PEMODELAN BIPLOT PADA KLASIFIKASI DATA METAGENOM
DENGAN K-MERS SEBAGAI EKSTRAKSI CIRI
DAN LVQ SEBAGAI CLASSIFIER
RINDI ANTIKA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2014
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Pemodelan Biplot pada Klasifikasi Data Metagenom dengan K-Mers sebagai Ekstraksi Ciri dan LVQ sebagai Classifier adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Desember 2014 Rindi Antika NIM G64124011
ABSTRAK
RINDI ANTIKA. Pemodelan Biplot pada Klasifikasi Data Metagenom dengan K-Mers sebagai Ekstraksi Ciri dan LVQ sebagai Classifier Dibimbing oleh AGUS BUONO.
Pembacaan genom satu organisme telah menjadi hal yang sudah biasa bagi sebagian besar para ilmuwan, sekarang para ilmuwan beralih ke pembacaan metagenom, yaitu pembacaan beberapa genom yang diambil sampel dari lingkungan. Namun dalam pembacaan fragmen metagenom bisa terjadi percampuran fragmen milik organisme A dengan organisme B yang disebabkan rangkaian overlap yang sama antar keduanya. Hal ini dapat di atasi dengan proses binning, dengan tujuan untuk mengklasifikasikan fragmen ke dalam tingkat taksonomi yang berbeda. Hasil akurasi yang diperoleh menggunakan metode LVQ berkisar 78.10% sampai 90.90%. Akurasi yang paling tinggi adalah 90.90 %, yaitu pada percobaan dengan data organisme sudah dikenal yang mempunyai panjang fragmen 10000 bp dan tidak menggunakan biplot. Hasil akurasi yang diperoleh tanpa menggunakan biplot lebih besar dibandingkan nilai akurasi yang menggunakan biplot karena biplot dilakukan reduksi dimensi hingga ±80% dari fitur/ ciri semula.
Kata kunci: metagenom, k-mers, biplot, LVQ
ABSTRACT
RINDI ANTIKA. Modeling on the Biplot Metagenom Data Classification with K-mers as Feature Extraction and LVQ as Classifier. Supervised by AGUS BUONO.
The reading of the genome one organism that it had become is used for the majority of the scientists, now the scientists turn to recitation metagenom , that is the reading of a sample of the genome taken some of the neighborhood. But in reading the fragment metagenom can happen the mixture of fragments of organisms A with B organism caused the same set of overlap between the two. This can be corrected with an binning process, with the purpose to classify fragments into different taxonomy levels. This can be corrected with an binning process, with the purpose to classify fragments into different taxonomic levels. Accuracy results obtained using methods lvq ranges 78.10 % to 90.90 %.Accuracy is 90.90 %, most high namely on trial with those organisms that have long been known and not use 10000 fragments bp biplot.Accuracy results obtained without using biplot larger than the value of accuracy that uses biplot because biplot done reduction finite-dimensional ± 80 % of features.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
PEMODELAN BIPLOT PADA KLASIFIKASI DATA METAGENOM
DENGAN K-MERS SEBAGAI EKSTRAKSI CIRI
DAN LVQ SEBAGAI CLASSIFIER
RINDI ANTIKA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2014
Penguji :
1 Dr Wisnu Anata Kusuma, ST MT 2 Toto Haryanto, SKom MSi
Judul Skripsi : Pemodelan Biplot pada Klasifikasi Data Metagenom dengan K-mers sebagai Ekstraksi Ciri dan LVQ sebagai Classifier
Nama : Rindi Antika NIM : G64124011
Disetujui oleh
Dr Ir Agus Buono, MSi MKom Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Puji dan syukur, selalu dan senantiasa dipanjatkan ke hadirat Allah atas rahmat dan hidayah-Nya sehingga laporan tugas akhir telah berhasil diselesaikan. Shalawat dan salam selalu dihaturkan ke pangkuan Nabi Muhammad SAW.Tema yang dipilih dalam penelitian ini sejak bulan Juli 2014 adalah Pemodelan Biplot pada Klasifikasi Data Metagenom dengan K-mers sebagai Ekstraksi Ciri dan LVQ sebagai Classifier.
Terima kasih penulis ucapkan kepada Bapak Dr Ir Agus Buono, MSi MKom selaku dosen pembimbing yang di tengah-tengah kesibukannya telah banyak memberikan bimbingan dan pengarahan. Bapak Dr Wisnu Anata Kusuma, ST MT dan Bapak Toto Haryanto, SKom MSi selaku penguji atas waktu, saran, dan koreksiannya. Ungkapan terima kasih juga diucapkan kepada Ayahanda Asid, Ibunda Saleha, serta keluarga yang senantiasa memberikan doa, semangat dan didikan serta dukungan moril, materiil, dan spirituil. Terima kasih diucapkan juga kepada teman-teman Ilmu Komputer Alih Jenis angkatan 7 atas kebersamaannya selama ini. Serta terimakasih kepada Bapak/Ibu Dosen dan Staf TU yang telah begitu banyak membantu baik selama pelaksanaan penelitian maupun pada masa perkuliahan.
Karya tulis ini masih jauh dari kesempurnaaan. Oleh karena itu, penulis mengharapkan saran dan kritik yang dapat digunakan untuk perbaikan di masa-masa yang akan datang.
Semoga karya ilmiah ini bermanfaat.
Bogor, Desember 2014 Rindi Antika
DAFTAR ISI
DAFTAR TABEL viii
DAFTAR GAMBAR viii
DAFTAR LAMPIRAN ix
PENDAHULUAN 1
Latar Belakang 1
Tujuan Penelitian 2
Perumusan Masalah 2
Ruang Lingkup Penelitian 2
Manfaat Penelitian 3
METODE PENELITIAN 3
Penyiapan Data 4
K-Mers 4
Biplot 5
K-Fold Cross Validation 6
Klasifikasi Learning Vector Quantization (LVQ) 6
Pengujian 7
Analisis dan Pembahasan 7
Ruang Lingkup Implementasi 7
HASIL DAN PEMBAHASAN 8
Praproses 8
K-Fold Cross Validation 11
Pelatihan 11
Pengujian 11
Evaluasi 12
SIMPULAN DAN SARAN 19
Simpulan 19
Saran 19
DAFTAR PUSTAKA 19
DAFTAR TABEL
1 Rincian data organisme dikenal (10000 fragmen) 8 2 Rincian data organisme belum dikenal (5000 fragmen) 8
3 Parameter LVQ 11
5 Hasil akurasi biplot (λ=2), organisme dikenal 12 4 Hasil akurasi tanpa biplot, organisme dikenal 12 6 Hasil akurasi biplot (λ=10), organisme dikenal 13 7 Hasil akurasi biplot (λ=64), organisme dikenal 15 8 Hasil akurasi tanpa biplot, organisme belum dikenal 17 9 Hasil akurasi biplot, organisme belum dikenal 17 11 Perbandingan waktu komputasi organisme belum dikenal 18 10 Perbandingan akurasi data organisme belum dikenal 17
DAFTAR GAMBAR
1 Metode Penelitian
32 K-Mers 4
3 Arsitektur LVQ 6
4 Biplot pada data 500bp, λ = 2 9
5 Biplot pada data 1000bp, λ = 2 9
6 Biplot pada data 5000bp, λ = 2 10
7 Biplot pada data 10000bp, λ = 2 10
8 Hasil akurasi tanpa biplot, dengan panjang fragmen 10000 12 9 Hasil akurasi biplot (λ=2), dengan panjang fragmen 10000 13 10 Hasil akurasi biplot (λ=10), dengan panjang fragmen 10000 14 11 Hasil akurasi biplot (λ=64), dengan panjang fragmen 10000 15 12 Perbandingan akurasi pada dataset organisme belum dikenal 16 13 Perbandingan waktu pada dataset organisme belum dikenal 16 14 Perbandingan akurasi pada data uji organisme yang belum dikenal 17 15 Perbandingan waktu komputasi pada data uji organisme yang belum
DAFTAR LAMPIRAN
1 Dataset organisme sudah dikenal (fragmen 10000) 21 2 Dataset oragnisme belum dikenal (fragmen 5000) 21 3 Pasangan basa yang diambil berdasarkan perhitungan nilai singular 22 4 Hasil percobaan pada organisme yang sudah dikenal 23 5 Hasil percobaan pada organisme yang belum dikenal 29
PENDAHULUAN
Latar Belakang
Genom merupakan informasi genetik berupa set lengkap molekul DNA yang dimiliki oleh organisme hidup. Informasi genetik yang dimiliki organisme hidup diturunkan ke generasi berikutnya. Deoxyribonucleic acid (DNA) adalah rantai ganda molekul sederhana (nukleotida) yang diikat bersama-sama dalam struktur helix yang dikenal dengan double helix. Nukleotida terdiri atas empat basa nitrogen, yaitu adenine, thymin, guanine, dan cytosine. Keempat basa nitrogen tersebut dapat direpresentasikan dalam alfabet yaitu A, T, G, dan C (de Carvalho 2003). Urutan nukleotida pada genom seluruhya telah dipetakan dengan menggunakan teknik sequencing untuk memperoleh fragmen genom.
Pembacaan genom satu organisme telah menjadi hal yang sudah biasa bagi sebagian besar para ilmuwan. Sekarang ini ilmuwan beralih ke pembacaan genom yang lebih kompleks, yaitu pembacaan genom yang diambil dari lingkungan atau disebut metagenom, yaitu pembacaan dilakukan tidak hanya satu organisme tapi beberapa organisme yang terkandung di dalamnya (Helianti 2008). Metagenomika merupakan ilmu yang mempelajari materi genetik yang langsung diperoleh dari sampel lingkungan tanpa budidaya laboratorium atau isolasi genom individu (Wu 2008). Sampel yang diambil dari lingkungan kemudian dilakukan sequencing. Sequencing tesebut menghasilkan beberapa fragmen milik banyak organisme, sehingga bisa terjadi percampuran fragmen milik organisme A dengan organisme B yang disebabkan rangkaian overlap yang sama antar keduanya. Hal ini mengakibatkan contigs yang dihasilkan salah. Untuk meminimalkan kesalahan ini, dapat diatasi dengan proses binning. Proses binning bertujuan untuk mengklasifikasikan fragmen ke dalam tingkat taksonomi yang berbeda, seperti pada level genus (Wooley at all. 2010).
Terdapat dua pendekatan proses binning, salah satunya pendekatan komposisi. Pendekatan komposisi yaitu masukan yang digunakan untuk pembelajaran berupa pasangan basa yang dihasilkan dari ekstraksi ciri. Pendekatan komposisi dibagi menjadi dua, yaitu pembelajaran yang dilakukan dengan contoh (supervised learning) dan pembelajaran yang dilakukan dengan observasi (unsupervised learning). Dalam pendekatan komposisi menggunakan unsupervised learning dilakukan pengelompokan (clustering). Pendekatan komposisi menggunakan supervised learning dilakukan pelatihan (trainning) untuk menunjukkan kelas observasi dan data baru (testing) akan diklasifikasikan berdasarkan kelas yang sudah ada.
Wu (2008) meggunakan k-mers untuk melakukan ektsraksi ciri DNA dengan metode Principal Component Analysis (PCA). Hasil dari penelitian Wu menunjukkan bahwa PCA dengan k-mers dapat menangkap karakter intrinsik dari fragmen metagenom pada berbagai tingkat taksonomi. Kombinasi linear PCA berbasis frekuensi k-mers cenderung lebih efektif dan stabil ketika panjang fragmen genom meningkat. Pengklasifikasian linear agak sederhana dapat mencapai akurasi yang tinggi untuk fragmen genom dari berbagai tingkat taksonomi bahkan pada tingkat spesifik seperti spesies.
2
Kusuma dan Akiyama (2011) melakukan penelitian mengenai klasifikasi fragmen metagenom berdasarkan characterization vector. Data yang digunakan terdiri dari atas data, yaitu 10000 data latih yang mempresentasikan organisme yang telah diketahui dan 5000 data uji yang mempresentasikan organisme baru. Panjang fragmen terdiri atas 500bp, 1kbp, 5kbp, 10kbp. Akurasi yang diperoleh dari penelitian tersebut untuk data latih adalah 81% pada panjang fragmen 500bp, 85% pada panjang fragmen 1kbp, 90% pada panjang fragmen 92% 10kbp. Sedangkan akurasi yang diperoleh untuk data uji adalah 78% pada panjang fragmen 500bp, 80% pada panjang fragmen 1kbp, 86% pada panjang fragmen 5kbp, 87% pada panjang fragmen 10kbp.
Elliyana (2014) juga melakukan penelitian mengenai klasifikasi fragmen metagenom. Data yang digunakan sama dengan penelitian Kusuma dan Akiyama (2011). Pada penelitian ini akurasi yang didapat cukup tinggi, pada organisme latih akurasi yang dicapai berkisar 88% sampai 99%, sedangkan untuk organisme uji akurasi yang dihasilkan berkisar 86% sampai 97%.
Berdasarkan hasil penelitian yang dilakukan oleh para peneliti sebelumnya. Dalam penelitian ini dilakukan pemodelan biplot pada klasifikasi data metagenom. Ekstraksi cir yang digunakan untuk fragmen metagenom adalah k-mers. Sedangkan pengklasifikasian yang dilakukan menggunakan metode learning vector quantization (LVQ). Biplot dilakukan untuk mereduksi dimensi fitur/ ciri dengan cara memilih mers yang sesuai.
Tujuan Penelitian
Tujuan penelitian ini adalah memodelkan biplot pada klasifikasi data metagenom dengan k-mers sebagai ekstraksi ciri dan lerning vektor quantization sebagai classifier.
Perumusan Masalah
Adapun perumusan masalah yang akan menjadi bahan analisis pada penelitian ini adalah:
1 Bagaimana akurasi yang diperoleh jika menggunakan metode LVQ? 2 Apakah penggunaan biplot mempengaruhi penilaian akurasi ?
3 Bagaimana perbedaan waktu komputasi jika menggunakan biplot dan tidak menggunakan biplot?
Ruang Lingkup Penelitian
Ruang lingkup penelitian ini meliputi:
1 Data yang digunakan merujuk dari penelitian Kusuma dan Akiyama (2011), yaitu dataset genus Agrobacterium, Bacillus, dan Staphylococcus
2 Jumlah data yang akan digunakan sebanyak 10000 fragmen organisme dikenal dan 5000 fragmen organisme belum dikenal
3 Panjang fragmen 500 bp, 1000 bp, 5000 bp, dan 10000 bp. Fragmen dihasilkan dari perangkat lunak Metasim.
3 4 Fragmen metagenom diasumsikan bebas error.
Manfaat Penelitian
Penelitian ini diharapkan dapat membantu para peneliti dalam pengklasifikasian fragmen metagenom berdasarkan tingkat genus khususnya genus Agrobacterium, Bacillus, dan Staphylococcus.
METODE PENELITIAN
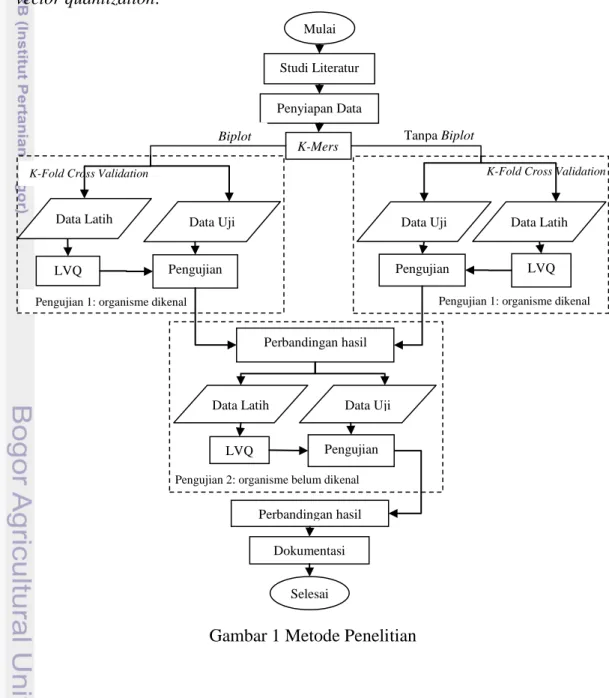
Skema metode penelitian dapat dilihat pada Gambar 1. Pada tahap awal yang dilakukan adalah mempelajari pustaka yang berkaitan dengan penelitian yang dilakukan. Studi mencakup metegenome, k-mers, biplot, klasifikasi learning vector quantization.
Gambar 1 Metode Penelitian
K-Fold Cross Validation
Pengujian 2: organisme belum dikenal
Pengujian 1: organisme dikenal Pengujian 1: organisme dikenal
Mulai Penyiapan Data K-Mers Perbandingan hasil Selesai Dokumentasi Studi Literatur Tanpa Biplot Biplot LVQ Pengujian Data Uji
K-Fold Cross Validation
Data Latih Pengujian LVQ Data Latih Data Uji Data Uji Data Latih Perbandingan hasil Pengujian LVQ
4
Penelitian ini dilakukan dengan beberapa tahapan proses, yaitu: penyiapan data fragmen metagenom, ekstraksi fitur fragmen dengan k-mers, pemodelan biplot, dataset organisme dikenal akan dibagi menjadi dua yaitu data uji dan data latih dengan metode k-fold cross validation, pengujian dilakukan dua kali dengan data yang berbeda, yaitu pada dataset organisme dikenal (10000 fragmen) dan dataset organisme belum dikenal (5000 fragmen). Data uji pada organisme dikenal diperoleh dari fungsi fold cross validation, kemudian dilakukan pengujian berdasarkan model LVQ yang diperoleh dari pelatihan. Demikian juga pada data organisme belum dikenal dilakukan hal yang sama. Dari hasil pengujian tersebut diperoleh akurasi, kemudian hasil akurasi tersebut akan dibandingkan hasilnya dengan hasil percobaan yang lainnya. Tahap terakhir adalah dilakukan dokumentasi.
Penyiapan Data
Data yang digunakan adalah dataset dari genus Agrobacterium, Bacillus, dan Staphylococcus. Dataset yang digunakan dibagi menjadi dua kelompok yaitu, data organisme yang sudah dikenal dan data organisme yang belum dikenal. Data organisme yang sudah dikenal teridiri dari 10 spesies dari 3 genus, sedangkan data organisme yang sudah dikenal terdiri dari 9 spesies dari 3 genus.
Dataset tersebut dibangkitkan dengan menggunakan perangkat lunak Metasim dengan format FASTA. Panjang fragmen yang digunakan adalah 500 bp, 1000bp, 5000bp, dan 1000 bp. Rincian dataset yang digunakan disajikan pada Lampiran 1 dan Lampiran 2.
K-Mers
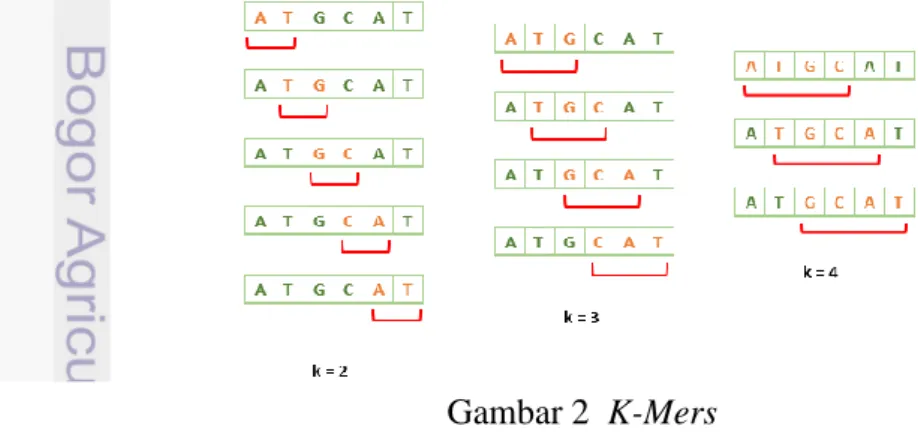
K-Mers merupakan metode ekstraksi ciri yang biasa digunakan pada biomolekuler. K-mers akan memunculkan pola k pada suatu waktu dalam sequence. Misal, jika ingin mendapatkan pola dari nukleotida dengan 4 basa utama, yaitu adenin, timin, guanin, sitosin. Nilai k yang digunakan adalah k=3, maka, hasil untuk trinukleotida adalah 43 = 64 base pair (bp). Perhitungan frekuensi k-mers ditunjukkan seperti Gambar 2.
Metode ini digunakan untuk mengetahui intensitas atau banyaknya kemunculan substring tertentu pada sebuah string. Intensitas kemunculan string
5 tersebut dapat dijadikan sebagai penciri dari suatu kelompok string. Data sekuens DNA merupakan data string. Oleh karena itu ekstraksi ciri yang digunakan pada penelitian ini untuk dataset DNA adalah K-Mers dengan k=3.
Biplot
Analisis biplot merupakan salah satu analisis eksplorasi peubah ganda yang mendeskripsikan keterkaitan antarpeubah serta perbandingan antar objek yang disajikan secara visual dalam grafik dua dimensi. Analisis biplot pertama kali menggunakan teknik penguraian nilai singular (singular value decomposition SVD) (Buono 2014). Setiap matriks nXp dapat ditulis dalam bentuk:
nXp = nUr x rLr x r(AT)p
Dalam hal ini, r adalah pangkat matriks X, sedangkan U, L dan A ditentukan berdasar akar ciri dan vektor ciri matriks XTX. Akar ciri disebut juga dengan eigen value atau karakteristik vektor atau latent root dan vector ciri disebut dengan eigen vektor atau karakteristik vektor atau latent vector. Jika i
merupakan akar ciri terbesar matriks XTX sehingga berlaku:
12 ... r > r+1 > ... >n = 0
Dengan vektor ciri yang bersesuaian dengan akar ciri ke i adalah vi. Matriks U, L, dan A di atas dirumuskan sebagai:
A = [v1 v2 ... vr] L = diagonal {i} = r ... 0 0 ... 0 0 ... 1 U = [1 2 .... r] dengan i = i i Xv 1 Perumusan biplot: X= U LAT= G H G = U = [g1 g2 ... gn]T H = LAT = [h1 h2 ... hp]
G mempresentasikan baris (biasanya objek) dan H mempresentasikan kolom (biasanya peubah).
hi = hi n 1
1
6
Pada tahapan penelitian ini dilakukan reduksi dimensi dari hasil ektraksi ciri dengan biplot yaitu dengan cara memilih mers yang sesuai. Pemilihan mers yang sesuai yaitu dengan melihat panjang vektor hi ( |hi| ).
K-Fold Cross Validation
K-Fold Cross Validation merupakan metode yang membagi data ke dalam k bagian. Hasil masing-masing dari bagian data tersebut akan dilakukan klasifikasi. Nilai k adalah nilai yang menunjukkan jumlah pembagian data menjadi k-subset data. Pada penelitian ini data dibagi menjadi dua yaitu 80% untuk data latih dan 20% untuk data uji. Oleh karena itu nilai k yang akan digunakan adalah 5. Perulangan yang akan dilakukan sebanyak 5 kali. Salah satu subset dijadikan sebagai data uji, sedangkan kempat data subset lainnya dijadikan data latih.
K-fold cross validation diterapkan pada dataset organisme dikenal (10000 fragmen).
Klasifikasi Learning Vector Quantization (LVQ)
Learning Vector Quantization (LVQ) adalah sebuah metode klasifikasi yang setiap unit output mempresentasikan sebuah kelas. LVQ mengklasifikasikan vektor input ke dalam kelas yang sama untuk vektor input yang memiliki vektor bobot terdekat (Widodo 2005). Arsitektur LVQ seperti yang ditunjukkan pada Gambar 3.
Keterangan dari arsitektur LVQ sebagai berikut: X, Y, dan Z merupakan kelas yang digunakan dalam pelatihan LVQ, w merupakan bobot dari LVQ, dan a1, a2, .., an adalah vector input.
LVQ digunakan untuk pengklasifikasian dengan target/ kelas sudah ditentukan. Arsitektur LVQ pada dasarnya sama dengan jaringan saraf tiruan, namun tidak ada topologi ketetanggan pada unit keluaran dan setiap unit keluaran mewakili jumlah kelas yang ada. Cara kerja LVQ ditunjukkan pada Gambar 3. Algoritme LVQ (Fausett 1994), yaitu:
1 Tentukan vektor referensi. Tentukan learning rate α(0).
2 Selama kondisi berhenti belum terpenuhi, lakukan langkah 3-6. 3 Untuk setiap vektor masukan x, lakukan langkah 4-5.
Gambar 3 Arsitektur LVQ a1 X Y Z a2 an ... w w w w w w w w w Keterangan: X, Y, Z : class a1, a2, …, an : neuron input
7 4 Temukan J sehingga ‖x -wj ‖ bernilai minimum.
5 Update nilai w sesuai ketentuan berikut:
Jika T = Cj maka w (new) = w(old) + [x – w(old)] Jika T ≠ Cj maka w (new) = w (old) - [x – w(old)] 6 Kurangi learning rate.
7 Cek kondisi berhenti.
Pada tahapan ini akan dilakukan pengklasifikasian pada data latih menggunakan Learning Vector Quantization (LVQ) sehingga didapatkan kelasnya.
Pengujian
Pengujian dilakukan dua kali yaitu pada dataset uji organisme dikenal yang diperoleh dari k-fold cross validation dan data organisme belum dikenal (5000 fragmen). Dataset uji akan diprediksi masuk ke dalam kelas sesuai dengan genusnya. Prediksi dilakukan berdasarkan data latih yang telah diklasifikasikan dengan menggunakan metode LVQ.
Analisis dan Pembahasan
Hasil prediksi tersebut akan dibandingkan dengan kelas aktualnya, hal ini dilakukan untuk membuktikan apakah dataset uji benar diklasifikasi atau salah diklasifikasi. Perhitungan nilai akurasi menggunakan persamaan berikut:
akurasi= data uji benar
data uji x 100%
Dari hasil akurasi tersebut akan diambil yang paling tinggi (maksimum) dari setiap fold, kemudian akan dibandingkan hasilnya.
Ruang Lingkup Implementasi
Lingkungan implementasi penelitian ini terdiri dari perangkat keras dan perangkat lunak, yaitu:
1 Perangkat keras berupa notebook:
Intel ® Dual Core ™ @ 2.20 GHz
RAM 2 GB
Harddisk kapasitas 320 GB 2 Perangkat lunak:
Sistem operasi Microsoft Windows 7 Professional
Simulator metagenom MetaSim versi 0.9.1
CodeBlocks
8
HASIL DAN PEMBAHASAN
Praproses
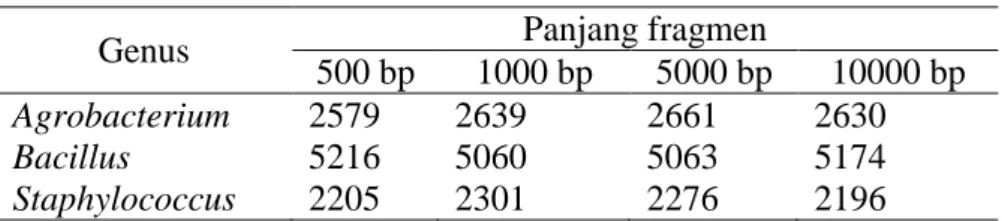
Setiap data dilakukan praproses menggunakan metsim, yaitu mengambil informasi DNA dengan panjang fragmen yang berbeda-beda, yaitu 500bp, 1000bp, 5000bp, 10000bp. Langkah selanjutnya adalah mengekstraksi fitur/ ciri menggunakan k-mers, k yang digunakan adalah k=3. Rincian data yang digunakan disajikan dalam Tabel 1 dan Tabel 2.
Pada penelitian ini dilakukan 48 percobaan, yaitu percobaan 1 sampai 40 menggunakan data uji yang diperoleh dari fold cross validation dan percobaan 41 sampai 48 menggunakan dataset organisme belum dikenal. Percobaan 1 sampai percobaan 4 data yang digunakan adalah data yang tidak dilakukan reduksi dimensi, dan percobaan 5 sampai percobaan 40 data yang digunakan adalah data yang telah direduksi dimensi dengan menggunakan biplot. Nilai λ (pangkat matriks) yang digunakan bervariasi yaitu 2, 10, dan 64. Banyaknya peubah yang diambil adalah 10, 20, dan 30 sehingga dimensi matriks awalnya 10000 x 64 setelah direduksi dimensi matriks yang dihasilkan 10000 x 10, 10000 x 20, 10000 x 30. Percobaan 41 sampai 44 dengan dataset organisme belum dikenal dan tidak dilakukan reduksi dimensi (tanpa biplot). Percobaan 45 sampai 48 dengan dataset organisme belum dikenal dan dilakukan reduksi dimensi dengan biplot, λ (pangkat matriks) yang digunakan adalah 64 dengan peubah 30, sehingga dimensi dari data tersebut adalah 5000 x 30.
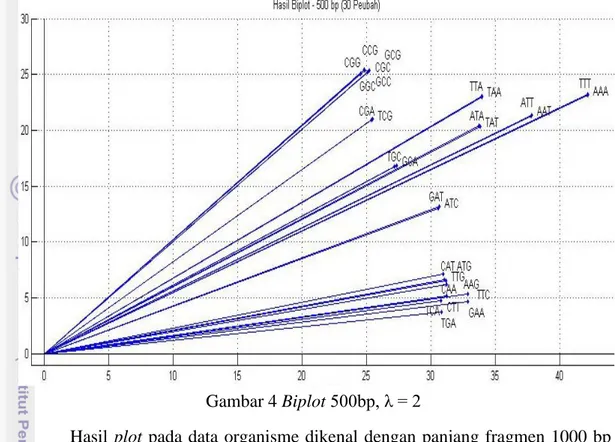
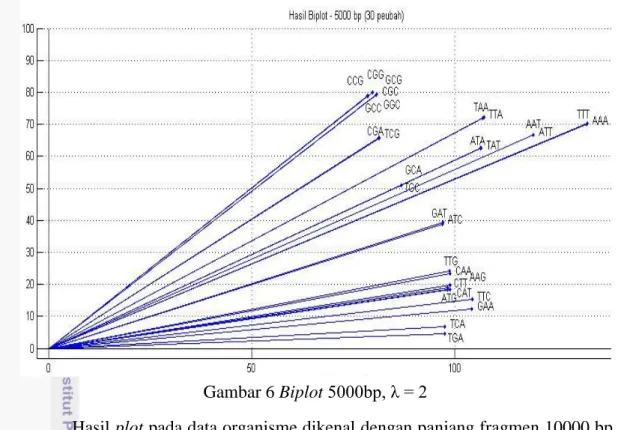
Hasil plot pada data organisme dikenal (10000 fragmen) dengan panjang fragmen 500 bp ditunjukkan pada Gambar 4.
Tabel 1 Rincian data organisme dikenal (10000 fragmen)
Genus Panjang fragmen
500 bp 1000 bp 5000 bp 10000 bp
Agrobacterium 2579 2639 2661 2630
Bacillus 5216 5060 5063 5174
Staphylococcus 2205 2301 2276 2196
Tabel 2 Rincian data organisme belum dikenal (5000 fragmen)
Genus Panjang fragmen
500 bp 1000 bp 5000 bp 10000 bp
Agrobacterium 1284 1328 1285 1258
Bacillus 2384 2264 2303 2292
9
Gambar 4 Biplot 500bp, λ = 2
Hasil plot pada data organisme dikenal dengan panjang fragmen 1000 bp ditunjukkan pada Gambar 5.
Gambar 5 Biplot 1000bp, λ = 2
Hasil plot pada data organisme dikenal dengan panjang fragmen 5000 bp ditunjukkan pada Gambar 6.
10
Gambar 6 Biplot 5000bp, λ = 2
Hasil plot pada data organisme dikenal dengan panjang fragmen 10000 bp ditunjukkan pada Gambar 7.
Gambar 7 Biplot pada data 10000bp, λ = 2
Rincian pasangan basa (peubah) yang diambil setelah dilakukan perhitungan nilai singular disajikan pada Lampiran 3.
11
K-Fold Cross Validation
Setelah dilakukan praproses kemudian dilakukan pembagian data dengan menggunakan k-fold cross validation, k yang digunakan adalah k=5 untuk semua percobaan. Penentuan data uji dan data latih berdasarkan data kelas. data kelas ini digunakan sebagai input pada fungsi cross validation. Kemudian data dipisahkan menjadi data latih dan data uji, dengan jumlah data latih ±8000, dan data uji ±2000 pada setiap fold. Kemudian data latih dan data uji akan dilakukan pelatihan dan pengujian menggunakan LVQ.
Pelatihan
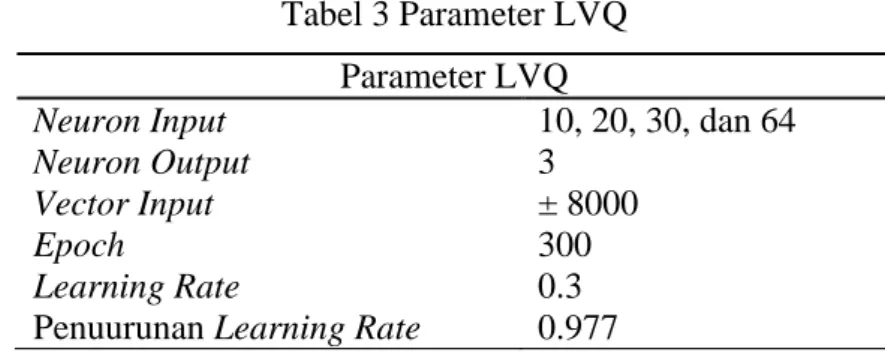
Pada tahapan ini dilakukan proses pelatihan dengan data latih yang diperoleh dari k-fold cross validation. Kemudian data latih tersebut dilakukan pelatihan dengan metode LVQ, sehingga mendapatkan model LVQ. Nilai bobot yang digunakan pada penelitian ini adalah data pertama dari setiap kelas. Parameter yang digunakan untuk setiap percobaan disajikan pada Tabel 3.
Tabel 3 Parameter LVQ Parameter LVQ
Neuron Input 10, 20, 30, dan 64
Neuron Output 3
Vector Input ± 8000
Epoch 300
Learning Rate 0.3
Penuurunan Learning Rate 0.977
Neuron masukan merupakan jumlah fitur penciri dari suatu fragmen DNA, neuron output merupakan jumlah kelas yang digunakan, jumlah kelas yang digunakan pada penelitian sebanyak 3 kelas, yaitu kelas Agrobacterium, Bacillus, dan Staphylococcus. Vektor masukan merupakan jumlah data yang akan dilakukan pelatihan. Hasil dari pelatihan ini adalah sebuah model yang nantinya akan digunakan pada data uji.
Pengujian
Pengujian dilakukan sebanyak dua kali yaitu dengan data uji organisme dikenal yang diperoleh dari fold cross validation dan dataset organisme belum dikenal. Kemudian data tersebut diklasifikasikan berdasarkan model LVQ yang telah didapatkan dari pelatihan data latih. Pengujian kedua dilakukan pada dataset organisme belum dikenal (5000 fragmen). Hasil akurasi yang diperoleh pada setiap percobaan pada Lampiran 4 dan Lampiran 5.
12
Evaluasi
Hasil akurasi akan dibandingkan hasilnya, kemudian akan dievaluasi. Berikut evaluasi dari setiap percobaan.
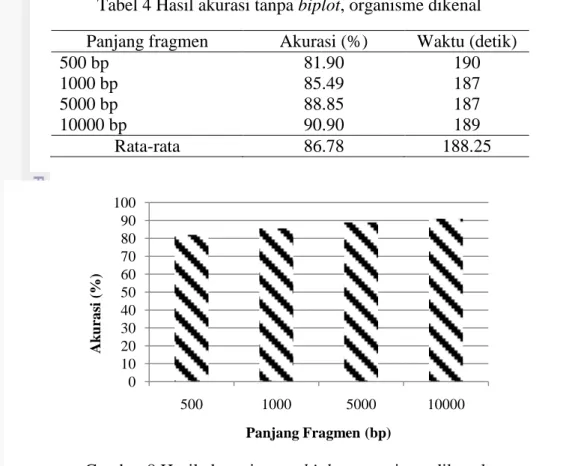
Percobaan 1-4 : Tanpa biplot, data organisme dikenal
Pada percobaan 1 sampai percobaan 4 akurasi yang diperoleh paling rendah adalah 81.90 % pada panjang fragmen 500 bp dan paling tinggi adalah 90.90 % pada panjang fragmen 10000 bp. Rata-rata waktu yang dibutuhkan untuk melakukan pelatihan dan pengujian adalah 188.25 detik. Hasil akurasi ditunjukkan pada Tabel 4 dan Gambar 8.
Percobaan 5-16 : Biplot, organisme dikenal
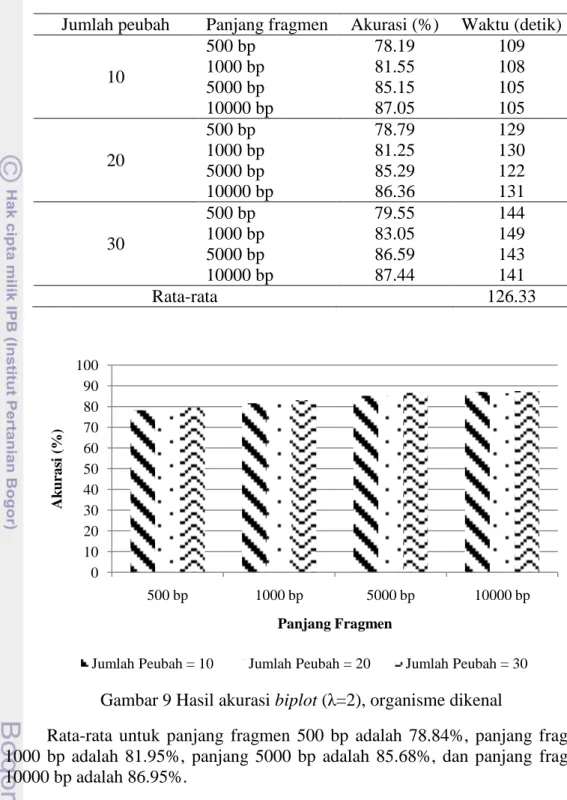
Pada percobaan 5 sampai percobaan 16, akurasi yang diperoleh paling rendah adalah 78.19% pada panjang fragmen 500 bp dengan jumlah peubah =10 dan paling tinggi adalah 87.44% pada panjang fragmen 10000 bp dengan jumlah peubah = 30. Rata-rata waktu yang dibutuhkan untuk melakukan pelatihan dan pengujian adalah 126.33 detik. Hasil akurasi ditunjukkan pada Tabel 5 dan Gambar 9.
Tabel 4 Hasil akurasi tanpa biplot, organisme dikenal Panjang fragmen Akurasi (%) Waktu (detik)
500 bp 81.90 190
1000 bp 85.49 187
5000 bp 88.85 187
10000 bp 90.90 189
Rata-rata 86.78 188.25
Gambar 8 Hasil akurasi tanpa biplot, organisme dikenal 0 10 20 30 40 50 60 70 80 90 100 500 1000 5000 10000 Ak ura si (%) Panjang Fragmen (bp)
13 Tabel 5 Hasil akurasi biplot (λ=2), organisme dikenal
Jumlah peubah Panjang fragmen Akurasi (%) Waktu (detik) 10 500 bp 78.19 109 1000 bp 81.55 108 5000 bp 85.15 105 10000 bp 87.05 105 20 500 bp 78.79 129 1000 bp 81.25 130 5000 bp 85.29 122 10000 bp 86.36 131 30 500 bp 79.55 144 1000 bp 83.05 149 5000 bp 86.59 143 10000 bp 87.44 141 Rata-rata 126.33
Gambar 9 Hasil akurasi biplot (λ=2), organisme dikenal
Rata-rata untuk panjang fragmen 500 bp adalah 78.84%, panjang fragmen 1000 bp adalah 81.95%, panjang 5000 bp adalah 85.68%, dan panjang fragmen 10000 bp adalah 86.95%.
Percobaan 17-28 : Biplot, organisme dikenal
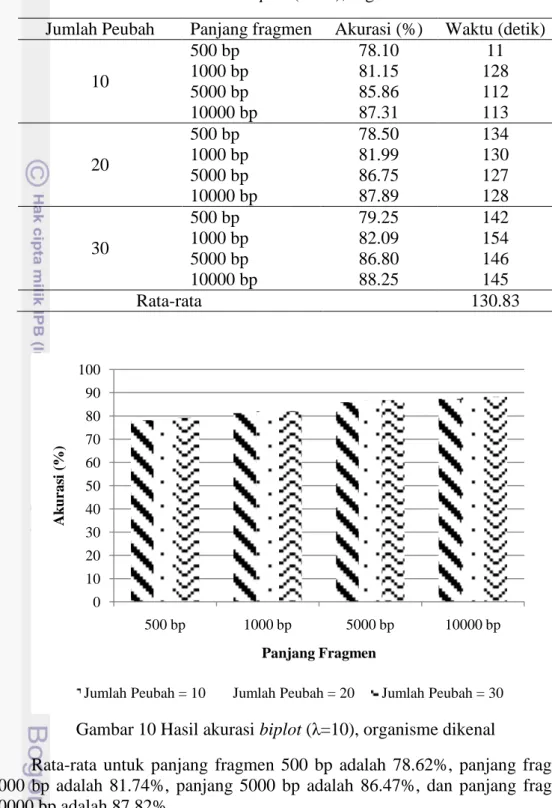
Pada percobaan 17 sampai percobaan 28 akurasi yang diperoleh paling rendah adalah 78.10 % pada panjang fragmen 500 bp dengan jumlah peubah = 10 dan paling tinggi adalah 88.25 % pada panjang fragmen 10000 bp dengan jumlah peubah = 30. Rata waktu yang dibutuhkan adalah 130.83 detik. Hasil akurasi ditunjukkan pada Tabel 6 dan Gambar 10.
0 10 20 30 40 50 60 70 80 90 100 500 bp 1000 bp 5000 bp 10000 bp Ak ura si (%) Panjang Fragmen
14
Tabel 6 Hasil akurasi biplot (λ=10), organisme dikenal
Jumlah Peubah Panjang fragmen Akurasi (%) Waktu (detik) 10 500 bp 78.10 11 1000 bp 81.15 128 5000 bp 85.86 112 10000 bp 87.31 113 20 500 bp 78.50 134 1000 bp 81.99 130 5000 bp 86.75 127 10000 bp 87.89 128 30 500 bp 79.25 142 1000 bp 82.09 154 5000 bp 86.80 146 10000 bp 88.25 145 Rata-rata 130.83
Gambar 10 Hasil akurasi biplot (λ=10), organisme dikenal
Rata-rata untuk panjang fragmen 500 bp adalah 78.62%, panjang fragmen 1000 bp adalah 81.74%, panjang 5000 bp adalah 86.47%, dan panjang fragmen 10000 bp adalah 87.82%. 0 10 20 30 40 50 60 70 80 90 100 500 bp 1000 bp 5000 bp 10000 bp Ak u ra si (%) Panjang Fragmen
15
Percobaan 29-40 : Biplot, organisme dikenal
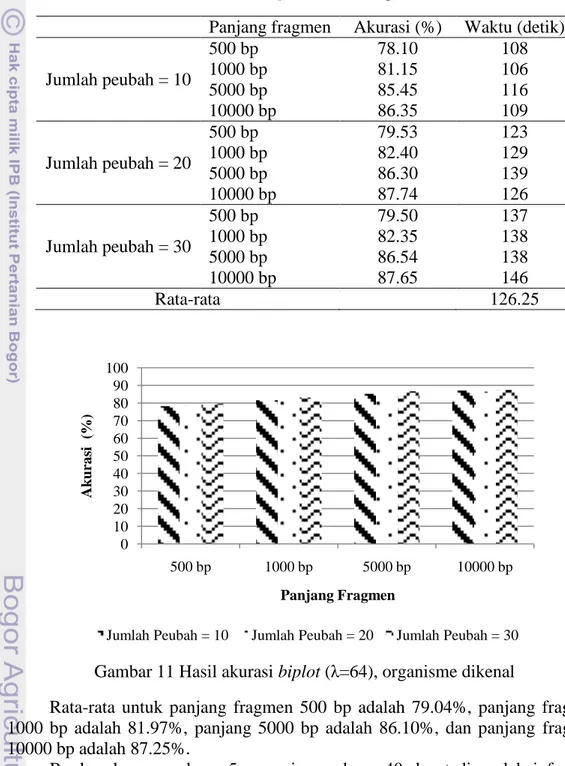
Pada percobaan 29 sampai percobaan 40 akurasi yang diperoleh paling rendah adalah 78.10 % pada panjang fragmen 500 bp dengan jumlah peubah =10 dan paling tinggi adalah 87.74 % pada panjang fragmen 10000 bp dengan jumlah peubah = 20. Rata-rata waktu yang dibutuhkan untuk melakukan pelatihan dan pengujian adalah 126.25 detik. Hasil akurasi ditunjukkan pada Tabel 7 dan Gambar 11.
Tabel 7 Hasil akurasi biplot (λ=64), organisme dikenal
Panjang fragmen Akurasi (%) Waktu (detik) Jumlah peubah = 10 500 bp 78.10 108 1000 bp 81.15 106 5000 bp 85.45 116 10000 bp 86.35 109 Jumlah peubah = 20 500 bp 79.53 123 1000 bp 82.40 129 5000 bp 86.30 139 10000 bp 87.74 126 Jumlah peubah = 30 500 bp 79.50 137 1000 bp 82.35 138 5000 bp 86.54 138 10000 bp 87.65 146 Rata-rata 126.25
Gambar 11 Hasil akurasi biplot (λ=64), organisme dikenal
Rata-rata untuk panjang fragmen 500 bp adalah 79.04%, panjang fragmen 1000 bp adalah 81.97%, panjang 5000 bp adalah 86.10%, dan panjang fragmen 10000 bp adalah 87.25%.
Berdasarkan percobaan 5 sampai percobaan 40 dapat diperoleh informasi bahwa semakin panjang fragmen maka nilai akurasi semakin meningkat. Akurasi
0 10 20 30 40 50 60 70 80 90 100 500 bp 1000 bp 5000 bp 10000 bp Ak ura si ( %) Panjang Fragmen
16
yang diperoleh pada percobaan tanpa biplot lebih tinggi dibandingkan percobaan menggunakan biplot, selisih berkisar 2.77% - 3.60%.
Perbandingan akurasi pada dataset organisme dikenal ditunjukkan pada Gambar 12.
Gambar 12 Perbandingan akurasi organisme dikenal
Pada percobaan tanpa biplot membutuhkan waktu komputasi lebih lama dibandingkan percobaan menggunakan biplot, selisihnya berkisar 56-63 detik. Perbandingan waktu komputasi ditunjukkan pada Gambar 13.
Gambar 13 Perbandingan waktu pada organisme dikenal
Percobaan 41-48: Data yang digunakan organisme belum dikenal
Pada percobaan 41 sampai percobaan 48 menggunakan dataset organisme belum dikenal. Percobaan tidak menggunakan biplot dimensi yang digunakan adalah 5000 x 64 dan yang menggukan biplot dimensinya adalah 5000 x 30. Pada percobaan ini hasil akurasi tertinggi adalah 90.90% pada panjang fragmen 10000 bp, sedangkan akurasi terendah adalah 81.86% pada panjang fragmen 500 bp. Rata-rata waktu yang dibutuhkan pada percobaan ini adalah 189.25 detik. Hasil akurasi tanpa biplot ditunjukkan pada Tabel 8.
0.00 10.00 20.00 30.00 40.00 50.00 60.00 70.00 80.00 90.00 100.00 500 bp 1000 bp 5000 bp 10000 bp Ak ura si ( %) Panjang Fragmen
Min (Biplot) Rata2 (Biplot) Max (Biplot)
Min (Tanpa Biplot) Rata2 (Tanpa Biplot) Max (Tanpa Biplot)
0.00 50.00 100.00 150.00 200.00 500 bp 1000 bp 5000 bp 10000 bp Wak tu (d eti k ) Panjang Fragmen
17
Pada percobaan yang menggunakan biplot diambil nilai λ dan jumlah peubah secara acak, yaitu λ=64 dan jumlah peubah=30. Pada percobaan ini hasil akurasi tertinggi adalah 87.56% pada panjang fragmen 10000 bp, sedangkan akurasi terendah adalah 79.04% pada panjang fragmen 500 bp. Rata-rata waktu yang dibutuhkan pada percobaan ini adalah 140.75 detik. Nilai akurasi ditunjukkan pada Tabel 9.
Perbandingan akurasi pada dataset organisme belum dikenal ditunjukkan pada Tabel 10 dan Gambar 14.
Tabel 10 Perbandingan akurasi data organisme belum dikenal Panjang
fragmen
Akurasi Tanpa Biplot (%)
Akurasi Biplot (%) Selisih (%)
500 bp 81.86 79.04 2.82
1000 bp 84.16 80.84 3.32
5000 bp 89.44 86.30 3.14
10000 bp 90.52 87.56 2.96
Tabel 9 Hasil akurasi biplot, organisme belum dikenal
Panjang Fragmen Akurasi (%) Waktu (detik)
500 bp 79.04 138
1000 bp 80.84 139
5000 bp 86.30 139
10000 bp 87.56 147
Rata-rata 140.75
Tabel 8 Hasil akurasi tanpa biplot, organisme belum dikenal Panjang Fragmen Akurasi (%) Waktu (detik)
500 bp 81.86 191
1000 bp 84.16 188
5000 bp 89.44 188
10000 bp 90.90 190
Rata-rata 189.25
Gambar 14 Perbandingan akurasi organisme belum dikenal 0.00 10.00 20.00 30.00 40.00 50.00 60.00 70.00 80.00 90.00 100.00 500 bp 1000 bp 5000 bp 10000 bp Ak ura si (%) Panjang Fragmen Tanpa Biplot Biplot
18
Pada percobaan tanpa biplot menghasilkan akurasi lebih rendah dibandingkan menggunkan biplot, namun perbedaannya tidak terlalu jauh, yaitu berkisar 2.82 % sampai 3.32 %.
Pada percobaan tanpa biplot membutuhkan waktu komputasi lebih lama dibandingkan percobaan menggunakan biplot, selisihnya berkisar 56-63 detik. Perbandingan waktu komputasi ditunjukkan pada Tabel 11 dan Gambar 15.
Tabel 11 Perbandingan waktu komputasi organisme belum dikenal Panjang fragmen Waktu Komputasi
Tanpa Biplot (detik)
Waktu Komputasi Biplot (detik) Selisih (detik) 500 bp 191 127 63.67 1000 bp 188 131 56.67 5000 bp 188 128 59.44 10000 bp 190 128 61.78
Gambar 15 Perbandingan waktu komputasi organisme belum dikenal Berdasarkan hasil pengujian pada organisme dikenal dan organisme belum dikenal menggunakan metode LVQ akurasi yang diperoleh berkisar 78.10% sampai 90.90%. Akurasi yang diperoleh ketika data tersebut tidak direduksi menggunakan biplot hasilnya lebih besar dibandingkan akurasi yang diperoleh ketika data tersebut direduksi dengan biplot, namun perbedaannya tidak terlalu jauh berkisar 2-3%. Salah satu faktor yang menyebabkan penurunan nilai akurasi karena fitur/ ciri yang direduksi sampai 80% dari fitur semula, dimensi yang digunakan setelah biplot adalah 10000 x 10 (peubah=10), 10000 x 20 (peubah=20), 10000 x 30 (peubah = 30).
Selain itu perbedaan ketika menggunakan biplot dengan tidak menggunakan biplot adalah waktu komputasi. Pada percobaan yang menggunakan biplot waktu komputasi lebih efektif, yaitu membutuhkan waktu rata-rata 130 detik untuk proses pelatihan dan pengujian, sedangkan percobaan yang tidak menggunakan biplot membutuhkan waktu rata-rata 189 detik. Hal ini dikarenakan dimensi yang menggunakan biplot lebih kecil sehingga pada proses pelatihan dan pengujian tidak membutuhkan waktu lama. Panjang fragmen juga dapat
0.00 50.00 100.00 150.00 200.00 250.00 500 bp 1000 bp 5000 bp 10000 bp Wa k tu ( det ik ) Panjang Fragmen Tanpa Biplot Biplot
19 mempengaruhi akurasi, semakin panjang fragmen maka semakin besar pula nilai akurasinya.
SIMPULAN DAN SARAN
Simpulan
Pada penelitian ini disimpulkan bahwa akurasi yang dihasilkan cukup baik yaitu berkisar 78.10% sampai 90.90% untuk semua data dengan menggunakan metode metode klasifikasi LVQ, dan ekstraksi ciri digunakan k-mers dengan nilai k=3. Akurasi yang paling tinggi adalah 90.90 %, yaitu pada percobaan dengan data organisme dikenal yang mempunyai panjang fragmen 10000 bp dan tidak menggunakan biplot (reduksi dimensi/ ciri). Pemodelan biplot juga berhasil dalam penelitian ini, akurasi yang diperoleh menggunakan biplot perbedaannya tidak terlalu besar, berkisar 2-3%, namun waktu komputasi menggunakan biplot lebih cepat dibandingkan tanpa biplot.
Saran
Akurasi yang diperoleh menggunakan biplot mungkin masih dapat ditingkatkan lagi, yaitu membentuk peubah baru dengan cara mengkombinasikan peubah yang mempunyai nilai keragaman kecil, sehingga tidak ada yang dihilangkan dari informasi data tersebut.
DAFTAR PUSTAKA
Buono, Agus. 2014. Lecture note kuliah magister matematika dan statistika ilmu komputer. Bogor (ID): Institut Pertanian Bogor.
de Carvalho Jr SA. 2003. Sequence Alignment Algorithms [disertasi]. London (GB): University for London.
Elliyana, F. 2014. Klasifikasi fragmen metagenom menggunakan fitur spaced N-Mers dan K-Nearest Neighbor [skripsi]. Bogor (ID): Institut Pertanian Bogor.
Fausett L. 1994. Fundamentals of Neural Networks: Architectures, Algorithms, and Applications. New Jersey (US): Prentice Hall.
Helianti I. 2008. Metagenomik, Era Baru Bioteknologi [Internet]. [di unduh 26
Juni 2014]. Tersedia pada:
http://ishelianti.wordpress.com/tag/metagenome/.
Kusuma WA, Akiyama Y. 2011. Metagenome fragmen binning based on characterization vector. International Conference on Bioinformatics and Biomedical Technology (ICBBT 2011); 2011 Mar 25–27; Sanya, China. Widodo TN. 2005. Sistem Neuro Fuzzy, Graha Ilmu, Yogyakarta.
Wooley JC, Godzik A, Friedberg I. 2010. A primer on metagenomics. PLos
20
Wu H. 2008. PCA-Based Linear Combinations Of Oligonucleotide Frequencies For Metagenomic Dna Fragmen Binning. Computational Intelligence in Bioinformatics and Computational Biology 2008. hlm 46-53.
21 Lampiran 1 Dataset organisme sudah dikenal (fragmen 10000)
Spesies Genus
Agrobacterium radiobacter K48 chromosome 2 Agrobacterium Agrobacterium tumefaciens str. C58 chromosome
circular
Agrobacterium vitis S4 chromosome 1
Bacillus amyloliquefaciens FZB42 Bacillus
Bacillus anthracis str. ‘Ames Ancestor’ Bacillus cereus 03BB102
Bacillus pseudofirmus OF4 chromosome
Staphylococcus aureus subsp. Sureus JH1 Staphylococcus Staphylococcus epidermidis 1228 chromosome
Staphylococcus haemolyticus JCSC1435 chromosome
Lampiran 2 Dataset oragnisme belum dikenal (fragmen 5000)
Spesies Genus
Agrobacterium radiobacter K48 chromosome 1 Agrobacterium Agrobacterium tumefaciens str. C58 chromosome linear
Agrobacterium vitis S4 chromosome 2
Bacillus pumilus SAFR-032 Bacillus
Bacillus subtilis subsp. subtilis str. 16B chromosome Bacillus thuringiensis str. Al Hakam chromosome
Staphylococcus carnosus subsp. carnosus TM300 chromosome
Staphylococcus Staphylococcus lugdunensis HKU09-01 chromosome
Staphylococcus saprophyticus subsp. saprophyticus ATCC 15305
22
Lampiran 3 Pasangan basa yang diambil berdasarkan perhitungan nilai singular Panjang fragmen Pangkat matriks (λ) Jumlah
peubah Pasangan Basa yang diambil
500bp 2 10 AAA TTT TAA TTA AAT ATT
TAT ATA CGC CGC
20 AAA TTT TAA TTA AAT ATT TAT ATA CGC CCG GCG CGG GCC GGC CTA CTT TAG AAG GCT AGC
30 AAA TTT TAA TTA AAT ATT TAT ATA CGC CCG GCG CGG GCC GGC CTA CTT TAG AAG GCT AGC ACG CGT GTT AAC TAC GTA TTC GAA ACT AGT
64 10 AAA TTT AAT TAA TTA ATT
ATA TAT AAG CTT
20 AAA TTT AAT TAA TTA ATT ATA TAT AAG CTT
30 AAA TTT AAT TAA TTA ATT ATA TAT AAG CTT CCG CGC TTC GAA AGT TAC CGG GCC ACT GTA AGA TAG GCG CTA GGC GCT AGC AAC TCT GTT
1000bp 2 10 AAA TTT TTA TAA ATT AAT
TAT ATA GCG CGC
20 AAA TTT TTA TAA ATT AAT TAT ATA GCG CGG CGC CCG GCC GGC CTT AAG CTA TAG AGC GCT
30 AAA TTT TTA TAA ATT AAT TAT ATA GCG CGG CGC CCG GCC GGC CTT AAG CTA TAG AGC GCT CGT GTT AAC ACG GAA GTA TAC TTC AGT ACT
64 10 AAA TTT TTA TAA ATT AAT
TAT ATA AAG CTT
20 AAA TTT TTA TAA ATT AAT TAT ATA AAG CTT CGG CCG GCG GGC CGC GCC TTC GAA CTA TAG
30 AAA TTT TTA TAA ATT AAT TAT ATA AAG CTT CGG CCG GCG GGC CGC GCC TTC GAA CTA TAG TCT TAC AGT GTA AGA AGC ACT GCT GTT AAC
23 Panjang fragmen Pangkat matriks (λ) Jumlah
peubah Pasangan Basa yang diambil TAT ATA CGC GCG
20 AAA TTT TTA TAA ATT AAT TAT ATA CGC GCG CGG CCG GGC GCC CTT AAG GCT CTA TAG AGC
30 AAA TTT TTA TAA ATT AAT TAT ATA CGC GCG CGG CCG GGC GCC CTT AAG GCT CTA TAG AGC GTT AAC GAA CGT ACG TTC TAC GTA ACT AGT
64 10 TTT AAA TTA TAA ATT TAT
ATA AAT AAG CTT
20 TTT AAA TTA TAA ATT TAT ATA AAT AAG CTT CGC GCG CGG GAA CCG TTC GCC GGC CTA TAG
30 TTT AAA TTA TAA ATT TAT ATA AAT AAG CTT CGC GCG CGG GAA CCG TTC GCC GGC CTA TAG AAC ACT GTT GCT AGT AGC AGA TCT TAC GTA
10000bp 2 10 AAA TTT TTA TAA ATT AAT
ATA TAT GCG GGCp
20 AAA TTT TTA TAA ATT AAT ATA TAT GCG CGG CGC CCG GGC GCC CTT AAG CTA TAG GCT AGC
30 AAA TTT TTA TAA ATT AAT ATA TAT GCG CGG CGC CCG GGC GCC CTT AAG CTA TAG GCT AGC AAC GTT GAA TTC CGT ACG TAC GTA ACT AGT
64 10 AAA CAA GAA TAA ACA CCA
GCA TCA AGA CGA
20 AAA CAA GAA TAA ACA CCA GCA TCA AGA CGA GGA TGA ATA CTA GTA TTA AAC CAC GAC TAC
30 AAA CAA GAA TAA ACA CCA GCA TCA AGA CGA GGA TGA ATA CTA GTA TTA AAC CAC GAC TAC ACC CCC GCC TCC AGC CGC GGC TGC ATC CTC Lampiran 4 Hasil percobaan pada organisme yang sudah dikenal
24
Percobaan Panjang fragmen Iterasi / fold Akurasi
1 500bp 1 80.11 % 2 81.65 % 3 80.74 % 4 79.60 % 5 81.86 % Akurasi maksimum = 81.90 % 2 1000bp 1 84.25 % 2 84.16 % 3 85.49 % 4 83.25 % 5 83.65 % Akurasi maksimum = 85.49 % 3 5000bp 1 88.85 % 2 87.64 % 3 87.99 % 4 88.40 % 5 87.36 % Akurasi maksimum = 88.85 % 4 10000bp 1 90.05 % 2 90.90 % 3 88.55 % 4 88.65 % 5 89.34 % Akurasi maksimum = 90.90 % 5 500bp 1 77.86 % 2 52.15 % 3 77.25 % 4 78.19 % 5 76.70 % Akurasi maksimum = 78.19 % 6 1000bp 1 50.60 % 2 50.60 % 3 81.55 % 4 50.60 % 5 78.65 % Akurasi maksimum = 81.55 % 7 5000bp 1 85.15 % 2 84.90 % 3 84.84 % 4 85.00 % 5 85.15 % Akurasi maksimum = 85.15 % 8 1000bp 1 84.45 % 2 85.30 % 3 85.55 % 4 86.20 %
25 Percobaan Panjang fragmen Iterasi / fold Akurasi
5 87.05 % Akurasi maksimum = 87.05 % 9 500bp 1 52.15 % 2 77.70 % 3 52.17 % 4 78.79 % 5 76.45 % Akurasi maksimum = 78.79 % 10 1000bp 1 80.70 % 2 81.25 % 3 80.95 % 4 80.50 % 5 79.30 % Akurasi maksimum = 81.25 % 11 5000bp 1 85.29 % 2 84.04 % 3 84.20 % 4 84.41 % 5 85.01 % Akurasi maksimum = 85.29 % 12 10000bp 1 84.70 % 2 85.60 % 3 86.36 % 4 86.19 % 5 85.25 % Akurasi maksimum = 86.36 % 13 500bp 1 79.55 % 2 77.20 % 3 79.15 % 4 78.50 % 5 77.35 % Akurasi maksimum = 79.55 % 14 1000bp 1 80.90 % 2 80.45 % 3 83.05 % 4 81.20 % 5 81.40 % Akurasi maksimum = 83.05 % 15 5000bp 1 85.90 % 2 85.25 % 3 84.71 % 4 84.40 % 5 86.59 % Akurasi maksimum = 86.59 % 16 10000bp 1 87.44 % 2 87.15 % 3 86.50 %
26
Percobaan Panjang fragmen Iterasi / fold Akurasi
4 86.06 % 5 86.10 % Akurasi maksimum = 87.44 % 17 500 bp 1 52.15 % 2 78.10 % 3 52.17 % 4 52.18 % 5 52.15 % Akurasi maksimum = 78.10 % 18 1000 bp 1 50.57 % 2 50.60 % 3 50.62 % 4 79.45 % 5 81.15 % Akurasi maksimum = 81.15 % 19 5000 bp 1 85.86 % 2 85.19 % 3 50.62 % 4 84.85 % 5 84.06 % Akurasi maksimum = 85.86 % 20 10000 bp 1 84.40 % 2 86.60 % 3 86.15 % 4 85.09 % 5 87.31 % Akurasi maksimum = 87.31 % 21 500 bp 1 78.50 % 2 78.25 % 3 52.17 % 4 52.18 % 5 77.10 % Akurasi maksimum = 78.50 % 22 1000 bp 1 81.35 % 2 81.30 % 3 81.85 % 4 81.99 % 5 79.80 % Akurasi maksimum = 81.99 % 23 5000 bp 1 84.00 % 2 86.75 % 3 85.64 % 4 86.55 % 5 84.65 % Akurasi maksimum = 86.75 % 24 10000 bp 1 87.55 % 2 87.89 %
27 Percobaan Panjang fragmen Iterasi / fold Akurasi
3 86.20 % 4 86.15 % 5 85.96 % Akurasi maksimum = 87.89 % 25 500 bp 1 78.29 % 2 78.66 % 3 78.85 % 4 79.25 % 5 77.90 % Akurasi maksimum = 79.25 % 26 1000 bp 1 81.80 % 2 81.61 % 3 82.09 % 4 81.20 % 5 81.70 % Akurasi maksimum = 82.09 % 27 5000 bp 1 86.80 % 2 86.56 % 3 85.40 % 4 84.10 % 5 84.64 % Akurasi maksimum = 86.80 % 28 10000 bp 1 87.11 % 2 88.25 % 3 85.85 % 4 86.55 % 5 86.64 % Akurasi maksimum = 88.25 % 29 500bp 1 52.15 % 2 78.10 % 3 52.17 % 4 52.18 % 5 52.15 % Akurasi maksimum = 78.10 % 30 1000bp 1 50.57 % 2 50.60 % 3 50.62 % 4 79.45 % 5 81.15 % Akurasi maksimum = 80.15 % 31 5000bp 1 84.65 % 2 84.60 % 3 85.45 % 4 50.65 % 5 85.30 % Akurasi maksimum = 85.45 % 32 1000bp 1 85.74 %
28
Percobaan Panjang fragmen Iterasi / fold Akurasi
2 85.75 % 3 86.35 % 4 85.61 % 5 85.95 % Akurasi maksimum = 86.35 % 33 500bp 1 78.00 % 2 52.15 % 3 79.53 % 4 77.86 % 5 76.25 % Akurasi maksimum = 79.53 % 34 1000bp 1 82.35 % 2 81.50 % 3 82.40 % 4 81.15 % 5 19.90 % Akurasi maksimum = 82.40 % 35 5000bp 1 85.39 % 2 86.30 % 3 85.30 % 4 85.70 % 5 84.69 % Akurasi maksimum = 86.30 % 36 10000bp 1 86.65 % 2 87.74 % 3 86.66 % 4 86.90 % 5 86.05 % Akurasi maksimum = 87.74 % 37 500bp 1 79.44 % 2 79.50 % 3 78.70 % 4 77.81 % 5 77.90 % Akurasi maksimum = 79.50 % 38 1000bp 1 81.85 % 2 81.15 % 3 80.86 % 4 81.19 % 5 82.35 % Akurasi maksimum = 82.35 % 39 5000bp 1 85.16 % 2 86.54 % 3 85.00 % 4 84.54 % 5 85.85 % Akurasi maksimum = 86.54 %
29 Percobaan Panjang fragmen Iterasi / fold Akurasi
40 10000bp 1 85.95% 2 87.15% 3 87.65% 4 86.00 % 5 86.75 % Akurasi maksimum = 87.65 %
Lampiran 5 Hasil percobaan pada organisme yang belum dikenal
Percobaan Panjang fragmen Akurasi
41 500 bp 81.90 % 42 1000 bp 85.49 % 43 5000 bp 88.85 % 44 10000 bp 90.90 % 45 500 bp 79.50 % 46 1000 bp 82.35 % 47 5000 bp 86.54 % 48 10000 bp 87.65 %
30
RIWAYAT HIDUP
Penulis dilahirkan di Jakarta pada tanggal 14 Maret 1992 dengan nama Rindi Antika. Penulis merupakan anak pertama dari dua bersaudara pasangan Asid dan Saleha.
Penulis menyelesaikan pendidikan Sekolah Menengah Atas di SMA Negeri 75 Jakarta, lulus pada tahun 2009. Pada tahun yang sama penulis melanjutkan pendidikan di Institut Pertanian Bogor Direktorat Program Diploma, Program Keahlian Teknik Komputer melalui jalur reguler.
Pada tahun 2012, penulis melanjutkan studi ke program S1 Ilmu Komputer Alih Jenis, Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.