PERBANDINGAN ALGORITA K-NN (K-NEAREST NEIGHBOR) DAN NAIVE BAYES PADA METODE FINGERPRINTING
BERBASIS WLAN
SKRIPSI
SENGLI EGANI 111401089
PROGRAM STUDI S1 ILMU KOMPUTER
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
MEDAN 2016
PERSETUJUAN
Judul : Perbandingan Algoritma K-NN (K-Nearest Neighbor) dan Naive Bayes pada Metode Fingerprinting Berbasis WLAN
Kategori : Skripsi
Nama : Sengli Egani Sitepu Nomor Induk Mahasiswa : 111401089
Program Studi : Sarjana (S1) Ilmu Komputer
Fakultas : Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara
Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Jos Timanta Tarigan, S.Kom, M.Sc Ade Candra, ST, M.Kom NIP. 198501262015041001 NIP. 197909042009121002
Diketahui/disetujui oleh
Program Studi S1 Ilmu Komputer Ketua,
Dr. Poltak Sihombing, M. Kom.
NIP. 196203171991031001
PERNYATAAN
PERBANDINGAN ALGORITMA K-NN (K-NEAREST NEIGHBOR) DAN NAIVE BAYES PADA METODE FINGERPRINTING
BERBASIS WLAN
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil karya saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing telah disebutkan sumbernya.
Medan, 1 September 2016
Sengli Egani Sitepu NIM. 111401089
UCAPAN TERIMA KASIH
Puji dan syukur kepada Tuhan Yesus Kristus, yang telah menuntun dan memampukan penulis untuk menyelesaikan skripsi ini, sebagai syarat untuk memperoleh gelar Sarjana Komputer dari Program Studi S1 Ilmu Komputer, Fakultas Ilmu Komputer dan Teknologi Informasi, Universitas Sumatera Utara.
Penulis juga bersyukur berada di antara pihak-pihak yang berperan penting dalam penyelesaian skripsi ini. Penulis berterimakasih kepada:
1. Bapak Prof. Dr. Runtung Sitepu, SH, M.Hum selaku Rektor Universitas Sumatera Utara
2. Bapak Prof. Dr. Opim Salim Sitompul, M.Sc selaku Dekan Fakultas Ilmu Komputer dan Teknologi Informasi
3. Bapak Dr. Poltak Sihombing, M. Kom. selaku Ketua Program Studi S1 Ilmu Komputer Fakultas Ilmu Komputer dan Teknologi Informasi
4. Bapak Ade Candra, ST, M.Kom selaku Dosen Pembimbing I dan Dosen Pembimbing Akademik yang dengan sabar telah membimbing dan memberikan arahan yang sangat berarti bagi penilis
5. Bapak Jos Timanta Tarigan, S.Kom, M.Sc selaku Dosen Pembimbing II yang telah memberikan arahan, nasehat dan bimbingan dalam menyelesaikan skripsi ini 6. Bapak Drs. Marihat Situmorang, M.Kom selaku Dosen Pembanding I yang telah
memberikan kritik dan saran dalam pembuatan skripsi ini
7. Bapak M. Andri Budiman, S.T., M. Comp. Sc., M.E.M. selaku Dosen Pembanding II yang telah memberikan kritik dan saran yang bermanfaat dari kekurangan skripsi ini
8. Seluruh dosen dan pegawai di Program Studi S1 Ilmu Komputer Fasilkom-TI USU yang telah membantu penulis dalam proses pembuatan skripsi ini
9. Papa dan mama tersayang, Lesta Sitepu dan Selita br Sembiring, S.Pd, yang dengan penuh kasih memberikan perhatian, dukungan, semangat, dan mendoakan penulis
10. Adik yang terkasih, Samuel Jon Heri Sitepu sebagai saudara dan sahabat yang selalu membantu dan mendoakan penulis
11. Ibu Pdt. Mindawati Perangin-angin, Ph.D selaku Ketua Runggun GBKP Kemenangan Tani, sahabat dan pembimbing spiritual yang menolong penulis dalam proses penelitian dan selalu memotivasi penulis melalui kesaksian hidupnya 12. Sahabat-sahabat di Program Studi S1 Ilmu Komputer USU, khususnya Febri Aro Gea, S.Kom, Baringin Sihite, S.Kom, Erwin M.H Sinaga, Rotua Dina Silitonga, Putri Paramita Manulang, Verawaty Sihite, Winda Sari Elisabet S., Andrus S.Kom, dan teman-teman KOM B 2011. Terima kasih atas semangat dan motivasi yang teman-teman diberikan kepada penulis
13. Kelompok Kecil Stenos Filos, Kelompok Kecil Theopilos dan Koordinasi UKM KMK USU 2015, tempat penulis bertumbuh secara rohani, bersekutu dan melayani di dalam Kristus
14. Seluruh pihak yang tidak dapat disebutkan penulis satu demi satu.
Penulis menyadari bahwa penelitian ini tidak sempurna. Dengan segala kelebihan dan kekurangannya, semoga skripsi ini bermanfaat bagi siapa saja yang membacanya.
Medan, 1 September 2016
Penulis
ABSTRAK
Metode fingerprinting dapat digunakan untuk mentukan posisi objek dalam ruangan menggunakan RSS (Received Signal Strength) sehingga dapat mengatasi keterbatasan GPS dalam menentukan posisi objek di dalam ruangan . Dalam menerapkan metode fingerprinting, ada dua algoritma yang sering digunakan yaitu K-Nearest Neighbor (K- NN) dan Naive Bayes. Penelitian ini bertujuan untuk mengetahui tingkat akurasi dan kecepatan perhitungan algoritma K-Nearest Neighbor dan Naive Bayes terhadap nilai RSS ketika memprediksi lokasi objek dalam ruangan menggunakan metode fingerprinting. Penelitian ini dilakukan di dua tempat yang memiliki karakteristik yang berbeda, yaitu rumah di Jalan Bunga Ncole No 28-A Medan dan gedung gereja GBKP Kemenangan Tani Medan. Pengambilan data dilakukan dengan grid 1 × 1 meter menggunakan 3 buah Acces Point (AP) dalam kondisi objek diam. Data pelatihan diperoleh dengan cara mengukur tiga kali nilai RSS disetiap titik, sementara itu data pengujian diperoleh dengan mengukur nilai RSS pada sebuah titik secara acak. Kondisi ruangan dan cara pengukuran pada data pelatihan dan data pengujian adalah sama.
Hasil penelitian ini membuktikan bahwa tingkat akurasi algoritma K-NN lebih tinggi dibandingkan dengan algoritma Naive Bayes untuk memprediksi lokasi objek dalam ruangan dengan metode fingerprinting meskipun rata-rata jarak eror algoritma K-NN lebih besar dibandingkan algoritma Naive Bayes. Kecepatan perhitungan Algoritma Naive Bayes lebih tinggi dibandingkan algoritma K-NN untuk memprediksi lokasi objek dalam ruangan meskipun selisihnya tidak begitu besar.
Kata kunci: SIG, Indoor Positioning, Fingerprinting, K-NN, Naive Bayes
ABSTRACT
Fingerprinting methods can be used to determine the position of indoor objects using the RSS (Received Signal Strength) so it may overcome the limitations of GPS to determine position of indoor object. There two algorithms which are often used to implement the fingerprinting methods, namely KNN and Naive Bayes. The goal of this research are to determine the level of the accuracy and the calculation speed of K- Nearest Neighbor algorithm and Naive Bayes against the value of RSS when predicting the location of indoor objects using fingerprinting method. This research was held in two places that have different characteristics, the researcher’s home at No. 28-A Jl.
Bunga Ncole, Medan and the building of GBKP Kemenangan Tani Medan. Data collection was done with grid size 1 × 1 meter and 3 AP in static object condition. The training data obtained by measuring three times the value of RSS at every spot, while the testing data obtained by measuring the value of the RSS at a random spot. Condition of the room and how to measurements on the training data and testing data are the same.
This research result proved that the level of accuracy of the K-NN algorithm was higher than Naive Bayes algorithm to predict the location of indoor objects with fingerprinting method even though the average error distance of K-NN algorithm is larger than Naive Bayes algorithm. Naive Bayes algorithm calculation speed is higher than K-NN algorithm to predict the location of indoor objects although the difference is not so large.
Keywords: GIS, Indoor Positioning, Fingerprinting, K-NN, Naive Bayes
DAFTAR ISI
Hal.
Persetujuan Pernyataan
Ucapan Terima Kasih Abstrak
Abstract Daftar Isi Daftar Tabel Daftar Gambar Daftar Lampiran
ii iii iv vi vii viii x xi xiii Bab 1
Bab 2
Bab 3
Pendahuluan
1.1. Latar Belakang 1.2. Rumusan Masalah 1.3. Batasan Masalah 1.4. Tujuan Penelitian 1.5. Manfaat Penelitian 1.6. Metodologi Penelitian 1.7. Sistematika Penulisan Landasan Teori
2.1.Sistem Informasi Geografis 2.2.Data Spasial
2.3.Fingerprinting
2.4.Algoritma K-Nearest Neighbor 2.5.Algotitma Naive Bayes
2.6.Pengukuran Kinerja Klasifikasi Analisis dan Perancangan
3.1 Analisis Sistem
3.1.1 Analisis masalah 3.1.2 Analisis kebutuhan
1 2 2 2 3 3 4
5 9 10 12 14 17
19 19 20
Bab 4
Bab 5
3.1.3 Analisis proses 3.2 Perancangan Sistem
3.2.1 Diagram use-case 3.2.2 Diagram aktivitas 3.2.3 Diagram Sequence 3.2.4 Diagram alir sistem 3.2.5 Perancangan antarmuka Implementasi dan Pengujian
4.1 Implementasi
4.1.1 Perangkat sistem 4.1.2 Antarmuka sistem 4.1.3 Pengumpulan data 4.2 Pengujian
4.2.1. Pengumpulan data uji pada lokasi pengujian 4.2.2. Perhitungan rata-rata jarak error
4.2.3. Perhitungan akurasi
4.2.4. Perhitungan kecepatan prediksi Kesimpulan dan Saran
5.1. Kesimpulan 5.2. Saran
21 22 22 28 32 35 37
43 43 44 47 58 58 64 65 67
69 70
Daftar Pustaka 71
DAFTAR TABEL
Tabel 3.1 Tabel 3.2 Tabel 3.3 Tabel 3.4 Tabel 3.5 Tabel 3.6 Tabel 3.7 Tabel 3.8 Tabel 3.9 Tabel 3.10 Tabel 4.1 Tabel 4.2 Tabel 4.3 Tabel 4.4 Tabel 4.5
Tabel 4.6 Tabel 4.7
Use-case narrative pelatihan Use-case narrative simpan Use-case narrative hapus Use-case narrative pengujian Use-case narrative K-NN Use-case narrative Naive Bayes
Keterangan rancangan antarmuka beranda Keterangan rancangan antarmuka pelatihan Keterangan rancangan antarmuka pengujian Keterangan rancangan antarmuka bantuan Perangkat keras sistem
Data pelatihan pada rumah peneliti
Data pelatihan pada gedung gereja GBKP Kemenangan Tani Informasi hasil pengujian di rumah rumah peneliti
Informasi hasil pengujian di gedung gereja GBKP Kemenangan Tani
Hasil perhitungan rata-rata jarak error
Rata-rata kecepatan algoritma saat memprediksi lokasi
23 23 24 25 26 27 38 39 40 42 44 49 52 60 63
65 68
DAFTAR GAMBAR
Gambar 2.1 Gambar 2.2 Gambar 2.3
Gambar 3.1 Gambar 3.2 Gambar 3.3 Gambar 3.4 Gambar 3.5 Gambar 3.6 Gambar 3.7 Gambar 3.8 Gambar 3.9
Gambar 3.10 Gambar 3.11 Gambar 3.12 Gambar 3.13 Gambar 3.14 Gambar 3.15 Gambar 3.16 Gambar 4.1 Gambar 4.2 Gambar 4.3 Gambar 4.4 Gambar 4.5 Gambar 4.6 Gambar 4.7
Hubungan SIG dan disiplin ilmu kebumian pendukung Tahapan proses fingerprinting
K-NN dengan nilai K-tetangga : (a) 1-NN, (b) 2-NN, (c) 3- NN, dan (d) 7-NN
Diagram ishikawa analisis permasalahan Diagram use-case system
Diagram aktivitas pelatihan Diagram aktivitas simpan Diagram aktivitas hapus Diagram aktivitas pengujian Diagram aktivitas K-NN Diagram aktivitas Naïve Bayes Diagram urutan sistem
Diagram urutan sistem (lanjutan) Diagram alir pelatihan sistem Diagram alir pengujian sistem Diagram alir K-NN dan Naive Bayes Rancangan antarmuka beranda Rancangan antarmuka pelatihan Rancangan antarmuka pengujian Rancangan antarmuka bantuan Antarmuka awal
Antarmuka pelatihan Antarmuka pengujian Antarmuka bantuan Denah rumah peneliti
Denah gedung Gereja GBKP Kemenangan Tani Titik pelatihan pada rumah penulis
5 12 14
20 22 28 29 30 30 31 31 33 34 35 36 37 38 39 40 41 45 45 46 47 48 48 49
Gambar 4.8
Gambar 4.9 Gambar 4.10
Gambar 4.11
Gambar 4.12
Gambar 4.13
Gambar 4.14
Gambar 4.15
Gambar 4.16 Gambar 4.17
Titik pelatiahan pada gedung gereja GBKP Kemenangan Tani
Lokasi titik uji yang terdapat pada rumah peneliti
Pengukuran nilai RSS pada posisi 30 di rumah penulis saat pengujian
Perhitungan asumsi posisi berdasarkan titik uji di rumah penulis
Lokasi titik uji yang terdapat pada gedung gereja GBKP Kemenangan Tani
Pengukuran nilai RSS pada posisi 1 di gedung gereja GBKP Kemenangan Tani
Perhitungan asumsi posisi berddasarkan titik uji di gedung gereja GBKP Kemenangan Tani
Perbandingan persentase akurasi algoritma K-NN dan Naive Bayes di (a) rumah peneliti, (b) gedung gereja GBKP
Kemenangan Tani.
Rata-rata persentase akurasi
Perhitungan kecepatan algoritma saat memprediksi lokasi
49
59 59
60
62
62
63
66
67 68
DAFTAR LAMPIRAN
Listing Program Curriculum Vitae
72 88
BAB 1
PENDAHULUAN
1.1. Latar Belakang
Posisi dalam ruangan (indoor positioning) adalah sebuah teknologi untuk menentukan koordinat lokasi geospasial dari sejumlah objek bergerak atau diam yang berada di lingkungan dalam ruangan. Indoor positioning system (IPS) biasanya memperkirakan lokasi target objek dari data pengamatan yang dikumpulkan oleh sekumpulan perangkat penginderaan atau sensor.
GPS merupakan salah satu positioning system yang popular saat ini, namun sistem ini tidak cocok untuk diterapkan untuk menentukan posisi dalam ruangan (indoor positioning), karena saat berada di dalam gedung bertingkat, sinyal dari satelit kemungkinan tidak dapat dicapai sampai ke GPS penerima, bahkan GPS tidak dapat menyampaikan informasi yang akurat mengenai posisi objek pada suatu ruangan (Sutarti, et al. 2012). Oleh sebab itu, maka perlu adanya sistem yang stabil dan akurat dalam pendeteksian lokasi objek di dalam ruang, yang dapat digunakan di rumah, di kantor atau di gedung lainnya.
Teknologi jaringan tanpa kabel (W-LAN) berkembang sangat pesat dan saat ini telah banyak digunakan di berbagai tempat sebagai media komunikasi. Teknologi W-LAN tidak hanya dapat digunakan sebagai media komunikasi, tetapi dapat dikembangkan sebagai sistem pendeteksian lokasi. Salah satunya dengan memanfaatkan pengukuran kekuatan sinyal RSS (Received Signal Strength) oleh receiver (penerima) yang dikirim oleh transmitter (pemancar). Besar nilai RSS inilah yang akan digunakan sebagai parameter dalam menentukan posisi suatu objek (Pasinggi, et al. 2014).
Fingerprinting merupakan metode untuk pemetaan pengukuran data (misalnya RSS) ke dalam grid-point di seluruh wilayah cakupan di lingkungan.
Fingerprinting seringkali digunakan dalam lokalisasi ruangan berbasis RSS, terutama pada saat korelasi analitis antara pengukuran RSS dan jarak sulit untuk ditentukan
karena adanya multipath dan interferensi (Sutarti, et al. 2012). Dalam menerapkan metode fingerprinting, ada dua algoritma yang sering digunakan yaitu K-Nearest Neighbor (K-NN) dan Naive Bayes. Kedua algoritma ini masing-masing memiliki kelebihan dan kekurangan dalam melakukan pengklasifikasian terhadap besar RSS yang diterima untuk menentukan estimasi posisi suatu objek didalam ruangan. Oleh sebab itu, penulis ingin membandingkan kedua algoritma ini secara langsung dalam penerapannya pada metode fingerprinting berbasis W-LAN.
1.2. Rumusan Masalah
Berdasarkan latar belakang di atas, maka rumusan masalah yang dapat diambil adalah : 1. Bagaimana memprediksi lokasi suatu objek dalam ruangan dengan
menggunakan metode fingerprinting berbasis W-LAN
2. Bagaimana perbandingan akurasi antara algoritma K-Nearest Neighbor dan Naive Bayes dalam menentukan posisi objek dalam ruangan.
1.3. Batasan Masalah
Batasan masalah yang dapat diambil dari latar belakang di atas adalah : 1. Pengukuran RSS dilakukan saat objek dalam kondisi diam.
2. Posisi ketinggian objek (Altitude) diabaikan.
3. Efek multipath dan propogasi dalam pengukuran kekuatan sinyal diabaikan.
4. Jumlah Acces Point (AP) yang digunakan sebanyak 3 buah.
5. Tool bahasa pemrograman yang digunakan ialah Sharp Develop 4.3 dan tool database management system (DBMS) yang digunakan adalah MySQL 6. Tool yang digunakan untuk mengukur RSS ialah Wifi Analyzer 3.02 yang dijalankan dengan menggunakan perangkat Android ASUS Fonepad K012.
7. Parameter perbandingan antara algoritma K-NN (K-Nearest Neighbor) dan Naive Bayes ialah keakurasian estimasi posisi dan running time.
8. Jumlah tetangga terdekat (K) pada algoritma K-NN bernilai 1.
1.4. Tujuan Penelitian
Tujuan penelitian ini adalah untuk mengetahui teknik untuk memprediksi lokasi objek dalam ruangan menggunakan metode fingerprint berbasis W-LAN dan mengetahui
akurasi perhitungan algoritma K-Nearest Neighbor dan Naive Bayes terhadap nilai RSS.
1.5. Manfaat Penelitian
Manfaat penelitian ini adalah dapat digunakan untuk membantu manusia ataupun mesin seperti robot dalam menentukan posisi suatu objek, posisi keberadaannya dan juga posisi lokasi yang ingin ditujunya didalam ruangan.
1.6. Metodologi Penelitian
Metode penelitian yang dilakukan dalam penelitian ini adalah : 1. Studi Literatur
Pada tahapan ini, penulis mengumpulkan bahan dan data sebagai referensi dari berbagai buku, jurnal, skripsi dan sumber lainnya yang berkaitan dengan sistem informasi geografis mengenaipemposisian dalam ruangan metode fingerprinting, K-NN (K-Nearest Neighbor) dan Naive Bayes.
2. Pengumpulan Data
Pada tahapan ini, penulis melakukan pengumpulan data di lokasi penelitian, yaitu di rumah peneliti sendiri dan Gedung Gereja GBKP Kemenangan Tani Medan untuk menyelesaikan laporan penulisan skripsi.
3. Perancangan Perangkat Lunak
Pada tahap ini, digunakan seluruh hasil analisis terhadap studi literatur yang dilakukan untuk merancang perangkat lunak yang akan dihasilkan. Dalam tahapan ini juga dilakukan perancangan model antarmuka serta proses kerja sistem untuk memudahkan dalam proses implementasi.
4. Implementasi dan Pegujian Sistem
Pada tahap ini dilakukan pemasukan data serta memproses data untuk mendapatkan hasil apakah sudah sesuai dengan yang diharapkan. Pengujian dilakukan dengan membandingkan hasil prediksi lokasi dari algoritma K-NN (K-Nearest Neighbor) dan Naive Bayes.
5. Dokumentasi dan Laporan
Tahap ini dilakukan dokumentasi dari implementasi serta hasil pengujian untuk mendukung laporan tugas akhir.
1.7. Sistematika Penulisan
Sistematika penulisan skripsi ini terdiri dari beberapa bagian utama sebagai beikut : BAB 1: PENDAHULUAN
Bab ini berisi perkenalan penelitian kepada pembaca serta penjelasan tentang rumusan masalah, batasan masalah, tujuan penelitian, manfaat penelitian, metodologi penelitian, dan sistematika penulisan.
BAB 2: LANDASAN TEORI
Hal-hal yang dijelaskan dalam bab ini adalah landasan teori yang diperlukan dalam melakukan penelitian, termasuk teori dan penjelasan mengenai algoritma K- Nearest Neighbor dan Naive Bayes.
BAB 3: ANALISIS DAN PERANCANGAN SISTEM
Dalam bab ini dijelaskan analisis masalah, analisis kebutuhan, perancangan antarmuka dan pemodelan.
BAB 4: IMPLEMENTASI DAN PENGUJIAN
Implementasi dari apa yang telah dianalisis dan dirancang dijelaskan dalam bab ini, yaitu antarmuka dan penjelasan akan setiap form yang ditampilkan. Pengujian menunjukkan bahwa perangkat lunak bekerja sesuai dengan yang diinginkan.
BAB 5: KESIMPULAN DAN SARAN
Bab ini menjelaskan bahwa penelitian yang dilakukan telah memenuhi tujuannya, apa yang dapat disimpulkan dari penelitian yang telah dilakukan. Selain itu, diberikan saran untuk hasil penelitian yang lebih baik dan penelitian selanjutnya yang berkaitan dengan penelitian yang telah diselesaikan.
BAB 2
LANDASAN TEORI
2.1. Sistem Informasi Geografis (SIG)
Sistem Informasi Geografis adalah sistem yang berbasiskan komputer yang digunakan untuk menyimpan dan memanipulasi informasi-informasi geografi. SIG dirancang untuk mengumpulkan, menyimpan, dan menganalisis objek-objek dan fenomena dimana lokasi merupakan karakteristik yang penting atau kritis untuk dianalisis (Bafdal, 2011).
SIG tidak berdiri dan berkembang sendiri. SIG terkait dan memerlukan disiplin ilmu kebumian yang lain. SIG berfungsi sebagai alat analisis dan alat pendukung pengambilan keputusan, sedangkan disiplin ilmu kebumian menyediakan kebutuhan yang diperlukan agar SIG dapat bekerja. Matematika berperan dalam pengembangan model data dalam SIG dan juga pengembangan teknis analisis. Sedangkan statistik berperan selain dalam pengembangan teknik analisis, juga berperan dalam aspek verifikasi dan validasi hasil analisis SIG.
Gambar 2.1 Hubungan SIG dan disiplin ilmu kebumian pendukung SIG merupakan sistem kompleks yang terintegrasi dengan sistem-sistem komputer lain di tingkat fungsional dan jaringan. Sistem SIG terdiri dari beberapa komponen sebagai berikut :
1) Perangkat keras
Pada saat ini perangkat SIG dapat digunakan dalam berbagai platform perangkat keras mulai dari PC Desktop, workstation hingga multi user host. Perangkat keras yang sering digunakan untuk SIG adalah komputer (PC), mouse, digitizer, printer, plotter dan scanner.
2) Perangkat lunak
SIG juga merupakan sistem perangkat lunak yang tersusun secara modular dimana basis data memegang peranan kunci. Setiap sub-sistem diimplementasikan dengan menggunakan perangkat lunak yang terdiri dari beberapa modul, hingga tidak mengherankan jika ada perangkat SIG yang terdiri dari ratusan modul program (*.exe) yang masing-masing dapat dieksekusi sendiri.
3) Data dan informasi geografis
SIG juga dapat mengumpulkan dan menyimpan data serta informasi yang diperlukan baik secara tidak langsung dengan cara meng-importnya dari perangkat-perangkat lunak SIG yang lain maupun secara langsung dengan cara mendijitasi data spasialnya dari peta dan memasukkan data atributnya dari tabel- tabel dan laporan.
4) Manajemen
Susunan keahlian kemampuan pengelola SIG sangat penting untuk menjalankan fungsi SIG. Secara sederhana keahlian yang penting dalam suatu SIG adalah manajer, ahli database, katografi, manajer sistem, programmer dan teknisi untuk pemasukan dan pengeluaran data.
SIG merupakan representasi dari dunia nyata di atas monitor komputer sebagaimana lembaran peta dapat merepresentasikan dunia nyata di atas keras. Tetapi SIG memiliki kekuatan lebih dan fleksibilitas dari pada lembaran kertas (Bafdal, 2011).
Peta merupakan gambaran dua dimensi dari dunia nyata, objek-objek yang direpresentasikan di atas peta disebut unsur peta atau map feature (contohnya sungai, taman, kebun, jalan dan lain-lain). Peta menggunakan titik, garis dan poligon dalam merepresentasikan objek-objek dunia nyata. Peta menggunakan simbol-simbol grafis dan warna untuk membantu dalam mengidentifikasi unsur-unsurnya. Skala dalam peta menentukan ukuran dan bentuk representasi unsur-unsurnya. Makin meningkat skala peta, makin besar ukuran unsur-unsurnya.
SIG menyimpan semua informasi deskriptif unsur-unsurnya sebagai atribut- atribut di dalam basis data. Kemudian SIG menghubungkan unsur-unsur diatas dengan tabel yang bersangkutan. Dengan demikian, atribut-atribut dapat diakses melalui lokasi unsur-unsur peta dan sebaliknya. Unsur-unsur peta dapat diakses melalui atribut- atributnya. Karena itu unsur tersebut dapat dicari dan ditemukan berdasarkan atribut- atributnya. SIG menghubungkan sekumpulan unsur-unsur peta dengan atribut- atributnya di dalam satuan yang disebut layer. Kumpulan dari layer-layer ini akan membentuk basisdata SIG.
SIG merupakan sistem komputer yang mampu menangani masalah basisdata spasial maupun basis data non-spasial. Sistem ini merelasikan lokasi geografi (data spasial) dengan informasi-informasi deskripsinya (non-spasial) sehingga para- penggunanya dapat membuat peta (analog atau digital) dan menganalisis informasinya dengan berbagai cara. Ada banyak cara dalam mengorganisasikan data dan informasi berikut analisis dan presentasinya yang menjadi daya tarik SIG. Informasi SIG dapat disajikan dalam bentuk :
1. Informasi SIG dalam bentuk tabel basis data
Informasi atribut biasanya digabungkan dan dibentuk menjadi tabel-tabel.
2. Informasi SIG dalam bentuk layer Peta Digital
Dengan mengorganisasikan informasi seperti ini, peta-prta dijital menyajikan lokasi-lokasi dimana objek-objek sesungguhnya berada di dunia nyata beserta hubungannnya satu sama lain.
Kemampuan SIG dapat dikenali dari fungsi-fungsi analisis yang dapat dilakukannya. Terdapat dua jenis fungsi analisis; fungsi analisis atribut (basis data) dan fungsi analisis spasial.
1. Fungsi Analisis Atribut
a. Operasi dasar basis data mencakup :
1. Membuat basisdata baru (create database) 2. Menghapus basisdata (drop database) 3. Membuat tabel basis data (create table) 4. Menghapus tabel basisdata (drop table)
5. Mengisi dan menyisipka data (record) ke dalam tabel (insert)
6. Membaca dan mencari data (field atau record) dari tabel basisdata (seek, find, search, retrieve)
7. Mengubah dan meng-edit data yang terdapat di dalam tabel basisdata (update, edit)
8. Menghapus data dari tabel basisdata (delete, zap, pack) 9. Membuat indeks untuk setiap tabel basis data
b. Perluasan operasi basisdata
1. Membaca dan menulis basisdata dalam sistem basisdata yang lain (export, import)
2. Dapat berkomunikasi dengan sistem basis data yang lain (misalkan dengan menggunakan driver ODBC)
3. Dapat menggunakan bahasa basis data standard SQL (Structures Query Language)
4. Operasi-operasi atau fungsi analisis lain yang sudah rutin digunakan di dalam sistem basisdata
2. Fungsi Analisis Spasial 1. Klasifikasi (reclassify)
Fungsi ini mengklasifikasikan kembali suatu data spasial (atau atribut) menjadi data spasial yang baru dengan menggunakan kriteria tertentu.
2. Network (jaringan)
Fungsi ini merujuk data spasial titik-titik (point) atau garis-garis (lines) sebagai suatu jaringan yang tidak terpisahkan. Fungsi ini sering digunakan di dalam bidang-bidang transportasi dan utility (misalnya aplikasi jaringan kabel listrik, komunikasi, pipa minyak dan lain-lain.
3. Overlay
Fungsi ini menghasilkan data spasial baru minimal dua data spasial yang menjadi masukannya. Sebagai contoh, bila untuk menghasilkan wilayah- wilayah yang sesuai untuk budidaya tanaman padi, diperlukan data ketinggian permukaan bumi, kadar air tanah, dan jenis tanah, maka fungsi analisis spasial overlay akan dikenakan terhadap ketiga data spasial tersebut.
4. Buffering
Fungsi ini akan menghasilkan data spasial baru yang berbentuk poligon atau zone dengan jarak tertentu dari data spasial yang menjadi masukannya. Data spasial titik akan menghasilkan data spasial baru yang berupa lingkaran- lingkaran yang mengelilingi titik pusatnya. Untuk data spasial garis akan
menghasilkan data spasial baru yang berupa poligon-poligon yang melingkupi garis-garis. Demikian pula untuk data spasial poligon akan menghasilkan data spasial baru berupa poligon-poligon yang lebih besar dan konsentris.
5. 3D analisis
Fungsi ini terdiri dari sub-sub fungsi yang berhubungan dengan pesentasi data spasial dalam ruang 3 dimensi. Fungsi analisis spasial ini banyak menggunakan fungsi interpolasi. Sebagai contoh, untuk menampilkan data spasial ketinggian, tataguna tanah, jaringan jalan dan utility dalam bentuk 3 dimensi.
6. Digital image processing
Fungsi ini dimiliki oleh perangkat SIG yang berbasiskan raster. Karena data spasial permukaan bumi (citra digital) banyak didapat dari perekaman data satelit yang berformat raster, maka banyak SIG raster yang juga dilengkapi dengan fungsi analisis ini.
Manfaat Sistem Informasi Georgafis sangatlah beragam, beberapa manfaat SIG sebagai berikut :
1. Sebagai analisis komunikasi dan integrasi antar disiplin ilmu terutama yang memerlukan informasi-informasi geosciences.
2. Memecahkan masalah seputar akurasi representasi, akurasi prediksi dan keputusan yang diambil berdasarkan represetasi, minimalisasi volume data yang digunakan, maksimalisasi kecepatan komputasi, kesesuaian dengan para pengguna, perangkat lunak dan proyek-proyek yang lain mengenai bumi.
2.2. Data Spasial
Data spasial mempunyai pengertian sebagai suatu data yang mengacu pada posisi, obyek, dan hubungan diantaranya dalam ruang bumi. Data spasial merupakan salah satu item dari informasi, dimana didalamnya terdapat informasi mengenai bumi termasuk permukaan bumi, dibawah permukaan bumi, perairan, kelautan, dan bawah atmosfir (Rajabidfard & williamson, 2001 dalam Bafdal, 2011). Data spasial dan informasi turunannya digunakan untuk menentukan posisi dari identifikasi suatu elemen di permukaan bumi (Rajabidfard, 2001 dalam Bafdal, 2011). Lebih lanjut lagi Rajabidfard (2001) dalam Bafdal (2011) menerangkan mengenai pentingnya peranan posisi lokasi yaitu: (1) pengetahuan mengenai lokasi dari suatu aktifitas memungkinkan
hubungannya dengan aktifitas lain atau elemen lain dalam daerah yang sama atau lokasi yang berdekatan dan (2) lokasi memungkinkan diperhitungkannya jarak, pembuatan peta, memberikan arahan dalam membuat keputusan spasial yang bersifat kompleks.
Data spasial dapat dihasilkan dari berbagai macam sumber, diantaranya adalah:
1. Citra satelit, data ini menggunakan satelit sebagai wahananya. Satelit tersebut menggunakan sensor untuk dapat merekam kondisi atau gambaran dari permukaan bumi. Umumnya diaplikasikan dalam kegiatan yang berhubungan dengan pemantauan sumber daya alam di permukaan bumi. Kelebihan dari teknologi ini adalah dalam kemampuannya merekam cakupan wilayah yang las dan tingkat resolusi dalam merekam objek yang sangat tinggi.
2. Peta analog, sebenarnya jenis peta ini merupakan versi awal dari data spasial, dimana yang membedakannya adalah hanya dalam bentuk penyimpanannya saja.
Peta analog merupakan bentuk tradisional dari data spasial, dimana data ditampilkan dalambentuk kertas atau film. Oleh karena itu dengan perkembangan teknologi saat ini peta analog tersebut dapat di scan menjadi format digital untuk kemudian dapat disimpan dalam basis data.
3. Foto udara, merupakan salah satu sumber data yang banyak digunakan untuk menghasilkan data spasial selain dari citra satelit. Perbedaan dengan citra satelit adalah hanya pada wahana dan cakupan wilayahnya. Biasanya foto udara menggunakan pesawat udara sebagai wahananya.
4. Data tabular, data ini berfungsi sebagai atribut bagi data spasial. Data ini umumnya berbentuk tabel. Salah satu contoh data ini yang umumnya digunakan adalah data sensus penduduk, data sosial, data ekonomi. Data tabular ini kemudian direlasikan dengan data spasial untuk menghasilkan tema data tertentu.
5. Data survei, data ini dihasilkan dari hasil survei atau pengamatan dilapangan.
Contohnya adalah pengukuran persil lahan dengan mnggunakan metode survei terestris.
2.3. Fingerprinting
Kata fingerprint (sidik jari) dalam penelitian ini mengacu pada pengukuran suatu stimulus fisik (misalnya sinyal radio) pada suatu tempat tertentu. Mirip dengan sidik jari manusia, fingerprint dari suatu tempat tertentu juga dapat digunakan untuk mengidentifikasi lokasi tersebut. Location Fingerprinting adalah sebuah metode yang
memanfaatkan hubungan antara beberapa pengukuran stimulus fisik dan sebuah lokasi tertentu (Kaemarungsi, 2005).
Dalam penelitian ini, stimulus fisik yang diukur ialah Received Signal Strength (RSS) yang diperoleh dari acces point (AP) yang ada pada suatu ruangan tertentu.
Keuntungan menggunakan RSS ialah dapat diimplementasikan secara langsung dalam sistem komunikasi nirkabel yang sudah tersedia tanpa memerlukan sinkronisasi antara receiver (pemancar) dan transmitter (penerima). Kelemahan menggunakan RSS ialah pengukuran nilai RSS dapat menunjukkan nilai yang bervariasi karena pengaruh interferensi dan efek multipath (yang disebabkan oleh refleksi, difraksi di ruangan dan adanya hambatan). Namun efek multipath ini dapat ditangani dengan mencari rata-rata (mean) dari nilai pengukuran yang bervariasi (Fang, et al. 2008 dalam Ginting, et al.
2012).
Fingerprinting biasanya bekerja dalam dua tahap: off-line (pelatihan) dan online (penentuan letak/pengujian). Untuk lebih memperjelas proses kedua tahap ini, perhatikan gambar 2.2.
Dalam tahap pelatihan, kekuatan sinyal dari AP dikumpulkan dari lokasi-lokasi yang berbeda untuk membangun database (basis data) atau disebut juga sebagai pemetaan lingkungan. Untuk menghasilkan basis data yang optimal, pemilihan Reference Point (RP) perlu dilakukan dengan cermat.
Dalam tahap penentuan letak, lokasi dapat dihitung dengan membandingkan pengukuran RSS yang diterima dengan pengukuran nilai yang disimpan dalam basis data.
Tahap Pelatihan
Tahap Penentuan Letak (Pengujian) Posisi RP(1)
Gambar 2.2 Tahapan proses fingerprinting
2.4. Algoritma K-Nearest Neighbor (K-NN)
K-Nearest Neighbour adalah salah satu metode yang menggunakan algoritma supervised dimana hasil dari sampel uji yang baru diklasifikasikan berdasarkan mayoritas dari kategori pada K-NN (Wahyu, 2013). Perbedaan antara supervisied learning dengan unsupervised learning adalah pada unsupervised learning, data belum memiliki pola apapun, dan tujuan dari unsupervised learning adalah untuk menemukan pola dalam sebuah data. Sedangkan tujuan dari algoritma supervised adalah menemukan pola baru dalam data dengan menghubungkan pola data yang sudah ada dengan data yang baru, atau dengan kata lain mengklasifikasi objek baru berdasarkan atribut dan sampel latih. Pengklasifikasian tidak menggunakan model apapun untuk dicocokkan dan hanya berdasarkan pada memori. Cara kerja singkat algoritma K-NN ialah diberikan sebuah koordinat titik uji, maka akan ditemukan sejumlah K objek (titik training) yang paling dekat dengan titik uji tersebut. Hasil akhir pengklasifikasian objek pada algoritma K-NN menggunakan voting terbanyak di antara klasifikasi dari K objek terdekat. Pada algoritma KNN terdapat beberapa aturan jarak yang dapat digunakan, yaitu Euclidean distance, City block atau Manhattan distance, Cosine dan Correlation. Dalam penelitian ini dekat atau jauhnya tetangga ditentukan berdasarkan
Store
Penerima (Mobile User) AP (1)
AP (2)
AP(3)
. . . (x,y)1
(x,y)2
(x,y)n
RSS1, RSS2, RSS3
RSS1, RSS2, RSS3
RSS1, RSS2, RSS3
(?,?) RSS1, RSS2, RSS3 Algoritma (x,y)
Database
Mobile user Mobile User
location
aturan jarak Eucledian (Euclidean Distance) yang didefenisikan sebagai berikut (Krisandi, et al. 2013) :
𝑑(𝑥𝑖,𝑥𝑗) = √∑𝑛𝑟=1(𝑎𝑟(𝑥𝑖) − 𝑏𝑘(𝑥𝑗))2 Keterangan :
𝑑(𝑥𝑖,𝑥𝑗) : Jarak Euclidean (Euclidean Distince) (𝑥𝑖) : record ke-i
(𝑥𝑗) : record ke-j (𝑎𝑟) : data latih ke-r (𝑏𝑘) : Data Uji ke-k i,j : 1,2,3,...n
Pada algoritma K-NN, data berdimensi q, jarak dari data tersebut ke data lain dapat dihitung. Nilai jarak inilah yang digunakan sebagai nilai kedekatan/kemiripan antara data uji dengan data latih. Nilai K pada K-NN berarti K-data terdekat dari data uji. Gambar 8.2memberikan contoh algoritma K-NN, tanda lingkaran untuk kelas 0, tanda persegi untuk kelas 1. Seperti yang ditujukan pada gambar 8.2 (a), jika K bernilai 1, kelas dari satu data latih sebagai tetangga terdekat (terdekat pertama) dari data uji tersebut akan diberikan sebagai kelas untuk data uji, yaitu kelas 1; jika K bernilai 2, akan diambil 2 tetangga terekat dari ata latih. Begitu juga jika nilai K adalah 3,4,5, dan sebaginya. Jika dalam K-tetangga ada dua kelas yang berbeda, akan diambil kelas dengan jumlah data terbanyak (voting mayoritas), seperti yang ditunjukkan pada gambar 8.2 (c) dan (d). Pada gambar tersebut terlihat bahwa kelas 0 mempunyai jumlah yang lebih banyak daripada kelas 1 sehingga data uji akan dikategorikan ke dalam kelas 0. Jika kelas dengan data terbanyak ada dua atau lebih, akan diambil kelas dari data dengan jumlah yang sama secara acak, seperti yang ditujukan pada gambar 8.2 (c).
Nilai k yang terbaik untuk algoritma ini tergantung pada data. Secara umum, nilai k yang tinggi akan menguruangi efek noise pada klasifikasi, tetapi membuat batasan antara setiap klasifikasi menjadi semakin kabur. Nilai k yang terbaik dapat dipilih dengan optimasi parameter, misalnya dengan menggunakan cross-validation.
Kasus khusus dimana klasifikasi diprediksikan berdasarkan data latih yang paling dekat (dengan kata lain, k=1) disebut algoritma nearest neighbor.
0 2 4 6 8
2 4 6 8 0
2 4 6 8
2 4 6 8
0 2 4 6 8
2 4 6 8 0
2 4 6 8
2 4 6 8
a. 1 tetangga terdekat b. 2 tetangga terdekat
c. 3 tetangga terdekat d. 1 tetangga terdekat
Gambar 2.3 K-NN dengan nilai K-tetangga : (a) 1-NN, (b) 2-NN, (c) 3-NN, dan (d) 7-NN
2.5. Algoritma Naive Bayes
Bayes merupakan teknik prediksi berbasis probabilistik sederhana yang berdasar pada penerapan teorema Bayes (atau aturan Bayes) dengan asumsi independensi (ketidaktergantungan) yang kuat (naif) (Prasetyo, 2012). Dengan kata lain, dalam Naive Bayes, model yang digunakan adalah “model fitur independen”.
Dalam Bayes (terutama Naive Bayes), maksud independensi yang kuat pada fitur adalah bahwa sebuah fitur pada sebuah data tidak berkaiatan dengan ada atau tidaknya fitur lain dalam data yang sama. Contohnya, pada kasus klasifikasi hewan dengan fitur penutup kulit, melahirkan, berat, dan menyususi. Dalam dunia nyata, hewan yang berkembang biak dengan cara melahirkan dipastikan juga menyususi. Di sini ada ketergantungan pada fitur menyusui karena hewan yang menyusui biasanya melahirkan, atau hewan yang bertelur biasanya tidak menyusui. Dalam Bayes, hal
tersebut tidak dipandang sehingga masing-masing fitur seolah tidak memiliki hubungan apapun.
Prediksi Bayes didasarkan pada teorema Bayes dengan formula sebagai berikut : 𝑃(𝐻|𝐸) = 𝑃(𝐸|𝐻) × 𝑃(𝐻)
𝑃(𝐸) Penjelasan dari formula tersebut adalah sebagai berikut :
𝑃(𝐻|𝐸) : probabilitas akhir bersyarat (conditional probability) suatu hipotesis H terjadi jika diberikan bukti (evidence) E terjadi.
𝑃(𝐸|𝐻) : probabilitas sebuah bukti E terjadi akan mempengaruhi hipotesis H.
𝑃(𝐻) : probabilitas awal (priori) hipotesis H terjadi tanpa memandang bukti apapun.
𝑃(𝐻) : Probabilitas awal (priori) bukti E terjadi tanpa memandang hipotesis/bukti yang lain
Ide dasar dari aturan Bayes adalah bahwa hasil dari hipotesis atau pristiwa (H) dapat diperkirakan berdasarkan pada beberapa bukti (E) yang diamati. Ada beberapa hal penting dari aturan Bayes tersebut, yaitu :
1. Sebuah probabilitas awal/priori H atau P(H) adalah probabilitas dari suatu hipotesis sebelum bukti diamati.
2. Sebuah probabilitas akhir H atau P(H|E) adalah probabilitas dari suatu hipotesis setelah bukti diamati.
Teorema Bayes juga bisa menangani beberapa bukti, misalnya ada E1, E2, dan E3, sehingga probabilitas akhir untuk hipotesis hujan dapat dihitung dengan cara berikut.
𝑃(𝐻|𝐸1, 𝐸2, 𝐸3) =𝑃(𝐸1, 𝐸2, 𝐸3|𝐻) × 𝑃(𝐻) 𝑃(𝐸1, 𝐸2, 𝐸3)
Karena asumsi yang digunakan untuk bukti ialah independen, bentuk di atas dapat diubah menjadi
𝑃(𝐻|𝐸1, 𝐸2, 𝐸3) =𝑃(𝐸1|𝐻) × 𝑃(𝐸2|𝐻) × 𝑃(𝐸3|𝐻) × 𝑃(𝐻) 𝑃(𝐸1) × 𝑃(𝐸2) × 𝑃(𝐸3)
Kaitan antara Naive Bayes dengan klasifikasi, kolerasi hipotesis dan bukti dengan klasifikasi adalah bahwa hipotesis dalam teorema Bayes merupakan label kelas yang
menjadi target pemetaan dalam klasifikasi, sedangkan bukti merupakan fitur-fitur yang menjadi masukan dalam model klasifikasi. Jika X adalah vektor masukan yang berisi fitur dan Y adalah label kelas, Naive Bayes dituliskan dengan P(Y|X). Notasi tersebut berarti probabilitas kelas Y didapatkan setelah fitur-fitur X diamati. Notasi ini disebut juga probabilitas akhir (posterior probability) untuk Y, sedangkan P(Y) disebut probabilitas awal (prior probability) Y.
Selama proses pelatihan harus dilakukan pembelajaran probabilitas akhir P(Y|X) pada model untuk setiap kombinasi X dan Y berdasarkan informasi yang didapat dari data latih. Dengan membangun model tersebut, suatu data uji X’ dapat diklasifikasikan dengan mencari nilai Y’ dengan memaksimalkan nilai P(Y’|X’) yang didapat.
Formulasi Naive Bayes untuk klasifikasi adalah
𝑃(𝑌|𝑋) =𝑃(𝑌) ∏𝑞𝑖=1𝑃(𝑋𝑖|𝑌) 𝑃(𝑋)
P(X|Y) adalah probabilitas data dengan vektor X pada kelas Y. P(Y) adalah probabilitas awal kelas Y. ∏𝑞𝑖=1𝑃(𝑋𝑖|𝑌) adalah probabilitas independen kelas Y dari semua fitur dalam vektor X. Nilai P(X) selalu tetap sehingga dalam perhitungan prediksi nantinya kita tinggal menghitung bagian ∏𝑞𝑖=1𝑃(𝑋𝑖|𝑌) dengan memilih yang terbesar sebagai kelas yang dipilih sebagai hasil prediksi. Sementara probabilitas indepenen ∏𝑞𝑖=1𝑃(𝑋𝑖|𝑌) tersebut merupakan pengaruh semua fitur dari data tehadap setiap kelas Y, yang dinotasikan dengan
𝑃(𝑋|𝑌 = 𝑦) = ∏ 𝑃(𝑋𝑖|𝑌 = 𝑦)
𝑞
𝑖=1
Setiap set fitur X={𝑋1, 𝑋2, 𝑋3, … , 𝑋𝑞} terdiri atas q atribut (q dimensi).
Umumnya, Bayes mudah dihitung untuk fitur bertipe kategoris. Namun untuk fitur dengan tipe numerik (kontinu) ada perlakuan khusus sebelum dimasukkan dalam Naive Bayes. Cara yang pertama adalah Melakukan diskretisasi pada setiap fitur kontinu dan mengganti nilai fitur kontinu tersebut dengan nilai interval diskret.
Pendekatan ini dilakuakan dengan mentransformasi fitur kontinu ke dalam fitur ordinal.
Sedangkan cara yang kedua adalah mengasumsikan bentuk tertentu dari distribusi probabilitas untuk fitur kontinu dan memperkirakan parameter distribusi dengan data pelatihan. Distribusi Gaussian biasanya dipilih untuk merepresentasikan probabilitas
bersyarat dari fitur kontinu pada sebuah kelas 𝑃(𝑋𝑖|𝑌), sedagkan distribusi Gaussian dikarakteristikkan dengan dua parameter: mean, µ dan varian, 𝜎2. Untuk setiap kelas 𝑦𝑗, probabilitas bersyarat kelas 𝑦𝑗untuk fitur 𝑋𝑖 adalah
𝑃(𝑋𝑖 = 𝑥𝑖|𝑌 = 𝑦𝑗) = 1
√2𝜋𝜎𝑖𝑗
𝑒𝑥𝑝
−(𝑥𝑖−𝜇𝑖𝑗)2 2𝜎𝑖𝑗2
Parameter 𝜇𝑖𝑗 bisa didapat dari mean sample 𝑋𝑖 (𝑥̅) dari semua data latih yang menjadi milik kelas 𝑦𝑗 , sedangkan 𝜎𝑖𝑗2 dapat diperkirakan dari varian sampel (𝑠2) dari data latih.
2.6. Pengukuran Kinerja Klasifikasi
Sebuah sistem yang melakukan klasifikasi diharapkan dapat melakukan klasifikasi semua set data dengan benar, tetapi tidak dapat dipungkiri bahwa kinerja suatu sistem tidak bisa 100% benar sehingga sebuah sistem klasifikasi juga harus diukur kinerjanya.
Akurasi adalah syarat terpenting dalam sistem pemposisian objek. Biasanya, jarak error diperoleh dari rata-rata jarak Euclidean antara lokasi estimasi dan lokasi sesungguhnya. Nilai Akurasi yang paling tinggi, menghasilkan sistem yang paling baik (Liu, et al. 2009).
Setelah diperoleh hasil perhitungan algoritma, maka dilakukan pengukuran kinerja dari algoritma tersebut dengan menghitung jarak error dari estimasi posisi yang dihasilkan oleh algoritma tersebut. Rumus untuk menghitung jarak error ialah (Ginting, et al. 2012) :
𝐽𝑎𝑟𝑎𝑘 𝐸𝑟𝑟𝑜𝑟 = √(𝑥 − 𝑥′)2+ (𝑦 − 𝑦′)2
Besarnya nilai rata-rata jarak error secara keseluruhan diperoleh dengan menggunakan persamaan
𝑅𝑎𝑡𝑎 − 𝑟𝑎𝑡𝑎 𝑗𝑎𝑟𝑎𝑘 𝐸𝑟𝑟𝑜𝑟 = ∑𝑛𝑖=1√(𝑥𝑖 − 𝑥𝑖′)2+ (𝑦𝑖− 𝑦𝑖′)2 𝑛
Keterangan :
(x,y) : lokasi yang sebenarnya (𝑥′, 𝑦′) : lokasi prediksi
n : banyaknya data pengujian
Besarnya persentase akurasi dapat dihitung dengan menggunakan persamaan
𝑃𝑒𝑟𝑠𝑒𝑛𝑡𝑎𝑠𝑒 𝐴𝑘𝑢𝑟𝑎𝑠𝑖 = 𝐽𝑢𝑚𝑙𝑎ℎ 𝑒𝑠𝑡𝑖𝑚𝑎𝑠𝑖 𝑝𝑜𝑠𝑖𝑠𝑖 𝑦𝑎𝑛𝑔 𝑎𝑘𝑢𝑟𝑎𝑡
𝐽𝑢𝑚𝑙𝑎ℎ 𝑡𝑜𝑡𝑎𝑙 𝑒𝑠𝑡𝑖𝑚𝑎𝑠𝑖 𝑝𝑜𝑠𝑖𝑠𝑖 × 100%
BAB 3
ANALISIS DAN PERANCANGAN SISTEM
3.1. Analisis Sistem
Analisis sistem merupakan tahapan yang dilakukan untuk mencari informasi mengenai kebutuhan-kebutuhan sistem, yang digunakan dalam merancang sebuah sistem sehingga memudahkan dalam mengimplementasikan tugas dari sistem tersebut.
Analisis sistem terdiri dari tiga fase yaitu analisis masalah, analisis kebutuhan dan analisis proses.
3.1.1. Analisis masalah
Saat ini kebutuhan akan posisi suatu objek tidak hanya untuk objek yang berada di luar ruangan tetapi juga objek yang berada di dalam ruangan. GPS merupakan salah satu positioning system yang popular saat ini, namun sistem ini tidak cocok untuk diterapkan untuk menentukan posisi dalam ruangan. Oleh sebab itu dibutuhkan suatu sistem yang dapat menentukan posisi objek dalam ruangan dengan keakuratan yang tinggi dan memanfaatkan peralatan yang ada. Masalah utama dalam penelitian ini adalah menentukan algoritma yang memiliki keakuratan yang tinggi dan kinerja yang cepat dengan menggunakan metode fingerprinting.
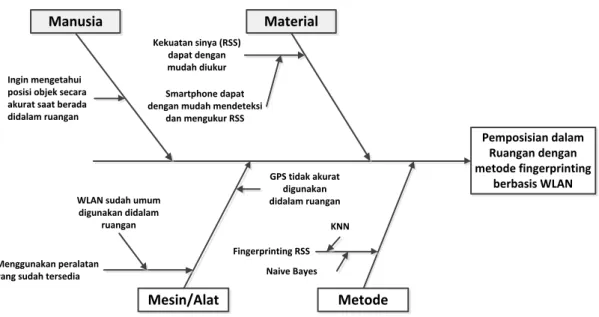
Untuk mengidentifikasi masalah tersebut digunakan diagram ishikawa atau disebut juga cause-and-effect diagram. Diagram ishikawa adalah sebuah alat visual untuk mengidentifikasi, mengeksplorasi dan secara grafik menggambarkan secara detail semua penyebab yang berhubungan dengan suatu permasalahan.
Pemposisian dalam Ruangan dengan metode fingerprinting
berbasis WLAN
Manusia
Mesin/Alat
Material
Metode
Ingin mengetahui posisi objek secara akurat saat berada didalam ruangan
Menggunakan peralatan yang sudah tersedia
WLAN sudah umum digunakan didalam
ruangan
GPS tidak akurat digunakan didalam ruangan
Fingerprinting RSS KNN
Naive Bayes Kekuatan sinya (RSS)
dapat dengan mudah diukur
Smartphone dapat dengan mudah mendeteksi
dan mengukur RSS
Gambar 3.1 Diagram ishikawa analisis permasalahan
Gambar 3.1 merupakan diagram yang menunjukkan sebab akibat dari penelitian ini.
Berawal dari kebutuhan manusia untuk mengetahui posisi objek yang berada di dalam ruangan secara akurat. Saat ini WLAN sudah sangat umum digunakan di dalam suatu ruangan dan tersedia lebih dari satu buah acces point (AP) didalam suatu gedung.
Dengan tersedianya AP didalam gedung maka kekuatan sinyal yang dihasilkan dapat dengan mudah di identifikasi dan ukur dengan menggunakan smartphone atau Tablet PC . Salah satu metode yang mudah untuk diterapkan untuk menentukan posisi objek ialah metode Fingerprinting. Untuk menerapkan metode fingerprinting, algoritma pengklasifikasian yang sering digunakan ialah K-Nearest Neighbor dan Naive Bayes.
Oleh sebab itu, dibutuhkan suatu penelitian untuk membandingkan keakurasian dari kedua algoritma tersebut ketika digunakan dalam metode fingerprinting untuk menentukan posisi objek di dalam ruangan berbasis WLAN.
3.1.2. Analisis Kebutuhan
Analisis kebutuhan merupakan analisis terhadap kondisi atau kemampuan yang harus dipenuhi oleh sistem untuk memahami sasaran produk. Dalam membuat sebuah sistem, langkah awal yang perlu dilakukan adalah menentukan kebutuhan. Terdapat dua jenis kebutuhan, yaitu kebutuhan fungsional dan kebutuhan nonfungsional. Kebutuhan fungsional adalah kebutuhan pengguna dan stakeholder sehari-hari yang akan dimiliki oleh sistem, dimana kebutuhan ini akan digunakan oleh pengguna dan stakeholder.
Sedangkan kebutuhan nonfungsional adalah kebutuhan yang memperhatikan hal-hal berikut yaitu performansi, kemudahan dalam menggunakan sistem, kehandalan sistem, keamanan sistem, keuangan, legalitas, dan operasional. (Nick Jenkins, 2005).
Kebutuhan fungsional yang wajib dimiliki sistem yang dikembangkan adalah:
1) Sistem dapat menyimpan nilai kekuatan sinyal dari 3 buah AP beserta dengan keterangan lokasinya ke dalam database sistem.
2) Sistem dapat memprediksi posisi objek sesuai dengan hasil pengukuran nilai RSS dari ketiga AP dalam tahap pengujian.
3) Sistem dapat menyajikan waktu yang dibutuhkan (running time) setiap kali pengujian dilakukan.
Sedangkan kebutuhan non-fungsional yang harus dimiliki sistem yang dikembangkan adalah:
1) Sistem memiliki tampilan muka yang user friendly dan tersedianya menu bantuan untuk membantu pengguna belajar menggunakan sistem.
2) Sistem hanya menggunakan perangkat yang telah tersedia dan digunakan secara umum sehingga menghemat biaya.
3) Waktu proses pelatihan dan pengujian relatif cepat.
4) Sistem dapat memperbaiki isi database jika terjadi kesalahan saat penyimpanan nilai RSS kedalam database.
5) Sistem dapat menampilkan dialog box ketika terjadi kesalahan dalam sistem.
3.1.3. Analisis Proses
Proses dalam penelitian ini diawali dengan proses pelatihan (offline) yaitu mengumpulkan nilai RSS dari ketiga AP di setiap titik grid 1 m x 1 m di dalam ruangan, kemudian nilai RSS tersebut di simpan pada database sistem. Kemudian dilakukan proses pengujian (online), yaitu menguji keakurasian posisi yang diperoleh dari perhitungan algoritma KNN dan Naive Bayes sesuai dengan nilai RSS yang diukur di sembarang tempat dalam ruangan. Selain keakurasian, lama proses runtime untuk sekali pengujian juga dihitung. Seluruh hasil pengujian akan dikumpulkan kemudian dihitung nilai error, tingkat keakurasian dan rata-rata lama proses pengujiannya sehingga dapat disimpulkan algoritma mana yang lebih baik digunakan untuk menentukan lokasi objek di dalam ruangan menggunakan metode fingerprinting
berbasis WLAN. Penelitian ini dilakukan di dua tempat, yaitu di rumah peneliti dan gedung Gereja GBKP Kemenangan Tani.
3.2. Perancangan Sistem
Perancangan sistem meliputi pembuatan use-case diagram, diagram aktivitas, diagram urutan, dan perancangan antarmuka.
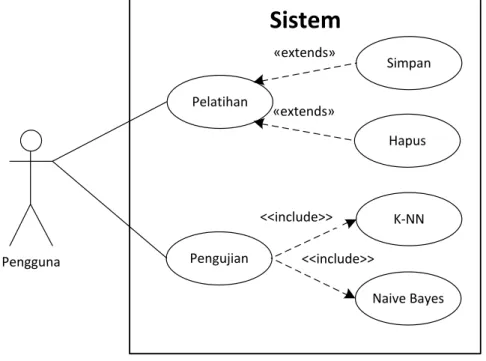
3.2.1. Diagram use-case
Diagram use-case merupakan pemodelan untuk menggambarkan kelakuan (behavior) sistem yang akan dibuat. Diagram use-case digunakan untuk mengetahui fungsi apa saja yang ada di dalam sebuah sistem dan siapa saja yang berhak menggunakan fungsi tersebut (Yulianto, et al. 2009). Aktor adalah segala hal diluar sistem yang akan menggunakan sistem tersebut untuk melakukan sesuatu (Kurt Bittner, Ian Spence.
2002). Aktor dalam penelitian ini ialah pengguna atau peneliti. Diagram use-case dapat dilihat pada gambar 3.2.
Pengguna
Sistem
Pelatihan
Pengujian
Simpan
Hapus
K-NN
Naive Bayes
«extends»
«extends»
«uses»
«uses»
<<include>>
<<include>>
Gambar 3.2 Diagram use-case sistem
Setiap use-case dijelaskan dalam use-case narrative. Tabel 3.1, tabel 3.2, tabel 3.3, tabel 3.4, tabel 3.5, dan tabel 3.6 merupakan use-case narrative dari setiap use-case yang ada di gambar 3.2.
Tabel 3.1 Use-case narrative pelatihan Nama use-case Pelatihan
Aktor Pengguna
Deskripsi Singkat
Use-case ini mendeskripsikan bagaimana pengguna menggunakan system untuk membuka dan menampilkan halaman pelatihan.
Preconditions Aplikasi telah berhasil dibuka dan halaman utama telah muncul.
Basic Flow of Events
Aksi aktor Respon sistem
Langkah 1: Memilih tab
“Pelatihan”
Langkah 2 : Menampilkan tab
“Pelatihan”.
Langkah 3 : Menampilkan data pelatihan pada tabel sesuai dengan tempat pelatihan yang aktif.
Alternative Flows
langkah 3 :
a. Jika data pelatihan pada tabel tidak tampil, maka cek alamat dan koneksi database dengan benar.
b. Jika pengguna ingin mengganti tempat pelatihan atau melihat data tempat pelatihan lainnya, maka pengguna dapat memilih radio button tempat pelatihan.
Post- conditions
Data pelatihan siap untuk diperbaharui sesuai dengan tempat pelatihan.
Tabel 3.2 Use-case narrative simpan Nama use-case Simpan
Aktor Pengguna
Deskripsi Singkat
Use-case ini mendeskripsikan bagaimana pengguna dapat menyimpan atau menambahkan data baru ke dalam database dan ditampilkan pada tabel data pelatihan sesuai dengan tempat pelatihan.
Preconditions Pengguna memilih tab pelatihan, tempat pelatihan dan data pelatihan pada
tabel telah ditampilkan.
Basic Flow of Events
Aksi aktor Respon sistem
Langkah 1: Memasukkan nilai AP1, AP2, AP3, Posisi dan lokasi pelatihan pada text box yang telah disediakan.
Langkah 2 : Menekan tombol
“Simpan”
Langkah 3 : Mengecek valid tidaknya data masukan
Langkah 4 : Jika valid maka data akan disimpan dan akan menampilkan data yang telah di- update pada tabel.
Alternative Flows
Langkah 4
a. Jika data masukan tidak valid, maka akan menampilkan pesan “Data tidak valid !”.
Post- conditions
Nilai RSS dari AP1, AP2, AP3 dan Posisi berhasil tersimpan di database sesuai dengan lokasi pelatihan.
Tabel 3.3 Use-case narrative hapus Nama use-case Hapus
Aktor Pengguna
Deskripsi Singkat
Use-case ini mendeskripsikan bagaimana pengguna dapat menghapus data yang telah tersimpan di database dan menampilkan data pelatihan terbaru pada tabel sesuai dengan tempat pelatihan.
Preconditions Pengguna memilih tab pelatihan, tempat pelatihan dan data pelatihan pada tabel telah ditampilkan.
Basic Flow of Aksi aktor Respon sistem
Events Langkah 1: Memasukkan nilai AP1, AP2, AP3, Posisi dan lokasi pelatihan pada text box yang telah disediakan.
Langkah 2 : Menekan tombol
“Hapus”
Langkah 3 : Mengecek valid tidaknya data masukan
Langkah 4 : Jika valid maka data akan dihapus dan akan menampilkan data yang telah di- update pada tabel.
Alternative Flows
Alur Alternatif langkah 4
a. Jika data tidak valid, maka akan menampilkan pesan “Data tidak ditemukan !”.
b. Jika data inputan tidak tersimpan sebelumnya di database, maka akan menampilkan pesan “Data tidak ditemukan, cek kembali inputan Anda!”.
Post- conditions
Nilai RSS yang sesuai dengan data inputan AP1, AP2, AP3 dan Posisi terhapus sesuai dengan lokasi pelatihan.
Tabel 3.4 Use-case narrative pengujian Nama use-case Pengujian
Aktor Pengguna
Deskripsi Singkat
Use-case ini mendeskripsikan bagaimana pengguna menggunakan system untuk membuka dan menampilkan halaman pengujian.
Preconditions Aplikasi telah berhasil dibuka dan halaman utama telah muncul.
Basic Flow of Events
Aksi Aktor Respon sistem
Langkah 1: Memilih tab “Pengujian”
Langkah 2 : Menampilkan tab
“Pengujian”.
Alternative Flows
-
Post- conditions
Tab “Pengujian” berhasil ditampilkan.
Tabel 3.5 Use-case narrative K-NN Nama use-case K-NN
Aktor Pengguna
Deskripsi Singkat
Use-case ini mendeskripsikan perhitungan estimasi posisi objek dalam ruangan berdasarkan data inputan dengan menggunakan algoritma K-Nearest Neighbor.
Preconditions Tab “Pengujian” berhasil ditampilkan.
Basic Flow of Events
Aksi Aktor Respon sistem
Langkah 1: Memasukkan nilai RSS dari AP1, AP2, AP3 dan lokasi pengujian.
Langkah 2 : Menekan tombol “Uji”.
Langkah 3 : Mengecek valid tidaknya data masukan.
Langkah 4 : Jika valid maka asumsi posisi, running time dan jarak error hasil pengujian dari algoritma K-NN, koordinat data uji dan asumsi posisi akan ditampilkan.
Langkah 5 : Menekan tombol
“Reset”.
Alternative Flows
Langkah 4 :
a. Jika tidak valid, maka akan menampilkan pesan “Data nilai RSS tidak valid !”.
b. Jika hasil pengujian tidak tampil, cek alamat atau koneksi database dengan benar.
Post- conditions
Asumsi posisi dan running time hasil pengujian dari algoritma K-NN ditampilkan.
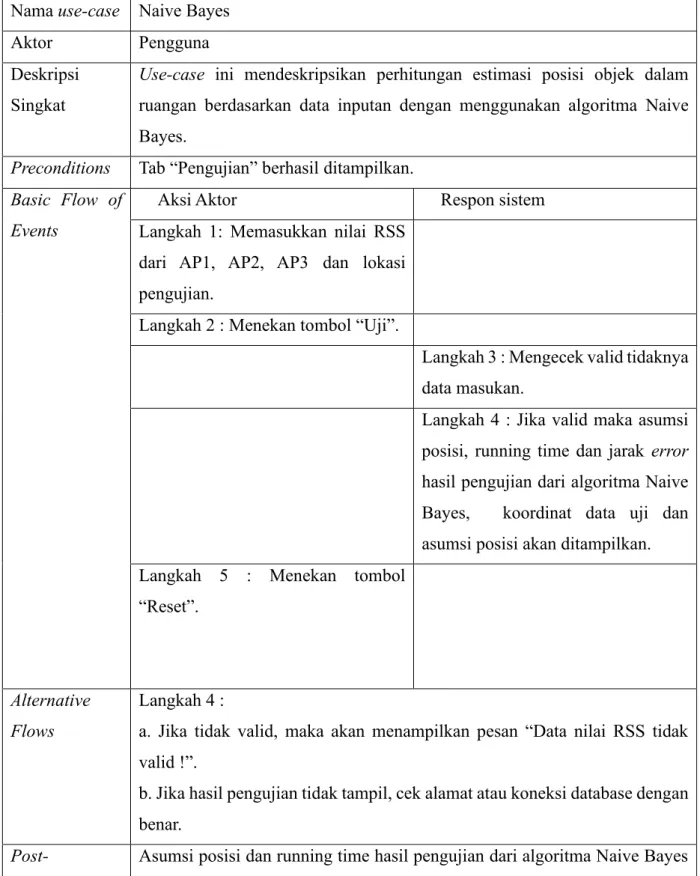
Tabel 3.6 Use-case narrative Naive Bayes Nama use-case Naive Bayes
Aktor Pengguna
Deskripsi Singkat
Use-case ini mendeskripsikan perhitungan estimasi posisi objek dalam ruangan berdasarkan data inputan dengan menggunakan algoritma Naive Bayes.
Preconditions Tab “Pengujian” berhasil ditampilkan.
Basic Flow of Events
Aksi Aktor Respon sistem
Langkah 1: Memasukkan nilai RSS dari AP1, AP2, AP3 dan lokasi pengujian.
Langkah 2 : Menekan tombol “Uji”.
Langkah 3 : Mengecek valid tidaknya data masukan.
Langkah 4 : Jika valid maka asumsi posisi, running time dan jarak error hasil pengujian dari algoritma Naive Bayes, koordinat data uji dan asumsi posisi akan ditampilkan.
Langkah 5 : Menekan tombol
“Reset”.
Alternative Flows
Langkah 4 :
a. Jika tidak valid, maka akan menampilkan pesan “Data nilai RSS tidak valid !”.
b. Jika hasil pengujian tidak tampil, cek alamat atau koneksi database dengan benar.
Post- conditions
Asumsi posisi dan running time hasil pengujian dari algoritma Naive Bayes ditampilkan.
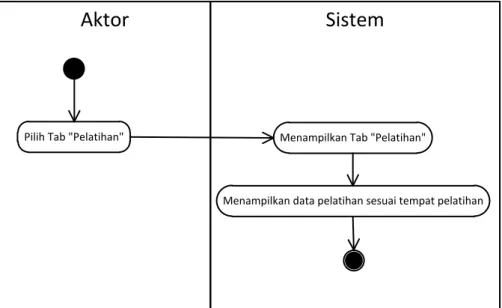
3.2.2. Diagram aktivitas
Activity diagram (diagram aktivitas) menggambarkan aliran kerja atau aktifitas dari sebuah sistem. Yang perlu diperhatikan dalam pembuatan diagram aktivitas ialah diagram aktifitas menggambarkan aktivitas sistem bukan aktivitas aktor (Yulianto, et al. 2009). Dalam sistem ini, urutan aktivitas pelatihan ditunjukkan oleh gambar 3.3, urutan aktivitas simpan ditunjukkan oleh gambar 3.4, urutan aktivitas hapus ditunjukkan oleh gambar 3.5, urutan aktifitas pengujian ditunjukkan oleh gambar 3.6, urutan aktivitas K-NN ditunjukkan oleh gambar 3.7, dan urutan aktifitas Naive Bayes ditunjukkan oleh gambar 3.8.
Aktor Sistem
Pilih Tab "Pelatihan" Menampilkan Tab "Pelatihan"
Menampilkan data pelatihan sesuai tempat pelatihan
Gambar 3.3 Diagram aktivitas pelatihan
Sistem Aktor
Tampilkan Data nilai RSS
Pilih tempat Input Posisi
Input nilai RSS
Simpan
Menyimpan data nilai RSS dan posisi sesuai lokasi pelatihan
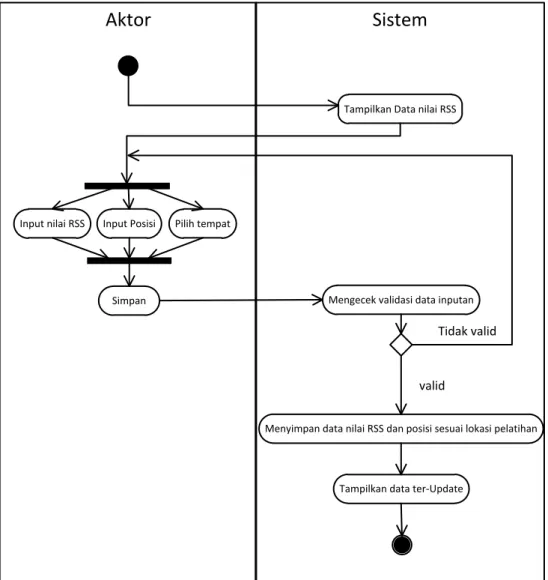
Tampilkan data ter-Update Mengecek validasi data inputan
valid
Tidak valid
Gambar 3.4 Diagram aktivitas simpan
Aktor Sistem
Tampilkan Data nilai RSS
Pilih tempat Input Posisi
Input nilai RSS
Hapus
Menghapus data nilai RSS dan posisi sesuai lokasi pelatihan
Tampilkan data ter-Update Mengecek validasi data inputan
valid
Tidak valid
Mengecek data inputan terdapat pada database
Ya
Tidak
Gambar 3.5 Diagram aktivitas hapus
Aktor Sistem
Pilih Tab "Pengujian" Menampilkan Tab "Pengujian"
Gambar 3.6 Diagram aktivitas pengujian
Sistem Aktor
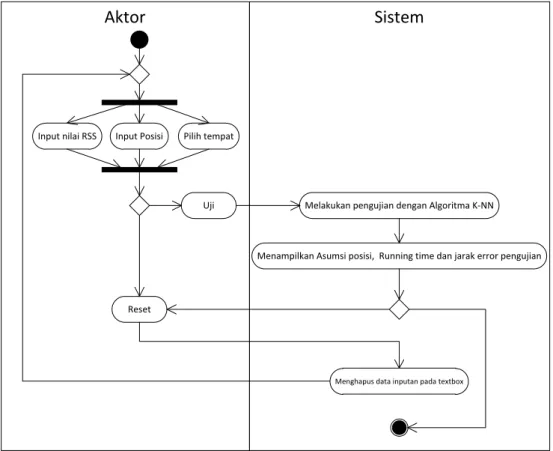
Input Posisi Input nilai RSS
Uji Melakukan pengujian dengan Algoritma K-NN
Reset
Menampilkan Asumsi posisi, Running time dan jarak error pengujian Pilih tempat
Menghapus data inputan pada textbox
Gambar 3.7 Diagram aktivitas K-NN
Sistem Aktor
Input Posisi Input nilai RSS
Uji Melakukan pengujian dengan Algoritma Naive Bayes
Reset
Menampilkan Asumsi posisi, Running time dan jarak error pengujian Pilih tempat
Menghapus data inputan pada textbox
Gambar 3.8 Diagram aktivitas Naïve Bayes
3.2.3. Sequence Diagram
Sequence diagram (diagram urutan) menggambarkan perilaku objek pada use-case dengan mendeskripsikan waktu hidup objek dan pesan yang dikirimkan dan diterima antar objek (Yulianto, et al. 2009). Diagram urutan dari penelitian ini dapat dilihat di Gambar 3.9.
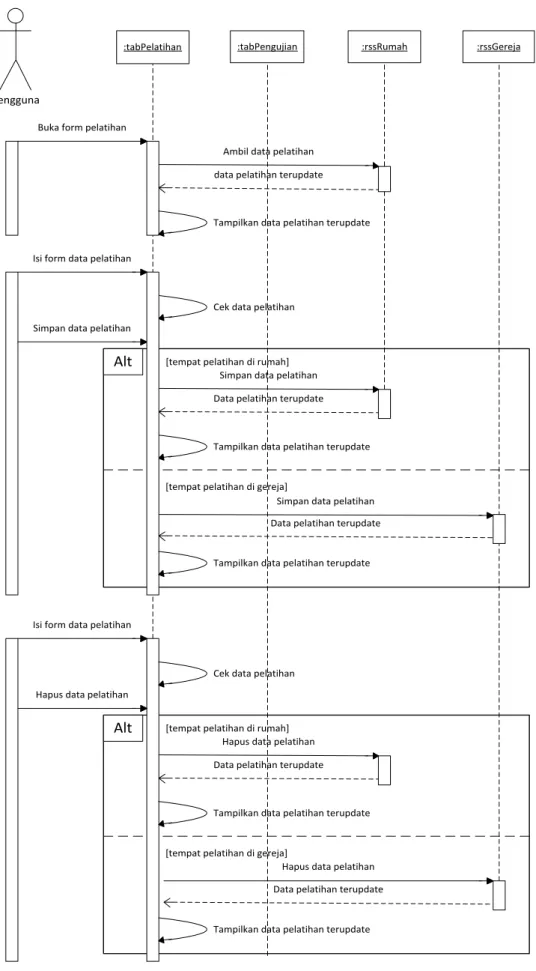
:tabPelatihan
Top Package::a
Buka form pelatihan
Ambil data pelatihan data pelatihan terupdate
Alt [tempat pelatihan di rumah]
[tempat pelatihan di gereja]
Alt [tempat pelatihan di rumah]
[tempat pelatihan di gereja]
:rssRumah
Isi form data pelatihan
Cek data pelatihan Simpan data pelatihan
Simpan data pelatihan Data pelatihan terupdate Tampilkan data pelatihan terupdate
Tampilkan data pelatihan terupdate
Simpan data pelatihan
:rssGereja
Data pelatihan terupdate
Tampilkan data pelatihan terupdate
Alt
Isi form data pelatihan
Cek data pelatihan Hapus data pelatihan
Hapus data pelatihan Data pelatihan terupdate
Tampilkan data pelatihan terupdate
Hapus data pelatihan Data pelatihan terupdate
Tampilkan data pelatihan terupdate
Alt
Pengguna
:tabPengujian
Gambar 3.9 Diagram urutan sistem
Alt [tempat pelatihan di rumah]
[tempat pelatihan di gereja]
Alt [tempat pelatihan di rumah]
[tempat pelatihan di gereja]
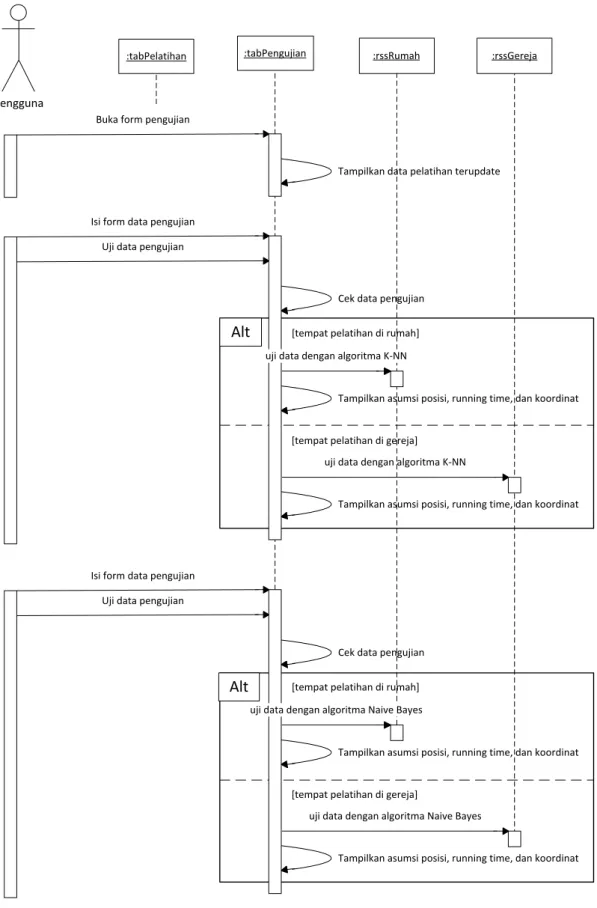
Buka form pengujian
Tampilkan data pelatihan terupdate
Isi form data pengujian
Cek data pengujian Uji data pengujian
Tampilkan asumsi posisi, running time, dan koordinat
uji data dengan algoritma K-NN
Tampilkan asumsi posisi, running time, dan koordinat
Alt
Isi form data pengujian
Cek data pengujian Uji data pengujian
Tampilkan asumsi posisi, running time, dan koordinat
uji data dengan algoritma Naive Bayes
Tampilkan asumsi posisi, running time, dan koordinat
Alt
:tabPelatihan :tabPengujian :rssRumah :rssGereja
uji data dengan algoritma Naive Bayes uji data dengan algoritma K-NN Top Package::aPengguna
Gambar 3.9 Diagram urutan sistem (lanjutan)
3.2.4. Diagram Alir Sistem