BAB II
KONSEP, LANDASAN TEORI, DAN KAJIAN TERDAHULU
2.1 Konsep
Konsep berkaitan dengan definisi-definisi atau pengertian-pengertian yang
menyangkut objek, proses, yang berkaitan dengan penelitian. Dalam KBBI dan
Kamus Linguistik, konsep diartikan sebagai gambaran mental dari objek, proses,
atau apa pun yang ada di luar bahasa, yang digunakan oleh akal budi untuk
memahami hal-hal lain. Hal-hal yang dibicarakan dalam penelitian ini merupakan
konsep-konsep yang mendasari penelitian.
2.1.1 Kekerabatan Bahasa
Kekerabatan dalam istilah linguistik diartikan sebagai hubungan antara dua bahasa atau lebih yang diturunkan dari sumber yang sama (KBBI, 2008 ).
Sedangkan, bahasa berkerabat diartikan sebagai bahasa yang mempunyai
hubungan genealogis dangan bahasa lain. Dengan demikian, bahasa yang
berkerabat adalah bahasa yang memiliki hubungan antara yang satu dengan yang
lainnya. Hubungan ini bisa jadi merupakan asal dari induk yang sama sehingga
terdapat kemiripan, atau dapat juga karena adanya ciri-ciri umum yang sama.
Dalam hal bahasa, kemiripan ini terutama terlihat dari segi fonologinya, atau
mungkin morfologi, bahkan sintaksisnya. Kridalaksana (2008:116) menjelaskan
dalam Kamus Linguistik bahwa Kekerabatan (genetic relationship) adalah
hubungan antara dua bahasa atau lebih yang diturunkan dari sumber bahasa induk
Bahasa-bahasa yang berada dalam satu rumpun yang sama tentulah
memiliki kekerabatan. Akan tetapi, tingkat kekerabatan bahasa-bahasa yang
berada dalam satu rumpun ini kemungkinan tidaklah sama. Sejauh mana tingkat
keeratan hubungan bahasa yang satu dengan yang lainnya dapat dilihat dari
kemiripan atau perbedaan dari bahasa-bahasa yang dibandingkan. Semakin mirip
kedua bahasa, semakin eratlah hubungan kekerabatannya. Semakin berbeda
kedua bahasa, semakin rengganglah hubungan kekerabatannya.
2.1.2 Bahasa Melayu
Bahasa Melayu adalah salah satu bahasa daerah yang digunakan di
Sumatera Utara yang berfungsi dan berkedudukan sebagai alat komunikasi,
pendukung kebudayaan, dan lambang identitas masyarakat Melayu. Selama
berabad-abad, bahasa Melayu berperan sebagai lingua franca di berbagai belahan
bumi. Bahasa Melayu digunakan dan dimanfaatkan untuk kelancaran komunikasi
dalam pergaulan, perdagangan, dan lainnya. Fungsi dan kedudukan bahasa terkait
erat dengan masyarakat penutur dan pemakai bahasa. Demikian pula dengan
kawasan tempat bahasa itu digunakan, dimanfaatkan, dan diperlukan.
Penggunaan bahasa Melayu tidak mengenal batas negara, bangsa, maupun
suku bangsa. Sekalipun dikenal rumusan bahwa orang Melayu adalah orang yang
berbahasa, berbudaya, dan bertempat tinggal di pemukiman masyarakat Melayu,
namun “kawasan penggunaan bahasa Melayu” dan “masyarakat pengguna bahasa
Melayu” tidaklah sempit. Selanjutnya, sekalipun yang dikenal sebagai budaya
utamanya adat bersendikan syaraq, syaraq bersendikan qitabullah, namun
penutur dan pemakai bahasa Melayu tidaklah terbatas hanya pada pemeluk agama
Islam (Ridwan, 2005:208).
Dalam perkembangannya, bahasa Melayu, khususnya yang berada di
Nusantara berkembang menjadi dialek-dialek atau bahkan terpecah menjadi
bahasa yang berdiri sendiri. Di Sumatera utara saja, dikenal bahasa Melayu
Langkat, bahasa Melayu Deli, bahasa Melayu Serdang, bahasa Melayu Bedagai,
bahasa Melayu Batubara, bahasa Melayu Asahan, bahasa Melayu Bilah, bahasa
Melayu Kotapinang, bahasa Melayu Panai, dan bahasa Melayu Kualoh.
Bahasa Melayu yang dijadikan objek penelitian adalah bahasa Melayu
Deli karena bahasa Melayu Deli dianggap yang paling dapat mewakili bahasa
Melayu secara keseluruhan dan karena bahasa Melayu Deli digunakan oleh
masyarakat Melayu yang tinggal di Medan.
2.1.2 Bahasa Batak
Dalam Kamus Linguistiknya, Kridalaksana menyebut bahasa Batak
dengan sebutan “Dialek-Dialek Batak”, yang menyiratkan bahwa bahasa Batak
memiliki banyak variasi yang masih tergolong dalam dialek. Terdiri atas bahasa
Batak (dialek) Karo/Alas/pakpak, bahasa Batak (dialek) Toba, bahasa Batak
(dialek) Simalungun, bahasa Batak (dialek) Angkola Mandailing. Hal ini
kemudian didukung oleh temuan Balai Bahasa Medan dalam kegiatan pemetaan
bahasa-bahasa di seluruh Nusantara dengan perhitungan dialektologi yang masih
bukan bahasa-bahasa yang berdiri sendiri. Perlu dicatat bahwa data yang
digunakan dalam kegiatan itu adalah data bahasa yang diperoleh pada tahun 1990.
Dengan kemungkinan adanya perubahan dalam kurun waktu setiap 10 tahun,
kenyaataan yang ada saat ini bisa jadi tidak lagi sama.
Sementara itu, Panggabean dalam tesisnya pada tahun 1994 menyebut
“Bahasa-Bahasa Batak” yang dimaknai bahwa variasi-variasi yang ada dalam
kelompok bahasa Batak sudah berdiri sebagai bahasa. Ini ditopang dengan
kenyataan bahwa masing-masing masyarakat Batak akan menganggap sukunya
sebagai suku yang berbeda dan berdiri sendiri. Masyarakat Batak
Mandailing/Angkola bertahan bahwa mereka adalah masyarakat yang berbeda,
bukan bagian dari Batak. Saat ini, hal itu berkembang lagi dengan kenyataan
bahwa Mandailing dengan Angkola pun tidak mau disamakan lagi. Begitu juga
yang terjadi dengan Simalungun, Karo, Pakpak/Dairi. Walaupun begitu, hal itu
bukanlah sesuatu yang terlalu penting mengingat dalam penelitian ini
perbandingan akan dilakukan dalam bahasa-bahasa yang jelas berbeda, bukan
dalam ranah bahasa Batak dan varian-variannya. Bahasa Batak yang akan
digunakan sebagai bahan kajian adalah bahasa Batak Toba.
Bahasa Batak Toba adalah salah satu bahasa daerah yang dipergunakan di
daerah sekitar
bahasa Batak Toba dewasa ini sekitar 2 juta jiwa dengan perincian 1,5 juta
Medan, Jakarta, dan di kota-kota besar lainnya, bahkan sampai Papua karena
“Orang Batak” terkenal dengan sifatnya yang keras dan memiliki semangat hidup
yang tinggi untuk mencapai kehidupan yang lebih baik.
2.1.3 Bahasa Nias
Bahasa Nias, atau Li Niha dalam bahasa aslinya, adalah
dipergunakan oleh penduduk di
bahasa di dunia yang masih belum diketahui persis dari mana asalnya. Namun,
seperti layaknya bahasa-bahasa yang ada di Nusantara, bahasa Nias juga termasuk
dalam rumpun Austronesia.
Bahasa Nias merupakan salah satu bahasa dunia yang masih bertahan
hingga sekarang dengan jumlah pemakai aktif sekitar setengah juta orang. Bahasa
ini dapat dikategorikan sebagai bahasa yang unik karena setiap akhiran katanya
berakhiran huruf vokal. Bahasa Nias mengenal enam huruf vokal, yaitu a,e,i,u,o
dan | ( http://id.wikipedia.org/wiki/Bahasa_Nias).
Bahasa Nias yang dijadikan objek penelitian adalah bahasa Nias dialek
Gunung Sitoli dengan alasan Kota Gunung Sitoli merupakan kota terbesar di
Pulau Nias sehingga bahasa Nias yang kemungkinan memiliki dialek-dialek akan
bertemu di Kota Gunung Sitoli yang dulunya merupakan ibukota Kabupaten Nias
sebelum Nias dimekarkan menjadi 5 kabupaten. Hal ini diharapkan dapat
2.2 Landasan Teori
Teori-teori yang digunakan dalam penelitian ini adalah teori-teori yang
berkaitan dengan Linguistik Historis Komparatif. Dalam Linguistik Historis
Komparatif dibicarakan kekerabatan bahasa berdasarkan sejarah timbulnya
bahasa-bahasa tersebut. Dalam hal ini, konsep bahasa purba yang dianggap
sebagai bahasa asal bahasa-bahasa turunan tentulah menjadi hal yang sangat
berperan dalam penetapan keluarga bahasa. Karena itulah, suatu telaah atau kajian
historis juga membicarakan kesamaan bentuk bahasa secara fonetis serta
perubahan-perubahannya, lewat korespondensi bunyi dan variasi-variasi bunyi
yang terdapat dalam bahasa-bahasa yang berkerabat, berupaya menetapkan
waktu pisah bahasa yang dibicarakan, juga memperkirakan usia
bahasa-bahasa tersebut melalui metode-metode tertentu.
2.2.1 Migrasi Bahasa
Dalam teori migrasi bahasa disebutkan adanya asumsi bahwa untuk
mencapai tempat-tempat yang sekarang didiami oleh bahasa tertentu,
penutur-penutur bahasa proto atau bahasa purba harus berpindah tempat dari suatu
wilayah proto (proto area) yang menjadi tempat asal penutur-penutur bahasa itu.
Ada dua dalil yang mendasari teori migrasi bahasa ini:
1. Wilayah asal bahasa-bahasa kerabat merupakan suatu daerah yang
bersinambung.
2. Jumlah migrasi yang mungkin direkonstruksi akan berbanding terbalik
Dalil pertama manyebutkan adanya wilayah asal bahasa, dengan kata lain,
adanya asumsi bahwa bahasa-bahasa yang berkerabat sebenarnya berasal dari satu
wilayah yang sama, dengan kata lain pula, berasal dari satu bahasa yang sama
yang kemudian berkembang menjadi bahasa-bahasa yang berbeda. Karena
bahasa-bahasa yang berkerabat merupakan bentuk percabangan dari satu bahasa
proto, maka semua bentuk itu dapat ditelusuri kembali melalui gerak-gerak yang
berasal dari wilayah yang bersinambung tadi. Yang dimaksud dengan wilayah
asal adalah wilayah dari bahasa yang menurunkan bahasa-bahasa yang setara
dewasa ini. Daerah asal bahasa-bahasa yang setara itu disebut Homeland atau
Negeri asal
Dalil kedua dapat dianggap sebagai kaidah “gerak yang paling minimal”.
Maksudnya, bila jumlah gerak dalam dua buah peluang migrasi yang
direkonstruksikan itu berbeda, maka migrasi dengan jumlah gerak yang paling
kecil mempunyai peluang yang paling besar sebagai migrasi yang sesungguhnya
pernah terjadi. (Keraf, 1984: 172-174).
2.2.2 Korespondensi Bunyi
Korespondensi bunyi atau kesepadanan bunyi, awalnya dikenal dengan
istilah hukum bunyi (Lautgesetz, Sound Law, Grimm’s Law), diartikan sebagai
hubungan yang teratur mengenai bunyi-bunyi bahasa yang didasarkan pada
kata-kata dengan makna yang mirip (Keraf, 1984:42). Seperti dijabarkan di bagian
pendahuluan, hukum bunyi ini awalnya dirumuskan oleh Jacob Grimm. Dalam
mendapatkan kenyataan bahwa ada pergeseran atau pertukaran bunyi yang
berlangsung secara teratur dalam bahasa-bahasa yang ditelitinya. Para ahli bahasa
pada masa itu yang dikenal dengan sebutan aliran Junggrammatiker memberi
perhatian yang besar pada hukum bunyi ini dan menyatakan bahwa hukum bunyi
ini berlaku tanpa kecuali.
Bahasa-bahasa yang ada dewasa ini diasumsikan berasal dari satu bahasa
yang sama. Perubahan-perubahan yang terjadi kemudian karena faktor waktu dan
letak geografis ternyata masih menyisakan kemiripan atau kesamaan dalam
beberapa bahasa. Bahasa-bahasa yang masih memiliki kemiripan inilah yang
disebut sebagai berkerabat. Dalam hal ini, perubahan yang terjadi masih dapat
diamati dan dirumuskan melalui hukum bunyi atau korespondensi bunyi yang
terdapat dalam bahasa-bahasa tersebut. Misalnya, dengan mempergunakan
kata-kata bilangan atau kata-kata-kata-kata yang menyangkut anggota tubuh (yang dianggap
universal karena dimiliki oleh semua bahasa di dunia) dapat ditentukan perangkat
korespondensi. Contoh: Melayu hidung
Ma’ayan urung
Banjar hidung
Lamalera irung
Jawa irung
Batak igung
Dari data-data tersebut, diperoleh perangkat korespondensi berikut:
/ h – ø - h – ø – ø – ø – ø /
/ i - u – i -- i – i – i – i /
/ d – r – d – r – r – g – l /
/ u – u – u – u – u – u – u /
/ G - G--- G - G - G - G - G /
Semakin banyak data yang diperbandingkan maka semakin banyak pula
kemungkinan untuk memperoleh perangkat korespondensi fonemisnya. Akan
tetapi, korespondensi fonemis ini tidak dapat dirumuskan dari satu pasangan kata
saja, data lain juga harus menunjukkan kesesuaian dengan data yang sebelumnya.
Dalam bahasa-bahasa Nusantara, kita dapat melihat contoh pada kata ‘batu’.
Dalam bahasa Melayu: batu, Jawa: watu, Batak: batu, Lamalera: foto. Dalam
pasangan kata ini terdapat indikasi adanya perangkat korespondensi fonemis: /b –
w – b – f /. Jika hubungan antara fonem-fonem itu menjadi perangkat
korespondensi fonemis yang sesungguhnya, maka harus dapat diperoleh dari
pasangan kata lain. Dan, memang itulah yang terjadi, dalam pasangan
kata-kata berikut:
Glos Melayu Jawa Batak Karo Lamalera
babi babi wawi babi fave
bulan bulan wulan bulan fula
buluh buluh wulu buluh fulo
2.2.3 Variasi Bunyi
Perubahan bunyi yang muncul secara teratur disebut korespondensi,
sedangkan perubahan bunyi yang muncul secara sporadis disebut variasi (Mahsun,
1995:28). Variasi bunyi dapat berupa perubahan dari yang sama menjadi berbeda,
dari yang berbeda menjadi sama, pelesapan atau penghilangan, penambahan, atau
perubahan letak bunyi-bunyi yang terdapat dalam kata-kata bahasa yang
berkerabat. Perubahan bunyi yang tergolong variasi adalah:
1. Asimilasi
Asimilasi merupakan suatu proses perubahan bunyi ketika dua fonem yang
berbeda dalam bahasa proto mengalami perubahan menjadi fonem yang sama
dalam bahasa sekarang atau proses perubahan satu segmen (bunyi) menjadi serupa
dengan yang lainnya. Asimilasi ini ada yang disebut asimilasi total atau identik,
dan ada yang disebut sebagai asimilasi parsial atau sebagian saja. Asimilasi total
atau identik terjadi apabila perubahan terjadi secara total. atau seluruhnya,
sedangkan asimilasi parsial terjadi apabila perubahan terjadi bila hanya sebagian
cirri-ciri fonetis bunyi-bunyi tersebut yang disamakan. Dalam bahasa Batak
banyak terjadi asimilasi bunyi.
Contoh: dang kuboto dakkuboto ‘tidak kutahu’
mambuka mabbuka ‘membuka’ dll.
2. Disimilasi
Disimilasi merupakan kebalikan dari asimilasi. Jika asimilasi perubahan
yang sama menjadi tidak sama. Dalam bahasa Proto Austronesia (PAN) dan
Melayu, hal ini terjadi:
Contoh: PAN Melayu
* t’ambut sambut ‘sambut’
* t’akit sakit ‘sakit’
3. Metatesis
Metatesis merupakan perubahan bunyi yang berkaitan dengan perubahan
letak bunyi-bunyi bahasa. Perubahan letak bunyi-bunyi ini akan menghasilkan
kata-kata yang berbeda tetapi masih berada dalam lingkup makna yang sama.
Contoh-contoh yang ada dalam bahasa Indonesia: lebat tebal, lajur jalur
4. Swarabakti
Swarabakti ini disebut juga sebagai bunyi pelancar atau pelancar bunyi.
Sering sekali bunyi-bunyi tertentu muncul ketika bunyi berupa gugus konsonan
atau gugus vokal hadir. Sebenarnya, sebagian beranggapan bahwa swarabakti ini
adalah bentuk penambahan bunyi seperti layaknya protesis, epentesis, dan
paragoge. Akan tetapi, dalam swarabakti atau bunyi pelancar ini, bunyi yang
muncul adalah bunyi-bunyi yang memang berfungsi untuk melancarkan bunyi.
Misalnya, bunyi /y/ hadir antara vokal /ia/, bunyi /w/ hadir di antara vokal /ua/,
dan bunyi /e/ hadir di antara konsonan /tr/, dll.
Contoh: siang siyang
uang uwang
2.2.4 Leksikostatistik
Linguistik Historis Komparatif melandaskan metodenya pada kesamaan
bentuk, tetapi kesamaan bentuk dalam perkembangan sejarah yang sama. Salah
satu metode dalam Linguistik Historis Komparatif ialah leksikostatistik, yang
berfungsi menentukan tingkat hubungan di antara dua bahasa dengan
membandingkan kosakata dari bahasa dan menentukan tingkat kesamaan di
antaranya.
Leksikostatistik adalah suatu teknik yang memungkinkan kita untuk
menentukan tingkat hubungan di antara dua buah bahasa, dengan menggunakan
cara yang paling mudah, yaitu dengan membandingkan kosa kata pada
bahasa-bahasa tersebut yang kemudian dapat dilihat dan ditentukan tingkat kesamaan di
antara kosa kata kedua bahasa (Crowley: 1992:168). Dengan demikian, sejauh
mana hubungan kekerabatan satu bahasa dengan bahasa lainnya dapat diketahui.
Menurut Crowley (1987: 191—192), metode leksikostatistik beroperasi di
bawah dua asumsi dasar. Asumsi pertama ialah bahwa beberapa bagian kosakata
dari sebuah bahasa sukar berubah daripada bagian lainnya. Apa yang dimaksud
dengan kosakata yang sukar berubah adalah kosakata dasar, yakni kata-kata yang
sangat intim dalam kehidupan bahasa, dan merupakan unsur-unsur yang
menentukan mati hidupnya suatu bahasa ( lihat juga Keraf, 1991: 123).
Kemudian, istilah ‘perubahan’ mengacu pada penggantian sebuah kata dengan
sebuah kata nonkerabat karena bentuk asli berubah maknanya sehingga
kemunculannya merujuk kepada sesuatu yang lain, atau karena sebuah kata
Asumsi kedua ialah bahwa perubahan kosakata dasar pada semua bahasa
adalah sama. Asumsi ini telah diuji pada 13 bahasa, di antaranya bahasa yang
memiliki naskah-naskah tertulis. Hasilnya menunjukkan bahwa dalam tiap 1.000
tahun, kosakata dasar suatu bahasa bertahan antara 86,4—74,4 %, atau dengan
angka rata-rata 80,5%. Tentu saja hal itu tidak dapat diartikan bahwa semua
bahasa akan bertahan dengan persentase rata-rata tersebut, karena semua bahasa
yang digunakan dalam eksperimen itu (kecuali dua bahasa) adalah bahasa-bahasa
Indo-Eropa.
Bila asumsi kedua diterima, retensi rata-rata kosakata dasar suatu bahasa
dalam tiap 1.000 tahun dapat dinyatakan dalam rumus: 80,5% x N. Simbol N
adalah jumlah kosakata dasar yang ada pada awal kelipatan 1.000 tahun yang
bersangkutan. Dari 200 kosakata dasar (N) suatu bahasa sesudah 1.000 tahun
pertama akan tinggal 80,5% x 200 kata = 161 kata. Sesudah 1.000 tahun kedua
akan tinggal 80,5% x 161 kata = 139,6 kata atau dibulatkan menjadi 140 kata.
Sesudah 1.000 tahun ketiga kosakata dasarnya tinggal 80,5 x 140 kata = 112,7
atau dibulatkan menjadi 113 kata, dan seterusnya.
“Leksikostatistik adalah metode pengelompokan bahasa yang dilakukan
dengan menghitung prosentase perangkat kognat/kerabat (Mahsun,1995:115)”.
Dalam penghitungan leksikostatistik, kata-kata yang memiliki kemiripan dari segi
fonetis atau morfologi akan dianggap sebagai kata yang berkerabat atau dikenal
dengan istilah kognat (cognate). Melalui kata-kata berkerabat inilah dilakukan
Menurut Keraf,(1984: 121) Leksikostatistik itu suatu teknik dalam
pengelompokan bahasa yang lebih cenderung mengutamakan peneropongan
kata-kata (leksikon) secara statistik, untuk kemudian berusaha menetapkan
pengelompokan itu berdasarkan persentase kesamaan dan perbedaan suatu bahasa
dengan bahasa lain. Dari konsep di atas, Keraf kemudian menjabarkan metode
kerja dalam leksikostatistik yang dapat dijadikan acuan dalam penelitian
kekerabatan bahasa.
Asumsi Dasar Leksikostatistik
Ada empat macam asumsi dasar yang dapat dipergunakan sebagai titik
tolak dalam usaha mencari jawaban mengenai usia bahasa, atau secara tepatnya
bilamana terjadi diferensiasi antara dua bahasa atau lebih (Keraf: 1984: 123)
Asumsi-asumsi dasar tersebut adalah :
1. Sebagian dari kosa kata suatu bahasa sukar sekali berubah bila
dibandingkan dengan bagian lainnya.
Kosa kata yang sukar berubah dalam asumsi dasar adalah kosa kata dasar yang
merupakan kata-kata yang sangat intim dalam kehidupan bahasa sekaligus
merupakan unsur-unsur yang menentukan mati hidupnya suatu bahasa. Kosa kata
yang diambil dalam metode leksikostatistik dibatasi jumlahnya, setelah diadakan
penilaian yang ketat dan pengujian-pengujian untuk menerapkan metode ini
secara baik. Yang ingin dicapai dalam seleksi ini adalah dapat disusun sebuah
daftar yang bersifat universal, artinya kosa kata yang dianggap harus ada pada
1. kata ganti;
2. kata bilangan;
3. kata-kata mengenai anggota badan (dan sifat atau aktivitasnya);
4. alam dan sekitarnya: udara, langit, air, gunung, dan sebagainya beserta sifat
atau aktivitasnya;
5. alat-alat perlengkapan sehari-hari yang sudah ada sejak permulaan: tongkat,
pisau, rumah, dan sebagainya.
Morris Swadesh mengusulkan sekitar 200 kosa kata dasar yang dianggapnya
universal, artinya bisa terdapat pada semua bahasa di seluruh dunia.
2. Retensi (ketahanan ) kosa kata dasar adalah konstan sepanjang masa.
Asumsi dasar yang kedua mengatakan bahwa dari kosa kata dasar yang ada
dalam suatu bahasa, suatu persentase tertentu selalu akan bertahan dalam 1.000
tahun. Kalau asumsi ini diterima, maka dari sebuah bahasa yang memiliki 200
kosa kata, sesudah 1.000 tahun akan bertahan 80,5%, dan dari sisanya sesudah
1.000 tahun kemudian akan bertahan lagi dalam persentase yang sama.
3. Perubahan kosa kata dasar pada semua bahasa adalah sama.
Setelah menguji beberapa bahasa dengan asumsi dasar ketiga ini, hasilnya
akan menunjukan bahwa dalam tiap 1000 tahun, kosa kata dasar suatu bahasa
bertahan dengan angka-angka rata-rata 80,5%. Apabila kita ingin menghitung
retensi ( ketahanan) kosa kata dasar kedua bahasa dengan mempergunakan asumsi
dasar kedua, dapat dinyatakan dengan rumus : 80.5% x N. N adalah jumlah kosa
80,5% x 200 = 161kata, sesudah 1000 tahun kedua akan tinggal 80,5% x161 kata
= 139,6 kata atau dibulatkan menjadi 140 kata. Selanjutnya sesudah 1000 tahun
ketiga kosa kata dasar yang tinggal adalah 80,5% x 140 kata = 112,7 kata atau
dibulatkan menjadi 113 kata, dan seterusnya (seperti yang dijabarkan oleh
Crowley di atas).
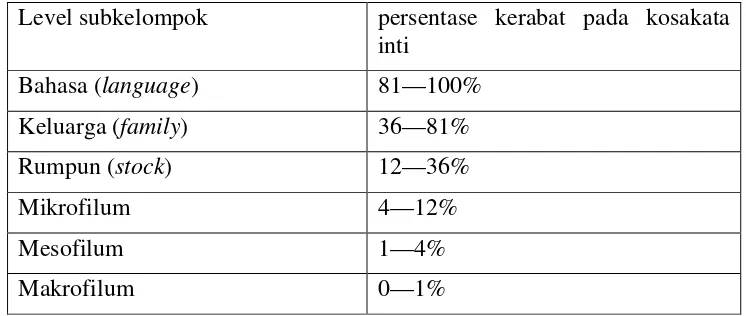
Dalam leksikostatistik, tataran yang berbeda dari subkelompok dinamai sebagai
berikut: Tabel 1
Penamaan Subkelompok Bahasa
Level subkelompok persentase kerabat pada kosakata inti
Bahasa (language) 81—100%
Keluarga (family) 36—81%
Rumpun (stock) 12—36%
Mikrofilum 4—12%
Mesofilum 1—4%
Makrofilum 0—1%
Dalam klasifikasi leksikostatistik, kesamaan pada tingkat 81-100% disebut
bahasa, kesamaan pada tingkat 36—81% disebut keluarga, kesamaan pada
tingkat 12-36% disebut rumpun, kesamaan pada tingkat 4-12% disebut
mikrofilum, kesamaan pada tingkat 1-4% disebut mesofilum, dan kesamaan pada
tingkat 0-1% disebut makrofilum. Namun, perlu dicatat bahwa ahli bahasa yang
berbeda adakalanya menggunakan hitungan yang berbeda.
Perbandingan yang sistematis memerlukan metode yang tepat. Penelitian
ini menggunakan metode perbandingan untuk menyusun perangkat ciri yang
kosakata dasar dari ketiga bahasa itu, yang disusun oleh Morris Swadesh. Daftar
kosakata itu membawa keuntungan dalam penelitian karena terdiri atas kata-kata
nonkultural serta retensi kata dasarnya telah diuji dalam bahasa-bahasa yang
memiliki naskah-naskah tertulis.
Keraf (1991: 127—130) mengatakan bahwa dalam membandingkan
kata-kata untuk menetapkan kata-kata-kata-kata kerabat dan kata-kata-kata-kata nonkerabat terdapat
asumsi bahwa fonem bahasa proto yang berkembang secara berlainan dalam
bahasa-bahasa kerabat akan berkembang secara konsisten dalam lingkungan
linguistis bahasa kerabat masing-masing. Dalam perbandingan itu, fonem-fonem
dalam posisi relatif sama dibandingkan satu sama lain. Bila terdapat hubungan
genetis, pasangan fonem tersebut akan timbul kembali dalam banyak pasangan
lain. Tiap pasangan yang sama yang timbul dalam hubungan itu merupakan
pantulan suatu fonem atau alofon dalam bahasa protonya (lihat juga Crowley).
4. Bila persentase dari dua bahasa kerabat (cognate) diketahui, maka dapat
dihitung waktu pisah kedua bahasa tersebut.
Berdasarkan asumsi dasar yang kedua, ketiga, dan keempat, kita dapat
menghitung usia atau waktu pisah bahasa-bahasa yang diteliti kalau diketahui
persentase kata kerabat kedua bahasa itu. Dan karena dalam tiap 1000 tahun kedua
bahasa kerabat itu masing –masing akan kehilangan kosa kata dasarnya dalam
persentase yang sama, maka waktu pisah dalam kedua bahasa itu harus dibagi
dua. Misalnya persentase kata kerabatnya adalah 80, 5%, maka waktu pisah kedua
Berdasarkan prinsip itu, waktu pisah kedua bahasa kerabat dengan prosentase
kata kerabat yang diketahui adalah seperti tertera dalam tabel berikut ini (Keraf:
1984: 125): Tabel 2
Perkiraan Waktu Pisah dan Usia Bahasa
Jumlah kata
kerabat antara A—
B
Persentase kata
kerabat
Usia (waktu pisah) antara bahasa A—
B sekian tahun yang lalu (sudah
dibagi 2)
Jika jumlah kata berkerabat antara dua bahasa yang ditelaah antara
200-162, dengan persentase 100-81, maka waktu pisah diperkirakan 0-500 tahun yang
lalu. Jika jumlah kata yang berkerabat antara 162-132 dengan persentase 81-66,
maka waktu pisah kedua bahasa diperkirakan antara 500-1000 tahun yang lalu.
Jika jumlah kata berkerabatnya 132-106, dengan persentase 66-53, maka waktu
pisah kedua bahasa itu diperkirakan 1000-1500 tahun yang lalu, dan seterusnya.
Setelah menghitung waktu pisah bahasa-bahasa yang dijadikan objek penelitian,
dijabarkan di atas dikaji dalam Linguistik Historis Komparatif dengan metode
yang disebut glotokronologi.
2.2.5 Glotokronologi
Glotokronologi adalah suatu teknik dalam linguistik historis yang berusaha
mengadakan pengelompokan dengan lebih mengutamakan perhitungan waktu
(time depth) atau perhitungan usia bahasa-bahasa kerabat. Dalam hal ini, usia
bahasa tidak dihitung secara mutlak dari suatu tahun tertentu, tetapi dihitung
secara umum, misalnya mempergunakan satuan ribuan tahun (millennium) (Keraf,
1984: 121).
Pendapat itu ditunjang oleh pakar yang lain, yaitu Terry Crowley yang
menyatakan, metode kedua yang biasanya digunakan untuk menentukan waktu
tepatnya kapan bahasa yang berkerabat berpisah disebut dengan glotokronologi.
Metode ini memungkinkan seorang linguis atau ahli bahasa mengetahui sudah
berapa lama bahasa-bahasa yang berkerabat yang dalam hal ini termasuk pada
level sub-grouping telah berpisah (Crowley, 1992:79). Jadi, jika leksikostatistik
berusaha melakukan pengelompokan bahasa berdasarkan waktu pisah
bahasa-bahasa yang diteliti, glotokronologi berusaha memperkirakan usia bahasa-bahasa-bahasa-bahasa
tersebut.
Hasil perhitungan tersebut dapat dikelompokkan Crowley (1992:179)
menjadi:
Tingkat Pengelompokan Tahun Pisah
Dialek dari satu bahasa Bahasa dari satu keluarga
Kurang dari 500 tahun
Keluarga dari satu rumpun Rumpun dari satu mikrofilum Mikrofilum dari satu mesofilum Mesofilum dari satu makrofilum
2500 sampai dengan 5000 tahun 5000 sampai dengan 7500 tahun 7500 sampai dengan 10.000 tahun Lebih dari 10.000 tahun
Pada kenyataannya, kedua bidang ini selalu dipakai berdampingan karena
untuk menghitung usia bahasa dengan teknik glotokronologi ini, harus
menggunakan leksikostatistik karena perhitungan yang dilakukan berangkat dari
hasil perhitungan leksikostatistik. Begitu juga sebaliknya, untuk melakukan
pengelompokan bahasa juga tidak terlepas dari masalah waktu yang dijadikan
sebagai landasan pengelompokan. Karena itu, banyak ahli yang pada dasarnya
menyamakan pengertian kedua istilah ini Gorys Keraf (1984:122).
Berbicara tentang usia bahasa, tidak terlepas dari pemikiran tentang
berapakah usia bumi? Pertanyaan ini juga akan sampai pada, berapakah usia
bahasa yang ada di bumi? Sebuah sumber menyatakan bumi ini berusia sekitar 4,6
miliar tahun (http://www.gotquestion.orang/indonesia/umur-bumi.html)
sedangkan sumber lain yang memperkirakan usia bahasa menyatakan bahwa
bahasa manusia sudah ada sejak 2.900 tahun Sebelum Masehi
(http://planet-berita.blogspot.com/2011/10/umur-bahasa-di-dunia.html) walaupun,
diinformasikan juga adanya temuan tentang bahasa tulis yang sudah berusia 50
ribu tahun, yaitu bahasa Sumerian. Lalu, berapakah usia bahasa-bahasa yang
dijadikan oebjek penelitian? Relevankah dengan perkiraan usia bumi dan bahasa
tertua tersebut? Tentunya hal ini akan menjadi temuan yang sangat menarik.
Penelitian yang berbicara tentang leksikostatistik antara lain adalah Ika
Indriani H. dengan judul Leksikostatistik Bahasa Batak Toba dengan Bahasa
Pakpak Dairi (2007). Dalam penelitian ini digunakan daftar kosa kata yang
disusun oleh Mahsun sebanyak 809 kosa kata. Akan tetapi, dalam penelitian ini
tidak digambarkan secara jelas perubahan-perubahan yang terjadi pada
bahasa-bahasa yang diteliti. Hasil penelitian tersebut menyatakan bahwa bahasa-bahasa Batak
Toba dan bahasa Pakpak Dairi merupakan bahasa tunggal pada 2.320-2200 tahun
yang lalu. Bahasa Batak Toba dan bahasa Pakpak Dairi mulai berpisah dari suatu
bahasa proto antara 320-200 sebelum Masehi (dihitung dari tahun 2000).
Suyata Pujiati Dari Leksikostatistik ke Glotokronologi: Analisis Sembilan
Bahasa di Indonesia (1998). Dalam penelitian ini dikaji kekerabatan Sembilan
bahasa di Indonesia, yaitu bahasa Batak, bahasa Minang, bahasa Melayu, bahasa
Banjar, bahasa Sunda, bahasa Jawa, bahasa Madura, bahasa Bali, dan bahasa
Bugis dengan alat bantu 100 kosakata dasar Swadesh. Penelitian ini dilakukan di
Yogyakarta dengan menggunakan mahasiswa sebagai informan. Pujiati
menggunakan teknik yang dikemukakan oleh Dyen dan hasil yang didapatkannya
adalah bahasa Batak dan bahasa Bugis merupakan bahasa proto atau bahasa
tertua, yang menurunkan bahasa yang lain, dari kesembilan bahasa yang diteliti
sehingga Pujiati menyebutnya sebagai bahasa proto Batak-Bugis. Bahasa proto
Batak-Bugis awalnya adalah bahasa satu bahasa. Dalam perjalanannya, induk
bahasa tersebut berpisah menjadi 3 subgrup: 1. Subgrup Batak, Melayu, Minang,
dan Banjar; 2. Subgrup Sunda , Jawa, dan Madura; 3. Subgrup Bali dan Bugis.
paling renggang atau jauh adalah Batak dan Bugis, sedangkan bahasa Melayu dan
bahasa Minang memiliki tingkat kekerabatan yang paling erat atau dekat.
Himpun Panggabean Telaah Bahasa-Bahasa Batak dari Segi
Leksikostatistik (1994). Dalam penelitian ini Panggabean menggunakan 300 kosa
kata dasar yang merupakan kombinasi dari Swadesh, Gudschinsky, Travis, Rea,
dan Keraf. Panggabean menyimpulkan bahwa bahasa-bahasa Batak mempunyai
tigkat kekerabatan dan waktu pisah yang tidak sama antara satu dengan yang
lainnya. Bahasa Batak Toba dan Angkola berada dalam satu bahasa yang sama,
dengan kata lain kekerabatan keduanya masih sangat erat sehingga salah satunya
berstatus dialek dari yang lain. Sedangkan bahasa-bahasa Batak yang lain berada
dalam lingkup keluarga. Dengan perincian, bahasa Karo, bahasa Alas, dan bahasa
Dairi berada dalam satu kemompok, dan bahasa Simalungun tidak berada dalam
kelompok kedua kelompok bahasa tersebut. Ini berarti, bahasa Simalungun berdiri
sendiri.
Selain itu, telaah kekerabatan bahasa-bahasa yang ada di Nusantara juga
banyak dilakukan oleh para pakar, seperti Kridalaksana, Blust, Dyen, Fernandes,