i
MENGGUNAKAN METODE OVERLAP MEASURE FUNCTION (STUDI KASUS SKRIPSI PROGRAM STUDI TEKNIK INFORMATIKA
UNIVERSITAS SANATA DHARMA YOGYAKARTA)
SKRIPSI
Diajukan untuk Memenuhi Salah Satu Syarat
Memperoleh Gelar Sarjana Komputer
Program Studi Teknik Informatika
Oleh:
Monica Pancaindrani Dewantari
075314060
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
ii
DOCUMENT USING METHOD OVERLAP MEASURE FUNCTION (A CASE STUDY OF INFORMATIC ENGINEERING FINAL PROJECT
DOCUMENT IN SANATA DHARMA UNIVERSITY YOGYAKARTA)
A THESIS
Presented as Partial Fulfillment of the Requirements
To Obtain the Sarjana Komputer Degre
In Informatics Engineering Department
By :
Monica Pancaindrani Dewantari
075314060
INFORMATICS ENGINEERING STUDY PROGRAM FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY YOGYAKARTA
v
HALAMAN PERSEMBAHAN
! ! ! "
#
$# % &
#
! ' "#
$ ( '# & # #
viii
ABSTRAK
Skripsi merupakan tugas akhir yang sangat penting bagi seorang mahasiswa, karena skripsi sebagai salah satu syarat lulus mahasiswa di perguruan tinggi. Mahasiswa sering mengambil jalan praktis dalam pengerjaan skripsi untuk mencari kemudahan. Dalam pengerjaan skripsi sering kali mahasiswa mengutip atau menggunakan beberapa atau keseluruhan kata – kata, kalimat, gagasan, ide, dan bagian – bagian lain hasil skripsi orang lain tanpa mencantumkan secara jelas sumber kutipan yang didapat. Hal ini sangat dilarang keras oleh setiap universitas , sebab mahasiswa yang melakukan tindakan plagiarisme tidak mencerminkan sikap kreatif sebagai kalangan terpelajar. Maka dari itu skripsi ini bertujuan membuat suatu sistem untuk mendeteksi tindakan plagiarisme dokumen skripsi yang dilakukan oleh mahasiswa Universitas Sanata Dharma.
Proses untuk melakukan pendeteksian plagiarisme dokumen skripsi diawali dengan melakukan proses preprocessing, yaitu tokenisasi, stopword removal, stemming, dan splitter kalimat. Kemudian dengan menggunakan metode overlap measure function yang akan menghasilkan nilai similarity (nilai bobot) dari setiap dokumen query yang dibandingkan dengan dokumen asli, nilai similarity dokumen tersebut yang akan menentukan deteksi plagiarisme yang disesuaikan dengan nilai threshold plagiarisme.
Skripsi ini menggunakan data 50 dokumen skripsi mahasiswa Teknik Informatika untuk pengujian deteksi plagiarisme, sebelum dideteksi terlebih dahulu harus melakukan pencarian nilai threshold, pencarian nilai threshold plagiarisme menggunakan persentase 50, 40 , dan 30 dari rata – rata jumlah similarity dari dokumen – dokumen yang benar – benar sama(dokumen dengan dirinya sendiri). Setelah dilakukan pengujian persentase nilai threshold ,persentase yang paling baik adalah 50 dibandingkan dengan 30 dan 40. Persentase 50 memiliki nilai precision 94,8%, sedangkan persentase 40 dengan precision 92,4% dan persentase 30% dengan precision 70%. Maka dari itu untuk mendeteksi plagiarisme pada sistem ini digunakan nilai threshold dengan persentase 50% yaitu 869,3 dan sistem ini berlaku untuk mendeteksi dokumen dengan panjang kalimat 100 sampai 500 kalimat dan panjang kata 5 sampai dengan 50 kata.
ix
ABSTRACT
Thesis is the final task which is very important for a college students, because of thesis is one of conditions for graduating college students. College Students often take a practical way to make things easy in doing their thesis. Sometimes they using all of the words, phrases, ideas, and the rest of the thesis of others without citation shall state clearly the source derived. It is strictly prohibited by any university, for students who commit acts of plagiarism does not reflect their creative attitude as the educated. This thesis aims to create a system to detect plagiarism action thesis documents carried by students at the University of Sanata Dharma.
Process to conduct thesis document plagiarism detection process begins with preprocessing, namely tokenisasi, stopword removal, stemming, and sentence splitter. Then by using the method of overlap measure function that will return the value of similarity (weighted value) of each document query is compared to the original document, the document similarity values that will define plagiarism detection threshold value is adjusted to plagiarism.
x
KATA PENGANTAR
Puji syukur penulis panjatkan kehadirat Tuhan Yang Maha Esa, yang telah
melimpahkan berkat dan rahmatNya sehingga penulis dapat menyelesaikan tugas
akhir yang berjudul “SISTEM PENDETEKSI PLAGIARISME DOKUMEN
SKRIPSI MENGGUNAKAN METODE OVERLAP MEASURE FUNCTION
(STUDI KASUS SKRIPSI PROGRAM STUDI TEKNIK INFORMASTIKA
UNIVERSITAS SANATA DHARMA YOGYAKARTA)”. Tugas akhir ini ditulis
sebagai salah satu syarat memperoleh gelar sarjana program studi Teknik
Informatika, Fakultas Sains dan Teknologi Universitas Sanata Dharma.
Dalam kesempatan ini, penulis mengucapkan terimakasih yang
sebesar-besarnya kepada :
1. Ibu P.H. Prima Rosa, S.Si.,M.Sc., selaku Dekan Fakultas Sains dan Teknologi
Universitas Sanata Dharma Yogyakarta.
2. Ibu Ridhowati Gunawan, S.Kom.,M.T., selaku ketua jurusan Program Studi
Teknik Informatika Universitas Sanata Dharma Yogyakarta.
3. Ibu Sri Hartati Wijono, S.Si.,M.Kom., selaku Dosen Pembimbing atas segala
waktu, kesabaran, serta memberi kritik dan saran yang membangun dalam
membantu penyelesaian tugas akhir ini.
4. Bapak Puspaningtyas Sanjoyo Adi S.T.,M.T., dan Bapak J.B.Budi Darmawan,
xii
DAFTAR ISI
HALAMAN JUDUL ... i
HALAMAN JUDUL (Bahasa Inggris) ... ii
HALAMAN PERSETUJUAN ... iii
HALAMAN PENGESAHAN ... iv
HALAMAN PERSEMBAHAN ... v
HALAMAN PERNYATAAN KEASLIAN KARYA ... vi
LEMBAR PERNYATAAN PERSETUJUAN ... vii
ABSTRAK ... viii
ABSTRACT ... ix
KATA PENGANTAR ... x
DAFTAR ISI ... xii
DAFTAR TABEL ... xviii
DAFTAR GAMBAR ... xx
BAB I PENDAHULUAN ... 1
1.1 Latar Belakang ... 1
1.2 Rumusan Masalah ... 5
xiii
1.4 Tujuan Penelitian ... 6
1.5 Luaran Yang Diharapkan ... 6
1.6 Metodologi Penelitian ... 6
1.7 Sistematika Penulisan ... 8
BAB II LANDASAN TEORI ... 9
2.1 Plagiarisme ... 9
2.1.1 Definisi Plagiarisme ... 9
2.1.2 Bentuk Plagiarisme ... 10
2.2 Definisi Sistem ... 15
2.3 Konsep Information Retrieval ... 17
2.3.1 Definisi Information Retrieval ... 17
2.3.2 Proses Preprocessing Teks Dokumen ... 19
2.4 Stemming Algoritma Nazief dan Adriani ... 22
2.5 Deteksi Plagiarisme ... 26
2.5.1 Overlap Measure Function ... 27
2.5.2 Algoritma ... 29
2.6 Recall dan Precision ... 31
xiv
3.1 Gambaran Umum Sistem ... 33
3.2 Analisis Kebutuhan Sistem ... 41
3.2.1 Definisi Aktor ... 41
3.2.2 Diagram Use Case ... 42
3.2.3 Definisi Use Case ... 44
3.2.4 Skenario Use Case ... 47
3.2.4.1 Skenario Use Case Login ... 47
3.2.4.2 Skenario Use Case Logout ... 48
3.2.4.3 Skenario Use Case Input Account ... 49
3.2.4.4 Skenario Use Case Edit Account ... 50
3.2.4.5 Skenario Use Case Hapus Account ... 52
3.2.4.6 Skenario Use Case Input Stopword ... 53
3.2.4.7 Skenario Use Case Edit Stopword ... 55
3.2.4.8 Skenario Use Case Hapus Stopword ... 57
3.2.4.9 Skenario Use Case Input Kata Dasar ... 58
3.2.4.10 Skenario Use Case Edit Kata Dasar ... 60
xv
3.2.4.12 Skenario Use Case Kelola Koleksi Dokumen Skripsi ... 62
3.2.4.13 Skenario Use Case Deteksi Plagiarisme Koleksi Dokumen Skripsi ... 64
3.2.4.14 Skenario Use Case Kelola Dokumen Skripsi Baru ... 65
3.2.4.15 Skenario Use Case Deteksi Plagiarisme Dokumen Skripsi ... 67
3.2.4.16 Skenario Use Case Pencarian Koleksi Dokumen Skripsi ... 68
3.2.5 Model Analisis... 70
3.2.5.1 Login... 70
3.2.5.2 Input Account ... 71
3.2.5.3 Edit Account ... 72
3.2.5.4 Hapus Account ... 73
3.2.5.5 Input Stopword ... 74
3.2.5.6 Edit Stopword ... 76
3.2.5.7 Hapus Stopword ... 77
3.2.5.8 Input Kata Dasar ... 78
xvi
3.2.5.10 Hapus Kata Dasar ... 81
3.2.5.11 Kelola Koleksi Dokumen Skripsi ... 83
3.2.5.12 Deteksi Plagiarisme Koleksi Dokumen Skripsi ... 85
3.2.5.13 Kelola Dokumen Skripsi Baru... 87
3.2.5.14 Deteksi Plagiarisme Dokumen Skripsi ... 89
3.2.5.15 Pencarian Koleksi Dokumen Skripsi ... 91
3.2.5.16 Logout ... 92
3.2.6 Diagram Konteks ... 93
3.2.7 Diagram Kelas Keseluruhan ... 93
3.3 Desain Sistem ... 95
3.3.1 Kelas Perancangan ... 95
3.3.2 Atribut dan Method ... 106
3.3.3 Perancangan Database ... 147
3.3.4 Antarmuka ... 150
3.3.5 Rencana Pengujian dan Evaluasi ... 162
BAB IV IMPLEMENTASI DAN PENGUJIAN ... 167
xvii
4.2 Implementasi Antarmuka ... 168
4.3 Implementasi Controller ... 180
4.4 Implemantasi Model ... 180
4.5 Implemantasi Entity ... 181
4.6 Method – Method Penting ... 183
4.7 Pengujian Hasil Manual dan Hasil Program ... 189
4.8 Pengujian Mencari Nilai Threshold ... 212
4.9 Pengujian Deteksi Plagiarisme... 213
4.10 Testing Deteksi Plagiarisme ... 218
4.11 Analisa Kelemahan Program ... 220
BAB V KESIMPULAN DAN SARAN ... 221
5.1 KESIMPULAN ... 221
5.2 SARAN ... 222
DAFTAR PUSTAKA ... 223
xviii
DAFTAR TABEL
Tabel 2.1 Kombinasi Awalan dan Akhiran yang Tidak Diijinkan ... 24
Tabel 2.2 Cara Menentukan Tipe Awalan untuk Kata yang Diawali dengan “te” ... 25
Tabel 2.3 Jenis Awalan Berdasarkan Tipe Awalannya... 26
Tabel 3.1 Hak Akses User... 41
Tabel 3.2 Deskripsi Use Case ... 44
Tabel 3.3 Skenario Use Case Login ... 47
Tabel 3.4 Skenario Use Case Logout ... 48
Tabel 3.5 Skenario Use Case Input Account ... 49
Tabel 3.6 Skenario Use Case Edit Account ... 51
Tabel 3.7 Skenario Use Case Hapus Account ... 52
Tabel 3.8 Skenario Use Case Input Stopword ... 54
Tabel 3.9 Skenario Use Case Edit Stopword ... 55
Tabel 3.10 Skenario Use Case Hapus Stopword ... 57
Tabel 3.11 Skenario Use Case Input Kata Dasar ... 58
Tabel 3.12 Skenario Use Case Edit Kata Dasar ... 60
Tabel 3.13 Skenario Use Case Hapus Kata Dasar ... 62
xix
Tabel 3.15 Skenario Use Case Deteksi Plagiarisme Koleksi Dokumen Skripsi ... 64
Tabel 3.16 Skenario Use Case Kelola Dokumen Skripsi Baru ... 66
Tabel 3.17 Skenario Use Case Deteksi Plagiarisme Dokumen Skripsi ... 67
Tabel 3.18 Skenario Use Case Pencarian Koleksi Dokumen Skripsi ... 69
Tabel 3.19 Kelas Perancangan ... 95
Tabel 3.20 Diagram Relasional Skripsi ... 148
Tabel 3.21 Diagram Relasional Kalimat ... 148
Tabel 3.22 Diagram Relasional DokumenSimilarity ... 149
Tabel 3.23 Diagram Relasional User ... 149
Tabel 3.24 Diagram Relasional Stopword ... 149
Tabel 3.25 Diagram Relasional Kamus ... 150
Tabel 4.1 Implementasi Controller ... 180
Tabel 4.2 Diagram Relasional Kamus ... 181
xx
DAFTAR GAMBAR
Gambar 2.1 Gambaran Sistem ... 16
Gambar 2.2 Gambaran Umum Information Retrieval ... 18
Gambar 2.3 Tahapan Preprocessing ... 19
Gambar 2.4 Tahapan Tokenisasi ... 20
Gambar 2.5 Proses Deteksi Plagiat PPChecker ... 27
Gambar 3.1 Gambaran Umum Sistem ... 37
Gambar 3.2 Algoritma Overlap Measure Function ... 38
Gambar 3.3 Alur Pencarian Nilai Threshold ... 40
Gambar 3.4 Diagram Use Case... 43
Gambar 3.5 Diagram Konteks ... 93
Gambar 3.6 Diagram Kelas Keseluruhan ... 95
Gambar 3.7 Diagram ERD ... 147
Gambar 3.8 Antarmuka Form Login ... 150
Gambar 3.9 Antarmuka Menu Utama Admin ... 151
Gambar 3.10 Antarmuka Tab Add Account ... 153
xxi
Gambar 3.12 Antarmuka Tab Stopword ... 155
Gambar 3.13 Antarmuka Tab Kamus ... 156
Gambar 3.14 Antarmuka Form Preprocessing Admin ... 157
Gambar 3.15 Antarmuka Form Deteksi ... 158
Gambar 3.16 Antarmuka Tab Preprocessing ... 160
Gambar 3.17 Antarmuka Tab Deteksi ... 161
Gambar 3.18 Antarmuka Form Pencarian Skripsi User ... 162
Gambar 4.1 Implementasi Antarmuka Form Login ... 168
Gambar 4.2 Implementasi Antarmuka Form Menu Utama Admin ... 169
Gambar 4.3 Implementasi Antarmuka Form Account Admin Tab Add Account 171
Gambar 4.4 Implementasi Antarmuka Form Account Admin Tab Edit Account ... 171
Gambar 4.5 Implementasi Antarmuka Form Setting Admin Tab Stopword ... 172
Gambar 4.6 Implementasi Antarmuka Form Setting Admin Tab Kamus ... 173
Gambar 4.7 Implementasi Antarmuka Form Preprocessing Admin ... 174
Gambar 4.8 Implementasi Antarmuka Form Deteksi ... 175
Gambar 4.9 Implementasi Antarmuka Form Menu Utama User ... 176
xxii
Gambar 4.11 Implementasi Antarmuka Form Preprocessing User Tab Deteksi ... 178
1 BAB
I
PENDAHULUAN 1.1Latar Belakang
Teknologi saat ini semakin berkembang pesat di berbagai bidang kehidupan
, hal ini begitu cepat mendorong banyak orang memanfaatkan teknologi untuk
melakukan pekerjaan – pekerjaan agar menjadi lebih praktis, efisien, efektif dan
akurat pengerjaannya dalam kehidupan sehari –hari. Oleh karena teknologi telah
berkembang sangat pesat, penyalahgunaan akan teknologi juga semakin
berkembang di berbagai kalangan masyarakat. Keinginan manusia untuk
melakukan hal yang mudah dan praktis memicu berbagai tindakan negatif, salah
satu tindakan negatif yang banyak dilakukan adalah plagiarisme . Plagiarisme
merupakan suatu tindakan yang menjiplak, mencuri gagasan, ide, atau hasil karya
orang lain, hal ini terjadi karena keterbatasan dan kurang kemampuan seseorang
dalam berkarya dan menghasilkan pemikiran,ide, atau gagasan yang baru.
Plagiarisme terjadi pada berbagai bentuk karya , seperti karya tulis , lagu, film,
dan berbagai karya yang lain. Akan tetapi yang paling sering diplagiat adalah
karya tulis karena sangat mudah untuk menjiplaknya. Menulis adalah suatu
kegiatan yang sulit, sebab dituntut keterampilan serta kemampuan menulis yang
lebih dan dapat menuangkan pemikiran ke dalam bentuk tulisan. Penulis tidak
adalah bagaimana menuliskan ide – ide milik sendiri yang ada dalam pikiran agar
benar – benar tersampaikan dalam bentuk tulisan. Karena menulis itu sulit, maka
membutuhkan waktu dalam mengerjakannya, dalam banyak kasus untuk
mempersingkat waktu banyak orang yang mencampurkan ide orang lain ke dalam
ide tulisannya sendiri. Dan ini yang dinamakan sebagai tindakan plagiarisme,
yang dengan sengaja menggunakan ide dan pemikiran orang lain tanpa
atribusi[1]. Maka dari itu diperlukan suatu cara untuk melakukan deteksi tindakan
plagiat terhadap karya tulis, agar tindakan plagiat tersebut dapat diatasi.
Tindakan plagiarisme terhadap karya tulis dapat terjadi dimana – mana, dan
paling banyak ditemukan pada dunia pendidikan mulai dari tingkat sekolah
sampai perguruan tinggi. Terutama pada tingkat perguruan tinggi, dikalangan
mahasiswa tindakan plagiarisme tidak menjadi hal asing lagi. Hal ini terjadi
karena mahasiswa hampir setiap hari mengerjakan tugas karya tulis dari dosen
seperti laporan, tugas, makalah dan skripsi. Apalagi dalam pengerjaan skripsi,
tindakan plagiat paling sering dilakukan padahal skripsi merupakan tugas akhir
untuk mencapai kelulusan bagi seorang mahasiswa, akan tetapi banyak
mahasiswa yang melakukan kecurangan dalam pengerjaannya. Dalam membuat
skripsi sering kali mahasiswa mengutip atau menggunakan beberapa atau
keseluruhan kata – kata, gagasan, ide, dan bagian – bagian lain hasil skripsi orang
lain[2]. Mereka melakukan tindakan plagiat tersebut karena kebanyakan
tidak ingin bersusah payah dalam menulis skripsi. Hal ini sangat dilarang keras
oleh setiap universitas , sebab mahasiswa yang melakukan tindakan plagiarisme
tidak mencerminkan sikap kreatif sebagai kalangan terpelajar.
Universitas Sanata Dharma merupakan salah satu perguruan tinggi swasta
yang melarang mahasiswa untuk melakukan tindakan plagiarisme terhadap
pembuatan skripsi. Saat ini Universitas Sanata Dharma menggunakan dokumen
digital skripsi untuk media penyimpanan dan pemberian informasi skripsi bagi
mahasiswa. Penggunaan dokumen digital skripsi oleh pihak universitas
dimaksudkan untuk membantu mahasiswa yang akan menempuh skripsi agar
mendapatkan informasi, pandangan,wawasan, dan referensi bagi skripsi yang
akan dibuat. Akan tetapi penggunaan dokumen digital skripsi tidak menjadi
efisien, dikarenakan mahasiswa melakukan penyalahgunaan dengan melakukan
plagiarisme terhadap dokumen skripsi yang disediakan oleh pihak universitas.
Mahasiswa yang tidak memiliki kreativitas dapat dengan mudah menyalin isi dari
dokumen digital skripsi. Karena dokumen digital skripsi dapat dengan mudah
diplagiat oleh mahasiswa, maka diperlukan sebuah sistem pendeteksi plagiarisme
terhadap dokumen skripsi.
Sistem pendeteksian plagiarisme pada dokumen skripsi ini sangat penting
dilakukan untuk usaha menemukan tindakan plagiat skripsi yang dilakukan oleh
mahasiswa. Saat ini beberapa sistem pendeteksi plagiarisme telah dibuat dengan
rabin karp [3][4]. Pada pendeteksian plagiarisme menggunakan rabin karp,
algoritma ini digunakan untuk mendeteksi plagiarisme dengan mencari pola
tulisan yang didapat dari substring-substring pada sebuah teks dalam dokumen,
algoritma ini menggunakan hashing untuk menemukan sebuah substring dalam
sebuah teks [3]. Pada pendeteksi plagiarisme menggunakan algoritma smith
waterman, dengan melakukan pembandingan antara dua dokumen untuk
mengetahui tingkat kemiripan antara kedua dokumen tersebut. Hasil
pembandingan dinyatakan dalam bentuk bobot atau nilai kemiripan dari dokumen
yang dibandingkan [4]. Sistem pendeteksian plagiarisme yang akan dibuat
menggunakan algoritma overlap measure function , algoritma ini mampu
mendeteksi plagiarisme dengan membandingkan beberapa dokumen yang telah
diekstrak. Dokumen – dokumen tersebut terlebih dahulu diolah dengan tahap
preprocessing dan dipecah menjadi per kalimat. Setelah didapatkan kalimat –
kalimat dari setiap dokuem asli dan dokumen query, selanjutnya kalimat tersebut
akan diproses ke dalam perhitungan overlap measure function untuk
mendapatkan nilai similarity antara dokumen – dokumen asli dengan dokumen
query. Lalu dari hasil perhitungan nilai - nilai similarity, akan dimasukkan ke
algoritma overlap measure function, untuk melakukan perbandingan nilai – nilai
similarity pada dokumen – dokumen asli dengan dokumen query, sehingga akan
disesuaikan dengan nilai threshold yang didapat sebelum proses pendeteksian
dilakukan [5].
1.2Rumusan Masalah
Berdasarkan latar belakang yang telah diuraikan di atas, maka rumusan
masalah yang didapatkan adalah
1. Bagaimana mengimplementasikan metode overlap measure function untuk
membangun sistem pendeteksi plagiarisme pada dokumen skripsi.
2. Bagaimana ketepatan metode overlap measure function dalam melakukan
deteksi plagiarisme pada dokumen skripsi
1.3Batasan Masalah
1. Pendeteksian plagiarisme hanya dilakukan pada topik sistem informasi
dokumen skripsi Program Studi Teknik Informatika Universitas Sanata
Dharma Yogyakarta.
2. Pendeteksian plagiarisme dokumen skripsi dilakukan pada teks Abstrak,Bab1,
dan Bab2 dari dokumen skripsi.
3. Jumlah data dokumen skripsi yang akan diproses pada sistem ini berjumlah 50
dokumen skripsi teknik informatika.
4. Pendeteksian plagiarisme dokumen skripsi hanya dilakukan pada dokumen
yang berbahasa Indonesia.
5. Pendeteksian plagiarisme dokumen skripsi hanya mendeteksi full text, gambar
6. Pendeteksian plagiarisme dokumen skripsi tidak menghiraukan adanya
kutipan dalam teks.
1.4Tujuan Penelitian
Tujuan dari penelitian ini adalah sebagai berikut :
1. Mendeteksi tindakan plagiarisme dokumen skripsi yang dilakukan oleh
mahasiswa Universitas Sanata Dharma.
2. Menguji ketepatan metode overlap measure function dalam usaha untuk
mendeteksi tindakan plagiarisme terhadap dokumen skripsi.
1.5Luaran Yang Diharapkan
Sebuah sistem yang dapat mendeteksi tindakan plagiarisme pada dokumen
skripsi mahasiswa Universitas Sanata Dharma Yogyakarta dengan menerapkan
metode overlap measure function.
1.6Metodologi Penelitian
Metodologi penelitian yang digunakan dalam penyelesaian tugas akhir ini
adalah sebagai berikut :
1. Studi pustaka
Studi literatur dilakukan untuk mempelajari dan memahami konsep tentang
tindakan plagiarisme, mempelajari bagaimana cara mendeteksi tindakan
plagiarisme, mempelajari metode overlap measure function yang akan
ilmu pemerolehan informasi. Konsep dan materi yang dipelajari didapatkan
dari berbagai sumber seperti buku dan internet.
2. Observasi
Untuk mendapatkan data tentang dokumen digital skripsi program studi
Teknik Informatika, maka penulis melakukan survei ke perpustakaan
Universitas Sanata Dharma Yogyakarta.
3. Analisis dan perancangan sistem
Melakukan analisis terhadap masalah dan kebutuhan sistem yang akan
dibangun. Lalu melakukan perancangan umum sistem sesuai dengan
kebutuhan sistem.
4. Pembuatan Sistem
Berdasarkan hasil analisis dan perancangan sistem, maka tahap selajutnya
adalah pembuatan sistem.
5. Implementasi dan pengujian
Tahap ini adalah tahap untuk menjalankan sistem yang telah dibuat, lalu
melakukan pengujian terhadap efektivitas dan efisiensi dari sistem
pendeteksian plagiarisme, dan melakukan pengujian terhadap ketepatan
metode overlap measure function yang dipergunakan untuk mendeteksi
6. Evaluasi
Menganalisis hasil implementasi dan membuat kesimpulan terhadap
penelitian tugas akhir yang telah dikerjakan.
1.7Sistematika Penulisan
Sistematika penulisan Tugas Akhir ini adalah sebagai berikut:
BAB I PENDAHULUAN
Bab ini berisi latar belakang masalah, rumusan masalah, batasan
masalah, tujuan penelitian, ,metodologi penelitian, dan sistematika
penulisan.
BAB II TINJAUAN PUSTAKA
Bab ini berisi landasan teori yang merupakan dasar – dasar teori yang
dipergunakan dalam membuat Tugas Akhir, yaitu teori tentang
plagiarisme, pemerolehan informasi dan metode overlap measure
function.
BAB III ANALISA DAN PERANCANGAN SISTEM
Bab ini berisi penjelasan mengenai analisa masalah, analisa kebutuhan
sisten dan penjelasan mengenai gambaran umum dari sistem yang
dibuat.
BAB IV IMPLEMENTASI SISTEM
Bab ini berisi hasil langkah – langkah implementasi dari sistem yang
BAB V PENUTUP
Bab ini berisi kesimpulan dan saran atas hasil penelitian dari Tugas
9
BAB II
LANDASAN TEORI
2.1Plagiarisme
2.1.1 Definisi Plagiarisme
Plagiarisme berasal dari bahasa Latin yaitu plagiarius yang berarti
penculik, atau dalam bahasa Latin yang lain yaitu plagus. Definisi plagiarisme
secara luas yaitu mengambil alih bahan, ide, gambar, tulisan oleh mereka
yang mengaku sebagai pencipta asli[6]. Beberapa definisi plagiarisme dalam
arti yang lebih khusus yang pertama yaitu tindakan yang dengan sengaja
menyalin kata – kata atau ide milik orang lain tanpa atribusi. Definisi
plagiarisme yang kedua yaitu membeli, meminjam, atau mencuri sebuah
makalah penelitian atau esai milik orang lain, kemudian menampilkannya
sebagai milik pribadi. Definisi yang ketiga yaitu mengambil garis besar
gagasan dan argumen milik orang lain, lalu dirangkai kembali menggunakan
kata – kata sendiri. Dan definisi khusus plagiarisme yang terakhir yaitu
menyajikan fakta atau data statistik tanpa mengutip sumber yang asli [1].
Plagiarisme adalah bentuk penyalahgunaan hak kekayaan intelektual
milik orang lain, yang mana karya tersebut direpresentasikan dan diakui
kreativitas banyak orang, kekosongan akan ide, kreativitas, dan sifat malas
yang memunculkan tindakan plagiarisme. Umumnya tindakan plagiarisme
marak dikalangan siswa dan mahasiswa, seharusnya mereka sebagai kalangan
terpelajar harus lebih produktif dalam berkarya dan menjauhi tindakan
plagiarisme untuk kepentingan pribadi. Beberapa alasan tindakan plagiarisme
semakin marak dilakukan yaitu kurangnya kesadaran beretika, perangkat
teknologi informasi dengan mobilitas tinggi yang memudahkan para plagiator
mengambil sumber - sumber milik orang lain melalui akses internet, agar
dapat memperoleh prestasi akademik yang memuaskan dengan berbagai
upaya, dan para plagiator yang semakin profesional dalam menggunakan dan
mencari material yang dibutuhkan [7].
2.1.2 Bentuk Plagiarisme
Bentuk-bentuk plagiarisme yang sering terjadi di dunia akademis
berdasarkan artikel Clough (2003:2) adalah:[2]
1. Plagiarisme kata per kata, merupakan penyalinan kalimat secara
langsung dari sebuah dokumen teks tanpa adanya pengutipan atau
perizinan.
2. Plagiarisme parafrase, merupakan penulisan ulang dengan
mengubah kata atau sintaksis, tetapi teks aslinya masih dapat
3. Plagiarisme sumber sekunder, merupakan perbuatan mengutip
kepada sumber asli yang didapat dari sumber sekunder dengan
menghiraukan teks asli dari sumber yang sebenarnya.
4. Plagiarisme struktur sumber, merupakan penyalinan / penjiplakan
struktur suatu argumen dari sebuah sumber.
5. Plagiarisme ide, merupakan penggunaan ulang suatu
gagasan/pemikiran asli dari sebuah sumber teks tanpa bergantung
bentuk teks sumber.
6. Plagiarisme authorship, merupakan pembubuhan nama sendiri
secara langsung pada hasil karya orang lain.
Bila dilihat dari berbagai macam bentuk-bentuk plagiarisme diatas,
dapat disimpulkan bahwa tindakan plagiarisme yang terjadi di dunia akademis
lebih cenderung kepada tindakan menggunakan kembali suatu bagian
dokumen teks berupa kata/kalimat dari suatu sumber yang tidak mengikuti
tata aturan hak cipta, seperti aturan pengutipan ( citation ) ataupun
ketidakjelasan sumber/pengarang asli
(bibliography).
Beberapa faktor yang dapat digunakan untuk mengidentifikasikan
1. Penggunaan kosa kata.
Menganalisis kosa kata yang digunakan dalam suatu tugas
terhadap penggunaan kosa kata sebelumnya dapat membantu
menentukan apakah mahasiswa benar-benar telah menulis teks
tersebut. Dengan menemukan suatu kosa kata baru dalam jumlah
yang besar (terutama kosa kata lanjut) dapat menentukan apakah
mahasiswa menulis teks tanpa melakukan plagiarisme.
2. Perubahan kosa kata.
Apabila penggunaan kosa kata berubah secara significant dalam
suatu teks, hal ini dapat mengindikasikan plagiarisme dengan cara
copy and paste.
3. Teks yang membingungkan.
Apabila alur dari suatu teks tidak halus dan tidak konsisten, hal ini
mengindikasikan penulis tidak menulis menggunakan
pemikirannya sendiri atau beberapa bagian dari tulisannya
bukanlah hasil karyanya.
4. Penggunaan tanda baca.
Tidak wajar apabila dua orang penulis menggunakan tanda baca
5. Jumlah kemiripan teks.
Pasti ada beberapa kemiripan antara beberapa teks yang menulis
dengan topic yang sama seperti nama-nama, istilah-istilah dan
sebagainya. Bagaimanapun, tidak wajar bila beberapa teks yang
berbeda memiliki kesamaan atau kemiripan teks dalam jumlah
yang besar.
6. Kesalahan ejaan yang sama.
Merupakan hal yang biasa terjadi bagi seorang penulis dalam
membuat suatu karya tulis. Menjadi tidak wajar bila beberapa teks
yang berbeda memiliki kesalahan-kesalahan yang sama dalam
pengejaan atau jumlah ejaan salah yang sama.
7. Distribusi kata – kata.
Tidak wajar apabila distribusi penggunaan kata dalam teks yang
berbeda memiliki kesamaan. Sebagai contoh, suatu teks memiliki
parameter yang sama untuk suatu distribusi statisitk yang
digunakan untuk menjelaskan penggunaan istilah.
8. Struktur sintaksis teks.
Hal ini menunjukan plagiarisme mungkin saja telah terjadi jika dua
wajar bila penggunaan struktur sintaksis yang digunakan oleh
beberapa penulis akan berbeda.
9. Rangkaian – rangkaian panjang kata yang sama.
Tidak wajar apabila suatu teks yang berbeda (bahkan yang
menggunakan judul yang sama) memiliki rangkaian/urutan
karakter yang sama.
10.Order kemiripan antar teks.
Hal ini bisa mengindikasikan plagiarisme apabila orde kecocokan
kata atau frase antar dua teks sama. Meskipun diajarkan untuk
menyajikan fakta-fakta dalam suatu aturan (contohnya pendahulan,
isi, kemudian kesimpulan), kurang wajar jika fakta-fakta yang
sama dilaporkan dalam orde yang sama.
11.Ketergantungan pada frasa atau kata tertentu.
Seorang penulis mungkin memilih penggunaan suatu kata atau
frase tertentu. Kekonsistenan penggunaan kata-kata tersebut dalam
suatu teks yang ditulis oleh orang lain dengan menggunankan kata
yang berbeda dapat mengindikasikan plagiarisme.
12.Frekuensi kata.
digunakan dengan frekuensi yang sama.
13.Keputusan untuk menggunakan kalimat panjang atau kalimat
pendek. Tanpa sepengetahuan kita, para penulis tentu memiliki
keputusan penggunaan panjang kalimat yang tidak biasa
dikombinasikan dengan fitur-fitur lain.
14.Teks yang dapat dibaca.
Penggunaan metrik/ukuran seperti index Gunning FOG, Flesch
Reading Ease Formula atau SMOG dapat membantu menentukan
suatu skor kemampuan. Tidak wajar apabila penulis yang berbeda
akan memiliki skor yang sama.
15.Referensi yang tidak jelas.
Apabila referensi yang muncul dalam suatu teks tetapi tidak
terdapat pada daftar pustaka, hal ini dapat mengindikasikan
plagiarisme cut and paste, dimana penulis tidak menyalin
referensinya secara lengkap.
2.2Definisi Sistem
Sistem adalah suatu kesatuan usaha yang terdiri dari bagian – bagian
yang berkaitan satu sama lain yang berusaha mencapai suatu tujuan dalam
– elemen yang saling berinteraksi secara teratur dalam rangka mencapai
tujuan atau sub tujuan[8]. Definisi sistem secara sederhana adalah suatu
kumpulan atau himpunan dari unsur atau variabel – variabel yang saling
terorganisasi, saling berinteraksi, dan saling bergantung satu sama lain [9] .
Arsitektur dari sistem digambarkan pada gambar 2.1 , gambar
tersebut menjelaskan bahwa di dalam sebuah sistem terdapat 4 elemen, yaitu
input, proses, kontroler, dan output. Keempat elemen tersebut saling
berhubungan untuk mencapai tujuan dari sebuah sistem. Pertama – tama
untuk melaksanakan sebuah sistem harus ada elemen input yang merupakan
hal – hal yang dimasukan ke dalam sistem, lalu input akan di proses sehingga
menghasilkan output dari sistem. Terdapat balikan yang berhubungan dengan
ke ketiga elemen yaitu input, proses, dan output untuk menjamin ketiga
elemen tersebut dapat berjalan dengan baik
Gambar 2.1 Gambaran Sistem[10]
Input Proses Output
2.3Konsep Information Retrieval
2.3.1 Definisi Information Retrieval
Information Retrieval adalah sebuah bidang yang berhubungan dengan
struktur, analisis, organisasi, penyimpanan, pencarian dan pemerolehan dari
informasi (Salton,1968). Gerard Salton merupakan orang yang pertama kali
mencetuskan bidang Information Retrieval pada tahun 1960, lalu menuangkan
konsep Information Retrieval dalam bukunya pada tahun 1968 [11].
Information Retrieval dipergunakan untuk menemukan kembali
informasi – informasi yang relevan terhadap kebutuhan pengguna dari suatu
kumpulan informasi secara otomatis ( Bunyamin,2008 ). Information
Retrieval berhubungan dengan pencarian informasi yang isinya tidak memiliki
struktur. Demikian pula ekspresi kebutuhan pengguna yang disebut query,
juga tidak memiliki struktur. Serta koleksi dokumen yang juga tidak
terstruktur[12]. Informasi retrieval merupakan bidang yang berkembang
secara paralel dengan sistem basis data selama beberapa tahun. Sistem basis
data lebih fokus pada query dan proses transaksional dari struktur data.
Sedangkan dalam Informasi retrieval ditemukan dokumen yang tidak
terstruktur , pencarian berdasarkan kata kunci dan tingkat kesamaan [13].
Pada gambar 2.2 menjelaskan tahapan berjalannya proses dari
kebutuhan informasi yang dimiliki oleh user, kebutuhan informasi tersebut
merupakan suatu permintaan kebutuhan oleh user yang akan diformulasikan
menjadi query. Permintaan user diformulasikan menjadi query agar sistem
dapat mengenali permintaan yang disampaikan oleh user kepada sistem.
Kemudian di sisi lain terdapat koleksi dokumen yang akan dilakukan proses
indexing sehingga menghasilkan indexed document . Lalu dilakukan
perbandingan query dengan kumpulan dokumen yang telah diproses
indexing, proses perbandingan ini juga disebut proses pencocokan. Dari
proses pencocokan, menghasilkan daftar peringkat dokumen yang relevan
terhadap query. Dokumen yang relevan diharapkan menempati urutan teratas,
setelah didapatkan dokumen yang relevan, akan dikembalikan kepada
kebutuhan user, apakah dokumen relevan tersebut sesuai dengan kebutuhan
yang dimiliki user.
Gambar 2.2 Gambaran Umun Information Retrieval[14]
Request Query Matching Index Information
Objects
Information need
Relevance
Collection
formulation
uses uses process
Is based on
2.3.2 Proses Preprocessing Teks Dokumen
Untuk melakukan pengelolaan terhadap dokumen diperlukan proses
preprocessing, karena teks yang terdapat dalam suatu dokumen bersifat tidak
terstruktur, memiliki dimensi yang tinggi, terdapat banyak noise , dan struktur
teks yang tidak baik. Proses preprocessing yang meliputi : stopword,
tokenizing, stemming dilakukan untuk mengubah teks dalam dokumen
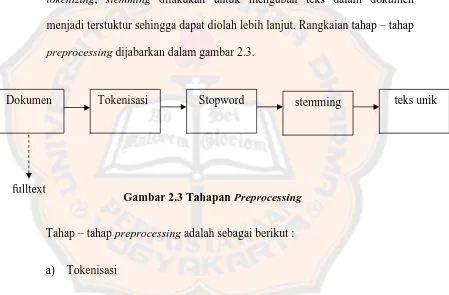
menjadi terstuktur sehingga dapat diolah lebih lanjut. Rangkaian tahap – tahap
preprocessing dijabarkan dalam gambar 2.3.
Gambar 2.3 Tahapan Preprocessing
Tahap – tahap preprocessing adalah sebagai berikut :
a) Tokenisasi
Tokenisasi diartikan sebagai proses untuk mengenali kata kata, pada
proses ini terjadi pemisahan kata dari kata – kata yang lain dan dari tanda
baca [14]. Tokenisasi adalah pembagian teks masukan menjadi kata-kata
secara individu. Kemudian kata-kata tersebut dikelompokkan dalam
blok-blok berukuran tertentu dan dinamakan token-sequence, sedangkan
kata-Dokumen Tokenisasi Stopword teks unik
fulltext
kata yang umum dan tidak memiliki makna yang penting tidak
diikutsertakan. Token atau term yang dianalisis dicatat dalam tabel,
bersama dengan lokasi kemunculannya dalam token-sequence juga
frekuensi atau banyaknya kemunculannya[15]. Tahapan proses tokenisasi
ditunjukan pada gambar 2.4
Contoh tahap tokenisasi :
Gambar 2.4 Tahapan Tokenisasi [16]
b) Stopword
Stopword adalah yaitu penyaringan (filtering) terhadap kata-kata yang
tidak layak untuk dijadikan sebagai pembeda atau sebagai kata kunci Friends, Romans, Coutrymen,
lend me your ears;
[Teks Masukan]
Friends
Romans
Coutrymen
Lend
me
your
ears
dalam pencarian dokumen sehingga kata-kata tersebut dapat dihilangkan
dari dokumen [17].
c) Stemming
Stemming merupakan suatu proses yang terdapat dalam sistem IR yang
mentransformasi kata yang terdapat dalam suatu dokumen ke
kata-kata akarnya (root word) dengan menggunakan aturan-aturan tertentu.
Sebagai contoh, kata bersama, kebersamaan, menyamai, akan distem ke
root wordnya yaitu “sama”. Proses stemming pada teks berbahasa
Indonesia berbeda dengan stemming pada teks berbahasa Inggris. Pada
teks berbahasa Inggris, proses yang diperlukan hanya proses
menghilangkan sufiks. Sedangkan pada teks berbahasa Indonesia, selain
sufiks, prefiks, dan konfiks juga dihilangkan. Stemming adalah salah satu
cara yang digunakan untuk meningkatkan performa IR dengan cara
mentransformasi katakata dalam sebuah dokumen teks ke kata dasarnya.
Algoritma Stemming untuk bahasa yang satu berbeda dengan algoritma
stemming untuk bahasa lainnya. Sebagai contoh Bahasa Inggris memiliki
morfologi yang berbeda dengan Bahasa Indonesia sehingga algoritma
stemming untuk kedua bahasa tersebut juga berbeda. Proses stemming
pada teks berbahasa Indonesia lebih rumit/kompleks karena terdapat
variasi imbuhan yang harus dibuang untuk mendapatkan root word dari
dikembangkan sebelumnya. Penggunaan algoritma stemming yang sesuai
mempengaruhi performa sistem IR [18].
2.4Stemming Algoritma Nazief dan Adriani
Algoritma stemming Nazief dan Adriani merupakan algoritma
stemming untuk teks bahasa Indonesia, langkah – langkah sebagai berikut :
[18]
1. Cari kata yang akan distem dalam kamus. Jika ditemukan maka
diasumsikan bahwa kata tersebut adalah root wood. Maka algoritma
berhenti.
2. Inflection Suffixes(“-lah”,”-kah”, “-ku”, ”-mu”, atau “-nya”) dibuang. Jika
berupa particles (“-lah”,”-kah”,”-tah”,”-pun”) maka langkah ini diulangi
lagi untuk menghapus Possesive Pronouns (“-ku”, ”-mu”, atau “-nya”)
jika ada.
3. Hapus Derivation Suffixes (“-i”, “-an”, atau “-kan”). Jika kata ditemukan
di kamus, maka algoritma berhenti. Jika tidak maka ke langkah 3a:
a. Jika an” telah dihapus dan huruf terakhir dari kata tersebut adalah
“-k”, maka “-k” juga ikut dihapus. Jika kata tersebut ditemukan dalam
kamus, maka algoritma berhenti. Jika tidak ditemukan maka lakukan
b. Akhiran yang dihapus (“-i”, “-an” atau “-kan”) dikembalikan, lanjut ke
langkah 4.
4. Hapus Derivation Prefix. Jika pada langkah 3 ada sufiks yang dihapus
maka pergi ke langkah 4a, jika tidak pergi ke langkah 4b.
a. Periksa tabel kombinasi awalan-akhiran yang tidak diijinkan. Jika
ditemukan maka algoritma berhenti, jika tidak pergi ke langkah 4b.
b. For i = 1 to 3, tentukan tipe awalan kemudian hapus awalan. Jika root
word belum juga ditemukan lakukan langkah 5, jika sudah maka
algoritma berhenti. Catatan: jika awalan kedua sama dengan awalan
pertama algoritma berhenti.
5. Melakukan Recoding.
6. Jika semua langkah telah selesai tetapi tidak juga berhasil maka kata awal
diasumsikan sebagai root word. Proses selesai.
Tipe awalan ditentukan melalui langkah - langkah berikut:[18]
1. Jika awalannya adalah: “di-”, “ke-”, atau “se-” maka tipe awalannya
secara berturut-turut adalah “di-”, “ke-”, atau “se-”.
2. Jika awalannya adalah “te-”, “me-”, “be-”, atau “pe-” maka dibutuhkan
3. Jika dua karakter pertama bukan “di-”, “ke-”, “se-”, “te-”, “be-”, “me-”,
atau “pe-” maka berhenti.
4. Jika tipe awalan adalah “none” maka berhenti. Jika tipe awalan adalah
bukan “none” maka awalan dapat dilihat pada Tabel 2.2. Hapus awalan
jika ditemukan.
Tabel 2.1 Kombinasi Awalan Akhiran Yang Tidak Diijinkan
Awalan Akhiran yang tidak diijinkan
be- -i
di- -an
ke- -i, -kan
me- -an
se- -i, -kan
Tabel 2.2 Cara Menentukan Tipe Awalan Untuk Kata Yang Diawali Dengan “te-”
Following Characters Tipe
awalan
Set1 Set2 Set3 Set4
“-r-“ Vowel - - ter-luluh
“-r-“ not (vowel or
“-r-”)
“-er-“ vowel ter
“-r-“ not (vowel or
“-r-”)
“-er-“ not vowel ter-
“-r-“ not (vowel or
“-r-”)
not “-er-“ - ter
not (vowel or
“-r-”)
“-er-“ vowel - none
not (vowel or
“-r-”)
“-er-“ not vowel - te
Tabel 2.3 Jenis Awalan Berdasarkan Tipe Awalannya
Tipe Awalan Awalan yang harus dihapus
di- di-
ke- ke-
se- se-
te- te-
ter- ter-
2.5Deteksi Plagiarisme
Sebagian besar dokumen saat ini disimpan dalam bentuk file digital,
hal tersebut memudahkan banyak orang untuk mengakses dokumen tersebut
dengan bebas, dan memberikan peluang besar bagi para plagiat untuk
melakukan tindakan plagiarisme. Plagiarisme merupakan tindakan
penjiplakan yang berbahaya dan merugikan orang lain. Oleh karena itu
diperlukan suatu cara pendeteksi plagiarisme untuk mengatasi tindakan
plagiat yang semakin banyak dikalangan masyarakat, sehingga dapat
melindungi hak cipta hasil karya seseorang. Pada paper Plagiarism Pattern
Checker in Document Copy Detection , menjelaskan pendeteksian plagiat
menggunakan overlap measure function[5]. Gambaran umum proses deteksi
plagiat PPChecker pada gambar 2.7, dapat dilihat bahwa terdapat dokumen
baru yang menjadi query dan terdapat kumpulan dokumen asli. Lalu dokumen
– dokumen tersebut akan melalui proses pembagian kalimat, kemudian
perhitungan nilai local similarity. Dan proses yang terakhir yaitu pencarian
nilai similarity dokumen. Sehingga dari nilai tersebut dapat dilakukan
Gambar 2.5 Proses Deteksi Plagiat PPChecker[5]
2.5.1 Overlap Measure Function
Overlap measure function merupakan sebuah metode perhitungan nilai
similarity/kemiripan antar dokumen. Selain itu metode ini dipergunakan untuk
membandingkan beberapa dokumen untuk mendapatkan informasi tentang
tindakan plagiarisme antara beberapa dokumen berdasarkan nilai similarity
dokumen terhadap query.
Rumus perhitungan nilai similarity pada overlap measure function [5] :
!
[1]
[2]
[3]
" #$ %| % ∈ ( % ∈
" #$)* #+,- . |/( 0( 0 |1 |2%33 0 0( || |
4 )* #+,- . 5| . | + | . |
. | | × 89:;<=>?;@AB C: CD EF10%G8HI8JKLM 0( 0
Keterangan rumus :
So = kalimat yang terdapat pada dokumen asli / koleksi
dokumen
Sq = kalimat yang terdapat pada dokumen query
wn = kata – kata pada sebuah kalimat dokumen asli
wm = kata – kata pada sebuah kalimat dokumen query
Comm(So , Sq ) = irisan himpunan So dan Sq
Diff(So , Sq ) = selisih himpunan So dan Sq
Syn(w) = sinonim dari kata, elemen ini tidak dipergunakan
dalam perhitungan karena tidak efektif. Dikarenakan
sinonim pada sebuah kata sangat banyak jumlahnya.
2.5.2 Algoritma
[5]
[6]
[7]
Algoritma yang dipergunakan untuk pendeteksian plagiarisme berdasarkan
perhitungan nilai similarity antara koleksi dokumen dengan query dokumen
yang merupakan hasil perhitungan dari rumus similarity overlap measure
function.
Tahap Algoritma [5]:
Input :
1 Dokumen_D = {D1,D2,D3...Dn} = himpunan dokumen pada
koleksi dokumen.
2 Di = {Si1,Si2,Si3,...,Sim} = himpunan kalimat pada setiap
dokumen pada koleksi dokumen.
3 Query = {QS1,QS2,QS3...QSt} = himpunan kalimat pada
dokumen query.
Keterangan input :
Terdapat masukan yang berupa koleksi dokumen ( Dokumen_D ) dan query
dokumen ( Query ). Tiap - tiap dokumen pada koleksi dokumen yaitu Di ,
akan dibagi – bagi menjadi perkalimat yaitu Sim , sehingga akan terbentuk
himpunan kalimat dari setiap dokumen koleksi. Hal tersebut juga diterapkan
pada dokumen query, dibagi per kalimat pada dokumen query yaitu QSt ,
Output :
1 For i = 1 to n
2 For j = 1 to t
3 Localsimilarity [1...j] = 0 ;
4 For k =1 to m
5 If |comm(Sik,QSj)| | Sik| /2
6 Localsimilarity [j] = max
{localsimilarity[j], Sim (Sik,QSj)}
7 End
8 End
10 Documentsimilarity[i] = jumlah dari localsimilarity
11 End
11 Urutan documentsimilarity
Keterangan :
Localsimilarity = nilai kemiripan untuk setiap kalimat dokumen query dengan
Documentsimilarity = nilai kemiripan setiap dokumen pada koleksi dokumen
dengan dokumen query.
2.6Recall dan Precision
Terdapat 2 pengukuran untuk mengukur kualitas dari penemuan teks, yaitu
[13]:
1. Precision
Precision adalah tingkat ketepatan hasil klasifikasi terhadap suatu
kejadian.
Keterangan
Precision : tingkat ketepatan
{Relevant} : kumpulan dokumen yang relevan
{Retrieved} : kumpulan dokumen yang ditemukan
2. Recall
Recall adalah tingkat keberhasilan mengenali suatu kejadian dari seluruh
33
BAB III
ANALISIS DAN PERANCANGAN SISTEM
3.1 Gambaran Umum Sistem
Universitas Sanata Dharma memiliki kumpulan dokumen skripsi yang
dibuat oleh mahasiswa yang telah lulus/alumni dari setiap tahun akademik.
Kumpulan dokumen tersebut disimpan dalam bentuk softcopy dan hardcopy,
dimaksudkan agar mahasiswa yang membutuhkan referensi pembuatan
skripsi dapat dengan mudah mengaksesnya. Akan tetapi pemberian akses
tersebut disalah gunakan oleh beberapa mahasiswa, banyak kasus mahasiswa
yang sedang menempuh skripsi melakukan tindakan plagiat terhadap skripsi –
skripsi yang telah disahkan. Dan biasanya dosen – dosen kesulitan untuk
meneliti apakah suatu dokumen skripsi benar – benar terjamin keaslian atau
tidak., sebab jumlah dari skripsi yang disimpan banyak sekali.
Dalam penulisan ini akan dibangun sebuah sistem yang berbasis
teknologi informasi, dipergunakan untuk mendeteksi tindakan plagiat pada
dokumen skripsi program studi teknik informatika Universitas Sanata Dharma
yang dilakukan oleh mahasiswa dalam pembuatan skripsi. Hasil yang akan
dikeluarkan oleh sistem ini yaitu informasi tentang tindakan plagiat yang
terjadi pada suatu dokumen yang dibuat oleh mahasiswa terhadap koleksi
diantara koleksi dokumen. Apakah suatu dokumen skripsi tersebut
plagiarisme dari dokumen skripsi yang lainnya. Dan juga akan menghasilkan
nilai batas tingkat kecenderungan tindakan plagiat yang dilakukan oleh
mahasiswa. Sistem ini ditujukan untuk dosen yang sedang membimbing
skripsi, agar memudahkan dosen tersebut untuk melakukan pengecekan
terhadap skripsi yang sedang dibimbingnya.
Gambar 3.1 merupakan gambaran umum sistem yang menjabarkan
tahap – tahap jalannya sistem pendeteksi plagiarisme dokumen skripsi. Sistem
ini akan dibagi menjadi 2 bagian sesuai dengan aktor yang terlibat di dalam
sistem yaitu user dan admin. Pada bagian user sistem ini akan mendeteksi
plagiarisme pada sebuah file dokumen skripsi baru dengan koleksi dokumen
skripsi yang ada dalam database. Sedangkan pada bagian admin akan
mendeteksi plagiarisme pada seluruh koleksi dokumen skripsi yang ada dalam
database. Inputan yang dimasukkan user pada sistem adalah sebuah file
dokumen skripsi yang memiliki ekstensi .txt, dan admin akan memasukkan
koleksi dokumen skripsi ke dalam sistem yang memiliki ekstensi .txt juga.
Proses pertama pada bagian user dan admin sama yaitu masing – masing
memasukkan inputan yang dimiliki, jika admin memasukkan skripsi sekaligus
banyak dalam 1 folder, sedangkan user memasukkan 1 file skripsi. Lalu dari
inputan tersebut kemudian akan dilakukan proses preprocessing mulai dari
kalimat). Proses preprocessing dilakukan pada teks agar kata – kata yang ada
pada teks menjadi unik. Setelah dilakukan proses preprocessing, hasilnya
adalah teks dokumen yang telah unik pada dokumen baru dan koleksi
dokumen. Kemudian proses selanjutnya yaitu, pada bagian user melakukan
perhitungan nilai similarity menggunakan overlap measure function dari
setiap kalimat pada setiap koleksi dokumen terhadap setiap kalimat pada
dokumen baru. Sedangkan pada bagian admin melakukan perhitungan nilai
similarity menggunakan overlap measure function dari setiap kalimat pada
setiap koleksi dokumen terhadap setiap kalimat pada setiap koleksi dokumen
yang lain. Setelah didapatkan nilai similarity, lalu diterapkan algoritma untuk
mendapatkan nilai similarity dokumen dari setiap koleksi dokumen terhadap
dokumen baru untuk user dan nilai similarity dokumen dari setiap koleksi
dokumen terhadap setiap koleksi dokumen yang lain pada admin. Sehingga
nilai – nilai similarity tersebut yang akan menjadi evaluasi, akan didapatkan
hasil pendeteksian plagiarisme untuk user. Dan untuk admin, sebelum
dilakukan proses pendeteksian plagiarisme admin terlebih dahulu harus
mencari nilai batas untuk menentukan tindakan plagiat, yaitu nilai batas
didapat dari membandingkan koleksi dokumen skripsi dengan dirinya sendiri,
cara membandingkan juga menggunakan metode overlap measure function
untuk mendapatka nilai similarity. Setelah nilai similarity didapat maka
dengan dokumen itu sendiri untuk mendapatkan nilai batas tindakan plagiat /
nilai threshold. Setelah didapat nilai batas tindakan plagiat, nilai tersebut akan
dipakai untuk pendeteksian plagiarisme terhadap koleksi dokumen skripsi.
Ketentuan plagiarisme yang dideteksi adalah pendeteksian dokumen
dengan dokumen yang lain dianggap plagiat jika kata per kata dokumen
memiliki kalimat sama / merupakan penyalinan kalimat dari dokumen yang
lain, tanpa memperhatikan urutan kalimat dan tidak memperhatikan kutipan
Untuk lebih jelasnya, proses pendeteksian plagiarisme menggunakan
metode overlap measure function melalui tahap – tahap sebagai berikut :
Gambar 3.2 Alur Algoritma Overlap Measure Function
Start
com(kala,kalq) > 0.5 FALSEFALSE local(kalq) = ocal (kalq)
local(kalq)
doksim >= threshold FALSEFALSE status = NO PLAGIAT
termTmp1 = hasil pemenggalan kata pada kal_query jum_kata1 = termTmp1.size ( )
kal_asli=select kalimat (dok_a)
termTmp = hasil pemenggalan kata pada kal_asli jum_kata = termTmp1.size ( )
TRUE
Sebelum melakukan pendeteksian plagiarisme terhadap dokumen
skripsi, maka harus ditentukan terlebih dahulu nilai batas / threshold tindakan
plagiat. Penentuan nilai batas dilakukan oleh admin, dengan membandingkan
dokumen – dokumen skripsi yang benar – benar sama (membandingkan
dokumen dengan dokumen itu sendiri/dirinya sendiri). Kemudian nilai
threshold diuji dari presentase 50% sampai 30%. Maka langkah – langkah
Gambar 3.3 Alur Pencarian Nilai Threshold
com(kala,kalq) > 0.5 FALSEFALSE local(kalq) = ocal (kalq)
local(kalq)
termTmp1 = hasil pemenggalan kata pada kal_query jum_kata1 = termTmp1.size ( )
kal_asli=select kalimat (dok_a)
termTmp = hasil pemenggalan kata pada kal_asli jum_kata = termTmp1.size ( )
total += doksim
3.2Analisa Kebutuhan Sistem
3.2.1 Definisi Actor
Berikut ini adalah aktor – aktor yang terlibat di dalam sistem. Terdapat
2 aktor yang dapat menggunakan sistem yaitu admin dan user. Aktor admin
merupakan aktor yang dapat mengelola kebutuhan – kebutuhan dari
penggunaan sistem. Sedangkan aktor user merupakan aktor yang hanya dapat
menggunakan sistem. Masing – masing aktor memiliki hak akses yang dapat
dilihat pada tabel di bawah ini.
Tabel 3.1 Hak Akses User
Aktor Hak Akses
Administrator - Login
- Kelola Account : input account, edit account , hapus account.
- Kelola Stopword : input stopword, edit stopword, hapus stopword.
- Kelola kamus : input kata dasar, edit kata dasar, dan hapus kata dasar
- Kelola Koleksi Dokumen Skripsi
- Deteksi Plagiarisme Dokumen Skripsi
- Logout
User - Login
- Deteksi Plagiarisme Dokumen Skripsi Baru dengan Koleksi Dokumen Skripsi
- Pencarian koleksi dokumen skripsi
- Logout
3.2.2 Diagram Use Case
Diagram use-case menjabarkan kebutuhan – kebutuhan pengguna
sistem terhadap sistem pendeteksi plagiarisme pada dokumen skripsi. Aktor –
aktor/pengguna yang terlibat dalam sistem ini ada 2 yaitu admin dan user.
Admin adalah pengguna yang secara khusus mengelola koleksi dokumen
yang ada, sedangkan user adalah pengguna yang mengelola dokumen baru.
Gambar 3.4 Diagram use case
Login Logout
<<depends on>>
3.2.3 Definisi Use Case
Tabel 3.2 di bawah ini menjabarkan secara umum use case yang
terdapat pada sistem pendeteksi plagiarisme pada dokumen skripsi
Tabel 3.2 Deskripsi Use Case
NO Use Case Deskripsi Use Case Pengguna
Sistem
1. Login Use case ini menggambarkan
proses untuk mengidentifikasi pengguna sistem. Agar dapat
menggunakan menu utama,
pengguna terlebih dahulu
melakukan login dengan
memasukkan username dan
password yang telah terdaftar.
Admin dan User
2. Input Account Use case ini mennggambarkan
proses memasukkan data
pengguna ( username , password, dan status) baru ke dalam sistem, agar pengguna dapat mengakses sistem.
Admin
3. Edit Account Use case ini menggambarkan
proses pembaharuan/perubahan data pengguna yaitu password yang telah tersimpan di dalam sistem.
Admin
4. Hapus Account Use case ini menggambarkan
proses penghapusan data
pengguna pada sistem.
Admin
proses penghapusan data stopword yang tersimpan dalam sistem. 8. Input Kata Dasar Use case ini menggambarkan
proses memasukan kata dasar baru ke dalam daftar kamus sistem.
Admin
9. Edit Kata Dasar Use case ini menggambarkan proses pembaharuan/perubahan kata dasar dalam daftar kamus yang telah tersimpan dam sistem.
Admin
10. Hapus Kata Dasar Use case ini menggambarkan proses penghapusa kata dasar pada daftar kamus sistem.
Admin
11. Kelola Koleksi Dokumen Skripsi
Use case ini menggambarkan proses pengelolaan koleksi dokumen skripsi yang akan di training, dengan melakukan pengelolaan teks pada koleksi yang meliputi pemenggalan teks menjadi kalimat, tokenisasi, stopword dan stemming.Kemudian dilakukan proses input koleksi dokumen (dalam jumlah sekaligus banyak, sesuai yang diinginkan).
Admin
12. Deteksi plagiarisme koleksi dokumen skripsi
Use case ini menggambarkan proses pendeteksian plagiarisme pada koleksi dokumen skripsi yang ada. Pendeteksian meliputi
perhitungan nilai batas
kecenderungan tindakan skripsi, perhitungan nilai similarity teks dengan overlap measure function, penerapan algoritma deteksi, penentuan deteksi dengan algoritma, dan view informasi hasil pendeteksain. proses pengelolaan dokumen skirpsibaru yang akan dideteksi
uder,dengan melakukan
pengelolaan teks pada doukem
tersebut yang meliputi
pemenggalan teks menjadi
kalimat, tokenisasi, stopword dan
stemming.Kemudian dilakukan
proses input dokumen tersebut ke dalam sistem.
14. Deteksi plagiarisme Dokumen Skripsi
Use case ini menggambarkan proses pendeteksian plagiarisme antara dokumen baru dengan koleksi dokumen yang ada. Deteksi plagiarisme meliputi sistem mampu menginputkan dokumen baru, mengelola koleksi dokumen ( pemenggalan kalimat, tokenisasi, stopword, dan stemming ), perhitungan nilai similarity teks dengan overlap measure function, penerapan algoritma, dan view informasi hasil pendeteksain plagiarisme.
User
15. Pencarian Koleksi Dokumen Skripsi
Use case ini menggambarkan proses pencarian koleksi dokumen skripsi yang tersimpan
3.2.4 Skenario Use Case
3.2.4.1Skenario Use Case Login
Nama Use Case : Login
Aktor : Admin/User
Deskripsi :Use Case ini menggambarkan proses pengguna keluar dari
sistem.
Skenario :
Tabel 3.3 Skenario Use Case Login
Aksi Aktor Reaksi Sistem
Skenario Normal
1. Aktor mengisikan username dan password pada form login.
2. Aktor menekan tombol login
3. Sistem mengautentifikasi username dan password yang dimasukkan ( sesuai dengan yang disimpan ).
4. Sistem menampilkan form menu utama admin.
Skenario Alternatif
1. Aktor mengisikan username dan password pada form login.
username dan password maka akan menampilkan pesan konfirmasi.
5. kembali ke tahap 1, skenario normal.
3.2.4.2Skenario Use Case Logout
Nama Use Case : Logout
Aktor : Admin/User
Deskripsi :Use Case ini menggambarkan proses untuk memasukkan data
pengguna, agar terdaftar di dalam sistem.
Skenario :
Tabel 3.4 Skenario Use Case Logout
Aksi Aktor Reaksi Sistem
Skenario Normal
1. Aktor berada pada form menu utama user/admin, aktor menekan tombol logout.
3.2.4.3Skenario Use Case Input Account
Nama Use Case : Inpu Account
Aktor : Admin
Deskripsi :Use Case ini menggambarkan proses untuk memasukkan data
pengguna baru, agar terdaftar di dalam sistem.
Skenario :
Tabel 3.5 Skenario Use Case Input Account
Aksi Aktor Reaksi Sistem
Skenario Normal
1. Aktor berada pada form menu utama admin, aktor menekan tombol account.
2. Sistem menampilkan form account admin.
3.Aktor menekan tab add account.
4. Sistem menampilkan halaman tab add account yang masih berada pada form account admin. Yang berisi isian username, password, dan status. Terdapat beberapa tombol, yaitu save, cancel dan back.
5. Aktor mengisikan data pengguna baru yang berupa, username, password dan status ( sebagai admin / user ).
7. Sistem akan menyimpan data pengguna baru, kemudian akan menampilkan konfirmasi proses simpan berhasil.
8. Aktor menekan tombol back.
9. Sistem akan kembali menuju form menu utama admin.
Skenario Alternatif
5. Jika saat aktor mengisikan data pengguna yang berupa username, password dan status ( sebagai admin / user ) tidak lengkap (tidak semua dari ketiganya terisi).
6. Aktor menekan tombol save.
7. Sistem akan menampilkan konfirmasi bahwa proses penyimapanan data pengguna baru gagal.
5. Jika saat aktor mengisikan data pengguna yang berupa username, password dan status ( sebagai admin / user ) terjadi kesalahan pengisian.
10. Aktor menekan tombol cancel.
11. Sistem akan me-reset semua isian pada form account admin.
3.2.4.4Skenario Use Case Edit Account
Nama Use Case : Edit Account
Deskripsi :Use Case ini menggambarkan proses untukmemperbaharui
data pennguna yang telah terdaftar dalam sistem.
Skenario :
Tabel 3.6 Skenario Use Case Edit Account
Aksi Aktor Reaksi Sistem
Skenario Normal
1. Aktor berada pada form menu utama admin, aktor menekan tombol account.
2. Sistem menampilkan form account admin.
3.Aktor menekan tab edit account
4. Sistem menampilkan halaman tab edit account yang masih berada pada form account admin. Yang berisi tabel user, isian username, password lama, dan password baru. Beserta 3 tombol yaitu update, delete, dan back.
5. Aktor memilih data pengguna yang akan di edit, dengan meng – klik baris data pada tabel.
6.Aktor mengisikan password lama dan password baru pada isian.
7. Aktor menekan tombol update.
9. Aktor menekan tombol back
10. Sistem akan kembali menuju form menu utama admin.
Skenario Alternatif
6.Aktor mengisikan password lama dan password baru pada isian. Jika Pengisian tidak lengkap.
7. Aktor menekan tombol update.
11. Sistem akan menampilkan konfirmasi bahwa proses pembaharuan data pengguna gagal.
3.2.4.5Skenario Use Case Hapus Account
Nama Use Case : Hapus Account
Aktor : Admin
Deskripsi :Use Case ini menggambarkan proses untuk menghapus data
pengguna.
Skenario :
Tabel 3.7 Skenario Use Case Hapus Account
Aksi Aktor Reaksi Sistem
Skenario Normal
2. Sistem menampilkan form account admin.
3.Aktor menekan tab edit account
4. Sistem menampilkan halaman tab edit account yang masih berada pada form account admin. Yang berisi tabel user, isian username, password lama, dan password baru. Beserta 3 tombol yaitu update, delete, dan back.
5. Aktor memilih data pengguna yang akan di hapus, dengan meng – klik baris data pada tabel.
6. Aktor menekan tombol delete.
8. Sistem akan melakukan penghapusan data, dan menampilkan konfirmasi proses penghapusan berhasil.
9. Aktor menekan tombol back
10. Sistem akan kembali menuju form menu utama admin.
3.2.4.6Skenario Use Case Input Stopword
Nama Use Case : Input Stopword
Aktor : Admin
Deskripsi :Use Case ini menggambarkan proses untuk memasukkan
stopword ke daftar stopword sistem.

![Gambar 2.1 Gambaran Sistem[10]](https://thumb-ap.123doks.com/thumbv2/123dok/1744575.2089048/39.595.100.514.295.621/gambar-gambaran-sistem.webp)
![Gambar 2.2 Gambaran Umun Information Retrieval[14]](https://thumb-ap.123doks.com/thumbv2/123dok/1744575.2089048/41.595.63.567.265.610/gambar-gambaran-umun-information-retrieval.webp)
![Gambar 2.4 Tahapan Tokenisasi [16]](https://thumb-ap.123doks.com/thumbv2/123dok/1744575.2089048/43.595.99.498.253.616/gambar-tahapan-tokenisasi.webp)