Komparasi Algoritma Klasifikasi untuk dataset iris dengan rapid miner
M. Adib Alkaromi
Program Studi Teknik Informatika STMIK Widya Pratama Jl. Patriot 25 Pekalongan
Telp (0285) 427816 Email: [email protected]
Abstrak
Data mining merupakan ilmu yang menggunakan data lampau sebagai acuan untuk mendapatkan sebuah pengetahuan baru. Salah satu peran utama data mining adalah klasifikasi. Dalam klasifikasi data lampau dihitung dan dijadikan sebagai model atau aturan untuk menentukan kelas dari data baru. Banyak algoritma klasifikasi dikembangkan dalam beberapa tahun terakhir. Beberapa algoritma klasifikasi terbaik antara lain C4.5, SVM serta Naïve Bayes. Dalam penelitian ini dibandingkan performa dari ketiga algoritma tersebut. Dengan menggunakan tools rapid miner dan dataset iris dari uci repository didapatkan bahwa algoritma C4.5 memiliki performa terbaik dengan tingkat akurasi sebesar 98,67%. Sedangkan Naïve Bayes memiliki tingkat akurasi sebesar 96,00% dan SVM sebesar 91,33%. Ketiga algoritma tersebut termasuk dalam golongan best classification karena memiliki tingkat akurasi diatas 90,00%.
Kata kunci: Klasifikasi, C4.5, SVM, Naïve Bayes
1 Pendahuluan 1.1 Latar Belakang
Data mining merupakan sebuah proses ekstraksi untuk mendapatkan suatu informasi yang sebelumnya tidak diketahui dari sebuah data [1]. Data mining dapat menganalisa kasus lama untuk menemukan pola dari data dengan menggunakan teknik pengenalan pola seperti statistik dan matematika [2]. Klasifikasi merupakan salah satu peran utama dari data mining. Terdapat banyak teknik klasifikasi data mining seperti yang tercantum dalam [1] [2] [3]. Klasifikasi membutuhkan data training untuk mengenali pola tertentu dari data dengan label atau hasil akhir. Kemudian pola tersebut dipakai untuk menentukan label yang belum diketahui dari data baru. Beberapa teknik klasifikasi yang terbaik menurut Wu et al (2007) [4] antara lain algoritma C-4.5, Support Vector Machine, serta Naïve Bayes.
Komparasi algoritma klasifikasi banyak dilakukan oleh peneliti [5] [6] [7] dengan hasil yang berbeda pula. Menggunakan data KAU-Odus Database Repository dengan 5.260
record dan 8 atribut, didapatkan C4.5 sebagai
algoritma dengan akurasi tertinggi dan tingkat error terendah dibandingkan dengan algoritma SVM, Naïve Bayes serta beberapa algoritma lain [7]. Untuk data alat simulasi bangunan dengan 67 juta record justru Naïve Bayes
menjadi metode yang memiliki tingkat akurasi tertinggi. Untuk komparasi yang lain dengan menggunakan 50 dataset yang berbeda didapatkan hasil Naïve Bayes merupakan algoritma dengan akurasi terbaik untuk data dengan 2 atribut serta k-NN merupakan yang terbaik untuk data denga 10 atribut [7].
Semakin banyak atribut yang relevan yang dipakai dalam klasifikasi akan mempengaruhi hasil akurasi dan kompleksitas waktu dari algoritma klasifikasi tersebut [3] [8] [9]. Tipe data dapat mempengaruhi performa suatu algoritma[7]. Beberapa model algoritma kuat hanya pada tipe data tertentu dan lemah pada tipe data yang lain [5] [6]. Penelitian ini akan melakukan perbandingan beberapa algoritma klasifikasi terbaik [4] yaitu C4.5, SVM dan Naïve Bayes untuk mengetahui model algoritma yang paling sesuai dan memiliki tingkat akurasi tertinggi untuk klasifikasi data iris.
1.2 Landasan Teori 1.2.1 Data Mining
Data Mining atau sering juga disebut
Knowledge Discovery in Database (KDD)
adalah sebuah bidang ilmu yang banyak membahas tentang pola sebuah data. Serangkaian proses guna mendapatkan pengetahuan atau pola dari kumpulan data
disebut dengan data mining[1]. Sebuah data yang besar bisa saja tidak berguna dan hanya akan menjadi sampah bila kita tidak dapat memanfaatkannya. Data mining menjawab masalah ini dengan menganalisa data yang besar tersebut kemudian membuat sebuah aturan, pola, ataupun model tertentu untuk mengenali data baru yang tidak berada dalam baris data yang tersimpan [10].
Data mining merupakan kegiatan yang meliputi pengumpulan dan pemakaian data historis untuk menemukan keteraturan, pola atau hubungan dalam set data [11]. Output dari data mining dapat dipakai untuk memperbaiki pengambilan sebuah keputusan di masa depan. Data ming memiliki kaitan dengan berbagai bidang ilmu yang lain seperti Machine
Learning, Statistik, Visualisasi serta database.
Gambar 1.1 merupakan posisi data mining dengan berbagai disiplin ilmu lain.
Gambar 1.1. Posisi Data Mining dengan Berbagai Disiplin Ilmu [11]
Walaupun tidak secara jelas membedakan data mining dengan disiplin ilmu lain, tetapi beberapa perbedaan dapat dilihat walau tidak terlalu tegas [11] seperti: Statistik lebih berdasarkan teori, lebih focus pada pengujian hipotesis. Machine Learning lebih bersifat heuristic, focus pada perbaikan performasi dari suatu teknik learning, juga meliputi real-time
learning dan robotic area yang tidak termasuk
dalam data mining. Sedangkan data mining sendiri merupakan gabungan teori dan heuristik, focus pada seluruh proses penemuan
knowledge / pola termasuk data cleansing, learning dan visualisasi dari hasilnya.
Beberapa peran utama data mining adalah:
Estimation, Prediction, Classification, Clustering dan Association. Dari semua
peranan data mining tersebut terbagi menjadi 2 berdasarkan metode pembelajarannya [11] yaitu Supervised Learning, Unsupervised
Learning. Perbedaan dari kedua metode
pembelajaran pada algoritma data mining
tersebut adalah jika dalam supervised learning harus memiliki data sampel atau sering disebut juga dengan data training. Sedangkan dalam
unsupervised learning tidak membutuhkan
data training. Salah satu contoh peran data mining dengan metode supervised learning adalah klasifikasi.
1.2.2 Klasifikasi
Klasifikasi merupakan salah satu peran utama dari data mining. Klasifikasi termasuk kedalam
supervised learning karena dalam proses
klasifikasi terdapat proses pembelajaran dengan data lampau. Proses ini digunakan algoritma untuk mengenali pola dari data yang nantinya dapat diterapkan kepada data baru yang belum diketahui kelompoknya. Teknik klasifikasi banyak diterapkan dalam dunia nyata seperti halnya dalam dunia medis[12], pendidikan [5] [13] [14] [15] [16], teknik bangunan [6], jaringan komputer [17], serta banyak digunakan dalam bidang lain.
Label dalam klasifikasi atau bisa juga disebut dengan atribut tujuan merupakan atribut yang akan dicari perhitungan algoritma data mining. Sebagai contoh dalam dunia medis jika ada pasien baru dengan gejala penyakit tertentu akan tetapi jenis penyakit yang dideritanya belum diketahui. Maka klasifikasi dapat menjadi sebuah alat untuk menentukan keputusan. Adanya data lampau atau yang nantinya disebut dengan data training akan banyak membantu dalam proses klasifikasi tersebut. Karena dengan banyaknya data
training akan mempengaruhi akurasi keakuratan klasifikasi suatu algoritma data mining. Banyaknya atribut juga akan dapat mempengaruhi performa suatu algoritma [10], walaupun atribut yang terlalu banyak atau biasa dikenal dengan data berdimensi tinggi akan mempengaruhi kompleksitas waktu dari algoritma. Semakin banyak atribut yang digunakan akan menjadikan proses komputasi akan semakin mahal, atau waktu komputasi akan semakin lama. Untuk menanggulangi hal tersebut dapat dilakukan pengurangan atribut data atau biasa juga disebut feature extraction dan feature selection [11].
Dalam melakukan suatu klasifikasi dibutuhkan data lampau yang nantinya akan diolah menjadi sebuah aturan ataupun sebuah pengetahuan baru. Masalah klasifikasi pada dasarnya adalah sebagai berikut [18]:
1.
Masalah Klasifikasi berangkat dari data2.
Data training akan diolah dengan menggunakan algoritma klasifikasi.3.
Masalah klasifikasi berakhir dengan dihasilkannya sebuah pengetahuan yang direpresentasikan dalam bentuk diagram, aturan atau pengetahuan.Klasifikasi diawali dengan adanya data awal yang dijadikan sebagai data pembelajaran algoritma atau disebut juga dengan data
training. Tentunya data training yang dimaksud adalah data dengan atribut tujuan atau atribut label. Yang dimaksud label adalah hasil akhir dari data yang nantinya akan dihitung dengan menggunakan suatu algoritma, Misalkan terdapat data registrasi mahasiswa dengan label registrasi / tidak registrasi. Data ini nantinya akan diolah oleh algoritma untuk mengetahui pola, aturan ataupun pengetahuan baru dari data. Nantinya pola atau pengetahuan baru ini dapat dijadikan sebagai alat bantu untuk memprediksi jika ada
record baru dengan label yang belum
diketahui. Akurasi dari algoritma berbeda tergantung dari tipe data yang diolahnya [7]. Klasifikasi dan prediksi sebenarnya hanya memiliki beberapa perbedaan kecil. Perbedaan yang mendasar adalah didalam prediksi data yang digunakan adalah data time series. Data
time series merupakan data yang didapatkan
berdasarkan jarak waktu tertentu. Contoh data rentet waktu ini misalnya adalah data dalam pasar modal yang selalu berubah dalam hitungan hari bahkan tiap jam.
Algoritma yang biasa dipakai dalam peroses klasifikasi sangatlah banyak. Beberapa algoritma klasifikasi terbaik menurut Wu et al (2010) [4] antara lain C4.5, Support Vektor Machine (SVM), serta Naïve Bayes (NB). Secara lebih mendalam algoritma tersebut akan dibahas di sub bab berikut:
1.2.3 C4.5
C4.5 Merupakan pengembangan dari algoritma ID3 [2] yang dikembangkan oleh Quinlan[3]. Algoritma C4.5 banyak digunakan peneliti untuk melakukan tugas klasifikasi. Output dari algoritma C4.5 adalah sebuah pohon keputusan atau sering dikenal dengan decissin tree. Dalam beberapa penelitian algoritma C4.5 ini menjadi pilihan terbaik dibandingkan dengan beberapa algoritma klasifikasi lain [4] [17].
Decision tree sendiri merupakan metode
klasifikasi dan prediksi yang sangat kuat dan terkenal [19]. Dalam decissin tree ini data
yang berupa fakta dirubah menjadi sebuah pohon keputusan yang berisi aturan dan tentunya dapat lebih mudah dipahami dengan bahasa alami. Model pohon keputusan banyak digunakan pada kasus data dengan output yang bernilai diskrit [11]. Walaupun tidak menutup kemungkinan dapat juga digunakan untuk kasus data dengan atribut numeric.
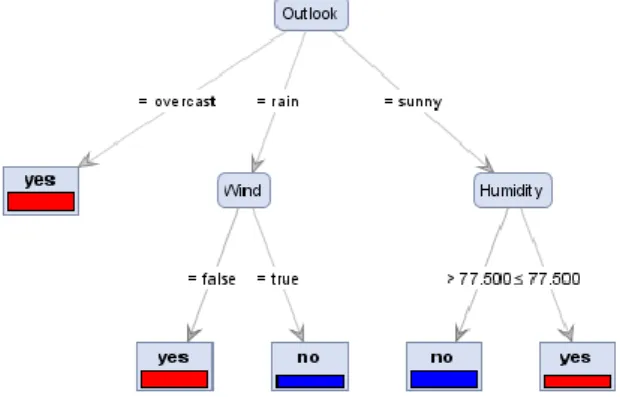
Setiap node dalam decision tree
merepresentasikan sebuah atribut. Sedangkan cabang dari node merupakan nilai dari atribut tersebut, serta daun merepresantasikan kelas. Node paling atas pada decision tree disebut sebagai root node. Root node ini tidak memiliki input serta bisa saja tidak memiliki
output dan bahkan dapat memiliki output lebih
dari satu. Internal root merupakan node percabangan yang hanya memiliki satu input dan memiliki minimal dua output. Leaf node atau terminal node merupakan node akhir yang hanya memiliki satu input serta tidak memiliki
output.
Gambar 1.2. Pohon Keputusan data Golf Gambar 1.2 menggambarkan keputusan untuk memprediksi apakah seseorang akan bermain golf. Root node atau atribut akar disimbolkan dengan persegi tumpul yang berada paling puncak yaitu outlook. Cabang disimbolkan dengan garis dan leaf node atau terminal node disimbolkan dengan persegi berujung yang berisi label atau tujuan yaitu yes atau no. Sedangkan internal node dalam gambar 2 disimbolkan juga persegi tupul yang berada antara root node dengan terminal node.
Langkah untuk membuat sebuah decision tree dari algoritma C4.5 adalah sebagai berikut [3]: 1. Mempersiapkan data training, data
training yaitu data yang diambil dari data
histori yang pernah terjadi sebelumnya atau disebut data masa lalu dan sudah dikelompokan dalam kelas-kelas tertentu.
2. Menentukan akar pohon. Akar pohon ditentukan dengan cara menghitung
GainRatio tertinggi dari masing-masing
atribut. Sebelum menghitung GainRatio, terlebih dahulu menghitung Total Entropy sebelum dicari masing-masing Entropy
class, adapun rumus mencari Entropy
seperti di bawah:
∑
Keterangan: S = Himpunan kasus n = jumlah partisi S
pi = proporsi dari Si terhadap S Dimana log2pi dapat dihitung dengan
cara:
3. Menghitung nilai GainRatio sebagai akar pohon, tetapi sebelumnya menghitung
Gain dan SplitEntropy (SplitInfo), rumus
untuk menghitung Gain seperti dibawah ini:
∑
Rumus untuk menghitung SplitEntropy, seperti di bawah ini:
∑
(
)
Rumus untuk menghitung GainRatio, dibawah ini:
Keterangan: S = Himpunan Kasus A = Atribut
n = jumlah partisi atribut A
|Si| = jumlah kasus pada partisi ke-i
|S| = jumlah kasus dalam S
4. Ulangi langkah ke-2 dan ke-3 hingga semua tupel terpartisi
5. Proses partisi pohon keputusan akan berhenti disaat:
a. Semua tupel dalam node N
mendapatkan kelas yang sama
b. Tidak ada atribut didalam tupel yang dipartisi lagi
c. Tidak ada tupel didalam cabang yang kosong
1.2.4 Support Vektor Machine (SVM) Support Vektor Mavchine (SVM) dikembangkan oleh Boser, Guyon dan Vapnik. SVM pertama kali dipresentasikan pada tahun 1992 di Annual Workshop on Computational Learning Theory [20]. SVM merupakan
supervised learning yang merupakan sebuah
kombinasi harmonis dari teori margin hyperplane (Duda&Hart,1973; Cover, 1965;
Vapnik, 1964) dan kernel yang diper kenalkan oleh Aronszanjn pada tahun 1950 serta beberapa konsep pendukung yang lain.
Prinsip dasasr SVM adalah linier classifier. Sedangkan pengembangan untuk masalah yang non linier dapat menambahkan kernel trick pada ruang kerja berdimensi tinggi. SVM berusaha mencari hyperplane terbaik pada input space. Hyperplane merupakan garis tengah yang memisahkan antara kelas satu dengan kelas yang lain dalam sebuah klasifikasi. Garis tengah terbaik didapatkan dengan mencari margin terbesar anatar kelas yang berbeda. Pencarian margin terbesar dapat diilustrasikan pada gambar 1.3 berikut. (a) menunjukkan banyak pilihan garis yang dapat memisahkan kelas -1 dengan kelas +1.
Sedangkan (b) menunjukkan pilihan terbaik dengan margin terbesar.
Gambar 1.3. Pemisahan dua kelas (class-1 dan class+1) dengan mencari margin terbesar [20]
Hyperplane terbaik merupakan garis tengah
antara garis luar kelas-1 dan garis luar kelas+1. Sedangkan garis terluar untuk kelas-1 dapat dihitung dengan rumus:
Sedangkan untuk kelas +1 dapat dihitung dengan rumus:
(
Sedangkan hyperplane dapat dihitung dengan rumus:
Keterangan:
W : Bobot dari sebuah atribut Xi : Atribut ke-i
b : Bias
1.2.5 Naïve Bayes
Naïve Bayes merupakan sebuah model klasifikasi statistik yang dapat digunakan untuk memprediksi probabilitas keanggotaan suatu kelas. Naïve Bayes didasarkan pada teorema bayes yang memiliki kemampuan klasifikasi serupa dengan decision tree dan neural network [19]. Teorema Bayes memiliki bentuk umum seperti:
Naive Bayes itu sendiri merupakan penyederhanaan dari teorema bayes. Berikut rumus Naive Bayes menurut:
Keterangan:
X : data dengan class yang belum diketahui
H : hipotesis data X, merupakan suatu class spesifik
P(H|X) : probabilitas hipotesis H berdasarkan
kondisi X (posteriori probability)
P(H) : probabilitas hipotesis H (prior probability)
P(X|H) : probabilitas X berdasarkan kondisi
pada hipotesis H
P(X) : probabilitas dari X
2 Metode Penelitian
Penelitian ini dilakukan dengan menggunakan metode eksperimen dan dengan alat bantu yaitu rapid miner. Komparasi akan dilakukan untuk mengetahui algoritma apa yang memiliki akurasi paling baik dengan menggunakan dataset iris.
2.1 Dataset
Dataset yang digunakan dalam penelitian ini adalah data iris. Data iris merupakan salah satu dataset yang banyak digunakan dalam proses klasifikasi. Data iris merupakan data publik yang dikeluarkan oleh uci repository. dalam data iris ada 4 atribut yang dapat mempengaruhi klasifikasi yaitu: sepal length,
sepal width, petal length, serta petal width.
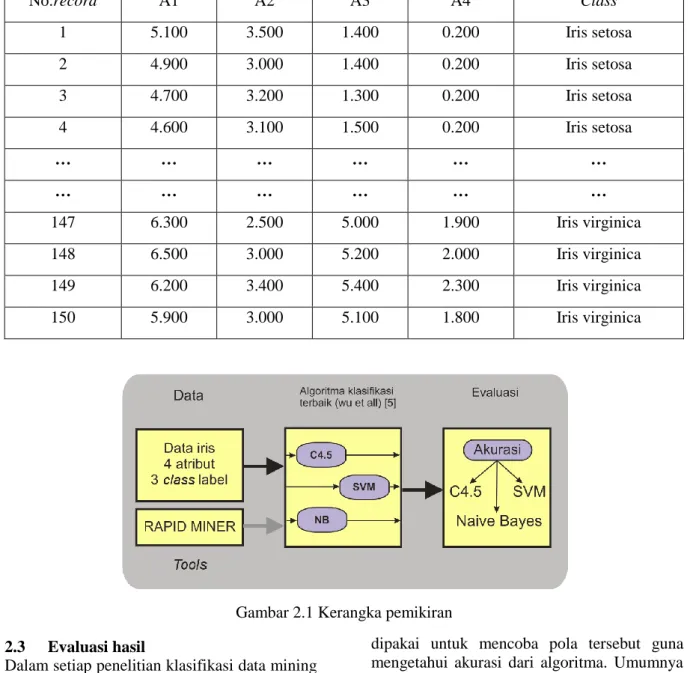
Atribut tujuan atau label dari data iris memiliki 3 kelas yaitu: iris setosa, iris versicolour, serta iris virginica. Tabel 2.1 menunjukkan potongan dataset data iris.
2.2 Kerangka pemikiran
Dalam penelitian ini sebelumnya juga dibuat sebuah kerangka pemikiran yang dapat menjadi acuan dalam melakukan penelitian.
Gambar 2.1 merupakan kerangka pemikiran dalam penelitian ini. Beberapa algoritma klasifikasi terbaik menurut wu [4] antara lain C4.5, SVM serta Naïve Bayes. Performa dari semua algoritma berbeda, jenis data juga akan mempengaruhi performa dari algoritma. Dataset yang digunakan adalah data iris yang nantinya akan dilakukan perhitungan dengan menggunakan tools rapid miner.
Tabel 2.1 Data iris
No.record A1 A2 A3 A4 Class 1 5.100 3.500 1.400 0.200 Iris setosa 2 4.900 3.000 1.400 0.200 Iris setosa 3 4.700 3.200 1.300 0.200 Iris setosa 4 4.600 3.100 1.500 0.200 Iris setosa … … … … … … … … … … … … 147 6.300 2.500 5.000 1.900 Iris virginica 148 6.500 3.000 5.200 2.000 Iris virginica 149 6.200 3.400 5.400 2.300 Iris virginica 150 5.900 3.000 5.100 1.800 Iris virginica
Gambar 2.1 Kerangka pemikiran 2.3 Evaluasi hasil
Dalam setiap penelitian klasifikasi data mining pasti terdapat evaluasi untuk mengetahui tingkat akurasi dari algoritma klasifikasi. Dalam sebuah klasifikasi terdapat pembagian data menjadi 2, yaitu data training dan data
testing. Data training merupakan bagian dari
data yang digunakan untuk membuat suatu pola atau pengetahuan baru. Sedangkan data
testing merupakan bagian data yang akan
dipakai untuk mencoba pola tersebut guna mengetahui akurasi dari algoritma. Umumnya percobaan dilakukan secara berulang guna mendapatkan hasil akurasi yang lebih kuat. Evaluasi yang digunakan dalam penelitian ini adalah dengan menghitung rata-rata dari keseluruhan percobaan yang dilakukan.
3 Hasil dan Pembahasan
Hasil dari penelitian ini menunjukkan bahwa algoritma C4.5 merupakan algoritma dengan performa terbaik dengan mendapatkan akurasi sebesar 98.67%. Sedangkan Naïve Bayes
mempunyai akurasi sebesar 96%. SVM dengan menggunakan data iris ternyata hanya mendapatkan akurasi sebesar 91.33%. Keseluruhan hasil dari penelitian ini dapat dilihat pada tabel 3.1 untuk C4.5, tabel 3.2 untuk Naïve Bayes, serta tabel 3.3 untuk SVM.
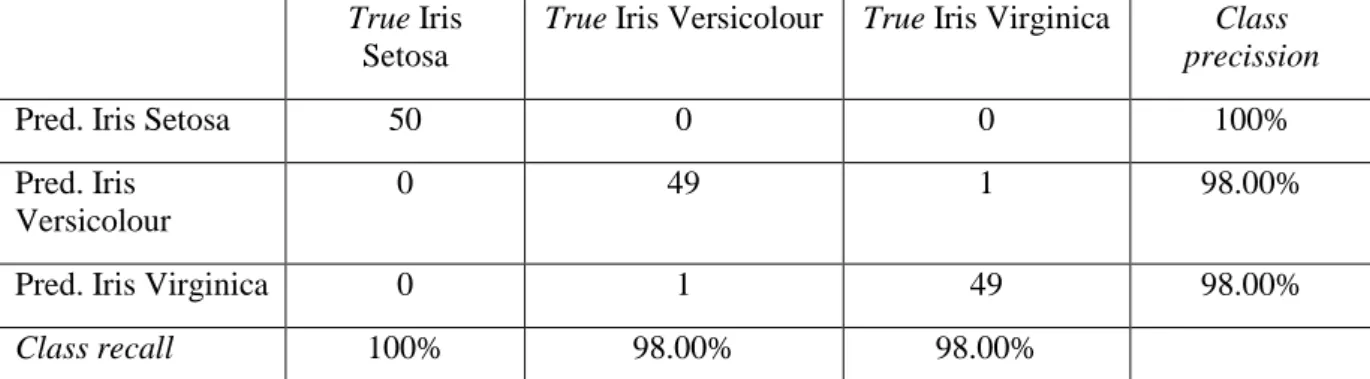
Tabel 3.1 Performa algoritma C4.5 untuk dataset iris
True Iris
Setosa
True Iris Versicolour True Iris Virginica Class precission
Pred. Iris Setosa 50 0 0 100%
Pred. Iris Versicolour
0 49 1 98.00%
Pred. Iris Virginica 0 1 49 98.00%
Class recall 100% 98.00% 98.00%
Tabel 3.2 Performa algoritma Naïve Bayes untuk dataset iris
True Iris
Setosa
True Iris Versicolour True Iris Virginica Class precission
Pred. Iris Setosa 50 0 0 100%
Pred. Iris Versicolour
0 47 3 94.00%
Pred. Iris Virginica 0 3 47 94.00%
Class recall 100% 94.00% 94.00%
Tabel 3.3 Performa algoritma SVM untuk dataset iris
True Iris
Setosa
True Iris Versicolour True Iris Virginica Class precission
Pred. Iris Setosa 49 0 0 100%
Pred. Iris Versicolour
1 40 2 93.02%
Pred. Iris Virginica 0 10 48 82.76%
Class recall 98.00% 80.00% 96.00%
4 Kesimpulan
Dari beberapa algoritma klasifikasi terbaik menurut Wu et al (2007) yaitu: C4.5, SVM, serta Naïve Bayes. Kesemuanya merupakan algoritma dengan golongan best classification. Karena akurasi dari kesemuanya menunjukkan angka diatas 90%. Dalam klasifikasi data iris C4.5 merupakan algoritma terbaik dengan
tingkat akurasi 98,67%. Sedangkan Naïve Bayes 96% dan SVM 91,33%.
5 Daftar Pustaka
[1] I. H. Witten, E. Frank, and M. A. Hall,
Data Mining: Practical Machine Learning Tools and Techniques 3rd Edition. Elsevier, 2011.
[2] D. T. Larose, Discovering Knowledge
in Data: an Introduction to Data Mining. John Wiley & Sons, 2005.
[3] J. Han and M. Kamber, Data Mining:
Concepts and Techniques Second Edition. Elsevier, 2006.
[4] X. Wu, V. Kumar, J. R. Quinlan, J. Ghosh, Q. Yang, H. Motoda, G. J. Mclachlan, A. Ng, B. Liu, P. S. Yu, Z. Z. Michael, S. David, and J. H. Dan,
Top 10 algorithms in data mining.
2007, pp. 1–37.
[5] A. H. M. Ragab, A. Y. Noaman, A. S. Al-Ghamdi, and A. I. Madbouly, “A Comparative Analysis of Classification Algorithms for Students College Enrollment Approval Using Data Mining,” 2014.
[6] A. Ashari, I. Paryudi, and A. M. Tjoa, “Performance Comparison between Naïve Bayes , Decision Tree and k-Nearest Neighbor in Searching Alternative Design in an Energy Simulation Tool,” vol. 4, no. 11, pp. 33–39, 2013.
[7] D. R. Amancio, C. H. Comin, D. Casanova, G. Travieso, O. M. Bruno, F. A. Rodrigues, and L. da F. Costa, “A Systematic Comparison of Supervised Classifiers,” 2013.
[8] Maimoon, Data Mining and Knowledge
Discovery Handbook. 2010.
[9] E. Alpaydin, Introduction to Machine
Learning Second Edition. 2010.
[10] E. Prasetyo, Data Mining Konsep dan
Aplikasi menggunakan Matlab.
Yogyakarta: Andi Offset, 2012, p. 353. [11] B. Santosa, Data Mining Teknik
Pemanfaatan Data untuk Keperluan Bisnis, Edisi Pert. Yogyakarta: Graha
Ilmu, 2007.
[12] A. Christobel and D. . Sivaprakasam, “An Empirical Comparison of Data Mining Classification Methods,” vol. 3, no. 2, pp. 24–28, 2011.
[13] D. Sugianti, “Algoritma Bayesian Classification Untuk Memprediksi Heregistrasi Mahasiswa Baru di STMIK Widya Pratama,” no. 2, pp. 1– 5, 2012.
[14] K. Hastuti, “Analisis komparasi algoritma klasifikasi data mining untuk prediksi mahasiswa non aktif,” vol. 2012, no. Semantik, pp. 241–249, 2012. [15] T. H. Pudjianto, F. Renaldi, and A.
Teogunadi, “Penerapan data mining untuk menganalisa kemungkinan pengunduran diri calon mahasiswa baru,” 2011.
[16] Kusrini, S. Hartati, R. Wardoyo, and A. Harjoko, “Perbandingan metode nearest neighbor dan algoritma c4.5 untuk menganalisis kemungkinan
pengunduran diri calon mahasiswa di stmik amikom yogyakarta,” vol. 10, no. 1, 2009.
[17] D. Widiastuti, “Analisa Perbandingan Algoritma SVM, Naïve Bayes, dan Decission Tree dalam
Mengklasifikasikan Serangan (Attack) pada Sistem Pendeteksi Intrusi,” Jur.
Sist. Inf. Univ. Gunadarma, pp. 1–8,
2007.
[18] S. Susanto and D. Suryadi, Pengantar
Data Mining: Menggali Pengetahuan dari Bongkahan Data. Yogyakarta:
Andi Offset, 2010, p. 116.
[19] Kusrini and L. E. Taufiq, Algoritma
Data Mining. Yogyakarta: Andi Offset,
2009.
[20] A. S. Nugroho, “SUPPORT VECTOR MACHINE : PARADIGMA BARU DALAM SOFTCOMPUTING,” pp. 92–99, 2008.
![Gambar 1.3. Pemisahan dua kelas (class-1 dan class+1) dengan mencari margin terbesar [20]](https://thumb-ap.123doks.com/thumbv2/123dok/4835200.3460829/5.892.239.697.112.366/gambar-pemisahan-kelas-class-class-mencari-margin-terbesar.webp)