SENTRA I - 235
EKSTRAKSI NAMA LOKASI DARI TWEETS INFORMASI
LALU LINTAS
Yuda Munarko
Universitas Muhammadiyah Malang
Kontak Person:
Yuda Munarko Jl. Raya Tlogomas 246
Malang
Telp: 0341-464318 ext. 247, Fax: 0341-460435, E-mail: yuda.munarko@gmail.com
Abstrak
The extraction of traffic information from twitter is widely studied. For this purpose, we need to identify the name of a location from the tweet traffic information. Unfortunately, up to this research, research to detect the location entity from the tweet traffic information is rarely done. Therefore, we examined how to identify location entity of the tweet using rule-based and Stanford NER. We used data from accounts Sby Traffic Services, RTMC Ditlantas Jatim and Radio Suara Surabaya. Based on our experiment, Stanford NER is superior compared to rule-base which precision, recall and F1 are 99.43%, 98.89%, 99.16%. However, precision, recall and F1 of rule-based method are not so far from Stanford NER, which are 94.5%, 95.10%, 94.8%.
Kata kunci: twitter, twet, NER, name entity recognition
Pendahuluan
Saat ini, sosial media seperti twitter telah menjadi sumber informasi alternatif bagi masyarakat secara umum. Sebagai contoh, jika seorang pengguna twitter ingin mengetahui kondisi lalu lintas di jalan tlogomas malang, mereka bisa memeriksanya melalui mesin pencari twitter dengan kata kunci “lalin tlogomas malang”. Hasil dari pencarian ini adalah tweet user lain yang memiliki kata kunci “lalin”, “tlogomas”, “malang” atau ketiganya; dengan mengurutkan berdasarkan waktu posting, dari yang paling baru ke yang paling lama, dan berdasarkan similaritas antara kata kunci dan tweet.
Namun perlu diketahui, bahwa ada kalanya tingkat kebaruan informasi yang didapatkan tidak seperti yang diharapkan, sehingga validitas informasi jadi rendah. Pada kasus pencarian kondisi lalu lintas seperti contoh di atas, tingkat validitas informasi akan semakin tinggi jika selisih waktu antara waktu tweet dan waktu saat pencarian mendekati nol. Kenyataannya, ada kemungkinan informasi yang didapatkan berasal dari tweet 3 jam yang lalu. Secara intuitif, jika ada data masa lampau dengan hari dan jam yang sama dengan saat pencarian saat ini, maka data masa lampau ini lebih valid jika dibandingkan dengan data tweet 3 jam yang lalu. Untuk itu perlu dibangun suatu basis data yang menghimpun data historis tentang jenis informasi tertentu pada kondisi tertentu. Dengan menggunakan data ini, diharapkan informasi yang didapatkan memiliki tingkat validitas lebih tinggi.
Dari dasar pemikiran ini, guna keperluan menghimpun data historis yang berhubungan dengan informasi lalu lintas, maka perlu mengekstraksi fitur-fitur data seperti, nama lokasi, kondisi lalu lintas dan waktu tweet. Pada ekstraksi nama lokasi, permasalahan yang timbul adalah format penulisan nama lokasi yang beraneka ragam, misalnya: “lawang-malang” yang menunjukkan “lawang” sebagai asal dan “malang” sebagai tujuan, “per4an kasin” yang menunjukkan perempatan kasin. Oleh karena itu perlu dibangun suatu sistem yang dapat mengidentifikasi nama lokasi dengan format data yang tidak standar.
I - 236 SENTRA
filterisasi adalah untuk memilah dan memilih data yang diperlukan saja. Untuk keperluan ini ada penelitian oleh Sriram et.al. [8] mengenai filterisasi menggunakan klasifikasi pesan pendek dan penelitian oleh Hannon et. al. [9] yang memberikan rekomendasi kegiatan “follow” berdasarkan pendekatan filterisasi. Sedangkan tujuan dari POS-tagging adalah untuk mengubah teks twitter ke model struktur bahasa. Hal ini perlu dilakukan, karena pada umumnya, penggunaan struktur data dirasa lebih praktis daripada menggunakan seluh kata yang tersedia. Bahkan untuk kasus ekstraksi kata, POS-tagging dianggap sebagai keharusan. Untuk POS-tagging Bahasa Indonesia, terdapat dua pendekatan utama yang biasa digunakan, yakni menggunakan pendekatan Hidden Markov Model [1] dan menggunakan pendekatan probabilistic [2].
Riset lainnya adalah riset yang berfokus pada tipe informasi tertentu, yakni seperti pada informasi lalu lintas [3][5] yang telah disebutkan di atas. Namun pada penelitian tersebut tidak dijelaskan bagaimana mereka memvalidasi data yang berhubungan dengan lokasi, baik itu nama tempat tweet dibuat serta asal dan tujuan yang ditempuh. Menurut pengetahuan terbaik kami, hingga saat ini belum ada penelitian yang berfokus untuk memperoleh nama lokasi dengan presisi yang tinggi. Memang ada penelitian yang meneliti geo-location dari pengguna twitter, seperti [10] yang membahas persebaran pengguna twitter, dan [11] yang memperkirakan lokasi pengguna, namun mereka berasumsi bahwa nama lokasi di twitter formatnya sudah standar.
Pada penelitian ini, dilakukan upaya untuk mengidentifikasi nama lokasi dari sekumpulan tweet informasi lalu lintas. Untuk keperluan penelitian ini akan digunakan pendekatan rule-based dan menggunakan Stanford NER [12]. Penggunaan ruled based disebabkan oleh jenis informasi yang ingin diekstraksi sudah sangat spesifik, yakni nama lokasi. Alasan lainnya adalah, jenis data yang digunakan mayoritas sudah memiliki aturan yang spesifik dan menggunakan kata-kata yang juga spesifik yang bisa digunakan untuk mendeteksi nama lokasi. Sedangkan penggunaan Stanford NER disebabkan karena metode ini terbukti handal untuk deteksi nama entitas berbahasa Inggris.
Metode Penelitian
Sumber data yang digunakan diambil dari tiga akun informasi di twitter, yakni RTMC_Jatim, SbyTrafficServ and e100ss. Untuk setiap sumber data, dikumpulkan antara 3.000 hingga 3.500 tweet. data yang diambil adalah data pada bulan April hingga Juni 2013.
Data Sby Traffic Services adalah data yang khusus ditujukan untuk memberikan informasi lalu lintas di kawasan Surabaya dan sekitarnya.Jenis tweet yang ada di Sby Traffic Services didominasi oleh data yang berasal dari Dishub (Dinas Perhubungan), kurang lebih sebesar 80%. Sedangkan sisanya adalah tweet yang dibuat oleh masyarakat umum yang ingin memberi informasi lalu lintas di lokasi tertentu. RTMC Ditlantas Jatim adalah akun twitter resmi milik Direktorat Lalu Lintas Polda Jatim. Lokasi lalu lintas yang dihadirkan meliputi area Jawa Timur secara keseluruhan, namun lebih didominasi kawasan Surabaya dan sekitarnya serta Malang dan sekitarnya. Karakteristik tweet di akun ini adalah, tata bahasa yang digunakan relatif lebih stabil jika dibandingkan dengan tweet di akun Sby Traffic Services. Hal ini disebabkan oleh minimnya tweet di RTMC Ditlantas Jatim yang dibuat oleh pihak luar atau masyarakat umum. Akun Radio Suara Surabaya merupakan akun yang berisi informasi umum yang dikelola oleh Stasiun Radio Suara Surabaya. Informasi yang ada di akun ini merupakan hasil partisipasi aktif masyarakat umum. Disebabkan oleh kontributor tweet di Radio Suara Surabaya berasal dari masyrakat umum, maka susunan kalimat yang digunakan juga beraneka ragam. Demikian juga pemilihan jenis kata yang digunakan juga akan sangat beragam. Contoh data dari ketiga sumber tweet secara terurut bisa dilihat di Tabel 1.
Table 1. Contoh tweet lalu lintas
RTMC_Jatim Dishub 14.27 wib: Lalin A Yani arah dalam kota (depan Cito) padat merambat.cc @e100ss @1031Genfmsby http://t.co/tQcLwXxgDU
SbyTrafficServ Arus lalin seputaran simpang 3 Japanan terpantau padat, baik arah Malang maupun Sby, karena volume kendaraan http://t.co/JMPtXiUsZP
e100ss RT @aripriyam: @e100ss Wilayah kebraon dan sekitarnya hujan deras disertai angin kencang. Harap berhati-hati bagi pengguna jalan.
SENTRA I - 237 terhadap 1500 tweet dimana masing-masing sumber data menyumbang 500 tweet. Setiap anotator akan membuat daftar frasa kata yang terdiri dari rangkaian
[kata pembuka/KB] nama lokasi [kata sambung/KS] nama lokasi [kata penutup/KT]
Contoh frasa yang dideteksi adalah “arah[KB] surabaya ramai[KT]” dan “lalin[KB] depan pasar lawang menuju[KS] surabaya macet[KT]”. Selanjutnya, dari frasa yang dideteksi ini dilakuan analisa lebih lanjut dengan menggunakan metode apriori [13] untuk mengetahui KB, KS dan KT yang secara meyakinkan bisa digunakan untuk mendeteksi nama lokasi secara otomatis.
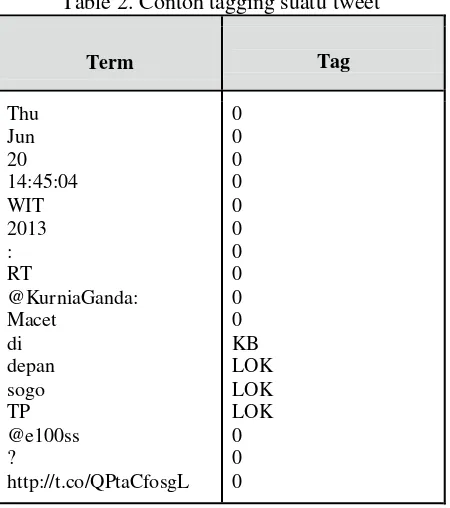
Sedangkan dalam pendekatan menggunakan Stanford NER, dilakukan pembuatan data training dengan melakukan tagging manual terhadap semua kata yang ada di 1500 tweet yang dianalisa pada metode rule based. Tag yang digunakan meliputi 0 untuk kata yang tidak penting, KB untuk kata pembuka,
Kemudian, dari data training, akan dibuat model dengan standard Stanford NER. Model yang sudah dibuat dapat digunakan untuk melakukan proses pengenalan nama lokasi secara otomatis pada koleksi tweet yang dimiliki.
Setelah rule dan model telah siap, langkah selanjutnya adalah melakukan evaluasi untuk mengetahui kinerja dari metode rule based dan Stanford NER terhadap data test yang juga terdiri dari 1500 tweet yang juga berasal dari ketiga data sumber dengan jumlah masing-masing 500.
Hasil Penelitian dan Pembahasan
I - 238 SENTRA
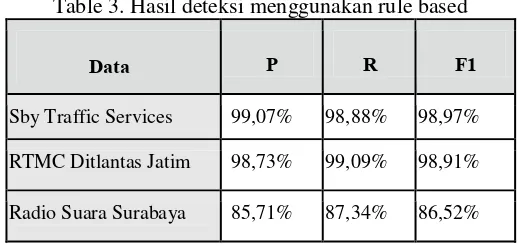
Table 3. Hasil deteksi menggunakan rule based
Data P R F1
Sby Traffic Services 99,07% 98,88% 98,97%
RTMC Ditlantas Jatim 98,73% 99,09% 98,91%
Radio Suara Surabaya 85,71% 87,34% 86,52%
Dari data di Tabel 3, bisa dilihat bahwa penggunaan rule based sangat baik jika sumber tweet adalah tweet yang terkontrol dengan baik. Tweet yang berasal dari Sby Traffic Services dan RTMC Ditlantas Jatim adalah tweet yang didominasi oleh kalimat dengan standar baku yang dibuat oleh pemilih akun. Sedangkan tweet dari Radio Suara Surabaya adalah tweet yang memiliki keanekaraman gaya bahasa lebih tinggi. Hal ini yang mungkin mempengaruhi perbedaan nilai precision dan recall untuk setiap data tes.
Untuk metode Stanford NER, didapatkan hasil yang relatif lebih baik daripada menggunakan rule based. Namun sebelum hasil evaluasi didapatkan, perlu dilakukan proses penggabungan lokasi jika ada kata dengan tag LOK saling bersebelahan. Sebagai contoh, untuk tweet di Tabel 2, maka lokasi yang dideteksi bukanlah “depan”, “sogo”, “tp”, namun “depan sogo TP”. Hasil pengujian dengan metode ini bisa dilihat di Tabel 4.
Table 4. Hasil deteksi menggunakan Stanford NER
Data P R F1
Sby Traffic Services 99,81% 98,85% 99,33%
RTMC Ditlantas Jatim 98,73% 99,09% 99,39%
Radio Suara Surabaya 99.75% 99.49% 98,76%
Dari Tabel 4 bisa dilihat bahwa hasil metode Stanford NER lebih baik dari pada rule based. Meskipun untuk data yang berasal dari Sby Traffic Services dan RTMC Ditlantas Jatim hasilnya hampir sama dengan rule based, namun peningkatan performa yang cukup baik terlihat pada data Radio Suara Surabaya. Sehingga bisa direkomendasikan bahwa untuk data tweet yang sifatnya terstruktur dengan baik dan seragam, bisa menggunakan rule based dan Stanford NER. Sedangkan untuk data tweet yang strukturnya beragam disarankan untuk menggunakan Stanford NER.
Kesimpulan
Identifikasi nama lokasi terhadap tweet informasi lakukan bisa digunakan metode rule based maupun Stanford NER. Keduanya mampu mengidentifikasi nama lokasi dengan precision dan recall yang tinggi. Namun, sebagai catatan, untuk data tweet yang berasal dari berbagai macam sumber dengan gaya bahasa yang beraneka ragam disarankan untuk menggunakan Stanford NER. Adapun hasil rata-rata precision, recall, dan F1 untuk tweet dari Sby Traffic Services, RTMC Ditlantas Jatim dan Radio Suara Surabaya nemggunakan rule based dan Stanford NER secara berurutan adalah 94,5% , 95,10% , 94,8% dan 99,43% , 98,89% , 99,16%.
Referensi
[1] Wicaksono, A. F., & Purwarianti, A. (2010). HMM Based Part-of-Speech Tagger for Bahasa
SENTRA I - 239 [2] Pisceldo, F., Manurung, R., & Adriani, M. (2009). Probabilistic Part-of-Speech Tagging for
Bahasa Indonesia. In The Third International MALINDO Workshop, Colocated Event ACL-IJCNLP.
[3] Endarnoto, S. K., Pradipta, S., Nugroho, A. S., & Purnama, J. (2011, July). Traffic Condition Information Extraction & Visualization from Social Media Twitter for Android Mobile Application. In Electrical Engineering and Informatics (ICEEI), 2011 International Conference on (pp. 1-4). IEEE.
[4] LI, Y., GUAN, Y., DONG, X., & LV, X. (2013). Language Modeling for Microblog Retrieval: Combine Multiple-bernoulli Model and Temporal Prior for Tweets Rank. Journal of Computational Information Systems, 9(6), 2339-2346.
[5] Ishino, A., Odawara, S., Nanba, H., & Takezawa, T. (2012, October). Extracting Transportation Information and Traffic Problems from Tweets during a Disaster. In IMMM 2012, The Second International Conference on Advances in Information Mining and Management (pp. 91-96). [6] Verma, S., Vieweg, S., Corvey, W. J., Palen, L., Martin, J. H., Palmer, M., ... & Anderson, K. M.
(2011, May). Natural Language Processing to the Rescue? Extracting" Situational Awareness" Tweets During Mass Emergency. InICWSM.
[7] Cha, M., Haddadi, H., Benevenuto, F., & Gummadi, P. K. (2010). Measuring User Influence in Twitter: The Million Follower Fallacy. ICWSM, 10, 10-17.
[8] Sriram, B., Fuhry, D., Demir, E., Ferhatosmanoglu, H., & Demirbas, M. (2010, July). Short text classification in twitter to improve information filtering. InProceedings of the 33rd international ACM SIGIR conference on Research and development in information retrieval (pp. 841-842). ACM.
[9] Hannon, J., Bennett, M., & Smyth, B. (2010, September). Recommending twitter users to follow using content and collaborative filtering approaches. InProceedings of the fourth ACM conference on Recommender systems (pp. 199-206). ACM.
[10] Mislove, A., Lehmann, S., Ahn, Y. Y., Onnela, J. P., & Rosenquist, J. N. (2011, July). Understanding the Demographics of Twitter Users. In ICWSM.
[11] Derczynski, L., Ritter, A., Clark, S., & Bontcheva, K. (2013). Twitter Part-of-Speech Tagging for
All: Overcoming Sparse and Noisy Data. Proceedings of Recent Advances in Natural Language Processing (RANLP). Association for Computational Linguistics.
[12] Finkel, J. R., Grenager, T., & Manning, C. (2005, June). Incorporating non-local information into information extraction systems by gibbs sampling. InProceedings of the 43rd Annual Meeting on Association for Computational Linguistics (pp. 363-370). Association for Computational Linguistics.