TUGAS SISTEM TEMU KEMBALI INFORMASI (STKI)
PERBANDINGAN KLASIFIKASI DOKUMEN MENGGUNAKAN
METODE NAÏVE BAYES DAN ROCCHIO
Disusun Oleh :
STKI - A
1. Luh Kiki Sidhi Cillasavet D 0910683060
2. Rini Rosidah 115060800111036
3. Suryanti Indahsari 115060807111034
PROGRAM STUDI INFORMATIKA/ ILMU KOMPUTER
PROGRAM TEKNOLOGI INFORMASI DAN ILMU KOMPUTER
UNIVERSITAS BRAWIJAYA
MALANG
BAB I
PENDAHULUAN
1.1 Latar Belakang
Kebutuhan akan informasi semakin meningkat seiring perkembangan teknologi dalam menyebarkan informasi kepada masyarakat. Informasi yang dibutuhkan mengalami perkembangan mulai dari informasi yang bersifat umum hingga informasi yang bersifat khusus. Banyaknya informasi dan dokumen yang tersedia mendorong manusia untuk mencari cara mendapatkan informasi dan dokumen yang tepat dalam waktu yang singkat. Apabila dokumen yang dicari berada pada kumpulan dokumen yang berjumlah sedikit, pencarian dapat dilakukan secara manual. Namun , apabila jumlah dokuen yang tersedia sangat besar, proses pencarian secara manual akan menghabiskan waktu dan tenaga. Apabila waktu pencarian yang terlalu lama, maka manfaat dari informasi yang diperoleh dapat berkurang. Oleh karena itu, diperlukan cara untuk memperoleh data secara cepat dan tepat.
Klasifikasi dokumen dapat membantu proses pencarian sebuah dokumen dengan cepat dan tepat. Banyak metode yang dikembangkan untuk melakukan suatu pencarian, salah satu
metode yang umum digunakan adalah dengan menggunakan metode klasifikasi. Beberapa contoh metode klasifikasi antara lain : Naïve Bayes, K-Nearest Neighbor, Rocchio, dan Vector
Space Model. Dengan banyaknya metode yang dapat digunakan dalam klasifikasi dokumen, maka diperlukan suatu perbandingan. Perbandingan hasil klasifikasi ditujukan untuk mengetahui metode mana yang dapat menghasilkan performasi lebih baik dari metode-metode yang digunakan tersebut. Dalam laporan ini akan dibahas mengenai perbandingan hasil klasifikasi
BAB II
DASAR TEORI
2.1 Metode Naïve Bayes
Metode klasifikasi ini diturunkan dari penerapan teorema bayes dengan asumsi independence(saling bebas). Naïve Bayes Classifier termasuk ke dalam algoritma pembelajaran bayes yang di bangun noleh data pelatihan untuk memperkirakan probabilitas dari setiap katagori yang terdapat pada ciri dokumen yang diuji [DUM-98:3]. Naïve Bayes Classifier adalah metode pengklasifikasian paling sederhana dari model pengklasifikasian dengan peluang, dimana
diasumsikan bahwa setiap atribut contoh (data sampel) bersifat saling lepas satu sama lain berdasarkan atribut kelas. Nilai peluang yang di dapatkan dari perhitungan dengan naïve bayes dapat digunakan untuk memprediksi kemungkinan dokumen dari anggota suatu kelas.
Naïve Bayes Classifier banyak di gunakan dalam melakukan klasifikasi dokumen teks. Pada penerapannnya , setiap posisi kata dalam dokumen harus diposisikan atau dianggap sebagai atribut. Persamaan pengkatagorian dokumen menggunakan naïve bayes adalah sebagai berikut [MIT-97:176] :
| |
Keterangan :
| : peluang kategori tertentu untuk kemunculan sebuah kata.
Jika data yang digunakan merupakan data kontinyu maka persamaan yang di gunakan adalah:
√
Naïve Bayes Classifier memberi nilai target kepada data baru menggunakan nilai VMAP, yaitu nilai kemungkinan tertinggi dari seluruh anggota himpunan set domain V[MIT-97:177].
Keterangan :
: fungsi yang mengembalikan index dari nilai maksimum dari sekumpulan himpunan data.
Teorema Bayes kemudian digunakan untuk menulis ulang persamaan yang di tulis menjadi 2.3 menjadi persamaan 2.4 sebagai berikut :
|
Pada persamaan 2.4 nilai P(a1,a2,a3,….,an) akan bernilai konstan untuk semua sehingga
persamaan 2.4 dapat ditulis menjadi persamaan 2.5 sebagai berikut :
|
Dengan asumsi bahwa teorema bayes bersifat independence (saling bebas) maka menyebabakan setiap kata pada kategori akan independent antara satu dengan lainnya [MIT-97:177]. Sehingga menjadi persamaan :
| |
Subtitusi persamaan 2.5 dengan persamaan 2.6 menjadi persamaan 2.7 :
|
Keterangan :
:nilai probabilitas hasil perhitungan Naïve Bayes Classifier untuk nilai fungsi target yang bersangkutan.
: Frekuensi kemunculan kata
( )
( | ) | |
Keterangan :
P( ) : Peluang jumlah dokumen ketegori tertentu terhadap seluruh dokumen
( | ) : Peluang kategori Wk ketika terdapat kemunculan sebuah kata vj.
: kumpulan dokumen yang memiliki nilai target vj
: jumlah dokumen yang digunakan dalam pelatihan (kumpulan data latih).
: jumlah total kata yang terdapat di dalam data tekstual yang memiliki nilai fungsi target yang sesuai.
: jumlah kemunculan kata Wk pada semua data tekstual yang memiliki nilai fungsi
target yang sesuai
| | : jumlah kata yang berbeda yang muncul dalam seluruh data tekstual yang digunakan
2.2 Metode Rocchio
Metode Rocchio relevance feedback adalah strategi reformulasi query paling populer karena sering digunakan untuk membantu user pemula suatu information retrieval systems. Dalam siklus relevance feedback, kepada user disajikan hasil pencarian dokumen, setelah itu user dapat memeriksa dan menandai dokumen yang benar-benar relevan[YDH-13].
Rocchio classifiers merupakan salah satu metode pembelajara supervised document classification. Metode klsifikasi rocchio membandingkan kesamaan isi antara data training dan
heuristic utama adalah klasifikasi rocchio yaitu skema pembobtan tfidf, metode pembelajaran rocchio disebut juga dengan tfidf Classifiers [FAT-13].
Didalam membandngkan kesamaan isi antara data training dan data test, tfidf classifiers menggunakan prototype vector untuk merepresentasikan kategori yang terbentuk dari data training, dengan kata lain prototype vector merupakan vector yang mewakili seluruh vector data training dalam setiap kategori. Tiga hal utama yang dapat dipakai pada klasifikasi tfidf adalah menggunakan skema pembobotan tfidf yang berguna untuk merepresentsikan dokumen ke dalam sebuah vector, merepresentasikan prototype setiap kategori dengan menjumlahkan vector –
vector dalam satu kategori dari data training, membandingkan kedekatan sudut antara vector data test dengan semua prototype vector [FAT-13].
Teknik ini menggunakan Vector Space Model untuk merepresentasikan setiap dokumen dalam korpus. Algoritma rocchio diasumsikan bahwa sebagian pengguna memiliki konsep umum pada dokumen yang relevan dan non-relevan sebagai saranan meningkatkan pencarian yang singkat dan presisi.
Langkah-langkah pengolahan query [FAT-13]:
a. Text Mining dan Klasifikasi Teks : mencari dan mengelompokkan dokumen ke dalam kategori tertentu
b. Parsering : memilah isi dokumen menjadi unit-unit kecil (token), yang berupa kata, frase, atau kalimat.
c. Stemming : proses penghilangan prefiks (awalan) dan sufiks (akhiran)
d. Inverted Index : struktur yang dioptimasi untuk menemukan kembali dokumen
Dalam menggunakan vector space model diperlukan batas-batas antar kelas untuk mengetahui klasifikasi yang sesuai. Teknik Rocchio menggunakan centroid untuk batas-batas tersebut.
⃗⃗⃗ | | ∑
Dimana Dc adalah himpunan dokumen di dalam korpus pada kelas c. sedangkan merupakan
Dan dengan menghitung kemiripan (similarity) antara dua vektor dokumen adalah
sebagai berikut:
Jika terdapat suatu kueri diproses menjadi sebuah vektor space, maka dapat dibandingkan dengan masing-masing centroid kelas yang ada pada korpus. Dengan dua pendekatan mencari kemiripan dua vektor space., vektor kueri dianggap mirip dengan sebuah centorid kelas dapaat dilakukan dengan menggunakan jarak (distance) atau menggunakan kemiripan (similarity). Jika menggunakan jarak, yang dicari adalah kelas yang memiliki jarak yang terkecil dengan kueri[YDH-13]. Dan jika menggunakan kemiripan yang dicari adalah kelas yang memiliki kemiripan yang paling besar dengan kueri, seperti yang ada di bawah[YDH-13]:
Menggunakan jarak
| |
Menggunakan kemiripan
BAB III
PEMBAHASAN
3.1Klasifikasi Dokumen dengan Naïve Bayes dan Rocchio
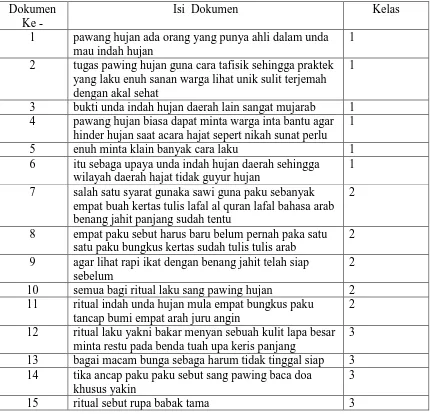
Klasifikasi dokumen dengan menggunakan metode Naïve Bayes dan Rocchio ini menggunakan 15 data training dan 5 data uji. Hasil klasifikasi dari data tersebut akan digolongkan kedalam 3 kategori kelas, yaitu class 1, class 2 dan class 3. Berikut merupakan dokumen yang digunkanan sebagai data latih.
Tabel 3.1 Dokumen data latih
Dokumen Ke -
Isi Dokumen Kelas
1 pawang hujan ada orang yang punya ahli dalam unda mau indah hujan
1
2 tugas pawing hujan guna cara tafisik sehingga praktek yang laku enuh sanan warga lihat unik sulit terjemah dengan akal sehat
1
3 bukti unda indah hujan daerah lain sangat mujarab 1 4 pawang hujan biasa dapat minta warga inta bantu agar
hinder hujan saat acara hajat sepert nikah sunat perlu 1
5 enuh minta klain banyak cara laku 1
6 itu sebaga upaya unda indah hujan daerah sehingga wilayah daerah hajat tidak guyur hujan
1
7 salah satu syarat gunaka sawi guna paku sebanyak empat buah kertas tulis lafal al quran lafal bahasa arab benang jahit panjang sudah tentu
2
8 empat paku sebut harus baru belum pernah paka satu satu paku bungkus kertas sudah tulis tulis arab
2
9 agar lihat rapi ikat dengan benang jahit telah siap sebelum
2
10 semua bagi ritual laku sang pawing hujan 2 11 ritual indah unda hujan mula empat bungkus paku
tancap bumi empat arah juru angin
2
12 ritual laku yakni bakar menyan sebuah kulit lapa besar minta restu pada benda tuah upa keris panjang
3
13 bagai macam bunga sebaga harum tidak tinggal siap 3 14 tika ancap paku paku sebut sang pawing baca doa
khusus yakin
3
Tabel 3.2 Dokumen Uji indonesia letak dekat garis khatulistiwa iklim tropis suhu jadi uap curah hujan tinggi.huj buat inovasi baru guna jatuh hujan cepat hujan buat bentuk butuh awan awan kadar air cepat angin lambat butuh butuh hujan buat buat sema awan bahan sifat higroskopik tumbuh butir butir hujan awan ingkat selanjut percepat jadi hujan awan cumulus awan bagus dia hujan buat lokasi ilih awan awan kriteria langkah selanjut semai butuh dia sawat fungsi angkut bubuk bubuk siap sebar awan awan
1 3 hujan.perbeda awan dingin awan hangat.menurut suhu lingkung fisik atmosfer mana awan awan beda awan
dingin cold cloud awan hangat warm cloud sebut awan dingin apabila bagi lingkung atmosfer suhu 0 derajat celcius awan banyak daerah lintang engah mana suhu
udara muka tanah suhu minus 0 derajat indonesia suhu udara muka tanah 20 300 derajat celcius dasar awan suhu 180 derajat celcius meski puncak awan embus lewat titik beku awan awan hangat sisa awan dingin awan semacam sebut mixed cloud
3
jadi hujan awan hangat uap air angkat atmosfer fungsi inti kondensasi uap air evaporasi embun inti kondensasi garam asal air laut sifat higroskopik semenjak mula kondensasi partikel ubah droplets titik air droplets kumpul bentuk awan partikel air eliling debu kristal garam ebal udara jatuh awan hujanproses jadi hujan awan nginproses mula kristal es tambah air super dingin supercooled water deposit uap air ada kristal es egang anan hujan awan
dingin sebut kristal es.pada udara naik atmosfer bentuk titik titik air awan tinggi tentu sumbu titik beku awan ubah kristal kristal es udara sekeliling dingin membe kristal tadi kristal tambah jaid butir salju
1 2 udara uap uap air lainnya.suhu udara panas matahar uap air kondensasi adat embun embun bentuk titik titik air suhu titik titik embun kumpul adat bentuk awan kaji neilburger 1995 tahap tetes tetes air ukur
jari jari 5 20 mm ukur tetes air jatuh cepat hujan:apabila suhu atmosfer dingin titik air membe ubah es itu apa suhu rendah hujan salju indonesia iklim tropis hujan salju sulit jadi.air hujan asal uap air laut 97 meski air laut air asin hujan air tawar akibat hukum fisika mana air uap awan kandung hilang ketahu garam mineral beda air air ubah titik titik kandung garam mineral luruh sendir kondensasi awan kumpul titik titik air bantu udara gerak dingin adiabatic
lembap nisbi rh nya tambah kondensasi mula inti kondensasi aktif apabila rh 78
3 2
3.2 Hasil Screenshoot program
DAFTAR PUSTAKA
[DUM-08] Dumais,Susan, Platt,John, dan Hackerman,David. 2008. “inductive Learning
Algorithm and Representation for text category”.
[FAT-13] Fatmawati, Triyah. 2013. Rocchio Clasification. Surabaya. Universitas Airlangga
[MIT-97] Mitchell, Tom M. 1997. “Machine Learning”. T.M.Mitchell, McGraw Hill.