ANALISIS MENG FAKULTA POLA KUNJ GGUNAKAN A DEPART AS MATEMAT INSTIT JUNGAN PEN N ALGORITM YUDYA PAR TEMEN ILMU TIKA DAN IL TUT PERTAN 2009 NGGUNA SIT MA TOTALLY RAMITA U KOMPUTE LMU PENGE NIAN BOGOR
TUS WEB IPB Y FUZZY ER ETAHUAN AL R B LAM 1
2 ANALISIS POLA KUNJUNGAN PENGGUNA SITUS WEB IPB
MENGGUNAKAN ALGORITMA TOTALLY FUZZY
Skripsi
Sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer pada Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
AYUDYA PARAMITA G64104069
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
3
ABSTRAK
AYUDYA PARAMITA. Analisis Pola Kunjungan Pengguna Situs Web IPB Menggunakan Algoritma
Totally Fuzzy. Dibimbing oleh ANNISA dan HERU SUKOCO.
Pola pengaksesan pengguna terhadap sebuah situs web biasanya tergambarkan dalam sebuah pola sekuensial. Pola sekuensial mengindikasikan bahwa transaksi biasanya terjadi secara sekuensial terhadap waktu. Untuk mengetahui trends dari pengguna situs web terkait pola pengaksesannya, dapat digunakan metode web mining. Salah satu teknik web mining yang dapat digunakan untuk mengetahui pola sekuensial yaitu Totally Fuzzy. Konsep fuzzy yang diterapkan dalam teknik web mining dapat lebih baik dalam menangani data numerik, karena himpunan fuzzy ”memperhalus” batasan yang tegas. Data numerik diubah menjadi bentuk data fuzzy menggunakan teknik Fuzzy C-Means yang menerapkan konsep ketidakmiripan dalam mengelompokkan suatu objek. Pola sekuensial yang memiliki frekuensi cukup tinggi kemudian dipresentasikan agar mudah dipahami dan diintrepretasikan. Informasi tersebut dapat digunakan oleh web master sebagai dasar untuk perancangan ulang disain sebuah situs web, baik tatanan antarmuka maupun isi.
Data yang digunakan pada penelitian ini adalah data log akses situs web IPB (www.ipb.ac.id) pada periode 5 Januari sampai dengan 18 Juni 2007. Data dikelompokkan ke dalam dua bagian, yaitu pengguna internal dan pengguna eksternal. Dalam hal ini digunakan alamat IP dari server proxy untuk mengasumsikan bahwa seorang pengguna termasuk ke dalam kelompok pengguna internal atau eksternal. Pada penelitian ini digunakan nilai ambang batas (threshold) dari 0,1 hingga 0,6 dengan peningkatan sebesar 0,05 dan nilai minimum support sebesar 3% hingga 56% untuk data pengguna internal serta 14% hingga 65% untuk data pengguna eksternal. Nilai minimum support tersebut ditentukan berdasarkan kondisi datanya.
Dari hasil percobaan didapatkan informasi bahwa bagi data pengguna internal jumlah item maksimal yang membentuk suatu pola sekuensial adalah 5-sequences, yaitu (home, rendah) (ipb-bhmn, rendah) (ipb-bhmn/akademik, rendah) (id/uploadedpictures, rendah) (id, rendah) dengan nilai fuzzy support tertinggi sebesar 56,66%, sedangkan bagi data pengguna eksternal, yaitu (home, rendah) (id, rendah) bhmn, rendah) bhmn/direktori, rendah) (ipb-bhmn/akademik, rendah) dengan nilai fuzzy support sebesar 64,84%. Hal tersebut menggambarkan pola sekuensial yang sering dilakukan oleh pengguna situs web IPB. Dengan nilai minimum support sebesar 10 %, terdapat delapan halaman yang sering diakses oleh pengguna internal IPB, yaitu halaman home, ipb-bhmn, ipb-bhmn/akademik, ipb-bhmn/others, ipb-bhmn/ipbphoto, id, id/uploaded pictures, dan ipb-bhmn/gallery. Dengan nilai minimum support yang sama yaitu 10%, terdapat tujuh halaman yang sering diakses oleh pengguna eksternal IPB, yaitu halaman home, bhmn, ipb-bhmn/direktori, ipb-bhmn/akademik, ip-bhmn/others, ipb-bhmn/ipbphoto dan id. Web master sebaiknya mengalokasikan link menuju halaman tersebut pada halaman utama serta di antara halaman-halaman pada pola sekuensial yang menggambarkan pola pengaksesan pengguna situs web IPB sehingga memudahkan pengguna dalam mengaksesnya.
4
Judul Skripsi
Nama
NIM
:
:
:
Analisis Pola Kunjungan Pengguna Situs Web IPB
Menggunakan Algoritma Totally Fuzzy
Ayudya Paramita
G64104069
Menyetujui :
Pembimbing I,
Pembimbing II,
Annisa S.Kom., M.Kom.
Heru Sukoco S.Si., M.T.
NIP 132311930 NIP 132282666
Mengetahui :
Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
Dr. drh. Hasim, DEA
NIP 131578806
5
RIWAYAT HIDUP
Penulis dilahirkan pada tanggal 28 Januari 1987 di Jakarta. Penulis merupakan anak pertama dari tiga bersaudara pasangan Dedi Suryadi dan Saryati Kosasih, S.H.
Pada tahun 2004 penulis lulus dari SMA Negeri 2 Bogor. Pada tahun yang sama penulis diterima di Program Studi Ilmu Komputer, Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor melalui jalur Undangan Seleksi Masuk IPB (USMI).
Selama mengikuti perkuliahan, penulis pernah menjadi pengurus Badan Eksekutif Mahasiswa FMIPA tahun kepengurusan 2005/2006. Selain itu, penulis juga pernah menjadi pengurus Himpunan Mahasiswa Ilmu Komputer (HIMALKOM) tahun kepengurusan 2004/2005. Pada tahun 2007, penulis pernah melakukan kegiatan praktik lapang selama dua bulan di Balai Besar Penelitian dan Pengembangan Bioteknologi dan Sumberdaya Genetik Pertanian (BB-BIOGEN).
6
KATA PENGANTAR
Puji syukur penulis panjatkan kepada Allah SWT atas segala rahmat dan karunia-Nya sehingga penulis dapat menyelesaikan tugas akhir dengan judul Analisis Pola Kunjungan Pengguna Situs Web IPB Menggunakan Algoritma Totally Fuzzy. Tugas akhir ini merupakan salah satu syarat untuk memperoleh gelar Sarjana Komputer di FMIPA IPB.
Penghargaan serta rasa terima kasih penulis sampaikan kepada Ibu Annisa, S.Kom., M.Kom. dan Bapak Heru Sukoco, S.Si., M.T. selaku pembimbing yang telah bersedia meluangkan waktu serta memberikan saran dan bimbingannya selama penelitian dan penulisan tugas akhir ini. Penghargaan dan rasa terima kasih juga penulis sampaikan kepada Bapak Endang, S.Kom., M.Kom. yang telah berkenan sebagai moderator dan penguji dalam pelaksanaan seminar dan sidang.
Penulis menyampaikan terima kasih dan penghargaan yang mendalam kepada seluruh keluarga, Bapak, Ibu, dan Adik tercinta yang senantiasa memberikan dukungan moral, doa, kasih sayang, dan perhatian. Penulis menyampaikan terima kasih kepada sahabatku (Venty, Dewi, Alfinda, Zee dan Cindy), Kak Irfan, Ilkom 41 (Tresna, Restu, Ajeng, Imam, Heny, Ferdi, Welly, Syadid, Hany, Anna, Intan, Ingrid, Indri, Mirza dan Noven) dan teman-teman satu bimbingan (Marissa, Iwan, Riza dan Jefry) atas dukungan, motivasi dan masukan yang telah diberikan. Terima kasih kepada teman-teman yang telah membantu selama penulisan tugas akhir dan memberi dukungan ketika seminar dan sidang. Semua teman-teman Ilkom 41 lainnya, terima kasih untuk canda tawa, persahabatan, dan kebersamaan selama kuliah di Ilkom IPB.
Penulis mengucapkan terima kasih kepada seluruh staf pengajar yang telah memberikan wawasan serta ilmu yang berharga selama penulis menuntut ilmu di Departemen Ilmu Komputer. Seluruh staf administrasi dan perpustakaan Departemen Ilmu Komputer FMIPA IPB yang selalu memberi kemudahan dalam mengurus segala macam hal berkaitan dengan perkuliahan, serta pihak-pihak lain yang tidak dapat disebutkan satu-persatu.
Penulis menyadari bahwa karya ilmiah ini masih jauh dari sempurna. Namun penulis berharap semoga karya ilmiah ini dapat memberikan manfaat bagi pembacanya.
Bogor, Januari 2009
7
DAFTAR ISI
Halaman
DAFTAR TABEL... vi
DAFTAR GAMBAR... vi
DAFTAR LAMPIRAN... vii
PENDAHULUAN Latar Belakang ... 1 Tujuan .. ... 1 Ruang Lingkup ... 1 Manfaat Penelitian ... ..1 TINJAUAN PUSTAKA Web mining ... 1
Knowledge Discovery in Database (KDD) ... 2
Association Rule Mining ... 3
Pola Sekuensial ... 3
Himpunan Fuzzy ... 3
Peubah Linguistik ... 3
Fuzzy C-Means ... 4
Fuzzy Cardinality ... 4
Fuzzy Candidate Sequence ... 4
File Log Akses ... 4
Totally Fuzzy ... 5
METODE PENELITIAN Proses Dasar Sistem ... 6
Lingkungan Pengembangan Sistem ... 10
HASIL DAN PEMBAHASAN Pembersihan Data ... 10
Seleksi Data ... 11
Transformasi Data ... 11
Web Mining ... 12
Pembentukan fuzzy support bagi masing-masing halaman situs web ... 12
Pembentukan frequent sequence ... 13
Evaluasi Pola ... 16
Representasi Pengetahuan ... 17
KESIMPULAN DAN SARAN Kesimpulan ... 19
Saran ... 19
DAFTAR PUSTAKA ... 20
LAMPIRAN ... 20
8
DAFTAR TABEL
Halaman
1 Deskripsi format data log akses ... 4
2 Data transaksi customer ... 7
3 Nilai derajat keanggotaan bagi customer 1 dengan nilai ambang batas sebesar 0,3 ... 8
4 Nilai fuzzy support bagi masing-masing item ... 8
5 Jumlah frequent sequence berdasarkan nilai ambang batas dan minimum support (internal) ... 14
6 Jumlah frequent sequence berdasarkan nilai ambang batas dan minimum support (eksternal) ... 15
7 Daftar pola sekuensial yang menarik (data internal) ... 17
8 Daftar pola sekuensial yang menarik (data eksternal) ... 17
9 Daftar fuzzy support yang memiliki nilai di atas 10% dengan threshold 0,3 (data internal) ... 18
10 Daftar fuzzy support yang memiliki nilai di atas 10% dengan threshold 0,3 (data eksternal) ... 18
DAFTAR GAMBAR
Halaman 1 Arsitektur web mining ... 22 Tahapan proses KDD ... 2
3 Algoritma CalcTotallySupport ... 5
4 Diagram alur metode penelitian ... 6
5 (a) Fungsi keanggotaan item Candy ... 7
5 (b) Fungsi keanggotaan item Soda ... 7
5 (c) Fungsi keanggotaan item Toothpaste ... 7
5 (d) Fungsi keanggotaan item Ball ... 7
5 (e) Fungsi keanggotaan item Video game ... 7
6 Proses scanning data customer 1 ... 9
7 (a) Fungsi keanggotaan halaman home bagi data pengguna internal ... 12
7 (b) Fungsi keanggotaan halaman home bagi data pengguna eksternal ... 12
8 (a) Jumlah frequent sequence dengan threshold 0,2 terhadap data pengguna internal ... 13
8 (b) Jumlah frequent sequence dengan threshold 0,4 terhadap data pengguna internal ... 13
8 (c) Jumlah frequent sequence dengan threshold 0,6 terhadap data pengguna internal ... 14
9 (a) Jumlah frequent sequence dengan threshold 0,2 terhadap data pengguna eksternal ... 15
9 (b) Jumlah frequent sequence dengan threshold 0,4 terhadap data pengguna eksternal ... 15
9 (c) Jumlah frequent sequence dengan threshold 0,6 terhadap data pengguna eksternal ... 15
10 Perbandingan waktu eksekusi (data pengguna internal) ... 16
11 Perbandingan waktu eksekusi (data pengguna eksternal) ... 16
12 Antarmuka grafis aplikasi ... 19
9
DAFTAR LAMPIRAN
Halaman
1 Tahapan algoritma Totally Fuzzy ... 22
2 Deskripsi field data log akses ... 23
3 Data yang telah melalui proses pembersihan data ... 24
4 Format data yang telah dikonversi ke dalam bentuk numerik ... 25
5 URL halaman situs web IPB yang telah dikonversi ke dalam bentuk numerik ... 26
6 Nilai fuzzy support bagi masing-masing halaman situs web bagi pengguna internal ... 27
7 Nilai fuzzy support bagi masing-masing halaman situs web bagi pengguna eksternal ... 31
8 Jumlah frequent sequences berdasarkan nilai ambang batas dan minimum support (internal) ... 35
9 Jumlah frequent sequences berdasarkan nilai ambang batas dan minimum support (eksternal) ... 38
1
PENDAHULUAN
Latar Belakang
Pola pengaksesan pengguna terhadap sebuah situs web biasanya tergambarkan dalam sebuah pola sekuensial. Pola sekuensial mengindikasikan bahwa transaksi biasanya terjadi secara serial terhadap waktu. Oleh karena itu, analisis terhadap pola sekuensial didasarkan pada urutan waktu atau urutan terjadinya suatu transaksi.
Salah satu metode yang digunakan untuk mendapatkan tatanan antarmuka dan isi yang strategis adalah sequential pattern mining. Metode tersebut pertama kali diperkenalkan oleh Agrawal & Srikant (1995) dan bertujuan untuk mencari kemunculan suatu item yang diikuti kemunculan item lain secara terurut berdasarkan waktu terjadinya transaksi. Metode ini dapat juga digunakan untuk mengetahui trends dari pengguna terkait pola pengaksesannya terhadap sebuah situs web.
Untuk ”memperhalus” batasan yang tegas yang terdapat pada data yang bernilai numerik maka diterapkan konsep fuzzy pada sequential
pattern mining. Pola tersebut dikarakterisasikan
oleh nilai support, yaitu persentase banyaknya transaksi yang mengikuti aturan tersebut.
Salah satu teknik web mining yang dapat digunakan untuk mengetahui pola sekuensial yaitu Totally Fuzzy. Teknik ini menggunakan metode Thresholded Sigma Count untuk mendapatkan nilai fuzzy cardinality dari tiap-tiap pengguna sebuah situs web (Fiot. C et al 2005). Pada pendekatan ini, masing-masing
fuzzy itemset diperhitungkan dalam proses
komputasi untuk mendapatkan nilai fuzzy
support.
Pemahaman terhadap user preference yang tercatat pada data log akses akan mengarahkan sebuah situs web semakin dekat dengan pengguna dan meningkatkan kualitas sebuah situs web, sehingga secara tidak langsung dapat meningkatkan besarnya kemungkinan sebuah situs web untuk tetap bertahan pada lingkungan bisnis yang kompetitif.
Tujuan Penelitian
Penelitian ini bertujuan untuk melihat trends dari pengguna yang mengakses situs web IPB.
Trends tersebut dapat dilihat berdasarkan
informasi mengenai besarnya beban akses suatu halaman pada situs web IPB. Berdasarkan informasi tersebut pada akhirnya dapat diketahui halaman-halaman yang sering dikunjungi oleh pengguna situs web IPB dan dapat digunakan untuk meningkatkan perancangan situs web berdasarkan pola pemakaian.
Ruang Lingkup Penelitian
Ruang lingkup untuk penelitian ini dibatasi pada penerapan metode Totally Fuzzy pada data log akses server web IPB dari tanggal 5 Januari 2007 hingga 18 Juni 2007. Data tersebut dikelompokkan ke dalam dua bagian, yaitu internal dan eksternal IPB. Analisa dilakukan terhadap kedua kelompok data tersebut. Penelitian ini akan menghasilkan informasi mengenai pola pengaksesan yang dilakukan oleh pengguna.
Manfaat Penelitian
Informasi yang didapatkan pada penelitian ini diharapkan dapat digunakan untuk meningkatkan performa dan perancangan situs web berdasarkan pola pemakaian, perubahan struktur dan rancangan web menjadi lebih strategis, mendapatkan pola akses pengunjung web IPB baik internal maupun eksternal yang mengakses situs web IPB (www.ipb.ac.id) dan mengetahui halaman-halaman situs web IPB yang sering dikunjungi oleh pengguna.
TINJAUAN PUSTAKA
Web mining
Web mining merupakan penerapan
teknik-teknik data mining untuk secara otomatis mengumpulkan dan mengekstrak informasi dari sebuah dokumen web. Web mining merupakan suatu teknik yang dapat membantu pengguna untuk menemukan suatu informasi dari sekumpulan data. Selain itu, web mining mengamati pola akses kunjungan pengguna pada sebuah situs web (Kamber 2006).
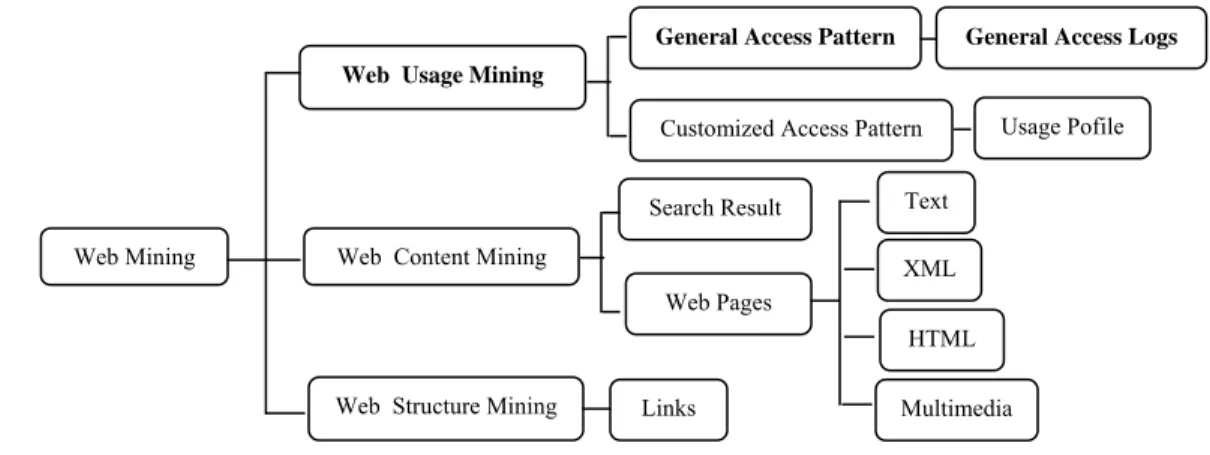
Secara umum web mining diklasifikasikan ke dalam tiga kategori berdasarkan jenis data yang diekstrak, yaitu web usage mining, web content
mining, dan web structure mining. Arsitektur web mining ditunjukkan pada Gambar 1.
2 Deskripsi mengenai masing-masing kategori
tersebut, yaitu : 1. Web usage mining
Web usage mining berusaha menemukan
nilai data berdasarkan pola tingkah laku
web surfer.
2. Web content mining
Menggambarkan proses penemuan informasi yang berasal dari konten, data atau dokumen sebuah web.
3. Web structure mining
Web structure mining mencoba
menemukan sebuah model pada struktur
link sebuah web.
Salah satu bagian dari web usage mining adalah General Access Pattern Tracking (GAPT). Gagasan utama pada GAPT adalah melihat secara umum trends pengguna yang mengakses situs web tersebut.
Informasi yang diperoleh dapat digunakan untuk perancangan ulang sebuah situs web sehingga memudahkan proses pengaksesan yang dilakukan oleh pengguna.
Knowledge Discovery from Data (KDD)
Knowledge Discovery from Data (KDD)
adalah suatu proses mengekstrak ilmu pengetahuan atau informasi yang berasal dari kumpulan data dalam jumlah besar (Kamber 2006). Data mining adalah proses penemuan pengetahuan yang menarik dari kumpulan data yang tersimpan pada basis data, data warehouse dan media penyimpanan informasi lainnya.
Tahapan-tahapan proses KDD diilustrasikan pada Gambar 2.
Gambar 2 Tahapan proses KDD (Han & Kamber 2006).
Deskripsi mengenai tahapan-tahapan tersebut adalah sebagai berikut :
1. Pembersihan data
Pembersihan terhadap data dilakukan untuk menghilangkan noise dan data yang tidak konsisten.
2. Integrasi data
Integrasi data dilakukan untuk menggabungkan data yang berasal dari berbagai sumber.
3. Seleksi data
Proses seleksi data merupakan proses pengambilan data yang relevan dengan proses analisis yang dilakukan.
4. Transformasi data
Data ditransformasikan atau digabungkan ke dalam bentuk yang sesuai untuk
di-mining dengan cara melakukan peringkasan
atau operasi agregasi. 5. Data mining
Merupakan proses yang penting dan merupakan tahapan ketika metode-metode
Data Mining
Knowledge
Gambar 1 Arsitektur web mining.
Web Mining
Web Usage Mining
Web Content Mining
Web Structure Mining
General Access Pattern
Customized Access Pattern Search Result
Web Pages
Links
General Access Logs
Usage Pofile Text
XML HTML Multimedia
3 cerdas diaplikasikan untuk mengekstrak
pola-pola dari kumpulan data. 6. Evaluasi pola
Merupakan suatu proses untuk mengidentifikasikan pola-pola tertentu pada data yang menarik dan mempresentasikan pengetahuan.
7. Representasi pengetahuan
Penggunaan visualisasi dan teknik representasi untuk menunjukkan penemuan pengetahuan hasil proses mining kepada pengguna.
Association Rule Mining
Aturan Asosiasi (association rule) atau analisis afinitas (affinity analysis) berkenaan dengan studi 'apa bersama apa'. Pada dasarnya aturan ini digunakan untuk menggambarkan keterkaitan antar item pada sekumpulan data (Santoso 2007).
Secara umum aturan asosiasi dapat dipandang sebagai proses yang terdiri dari 2 tahap (Kamber 2006), yaitu :
1. Menemukan kumpulan frequent item. Sebuah itemset dikatakan frequent item jika memiliki frekuensi kemunculan minimal sama dengan nilai minimum support.
2. Membangkitkan aturan asosiasi dari itemset yang dikatakan frequent item. Aturan ini harus memenuhi nilai minimum support. • Support
Support bagi suatu aturan asosiasi adalah proporsi banyaknya kejadian pada basis data dimana proporsi sekumpulan item A dan proporsi sekumpulan item B terdapat pada sebuah transaksi. Definisi dari support, yaitu sebagai berikut :
support(A→B) = P(A U B) (1)
Pola Sekuensial
Pola sekuensial adalah daftar urutan dari sekumpulan item. Sebuah pola sekuensial dikatakan maksimal jika tidak mengandung pola sekuensial lainnya (Wang et al 2005). Sebuah pola sekuensial dengan item disebut dengan
k-sequence. Panjang pada sebuah pola sekuensial
adalah jumlah item yang terdapat pada pola sekuensial tersebut dan dilambangkan dengan |s|. Sebuah subsequence s’ dari s dilambangkan dengan s’ ⊆ s. Misalkan, sebuah pola sekuensial
a = <a1a2...an> merupakan subsequence dari b =
<b1b2...bm> jika terdapat integer i1 < i2 < ...in, 1
≤ ik ≤ m, sehingga a1 ⊆ b1, a2 ⊆ b2, ...., an ⊆ bm. Diberikan basis data transaksi D dan ambang batas minimum support ε, maka dapat didefinisikan sequential pattern mining adalah mencari nilai frequent sequence yang maksimal di antara semua pola sekuensial yang mempunyai nilai support lebih besar atau sama dengan ε. Dalam hal ini, waktu terjadinya transaksi juga akan dipertimbangkan dalam pencarian pola sekuensial.
Himpunan Fuzzy
Logika fuzzy merupakan generalisasi dari logika klasik yang hanya memiliki dua nilai keanggotaan, yaitu 0 dan 1. Dalam logika fuzzy nilai kebenaran suatu pernyataan berkisar dari sepenuhnya benar ke sepenuhnya salah. Inti dari himpunan fuzzy, yaitu fungsi keanggotaan yang menggambarkan hubungan antara domain himpunan fuzzy dengan nilai derajat keanggotaan. Hal yang membedakan antara himpunan boolean dan fuzzy, yaitu elemen pada himpunan fuzzy memiliki nilai derajat keanggotaan t (Cox 2005).
Hubungan pada himpunan fuzzy bersifat fungsional karena mengembalikan sebuah derajat keanggotaan untuk nilai yang terdapat pada domain x. Definisi dari derajat keanggotaan sebuah himpunan fuzzy f adalah sebagai berikut :
t = f(s,x) (2)
Peubah Linguistik
Peubah linguistik merupakan sebuah himpunan fuzzy yang membentuk aturan tertentu untuk sebuah variabel dan digunakan pada aturan fuzzy sebagai bagian dari hubungan fuzzy (Cox 2005).
Peubah linguistik dikarakterisasikan oleh
quintaple (x, T(x), X, G, M) dengan x adalah
nama peubah, T(x) adalah kumpulan dari
linguistic term, X adalah nilai interval x, G
adalah aturan sintak yang membangkitkan term dalam T(x), M adalah aturan semantik yang bersesuaian dengan nilai linguistik M(A), dengan M(A) menunjukkan fungsi keanggotaan untuk himpunan fuzzy dalam X. Sebagai contoh, jika frekuensi pengaksesan dipresentasikan
4 sebagai peubah linguistik, maka himpunan dari
linguistic term T(frekuensi akses) menjadi : T(frekuensi akses) = {rendah, sedang, tinggi}
Setiap term dalam T(frekuensi akses) dikarakterisasikan oleh himpunan fuzzy dalam X. Fuzzy C-Means
Fuzzy C-Means merupakan salah satu
metode pengklasteran data, dimana objek dikelompokkan ke dalam k kelompok atau klaster. Untuk melakukan teknik klastering ini, nilai k harus ditentukan terlebih dahulu. Pada teknik ini digunakan ukuran ketidakmiripan dalam mengelompokkan objek-objek tersebut. Ketidakmiripan bisa diterjemahkan dalam konsep jarak (Cox 2005).
Pada Fuzzy C-Means, setiap data bisa menjadi anggota dari beberapa klaster. Sesuai dengan konsep fuzzy yang berarti samar, maka batas-batas klaster dalam Fuzzy C-Means adalah
soft. Dalam Fuzzy C-Means, pusat klaster
dihitung dengan mencari nilai rata-rata dari semua titik dalam suatu klaster dengan diberi bobot berupa tingkat keanggotaan (degree of
belonging) dalam klaster tersebut.
Fuzzy Cardinality
Terdapat tiga metode untuk mengkomputasikan nilai fuzzy cardinality (Fiot
et al. 2005), yaitu :
1. Menghitung semua elemen yang memiliki nilai derajat keanggotaan tidak sama dengan nol.
2. Hanya memperhitungkan elemen yang memiliki nilai derajat keanggotaan lebih besar dari nilai ambang batas (threshold) yang telah didefinisikan.
3. Menambahkan nilai derajat keanggotaan dari masing-masing elemen. Metode perhitungan ini disebut juga Sigma Count. 4. Menambahkan nilai derajat keanggotaan
dari masing – masing elemen yang memiliki nilai lebih besar dari nilai ambang batas (threshold) yang telah ditentukan. Metode penghitungan ini disebut juga Thresholded
Sigma Count.
Fuzzy Candidate Sequence
Untuk membangkitkan suatu elemen kandidat pola sekuensial fuzzy maka harus terlebih dahulu dilakukan proses validasi, yaitu untuk memeriksa apakah dua buah fuzzy item yang terdapat pada sebuah fuzzy itemset tidak menunjuk pada sebuah atribut yang sama (Fiot
et al 2005).
Langkah awal yang harus dilakukan adalah menghitung nilai fuzzy support bagi masing-masing item dan hanya item yang memiliki nilai support lebih besar dari nilai minimum
support yang akan disimpan sebagai frequent sequence dengan nilai k berukuran satu.
Kandidat pola sekuensial dengan ukuran k, dikatakan sebagai k-sequence, diperoleh dengan mengkombinasikan frequent sequence dengan ukuran k-1. Proses tersebut akan berhenti jika tidak memungkinkan lagi untuk membangkitkan kandidat pola sekuensial dengan ukuran k+1. File Log Akses
Pengelolaaan server web secara efektif membutuhkan feedback atau aktivitas kinerja
server serta permasalahan-permasalahan yang
mungkin terjadi. Feedback ini dapat berupa informasi mengenai pengguna-pengguna yang mengakses situs web, apa yang diakses dan statusnya serta waktu pengaksesan. Informasi tersebut tersimpan pada server web terutama data log akses (Purnomo & Anindito 2006).
Common Log Format (CLF) untuk setiap
baris data pada log akses, yaitu :
remotehost rfc931 authuser [date] ”request” status bytes
Tabel 1 Deskripsi format data log akses Field Deskripsi
Remotehost Nama host atau alamat IP dari pengguna yang mengakses situs web.
rfc931 User name dari pengguna pada remote system seperti yang
dispesifikasikan pada RFC931.
Authuser Username yang melakukan
otentifikasi seperti yang dispesifikasikan pada RFC931. [date] Informasi tanggal dan waktu
saat melakukan request HTTP pewaktuan lokal.
5 Field Deskripsi
”request” Informasi HTTP request dari
pengguna.
Status Angka numerik yang
menyatakan kode status dari HTTP yang dikirimkan kepada pengguna.
Bytes Panjang bytes dari data yang dikirimkan kepada pengguna. Sumber : http://www-group.slac.stanford.edu
/techpubs/logfiles/info.html Totally Fuzzy
Diberikan sebuah basis data transaksi D yang berisi data yang mencatat transaksi yang dilakukan customer. Misalkan T adalah sekumpulan transaksi. Masing-masing transaksi meliputi tiga informasi : customer-id, waktu terjadinya transaksi, dan sekumpulan item. Sebuah itemset, (i1,i2,...,ik), merupakan himpunan bagian I = {i1,i2,..,im}. Sebuah pola sekuensial s merupakan himpunan item yang tidak kosong, yang dilambangkan dengan <s1s2...sp>. Secara umum, support bagi sebuah pola sekuensial adalah persentase customer yang memiliki s pada transaksi yang dilakukannya.
Sebuah fuzzy item didefinisikan sebagai hubungan antara sebuah item dengan sebuah
fuzzy set yang bersesuaian. Sebuah fuzzy item
dinotasikan dengan (x,α) dimana x merupakan sebuah item dan α merupakan fuzzy set dari item yang bersangkutan. Misalkan, (/php/tutor.htm,
lot) adalah sebuah fuzzy item dengan lot
merupakan sebuah fuzzy set yang didefinisikan oleh suatu derajat keanggotaan (membership
degree) pada pengaksesan item /php/tutor.htm.
Sebuah fuzzy itemset adalah himpunan fuzzy
item. Sebuah fuzzy itemset dinotasikan dengan
(X,A) dengan X menunjukkan kumpulan item dan A kumpulan dari fuzzy set dari item yang bersangkutan. Sebuah fuzzy sequence S = <s1... sn> adalah sebuah pola sekuensial yang terdapat pada fuzzy itemset, misalkan [(/php/tutor.htm,
lot) (/php/faq.php, little) (/php/functions.php, lot)].
Cara untuk mengkomputasikan nilai fuzzy
cardinality pada algoritma Totally Fuzzy adalah
dengan menggunakan metode Thresholded
Sigma Count (Fiot. C et al 2005). Nilai derajat
keanggotaan μα suatu atribut t pada domain x dinotasikan dengan μα(t[x]) dan nilai ambang
batas (threshold) dinotasikan dengan ω. Nilai derajat keanggotaan αa pada algoritma Totally Fuzzy didefinisikan sebagai berikut :
(3)
Formulasi penghitungan nilai Support
Totally Fuzzy (STF) bagi seorang customer c,
yaitu :
(4)
Nilai fuzzy support Fsupp bagi sebuah fuzzy
sequence dikomputasikan sebagai rasio jumlah customer yang memiliki pola sekuensial fuzzy
tertentu pada transaksi yang dilakukannya dibandingkan dengan jumlah total customer C pada basis data.
(5)
Derajat nilai sebuah fuzzy support STF(c,gS)
mengindikasikan bahwa pada transaksi yang dilakukan oleh seorang customer c terdapat
fuzzy sequence gS. Derajat nilai fuzyy support
dikomputasikan dengan menggunakan algoritma
CalcTotallySupport seperti yang ditunjukkan
pada Gambar 3. CalcTotallySupport
– Input : gS, candidate k-sequence;
Output : Fsupp fuzzy support for the sequence gS;
Fsupp, nbSupp,m 0;
For each customer client c Є C do m FindTotallySeq(g-S, Tc)
[the customer support degree is aggregated to
the current support]
nbSupp += m; End for
Fsupport nbSupport/T;
Return Fsupp;
Gambar 3 Algoritma CalcTotallySupport. Untuk menentukan sebuah frequent sequence, nilai minimum support ditentukan terlebih dahulu oleh pengguna. Sebuah pola sekuensial
fuzzy dikatakan frequent sequence jika
memenuhi kondisi bahwa support (s) > minSupp.
α
a(t[x]) =
{
μ 0 else a (t[x]) if μa(t[x]) > ωΣ
cєC Fsupp(X,A) =___________
C
[ S
TF(c,gS)]
STF (c, (X,A)) = [x, a] Є (X, A) [ αa (tj[x]) ] j = 1 θc6 Gagasan utama dari sequential pattern mining
adalah untuk menemukan semua pola sekuensial yang memiliki nilai support lebih besar dari nilai
minimum support yang diberikan (Fiot. C et al
2005). Diagram alir metode Totally Fuzzy secara lengkap dapat dilihat pada Lampiran 1.
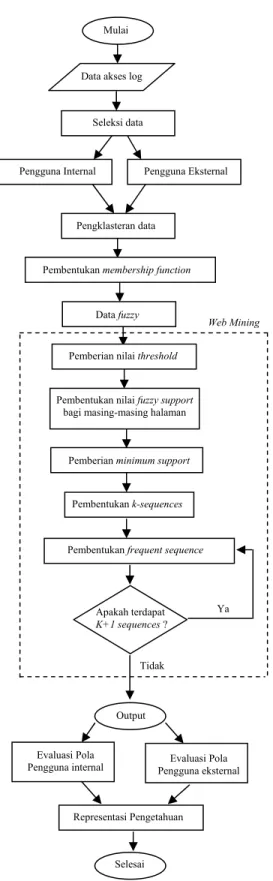
METODE PENELITIAN Proses Dasar Sistem
Proses dasar sistem mengacu pada proses dalam Knowledge Discovery from Data (KDD). Algoritma Totally Fuzzy diterapkan pada tahap
web mining. Diagram alur metode penelitian
dapat dilihat pada Gambar 4. Tahapan KDD tersebut dapat diuraikan sebagai berikut : 1. Pembersihan data
Data yang mencatat kode status selain 200 tidak akan diikutsertakan pada tahap selanjutnya. Kode status 200 mengindikasikan bahwa request berhasil dilakukan dan dikirimkan dari server web kepada pengguna.
2. Seleksi data
Pada tahap seleksi data dilakukan pemilihan atribut data yang dibutuhkan sebagai masukkan yang digunakan dalam tahap web mining. Terdapat tiga buah atribut yang akan digunakan yaitu : remotehost / alamat IP, date / tanggal pengaksesan yang dilakukan pengguna dan URL yang diminta oleh pengguna. Selanjutnya dilakukan pemisahan data yang mencatat
request dari pengguna yang berasal dari internal
dan eksternal IPB. 3. Transformasi data
Data diubah ke dalam bentuk yang sesuai sebagai masukkan bagi algoritma Totally
Fuzzy. Data tersebut dikelompokkan
berdasarkan alamat IP masing-masing pengguna, selanjutnya diurutkan secara menaik berdasarkan waktu pengaksesannya.
Sebagai ilustrasi tahapan algoritma Totally
Fuzzy maka akan digunakan kumpulan data
transaksi seperti yang ditunjukkan pada Tabel 2, sel yang kosong menunjukkan bahwa customer tidak melakukan pembelian terhadap item yang bersangkutan. Notasi Cn digunakan untuk
melambangkan customer dan d digunakan untuk melambangkan hari pada saat customer tersebut melakukan pembelian produk.
Web Mining
Gambar 4 Diagram alur metode penelitian.
Data akses log Mulai
Seleksi data
Pengguna Eksternal
Pengklasteran data
Pembentukan membership function
Data fuzzy
Pemberian nilai threshold
Pembentukan nilai fuzzy support bagi masing-masing halaman
Pemberian minimum support
Pembentukan k-sequences Ya Tidak Evaluasi Pola Pengguna internal Representasi Pengetahuan Apakah terdapat K+1 sequences ? Selesai Output
Pembentukan frequent sequence
Evaluasi Pola Pengguna eksternal Pengguna Internal
S haru data func met bagi Gam akhi yang 0 0 0 0 1 0 0 0 0 1 Su 0 0 Sebelum melal us diubah terle a fuzzy. Fung ction) didapa ode Fuzzy C i masing-mas mbar 5(a), 5( irnya didapatk g memiliki nila 0 0.2 0.4 0.6 0.8 1 1.2 0 0.2 0.4 0.6 0.8 1 1.2 T umber : Fiot. Mini little 1 2 1 ,5 1 1 ,5 little Customer D C1 d d d d d C2 d d d d C3 d d d d d C4 d d d d d d
lui tahap minin ebih dahulu k gsi keanggotaa
atkan dengan
C-Means. Fung
sing item dit (b), 5(c), 5(d) kan data dala
ai yang berkisa 1 1 Tabel 2 Data t C et al. Spee ing. Technical 2 3 4 Candy 5 (a) 2 3 4 Soda lot 5 (b) Date Candy d1 2 d2 1 d3 4 d4 d5 d1 2 d2 d3 d4 3 d1 d2 3 d3 d4 d5 d1 d2 d3 2 d4 d5 d6 ng, data terseb ke dalam bentu an (membersh n menerapk gsi keanggota tunjukkan pa dan 5(e). Pa m bentuk fuz ar antara 0 dan transaksi custo
edy, Mini and
Report 5035, h lot 5 5 Item Toothpaste 3 4 1 2 2 but uk hip an an da da zzy n 1. omer Totally Fuzzy: http://ww.lirmm ms Soda Ball 1 1 1 5 2 1 2 1 4 2 3 2 0 0.2 0.4 0.6 0.8 1 1.2 0 0.2 0.4 0.6 0.8 1 1.2 0 0.2 0.4 0.6 0.8 1 1.2 : Three Ways f m.fr. 1 1 0.5 little m 1 1 0,5 few 1 1 0,5 few Gambar 5 (a Fungsi keang Videogame 2 3 5 4 1 1 1
for Fuzzy Sequ
2 3 4 Toothpaste 5 (c) medium 2 3 4 lot Ball 5 (d) 2 3 4 medium Videogame a), 5 (b), 5 (c), ggotaan masin 5 (e) . uential Pattern 5 lot 5 t 5 lot 5 (d) dan 5 (e) ng-masing item 7 ns ) m.
8 Tabel 3 merupakan konversi data yang
terdapat pada Tabel 2 ke dalam bentuk derajat keanggotaan fuzzy. Fungsi keanggotaan tersebut dibentuk berdasarkan data yang terdapat pada basis data transaksi. Setiap nilai atau frekuensi pengaksesan memiliki nilai derajat keanggotaan tertentu terhadap masing-masing fuzzy set.
Pada penelitian ini nilai k atau fuzzy set akan ditentukan terlebih dahulu, yaitu frekuensi pengaksesan rendah, sedang dan tinggi.
4. Web Mining
Tahap ini merupakan inti untuk melakukan analisis terhadap data. Pada tahap ini diterapkan penggunaan algoritma Totally Fuzzy yang diperkenalkan oleh Celine Fiot, Anne Laurent dan Maguelonne Teisseire (2005).
Tahapan-tahapan yang akan digunakan pada metode tersebut, yaitu:
a. Menentukan nilai ambang batas (threshold) ώ terhadap data. Sebagai ilustrasi pengguna menentukan nilai ambang batas ώ sebesar 0,2 , maka nilai derajat keanggotaan yang lebih kecil dari 0,2 tidak diperhitungkan dan bernilai 0.
b. Penerapan algoritma Totally Fuzzy bagi masing-masing kandidat pola sekuensial yang terbentuk, yaitu :
1. Dilakukan proses pembentukan kandidat pola sekuensial yang hanya mengandung sebuah item atau
1-sequence. Proses komputasi dilakukan
dengan menggunakan Thresholded Sigma
Count. Nilai fuzzy support bagi item
berukuran satu ditunjukkan pada Tabel 4. Nilai tersebut didapatkan dengan menggunakan algoritma Totally Fuzzy.
Hanya pola sekuensial yang merupakan frequent sequence yang akan diikutsertakan dalam tahap selanjutnya. Misalkan ditentukan nilai minimum support sebesar 55 %, maka hanya item [candy,
little], [toothpaste, medium], [soda, lot],
[videogame, medium] dan [videogame, lot] yang merupakan frequent sequence dan diikutsertakan dalam proses pembentukan kandidat item berukuran dua.
2 Pada tahap ini selanjutnya akan dilakukan proses scanning data untuk memeriksa apakah pada transaksi yang dilakukan oleh tiap pengguna terdapat
item yang merupakan item pertama
pada kandidat pola sekuensial yang dicari. Jika ya, maka dilakukan proses pembentukan sebuah path baru. Masing-masing path menyimpan tiga buah informasi yaitu : item pada pola sekuensial yang telah ditemukan (Seq),
item yang selanjutnya akan dicari
(curIS), dan nilai derajat keanggotaan (curDeg). Hanya path yang memiliki nilai derajat keanggotaan yang paling tinggi yang akan disimpan.
Items
Candy (%) Toothpaste (%) Soda (%) Ball (%) Videogame (%) li L li m L li L f L f m L 87,5 50 25 62,5 37,5 25 100 25 50 0 62,5 67,5
Tabel 4 Nilai fuzzy support bagi masing-masing item
D
Items
Candy Toothpaste Soda Ball Videogame li L li m L li L f L f m L d1 1 0 d2 1 0 0 0,5 0,5 0,5 0,5 d3 0 1 0,5 0,5 d4 0,5 0,5 0 1 d5 0 1 0 1 0
Tabel 3 Nilai derajat keanggotaan bagi customer 1 dengan nilai ambang batas sebesar 0,3
Keterangan :
li : little, L : lot, m: medium, f : few
Keterangan :
9 <([candy,little])([soda,lot])>, ø ,[0,75]) <([candy,little])([soda,lot])>, ø ,[1]) d1 pth1 pth1 : updated <([candy,little])>,([soda,lot]),[1]) d2 pth1 : updated & closed <([candy,little])([soda,lot])>, ø ,[0,75]) pth2 : created <([candy,little])>,([soda,lot]),[1]) d3 pth1 : deleted pth2 : updated & closed d4 pth2 : not changed d5 pth2 : improved pth2 : return of curDeg
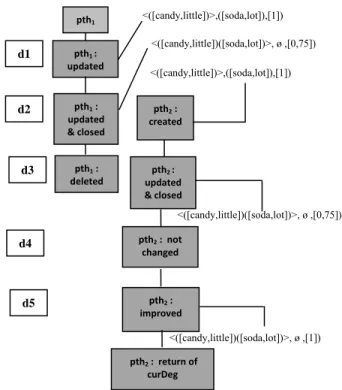
Sebagai ilustrasi penerapan algoritma Totally
Fuzzy, maka akan dilakukan proses komputasi
pada data transaksi seperti yang terdapat pada Tabel 3 untuk mendapatkan nilai fuzzy support terhadap kandidat pola sekuensial gS = <([candy,little]),([soda,lot]) bagi customer 1.
Sebagai langkah awal yang harus dilakukan yaitu proses inisialisasi untuk membentuk sebuah path kosong pth1 = (ø,([candy,little]), 0).
Pth1 bernilai 0 karena belum dilakukan proses scanning terhadap data transaksi.
Langkah-langkah proses scanning data menggunakan algoritma Totally Fuzzy adalah sebagai berikut :
• Pada transaksi d1 : lakukan proses update pada path pth1, karena transaksi pada d1
terdapat ([candy,little]) yang merupakan
item pertama pada kandidat pola sekuensial
yang dicari, sehingga pth1 saat ini bernilai pth1 = (<([candy, little])>, ([soda, lot]), [1]).
• Pada transaksi d2 : lakukan proses pembentukan sebuah path baru pth2 =
(<([candy, little])>,([soda, lot]), [1]). • Selanjutnya lakukan proses update pada
pth1 karena ([soda, lot]) yang merupakan curIS pada pth1 terdapat pada transaksi d2,
sehingga pth1 saat ini bernilai pth1 =
(<([candy, little])([soda, lot]), ø, [0,75]). Nilai curDeg pada pth1 saat ini didapatkan
dari nilai curDeg pth1 sebelum proses update dijumlahkan dengan nilai derajat
keanggotaan ([soda, lot]) pada transaksi d2, kemudian dicari nilai rataannya. Saat ini
curDeg pada pth1 bernilai 0,75. Pth1 ditutup
(path closed) karena telah mengandung semua item pada itemset pola sekuensial yang dicari.
• Pada transaksi d3 : lakukan proses update pada pth2 karena [soda,lot] yang merupakan curIS pada pth2 terdapat pada transaksi d3,
sehingga pth2 saat ini bernilai pth2=(<([candy,little])([soda,lot])>,ø,[0,75]
). Pth2 ditutup karena telah mengandung
semua item pada itemset pola sekuensial yang dicari.
• Untuk optimasi proses scanning terhadap datanya, maka untuk dua path yang telah lengkap (path tersebut telah mencakup semua itemset pada pola sekuensial yang dicari), hanya satu path yang memiliki nilai derajat keanggotaan terbesar yang akan disimpan. Karena pth1 dan pth2 memiliki
nilai yang sama. Maka hanya salah satu dari
path tersebut yang akan dibuang. Misalkan,
nilai pada pth1 yang dibuang, maka nilai
pada pth2 yang akan mewakili besarnya
derajat keanggotaan customer 1 terhadap pola sekuensial ([candy, little], [soda, lot)].
Gambar 6 Proses scanning data customer 1.
• Pada transaksi d5 : Terdapat [soda,lot] yang memiliki nilai lebih tinggi yaitu 1, sehingga terjadi proses improved terhadap nilai
curDeg pada pth2. Nilai pth2 yang
sebelumnya bernilai 0,75 mengalami peningkatan menjadi 1. Nilai tersebut berasal dari nilai [candy, little] yang terdapat pada transaksi d1 dijumlahkan dengan nilai [soda, lot] yang terdapat pada transaksi d5, kemudian dicari nilai rataannya. Selanjutnya proses scanning data dilanjutkan seperti ditunjukkan pada Gambar 6.
• Lakukan langkah-langkah diatas bagi masing-masing customer. Nilai fuzzy
cardinality bagi masing-masing customer
dijumlahkan kemudian dibagi dengan jumlah total customer pada basis data transaksi sehingga didapatkan nilai persentase fuzzy support bagi kandidat pola sekuensial <([candy, little]),([soda, lot])> sebesar 93,75 %.
10 3 Nilai fuzzy support bagi frequent
sequence dengan ukuran k diperoleh
dengan mengkombinasikan frequent
sequence dengan ukuran k-1. Proses
ini akan berhenti jika tidak memungkinkan lagi untuk membangkitkan kandidat pola sekuensial dengan ukuran k+1. Tahapan algoritma Totally Fuzzy secara lengkap dapat dilihat pada Lampiran 1.
5. Analisis Pola
Pada tahap ini akan dianalisis pola sekuensial mana yang dikatakan frequent
sequence dan mewakili pola pengaksesan
pengguna.
6. Representasi pengetahuan
Pola sekuensial yang telah ditemukan kemudian dipresentasikan kepada pengguna agar mudah dipahami dan diinterpretasikan. Lingkungan Pengembangan Sistem
Spesifikasi perangkat keras dan perangkat lunak yang digunakan dalam pengembangan sistem adalah sebagai berikut :
a. Perangkat keras dengan spesifikasi : • Processor : Intel(R) Core(TM) 2 Duo • Memory : 1 GB
• Harddisk : 160 GB
• Monitor 12.1” WXGA dengan resolusi 1024 x 768 pixel
• Alat input : mouse dan keyboard b. Perangkat lunak yang digunakan :
• Sistem Operasi : Microsoft Windows XP Professional dan Linux Ubuntu Feasty Fawn 7.10
• Microsoft Excel 2007 sebagai lembar kerja (worksheet) dalam pengolahan data. • Matlab 7.0.1 sebagai bahasa
pemrograman.
• GAWK sebagai media yang digunakan untuk praproses data.
HASIL DAN PEMBAHASAN
Data yang digunakan dalam penelitian ini adalah data log akses server web situs web IPB (www.ipb.ac.id). Data tesebut merupakan data pada server web IPB selama periode waktu 5 Januari hingga 18 Juni 2007 yang diperoleh
dalam bentuk file Common Log Format (CLF). Deskripsi data tersebut dapat dilihat pada Lampiran 2.
Sebelum di-mining, data harus melewati tahap praproses (preprocessing) terlebih dahulu yang meliputi pembersihan data, transformasi data, dan seleksi data. Hal ini dilakukan agar data benar-benar lengkap, valid, dan sesuai dengan masukkan yang dibutuhkan oleh algoritma.
Pembersihan Data
Pada tahap ini dilakukan proses pembersihan terhadap data, data yang dibuang dan tidak diikutsertakan dalam tahap berikutnya, yaitu : 1. Data yang mencatat request terhadap
resource data citra, yaitu jpg, png dan gif
yang berukuran < 6 KB. Data citra yang berukuran > 6 KB dianggap merupakan sebuah konten dari halaman situs web dan bukan data yang hanya merupakan data pelengkap dari sebuah halaman situs web. 2. Data yang mencatat proses request terhadap
data css, emz, ico, js, robots, swf, vbs, cgi, exe dan template.
3. Data yang mencatat kode status 401, 403, dan 404. Kode status 401, 403, dan 404 menunjukkan bahwa terjadi kegagalan (failed) dalam proses request. Kode status 401 menunjukkan bahwa terjadi kegagalan dalam proses autentifikasi, kode status 403 menunjukkan bahwa terdapat suatu larangan tertentu dalam proses request (forbidden request) terhadap subdirektori yang diminta oleh pengguna, dan kode status 404 menunjukkan bahwa file yang diminta oleh pengguna tidak ditemukan pada server (file not found).
Data yang diikutsertakan dalam tahap selanjutnya, yaitu :
1. Data yang mencatat kode status 200. Kode status 200 mengindikasikan bahwa request berhasil dilakukan dan server web mengirimkan halaman situs yang diminta kepada pengguna.
2. Data yang mencatat request terhadap sebuah halaman situs web.
Pada tahap ini dihasilkan koleksi data yang valid dan sesuai dengan input yang dibutuhkan oleh algoritma Totally Fuzzy. Setelah dilakukan proses pembersihan data maka diperoleh data
11 bersih sebanyak 2.268.596 record yang terdiri
atas 25.162 record yang berasal dari pengguna internal dan 2.243.434 record yang berasal dari pengguna eksternal. Contoh data yang telah melalui tahap pembersihan data ditunjukkan pada Lampiran 3.
Seleksi Data
Koleksi data log akses server web IPB yang tersedia kemudian diseleksi untuk mendapatkan data yang akan di-mining.
Prosedur yang dilakukan pada tahap seleksi data adalah sebagai berikut :
1. Memilih tiga atribut dari tujuh atribut yang tersedia. Pada log akses tercatat tujuh buah atribut. Namun atribut yang akan digunakan sebagai masukkan bagi algoritma Totally
Fuzzy hanya tiga atribut, yaitu remotehost /
alamat IP, date atau tanggal terjadinya proses pengaksesan, dan URL yang diakses oleh pengguna.
2. Melakukan pemisahan data yang mencatat
request dari pengguna yang berasal dari
internal dan eksternal IPB. Untuk dapat mengetahui bahwa request tersebut berasal dari internal maupun eksternal IPB dapat dilihat dari remotehost / alamat IP server
proxy masing-masing pengguna. Alamat IP
dari server proxy kelompok pengguna yang berasal dari internal IPB, yaitu berkisar di antara 10.x.x.x s/d 10.255.255.255 (class A), 172.16-18.x.x s/d 172.32.x.x (class B), 192.168.0.0 s/d 192.168.255.255 (class C) dan 118.97.49.x, sedangkan alamat IP dari
proxy selain alamat IP dari server proxy
yang termasuk ke dalam kelompok pengguna internal akan dianggap sebagai kelompok pengguna eksternal.
Transformasi Data
Pada tahap ini dilakukan beberapa proses transformasi data, yaitu :
1. Proses konversi format data yang sesuai untuk digunakan sebagai masukkan algoritma. Data yang semula terdapat dalam bentuk Common Log Format (CLF) kemudian ditransformasikan terlebih dahulu ke dalam format text (*.txt) dan selanjutnya diubah ke dalam format data Microsoft Excel (*.xlsx). Data dalam format *.xlsx inilah yang kemudian akan digunakan
sebagai masukkan bagi algoritma Totally
Fuzzy.
2. Data dikelompokkan berdasarkan alamat IP masing-masing pengguna. Kemudian data diurutkan berdasarkan hari pengaksesan serta dilakukan penghitungan banyaknya pengaksesan terhadap masing-masing halaman situs web bagi tiap pengguna. Setelah melalui tahapan tersebut maka untuk kelompok pengguna internal terdapat 572 baris data dengan 54 alamat IP yang berbeda, sedangkan untuk kelompok pengguna eksternal terdapat sebanyak 393.622 baris data dengan 30.269 alamat IP yang berbeda.
3. Proses konversi atribut ke dalam bentuk numerik. Atribut tanggal yang semula berformat date ditransformasikan ke dalam bentuk numerik (datenum). Selain itu, alamat IP dan URL dinotasikan ke dalam bentuk numerik dengan kode yang bersifat unik. Format data tersebut dapat dilihat pada Lampiran 4 dan 5. Hal tersebut dilakukan agar lebih sederhana dan mempermudah proses komputasi terhadap data. Alamat IP dikonversikan ke dalam bentuk numerik dengan menggunakan rumus sebagai berikut :
(5) Simbol w, x, y dan z menggambarkan digit pada alamat IP yang dipisahkan oleh tanda titik. Nilai maksimum w, x ,y dan z adalah 255, yang menunjukkan nilai maksimum digit angka pada alamat IP. 4 Data ditransfomasi ke dalam bentuk
himpunan fuzzy yang memiliki nilai berkisar antara 0 dan 1. Pada tahap ini digunakan metode Fuzzy C-Means untuk membentuk fungsi keanggotaan. Fungsi keanggotaan tersebut dibentuk berdasarkan data yang diperoleh bagi masing-masing halaman situs web. Masing-masing halaman situs web dipartisi ke dalam tiga fuzzy set, yaitu yang memiliki frekuensi pengaksesan rendah, sedang dan tinggi. Dari data tercatat 41 halaman situs web yang diakses oleh pengguna internal dan 48 halaman situs web yang diakses pengguna eksternal. Bagi masing-masing halaman situs web tersebut akan dibentuk fungsi keanggotaan (membership function) sehingga didapatkan nilai derajat keanggotaan bagi
12 masing frekuensi pengaksesan. Gambar 7(a)
dan 7(b) menunjukkan fungsi keanggotaan halaman home bagi data pengguna internal dan eksternal.
Gambar 7(a) dan 7(b) adalah fungsi keanggotaan halaman home bagi data pengguna internal dan eksternal. Web Mining
Tahapan web mining diterapkan dengan menggunakan metode Totally Fuzzy (Fiot. C et
al 2005) untuk membentuk semua kemungkinan frequent sequence. Secara garis besar, proses ini
dibagi menjadi 2 bagian, yaitu melakukan proses komputasi untuk mendapatkan nilai fuzzy
support bagi masing-masing fuzzy item dan
hanya item dengan nilai support lebih besar dari nilai minimum support yang akan disimpan sebagai frequent sequence berukuran satu. Kemudian melakukan proses pembentukan kandidat pola sekuensial berukuran k yang didapatkan dari kombinasi frequent sequence berukuran k-1.
Proses tersebut akan berhenti jika tidak memungkinkan lagi untuk melakukan proses pembentukan kandidat pola sekuensial berukuran k+1. Percobaan dilakukan terhadap dua kelompok data, yaitu pengguna internal dan eksternal IPB yang telah mengakses situs web IPB (www.ipb.ac.id) dan telah melewati tahapan praproses (data internal sebanyak 25.162 record
dan data eksternal sebanyak 112.140 record). Dalam pengambilan data eksternal diterapkan metode Simple Random Sampling. Hal ini dikarenakan jumlah data pengguna eksternal yang tersedia dalam jumlah yang besar dan terdapat keterbatasan dalam perangkat lunak yang digunakan.
Pada data pengaksesan pengguna eksternal di antara 5 Januari hingga 18 Juni 2007 dengan selang waktu satu minggu dilakukan pengambilan data hanya pada hari dengan jumlah pengguna terbanyak (ditunjukkan dari banyaknya jumlah alamat IP pengguna yang berbeda pada data per hari). Alamat IP yang berbeda diasumsikan sebagai pengguna yang berbeda. Kemudian dilakukan proses analisis terhadap data yang mencatat request terhadap situs web IPB hingga hierarki level tiga. Pembentukan fuzzy support bagi masing-masing halaman situs web
Sebagai langkah awal pengguna harus terlebih dahulu menentukan nilai ambang batas (threshold). Nilai ambang batas (threshold) digunakan untuk menyaring data pada basis data
fuzzy, sedangkan nilai minimum support
digunakan untuk menyaring nilai fuzzy support bagi masing-masing pola sekuensial setelah dilakukan proses komputasi menggunakan algoritma Totally Fuzzy. Nilai derajat
keanggotaan yang bernilai lebih kecil dari nilai ambang batas tidak akan diperhitungkan. Metode ini dikenal juga sebagai Thresholded
Sigma Count.
Selanjutnya dilakukan proses komputasi bagi masing-masing halaman situs web dengan menggunakan algoritma Totally Fuzzy sehingga didapatkan nilai persentase pengaksesan bagi masing-masing halaman situs web dengan kategori pengaksesan rendah, sedang dan tinggi. • Data Pengguna Internal IPB
Data hasil percobaan didapatkan dengan penerapan algoritma Totally Fuzzy pada data pengguna internal IPB yang mengakses situs web IPB (www.ipb.ac.id) dengan time
constraint sekitar 6 bulan. Pada data log akses
situs tersebut tercatat 41 halaman web yang diakses oleh pengguna. Percobaan dilakukan terhadap beberapa nilai ambang batas di antara 0,1 hingga 0,6 dengan penambahan nilai ambang batas sebesar 0,05. Nilai fuzzy support 0 0.2 0.4 0.6 0.8 1 1.2 1 0 0.2 0.4 0.6 0.8 1 1.2 1 0,5 1 1 1,5 2 2,5 3 3,5 4 7 (a)
rendah sedang tinggi
1
0,5
5 10 15 20 25 7 (b)
13 terhadap masing-masing halaman web
berdasarkan nilai ambang batas secara lengkap dapat dilihat pada Lampiran 6.
Dari data hasil percobaan menunjukkan bahwa hanya delapan halaman yang memiliki nilai fuzzy support di atas 10% dengan nilai ambang batas sebesar 0,3 yaitu halaman 10 (home), halaman 11 (ipb-bhmn), halaman 18 bhmn/akademik), halaman 21 (ipb-bhmn/others), halaman 22 (ipb-bhmn/ipbphoto), halaman 28 (id/), halaman 34 (id/uploadpictures) serta halaman 54 (ipb-bhmn/gallery) .
Halaman-halaman tersebut merupakan halaman yang sering diakses oleh pengguna situs web IPB yang berasal dari ruang lingkup internal IPB karena memiliki nilai fuzzy support yang cukup besar dibandingkan halaman lainnya. • Data Pengguna Eksternal IPB
Percobaan dilakukan terhadap data pengguna eksternal IPB yang mengakses situs web IPB (www.ipb.ac.id) dengan time constraint sekitar 6 bulan. Dari data yang tercatat pada data log akses situs web tersebut tercatat 48 halaman yang diakses oleh pengguna.
Data hasil percobaan didapatkan dengan penerapan algoritma Totally Fuzzy dengan beberapa nilai ambang batas di antara 0,1 hingga 0,6 dengan penambahan nilai ambang batas sebesar 0,05. Nilai fuzzy support terhadap masing-masing halaman web berdasarkan nilai ambang batas secara lengkap dapat dillihat pada Lampiran 7.
Dari data hasil percobaan menunjukkan bahwa hanya tujuh halaman yang memiliki nilai
fuzzy support di atas 10%, yaitu halaman 10
(home), halaman 11 (ipb-bhmn), halaman 12 bhmn/direktori), halaman 18 (ipb-bhmn/akademik), halaman 21 (ipb-bhmn/others), halaman 22 (ipb-bhmn/ipbphoto), dan halaman 28 (id/).
Pembentukan frequent sequence
Pada tahap ini, metode sequential pattern
mining diterapkan untuk membentuk semua
kemungkinan frequent sequences dengan menggunakan algoritma Totally Fuzzy. Sebuah
sequence berukuran k merupakan kombinasi dari sequence berukuran k-1.
• Data Pengguna Internal IPB
Dilakukan percobaan terhadap data pengguna internal IPB yang tercatat pada data log akses server web situs web IPB dengan
time constraint sekitar 6 bulan. Pengujian dilakukan dengan minimum support dari 3% hingga 56% serta variasi nilai ambang batas dari 0,1 hingga 0,6 dengan penambahan sebesar 0,05. Grafik yang menunjukkan jumlah frequent
sequence yang terbentuk dengan threshold
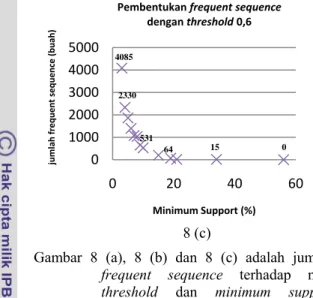
sebesar 0,2 , 0,4 dan 0,6 serta beberapa variasi nilai minimum support dapat dilihat pada Gambar 8 (a), 8 (b) dan 8 (c).
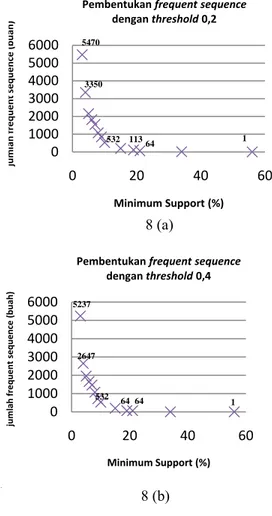
Dari grafik pada Gambar 8 (a), 8 (b) dan 8 (c), jumlah maksimal frequent sequences yang terbentuk adalah 5.470, 5.237 dan 4.085 buah pada posisi minimum support 3%. Nilai
minimum support tertinggi hingga masih
terdapat frequent sequence yang terbentuk adalah 56% dengan nilai ambang batas sebesar 0,2 dan 0,4 yaitu 1-sequence sebanyak satu buah. 0 1000 2000 3000 4000 5000 6000 0 20 40 60 jumlah frequent sequence ( buah) Minimum Support (%) Pembentukan frequent sequence dengan threshold 0,2 0 1000 2000 3000 4000 5000 6000 0 20 40 60 jumla h frequent sequence (buah) Minimum Support (%) Pembentukan frequent sequence dengan threshold 0,4 1 1 64 64 113 64 532 532 3350 5470 2647 5237 8 (b) 8 (a)
14
Pada beberapa minimum support yang digunakan pada saat percobaan, ternyata
frequent sequence tidak terbentuk. Hal ini
disebabkan karena tidak adanya 2-sequences yang terbentuk. Tidak terbentuknya 2-sequences disebabkan oleh semua 2-sequences hasil penggabungan dari kombinasi 1-sequence mempunyai nilai fuzzy support lebih rendah dari nilai minimum support.
Nilai fuzzy support 1-sequence tertinggi pada setiap nilai threshold umumnya berkisar di antara 55-56% yang didapatkan dari proses komputasi sequence (10 2) atau halaman home dengan kategori pengaksesan rendah. Hal ini dikarenakan halaman home pada situs web IPB sudah mencakup semua link menuju informasi
yang diinginkan oleh pengguna dan untuk mengakses menu lain umumnya pengguna harus melewati halaman home ini terlebih dahulu. Nilai fuzzy support berdasarkan nilai ambang batas dan minimum support secara lengkap dapat dilihat pada Lampiran 8.
Berdasarkan data hasil percobaan pada Tabel 5 dapat dilihat bahwa semakin besar nilai
minimum support yang diberikan maka akan
semakin sedikit jumlah maksimal frequent
sequences yang terbentuk. Banyaknya
maksimal item yang dapat dibentuk pada sebuah
sequence adalah lima buah (5-sequences), yaitu
terbentuk ketika diberikan nilai minimum
support sebesar 15%. Hal tersebut menunjukkan
bahwa terdapat paling banyak lima halaman yang diakses oleh pengguna internal IPB secara sekuensial. Contoh 5-sequences yang terbentuk adalah [(10 2) (11 2) (18 2) (34 2) (28 2)] dengan nilai fuzzy support sebesar 56,30%. • Data Pengguna Eksternal IPB
Data hasil percobaan didapatkan dari penerapan algoritma Totally Fuzzy pada data pengguna eksternal IPB yang mengakses situs web IPB (www.ipb.ac.id) dengan time
constraint sekitar 6 bulan dapat dilihat pada
lampiran 9. Percobaan dilakukan dengan
minimum support dari 14% hingga 65% serta
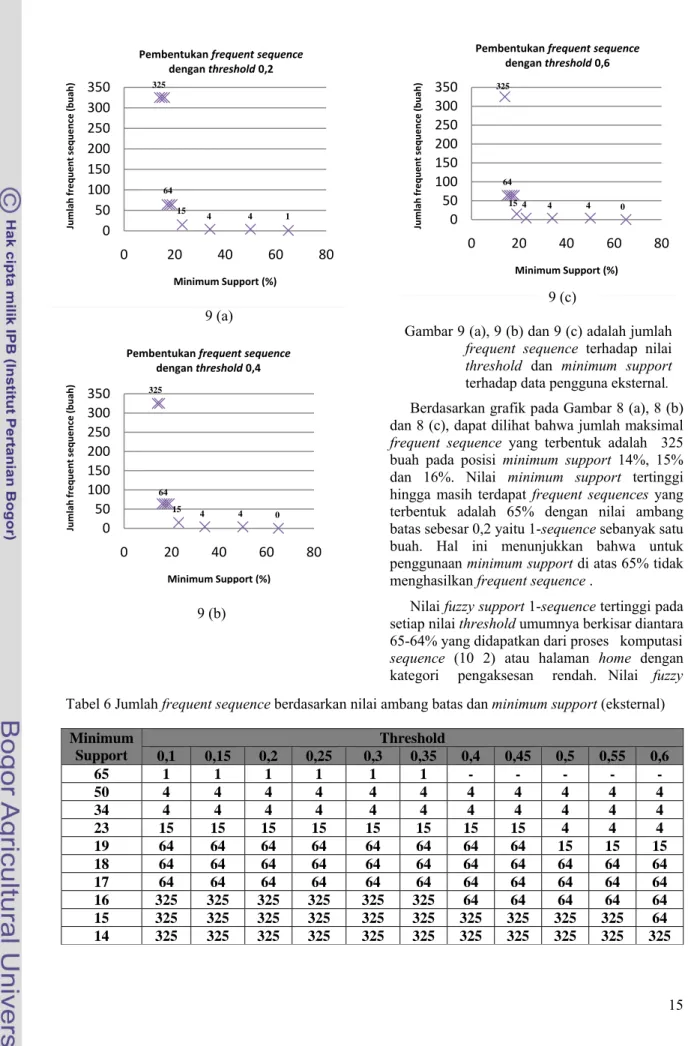
variasi nilai ambang batas dari 0,1 hingga 0,6 dengan penambahan sebesar 0,05. Gambar 9 (a), 9 (b) dan 9 (c) menggambarkan jumlah frequent
sequence yang terbentuk berdasarkan nilai
ambang batas dan minimum support. 0 1000 2000 3000 4000 5000 0 20 40 60 jumla h frequent sequence (buah) Minimum Support (%) Pembentukan frequent sequence dengan threshold 0,6 Minimum Support Threshold 0,1 0,15 0,2 0,25 0,3 0,35 0,4 0,45 0,5 0,55 0,6 56 1 1 1 1 1 1 1 1 - - - 34 15 15 15 15 15 15 15 15 15 15 15 21 64 64 64 64 64 64 64 64 64 64 15 19 113 113 113 113 113 113 64 64 64 64 64 15 200 200 200 200 200 200 200 200 200 200 200 10 532 532 532 532 532 532 532 532 531 531 531 9 845 846 777 780 717 784 720 720 653 716 653 8 1.149 1.146 1.076 1.072 998 1.149 1.074 1.153 1.150 1.003 1.036 7 1.553 1.384 1.545 1.458 1.546 1.468 1.467 1.554 1.385 1.303 1.076 6 1.814 1.631 1.816 1.723 1.817 1.652 1.652 1.743 1.564 1.479 1.396 5 2.152 1.957 2.153 2.055 2.150 2.052 1.958 2.058 1.867 1.959 1.864 4 3.590 3.214 3.350 3.043 3.362 2.866 2.647 2.721 2.505 2.613 2.330 3 5.465 5.025 5.470 4.997 5.474 4.944 5.237 4.996 4.894 5.183 4.085
Tabel 5 Jumlah frequent sequence berdasarkan nilai ambang batas dan minimum support (internal) Gambar 8 (a), 8 (b) dan 8 (c) adalah jumlah
frequent sequence terhadap nilai threshold dan minimum support
terhadap data pengguna internal 0 15 64 531 2330 4085 8 (c)
15 Minimum Support Threshold 0,1 0,15 0,2 0,25 0,3 0,35 0,4 0,45 0,5 0,55 0,6 65 1 1 1 1 1 1 - - - 50 4 4 4 4 4 4 4 4 4 4 4 34 4 4 4 4 4 4 4 4 4 4 4 23 15 15 15 15 15 15 15 15 4 4 4 19 64 64 64 64 64 64 64 64 15 15 15 18 64 64 64 64 64 64 64 64 64 64 64 17 64 64 64 64 64 64 64 64 64 64 64 16 325 325 325 325 325 325 64 64 64 64 64 15 325 325 325 325 325 325 325 325 325 325 64 14 325 325 325 325 325 325 325 325 325 325 325 9 (a) 9 (b)
Berdasarkan grafik pada Gambar 8 (a), 8 (b) dan 8 (c), dapat dilihat bahwa jumlah maksimal
frequent sequence yang terbentuk adalah 325
buah pada posisi minimum support 14%, 15% dan 16%. Nilai minimum support tertinggi hingga masih terdapat frequent sequences yang terbentuk adalah 65% dengan nilai ambang batas sebesar 0,2 yaitu 1-sequence sebanyak satu buah. Hal ini menunjukkan bahwa untuk penggunaan minimum support di atas 65% tidak menghasilkan frequent sequence .
Nilai fuzzy support 1-sequence tertinggi pada setiap nilai threshold umumnya berkisar diantara 65-64% yang didapatkan dari proses komputasi
sequence (10 2) atau halaman home dengan
kategori pengaksesan rendah. Nilai fuzzy 0 50 100 150 200 250 300 350 0 20 40 60 80 Jumlah frequent sequence ( buah) Minimum Support (%) Pembentukan frequent sequence dengan threshold 0,2 0 50 100 150 200 250 300 350 0 20 40 60 80 Jumlah frequent sequence ( buah) Minimum Support (%) Pembentukan frequent sequence dengan threshold 0,4 0 50 100 150 200 250 300 350 0 20 40 60 80 Jumlah frequent sequence ( buah) Minimum Support (%) Pembentukan frequent sequence dengan threshold 0,6
Tabel 6 Jumlah frequent sequence berdasarkan nilai ambang batas dan minimum support (eksternal) Gambar 9 (a), 9 (b) dan 9 (c) adalah jumlah
frequent sequence terhadap nilai threshold dan minimum support
terhadap data pengguna eksternal. 325 64 15 4 4 1 325 64 15 4 4 0 325 64 4 4 4 15 0 9 (c)
16
support berdasarkan nilai ambang batas dan minimum support secara lengkap dapat dilihat
pada Lampiran 9.
Dengan menerapkan algoritma Totally Fuzzy ternyata jumlah maksimal item yang dapat dibentuk pada sebuah pola sekuensial adalah lima buah (5-sequences). Hal ini menunjukkan bahwa jumlah halaman yang diakses oleh pengguna eksternal secara sekuensial adalah paling banyak lima halaman. Contoh
5-sequences yang terbentuk adalah [(10 2) (28 2)
(12 2) (11 2) (18 2)] dengan nilai fuzzy support sebesar 64,84%.
Berdasarkan data pada Tabel 6 diperoleh informasi bahwa peningkatan nilai threshold ternyata tidak terlalu mempengaruhi jumlah
frequent sequence yang terbentuk kecuali untuk
pembentukan 1-sequence. Variasi jumlah
frequent sequence yang terbentuk lebih
dipengaruhi oleh variasi nilai minimum support . Waktu eksekusi yang diperlukan untuk membentuk frequent sequence sangat
dipengaruhi oleh nilai ambang batas dan
minimum support yang digunakan.
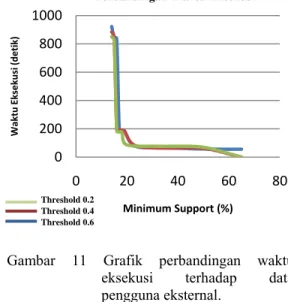
Perbandingan waktu eksekusi yang diperlukan untuk membentuk frequent sequence dari seluruh percobaan yang telah dilakukan dapat dilihat pada Gambar 10 dan 11.
Gambar 11 Grafik perbandingan waktu eksekusi terhadap data pengguna eksternal.
Menurut Gambar 10 dan 11, semakin tinggi nilai minimum support yang digunakan maka semakin cepat waktu yang diperlukan untuk membentuk frequent sequence. Hal ini disebabkan semakin besar nilai minimum
support maka akan semakin sedikit sequence
yang membentuk frequent sequence sehingga waktu komputasi untuk pembentukan frequent
sequence akan semakin cepat. Jumlah pola
sekuensial yang semakin sedikit disebabkan oleh banyaknya pola sekuensial yang memiliki nilai
fuzzy support di bawah nilai minimum support
yang digunakan. Selain itu, juga diperoleh informasi bahwa semakin besar nilai ambang batas yang diberikan maka akan semakin cepat waktu yang digunakan untuk membentuk
frequent sequence.
Hal tersebut disebabkan karena makin sedikitnya jumlah data yang memiliki nilai di atas nilai ambang batas yang ditentukan.
Evaluasi Pola
Seluruh frequent sequence yang dihasilkan pada tahap web mining kemudian dievaluasi untuk mendapatkan pola sekuensial. Evaluasi dilakukan dengan mencari frequent sequence yang maksimal dari seluruh frequent sequences yang ada. Suatu pola sekuensial dikatakan maksimal jika pola sekuensial tersebut tidak termuat pada pola sekuensial lainnya.
Dari seluruh pola sekuensial yang terbentuk diambil pola sekuensial yang memiliki nilai 0 50 100 150 200 250 300 350 400 0 20 40 60 Waktu Eksekusi (d et ik) Minimum Support (%) Perbandingan Waktu Eksekusi
0 200 400 600 800 1000 0 20 40 60 80 Waktu Eksekusi (d et ik) Minimum Support (%) Perbandingan Waktu Eksekusi
Gambar 10 Grafik perbandingan waktu eksekusi terhadap data pengguna internal. Threshold 0.2 Threshold 0.4 Threshold 0.6 Threshold 0.2 Threshold 0.4 Threshold 0.6