5
BAB II
LANDASAN TEORI
Pada BAB II ini akan disampaikan materi-materi yang berkaitan dengan konsep data mining, yang merupakan landasan bagi pembahasan klasifikasi untuk evaluasi kinerja pegawai.
2. 1 Tinjauan Study
Penelitian yang berhubungan dengan penelitian ini adalah :
a. Penelitian yang dilakukan Norbetus Krisandi, Helmi dan Bayu Prihandono [3] menjelaskan suatu metode menggunakan algoritma supervised, dimana hasil dari sampel uji yang baru diklasifikasikan berdasarkan mayoritas dari kategori pada K-NN. Penelitian ini menguji tentang Algoritma K-NN dan mengaplikasikan Algoritma Kn- NN dalam kasifikasi data. Algortima K-NN akan digunakan dalam klasifikasi data hasil produksi kelapa sawit pada PT. Minamas dari 50 kelompok tani pada periode Juli-Desember 2011. Hasil Produksi yang dominan adalah produksi dari kelompok tani yang terletak pada C1 dengan 17 anggota dengan presentase 34 %.
b. Penelitian yang dilakukan Mardiani [4] mengklasifikasikan dan memprediksi mahasiswa mana yang akan bertahan terus kuliah dan yang mana yang tidak meneruskan kuliah pada semester berikutnya.
Algoritma yang digunakan adalah CART, dari data training akan ditentukan hasilnya didata testing dan dari hasil tersebut, bisa didapat pola bagi mahasiswa baru yang kemungkinan akan melanjutkan kuliah di semester 2 atau tidak.
Hasil klasifikasi pada testing sebanyak 188 mahasiswa angkatan 2011 diperkirakan 168 yang akan terus melanjutkan kuliah pada semester 2 dan sisanya sebanyak 20 mahasiswa tidak akan melanjutkan kuliah.
c. Penelitian yang dilakukan oleh Febti Eka Pratiwi dan Ismaini Zain [5]
mengklasifikasikan pengangguran terbuka dimana metode yang digunakan adalah Algoritma CART. CART dapat digunakan pada skala data kategorik maupun rasio. Data yang digunakan pada penelitian adalah data sekunder dari hasil survei angkatan kerja nasional (SAKERNAS) bulan Agustus 2012. Klasifikasi pengangguran provinsi Sulawesi Utara dengan metode CART adalah status dalam rumah tangga, jenis kelamin, usia, pendidikan terakhir dan status perkawinan. Hasil yang diperoleh pada penelitian ini memiliki ketepatan klasifikasi 78,90 persen.
d. Penelitian yang dilakukan oleh Nursalim, Suprapedi, dan H. Himawan [2] mengklasifikasikan bidang kerja lulusan dimana metode yang digunakan adalah K-Nearest Neighbor yang memiliki kinerja terbaik dengan nilai accuracy yaitu 83.33% dan nilai Area Under The Curve (AUC) adalah 0.90.
Tabel 1. State Of The Art 1
No Publication Masalah Metode Hasil
1 Henry Leidiyana,
“Penerapan Algoritma K- Nearest Nighbor Untuk Penentuan Resiko Kredit Kepemilikan Kendaraan Bermotor”.
Jurnal Penelitian Ilmu Komputer, System
Embedded dan Logic, 1(1) : 65- 76 (2013)
Penentuan resiko sistem kredit pada kendaraan
bermotor, untuk mengurangi resiko kehacuran suatu perusahaan pembiayaan.
K-Nearest Neighbor
Mengukur performa menggunakan metode cross validation, confusion matrix dan curva ROC
danmenghasilkan akurasi nilai AUC berturut-turut 81,46%
dan 0,984. Karena nilai AUC berada dalam rentang 0,9 sampai 1,0 maka metode tersebut dalam kategori sangat baik.
2. Nursalim, Suprapedi, dan Himawan,
“Klasifikasi
Klasifikasi bidang kerja lulusan dengan data mining k-nearest
K-Nearest Neighbor
Dari Hasil menggunkan
confusion matrix dan ROC Curve dapat
Bidang Kerja Lulusan Menggunakan Algoritma K- Nearest Neighbor”.
Jurnal Teknologi Informasi, volume 10 nomor 1, April 2014, ISSN
neighbor disimpulkan bahwa
data mining K-nearest Neighbor memiliki kinerja terbaikuntuk klasifikasi bidang kerja lulusan dengan nilai accuracy yaitu 83,33 % dan nilai AUC adalah 0,900
3. Febti Eka Pratiwi,dan Izmaini
Zain,”Klasifikasi Pengangguran Terbuka Menggunakan CART(Classifica tion and
Regression Tree) di Provinsi Sulawesi Utara”
Klasifikasi pengangguran terbuka menggunakan CART(Classificati on and Regression Tree) di Provinsi Sulawesi Utara
CART(Clas sification and
Regression Tree)
Dari hasil
menggunakan metode CART dapat
disimpulkan bahwa data mining CART memliki ketepatan 78,90%
4. Mardiani,”
Penerapan Klasifikasi Dengan
Algoritma CART Untuk Prediksi Kuliah Bagi Mahasiswa Baru, Seminar
Nasional Aplikasi Teknologi Informasi Yogyakarta, 15- 16 Juni 2012.
Resiko mahasiswa baru yang masih mempunyai kemungkinan tidak melanjutkan kuliah untuk seterusnya.
CART Dari 11 kemungkinan kombinasi
menggunakan 3 atribut utama
mahasiswa yang aktif atau tidak aktif pada semester2, didapatkan root node yaitu
IPK<=1. Hasil Klasifikasi pada data testing sebanya 188 mahasiswa angkatan 2011 diperkirakan 168 yang akan terus melanjutkan kuliah pada semester 2 dan sisanya tidak akan melanjutkan kuliah
2. 2 Tinjauan Pustaka 2.2.1 Evaluasi Kerja
Evaluasi kerja adalah proses penilaian kinerja yang berfungsi melihat tanggung jawab pegawai dalam menyelesaikan pekerjaannya, apakah terjadi peningkatan atau penurunan sehingga kepala bagian produksi maupun perusahaan dapat memberikan suatu dorongan motivasi untuk melihat knerja aparatur kedepannya. Evaluasi harus sering dilakukan agar masalah yang dihadapi dapat diketahui dan dicari jalan keluar yang baik [6].
2.2.2 Data Mining
Data mining adalah suatu konsep yang digunakan untuk menemukan pengetahuan yang tersembunyi di dalam database. Data mining merupakan proses semi otomatik yang menggunakan teknik statistik, matematika, kecerdasan buatan dan mesin pembelajaran untuk mengekstrasi dan mengidentifikasi pokok informasi pengetahuan potensial yang tersimpan didalam database besar. Data mining termasuk bagian dari proses KDD (Knowledge Discovery in Database) yang terdiri dari beberapa tahapan seperti pemilihan data, pra pengolahan, transformasi, data mining dan evaluasi hasil. KDD merupakan sebuah proses yang terdiri dari serangkaian proses interasi yang terurut, dan data mining merupakan salah satu langkah dalam proses KDD. Urutan Langkah dalam KDD adalah sebagai berikut[2] : 1. Pembersihan Data
Pembersihan terhadap data dilakukan untuk menghilangkan gangguan dan inkonsisten data.
2. Integrasi Data
Proses integrasi data dilakukan untuk menggabungkan data dari berbagai sumber.
3. Seleksi Data
Seleksi data dilakukan untuk mengambil data yang berhubungan, yang akan digunakan untuk proses analisis dalam data mining.
4. Transformasi Data
Proses ini dilakukan untuk mentrasformasikan data ke dalam bentuk yang tepat untuk di-mine.
5. Data Mining
Data mining merupakan proses untuk mengaplikasikan suatu metode untuk mengekstrak pola-pola dalam data.
6. Evaluasi Pola
Evaluasi pola diperlukan untuk mengidentifikasi beberapa pola menarik yang mempresentasikan pengetahuan.
7. Presentasi Pengetahuan
Mempresentasikan pengetahuan yang telah digali kepada pengguna dengan menggambarkan pengetahuan tersebut.
2.2.3 Pengelompokan Data Mining
Ada beberapa teknik yang dimiliki data mining berdasarkan tugas yang bisa dilakukan, yaitu [6]:
1. Deskripsi
Para peneliti biasanya mencoba menemukan cara mendiskripsikan pola dan tren yang tersembunyi dalam data.
2. Estimasi
Estimasi mirip dengan klasifikasi, kecuali variabel tujuan yang lebih kearah numerik dari kategori.
3. Prediksi
Prediksi memiliki kemiripan dengan estimasi dan klasifiksi. Hanya saja prediksi hasilnya menunjukan sesuatu yang belum terjadi.
4. Klasifikasi
Dalam klasifikasi variabel tujuan bersifat kategorik . Misalnya, kita akan mengklasifikasikan pendapatan dalam dua kelas, yaitu pendapatan sedang, dan pendapatan rendah.
5. Clustering
Clustering lebih ke arah pengelompokan record, pengamatan atau kasus dalam kelas yang memiliki kemiripan.
6. Asosiasi
Mengidentifikasi hubungan antara berbagai peristiwa yang terjadi pada satu waktu.
2.2.4 Klasifikasi
Klasifikasi merupakan proses untuk menemukan model atau fungsi yang menjelaskan atau membedakan konsep atau kelas data, dengan tujuan untuk mendapatkan memeprkirakan kelas dari suatu objek yang labelnya tidak diketahui [3]. Klasifikasi data terdiri dari 2 langkah proses. Pertama adalah learning(fase training), dimana algoritma klasifikasi dibuat untuk menganalisa data training lalu direpresentasikan dalam bentuk rule klasifikasi. Proses kedua adalah klasifikasi, dimana data tes digunakan untuk memperkirakan akurasi dari rule klasifikasi.
Proses klasifikasi didasarkan pada empat komponen [7]:
a. Kelas
Variabel dependen yang berupa kategorikal yang mempresentasikan
‘label’ yang terdapat pada objek.
b. Predictor
Variabel independen yang direpresentasikan oleh karakteristik (atribut) data.
c. Training Dataset
Satu set data yang berisi nilai dari kedua komponen di atas yang digunakan untuk menentukan kelas yang cocok berdasarkan predictor.
d. Testing Dataset
Berisi data baru yang akan diklasifikasikan oleh model yang telah dibuat dan akurasi klasifikasi dievaluasi.
2.2.5 Algoritma K-Nearest Neighbor
Algoritma K-Nearest Neighbor adalah suatu metode yang menggunakan algoritma supervised. Perbedaan antara supervised learning dengan unsupervised adalah pada supervised learning bertujuan untuk menemukan pola baru dalam data dengan menghubungkan pola data yang sudah ada dengan data yang baru.
Sedangkan unsupervised learning data belum memiliki pola yang jelas dan tujuan unsupervised learning untuk menemukan pola dalam sebuah data. Tujuan dari algoritma K-NN adalah untuk mengklasifikasikan objek baru berdasarkan atribut dan training samples [2].
Algoritma K-NN adalah sebuah metode untuk melakukan klasifikasi terhadap objek berdasarkan data pembelajaran yang jaraknya paling dekat dengan objek tersebut [8]. Teknik ini sangat sederhana dan mudah diimplementasikan. Data pembelajaran diproyeksikan ke ruang berdimensi banyak, dimana masing-masing dimensi merepresentasikan fitur dari data. Ruang ini menjadi bagian-bagian yang berdasarkan klasifikasi data pembeljaran sebuah titik pada ruang ini ditandai kelas C jika kelas C merupakan klasifikasi yang paling banyak ditemui pada k buah tertangga terdekat titik tersebut. Dekat atau jauhnya tetangga biasanya dihitung berdasakan jarak Euclidean.
Untuk menentukan jarak antara dua titik yaitu titik pada data training (x) dan titik pada data testing (y) maka digunakan rumus Euclidean sebagai berikut :
D(x.y) = Keterangan :
D(x,y) = Jarak euclidean = data training y = data testing
n = jumlah atribut individu antara 1 s/d n
Kelebihan dari algoritma K-NN adalah sebagai berikut [9]:
a. Mampu menghasilkan data yang akurat atau jelas (menggunakan turunan perkalian kuadrat pada besaran jarak ) b. Efektif dan cocok digunakan untuk data yang besar.
Dari bebera kelebihan yang dimiliki algoritma K-NN juga memiliki kekurangan yaitu :
a. Membutuhkan nilai K sebagai parameter.
b. Jarak dari data percobaan belum jelas dengan tipe jarak yang digunakan serta dengan atribut yang digunakan untuk menghasilkan yang paling baik, maka harus menggunakan semua atribut atau hanya 1 atribut yang pasti.
c. Perhitungan harga sangat tinggi karena percobaan ini menggunakan perhitungan jarak dari beberapa query untuk semua data percobaan.
Metode Evaluasi dan Validasi
Untuk mengukur akurasi algoritma klasifikasi, metode yang digunakan antara lain cross validation, confusion matrix, dan kurva ROC (Receiver Operating Characteristic). Untuk mengembangkan aplikasi (development) berdasarkan model yang dibuat, digunakan rapid Miner [7].
a. Cross validation
Cross Validation adalah pengujian standar yang dilakukan untuk memeprediksi tingkat eror. Data training dibagi secara random kedalam beberapa bagian dengan perbandingan yang sama kemudian tingkat eror dihitung bagian demi bagian, selanjutnya hitung rata-rata seluruh tingkat eror untuk mendapatkan tingkat eror secara keseluruhan [10].
b. Confusion Matrix
Metode ini menggunakan tabel matriks, jika dataset hanya terdiri dari dua kelas, kelas yang satu dianggap sebagai positif dan yang lainnya negatif. True positives adalah jumalah record positif yang diklasifikasikan sebagai positif, false positives adalam jumlah record negatif yang diklasifikasikan sebagai positif, false negatives adalah jumlah record positif yang diklasifikasikan sebagai negatif, true negatives adalah jumlah record negatif yang diklasifikasikan sebagai negatif, kemudian masukan data uji. Setalah data uji dimasukan ke dalam confusion matrix, hitung nilai-nilai yang telah dimasukan tersebut untuk menghitung jumlah sensitivity(recall), specificity, precision dan accuracy.
Sensitivity digunakan untuk membandingkan jumlah TP terhadap jumlah record yang positif sedangkan secificity adalah perbandingan jumlah TN terhadap jumlah record yang negatif.
Untuk menghitung digunakan persamaan di bawah ini :
Sensitivity = Specificity = Precision =
Accuracy = Sensitivity
+ Specificity
Keterangan :
TP = jumlah true positif TN = jumlah true negatif P = jumlah record positif N = Jumlah tupel negatif FP = Jumlah false positif 2.2.6 Algoritma CART
CART ( Classification and Regression Trees ) dikembangkan oleh Leo Breiman, Jerome H. Friedman, Richard A. Olshen dan Charles J.
Stone sekitar tahun 1980-an CART merupakan metode nonparametrik yang dapat memilih peubah dan interaksi yang paling mempengaruhi peubah responmetode atau algoritma dari salah satu teknik eksplorasi data yaitu teknik pohon keputusan [11]. CART termasuk algoritma yang sederhana namun merupakan metode yang kuat. CART bertujuan untuk mendapatkan suatu kelompok data yang akurat sebagai penciri dari suatu pengklasifikasian, selain itu CART digunakan untuk menggambarkan hubungan antara variabel respon(variabel dependen atau tak bebas ) dengan satu atau lebih variabel prediktor (variabel independen atau bebas ). Model pohon yang dihasilkan bergantung pada skala variabel respon, jika variabel respon data beberbentuk kontinu maka model pohon yang dihasilkan adalah regression trees(pohon regresi) sedangkan bila variabel respon mempunyai skala kategorik maka pohon yang dihasilkan adalah classification tress(pohon klasifikasi) [12].
CART mempunyai beberapa kelebihan dibandingkan metode klasifikasi lainnya, yaitu hasilnya yang didapatlebih mudah diinterpretasikan, lebih akurat dan lebih cepat penghitungannya, selain itu CART bisa diterapkan untuk data yang mempunyai jumlah besar, variabel yang sangat banyak dan dengan skala variabel campuran melalui prosedur pemilahan biner [5]. Data learning digunakan untuk pembentukan pohon klasifikasi optimal sedangkan data testing digunakan untuk validasi model yaitu seberapa besar kemampuan model dalammemprediksi data baru. Pohon keputusan dibentuk dengan menggunkan algoritma penyekatan rekursif secara biner.
Pemilahan dilakukan untuk memilah data menjadi 2 kelompok, yaitu kelompok yang masuk simpul kiri dan yang masuk simpul kanan.
Pemilahan dilakukan pada tiap simpul sampai didapatkan suatu simpul terminal/akhir.Variabel yang memilah pada simpul utama adalah variabel terpenting dalam menduga kelas dari amatan.
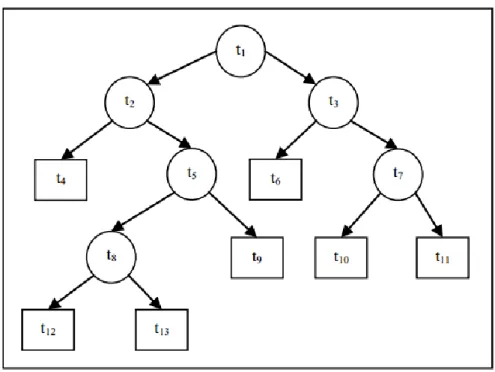
Simpul utama (root node) dinotasikan sebagai t1, sedangkan simpul t2,t3,t5,t7 dan t8 disebut simpul dalam (internal nodes ). Simpul terakhir yang juga disebut sebagai simpul terminal (terminl nodes) adalah t4,t6,t9,t10,t11,t12, dan t13 dimana tidak terjadi lagi pemilahan. Kedalaman pohon (depth) dihitung dimulai dari simpul utama atau t1 yang berada pada kedalamn 1, sedangkan t2 dan t3 berada pada kedalaman 2. Begitu seterusnya sampai pada simpul terminal t12 dan t13 yang berada pada kedalaman 5.
Langkah-langkah penerapan algoritma CART adalah sebagai berikut : 1. Pembentukan Pohon klasifikasi
Proses pembentukan pohon klasifikasi terdiri atas 3 tahapan, yaitu a. Pemilihan (classifier)
Gambar 2.1 Struktur Pohon Klasifikasi 1
Sampel data learning (L) yang masih bersifat heterogem digunakan untuk pembentukan pohon klasifikasi. Sampel tersebut akan diseleksi berdasarkan aturan pemilahan dan kriteria goodness-of-split dan pemilihan pemilah tergantung pada jemis variabel responnya. Metode pemilihan pemilah menggunakan Impurity measure i(t) merupakan pengukuran tingkat keheterogenann suatu kelas dari suatu simpul tertentu dalam pohon klasifikasi yang dapat memebantu kita menenmukan fungsi pemilah yang optimal.
Beberapa fungsi Impurity measure i(t) adalah sebagai berikut : i. Indeks Gini : i(t) =
ii. Indeks Informasi : i(t) = -
P adalah peluang j pada simpul t. Goodness of Spilt merupakansuatu evaluasi pemilahan oleh pemilahan s pada simpul t yang didefinisikan sebagai penurunan keheterogenan dan didefinisikan sebagai berikut :
Pemilahan yang menghasilkan nilai lebih tinggi merupakan pemilah yang lebih baik karena hal ini memungkinkan untuk mereduksi keheterogenan secara lebih signifikan. Metode pemilahan yang sering digunakan adalah indeks Gini, hal tersebut dikarenakan lebih mudah dan sesuai untuk diterapkan dalam berbagai kasus dan mempunyai perhitungan yang sederhana dan cepat.
b. Penentuan Simpul Terminal
Suatu simpul t akan menjadi terminal atau tidak akan dipilih kembali bila pada simpul t tidak terdapat penurunan keheterogenan secara berarti atau adanya batasan minimum n seperti hanya terdapat satu pengamatan pada setiap simpul anak.Jumlah kasus minimum dalam suatu terminal akhir umumnya adalah 5, dan apakah hal itu terpenuhi maka pengembangan pohon dihentikan.
c. Penandaan label kelas
Penandaan label kelas pada simpul terminal dilakukan berdasarkan aturan jumlah terbanyak. Label kelas simpul terminal t adalah jo yang memberi nilai dugaan kesalahan pengklasifikasian simpul t terbesar.
Proses pembentukan pohon klasifikasi berhenti saat terdapat hanya satu pengamatan dalam tiap-tiap simpul anak atau adanya batasan minimum n, semua pengamatan dalam tiap simpul anak identik, dan adanya batasan jumlah level.
p = max jp =max
dengan
p : proporsi kelas j pada simpul
Nj(t) :jumlah pengamatan kelas j pada simpul t N(t) : jumlahpengamatan pada simpul t.
2. Pemangkasan Pohon Klasifikasi
Bagian pohon yang kurang penting dilakukan pemangkasan sehingga didapatkan pohon klasifikasi yang optimal. Pemangkasan didasarkan pada suatu penilaian ukuran sebuah pohon tanpa mengorbankan kebaikan ketepatan melalui pengurangan simpul pohon sehingga dicapai ukuran pohon yang layak. Ukuran pemangkasan yang digunakan untuk memperoleh ukuran pohon yang layak tersebut adalah Cost complexity minimum [5]
3. Penentuan Pohon klasifikasi Optimal
Ukuran pohon yang besar akan meyebabkan nilai kompleksitas yang tinggi kareana struktur data yang digambarkan cenderung komplek, sehingga perlu dipilih pohon optimal yang berukuran sederhana tetapi memberikan nilai penduga pengganti cukup kecil. Ada dua jenis penduga pengganti, penduga sampel uji(test sample estimate) dan penduga validasi silang lipat V (cross validation V-fold estimate).
Penelitian ini menggunakan penduga sampel uji (test sample estimate) karena cross validation V-fold estimate digunakan untuk jumlah sampel kecil(kurang dari 3000).
Penelitian ini mengguankan penduga sampel uji (test sampel estimate) untuk penentuan pohon optimal.
2. 3 Kerangka Pemikiran
Gambar 2.2 Kerangka Pemikiran 1