46 3.1Gambaran Umum
Manusia mempunyai kemampuan untuk belajar sejak dia dilahirkan, baik diajarkan maupun belajar sendiri, hal ini dikarenakan manusia mempunyai jaringan saraf. Kemampuan ini ditiru dan diaplikasikan kedalam komputer, baik untuk menyelesaikan masalah-masalah yang dapat dilakukan oleh algoritma maupun yang tidak dapat diselesaikan oleh algoritma yang disebut dengan jaringan saraf tiruan atau Artificial Neural Network, yang selanjutnya akan disebut ANN.
ANN mempunyai kemampuan untuk mempelajari dan menambah pengetahuan-pengetahuan yang didapat mulai dari proses dijalankan sampai proses berhenti untuk mendapatkan hasil yang optimal. Pengetahuan-pengetahuan yang didapat, disimpan dengan tujuan yang salah satunya digunakan untuk penentuan pada perencanaan perjalanan (untuk selanjutnya akan disebut path planning).
Salah satu paradigma pembelajaran ANN adalah Reinforcement Learning.
Reinforcement Learning merupakan metode pembelajaran yang berdasarkan reward, dimana jika path atau hal yang dipilih merupakan hal yang menuju ke sesuatu yang benar atau hal yang dilakukannya itu benar, dalam hal ini yaitu mencapai goal, maka
path yang telah dipilih akan diberi reward. Salah satu metode dalam Reinforcement Learning adalah metode Q-learning.
Path planning adalah suatu metode untuk menentukan jalan atau jalur ke tujuan yang ditentukan atau diinginkan. Path planning membuat subjek dapat
mempermudah menentukan path mana yang harus dilalui dan yang terbaik sesuai dengan kriteria yang diinginkan oleh subjek.
Dalam dunia game, path planning yang dibuat, digunakan untuk mengarahkan avatar menuju target atau goal yang diinginkan. Avatar merupakan istilah untuk tokoh utama yang bergerak atau berperan dan melakukan semua interaksi dalam dunia game atau biasa dikenal dengan sebutan pemain(player). Selama avatarmenuju target, avatar akan menemui berbagai obstacle, namun avatar
memiliki kemampuan untuk menghindari setiap obstacle.
Avatar akan diberi kemampuan untuk belajar dan berpikir dengan menggunakan metode pembelajaran Reinforcement Learning yaitu Q-learning. Dengan adanya Q-learning dalam avatar, avatar akan mendapatkan pengetahuan atas kesalahan yang pernah dilakukan sebelumnya dan pengetahuan atas berhasilnya jalur yang dilaluinya sehingga dapat mengenal obstacle yang ada dan path terbaik yang akan dilaluinya. Jika avatar menemukan pengetahuan baru, avatar akan menambahkan pengetahuan barunya ke dalam pengetahuan dasar yang telah dimiliki sebelumnya. Pengetahuan yang diperlukan oleh Q-learning yang terdapat dalam
avatar adalah path yangdapat digunakan untuk menempuh goal yang belum pernah ditempuh sebelumnya namun sudah diketahui letaknya.
Secara umum, path planning pada dunia game saat ini memiliki beberapa kekurangan, yaitu:
1. Avatar pada game saat ini tidak memiliki kemampuan belajar dalam melewati obstacle yang ada.
2. Avatar hanya melalui jalan yang sama saja pada map, sesuai dengan algoritma yang digunakan atau bersifat statik.
3.2Metode
Metode yang akan dipakai di dalam perancangan yaitu: 3.2.1 Q-Learning
ANN yang digunakan merupakan Reinforcement Learning dimana avatar
dapat belajar sendiri, metode pembelajaran Reinforcement Learning yang digunakan adalah Q-learning dimana ANN pada awalnya diberikan pelatihan yang dilaksanakan sebelumnya, jika terdapat perubahan dan pengetahuan baru, maka pengetahuan yang baru akan disimpan sehingga pada saat avatar menemui permasalahan yang serupa, maka diharapkan agar avatar dapat menemukan path
yang sesuai.
3.2.2 Backtracking
Pencarian solusi yang umum dilakukan adalah backtracking, dimana pada saat tidak ditemukan path yang bisa ditempuh, maka avatar akan bergerak mundur sehingga dapat mengambil path yang sebelumnya belum ditempuh. Dengan melakukan backtracking, sehingga dapat ditentukan apakah ada solusi untuk menyelesaikan permasalahan yang didapat. Adanya backtracking juga mempercepat proses path planning, karena tidak perlu melalui path yang sama berulang-ulang kali.
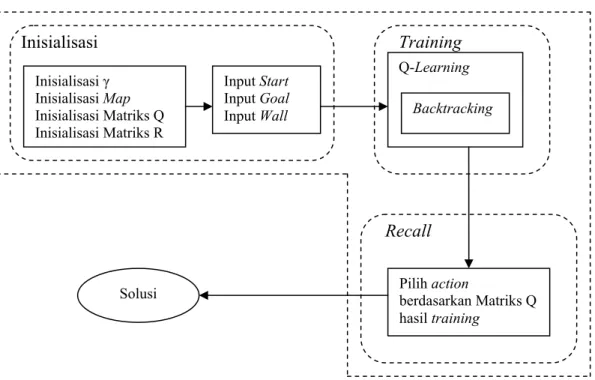
3.3Alur Secara Umum
Gambar 3.1 Alur Secara Umum
3.4Inisialisasi
Pada tahap ini merupakan awal proses path planning dengan mengunakan metode Reinforcement Learning, yaitu dengan menggunakan Q-learning. Pada tahap ini dibagi menjadi 2 bagian inisialisasi, yaitu inisialisasi matriks dan parameter dan inisialisasi obyek.
3.4.1 Inisialisasi matriks dan parameter
Saat map dibuat, map pada umumnya berupa koordinat, tapi dengan menggunakan metode Q-learning, koordinat pada map akan direpresentasikan dalam bentuk state, dimana setiap state mewakili salah satu posisi pada map, misalnya pada
Backtracking Q-Learning Training Inisialisasi γ Inisialisasi Map Inisialisasi Matriks Q Inisialisasi Matriks R Inisialisasi Input Start Input Goal Input Wall Pilih action berdasarkan Matriks Q hasil training Recall Solusi
kasus map berukuran 3 X 3 (lihat gambar 3.2), pada koordinat (2,3) diwakili oleh
state 6. Setiap state mempunyai beberapa action yang menghubungkan state satu ke
state yang lainnya. Jumlah action yang terdapat pada tiap state mengikuti aturan yang berlaku. Aturan yang berlaku adalah action hanya menghubungkan state yang berlaku, misalnya besar map 3x3 (lihat gambar 3.2), maka pada state 1 akan mempunyai 3 action, yaitu action yang menuju ke state 2, ke state 4, dan ke state 5.
Dengan adanya hubungan yang terbentuk pada tiap state, maka perlu dibentuk suatu matriks yang menjelaskan model keadaan map yang terhubung. Bentuk matriks didapat dari kuadrat besarnya map, jadi pada kasus map dengan ukuran 3 X 3, maka mempunyai ukuran matriks 9 X 9.
Gambar 3.2 State didalam Map
Matriks yang terbentuk nanti akan dibagi menjadi 2 macam matriks yang memiliki fungsi tersendiri. Matriks tersebut adalah matriks R dan matriks Q.
3.4.1.1Inisialisasi matriks R
Matriks R di dibuat dengan tujuan untuk membentuk permodelan yang ada di
map ke dalam bentuk matriks, karena itu dilakukan pembentukan nilai pada matriks R yang merepresentasikan state pada map.
Dalam path planning, dibutuhkan adanya pengetahuan akan lingkungan yang akan dilalui. Perlu diketahui bahwa lingkungan yang tergambar terdiri dari berbagai
state, states tersebut saling terkoneksi melalui action yang ada, dimana dalam proses
path planning, action tersebut akan membimbing statemenuju ke state sekitarnya.
Gambar 3.3 Map yang belum mempunyai avatar, goal, dan obstacle
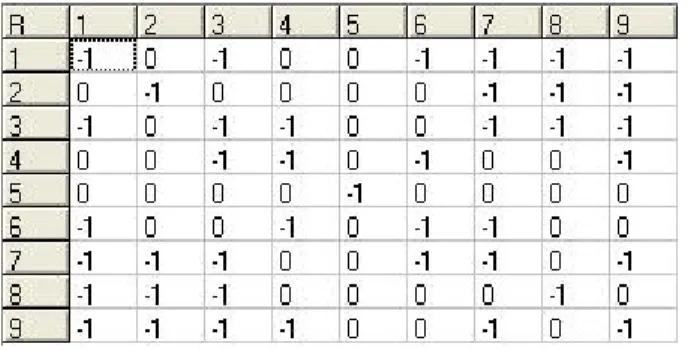
Matriks R awalnya hanya akan berisi 0 dan -1. Nilai 0 memiliki arti sebagai penghubung antar state, sedangkan nilai -1 artinya state yang tidak terhubung.
Gambar 3.4 Map yang mempunyai avatar, goal, dan obstacle
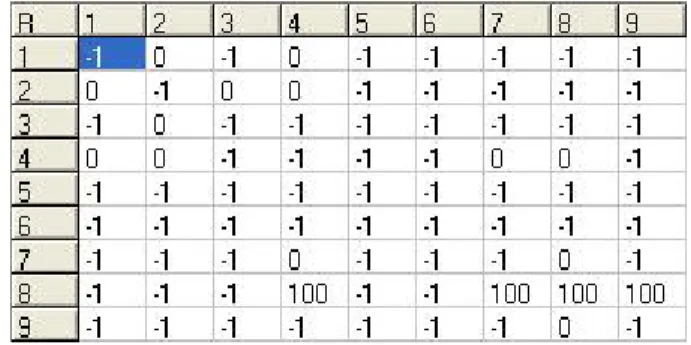
Tabel 3.3 Inisialisasi matriks R pada Map yang telah terisi
Setelah map diisi dengan start, goal, dan obstacle, maka nilai dalam matriks R akan berubah, perubahan nilai yang terjadi yaitu pada matriks yang menunjuk goal
(hijau) dan pada matriks yang menunjuk obstacle(merah). Matriks yang menuju goal
dan goal itu sendiri akan diberikan nilai 100 sebagai reward yang nantinya akan mempengaruhi perubahan nilai pada matriks Q. Sedangkan Matriks yang menuju ke
obstacle, dari obstacle dan di obstacle itu sendiri akan diberi nilai -1 karena tidak ada yang bisa menuju ke obstacle, dari obstacle dan obstacle ke dirinya sendiri.
3.4.1.2Inisialisasi matriks Q
Matriks Q diinisialisai untuk menyimpan nilai Q-value dan representasi dari hasil pembelajaran. Pada awal matriks Q dibentuk, nilai yang terdapat pada matriks Q bernilai 0 semua, hal ini untuk menunjukkan pada awalnya avatar tidak memiliki pengetahuan apa-apa. Matriks Q akan mengalami perubahan nilai pada proses
training dan pada akhirnya nilai yang didapat akan digunakan untuk proses path planning yang optimal. Untuk mengetahui gambar map dapat dilihat di gambar 3.3 (
Map yang belum mempunyai avatar, goal, dan obstacle ).
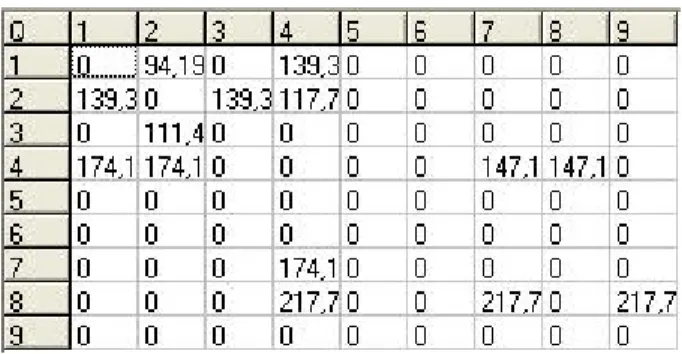
Tabel 3.4 Iniliasisasi Matriks Q pada map yang kosong
Untuk mengetahui gambar map untuk tabel 3.5 dibawah ini dapat dilihat di gambar 3.4 ( Map yang mempunyai avatar, goal, dan obstacle )
Tabel 3.5 Inisialisasi matriks Q pada Map yang telah terisi Nilai-nilai pada matriks Q berubah setelah mengalami proses training.
3.4.1.3Inisialisasi Learning Parameter
Learning parameter adalah parameter yang digunakan dalam Q-Learning
dalam proses pembelajarannya. Nilai learning parameter ini berkisar antara 0 sampai dengan 1. Makin kecil nilai learning parameter maka avatar akan lebih memperhitungkan immediate reward, yang berarti akan nilai akan mencapai
convergence lebih cepat. Nilai yang mendekati 1 akan lebih lama mencapai
convergence namun dapat memberikan hasil persebaran reward yang lebih baik sehingga meningkatkan optimalitas. Nilai yang lebih besar atau sama dengan 1 menyebabkan tidak tercapainya convergence, dan nilai yang kurang dari 0 atau sama dengan 0 mengakibatkan penurunan reward sehingga perhitungan akan sama sekali tidak akurat.
3.4.2 Inisialisasi Obyek
Inisialisasi obyek berfungsi untuk menentukan obyek-obyek apa saja yang berada dalam map pada suatu game. Pada permasalahan ini, obyek yang terdapat adalah avatar, goal, dan obstacle.
3.4.2.1Avatar
Avatar mempunyai sifat dapat bergerak ke 8 arah dan mempunyai kemampuan belajar dengan menggunakan metode Q-learning dan Backtracking
untuk merencanakan path yang akan dilaluinya. 3.4.2.2Goal
Proses yang dilakukan aplikasi ini adalah membuat avatar dapat menemukan
path menuju goal. Adapun goal yang dipetakan ke dalam array dapat diketahui lokasinya oleh avatar, sehingga avatar dapat mencapai goal yang ditentukan.
3.4.2.3Obstacle
Dalam usaha avatar mencapai goal, akan menemukan obstacle yang diletakkan dalam koordinat tertentu, sesuai dengan keinginan user. Obstacle ini berupa wall yang diletakkan di dalam map dan harus dihindari oleh avatar.
3.5 Proses Training
Training adalah proses pembelajaran dimana dalam tahap ini, avatar akan mencoba path yang nantinya akan ditempuh sebelum dia melakukan proses path planning yang akan dihadapi. Seperti makhluk hidup, avatar hanya mengetahui path
yang akan ditempuh jika dia sudah punya pengalaman akan path yang pernah dilaluinya. Dalam proses training, avatar menggunakan metode pembelajaran
Reinforcement Learning dengan metode Q-learning yang telah dimodifikasi, adapun rumus Q-learning yang digunakan adalah:
di mana:
• Q(state,action) adalah nilai Q dari pengambilan action di state saat ini. • R(state,action) adalah nilai R atau reward yang diperoleh saat state
mengambil action.
• γ adalah learning parameter yang nilainya 0≤γ ≤1
• Q(next.state,next.all.action) adalah nilai Q dari kemungkinan semua
action pada state berikutnya.
)] . . , . ( [ ) , ( ) ,
(state action R state action Max Q next state next all action
Pada saat proses training memulai iterasi, akan diacak state mana yang akan menjadi initial state awal. State yang diacak adalah state yang bukan obstacle. Kemudian dari state tersebut akan dipilih action mana yang akan dipilih dari sejumlah action yang tersedia. Pada saat pemilihan action ini, terdapat proses
backtracking, dimana jika state yang pernah dilalui maka akan mengambil action lain namun jika tidak ditemukan action lain maka avatar akan mundur ke state berikutnya dan akan mencari action yang belum pernah diambil hingga ia mencapai goal.
1. Set parameter γ dan environment reward sesuai pada map yang ditentukan.
2. Inisialisasi table Q(s,a) menjadi 0. 3. For setiap episode:
i. Choose state awal sebagai currentstate s secara acak ii. If state awal = wall then lakukan langkah ke - i. iii. Do while not state goal
a. Amati currentstate s(t)
b. Tentukan action a dari state s secara acak c. Amati nextstate s’(t)
d. If nextstate s’(t) pernah dipakai lakukan langkah ke-b
e. If nextstate s’(t) pernah dipilih semua, mundur. Currentstate s(t) Å s(t-1)
f. If nextstate s’ belum pernah dipakai then
Terima reward R
Amati nextstate
Update tabel Q(s,a) dengan Q(s,a)År+ γ*max ΣQ(s’,a’)
Jadikan state saat ini menjadi next state.
g. End if iv. End dowhile 4. End for
3.6Recall
Hasil perhitungan Matriks Q akan akan diambil dan diproses untuk menemukan path yang akan dicari sehingga dapat ditemukan hasil Planning yang optimal. Berdasar Start, Goal dan Obstacle yang telah dimasukkan sebelumnya akan diproses berdasarkan pseudocode berikut :
3.7Perancangan Aplikasi
Proses-proses yang terjadi dalam aplikasi path planning dengan menggunakan metode Q-learning dan backtracking adalah sebagai berikut:
1. Pada mulanya ditentukan ukuran map, nilai gamma dan jumlah iterasi sesuai dengan ukuran dan nilai yang diinginkan dengan melakukan input di menu
pada gambar 3.7.
2. Setelah ukuran dan nilai ditentukan, maka diinisialisasi matriks Q dan matriks R. Nilai pada matriks R dirancang berdasarkan pada map yang telah ditentukan. Matriks Q yang ukurannya sama dengan matriks R, tetapi memiliki nilai matriks yang berbeda.
3. Langkah berikutnya adalah menentukan state start, goal, dan obstacle.Start,
goal dan obstacle ditentukan dengan memilih koordinat [x,y] yang terletak 1. Set current state = initial state
2. Find action from current state that have maximum Q Value 3. If maximum Q Value not change then path not found
4. Set Current State = next state
pada map. Dimana koordinat x menyatakan kolom pada map dan y menyatakan baris pada map. Koordinat tersebut kemudian disimpan dalam bentuk state dimana nilai state didapat dengan rumus
x column y
state=( −1)* + .
4. Setelah itu, proses training dijalankan dengan melakukan perhitungan menggunakan metode Q-learning dan backtracking. Untuk algoritma metode yang digunakan dapat dilihat pada halaman 55.
5. Apabila proses training telah selesai dijalankan, maka dapat dilakukan proses
find yang menghasilkan path planning. Proses find ini dilakukan dengan mencari nilai maximum dari matriks Q yang telah berubah pada proses
training. Jika nilai maximum dari matriks Q bukan goal state, berarti path
yang dicari tidak ditemukan.
3.7.2State Transition Diagram (STD)
State-Transition Diagram (STD) adalah suatu model yang menggambarkan bagaimana sifat ketergantungan sistem saat mendapatkan event dari luar dan juga menggambarkan hubungan transisi atau perubahan antar state. STD menggunakan simbol sebagai berikut:
Gambar 3.5 State Transition Diagram
Simbol kotak menggambarkan state dan tanda panah menggambarkan kondisi dan aksi yang akan dilakukan dari suatu state ke state lain.
a. STDMenu Utama
d. STDMenuMatrix Q MATRIX Q TAMPILKAN NILAI MATRIX Q MUNCUL FORM MATRIX Q
Menampilkan nilai pada matrix Q
Tombol OK
Keluar dari Form Matrix Q
KLIK TOMBOL OK
e. STDMenuMatrix R MATRIX R TAMPILKAN NILAI MATRIX R MUNCUL FORM MATRIX R
Menampilkan nilai pada matrix R
Tombol OK
Keluar dari Form Matrix R
KLIK TOMBOL OK
f. STDMenuAbout Us ABOUT US MENAMPILKAN ABOUT US MUNCUL FORM ABOUT US Menampilkan About us Tombol OK
Keluar dari Form About us
KLIK TOMBOL OK
g. STDMenuProgram Help PROGRAM HELP MENAMPILKAN PROGRAM HELP MUNCUL FORM PROGRAM HELP Menampilkan program Help Tombol OK
Keluar dari Form Program Help
KLIK TOMBOL OK
3.7.3Perancangan Layar
3.7.3.1Perancangan Main Menu
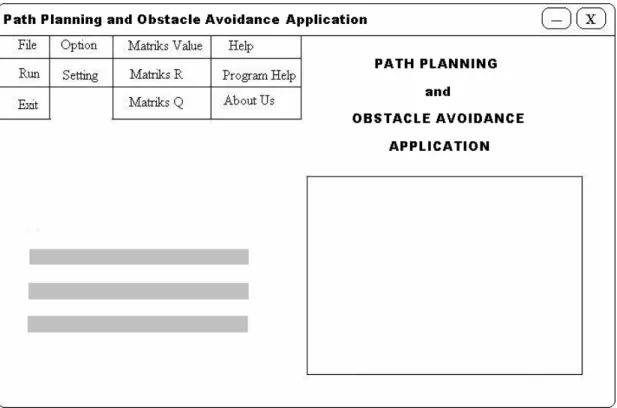
Gambar 3.6 Rancangan Main Menu
Menu ini adalah tampilan awal dari aplikasi. Pada layar ini ditampilkan judul program dan pembuatnya. Pada menu ini user dapat memilih menu lainnya, yaitu:
File, Option, Matriks Value, Help. Pada setiap menu pilihan juga terdapat submenu
3.7.3.2Perancangan Menu Run
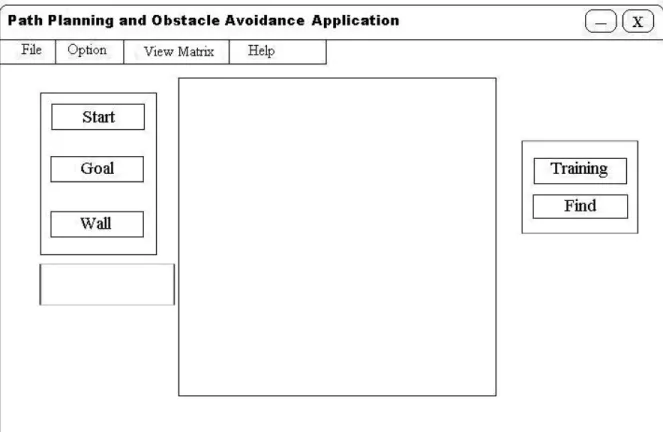
Gambar 3.7 Rancangan Menu Run
Form ini berfungsi untuk melihat path planning yang diinginkan user. Hal yang dapat dilakukan oleh user adalah menentukan letak start, goal dan obstacle
yang diinginkan dengan mengklik tombol yang ada di kotak objek. Setelah user
menentukan start dan goal serta obstacle, maka agar path dapat ditemukan, diperlukan proses training dengan mengklik tombol training, lalu user dapat mencari
path yang dapat ditempuhnya dengan mengklik tombol find. User tidak hanya dapat melakukan aplikasi path planning namun juga dapat menampilkan form lain sesuai dengan submenuform yang dipilih.
Pada saat user menentukan lokasi start maka koordinat start yang ditentukan akan disimpan. Sedangkan saat goal ditentukan oleh user, maka akan dilakukan perubahan nilai di matriks R, yang menjadi reward ketika state memasuki goal. Ketika user menentukan obstacle yang ada, maka nilai di matriks R yang menjadi pernyatakan action ke stateobstacle akan diubah.
Proses training akan mengubah nilai di matriks Q sesuai dengan iterasi yang telah ditentukan. Pada tiap iterasi akan diacak state yang menjadi state awal, kemudian state akan bergerak sesuai dengan memilih action yang tersedia secara acak. Tiap iterasi akan berakhir ketika state bergerak menuju goal state. Jika goal state tidak ditemukan, namun semua state yang dapat ditempuh sudah dilalui, maka proses iterasinya akan dihentikan.
Pada proses find akan dimunculkan path dari state start sampai dengan state goal sesuai dengan kemungkinan terbesar suatu actionmenuju goal.
3.7.3.3Perancangan Menu Setting
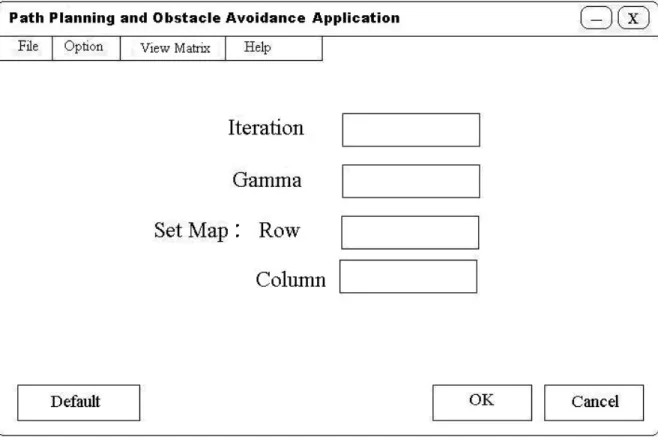
Gambar 3.8 Rancangan Menu Setting
Pada form ini berfungsi untuk menentukan banyaknya iterasi, nilai gamma, besarnya map yang diinginkan oleh user. User juga dapat mengembalikan kembali semua setting yang telah diubah ke setting awal sebelum diubah.
3.7.3.4Perancangan Matriks R
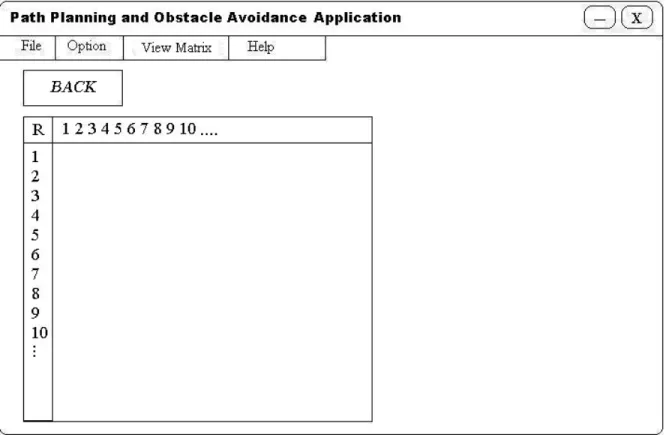
Gambar 3.9 Rancangan Matriks R
Pada form ini bertujuan untuk menampilkan nilai matriks R dengan menggunakan metode Q-learning. User dapat melihat nilai-nilai awal yang terdapat pada matriks R tempat avatar akan belajar.
3.7.3.5Perancangan Matriks Q
Gambar 3.10 Rancangan Matriks Q
Pada form ini bertujuan untuk menampilkan nilai matriks Q dengan menggunakan metode Q-learning. User dapat melihat nilai-nilai yang terdapat pada matriks Q yang akan berubah seiring dengan proses training dan iterasi.
3.7.3.6Perancangan Menu Help
Gambar 3.11 Rancangan Menu Help
Form ini berfungsi untuk membantu user yang tidak tahu cara menggunakan aplikasi ini. Form ini juga menjelaskan setiap fungsi dan sub menu apa saja yang bisa dipilih.
3.7.3.7Perancangan About Us
Gambar 3.12 Rancangan About Us