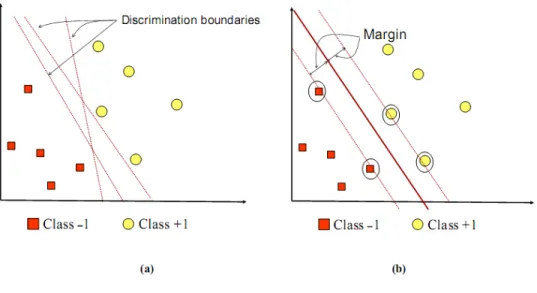
5
BAB II
TINJAUAN PUSTAKA
2.1 Multimedia Information Retrieval
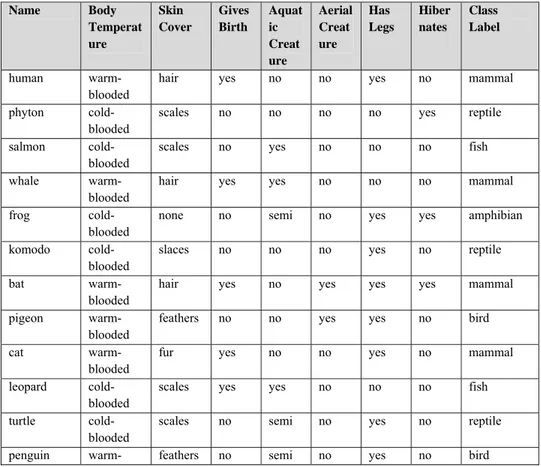
Internet merupakan sebuah loncatan besar dalam dunia tehnologi manusia yang perkembangannya semakin cepat dari waktu ke waktu. Pemanfaatan tehnologi internet semain beragam, mulai dari surat elektronik (email) sampai pada pengiriman video (video streaming), bahkan digunakan sebagai media komunikasi jarak jauh (teleconference) tanpa mengenal batas-batas teritorial negara.Pengguna internet tinggal memilih sejauh mana mereka akan melakukan sesuatu dengan bantuan tehnologi internet ini, karena internet merupakan sebuah dunia baru, dimana tidak mengenal adanya batas waktu dan batas wilayah.
Kondisi tersebut memunculkan kebutuhan untuk pencarian data yang komprehensif dimana dapat mencari data teks, gambar, video ataupun suara. Hal ini yang disebut sebagai Multimedia Information Retrieval System (MIRS).
Sehingga MIRS dapat didefinisikan sebagai sebuah sistem manajemen (penyimpanan, retrival dan manipulasi) dari berbagai tipe data(Nordbotten, 2008).
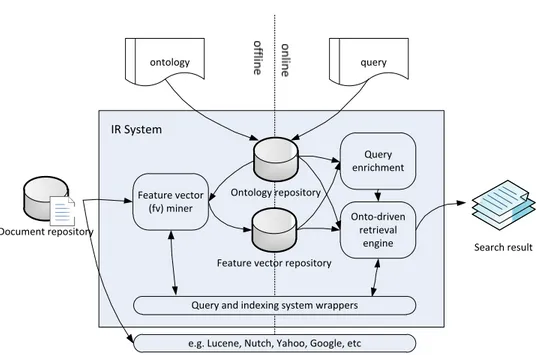
Dalam prakteknya arsitektur dari MIRS dapat digambarkan sebagai berikut:
Feature vector (fv) miner
Query enrichment
Onto‐driven retrieval
engine Document repository
Search result
ontology query
Ontology repository
Feature vector repository
Query and indexing system wrappers
e.g. Lucene, Nutch, Yahoo, Google, etc