BAB 2
KAJIAN TEORITIS
2.1 Deskripsi Teori
2.1.1 Konsep Dasar Rekayasa Piranti Lunak 2.1.1.1 Pengertian Rekayasa Piranti Lunak
Pengertian rekayasa piranti lunak pertama kali diperkenalkan oleh Fritz Bauer sebagai penetapan dan penggunaan prinsip-prinsip rekayasa dalam usaha mendapatkan piranti lunak yang ekonomis, yaitu piranti lunak yang terpercaya dan bekerja efisien pada mesin atau komputer (Pressman,1992,p19).
2.1.1.2 Paradigma Rekayasa Piranti Lunak
Terdapat lima paradigma (model proses) dalam merekayasa suatu piranti lunak, yaitu The Classic Life Cycle atau sering juga disebut Waterfall Model, Prototyping Model, Fourth Generation Techniques (4GT), Spiral Model, dan Combine Model. Pada penulisan skripsi ini dipakai model Waterfall Model.
Menurut Pressman (1997, p19) piranti lunak telah menjadi elemen kunci dari evolusi computer based-system dan computer product. Selama lebih dari empat dekade terakhir, piranti lunak telah berkembang dari sebuah pemecahan berorientasi permasalahan dan alat analisis informasi menjadi sebuah industri sendiri. Namun kebiasaan pemrogram awal dan sejarah telah dengan sendirinya menciptakan sekumpulan masalah yang hingga kini masih
ada. Piranti lunak telah menjadi faktor pembatas dalam evolusi computer-based systems. Berangkat dari itulah dikembangkan metode yang menyediakan framework untuk membangun piranti lunak dengan kualitas lebih tinggi.
Rekayasa piranti lunak (Software Engineering) berdasarkan Pressman (1997, p23) adalah studi pendekatan untuk pengaplikasian secara sistematis, pendekatan terukur untuk pengembangan, operasi dan pemeliharaan dari sebuah piranti lunak.
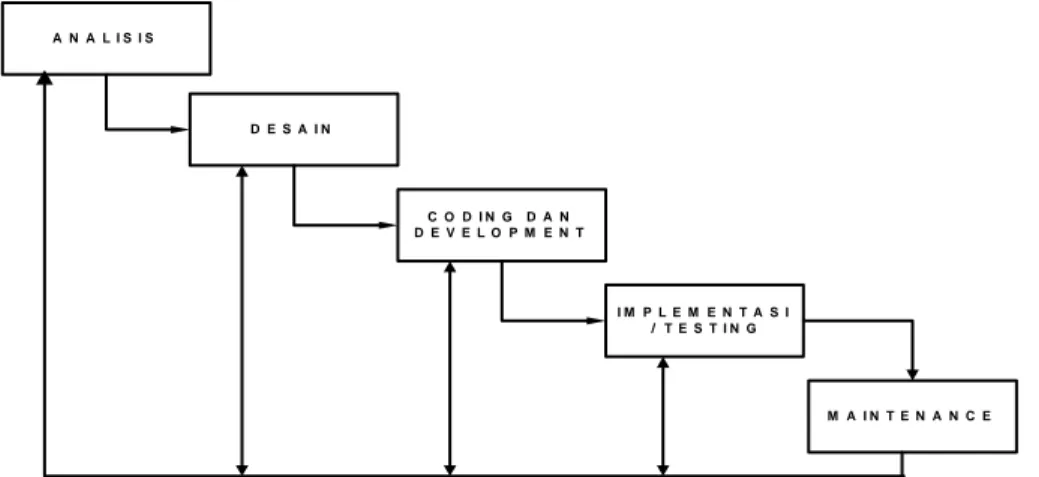
Waterfall model meliputi langkah-langkah analisis masalah atau kebutuhan user, mendesain aplikasi yang akan dibuat, coding dan yang terakhir mengimplementasikan aplikasi yang sudah dibuat untuk kemudian dievaluasi oleh pengguna. Pada Waterfall model dapat dilakukan revisi disetiap prosesnya (Pressman,1997, p20-21).
Menurut Pressman (1992, p20-21), ada enam tahap dalam Waterfall Model, seperti pada gambar 2.1 berikut adalah penjabarannya:
A N A L I S I S D E S A I N C O D I N G D A N D E V E L O P M E N T I M P L E M E N T A S I / T E S T I N G M A I N T E N A N C E
2.1.2 Interaksi Manusia dan Komputer
Seiring dengan perkembangannya teknologi informasi, program-program baru bermunculan dengan perancangan yang menarik. Namun hal itu belumlah cukup, karena pengguna (user) menginginkan adanya interaksi dengan program-program yang mudah dioperasikan (user-friendly) agar user lebih mudah menjalankan program tersebut. Program yang interaktif ini perlu dirancang dengan baik sehingga user dapat merasa senang dan juga dapat ikut berinteraksi dengan baik dalam menggunakannya.
2.1.2.1 Program Interaktif
Suatu program yang interaktif dan baik harus bersifat user friendly. Shneiderman (1998, p15) menjelaskan lima kriteria yang harus dipenuhi oleh suatu program yang user friendly, yaitu:
1. Waktu belajar yang tidak lama
2. Kecepatan penyajian informasi yang tepat. 3. Tingkat kesalahan pemakaian rendah.
4. Penghafalan sesudah melampaui jangka waktu. 5. Kepuasan pribadi.
Suatu Program yang interaktif dapat dengan mudah dibuat dan dirancang dengan suatu perangkat bantu pengembang sistem antarmuka, seperti Visual Basic, Visual Fox Pro, Borland Delphi dan sebagainya. Keuntungan penggunaan perangkat bantu untuk mengembangkan antarmuka menurut Santosa (1997, p7) yaitu:
2. Program antar mukanya menjadi mudah ditulis dan lebih ekonomis untuk dipelihara.
2.1.2.2 Pedoman untuk Merancang User Interface
Terdapat beberapa pedoman yang dianjurkan dalam merancang suatu program guna mendapatkan suatu program yang user friendly.
2.1.2.2.1 Delapan Aturan Emas
Menurut Shneiderman (1998, p74-75), untuk merancang sistem interaksi manusia dan komputer yang baik, harus memperhatikan delapan aturan utama dalam perancangan antarmuka, seperti yang dijelaskan dibawah ini, yaitu :
1. Strive for consistency (Berusaha keras untuk konsisten). Harus selalu berusaha konsisten dalam merancang tampilan.
2. Enable frequent user to use shortcuts (Memungkinkan frequent users menggunakan shortcuts).
Umumnya user yang sudah sering menggunakan aplikasi lebih menginginkan kecepatan dalam mengakses fungsi yang diinginkan. Jadi tingkat interaksi yang diminta adalah yang pendek atau singkat dan langsung menuju ke fungsi tersebut. Untuk itu, perlu disiapkan tombol spesial atau perintah tersembunyi.
3. Offer informative feed back (Memberikan umpan balik yang informatif).
Umpan balik harus diberikan untuk memberikan informasi kepada user sesuai dengan aksi (action) yang dilakukan. Umpan balik bisa
berupa konfirmasi atas suatu aksi. Misalnya setelah melakukan fungsi simpan dapat diberikan informasi bahwa data telah disimpan.
4. Design dialogs to yield closure (Merancang dialog untuk menghasilkan keadaan akhir).
Umpan balik atas akhir dari suatu proses adalah pengorganisasian aksi yang baik sehingga user mengetahui kapan awal dan akhir dari suatu aksi. Akan sangat membantu jika user akan mendapat sinyal untuk melanjutkan aksi lainnya. Misalnya pada saat akan menutup suatu program akan ditampilkan konfirmasi penutupan.
5. Offer simple error handling (Memberikan pencegahan kesalahan dan penanganan kesalahan yang sederhana).
Sistem dirancang sedemikian rupa sehingga dapat mencegah user dalam membuat kesalahan. Contohnya, penggunaan menu seleksi untuk membatasi input (masukkan) dari user, validasi pengisian data pada form (layar) agar data yang diisi sesuai dengan ketentuan. Bila terjadi ketentuan kesalahan sistem harus dapat memberikan instruksi yang sederhana, konstruktif dan spesifik untuk perbaikan.
6. Permit easy reversal of actions (Mengizinkan pembalikan aksi (Undo) dengan mudah).
Terkadang user tidak sengaja melakukan aksi yang tidak diinginkan, untuk itu user ingin melakukan pembatalan aksi yang dilakukan. Sistem harus banyak memberikan fungsi pembatalan. User akan merasa lebih aman dan tidak harus takut dalam mencoba dan memakai sistem tersebut.
7. Support internal locus of control (Mendukung user menguasai sistem atau inisiator, bukan responden).
User yang berpengalaman sangat mendambakan kontrol yang kuat pada sistem, sehingga mereka merasa menguasai sistem tersebut. Sistem yang tidak terduga dan sulit dalam melakukan aksi akan menyulitkan user.
8. Reduce short term memory load (Mengurangi beban ingatan jangka pendek).
Keterbatasan memori pada manusia harus dapat disajikan oleh program, dimana manusia hanya dapat mengingat sebagian informasi yang diberikan. Perancangan program harus sederhana.
2.1.2.2.2 Pedoman Merancang Tampilan Data
Beberapa pedoman yang disarankan untuk digunakan dalam merancang tampilan data yang baik menurut Smith dan Mosier yang dikutip oleh Shneiderman (1998, p80) yaitu:
1. Konsistensi tampilan data, istilah, singkatan, format dan sebagainya harus standar;
2. Beban ingatan yang sesedikit mungkin bagi pengguna. User tidak perlu mengingat informasi dari layar yang satu ke layar yang lain; 3. Kompatibilitas tampilan data dengan pemasukan data. Format
tampilan informasi perlu berhubungan erat dengan tampilan pemasukan data.
4. Fleksibilitas kendali pengguna terhadap data. User harus dapat memperoleh informasi dari tampilan dalam bentuk yang paling memudahkan.
2.1.2.2.3 Teori Waktu Respon
Waktu repson dalam sistem komputer menurut Sneiderman (1998, p352) adalah jumlah detik dari saat pemakai memulai aktifitas (misalnya dengan menekan tombol enter atau tombol mouse) sampai komputer menampilkan hasilnya di display atau printer.
Beberapa pedoman yang disarankan mengenai kecepatan waktu respons pada suatu program menurut Shneiderman (1998, p367) yaitu: 1. Pemakai lebih menyukai waktu respon yang lebih pendek;
2. Waktu respon yang panjang (lebih dari 15 detik) mengganggu;
3. Waktu respon yang lebih pendek menyebabkan waktu pengguna berpikir lebih pendek;
4. Langkah yang lebih cepat dapat meningkatkan produktivitas, tetapi juga dapat meningkatkan tingkat kesalahan;
5. Waktu respon harus sesuai dengan tugasnya:
a. Untuk mengetik, menggerakkan kursor, memilih dengan mouse: 50 – 150 milidetik;
b. Tugas sederhana yang sering: < 1 detik;
c. Tugas biasa: 2 - 4 detik, Tugas kompleks: 8 – 12 detik; 6. Pemakai harus diberi tahu mengenai penundaan yang panjang.
2.1.3 Optimalisasi
Optimal adalah suatu keadaan yang menghasilkan hasil yang maksimal dengan usaha seminimal mungkin. Menurut Kamus Besar Bahasa Indonesia (1997, p705), optimal adalah kondisi yang terbaik (menguntungkan), mengoptimalkan adalah menjadikan paling baik dan optimalisasi adalah proses, cara, pembuatan mengoptimalkan.
2.1.4 Pengolahan Data
Menurut Supranto (2001, p24-25), agar data yang telah dikumpulkan berupa data mentah dapat berguna, maka data tersebut perlu diolah. Pengolahan data pada dasarnya merupakan suatu proses memperoleh data/angka ringkasan berdasarkan kelompok data mentah. Data/angka ringkasan dapat berupa jumlah(total), proporsi, persentase, rata-rata dan sebagainya. Tujuan dari pengolahan data adalah mendapatkan data statistik yang digunakan untuk melihat atau menjawab persoalan secara agregat atau kelompok, bukan satu per satu secara individu.
Metode Pengolahan Data
Secara umum, metode pengolahan data dapat dibedakan menjadi dua, yaitu pengolahan data secara manual (manual data processing) dan pengolahan data secara elektronik (electronical data processing). Untuk menentukan metode pengolahan data yang lebih baik, tergantung dari berapa besar ukuran datanya. Jika hasil observasi yang dikumpulkan jumlahnya sedikit, maka dapat dilakukan pengolahan data secara manual. Akan tetapi, jika jumlah observasi sangat besar, maka pengolahan data secara elektronik (dengan komputer) merupakan cara efektif.
2.1.5 Populasi dan Sampel
Berdasarkan Suharyadi (2004, p323) populasi adalah kumpulan dari semua kemungkinan orang-orang, benda-benda dan ukuran lain yang menjadi objek perhatian atau kumpulan seluruh objek yang menjadi perhatian. Sedangkan sampel adalah suatu bagian dari populasi tertentu yang menjadi perhatian.
Gambar 2.2 Hubungan Populasi dan Sampel
Populasi pada kenyataannya dapat dikelompokkan menjadi dua bagian yaitu populasi terbatas (finite) dan tidak terbatas (infinite). Populasi terbatas adalah populasi yang unsurnya terbatas berukuran N. Sedangkan populasi tidak terbatas adalah suatu populasi yang mengalami proses secara terus-menerus sehingga ukuran N menjadi tidak terbatas perubahan nilainya.
Sampel merupakan bagian dari populasi. Dengan menggunakan sampel, maka dapat diperoleh suatu ukuran yang dinamakan statistik. Dalam statistika induktif terdapat kecenderungan membuat kesimpulan umum yang didasarkan pada informasi dari sampel atau statistik. Parameter adalah ukuran dari populasi sedangkan, statistik adalah ukuran dari sampel.
Sampel dapat dibedakan kedalam dua kelompok yaitu sampel probabilitas dan sampel nonprobabilitas. Sampel probabilitas merupakan satu sampel yang dipilih sedemikian rupa dari populasi sehingga masing-masing anggota populasinya
memiliki probabilitas atau peluang yang sama untuk dijadikan sampel. Sampel nonprobabilitas merupakan suatu sampel yang dipilih sedemikian rupa dari populasi sehingga setiap anggota tidak memiliki probabilitas atau peluang yang sama untuk dijadikan sampel.
2.1.6 Metode Penarikan Sampel
Berdasarkan Suharyadi (2004, p325-332), ada beberapa metode yang dapat digunakan untuk memilih sampel dari populasi. Dari metode-metode tersebut tidak ada metode “terbaik” untuk memilih sampel dari populasi. Namun demikian setiap metode penarikan sampel atau Sampling Technique memiliki tujuan yang sama yaitu memberikan kesempatan untuk menentukan unsur atau anggota populasi untuk dimasukkan ke dalam sampel.
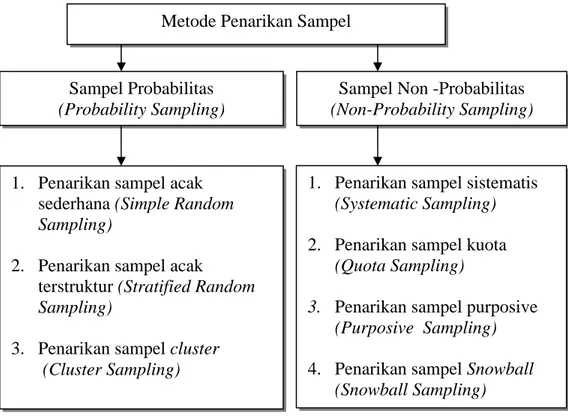
Pada dasarnya metode penarikan sampel dapat dikelompokan menjadi dua bagian yaitu probability sampling dan nonprobability sampling. Secara skematis metode penarikan sampel dapat dilihat pada Gambar 2.3.
Gambar 2.3 Skema Metode Penarikan Sampel
2.1.6.1 Simple Random Sampling
Metode penarikan sampel acak sederhana (Simple Random Sampling) adalah penarikan sampel dari populasi secara acak tanpa memperhatikan tingkatan yang ada didalam populasi dan setiap populasi memiliki kesempatan yang sama untuk dijadikan sampel.
Metode penarikan sampel acak sederhana dapat dilakukan dengan beberapa cara, antara lain: sistem kocok dan menggunakan tabel acak. Setelah mendapatkan nomor acak untuk sampel, maka dapat dicocokkan pada daftar anggota populasi, sehingga sampel dapat dialokasikan.
Sampel Probabilitas (Probability Sampling)
Metode Penarikan Sampel
Sampel Non -Probabilitas (Non-Probability Sampling)
1. Penarikan sampel acak sederhana (Simple Random Sampling)
2. Penarikan sampel acak
terstruktur (Stratified Random Sampling)
3. Penarikan sampel cluster (Cluster Sampling)
1. Penarikan sampel sistematis (Systematic Sampling) 2. Penarikan sampel kuota
(Quota Sampling)
3. Penarikan sampel purposive (Purposive Sampling) 4. Penarikan sampel Snowball
2.1.6.2 Stratified Random Sampling
Metode penarikan sampel acak terstatifikasi/berstrata (Stratified Random Sampling) adalah metode penarikan sampel dengan cara membagi populasi ke dalam kelompok yang mempunyai anggota atau unsur yang homogen. Kemudian sampel diambil secara acak dari tiap kelompok. Penarikan sampel acak terstratifikasi dilakukan dengan membagi anggota populasi dalam beberapa subkelompok yang disebut strata, lalu suatu sampel dipilih dari masing-masing stratum.
Gambar 2.4 Stratified Random Sampling
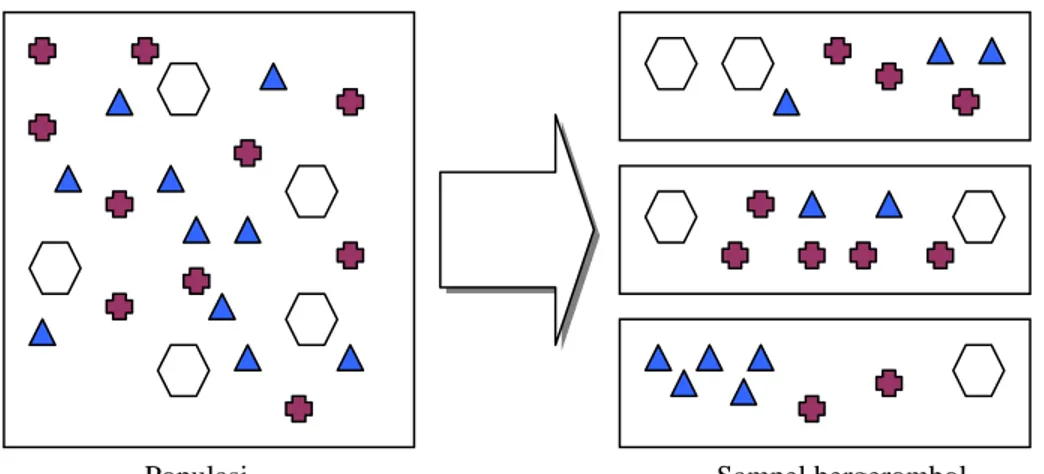
2.1.6.3 Cluster Sampling
Metode penarikan sampel bergerombol (Cluster Sampling) adalah teknik memilih sampel dari kelompok unit-unit yang kecil/gerombol (cluster) dari sebuah populasi yang relatif besar dan tersebar luas. Anggota setiap kelompok bersifat heterogen. Pembentukan unit tidak didasarkan pada kesamaan anggota.
Gambar 2.5 Cluster Random Sampling
2.1.6.4 Systematic Sampling
Metode penarikan sampel sistematis (Systematic Sampling) adalah teknik penarikan sampel berdasarkan urutan dari anggota populasi yang telah diberi nomor urut. Apabila setiap unsur atau anggota populasi disusun dengan cara tertentu secara alfabetis, dari besar-kecil atau sebaliknya, kemudian dipilih titik awal secara acak lalu setiap anggota ke-i dari populasi dipilih sebagai sampel.
2.1.6.5 Quota Sampling
Metode penarikan sampel kuota (Quota Sampling) adalah penarikan sampel dari populasi yang mempunyai ciri-ciri tertentu sampai jumlah atau kuota yang diinginkan. Tujuan penarikan sampel kuota adalah untuk memperbaiki keterwakilan seluruh komponen dalam populasi. Maksud dari keterwakilan ini supaya seluruh karakteristik dalam populasi dapat terwakili dan tergambarkan dengan baik.
2.1.6.6 Purposive Sampling
Metode penarikan sampel bertujuan (Purposive Sampling) adalah penarikan sampel yang dilakukan dengan pertimbangan tertentu. Pertimbangan tersebut didasarkan pada kepentingan atau tujuan penelitian.
Metode penarikan sampel dengan purposive terdapat dua cara, antara lain:
1. Convenience Sampling, yaitu metode penarikan sampel berdasarkan keinginan peneliti sesuai dengan tujuan penelitian.
2. Judgment Sampling, yaitu metode penarikan sampel berdasarkan penilaian terhadap karakteristik anggota sampel yang disesuaikan dengan tujuan penelitian. Metode ini biasanya dilakukan untuk penelitian yang bersifat kualitatif.
2.1.6.7 Snowball Sampling
Metode penarikan sampel snowball, digunakan bila populasi yang tersedia sangat spesifik. Cara penarikan sampel dengan teknik ini dilakukan secara berantai, mulai dari ukuran sampel yang kecil, makin lama menjadi besar seperti halnya bola salju mengelinding menuruni bukit.
2.1.7 Kesalahan Penarikan Sampel
Menurut Sugiarto et al.(2003 ,p333), dengan metode-metode penarikan sampel yang tersedia, diharapkan bahwa sampel yang baik, merupakan miniatur dari populasi. Oleh karena itu, indikator dari sampel yaitu statistik, seharusnya sama dengan indikator populasi yaitu parameter. Usaha-usaha untuk mendekatkan nilai
statistik dengan parameter dilakukan dengan memperoleh sampel yang tepat yang mewakili setiap anggota populasi.
Beberapa metode dapat digunakan, seperti yang telah disebutkan. Namun demikian, karena jumlah sampel hanyalah sebagian dari populasi tidak dapat dihindari bahwa baik nilai rata-rata hitung maupun standar deviasi sampel tidak sama persis dengan nilai rata-rata hitung maupun standar deviasi populasi. Perbedaan antara nilai statistik dengan parameter disebut kesalahan penarikan sampel (sampling error), (Suharyadi, 2004, p323).
Meskipun demikian penarikan sampel yang berulang-ulang biasanya menghasilkan besaran suatu karakteristik populasi yang berbeda-beda antar satu sampel ke sampel lainnya. Sampling error mencerminkan keheterogenan atau peluang munculnya perbedaan dari satu sampel dengan sampel yang lain karena perbedaan individu yang terpilih dari berbagai sampel tersebut. Sampling error dapat diperkecil dengan memperbesar ukuran sampel meskipun upaya ini mengakibatkan peningkatan biaya survei.
2.1.8 Teori Pendugaan Statistik
Teori pendugaan statistik berdasarkan Suharyadi (2004, p357), adalah suatu proses dengan menggunakan statistik sampel untuk menduga parameter populasi. Pendugaan mengenai nilai sebenarnya dari parameter yang didasarkan pada sampel mengandung unsur ketidakpastian (uncertainty), artinya bisa saja suatu dugaan benar dan salah. Hal tersebut dapat terjadi karena data yang digunakan adalah data pendugaan atau taksiran sampel yang mengandung kesalahan dalam penarikan sampel.
Pendugaan Titik Parameter Populasi
Pendugaan adalah seluruh proses dengan menggunakan statistik sampel untuk menduga parameter yang tidak diketahui. Suatu penduga titik (point estimator) adalah pendugaan yang terdiri dari satu nilai saja yang digunakan untuk menduga parameter.
Penduga titik untuk nilai rata-rata (x), ragam (s2) dan simpangan baku (s) didefinisikan oleh Hogg dan Tanis (2001,p10-14,p118-125).
Nilai rata-rata dapat dihitung dengan rumus :
n Xi x n i
∑
= = 1 Persamaan (2.1) dimana : Xi = X1, X2,X3... Xnn = Jumlah sampel yang diambil
Ragam dari sebuah contoh acak x1,x2,...,xn didefinisikan sebagai :
1
-n
)
(
2 1 2x
x
n i i s∑
=−
=
Persamaan (2.2)Persamaan 2.2 diatas dapat diturunkan menjadi :
1) -n(n ) ( 2 1 1 2 2
∑
∑
= = − = n i i n i i x x n s Persamaan (2.3)dimana : s2 : Ragam sampel xi : Data ke-i n : Jumlah sampel
Standar deviasi atau Simpangan baku atau galat baku dari sampel (dilambangkan dengan s) didefinisikan sebagai akar dari ragam.
1) -n(n ) ( 2 1 1 2
∑
∑
= = − = n i i n i i x x n s Persamaan (2.4) Sifat-sifat pendugaPenduga yang baik adalah penduga yang mendekati nilai parameter sebenarnya. Agar data yang diambil berguna maka data tersebut haruslah objektif (seusai dengan kenyataan sebenarnya), representatif (mewakili keadaan yang sebenarnya), variasinya kecil, tepat waktu dan relevan (Sugiarto et al.,2003, p7). Berikut adalah sifat-sifat penduga yang baik:
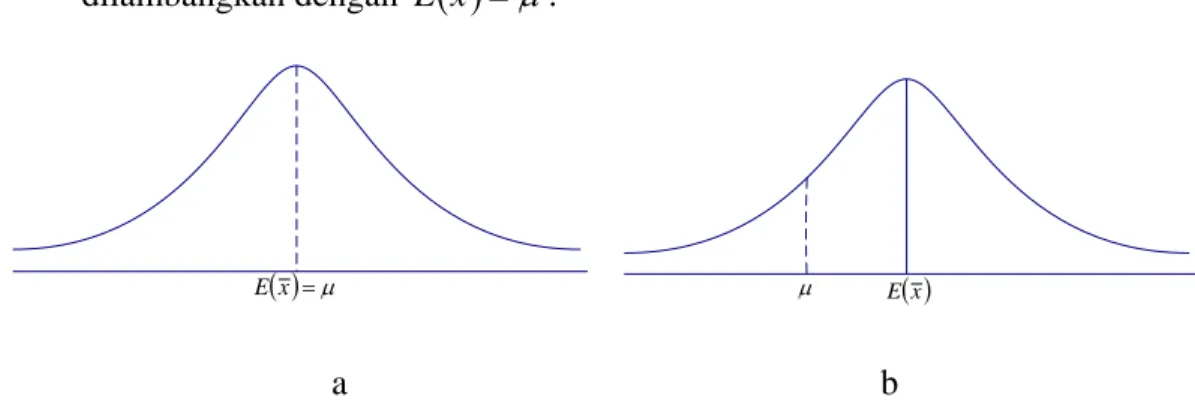
1. Penduga tidak bias
Suatu penduga dikatakan tidak bias apabila rata-rata atau nilai harapan (Expected value, x) dari statistik sampel, sama dengan parameter populasi (μ). Atau dapat dilambangkan dengan E
( )
x =μ.( )x =μ
E μ E( )x
a b
Gambar 2.6 a dan b sebagai Penduga Tidak Bias dan Bias
Pada gambar a, penduga bersifat tidak bias, karena E
( )
x = μ, sedangkan pada gambar b, menunjukkan penduga yang bias, karena E( )
x ≠μ. Jadi apabila nilai dugaan semakin mendekati parameter, maka dugaannya semakin baik.2. Penduga efisien
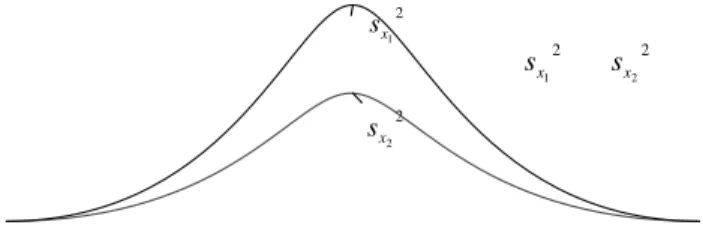
Penduga yang efisien (efficient estimator) adalah penduga yang tidak bias dan mempunyai ragam terkecil
( )
sx2 dari penduga-penduga lainnya. Kalau ada dua penduga yang tidak bias misalkan x1danS x2di mana 21 x s < 2 2 x s maka dapat disimpulkan bahwa penduga x1 lebih baik dari penduga x2. Penduga dengan
standar deviasi yang paling kecil adalah penduga yang efisien.
2 2 x s 2 1 x s 2 1 x s sx22
Gambar 2.7 Hubungan Penduga Efisien 3. Penduga konsisten
Penduga yang konsisten (consistent estimator) adalah nilai dugaan (x) yang semakin mendekati nilai sebenarnya dengan semakin bertambahnya jumlah sampel (n). Jadi, ukuran sampel yang semakin besar cenderung memberikan penduga yang konsisten dibandingkan dengan ukuran sampel yang kecil.
xmerupakan penduga yang konsisten terhadap μ, karena apabila n mendekati N, maka μx mendekati x1, dan apabila n = N, maka x=μ.
Pendugaan Interval
Dengan menggunakan penduga titik, nilai statistik dari satu sampel ke sampel lainnya dapat sama, tetapi mungkin juga berbeda. Dalam statistika, ketepatan digambarkan dengan standar deviasinya, seberapa jauh nilai dalam sampel tersebar
dari nilai tengahnya, semakin kecil maka semakin baik. Oleh karena itu, dengan memperhatikan peranan standar deviasi, pendugaan titik digantikan dengan pendugaan interval, (Suharyadi, 2004, p362).
Pendugaan interval adalah suatu interval yang menyatakan selang dimana suatu parameter populasi mungkin berada. Hal ini didasarkan atas pertimbangan bahwa suatu nilai dugaan tidak mungkin dapat dipercaya 100%, karena nilai tersebut didasarkan pada sampel yang merupakan bagian dari populasi. Suatu selang kepercayaan/interval keyakinan (confidence interval) yang dibatasi oleh dua buah nilai yang disebut batas bawah dan batas atas.
Interval keyakinan untuk rata-rata hitung populasi adalah interval yang memiliki probabilitas besar mengandung rata-rata hitung populasi. Bentuk umum selang kepercayaan, didefinisikan sebagai:
{
x−Z.sx <μ< x+Z.sx}
=1−αP Persamaan (2.5)
dimana: x : statistik yang dipakai untuk menduga paramater populasi (rata-rata)
μ : parameter populasi yang tidak diketahui sx : standar deviasi distribusi sampel statistik.
Z : Suatu nilai yang ditentukan oleh probabilitas yang berhubungan dengan pendugaan interval, nilai Z diperoleh dari tabel luas dibawah kurva normal.
1-α : Probabilitas atau tingkat keyakinan yang sudah ditentukan. x−Z.sx : Nilai batas bawah keyakinan
2.1.9 Sampel Bergerombol (Cluster Sampling)
Anggota dari suatu kelompok/gerombol adalah bersifat heterogen, artinya didalam setiap kelompok terdapat beberapa elemen yang mencerminkan populasinya. Sehingga pengamatan terhadap populasi dapat diwakili dengan pengamatan terhadap beberapa kelompok yang terpilih saja.
Untuk survei-survei yang penarikan sampelnya terdiri dari suatu kelompok atau berkelompok dari unit-unit yang lebih kecil dinamakan elemen-elemen atau subunit-subunit.
2.1.9.1 Single Stage Cluster Sampling
Teknik penarikan sampel bergerombol dimana penarikan sampelnya hanya dilakukan satu tahap.
Prosedur penarikan sampel bergerombol satu tahap :
1. Menetapkan kelompok-kelompok atau gerombol-gerombol yang sesuai dengan permasalahan yang dihadapi. Banyaknya elemen dalam gerombol seharusnya menjadi relatif kecil dibandingkan ukuran populasi.
2. Apabila gerombol yang tepat telah ditentukan, maka kerangka penarikan sampel berupa daftar semua gerombol dalam populasi harus disusun. Sehingga kerangka penarikan sampel yang berupa susunan daftar semua gerombol di dalam populasi terbentuk. Dengan demikian yang menjadi unit penarikan sampel disini adalah gerombol-gerombol tersebut.
3. Lakukan pemilihan sampel gerombol dengan menggunakan teknik penarikan sampel sederhana. Sehingga dengan akan terpilih sampel acak sederhana dari gerombol-gerombol yang ada dalam kerangka itu. Dari
penarikan sampel yang telah dilakukan, pendugaan terhadap parameter populasi dapat dilakukan.
• Equal Size
Penarikan subsampel dimana jumlah unitnya sama untuk setiap gerombol yang terpilih.
Gambar 2.8 Single Stage Cluster Sampling – Equal Size
• Unequal Size
Penarikan subsampel dimana jumlah unitnya tidak sama untuk setiap gerombol yang terpilih.
Gambar 2.9 Single Stage Cluster Sampling – Un Equal Size Populasi
Sampel tahap 1
Sampel sudah digerombolkan
8
8
8
Populasi Sampel sudah digerombolkan
Sampel tahap 1 8
7 10
Penduga bagi nilai rata-rata populasi, μ:
∑
∑
= = = n i i n i i m y y 1 1 Persamaan (2.6)Ragam dugaan dari y :
(
)
⎪ ⎪ ⎭ ⎪⎪ ⎬ ⎫ ⎪ ⎪ ⎩ ⎪⎪ ⎨ ⎧ − − ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − =∑
= 1 1 ) ( ˆ 1 2 2 n m y y M n N n N y V n i i i Persamaan (2.7)dimana : M dapat diduga oleh m jika M tidak diketahui
Akar pangkat dua dari ragam dugaan nilai rata-rata merupakan galat baku dugaan dari nilai rata-rata yang dinotasikan dengan s(y). Dengan menggunakan taraf kepercayaan (1-α)100%, batas galat pendugaan nilai rata-rata, BG(y), ditentukan sebagai:
BG(y) =
2
α
Z s(y) Persamaan (2.8)
Galat pendugaan nilai rata-rata:
( )
( )
{
G y <BG y}
=1−αP Persamaan (2.9)
Selang kepercayaan (1-α)100% bagi nilai rata-rata populasi μ:
( )
( )
{
y−BG y <μ <y+BG y}
=1−αP Persamaan (2.10)
Penduga ragam dalam persamaan 2.7 adalah berbias dan penduga yang baik dari V
( )
y akan diperoleh hanya jika n berukuran besar misal n >20 gerombol. Bias tidak muncul jika ukuran gerombol m1,m2,…,mN adalah sama besar.Penduga nilai total populasi, τ :
∑
∑
= = = = n i i n i i m y M y M 1 1 ˆ τ Persamaan (2.11)Ragam dugaan dari τˆ:
(
)
⎪ ⎪ ⎭ ⎪⎪ ⎬ ⎫ ⎪ ⎪ ⎩ ⎪⎪ ⎨ ⎧ − − ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − = = =∑
= ) 1 ( ) ( ˆ ) ( ˆ ) ˆ ( ˆ 1 2 2 2 n n m y y N n N N y V M y M V V n i i i τ Persamaan (2.12)Akar pangkat dua dari ragam dugaan nilai total merupakan galat baku dugaan dari nilai total yang dinotasikan dengan s(τˆ). Dengan menggunakan taraf kepercayaan (1-α)100%, batas galat pendugaan nilai rata-rata, BG(τˆ), ditentukan sebagai:
BG(τˆ) =
2
α
Z s(τˆ) Persamaan (2.13) Galat pendugaan nilai total, G(τˆ), :
( )
( )
{
Gτˆ <BGτˆ}
=1−αP Persamaan (2.14)
Selang kepercayaan (1-α)100% bagi nilai total populasi, τˆ:
( )
( )
{
τˆ−BGτˆ <μ <τˆ+BGτˆ}
=1−αP Persamaan (2.15)
Keterangan:
N = banyaknya cluster dalam populasi (i=1,2,…,N) n = banyaknya cluster terpilih
Mi = banyaknya unit dalam cluster ke-i populasi mi = banyaknya unit terpilih dalam cluster ke-i
m =
∑
= n i i m n 1 1=rata-rata ukuran cluster untuk sampel.
M =
N M
= rata-rata ukuran cluster dalam populasi
i
y = total dari semua nilai pengamatan karakteristik dalam cluster ke-i. Dengan banyaknya elemen dalam populasi, M , tidak diketahui, sehingga beberapa persamaan tentang pendugaan nilai total populasi tidak dapat digunakan. Apabila banyaknya elemen dalam populasi (M) tidak diketahui, maka tidak mungkin untuk menggunakan penduga My, tetapi perlu menggunakan penduga lain bagi total populasi yang tidak tergantung pada M. Besaran y merupakan penduga nilai rata-rata: t
n y y n i i t
∑
= = 1 Persamaan (2.16) ty merupakan penduga tak bias rata-rata dari N gerombol dalam populasi yang ekuivalen dengan total populasi τˆ.
Penduga nilai total populasi τˆ, yang tidak tergantung pada banyaknya elemen dalam populasi, M :
n y N y N n i i t
∑
= = = 1 ˆ τ Persamaan (2.17) Ragam dugaan τˆ:( )
( )
( )
(
)
⎪ ⎪ ⎭ ⎪⎪ ⎬ ⎫ ⎪ ⎪ ⎩ ⎪⎪ ⎨ ⎧ − − − = = =∑
= ) 1 ( ˆ ˆ ˆ ˆ 1 2 2 2 n n y y N n N N y V N y N V V n i t i t t τ Persamaan (2.18)Pendugaan nilai proporsi populasi.
Pendugaan ini dilakukan jika observasi berupa persentase dari jumlah obyek yang diamati.
Penduga bagi nilai proporsi populasi, p :
∑
∑
= = = n i i n i i m a p 1 1 Persamaan (2.19)Ragam dugaan dari p:
( )
(
(
)
)
⎪ ⎪ ⎭ ⎪⎪ ⎬ ⎫ ⎪ ⎪ ⎩ ⎪⎪ ⎨ ⎧ − − ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − =∑
= 1 1 ˆ 1 2 2 n n pm a M N n N p V n i i i Persamaan (2.20)dimana: M dapat diduga oleh m apabila M tidak diketahui
Akar pangkat dua dari ragam dugaan nilai proporsi merupakan galat baku dugaan dari nilai proporsi yang dinotasikan dengan s(p). Dengan menggunakan taraf kepercayaan (1-α)100%, batas galat pendugaan nilai proporsi, BG(p), ditentukan sebagai:
BG(p) =
2
α
Z s(p) Persamaan (2.21)
Galat pendugaan nilai proporsi:
( )
( )
{
G p <BG p}
=1−αP Persamaan (2.22)
Selang kepercayaan (1-α)100% bagi nilai proporsi populasi, p:
( )
( )
{
p−BG p <P< p+BG p}
=1−αP Persamaan (2.23)
Keterangan:
ai = total banyaknya elemen dalam cluster ke-i yang memiliki karakteristik yang diobservasi atau nilai proporsi nilai pengamatan dalam cluster ke-i
Penentuan ukuran sampel, untuk pendugaan nilai rata-rata populasi:
2 2 2 2 2 2 c c Z M NG NZ n σ σ + = Persamaan (2.24)
dimana : σc2 diduga olehsc2 dan M oleh m
Z: Suatu nilai yang ditentukan oleh probabilitas yang berhubungan dengan pendugaan interval, nilai Z diperoleh dari tabel luas dibawah kurva normal
G: Galat pendugaan N: Ukuran populasi.
Besaran ragam populasi, 2
c
σ dapat diduga berdasarkan ragam sampel
2 c s :
(
)
1 2 1 * * 1 * 1 * 1 2 2 2 * 1 2 2 − + − = − − =∑
∑
∑
∑
= = = = n m y m y y y n m y y s n i n i n i i i i i n i o i c Persamaan (2.25) dimana: iy = total nilai pengamatan dalam cluster ke-i i
m = banyaknya elemen dalam cluster ke-i
*
n = banyaknya cluster yang terpilih pada survei pendahuluan y = nilai rata-rata sampel yang dihitung dengan menggunakan :
∑
∑
= = = * * 1 1 n i i n i i m y y Persamaan (2.26)Besaran rata-rata ukuran cluster untuk populasi, M , dapat diduga oleh
m dengan: * 1 * n m m n i i
∑
= = Persamaan (2.27)Penentuan ukuran sampel, untuk pendugaan nilai proporsi populasi:
2 2 2 2 2 2 c c Z M NG NZ n σ σ + = Persamaan (2.28)
dimana : σc2 diduga oleh
2
c
s dan M oleh m
Z: Suatu nilai yang ditentukan oleh probabilitas yang berhubungan dengan pendugaan interval, nilai Z diperoleh dari tabel luas dibawah kurva normal.
G: Galat pendugaan N: Ukuran populasi
Besaran ragam populasi, σc2 dapat diduga berdasarkan ragam sampel,
2 c s :
(
)
1 1 2 2 − − =∑
= n pm a s n i i i c Persamaan (2.29)2.1.9.2 Multi Stages Cluster Sampling
Teknik penarikan sampel bergerombol dimana penarikan sampel dan subsampelnya dilakukan lebih dari satu tahap.
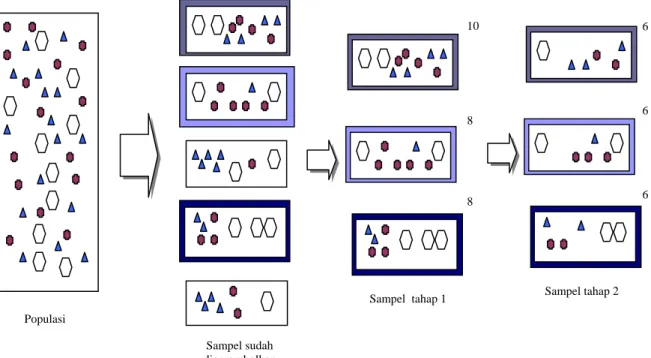
• Two Stages Cluster Sampling
Teknik penarikan sampel bergerombol dimana penarikan sampel dan subsampelnya dilakukan dua tahap.
Gambar 2.10 Two Stages Cluster Sampling Prosedur penarikan sampel bergerombol dua tahap:
1. Menetapkan gerombol-gerombol yang sesuai dari populasi itu, kemudian mendaftarkan semua gerombol yang telah ditetapkan itu kedalam kerangka penarikan sampel (sampling frame);
2. Memilih sampel acak sederhana yang ditarik dari kerangka penarikan contoh berupa daftar semua gerombol dalam populasi. Pemilihan ini disebut sebagai pemilihan tahap pertama;
10 8 8 6 6 Sampel sudah digerombolkan Populasi
Sampel tahap 1 Sampel tahap 2 6
3. Membentuk kerangka penarikan sampel tahap kedua berupa daftar semua elemen-elemen yang ada disetiap gerombol sampel atau gerombol terpilih dalam pemilihan tahap pertama;
4. Memilih sampel acak sederhana berupa sebagian elemen-elemen dari setiap gerombol terpilih. Pemilihan ini disebut pemilihan tahap kedua yang akan menghasilkan sampel tahap dua, atau disebut juga sebagai two-stage cluster sampling.
Penduga takbias bagi parameter rata-rata populasi, μ :
⎪ ⎪ ⎭ ⎪⎪ ⎬ ⎫ ⎪ ⎪ ⎩ ⎪⎪ ⎨ ⎧ ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ =
∑
= n y M M N y n i i i 1 Persamaan (2.30)Ragam dugaan dari y :
( )
⎪⎭ ⎪ ⎬ ⎫ ⎪⎩ ⎪ ⎨ ⎧ ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ + ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − =∑
− n i i i i i i i b m s M m M M M nN s M n N n N y V 1 2 2 2 2 2 1 1 ˆ dimana :(
)
1 1 2 2 − − =∑
= n y M y M s n i i ib , merupakan ragam dari sampel tahap1
(
)
1 2 2 − − =∑
i m i ij i m y y s i, merupakan ragam dari sampel tahap 2.
Persamaan (2.31) Akar pangkat dua dari ragam dugaan nilai rata-rata merupakan galat baku dugaan dari nilai rata-rata yang dinotasikan dengan s(y). Dengan menggunakan taraf kepercayaan (1-α)100%, batas galat pendugaan nilai rata-rata, BG(y), ditentukan sebagai:
BG(y) =
2
α
Z s(y) Persamaan (2.32) Galat pendugaan nilai rata-rata:
( )
( )
{
G y <BG y}
=1−αP Persamaan (2.33)
Selang kepercayaan (1-α)100% bagi nilai rata-rata populasi μ:
( )
( )
{
y−BG y <μ <y+BG y}
=1−αP Persamaan (2.34)
Pendugaan nilai total populasi, τˆ :
n y M N y M n i i i
∑
= = = 1 ˆ τ Persamaan (2.35)Ragam dugaan dari τˆ :
( )
V( )
My M V( )
y Vˆτˆ = ˆ = 2 ˆ ⎭ ⎬ ⎫ ⎩ ⎨ ⎧ ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − + ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − =∑
= n i i i i i i i b m s M m M M n N s n N N n N 1 2 2 2 2 Persamaan (2.36)Akar pangkat dua dari ragam dugaan nilai total merupakan galat baku dugaan dari nilai total yang dinotasikan dengan s(τˆ). Dengan menggunakan taraf kepercayaan (1-α)100%, batas galat pendugaan nilai rata-rata, BG(τˆ), ditentukan sebagai:
BG(τˆ) =
2
α
Z s(τˆ) Persamaan (2.37) Galat pendugaan nilai total, G(τˆ), :
( )
( )
{
Gτˆ <BGτˆ}
=1−αP Persamaan (2.38)
Selang kepercayaan (1-α)100% bagi nilai total populasi, τˆ:
( )
( )
{
τˆ−BGτˆ <μ <τˆ+BGτˆ}
=1−αKeterangan:
N = banyaknya cluster dalam populasi (i=1,2,…,N) n = banyaknya cluster terpilih
Mi = banyaknya unit dalam cluster ke-i populasi mi = banyaknya unit terpilih dalam cluster ke-i
M =
∑
= N i i M 1= banyaknya elemen dalam populasi
m =
∑
= n i i m n 1 1=rata-rata ukuran cluster untuk sampel
M =
N M
= rata-rata ukuran cluster dalam populasi
ij
y = nilai pengamatan ke-j dalam sampel dari cluster ke-i
i y =
∑
= i m j ij i y m 1 1= nilai rata-rata sampel untuk cluster ke –i Penduga ratio bagi nilai rata-rata populasi.
Digunakan jika tidak diketahui banyaknya elemen yang ada dalam populasi tersebut (M).
Penduga nilai rasio bagi nilai rata-rata populasi, μ :
∑
∑
= = = n i i n i i i r M y M y 1 1 Persamaan (2.40)Ragam dugaan dari yr :
( )
⎪⎭ ⎪ ⎬ ⎫ ⎪⎩ ⎪ ⎨ ⎧ ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − + ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − =∑
= i i i i i n i i r r m s M m M M M nN s M n N n N y V 2 1 2 2 2 2 1 1 ˆdimana :
(
)
1 1 2 2 2 − − =∑
= n y i y M s n i r i r(
)
n i m i y y s i m j ij i i ,.., 1 ; 1 1 2 2 = − − =∑
=Apabila M tidak diketahui, maka M diduga oleh:
n M M n i i
∑
= = 1 ˆ Persamaan (2.41)Akar pangkat dua dari ragam dugaan nilai rata-rata merupakan galat baku dugaan dari nilai rata-rata yang dinotasikan dengan s(yr). Dengan menggunakan taraf kepercayaan (1-α)100%, batas galat pendugaan nilai rata-rata, BG(yr), ditentukan sebagai:
BG(yr) =
2
α
Z s(yr) Persamaan (2.42) Galat pendugaan nilai rata-rata:
( )
( )
{
G yr <BG yr}
=1−αP Persamaan (2.43)
Selang kepercayaan (1-α)100% bagi nilai rata-rata populasi μ:
( )
( )
{
yr −BG yr <μ < yr +BG yr}
=1−αP Persamaan (2.44)
Pendugaan nilai proporsi populasi.
Pendugaan ini dilakukan jika observasi berupa persentase dari jumlah obyek yang diamati. Penduga bagi nilai proporsi populasi, p :
i i i m a p = dan
∑
∑
= = = n i i n i i i r M p M p 1 1 Persamaan (2.45)Ragam dugaan dari pr:
( )
(
)
⎪⎭ ⎪ ⎬ ⎫ ⎪⎩ ⎪ ⎨ ⎧ − − ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − + ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − =∑
= 1 1 1 1 ˆ 1 2 2 2 2 i i i i i i n i i r r m p p M m M M M nN s M n N n N p V dimana :(
)
1 1 2 2 2 − − =∑
= n p p M s n i r i ir , merupakan ragam dari sampel tahap 1
n M M n i i
∑
= = 1, merupakan ragam dari sampel tahap 2
Persamaan (2.46) Akar pangkat dua dari ragam dugaan nilai proporsi merupakan galat baku dugaan dari nilai proporsi yang dinotasikan dengan s(pr). Dengan menggunakan taraf kepercayaan (1-α)100%, batas galat pendugaan nilai proporsi, BG(pr), ditentukan sebagai:
BG(pr) =
2
α
Z s(pr) Persamaan (2.47) Galat pendugaan nilai proporsi:
( )
( )
{
G pr <BG pr}
=1−αP Persamaan (2.48)
Selang kepercayaan (1-α)100% bagi nilai proporsi populasi, p:
( )
( )
{
pr −BG pr <μ< pr +BG pr}
=1−αP Persamaan (2.49)
Keterangan:
Mi = banyaknya unit dalam cluster ke-i populasi mi = banyaknya unit terpilih dalam cluster ke-i
ai = banyaknya elemen dalam sampel yang ditarik dari cluster ke-i yang memiliki karakteristik tertentu yang diobservasi
pi = proporsi dari elemen-elemen dalam sampel yang ditarik dari cluster ke-i yang memiliki karakteristik tertentu yang diobservasi
2.1.10 Metode SRS ( Simple Random Sampling)
Metode SRS adalah salah satu metode penarikan sampel yang digunakan untuk memilih sampel dari populasi dengan cara sedemikian rupa sehingga setiap anggota populasi mempunyai peluang yang sama besar untuk diambil sebagai sampel. Semua anggota populasi menjadi anggota dari kerangka sampel.
Metode penarikan sampel acak sederhana dapat dilakukan dengan beberapa cara, antara lain: sistem kocok dan menggunakan tabel acak. Setelah mendapatkan nomor acak untuk sampel, maka dapat dicocokkan pada daftar anggota populasi, sehingga sampel dapat dialokasikan.
Dalam SRS, ada dua jenis populasi yang terlibat, yaitu: populasi terbatas (finite population) dan populasi tidak terbatas (infinite population). Populasi terbatas artinya jumlah anggota populasi dapat diketahui dengan pasti. Sedangkan papa populasi tidak terbatas, anggota-anggota populasi secara teoritis tidak mungkin diketahui semuanya.
Untuk penarikan sampel bisa dilakukan dengan pengambilan (with replacement) atau tanpa pengembalian (without replacement). Penarikan sampel dengan pengembalian, umum dipakai pada populasi acak terbatas, artinya setiap individu yang telah terambil dikembalikan ke dalam kerangka sampel lagi sehingga memiliki peluang lagi untuk terambil kembali sebagai sampel. Penarikan sampel tanpa pengembalian, umum dipakai pada populasi acak tak terbatas, dalam hal ini
penarikan sampel dilakukan dengan tidak mengembalikan kembali individu yang telah terambil sebagai sampel ke dalam kerangka sampel.
2.1.10.1 Prosedur Penarikan Sampel Acak Sederhana
Ada dua buah syarat yang perlu dipenuhi untuk menggunakan teknik penarikan sampel acak sederhana, yaitu:
1. Unit-unit dalam populasi harus diketahui dahulu dengan jelas. Serta dapat diidentifikasikan dengan tepat sehingga kerangka penarikan sampel (sampling frame) dapat dibentuk.
2. Keragaman sifat populasi yang akan dipelajari harus dapat bersifat relatif homogen, dalam pengertian bahwa populasi itu mempunyai ragam yang kecil atas sifat yang akan dipelajari itu. Unit-unit dalam populasi itu harus mempunyai sifat yang relatif homogen.
2.1.11 Diagram Alir (Flowchart)
Diagram alir merupakan alat bantu pemrograman yang biasanya digunakan. Diagram alir (flowchart) membantu programmer dalam mengorganisasikan pemikiran mereka dalam pemrograman, terutama bila dibutuhkan penalaran yang tajam dalam logika prosedur suatu program.
2.1.12 Diagram Transisi ( State Trasition Diagram)
Menurut Hoffer (1996, p364) STD adalah sebuah diagram yang menggambarkan bagaimana proses saling berhubungan dalam suatu waktu. STD menggambarkan state yang dimiliki sistem komputer dan kejadian yang menyebabkan perubahan state ke state lainnya. State Transition Diagram merupakan
sebuah modeling tool yang digunakan untuk mendeskripsikan sistem yang memiliki ketergantungan terhadap waktu.
Komponen-komponen utama STD adalah: 1. State, disimbolkan dengan
State merepresentasikan reaksi yang ditampilkan ketika suatu tindakan dilakukan. Ada dua jenis state yaitu: state awal dan state akhir. State akhir dapat berupa beberapa state, sedangkan state awal tidak boleh lebih dari satu.
2. Arrow, disimbolkan dengan
Arrow sering disebut juga dengan transisi state yang diberi label dengan ekspresi aturan, label tersebut menunjukkan kejadian yang menyebabkan transisi terjadi. 3. Condition dan Action, disimbolkan dengan
State 1 State 2
Condition Action
Gambar 2.11 Hubungan State, Conditon dan Action
Untuk melengkapi STD diperlukan 2 hal lagi yaitu condition dan action. Condition adalah suatu event pada lingkungan eksternal yang dapat dideteksi oleh sistem, sedangkan action adalah yang dilakukan oleh sistem bila terjadi perubahan state atau merupakan reaksi terhadap kondisi. Aksi akan menghasilkan keluaran atau tampilan.
Ada dua pendekatan untuk membuat STD yaitu :
1. Identifikasi setiap kemungkinan state dari sistem dan gambarkan masing-masing state pada sebuah kotak. Lalu buatlah hubungan antara state tersebut.
2.2 Penelitian yang Relevan
Skirpsi S1: Analisis dan Perancangan Program Aplikasi Penentuan Besar dan Penarikan Sampel Acak dengan Menggunakan Metode Simple dan Systematic Random Sampling. Univetsitas Bina Nusantara, Jakarta.
Oleh: David Sutanto, 2004.
Aplikasi Statistika Modern : “Quick Count”
Laporan teknis berkala, ISSN 0853-6730, volume 13 no. 1 Maret 2005, MIPA Universitas Bina Nusantara, Jakarta.
Oleh Bagus Sumargo.
Efektivitas Imunisasi Campak di Kabupaten Kuningan, Jawa Barat Buletin Penelitian Kesehatan Volume XX no. 4, 1992
Oleh Djoko Yuwono dan Imran Lubis.
http://www.litbang.depkes.go.id/Publikasi_BPPK/Buletin_BPPK/BUL92C.HTM
Hubungan Pola Asuh Orang Tua Dengan Agresivitas Remaja Oleh: Tarsis Tarmudji
http://www.depdiknas.go.id/Jurnal/37/hubungan_pola_asuh_orang_tua.htm
Dietary Fiber Intake of Adolescents in Jakarta Department of Nutrition Faculty of Medicine University of Indonesia.
Oleh: Walujo Soerjodibroto.
http://www.e-jima.com/pdf/ori03_v05_n03.pdf#search='penelitian%20cluster %20sampling'