang dianggap tidak penting. Stopword berbahasa Inggris yang telah didefinisikan berjumlah 143 kata (Lampiran 2), dan tersimpan dalam basis data. Sampai pada tahap ini, diperoleh 7279 kata unik.
Pemilihan Fitur Ciri
12
(Tabel 7). Hal ini membuktikan proses ini mampu mengurangi jumlah kata yang akan diproses. Selanjutnya hanya kata-kata ini yang akan diproses.
Tabel 7 Hasil tahap pemilihan fitur ciri dengan taraf nyata 0.001
Kelas Jumlah
kata unik
earn 615
¬earn 1101
Total 1716
Pembobotan Kata
Seluruh kata yang diperoleh dari tahap pemilihan fitur akan dihitung bobotnya pada masing-masing dokumen. Pada tahap ini menghasilkan matriks vektor yang digunakan sebagai data latih dan data uji, yang masing-masing tersimpan pada file berformat CSV. Kedua file ini dibuat dari pembangunan program menggunakan bahasa pemrograman PHP dan MySQL. Matriks data latih berukuran 3110 × 1716, jumlah baris menunjukkan jumlah dokumen latih yaitu 3110 dan jumlah kolom menunjukkan jumlah kata penciri yaitu 1716. Matriks data uji berukuran 1252 × 1716, jumlah baris menunjukkan jumlah dokumen uji yaitu 1252 dan jumlah kolom menunjukkan jumlah kata penciri yaitu 1716.
Penelitian ini akan membandingkan 2 metode pembobotan, yaitu tf dan tf-idf. Penghitungan bobot kata dengan metode pembobotan tf hanya memerhatikan frekuensi kemunculan kata pada masing-masing dokumen, karena adanya asumsi bahwa semakin sering suatu kata muncul dalam suatu dokumen, kata tersebut semakin penting. Nilai bobotnya diperoleh dari jumlah kemunculan kata di dalam sebuah dokumen tertentu. Apabila suatu kata tertentu tidak muncul dalam sebuah dokumen, maka bobotnya bernilai nol. Di samping itu, pada metode pembobotan tf-idf selain memerhatikan frekuensi kemunculan sebuah kata di dalam sebuah dokumen tertentu, juga memperhitungkan jumlah dokumen yang mengandung kata tersebut. Keduanya memberikan nilai bobot yang berbeda untuk matriks data latih dan data uji. Artinya, untuk proses klasifikasi selanjutnya juga dihasilkan 2 buah model SVM.
Klasifikasi Dokumen
Dalam klasifikasi dokumen, data latih dari proses sebelumnya diperlukan untuk membuat model SVM. Model SVM adalah model klasifikasi berbasis ruang vektor. Seluruh vektor dokumen dipetakan kemudian dicari fungsi pemisah kedua kelas. Proses ini dilakukan menggunakan LIBSVM pada Matlab R2008b. Proses pemodelan SVM oleh Matlab dapat dilihat pada Lampiran 3.
Proses diawali dengan pembacaan file data latih berformat CSV, dilakukan dengan fungsi csvread(). Data ini merupakan data matriks, kolom pertama menyatakan label kelas dari dokumen. Kolom kedua dan seterusnya sampai kolom terakhir menyatakan fitur dari masing-masing dokumen. Penggunaan fungsi
13 untuk proses selanjutnya. Selanjutnya, proses yang sama dilakukan pada file data uji.
Pemodelan SVM memerlukan parameter sesuai dengan fungsi kernel yang digunakan. Menurut Hsu et al. (2003), akurasi model yang dihasikan dari proses pelatihan dengan SVM sangat bergantung pada fungsi kernel serta parameter yang digunakan. Oleh karena itu performansinya dapat dioptimasi dengan mencari (mengestimasi) parameter terbaik. Parameter yang diperlukan untuk kernel RBF yaitu c (cost) dan γ (gamma). Untuk menentukan nilai terbaik dari kedua parameter ini dilakukan proses grid search. Akurasi diperoleh dari persentase data yang diklasifikasikan dengan benar.
Proses grid search pada Matlab dilakukan dengan memanggil fungsi
test_grid_rbf(). Proses ini dilakukan untuk mendapatkan nilai c (cost) terbaik pada rentang 2-5 ≤ c ≤ 215 dan parameter γ (gamma) terbaik pada rentang 2-15 ≤ γ ≤ 23. Parameter dikatakan terbaik jika mencapai nilai akurasi tertinggi dalam proses ini. Tabel 8 menyajikan parameter terbaik untuk masing-masing model SVM.
Tabel 8 Hasil akurasi parameter terbaik Metode
pembobotan
Parameter
Akurasi
с (cost) γ (gamma)
tf 27 1.22070 × 10-4 93.8907%
tf-idf 27 2.44141 × 10-4 93.6013%
Selanjutnya, pemodelan SVM dilakukan dengan memanggil fungsi
svmtrain ( training_label_vector, training_instance_matrix, '-t 2 -c 128 -g 0.00012207') untuk pembobotan tf. Parameter dalam fungsi tersebut dijelaskan sebagai berikut:
training_label_vector, merupakan vektor label kelas dari data latih.
training_instance_matrix, merupakan matriks fitur dari data latih.
'-t 2 -c 128 -g 0.00012207', merupakan parameter untuk LIBSVM. Nilai yang mengikuti string -t menyatakan jenis fungsi kernel yang digunakan,
2 berarti kernel RBF. Nilai yang mengikuti string -c menyatakan nilai parameter c (cost) yang digunakan, yaitu 128. Nilai yang mengikuti string -g
menyatakan nilai parameter γ (gamma) yang digunakan, yaitu 0.00012207. Untuk pembobotan tf-idf, fungsi yang dipanggil yaitu svmtrain ( training_label_vector, training_instance_ matrix, '-t 2 -c 128 -g 0.000244141').
Pengujian
14
cara jumlah dokumen yang diklasifikasikan dengan benar dibagi jumlah keseluruhan dokumen uji.
Pada data uji yang menggunakan metode pembobotan tf, jumlah dokumen kelas earn yang diklasifikasikan dengan benar adalah 941 dan yang salah berjumlah 85. Jumlah dokumen kelas ¬earn yang diklasifikasikan dengan benar adalah 226 dan yang salah berjumlah 0 (Tabel 9). Di samping itu, pada data uji yang menggunakan metode pembobotan tf-idf, jumlah dokumen kelas earn yang diklasifikasikan dengan benar adalah 940 dan yang salah berjumlah 87. Jumlah dokumen kelas ¬earn yang diklasifikasikan dengan benar adalah 224 dan yang salah berjumlah 1 (Tabel 10). Hasil akurasi dari model SVM dengan metode pembobotan tf dan tf-idf yang dihitung dengan menggunakan rumus pada persamaan 2 berturut-turut sebesar 93.2109% dan 92.9712%. Proses pengujian oleh Matlab dilakukan dengan memanggil fungsi svmpredict (testing_label_vector, testing_instance_matrix, modelsvm)
(Lampiran 3). Parameter dalam fungsi tersebut dijelaskan sebagai berikut:
testing_label_vector, merupakan vektor label kelas dari data uji.
testing_instance_matrix, merupakan matriks fitur dari data uji.
modelsvm, merupakan model yang dihasilkan dari proses pemodelan SVM. Tabel 9 Confusion matrix klasifikasi SVM dengan pembobotan tf
Prediksi Observasi
earn ¬ earn
earn 941 85
¬ earn 0 226
Tabel 10 Confusion matrix klasifikasi SVM dengan pembobotan tf-idf
Prediksi Observasi
earn ¬ earn
earn 940 87
¬ earn 1 224
15 Hal lain yang mempengaruhi kinerja klasifikasi SVM yaitu pemilihan fitur ciri dari kedua kelas dan pemilihan parameter terbaik dalam pembangunan model SVM. Proses pemilihan fitur terbukti dapat meminimalkan jumlah kata penciri yang akan digunakan pada proses selanjutnya. Proses pemilihan parameter yang menghasilkan akurasi paling tinggi dapat memberikan akurasi yang tinggi juga pada proses pengujian. Ketepatan dalam menggunakan metode-metode tersebut di atas dapat membuat metode SVM semakin baik dalam mengklasifikasikan dokumen ke dalam 2 kelas.
SIMPULAN DAN SARAN
Simpulan
Setelah melakukan penelitian ini, diperoleh simpulan bahwa metode SVM mampu melakukan klasifikasi dokumen berita berbahasa Inggris dengan jumlah data yang besar (3110 × 1716 data latih dan 1252 × 1716 data uji). Kernel RBF dapat diterapkan pada SVM untuk melakukan klasifikasi. Metode ini menghasilkan akurasi yang baik yaitu sebesar 93.21% dengan menggunakan chi-square sebagai metode pemilihan fitur serta tf sebagai metode pembobotan. Hasil tersebut menjadi pembanding penggunaan metode pemilihan fitur chi-square dan pembobotan tf-idf yang menghasilkan akurasi sebesar 92.97%. Dengan demikian, pembobotan tf lebih baik daripada pembobotan tf-idf dalam melakukan klasifikasi dokumen.
Saran
Pengembangan lebih lanjut dari penelitian ini adalah klasifikasi dokumen multikelas dengan menggunakan dokumen yang sama dengan yang digunakan pada penelitian ini. Dapat pula dicobakan metode pembobotan lain yang memperbaiki pembobotan tf, misalnya dengan menggunakan pembobotan system for the mechanical analysis and retrieval of text (SMART) atau yang lebih sering disebut SMART notation. Dengan demikian, dapat diketahui metode pembobotan mana yang lebih baik dalam melakukan klasifikasi dokumen.
DAFTAR PUSTAKA
Borovikov EA. 2005. An Evaluation of Support Vector Machines as a Pattern Recognition Tool. Maryland (US): University of Maryland Pr.
16
Gijsberts A. 2007. Evolutionary optimization of kernel [tesis]. Delft (NL): Delft University of Technology.
Hsu CW, Chang CC, Lin CJ. 2003. A Practical Guide to Support Vector Classification. Department of Computer Science and Information Engineering (TW): National Taiwan University.
Joachims T. 1998. Text categorization with support vector machines: learning with many relevant features. Machine Learning: ECML-98. 1398:137-142.doi: 10.1007/BFb0026683.
Manning CD, Raghavan P, Schütze H. 2008. An Introduction to Information Retrieval. Cambridge (GB): Cambridge Univ Pr.
Putri AD. 2013. Klasifikasi dokumen teks menggunakan metode support vector machine dengan pemilihan fitur chi-square [skripsi]. Bogor (ID): Institut Pertanian Bogor.
Santosa B. 2000. Data Mining Teknik Pemanfaatan Data untuk Keperluan Bisnis. Yogyakarta (ID): Graha Ilmu.
Tan P, Steinbach M, Kumar V. 2006. Introduction to Data Mining. Minneapolis (US): Addison Wesley.
17 Lampiran 1 Contoh dokumen Reuter-21578
<REUTERS TOPICS="YES" LEWISSPLIT="TRAIN" CGISPLIT="TRAINING-SET" OLDID="5552" NEWID="9">
<DATE>26-FEB-1987 15:17:11.20</DATE> <TOPICS><D>earn</D></TOPICS>
<PLACES><D>usa</D></PLACES> <PEOPLE></PEOPLE>
<ORGS></ORGS>
<EXCHANGES></EXCHANGES> <COMPANIES></COMPANIES> <UNKNOWN>F
f0762reute
r f BC-CHAMPION-PRODUCTS-<CH 02-26 0067</UNKNOWN> <TEXT>
<TITLE>CHAMPION PRODUCTS <CH> APPROVES STOCK SPLIT</TITLE> <DATELINE> ROCHESTER, N.Y., Feb 26 - </DATELINE>
<BODY>Champion Products Inc said its
board of directors approved a two-for-one stock split of its common shares for shareholders of record as of April 1, 1987. The company also said its board voted to recommend to
shareholders at the annual meeting April 23 an increase in the authorized capital stock from five mln to 25 mln shares.
18
19 Lampiran 3 Instruksi Matlab pada pemodelan dan pengujian
1. Pembobotan tf
datatrain = csvread('training_tf.csv'); labels = datatrain(:,1);
features = datatrain(:,2:end); features_sparse = sparse(features);
libsvmwrite('datatrainlibsvm_tf.train', labels, features_sparse); [label_vector,instance_matrix]=libsvmread('datatrainlibsvm_tf. train');
test_grid_rbf(label_vector, instance_matrix); %grid search
[training_label_vector, training_instance_matrix]=libsvmread('data trainlibsvm_tf.train');
datatest = csvread('testing_tf.csv'); labels = datatest(:,1);
features = datatest(:,2:end);
features_sparse = sparse(features);
libsvmwrite('datatestlibsvm_tf.test', labels, features_sparse); [testing_label_vector, testing_instance_matrix]=libsvmread('data testlibsvm_tf.test');
model_tf = svmtrain(training_label_vector,training_instance_matrix, '-t 2 -c 128 -g 0.00012207');
[predict_label_tf, accuracy_tf, dec_values_tf] = svmpredict (testing_label_vector, testing_instance_matrix, model_tf); Accuracy = 93.2109% (1167/1252) (classification)
2. Pembobotan tf-idf
datatrain = csvread('training_tfidf.csv'); labels = datatrain(:,1);
features = datatrain(:,2:end); features_sparse = sparse(features);
libsvmwrite('datatrainlibsvm_tfidf.train',labels,features_sparse); [label_vector,instance_matrix]=libsvmread('datatrainlibsvm_tfidf. train');
test_grid_rbf(label_vector, instance_matrix); %grid search
[training_label_vector, training_instance_matrix]=libsvmread('data trainlibsvm_tfidf.train');
datatest = csvread('testing_tfidf.csv'); labels = datatest(:,1);
features = datatest(:,2:end);
features_sparse = sparse(features);
libsvmwrite('datatestlibsvm_tfidf.test', labels, features_sparse); [testing_label_vector, testing_instance_matrix]=libsvmread('data testlibsvm_tfidf.test');
model_tfidf = svmtrain(training_label_vector, training_instance_ matrix, '-t 2 -c 128 -g 0.000244141');
[predict_label_tfidf, accuracy_tfidf, dec_values_tfidf] = svmpredict(testing_label_vector, testing_instance_matrix, model_tfidf);
20
RIWAYAT HIDUP
Penulis dilahirkan di Ponorogo pada tanggal 19 Juli 1991. Penulis merupakan anak kedua dari pasangan Markus Katirin dan Sutini. Pada tahun 2010, penulis menamatkan pendidikan di SMA Negeri 1 Ponorogo. Penulis berkesempatan melanjutkan studi di Institut Pertanian Bogor melalui jalur Undangan Seleksi Masuk IPB (USMI) di Program Sarjana Ilmu Komputer Depertemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam.
10
HASIL DAN PEMBAHASAN
Pengumpulan Dokumen
[image:35.595.125.432.231.571.2]Tahapan awal yang dilakukan dalam penelitian adalah mengolah dokumen XML yang akan menjadi korpus. Terdapat 21578 dokumen berita yang terdiri atas 135 topik. Seluruh dokumen tersimpan dalam 22 file berformat XML dengan rincian terdapat pada Tabel 5.
Tabel 5 Deskripsi data penelitian Nama file Ukuran file
(kB)
Jumlah dokumen
Rata-rata (kB)
reut2-000.xml 1287 1000 1.287
reut2-001.xml 1219 1000 1.219
reut2-002.xml 1183 1000 1.183
reut2-003.xml 1262 1000 1.262
reut2-004.xml 1285 1000 1.285
reut2-005.xml 1350 1000 1.350
reut2-006.xml 1219 1000 1.219
reut2-007.xml 1221 1000 1.221
reut2-008.xml 1371 1000 1.371
reut2-009.xml 1302 1000 1.302
reut2-010.xml 1333 1000 1.333
reut2-011.xml 1268 1000 1.268
reut2-012.xml 1287 1000 1.287
reut2-013.xml 1099 1000 1.099
reut2-014.xml 1098 1000 1.098
reut2-015.xml 1223 1000 1.223
reut2-016.xml 1280 1000 1.280
reut2-017.xml 1505 1000 1.505
reut2-018.xml 1223 1000 1.223
reut2-019.xml 1226 1000 1.226
reut2-020.xml 1020 1000 1.020
reut2-021.xml 604 578 1.045
Contoh dokumen Reuters-21578 dapat dilihat pada Lampiran 1. Ada beberapa tag di dalam setiap dokumen, namun beberapa tag yang penting untuk diperhatikan untuk proses selanjutnya yaitu:
<TOPICS></TOPICS>, tag ini menunjukkan topik bahasan dari dokumen, yang akan dijadikan nama kelas dari setiap dokumen.
<TITLE></TITLE>, menunjukkan judul dari dokumen berita.
<BODY></BODY>, merupakan isi berita dari dokumen.
11 dilakukan dengan membuat program menggunakan bahasa pemrograman PHP dan MySQL. Secara sederhana, yang dilakukan program ini yaitu membaca setiap file, dan mengambil string yang diapit oleh tag <TOPICS></TOPICS> disimpan sebagai topik dokumen, tag <TITLE></TITLE> disimpan sebagai judul dokumen, serta tag <BODY></BODY> disimpan sebagai isi dokumen untuk setiap dokumen. Struktur tabel pada basis data disajikan dalam Tabel 6.
Tabel 6 Struktur tabel dokumen latih dan dokumen uji
Tabel Field Tipe data
training
testing
id topic title body id topic title body
integer varchar varchar text integer varchar varchar text
Tokenisasi dan Pembuangan Stopword
Tokenisasi dan pembuangan stopword dilakukan dengan membuat program menggunakan bahasa pemrograman PHP dan MySQL. Proses diawali dengan mengambil dokumen latih pada basis data. Lalu dilanjutkan dengan penghapusan tanda baca dan karakter numerik serta pengubahan huruf kapital menjadi huruf kecil. Token yang didefinisikan sebagai suatu kata didapatkan dengan memisahkan dokumen berdasarkan karakter spasi putih (white space) kemudian dihitung frekuensinya. Dalam tahap ini diperoleh 160320 kata hasil tokenisasi terhadap dokumen latih.
Seluruh kata tersebut disaring dengan membuang kata-kata tidak penting atau stopword, seperti “the”, “and”, “but”, dan lain-lain. Pendefinisian stopword dilakukan berdasarkan kata hasil tokenisasi dengan frekuensi kemunculan sangat tinggi dan sangat rendah, dari sini dipilih kata-kata yang dianggap tidak penting. Stopword berbahasa Inggris yang telah didefinisikan berjumlah 143 kata (Lampiran 2), dan tersimpan dalam basis data. Sampai pada tahap ini, diperoleh 7279 kata unik.
Pemilihan Fitur Ciri
[image:36.595.179.442.200.327.2]12
(Tabel 7). Hal ini membuktikan proses ini mampu mengurangi jumlah kata yang akan diproses. Selanjutnya hanya kata-kata ini yang akan diproses.
Tabel 7 Hasil tahap pemilihan fitur ciri dengan taraf nyata 0.001
Kelas Jumlah
kata unik
earn 615
¬earn 1101
Total 1716
Pembobotan Kata
Seluruh kata yang diperoleh dari tahap pemilihan fitur akan dihitung bobotnya pada masing-masing dokumen. Pada tahap ini menghasilkan matriks vektor yang digunakan sebagai data latih dan data uji, yang masing-masing tersimpan pada file berformat CSV. Kedua file ini dibuat dari pembangunan program menggunakan bahasa pemrograman PHP dan MySQL. Matriks data latih berukuran 3110 × 1716, jumlah baris menunjukkan jumlah dokumen latih yaitu 3110 dan jumlah kolom menunjukkan jumlah kata penciri yaitu 1716. Matriks data uji berukuran 1252 × 1716, jumlah baris menunjukkan jumlah dokumen uji yaitu 1252 dan jumlah kolom menunjukkan jumlah kata penciri yaitu 1716.
Penelitian ini akan membandingkan 2 metode pembobotan, yaitu tf dan tf-idf. Penghitungan bobot kata dengan metode pembobotan tf hanya memerhatikan frekuensi kemunculan kata pada masing-masing dokumen, karena adanya asumsi bahwa semakin sering suatu kata muncul dalam suatu dokumen, kata tersebut semakin penting. Nilai bobotnya diperoleh dari jumlah kemunculan kata di dalam sebuah dokumen tertentu. Apabila suatu kata tertentu tidak muncul dalam sebuah dokumen, maka bobotnya bernilai nol. Di samping itu, pada metode pembobotan tf-idf selain memerhatikan frekuensi kemunculan sebuah kata di dalam sebuah dokumen tertentu, juga memperhitungkan jumlah dokumen yang mengandung kata tersebut. Keduanya memberikan nilai bobot yang berbeda untuk matriks data latih dan data uji. Artinya, untuk proses klasifikasi selanjutnya juga dihasilkan 2 buah model SVM.
Klasifikasi Dokumen
Dalam klasifikasi dokumen, data latih dari proses sebelumnya diperlukan untuk membuat model SVM. Model SVM adalah model klasifikasi berbasis ruang vektor. Seluruh vektor dokumen dipetakan kemudian dicari fungsi pemisah kedua kelas. Proses ini dilakukan menggunakan LIBSVM pada Matlab R2008b. Proses pemodelan SVM oleh Matlab dapat dilihat pada Lampiran 3.
Proses diawali dengan pembacaan file data latih berformat CSV, dilakukan dengan fungsi csvread(). Data ini merupakan data matriks, kolom pertama menyatakan label kelas dari dokumen. Kolom kedua dan seterusnya sampai kolom terakhir menyatakan fitur dari masing-masing dokumen. Penggunaan fungsi
13 untuk proses selanjutnya. Selanjutnya, proses yang sama dilakukan pada file data uji.
Pemodelan SVM memerlukan parameter sesuai dengan fungsi kernel yang digunakan. Menurut Hsu et al. (2003), akurasi model yang dihasikan dari proses pelatihan dengan SVM sangat bergantung pada fungsi kernel serta parameter yang digunakan. Oleh karena itu performansinya dapat dioptimasi dengan mencari (mengestimasi) parameter terbaik. Parameter yang diperlukan untuk kernel RBF yaitu c (cost) dan γ (gamma). Untuk menentukan nilai terbaik dari kedua parameter ini dilakukan proses grid search. Akurasi diperoleh dari persentase data yang diklasifikasikan dengan benar.
Proses grid search pada Matlab dilakukan dengan memanggil fungsi
test_grid_rbf(). Proses ini dilakukan untuk mendapatkan nilai c (cost) terbaik pada rentang 2-5 ≤ c ≤ 215 dan parameter γ (gamma) terbaik pada rentang 2-15 ≤ γ ≤ 23. Parameter dikatakan terbaik jika mencapai nilai akurasi tertinggi dalam proses ini. Tabel 8 menyajikan parameter terbaik untuk masing-masing model SVM.
Tabel 8 Hasil akurasi parameter terbaik Metode
pembobotan
Parameter
Akurasi
с (cost) γ (gamma)
tf 27 1.22070 × 10-4 93.8907%
tf-idf 27 2.44141 × 10-4 93.6013%
Selanjutnya, pemodelan SVM dilakukan dengan memanggil fungsi
svmtrain ( training_label_vector, training_instance_matrix, '-t 2 -c 128 -g 0.00012207') untuk pembobotan tf. Parameter dalam fungsi tersebut dijelaskan sebagai berikut:
training_label_vector, merupakan vektor label kelas dari data latih.
training_instance_matrix, merupakan matriks fitur dari data latih.
'-t 2 -c 128 -g 0.00012207', merupakan parameter untuk LIBSVM. Nilai yang mengikuti string -t menyatakan jenis fungsi kernel yang digunakan,
2 berarti kernel RBF. Nilai yang mengikuti string -c menyatakan nilai parameter c (cost) yang digunakan, yaitu 128. Nilai yang mengikuti string -g
menyatakan nilai parameter γ (gamma) yang digunakan, yaitu 0.00012207. Untuk pembobotan tf-idf, fungsi yang dipanggil yaitu svmtrain ( training_label_vector, training_instance_ matrix, '-t 2 -c 128 -g 0.000244141').
Pengujian
14
cara jumlah dokumen yang diklasifikasikan dengan benar dibagi jumlah keseluruhan dokumen uji.
Pada data uji yang menggunakan metode pembobotan tf, jumlah dokumen kelas earn yang diklasifikasikan dengan benar adalah 941 dan yang salah berjumlah 85. Jumlah dokumen kelas ¬earn yang diklasifikasikan dengan benar adalah 226 dan yang salah berjumlah 0 (Tabel 9). Di samping itu, pada data uji yang menggunakan metode pembobotan tf-idf, jumlah dokumen kelas earn yang diklasifikasikan dengan benar adalah 940 dan yang salah berjumlah 87. Jumlah dokumen kelas ¬earn yang diklasifikasikan dengan benar adalah 224 dan yang salah berjumlah 1 (Tabel 10). Hasil akurasi dari model SVM dengan metode pembobotan tf dan tf-idf yang dihitung dengan menggunakan rumus pada persamaan 2 berturut-turut sebesar 93.2109% dan 92.9712%. Proses pengujian oleh Matlab dilakukan dengan memanggil fungsi svmpredict (testing_label_vector, testing_instance_matrix, modelsvm)
(Lampiran 3). Parameter dalam fungsi tersebut dijelaskan sebagai berikut:
testing_label_vector, merupakan vektor label kelas dari data uji.
testing_instance_matrix, merupakan matriks fitur dari data uji.
modelsvm, merupakan model yang dihasilkan dari proses pemodelan SVM. Tabel 9 Confusion matrix klasifikasi SVM dengan pembobotan tf
Prediksi Observasi
earn ¬ earn
earn 941 85
¬ earn 0 226
Tabel 10 Confusion matrix klasifikasi SVM dengan pembobotan tf-idf
Prediksi Observasi
earn ¬ earn
earn 940 87
¬ earn 1 224
15 Hal lain yang mempengaruhi kinerja klasifikasi SVM yaitu pemilihan fitur ciri dari kedua kelas dan pemilihan parameter terbaik dalam pembangunan model SVM. Proses pemilihan fitur terbukti dapat meminimalkan jumlah kata penciri yang akan digunakan pada proses selanjutnya. Proses pemilihan parameter yang menghasilkan akurasi paling tinggi dapat memberikan akurasi yang tinggi juga pada proses pengujian. Ketepatan dalam menggunakan metode-metode tersebut di atas dapat membuat metode SVM semakin baik dalam mengklasifikasikan dokumen ke dalam 2 kelas.
SIMPULAN DAN SARAN
Simpulan
Setelah melakukan penelitian ini, diperoleh simpulan bahwa metode SVM mampu melakukan klasifikasi dokumen berita berbahasa Inggris dengan jumlah data yang besar (3110 × 1716 data latih dan 1252 × 1716 data uji). Kernel RBF dapat diterapkan pada SVM untuk melakukan klasifikasi. Metode ini menghasilkan akurasi yang baik yaitu sebesar 93.21% dengan menggunakan chi-square sebagai metode pemilihan fitur serta tf sebagai metode pembobotan. Hasil tersebut menjadi pembanding penggunaan metode pemilihan fitur chi-square dan pembobotan tf-idf yang menghasilkan akurasi sebesar 92.97%. Dengan demikian, pembobotan tf lebih baik daripada pembobotan tf-idf dalam melakukan klasifikasi dokumen.
Saran
Pengembangan lebih lanjut dari penelitian ini adalah klasifikasi dokumen multikelas dengan menggunakan dokumen yang sama dengan yang digunakan pada penelitian ini. Dapat pula dicobakan metode pembobotan lain yang memperbaiki pembobotan tf, misalnya dengan menggunakan pembobotan system for the mechanical analysis and retrieval of text (SMART) atau yang lebih sering disebut SMART notation. Dengan demikian, dapat diketahui metode pembobotan mana yang lebih baik dalam melakukan klasifikasi dokumen.
DAFTAR PUSTAKA
Borovikov EA. 2005. An Evaluation of Support Vector Machines as a Pattern Recognition Tool. Maryland (US): University of Maryland Pr.
17 Lampiran 1 Contoh dokumen Reuter-21578
<REUTERS TOPICS="YES" LEWISSPLIT="TRAIN" CGISPLIT="TRAINING-SET" OLDID="5552" NEWID="9">
<DATE>26-FEB-1987 15:17:11.20</DATE> <TOPICS><D>earn</D></TOPICS>
<PLACES><D>usa</D></PLACES> <PEOPLE></PEOPLE>
<ORGS></ORGS>
<EXCHANGES></EXCHANGES> <COMPANIES></COMPANIES> <UNKNOWN>F
f0762reute
r f BC-CHAMPION-PRODUCTS-<CH 02-26 0067</UNKNOWN> <TEXT>
<TITLE>CHAMPION PRODUCTS <CH> APPROVES STOCK SPLIT</TITLE> <DATELINE> ROCHESTER, N.Y., Feb 26 - </DATELINE>
<BODY>Champion Products Inc said its
board of directors approved a two-for-one stock split of its common shares for shareholders of record as of April 1, 1987. The company also said its board voted to recommend to
shareholders at the annual meeting April 23 an increase in the authorized capital stock from five mln to 25 mln shares.
18
19 Lampiran 3 Instruksi Matlab pada pemodelan dan pengujian
1. Pembobotan tf
datatrain = csvread('training_tf.csv'); labels = datatrain(:,1);
features = datatrain(:,2:end); features_sparse = sparse(features);
libsvmwrite('datatrainlibsvm_tf.train', labels, features_sparse); [label_vector,instance_matrix]=libsvmread('datatrainlibsvm_tf. train');
test_grid_rbf(label_vector, instance_matrix); %grid search
[training_label_vector, training_instance_matrix]=libsvmread('data trainlibsvm_tf.train');
datatest = csvread('testing_tf.csv'); labels = datatest(:,1);
features = datatest(:,2:end);
features_sparse = sparse(features);
libsvmwrite('datatestlibsvm_tf.test', labels, features_sparse); [testing_label_vector, testing_instance_matrix]=libsvmread('data testlibsvm_tf.test');
model_tf = svmtrain(training_label_vector,training_instance_matrix, '-t 2 -c 128 -g 0.00012207');
[predict_label_tf, accuracy_tf, dec_values_tf] = svmpredict (testing_label_vector, testing_instance_matrix, model_tf); Accuracy = 93.2109% (1167/1252) (classification)
2. Pembobotan tf-idf
datatrain = csvread('training_tfidf.csv'); labels = datatrain(:,1);
features = datatrain(:,2:end); features_sparse = sparse(features);
libsvmwrite('datatrainlibsvm_tfidf.train',labels,features_sparse); [label_vector,instance_matrix]=libsvmread('datatrainlibsvm_tfidf. train');
test_grid_rbf(label_vector, instance_matrix); %grid search
[training_label_vector, training_instance_matrix]=libsvmread('data trainlibsvm_tfidf.train');
datatest = csvread('testing_tfidf.csv'); labels = datatest(:,1);
features = datatest(:,2:end);
features_sparse = sparse(features);
libsvmwrite('datatestlibsvm_tfidf.test', labels, features_sparse); [testing_label_vector, testing_instance_matrix]=libsvmread('data testlibsvm_tfidf.test');
model_tfidf = svmtrain(training_label_vector, training_instance_ matrix, '-t 2 -c 128 -g 0.000244141');
[predict_label_tfidf, accuracy_tfidf, dec_values_tfidf] = svmpredict(testing_label_vector, testing_instance_matrix, model_tfidf);
2
Perumusan Masalah
Perumusan masalah pada penelitian ini adalah:
1 Apakah SVM dengan kernel RBF mampu melakukan klasifikasi dokumen berita berbahasa Inggris?
2 Apakah pembobotan tf cukup baik dalam klasifikasi dokumen?
Tujuan Penelitian
Tujuan penelitian ini adalah:
1 Melakukan klasifikasi dokumen berita berbahasa Inggris menggunakan metode SVM dengan kernel RBF.
2 Membandingkan pembobotan tf dan tf-idf dalam klasifikasi dokumen.
Manfaat Penelitian
Penelitian ini diharapkan dapat membantu dalam mengelompokkan dokumen berita berdasarkan kategori yang telah ditentukan secara otomatis.
Ruang Lingkup Penelitian
Ruang lingkup penelitian ini meliputi:
1 Penelitian difokuskan kepada klasifikasi dokumen berbahasa Inggris dalam 2 kelas menggunakan metode SVM dengan kernel RBF.
2 Penelitian juga berfokus pada pembandingan metode pembobotan tf dan tf-idf dalam klasifikasi dokumen.
3 Penelitian dibatasi pada percobaan metode dalam klasifikasi, tanpa membangun sebuah sistem pengklasifikasi otomatis.
METODE
Garis besar alur pengerjaan penelitian ini disajikan dalam Gambar 1. Beberapa tahapan dari sistem meliputi pengumpulan dokumen, praproses, pembagian data, pemodelan, dan pengujian.
3 .
Gambar 1 Tahapan penelitian
Pengumpulan Dokumen
Dokumen yang digunakan dalam penelitian ini adalah koleksi dokumen Reuters-21578, yang merupakan dokumen berita berbahasa Inggris yang muncul pada Reuter’s newswire tahun 1987. Dokumen Reuters-21578 tersedia pada http://www.daviddlewis.com/resources/testcollections/reuters21578/. Dokumen ini disimpan dalam format XML (extensible markup language). XML adalah bahasa yang mampu menyimpan data secara ringkas dan mudah diatur, serta banyak digunakan untuk pertukaran informasi di internet.
Secara keseluruhan, koleksi dokumen berjumlah 21578 dokumen yang terdiri atas 135 topik. Penelitian ini hanya menggunakan dokumen dengan 6 topik yang selanjutnya ditentukan menjadi 2 kelas, yakni earn dan ¬earn (not earn). Kelas earn adalah dokumen yang memiliki topik earn. Kelas ¬earn adalah dokumen yang memiliki topik trade, ship, crude, grain, dan interest. Pemilihan topik didasarkan pada jumlah dokumen terbanyak dalam koleksi
Dokumen dibagi menjadi dokumen latih dan dokumen uji masing-masing dengan proporsi 70% dan 30%. Data latih akan digunakan untuk melatih sistem sehingga dihasilkan model klasifikasi SVM. Data uji digunakan untuk pengujian hasil klasifikasi.
Tokenisasi dan Pembuangan Stopword
4
Tahap selanjutnya adalah pembuangan kata yang dianggap tidak penting, biasa disebut stopword. Pada umumnya, kata-kata yang sering muncul di banyak dokumen juga dibuang. Kata ini tidak sesuai untuk dijadikan penciri suatu dokumen. Kata-kata yang termasuk dalam stopword ini kemudian dibuang dan tidak diikutsertakan dalam proses selanjutnya.
Pemilihan Fitur Ciri
Menurut Manning et al. (2008), pemilihan fitur merupakan suatu proses memilih subset dari setiap kata unik yang ada di dalam himpunan dokumen latih yang akan digunakan sebagai fitur di dalam klasifikasi dokumen. Pemilihan fitur memiliki 2 tujuan utama. Pertama, membuat proses pelatihan dan penggunaan fungsi klasifikasi lebih efisien dengan mengurangi jumlah kata yang digunakan. Kedua, hal ini dapat meningkatkan akurasi hasil klasifikasi.
Ada beberapa metode pemilihan fitur yang