Bab 2
Tinjauan Pustaka
2.1
Penelitian Terdahulu
Pada penelitian data warehouse terdahulu dengan judul Perancangan dan Pembangunan OLAP pada Data Warehose Menggunakan Pendekatan Multidimensional (Studi Kasus Tingkat Kelulusan di Salatiga), data warehouse digunakan untuk membantu penyediaan data yang dibutuhkan dalam pengukuran kinerja proses belajar mengajar. Informasi yang dihasilkan pada data warehouse adalah perbandingan hasil lulus dan tidak lulus, tingkat kelulusan mata pelajaran dan summary dari nilai tiap pelajaran. Proses multidimensional query dilakukan dengan menggunakan pivoting table dan chart. Pengguna dapat memanipulasi data yang tampil pada setiap sumbunya seperti yang dapat dilakukan pada pivot table (Pinem, 2009).
penelitian ini data yang digunakan adalah data hasil panen padi dan palawija. Yang membedakan penelitian ini dengan penelitian diatas adalah jenis data yang digunakan dan terdapat menu tambahan yaitu menu input data yang hanya bisa dilakukan oleh admin selain itu juga terdapat menu proyeksi penduduk.
2.2
Landasan Teori2.2.1 Definisi Demografi
Pengertian Demografi :
1. Ilmu yang mempelajari penduduk suatu wilayah dari segi jumlah, struktur (komposisi) dan perkembangannya (perubahannya), Multilingual Demographic Dictionary (IUSSP, 1982).
2. Ilmu yg mempelajari jumlah, persebaran, teritorial, komposisi penduduk, dan perubahan serta sebab-sebabnya yg biasa timbul karena natalitas, mortalitas, migrasi, dan mobilitas sosial. (Hauser dan Duncan, 1959).
3. Studi matematik dan statistik terhadap jumlah, komposisi, distribusi spasial dari penduduk manusia, dan perubahan-perubahan dari aspek tersebut selalu terjadi akibat proses fertilitas, mortalitas, perkawinan, migrasi dan mobilitas sosial. (Bogue, 1969).
2.2.2 Proyeksi Penduduk
demikian, kedua istilah ini sebenarnya memiliki perbedaan yang sangat mendasar. Berbagai literature menyatakan proyeksi penduduk sebagai prediksi (ramalan) yang didasarkan pada asumsi rational tertentu yang dibangun untuk kecenderungan masa yang akan datang dengan menggunakan peralatan statistik atau perhitungan matematik. Disisi lain peramalan (forecast) penduduk bisa saja dengan atau tanpa asumsi dan atau kalkulasi. Tanpa kondisi/syarat tertentu atau pendekatan tertentu. (Smith, 2001)
Dari berbagai literature, terdapat banyak metode dalam proyeksi penduduk. Masing-masingnya memiliki asumsi sendiri, kekuatan dan kelemahan. Model-model yang umum yang biasanya digunakan untuk proyeksi penduduk diantaranya adalah: 1. Model ekstrapolasi trend, yang diantaranya terdiri dari:
o Model Linear (Aritmethic) o Model Geometric
o Model Parabolic 2. Model Komponen Kohor 3. Model Ratio
o Model “Constant Share” o Model “Shift Share” o Model “Share of Growth” 2.2.2.1 Model Ektrapolasi Trend
Model ekstrapolasi trend secara sederhana menggunakan
penduduk masa yang akan datang. Metode ini adalah metode
yang digunakan dalam rangka proyeksi penduduk. Selain itu,
metode ini juga digunakan untuk menghitung tingkat dan ratio
pada masa yang akan datang berdasarkan tingkat dan ratio pada
masa yang lalu.
Model ekstrapolasi trend yang banyak digunakan adalah
model linear, geometric dan parabolic. Asumsi dasar dari model
ini adalah pertumbuhan atau penurunan akan berlanjut tanpa
batas. Namun demikian, asumsi tersebut tidak mungkin
diberlakukan jika proyeksi yang disusun adalah proyeksi jangka
panjang. Misalnya jika populasi di suatu daerah berkurang, dalam
jangka panjang model ini akan memproyeksikan penduduk
menjadi nol, dan bahkan menjadi negatif. Demikian juga, jika
jumlah penduduk di suatu daerah yang meningkat, tidak mungkin
akan meningkat pada jumlah yang tanpa batas. Dalam
kenyataannya, penduduk hanya akan meningkat sampai suatu
tingkat dengan kapasitas yang maksimum dan kemudian akan
kembali turun atau stabil dalam kaitannya dengan kepadatan
penduduk, biaya hidup dan kualitas hidup. Oleh karenanya,
penggunaan model ekstrapolasi trend membutuhkan pemahaman
yang baik tentang kecenderungan pertumbuhan masa lalu untuk
membuat estimasi dengan batasan yang masuk akal (reasonable).
a. Model Linear (Aritmethic)
Model linear adalah teknik proyeksi yang paling
persamaan derajat pertama (first degree equation). Berdasarkan
hal tersebut, penduduk diproyeksikan sebagai fungsi dari waktu,
dengan persamaan (Klosterman, 1990):
Pt=α + βT
Dimana :
Pt = penduduk pada tahun proyeksi t
α = intercept = penduduk pada tahun dasar
β = koefisien = rata-rata pertambahan penduduk
T = periode waktu proyeksi = selisih tahun proyeksi dengan
tahun dasar
Hasil proyeksi akan berbentuk suatu garis lurus. Model ini
berasumsi bahwa penduduk akan bertambah/berkurang sebesar
jumlah absolute yang sama/tetap (β) pada masa yang akan datang
sesuai dengan kecenderungan yang terjadi pada masa lalu. Ini
berarti bahwa, jika Pt+1 dan Pt adalah jumlah populasi dalam
tahun yang berurutan, Pt+1 – Pt yang adalah perbedaan pertama
yang selalu tetap (konstan). Mengacu pada (Pittengar, 1976),
mengemukakan bahwa model ini hanya digunakan jika data yang
tersedia relatif terbatas, sehingga tidak memungkinkan untuk
menggunakan model lain. Model ini hanya dapat diaplikasikan
untuk wilayah kecil dengan pertumbuhan yang lambat, dan tidak
tepat untuk proyeksi pada wilayah-wilayah yang lebih luas
b. Model Geometric.
Asumsi dalam model ini adalah penduduk akan
bertambah/berkurang pada suatu tingkat pertumbuhan
(persentase) yang tetap. Misalnya, jika Pt+1 dan Pt adalah jumlah
penduduk dalam tahun yang berurutan, maka penduduk akan
bertambah atau berkurang pada tingkat pertumbuhan yang tetap
(yaitu sebesar Pt+1/Pt ) dari waktu ke waktu. Proyeksi dengan
tingkat pertumbuhan yang tetap ini umumnya dapat diterapkan
pada wilayah, dimana pada tahun-tahun awal observasi
pertambahan absolut penduduknya sedikit dan menjadi semakin
banyak pada tahun-tahun akhir. Model geometric memiliki
persamaan umum (Klosterman, 1990):
Pn= Po(1+r)t (2.1)
Persamaan diatas dapat ditransformasi kedalam bentuk
linear melalui aplikasi logaritma, menjadi sebagai berikut:
Log ( 1+r) = log Pn – Log Po (2.2) t
Dimana :
Pn = jumlah penduduk pada akhir periode (orang ), Po = jumlah penduduk pada awal periode ( orang ), r = tingkat pertumbuhan penduduk (%),
c. Model Parabolic.
Model parabolic seperti model geometric berasumsi
bahwa penduduk suatu daerah tidak tumbuh dalam bentuk linear.
Namun demikian, tidak seperti model geometrik (yang berasumsi
tingkat pertumbuhan konstan dari waktu ke waktu), pada model
parabolic tingkat pertumbuhan penduduk dimungkinkan untuk
meningkat atau menurun. Model ini menggunakan persamaan
derajat kedua yang ditunjukkan sebagai berikut:
Pt=α + β1T + β2T2
Model parabolic memiliki dua koefisien yaitu β1dan β2.
β1 adalah koefisien linear (T) yang menunjukkan pertumbuhan
konstan, dan β2 adalah koefisien non-linear yang (T2) yang
menyebabkan perubahan tingkat pertumbuhan. Tanda positif atau
negatif pada β1dan β2 bervariasi tergantung pada apakah tingkat
pertumbuhan tersebut akan meningkat atau menurun.
Berdasarkan variasi pada tanda β1dan β2, model akan
menghasilkan empat skenario sebagai berikut:
Tabel 2.1 Skenario dalam Model Parabolik β1 β2 Efek terhadap pertumbuhan penduduk
+ +
Pertambahan yang semakin meningkat Penduduk bertambah
Kurva cekung ke atas (Concave upward) + - Pertambahan yang semakin berkurang
Kurva cekung ke bawah (concave downward)
- +
Pertambahan yang semakin berkurang Penduduk bertambah
Kurva cekung ke atas (Concave upward)
- -
Pertambahan yang semakin meningkat Penduduk berkurang
Kurva cekung ke bawah (concave downward)
Disarankan demographer untuk terlebih dahulu
mencermati (menguji coba) model ini ketika akan diaplikasikan
pada suatu daerah. Menurutnya, meskipun model ini baik untuk
daerah dengan pertumbuhan atau penurunan yang cepat, namun
demikian proyeksi jangka panjang akan menghasilkan angka
yang sangat besar atau sangat kecil (Klosterman, 1990).
2.2.3 Online Analytical Processing (OLAP)
Online Analytical Processing (OLAP) adalah salah satu tools yang digunakan untuk mengakses informasi dalam data warehouse. Teknologi OLAP memungkinkan data warehouse digunakan secara efektif untuk proses online analysis, serta memberikan respon yang cepat terhadap analytical query yang kompleks (Amo, 2000).
digunakan untuk menemukan hubungan antara suatu item yang belum ditemukan. Pada basis data OLAP tidak perlu memiliki ukuran besar seperti data warehouse, karena tidak semua transaksi membutuhkan analisis tren. Dengan menggunakan open database connectivity (ODS), data dapat diimpor dari basis data relasional menjadi suatu basis data multidimensi untuk OLAP.
OLAP adalah suatu teknologi yang menawarkan high performance akses pada data untuk dapat dianalisis secara multidimensional. OLAP dapat digunakan untuk melaksanakan perbandingan volume data yang besar. Berdasarkan struktur basis datanya OLAP dibedakan menjadi 3 kategori utama:
a. Relational Online Analytical Processing (ROLAP)
Secara umum OLAP dibangun diatas relational database sistem yang dikenal dengan relational OLAP (ROLAP). ROLAP menggunakan relational database (RDBMS) untuk menyimpan data dengan menggunakan star schema atau snowflake schema yang menghasilkan query analisis didalam SQL.
1. Skala data yang digunakan besar. 2. Menggunakan teknologi yang terbaru. 3. Lambat dalam menjalankan query. 4. Desain dan perawatan yang tinggi.
b. Multidimensional Online Analytical Processing (MOLAP) Multidimensional Online Analytical Processing (MOLAP) adalah OLAP yang secara langsung mengarah pada basis data multidimensi. MOLAP memproses data yang telah disimpan dalam array multidimensional dimana semua kombinasi data yang mungkin dicerminkan, masing-masing di dalam suatu sel yang dapat diakses secara langsung.
Database menyajikan model geometrik objek (point, line, polygon dll) di dalam ruang multidimensional. MOLAP dapat digunakan sebagai poin pada ruang multidimensional sebagai atribut dan manfaat dari teknik database. Walaupun berbeda dengan operasi pada database yang overlap (tumpang tindih), MOLAP bermanfaat untuk mengembangkan ruang lingkup yang ada pada database. (Guting, 1994)
MOLAP dibangun secara rinci untuk menangani multidimensional query secara cepat dan efisien pada multidimensional data yang didalamnya terdapat agregasi data.Karakteristik MOLAP meliputi :
1. Memiliki respon yang tinggi pada saat query dilakukan. 2. Multidimensional query.
4. Skala dan volume data rendah.
Pada tugas akhir ini sistem yang dibangun akan menggunakan MOLAP, karena pertimbangan karakteristik MOLAP yang bersifat multidimensional query.
c. Hybrid Online Analytical Processing (HOLAP)
Hybrid Online Analytical Processing (HOLAP) merupakan kombinasi antara ROLAP dengan MOLAP. HOLAP dikembangkan untuk mengkombinasikan antara kapasitas data pada ROLAP yang besar dengan kemampuan proses pada MOLAP. (Weinberger, 1999)
OLAP (On-Line Analytical Processing) adalah suatu pernyataan yang bertolak belakang atau kontras dengan OLTP (On-Line Transaction Processing). OLAP menggambarkan sebuah kelas teknologi yang dirancang untuk analisis dan akses data secara khusus. Apalabila pada proses transaksi pada umumnya semata-mata adalah pada relational database, OLAP muncul dengan sebuah cara pandang multidimensi data. Cara pandang multidimensi ini didukung oleh teknologi multidimensi database. Cara ini memberikan teknik dasar untuk kalkulasi dan analisis oleh sebuah aplikasi bisnis.
Sistem yang memungkinkan para manajer untuk memperoleh penjelasan tentang pencapaian perusahaan melalui suatu pandangan data yang bervariasi, luas, dan terorganisir untuk mencerminkan multidimensional data menyangkut data dari perusahaan (Codd, 1993).
OLAP memberikan pengertian yang mendalam tentang data dengan cepat, konsisten, akses variasi data yang luas pada informasi data yang dihasilkan. Kontras dengan database, OLAP menjawab pertanyaan seperti “jika?” dan “mengapa?” sebagai tambahan “untuk siapa?” dan “apa?”. OLAP digunakan untuk membangun sistem pengambilan keputusan yang membantu penjabaran data.(Goil, 1997)
2.2.4 Data Warehouse
Kebutuhan pemanfaatan Data Warehouse disejumlah organisasi didasarkan pada dua pertimbangan, pertama kebutuhan operasional, yang mendukung fungsional kegiatan transaksi bisnis setiap hari, optimasi dengan respon yang cepat pada proses transaksi dan representasi bersifat waktu nyata pada identifikasi status bisnis. Kedua kebutuhan informasi, digunakan untuk pengelolaan dan pengendalian bisnis dalam bentuk analisis data untuk pengambilan keputusan status organisasi dimasa sekarang dan masa mendatang (Gatziu dan Athanasios, 1999).
Beberapa karakteristik Data Warehouse sebagai berikut : 1. Subject oriented
Aplikasi untuk operasi perusahaan berorientasi pada proses (mengotomasi fungsi-fungsi dari proses bersangkutan atau function oriented). Misalnya di bank, aplikasi kredit mengotomasi fungsi-fungsi: verifikasi lamaran dan credit checking, pemeriksaan kolateral, approval, pendanaan, tagihan, dan seterusnya. Didalam data warehouse data-data yang dihasilkan dari proses kredit ini, diatur kembali dan diintegrasikan dengan data-data dari fungsi-fungsi lain, agar berorientasi pada misalnya nasabah dan produk.
2. Integrated
ada kolateral, untuk rekening koran ada overdraft) di dalam data warehouse data-data yang sama harus diintegrasikan disatu database, termasuk misalnya diseragamkan formatnya (sederhana tetapi paling sering terjadi aplikasi-aplikasi sering dibeli vendor berbeda, dibuat dengan atau dijalankan di teknologi berbeda-beda).
3. Time variant
Data warehouse menyimpan sejarah (historical data). Waktu merupakan tipe atau bagian data yang sangat penting didalam data warehouse. Di dalam data warehouse sering disimpan macam-macam waktu, seperti waktu suatu transaksi terjadi atau dirubah atau dibatalkan, kapan data dibutuhkan, kapan masuk ke komputer, kapan masuk ke data warehouse; juga hampir selalu disimpan versi, misalnya terjadi perubahan definisi kode pos, maka yang lama dan yang baru ada semua didalam data warehouse kita.
4. Non-volatile
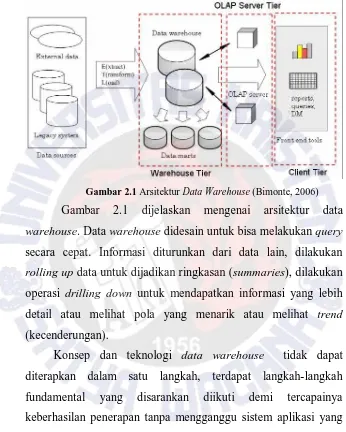
Gambar 2.1 Arsitektur Data Warehouse (Bimonte, 2006)
Gambar 2.1 dijelaskan mengenai arsitektur data warehouse. Data warehouse didesain untuk bisa melakukan query secara cepat. Informasi diturunkan dari data lain, dilakukan rolling up data untuk dijadikan ringkasan (summaries), dilakukan operasi drilling down untuk mendapatkan informasi yang lebih detail atau melihat pola yang menarik atau melihat trend (kecenderungan).
Konsep dan teknologi data warehouse tidak dapat diterapkan dalam satu langkah, terdapat langkah-langkah fundamental yang disarankan diikuti demi tercapainya keberhasilan penerapan tanpa mengganggu sistem aplikasi yang sudah ada.
2. Melakukan penyalinan dan konversi data secara regular dalam jangka waktu yang telah ditentukan dari aplikasi atau system yang sudah ada menjaadi satu jenis basis data. Mekanisme ini dilakukan dalam interval waktu tertentu dengan dukungan otomatisasi yang dimiliki oleh aplikasi teknologi data warehouse. Langkah ini dikenal dengan Offline Data Warehouse.
3. Melakukan penyalinan dan konversi data secara “real time” atau dengan kata lain otomatisasi dilakukan setiap kali terjadi perubahan pada data dari aplikasi atau system yang sudah ada. Langkah ini dikenal dengan Real Time Data Warehouse.
4. Setiap tejadi perubahan data baik pada data warehouse maupun pada data opersional aplikasi keduanya saling mensinkronisasi. Langkah ini dikenal dengan Integrated Data Warehouse. (Ferdiana, 2008)
2.2.5 Data Mining
Data mining adalah suatu proses ekstraksi atau penggalian data dan informasi yang besar, yang belum diketahui sebelumnya, namun dapat dipahami dan berguna dari database yang besar serta digunakan untuk membuat suatu keputusan bisnis yang sangat penting. (Connolly dan Begg, 2005).
Data mining menggambarkan sebuah pengumpulan teknik-teknik dengan tujuan untuk menemukan pola-pola yang tidak diketahui pada data yang telah dikumpulkan. Data mining memungkinkan pemakai "menemukan pengetahuan" dalam database yang tidak mungkin diketahui keberadaannya oleh pemakai. (Berson dan Smith, 2001)
Data mining mengidentifikasikan fakta-fakta atau kesimpulan-kesimpulan yang disarankan berdasarkan penyaringan melalui data untuk menjelajahi pola-pola atau anomali-anomali data. Data mining mempunyai lima fungsi yaitu:
1. Classification
Classification yaitu menyimpulkan definisi-definisi karakteristik dari sebuah grup. Contoh: pelanggan-pelanggan perusahaan yang telah berpindah ke saingan perusahaan yang lain.
2. Clustering
pada clustering tidak terdapat definisi-definisi karakteristik awal yang diberikan pada waktu classification).
3. Association
Association yaitu mengidentifikasikan hubungan antara kejadian-kejadian yang terjadi pada suatu waktu seperti isi-isi dari keranjang belanja.
4. Sequencing
Hampir sama dengan association, sequencing mengidentifikasikan hubungan-hubungan yang berada pada suatu periode waktu tertentu seperti pelanggan-pelanggan yang mengunjungi supermarket secara berulang-ulang.
5. Forecasting
Forecasting memperkirakan nilai pada masa yang akan datang berdasarkan pola-pola dengan sekumpulan data yang besar seperti peramalan permintaan pasar. (Turban,Rainer, dan Potter, 2005)
Tujuan dari data mining antara lain :
1. Explanatory
Untuk menjelaskan beberapa kondisi penelitian, seperti mengapa penjualan truk pick-up meningkat di Colorado.
2. Confirmatory
3. Exploratory
Untuk menganalisis data untuk hubungan yang baru dan tidak diharapkan, seperti halnya pola apa yang cocok untuk kasus penggelapan kartu kredit. (Hoffer, Prescott, dan McFadden, 2004)
Banyak perusahaan-perusahaan menggunakan data mining untuk :
- Correct data
Pada saat proses menggabungkan basis data secara besar-besaran, banyak perusahaan menemukan data yang digabungkan tersebut tidak lengkap, dan terdiri dari informasi yang salah dan bertentangan. Dengan menggunakan teknik data mining, dapat membantu untuk mengidentifikasi dan membetulkan kesalahan dengan cara yang konsisten.
- Discover Knowledge
Proses mencari pengetahuan bertujuan untuk menentukan dengan jelas relationship, pattern, atau correlations yang tersembunyi dari berbagai tempat penyimpanan data di dalam basis data. - Visualize Data
Sebagai salah satu bagian dari sistem informasi, data mining menyediakan perencanaan dari ide hingga implementasi akhir. Komponen-komponen dari rencana data mining adalah sebagai berikut :
1. Analisis Masalah (Analyzing the Problem)
Data asal atau data sumber harus bisa ditaksir untuk dilihat apakah data tersebut memenuhi kriteria data mining. Kualitas kelimpahan data adalah faktor utama untuk memutuskan apakah data tersebut cocok dan tersedia sebagai tambahan. Hasil yang diharapkan dari dampak data mining harus dengan hati-hati dimengerti dan dipastikan bahwa data yang diperlukan membawa informasi yang bisa diekstrak.
2. Mengekstrak dan Membersihkan data (Extracting and Cleansing The Data)
Data pertama kali diekstrak dari data aslinya, seperti dari OLTP basis data, text file, Microsoft Access Database, dan bahkan dari spreadsheet, kemudian data tersebut diletakkan dalam data warehouse yang mempunyai struktur yang sesuai dengan data model secara khas. Data Transformation Services (DTS) dipakai untuk mengekstrak dan membersihkan data dari tidak konsistennya dan tidak kompatibelnya dengan format yang sesuai.
3. Validitas Data (Validating The Data)
untuk memastikan bahwa semua data yang ada adalah data sekarang dan tetap.
4. Membuat dan melatih model (Creating and Training The Model)
Ketika algoritma diterapkan pada model, struktur telah dibangun. Hal ini sangatlah penting pada saat ini untuk melihat data yang telah dibangun untuk memastikan bahwa data tersebut menyerupai fakta di dalam data sumber.
5. Query data dari model data mining (Querying the Model
Data)
Ketika model yang cocok telah diciptakan dan dibangun, data yang telah dibuat tersedia untuk mendukung keputusan. Hal ini biasanya melibatkan penulisan front end query aplikasi dengan program aplikasi / suatu program basis data.
6. Evaluasi validitas dari mining model (Maintaining The Validity of The Data Mining Model)
Setelah model data mining terkumpul, lewat beberapa waktu karakteristik data awal seperti granularitas dan validitas mungkin berubah. Karena model data mining dapat terus berubah seiring perkembangan waktu. (Seidman, 2001)
2.2.6 Data Cube
dibangun dari subset berbagai atribut dalam basisdata. Dengan demikian atribut digunakan untuk menentukan atribut lainnya. Beberapa atribut diseleksi dan dipilih dan ditetapkan sebagai atribut dimensi atau fungsional. (Ivanova dan Rachev, 2004).
Sebagai contoh adalah atribut dalam bentuk multidimensional dalam data cube produksi panen padi dan palawija di wilayah Jawa Tengah, (a) dan klasifikasi hierarkikal dimensi waktu dan tempat dari data cube (b) Operator data cube berfungsi untuk mendukung berbagai agregat. Data cube menggunakan agregat untuk menghitung semua kemungkinan kombinasi yang dapat dicapai dari keseluruhan dimensi yang ada. Operasional ini digunakan untuk menjawab query OLAP yang menggunakan agregasi dalam berbagai kombinasi atribut. Data dapat diorganisir ke dalam data cube oleh kalkulasi semua kemungkinan kombinasi menggunakan group-by. Jadi, jika suatu himpunan data dengan atribut k maka besarnya kalkulasi kombinasi yang mungkin pada agregat adalah 2k group-by. (Gray, 1996)
Operator data cube dapat digeneralisasi pada histogram, cross tabulation, roll-up, drill down dan subtotal yang dibutuhkan dalam analisis financial (Handojo, 2004).
Hal ini dapat ditempuh dengan cara :
2. Slicing-dicing, melakukan proses seleksi subset pada cube. Memberikan nilai yang tepat pada atribut dalam dimensi, melakukan visualisasi dalam bentuk 3D-cube.
3. Roll-up, beberapa dimensi memiliki hirarkikal yang ditentukan sebelumnya. Agregasi dapat menentukan tingkatan hirarkikal data. Sebagai contoh adalah penentuan hierarkikal waktu hari → minggu→ bulan → tahun .
4. Drill-down, Operasional kebalikannya, dari hierarkikal rendah menuju hierarkikal lebih tinggi secara detail.
5. Analisis trend melalui urutan periode waktu tertentu.
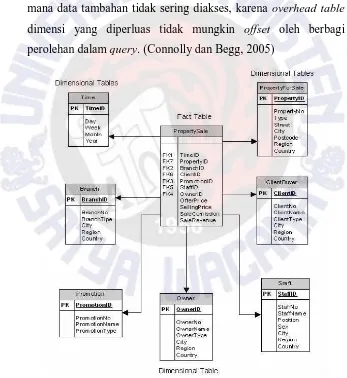
2.2.7 Star schema dan Snowflake Schema
informasi berupa teks. Skema bintang dapat digunakan untuk mempercepat kinerja query dengan denormalisasi informasi ke dalam sebuah tabel dimensi. Denormalisasi tepat ketika terdapat sejumlah entity yang berhubungan dengan tabel dimensi yang sering diakses, menghindari overhead dari penggabungan tabel tambahan untuk mengakses atribut. Denormalisasi tidak tepat di mana data tambahan tidak sering diakses, karena overhead table dimensi yang diperluas tidak mungkin offset oleh berbagi perolehan dalam query. (Connolly dan Begg, 2005)
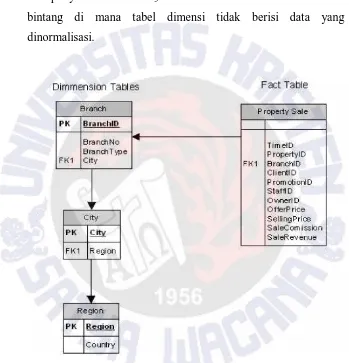
Terdapat variasi dari skema bintang yang disebut snowflake schema, yang memungkinkan dimensi untuk mempunyai dimensi. Snowflake schema adalah variasi dari skema bintang di mana tabel dimensi tidak berisi data yang dinormalisasi.
Gambar 2.3 Contoh Skema Snowflake (Connolly dan Begg, 2005)