Fakultas Ilmu Komputer
Universitas Brawijaya
3331
Klasifikasi Jenis Kelamin Pengguna Twitter dengan menggunakan Metode
BM25 dan K-Nearest Neighbor (KNN)
Annisa Selma Zakia1, Indriati2, Marji3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Twitter merupakan jejaring sosial microblogging dimana seseorang dapat menulis hingga 280 karakter dalam satu kali tweet. Indonesia menempati urutan ke-5 pengguna Twitter terbanyak di dunia. Melihat banyaknya pengguna Twitter di Indonesia tentu dapat dimanfaatkan oleh perusahaan dalam menciptakan strategi bisnis baru untuk melayani pelanggannya namun, sebagian pengguna akun sosial merasa keberatan jika harus mengungkapkan identitasnya. Perusahaan pun akan membutuhkan waktu lama jika ia harus bertanya satu demi persatu kepada pengguna Twitter mengenai identitas diri mereka. Masalah tersebut dapat diselesaikan dengan cara mengembangkan sistem untuk melakukan klasifikasi berdasarkan tweet dari pengguna, sistem tersebut dirancang menggunakan metode BM25 sebagai metode untuk menghitung kemiripan antar dokumen dan KNN sebagai metode untuk melakukan klasifikasi data. Pengujian sistem dilakukan dengan memasukkan 1000 dokumen, kemudian dokumen tersebut dilakukan uji K-Fold Cross Validation dengan menggunakan K = 10 sehingga didapatkan 900 dokumen latih dan 100 dokumen uji pada setiap partisi K. pengujian selanjutnya adalah pengujian nilai ketetanggaan, nilai ketetanggaan yang digunakan adalah 1, 3, 5, 7, 10, 20, 30, 40 dan 50, hasil pengujian menunjukkan bahwa nilai ketetanggaan yang optimal ialah k=3. Pada k=3 nilai akurasi, precision, recall dan F-Measure dari rerata 10-Fold Cross Validation adalah 68,6%, 67,63%, 71,52% dan 69,34%.
Kata kunci: BM25, klasifikasi, KNN, text mining, twitter.
Abstract
Twitter is a microblogging social network where one can write up to 280 characters in one tweet. Indonesia emerged as the fifth largest country in terms of Twitter users. Seeing how many Twitter users in Indonesia can certainly be used by companies in creating new business strategies to serve their customers, but some social account users objection if they have to reveal their identities. These problems can be solved by developing a system for classifying based on tweets from users, this system is certainly useful because it saves time. The system is designed using the BM25 method for calculating similarities between documents and KNN for classifying data. the system used 1000 documents, then the document is tested with K-Fold Cross Validation using K = 10 so that 900 training documents and 100 testing documents are obtained on each K. The next test is about neighbor values, neighbor values used are 1, 3, 5, 7, 10, 20, 30, 40 and 50, the test results show that the optimal neighbor value is k = 3. At k = 3 the value of accuracy, precision, recall and F-Measure of the average Cross Validation 10 fold are 68.6%, 67.63%, 71.52% and 69.34%.
Keywords: BM25, classification, KNN, text mining, twitter
1. PENDAHULUAN
Twitter adalah jejaring sosial microblogging dimana seseorang dapat menulis hingga 280 karakter dalam satu kali tweet. Fungsi lain dari Twitter adalah ia dapat digunakan untuk mencari tahu apa yang sedang populer saat ini baik kejadian dalam negeri
maupun mancanegara. Berdasarkan data PT Bakrie Telecom, Twitter memiliki 19,5 juta pengguna di Indonesia dari total 500 juta pengguna global (Kominfo, 2019).
Melihat banyaknya jumlah pengguna Twitter di Indonesia, tentu pengguna Twitter tidak hanya berasal dari satu golongan. Pengguna Twitter dapat dibagi menjadi beberapa
golongan salah satunya jenis kelamin. Profil pengguna sosial media dapat dimanfaatkan dalam beberapa bidang yaitu, security, analisis forensik dan domain komersial, tetapi sebagian pengguna tidak suka jika harus mengungkapkan identitasnya.
Faktor tersebut menjadikan alasan mengapa dibutuhkan sistem yang dapat melakukan klasifikasi jenis kelamin. Kemudian hasil dari klasifikasi tersebut dapat dimanfaatkan oleh perusahaan atau pelaku usaha dengan cara menciptakan strategi bisnis baru untuk melayani pelanggannya. (Reddy, Vardhan & Reddyc, 2017).
Salah satu metode klasifikasi yang umum digunakan adalah K-Nearest Neighbor (KNN). KNN bekerja berdasarkan jarak terdekat ketetanggaan antar objek. Secara umum semakin tinggi nilai k maka akan mengurangi pengaruh noise pada proses klasifikasi (Subramanian, 2019). Namun, metode klasifikasi ini memiliki kelemahan yaitu, dalam menentukan nilai k harus melakukan beberapa kali percobaan.
Sebelumnya telah terdapat penelitian terkait pada topik yang dibawakan. Pada penelitian Goenawan, dkk (2019). Penelitian ini terkait klasifikasi jenis kelamin dengan membandingkan metode AdaBoost, XGBoost,
Naïve Bayes dan SVM. Berdasarkan hasil
akurasi penelitian Naïve Bayes merupakan metode paling baik sebesar 78,61%.
Kemudian, penelitian oleh Huq, dkk (2019). Penelitian tesebut membandingkan metode KNN dan SVM dan menghasilkan nilai akurasi terbesar yaitu 84,32% dengan menggunakan metode KNN. Hasil tersebut lebih besar dibandingkan dengan penelitian Goenawan, dkk (2019) dengan menggunakan metode Naïve Bayes.
Metode pembobotan kata dalam text mining umumnya menggunakan TF-IDF, sedangkan dalam penelitian Wang, dkk (2017) yang membandingkan beberapa metode pembobotan kata yaitu, TF, TF-IDF, LogTF-IDF dan BM25 kemudian dilanjutkan oleh metode klasifikasi SVM. Pembobotan kata menggunakan BM25 menghasilkan nilai akurasi terbaik sebesar 77,1%. Kemudian terdapat penelitian Prana, dkk (2019), penelitian tersebut berupa klasifikasi dengan menggunakan BM25 dan KNN. Pada penelitian tersebut dihasilkan nilai akurasi tertinggi yaitu 86,6% dengan menggunakan nilai ketetanggaan sebesar 3. Mengacu pada penelitian Wang, dkk (2016) dimana menggunakan metode BM25 dan SVM yang
mana hasil akurasi tidak lebih besar dari penelitian Prana, dkk (2019), oleh karena itu, penulis memutuskan untuk menggunakan metode KNN dalam melakukan klasifikasi data dan menggunakan metode BM25 untuk melakukan pembobotan kata. Diharapkan sistem ini dapat menghasilkan nilai pengujian yang lebih baik.
2. DASAR TEORI 2.1. Twitter
Twitter adalah jejaring sosial microblogging dimana seseorang dapat menulis hingga 280 karakter dalam satu kali tweet. Twitter melakukan posting secara real-time. Fungsi lain pengunaan Twitter ialah dapat digunakan untuk mencari tahu apa yang sedang populer baik kejadian dalam negeri maupun luar negeri (Twitter Essential Training, 2017).
2.2. Text Mining
Menurut Arni (2018) Text mining merupakan proses mengeksplorasi dan menganalisis sejumlah data teks tidak terstruktur, dibantu oleh perangkat lunak yang dapat mengidentifikasi konsep, pola, topik, kata kunci, dan atribut lainnya dalam data. salah satu contoh dari jenis
text mining ialah klasifikasi data.
2.3. Preprocessing
Preprocessing ialah proses untuk melakukan seleksi data dan membuat data tersebut siap untuk diolah. Tidak terdapat tahapan khusus dalam melakukan preprocessing namun pada umumnya preprocessing terdapat beberapa tahap yaitu, cleaning yang berfungsi untuk menghapus angka, username, hashtag, URL serta simbol lain. Kemudian dilanjutkan dengan
case folding, proses tersebut berfungsi untuk
menyeragamkan kalimat menjadi lowercase. Setelah itu tokenisasi yaitu, memecah kalimat menjadi kata demi kata. Proses terakhir ialah
stemming, sistem akan mentransformasikan kata
menjadi kata dasar. 2.4. Pembobotan Kata
Pembobotan kata dalam metode BM25 dapat dibagi menjadi 2 bagian yaitu, IDF dan BM25. Perhitungan IDF. IDF merupakan Perhitungan IDF pada BM25 dapat dilihat pada Persamaan 1.
𝑖𝑑𝑓(𝑡) = 𝑙𝑜𝑔𝑁−𝑑𝑓𝑡 +0,5 𝑑𝑓𝑡 +0,5 (1)
Keterangan:
• idf(t) = hasil perhitungan idf pada term tertentu
• N = jumlah dokumen
• dft = jumlah dokumen yang
memuat term tertentu
Setelah menghitung nilai IDF, selanjutnya menghitung nilai BM25. Model Okapi BM25 merupakan kombinasi model probabilistik dan pembobotan lokal (term frequency). Perhitungan nilai BM25 dapat dilihat pada Persamaan 2. Mengacu pada penelitian Barios, et al,. (2015) maka nilai k_1 dan b yang digunakan adalah 1,2 dan 0,75.
𝑅𝑆𝑉(𝑑) = ∑ 𝑖𝑑𝑓(𝑡) (𝑘1+1)×𝑡𝑓(𝑡𝑑) 𝑘1((1−𝑏)+𝑏×(𝐿𝑎𝑣𝑒𝐿𝑑))+𝑡𝑓(𝑡𝑑)
𝑡∈𝑞 (2)
Keterangan:
• 𝑅𝑆𝑉(𝑑) = retrieval status value untuk suatu dokumen
• 𝑡 = term
• 𝑡𝑓(𝑡𝑑) = frekuensi term t dalam dokumen d.
• 𝐿𝑑 = panjang dokumen d.
• 𝐿𝑎𝑣𝑒 = rata-rata panjang dokumen secara keseluruhan
• 𝑏 = konstanta panjang dokumen, nilai berkisar 0 ≤ 𝑏 ≤ 1.
• 𝑘1 = nilai konstanta frekuensi term, nilai berkisar 1,2 ≤ 𝑘1≤ 2
• 𝑖𝑑𝑓(𝑡) = hasil perhitungan nilai idf 2.5. Klasifikasi Data
Algoritme K-Nearest Neighbor adalah metode untuk klasifikasi terhadap objek berdasarkan k jarak terdekat dari data uji dengan data latih. Pada algortime KNN kelas yang paling banyak muncul selanjutnya akan menjadi kelas hasil dari klasifikasi (Johar, et al., 2016). 2.6. Evaluasi
Evaluasi diperlukan untuk menguji validitas sistem. Pada evaluasi sistem kali ini menggunakan 5 pengujian. Pengujian yang digunakan yaitu, K-Fold Cross Validation, akurasi, precision, recall dan f-score. Pengujian tersebut K-Fold Cross Validation.
pengujian K-Fold Cross Validation
berfungsi untuk melihat validitas dari machine
learning yang sudah dibuat. Pengujian berikutnya adalah pengujian akurasi, pengujian akurasi digunakan untuk melihat nilai keefektifan dari suatu sistem, formula perhitungan nilai akurasi dapat dilihat pada
Persamaan 3. Pengujian nilai precision berfokus untuk menguji kelas dari label data yang diberikan oleh classifier, formula perhitungan
precision dapat dilihat pada Persamaan 4.
Perngujian recall befokus untuk menguji nilai efektivitas classifier, formulasi perhitungan
recall dapat dilihat pada Persamaan 5. Pengujian
terakhir merupakan pengujian f-score, pengujian tersebut dapat diasumsikan sebagai nilai rata-rata dari precision dan recall (Sokolova & Lapalme, 2009). Formula perhitungan f-score dapat dilihat pada Persamaan 6.
𝐴𝑘𝑢𝑟𝑎𝑠𝑖 = 𝑡𝑝+𝑡𝑛 𝑡𝑝+𝑓𝑝+𝑓𝑛+𝑡𝑛× 100% (3) 𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 = 𝑡𝑝 𝑡𝑝+𝑓𝑝× 100% (4) 𝑅𝑒𝑐𝑎𝑙𝑙 = 𝑡𝑝 𝑡𝑝+𝑓𝑛× 100% (5) 𝐹1= 𝑃 × 𝑅 𝑃 +𝑅× 100% (6) Keterangan: • tp = true positive • tn = true negative • fp = false positive • fn = false negative • P = precision • R = recall 3. METODOLOGI 3.1. Pengumpulan Data
Metode pengumpulan data bersifat primer dan kualitatif. Data didapatkan dari situs Twitter.com kemudian data bersifat kulitatif karena hasil yang didapatkan berupa kalimat, kemudian kalimat tersebut akan dilakukan
preprocessing.
Pengambilan data dalam penelitian menggunakan cara menyebar kuesioner campuran kepada responden yaitu, 25 berjenis kelamin perempuan dan 25 berjenis kelamin laki-laki, tweet yang diambil pada setiap responden berjumlah 20 sehingga didapatkan total data berjumlah 1000. Selanjutnya, data akan dimasukkan ke dalam kelas yang sesuai.
Proses klasifikasi membutuhan dokumen latih dan dokumen uji, dalam pembagiandokumen latih dan dokumen uji akan menggunakan K-Fold Cross Validation dengan besar K=10.
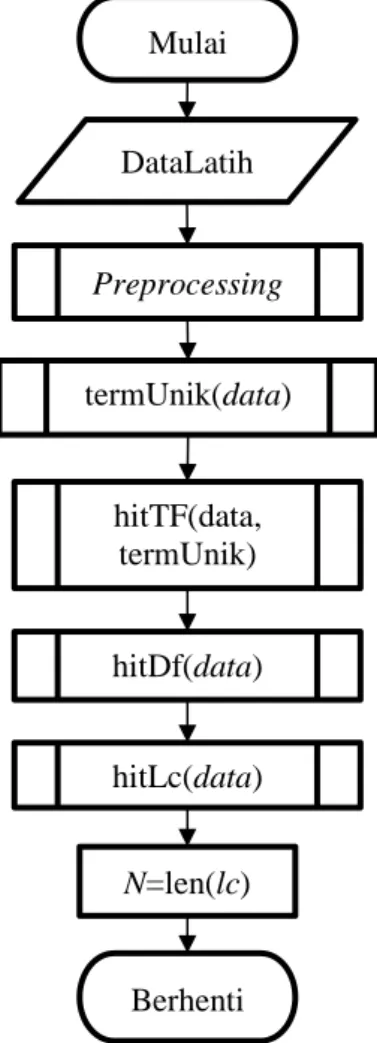
Diagram alir pada sistem dapat dibagi menjadi 2 sub bagian besar yaitu, pelatihan dan pengujian. Pada bagian pelatihan data yang masuk akan melalui proses preprocessing, kemudian mendapatkan term unik, setelah selesai sistem akan menghitung nilai tf, df, lc dan avlc, dan N dimana N menrupakan nilai panjang dari dokumen latih. Diagram alir lebih lengkap dapat melihat Gambar 1.
Gambar 1. Diagram Alir Tahap Pelatihan Setelah selesai melakukan tahap pelatihan selanjutnya sistem akan melaksanakan tahap pengujian. Pada tahap pengujian sistem akan melakukan hal yang sama hingga preprocessing. Setelah melewati preprocessing sistem akan melakukan perhitungan nilai tf untuk data uji, dilanjutkan menghitung nilai idf, kemudian menghitung nilai BM25. Terakhir, melakukan klasifikasi dengan metode KNN dan mengeluarkan hasil dari nilai klasifikasi. Diagram alir pengujian dapat dilihat pada Gambar 2.
Gambar 2. Diagram Alir Tahap Pengujian
4. PENGUJIAN DAN ANALISIS 4.1. Pengujian Sistem
Pengujian sistem dilakukan untuk mengevaluasi algoritme yang sudah diusulkan. Pada pengujian K-Fold Cross Validation data akan dibagi menjadi 10 kelompok dengan perbandingan data latih : data uji (1 : 9). Setiap partisi data akan dihitung nilai akurasi,
precision, recall dan f-score dengan menggunakan nilai ketetanggaan beragam yaitu, 1, 3, 5, 7, 10, 20, 30, 40 dan 50.
Pada Tabel 1 didapatkan hasil tertinggi dalam akurasi adalah 76% pada saat menggunakan data ke-7 dan ke-8 dengan nilai ketetanggan 3, 10 dan 20. Nilai rerata tertinggi yang didapatkan sebesar 68,9%, didapatkan saat nilai ketetanggaan 40.
Preprocessing DataLatih Mulai Berhenti termUnik(data) hitTF(data, termUnik) hitLc(data) N=len(lc) hitDf(data) Preprocessing KNN(BM25, label, k) DataUji Mulai Berhenti hitBM25(idf, termUji,lc,avlc) hitTFUji(data, tfLatih, dfLatih) hitIdf(data, ldok) Hasil Klasifikasi
Tabel 1. Pengujian Nilai Akurasi Par tisi Nilai Ketetanggaan 1 3 5 7 10 20 30 40 50 1 65 66 67 59 62 65 68 68 67 2 69 69 70 69 69 68 68 63 63 3 66 67 70 70 69 71 69 69 68 4 65 59 60 64 65 61 64 64 63 5 68 69 66 62 66 64 66 67 65 6 68 69 68 67 70 66 66 66 69 7 63 76 72 72 70 76 73 74 69 8 67 66 68 72 76 73 74 74 70 9 72 73 70 67 68 66 70 73 75 10 70 72 69 69 68 71 70 71 73 Rera ta 67.3 68.6 68 67.1 68.3 68.1 68.8 68.9 68.2
Merujuk kepada Tabel 2 dapat dilihat bahwa nilai precision tertinggi yaitu 81,1% dalam partisi ke-9 pada saat nilai ketetangaan 50. Nilai rerata tertinggi yang didapatkan sebesar 70,3%, nilai tersebut didapatkan pada saat nilai ketetanggaan 10.
Tabel 2. Pengujian Nilai Precision
Par tisi Nilai Ketetanggaan 1 3 5 7 10 20 30 40 50 1 66.7 64.9 67.3 59.3 62.8 66.7 71.1 72.1 68.0 2 65 68.0 69.4 68.8 71.4 70.7 69.8 63.0 64.3 3 62 63.3 65.4 65.4 66.7 69.8 66.0 65.3 65.2 4 75 65.2 65.3 70.2 75.0 66.7 68.6 71.1 70.5 5 66.1 69.1 65.0 61.7 68.0 66.0 69.6 68.6 68.1 6 66.7 68.8 66.7 66.7 73.2 68.3 67.4 66.7 70.5 7 60.4 73.5 69.4 68.6 70.7 71.7 69.2 69.1 63.8 8 61.8 60 63.0 66.1 72.0 68.6 67.9 67.9 64.3 9 70.8 69.8 65.5 64.2 69.1 66.7 69.6 75.6 81.1 10 72.9 73.8 72.4 72.4 74.5 75.0 75.5 74.1 76.8 Rer ata 66.7 67.6 66.9 66.3 70.3 69.0 69.5 69.4 69.2
Merujuk kepada Tabel 3 dapat dilihat bahwa nilai recall tertinggi yaitu 82,6% dalam partisi ke-8 pada saat nilai ketetangaan 30 dan 40. Nilai rerata tertinggi yang didapatkan sebesar 71,5%, nilai tersebut didapatkan pada saat nilai ketetanggaan 3.
Tabel 3. Pengujian Nilai Recall
Par tisi Nilai Ketetanggaan 1 3 5 7 10 20 30 40 50 1 62,8 72,6 68,6 62,8 62,8 62,8 62,8 60,8 66,7 2 79,6 69,4 69,4 67,4 61,2 59,2 61,2 59,2 55,1 3 67,4 67,4 73,9 73,9 65,2 65,2 67,4 69,6 65,2 4 54,6 54,6 58,2 60,0 54,6 58,2 63,6 58,2 56,4 5 78,9 73,1 75,0 71,2 65,4 63,5 61,5 67,3 61,5 6 69,4 67,4 69,4 65,3 61,2 57,1 59,2 61,2 63,3 7 61,7 76,6 72,3 74,5 61,7 80,9 76,6 80,9 78,7 8 73,9 78,3 73,9 80,4 78,3 76,1 82,6 82,6 78,3 9 70,8 77,1 79,2 70,8 60,4 58,3 66,7 64,6 62,5 10 75,4 79,0 73,7 73,7 66,7 73,7 70,2 75,4 75,4 Rer ata 69,4 71,5 71,4 70,0 63,7 65,5 67,2 68,0 66,3
Pada Tabel 4 dapat dilihat bahwa nilai f-score tertinggi didapatkan pada saat partisi ke-10 dengan nilai ketetanggan 3 yaitu sebesar 76,27%. Kemudian, untuk nilai rata-rata f-score tertinggi didapatkan pada saat ketanggaan 3 dengan nilai 69,34%.
Tabel 4. Pengujian Nilai F-Score
Par tisi Nilai Ketetanggaan 1 3 5 7 10 20 30 40 50 1 64.7 68.5 68.0 61.0 62.8 64.7 66.7 66.0 67.3 2 71.6 68.7 69.4 68.0 65.9 64.4 65.2 61.1 59.3 3 64.6 65.3 69.4 69.4 65.9 67.4 66.7 67.4 65.2 4 63.2 59.4 61.5 64.7 63.2 62.1 66.0 64.0 62.6 5 71.9 71.0 69.6 66.1 66.7 64.7 65.3 68.0 64.7 6 68.0 68.0 68.0 66.0 66.7 62.2 63.0 63.8 66.7 7 61.1 75.0 70.8 71.4 65.9 76.0 72.7 74.5 70.5 8 67.3 67.9 68.0 72.6 75.0 72.2 74.5 74.5 70.6 9 70.8 73.3 71.7 67.3 64.4 62.2 68.1 69.7 70.6 10 74.1 76.3 73.0 73.0 70.4 74.3 72.7 74.8 76.1 Rera ta 67.7 69.3 69.0 68.0 66.7 67.0 68.1 68.4 67.4
Setelah selesai menguji nilai akurasi, precision,
recall dan f-score. Hasil dari rata-rata pengujian 10-Fold Cross Validation dapat dilihat pada
Tabel 5. Berdasarkan Tabel 5 dapat dikatakan bahwa nilai keteanggaan 3 merupakan nilai k yang paling optimal. Hal tersebut didasari oleh nilai f-score tertinggi.
Tabel 5. Hasil Rata-rata Nilai Pengujian
k Akurasi precision Recall f-score
1 67,3 66,74 69,44 67,72 3 68,6 67,63 71,52 69,34 5 68,0 66,93 71,36 68,95
7 67,1 66,32 69,99 67,95 10 68,3 70,33 63,74 66,68 20 68,1 69,01 65,49 67,03 30 68,8 69,46 67,18 68,10 40 68,9 69,35 67,97 68,36 50 68,2 69,24 66,31 67,36 4.2.
Analisis
Pada pengujian K-Fold Cross Validation
didapatkan bahwa iterasi ke-10 merupakan
data paling baik, dikatakan demikian karena
pada pengujian nilai f-score iterasi ke-10
memiliki nilai tertinggi. Pemilihan nilai
f-score sebagai acuan nilai terbaik karena
dalam perhitungan nilai f-score melibatkan
nilai precision serta recall. Melalui hasil
pengujian
tersebut
dibuktikan
bahwa
penyebaran data yang seimbang dalam
dataset turut mempengaruhi hasil dari
kinerja sistem.
Gambar 3. Grafik Rata-rata Pengujian
Gambar 3 merupakan visualisasi Tabel 5 yang berisi nilai rata-rata setiap pengujian dengan semua nilai ketetanggaan. Berdasarkan Gambar 6 maka, nilai k yang optimal adalah 3. Hal ini dikarenakan nilai f-score dari hasil pengujian jika k lebih rendah dari 3 maka hasilnya cenderung naik lalu, jika lebih besar dari 3 hasil akan cenderung menurun. Penentuan nilai k yang terlalu kecil tidak dianjurkan dalam metode klasifikasi KNN. Hal tersebut disebabkan oleh terdapatnya data noise dalam penyebaran kelas.
Data noise merupakan suatu data yang tidak
sesuai dengan mayoritas di sekitarnya, sehingga data bersifat anomali. Contohnya, jika data kelas laki-laki berada dalam sekumpulan data kelas perempuan. Jika menggunakan nilai k=1 maka, terdapat kemungkinan bahwa data anomali merupakan tetangga terdekat dari data uji sehingga, sistem akan melabeli kelas data uji dengan label kelas data anomali atau noise. Hal tersebut menyebabkan rendahnya hasil kinerja sistem.
Rendahnya hasil pengujian tidak hanya berdasarkan pada penyebaran data yang kurang merata. Berdasarkan gambar 6 hasil terendah dalam pengujian nilai rata-rata terdapat pada saat nilai ketetanggaan 10, walaupun setelah k=10 hasil pengujian mengalami peningkatan, tetapi nilai dalam pengujian tidak melebihi nilai k=3. Hal tersebut membuktikan bahwa jika nilai k yang terlalu besar maka akan ada banyak data yang sebenarnya tidak mirip dengan data uji namun ikut terhitung dalam proses penentuan klasifikasi sehingga nilai pengujian sistem akan cenderung lebih rendah.
5. KESIMPULAN DAN SARAN
Berdasarkan hasil analisis yang didapatkan dari penelitian pada bab sebelumnya, maka didapatkan kesimpulan bahwa, Metode BM25 dan KNN sudah mampu melakukan klasifikasi jenis kelamin pada pengguna Twitter berdasarkan tweet dari pengguna tersebut. Proses klasifikasi dijalankan dengan memasukan nilai k dan data uji, kemudian sistem akan melakukan proses klasifikasi secara otomatis.
Nilai optimal ketetanggaan pada KNN pada penelitian adalah k=3. Penggunaan nilai k=3 menghasilkan nilai yang f-score yang lebih baik. Nilai pengujian k=3 adalah 68,6%, 67,63%, 71,52% dan 69,34% untuk nilai akurasi,
precision, recall dan f-score. Saat nilai k lebih
dari 3 hingga 10 hasil yang dikeluarkan mengalami penurunan, kemudian nilai tersebut mengalami kenaikan pada saat k lebih dari 10 tetapi hasil yang didapatkan tidak melebihi nilai
k=3.
Saran untuk penelitian selanjutnya adalah menggunakan metode klasifikasi lain sebagai perbandingan dengan metode KNN. Saran kedua, dapat menggunakan metode tambahan seperti untuk melakukan perbaikan kata agar tidak terdapat singkatan atau kata yang tidak baku. 63 65 67 69 71 73 1 3 4 5 10 20 30 40 50 Rat a-ra ta Nilai Ketetanggaan
Nilai Rata-rata dari Pengujian
Akurasi Precision
6. DAFTAR PUSTAKA
Arni, U. D., 2018. Apa Itu Text Mining ?.
[Online] Tersedia di:
<https://garudacyber.co.id/artikel/1254-apa-itu-text-mining> [Diakses 30 Agustus 2019].
Goenawan, R. N., William, C., Derwin, S. & Fredy, P., 2019. Gender Demography Classification on Instagram based on User's Comments Section. Procedia Computer Science, 12-13 September, pp. 64-71.
Huq, M. R., Ali, A. & Rahman, A., 2017. Sentiment Analysis on Twitter Data using KNN and SVM. International Journal of Advanced Computer Science and Applications (IJACSA) , Volume 6, pp. 19-25.
Johar, A., Yanosma, D. & Anggraini, K., 2016.
IMPLEMENTASI METODE
K-NEAREST NEIGHBOR (KNN) DAN SIMPLE ADDITIVE WEIGHTING
(SAW) DALAM PENGAMBILAN
KEPUTUSAN SELEKSI
PENERIMAAN ANGGOTA
PASKIBRAKA (Studi Kasus : Dinas Pemuda dan Olahraga Provinsi Bengkulu). Jurnal Pseudocode, III(2), pp. 98-112.
Kominfo, 2019. Kominfo : Pengguna Internet di Indonesia 63 Juta Orang. [Online]
Tersedia di:
<https://www.kominfo.go.id/content/deta il/3415/kominfo-pengguna-internet-di-indonesia-63-juta-orang/0/berita_satker> [Diakses 29 Agustus 2019].
Prana, P. A., Indriati & Adikara, P. P., 2019. Klasifikasi Komentar Body Shaming Beauty Vlogger Pada Youtube Menggunakan Metode BM25 dan K-Nearest Neighbor. Jurnal Pengembangan Teknologi Informasi dan Ilmu Komputer, Volume 3, pp. 7328-7334.
Reddy, T. R., Vardhan, B. V. & Reddy, P. V., 2017. A Document Weighted Approach for Gender and Age Prediction Based on Term. International Journal of Engineering, Volume 30, pp. 643-651. Sokolova, M. & Lapalme, G., 2009. A
systematic analysis of performance measures for classification tasks. Information Processing and Management,
pp. 427-437.
Twitter Essential Training, 2017. Understand Twitter and microblogging. [Online]
Tersedia di:
<https://www.lynda.com/Twitter-
tutorials/Understand-Twitter-microblogging/560062/586958-4.html> [Diakses 28 08 2019].
Wang, L., Tanaka, M. & Yamana, H., 2016. What is your Mother Tongue?: Improving Chinese native language identification by cleaning noisy data and adopting BM25. IEEE International Conference on Big Data Analysis (ICBDA), pp. 1-6.