PENDEKATAN DATA MINING
Oleh:
Yuandri Trisaputra G64120004 2012 Oktarina Safar Nida G14120052 2012
INSTITUT PERTANIAN BOGOR BOGOR
Daftar Isi PENDAHULUAN ... 4 Latar Belakang... 4 Tujuan ... 5 Manfaat ... 6 TINJAUAN PUSTAKA ... 6 Analisis Korespondensi ... 6 Algoritme J48 ... 6
Regresi Logistik Biner ... 7
Klasifikasi dan Prediksi ... 7
K-Fold Cross Validation ... 8
Confusion Matrix ... 8
METODE ... 9
Data Penelitian... 9
Proses data dan pembentukan model ... 9
Implementasi Program... 10
Lingkungan Pengembangan ... 11
PEMBAHASAN ... 11
Eksplorasi Data ... 11
Percobaan Klasifikasi Desa ... 15
Model Pohon Keputusan ... 15
Model Regresi Logistik ... 17
Kombinasi Peluang Pohon Keputusan dan Regresi Logistik ... 17
Implementasi Program... 18
KESIMPULAN ... 19
Abstrak
Desa merupakan satuan daerah terkecil yang bisa dilihat gambaran pembangunannya melalui data Potensi Desa (Podes) yang dikeluarkan oleh Badan Pusat Statistik (BPS). Pada tahun 2015, pemerintah fokus kepada pembangunan desa, sehingga dibentuklah kementerian desa, pembangunan daerah tertinggal, dan transmigrasi melalui Peraturan Presiden Nomor 12 Tahun 2015. Fokus pemerintah kepada pembangunan desa ini menarik untuk diperhatikan karena pembangunan yang tepat sasaran merupakan hal mutlak yang diperlukan. Persentase desa tidak tertinggal tertinggi didominasi oleh desa di Pulau Jawa. Analisis korespondensi dilakukan untuk mengidentifikasi hubungan pulau-pulau di Indonesia melalui sarana listrik (PLN dan NON-PLN) dan sarana irigrasi. Melalui analisis korespondensi, pulau yang terdiri dari Papua dan Papua Barat terlihat relatif dekat digambarkan dengan variabel non-irigrasi. Sementara Pulau Jawa sangat digambarkan dengan variabel PLN.
Proses klasifikasi terhadap sebuah desa dengan ciri tertentu dapat dilakukan untuk menduga desa tersebut termasuk ke dalam desa tertinggal atau tidak sehingga pembangunan yang dilakukan pemerintah akan tepat sasaran. Data mengenai potensi 77,961 desa di Indonesia dengan berbagai fitur menarik untuk diamati. Dalam penggalian data (data mining) diperlukan adanya metode klasifikasi untuk membantu pemerintah dalam pengklasifikasian status sebuah desa tertinggal atau tidak. Melalui metode pencarian Best First dan evaluasi Subset, terdapat 7 variabel yang berpengaruh terhadap penentuan desa tertinggal. Klasifikasi desa tertinggal dengan algoritme pohon keputusan menghasilkan aturan klasifikasi dengan keakuratan sebesar 75% dengan 10-fold cross validation. Sementara regresi logistik menghasilkan keakuratan sebesar 66%. Kombinasi peluang regresi logistik dan peluang pada pohon keputusan menjadi peluang akhir yang digunakan, kombinasi tersebut menghasilkan akurasi sebesar 77%. Melalui model yang dihasilkan dari kombinasi yang cukup akurat tersebut, model klasifikasi desa tertinggal disimulasikan ke dalam sistem klasifikasi berbasis web.
Kata Kunci: desa tertinggal, klasifikasi, korespondensi, potensi desa, pohon keputusan, regresi logistik
PENDAHULUAN
Latar Belakang
Rencana Pembangunan Jangka Menengah (RPJM) Nasional tertulis pada peraturan pemerintah No.7 tahun 2005. Pada tahun 2004-2009 digambarkan bahwa kesenjangan pembangunan antar daerah masih lebar, seperti:
● antara Jawa – Luar Jawa,
● antara Kawasan Barat Indonesia (KBI) – Kawasan Timur Indonesia (KTI), serta ● antara kota – desa.
Desa merupakan satuan daerah terkecil yang bisa dilihat pembangunan desa, salah satunya melalui data Potensi Desa (Podes) yang dikeluarkan oleh Badan Pusat Statistik (BPS). Data Podes adalah data kewilayahan (spasial) yang menekankan pada penggambaran situasi wilayah. Cakupan wilayah dan kegiatan pendataan Podes 2011 dilakukan terhadap seluruh wilayah administrasi pemerintahan setingkat desa (desa, kelurahan, nagari/jorong) di seluruh Indonesia, termasuk Unit Permukiman Transmigrasi (UPT) dan Satuan Permukiman Transmigrasi (SPT) yang masih dibina oleh kementerian terkait.
Pada tahun 2015, pemerintah fokus kepada pembangunan desa sehingga dibentuklah kementerian desa, pembangunan daerah tertinggal, dan transmigrasi melalui Peraturan Presiden Nomor 12 Tahun 2015. Fokus pemerintahan kepada pembangunan desa ini menarik untuk diperhatikan karena pembangunan yang tepat sasaran merupakan hal mutlak yang diperlukan. Menurut Kementerian Pekerjaan Umum (2011), desa tertinggal merupakan kawasan perdesaan yang ketersediaan sarana dan prasarana dasar wilayahnya kurang/tidak ada (tertinggal) sehingga menghambat pertumbuhan/perkembangan kehidupan masyarakatnya dalam bidang ekonomi (kemiskinan) dan bidang pendidikan (keterbelakangan).
Proses klasifikasi terhadap sebuah desa dengan ciri tertentu dapat dilakukan untuk menduga/mengidentifikasi desa tersebut termasuk ke dalam desa tertinggal atau tidak sehingga pembangunan yang dilakukan pemerintah akan tepat sasaran. Data mengenai potensi seluruh desa di Indonesia menjadi menarik untuk diamati. Dalam penggalian data (data mining) diperlukan suatu metode klasifikasi untuk
membantu pemerintah dalam pengklasifikasian status sebuah desa tertinggal atau tidak.
Pada data mining dikenal beberapa metode untuk proses klasifikasi. Metode tersebut diantaranya Neural Network, Fuzzy, Support Vector Machine, dan
Decision Tree (Pohon Keputusan). Algoritme pohon keputusan dikenal selama ini sebagai algoritme yang cukup sederhana dan akurat dalam proses klasifikasi dibanding dengan algoritme klasifikasi lainnya. Selain itu, algoritme pohon keputusan juga lebih mudah diimplementasikan ke dalam sebuah program. Peluang sebuah desa masuk dalam kategori desa tertinggal berdasarkan fitur-fitur yang ada dapat ditentukan melalui metode Regresi Logistik. Regresi Logistik merupakan metode pendugaan dalam statistika yang memiliki respon kategorik. Pada kasus ini respon kategorik yang digunakan merupakan biner yaitu desa tertinggal (1) dan desa tidak tertinggal (0). Selain penentuan kelas desa tertinggal, metode pencarian
Best First dan evaluasi Subset juga digunakanuntuk mencari variabel apa saja yang memengaruhi suatu desa dikatakan tertinggal atau tidak.
Oleh karena itu, pada penelitian ini algoritme pohon keputusan diterapkan dengan 10-fold cross validation. Sementara melalui regresi logistik dapat ditentukan besar peluang sebuah desa masuk dalam kategori tertinggal. Pada regresi logistik dapat ditentukan sendiri nilai cuts off yang sesuai dengan analisis pemerintah. Kombinasi peluang regresi logistik dan peluang pada pohon keputusan menjadi peluang akhir yang digunakan. Selain itu, model yang dihasilkan dari kombinasi pohon keputusan dan regresi logistik tersebut disimulasikan ke dalam sistem berbasis web.
Tujuan
Tujuan dari penelitian ini adalah:
1. Mengeksplorasi status daerah di Indonesia dengan berbagai kriteria situasi desa. 2. Menerapkan algoritme pohon keputusan dan regresi logistik untuk klasifikasi
desa tertinggal.
3. Mengidentifikasi peluang sebuah desa menggunakan algoritme pohon keputusan dan regresi logistik.
4. Menentukan peluang sebuah desa masuk dalam kategori tertinggal dengan menggunakan kombinasi regresi logistik dan peluang aturan pohon keputusan. 5. Membuat program untuk klasifikasi desa tertinggal berbasis web.
Manfaat
1. Memberikan pengetahuan mengenai gambaran kondisi desa-desa di Indonesia guna pembangunan tepat sasaran.
2. Memberikan kemudahan dalam pengecekan status desa tertinggal melalui teknologi sistem informasi berbasis web.
TINJAUAN PUSTAKA Analisis Korespondensi
Analisis korespondensi adalah ilmu yang mempelajari hubungan antara dua atau lebih peubah kualitatif. Analisis ini digunakan untuk eksplorasi data dari tabel kontingensi. Analisis korespondensi ini meproyeksikan banyak peubah ke dalam grafik berdimensi 2 dengan jarak Euclidan (Matjiik dan Sumertajaya 2011).
Algoritme J48
Algoritme J48 adalah algoritme untuk membentuk pohon keputusan yang digunakan untuk klasifikasi. Pohon keputusan merupakan metode klasifikasi dan prediksi yang sangat kuat dan terkenal. Metode pohon keputusan mengubah fakta yang besar menjadi pohon keputusan yang merepresentasikan aturan. Aturan dapat mudah dipahami dengan bahasa alami. Aturan tersebut dapat diekspresikan dalam bentuk bahasa basis data seperti SQL (Structured Query Language) untuk mencari
record kategori tertentu. Pohon keputusan juga berguna untuk mengeksplorasi data, menemukan hubungan tersembunyi antara sejumlah variabel input dengan variabel target. Pohon keputusan memadukan antara eksplorasi data dan dan pemodelan, sehingga pohon keputusan sangat bagus sebagai langkah awal dalam proses pemodelan bahkan ketika dijadikan sebagai model akhir dari beberapa teknik lain. Melalui algoritme keputusan dapat ditentukan peluang sebuah data masuk ke kelas tertentu berdasarkan peluang di dalam node pohon keputusan.
Regresi Logistik Biner
Regresi logistik biner adalah analisis statistika yang digunakan untuk menjelaskan hubungan antara peubah respon yang berskala kategori biner dengan satu atau lebih peubah penjelas yang berskala kategori atau kontinu. Pada model regresi logistik tidak diperlukan adanya pengujian asumsi yaitu uji normalitas dan uji asumsi klasik (uji heteroskedastisitas dan uji autokorelasi). Metode kuadrat terkecil sudah tidak tepat lagi digunakan untuk data regresi yang memiliki variabel respon biner.
Model regresi logistik menggunakan transformasi logit. Pada model ini, yang diregrsikan adalah peluang variabel respon sama dengan 1 dibentuk dengan menyatakan E(Y=1|x) sebagai π(x). Hosmer dan Lemeshow (2000) menjelaskan bahwa model regresi logistik π(x) dinotasikan sebagai berikut:
ᴨ(𝑥) = exp(𝛽 + 𝛽𝑥1 + ⋯ … + 𝛽𝑥𝑝) 1 + exp(𝛽 + 𝛽𝑥1 + ⋯ … + 𝛽𝑥𝑝) dengan:
𝑔(𝑥) = 𝛽0+ 𝛽1𝑥1 + ⋯ + 𝛽𝑝𝑥𝑝 𝛽0 = konstanta
𝛽𝑖 = koefisien regresi logistik
i = 1, 2, …, p
p = banyak peubah penjelas
Klasifikasi dan Prediksi
Klasifikasi merupakan penempatan objek-objek ke salah satu dari beberapa kategori yang telah ditetapkan sebelumnya. Klasifikasi bertujuan untuk memperoleh aturan yang dapat digunakan untuk memprediksi label kelas dari objek yang tidak yang tidak diketahui label kelasnya. (Tan dan Ning2006)
Klasifikasi terdiri atas dua proses yaitu tahap induktif yang merupakan tahap membangun model klasifikasi dari data latih dan tahap deduktif yang merupakan tahap menerapkan model untuk data uji. Klasifikasi mempunyai dua teknik pembelajaran yaitu eager learner yang membuat model berdasarkan atribut
yang melakukan proses pemodelan dari data latih ketika ada data uji yang akan diklasifikasikan (Tan dan Ning2006).
K-Fold Cross Validation
K-fold cross validation dilakukan untuk membagi data latih dan data uji. K
-fold cross validation mengulang k-kali untuk membagi sebuah himpunan contoh secara acak menjadi ksubset yang saling bebas, setiap ulangan disisakan satu subset
untuk pengujian dan subset lainnya untuk pelatihan (Fu 1994). Pada metode tersebut, data awal dibagi menjadi k subset atau “fold” yang saling bebas secara
acak, yaitu S1, S2, ..., Sk, dengan ukuran setiap subset kira-kira sama. Pada iterasi ke-i, subset Si diperlukan sebagai data pengujian dan subset lainnya diperlukan sebagai data pelatihan. Prosedur ini diulang sebanyak k-kali sedemikian sehingga setiap subset digunakan untuk pengujian tepat satu kali. Total akurasi ditentukan dengan menjumlahkan akurasi untuk semua k proses tersebut (Ulya 2013).
Confusion Matrix
Evaluasi model klasifikasi berdasar pada proporsi antara data uji yang diprediksi secara tepat dengan total seluruh prediksi (Tan dan Ning 2006). Informasi mengenai klasifikasi sebenarnya (aktual) dengan klasifikasi hasil prediksi disajikan dalam bentuk tabel yang disebut confusion matrix seperti ditunjukan pada Tabel 1.
Tabel 1 Confusion matrix
Jumlah baris dan kolom pada tabel bergantung pada banyaknya kelas target. Akurasi merupakan proporsi jumlah prediksi yang tepat. Contoh perhitungan akurasi untuk tabel tersebut adalah (Faiza 2009):
𝐴𝑘𝑢𝑟𝑎𝑠𝑖 = 𝐽𝑢𝑚𝑙𝑎ℎ𝑝𝑟𝑒𝑑𝑖𝑘𝑠𝑖𝑦𝑎𝑛𝑔𝑡𝑒𝑝𝑎𝑡 𝑇𝑜𝑡𝑎𝑙𝑝𝑟𝑒𝑑𝑖𝑘𝑠𝑖 𝑖=
𝑎 + 𝑑 𝑎 + 𝑏 + 𝑐 + 𝑑 Kelas Prediksi
Kelas Aktual Kelas 1 Kelas 2
Kelas 1 A b
METODE
Pada tahap eksplorasi data akan dilakukan berbagai analisis deskriptif melalui
chart mengenai gambaran kondisi di berbagai daerah di Indonesia. Pada pembangunan model klasifikasi akan dilakukan dalam beberapa tahap. Tahap-tahap tersebut disajikan pada Gambar 1.
Data Penelitian
Data yang digunakan pada penelitian ini adalah data potensi desa 2011 dari Badan Pusat Statistik. Data tersebut terdiri dari 77,961 desa dan 1501 variabel utama yang terdiri dari variabel numerik dan kategorik. Variabel tersebut direduksi menjadi 205 variabel.
Gambar 1 Tahapan Penelitian
Proses data dan pembentukan model
Proses data dan pembentukan model untuk identifikasi desa tertinggal dapat dilihat pada Gambar 2. Dataset sebagai input yang digunakan dalam makalah ini adalah data potensi desa tahun 2011 dengan 205 fitur (variabel numerik) dan class
desa tertinggal atau tidak tertinggal berdasarkan kriteria Kementerian Pekerjaan Umum dan Perumahan Rakyat Republik Indonesia. Rincian fitur yang digunakan bisa dilihat pada lampiran 1. Cleaning data digunakan untuk praproses data. Data yang digunakan adalah data 77,961 desa di Indonesia pada tahun 2011.
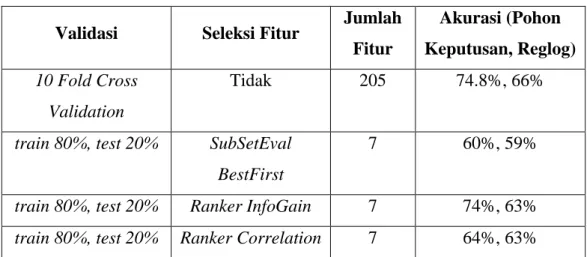
Setelah proses cleaning data maka dilakukan percobaan untuk mendapatkan kombinasi antara banyak fitur dan akurasi. Kombinasi antara banyak fitur dan akurasi tersedia pada Tabel 2.
Akuisisi
data Dataset
Eksplorasi data Proses data dan pembentukan
model serta evaluasi model
Implementasi program
Gambar 2 Proses data dan pembentukan model klasifikasi Tabel 2 Percobaan
Validasi Seleksi Fitur Fitur yang digunakan
10 Fold Cross Validation Tidak 205 Fitur
train 80%, test 20% SubSetEval BestFirst 7 Fitur
train 80%, test 20% Ranker InfoGain 7 Fitur
train 80%, test 20% Ranker Correlation 7 Fitur
Output dari percobaan ini adalah aturan-aturan klasifikasi untuk desa di Indonesia dan pendugaan class desa. Model terbaik akan diterapkan pada sistem untuk mengidentifikasi desa tertinggal.
Implementasi Program
Implementasi program dilakukan berdasarkan model terbaik yang didapatkan pada tahap pembentukan model. Program yang dibuat berbasis web. Web akan menampilkan hasil identifikasi desa tertinggal berdasarkan input yang sesuai dengan variabel atau fitur yang digunakan. Selain itu, program yang dibuat akan menampilkan peluang kombinasi dari model pohon keputusan dan regresi logistik.
Percobaan
Melakukan penyeleksian fitur kembali dan membandingkannya kombinasi antara jumlah fitur dan keakuratan dalam klasifikasi. Kemudian dipilih
kombinasi dengan keakuratan terbaik.
Cleaning Data
Mengatasi missing value berdasarkan dengan variabel lain yang masih ada
hubungannya. Misal: variabel x merupakan jumlah puskesmas namun terdapat missing
value, sehingga di cek pada variabel y (terdapati atau tidak terdapat puskesmas) jika ternyata tidak terdapat puskesmas maka variable x diisi dengan 0. Melakukan
pemilihan fitur dari 1501 fitur utama.
Klasifikasi dengan Regresi Logistik
Regresi dengan respons (class) 1 untuk desa tertinggal dan 0 untuk desa tidak tertinggal.
Klasifikasi dengan Pohon Keputusan
Algoritma J48 untuk menentukan
Lingkungan Pengembangan
Spesifikasi perangkat keras dan perangkat lunak yang digunakan dalam penelitian yaitu sebagai berikut:
1. Perangkat Keras terdiri dari: Processor Intel Core i3, Memori 6 GB, Harddisk 500 GB, Layar 14 inci, Mouse dan Keyboard.
2. Perangkat Lunak:
● Sistem operasi Windows 8
● Microsoft Excel 2013 dan EmEditor sebagai lembar pengolahan data tambahan, media merapihkan data penggabungan data, pembersihan data, dan transformasi data
● SPSS 23 untuk melakukan proses data mining klasifikasi.
PEMBAHASAN Eksplorasi Data
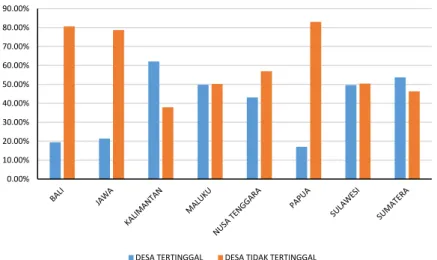
Dataset sebagai input yang digunakan dalam makalah ini adalah data potensi desa tahun 2011 dengan 205 fitur (variabel numerik) dan class desa tertinggal atau tidak tertinggal berdasarkan kriteria Kementerian Pekerjaan Umum dan Perumahan Rakyat Republik Indonesia. Cleaning data digunakan untuk praproses data. Persentase kelas desa tertinggal dan tidak tertinggal di setiap pulau di Indonesia digambarkan pada Gambar 3.
Gambar 3 Persentase Desa Tertinggal dan Tidak Tertinggal di setiap Pulau di Indonesia 0.00% 10.00% 20.00% 30.00% 40.00% 50.00% 60.00% 70.00% 80.00% 90.00%
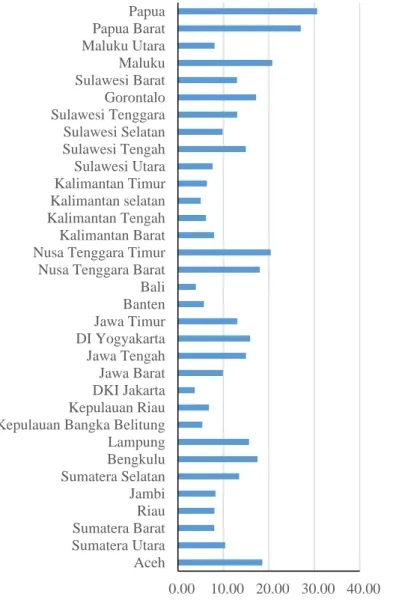
Kriteria desa tertinggal di Indonesia diindikasikan melalui prasarana dan sarana dasar wilayah, perekonomian masyarakat, tingkat pendidikan, dan produktivitas masyarakat yang rendah. Perekonomian masyarakat, tingkat pendidikan, dan produktivitas masyarakat yang rendah tentu bisa digambarkan dengan jumlah penduduk miskin pada suatu daerah. Persentase penduduk miskin di Indonesia digambarkan pada Gambar 4.
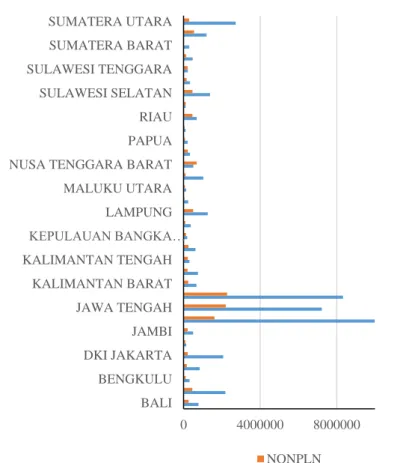
Sarana dan prasarana wilayah meliputi air bersih, irigrasi, dan listrik merupakan dasar kebutuhan suatu masyarakat dalam sebuah desa. Penggunaan listrik Perusahaan Listrik Negara (PLN) didominasi oleh provinsi di Pulau Jawa. Jumlah pengguna listrik PLN dan NONPLN di Indonesia digambarkan pada Gambar 5. Sementara jumlah desa dengan irigrasi digambarkan pada Gambar 6.
Gambar 4 Persentase Penduduk Miskin di Indonesia Tahun 2012 0.00 10.00 20.00 30.00 40.00 Aceh Sumatera Utara Sumatera Barat Riau Jambi Sumatera Selatan Bengkulu Lampung Kepulauan Bangka Belitung Kepulauan Riau DKI Jakarta Jawa Barat Jawa Tengah DI Yogyakarta Jawa Timur Banten Bali Nusa Tenggara Barat Nusa Tenggara Timur Kalimantan Barat Kalimantan Tengah Kalimantan selatan Kalimantan Timur Sulawesi Utara Sulawesi Tengah Sulawesi Selatan Sulawesi Tenggara Gorontalo Sulawesi Barat Maluku Maluku Utara Papua Barat Papua
Gambar 5 Jumlah RT Pengguna Listrik di Indonesia Tahun 2011
Gambar 6 Jumlah Desa dengan Irigrasi dan Non-Irigrasi di Indonesia Tahun 2011
0 4000000 8000000 BALI BENGKULU DKI JAKARTA JAMBI JAWA TENGAH KALIMANTAN BARAT KALIMANTAN TENGAH KEPULAUAN BANGKA… LAMPUNG MALUKU UTARA NUSA TENGGARA BARAT PAPUA RIAU SULAWESI SELATAN SULAWESI TENGGARA SUMATERA BARAT SUMATERA UTARA NONPLN 0 2000 4000 6000 8000 BALI BENGKULU DKI JAKARTA JAMBI JAWA TENGAH KALIMANTAN BARAT KALIMANTAN TENGAH KEPULAUAN… LAMPUNG MALUKU UTARA NUSA TENGGARA… PAPUA RIAU SULAWESI SELATAN SULAWESI TENGGARA SUMATERA BARAT SUMATERA UTARA
Persentase penduduk miskin tertinggi di Indonesia didominasi oleh provinsi di Luar Jawa terutama di bagian Timur Indonesia, yaitu Papua, Papua Barat, dan Maluku. Hal tersebut sejalan dengan jumlah Rumah Tangga (RT) pengguna PLN di Indonesia masih sangat sedikit di kawasan Papua, Papua, Papua Barat, Maluku dan Maluku Utara berlawanan dengan RT di Pulau Jawa. Desa terbanyak dengan irigrasi juga didominasi oleh desa di Pulau Jawa. Hal ini merupakan gambaran kesenjangan pembangunan yang terjadi di Pulau Jawa dan Luar Pulau Jawa.
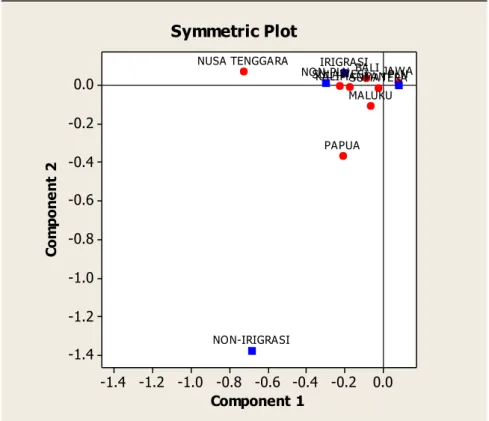
Analisis korespondensi dilakukan untuk mengidentifikasi hubungan pulau-pulau di Indonesia, sarana listrik (PLN dan NON-PLN), dan sarana irigrasi. Melalui analisis korespondensi dengan plot pada Gambar 7. Pulau Papua yang terdiri dari Papua dan Papua Barat terlihat paling dekat digambarkan dengan variabel non-irigrasi. Hal ini menunjukan bahwa di daerah tersebut merupakan daerah dengan desa non irigrasi paling banyak. Sementara Pulau Jawa sangat dekat digambarkan dengan variabel PLN. Hal ini sejalan bahwa desa di di Pulau Jawa sudah lebih maju mengenai sarana akses listriknya dibandingkan dengan desa di pulau lainnya menurut keberadaan PLN. 0.0 -0.2 -0.4 -0.6 -0.8 -1.0 -1.2 -1.4 0.0 -0.2 -0.4 -0.6 -0.8 -1.0 -1.2 -1.4 Component 1 C o m p o n e n t 2 PLN NON-PLN NON-IRIGRASI IRIGRASI SUMATERA SULAWESI PAPUA NUSA TENGGARA MALUKU KALIMANTANJAWABALI Symmetric Plot
Gambar 7 Plot Korespondensi antara Pulau di Indonesia dan Sarana Listrik dan Irigrasi
Percobaan Klasifikasi Desa
Data potensi desa tahun 2011 dengan 205 fitur dan kelas desa tertinggal atau tidak tertinggal berdasarkan kriteria Kementerian Pekerjaan Umum dan Perumahan Rakyat Republik Indonesia digunakan sebagai input klasifikasi pada penelitian ini. Hasil akurasi model klasifikasi dengan kombinasi validasi dan fitur dapat dilihat pada Tabel 3.
Tabel 3 Hasil akurasi model
Validasi Seleksi Fitur Jumlah Fitur Akurasi (Pohon Keputusan, Reglog) 10 Fold Cross Validation Tidak 205 74.8%, 66%
train 80%, test 20% SubSetEval BestFirst
7 60%, 59%
train 80%, test 20% Ranker InfoGain 7 74%, 63%
train 80%, test 20% Ranker Correlation 7 64%, 63%
Dengan melihat Tabel 2, tingkat akurasi terbaik didapat pada validasi data training 10-Fold Cross Validation dengan penggunaan 205 fitur. Setelah didapatkan kombinasi antara fitur dan akurasi yang terbaik maka dilakukan klasifikasi dengan algoritma pohon keputusan dan regresi logistic. Tujuh variabel atau atribut yang paling berpengaruh dalam penentuan desa tertinggal adalah variabel R803B (Jumlah Surau atau Langgar), R401E, (Jumlah Keluarga), R705B (Jumlah Posyandu yang aktif setiap sebulan sekali), R710A (Jumlah Kematian warga setahun terakhir), R1310 (Jumlah anggota linmas/hansip), R304C (Jumlah SLS terkecil di Desa/Kelurahan), R901B (Jarak ke gedung bioskop terdekat), dan R704JK3 (Jumlah Posyandu).
Model Pohon Keputusan
Pohon keputusan dijalankan menggunakan SPSS 23 dengan 10 Fold Cross Validation (CV). Metode yang digunakan pada pohon keputusan ini adalah Growth Method CHAID (multiway split). Rule yang dihasilkan pada algoritme pohon keputusan ini sebanyak 143 rule. Confusion Matrix pohon keputusan dapat dilihat
pada Tabel 4. Presentase kebenaran pengklasifikasian sebanyak 74.8%. Melalui Tabel 3 di bawah dapat diketahui bahwa sebanyak 23662 data desa tertinggal benar diklasifikasi sebagai desa tertinggal, 34646 data desa tidak tertinggal benar diklasifikasi sebagai desa tidak tertinggal. Sementara itu, terdapat 7468 desa tertinggal salah diklasifikasi ke dalam desa tidak tertinggal dan 121267 desa tidak tertinggal tertinggal salah diklasifikasi ke dalam desa tertinggal.
Tabel 3 Confusion Matrix Pohon Keputusan
Model pohon keputusan yang didapat menghasilkan keputusan dengan kedalaman maksimal 3. Contoh pohon keputusan pada kedalaman 1 dan 3 dapat dilihat pada Gambar 8 dan Gambar 9.
Gambar 8 Pohon Keputusan dengan Kedalaman 1
Berdasarkan pohon keputusan yang dihasilkan, didapatkan aturan-aturan atau rule yang dapat mengidentifikasikan sebuah desa dikategorikan sebagai desa tertinggal atau tidak. Contoh rule yang didapat sebagai berikut: Jika Jumlah surat miskin/SKTM yang dikeluarkan Desa lebih besar dari 60 dan SKTM yang dikeluarkan Desa kurang dari sama dengan 115 dan Jumlah Posyandu yang aktif setiap sebulan sekali lebih besar dari 2 dan Jumlah Posyandu yang aktif setiap sebulan sekali kurang dari sama dengan 3 dan Jumlah keluarga buruh tani lebih dari 51, maka Desa dikategorikan "Tidak Tertinggal". Rule tersebut mempunyai peluang sebesar 0.693359 berdasarkan dataset yang digunakan.
Model Regresi Logistik
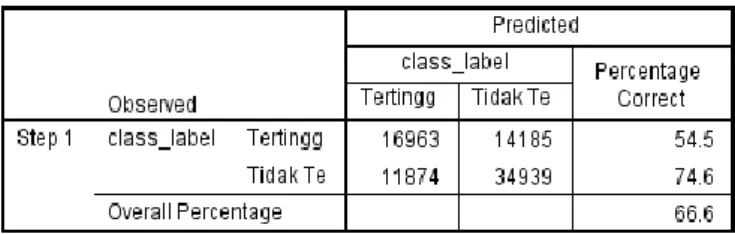
Regresi logistik dijalankan dengan 10 Fold Cross Validation (CV). Metode yang digunakan yaitu Binary Logistic Regression. Model yang didapatkan dalam bentuk fungsi peluang desa yang dikategorikan desa tidak tertinggal. Akurasi yang didapat sebesar 66.6%, Confusion Matrix dapat dilihat pada Tabel 4.
Tabel 4 Confusion Matrix Regresi Logistik
Kombinasi Peluang Pohon Keputusan dan Regresi Logistik
Kombinasi peluang dari model pohon keputusan dan regresi logistik digunakan untuk menentukan hasil akhir suatu desa dikategorikan sebagai desa tertinggal atau tidak tertinggal. Peluang kombinasi tersebut didapatkan berdasarkan nilai akurasi dari model yang dibangun. Nilai peluang akan dikalikan dengan proporsi dari akurasi model. Dengan demikian, akurasi yang lebih besar akan memiliki bobot yang lebih besar untuk menentukan hasil akhir klasifikasi/identifikasi. Persamaan kombinasi peluang pohon keputusan regresi logistik dapat dilihat pada Persamaan 1.
𝐴𝑘𝑢𝑟𝑎𝑠𝑖𝑝𝑘
𝐴𝑘𝑢𝑟𝑎𝑠𝑖𝑝𝑘+𝐴𝑘𝑢𝑟𝑎𝑠𝑖𝑟𝑒𝑔𝑟𝑒𝑠𝑖𝑙𝑜𝑔𝑖𝑠𝑡𝑖𝑘𝑃1+
𝐴𝑘𝑢𝑟𝑎𝑠𝑖𝑟𝑒𝑔𝑟𝑒𝑠𝑖𝑙𝑜𝑔𝑖𝑠𝑡𝑖𝑘
dengan:
pk : pohon keputusan
𝑃1 : peluang dari model pohon keputusan
𝑃2 : peluang dari model regresi logistik.
Berdasarkan model yang didapat, akurasi dari pohon keputusan adalah 0.75 sedangkan akurasi dari regresi logistik adalah 0.67. Oleh hal itu, rumus peluang untuk penentuan klasifikasi desa tertinggal dapat dilihat pada Persamaan 2. Akurasi yang didapat menggunakan kombinasi ini sebesar 77%. Akurasi cukup baik untuk digunakan sebagai pengklasifikasian.
0.75
0.75+0.67𝑃1+ 0.67
0.75+0.67𝑃2 (2)
Implementasi Program
Program yang dibuat untuk klasifikasi status desa ini berbasis web. Web akan menampilkan hasil identifikasi desa tertinggal berdasarkan input yang sesuai dengan variabel atau fitur yang digunakan. Selain itu, program yang dibuat akan menampilkan peluang kombinasi dari model pohon keputusan dan regresi logistik. Gambar 9 menampilkan halaman utama dari program. Pada halaman ini terdapat menu identification untuk melakukan identifikasi desa. Menu identification akan menampilkan daftar pertanyaan yang harus diisi untuk proses identifikasi. Tampilan menu Identification dapat dilihat pada Gambar 10.
Gambar 10 Tampilan Menu Identification
Setelah seluruh pertanyaan diisi program akan menampilkan hasil identifikasi seperti Gambar 11.
Gambar 10 Hasil/Output Identifikasi
KESIMPULAN
Melalui analisis simulasi yang telah dilakukan diperoleh simpulan sebagai berikut:
1. Daerah di Pulau Jawa sudah cukup baik dalam pembangunan desa, perlu dilakukan pembangunan desa yang lebih baik di luar Pulau Jawa.
2. Algoritme pohon keputusan dan regresi logistik dapat diterapkan dalam data podes. Klasifikasi menggunakan pohon keputusan dengan algoritma J48 menghasilkan akurasi sebesar 74.8%. Sementara itu, klasifikasi menggunakan regresi logistik didapatkan akurasi sebesar 66.6%
3. Peluang sebuah desa dapat diidentifikasi menggunakan algoritme pohon keputusan dan regresi logistik.
4. Peluang sebuah desa masuk dalam kategori tertinggal dengan dapat ditentukan menggunakan kombinasi regresi logistik dan peluang aturan pohon keputusan. Penggunaan kombinasi peluang regresi logistik dan pohon keputusan menghasilkan akurasi yang lebih baik, yaitu sebesar 77%
5. Sistem berbasis web dibuat untuk klasifikasi desa tertinggal di Indonesia dengan menggunakan kombinasi regresi logistik dan pohon keputusan.
DAFTAR PUSTAKA
[BPS] Badan Pusat Statistik. [tahun terbit tidak diketahui]. Number and Percentage of Poor People, Poverty Line, Poverty Gap Index, Poverty Severity Index by Province, September 2012. [Internet]. [diunduh 2016 April 12]. Tersedia di http://www.bps.go.id.
Ulya F. 2009. Klasifikasi debitur kartu kredit menggunakan algoritme k-nearest neighbor untuk kasus imbalanced data. [skripsi]. Bogor (ID): IPB
Faiza NN. 2009. Prediksi tingkat keberhasilan mahasiswa tingkat I IPB dengan metode k-Nearest Neighbor. [skripsi]. Bogor (ID): IPB
Fu L. 1994. Neural Network in Computer Intelligence. Singapura: McGraw Hill. Hosmer DW, Lemeshow S. 2000. Applied Logistic Regression. Ed ke-2. New York:
John Wiley and Sons, Inc.
Mattjik AA, Sumertajaya IM. 2011. Sidik Peubah Ganda dengan Menggunakan SAS. Bogor: IPB Press
Tan, Pang-Ning. 2006. Introduction to Data Mining. Boston: Pearson Education, Inc.