PREDIKSI CACAT SOFTWARE
TESIS
RISKI ANNISA 14001913
PROGRAM PASCASARJANA MAGISTER ILMU KOMPUTER SEKOLAH TINGGI MANAJEMEN INFORMATIKA DAN KOMPUTER
NUSA MANDIRI JAKARTA
2018
TESIS
Diajukan sebagai salah satu syarat untuk memperoleh gelar Magister Ilmu Komputer (M.Kom)
RISKI ANNISA 14001913
PROGRAM PASCASARJANA MAGISTER ILMU KOMPUTER SEKOLAH TINGGI MANAJEMEN INFORMATIKA DAN KOMPUTER
NUSA MANDIRI JAKARTA
SURAT PERNYATAAN ORISINALITAS Yang bertanda tangan di bawah ini :
Nama : Riski Annisa NIM : 14001913
Program Studi : Magister Ilmu Komputer Jenjang : Strata Dua (S2)
Konsentrasi : Software Engineering
Dengan ini menyatakan bahwa tesis yang telah saya buat dengan judul: “Algoritma Point Center Pada Klasterisasi K-Means Untuk Meningkatkan Ketepatan Prediksi Cacat Software” adalah hasil karya sendiri, dan semua sumber baik yang kutip maupun yang dirujuk telah saya nyatakan dengan benar dan tesis belum pernah diterbitkan atau dipublikasikan dimanapun dan dalam bentuk apapun.
Demikianlah surat pernyataan ini saya buat dengan sebenar-benarnya. Apabila dikemudian hari ternyata saya memberikan keterangan palsu dan atau ada pihak lain yang mengklaim bahwa tesis yang telah saya buat adalah hasil karya milik seseorang atau badan tertentu, saya bersedia diproses baik secara pidana maupun perdata dan kelulusan saya dari Program Pascasarjana Magister Ilmu Komputer Sekolah Tinggi Manajemen Inbentukika dan Komputer Nusa Mandiri dicabut/dibatalkan.
Jakarta, 9 Januari 2018 Yang menyatakan,
Materai Rp. 6.000,-
Riski Annisa
Tesis ini diajukan oleh : Nama : Riski Annisa NIM : 14001913
Program Studi : Magister Ilmu Komputer Jenjang : Strata Dua (S2)
Konsentrasi : Software Engineering
Judul Tesis : “Algoritma Point Center Pada Klasterisasi K-Means Untuk Meningkatkan Ketepatan Prediksi Cacat Software”
Untuk berhasil dipertahankan dihadapan Dewan Penguji dan diterima sebagai bagian persyaratan yang diperlukan untuk memperoleh gelar Magister Ilmu Komputer (M.Kom) pada Program Pascasarjana Magister Ilmu Komputer Sekolah Tinggi Manajemen Informatika dan Komputer Nusa Mandiri (STMIK Nusa Mandiri).
Jakarta, 9 Januari 2018 STMIK Nusa Mandiri
Kepala Program Studi Ilmu Komputer
Dr. Dwiza Riana, S.Si, M.M, M.Kom
D E W A N P E N G U J I
Penguji I : (...) ...
Penguji II : (...) ...
Penguji III / : Dr. Didi Rosiyadi, M. Kom ...
Pembimbing
KATA PENGANTAR
Puji syukur alhamdullillah, penulis panjatkan kehadirat Allah, SWT, yang telah melimpahkan rahmat dan karunia-Nya, sehingga pada akhirnya penulis dapat menyelesaikan tesis ini tepat pada waktunya. Dimana tesis ini penulis sajikan dalam bentuk buku yang sederhana. Adapun judul tesis, yang penulis ambil sebagai berikut “Algoritma Point Center Pada Klasterisasi K-Means Untuk Meningkatkan Ketepatan Prediksi Cacat Software”.
Tujuan penulisan tesis ini dibuat sebagai salah satu untuk mendapatkan gelar Magister Ilmu Komputer (M.Kom) pada Program Pascasarjana Magister Ilmu Komputer Sekolah Tinggi Manajemen Informatika dan Komputer Nusa Mandiri (PPs MIK STMIK Nusa Mandiri).
Tesis ini diambil berdasarkan hasil penelitian atau riset mengenai Algoritma clustering K-means untuk penentuan centroid awal yang random yang penulis implementasikan pada dataset uji NASA MDP. Penulis juga lakukan mencari dan menganalisa berbagai macam sumber referensi, baik dalam bentuk jurnal ilmiah, buku-buku literatur, internet, dll yang terkait dengan pembahasan pada tesis ini.
Penulis menyadari bahwa tanpa bimbingan dan dukungan dari semua pihak dalam pembuatan tesis ini, maka penulis tidak dapat menyelesaikan tesis ini tepat pada waktunya. Untuk itu ijinkanlah penulis kesempatan ini untuk mengucapkan ucapan terima kasih yang sebesar-besarnya kepada :
1. Allah SWT yang selalu mencurahkan nikmat dan rahmatNya pada saya sehingga saya dapat menyelesaikan tesis ini tepat pada waktunya.
2. Bapak Dr. Didi Rosiyadi, M. Kom selaku pembimbing tesis yang telah menyediakan waktu, pikiran dan tenaga dalam membimbing penulis dalam menyelesaikan tesis ini.
3. Orang tua dan keluarga tercinta yang telah memberikan dukungan material dan moral kepada penulis.
4. Seluruh staf pengajar (dosen) PPs MIK STMIK Nusa Mandiri yang telah memberikan pelajaran yang berarti bagi penulis selama menempuh studi.
dukungan untuk menyelesaikan thesis ini.
7. Jordy Ranu Aprilian yang selalu memberikan dukungan moral dan spiritual kepada penulis.
8. Rekan-rekan seangkatan STMIK Nusa Mandiri.
Serta semua pihak yang terlalu banyak untuk penulis sebutkan satu persatu sehingga terwujudnya penulisan tesis ini. Penulis menyadari bahwa penulisan tesis ini masih jauh sekali dari sempurna, untuk itu penulis mohon kritik dan saran yang bersifat membangun demi kesempurnaan penulisan karya ilmiah yang penulis hasilkan untuk yang akan datang.
Akhir kata semoga tesis ini dapat bermanfaat bagi penulis khususnya dan bagi para pembaca yang berminat pada umumnya.
Jakarta, 9 Januari 2018
Riski Annisa Penulis
SURAT PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS
Yang bertanda tangan di bawah ini, saya : Nama : Riski Annisa
NIM : 14001913
Program Studi : Magsiter Ilmu Komputer Jenjang : Strata Dua (S2)
Konsentrasi : Software Engineering Jenis Karya : Tesis
Demi pengembangan ilmu pengetahuan, dengan ini menyetujui untuk memberikan ijin kepada pihak Program Pascasarjana Magister Ilmu Komputer Sekolah Tinggi Manajemen Informatika dan Komputer Nusa Mandiri (STMIK Nusa Mandiri) Hak Bebas Royalti Non-Eksklusif (Non-exclusive Royalti-Free Right) atas karya ilmiah kami yang berjudul : “Algoritma Point Center Pada Klasterisasi K-Means Untuk Meningkatkan Ketepatan Prediksi Cacat Software” beserta perangkat yang diperlukan (apabila ada).
Dengan Hak Bebas Royalti Non-Eksklusif ini pihak STMIK Nusa Mandiri berhak menyimpan, mengalih-media atau bentuk-kan, mengelolaannya dalam pangkalan data (database), mendistribusikannya dan menampilkan atau mempublikasikannya di internet atau media lain untuk kepentingan akademis tanpa perlu meminta ijin dari kami selama tetap mencantumkan nama kami sebagai penulis/pencipta karya ilmiah tersebut.
Saya bersedia untuk menanggung secara pribadi, tanpa melibatkan pihak STMIK Nusa Mandiri, segala bentuk tuntutan hukum yang timbul atas pelanggaran Hak Cipta dalam karya ilmiah saya ini.
Demikian pernyataan ini saya buat dengan sebenarnya.
Jakarta, 9 Januari 2018 Yang menyatakan,
Materai Rp. 6.000,-
Riski Annisa
Nama : Riski Annisa
NIM : 14001913
Program Studi : Magsiter Ilmu Komputer Jenjang : Strata Dua (S2)
Konsentrasi : Software Engineering
Judul : “Algoritma Point Center Pada Klasterisasi K-Means Untuk Meningkatkan Ketepatan Prediksi Cacat Software”
Algoritma k-means merupakan algoritma clustering yang sering dan mudah digunakan. Algoritma ini sangat sensitive terhadap titik centroid yang dipilih secara random sehingga tidak dapat menghasilkan hasil optimal. Dalam penelitian ini mengusulkan algoritma yang dinamakan point center untuk mengatasi nilai centroid yang random pada k-means kemudian menerapkannya untuk memprediksi kesalahan pada modul program serta memberikan kontribusi dalam pengembangan model klasterisasi untuk menangani data seperti data prediksi cacat software.
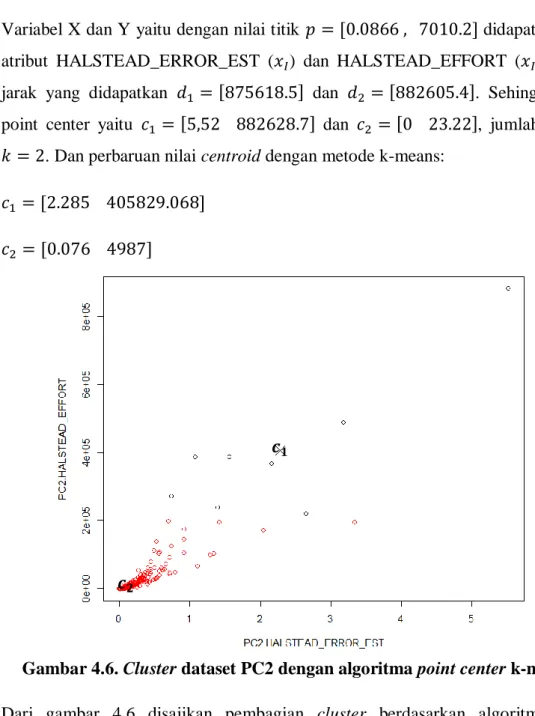
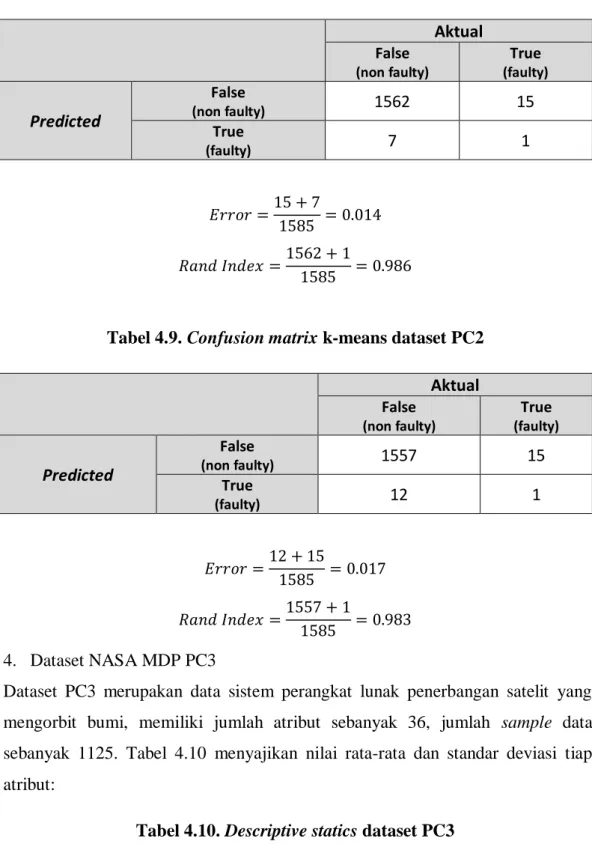
Algoritma ini berdasarkan pemilihan variabel X dan Y yang menentukan anggota cluster. Algoritma yang diusulkan diuji dengan 10 dataset, 9 dataset diantaranya adalah dataset untuk prediksi cacat software mendapatkan hasil error yang lebih rendah, terjadi penurunan tingkat error dan nilai Rand Index yang lebih tinggi jika menggunakan teknik klusterisasi dengan metode yang diusulkan. Hasil eksperimen menunjukkan bahwa algoritma yang diusulkan sangat efektif dan dapat meningkatkan kinerja algoritma k-means sebesar 13,1% dibandingkan dengan nilai centroid yang didapatkan secara random pada algoritma simple k-means.
Kata kunci:
K-means, cluster, centroid, cacat software.
ABSTRACT
Name : Riski Annisa
NIM : 14001913
Study of Program : Magsiter Ilmu Komputer Levels : Strata Dua (S2)
Concentration : Software Engineering
Tittle : “Improved Point Center Algorithm for K-Means Clustering to increase Software Defect Prediction”
The k-means algorithm is a frequent and easy-to-use clustering algorithm. This algorithm is very sensitive to the centroid point chosen randomly so it can not produce optimal results. In this research proposed an algorithm called point center to overcome the random centroid value on k-means then apply it to predict the error in the program module as well as to contribute in the development of clustering model to handle data such as data defect prediction software. The algorithm is based on the selection of variables X and Y that determine cluster members. The proposed algorithm was tested with 10 datasets, 9 datasets of which the dataset for the software defect predicted resulted in lower error results, decreased error rates and higher Rand Index values when using clustering techniques with the proposed method. The experimental results show that the proposed algorithm is very effective and can improve the performance of k-means algorithm by 13.1% compared to randomly obtained centroid value on simple k-means algorithm.
Keywords: K-means, cluster, centroid, software defect.
SURAT PERNYATAAN ORISINALITAS ... iii
HALAMAN PENGESAHAN ... iv
KATA PENGANTAR ... v
SURAT PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS ... vii
ABSTRAK ... viii
ABSTRACT ... ix
DAFTAR ISI ... x
DAFTAR TABEL ... xii
DAFTAR GAMBAR ... xiii
DAFTAR LAMPIRAN ... xiv
... 1
1.1 Latar Belakang Masalah ... 1
1.2 Identifikasi Masalah ... 3
1.3 Rumusan Masalah ... 3
1.4 Tujuan Penelitian ... 3
1.5 Manfaat Penelitian ... 3
1.6 Hipotesis ... 3
1.7 Sistematika Penulisan ... 4
... 5
2.1 Tinjauan Studi ... 6
2.2 Tinjauan Pustaka ... 15
2.2.1 Software Defect Prediction ... 15
2.2.2 Clustering ... 18
2.2.3 Semi-supervised Learning ... 20
2.2.4 K-means ... 20
2.2.5 Evaluasi Cluster ... 22
2.3 Kerangka Pemikiran ... 23
... 25
3.1 Desain Penelitian... 25
3.2 Pengumpulan Data ... 26
3.3 Pengolahan Awal Data ... 29
3.4 Metode yang Diusulkan ... 29
3.5 Eksperimen dan Pengujian Metode ... 30
3.6 Evaluasi Validasi Hasil ... 33
... 34
4.1 Hasil ... 34
4.2 Pembahasan ... 67
... 73
5.1 Kesimpulan ... 73
5.2 Saran ... 73
LEMBAR KONSULTASI……….83
Tabel 1.1. Korelasi RP-RQ-RO ... 4
Tabel 2.1. State-of-the-arts ... 8
Tabel 2.2. Confusion Matrix... 23
Tabel 3.1. Deskripsi Dataset NASA MDP ... 26
Tabel 3.2. Daftar Atribut Dataset NASA MDP ... 27
Tabel 3.3. Deskripsi Atribut Dataset NASA MDP ... 28
Tabel 3.4. Confusion Matrix... 33
Tabel 4.1. Descriptive statics dataset iris ... 35
Tabel 4.2. Confusion matrix proposed method dataset iris ... 37
Tabel 4.3. Confusion matrix k-means dataset iris ... 37
Tabel 4.4. Descriptive statics dataset PC1 ... 37
Tabel 4.5. Confusion matrix proposed method dataset PC1 ... 40
Tabel 4.6. Confusion matrix k-means dataset PC1 ... 41
Tabel 4.7. Descriptive statics dataset PC2 ... 41
Tabel 4.8. Confusion matrix proposed method dataset PC2 ... 44
Tabel 4.9. Confusion matrix k-means dataset PC2 ... 44
Tabel 4.10. Descriptive statics dataset PC3 ... 44
Tabel 4.11. Confusion matrix proposed method dataset PC3 ... 47
Tabel 4.12. Confusion matrix proposed method dataset PC3 ... 48
Tabel 4.13. Descriptive statics dataset PC4 ... 48
Tabel 4.14. Confusion matrix proposed method dataset PC4 ... 50
Tabel 4.15. Confusion matrix k-means dataset PC4 ... 51
Tabel 4.16. Descriptive statics dataset MW1 ... 51
Tabel 4.17. Confusion matrix proposed method dataset MW1 ... 54
Tabel 4.18. Confusion matrix k-means dataset MW1... 55
Tabel 4.19. Descriptive statics dataset CM1 ... 55
Tabel 4.20. Confusion matrix proposed method dataset CM1 ... 57
Tabel 4.21. Confusion matrix k-means dataset CM1... 58
Tabel 4.22. Descriptive statics dataset KC1 ... 58
Tabel 4.23. Confusion matrix proposed method dataset KC1 ... 60
Tabel 4.24. Confusion matrix k-means dataset KC1 ... 61
Tabel 4.25. Descriptive statics dataset KC3 ... 61
Tabel 4.26. Confusion matrix proposed method dataset KC3 ... 63
Tabel 4.27. Confusion matrix k-means dataset KC3 ... 64
Tabel 4.28. Descriptive statics dataset MC2 ... 64
Tabel 4.29. Confusion matrix proposed method dataset MC2 ... 67
Tabel 4.30. Confusion matrix k-means dataset MC2... 67
Tabel 4.31. Tabel Jumlah Cluster (𝑘) ... 68
Tabel 4.32. Hasil Pengujian Metode Berdasarkan Persentase Tingkat Error ... 68
Tabel 4.33. Hasil Pengujian Metode berdasarkan nilai Rand Index ... 70
Tabel 4.34. Jumlah Modul Cacat Software ... 71
DAFTAR GAMBAR
Gambar 2.1. Penerapan k-means ... 21
Gambar 2.2. Kerangka Pemikiran ... 24
Gambar 3.1. Tahapan Penelitian... 25
Gambar 3.2. Proposed Method ... 32
Gambar 4.1. Titik center data iris ... 35
Gambar 4.2. Cluster dataset iris dengan algoritma point center k-means ... 36
Gambar 4.3. Titik center data PC1 ... 39
Gambar 4.4. Cluster dataset PC1 dengan algoritma point center k-means ... 40
Gambar 4.5. Titik center data PC2 ... 42
Gambar 4.6. Cluster dataset PC2 dengan algoritma point center k-means ... 43
Gambar 4.7. Titik center data PC3 ... 46
Gambar 4.8. Cluster dataset PC3 dengan algoritma point center k-means ... 47
Gambar 4.9. Titik center data PC4 ... 49
Gambar 4.10. Cluster dataset PC4 dengan algoritma point center k-means ... 50
Gambar 4.11. Titik center data MW1 ... 53
Gambar 4.12. Cluster dataset MW1 dengan algoritma point center k-means ... 54
Gambar 4.13. Titik center data CM1 ... 56
Gambar 4.14. Cluster dataset CM1 dengan algoritma point center k-means ... 57
Gambar 4.15. Titik center data KC1 ... 59
Gambar 4.16. Cluster dataset KC1 dengan algoritma point center k-means ... 60
Gambar 4.17. Titik center data KC3 ... 62
Gambar 4.18. Cluster dataset KC3 dengan algoritma point center k-means ... 63
Gambar 4.19. Titik center data MC2 ... 65
Gambar 4.20. Cluster dataset MC2 dengan algoritma point center k-means ... 66
Gambar 4.21. Perbandingan Presentase Error 10 Dataset... 69
Gambar 4.22. Perbandingan Rand Index metode k-means dan metode yang diusulkan ... 71
Source code metode k-means dengan tools R ... 77 Source code proposed method dengan tools R ... 79
PENDAHULUAN
1.1 Latar Belakang Masalah
Era saat ini ditandai dengan kemajuan teknologi dan informasi yang konstan yaitu software ada dimana-mana seperti: Software web, mobile, desktop, embedded, atau distribusi software dikembangkan untuk membantu dalam mencapai tujuan dengan lebih mudah, cepat dan efisien (Siavvas, Chatzidimitriou, & Symeonidis, 2017). Hal tersebut menimbulkan masalah kualitas software bagi pengguna serta perusahaan pengembangan software. Untuk menghasilkan software yang berkualitas, tahap pengujian memegang peran yang cukup penting (Arar & Ayan, 2015). Dari hasil tahap pengujian kemudian dikelompokkan menjadi dua kategori, yaitu software cacat dan tidak cacat.
Software yang cacat adalah software yang error, gagal, atau salah yang menghasilkan hasil yang tidak diharapkan yang dilakukan pengembang software dari cacat kesalahan pada kode dan kegagalan sistem yang salah selama eksekusi (Wahono, 2015). Dalam suatu penelitian menyelidiki 3747 cacat dari 70 sistem software yang dikembangkan oleh 29 organisasi penerbangan China menunjukkan sebesar 87% cacat software (Huang & Liu, 2017). Secara tradisional metode machine learning untuk software defect prediction dimodelkan untuk klasifikasi dengan dataset sehingga bisa membedakan antara dua kategori, dan beberapa modul perangkat lunak dikategorikan menjadi cacat dan tidak cacat (Mesquita, Rocha, Gomes, & Rocha Neto, 2016).
Untuk mengkategorikan modul perangkat lunak menjadi cacat dan tidak cacat dibutuhkan proses klusterisasi untuk memberi label perangkat lunak dan menangkap kesalahan cluster pada perangkat lunak. Penelitian dalam software defect prediction berfokus pada pada topik clustering dan asosiasi sebesar 1,41%, metode unsupervised learning seperti clustering dapat digunakan untuk prediksi cacat pada modul perangkat lunak, selain itu juga pada kasus dimana label kesalahan tidak tersedia (Wahono, 2015). Klasterisasi adalah proses
(Rahman & Islam, 2014) dan juga merupakan bidang penelitian yang termasuk dalam analisis data dan machine learning (Cleuziou, 2008).
Salah satu algoritma klusterisasi adalah algoritma k-means yaitu merupakan algoritma pengklusteran yang sederhana dan umumnya terkenal sangat cepat (Žalik, 2008) (Reddy & Jana, 2012). Algoritmanya cukup mudah untuk diimplementasi dan dijalankan, mudah disesuaikan dan banyak digunakan (Wu et al., 2008). Prinsip utama dari teknik ini adalah menyusun k buah partisi/pusat massa (centroid)/rata-rata mean dari sekumpulan data. Algoritma K-means dimulai dengan pembentukan partisi klaster di awal kemudian secara iteratif partisi klaster ini diperbaiki hingga tidak terjadi perubahan yang signifikan pada partisi klaster (Witten, Frank, & Hall, 2011). Namun, masalah utama dengan metode ini adalah tidak dapat memastikan hasil optimal karena pemilihan titik awal (centroid) yang dipilih secara random (Nidheesh, Abdul Nazeer, & Ameer, 2017)(Erisoglu, Calis,
& Sakallioglu, 2011)(Duwairi & Abu-Rahmeh, 2015).
Pada penelitian ini, algoritma yang dinamakan point center untuk klusterisasi k-means diusulkan sebagai inisiasi algoritma k-means untuk mengatasi centroid awal yang random dan berfokus pada masalah yang terjadi apabila kegagalan data perangkat lunak untuk kesalahan cluster modul pada perangkat lunak. Dalam penelitian ini algoritma K-means dengan algoritma point center akan diterapkan untuk memprediksi kesalahan pada modul program.
Tujuan dari penelitian ini adalah menerapkan algoritma yang dinamakan point center untuk menemukan centroid awal algoritma k-means, kemudian menerapkannya untuk memprediksi kesalahan pada modul program. Tingkat kesalahan keseluruhan dari pendekatan prediksi ini dibandingkan dengan algoritma k-means dengan centroid yang random. Klasterisasi yang digunakan untuk mendapatkan nilai cluster center terbaik algoritma k-means sehingga membuktikan keefektifan algoritma.
1.2 Identifikasi Masalah
Berdasarkan latar belakang masalah yang diuraikan di atas, masalah penelitian (Research Problem) yang diangkat pada penelitian ini adalah:
Algoritma K-means sangat sensitive terhadap titik awal (centroid) yang dipilih secara random sehingga tidak dapat menghasilkan hasil optimal.
1.3 Rumusan dan Batasan Masalah
Berdasarkan latar belakang masalah dan identifikasi masalah, maka pada penelitian ini dibuat rumusan masalah (Research Question) bahwa seberapa meningkat performa algoritma k-means jika pemilihan centroid awal dipilih menggunakan algoritma yang dinamakan point center diintegrasikan untuk meng- cluster modul perangkat lunak. Batasan masalah pada penelitian ini adalah menerapkan algoritma yang dinamakan point center sebagai penentu nilai centroid untuk clustering k-means dan diintegrasikan pada dataset prediksi cacat software sehingga dapat memprediksi kesalahan modul software.
1.4 Tujuan Penelitian
Tujuan dari penelitian (Research Objective) ini adalah untuk meningkatkan kinerja algoritma k-means dengan menerapkan algoritma yang dinamakan point center dan menerapkan pada prediksi cacat software, sehingga dapat memprediksi kesalahan pada modul software dengan tepat.
1.5 Manfaat Penelitian
Hasil penelitian ini diharapkan dapat digunakan untuk mengembangkan prediksi cacat software agar lebih tepat memprediksi kesalahan pada modul software. Selain itu dapat memberikan kontribusi dalam pengembangan model klasterisasi untuk menangani data seperti data prediksi cacat software.
1.6 Hipotesis
Berdasarkan masalah di atas maka hipotesis dapat disajikan dengan RP (Research Problem), RQ (Research Questions), dan RO (Research Object).
Hubungan antara ketiganya dapat dilihat pada table berikut:
Research Problem (RP) Research Question (RQ) Research Objective (RO) Algoritma K-means
sangat sensitive terhadap titik awal (centroid) yang dipilih secara random sehingga tidak dapat
menghasilkan hasil optimal.
Seberapa meningkat kinerja algoritma k- means dengan
menambahkan algoritma yang dinamakan point center untuk nilai centroid awal untuk memprediksi kesalahan pada modul program?
Meningkatkan kinerja algoritma k-means dengan menerapkan algoritma yang dinamakan point center pada prediksi cacat software, sehingga dapat memprediksi kesalahan pada modul software dengan tepat.
1.7 Sistematika Penulisan
Pada penelitian ini akan dibagi menjadi lima bab dan disetiap bab akan dibagi lagi menjadi beberapa subbab sesuai topik yang dibahas. Sistematika pada penulisan ini adalah:
BAB I PENDAHULUAN
Pada bab ini akan dibahas mengenai latar belakang masalah, identifikasi masalah, rumusan masalah, tujuan penelitian, manfaat penelitian, dan sistematika penulisan.
BAB II LANDASAN TEORI
Pada bab ini akan dibahas mengenai tinjauan studi yang berisi metode untuk menyelesaikan data dengan penentuan centroid awal pada k-means yang sudah pernah digunakan dan diusulkan, selain itu pada bab ini juga akan dibahas mengenai tinjauan pustaka.
BAB III METODE PENELITIAN
Pada bab ini akan dibahas mengenai hasil dari penelitian dan pembahasannya. Hasil pada bab ini akan menunjukkan ukuran dari performa metode yang diusulkan dibandingkan dengan metode awal.
BAB IV PENUTUP
Pada bab ini akan berisi kesimpulan dari hasil penelitian dan saran untuk penelitian lebih lanjut.
LANDASAN TEORI
2.1 Tinjauan Studi
Bishnu dan Bhattacherjee meneliti masalah prediksi kesalahan pada modul perangkat lunak, dengan menerapkan algoritma K-means berbasis Quad Tree. Quad Tree diterapkan untuk menemukan pusat cluster awal yang akan dimasukkan ke algoritma K-means. Tingkat kesalahan dari prediksi kesalahan perangkat lunak algoritma Quad Tree K-means (QDK) sebanding dengan pendekatan pembelajaran NB dan DA. Hasil dari penelitian ini menunjukkan bahwa algoritma QDK bekerja sebagai algoritma inisiasi yang efektif (Bishnu & Bhattacherjee, 2012).
Ghousia Usman, Usman Ahmad, dan Muddasar Ahmad meneliti algoritma standard K-means yang sulit untuk mendapatkan nilai centroid yang memberikan kualitas cluster yang baik. Penelitian ini mengusulkan sebuah metode untuk pemilihan centroid awal yaitu dengan mengevaluasi jarak antara titik data sesuai kriteria kemudian mencoba mencari titik terdekat lalu akhirnya memilih centroid yang sebenarnya dan membuat pengelompokan lebih baik. Hasil yang didapatkan dengan algoritma clustering k-means ini memberika peningkatan akurasi dan kefektifan lebih baik daripada sebelumnya (Usman, Ahmad, & Ahmad, 2013).
M. Emre Celebi, Hassan A. Kingravi, dan Patricio A. Vela meneliti masalah algoritma k-means yang sangat sensitive terhadap penempatan cluster center awal.
Penelitian ini memaparkan metode inisiasi k-means dengan penekanan pada efisiensi komputasi kemudian membandingkan delapan metode inisiasi waktu linier yang umum digunakan dengan menggunakan berbagai kriteria performa. Dari hasil analisis menunjukkan bahwa metode inisiasi yang terkenal seperti Forgy, Macqueen, dan MaxMin performanya sering jelek dan alternatif yang jauh lebih baik daripada metode memiliki persyaratan komputasi yang berimbang (Celebi, Kingravi, & Vela, 2013).
Md Anisur Rahman, Md Zahidul Islam, dan Terry Bossomaier meneliti tentang dua teknik clustering yang disebut ModEx and Seed-Detective. Seed-
menggunakan ModEx untuk menghasilkan centroid awal yang berkualitas tinggi yang kemudian diberikan untuk K-means untuk menghasilkan cluster akhir. Benih awal berkualitas tinggi diharapkan bisa menghasilkan cluster berkualitas tinggi melalui K-Means. Performa dari Seed-Detective and ModEx dibandingkan dengan performa dari Ex-Detective, PAM, Simple K-Means (SK), Basic Farthest Point Heuristic (BFPH) and New Farthest Point Heuristic (NFPH). Penelitian ini menggunakan tiga cluster kriteria evaluasi yaitu F-measure, Entropy dan Purity dan empat dataset alam. Teknik yang diusulkan berkinerja lebih baik daripada teknik yang ada dalam kriteria evaluasi F-measure, Entropy and Purity. Hasil uji coba menunjukkan signifikansi statistik dari keunggulan Seed-Detective dan ModEx lebih dari teknik yang ada (Rahman, Islam, & Bossomaier, 2015).
Erisoglu, Calis, Sakallioglu meneliti masalah algoritma k-means yang sensitif terhadap nilai titik awal sebagai cluster center yang dipilih secara random kemudian mengusulkan sebuah algoritma untuk menghitung pusat klaster awal dalam algoritma k-means. Hasil eksperimen menunjukkan peningkatan dibandingkan dengan pemilihan pusat cluster awal yang random (Erisoglu et al., 2011).
Berdasarkan penelitian diatas, penelitian ini untuk mengatasi nilai centroid awal yang random pada klusterisasi k-means dan berfokus pada masalah yang terjadi pada kegagalan perangkat lunak untuk kesalahan cluster modul perangkat lunak. Dalam penelitian ini algoritma k-means den algoritma point center akan diterapkan untuk memprediksi kesalahan pada modul program.
Judul dan Penulis Masalah Kontribusi Dataset Pengukuran An Improved Overlapping k-
Means Clustering Method for Medical Application
(Khanmohammadi, Adibeig, &
Shanehbandy, 2017)
Algoritma overlapping k-means bergantung pada nilai pusat awal cluster centroid yang dipilih secara random.
Mengusulkan metode Hybrid yang
menggabungkan algoritma k-harmonic means dan algoritma overlapping k- means
Medical Datasets : - Liver Disorder,
- Breast Cancer, Wisconsin (Original),
- Indian Liver, Patients, - Heart Disease (Original), - Heart Disease (Statlog), - Hepatitis,
- Parkinsons, - Breast Cancer,
- Wisconsin (Diagnostic) - Dermatology,
- Lung Cancer,
- Homogeneity - Completeness - Rag Bag
- Cluster size-quantity trade off
Evolutionary k-means for distributed data sets (Naldi &
Campello, 2014)
k-means sensitif terhadap pemilihan prototipe cluster awal, karena dapat bertemu solusi suboptimal jika prototipe awal tidak dipilih dengan benar
penggunaan algoritma evolusioner untuk mengatasi k-means keterbatasan dan pada saat yang sama untuk
menangani data terdistribusi. Dua
pendekatan distribusi yang berbeda diadopsi:
1. Memperoleh model akhir identik dengan versi terpusat dari algoritma clustering;
data terdistribusi dari beberapa repository
kecepatan
Judul dan Penulis Masalah Kontribusi Dataset Pengukuran 2. Menghasilkan dan
memilih kelompok untuk setiap bagian data terdistribusi dan
menggabungkan mereka setelah itu.
A new algorithm for initial cluster centers in k-means algorithm (Erisoglu et al., 2011)
Algoritma k-means sangat sensitif terhadap titik awal yang dipilih sebagai pusat cluster
Algoritma ini didasarkan pada memilih dua variabel p yang paling
menggambarkan perubahan dalam dataset sesuai dengan dua sumbu. Proses ini diulang sampai jumlah pusat klaster awal sama dengan jumlah yang telah ditetapkan cluster.
Kemudian, anggota cluster masing-masing poin yang ditentukan sesuai dengan pusat cluster awal calon dan memilih dua sumbu.
Untuk variabel p, pusat esensial klaster inisiasi dibuat menggunakan keanggotaan klaster ditentukan.
Iris, wine, recognition, letter, image recognition, Ruspini, Spam- base
dari UCI
(http://archive.ics.uci.edu/ml/
datasets.html) Machine Learning Repository.
Error percentage
A novel approach for initializing the spherical K-means clustering algorithm (Duwairi & Abu- Rahmeh, 2015)
Penentuan bobot awal yang secara acak dan semaunya
Algoritma yang diusulkan (disebut inisiasi K-means) melebihi K-means
(random) ketika intra klaster kesamaan dan klaster kekompakan yang dipertimbangkan untuk beberapa nilai k (jumlah cluster)
Datasets:
21.826 dokumen,
20 news group collection terdiri dari 20.000 dokumen
mengukur intra klaster kesamaan, klaster kekompakan dan waktu untuk berkumpul
Improved k-means clustering algorithm by getting initial centroids (Usman et al., 2013)
algoritma K-means standar komputasi nya menarik biaya untuk mendapatkan centroid yang memberikan hasil cluster kualitas baik.
Mengusulkan sebuah metode untuk clustering yang efektif dengan memilih centroid awal.
Pertama, algoritma ini mengevaluasi jarak antara titik data sesuai dengan kriteria; kemudian mencoba untuk mencari tahu titik data terdekat yang mirip;
akhirnya pilih centroid aktual dan merumuskan cluster yang lebih baik.
Artificial datasets akurasi dan efektivitas
A hybrid clustering technique combining a novel genetic algorithm with k-means (Rahman
& Islam, 2014)
K-Means umumnya sangat sensitif terhadap kualitas bobot awal (pusat kluster). K-means dapat menghasilkan
Mengusulkan teknik pengelompokan
berdasarkan novel genetic algorithm yang mampu secara otomatis
menemukan jumlah yang
20 datasets, PID datasets, and WQ datasets
Xie- Beni Index, SSE, our novel cluster evaluation criteria (COSEC), F- Measure, Entropy, and Purity
Judul dan Penulis Masalah Kontribusi Dataset Pengukuran kualitas hasil
pengelompokan yang jelek karena buruknya kualitas bobot awal
tepat dari cluster dan mengidentifikasi gen yang tepat melalui pendekatan pilihan populasi awal baru Software Fault Prediction Using
Quad Tree-Based K-Means Clustering Algorithm
(Bishnu & Bhattacherjee, 2012)
Algoritma k-means memiliki kekurangan yaitu:
1. Jumlah cluster sulit untuk diidentifikasi 2. Sulitnya memilih
pusat cluster awal yang sesuai sehingga mengakibatkan clustering tidak sesuai
3. Algoritma k-means sensitif terhadap noise
Mengusulkan metode quad tree untuk menentukan pusat cluster dan
menerapkan pada algoritma k-means untuk
memprediksi kesalahan dalam modul program
- AR3 - AR4 - AR5 - Iris - SYD1 - SYD2
- FPR - FNR - NOI - SSE
- Percent Error - Gain
Improved K-Means Clustering Algorithm by Getting Initial Cenroids (Usman et al., 2013)
Algoritma k-means standar secara komputasi sulit mendapatkan nilai centroid yang
memberikan hasil baik dalam kualitas klaster
Penelitian ini mengusulkan sebuah metode untuk pemilihan centroid awal yaitu dengan mengevaluasi jarak antara titik data sesuai kriteria kemudian mencoba mencari titik terdekat lalu akhirnya memilih centroid yang sebenarnya dan
Data matrix - akurasi
membuat pengelompokan lebih baik.
ModEx and Seed-Detective: Two novel techniques
for high quality clustering by using good initial
seeds in K-Means (Rahman et al., 2015)
Algoritma k-means membutuhkan penginputan jumlah cluster kemudian secara acak memilih centroid yang sama untuk pusat cluster
Seed-Detective menggunakan ModEx untuk menghasilkan centroid awal yang berkualitas tinggi yang kemudian diberikan untuk K-means untuk
menghasilkan cluster akhir.
Benih awal berkualitas tinggi diharapkan bisa menghasilkan cluster berkualitas tinggi melalui K-Means.
A toy dataset - times (in seconds) - F-measure
- Entropy - Purity
A comparative study of efficient initialization methods for the k- means clustering algorithm (Celebi et al., 2013)
Algoritma k-means yang sangat sensitive terhadap penempatan cluster center awal
Penelitian ini memaparkan metode inisiasi k-means dengan penekanan pada efisiensi komputasi
kemudian membandingkan delapan metode inisiasi waktu linier yang umum digunakan dengan menggunakan berbagai kriteria performa.
- Breast cancer wisconsin (original
- Cloud cover
- Concrete compressive strength
- Corel image features - Covertype
- Ecoli
- Steel plates faults - Glass identification - Heart disease - Ionosphere - ISOLET
- Landsat satellite (Statlog)
- SSE
- RAND INDEX - Number iteration - CPU time
Judul dan Penulis Masalah Kontribusi Dataset Pengukuran - Letter recognition
- MAGIC gamma telescope
- Multiple features (Fourier)
- MiniBooNE particle identification - Musk (Clean2) - Optical digits
- Page blocks classification - Parkinsons
- Pen digits - Person activity - Pima Indians diabetes - Image segmentation - Shuttle (Statlog) - SPECTF heart - Telugu vowels (Pal &
Majumder, 1977) - Vehicle silhouettes
(Statlog)
- Wall-following robot navigation
- Wine quality
- World TSP (Cook, 2011) - Yeast
An efficient k-means clustering filtering algorithm using density based initial cluster center (Kumar
& Reddy, 2017)
Algoritma k-means dipengaruhi oleh tingkat pemisahan antara pusat cluster awal
Mengusulkan metode seleksi benih awal yang efisien RDBI untuk memperbaiki kinerja metode K-means. Metode RDBI menentukan pusat cluster yang terpisah dengan menggunakan pendekatan berbasis density dan distance pusat cluster.
- Image segmentation - Pen digits
- Letter recognition - Shuttle
- Poker hand
- Running time - accuracy
An Enhanced Deterministic K- Means Clustering
Algorithm for Cancer Subtype Prediction from Gene
Expression Data (Nidheesh et al., 2017)
Algoritma k-means mempunyai sifat pemilihan titik centroid awal yang dilakukan secara acak
Mengusulkan pemilihan centroid awal dengan memilih titik data dalam daerah padat dan dipisahkan dalam ruang fitur sebagai centroid berdasarkan pada
serangkaian kumpulan data genetika kanker
- NCBI GEO datasets - Monti et al. datasets - UCI machine learning
repository
- Rand Index
2.2 Tinjauan Pustaka
Sebelum melakukan penelitian lebih lanjut, diperlukan kajian yang berisi teori-teori terhadap penelitian untuk mengetahui lebih lanjut mengenai metode dan objek penelitian yang dilakukan dalam penelitian ini.
2.2.1 Software Defect Prediction
Software defect prediction adalah teknologi yang sangat penting digunakan untuk memprediksi kerusakan pada modul perangkat lunak dan untuk meningkatkan kualitas sistem perangkat lunak (Li, Huang, & Li, 2015).
Software defect prediction merupakan salah satu kegiatan pada tahap pengujian Software Development Life Cycle, yaitu dengan mengidentifikasi modul cacat secara ektensif dan sumber pengujian dapat digunakan secaara efisien tanpa melanggar Batasan (Arora, Tetarwal, & Saha, 2015).
Software defect adalah software yang error, gagal, atau salah yang menghasilkan hasil yang tidak diharapkan yang dilakukan pengembang software dari cacat kesalahan pada kode dan kegagalan sistem yang salah selama eksekusi.
Cacat adalah kesalahan pada kode, kegagalan adalah proses yang salah selama eksekusi, kesalahan pengembang juga dapat didefinisikan sebagai kesalahan (Wahono, 2015).
1. Topik Penelitian Software Defect Prediction
Dalam prediksi cacat software menurut (Wahono, 2015), topik penelitian yang dipilih berfokus pada:
a. Estimation: Memperkirakan jumlah cacat dalam system perangkat lunak dengan algoritma estimasi.
b. Assosiation: Menemukan asosiasi cacat menggunakan algoritma asosiasi.
c. Classification: Mengelompokkan kecacatan modul perangkat lunak biasanya menjadi dua kelas yaitu cacat dan tidak cacat dengan menggunakan algoritma klasifikasi.
d. Clustering: Mengelompokkan cacat perangkat lunak berdasarkan objek menggunakan algoritma clustering.
pada perangkat lunak.
2. Bidang Penelitian Software Defect Prediction
Ada beberapa masalah yang dihadapi dalam prediksi cacat software yang sering diajukan oleh periset (Arora et al., 2015) yaitu:
a. Hubungan antara Attributes dan Fault
Para periset tidak dapat mengidentifikasi subset atribut umum sebagai factor penting untuk modul menjadi tidak benar atau non fault dan ada juga kontroversi antara tingkat metrik yang akan diterapkan, metrik kebutuhan, metrik perancangan atau metrik code untuk tujuan analisis. Berbagai penelitian telah dilakukan namun rangkaian atribut dilakukan dalam waktu yang berbeda, beberapa penelitian mencoba mengatasi masalah tersebut namun tidak satupun mampu membangun asosiasi umum antara atribut dan fault.
b. Tidak ada Standar Pengukuran untuk Penilaian Performa
Dalam studi penelitian bidang ini banyak ketidak konsistenan dalam pelaporan performa serta tidak ada kriteria standar yang ditetapkan untuk menganalisis dan membandingkan model prediksi cacat. Dalam penelitian bidang ini disarankan untuk melaporkan recall dalam kombinasi kriteria lain namun tidak ada standar yang ditawarkan.
c. Isu dengan Cross-Software Defect Prediction
Dalam penelitian bidang ini secara umum biasanya lebih sering menggunakan data yang tersedia secara local karena sangat mirip dengan data yang diuji namun sebagian besar waktu tim manajemen resiko sebuah organisasi menghadapi masalah tidak ada informasi di situs lokal. Tidak adanya data training munkin karena berbagai alasan, seperti tidak ada proyek serupa yang sebelumnya telah dikembangkan atau teknologi saat ini telah berubah. Untuk mengatasi masalah tersebut, peneliti menemukan solusi dengan cross-software defect prediction yaitu model defect prediction dikembangkan pada satu proyek dan diperiksa pada proyek
company belum menjanjikan jika belum ada cakupan perbaikan yang besar di bidang ini.
d. Tidak ada Kerangka Umum yang Tersedia
Isu lain terkait dengan bidang yang akan dating adalah para peneliti yang berbeda telah menggunakan Teknik yang berbeda pada rangkaian data yang berbeda, akan tetapi tidak ada kerangka kerja atau prosedur yang standar dalam menerapkan proses software defect prediction pada proyek perusahaan lokal. Beberapa penelitian mengusulkan kerangka kerja yang berbeda untuk menerapkan model software defect prediction, meskipun begitu telah terbukti menguntungkan dan tidak bersifat umum.
e. Ekonomi Software Defect Prediction
Dalam ilmu software defect prediction membahas sebagian pekerjaan yang telah dilakukan dan sangat sedikit berfokus pada ekonominya. Kesalahan klasifikasi terbukti mahal dalam kasus pada komponen yang dianggap salah. Oleh karena itu, kapan dan berapa banyak utilitas yang dimilikinya sangat penting. Dalam beberapa penelitian telah mempertimbangkan aspek ekonomis dari model software defect prediction namun diperlukan eksplorasi lagi dalam bidang ini.
f. Masalah Class Imbalance
Model efisiensi kesalahan software sangat dipengaruhi distribusi data class training, jika jumlah instance yang termasuk dalam satu kelas lebih banyak daripada jumlah instance kelas lain maka masalahnya dikenal sebagai masalah ketidakseimbangan kelas. Berbagai Teknik telah diusulkan untuk mengatasi masalah ini, namun tidak ada satu Teknik pun yang mengungguli yang lain dalam suatu penelitian. Oleh karena itu, tidak bisa mengambil kesimpulan teknik yang harus diterapkan untuk mengatasi masalah ketidak seimbangan kelas.
3. Dataset Software Defect Prediction
Data prediksi kesalahan software berasal dari NASA MDP dan PROMISE repository, kumpulan dataset NASA banyak digunakan dan menawarkan keuntungan yang unik dalam hal reproduktifitas studi dan dataset NASA diambil dari proyek opensource di ranah publik (Moeyersoms, Junqué De Fortuny,
menganalisis kinerja software defect prediction sebanyak 71 studi, 64,79% dari penelitian menggunakan dataset publik yang berada di PROMISE repository dan NASA MDP dan 35,21% dari penelitian dataset pribadi dimiliki oleh perusahaan swasta dan tidak didistribusikan sebagai kumpulan data publik (Wahono, 2015).
2.2.2 Clustering
Dalam aplikasi perlu untuk membagi data poin menjadi kelompok, pemisahan sejumlah titik data ke dalam sejumlah kelompok kecil sangat membantu dalam meringkas data dan memahaminya di berbagai aplikasi data mining, cara pembagian data kedalam kelompok yang berisi titik data yang serupa disebut clustering (Aggarwal, 2015).
Clustering adalah segmentasi populasi heterogen ke dalam sejumlah subkelompok atau kelompok yang lebih homogen, dalam pengelompokan tidak ada kelas yang telah ditentukan dan tidak ada contohnya serta pengelompokan dikelompokkan berdasarkan kemiripan (Berry & Linoff, 2004).
Clustering adalah proses pengelompokan serupa dalam cluster dan yang berbeda dalam kelompok yang berbeda. kelompok menangani berbagai aplikasi termasuk analisis jaringan sosial, rekayasa perangkat lunak, dan cyber crime (Rahman & Islam, 2014).
1. Penerapan Clustering
Pengelompokan clustering menjadi dasar bagi sejumlah model yang disesuaikan untuk berbagai aplikasi. Beberapa contoh aplikasi (Aggarwal, 2015) yaitu:
a. Data summarization: Masalah clustering dapat dianggap sebagai suatu bentuk summarization data karena data mining merupakan penggalian informasi ringkasan dari data. Proses pengelompokan biasanya merupakan langkah awal dalam banyak pengolahan algoritma data mining.
b. Segmentasi pelanggan: Ini dilakukan untuk menganalisis kelompok pelanggan sejenis. Contoh penerapan segmentasi pelanggan adalah
penyaringan kolaboratif dimana preferensi yang disebutkan dalam kelompok pelanggan digunakan untuk membuat rekomendasi dalam grup.
c. Analisis jaringan sosial: Dalam data jaringan sosial, pertemanan dikelompokkan secara ketat berdasarkan hubungan keterkaitan dan seringkali mengelompokkan teman atau komunitas. Masalah masyarakat ini salah satu analisis social yang banyak dipelajari karena pemahaman lebih luas tentang perilaku manusia dalam dinamika masyarakat..
d. Masalah data mining lainnya: karena data representasi diringkas, masalah pengelompokan memungkinkan muncul masalah data mining lainnya.
Misalnya, pengelompokan yang digunakan sebagai langkah preprocessing dalam model pendeteksian klasifikasi dan outlier.
2. Pengelompokan Clustering
Clustering dapat dikelompokkan menjadi tiga kategori yaitu, unsupervised, semi-supervised, dan supervised (Dean, 2014):
a. Unsupervised: tujuan pengelompokan unsupervised ini yaitu untuk memaksimalkan kesamaan intracluster dan untuk meminimalkan kesamaan intercluster dengan similarity/dissimilarity. Pengelompokan ini tidak memiliki variable target atau kelas. Teknik clustering yang paling banyak digunakan adalah k-means dan hierarchial clustering.
b. Semi-supervised clustering: selain unsupervised, clustering semi- supervised menggunakan informasi kelas untuk meningkatkan hasil pengelompokan. Informasi digunakan untuk menyesuaikan kesamaan atau memodifikasi pencarian cluster. Selain tujuan pengelompokan unsupervised, pengelompokan semi-supervised memiliki tujuan untuk mendapatkan konsistensi yang tinggi antara cluster dan informasi dari kelas.
c. Supervised clustering: tujuan pengelompokan supervised yaitu untuk mengidentifikasi kelompok yang memiliki kepadatan probabilitas tinggi berkenaan dengan kelas individu. Pengelompokan supervised digunakan apabila ada variable target atau kelas dan satu set data training yang mencakup variable ke cluster.
Dalam semi-supervised learning contoh yang diberi label digunakan untuk meningkatkan keefektifan klasifikasi meskipun data yang berlabel tidak mengandung informasi distribusi data namun data tersebut mengandung informasi clustering (Aggarwal, 2015). Diantara supervised dan unsupervised learning terdapat semi-supervised learning yang tujuannya adalah klasifikasi namun masukan tersebut berisi data yang tidak berlabel dan berlabel, dan juga untuk menambahkan sejumlah kecil data berlabel dengan kumpulan data tanpa label (Witten et al., 2011).
2.2.4 K-means
Metode hierarki yang paling terkenal dan tertua adalah k-means yang dirancang untuk variable kontinyu, yaitu dengan mengidentifikasi point gabungan yang disebut centroid untuk membangun kelompok dan menghubungkan ke centroid terdekat (Azzalini & Scarpa, 2012). Algoritma k-means merupakan algoritma yang paling banyak digunakan dan mengacu pada pencarian sejumlah cluster dalam jarak terdekat dari titik data, pertama kali ditemukan oleh J.B.
MacQueen pada tahun 1967 (Berry & Linoff, 2004). K-means adalah salah satu teknik clustering yang banyak digunakan dan sederhana, cara kerjanya dengan mempartisi data ke dalam cluster dengan mendatangani masing-masing objek ke centroid cluster terdekatnya berdasarkan jarak yang digunakan (Dean, 2014).
Dalam algoritma k-means, jumlah titik data Euclidean ke titik terdekat digunakan untuk mengukur fungsi objektif pengelompokan:
𝐷𝑖𝑠𝑡(𝑋̅𝑖, 𝑌̅𝑗) = ||𝑋̅𝑖− 𝑌̅𝑗||22 (2.1) Dimana, || . ||𝑝 menjelaskan 𝐿𝑝-norm, (𝑋̅𝑖, 𝑌̅𝑗) dilihat sebagai squared error mendekati titik data terdekatnya. Tujuannya meminimalkan kesalahan square titik data yang berbeda dan biasa disebut SSE (Aggarwal, 2015).
Algoritma k-means secara iterative memperbarui 𝑘 cluster center 𝑐1, 𝑐2, … 𝑐𝑘 dengan memindahkan setiap center ke rata-rata titik lebih dekat dari pusat lainnya.
𝑐1, … 𝑐𝑘∈ 𝑅𝑑. Kemudian partisi point menjadi 𝑘 melalui 𝑆𝑗 ← {𝑝𝑖 ∶ 𝑐𝑗 adalah pusat terdekat 𝑝𝑖}, dimana 𝑠𝑗 ← |𝑆𝑗| selanjutnya perpindahan masing-masing center ke rata-rata dari point terkait dimana:
𝑚𝑗 ←
Sj i
p dan i
j j
j s
c ' m (2.2)
aturan ini diulang untuk sejumlah iterasi tertentu sampai kriteria terpenuhi (Aggarwal & Yu, 2008).
Algoritma k-means umumnya terdiri dari langkah-langkah sebagai berikut (Larose, 2005):
1. Tentukan berapa banyak cluster 𝑘 yang dalam dataset.
2. Pilih secara random nilai 𝑘 centroid sebagai cluster center awal.
3. Untuk setiap data cari cluster center terdekat dalam artian masing-masing data mempunyai cluster center terdekat mewakili partisi dari kumpulan data 𝑐1, 𝑐2, … , 𝑐𝑘 . Tahap ini dihitung dengan Euclidean distance.
4. Untuk 𝑘 cluster, cari centroid cluster dan perbarui masing-masing cluster center ke nilai centroid yang baru. Misal 𝑛 data point, (𝑎1, 𝑏1, 𝑐1), (𝑎2, 𝑏2, 𝑐2), … (𝑎𝑛, 𝑏𝑛, 𝑐𝑛) , centroid dari titik-titik ini adalah pusat yang terletak di titik (∑ 𝑎𝑖/𝑛 , ∑ 𝑏𝑖/𝑛 , ∑ 𝑐𝑖/𝑛).
5. Ulangi langkah 3 sampai 5 sampai konvergensi data
Gambar 2.1. Penerapan k-means
pada dua data simulasi, simulasi data dengan menggunakan tiga cluster, 𝑝 = 2 variabel, data yang dipilih dibedakan menurut jenis simbol sesuai yang berlaku pada konfigurasi awal. Jenis hasil yang sama dipertahankan saat konfigurasi centroid awal berubah (Azzalini & Scarpa, 2012).
2.2.5 Evaluasi Cluster
Standar pengukuran kesamaan cluster adalah varians sehingga rangkaian kelompok terbaik mungkin rangkaian yang memiliki nilai terendah namun pengukuran ini tidak memperhitungkan ukuran cluster. Tujuan umum pengukuran bekerja dengan deteksi cluster yaitu mengambil ukuran kemiripan atau metrik jarak pandang yang digunakan untuk membentuk cluster dan menggunakannya untuk membandingkan jarak rata-rata antara anggota cluster dan cluster centroid dengan jarak rata-rata antara cluster centroid (Berry & Linoff, 2004).
Kriteria evaluasi digunakan terutama untuk mengetahui variabilitas atau noise pada cluster, untuk mengetahui jumlah cluster yang optimal untuk data, untuk membandingkan algoritma clustering terhadap kualitas solusinya, dan untuk membandingkan dua set hasil yang diperoleh dari analisis klaster (Dean, 2014).
1. Confusion Matrix
Confusion matrix menyediakan metode intuitif untuk menilai clustering secara visual dan sangat penting untuk merancang tindakan untuk mengevaluasi keseluruhan kualitas confusion matrix (Aggarwal, 2015). Dalam masalah dua kelas, misalnya positif dan negative pada classifier 𝑓(𝑥|∅) di training set, biasanya diprediksi bahwa 𝑥 yang diambil dari set validasi positif misalnya jika 𝑓(𝑥|∅) ≥ 𝜃, untuk beberapa permulaan 𝜃 dan diasumsikan bahwa 𝑓(𝑥|∅) ∈ [0,1]
memperkirakan probabilitas posterior bahwa 𝑥 adalah contoh positif yaitu 𝑃̂(+|𝑥) ≡ 𝑓(𝑥|∅). Kemudian 𝑥 adalah contoh negative jika 𝑓(𝑥|∅) < 𝜃 dan 𝑃̂(−|𝑥) ≡ 1 − 𝑓(𝑥|∅). Ada empat variable untuk membentuk confusion matrix (Irsoy, Yildiz, & Alpaydin, 2012):
Tabel 2.2. Confusion Matrix Aktual
True False
Predicted True True Positive (TP) False Negative(FN) False False Positive (FN) True Negative (TN)
2. Rand Index
Rand index diciptakan tahun 1971 adalah kriteria sederhana yang digunakan untuk membandingkan struktur pengelompokan yang diinduksi dengan struktur pengelompokan tertentu dengan aturan:
a : jumlah pasang di cluster sama dengan 𝑐1 dan jumlah 𝑐2
b : jumlah pasang contoh di cluster sama dengan 𝑐1 , tapi di cluster tidak sama dengan 𝑐2
c : jumlah pasang contoh di cluster sama dengan 𝑐2, tapi di cluster tidak sama dengan 𝑐1
d : jumlah pada di cluster berbeda dengan 𝑐1 dan 𝑐2
Artinya jumlah a dan d positif, dan b dan c negatif. Rand index dirumuskan:
𝑅𝑎𝑛𝑑 𝐼𝑛𝑑𝑒𝑥 = 𝑎+𝑑
𝑎+𝑏+𝑐+𝑑 (2.3) Rand index yang berada di antara 0 dan 1, apabila partisi tersebut sempurna rand index nya adalah 1 (Maimon & Rokach, 2010).
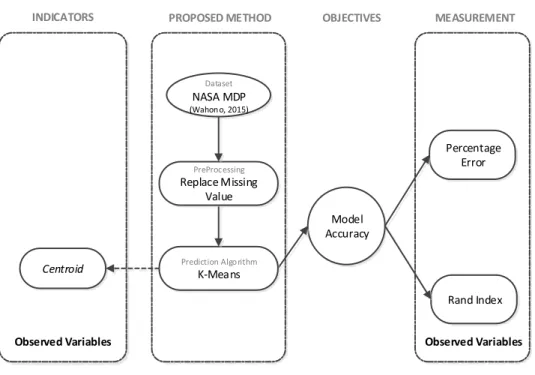
2.3 Kerangka Pemikiran
Kerangka pemikiran pada penelitian ini dapat dilihat pada Gambar 2.2 yang terdiri dari beberapa tahap. Masalah penelitian ini adalah penentuan centroid awal pada algoritma K-means. Dataset yang memiliki data nilai yang kosong akan dilakukan preprocessing data dengan Replace Missing Value kemudian akan mendapatkan dataset baru. Tujuan dari penelitian ini adalah untuk meningkatkan kinerja algoritma k-means agar mendapatkan kualitas cluster yang optimal. Untuk mengevaluasi kinerja dari metode yang diusulkan digunakan Error percentage dan
Observed Variables Observed Variables PROPOSED METHOD OBJECTIVES
Model Accuracy
MEASUREMENT
Percentage Error INDICATORS
Centroid
Dataset
NASA MDP
(Wahono, 2015)
Prediction Algorithm
K-Means
Meningkatkan Ketepatan Prediksi Cacat Software
Rand Index
PreProcessing
Replace Missing Value
Gambar 2.2. Kerangka Pemikiran
METODE PENELITIAN
3.1 Desain Penelitian
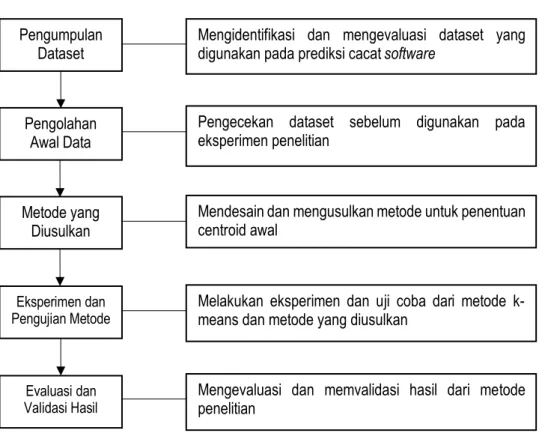
Penelitian adalah aktivitas yang bertujuan untuk memberikan kontribusi original terhadap pengetahuan (Dawson, 2009). Sedangkan menurut Berndtsson, istilah penelitian digunakan untuk aktivitas penyelidikan dan investigasi sistematis dengan tujuan menemukan atau merevisi fakta, teori, aplikasi, dan lain-lain yang tujuannya untuk menemukan dan menyebarkan pengetahuan baru (Berndtsson, Hansson, Olsson, & Lundell, 2008). Ada empat metode penelitian umum yang digunakan baik secara individu ataupun kelompok diantaranya: action research, experiment, case study dan survey. Metode penelitian yang dilakukan dalam penelitian ini adalah metode penelitian eksperimen, dengan tahapan penelitian yang disajian Gambar 3.1 sebagai berikut:
Pengumpulan Dataset
Pengolahan Awal Data
Metode yang Diusulkan
Eksperimen dan Pengujian Metode
Evaluasi dan Validasi Hasil
Mengidentifikasi dan mengevaluasi dataset yang digunakan pada prediksi cacat software
Pengecekan dataset sebelum digunakan pada eksperimen penelitian
Mendesain dan mengusulkan metode untuk penentuan centroid awal
Melakukan eksperimen dan uji coba dari metode k- means dan metode yang diusulkan
Mengevaluasi dan memvalidasi hasil dari metode penelitian
Gambar 3.1. Tahapan Penelitian
Penelitian ini menggunakan dataset NASA MDP karena sangat umum digunakan untuk prediksi cacat software dan dapat diperoleh di PROMISE repository. Dari tahun 2000 sampai 2013 sebesar 64,79% penelitian cacat software menggunakan dataset NASA MDP (Wahono, 2015). Setiap dataset NASA MDP terdiri dari beberapa module software dan karakteristik atribut. Modul yang terdapat cacat dikategorikan sebagai fault prone dan yang tidak cacat dikategorikan sebagai non fault prone selain itu juga terdiri dari atribut kompleksitas McCabe dan Halstead.
Selain menggunakan dataset NASA MDP (CM1, KC1, KC3, MC2, MW1, PC1, PC2, PC3, PC4), penelitian ini juga menggunakan dataset iris karena dataset iris sering digunakan untuk pengujian algoritma clustering, mempunyai 3 class (setosa, viginica, dan versicolor) dan 150 sample, masing-masing class terbagi menjadi 50 class data serta mumpunyai 4 atribut (sepal length, sepal width, petal length, dan petal width).
Tabel 3.1. Deskripsi Dataset NASA MDP Dataset
NASA MDP
Deskripsi Bahasa Pemrograman
Jumlah Modul
Jumlah Modul
Cacat
Presentase Cacat
CM1 Spaceraft instrument C 344 42 12,20%
KC1 Storage management
for ground data C++ 2096 325 15,5%
KC3 Storage management
for ground data Java 200 36 18%
MW1
Zero gravity
experiment related to combustion
C 264 27 10,22%
PC1
Flight software from an earth orbiting satellite
C 759 61 8,03%
PC2 Dynamic simulator for
attitude control system C 1585 16 1,01%
PC3 Flight software for
earth orbiting satellite C 1125 140 12,44%
PC4 Flight software for
earth orbiting satelite C 1399 178 12,72%
MC2 Video guidance
system C 127 44 34,64%