KOMPARASI ALGORITMA KLASIFIKASI UNTUK SENTIMEN ANALYSIS DJ.ID PADA TWITTER
Bebas
11
0
0
Teks penuh
(2)
(3)
(4)
(5)
(6)
(7)
(8)
(9)
(10)
(11)
Gambar
+4
Dokumen terkait
Berdasarkan pengamatan yang telah dilakukan terhadap tiga classifier berbeda untuk membuat model analisa sentimen twit tentang insiden kebocoran data Tokopedia, dapat
Bagaimana menerapkan algoritma Convolutional Neural Network dalam analisis sentimen pada data yang di dapat dari media sosial twitter tentang pemindahan ibu
Dari hasil penelitian terhadap analisis sentimen data twitter dengan menggunakan text mining pada suatu produk dapat disimpulkan sebagai berikut : 1. Algoritma Naïve Bayes
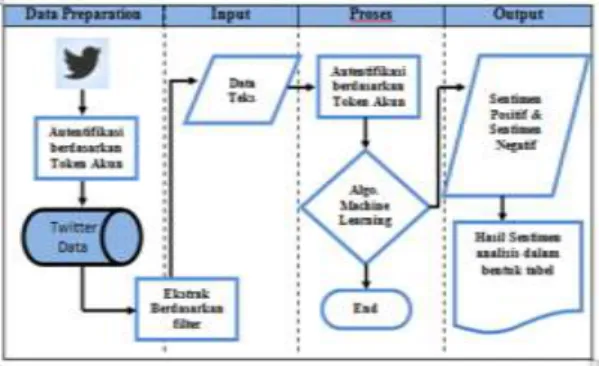
Proses ini dilakukan menggunakan metode 10-fold cross validation, yaitu metode membagi dataset menjadi 10 bagian yang mana 1 bagian diantaranya menjadi data uji
hortensis Becker disebut nilam sabun (Nuryani, 2006a). patchouli) merupakan tanaman yang memiliki aroma khas dan rendemen minyak daun keringnya tinggi yaitu 2,5-5%
Penerapan dari algoritma SVM dalam melakukan analisis sentimen pada media sosial Twitter terhadap vaksin COVID- 19 dilakukan dengan melalui beberapa tahapan, yaitu
The data collection stage is done by taking tweet data with sentiment label. Every data already contains a label or class from each twit. Label of the data is a negative,
Bagaimana analisis sentimen pengguna media sosial twitter terhadap review layanan ekspedisi JNE dan J&T Express dengan klasifikasi menggunakan algoritma Naïve Bayes.. Bagaimana
