48
Klasifikasi Batubara Berdasarkan Jenis Kalori dengan
Menggunakan Algoritma K-Nearest Neighbor (K-NN)
(Studi Kasus: PT Pancaran Surya Abadi Kecamatan Anggana
Kabupaten Kutai Kartanegara Provinsi Kalimantan Timur)
Retno Pratiwi
1,*, Sri Wahyuningsih
2, Fidia Deny Tisna Amijaya
21Laboratorium Statistika Komputasi, Jurusan Matematika, FMIPA, Universitas Mulawarman 2Program Studi Statistika, Jurusan Matematika, FMIPA, Universitas Mulawarman
Email korespondensi: [email protected]
Abstracts Coal is sedimentary rocks containing the main elements Carbon (C), Hydrogen (H), and
Oxygen (O). As one of nergy commodity, coal has been explored and exploited in order to fulfill the energy needs of world community. Inspection on coal sample in the laboratory according to company operational standard is based on Air Dried Basis (ADB) namely as total moisture, moisture, ash, volatile matter, fixed carbon, total sulphur and Gross Calorific Value. PT Pancaran Surya Abadi Anggana Subdistrict Kutai Kartanegara classified coal by calorific type such as antrachite, bituminous, and sub-bituminous. K-Nearest Neighbor (K-NN) algorithm is used to determine the classification prediction. In order to more accurately predict the classification of prediction, K-Fold Cross Validation technique is used to obtain optimal K value in K-Nearest Neighbor Algorithm (K-NN). In this study, firstly the optimal K value is determined to be used on K-NN Algorithm to predict coal classification in PT Pancaran Surya Abadi. The optimal K value is searched by experimenting 1-Fold Cross Validation, 5-Fold Cross Validation, and 10-Fold Cross Validation using 90:10 proportion of data. Secondly, writer determine the percentage of prediction accuracy of coal classification in PT Pancaran Surya Abadi using K-Nearest Neighbor Algorithm (K-NN) with optimal value of K. The result shows that the optimal K value used in the K-NN Algorithm at PT Pancaran Surya Abadi is 1-NN obtained in the 10-Fold Cross Validation experiment. Furthermore, the result shows that the percentage accuracy of coal prediction at PT Pancaran Surya Abadi using 1-NN at 10-Fold Cross Validation is 100%.
Keywords: classification, coal, k optimal, k-nearest neighbor.
Pendahuluan
Klasifikasi dapat didefinisikan sebagai suatu pekerjaan yang melakukan proses pelatihan atau pembelajaran terhadap fungsi target yang memetakan setiap vektor ke dalam satu dari sejumlah label kelas yang tersedia. Proses pelatihan akan menghasilkan suatu model yang kemudian disimpan sebagai memori. Klasifikasi adalah pembagian kasus atau objek menurut kelas-kelas berdasarkan ciri-ciri persamaan dan perbedaan [1].
Machine learning adalah salah satu disiplin ilmu dari computer science yang mempelajari bagaimana membuat komputer atau mesin itu mempunyai suatu kecerdasan di dalam pembelajaran [2]. Algoritma-algoritma klasifikasi berdasarkan pembelajaran dapat dibagi menjadi dua macam, yaitu eager learner dan lazy learner [1]. Algoritma-algoritma yang masuk kategori lazy learner hanya sedikit melakukan proses pelatihan (atau bahkan tidak sama sekali). Algoritma-algoritma kategori lazy learner hanya menyimpan sebagian atau seluruh data latih kemudian, menggunakan data latih tersebut ketika proses prediksi. Algoritma-algoritma
klasifikasi yang masuk kategori ini diantaranya adalah rote classifier, K-Nearest Neighbor (K-NN), Fuzzy K-Nearest Neighbor (FK-NN) dan regresi linier [1].
Algoritma K-Nearest Neighbor (K-NN) menjadi salah satu metode berbasis Nearest Neighbor yang paling tua dan populer. Nilai K yang digunakan menyatakan jumlah tetangga terdekat yang dilibatkan dalam penentuan prediksi label kelas pada data uji. Dari K tetangga terdekat yang terpilih kemudian dilakukan voting kelas. Kelas dengan jumlah suara tetangga terbanyaklah yang diberikan sebagai label kelas hasil prediksi pada data uji tersebut [1].
Batubara merupakan komoditas energi yang semakin banyak dieksplorasi dan dieksploitasi untuk pemenuhan kebutuhan energi masyarakat dunia. Batubara merupakan istilah yang luas untuk keseluruhan bahan bersifat karbon yang terjadi secara ilmiah. Batubara dikenal sebagai emas hitam. Masyarakat mengenalnya sebagai batu hitam yang bisa terbakar. Penafsiran hasil pemeriksaan laboratorium untuk mengetahui klasifikasi batubara tidak
49 dapat menggunakan satu jenis hasil pemeriksaan laboratorium saja, tetapi menggunakan gabungan beberapa hasil pemeriksaan. Hal itu disebabkan sifat hasil pemeriksaan laboratorium pada batubara menjadi tidak spesifik [3].
Berdasarkan uraian di atas, penulis tertarik untuk mengkaji analisis klasifikasi algoritma yang masuk kategori lazy learner dengan mengambil studi kasus klasifikasi batubara di PT Pancaran Surya Abadi yang merupakan salah satu perusahaan penambang batubara di Kecamatan Anggana Kutai Kartanegara. Dengan demikian penulis mengusulkan penelitian yang berjudul “Klasifikasi Batubara Berdasarkan Jenis Kalori dengan Menggunakan Algoritma K-Nearest Neighbor (K-NN) (Studi Kasus: PT Pancaran Surya Abadi Kecamatan Anggana Kabupaten Kutai Kartanegara Provinsi Kalimantan Timur)”. Metodologi
Data penelitian diambil di PT Pancaran Surya Abadi yang berlokasi di Jalan Serindit 1 Nomor 19 Samarinda Provinsi Kalimantan Timur. Penelitian dilakukan dari bulan Maret 2017 hingga Juni 2017 dan untuk analisis data dilakukan di Laboratorium Statistika Komputasi, Fakultas Matematika dan Ilmu Pengetahuan Alam, Universitas Mulawarman, Samarinda. Metode yang digunakan adalah metode K-NN (K-Nearest Neighbor), yaitu melakukan klasifikasi berdasarkan kemiripan suatu data dengan data yang lain atau berdasarkan klasifikasi K tetangga terdekat [5]. Tahapan penelitian meliputi; analisis statistika deskriptif, normalisasi data, pembagian data training dan data testing, randomisasi data, penentuan nilai K optimal, melakukan prediksi klasifikasi dengan K-NN, uji akurasi dan kesimpulan.
Hasil dan Pembahasan
Analisis statistika deskriptif bertujuan untuk menggambarkan jumlah klasifikasi masing-masing batubara (antrachite, bituminous, dan sub-bituminous) yang dimiliki oleh PT Pancaran Surya Abadi Kecamatan Anggana Kutai Kartanegara Provinsi Kalimantan Timur. Jumlah klasifikasi batubara PT Pancaran Surya Abadi untuk masing-masing kelas (antrachite, bituminous, dan sub-bituminous) disajikan dalam bentuk grafik batang seperti pada Gambar 1.
Berdasarkan Gambar 1, PT Pancaran Surya Abadi melakukan sampling (pengambilan sampel batubara) sebanyak 37 kali dengan klasifikasi batubara antrachite sebanyak 1
data, bituminous sebanyak 11 data, dan sub-bituminous sebanyak 25 data.
Gambar 1. Jumlah klasifikasi batubara sub-bituminous, bituminous dan antrachite
di PT Pancaran Surya Abadi
Langkah selanjutnya adalah melakukan randomisasi data. Normalisasi data bertujuan untuk membuat semua variabel berada dalam jangkauan yang sama sehingga fungsi dalam klasifikator dapat seimbang [1]. Di bawah ini merupakan persamaan perhitungan normalisasi data:
N i ik kx
N
x
1x
1
N 1 i 2)
(
x
1
1
ik ik kx
x
N
k k ik ikx
x
x
ˆ
di mana: N = banyak data ikx = data ke-
i
pada variabel ke-k
di manak
1
,
2
,...,
r
k
x = rata-rata pada variabel ke-
k
2 k = varians k = standar deviasi ik
xˆ = normalisasi data data ke-
i
variabel ke-
k
Setelah melakukan randomisasi data, data dibagi menjadi data training dan data testing dengan proporsi 90:10. Data training yang dimaksud adalah data yang digunakan untuk melakukan penentuan nilai K optimal dari Algoritma K-Nearest Neighbor dengan menggunakan teknik K-Fold Cross Validation. Data testing digunakan untuk melihat persen akurasi hasil prediksi klasifikasi batubara dengan menggunakan Algoritma K-Nearest Neighbor (K-NN) dibandingkan dengan hasil pemeriksaan laboratorium batubara PT Pancaran Surya Abadi. Banyak data training
(1)
(2)
50 dan testing dihitung menggunakan Persamaan: Jumlah data training
%
100
x
100
training
data
proporsi
=x37
100
90
= 33,3 = 33 Jumlah data testing=
N
– Jumlah data training= 37 – 33 = 4
Dapat diketahui bahwa, proporsi 90:10 data terbagi menjadi 33 data training dan 4 data testing seperti pada Tabel 1 dan Tabel 2 berikut ini:
Tabel 1. Data training
Tabel 2. Data testing
Langkah selanjutnya yang dilakukan adalah melakukan randomisasi. Data training sebanyak 33 data dirandomisasi dengan menggunakan Software Octave hingga memunculkan data hasil randomisasi yang digunakan untuk penentuan nilai K optimal. Kemudian, mencari nilai K optimal dengan teknik K-Fold Cross Validation. Pencarian nilai K optimal dengan teknik K-Fold Cross Validation akan dilakukan dengan tiga percobaan. Percobaan pertama menggunakan 1-Fold Cross Validation untuk nilai K=1, 3, 5, 7, 9, 11, 13, dan 15. Percobaan kedua menggunakan 5-Fold Cross Validation untuk nilai K=1, 3, 5, 7, 9, 11, 13, dan 15, dan percobaan ketiga menggunakan 10-Fold Cross Validation untuk nilai K=1, 3, 5, 7, 9, 11, 13, dan 15. Dari ketiga percobaan tersebut akan dilihat nilai persentase akurasi prediksi klasifikasi. Nilai K-NN yang memiliki persentase akurasi prediksi klasifikasi terbesar dari ketiga percobaan tersebut akan digunakan sebagai K optimal dalam K-NN.
Langkah-langkah dalam menentukan nilai K optimal dengan 1-Fold Cross Validation,
5-Fold Cross Validation, dan 10-5-Fold Cross Validation adalah
a. Melakukan randomisasi data b. Menentukan subset data c. Menghitung jarak Euclidean
d. Melakukan prediksi dengan K-Nearest Neighbor
e. Menguji akurasi hasil prediksi klasifikasi dengan data aslinya [4]. Untuk 1-Fold Cross Validation, jumlah data dalam satu subset dapat dihitung dengan menggunakan persamaan: i
K
n
b
3
1
33
di mana:b
= banyak data di dalam satu subsetn
= banyak data yang digunakan K = nilai K-Fold Cross ValidationBerdasarkan perhitungan tersebut, jumlah data dalam satu subset adalah 33 data. Masing-masing data tersebut mendapatkan giliran untuk menjadi data testing. Apabila 32 data menjadi data training, maka satu data lainnya menjadi data testing. Data training dan data testing tersebut digunakan untuk menghitung jarak Euclidean.
r i ik iky
x
y
x
d
1 2)
(
)
,
(
di mana: ikx
= nilai ke-i
variabel ke-k
darix
ik
y
= nilai ke-i
variabel ke-k
dariy
r
= jumlah variabeld = Jarak Euclidean
Perhitungan jarak Euclidean dilakukan hingga sampel ke 32 (Sampel A-32). Kemudian dilanjutkan dengan mengurutkan (rank) hasil perhitungan jarak Euclidean pada Tabel 3.
Berdasarkan Tabel 3, pada penggunaan 1-NN, prediksi klasifikasinya adalah label kelas 3 (sub-bituminous) karena label kelas 3 adalah modus dari rank pertama. Pada penggunaan 3-NN, prediksi klasifikasinya adalah label kelas 3 (sub-bituminous) karena label kelas 3 adalah modus dari rank pertama sampai dengan rank ketiga. Pada penggunaan 5-NN, prediksi klasifikasinya adalah label kelas 3 (sub-bituminous) karena label kelas 3 adalah modus dari rank pertama sampai dengan rank kelima. Dan seterusnya hingga prediksi dengan menggunakan 15-NN. Selanjutnya, (4)
(5)
(6)
51 prediksi klasifikasi menggunakan K-NN dengan nilai K=1, 3, 5, 7, 9, 11, 13, dan 15 pada 1-Fold Cross Validation dibandingkan dengan klasifikasi data asli untuk semua percobaan 33 data training yang dapat dilihat pada Tabel 4.
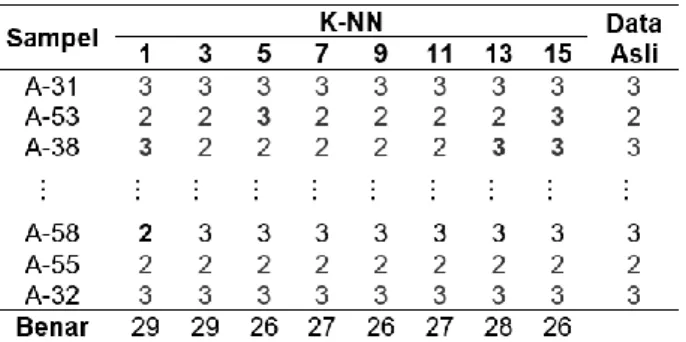
Berdasarkan Tabel 4, dapat dilihat bahwa sel dengan angka yang ditebalkan memiliki perbedaan prediksi klasifikasi dengan data aslinya. Kemudian akan dihitung jumlah klasifikasi data prediksi yang sama dengan klasifikasi data asli untuk tiap K-NN. Semakin besar jumlah klasifikasi data prediksi yang sama dengan klasifikasi data asli maka semakin besar kemungkinan nilai K pada percobaan tersebut menjadi K optimal. Dari 33 data, untuk 1-NN dan 3-NN diketahui dapat memprediksi lebih banyak daripada K-NN lainnya yaitu 29 data.
Tabel 3. Rank Jarak Euclidean 32 Data Training Terhadap Sampel A-31
Data Training Data Testing A-31 Batas K-NN Hasil Klasifikasi Sampel Klasifikasi d A-32 3 0,832 1-NN 3 A-33 3 1,37 A-41 3 3,318 3-NN 3 A-45 3 3,442 A-40 3 3,452 5-NN 3 A-62 2 3,564 A-43 3 3,611 7-NN 3 A-53 2 3,697 A-57 3 3,898 9-NN 3 A-50 3 3,912 A-61 3 3,922 11-NN 3 A-63 3 4,072 A-52 2 4,074 13-NN 3 A-44 3 4,089 A-54 2 4,094 15-NN 3 A-58 3 4,12 A-46 2 4,304 A-47 2 4,402 A-34 3 4,447 A-60 3 4,469 A-48 2 4,547 A-59 3 4,589 A-37 3 4,662 A-35 3 4,665 A-36 3 4,685 A-42 2 4,712 A-51 1 4,922 A-38 3 5,625 A-39 3 5,811 A-56 2 5,841 A-55 2 5,923 A-49 2 10,45
Tabel 4. Perbandingan Prediksi Klasifikasi K-NN dengan Klasifikasi pada Data Asli untuk 1-Fold Cross Validation.
Selanjutnya, Persentase akurasi prediksi klasifikasi dihitung dengan menggunakan persamaan berikut [6]: % 100 x b akj benar diprediksi yang data Jumlah
Persentase akurasi prediksi klasifikasi pada 1-Fold Cross Validation menggunakan K-NN dengan nilai K=1, 3, 5, 7, 9, 11, 13, dan 15 dapat dilihat pada Tabel 3. Berdasarkan Tabel 3, urutan persentase akurasi prediksi klasifikasi pada 1-Fold Cross Validation untuk 1-NN dan 3-NN sebesar 87,8 % dilanjutkan dengan persentase 13-NN sebesar 84,8%. Untuk 7-NN dan 11-NN memiliki persentase akurasi sebesar 81,8%, serta untuk 5-NN, 9-NN, dan 15-NN memiliki akurasi sebesar 78,8%. Dapat disimpulkan bahwa K-NN yang memiliki persentase akurasi prediksi klasifikasi tertinggi untuk 1-Fold Cross Validation adalah 1-NN dan 3-NN.
Tabel 5. Persentase Akurasi Prediksi Klasifikasi untuk 1-Fold Cross Validation K-NN Akurasi (%) 1-NN 87,8 3-NN 87,8 5-NN 78,7 7-NN 81,8 9-NN 78,8 11-NN 81,8 13-NN 84,8 15-NN 78,8
Langkah yang sama juga dilanjutkan pada 5-Fold Cross Validation dan 10-5-Fold Cross Validation. Persentase akurasi prediksi klasifikasi untuk 1-Fold Cross Validation, begitu juga dengan percobaan 5-Fold Cross Validation, dan 10-Fold Cross Validation. Hasil persentase akurasi prediksi klasifikasi gabungan dari ketiga percobaan tersebut dapat dilihat pada Tabel 6.
52 Tabel 6. Persentase Akurasi Penentuan K
Optimal untuk Keseluruhan Perhitungan K-NN Persentase Akurasi (%) 1 FCV 5 FCV 10 FCV 1NN 87,8 81,9 89,2 3NN 87,8 79,04 83,3 5NN 78,7 75,7 79,2 7NN 81,8 81,42 79,2 9NN 78,8 84,76 79,2 11NN 81,8 88,09 85,8 13NN 84,8 81,9 83,3 15NN 78,8 79,04 77,5
Berdasarkan Tabel 6, dapat dilihat bahwa nilai nilai K optimal terdapat pada percobaan 10-Fold Cross Validation dengan persentase sebesar 89,2%. Dapat disimpulkan bahwa K optimal yang akan digunakan pada Algoritma K-Nearest Neighbor (K-NN) untuk memprediksi klasifikasi batubara di PT Pancaran Surya Abadi adalah 1-NN karena memiliki persentase akurasi tertinggi dibandingkan dengan K-NN lainnya.
Selanjutnya, nilai K optimal tersebut akan digunakan dalam algoritma K-NN untuk memprediksi klasifikasi batubara di PT Pancaran Surya Abadi. Prediksi klasifikasi batubara di PT Pancaran Surya Abadi menggunakan proporsi data training dan data testing 90:10 sehingga jumlah data training sebanyak 33 data dan data testing sebanyak 4 data.
Tabel 7. Perhitungan jarak Euclidean yang Telah di Rank
Rank Data Training
Data Testing A-64 Sampel Klasifikasi d 1 A-53 2 1,2972 2 A-62 2 1,0858 3 A-54 2 1,7721 … … … … 31 A-39 3 4,1437 32 A-51 1 4,0791 33 A-49 2 8,7449
Pada Tabel 7, selain data testing A-64, data testing lain yang digunakan adalah semua data testing yang telah ditentukan berdasarkan pembagian proporsi data. Klasifikasi Algoritma K-NN dengan 1-NN artinya menentukan klasifikasi data testing dengan melihat modus klasifikasi data training yang sudah diurutkan pada ranking pertama saja. Hasil prediksi data testing dapat dilihat pada Tabel 8.
Tabel 8. Perbandingan Hasil Prediksi Klasifikasi 1-NN dengan Klasifikasi Asli untuk Data Testing
Data Testing Hasil Prediksi Klasifikasi Asli Keterangan A-64 2 2 Sama A-65 2 2 Sama A-66 2 2 Sama A-67 3 3 Sama
Berdasarkan Tabel 8, terdapat kesamaan prediksi klasifikasi 1-NN dengan klasifikasi pada data asli untuk data testing. Maka, hasil prediksi klasifikasi 1-NN dengan klasifikasi asli untuk data testing adalah sebagai berikut:
%
100
x
4
4
%
100
x
1
100
%
Berdasarkan perhitungan tersebut dapat disimpulkan bahwa persentase akurasi prediksi klasifikasi batubara di PT Pancaran Surya Abadi menggunakan Algoritma K-Nearest Neighbor (K-NN) dengan nilai 1-NN adalah 100%.
Kesimpulan
Nilai K optimal yang digunakan pada Algoritma K-Nearest Neighbor (K-NN) untuk memprediksi klasifikasi batubara di PT Pancaran Surya Abadi dengan melakukan percobaan 1-Fold Cross Validation, 5-Fold Cross Validation, dan 10-Fold Cross Validation adalah 1-NN. K optimal tersebut didapatkan pada percobaan 10-Fold Cross Validation dengan persentase akurasi sebesar 89,2%. Sedangkan untuk persentase akurasi prediksi klasifikasi batubara di PT Pancaran Surya Abadi menggunakan Algoritma K-Nearest Neighbor (K-NN) dengan nilai K yang sudah optimal yaitu 1-NN sebesar 100%.
Daftar Pustaka
[1] Prasetyo, Eko. (2014). Data Mining Mengolah Data Menjadi Informasi Menggunakan Matlab Edisi I. Yogyakarta: Penerbit Andi.
[2] Mitchell, Tom M. (2008). Machine Learning. New York: McGraw-Hill Science.
[3] Arif, Irwandy. (2014). Batubara Indonesia. Jakarta: PT Gramedia Pustaka Utama. [4] Pandie, Emerensye. (2012).
Implementasi Algoritma Data Mining K-Nearest Neighbor (KNN) dalam Pengambilan Keputusan Pengajuan Kredit. Jurnal Ilmu Komputer Universitas Nusa Cendana.
53 [5] Wu, Xindong dan Kumar, Vipin. (2009).
The Top Ten Algorithms in Data Mining. New York: CRC Press.
[6] Rodiyansyah, Sandi F. (2013). Klasifikasi Posting Twitter Kemacetan Lalu Lintas
Kota Bandung Menggunakan Naïve Bayesian Classification. Jurnal Universitas Pendidikan Indonesia.