PEMANFAATAN INVERTED INDEX PADA PROSES PENELUSURAN KESAMAAN
ISI FILE DOKUMEN PDF TUGAS AKHIR MAHASISWA
Djoni Setiawan K.1, Hendra Bunyamin2
1Program Studi D3 Teknik Informatika, Fakultas Teknologi Informasi
2Program Studi Teknik Informatika, Fakultas Teknologi Informasi
Universitas Kristen Maranatha Bandung Jl. Prof. drg. Suria Sumantri 65, Bandung, 40164
E-mail: [email protected], [email protected] ABSTRAKS
Penelusuran kesamaan isi tulisan pada sebuah karya tulis ilmiah merupakan salah satu cara untuk mengurangi atau menghilangkan kejadian plagiarisme di kalangan para peneliti, termasuk para mahasiswa yang sedang menempuh proses pendidikan tinggi. Penelitian ini ditujukan untuk membuat sebuah aplikasi berbasis web sederhana dengan menggunakan inverted index untuk mencari seberapa banyak kesamaan sebuah dokumen dengan data dokumen yang telah dimiliki. Seluruh dokumen pembanding disimpan dalam basis data lokal untuk memudahkan proses pencarian datanya. Adapun dokumen yang dibandingkan merupakan file PDF yang dapat merupakan sebagian atau seluruh laporan tugas akhir mahasiswa yang ditulis dalam Bahasa Indonesia. Berdasarkan hasil percobaan yang telah dilakukan, aplikasi yang dihasilkan telah dapat mengukur berapa besar kesamaan kesamaan kalimat dan dokumen yang diberikan terhadap dokumen referensi yang telah tersimpan di dalam basis data.
Kata Kunci: inverted index, kesamaan, dokumen, website, basis data
1. PENDAHULUAN 1.1 Latar Belakang
Karya tulis merupakan salah satu bentuk luaran dari proses pembelajaran pada tingkat pendidikan tinggi. Bentuk karya tulis yang dihasilkan dapat disajikan dalam berbagai bentuk, antara lain rangkuman, kajian literasi, artikel ilmiah, karya tulis ilmiah, laporan tugas, hingga laporan tugas akhir. Semua bentuk karya tulis tersebut berisi rangkaian kata dan kalimat yang bersumber dari hasil kutipan berbagai sumber atau berasal dari hasil pemikiran sendiri penulis.
Permasalahan yang muncul dari sebuah hasil karya tulis tersebut adalah bagaimana membuktikan bahwa hasil karya tulis tersebut merupakan hasil pekerjaan atau pemikiran penulis itu sendiri, serta berapa besar kemiripannya dengan karya tulis lain yang telah ada. Tidak menutup kemungkinan hasil karya tulis tersebut merupakan sebagian atau seluruhnya merupakan hasil karya tulis orang lain dan dituliskan kembali. Proses penulisan suatu karya tulis juga memberikan peluang untuk menuliskan suatu kalimat atau hasil pemikiran penulis lain, tanpa menyertakan informasi penulis aslinya. Kondisi inilah yang sering menyebabkan seorang penulis karya tulis dinyatakan melakukan tindakan plagiat.
Untuk mengukur seberapa banyak kesamaan suatu tulisan dengan tulisan lainnya yang telah dibuat terlebih dahulu diperlukan adanya suatu proses pencarian dan pembandingan isi tulisan-tulisan tersebut. Akan tetapi proses pencarian kemiripan ini tidaklah mudah, karena terbatasnya sumber pembanding yang dimiliki oleh seseorang. Hal ini menjadi tantangan tersendiri yang menarik, khususnya untuk hasil karya laporan tugas akhir para mahasiswa. Isi laporan tugas akhir para mahasiswa tersebut dapat berisi tulisan yang sama atau mirip satu dengan yang lainnya, khususnya bagi tugas akhir yang memiliki bidang kajian yang sama, memiliki irisan satu dengan yang lain, atau telah pernah dilakukan oleh mahasiswa sebelumnya.
Salah satu pendekatan yang dapat dilakukan untuk membantu proses pencarian kesamaan tersebut adalah dengan menggunakan bantuan aplikasi komputer. Untuk melakukan pencarian kesamaan isi tulisan dalam Bahasa Inggris, perusahaan iParadigms LLC. telah mengembangkan aplikasi berbasis web mulai tahun 1997. Berdasarkan informasi yang diperoleh melalui (iParadigms LLC., 2017), aplikasi ini telah digunalah oleh lebih dari 30 juta pelajar dari 15.000 institusi dari 150 negara. Permasalahan yang muncul pada penggunaan aplikasi ini adalah masalah bahasa. Kemampuan aplikasi ini untuk mendeteksi kesamaan tulisan dalam Bahasa Indonesia dirasakan masih kurang, karena terbatasnya data dokumen pembanding yang dimiliki oleh aplikasi tersebut. Hal lainnya yang menjadi masalah adalah pembiayaan. Untuk dapat menggunakan aplikasi ini, pengguna perlu mengeluarkan biaya yang tidak sedikit (lebih dari serratus dolar Amerika).
Untuk mempermudah proses pencarian referensi kata dalam skala besar adalah dengan menggunakan teknik
inverted index (Manning, et al., 2009). Pada teknik ini setiap data yang dijadikan referensi akan disusun dalam
bentuk sebuah indeks kata. Akibat penyusunan data tersebut dalam bentuk sebuah indeks kata, maka ukuran data referensi yang digunakan dapat lebih kecil dibandingkan dengan menyimpan referensi tersebut dalam kalimat lengkap. Teknik inverted index ini dapat dikembangkan lebih lanjut dengan membuat relasi kata tersebut dengan kalimat asal yang digunakan dan dokumen yang menggunakan kata tersebut. Sehingga secara tidak langsung
setiap kata yang ditemukan dalam sebuah dokumen akan dapat dicari penggunaannya pada dokumen lainnya. Kondisi ini memungkinkan teknik inverted index untuk dapat digunakan sebagai salah satu teknik pencarian kesamaan isi dokumen terhadap referensi yang digunakan.
1.2 Rumusan Masalah
a. Bagaimana mengukur tingkat atau besar kesamaan isi sebuah dokumen terhadap dokumen lainnya?
b. Bagaimana mengembangkan pusat data dokumen pembanding yang mendukung proses pencarian kesamaan dokumen yang diperlukan?
c. Bagaimana memanfaatkan inverted index untuk membantu proses pengukuran tingkat kesamaan isi dokumen?
Ada pun batasan masalah yang digunakan dalam penelitian ini adalah sebagai berikut: a. Jenis file dokumen yang digunakan sebagai masukan aplikasi adalah berjenis PDF.
b. File PDF yang digunakan merupakan hasil konversi dari file teks, bukan hasil dari proses scanning. c. Resolusi layar tampilan minimal yang digunakan adalah 1024 x 768 pixel.
d. Bahasa yang digunakan dalam dokumen adalah Bahasa Indonesia e. Basis data yang digunakan adalah MySql Server 5.6.35.
f. Aplikasi purwarupa yang dibuat berbentuk sebuah portal website.
g. Web Server yang digunakan adalah Apache Server versi 2.4.28.
h. Bahasa pemrograman yang digunakan adalah PHP versi 5.6.30
1.3 Tujuan Penelitian
Untuk mengatasi permasalahan kebutuhan aplikasi yang dapat mengukur besar atau tingkat kesamaan isi tulisan suatu dokumen dengan dokumen yang telah ada sebelumnya, maka pada penelitian ini dikembangkan sebuah aplikasi purwarupa untuk melakukan proses pengukuran tingkat atau besar kesamaannya tersebut yang diharapkan dapat membantu menghindari kejadian plagiarisme.
1.4 Metodologi Penelitian
Penelitian ini merupakan bagian dari penelitian untuk menentukan standar corpus yang sekiranya dapat untuk digunakan untuk mengidentifikasi ciri informasi pada suatu bidang keilmuan. Salah satu tahap dalam proses penentuan standar tersebut adalah mencari kata-kata yang sering digunakan dalam pembahasan masalah suatu bidang keilmuan. Proses identifikasi kata-kata inilah yang diharapkan dapat menjadi salah satu solusi untuk mengukur tingkat kesamaan isi dokumen. Ada pun metodologi yang digunakan dalam mengembangkan aplikasi untuk mengukur tingkat kesamaan isi dokumen tersebut adalah sebagai berikut:
1. Melakukan studi literatur terhadap teori dan konsep pendeteksian kesamaan tulisan dan pembacaan data pada
file PDF. Tahap ini ditujukan untuk memahami berbagai jenis bentuk plagiarism yang dapat muncul, beserta
dengan ciri-cirinya masing-masing. Hal lain yang diperlukan dalam tahap ini adalah pemahaman yang lebih lanjut mengenai proses penulisan dan pembacaan isi file PDF (sebagai masukan dari aplikasi). Proses pembacaan ini perlu diketahui agar dapat digunakan untuk melakukan ekstraksi terhadap isi dari sebuah file PDF.
2. Melakukan studi literatur dan pendalaman terhadap inverted index. Tahapan ini digunakan untuk dapat memahami proses yang terjadi dalam inverted index dan hubungannya dengan proses penentuan kesamaan isi dokumen dalam mengantisipasi terjadinya plagiarism.
3. Melakukan desain aplikasi dan basis data pendeteksian kesamaan isi dokumen. Berdasarkan apa yang diperoleh pada tahap 1 dan 2, aplikasi pengukur kesamaan isi dokumen dibangun dengan menggunakan pemodelan UML. Aplikasi tersebut tidak dapat bekerja tanpa adanya suatu basis data yang mendukungnya. Untuk memenuhi kebutuhan basis data tersebut, maka pada tahap ini didesain pula struktur basis data dengan menggunakan pemodelan Crow’s foot.
4. Desain aplikasi dan basis data yang diperoleh pada tahap 3 diimplementasikan dalam bentuk sebuah purwarupa yang dioperasikan secara lokal terlebih dahulu.
5. Melakukan pemilihan dokumen yang akan dijadikan sebagai dokumen pembanding dan dokumen yang dibandingkan. Dokumen referensi yang digunakan adalah dokumen laporan tugas akhir dan makalah yang telah diserahkan kepada pihak fakultas dan universitas sebagai bagian dari pelaksanaan tugas akhir para mahasiswa. Sedangkan dokumen yang diujikan dibuat dengan menggunakan dokumen baru, menggabungkan sebagian dokumen referensi, dan menggunakan seluruh isi dokumen Hal ini memungkinkan untuk membagi dokumen yang diujikan tersebut menjadi tiga kelompok besar, yaitu dokumen yang tidak memiliki kesamaan, memiliki kesamaan sebagian, dan sama seluruhnya.
6. Melakukan proses pengujian aplikasi dengan menggunakan seluruh dokumen referensi dan dokumen uji yang telah ditetapkan dalam langkah 5.
7. Berdasarkan hasil pengamatan hasil pengujian yang diperoleh, maka dilakukan analisis apakah diperlukan adanya perbaikan atau tidak.
8. Seluruh hasil kajian teoritis dan hasil pengujian dituangkan dalam bentuk laporan tertulis sebagai bagian dari proses penelitian induk.
2. TINJAUAN PUSTAKA 2.1 Plagiarisme
Plagiarisme merupakan suatu kegiatan yang wajib dihindari oleh semua orang, baik yang dilakukan secara sengaja atau pun yang dilakukan secara tidak sengaja. Terlebih dalam bidang akademis, tindakan plagiarisme merpakan suatu tindakan yang sangat tidak pantas untuk dilakukan. Berikut adalah beberapa pengertian plagiarisme yang dapat ditemukan:
a. Kamus Besar Bahasa Indonesia (Kemendikbud, 2017) mendefinisikan plagiarisme sebagai “penjiplakan yang melanggar hak cipta”
b. Merriam-Webster Online (Merriam-Webster Inc., 2018) mendefinisikan plagiarisme sebagai “1) an act or
instance of plagiarizing 2) something plagiarized”. Sedangkan kata plagiarize sendiri, (Merriam-Webster,
Inc., 2018) mendefinisikannya sebagai “1) to steal and pass of f (the ideas or words of other) as one’s own:
use (another’s production) without crediting the source 2) to commit literary theft: present as new and original an idea or product derived from an existing source”.
c. Plagiarisme.org (iParadigms LLC., 2017) menyatakan bahwa plagiarisme sebagai “an act of fraud. It
involves both stealing someone else’s work and lying about it afterward”.
Berdasarkan seluruh definisi tersebut, terlihat bahwa kegiatan plagiarisme dapat didefinisikan sebagai tindakan pelanggaran hak cipta yang dapat dilakukan dengan cara menjiplak, mengaku suatu hasil karya seabgai hasil diri sendiri, atau menggunakan hasil karya orang lain tanpa menyertakan informasi pembuat aslinya sebagai rujukan. Oleh karena kegiatan ini dapat secara langsung atau tidak langsung merugikan orang lain, maka tindakan ini harus dihindari terlebih pada kegiatan ilmiah dalam lingkungan pendidikan tinggi.
Antisipasi atas kegiatan plagiarisme ini telah dilakukan pula oleh Pemerintah Indonesia. Berdasarkan Peraturan Menteri Pendidikan Nasional Republik Indonesia Nomor 17 Tahun 2010, tindakan yang termasuk dalam kegiatan plagiarisme adalah (Nuh, 2010):
a. Mengacu dan/atau mengutip istilah, kata-kata dan/atau kalimat, data, dan/atau informasi dari suatu sumber tanpa menyebutkan sumber dalam catatan kutipan dan/atau tanpa menyatakan sumber secara memadai. b. Mengacu dan/atau mengutip secara acak istilah, kata-kata, dan/atau kalimat, data, dan/atau informasi dari
suatu sumber tanpa menyebutkan sumber dalam catatan kutipan dan/atau tanpa menyatakan sumber secara memadai.
c. Menggunakan sumber gagasan, pendapat, pandangan, atau teori tanpa menyatakan sumber secara memadai. d. Merumuskan dengan kata-kata dan/atau kalimat sendiri dari sumber kata-kata dan/atau kalimat, gagasan,
pendapat, pandangan, atau teori tanpa menyatakan sumber secara memadai.
e. Menyerahkan suatu karya ilmiah yang dihasilkan dan/atau telah dipublikasikan oleh pihak lain sebagai karya ilmiahnya tanpa menyatakan sumber secara memadai.
2.2 Struktur File PDF
Istilah file merupakan sebuah ungkapan yang digunakan untuk menyimpan sesuatu. Dalam dunia dijital sebuah file dapat dinyatakan sebagai tempat dimana data, informasi, pengaturan, atau perintah yang digunakan oleh komputer disimpan secara dijital (Emberton, 2017). Oleh karena informasi atau jenis data yang tersimpan dalam sebuah file dapat beraneka ragam, maka setiap file memiliki jenis dan ciri masing-masing. Salah satu file tersebut adalah file PDF.
File PDF merupakan jenis file yang diperkenalkan oleh Adobe Inc. sejak 1993 (Adobe, 2008). Sejak
diperkenalkan, file PDF telah menjadi sebuah standar dalam proses pengiriman data dan informasi Keunggulan yang ditawarkan oleh Adobe dalam penggunaan jenis file ini adalah factor keamanan, kemudahan untuk disebarkan, kemampuan pengelolaan, dan kemudahan dalam penyimpanan untuk masa mendatang. Sebagai bukti bahwa file PDF telah menjadi standar internasional adalah disetujuinya dokumen PDF 1.7 oleh komisi teknis ISO menjadi standar internasional ISO 32000-1 pada Januari 2008.
Berdasarkan struktur file yang digunakan, file berjenis PDF memiliki empat komponen utama, yaitu objek, struktur file, struktur dokumen, dan content stream seperti yang terlihat pada Gambar 1.
Gambar 1. Komponen File PDF
Berdasarkan struktur file PDF yang terdapat dalam (Adobe, 2008), bagian komponen objek digunakan untuk menyimpan perintah dan informasi penting dari data yang diwakilinya. Bagian struktur file digunakan untuk menentukan bagaimana objek-objek yang dimiliki disimpan, bagaimana mengaksesnya, dan bagaimana mengubah data yang disimpannya. Bagian struktur dokumen digunakan untuk menentukan bagaimana tipe dasar objek data yang digunakan untuk merepresentasikan komponen dari sebuah tampilan data PDF (halaman, huruf, notasi, dan lain sebagainya. Bagian content stream digunakan untuk menyimpan urutan instruksi yang mengatur tampilan sebuah halaman atau gambar.
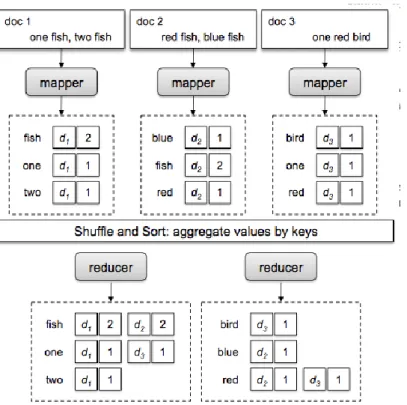
2.3 Inverted Index
Inverted Index merupakan sebuah teknik yang digunakan untuk menghubungkan sebuah data dengan
informasi kemunculan data tersebut dalam sebuah koleksi data (Lin & Dyer, 2010). Seluruh data yang tersimpan dalam sebuah dokumen dapat dipetakan dalam bentuk sebuah peta keterhubungan yang mengandung data tersebut dan kemunculan data tersebut (lihat Gambar 2).
Gambar 2. Inverted Index
Secara sederhana proses yang terjadi dalam teknik inverted index yang terjadi pada Gambar 2 dapat dinyatakan dalam tiga tahap proses. Pada tahap pertama, data yang terdapat dalam masing-masing dokumen akan diuraikan hingga diperoleh kelompok data tunggal yang diperlukan. Selanjutnya data yang terdapat di dalam masing-masing dokumen akan dihitung jumlah kemunculannya berdasarkan data tunggal yang telah diperoleh. Selain dilakukan proses perhitungan jumlah kemunculan, pada proses ini juga dilakukan proses pembuatan peta keterhubungan antara data tunggal yang muncul dengan informasi dokumen dimana data tunggal tersebut ditemukan. Pada tahap kedua, seluruh data tunggal yang diperoleh akan diurutkan untuk mempercepat
tunggal dalam bentuk sebuah kamus data (dictionary) dan peta keterhubungan dalam sebuah posting list. Kamus yang dihasilkan akan berisi data tunggal beserta dengan jumlah frekuensi kemunculannya dalam dokumen. Sedangkan posting list akan memuat lokasi dokumen diman data tunggal dalam kamus tersebut muncul. Gambar 3 adalah contoh lain dari penggunaan teknik inverted index.
Gambar 3. Contoh Proses Inverted Index 3. DESAIN DAN HASIL IMPLEMENTASI APLIKASI PURWARUPA 3.1 Desain Cara Kerja Aplikasi Purwarupa
Secara garis besar, cara kerja yang dilakukan oleh aplikasi pengukur kesamaan dokumen ini adalah dengan cara memasukkan dokumen yang akan diukur ke dalam aplikasi, menguraikan isi dokumen, dan mencari kesamaannya dalam dokumen pembanding. Apabila proses tersebut diuraikan secara lebih detail, maka Gambar 4 merupakan detail desain cara kerja aplikasi purwarupa yang dibangun dalam penelitian ini.
Proses dimulai dengan pengunggahan file PDF yang akan diukur tingkat kesamaannya ke dalam aplikasi yang digunakan. File ini akan diunggah ke dalam web server untuk memudahkan proses selanjutnya. Penyimpanan file dalam web server ini lebih ditujukan untuk memungkinkan proses pengukuran kembali ketika dokumen referensi yang tersimpan dalam database telah bertambah tanpa perlu melakukan proses pengunggahan lagi. File yang telah diunggah tersebut selanjutnya akan mengalami proses ekstraksi data untuk mengindentifikasi jenis file yang diunggah dan mengeluarkan data kata dan kalimat yang tersimpan di dalamnya. Ketika proses identifikasi jenis file menyatakan bahwa file yang diunggah bukan file PDF, maka aplikasi akan memberikan pesan kesalahan dan dokumen yang telah diunggah tersebut dapat dibuah dari web server. Jika file yang telah diunggah tersebut merupakan file PDF, maka seluruh isi dokumen tersebut akan diambil dalam bentuk kalimat dan kata. Setiap kalimat kalimat dan kata yang diperoleh selanjutnya akan disimpan dalam basis data untuk mempermudah proses selanjutnya.
Gambar 4. Model Proses Aplikasi Purwarupa
Kata yang telah diperoleh hasil ektraksi tersebut selanjutnya dibandingkan dengan daftar kata yang dianggap dapat diabaikan (stop words). Sisa dari hasil pengurangan kata inilah yang dianggap sebagai kata dan kalimat kunci yang akan dicari kesamaannya dengan kata dan kalimat dari dokumen yang lain. Sisa kata dan kalimat inilah yang menjadi masukan utama bagi proses pengukuran tingkat kesamaan isi dokumen selanjutnya.
Proses pengolahan selanjutnya dilakukan pada bagian data processing. Pada bagian ini seluruh kata-kata yang tersisa dipetakan dengan menggunakan teknik inverted index untuk menyederhanakan proses perbandingan kalimat. Hasil dari pemetaan inverted index ini disimpan dalam basis data untuk dilakukan perhitungan tingkat kesamaan dengan dokumen yang telah tersimpan di dalam basis data sebelumnya dan menjadi dokumen referensi pembanding bagi dokumen yang lainnya. Hasil dari proses perhitungan tingkat kesamaan ini disimpan kembali dalam basis data untuk ditampilkan dalam bentuk sebuah laporan sederhana. Pada dasarnya bentuk laporan kesamaan tersebut ditampilkan dalam bentuk daftar kalimat-kalimat yang memiliki kesamaan dengan kalimat referensi yang telah disimpan dalam basis data sebelumnya beserta dengan persentase kesamaan yang ditemukan.
3.2 Rancangan Struktur Basis Data
Berdasarkan penjelasan cara kerja yang telah disebutkan pada bagian 3.1 dan model proses yang terlihat pada Gambar 4, terlihat bahwa aplikasi purwarupa yang dikembangkan dalam penelitian ini menggunakan sebuah basis data untuk menyimpan seluruh data dokumen referensi dan hasil pengukuran kesamaan yang dilakukan. Untuk memenuhi kebutuhan tersebut, desain basis data yang digunakan dalam penelitian ini dapat dimodelkan dalam sebuat entity relationship diagram seperti yang terlihat pada Gambar 5.
Secara garis besar, entitas yang digunakan dalam rancangan basis data yang digunakan terdiri dari sembilan entitias. Entitias tbBadPhrase digunakan untuk menyimpan kata atau frase yang akan dihilangkan dari data masukan pada dokumen yang akan diukur tingkat kesamaannya. Entitas tbPengguna digunakan untuk menyimpan data pemilik dokumen dan pihak-pihak yang berhak mengoperasikan aplikasi yang dibangun. Entitas tbDokumen digunakan untuk menyimpan data dokumen yang diunggah pengguna untuk diukur tingkat kesamaannya dengan dokumen lainnya. Entitas tbJnsDokumen digunakan untuk menyimpan jenis dokumen yang dimasukkan oleh para pengguna aplikasi ini (entitas ini merupakan hasil masukan dari para pengguna aplikasi pada saat presentasi sistem ini pertama kali secara internal). Entitas tbDokumenFile digunakan untuk menyimpan data file terkait dokumen yang diunggah oleh pengguna aplikasi. tbDokumenIsi digunakan untuk menyimpan data kalimat yang diperoleh dari proses ekstraksi dokumen yang telah dilakukan beserta dengan rata-rata persentase tingkat kesamaannya dengan dokumen lain yang ditemukan dalam basis data. Entitas tbDokumenSama digunakan untuk menyimpan data yang memiliki kesamaan isi dengan dokumen yang dibandingkan beserta dengan persentase kesamaannya. Entitas tbdokumenKata digunakan untuk menyimpan data kata-kata yang dimiliki oleh setiap kalimat dalam dokumen yang diukur kesamaannya dengan dokumen lain dan mengabaikan semua kata yang tercantum pula dalam entitas tbBadPharase. Entitas tbKata digunakan untuk menyimpan seluruh daftar kata yang dapat ditemukan dalam seluruh dokumen yang telah mengalami proses ekstraksi melalui aplikasi yang dikembangkan sebagai indeks kata untuk memudahkan proses pencarian kata.
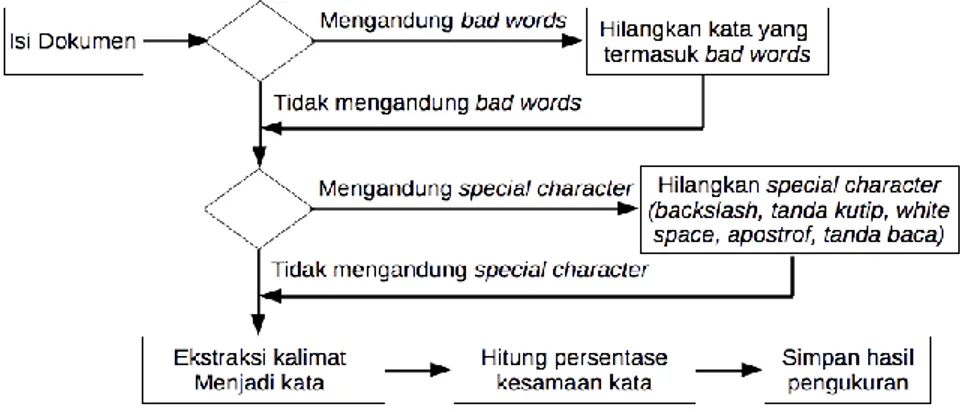
3.3 Mekanisme Pengukuran Tingkat Kesamaan
Untuk menghitung tingkat kesamaan isi dokumen yang diunggap pengguna aplikasi dilakukan beberapa tahap. Tahapan-tahapan yang dilakukan tersebut dapat digambarkan seperti yang terlihat pada Gambar 6. Tahap pertama yang dilakukan adalah proses penghilangakan kata-kata yang termasuk dalam bad words yang telah dimasukkan ke dalam entitas tbBadPhrase. Proses ini lebih ditujukan untuk menghilangkn kata-kata yang umum digunakan, misalnya kata sambung dan kata-kata yang termasuk ke dalam bentuk dasar laporan tugas akhir, Proses selanjutnya adalah proses untuk menghilangkan beberapa karakter khusus, yaitu tanda baca, tanda kutip, tanda backslash, dan karakter white space yang mungkin muncul akibat proses penghapusan kata yang termasuk dalam bad words. Hasil akhir dari proses ini diasumsikan sebagai isi pokok dari dokumen laporan tugas akhir yang penting.
Proses terakhir yang dilakukan adalah melakukan proses ekstraksi dari seluruh kalimat yang masih tersisa menjadi kumpulan kata-kata tunggal. Seluruh kata tunggal ini, selanjutnya dibuatkan sebuah peta keterakitan (sesuai dengan teori dari inverted index) untuk membantu proses perhitungan tingkat kesamaan isi dokumen. Berdasarkan data kata-kata yang telah dibuat indeksnya tersebut, maka proses perhitungan persentase kesamaan kata dapat dilakukan terhadap seluruh data dokumen referensi yang telah tersimpan sebelumnya di dalam basis data yang digunakan. Hasil perhitungan kesamaan tersebut, selanjutnya disimpan ke dalam basis data yang digunakan dan indeks kata yang dihasilkan disimpan pula sebagai dokumen referensi untuk dokumen lainnya yang akan diunggah selanjutnya.
Gambar 6. Proses Pengukuran Tingkat Kesamaan Isi Dokumen 3.4 Bentuk Tampilan Laporan Tingkat Kesamaan
Sebagai mana yang telah disebutkan pada bagian 3.1, hasil dari proses pengukuran yang telah dilakukan (Gambar 6) dapat disajikan dalam bentuk sebuah laporan tingkat kesamaan sederhana. Pada aplikasi purwarupa yang dikembangkan dalam penelitian ini, laporan tingkat kesamaan yang digunakan terbagi menjadi tiga laporan. Laporan pertama adalah laporan yang menunjukkan persentase minimal, maksimal, dan rata-rata yang diperoleh dari hasil perbandingan seluruh kalimat yang dimiliki oleh sebuah dokumen (lihat Gambar 7). Laporan ini digunakan untuk memberikan gambaran seberapa tinggi tingkat kesamaan yang dapat muncul dari kalimat-kalimat yang terkandung dalam dokumen yang terkait.
Gambar 7. Contoh Laporan Tingkat Kesamaan Dokumen
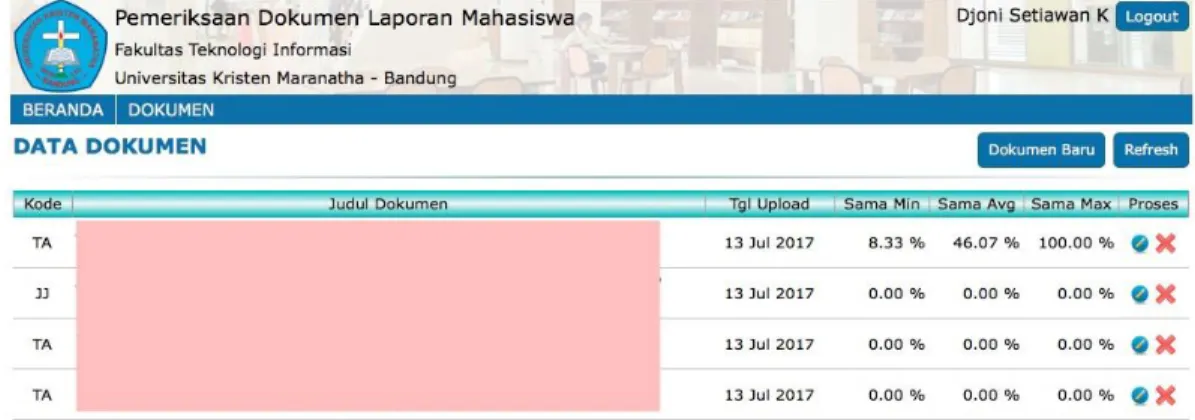
Jika sebuah dokumen laporan tugas akhir terdiri dari beberapa file, maka informasi tingkat kesamaan dari masing-masing file dapat pula ditampilkan seperti yang terlihat pada Gambar 8. Pada contoh Gambar 8, terlihat bahwa sebuah dokumen laporan tugas akhir terdiri dari 6 buah file. Masing-masing file tersebut telah melalui proses pengukuran tingkat kesamaan dan memperoleh data kesamaan minimum, maksimum dan rata-rata untuk setiap kalimat yang terkandung di dalam masing-masing file.
Gambar 8. Contoh Laporan Tingkat Kesamaan Isi File
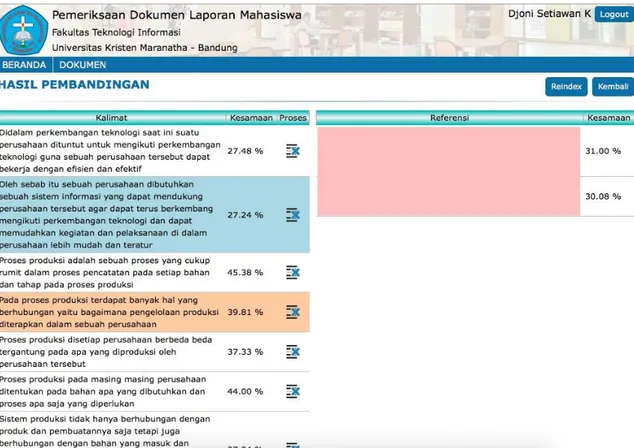
Hasil yang lebih detail untuk masing file dapat dilihat pada laporan tingkat kesamaan dari masing-masing baris yang terkandung pada sebuah file (lihat Gambar 9). Pada kolom kiri halaman tampilan tingkat kesamaan kalimat, dicantumkan isi kalimat dalam dokumen yang sedang diperiksa beserta dengan rata-rata kesamaan dengan kalimat-kalimat yang dimiliki oleh dokumen referensi yang digunakan. Sedangkan pada kolom kanan halaman tampilan tersebut ditampilkan dokumen referensi yang mengandung kalimat yang hampir sama dengan kalimat yang ditampilkan pada kolom kiri beserta dengan rata-rata kesamaan kalimat yang ditemukan di dalamnya.
Gambar 9. Contoh Laporan Tingkat Kesamaan Kalimat 4. SIMPULAN DAN SARAN
Berdasarkan hasil penelitian dan pengujian yang telah dilakukan pada aplikasi purwarupa yang dihasilkan dalam penelitian ini dapat disimpulkan bahwa aplikasi purwarupa yang dihasilkan telah dapat mengukur tingkat kesamaan dokumen PDF yang diuanggah ke dalamnya. Hal ini terlihat dari tingkat ketepatan kesamaan hasil pengukuran dengan tingkat kesamaan yang telah ditentukan pada masing-masing dokumen uji yang telah dipersiapkan. Ada pun tingkat perbedaan yang muncul pada hasil pengukuran terhadap nilai yang telah ditetapkan memiliki selisih kurang dari 12%.
Pemanfaatan teknik inverted index telah terbukti dapat membantu proses pencarian kesamaan isi dokumen, walaupun posisi dari kata yang digunakan tidak berada dalam urutan yang sama. Kemampuan pencarian ini dimungkinkan terjadi akibat dari proses pembandingan yang dilakukan adalah terhadap data terkecil dari dokumen tersebut, yaitu kata yang terkandung dalam setiap kalimat. Dengan adanya tabel indeks kata yang dihasilkan sebagai hasil sampingan dari teknik inverted index dapat ditemukan pula kata-kata yang sering digunakan untuk setiap bidang kajian yang tertuang dalam laporan tugas akhir yang dijadikan dokumen referensi dan uji.
Untuk kedepannya, aplikasi purwarupa ini masih perlu dilakukan pengembangan yang lebih lanjut. Pengembangan yang masih dirasakan perlu adalah kemampuan untuk mencari kata dasar dari kata-kata yang telah mengalami penambahan imbuhan (awalan atau akhiran) agar lebih meningkatkan akurasi dari pengukuran kesamaan isi dokumen yang dilakukan. Hal lainnya yang masih dirasakan kurang adalah kemampuan untuk menentukan konteks kalimat yang digunakan. Kemampuan penentuan konteks kalimat tersebut dirasakan perlu untuk menentukan kaitan urutan kata yang digunakan agar dapat membedakan antara kalimat lengkap dan kalimat tidak lengkap.
Aplikasi purwarupa yang dihasilkan masih perlu dilengkapi pula dengan kemampuan untuk menentukan jenis plagiarisme yang dilakukan oleh pengunggah dokumen. Hal ini masih belum dapat dilakukan karena terbatasnya sumber dokumen pembanding dan tidak adanya fitur yang dapat mencari dokumen-dokumen yang telah dihasilkan di luar sumber yang dimiliki saat ini (misalnya adalah makalah yang telah dipublikasikan dalam jurnal atau seminar, tulisan yang pernah diterbitkan dalam surat kabar atau majalah, tulisan yang tercantum dalam sumber-sumber referensi yang digunakan, dan sebagainya). Untuk mengatasi masalah ini dirasakan perlu untuk memperlengkapi aplikasi purwarupa yang telah dibuat dengan kemampuan untuk mencari melalui jaringan
PUSTAKA
Adobe. 2008. Document Management – Portable Document Format Part 1: PDF1.7. San Jose: Adobe System Incorporated.
Emberton, N. 2017. File, (Online), (dari https://www.computerhope.com/jargon/f/file.htm, diakses 2 Juni 2017). Kemendikbud. 2017. Kamus Besar Bahasa Indonesia (KBBI): Kamus Versi Online/Daring, (Online),
(http://kbbi.web.id/plagiarisme, diakses 6 Juni 2017).
iParadigms LLC. 2017. About Us, (Online), (http://turnitin.com/en_us/about-us/our-company, diakses 5 Juni 2017).
iParadigms LLC. 2017. What is Plagiarism, (Online), (http://www.plagiarism.org/article/what-is-plagiarism, diakses 6 Juni 2017).
Lin, J., & Dyer, C. 2010. Data-Intensive Text Processing with MapReduce. Toronto: Morgan & Claypool Publishers.
Manning, C., Raghavan, P., & Schütze, H. 2009. Inverted Indexing, (Online), (dari http://home.deib.polimi.it/lbondi/data/uploads/irdm15-16/slides/07_inverted_indexing_v1.pdf, diakses 10 Juni 2017).
Merriam-Webster Inc. 2018. Plagiarism, (Online), (dari https://www.merriam-webster.com/dictionary/ plagiarism, diakses 3 Februari 2018).
Merriam-Webster Inc. 2018. Plagiarize, (Online), (dari https://www.merriam-webster.com/dictionary/plagiarize, diakses 3 Februari 2018).
Nuh, M.. 2010. Permendiknas No. 17 Tahun 2010 Tentang Pencegahan dan Penanggulangan Plagiat di
Perguruan Tinggi, (Online), (dari