BAB II. LANDASAN TEORI
2.1. Retrieval Citra Berbasis Konten
Dalam berbagai aplikasi computer vision yang banyak digunakan adalah proses meretrif citra yang diinginkan dari koleksi citra yang besar berdasarkan fitur yang dapat secara otomatis diekstrak dari citra tersebut. Sistem ini disebut RCBK (Retrieval Citra Berbasis Konten). RCBK telah menjadi perhatian banyak orang dalam retrieval citra sehingga berbagai teknik pun diusulkan untuk mendapatkan hasil yang lebih baik. Algoritma yang digunakan dalam RCBK dapat dibagi menjadi 2 bagian, yaitu : ekstraksi dan pengenalan.
Ekstraksi mengubah konten citra ke berbagai fitur konten. Ekstraksi fitur adalah proses menghasilkan fitur yang akan digunakan dalam seleksi dan pengenalan. Seleksi fitur mengurangi jumlah fitur yang ada untuk pengenalan fitur. Fitur- fitur yang merupakan diskriminator dipilih dan digunakan dalam proses pengenalan. Fitur yang tidak dipakai dibuang.
Dari dua bagian tersebut, ekstraksi fitur merupakan bagian yang paling penting karena fitur diskriminasi yang ada mempengaruhi efektivitas proses pengenalan. Hasil akhir dari proses ekstraksi adalah sejumlah fitur yang biasa disebut fitur vektor yang merepresentasikan sebuah citra.
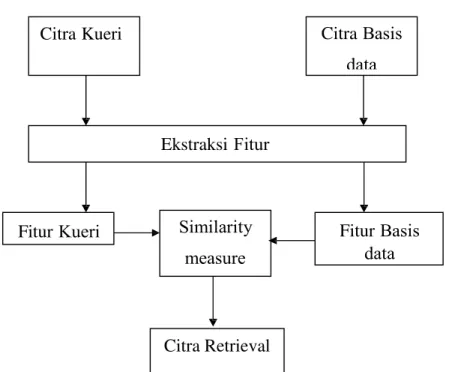
Citra Kueri Citra
Ekstraksi
Fitur Fitur
Citra Retrieval
Gambar 2. 1 Diagram Proses RCBK.
Umumnya sistem RCBK terdiri dari tiga modul utama seperti modul basis data, modul kueri dan modul retrieval. Pada modul basis data, fitur vektor (warna, tekstur, bentuk) diekstrak dari citra basis data. Fitur vektor tersebut kemudian disimpan dengan citra aslinya. Di lain pihak, ketika citra query memasuki modul kueri, fitur vektor dari citra kueri diekstrak. Pada modul retrieval, fitur vektor kueri yang telah diekstrak akan dibandingkan dengan fitur vektor yang disimpan pada citra basis data. Hasil dari kueri, citra yang mirip diretrif berdasarkan nilai kemiripan tertinggi, sehingga citra yang diharapkan dapat diambil dari citra yang telah diretrif, seperti ditunjukkan pada gambar 2.1.
2.1.1.
Retrieval Citra Medis
Retrieval citra berbasis konten yang telah dipelajari untuk aplikasi non medis bisa digunakan pada domain medis. Citra medis mengandung fitur yangkaya, bervariasi dan halus yang merupakan fitur yang penting secara klinis. Hal inilah yang membedakan retrieval pada domain medis dengan retrieval pada domain multimedia (Akgul, Rubin, Beaulieu, Greenspan, & Acar, 2011).
Kueri berdasarkan deskriptor citra konten dapat membantu dalam proses diagnosis. Fitur visual dapat digunakan untuk mencari citra yang diinginkan dan meretrif informasi yang relevan untuk kasus klinis. Salah satu contohnya adalah retrieval citra berbasis konten yang mendukung citra medis otak.
2.2.
Ekstraksi Fitur
Fitur didefinisikan sebagai fungsi dari satu atau lebih pengukuran yang masing-masing menentukan sifat kuantitatif dari suatu objek dan dihitung sedemikian rupa sehingga mengkuantifikasikan beberapa karakteristik objek yang signifikan.
Berbagai fitur diklasifikasikan sebagai berikut :
- Fitur umum : Fitur aplikasi independen seperti warna, tekstur, dan bentuk. Menurut tingkat abstraksi, fitur ini dapat dibagi lagi menjadi :
o Fitur piksel : Fitur dihitung pada setiap piksel, misalnya warna, lokasi. o Fitur lokal : Fitur dihitung dari hasil bagian citra dari segmentasi citra
o Fitur global : Fitur dihitung dari seluruh citra atau bagian dari suatu citra. - Fitur Domain-Specific : Fitur aplikasi dependen seperti wajah manusia, sidik
jari dan fitur konseptual. Fitur-fitur ini merupakan sintesis fitur tingkat rendah (low-level) untuk domain tertentu.
Di sisi lain, semua fitur dapat diklasifikasikan menjadi fitur tingkat rendah dan fitur tingkat tinggi (high-level). Fitur tingkat rendah dapat diekstrak langsung dari citra asli, sedangkan ekstraksi fitur tingkat tinggi berdasarkan fitur tingkat rendah.
2.2.1. Warna
Fitur warna adalah salah satu fitur visual yang paling banyak digunakan dalam retrieval citra (Sumana, 2008). Kita menggunakan warna setiap hari untuk mengatakan perbedaan antara objek, tempat, dan waktu. Biasanya warna didefinisikan dalam ruang warna tiga dimensi. Hal tersebut bisa berupa RGB (Red, Green, & Blue) seperti yang terihat pada gambar 2.2, HSV (Hue, Saturation, &
Value) seperti yang terlihat pada gambar 2.3 atau HSB (Hue, Saturation, &
Brightness).
Gambar 2. 3 Ruang Warna HSV (Candan & Sapino, 2010)
Citra yang dicirikan oleh fitur warna memiliki banyak keuntungan antara lain : a. Ketahanan. Histogram warna invarian terhadap rotasi gambar pada sumbu
axis dan perubahan yang kecil ketika di rotasi atau diskalakan. Biasanya juga tidak sensitif terhadap perubahan dalam resolusi gambar, histogram dan oklusi.
b. Efektivitas. Ada relevansi yang tinggi antara citra kueri dengan citra ekstrak yang sesuai.
c. Kesederhanaan implementasi. Pembentukan histogram warna merupakan proses langsung, termasuk pemindaian citra, menempatkan nilai warna pada resolusi histogram dan membentuk histogram menggunakan komponen warna sebagai index.
d. Kesederhanaan komputasi. Perhitungan histogram mempunyai kompleksitas O(X, Y ) untuk citra dengan ukuran X × Y . Kompleksitas untuk kesesuaian citra tunggal adalah linear, O(n), dimana n adalah jumlah warna yang berbeda atau resolusi histogram.
e. Kebutuhan kapasitas yang rendah. Ukuran histogram warna secara signifikan lebih kecil dari pada citra itu sendiri.
2.2.2.
Tekstur
Tekstur adalah properti bawaan dari semua permukaan yang mendeskripsikan pola visual, masing-masing memiliki properti kehomogenan. Tekstur mengandung informasi penting mengenai susunan struktur dari permukaan, seperti awan, daun, batu bata, kain, dan lain-lain. Tekstur sendiri tidak mempunyai kemampuan untuk mencari citra yang mirip, tapi tekstur dapat digunakan untuk mengklasifikasikan citra bertekstur dari citra yang tidak bertekstur, kemudian dikombinasikan dengan atribut visual lain seperti warna untuk melakukan retrieval secara lebih efektif.
Ada dua jenis pendekatan ekstraksi fitur tekstur, antara lain pada domain spasial dan domain spektral. Klasifikasi metode ekstraksi fitur tekstur ditunjukkan pada gambar 2.4.
Gambar 2. 4 Klasifikasi Metode Ekstraksi Fitur Tekstur (Sumana, 2008) Pendekatan domain spasial peka terhadap noise sehingga perubahan kecil
pada citra yang disebabkan oleh noise dapat mempengaruhi keseluruhan proses ekstraksi fitur. Ketika citra yang sama dengan dan tanpa noise dibandingkan, nilai dari fitur tekstur berbeda, sehingga walaupun citranya mirip dan ada noise, citra tersebut mungkin tidak akan diretrif dalam CBIR yang menggunakan fitur spasial.
Gambar 2. 5 Citra Gaussian Noise (mean = 0, varian = 0,01) pada citra sebelah kiri (Sumana, 2008).
Pada gambar 2.5, citra sebelah kanan dibuat dengan menambahkan Gaussian noise pada citra sebelah kiri. Mean dan standar deviasi kemudian dikalkulasi dari koefisien domain spasialnya. Citra sebelah kirim mempunyai mean 198.26 dan standar deviasi 52.84. Akan tetapi, citra sebelah kanan mempunyai mean 196,88 dan standar deviasi 56,97. Jika retrieval dilakukan dengan menggunakan tekstur spasial, kedua citra tersebut akan diperlakukan sebagai citra yang berbeda karena fitur masing-masing mempunyai perbedaan yang besar.
Fitur tekstur Tamura merupakan jenis fitur pada domain spasial. Fitur tekstur Tamura terdiri dari 6 komponen, antara lain: kekasaran (coarseness), kontras (contrast), direksional (directionality), kesesuaian (likeliness), keteraturan (regularity) dan kekesatan (roughness). Di antara semua komponen tersebut, kekasaran, kontras dan direksional dianggap lebih penting. Deskriptor
fitur Tamura tidak efektif jika digunakan untuk merepresentasikan citra yang cacat karena fitur ini sensitif terhadap skala dan orientasi (Sumana, 2008).
Di sisi lain, metode pada domain spektral seperti wavelet multi resolusi, filter Gabor, Transformasi Kosinus Diskrit dan model multiresolution simultaneous autoregressive memiliki keuntungan yaitu tidak sensitif terhadap noise. Oleh karena itu, transformasi ini banyak digunakan untuk merepresentasikan tekstur citra. Karena keuntungan dari fitur tekstur domain spektral atas metode spasial, domain spektral telah banyak digunakan dalam CBIR.
2.2.3.
Bentuk
Retrieval citra berdasarkan bentuk berbasis pada pengukuran kemiripan antara bentuk yang diwakili dengan fiturnya. Bentuk adalah fitur visual yang penting dan merupakan salah satu fitur sederhana untuk deskripsi konten citra. Deskripsi konten citra sulit diterapkan karena pengukuran kemiripan antar bentuk sulit dilakukan. Oleh karena itu, ada dua langkah penting dalam CBIR berdasarkan bentuk, antara lain : ekstraksi fitur dan pengukuran kemiripan antar fitur yang diekstrak. Deskriptor bentuk dapat dibagi menjadi dua kategori utama, yaitu berbasis wilayah dan berbasis kontur. Metode berbasis wilayah menggunakan seluruh wilayah dari sebuah objek sebagai deskripsi bentuk, sedangkan metode berbasis kontur hanya menggunakan informasi yang ada di kontur sebuah objek.
Representasi bentuk berbasis wilayah menggunakan seluruh wilayah dari bentuk seperti yang terlihat pada gambar 2.6.
Gambar 2. 6 Berbasis Batas & Berbasis Wilayah ( (Kondekar, Kolkure, & Kore, 2010)
Penjelasan singkat deskriptor bentuk sebagai berikut :
- Fitur dikalkulasi dari kontur objek : circularity, aspect ratio, discontinuity angle irregularity, length irregularity, complexity, right-angleness, sharpness, directedness. Those are translation, rotation (kecuali sudut), dan scale
invariant shape descriptors. Hal ini memungkinkan untuk mengekstrak kontur
citra dari tepi yang terdeteksi. Dari objek kontur, informasi tentang bentuk berasal.
- Deskriptor berbasis wilayah menggunakan satu set momen Zernike yang dihitung pada pusat citra.
2.3.
Non-Negative Matrix Factorization
Non-Negative Matrix Factorization (NNMF) adalah teknik reduksi dimensi
linear yang memiliki batasan non-negatif. Batasan ini menghasilkan suatu representasi berbasis-bagian karena batasan ini hanya memperbolehkan penambahan, bukan pengurangan ataupun kombinasi keduanya (Okun, 2004)
kolomnya adalah sebuah vektor non-negatif dimensi n dari basis data aslinya (vektor m). Permasalahan umum NNMF adalah mencari dua matriks baru W dan H hasil reduksi untuk memperkirakan matriks A dari produk WH. Setiap kolom dari W berisi vektor dasar sementara setiap kolom H berisi bobot yang diperlukan memperkirakan kolom A yang sesuai menggunakan vektor dasar dari W.
𝐴 ≈ 𝑟 . 𝑟 ... (2.1)
Dimensi matriks W dan H adalah n x r dan r x m. Biasanya, jumlah kolom matriks baru W dipilih sehingga r << m. Pemilihan nilai r umumnya tergantung aplikasi, bisa juga tergantung karakteriktik basis data tertentu dalam aplikasi.
NNMF menggunakan suatu prosedur iteratif untuk memodifikasi nilai awal dari 𝑟 dan 𝑟 supaya hasilnya WH mendekati A. Prosedur tersebut berhenti ketika pendekatan error konvergen atau jumlah iterasi yang ditentukan tercapai. Dekomposisi NNMF tidak unik, matriks W dan H bergantung pada penggunaan algoritma NNMF dan perhitungan error digunakan untuk memeriksa konvergensi.
Pendekatan untuk permasalahan NNMF adalah memperkirakan matriks A dengan menghitung matriks W dan H untuk memperkecil perbedaan Frobenius
norm A – WH. Secara matematis, dapat dirumuskan sebagai berikut :
∈ 𝑅 adalah suatu matriks input non-negatif.
∈ 𝑅 dan ∈ 𝑅 dengan bilangan integer r < m. Tujuannya adalah untuk memecahkan masalah optimasi.
||𝐴 ≈ ||
.𝐻 dengan ≥ dan ≥ untuk setiap i dan j.
(MU), alternating lease squares (ALS), dan gradien descent GC) (Berry & Kogan, 2010). Algoritma umum NNMF ditunjukkan dalam pseudocode sebagai berikut :
Diberikan matriks A E Rmxn dengan k << min {m,n} for rep = 1 to maxrepetition do
W = rand(m,k); H = rand(k,n);
for i = 1 to maxiter do
Lakukan langkah NNMF update Cek kriteria terminasi
end for end for
Kebanyakan algoritma memerlukan faktor inisialisasi W dan H, tetapi beberapa algoritma (seperti alternating lease squares (ALS)) hanya memerlukan 1 faktor inisialisasi.
Langkah update untuk algoritma Multiplicative update adalah berdasarkan fungsi objektif mean squared error. Kemudian menambahkan nilai 𝜎 untuk menghindari pembagian oleh nol. Nilai yang biasa digunakan untuk 𝜎 adalah 10-9. Berikut adalah langkah Multiplicative update dapat dilakukan dengan cara :
a. 𝑐 ← 𝑐 𝑇 𝑐 𝑇 𝐻 𝑐 + ... (2.2) b. 𝑐 ← 𝑐 𝐻𝐻𝐻𝑇𝑇 𝑐 𝑐 + ... (2.3)
kemudian dihitung pada iterasi pertama. Setiap elemen non negatif yang dihasilkan dari komputasi least squared diset menjadi 0 untuk memastikan non- negatifitas. Berikut adalah langkah update untuk alternating lease squares (ALS).
- Untuk H.
WTWH = WTA;... (2.4) Set semua elemen negatif pada H menjadi 0.
- Untuk W.
HHTWT = HAT; ... (2.5) Set semua elemen negatif pada W menjadi 0.
Kedua algoritma MU dan ALS adalah iteratif dan bergantung pada inisialisasi dari W dan H. Karena iterasi biasanya konvergen ke local minimum, beberapa algoritma berjalan dengan menggunakan inisialisasi acak yang berbeda untuk mendapatkan solusi yang terbaik.
Kompleksitas perhitungan Algoritma MM adalah O(rnm) tiap iterasi (Pauca, Shahnaz, Berry, & Plemmons, 2004). Jika data ditambahkan ke basis data, data tersebut dapat ditambahkan secara langsung pada matriks dasar W dengan sedikit modifikasi pada matriks H, atau jika r diubah, maka iterasi selanjutnya dapat diterapkan mulai dari W dan H saat itu sebagai perkiraan awal. Keuntungan dari NNMF adalah :
1. Sparsity dan nonnegativity. Faktorisasi mengatur properti ini pada matriks asli.
3. Interpretabilitas. Basis vektor biasanya sesuai dengan properti konseptual data. Kekurangan dari NNMF adalah masalah konvergen. Tidak seperti SVD dan faktorisasinya yang unik, NNMF tidak mempunyai faktorisasi yang unik, karena algoritma NNMF yang berbeda dapat konvergen ke local minimal yang berbeda sehingga inisialisasi awal menjadi kritikal.
2.4.
Canny Edge Detection
Analisis citra bertujuan untuk mengindentifikasi parameter-parameter yang diasosiasikan dengang cirri (feature) dari objek didalam citra, Untuk selanjutnya parameter tersebut digunakan dalam menginterprestasi citra. Analisis citra pada dasarnya terdiri dari tiga tahapan, yaitu ekstraksi ciri (feature extraction), segmentasi dan klasifikasi.
Pendeteksian tepi merupakan langkah pertama untuk melengkapi informasi di dalam citra. Tepi mencirikan batas-batas objek dan karena itu tepi berguna untuk proses segmentasi dan idetifikasi objek didalam citra.
Tujuan operasi pendeteksian tepi adalah untuk meningkatkan penampakan garis batas suatu daerah atau objek didalam citra. Salah satu teknik atau metode dalam pendeteksian tepi adalah metode canny. Pemilihan metode canny ini adalah karena metode ini memiliki beberapa kelebihan dalam mengekstrak tepian dengan kebebasan pemilihan parameter yang digunakan.
Canny edge detector ditemukan oleh Maar dan Hilderth yang meneliti pemodelan persepsi visual manusia. Dalam memodelkan pendeteksian tepi, dia
menggunakan ideal step edge, yang direpresentasikan dengan fungsi sign satu dimensi. Pendekatan algoritma canny dilakukan dengan konvolusi fungsi image dengan operator Gaussian dan turunan-turunannya.
Fungsi Gausian dalam satu dimensi dapat direpresentasikan sebagai berikut : 𝑥 = √ 𝜋 𝜎 𝑒−𝑥 𝜋 ... (2.6) Turunan pertama : ′ 𝑥 = √ 𝜋 𝜎− 𝑒−𝑥 𝜋 ... (2.7) Turunan kedua : ′ 𝑥 = − √ 𝜋 𝜎 𝑒 −𝑥 𝜋 [− 𝜎 ] ... (2.8)
Turunan pertama dari fungsi citra yang dikonvolusikan dengan fungsi Gaussian, yaitu :
G(x,y) = D [Gauss (x,y) * f(x,y)] ... (2.9) Ekivalen dengan fungsi citra yang dikonvolusikan dengan turunan dari fungsi Gaussian:
G(x,y) = D [Gauss{x,y)*f(x,y)] ... (2.10) Oleh karena itu, memungkinkan untuk mengkombinasikan tingkat kehalusan dan pendeteksian tepian ke dalam suatu konvolusi dalam satu dimensi dengan dua arah yang berbeda (vertical dan horizontal). Hal ini berlaku dalam mengkonvolusikan turunan pertama Gaussian untuk pencarian puncak, atau dengan turunan kedua Gaussian untuk mencari zero-crossing nya.
Ada beberapa criteria pendeteksi tepian paling optimum yang dapat dipenuhi oleh metode Canny, yaitu :
1. Mendeteksi dengan baik (criteria deteksi)
Kemampuan untuk meletakkan dan menandai semua tepi yang ada sesuai dengan pemilihan parameter-parameter konvolusi yang dilakukan. Sekaligus juga memberikan fleksibilitas yang sangat tinggi dalam hal menentukan tingkat deteksi ketebalan tepi sesuai yang diinginkan.
2. Melokalisasi dengan baik (Kriteria lokalisasi)
Dengan canny dumungkinkan dihasilkannya jarak yang minimum antara tepi yang dideteksi dengan tepi yang asli.
3. Respon yang jelas (criteria respon)
Hanya ada satu respon untuk tiap tepi . Sehingga mudah dideteksi dan tidak menimbulkan kerancuan pada pengolahan citra selanjutnya.
Dengan rumusan John F. Canny tentang kriteria ini, maka Canny edge detector optimal untuk Kelas tepian tertentu (dikenal sebagai step edge). Algoritma Canny berjalan dalam 5 langkah yang terpisah yaitu:
1. Smoothing : Mengaburkan gambar untuk menghilangkan noise
2. Finding gradien : Tepian harus ditandai pada gambar memiliki gradien yang besar.
3. Non-maksimum-suppresion : Hanya maxima lokal yang harus ditandai sebagai edge.
5. Edge Tracking by hysteresis : Tepian final ditentukan dengan menekan semua sisi yang tidak terhubung dengan tepian yang sangat kuat.
Tidak dapat dipungkiri bahwa semua gambar yang diambil dari kamera akan berisi sejumlah noise. Untuk mencegah noise salah dideteksi sebagai tepian, maka noise harus dikurangi. Oleh karena itu pada langkah pertema gambar harus diperhalus dengan mengggunakan Gaussian filter. Inti dari Gaussian filter adalah standar deviasi dengan σ = 1.4.
Algoritma Canny pada dasarnya menemukan titik tepi pada gambar grayscale dengan perubahan nilai intensitas yang paling besar, daerah ini ditemukan dengan menentukan gradien gambar. Gradien pada setiap piksel gambar yang telah diperhalus ditentukan dengan menerapkan operator Sobel. Langkah Kedua adalah memperkirakan gradien pada arah x dan y. Hal tersebut ditunjukkan dalam Persamaan (2).
𝐾𝑐 = [−
− ] ... (2.11) 𝐾𝑐 = [ ] ... (2.12)
Magnitudo gradien (juga dikenal sebagai kekuatan tepi) dapat ditentukan sebagai jarak Euclidean yang diukur mengukur dengan menerapkan hukum Pythagoras seperti yang ditunjukkan dalam Persamaan (3). Yang terkadang disederhanakan dengan menerapkan ukuran jarak Manhattan seperti yang ditunjukkan
dalam Persamaan (4) untuk mengurangi kompleksitas komputasi. | | = √ + | | = | | + | | ... (2.13)
dimana:
Gx dan Gy adalah gradien pada masing-masing arah x dan y.
Gambar dengan gradien yang besar sering menunjukkan tepian yang cukup jelas. Namun, tepian biasanya luas dan dengan demikian tidak dapat menunjukkan persis di mana tepian yang sebenarnya. Untuk menentukan tepian yang sebenarnya ini, arah tepian harus ditentukan dan disimpan seperti ditunjukkan dalam Persamaan (5)
𝜃 = 𝑎𝑟𝑐 tan || | | ... (2.14)
Pada langkah ketiga bertujuan untuk mengkorversikan tepian yang masih blurred pada gambar hasil magnitude gradien hingga menghasilkan tepian yang tajam. Pada dasarnya hal ini dilakukan dengan mempertahankan semua maxima lokal dalam gambar gradien dan menghapus segala sesuatu yang lain.
Algoritma adalah untuk setiap piksel pada gambar gradien adalah sebagai berikut: 1. Putar arah gradien θ ke arah 45ْ terdekat, kemudian hubungkan dengan 8 titik
tetangga yang terhubung dengannya.
2. Bandingkan nilai piksel tepian saat ini dengan nilai piksel tepian dalam arah positif dan negative gradien. Jika arah gradien adalah utara (θ =90 ◦), bandingkan dengan piksel ke utara dan selatan.
3. Jika nilai piksel tepian saat ini adalah yang terbesar, maka simpan nilai tepian tersebut, namun jika bukan, hapus nilai tersebut.
Piksel tepian yang tersisa setelah dilakukan penghapusan non maksimum ditandai dengan nilai piksel per piksel yang kuat. Kebanyakan dari titik ini adalah
tapian yang nyata pada gambar, akan tetapi beberapa kemungkinan disebabkan oleh noise atau variasi wana karena permukaan yang kasar. Cara paling sederhana untuk membedakannya adalaha menggunakan nilai threshold (ambang batas) sehingga hanya tepian dengan nilai yang kuar yang akan dipertahankan. Disini pada algoritma Canny menggunakan sistem thresholding ganda dimana tepian dengan nilai yang lebih besar dari threshold atas ditandai sebagai titik kuat, tepian dengan nilai yang lebih kecil dari threshold bawah akan dihapus, dan tepian dengan nilai piksel antara threshold atas dengan threshold bawah akan ditandai sebagai tepian yang lemah.
Tepian yang kuat diintepretasikan sebagai " tepian yang pasti " dan dapat segera dimasukkan sebagai tepian pada gambar akhir. Tepi lemak termasuk jika dan hanya jika mereka terhubung ke tepi yang kuat, dengan logika bahwa noise dan variasi warna tidak mungkin untuk menghasilkan tepi yang kuat (dengan penyesuaian yang tepat dari thresholding). Dengan demikian tepian yang kuatlah yang akan menghasilkan tepian yang asli pada gambar. Tepian yang lemah dapat terjadi karena memang merupakan tepian yang nyata atau noise / variasi warna.
2.5.
Penyakit Otak
1. Penyakit Alzheimer
Penyakit Alzheimer merupakan penyebab tersering timbulnya dementia dan menyebabkan gangguan kognitif pada populasi usia lanjut (Jayadev, et al., 2008). Alzheimer juga dikatakan sebagai penyakit yang sinonim dengan orang tua sebab mempengaruhi 1 dari 10 individu yang berada dalam usia 60 tahun, dan hampir
setengah jumlah tersebut terkena penyakit ini dengan usia hidup mencapai 85 tahun (Cowley, 2000)
Penyakit Alzheimer pertama kali diinvestigasi oleh Alois Alzheimer seorang Psikiatri dan Neuropatolog pada awal abad ke 20 (Bannati & Beyreuther, 1995). Penyakit Alzheimer adalah suatu kondisi di mana sel-sel saraf di otak mati, sehingga sinyal-sinyal otak sulit ditransmisikan dengan baik. Gejala umum penyakit Alzheimer meliputi hal-hal seperti gangguan memori dan berpikir, kebingungan, berpikir abstrak, perubahan kepribadian dan perilaku, masalah dengan bahasa dan komunikasi, memburuknya kemampuan visual dan spasial, kehilangan motivasi atau inisiatif dalam menjalani kehidupan, kehilangan pola tidur normal yang seperti biasanya penyebab utama penyakit Alzheimer terdiri atas beberapa hal baik itu pengaruh lingkungan maupun imunologis dan trauma (Japardi, 2000). Perbedaan antara otak normal dan otak yang mengidap penyakit Alzheimer dapat dilihat pada gambar 2.7.
Gambar 2. 7 Perbandingan Otak Normal Dan Otak Alzheimer (http://www.alz.org/braintour/healthy_vs_alzheimers.asp)
2. Penyakit Glioma
Glioma merupakan salah satu penyakit yang paling ditakuti, karena menyerang otak sebagai organ sentral yang sangat penting bagi kelangsungan hidup manusia. Angka harapan hidup penderita glioma dipengaruhi beberapa faktor yaitu
usia, stadium dan jenis histopatologisnya, Karnofsky Performance Status, luas pembedahaan, ada tidaknya defisit neurologis, dan modalitas terapinya (Bomford, Kunkler, & Muiller, 2003).
Glioma merupakan tumor otak yang paling banyak dijumpai, sekitar 50% dari tumor otak primer dibanding tumor otak primer lainnya, seperti meningioma (15%), adenoma (8%), neurinoma (7%) dan sisanya tumor sekunder atau tumor metastasis sebesar 20%. Letak tumor pada orang dewasa 60% terletak pada supratentorial dan berasal dari korteks dan hemisfer otak dan pada anak-anak 70% terletak pada infratentorial yang berasal dari serebelum, batang otak dan mesensefalon. Insiden pada pria lebih banyak dibanding dengan wanita dengan perbandingan 55:45 (Harsono, 2000). Gambar otak yang mengidap glioma dapat dilihat pada gambar 2.8.
Gambar 2. 8 MRI Otak Mengidap Glioma (Meiyan, Mei , Zhental, Qianjin, & Wufan, 2012)