Abstrak—Prediksi kebangkrutan adalah hal yang penting
dilakukan dalam penentuan keputusan suatu perusahaan. Dengan kemampuan komputasi yang semakin memadai, prediksi kebangkrutan bisa dilakukan dengan teknik penggalian data berdasarkan variabel-variabel prediktor, seperti aset, laba, dan rugi dari perusahaan tersebut. Sebuah studi yang dilakukan oleh Li & Sun [1] mengusulkan model prediksi kebangkrutan. Model tersebut adalah Bagging Nearest Neighbor Support Vector Machine (BNNSVM). Studi ini bertujuan untuk mengembangkan
perangkat lunak menggunakan model BNNSVM untuk prediksi kebangkrutan. BNNSVM adalah metode yang menggabungkan metode klasifikasi k-nearest neighbor, support vector machine,
dan bagging. Berdasarkan uji coba yang dilakukan, perangkat
lunak yang dikembangkan terbukti mampu melakukan prediksi kebangkrutan. Hal ini ditunjukkan oleh akurasi prediksi tertinggi yang mencapai 86.23%.
Kata Kunci—bagging, BNNSVM, k-nearest neighbor,prediksi
kebangkrutan, support vector machine. I. PENDAHULUAN
ALAM menjalankan bisnis, sebuah perusahaan bisa mendapat banyak keuntungan atau justru bisa mengalami kerugian. Di saat persaingan bisnis semakin ketat seperti yang terjadi sekarang ini, prediksi kebangkrutan adalah hal yang penting dilakukan agar nasib perusahaan dan karyawannya bisa ditentukan. Perusahaan memiliki data seperti total aset, inventori, laba, dan rugi yang dapat mencerminkan kondisi perusahaan. Dari data tersebut, dapat diprediksi apakah perusahaan masih akan berjalan lancar atau akan mengalami kebangkrutan. Dengan kemampuan komputasi yang semakin memadai, prediksi kebangkrutan bisa dilakukan dengan metode penggalian data berdasarkan variabel-variabel prediktor dari perusahaan tersebut.
Sampai saat ini, sudah banyak metode yang ditawarkan untuk menyelesaikan permasalahan prediksi kebangkrutan. Salah satu di antaranya adalah penggunaan metode k-nearest neighbor. Akan tetapi, K-nearest neighbor memiliki kekurangan dalam hal sensitivitas terhadap outlier dan pemilihan nilai k acak.
Pada beberapa kasus prediksi, tak terkecuali prediksi kebangkrutan, data latih yang digunakan memiliki noise dan outlier sehingga menyebabkan model klasifikasi tidak stabil dan rentan terjadi overfitting.
Salah satu metode untuk prediksi kebangkrutan yang
diusulkan untuk memperbaiki kelemahan metode yang sudah ada adalah metode yang berbasis Nearest Neighbor Support Vector Machine [1]. Pada implementasinya, algoritma bagging (bootstrap aggregating) akan diintegrasikan dengan metode Nearest Neighbor Support Vector Machine menjadi metode Bagging Nearest Neighbor Support Vector Machine (BNNSVM) [1].
Tujuan dari studi ini adalah mengembangkan perangkat lunak yang mengimplementasikan metode Bagging Nearest Neighbor Support Vector Machine [1] untuk prediksi kebangkrutan. Hasil implementasi kemudian diuji coba dengan membandingkan hasilnya terhadap metode klasifikasi lain. Dengan adanya implementasi ini, diharapkan perusahaan dapat mencegah atau setidaknya mendapat peringatan awal terhadap risiko kebangkrutan.
Artikel ini tersusun sebagai berikut. Metode Bagging Nearest Neighbor Support Vector Machine dijelaskan pada Bagian II. Desain perangkat lunak, yang terdiri dari desain data dan desain proses, dijelaskan pada Bagian III. Implementasi dari desain perangkat lunak, berupa implementasi struktur data dan struktur proses, dijelaskan pada Bagian IV. Selanjutnya pada Bagian V dijelaskan mengenai pengujian sistem dan analisisnya. Terakhir, kesimpulan dari implementasi BNNSVM untuk prediksi kebangkrutan dijelaskan di Bagian VI.
II. METODOLOGI
Bagging Nearest Neighbor Support Vector Machine (BNNSVM) merupakan gabungan dari tiga metode yaitu k-nearest neighbor, support vector machine, dan bootstrap aggregating.
A. K-Nearest Neighbor
Pada permasalahan klasifikasi, diberikan sebuah himpunan data [2]
( ) ( ) ( ) (1) dengan x adalah himpunan nilai atribut dari sebuah record data dan y adalah kelas atau kategori data tersebut. Dimisalkan terdapat suatu data yang tidak diketahui kategorinya, maka kategori data tersebut dapat ditentukan dengan mengambil kategori atau kelas terbanyak dari k data terdekatnya pada himpunan data D. Metode klasifikasi ini disebut dengan
k-Pengembangan Perangkat Lunak Prediktor
Kebangkrutan Menggunakan Metode
Bagging
Nearest Neighbor Support Vector Machine
Mohamat Ulin Nuha, Isye Arieshanti, dan Yudhi Purwananto
Jurusan Teknik Informatika, Fakultas Teknologi Informasi, Institut Teknologi Sepuluh Nopember (ITS) Jl. Arief Rahman Hakim, Surabaya 60111
E-mail: [email protected]
nearest neighbor (KNN).
Untuk melakukan klasifikasi dengan k-nearest neighbor dibutuhkan tiga parameter yaitu himpunan data, jarak antar data, dan nilai k. Nilai k di sini adalah jumlah data nearest neighbor yang akan dicari Salah satu cara untuk menghitung jarak antar data [2].
Salah satu cara untuk menghitung jarak dari dua data adalah dengan Euclidean distance. Rumusan Euclidean distance dari data p dan q adalah
( ) √∑ ( ) (2)
dengan pidan qi masing-masing adalah nilai atribut dari data p dan data q dan n adalah jumlah atribut dari masing-masing data [2].
Pada studi ini, KNN tidak digunakan untuk membuat model klasifikasi melainkan untuk mendapatkan data latih baru dari data latih asal.
B. Support Vector Machine
Support vector machine (SVM) adalah metode klasifikasi yang bekerja dengan cara mencari hyperplane dengan margin terbesar [2]. Hyperplane adalah garis batas pemisah data antar-kelas, sedangkan margin adalah jarak antara hyperplane dengan data terdekat pada masing-masing kelas. Adapun data terdekat dengan hyperplane pada masing-masing kelas inilah yang disebut support vector [2].
Suatu permasalahan klasifikasi linier dengan data latih
dan kelas label dirumuskan pada [2]:
( ) ( ) (3) fungsi hyperplane SVM didefinisikan sebagai berikut [2]:
( ) (4) Nilai w adalah koefisien vektor dan b adalah nilai bias.
Hyperplane yang dicari adalah hyperplane dengan nilai margin terbesar. Memaksimalkan margin dapat dilakukan dengan menyelesaikan persamaan berikut [2]:
‖ ‖
(5)
dengan konstrain
(( ) )
dengan xi adalah data latih, yi adalah kelas label, w dan b adalah parameter yang dicari nilainya.
Pada kasus klasifikasi linier SVM ketika terdapat data yang tidak dapat dikelompokkan dengan benar (nonseparable case), rumusan SVM ditambah dengan adanya variabel slack. Persamaan 5 kemudian diubah menjadi berikut [2]
‖ ‖ ∑
(6)
dengan konstrain
( ( ))
Pada Persamaan 6, ξi adalah variabel slack. Variabel slack digunakan untuk memberikan penalti terhadap data yang tidak memenuhi persamaan hyperplane (( ) ) .
Untuk meminimalkan nilai variabel slack, pada rumusan diberikan penalti dengan menambahkan nilai costC. Nilai cost C dipilih untuk mengontrol keseimbangan antara nilai margin dan error klasifikasi. Semakin besar nilai C, maka penalti yang diberikan terhadap data error juga semakin besar [3]. ||
Permasalahan optimisasi nilai w dan b pada Persamaan 5 dapat diselesaikan dengan cara transformasi persamaan ke dalam bentuk dual. Terlebih dahulu, Persamaan 5 diubah menjadi fungsi Lagrangian [2]
( ) ‖ ‖ ∑ ( (( ) )) (7)
dengan α adalah Lagrange multiplier yang bernilai non-negatif. Solusi permasalahan optimisasi dengan fungsi di atas adalah dengan meminimalkan fungsi L(w,b,α) terhadap variabel w dan b. Meminimalkan fungsi L(w,b,α) terhadap w dan b dapat dilakukan dengan mencari derivatif atau turunan pertama dari fungsi tersebut terhadap w dan b sebagai berikut [2]
( )
∑ (8) ( )
∑ (9)
Dengan mensubstitusi Persamaan 8 dan 9 ke dalam persamaan primal SVM pada Persamaan 7, didapatkan persamaan dual SVM berikut [2]
∑ ∑ (10)
Selanjutnya, formulasi SVM dalam bentuk dual adalah sebagai berikut [3]
∑ ∑
(11)
dengan konstrain
( ) ; ∑ .
Konstrain pada Persamaan 11 berlaku untuk kasus klasifikasi linier SVM dengan data yang dapat dikelompokkan ke dalam kelas yang benar (separable case). Adapun untuk kasus nonseparable case, konstrain tersebut diubah menjadi [2]. Decision function klasifikasi linier SVM ditunjukkan pada persamaan berikut [2]:
( ) ( ) ((∑ ) ) (12)
Masalah dalam domain dunia nyata (real world problem) pada umumnya jarang yang dapat dipisahkan secara linier (linearly separable). Untuk menyelesaikan permasalahan nonlinier, SVM dimodifikasi dengan memasukkan fungsi kernel. Pada klasifikasi nonlinier SVM, data x dipetakan oleh fungsi Φ(x) ke ruang vektor dengan dimensi yang lebih tinggi. Pada ruang vektor yang baru, hyperplane linier yang memisahkan kedua kelas dapat dibuat [2].
Algoritma SVM pada klasifikasi nonlinier mirip pada klasifikasi linier kecuali bahwa dot product xi.xj pada Persamaan 11 diganti dengan fungsi kernel K.
Fungsi kernel K adalah sebuah fungsi sedemikian sehingga untuk semua xi, xj ϵ X
( ) ( ) ( ) (13) dengan Φ adalah pemetaan dari input spaceX ke feature space F berdimensi lebih tinggi [3].
Ada banyak fungsi kernel yang bisa digunakan. Beberapa fungsi kernel yang biasanya dipakai adalah kernel Polynomial dan kernel RBF. Fungsi kernel Polynomial adalah sebagai berikut [4]:
( ) ( ) (14) dengan γ adalah parameter gamma, cnadalah koefisien kernel dan d adalah degree atau derajat polynomial. Adapun fungsi kernel RBF adalah sebagai berikut [4]:
( ) ( ) (15) dengan γadalah parameter gamma pada fungsi RBF.
Dengan penerapan fungsi kernel, persamaan optimisasi SVM dapat diubah menjadi [4]:
(16)
dengan konstrain
Pada Persamaan 16 di atas, e adalah vektor dengan anggota bernilai 1, , C adalah nilai cost, dan Q adalah kernel matrix ( ).
Dengan menggunakan hubungan primal-dual, didapatkan persamaan w dan b optimum sebagai berikut [2]:
∑ ( ) (17) { (∑ ( ) ( ) ) } (18)
dan decision function klasifikasi nonlinier SVM yang sebagai berikut [2]:
( ) ( ( ) )
(∑ ( ) ( ) ) (19) Pada studi ini, model klasifikasi SVM dibuat dengan bantuan library LIBSVM [5].
C. Bootstrap Aggregating
Bagging (bootstrap aggregating) adalah salah satu metode ensemble yang cara kerjanya adalah membuat beberapa sampel data baru dari data latih asli. Sampel data dipilih secara acak berdasarkan distribusi uniform. Sampel data dibuat dengan cara sampling with replacement, yaitu beberapa record pada data latih yang sudah pernah diambil untuk satu sampel data bisa diambil lagi untuk sampel data tersebut, atau dengan kata lain pada satu sampel data bisa terdapat record yang nilainya sama. Sampel himpunan data baru yang dihasilkan disebut dengan bootstrap sample. Masing-masing bootstrap sample yang dihasilkan kemudian dilatih untuk menghasilkan model klasifikasi [2].
Hasil prediksi dari beberapa model klasifikasi tersebut digabungkan untuk mendapatkan prediksi akhir. Pada regresi, hasil akhir didapatkan dengan menggabungkan model dan merata-rata output, sedangkan pada klasifikasi, hasil akhir
didapatkan dengan voting atau memilih kelas terbanyak pada hasil klasifikasi m model [2].
Bagging dapat mengurangi variance dari base classifier atau model klasifikasi yang dibuat dengan data latih asli. Performa bagging bergantung pada kestabilan base classifier. Jika base classifier tidak stabil, bagging dapat mengurangi galat yang disebabkan oleh fluktuasi pada data latih. Namun jika base classifier sudah stabil, bagging tidak mampu meningkatkan performa base classifier secara signifikan. Karena masing-masing record memiliki peluang sama untuk bisa terpilih pada sampel data, bagging tidak berfokus pada record tertentu pada data latih. Dengan demikian, hasil model dengan bagging tidak rentan terhadap model overfitting ketika diterapkan pada data yang ber-noise [2].
D. Bagging Nearest Neighbor Support Vector Machine Tahapan prediksi dengan metode Nearest Neighbor Support Vector Machine (NNSVM) adalah sebagai berikut [1]:
1.Data latih dibagi menjadi data trs (train set) dan data ts (test set) melalui proses cross validation.
2.Masing-masing record pada data ts dicari k-nearest neighbor-nya pada data trs. Himpunan data k-nearest neighbor ini disebut dengan ts_nns_bd.
3.Membuat model klasifikasi dari data ts_nns_bd. Model klasifikasi yang dihasilkan disebut dengan NNSVM. 4.Melakukan prediksi data uji dengan model NNSVM.
Algoritma bagging kemudian diintegrasikan pada model NNSVM sehingga menghasilkan model BNNSVM. Dengan demikian, tahapan prediksi dengan metode BNNSVM adalah sebagai berikut [1]:
1.Membuat 10 base training set baru dari data trs dengan jumlah record sama dengan jumlah record pada data trs. Base training set dibuat dengan cara sampling with replacement.
2.Membuat 10 model NNSVM dari 10 base training set yang dibuat pada tahap 1.
3.Membuat prediksi data uji dengan 10 model NNSVM yang telah dibuat.
4.Untuk masing-masing record pada data uji, dilakukan voting terhadap hasil prediksi yang didapatkan pada tahap sebelumnya.
5.Prediksi akhir didapatkan dari hasil voting. Jika hasil voting untuk kelas positif dan kelas negatif sama, prediksi akhir dari record tersebut adalah kelas negatif.
III. DESAINPERANGKATLUNAK
Tujuan dari studi ini adalah membuat perangkat lunak yang mengimplementasikan metode BNNSVM. Oleh karena itu, perlu dibuat desain perangkat lunak berupa desain data dan desain proses.
A. Desain Data
Perancangan data merupakan hal yang penting untuk diperhatikan agar perangkat lunak beroperasi dengan benar. Data yang dibutuhkan dalam membangun perangkat lunak untuk proses implementasi terdiri dari data masukan dan data keluaran.
Data masukan untuk perangkat lunak yang dibangun adalah Wieslaw dataset [4] dan Australian credit approval dataset [5]. Wieslaw dataset adalah data kebangkrutan dari 130 perusahaan selama periode tahun 1997-2001 sedangkan Australian credit approval adalah data persetujuan kartu kredit yang bisa didapatkan di UCI Machine Learning Repository. Adapun keterangan dari Wieslaw dataset dan Australian credit approval dataset dapat dilihat pada Tabel 1.
Data keluaran untuk perangkat lunak ini terdiri dari data keluaran tahap latih dan data keluaran tahap uji. Data keluaran tahap latih berupa model klasifikasi BNNSVM. Adapun data keluaran data uji berupa hasil prediksi, yaitu positif dan negatif. Hasil prediksi positif berarti data tersebut tergolong data yang termasuk tidak bangkrut (Wieslaw dataset) atau data kredit yang disetujui (Australian credit approval). Adapun hasil prediksi negatif berarti data tersebut tergolong data yang termasuk bangkrut atau data kredit yang ditolak.
B. Desain Proses
Proses prediksi kebangkrutan dengan BNNSVM terdiri dari dua tahap yaitu tahap latih dan tahap uji. Tahap latih adalah tahap pembelajaran yang dilakukan oleh sistem terhadap data latih. Masukan dari tahap ini adalah data latih dan keluarannya adalah model klasifikasi. Adapun tahap uji merupakan tahapan prediksi data uji berdasarkan model klasifikasi yang telah dibuat. Sebelum memasuki tahap latih dan tahap uji, dataset dibagi menjadi data latih dan data uji dengan metode cross validation.
Tahap latih terdiri dari beberapa bagian yaitu:
1.Data latih dibagi menjadi data trs (train set) dan data ts (test set) melalui proses cross validation.
2.Membuat 10 base training set baru dari data trs. Base training set dibuat dengan cara sampling with replacement. 3.Masing-masing record pada data ts dicari k-nearest
neighbor-nya pada data 10 base training set. Dengan demikian akan terbentuk 10 himpunan data k-nearest neighbor.
4.Membuat model klasifikasi support vector machine dari 10 himpunan data k-nearest neighbor. Model yang dihasilkan disebut dengan model BNNSVM. Pada pembentukan model BNNSVM, parameter yang ditentukan pengguna adalah jumlah cross validation, jumlah nearest neighbor, nilai cost SVM, jenis kernel SVM, nilai gamma untuk kernel RBF, dan nilai degree untuk kernel Polynomial.
Tahap uji juga terdiri dari beberapa bagian yaitu:
1.Melakukan prediksi data uji dengan 10 model BNNSVM. 2.Untuk masing-masing record pada data uji, dilakukan
voting terhadap hasil prediksi yang didapatkan pada tahap sebelumnya.
3.Menentukan prediksi akhir berdasarkan hasil voting.
Tabel 1.
Keterangan Wieslaw Dataset dan Australian Credit Approval Dataset
Dataset Jumlah Record Jumlah Atribut
Wieslaw 240 30
Australian credit approval 690 14
IV. IMPLEMENTASI
Implementasi prediksi kebangkrutan dengan metode BNNSVM dilakukan dengan bahasa pemrograman Java dan IDE Netbeans 7.0. Implementasi ini terdiri dari dua bagian yaitu implementasi struktur data dan implementasi proses. A. Implementasi Struktur Data
Struktur data yang digunakan pada perangkat lunak ini adalah struktur data buatan bernama Vector dan Dataset. Kelas Vector merepresentasikan satu record pada dataset. Adapun kelas Dataset merepresentasikan keseluruhan record pada dataset. Kelas Dataset berisi linked list dari kelas Vector. B. Implementasi Proses
Implementasi proses atau logika pada perangkat lunak yang dibuat dilakukan pada beberapa kelas yaitu kelas Bagging, NearestNeighbor, SVMTraining, dan SVMTesting. Adapun fungsi-fungsi utama pada empat kelas tersebut adalah sebagai berikut
public static Dataset[] bootstrapping(Dataset dataset) {
int ds_size = dataset.size(); Dataset[] bootstrap = new Dataset[baseNumber];
Vector vector;
for (int i = 0; i < getBaseNumber(); i++) { Dataset ds = new Dataset();
ds.setHeader(dataset.getHeader()); int[] random = randomize(ds_size); for (int j = 0; j < ds_size; j++) { vector = dataset.getVector(random[j]); ds.addVector(vector); } bootstrap[i] = ds; } return bootstrap; }
Gambar 1. Kode sumber fungsi boostrapping pada kelas Bagging
public static Dataset getKNearestNeighbors(Vector testing, Dataset training, int k) {
HashMap<Integer, Double> distance = new HashMap<Integer, Double>();
for (int i = 0; i < training.size(); i++) { Double dist = countEuclideanDistance(testing, training.getVector(i)); distance.put(i, dist); } LinkedList<Integer> topKDistances = getTopKDistances(distance, k);
Dataset kNearestNeighbors = new Dataset(); for (int i = 0; i < topKDistances.size(); i++) { Vector v = training.getVector(topKDistances.get(i)); kNearestNeighbors.addVector(v); } return kNearestNeighbors; }
Gambar 2. Kode sumber fungsi getKNearestNeighbors pada kelas NearestNeighbor
private void train() throws IOException {
parse_parameter(kernel, cost, degree, gamma, filename);
read_problem();
model = svm.svm_train(prob, param);
svm.svm_save_model(model_file_name, model); }
Gambar 3. Kode sumber fungsi train pada kelas SVMTraining private void test(String testingfile, String modelfile, String outputfile) {
int i, predict_probability = 0; input = new BufferedReader(new FileReader(testingfile));
DataOutputStream output = new
DataOutputStream(new BufferedOutputStream(new FileOutputStream(outputfile)));
svm_model model =
svm.svm_load_model(modelfile); predict(input, output, model, predict_probability);
input.close(); output.close(); }
Gambar 4. Kode sumber fungsi predict pada kelas SVMTesting public static LinkedList<Double>
aggregating(LinkedList<LinkedList<Double>> output) {
LinkedList<Double> predicted = new
LinkedList<Double>(); int positive; int negative; int hsize = output.size();
int vsize = output.get(0).size(); for (int i = 0; i < vsize; i++) { positive = 0; negative = 0; for (int j = 0; j < hsize; j++) {
if (output.get(j).get(i)==1.0) positive++; else negative++;
}
if (positive > negative) predicted.add(1.0); else predicted.add(-1.0);
}
return predicted; }
Gambar 5. Kode sumber fungsi aggregating pada kelas Bagging V. PENGUJIANSISTEM A. Evaluasi Hasil Prediksi
Fungsi yang digunakan untuk evaluasi hasil prediksi pada studi ini adalah fungsi akurasi. Akurasi didapatkan dengan membandingkan jumlah data yang terprediksi benar dengan jumlah semua data.
Penjelasan lebih lanjut mengenai fungsi akurasi dapat dilihat pada confusion matrix berikut
Tabel 2.
Confusion Matrix Hasil Prediksi Kelas Aktual Positif Negatif Kelas
Prediksi Negatif Positif False Negative (FN) True Positive (TP) True Negative (TN) False Positive (FP)
Rumusan untuk akurasi adalah
(20)
B. Skenario Pengujian Sistem
Pengujian sistem prediksi kebangkrutan terdiri dari beberapa skenario yaitu:
1. Uji coba dengan nilai parameter k pada k-nearest neighbor yang berbeda-beda.
2. Uji coba dengan nilai parameter cost SVM yang berbeda-beda.
3. Uji coba dengan kernel Polynomial dan nilai degree yang berbeda-beda.
4. Uji coba dengan kernel RBF dan nilai gamma yang berbeda-beda.
5. Uji coba perbandingan dengan metode klasifikasi lain C. Hasil
Berikut adalah hasil pengujian sistem terhadap Wieslaw dataset dan Australian credit approval dataset dengan lima skenario uji coba di atas.
Gambar 6 menunjukkan hasil uji coba dengan nilai k pada k-nearest neighbor yang berbeda-beda. Sumbu x menyatakan nilai k dan sumbu y menyatakan persentase akurasi. Pada grafik hasil uji coba, akurasi terbaik didapatkan pada nilai k = 8 untuk Wieslaw dataset dan nilai k = 10 untuk Australian credit approval dataset.
Gambar 7 menunjukkan grafik hasil uji coba dengan nilai cost berbeda-beda. Pada grafik hasil uji coba, akurasi terbaik didapatkan pada nilai cost=1 untuk Wieslaw dataset dan Australian credit approval dataset.
Gambar 8 menunjukkan grafik hasil uji coba dengan kernel Polynomial dan nilai degree berbeda-beda. Pada grafik hasil uji coba, akurasi terbaik didapatkan pada nilai degree = 2 baik untuk Wieslaw dataset maupun untuk Australian credit approval dataset.
Gambar 9 menunjukkan grafik hasil uji coba dengan kernel RBF dan nilai gamma berbeda-beda. Pada grafik hasil uji coba, akurasi terbaik didapatkan pada nilai gamma = 0.001 baik untuk Wieslaw dataset maupun untuk Australian credit approval dataset.
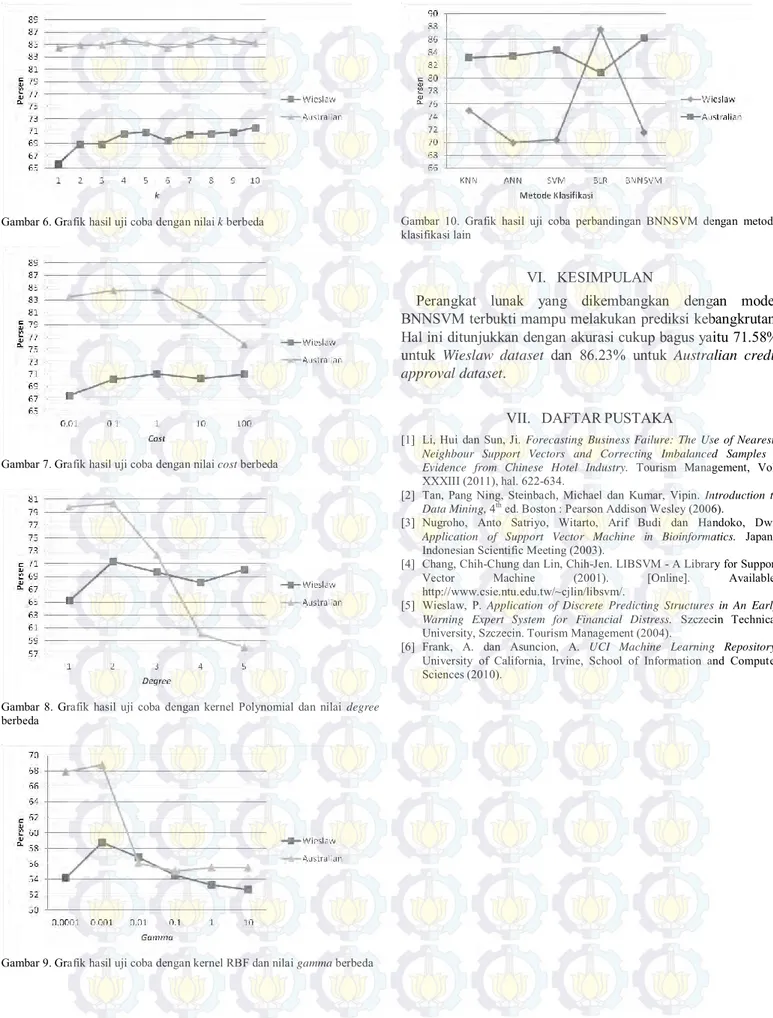
Gambar 10 menunjukkan grafik hasil uji coba perbandingan BNNSVM dengan metode klasifikasi lain. Tingkat akurasi prediksi kebangkrutan dengan BNNSVM pada Wieslaw dataset mengungguli metode ANN (artificial neural network) dan SVM (support vector machine), namun berada di bawah metode KNN (k-nearest neighbor) dan BLR (binary logistic regression). Adapun untuk Australian credit approval dataset, tingkat akurasi BNNSVM mengungguli metode-metode klasifikasi lain.
Gambar 6. Grafik hasil uji coba dengan nilai k berbeda
Gambar 7. Grafik hasil uji coba dengan nilai cost berbeda
Gambar 8. Grafik hasil uji coba dengan kernel Polynomial dan nilai degree berbeda
Gambar 9. Grafik hasil uji coba dengan kernel RBF dan nilai gamma berbeda
Gambar 10. Grafik hasil uji coba perbandingan BNNSVM dengan metode klasifikasi lain
VI. KESIMPULAN
Perangkat lunak yang dikembangkan dengan model BNNSVM terbukti mampu melakukan prediksi kebangkrutan. Hal ini ditunjukkan dengan akurasi cukup bagus yaitu 71.58% untuk Wieslaw dataset dan 86.23% untuk Australian credit approval dataset.
VII. DAFTARPUSTAKA
[1] Li, Hui dan Sun, Ji. Forecasting Business Failure: The Use of Nearest-Neighbour Support Vectors and Correcting Imbalanced Samples - Evidence from Chinese Hotel Industry. Tourism Management, Vol. XXXIII (2011), hal. 622-634.
[2] Tan, Pang Ning, Steinbach, Michael dan Kumar, Vipin. Introduction to Data Mining, 4th ed. Boston : Pearson Addison Wesley (2006).
[3] Nugroho, Anto Satriyo, Witarto, Arif Budi dan Handoko, Dwi. Application of Support Vector Machine in Bioinformatics. Japan : Indonesian Scientific Meeting (2003).
[4] Chang, Chih-Chung dan Lin, Chih-Jen. LIBSVM - A Library for Support Vector Machine (2001). [Online]. Available: http://www.csie.ntu.edu.tw/~cjlin/libsvm/.
[5] Wieslaw, P. Application of Discrete Predicting Structures in An Early Warning Expert System for Financial Distress. Szczecin Technical University, Szczecin. Tourism Management (2004).
[6] Frank, A. dan Asuncion, A. UCI Machine Learning Repository. University of California, Irvine, School of Information and Computer Sciences (2010).