Fakultas Ilmu Komputer
Universitas Brawijaya
3948
Klasifikasi
Spam
Pada Twitter Menggunakan Metode
Improved K-Nearest
Neighbor
Dea Zakia Nathania1, Indriati2, Fitra Abdurrachma Bachtiar3
Program Studi Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Twitter merupakan salah satu layanan aplikasi yang populer karena dapat digunakan untuk berinteraksi dan berkomunikasi dalam kehidupan sehari-hari. Untuk dapat menyebarkan informasi secara cepat maka banyak bermunculan berbagai macam perangkat lunak otomasi. Karena Twitter tidak memeriksa secara ketat mengenai otomasi pada tweet, maka tidak ada pencegahan pemakaian
bot secara teratur. Keterbukaan penggunaan layanan otomasi atau automation tweet pada Twitter inilah yang menyebabkan munculnya pasar Spam-as-a-Service yang terdiri dari program pemalsuan, layanan pemendek berbasis iklan dan penjualan akun. Masing-masing layanan ini memungkinkan
spammer untuk melakukan proses penyebaran spam dengan menggunakan layanan automation tweet. Sehingga dibutuhkan suatu penelitian untuk melakukan klasifikasi pada tweet untuk mengetahui jenis kategorinya termasuk ke dalam kategori spam atau bukan spam. Proses klasifikasi spam diawali dengan preprocessing yang terdiri dari beberapa tahapan yaitu cleansing, case folding, tokenisasi,
filtering dan stemming. Dilanjutkan dengan proses term weghting, hingga proses klasifikasi dengan menggunakan metode Improved K-Nearest Neighbor. Hasil yang diperoleh berdasarkan implementasi dan pengujian penelitian Klasifikasi Spam pada Twitter ini menghasilkan rata-rata Precision sebesar 0.8946, Recall sebesar 0.9405, F-Measure sebesar 0.9155 dan hasil akurasi sebesar 89.57%. Dimana jumlah dokumen, perbandingan atau keseimbangan proporsi data latih dan penentuan nilai k-values
yang digunakan berpengaruh terhadap baik atau tidaknya proses klasifikasi terhadap dokumen.
Kata Kunci: Text Mining, Klasifikasi, Spam, Twitter, Improved K-Nearest Neighbor
Abstract
Twitter is a service application that is popular because it can be used to interact and communicate in everyday life. A lot of various new types of automation software increases to disseminate information immediately. Twitter does not strictly check the automation tweet, therefore there is no prevention of the use of bot on a regular basis. Low restriction of the use of automation services on Twitter led to the emergence of market Spam-as-a-Service consisting of counterfeiting program, abridgement ad-based on service and sales account. Each of these services allows spammers to do the spam deployment process by using automation tweet services. So it is necessary to do a research on the classification of the tweet to know the type of category is included in the category of spam or not spam. Spam classification process begins with the preprocessing consists of several stages, namely; cleansing, case folding, tokenization, filtering and stemming. The next step are process of term weighting, until the process of classification using Improved K-Nearest Neighbor method. The results obtained on the basis of implementation and testing research of the classification of Spam on Twitter produces an average Precision of 0.8946, Recall of 0.9405, F-Measure of 0.9155 and results accuracy of 89.57%. Where is the number of documents, a comparison or balance the proportion of training data and the determination of k-values that are used too well or whether the process of classification of the document.
Keywords: Text Mining, Clasification, Spam, Twitter, Improved K-Nearest Neighbor
1. PENDAHULUAN
Internet merupakan salah satu teknologi
yang berkembang pesat hingga saat ini dimana
digunakan untuk mendapatkan dan
menyebarkan informasi (Bintang, 2013).
layanan aplikasi yang populer karena dapat
digunakan untuk berinteraksi dan
berkomunikasi dalam kehidupan sehari-hari. Di antara OSN yang ada, Twitter merupakan salah satu yang populer pada kategori ini (Teljstedt, 2016).
Twitter menawarkan suatu konsep mikroblog yang memungkinkan penggunanya
untuk dapat berinteraksi dengan
mempublikasikan pesan atau tulisan berbasis teks pendek hingga 140 karakter yang sering dikenal dengan sebutan tweet (Teljstedt, 2016). Sejak awal bulan November 2017, Twitter menambah batas karakter pesan atau tulisannya menjadi 280 karakter (Rosen, 2017). Dengan berubahnya pertanyaan pada bagian tweet input box dari “Apa yang Anda Lakukan?” menjadi
“Apa yang Terjadi?” telah menunjukkan bahwa
Twitter ingin menghapus konsep mengenai hanya melakukan pembaruan status pribadi saja yang dapat dilakukan (Stone, 2009). Dengan jutaan pengguna yang saling berhubungan, kini Twitter telah menjadi sarana yang ideal untuk menyuarakan opini hingga menyebarkan berita langsung (Xiong dan Liu, 2014). Sehingga untuk menjangkau khalayak yang besar memungkinkan adanya perangkat lunak yang dirancang untuk melakukan posting tweet
secara otomatis yang juga dikenal dengan bot
(Teljstedt, 2016).
Karena Twitter tidak memeriksa secara ketat mengenai otomasi pada tweet, maka tidak ada pencegahan pemakaian bot secara teratur. Sehingga Kini muncul Cyborg yang merujuk pada Bot-Assisted Human atau bot yang dibantu oleh manusia. Cara kerja Cyborg diawali dengan mendaftarkan akun, dilanjutkan dengan mengatur program otomatis untuk dapat melakukan posting tanpa perlu melakukan daring pada satu waktu tertentu (Chu et al., 2012). Istilah lain dari bot pada Twitter adalah layanan otomasi atau automation tweet dimana merupakan suatu proses dari akun yang secara
otomatis memposting tweet dengan
menggunakan aplikasi otomasi tertentu untuk menyebarkan konten (Chu et al., 2012). Keterbukaan penggunaan layanan otomasi pada Twitter inilah yang menyebabkan munculnya pasar Spam-as-a-Service yang terdiri dari program pemalsuan, layanan pemendek berbasis iklan dan penjualan akun. Masing-masing layanan ini memungkinkan spammer
untuk melakukan proses penyebaran spam
dengan menggunakan layanan automation tweet
(Thomas et al., 2011).
Prayoga (2017) telah melakukan penelitian untuk mendeteksi spam pada Twitter dengan menggunakan metode Naïve Bayes dan KNN. Berdasarkan hasil pengujian akurasi yang dilakukan, metode Naïve Bayes memiliki persentase akurasi yang lebih tinggi sebesar 82% dibandingkan dengan metode KNN yang mendapatkan hasil akurasi sebesar 71%.
Berkembangnya kemunculan spam pada Twitter menjadi salah satu permasalahan yang muncul. Sehingga dibutuhkan suatu penelitian untuk melakukan klasifikasi pada tweet untuk mengetahui jenis kategorinya. Salah satu metode yang dapat digunakan untuk melakukan klasifikasi adalah Improved K-Nearest Neighbor. Metode ini melakukan modifikasi di dalam penentuan nilai k-values. Pemilihan
metode Improved K-Nearest Neighbor
didasarkan pada penelitian milik Sianturi, Marji dan Sutrisno (2014) yang membandingkan kinerja dari metode Naïve Bayes dan Improved K-NN dalam implementasi sistem klasifikasi
spam email. Dimana dari hasil F-Measure
dalam penelitian tersebut menyatakan bahwa metode Improved K-Nearest Neighbor lebih baik dalam proses pengklasifikasian pada spam email dibandingkan dengan Naïve Bayes.
Berdasarkan paparan permasalahan diatas, penulis mengusulkan untuk melakukan klasifikasi terhadap tweet sebagai dokumen ke dalam dua jenis kategori spam atau bukan spam
menggunakan metode Improved K-Nearest Neighbor yang diharapkan dapat memberikan hasil yang lebih baik dibandingkan dengan penelitian sebelumnya yang dilakukan oleh Prayoga (2017).
2. LANDASAN KEPUSTAKAAN
2.1 Text Mining
Text Mining merupakan proses pencarian atau penggalian informasi yang berguna dari sumber data tekstual dimana mencoba untuk menemukan pola yang menarik dari database
yang cukup besar (Nayak et al., 2016).
2.2 Preprocessing
1. Cleansing
Tahapan cleansing dilakukan untuk mengurangi noise yang dimulai dengan melakukan proses penghilangan atau penghapusan karakter HTML, URL, email,
hashtag (#hashtag), ikon emosi dan username
(@username) (Nur dan Santika, 2011). 2. Case Folding
Case folding merupakan tahapan untuk mengubah masukan yang berupa huruf menjadi huruf kecil (lower case).
3. Tokenisasi
Tokenisasi merupakan proses membuat daftar token/term/kata yang digunakan sebagai masukan untuk proses metode berikutnya (Nayak et al., 2016). Sederhananya adalah memisahkan setiap kata yang dipisahkan oleh
whitespace di dalam suatu dokumen. 4. Filtering
Filtering atau stopword removal merupakan tahapan yang digunakan untuk menghapus kata yang termasuk dalam stoplist yang jika
dihilangkan masih memiliki makna
(Wahyuningtyas, 2016).
5. Stemming
Stemming merupakan proses pengubahan
bentuk kata menjadi kata dasar atau tahap mencari root kata pada setiap kata. Dengan dilakukannya proses ini maka setiap kata yang berimbuhan akan berubah menjadi kata dasar sehingga dapat mengoptimalkan proses (Herdiawan, 2015).
2.3 Term Weighting
1.
Term
Frequency
(TF)
dan
Term
Weighting
(Wtf)
TFt,d merupakan banyaknya kemunculan terms/token/kata t dalam dokumen d. TF dapat juga disebut dengan istilah frekuensi dalam dalam satu dokumen (Xia dan Chai, 2011). Sedangkan Wtf merupakan proses perhitungan atau pembobotan pada setiap terms/token/kata t. Berikut merupakan persamaan perhitungan pembobotan dari TF: Document Frequency (IDFt)
DFt merupakan banyaknya dokumen yang mengandung terms/token/kata t. Sedangkan IDFtmerupakan hasil invers dari DFt. Berikut
merupakan persamaan untuk menghitung IDFt
yang diusulkan oleh Jones (1972):
𝑖𝑑𝑓𝑡= log10𝑁/𝑑𝑓𝑡 (2)
Pembobotan TF.IDF dari suatu
terms/token/kata t merupakan hasil perkalian dari TF Weight dengan IDFt (Manning, Raghavan dan Schutze, 2009).
𝑤𝑡,𝑑= 𝑤𝑡𝑓𝑡,𝑑∗ 𝑖𝑑𝑓𝑡
Dilanjutkan dengan perhitungan normalisasi terhadap nilai Wt,d.
𝑤𝑡,𝑑= 𝑤𝑡,𝑑 √∑𝑛𝑡=1𝑤𝑡,𝑑2
(4)
2.4 K-Nearest Neighbor
K-Nearest Neighbor merupakan metode
pembelajaran berbasis instance (contoh) dimana menghitung kesamaan antara data uji dengan data latih yang mempertimbangkan nilai kesamaan tertinggi sejumlah k (Zheng et al., 2015).
2.5 Cosine Similarity
Cosine similarity merupakan fungsi yang digunakan untuk menghitung besarnya derajat kemiripan di antara dua vektor (dokumen dan
query) (Herdiawan, 2015).
Berikut merupakan persamaan untuk menghitung nilai similarity diantara dua vektor:
Dengan Normalisasi, yang diawali dengan perhitungan menggunakan persamaan persamaan (4).
2.6 Improved K-Nearest Neighbor
Metode Improved K-Nearest Neighbor
merupakan metode dimana melakukan
modifikasi di dalam penentuan nilai k-values. Penetapan awal nilai k-values tetap dilakukan, hanya saja dilakukan pada tiap-tiap kategori yang memiliki nilai k-values yang berbeda. Perbedaan nilai k-values yang dimiliki disesuaikan dengan tingkat besar kecilnya jumlah dokumen/data latih pada tiap-tiap kategori yang ada (Herdiawan, 2015).
Setelah melakukan perhitungan Cosine
similarity maka akan dilanjutkan dengan
melakukan pengurutan hasil perhitungan
Cosine similarity secara menurun pada setiap kategori. Dilanjutkan dengan perhitungan nilai
k-values yang baru (n) (Herdiawan, 2015).
𝑛 = ( k∗N(c𝑚) jumlah dokumen/data latih terbanyak pada semua kategori yang ada
Sejumlah n dokumen yang terpilih pada masing-masing kategori merupakan top n
dokumen atau dokumen teratas yang memiliki nilai kesamaan paling besar pada masing-masing kategori (Putri, 2013).
Dalam menentukan hasil kategori, dilakukan perbandingan similaritas pada masing-masing kategori. Persamaan (8) menyatakan nilai maksimum dari perbandingan antara kemiripan dokumen X dengan dokumen latih dj sejumlah top n tetangga pada suatu kategori dengan dokumen X terhadap dokumen
latih dj sejumlah top n tetangga pada training set (Baoli, Shiwen dan Qin, 2003).
𝑝(𝑥, 𝑐𝑚) = 𝑎𝑟𝑔𝑚𝑎𝑥𝑚 Σdj∈𝑡𝑜𝑝 𝑛 𝑘𝑁𝑁(cΣd m)𝑠𝑖𝑚(𝑥,𝑑𝑗)𝑦(𝑑𝑗.𝑐𝑚)
j∈𝑡𝑜𝑝 𝑛 𝑘𝑁𝑁(cm)𝑠𝑖𝑚(𝑥,𝑑𝑗)
(8) Dimana:
- p(x,cm) : probabilitas dokumen x
menjadi anggota kategori cm
- 𝑠𝑖𝑚(𝑥, 𝑑𝑗) : kemiripan antara dokumen x
dengan dokumen latih dj
- top n kNN : top n tetangga
Berdasarkan perhitungan menggunakan persamaan (8), maka selanjutnya akan dibandingkan hasil probabilitas untuk masing-masing kategori. Hasil kategori akan mengacu kepada hasil probabilitas terbesar (Putri, 2013).
2.7 Precision, Recall, F-Measure dan
Akurasi
Confusion matrix merupakan jenis
perhitungan akurasi yang sering digunakan untuk menghitung hasil akurasi dalam suatu penelitian. Evaluasi dengan menggunakan tabel
confusion matrix ini dilakukan dengan cara membandingkan kategori hasil aktual dengan kategori hasil prediksi (Manning, Raghavan dan Schutze, 2009):
Tabel 1 Confusion Matrix
Hasil Aktual Hasil Prediksi
Spam Bukan Spam Spam TP FN
Bukan Spam FP TN
Precision merupakan proporsi dari suatu set yang diperoleh yang relevan (Putri, 2013).
𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 =TP+FPTP (9)
Recall merupakan proporsi dari semua dokumen yang relevan dikoleksi termasuk dokumen yang diperoleh (Putri, 2013).
𝑅𝑒𝑐𝑎𝑙𝑙 =TP+FNTP (10)
F-Measure lebih menekankan terhadap
kinerja dari precision dan recall (Herdiawan, 2015).
Dan untuk mendapatkan nilai akurasi dari penelitian yang dilakukan, berikut merupakan persamaan yang digunakan untuk mendapatkan nilai akurasi:
𝐴𝑘𝑢𝑟𝑎𝑠𝑖 =TP+FN+FP+TNTP+TN ∗ 100% (12)
3. METODOLOGI
Dalam melakukan penelitian ini melalui beberapa tahapan yang dilakukan. Dimulai dengan pencarian literatur yang sesuai, pengumpulan data, analisis kebutuhan, perancangan, implementasi, pengujian dan analisis. Dan tahapan yang terakhir adalah penarikan kesimpulan berdasarkan hasil pengujian dan analisis yang telah dilakukan.
Diagram alir untuk melakukan klasifikasi
spam pada Twitter menggunakan metode
Improved K-Nearet Neighbor ditunjukkan pada Gambar 1.
Gambar 1 Diagram Alir Klasifikasi Spam pada Twitter Menggunakan Improved K-Nearest Neighbor
1. Input Dokumen
Input dokumen berupa tweet dimana digunakan sebagai data yang akan diuji untuk menentukan hasil kategori berupa spam atau bukan spam.
2. Preprocessing
Preprocessing terhadap dokumen berupa
teks digunakan untuk mendapatkan data dalam bentuk yang terstruktur sehingga dapat memudahkan proses perhitungan yang dilakukan selanjutnya. Textpreprocessing yang dilakukan disesuaikan dengan tahapan-tahapan yang terdiri dari cleansing, case folding,
tokenisasi, filtering dan stemming. 3. Perhitungan TF-IDF
Perhitungan pembobotan (term weighting) dilakukan dengan menggunakan TF-IDF dimana IDF dapat mengindikasikan seberapa unik atau berbedanya kemunculan kata pada kumpulan dokumen yang ada. Persamaan yang digunakan telah dijelaskan pada persamaan (1) hingga (4) yang digunakan untuk mencapai nilai Wt,d yang telah dinormalisasikan.
4. Perhitungan Cosine Similarity
Setelah mendapatkan hasil normalisasi dari perhitungan TF-IDF Weighting (Wt,d), maka proses klasifikasi akan lebih mudah dilakukan. Sebelum menentukan nilai k-values yang digunakan dalam proses klasifikasi, maka dilakukan perhitungan nilai cosine similarity
terlebih dahulu. Persamaan yang digunakan dalam menghitung nilai cosine similarity telah dijelaskan pada persamaan (6) yang mana persamaan tersebut dapat dihitung jika nilai Wt,d sudah dinormalisasikan. Nilai cosine similarity
yang dihitung adalah data latih terhadap data uji yang ingin diketahui hasil kategorisasinya. 5. Proses Klasifikasi Improved K-Nearest
Neighbor
Dilanjutkan dengan proses perhitungan k-values baru (n) yang dijelaskan pada persamaan (7) mengenai proporsi untuk menetapkan nilai n
pada masing-masing kategori. Setelah didapatkan nilai n (k-values baru) pada masing-masing kategori. Maka proses selanjutnya adalah menghitung nilai dari probabilitas dokumen uji pada masing-masing kategori dengan menggunakan persamaan (8).
6. Hasil Klasifikasi
Setelah seluruh tahapan proses dilalui, maka akan menghasilkan kategori terhadap dokumen uji (tweet) berdasarkan nilai terbesar dari hasil perhitungan probabilitas yang dihasilkan.
4. IMPLEMENTASI
Antarmuka pada aplikasi Klasifikasi Spam
1. Tampilan Halaman Awal
Gambar 2 Tampilan Halaman Awal
2. Tampilan Halaman Data Latih
Gambar 3 Tampilan Halaman Data Latih
3. Tampilan Halaman Pengujian
Gambar 4 Tampilan Halaman Pengujian
5. PENGUJIAN DAN ANALISIS
5.1 Precision, Recall, F-Measure dan
Akurasi
Untuk mengetahui pengaruh dari jumlah data latih dan nilai k-values terhadap efektifitas sistem klasifikasi, maka akan dilakukan proses pengujian dengan beberapa skenario yang dibentuk. Masing-masing dari skenario pengujian memiliki jumlah data latih dan nilai
k-values awal yang berbeda-beda dimana
seluruh skenario yang ada menggunakan jumlah data uji yang sama yaitu sebanyak 100 dokumen secara keseluruhan. Tabel 2 merupakan skenario yang dibangun untuk proses pengujian.
Tabel 2 Skenario Pengujian
1. Hasil Pengujian Skenario 1
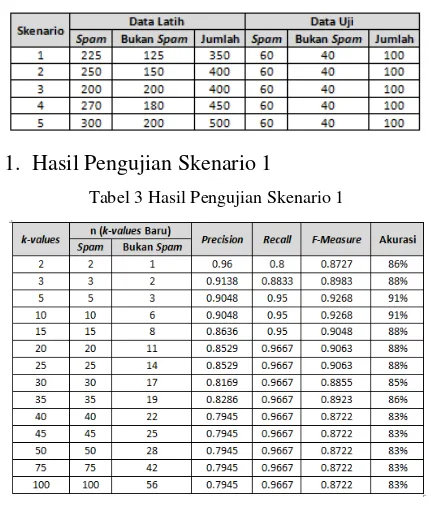
Tabel 3 Hasil Pengujian Skenario 1
Pada Tabel 3 ditunjukkan hasil pengujian skenario 1, dimana nilai F-Measure tertinggi berada pada nilai k-values awal=5 dan 10 sebesar 0.9268 dan terendah pada nilai k-values
awal=40, 45, 50, 75 dan 100 sebesar 0.8722. Nilai F-Measure pada nilai k-values awal =40, 45, 50, 75 dan 100 menjadi bernilai rendah karena semakin banyak dokumen dari data latih yang dibandingkan terhadap data uji, sehingga probabilitas untuk masing-masing kategori memiliki selisih yang sangat kecil dan dapat menghasilkan kategori prediksi yang tidak sesuai dengan kategori aktual.
2. Hasil Pengujian Skenario 2
Tabel 4 Hasil Pengujian Skenario 2
Pada Tabel 4 ditunjukkan hasil pengujian skenario 2, dimana nilai F-Measure tertinggi berada pada nilai k-values awal=10 sebesar 0.9355 dan terendah pada nilai k-values
menjadi bernilai rendah karena semakin banyak dokumen dari data latih yang dibandingkan terhadap data uji, sehingga probabilitas untuk masing-masing kategori memiliki selisih yang sangat kecil dan dapat menghasilkan kategori prediksi yang tidak sesuai dengan kategori aktual.
3. Hasil Pengujian Skenario 3
Tabel 5 Hasil Pengujian Skenario 3
Pada Tabel 5 ditunjukkan hasil pengujian skenario 3. Karena data latih yang digunakan untuk masing-masing kategori memiliki jumlah yang sama, maka n (k-values baru) yang dihasilkan akan sama dengan k-values awalnya. Nilai F-Measure tertinggi berada pada nilai k-values awal=10, 15, dan 20 sebesar 0.9322 dan terendah pada nilai k-values awal=2 sebesar 0.8929. Dengan nilai k-values awal sebesar 2 mengakibatkan nilai F-Measure menjadi bernilai rendah karena hanya membandingkan dokumen uji dengan dua dokumen latih.
4. Hasil Pengujian Skenario 4
Tabel 6 Hasil Pengujian Skenario 4
Pada Tabel 6 ditujukkan hasil pengujian skenario 4, dimana nilai F-Measure tertinggi berada pada nilai k-values awal=5 sebesar 0.9431 dan terendah pada nilai k-values awal=2 sebesar 0.9027. Nilai n (k-values baru) pada kategori bukan spam bernilai 1, sehingga mengakibatkan nilai F-Measure menjadi bernilai rendah karena hanya membandingkan dokumen uji dengan satu dokumen latih.
5. Hasil Pengujian Skenario 5
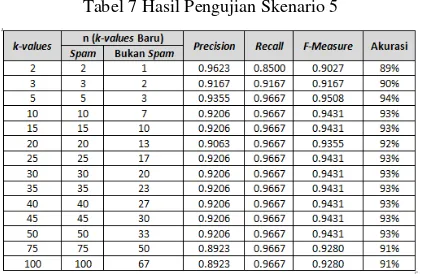
Tabel 7 Hasil Pengujian Skenario 5
Pada Tabel 7 ditunjukkan hasil pengujian skenario 5, dimana nilai F-Measure tertinggi berada pada nilai k-values awal=5 sebesar 0.9508 dan terendah pada nilai k-values awal=2 sebesar 0.9027. Nilai n (k-values baru) pada kategori bukan spam bernilai 1, mengakibatkan nilai F-Measure menjadi bernilai rendah karena hanya membandingkan dokumen uji dengan satu dokumen latih.
6. Rata-rata Precision, Recall dan F-Measure
Tabel 8 merupakan rata-rata dari hasil perhitungan Precision, Recall dan F-Measure
untuk masing-masing skenario yang dilakukan:
Tabel 8 Rata-rata Precision, Recall dan F-Measure
Skenario Precision Recall F-Measure
1 0.8479 0.9452 0.8915
2 0.8737 0.9408 0.9049
3 0.9387 0.9071 0.9224
4 0.8935 0.9548 0.9223
5 0.9193 0.9548 0.9362
Dari Tabel 8 diatas didapatkan bahwa rata-rata F-Measure terbaik berada pada skenario 5 dengan jumlah data latih sebanyak 500 dokumen dengan nilai 0.9362. Hal ini terjadi karena jumlah data latih yang digunakan lebih banyak dibandingkan dengan skenario 2, 3, 4 atau 5 sehingga nilai F-Measure yang dihasilkan menjadi yang terbaik. Gambar 5 merupakan bentuk grafik dari Tabel 8.
5.2 Analisis
Dari hasil evaluasi yang telah dilakukan, dapat diketahui bahwa terdapat beberapa faktor yang mempengaruhi ketepatan hasil klasifikasi yang dilakukan dengan menggunakan metode
Improved K-Nearest Neighbor. Dari proses
pengujian yang dilakukan dengan
menggunakan 100 data uji, diketahui bahwa semakin banyak jumlah data latih yang digunakan, maka semakin baik pula nilai F-Measure yang akan dihasilkan. Hal ini dapat dilihat dari peningkatan dari rata-rata nilai F-Measure pada skenario 1 hingga skenario 5.
Rata-rata F-Measure terendah berasal dari skenario 1, hal ini disebabkan karena data latih yang digunakan paling sedikit dan proporsi pada masing-masing kategori memiliki perbandingan yang paling besar dibandingkan dengan skenario yang lain, yaitu kategori spam
sebanyak 225 dokumen dan kategori bukan
spam sebanyak 125 dokumen. Proporsi jumlah data latih dengan perbandingan yang cukup besar akan mengakibatkan dokumen memiliki kecenderungan untuk masuk ke dalam kategori dengan jumlah data latih terbanyak.
Pada skenario 3 dan skenario 4 memiliki rata-rata F-Measure dengan selisih yang sangat sedikit. Skenario 3 memiliki jumlah data latih yang seimbang pada masing-masing kategori, sedangkan skenario 4 memiliki jumlah data latih yang lebih banyak dibandingkan dengan skenario 3 dengan perbandingan kategori spam
sebanyak 270 dokumen dan kategori bukan
spam sebanyak 180 dokumen. Dari dua hasil skenario inilah dapat ditarik kesimpulan bahwa dibutuhkan kecermatan di dalam pemilihan besarnya jumlah data latih yang akan digunakan, sehingga sistem yang dibangun dapat berjalan dengan baik, seimbang dan dapat menghasilkan kategori yang sesuai.
Nilai Precision, Recall dan F-Measure
terendah didapatkan jika nilai k-values yang digunakan terlalu sedikit (k-values awal=2) atau terlalu banyak yang ditunjukkan pada hasil
masing-masing skenario yang dapat
mengakibatkan terjadinya kesalahan pada hasil klasifikasi. Sehingga diperlukan pula kecermatan untuk memilih nilai k-values awal terbaik untuk menghasilkan kategori yang sesuai.
6. KESIMPULAN
Berikut merupakan kesimpulan yang didapatkan dari hasil penelitian Klasifikasi
Spam pada Twitter Menggunakan Metode
Improved K-Nearest Neighbor:
Metode Improved K-Nearest Neighbor
dapat diterapkan dalam proses klasifikasi spam
dengan input yang berupa tweet. Dokumen
tweet tersebut akan melalui beberapa tahapan mulai dari preprocessing, perhitungan term weighting hingga perhitungan cosine similarity
(derajat kemiripan) terhadap data latih yang digunakan. Dilanjutkan dengan mengurutkan tingkat kemiripan, penentuan k-values baru hingga menghasilkan kategori terhadap dokumen.
Proses pengujian penelitian Klasifikasi
Spam pada Twitter Menggunakan Metode
Improved K-Nearest Neighbor menghasilkan rata-rata Precision sebesar 0.8946, Recall
sebesar 0.9405, F-Measure sebesar 0.9155 dan hasil akurasi sebesar 89.57%. Dimana jumlah dokumen, perbandingan atau keseimbangan proporsi data latih dan penentuan nilai k-values
yang digunakan berpengaruh terhadap baik atau tidaknya proses klasifikasi terhadap dokumen berupa tweet.
Skenario untuk membandingkan hasil pengujian Improved K-Nearest Neighbor
dengan K-Nearest Neighbor menggunakan jumlah data latih sebanyak 500 dokumen. Berdasarkan hasil pengujian yang dilakukan dapat disimpulkan bahwa metode Improved K-Nearest Neighbor memberikan hasil yang lebih baik dengan hasil akurasi sebesar 92% dibandingkan dengan menggunakan metode K-Nearest Neighbor dengan hasil akurasi sebesar 88%.
7. DAFTAR PUSTAKA
Baoli, L., Shiwen, Y. dan Qin, L., 2003. An Improved k-Nearest Neighbor Algorithm for Text Categorization. Reading, p.678. Chu, Z., Gianvecchio, S., Wang, H. dan Jajodia,
S., 2012. Detecting Automation of Twitter Accounts: Are You a Human, Bot, or Cyborg? IEEE Transactions on Dependable and Secure Computing, 9(6), pp.811–824.
Herdiawan, 2015. Analisis Sentimen Terhadap TELKOM Indihome berdasarkan Opini Publik menggunakan Metode Improved K-Nearest Neighbor.
Manning, C.D., Raghavan, P. dan Schutze, H., 2009. An Introduction to Information Retrieval. [online] Cambridge, England: Cambridge University Press. Tersedia di: <http:// www.informationretrieval.org/>. Prayoga, F.A., Pinandito, A. and Perdana, R.S.,
2018. Rancang Bangun Aplikasi Deteksi Spam Twitter menggunakan Metode Naive Bayes dan KNN pada Perangkat
Bergerak Android. Jurnal
Pengembangan Teknologi Informasi dan Ilmu Komputer, 2(2), pp.554–564. Putri, P.A., 2013. Implementasi Metode
Improved K-Nearest Neighbor pada Analisis Sentimen Twitter Berbahasa Indonesia. S1. Universitas Brawijaya. Sianturi, M., Marji dan Sutrisno, 2014.
Perbandingan Kinerja Metode Naïve Bayesian dengan Metode Improved
K-NN dlam Implementasi Sistem
Pengklasifikasian Spam Email.
Stone, B., 2009. What’s Happening. [online] Tersedia di: <https://blog.twitter.com/offi cial/en_us/a/2009/whats-happening.html > [Diakses 26 Oktober 2017].
Teljstedt, E.C., 2016. Separating Tweets from Croaks (Detecting Automated Twitter Accounts with Supervised Learning and Synthetically Constructed Training Data ). [online] Tersedia di:<www.kth.se/csc>. Thomas, K., Grier, C., Paxson, V. dan Song, d., 2011. Suspended Accounts in Retrospect: An Analysis of Twitter Spam. pp.243– 258.
Wahyuningtyas, A., 2016. Deteksi Spam Pada Twitter menggunakan Algoritme Naïve Bayes. S1. Institut Pertanian Bogor. Xiong, F. dan Liu, Y., 2014. Opinion formation
on social media: an empirical approach.
Chaos, Tersedia di: <http://www.ncbi. nlm.nih.gov/pub med/24697392>.