IMPLEMENTASI GENERALIZED LATENT SEMANTIC
ANALYSIS UNTUK PENILAIAN OTOMATIS JAWABAN
ESAI SISWA PADA TINGKAT SEKOLAH MENENGAH
ATAS (SMA)
Ruslan
1,3),Gunawan
1), Suhatati Tjandra
2)1
Program Studi Teknologi Informasi Sekolah Tinggi Teknik Surabaya,
2
Program Studi Teknik Informatika Sekolah Tinggi Teknik Surabaya,
3
SMA Santa Maria Surabaya,
Jalan Ngagel Jaya Tengah 73 - 77, Surabaya Indonesia
[email protected], [email protected], [email protected]
ABSTRAK
Sistem penilaian dan koreksi otomatis pada jawaban esai untuk penilaian hasil belajar siswa telah menjadi kajian penelitian di bidang pendidikan sejak dulu hingga kini. Pada umumnya bentuk evaluasi yang digunakan untuk mengukur kemampuan siswa dibagi menjadi 2(dua) kategori tes yang meliputi: 1) Multiple Choice (pilihan ganda) dan 2) Essay (jawaban uraian). Penelitian ini bertujuan untuk membuat aplikasi yang dapat membantu dalam melakukan penilaian jawaban soal essay secara otomatis melalui pendekatan Algoritma Generalized Latent Semantic Analysis (GLSA). Pada Algoritma ini terdapat 3 (tiga) proses utama yang meliputi preprocessing, GLSA, dan penilaian. Pada preprocessing terdapat beberapa tahapan, seperti: tokenisasi, stopword, stemming, dan term weigh. Sementara pada proses GLSA memiliki metode reduksi dimensi untuk mengambil kata-kata kunci yang dibandingkan dengan jawaban-jawaban kunci yang tersedia. Proses ini menggunakan n-gram yang berupa unigram, bigram, dan trigram sebagai tahapan kombinasi kata pada pembentukan matriks jawaban siswa dan jawaban guru. Dari proses ini, selanjutnya dibandingkan dengan tahapan penilaian melalui cosine similarity untuk memperoleh nilai siswa berdasarkan kesamaan n-gram dari jawaban siswa dan jawaban guru. Hasil yang diperoleh akan menilai jawaban essay siswa secara otomatis dengan menggunakan trigram. Simpulan hasil akurasi yang diperoleh adalah rata-rata untuk mata pelajaran Sejarah dan Sosiologi pada jenjang Sekolah Menengah Atas (SMA) mencapai 89%.
Kata kunci : Penilaian Otomatis, Latent Semantic Analysis, Generalized Latent Semantic Analysis, Singular Value Decomposition, N-gram.
ABSTRACT
Correction and assessment system on essay answer for assessment of student learning outcomes, has been a study research on education from the past until now. In general, the form of evaluation used to measure student’s ability was divided into 2 test category, which are: 1) Multiple Choice and 2) Essay. This research was intended to create applications that can assist in performing an automatic essay assessment of answers through Generalized Latent Semantic Analysis (GLSA) algorithm approach.For this algorithm, there are 3 main process which comprehend preprocessing, GLSA, and assessment. On preprocessing, there are several stages, which are: tokenization, stopword, stemming and term weigh. Meanwhile, on GLSA process, has a dimention reduction method to pick keywords that were compared with the available key answers. This process uses n-gram which consists unigram, bigram and trigram as a combination steps to create matrix of students and teachers answers. From this process, then compared with the assessment stage through cosine similarity to obtain student’s score based on n-gram similarity from students and teachers answers.The obtained result will assess student’s essay answer automatically using trigram. Obtained conclusion of accuracy result is the average for history and sosiology subject on Senior High School stage reached 89%.
Keywords : Automatic scoring, Latent Semantic Analysis, Generalized Latent Semantic Analysis, Singular Value Decomposition, N-gram.
1. PENDAHULUAN
Pada bagian ini akan dijelaskan mengenai latar belakang, tujuan penelitian, batasan masalah dan tinjauan pustaka terkait penelitian.
Latar Belakang
Proses penilaian hasil belajar atau ujian siswa biasanya menggunakan soal berupa pilihan ganda dan soal
essay. Meskipun penilaian secara essay relatif sulit dilakukan secara obyektif, tapi soal essay dipandang
masih diperlukan untuk melakukan proses evaluasi belajar. Hal ini dikarenakan bentuk essay memiliki kelebihan dalam merepresentasikan kemampuan siswa dalam memahami hasil pembelajaran. Sistem Penilaian dan koreksi otomatis pada jawaban essay telah menjadi fokus utama untuk bahan penelitian sejak dulu sampai sekarang. Penggunaan e-learning memungkinkan pembelajaran dilakukan dengan jumlah siswa yang banyak, sehingga diperlukan sistem penilaian otomatis (autograding) pada jawaban dari soal-soal e-learning. Sistem penilaian otomatis pada jawaban essay harus memegang prinsip konsisten dan penggunaan waktu serta biaya yang kecil sehingga nilai obyektivitasnya akan dapat dipertanggungjawabkan.
Tujuan Penelitian
Tujuan dan Manfaat dari penelitian ini adalah menerapkan sistem penilaian ujian essay secara otomatis berbasis web secara online menggunakan metode GLSA, menghasilkan sebuah sistem penilaian ujian yang memiliki tingkat akurasi yang tinggi serta aplikasi yang dapat membantu guru dalam melakukan penilaian ujian essay siswa agar lebih efektif dan efisien.
Batasan Masalah
Batasan-batasan yang diberikan dalam penelitian ini, antara lain: Program penilai essay secara otomatis yang digunakan pada mata pelajaran Sejarah dan Sosiologi. Program penilai essay secara otomatis ini hanya bisa digunakan untuk soal-soal berbahasa Indonesia, Program penilai essay secara otomatis ini akan digunakan untuk menilai soal-soal essay pada tingkat Sekolah Menengah Atas (SMA), Program penilai essay secara otomatis ini tidak dapat digunakan untuk soal-soal essay yang berisi rumus, gambar, dan tabel.
Tinjauan Pustaka
Berikut ini akan membahas secara singkat mengenai landasan teori yang digunakan pada penelitian ini.
Automated Essay Scoring (AES)
Automated Essay Scoring (AES) merupakan salah satu cabang dari bidang document classification.
AES merupakan teknologi yang sedang berkembang, yang digunakan untuk menilai esai secara otomatis. Akurasi dan keandalan sistem AES juga telah terbukti tinggi. Sampai saat ini, peningkatan mutu mesin penilai esai masih berlanjut dan berbagai studi dilangsungkan untuk meningkatkan tingkat efektifitas sistem AES karena AES berguna untuk mengatasi masalah waktu, biaya, dan generalisasi isu pada esai [1]. Berdasarkan penelitian yang dilakukan Dikli [1] hingga saat ini, terdapat empat tipe AES, yang secara luas digunakan oleh perusahaan pengujian, universitas, dan sekolah-sekolah umum, diantaranya adalah Project Essay Grader (PEG) yang merupakan sistem pertama yang diciptakan untuk menilai esai,
Intelligent Essay Assessor (IEA) yang merupakan sistem penilai esai yang menggunakan metode Latent Semantic Analysis, E-rater yang digunakan Educational Testing Service untuk menilai esai pada Graduate
Management Admissions Test, dan IntelliMetric, AES yang dikembangkan oleh Vantage Learning dan digunakan oleh College Board.
Information Retrieval (IR)
Information Retrieval (IR) dapat didefinisikan sebagai penerapan teknologi komputer untuk perolehan, pengorganisasian, penyimpanan, pencarian dan pendistribusian informasi[3]. IR adalah sebuah aktivitas, dan seperti aktivitas lainnya IR juga memiliki tujuan. Contoh sederhana dari IR adalah ketika orang mencari informasi menggunakan search engine dengan memberikan query untuk mendapatkan informasi yang diinginkan. Query yang diberikan belum tentu memberikan hasil pencarian yang baik. Walaupun begitu, query hanya sebagai kata kunci untuk sebuah search engine dalam melakukan pencarian untuk mendapatkan hasil yang diinginkan oleh orang tersebut [3].
Latent Semantic Analysis
Latent Semantic Analysis (LSA) merupakan metode yang menggunakan model statistik matematis yang
digunakan untuk menganalisa struktur semantik suatu teks. LSA digunakan untuk menilai esai dengan mengkonversi esai menjadi matriks-matriks yang diberi nilai pada masing-masing term untuk dicari kesamaan dengan term referensi [8]. Langkah-langkah LSA dalam menilai esai meliputi: Text Preprocessing, Term Dokumen Matrix, Singular Value Decomposition, dan Cosine Similarity.
Singular Value Decomposition (SVD) merupakan teorema aljabar linear yang mengatakan bahwa persegi
panjang matriks A dapat dipecah menjadi tiga matriks, yaitu: a.) Matriks orthogonal U
b.) Diagonal matriks S
c.) Transpose dari matriks V orthogonal.
Yang dapat dirumuskan seperti pada rumus 1 berikut ini:
= ... (1) Amn = matriks awal
Umm = matriks orthogonal U Smn = diagonal matriks S
VTnn = transpose matriks V orthogonal
Cosine Similarity digunakan untuk menghitung nilai kosinus sudut antar vektor dokumen dengan vektor query, semakin kecil sudut yang dihasilkan, maka tingkat kemiripan esai semakin tinggi. Vektor
merupakan besaran yang memiliki nilai dan arah.
Cosine Similarity dapat dirumuskan seperti pada rumus 2 berikut ini:
cos = • | || |= ∑ ∑ ( ) ∑ ( ) ... (2) Keterangan : A = vektor dokumen B = vektor query
• B = perkalian dot vektor A dan vektor B |A| = panjang vektor A
| | = panjang vektor B
| ||B| = cross product antara |A| dan |B|
α = sudut yang terbentuk antar vektor A dan B
N-Gram
Sebuah n-gram adalah rangkaian bersambung dari n objek atas rangkaian kata atau tulisan yang sudah ada. Objek tersebut dapat berupa fonem, suku kata, huruf, kata, atau pasangan kata berdasarkan aplikasi. Sejumlah n-gram diperoleh dari sebuah tulisan ataupun korpus bahasa. Sebuah n-gram berukuran satu disebut sebagai “unigram”; ukuran dua adalah “digram” atau lebih umum disebut “bigram”; ukuran tiga adalah “trigram”. Untuk ukuran yang lebih besar kadang disebut sebagai nilai dari n, contohnya “four-gram”, “five-“four-gram”, dan seterusnya. Fungsi dari N-Gram Similarity Algorithm adalah membentuk kombinasi kata yang bisa dibentuk dari suatu kalimat. N merupakan jumlah kata yang dibentuk, untuk 2 kata maka disebut 2-Gram dan 3 kata disebut 3-Gram. Misalkan: “Resistor adalah komponen elektronik dua kutub yang didesain untuk mengatur tegangan listrik dan arus listrik” maka 2-Gram adalah: “Resistor adalah, adalah komponen, komponen elektronik, dst”. N-Gram kunci jawaban dan N-Gram jawaban siswa inilah yang nanti dibandingkan untuk mencari ada kesamaan atau tidak.
2. METODE PENELITIAN
Pada bagian ini akan dijelaskan metode penelitian ini yang meliputi prosedur penelitian,input output, arsitektur sistem dan proses konversi nilai.
Prosedur Penelitian
Penelitian ini pada dasarnya lebih mengedepankan aspek implementasi dan analisis suatu teori, tentang penilaian esai secara otomatis dengan menggunakan pendekatan algoritma Generalized Latent Semantic Analysis. Seperti pada penelitian-penelitian tentang analisis atau pembuktian suatu teori yang banyak menerapkan metode studi kepustakaan, demikian halnya pada penelitian ini, penulis lebih banyak melakukan studi kepustakaan dengan mengambil referensi dari internet, ebook, paper, jurnal, skripsi,
tesis, maupun buku-buku yang berkaitan dengan algoritma pemrograman, penilaian otomatis, stemming khususnya pada bahasa Indonesia, pembentukan kata pada Bahasa Indonesia, dan berbagai literatur ilmiah lainnya. Referensi utama lain adalah penelitian yang dilakukan oleh Islam dan Hoque[2] yang menerapkan algoritma GLSA dalam test esai secara otomatis, dan juga penelitian yang dilakukan oleh Tala[8] yang meneliti algoritma stemming bahasa Indonesia berbasis aturan bukan berdasarkan kamus kata dasar. Selain itu referensi lain dari penelitian yang dilakukan Anak Agung dan Henry[6] yang menerapkan Algoritma GLSA dengan menggunakan bigram dan PMI (Point-wise Mutual Information) sebagai pengukuran kemiripan kata.
Input Output
Input dari penelitian ini adalah kumpulan dari jawaban essay siswa. Mata pelajaran Sejarah terdapat 5 soal esai dengan rincian: 91 jawaban siswa dan 2 jawaban guru yang berjumlah total 465 jawaban. Mata pelajaran Sosiologi terdapat 4 soal esai dengan rincian: 61 jawaban siswa dan 1 jawaban guru yang berjumlah total 248 jawaban.
Arsitektur Sistem
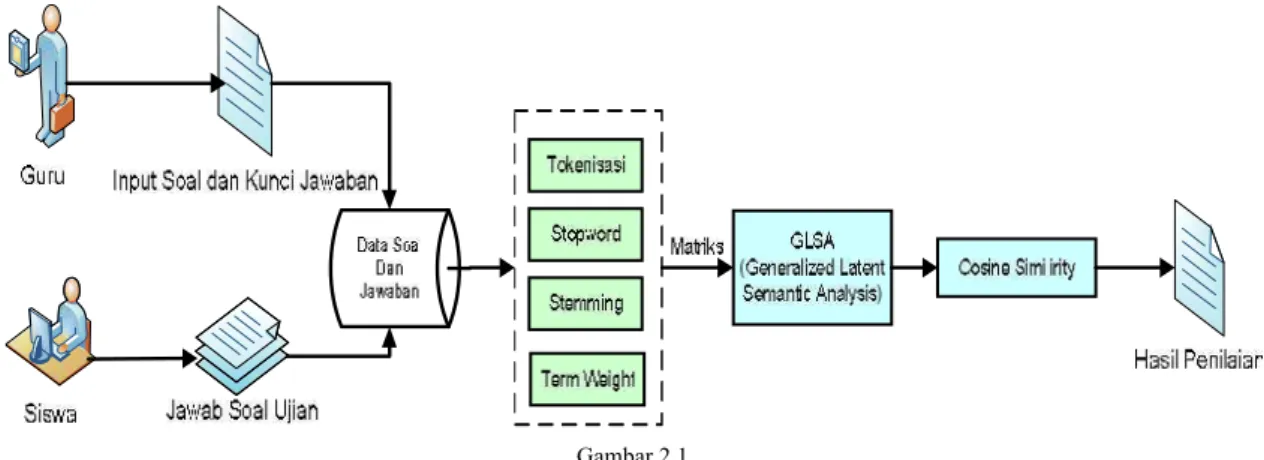
Pada arsitektur sistem ini terdapat 2 aktor utama yaitu guru sebagai pembuat soal dan jawaban serta siswa yang menjawab soal ujian, semua data ini akan disimpan ke dalam database sistem dan dilakukan proses pengolahan meliputi: preprocessing, pembentukan n-gram dan proses pengolahan nilai menggunakan
cosine similarity. Secara jelas arsitektur sistem GLSA ini dapat digambarkan pada gambar 1.
Proses Konversi Nilai
Proses konversi nilai dilakukan setelah proses cosine similarity.Terdapat dua macam inputan yaitu nilai
cosine similarity dan bobot soal.
Misalkan terdapat P soal
Input : Cosine similarity = {C1,C2, ...Cp} Bobot = {B1,B2, ...Bp}
Hasil pembobotan dapat dirumuskan seperti pada rumus 3.
Hasil Pembobotan (H) = ∑∑ ... (3) Dari hasil pembobotan akan dirubah menjadi nilai dengan rentang 0 - 100, yang dapat digambarkan pada tabel 1.
Gambar 2.1 menunjukkan bahwa proses inputan dilakukan oleh guru dan siswa, selanjutnya dilakukan proses preprocessing yang meliputi proses tokenisasi dimana pada proses ini semua kalimat akan dijadikan token kata kemudian dilakukan proses menghapus stopword yang membuang semua kata umum yang tidak memiliki makna, proses stemming yang mengubah menjadi kata dasar dan pada akhirnya dilakukan proses term weight (pembobotan kata) yang akan menghasilkan matriks jawaban siswa dan guru dilanjutkan proses GLSA yang akan membentuk vektor jawaban siswa dan guru dan pada tahap akhir dilakukan proses hasil penilaian yang diukur menggunakan cosine similarity.
Gambar 2.1
0,00 - 0,10 1 - 20
0,10 - 0,30 20- 40
0,30 - 0,60 40-70
0,60 - 0,80 70-90
0,80 - 1,00 90-100
Misalkan hasil pembobotan berada di range x hingga y, maka akan diubah menjadi x' hingga y'. Maka nilai sistem dapat dirumuskan seperti pada rumus 4.
Nilai Sistem (S) = ( ′− ′) + ′ ... (4)
3. HASIL DAN PEMBAHASAN
No Mata Pelajaran Jumlah Soal Esai Jumlah Jawaban Siswa Jumlah Jawaban Guru Total Jawaban Siswa Total Jawaban Guru Total Jawaban 1 Sejarah 5 91 2 455 10 465 2 Sosiologi 4 61 1 244 4 248 Analisa Preprocessing
Proses ujicoba menggunakan 2 mata pelajaran (Sosiologi dan Sejarah). Mata pelajaran sejarah terdapat 5 soal dengan jumlah jawaban siswa sebanyak 455 jawaban dan 10 jawaban dari jawaban guru sehingga totalnya adalah 465 jawaban, Sedangkan mata pelajaran sosiologi berjumlah total 248 jawaban secara keseluruhan. Secara detail dijabarkan pada tabel 3.1.
Tabel 3.1 menunjukkan banyaknya dataset (sejarah dan sosiologi) dengan total jawaban sebanyak 713 jawaban baik siswa dan guru.
Pada tahap preprocessing meliputi 2 bagian yaitu menghapus stopword dan proses stemming, semua proses ini dilakukan dengan template seperti ditunjukkan pada tabel 3.2. Tabel 3.2 berisi inputan jawaban siswa.
Setelah dilakukan proses prepocosessing maka akan dituliskan kembali hasil stopword dan stemming seperti yang ditunjukkan pada tabel 3.3.
Tabel 2.1 Pembobotan Nilai Hasil
Pembobotan(x-y) Nilai Sistem(x'-y')
Tabel 3.1 Inputan Jawaban Siswa dan Guru
Pada proses analisa nilai sistem melibatkan proses pembentukan vektor dokumen jawaban siswa dan guru serta melalui proses N-Gram.
Algoritma Human Rater Essay Vector Creation Input : Essay Kunci Guru E = {E1,E2,....Ep}
Output : Essay vector kunci guru D = { D1,D2,...Dp} 1. FOR i = 1 TO p DO
a. Hapus Stop-words dari essay E
b. Stem kata-kata dari essay jawaban guru ENDFOR
2. Pilih N-gram untuk index-term dari n-gram oleh dokumen matriks 3. Bentuk N-Gram dari dokumen matriks,Amxp
4. Decompose matriks Amxp menggunakan SVD, dimana persamaannya akan menjadi = × ×
5. Truncate/potong/reduksi dari U,S dan VT
dan buatlah menjadi persamaan berikut : = × ×
6. FOR j=1 TO p DO
Bentuklah essay vektor kunci = × × ENDFOR
Ket : merupakan data jawaban guru yang didapatkan dari 2 jawaban guru.
Tabel 3.3 merupakan hasil proses menghapus stopword dan proses stemming menggunakan algoritma Tala [8].
Analisa Nilai Sistem
N-Gram yang digunakan adalah trigram yang merupakan kombinasi dari 3 kata, Hasil proses nilai sistem dapat ditunjukkan pada gambar 3.1.
Tabel 3.3 Proses Preprocessing Jawaban Siswa dan Guru
Gambar 3.1 Proses Nilai Sistem GLSA
Analisa Akurasi
Proses menentukan akurasi melibatkan dua mata ujian (sejarah dan sosiologi). Proses perhitungan akurasi menggunakan metode perhitungan standar deviasi yang didapatkan dari selisih nilai sistem GLSA dan nilai guru. Setelah didapatkan selisih nilai dilakukan proses perhitungan error rate dari total jawaban siswa. Proses akurasi dapat dijabarkan dibawah ini.
Misalkan :
Jumlah Siswa adalah n siswa
Nilai sistem adalah S = {S1,S2 , ....Sn} Nilai Guru adalah G = {G1,G2, ....Gn} Nilai Maximal adalah M
Maka akan dilakukan perhitungan selisih nilai guru dan nilai sistem untuk mendapatkan error rate, rumusnya ditunjukkan pada rumus 5.
Error Rate =
∑
... (5)
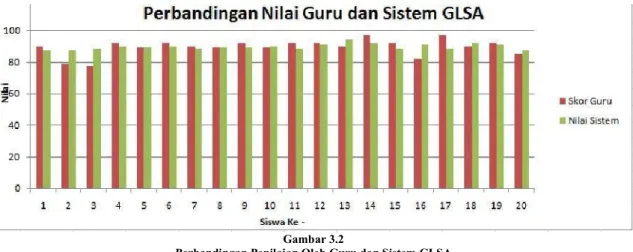
Setelah didapatkan error rate maka dapat dihitung akurasi dengan menggunakan rumus 6 berikut ini: Akurasi = 1 - Error Rate ... (6) Pada gambar 3 menunjukkan perbandingan antara nilai dari guru dan nilai sistem untuk 20 siswa pada mata pelajaran sejarah.
Mata Pelajaran Jumlah Data Akurasi
Sejarah 455 90,76 %
Sosiologi 244 87,79 %
Rata-rata 89.275 %
Pada gambar 3.1 memiliki inputan data training berupa dua jawaban guru. Selain itu terdapat sampel data testing sebanyak empat nilai siswa yang sudah diproses.
Gambar 3.2 menunjukkan nilai yang diberikan sistem memiliki korelasi yang positif dengan nilai yang diberikan oleh guru, hal ini menunjukkan sistem penilaian GLSA baik dalam proses penilaian kesamaaan jawaban guru dan jawaban siswa.
Gambar 3.2
Perbandingan Penilaian Oleh Guru dan Sistem GLSA
Dari tabel 3.4 dapat dilihat bahwa untuk mata pelajaran sejarah memiliki nilai akurasi mencapai 90,76% sedangkan mata pelajaran sosiologi dengan jumlah data yang lebih sedikit mencapai tingkat akurasi mencapai 87,79% dengan demikian dapat diambil rata-rata akurasi dari proses GLSA untuk 699 data jawaban siswa mencapai 89,27 % yang artinya nilai sistem sudah mendekati nilai human
grader/guru.
Hasil pengukuran akurasi dari dua mata pelajaran (sejarah dan sosiologi) dapat dilihat pada tabel 5. Tabel 3.4 Pengukuran Akurasi dari 2 Mata Pelajaran
4. PENUTUP
Berdasarkan hasil pengujian yang dilakukan, dapat disimpulkan bahwa pengembangan GLSA (Generalized Latent Semantic Analysis) yang menggunakan N-Gram dapat digunakan untuk mengevaluasi kombinasi urutan kata pada jawaban esai siswa. Hasil percobaan pada dua mata pelajaran, yaitu Sejarah dan Sosiologi menunjukkan korelasi positif yang kuat antara nilai human grader (guru) dan nilai sistem GLSA. Tingkat akurasi GLSA yang mencapai rata-rata 89,27 % untuk 699 jawaban esai dari 2 bidang studi (Sejarah dan Sosiologi) membuktikan GLSA dapat mengatasi beberapa keterbatasan LSA (Latent Semantic Analysis) dalam hal pendeteksian kalimat yang memiliki kesalahan sintaksis ataupun kata-kata umum yang hilang. Penulis menilai bahwa sistem penilaian jawaban esai secara otomatis ini dapat dikembangkan lebih luas lagi dan sistem pengembangannya tidak hanya terbatas pada kata-kata, rumus, tabel dan lain-lain.
5. DAFTAR PUSTAKA
[1] Dikli S., An Overview of Automated Scoring of Essays. 2006. The Journal of Technology, Learning, and Assessment. Volume 5 Number 1, Stanford University
[2] Islam,M.M.; Hoque,A.S.M.L.; Automatic essay scoring using Generalized Latent Semantic Analysis, Computer and Information Technology(ICCIT),2010 13th International Conference on.,vol., no., pp.358-363, 23-25 Dec. 2010 .
[3] Jackson & Moulinier (2002) NLP for Online Applications
[4] Matveeva,Irina. "Generalized Latent Semantic Analysis for Document Representation" . Disertasi (2008) University of Chicago. Chicago, USA.
[5] Olney,Andrew M. "Generalizing Latent Semantic Analysis". 2009 IEEE International Conference on Semantic Computing. University of Memphis. Memphis,USA
[6] Ratna, A. A. P., Henry Artajaya, Boma A.A. 26-29 Aug.2013. GLSA Based Online Essay Grading System. International COnference on Teaching,Assessment and Learning for Engineering(TALE) [7] T. Kakkonen, N. Myller, J. Timonen, and E. Sutinen, “Comparison of dimension reduction methods
for automated essay grading,” Journal of Educational Technology& Society, vol. 11, no. 3, pp. 275-288, 2008.
[8] Tala, Fadillah Z.2003. A Study of Stemming Efect on Information Retrieval in Bahasa Indonesia. Insitute for Logic,Language and Computation Universiteit van Amsterdam The Nederlands.
[9] Valenti S, Neri F and Cucchiarelli A. An overview of current research on automatedessay grading. Journal of Information Technology Education. 2:319-330. 2003
[10] Wild,F.Stahl,C. Stermsek,G.Neumann : Parameters driving effectiveness of automated essay scoring with LSA in : Proceedings of th 9th International Computer Assisted Assesment Conference (CAA) pp 485-494

![Tabel 3.3 merupakan hasil proses menghapus stopword dan proses stemming menggunakan algoritma Tala [8]](https://thumb-ap.123doks.com/thumbv2/123dok/4515203.3271172/6.892.105.744.138.357/tabel-proses-menghapus-stopword-proses-stemming-menggunakan-algoritma.webp)