Fakultas Ilmu Komputer
Universitas Brawijaya
10900
Implementasi Metode FKNN (Fuzzy K-Nearest Neighbor) Untuk Diagnosis
Penyakit Tanaman Kentang
Jiwandani Andromeda1, Nurul Hidayat2, Ratih Kartika Dewi3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected],3[email protected]
Abstrak
Solanum taberosum (Kentang) salah satu makanan pokok manusia karena merupakan salah satu umbi yang memiliki kandungan yang baik. Kandungan protein dan karbohirat bisa terbilang seimbang sehingga baik untuk kesehatan. Produksi kentang pada negara Indonesia mengalami pengurangan produksi 9,82%, dari tahun 2009 1.176.304 ton dan pada pada tahun 2010 menjadi 1.060.805 ton. Produksi kentang pada tahun 2009 juga menurun 16,51 ton/hektar menjadi 15,95 ton/hektar. Budidaya kentang selama ini memiliki beberapa kendala seperti penyakit dan hama. Penyakit late blight (hawar daun) adalah penyakit utama tanaman kentang. Penyakit ini memiliki heterogen genetik yang banyak sehingga tanaman menjadi rentan patah. Kerugian yang disebabkan terbilang tinggi pada tanaman kentang, terutama pada cuaca dengan kelembapan yang tinggi. Solusi agar tanaman ini mudah untuk dikembangkan salah satunya dengan menggunakan varietas yang memiliki genetik yang lebih tahan dengan ras P. Infestans yang dijumpai pada spesies kentang liar. Namun pemanfaatan genetik tanaman kentang liar tidak dapat digunakan untuk pengembangan tanaman kentang komersial dikarenakan mempunyai genetik yang berbeda. Untuk mengurangi kegagalan dalam budidaya kentang, saat ini sangat dibutuhkan teknologi perangkat lunak untuk membantu mendeteksi penyakit lebih dini pada kentang agar mempermudah petani dalam budidaya tanaman kentang.
Kata Kunci: Kentang, Logika fuzzy, aplikasi deteksi penyakit kentang, pengujian akurasi. Abstract
Solanum taberosum (Potatoes) is one of the staple foods of humans because it is one of the tubers that has a good content. The content of protein and carbohirat can be fairly balanced so it is good for health. Potato production in Indonesia experienced a 9.82% reduction in production, from 1,176,304 tons in 2009 and in 2010 to 1,060,805 tons. Potato production in 2009 also decreased by 16.51 tons / hectare to 15.95 tons / hectare. Potato cultivation so far has several obstacles such as diseases and pests. Late blight is a major disease in potato plants. This disease has a lot of genetic heterogeneity so that plants become vulnerable to broken. Losses caused are fairly high in potato plants, especially in weather with high humidity. One of the solutions to make this plant easy to develop is by using varieties that have genetic resistance to the P. infestans race found in wild potato species. However, the genetic utilization of wild potato plants cannot be used for the development of commercial potato plants because they have different genetic makeup. To reduce failures in potato cultivation, software technology is currently needed to help detect diseases early on potatoes in order to facilitate farmers in potato cultivation.
1. PENDAHULUAN
Niederhauser (1993), mengatakan bahwa Solanum taberosum (Kentang) salah satu makanan pokok manusia. Dengan kandungan gizi yang baik. Kandungan protein dan karbohirat bisa terbilang seimbang. Sehingga baik untuk kesehatan”.
Menurut Burlingame (2009), susunan paling tepat supaya mempengaruhi kualitas kentang lebih baik harus mengandung serat 3,3%, karotenoid total 2700 mcg/100 gr asam askorbat 42 mg/100 gr, kalium 693,8 mg/100 gr, dan fenol antioksidan asam klorogenat 1570 mcg/100 gr a-nutrisi α-solanin 0,001- 47,2 mg/100 gr, dan jumlah protein yang lebih rendah 0,85-4,2%, asam amino, mineral dan vitamin lain serta komponen bioaktif. Produksi kentang pada negara Indonesia mengalami pengurangan produksi 9,82%, dari tahun 2009 1.176.304 ton dan pada pada tahun 2010 menjadi 1.060.805 ton. Produksi kentang pada tahun 2009 juga menurun 16,51 ton/hektar menjadi 15,95 ton/hektar.
Menurut Cooke et al.(2003) “Budidaya kentang selama ini memiliki beberapa kendala seperti penyakit dan hama. Penyakit late blight (hawar daun) adalah penyakit utama tanaman kentang. Penyakit ini memiliki heterogen genetik yang banyak sehingga tanaman menjadi rentan patah. Kerugian yang disebabkan terbilang tinggi pada tanaman kentang, terutama pada cuaca dengan kelembapan yang tinggi”.
Menurut Helgeson et al. (1998) Solusi agar tanaman ini mudah untuk dikembangkan salah satunya dengan menggunakan varietas yang memiliki genetik yang kuat terhadap ras P. Infestans yang dijumpai pada spesies kentang liar. Namun pemanfaatan genetik tanaman kentang liar tidak dapat digunakan untuk pengembangan tanaman kentang komersial dikarenakan mempunyai genetik yang berbeda.
Untuk mengurangi kegagalan dalam budidaya kentang, saat ini sangat dibutuhkan teknologi perangkat lunak untuk membantu mendeteksi penyakit lebih dini pada kentang agar mempermudah petani dalam budidaya tanaman kentang.
Menurut Aroquiaraj (2014). Metode yang dapat diterapkan pada perangkat lunak salah satunya adalah klasifikasi. Klasifikasi, adalah pembagian atau pengelompokan berdasarkan
ciri tertentu menulut kelas-kelas berdasar atribut atau fitur yang berupa data diskrit ataupun kontinyu. Algoritma yang digunakan saat ini adalah Fuzzy K-Nearest Neighbor (FK-NN) adalah penggabungan K-Nearest Neighbor (K-NN) dengan fuzzy. Nilai-nilai yang sudah sudah diambil akan di ubah menjadi nilai biner, dan di klasifikasikan sesuai spesifikasi tertentu mdengan metode Fuzzy untuk mencari nilai tetangga terbaik dan digunakan sebagai perhitungan bobot untuk menemukan jawaban terbaik.
maka judul yang diputuskan sebagai penelitian ini adalah “Implementasi Metode FKNN (Fuzzy K-Nearest Neighbor) untuk Diagnosis Penyakit Tanaman kentang”.
2. LANDASAN KEPUSTAKAAN
Pada penelitian Iqbal et al (2014). Dengan metode ini didapatkan akurasi sebesar 90% dan standar deviasi 17,32% berobjekan kentang dengan metode VFI5 (Voting Feature Interval). Yang mengklasifikasikan dalam dua kelas, dan diharapkan sebagai diagnosa awal dengan hasil klasifikasi serta mencari tingkat akurasinya.
Algoritma ini juga sudah diterapkan untuk klasifikasian penyakit dengan akurasi sebesar 98%. penelitian tersebut untuk melakukan diagnosis penderita gagal ginjal yang dilakukan oleh Andrianto Deny, data yang digunakan adalah kondisi tertentu pasien, dan dihansilkan seorang pasien menderita penyakit tersebut atau tidak.
Penelitian selanjutnya dengan akurasi sebesar 100% yang dilakukan oleh Andika Satria digunakan sebagai ketepatan waktu lulus, data yang dibutuhkan pada adalah nilai indeks prestasi setiap smester, dan dapat memperoleh nilai sebagai penentuan seeorang tepat waktu atau sebaliknya.
Penelitian selanjutnya dengan akurasi terbaik 84% dengan nilai K = 4 oleh Satria Dwi Nugraha dengan data umur, berat dan tinggi badan pada penelitian ini dapat ditentukan apakah seorang balita memenuhi standar gizi yang baik atau tidak.
3. METODOLOGI
Tahap metodologi penelitian yang digunakan adalah studi. literatur, Analisis Kebutuhan, Pengumpulan Data, Perancangan Sistem, implementasi, pengujian, dan pengambilan kesimpulan. Adapun diagram alur metodologi penelitian tersebut seperti dal.am
Gambar 3.1
Gambar 3. 1 Metodologi penelitian 3.1. Studi Literatur
Studi literatur adalah pustaka-pustaka yang menunjang hubungan dengan klasifikasi penyakit pada tanaman kentang di antaranya : kajian pustaka, data mining, klasifikasi, metode Fuzzy K-Nearest Neighbor (FK-NN) dan penyakit pada tanaman kentang. Pustaka-pustaka bersumber dari penelitian sebelumnya, jurnal, e-book dan internet.
3.2. Analisis Kebutuhan
Untuk mengenali seluruh kebutuhan maka dilakukan analisa kebutuhan yang diperlukan sebagai pembangun sistem diagnosis penyakit tanaman kentang dengan metode Fuzzy K-Nearest Neighbor (FK-NN).
3.3. Pengumpulan Data
Berbagai gejala dan jenis penyakit adalah tahapan dalam pengumpulan data yang dibutuhkan, setiap penyakit tanaman kentang. Sumber data diperoleh dari hasil wawancara untuk memperoleh pengetahuan tentang gejala – gejala penyakit tanaman kentang serta cara mengatasinya.
3.4. Perancangan Sistem
Perancangan sistem dibuat untuk merancang pendeteksi penyakit kentang menggunakan algoritme Fuzzy K-Nearest Neighbor (FK-NN). Tahapan perancangan yaitu: Deskripsi sistem dengan mengklasifikasi penyakit tanaman kentang, Preprocessing data berisi data-data yang diperlukan dalam implementasi sistem, data penyakit dan gejala penyakit, Perancangan sistem terdiri dari deskripsi/gambaran umum sistem berupa model
dan proses FK-NN yang dijelaskan dengan diagram alir, Perhitungan manual : desain antarmuka, dan perancangan pengujian.
3.5. Implementasi Sistem
Implementasi sistem merupakan penerapkan hasil studi literatur dan analisis kebutuhan yang dikerjakan sesuai perancangan
sistem yang dibuat.
3.6. Pengujian dan Analisis
Pengujian yang dilakukan dengaan pengujian akurasi untuk mengukur tingkat akurasi sistem diagnosis penyakit tanaman kentang. Pengujian tingkat akurasi dilakukan dengan membandingkan hasil keluaran dari sistem dengan data sebenarnya.
3.7. Kesimpulan dan Saran
Setelah semua proses dijalankan dengan baik maka selanjutnya adalah proses penarikan kesimpulan, yang didapat dari pengujian dan analisis terhadap aplikasi. Sedangkan saran bertujuan untuk memperbaiki kekurangan pada sistem serta dijadikan sebagai referensi dan bahan pengembangan pada penelitian berikutnya
.
4. ANALISIS KEBUTUHAN DAN PERANCANGAN
Tahap ini berisi tentang
komponen-komponen
penyusun
sistem
pakar,
komponen – komponen dari sistem pakar
itu
sendiri
terdiri
dari
perolehan
pengetahuan,
mesin
inferensi,
dasar
pengetahuan,
fasilitas
penjelas
dan
rancangan interface pengguna.
4.1. Perancangan Proses
Pada tahap ini, dilakukan perancangan sistem yang terdiri dari komponen-komponen penyusun sistem pakar, komponen – komponen dari sistem pakar itu sendiri terdiri dari akuisisi pengetahuan, mesin inferensi, basis pengetahuan, fasilitas penjelas dan rancangan antarmuka pengguna.
4.1.1. Akuisisi Pengetahuan
Akusisi adalah tahap
pengumpulan data dari pakar atau dinas terkait. pengetahuan bisa didapat dari buku, internet ataupun dari pakar. Ada beberapa metode yang dapat digunakandalam akusisi pengetahuan.
4.1.2. Basis Pengetahuan
Untuk memahami dan memecahkan permasalahan digunakan basis pengetahuan yang berasal dari pakar, elmen dasar dari basis pengetahuan yaitu fakta dan aturan khusus yang digunakan untuk mengarahkan pengguna pengetahuan sebagai selusi dalam suatu domain dan representasi dari seorang pakar.
4.2. Struktur Fuzzy K-Nearest Neighbor (FK-NN)
Pada tahapan ini dijelaskan. mengenai alur proses sistem dalam melakukan pemrosesan data uji serta data latih penyakit tanaman kentang dengan menggunakan algortima Fuzzy
K-Nearest Neighbor. Adapaun tahapan .dari
proses tersebut yaitu ditunjukkan oleh Gambar 4.1.
Gambar 4.1 Diagram Alir Tahapan Fuzzy K-NN
Berdasarkan Gambar 4.1 algoritma klasifikasi yang akan digunakan adalah Fuzzy K-Nearest
Neighbor yang terdiri atas dua proses utama
yaitu antara lain :
1. Proses K-Nearest Neighbor
Adalah suatu proses pengklasifikasian terhadap data uji untuk dimasukkan ke dalam suatu kelas penyakit. Proses pengklasifikasian tersebut menggunakan jarak euclidean distance antara data latih dan data uji. Dan selanjutnya mayoritas kelas pada sejumlah k (tetangga terdekat) digunakan untuk menetukkan data uji masuk ke dalam salah satu kelas prediksi.
2. Proses Fuzzy K-Nearest Neighbor
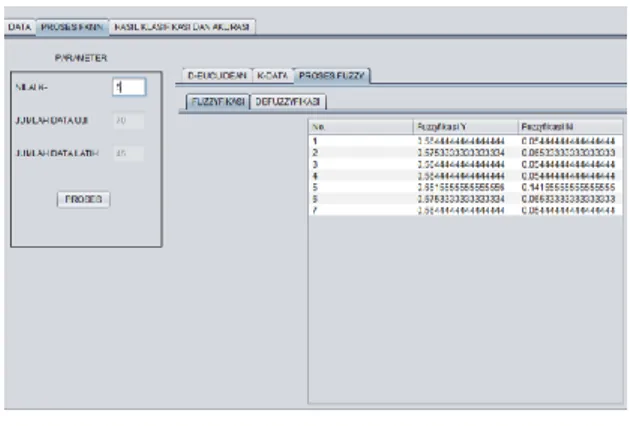
Pada tahap ini data uji diberikan nilai keanggotaan setelah diproses mengg.unakan metode K-NN sehingga setiap data uji mem.punyai nilai relat.if pada setiap k.elas dimana kelas dengan nilai keanggotaan yang lebih besar ialah yang menjadi kelas hasil pada pr.oses FK-NN.
5. IMPLEMENTASI
Berikut ini adalah antar muka implementasi dari sistem deteksi tanaman kentang.
Gambar 5.1 Pilih Data Latih
Gambar 5.2 Pilih Data Uji
Gambar 5.3 Eucledian Distance berdasarkan K data
Gambar 5.4 Fuzzifikasi
Gambar 5.5 Pengujian Akurasi
Pada Gambar 5.1 dan Gambar 5.2 menunjukan halaman pengambilan data latih dan data Uji terdapat browse untuk pilih file data, tombol ambil data untuk mengambil data, selanjutnya adalah pengambilan nilai K pada Gambar 5.3 terdapat tombol proses setelah memasukan nilai K dan menampilkan hasil euclidean distance, pada gambar 5.4 menunjukan hasil dari proses Fuzzy, dan pada halaman terakhir Gambar 5.5 adalah hasil dari akurasi.
6. PENGUJIAN DAN ANALISIS
6.1. Pengujian Akurasi
Data uji yang didapatkan dari pakar dengan hasil yang diperoleh oleh sistem digunakan sebagai acuan pengujian akurasi. Data testing yang didapatkan sebanyak 70
data. Kemudian akan dilakukan percobaan dengan masukan sesuai data uji dengan jumlah K yangiberbeda-beda, nilai K yang digunakan adalah 5, 10, 15 dan 20, kemudian nilai akurasi akan dihitungiberdasar- kan jumlah data uji yang memiliki keluaran sama dengan diagnosis pakar.Untuk mendapat-
kan nilai akurasi akan dilakukan uji kecocokan antara keluaran sistem dengan data uji yang didapatkan dari pakar
6.1.1 Pengujian dengan nilai K = 5
Dari hasil pengujian didapatkan sebanyak 12 data uji yang memiliki hasil klasifikasi berbeda dengan kelas sebenarnya, dari hasil tersebut kemudian akan dihitung akurasinya sehingga dihasilkan akurasi = 85,86%.
6.1.2 Pengujian dengan nilai K = 10
Dari hasil pengujian didapatkan sebanyak 9 data uji yang memiliki hasil klasifikasi berbeda dengan kelas sebenarnya, dari hasil tersebut kemudian akan dihitung akurasinya sehingga dihasilkan akurasi = 87,14%.
6.1.3 Pengujian dengan nilai K = 15
Dari hasil pengujian didapatkan sebanyak 2 data uji yang memiliki hasil klasifikasi berbeda dengan kelas sebenarnya, dari hasil tersebut kemudian akan dihitung akurasinya sehingga dihasilkan akurasi = 91,43%.
6.1.4 Pengujian dengan nilai K = 20
Dari hasil pengujian didapatkan sebanyak 14 data uji yangimemiliki hasil klasifikasi berbeda dengan kelas sebenarnya, dari hasil tersebut kemudian akan dihitung akurasinya sehingga dihasilkan akurasi = 81,43%.
6.2 Analisis Pengujian Akurasi
Menurut hasil pengujian dengan nilai K yang digunakan adalah 5, 10, 15, dan 20 terjadi beberapa ketidaksesuaian data antara output hasil pakar dan hasil sistem.
6.2.1 Analisis pengujian dengan nilai K=5
Presentase pengujian akurasi dengan nilai K=4 dihasilkan presentase sebesar 85,86%. Dari hasil diagnosis sistem didapat 2 kesalahan yang disebabkan oleh gejala pada dua penyakit sedangkan satu output penyakit yang dihasilkan oleh sistem. Sehingga hal ini dapat disimpulkan bahwasanya hasil spesifik akan mempengaruhi tingkat akurasi. Semakin spesifik suatu gejala akan semakin bagus hasil dari akurasi dan semakin umum suatu gejala maka akan semakin buruk hasil akurasi.
6.2.2 Analisis pengujian dengan nilai K=10
menghasilkan akurasi 87,14%. Dari diagnosa sistem terdapat data salah sebanyak 5, Hal ini terjadi karena 5 data tersebut dimiliki lebih dari 1 jenis penyakit sedangkan sistem hanya menghitung dengan hasil 1 output saja. hasil spesifik akan mempengaruhi tingkat akurasi. Semakin spesifik suatu gejala akan semakin bagus hasil dari akurasi dan semakin umum suatu gejala maka akan semakin buruk hasil akurasi.
6.2.3 Analisis pengujian dengan nilai K=15
Perhitungan persentase akurasi nilai K=10 adalah 91,43%. Hal ini menunjukkan adanya 2 kesalahan sistem diagnosis yang terjadi karena Hal ini terjadi karena 2 data tersebut dimiliki lebih dari 1 jenis penyakit sedangkan sistem hanya menghitung dengan hasil 1 output saja.. hasil spesifik akan mempengaruhi tingkat akurasi. Semakin spesifik suatu gejala akan semakin bagus hasil dari akurasi dan semakin umum suatu gejala maka akan semakin buruk hasil akurasi.
6.2.4 Analisis pengujian dengan nilai K=20
Perhitungan akurasi didapatkan presentase sebesar 81,42%. Terdapat 14 kesalahan hasil diagnosis sistem, Hal ini terjadi karena 14 data tersebut dimiliki lebih dari 1 jenis penyakit sedangkan sistem hanya menghitung dengan hasil 1 output saja. hasil spesifik akan mempengaruhi tingkat akurasi. Semakin spesifik suatu gejala akan semakin bagus hasil dari akurasi dan semakin umum suatu gejala maka akan semakin buruk hasil akurasi.
. Rata-rata hasil analisis perhitungan pada masing-masing nilai didapatkan presentase sebesar 86.46%. Hal ini menunjukkan bahwa metode K-nearest neighbor ini sangat baik digunakan karena akurasi cukup tinggi.
7.
KESIMPULAN
Dapat ditarik sebuah kesimpulan dari hasil
pengujian :
1. Sistem diagnosis penyakit pada tanaman
kentang berhasil diimplentasi dalam bentuk
perangkat lunak dengan fungsi melakukan
diagnosis penyakit pada tanaman kentang.
2. Dengan pencapaian akurasi yang paling
baik sebesar 86,785% dan jumlah K tidak
terlalu berpengaruh pada akurasi, karena
setelah diuji ternyata semakin banyak nilai
K tidak membuktikan semakin kecil
akurasinya, Dan semakin kecil nilai K tidak
membuktikan semakin besar akurasinya.
8. DAFTAR PUSTAKA
Gunadi, N. 1997. Pengaruh Ketinggian Tempat dan Bahan Tanaman terhadap Pertumbuhan dan Hasil Kentang Asal Biji Botani. Balai Pengkajian Tehknologi Pertanian Sulawesi Tenggara. Jurnal Hortikultura Vol. 7 No. 2 : 642 – 652. http//katalog.pustaka-deptan- go.id.
Elvianti. Penerapan metode Modified k-Nearest Neighbor untuk klasifikasi penderita penyakit liver [Skripsi]. 2015.
Febrealty, Eka. Klasifikasi Status Gizi balita menggunakan metode k-Nearest Neighbor [Skripsi]. 2011.
Henny. Penerapan k-Nearest Neighbor untuk penentuan resiko kredit kepemilikan kendaraan bermotor .2013.
Imanuel, Ricky; Kusrini, Muhammad Arief Rudyanto. Analisa prediksi tingkat pengunduran diri mahasiswa dengan metode k-Nearest Neighbor. 2014.
Johanes W.Yodha dan Achmad Wahid K., Pengenalan motif batik menggunakan Deteksi Tepi Canny dan k-Nearest Neighbor. 2014.
[BPTP-Jatim]. Balai Pengkajian Teknologi Pertanian Jawa Timur. 2010. Ketersediaan benih kentang. Dalam 13 http://jatim.litbang.deptan.go.id [12 Juni 2011].