Multilevel MPSoC Performance Evaluation Using
MDE Approach
(Invited Paper)
Rabie Ben Atitallah, Lossan Bonde, Smail Niar, Samy Meftali, Jean-Luc Dekeyser
INRIA-FUTURS, DaRT Project
Synergie Park, 6 bis Avenue Pierre et Marie Curie 59260 Lezennes, France
Email:{benatita, bonde, niar, meftali, dekeyser}@lifl.fr
Abstract— In this paper, we present a multilevel framework
for MultiProcessor Systems-on-Chip (MPSoC) that makes fast simulation and performance evaluation possible in the design flow. In this framework, we use the Model-Driven Engineering (MDE) approach within the GASPARD design flow. Two target simulation models at the Cycle Accurate Bit Accurate (CABA) and the timed Programmers view (PVT) abstraction levels are defined. In addition, in this paper, a set of meta-models corresponding to the simulation models and the deployment phase are also detailed. The latter meta-model allows hardware component refinement with performance parameters specifica-tion. Experimental results show the usefulness of our framework to decrease the design complexity of MPSoC architecture and to acheive high speedup simulation with a negligible estimation error margin.
I. INTRODUCTION
Designing next generation MultiProcessor Systems-on-Chip (MPSoC) dedicated to high-performance embedded applica-tions, such as networking and communication applicaapplica-tions, will be increasingly complex. An efficient and fast design space exploration (DSE) of such systems needs a set of tools capable of estimating performance at different abstraction levels in the design flow. Traditional approaches to perfor-mance estimation at the Register Transfer Level (RTL) cannot adequately support the level of complexity needed for future MPSoC since RTL tools require great quantities of simulation time to explore the huge architectural solution space. In this paper, we focus on higher abstraction levels especially on the CABA (Cycle Accurate Bit Accurate) and the TLM (Transaction Level Modeling). Recently, significant research efforts have been expended to evaluate MPSoC architectures at the CABA (Cycle Accurate Bit Accurate) level [1] [2] in an attempt to reduce simulation time. Usually, to move from the RTL to the CABA level, hardware implementation details are hidden from the processing part of the system, while preserving system behavior at the clock cycle level. Though using the CABA level has allowed accurate performance estimation, MPSoC space exploration at this level is not yet sufficiently rapid compared to RTL [3].
For this reason, we are also interested on the use of Trans-action Level Modeling (TLM) in an MPSoC design which corresponds to a set of abstraction levels that simplifies the
description of inter-module communication transactions using objects (i.e. words or frames) and channels between the com-municating modules [4] [5]. Consequently, modeling MPSoC architectures becomes easier and faster than at the CABA level. Not only does TLM speed up the simulation process, but TLM can also be enhanced with timing annotations (T-TLM) that allow the user to estimate his/her application/architecture adequacy. For our framework, the timed transactional level has been designed in the context of PVT level [6].
In our work, we adopt a multilevel performance estimation strategy. Simulation at the PVT permits a rapid exploration of a large solution space by eliminating non-interesting regions from the DSE process. The solutions selected at this level are then forwarded for a new exploration at CABA level. Because performance estimation at this level is more accu-rate, it is possible at the price of less simulation speed, to locate the most efficient architecture configurations. As our objective in this paper is to design tool for rapid MPSoC design space exploration (DSE), Model Driven Engineering (MDE) approach [7] is used. In fact MDE consists of a generative approach that enables to partially or totally generate application implementations from high-level models. After a high level hardware architecture description, a deployment meta-model is defined allowing component refinement and set-ting parameters linked to the micro-architectural specifications and performance estimation models. Meta-models describing interfaces connecting the modules in CABA and PVT levels are also defined to allow automatic code generation of the hardware architecture.
The rest of this paper is organized as follows. The Gaspard design flow is presented in section 2. The CABA meta-model is introduced in section 3. Details about the PVT level and the performance estimation strategy are presented in section 4. The deployment meta-model is described in section 5. Section 6 presents the experimental results obtained when applying the proposed framework for an MPSoC architecture. Finally, section 7 gives our conclusions and prospects for future research.
II. GASPARDDESIGNFLOW
The Gaspard (Graphical Array Specification for Parallel and Distributed Computing) tool [8] proposes an entire en-vironment for MultiProcessor System-on-Chip (MPSoC) de-sign. Gaspard is based on an Y-chart co-design illustrated in Fig.1. Within our Gaspard environment, we use the model-driven engineering (MDE) approach for decreasing the design complexity and thus reducing the time-to-market. To do so, meta-models which correspond to several design levels are proposed. From the higher to lower level design, using au-tomatic and semi-auau-tomatic model to model transformation techniques allows obtaining more and more detailed about the system specification. On the top of the Y and at the functional level, the left part corresponds to the software application meta-model, while the right part describes the hardware ar-chitecture meta-model. At this level, using UML description language, developers could modelize a given architecture and the corresponding application to be executed on. As a second step, an association mechanism is integrated in our design flow that allows the mapping of the software tasks and data on the hardware architecture modules. After this phase, a deployment meta-model is defined, the objective is to enhance the hardware and software components with information cor-responding to the system target implementation. In this meta-model, hardware micro-architectural details will be specified in order to be used for system performance estimation. The Gaspard environment supports several simulation models at different abstraction levels such as TLM (Transaction Level Model) and RTL (Register Transfer Level) levels. The key point is the reuse of pre-defined hardware and software com-ponents (Intellectual Proprieties: IPs) from libraries. For each abstraction level, we define a meta-model which describes the module interfaces and objects (Buses, Channels) connecting the communicating IPs.
Fig. 1. Gaspard design flow
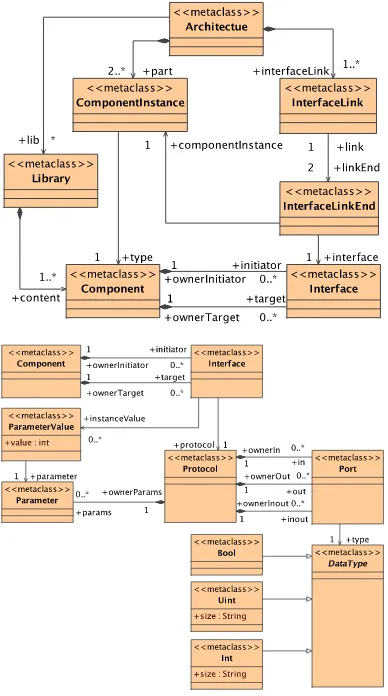
Fig. 2. CABA meta-model
III. CYCLEACCURATEBITACCURATEMETA-MODEL
Fig.2 illustrates the meta-model describing the hardware architecture at the CABA level. A given architecture instanti-ates hardware components from the appropriate library. Each hardware component uses initiator and/or target interfaces to communicate with other components. These interfaces are described at the signal level and define a communication protocol.
At this level, hardware components are implemented at the cycle accurate level so performance estimation is given by the micro-architectural simulator in number of cycles. However, simulation at the CABA level needs some architectural param-eter specifications such as cache size, etc. These paramparam-eters will be specified at the deployment phase as will be shown in the section 6.
IV. TIMEDPROGRAMMER’SVIEWMETA-MODEL
Fig. 3. PVT meta-model
and write methods (Fig.3). To load or store data, masters call
read() or write()functions are passed through the port to the channel interface. At the level of slaves, the transaction will be recovered to execute the corresponding methods and to send the response.
For performance estimation at this level, our strategy is based on identifying each components pertinent activities: the num-ber and types of executed instructions for the processor; hits and misses for the caches; the number of transmitted/received packets for the interconnection network; the number of read and write operations for the shared memory modules, etc. A counter, incremented during simulation, is attributed to each activity type. In addition to counting the activities, execution time estimation also requires attributing an execution time to each activity. These times must be carefully determined to satisfy to the precision criterion. In our approach, ex-ecution times are measured from the CABA platform [1] and injected into the timing model. To allow establishing the same event (e.g., misses, instruction execution, collisions)
sequencing obtained at the CABA level, wait(..) instructions
Fig. 4. Deployment meta-model
with arguments determined by the platform configuration are inserted in the simulator. The activities execution time and platform configurations parameters will be specified at the deployment phase.
V. DEPLOYMENTMETA-MODEL
The Deployment phase defines the target simulation abstrac-tion level (e.g. SystemC CABA level) or the real implemen-tation of the platform (e.g. VHDL Altera STRATIX EP1S10 development board). Fig.4 presents the general deployment meta-model; a set of parameters which depend on the com-ponent type (e.g. processor, memory), the target simulation model and the description language are associated to each hardware component. In general, lower level parameters are also available for higher level with adding information for timing annotations.
VI. EXPERIMENTALRESULTS
In order to evaluate the usefulness of the proposed frame-work, we modelize an MPSoC architecture at the high level (Fig.5). First, our objective is to generate the corresponding CABA and PVT simulation models after a deployment phase using the MDE approach. Second, we are concerned to com-pare the speedup of the simulation and the accuracy of the performance between the two simulation models.
As an application, we parallelized the matrix multiplication application to be executed on the platform. Taking as an input the associated model, we perform the deployment specification phase. Though for space reasons, we present only the example of data cache memory component deployment specification for CABA and PVT SystemC [9] simulation (Fig.6). In addition to the architectural parameters, the data cache at the PVT level
<<HardwareComponent>>
QuadriPro
<<HardwareComponent>>
procUnit : ProcessingUnit [4]
bus
<<Memory>>
instMem : InstructionMem
bus <<Memory>>
dataMem : DataMem [4]
bus
procunit [4] privatemem [4]
instmem <<Memory>>
DataMem
bus
Fig. 6. CABA and PVT data cache Deployment specification
needs timing information that will be deduced from the CABA level.
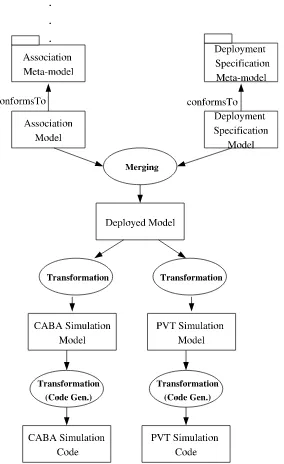
As Gaspard is based on MDE approach, models transforma-tions hold an important part in its methodology. Fig.7 gives an overview of the main transformations in Gaspard design flow. The association model and the deployment specification model are merged to produce a deployed model. From this deployed model, a first set of transformations are performed to generate platform simulation models corresponding to the
CABA and PVT levels. A second set of transformations (Code
Gen.) take as inputs these models and generate the SystemC
code for the associated architecture.
In our experimental simulation, we import various hardware components (Processor, data and instruction caches,
intercon-Fig. 7. Transformation phases
4 6 8 10 12 14 16
4 8 12 16
Num be r of pro ce s s ors
S
im
u
la
ti
o
n
s
p
e
e
d
u
p
256 Bytes
512 Bytes
1 KB
2 KB
4 KB
8 KB
16 KB
32 KB
Fig. 8. Simulation speedup between CABA and PVT
nect and memories) from CABA [1] and PVT [8] libraries. We executed our application for the CABA and PVT levels using systems with 4 up to 16 processors. Instruction and data cache size varied from 256 bytes to 32 Kbytes in order to evaluate the impact of increasing traffic in the interconnect on the speedup factor. The results of the simulation were quite interesting (Fig.8). PVT made it possible to accelerate the simulation by a factor of up to 14. For The performance error with PVT was reduced to nearly zero.
VII. CONCLUSION
In this paper, we proposed an efficient framework for MPSoC multilevel simulation and performance estimation. MDE approach is used to decrease the design complexity of such systems and accelerates the design space exploration. Experimental results show that high speedup simulation with a negligible estimation error margin can be achieved early in the design flow. As future research, we plan to apply the same methodology for more complex architectures and we hope to enhance simulation models with energy estimation tools for reliable design space exploration
REFERENCES
[1] SoCLib project, 2003,http://soclib.lip6.fr/.
[2] L. Benini et al., “MPARM: Exploring the Multi-Processor SoC Design Space with SystemC,”Springer J. of VLSI Signal Processing, 2005. [3] R. Ben Atitallah et al., “Estimating energy consumption for an MPSoC
architectural exploration,” inARCS ’06, Frankfurt, Germany, 2006. [4] D. Gajski et al., SpecC:Specification Language and Methodology.
Kluwer, 2000.
[5] T. Groetker et al.,System Design with SystemC. Kluwer, 2003. [6] A. Donlin, “Transaction level: flows and use models,” inCODES+ISSS
’04, Stockholm, Sweden.
[7] S. Grard, J.-P. Babeau, and J. Champeau, Eds.,Model Driven Engineering for Distributed Real-Time Embedded Systems. ISTE, Hermes science and Lavoisier, August 2005, ch. Model Driven Architecture for Intensive Embedded Systems.
[8] Laboratoire dinformatique fondamentale de Lille, Universite des sciences et technologies de Lille.,http://www.lifl.fr/west/gaspard/. [9] SystemC v2.1 Language Reference Manual, Open SystemC Initiative,