7
LANDASAN TEORI 2.1. Sewa Guna Usaha (Leasing)
2.1.1. Pengertian Leasing
Menurut Kieso (2003, p1086), sewa guna usaha (lease) adalah suatu perjanjian bersifat kontraktual antara lessor (pihak yang menyewakan) dan lessee (pihak yang menyewa) yang memberikan lessee hak untuk menggunakan properti tertentu, yang dimiliki oleh lessor, selama jangka waktu tertentu sebagai ganti pembayaran uang sewa yang umumnya dibayar secara periodik dan besarnya sudah ditetapkan. Sedangkan, menurut Stice (2005, p294), sewa guna usaha (lease) adalah sebuah kontrak yang merinci persyaratan-persyaratan di mana pemilik properti, yaitu lessor (yang menyewakan) mentransfer hak penggunaan properti kepada lessee (penyewa).
Menurut Stice (2005, p295), terdapat beberapa keuntungan bagi lessee daripada pembelian, seperti tanpa uang muka, lessee dapat menghindari resiko kepemilikan, dan fleksibel karena perusahaan dapat dengan mudah mengganti aktiva untuk menanggapi perubahan bisnis. Menurut Stice (2005, p296), lessor mendapat beberapa keuntungan dari usaha sewa guna usaha (leasing), seperti peningkatan penjualan, hubungan bisnis yang berkelanjutan melalui lease antara lessor dan lessee, dan apabila kondisi ekonomi menghasilkan nilai sisa yang signifikan pada akhir masa sewa, lessor dapat menyewakan properti ke lessee lain atau menjual properti dan mendapat keuntungan.
Menurut Stice (2005, p298), untuk tujuan akuntansi, sewa guna usaha dipisahkan menjadi dua bagian, sewa guna usaha modal (capital lease) dan
sewa guna usaha operasi (operating lease). Sewa guna usaha modal dicatat seolah-olah perjanjian sewa guna usaha mengalihkan kepemilikan aktiva dari lessor kepada lessee. Jika sewa guna usaha dicatat sebagai sewa guna usaha modal, lessor mengakui adanya penjualan aktiva pada saat penandatanganan sewa guna usaha, lessee akan mengakui aktiva yang disewagunausahakan, dan juga kewajiban untuk pembayaran di masa depan, di neracanya.
Sedangkan, sewa guna usaha operasi dicatat sebagai perjanjian sewa, tanpa transfer kepemilikan aktiva yang berkaitan dengan sewa guna usaha tersebut. Lessor tidak mengakui adanya penjualan aktiva pada tanggal penandatanganan sewa guna usaha, melainkan mengakui adanya pendapatan sewa guna usaha setiap tahunnya saat pembayaran diterima. Lessee tidak mengakui aktiva yang disewagunausahakan, dan tidak ada kewajiban sewa guna usaha yang dilaporkan, tetapi hanya melaporkan beban sewa guna usaha periodik yang jumlahnya sama dengan pembayaran tahunan sewa guna usaha. 2.1.2. Karakteristik Sewa Guna Usaha
Menurut Stice (2005, pp299–302), sewa guna usaha memiliki beberapa karakteristik, yaitu jenis-jenis syarat kontrak yang biasa terdapat dalam perjanjian sewa guna usaha, di antaranya :
• Syarat untuk pembatalan dan denda
Beberapa sewa guna usaha tidak dapat dibatalkan, kecuali yang syarat pembatalan dan dendanya sangat mahal sehingga kemungkinan besar pembatalan tidak akan terjadi.
• Pembaruan kontrak dan opsi pembelian (opsi pembelian murah)
Sewa guna usaha sering memasukkan syarat yang memberikan lessee hak untuk membeli properti yang disewagunausahakan pada suatu saat di masa depan. Jika harga pembelian tertentu diperkirakan kurang dari nilai pasar wajar pada tanggal opsi pembelian digunakan, maka opsi tersebut disebut opsi pembelian murah (bargain purchase option). Perjanjian sewa guna usaha yang memasukkan opsi pembelian umumnya berakhir dengan perpindahan kepemilikan aktiva dari lessor ke lessee. • Persyaratan sewa guna usaha
• Masa manfaat aktiva (masa sewa guna usaha / lease term)
Masa sewa guna usaha (lease term) adalah periode waktu dari permulaan sampai akhir sewa guna usaha. Permulaan terjadi ketika properti yang disewagunausahakan ditransfer kepada lessee. Akhir masa sewa guna usaha lebih fleksibel karena banyak sewa guna usaha memasukkan syarat yang memperbolehkan lessee memperpanjang periode sewa guna usaha. • Nilai sisa aktiva
Nilai pasar properti yang disewagunausahakan pada akhir masa sewa guna usaha disebut dengan nilai sisa atau nilai residu (residual value). Beberapa kontrak sewa guna usaha mengharuskan lessee menjamin nilai sisa minimum. Jika nilai pasar pada akhir masa sewa guna usaha jatuh di bawah nilai sisa yang dijamin (guaranteed residual value), lessee harus membayar selisihnya. Syarat ini untuk melindungi lessor dari kerugian karena penurunan yang tidak diharapkan atas nilai pasar aktiva.
• Pembayaran minimum sewa guna usaha
Pembayaran minimum sewa guna usaha (minimum lease payment) adalah pembayaran sewa yang diharuskan selama masa sewa guna usaha ditambah setiap jumlah yang dibayarkan untuk nilai sisa termasuk lewat suatu opsi pembelian atau suatu jaminan terhadap nilai sisa. Pembayaran sewa guna usaha sering kali terdiri dari jumlah minimum yang tetap dengan pembayaran yang didasarkan pada penjualan yang dilakukan oleh lessee, dan biaya pelaksanaan atau biaya eksekusi (executory cost) yang tidak dianggap sebagai bagian dari pembayaran minimum sewa guna usaha, seperti asuransi, pemeliharaan, dan pajak yang terkait dengan properti yang disewagunausahakan.
• Tingkat bunga implisit dalam perjanjian sewa guna usaha
Tingkat bunga yang digunakan dalam menghitung pembayaran sewa guna usaha disebut tingkat bunga implisit (implicit interest rate). Tingkat pinjaman yang meningkat atau tingkat bunga pinjaman inkremental (incremental borrowing rate), yaitu tingkat di mana lessee dapat meminjam sejumlah uang yang diperlukan untuk membeli aktiva yang disewagunausahakan, dengan mempertimbangkan situasi keuangan lessee dan kondisi yang terjadi di pasar.
• Tingkat resiko yang diasumsikan oleh lessee, termasuk di dalamnya pembayaran biaya-biaya tertentu, seperti pemeliharaan, asuransi, dan pajak.
2.2. Pemasaran
2.2.1. Pengertian Pemasaran
Menurut Kotler (2004, p5), pemasaran adalah suatu proses sosial dan manajerial dimana individual dan grup memenuhi kebutuhan dan keinginan mereka melalui penciptaan dan pertukaran produk dan nilai dengan pihak lain. Tujuan pemasaran adalah menarik pelanggan baru, menjaga pelanggan yang sudah ada, dan menambah jumlah pelanggan dengan cara memberikan kepuasan. Sedangkan, menurut Boer (1999, p170), pemasaran adalah suatu bidang ilmu yang memposisikan produk dan semua atributnya, termasuk harga dan saluran distribusinya.
2.2.2. Proses-proses Pemasaran
Menurut Kotler (2004, pp53-62), proses pemasaran terdiri dari empat tahap, yaitu:
1. Menganalisis peluang pemasaran
Dilakukan dengan cara segmentasi pasar, yaitu membagi pasar menjadi grup-grup pembeli yang berbeda satu sama lain dengan kebutuhan, karakteristik, dan kebiasaan serta memerlukan produk dan kegiatan pemasaran yang berbeda satu sama lain. Segmen pasar merupakan kumpulan pelanggan yang bereaksi sama terhadap suatu usaha pemasaran.
Sedangkan menurut Boer (1999, p178), segmentasi pasar adalah pendefinisian target pasar. Segmentasi pasar merupakan proses pengurangan pasar heterogen yang besar menjadi segmen-segmen pasar homogen yang lebih kecil. Berdasarkan kompetensi, sumber daya, dan saluran pemasaran yang sudah ada, perusahaan kemudian memutuskan
untuk meneliti dan mengembangkan produk-produk yang ditargetkan khusus untuk satu atau lebih segmen pasar tersebut.
2. Memilih target pasar
Menetapkan target pasar adalah suatu proses mengevaluasi tiap-tiap segmen pasar dan memilih satu atau lebih segmen pasar untuk dimasuki. Setelah target pasar ditentukan, dilakukan positioning pasar, yaitu proses penyesuaian produk agar dapat bersaing dengan produk yang ada di dalam pola pikir pelanggan yang menjadi target pasar.
3. Mengembangkan bauran pemasaran 4. Me-manage usaha pemasaran
Terdapat empat fungsi manajemen pemasaran : Analisis pemasaran
Merupakan kegiatan menganalisis pasar dan lingkungan pemasaran untuk menemukan peluang dan menghindari ancaman. Dalam kegiatan ini kekuatan dan kelemahan perusahaan, termasuk kegiatan pemasaran saat ini dan yang mungkin diterapkan akan dianalisis untuk menemukan peluang mana yang dapat diambil.
Perencanaan pemasaran
Pada tahap ini akan diputuskan strategi pemasaran apa yang dapat membantu perusahaan mencapai semua tujuan strategisnya.
Pengendalian pemasaran
Adalah proses mengukur dan mengevaluasi hasil strategi dan rencana pemasaran dan mengambil tindakan perbaikan untuk menjamin tujuan tetap tercapai. Pengendalian pemasaran terdiri dari dua jenis :
- Pengendalian operasi, termasuk di dalamnya pengecekan performance yang ada dengan rencana tahunan dan melakukan tindakan perbaikan jika diperlukan. Tujuannya adalah untuk menjamin perusahaan mencapai penjualan, keuntungan, dan tujuan lainnya yang telah ditentukan dalam rencana tahunan. Dan juga termasuk menentukan tingkat keuntungan yang berbeda untuk tiap produk, tempat, pasar, dan saluran pemasaran.
- Pengendalian strategis 2.2.3. Strategi Kompetitif Dasar
Menurut Kotler (2004, p574), terdapat tiga strategi pemenang : - Overall cost leadership
- Diferensiasi
Membuat program pemasaran dan produk yang berbeda sehingga dapat menjadi pemimpin dalam kelasnya di industri sehingga dalam kelompok harga yang relative sama, pelanggan lebih menginginkan produk merk perusahaan ini.
- Fokus
Memfokuskan seluruh usaha perusahaan dalam melayani (memenuhi kebutuhan) beberapa segmen pasar daripada memenuhi kebutuhan seluruh pasar.
Ada tiga strategi kompetitif pemasaran baru yang menyarankan agar perusahaan menjadi pemimpin dengan memberikan nilai maksimum kepada pelanggannya. Strategi ini dikenalkan oleh Michael Treacy dan Fred Wiersema (Kotler, 2004, pp574-575). Strategi ini terdiri dari :
- Operational excellence - Customer intimacy
Dengan cara melakukan segmentasi pasar dan membuat produk atau jasa yang sesuai dengan kebutuhan target pelanggan. Perusahaan mengkhususkan dirinya untuk memenuhi kebutuhan pelanggan yang unik melalui hubungan yang akrab dan pengetahuan yang mendetail mengenai pelanggan. Perusahaan yang menerapkan strategi ini membangun database pelanggan secara mendetail untuk keperluan segmentasi dan membuat target pelanggan, dan mendukung orang-orang pemasarannya untuk merespon secara cepat kebutuhan-kebutuhan pelanggan. Perusahaan menerapkan strategi ini untuk melayani pelanggan yang ingin membayar premium untuk mendapatkan secara tepat apa yang diinginkan.
- Product leadership
2.3. Database
Menurut Connolly (2005, p15), database adalah kumpulan dari data yang saling berhubungan secara logic di mana data tersebut didesain untuk memenuhi kebutuhan informasi suatu organisasi dan juga termasuk deskripsi dari data yang terdapat di dalam database. Database tidak hanya menyimpan data operasional perusahaan, tetapi juga metadata. Metadata adalah suatu kumpulan data yang
terintegrasi yang mendeskripsikan data itu sendiri. Database terdiri dari entitas, atribut, dan hubungan antar entitas yang ada. Suatu entitas adalah objek nyata (orang, tempat, benda, konsep, atau kejadian) dalam perusahaan yang disimpan dalam database. Atribut adalah property yang mendeskripsikan suatu objek yang disimpan dalam database, dan relationship adalah hubungan antar entitas dalam database.
DBMS (Database Management System) merupakan suatu sistem software yang memungkinkan user mendefinisikan, membuat, memperbaharui, dan mengontrol akses ke dalam database. DBMS merupakan software yang menghubungkan program aplikasi dengan database (Connolly, 2005, p16). Program aplikasi adalah program komputer yang dapat berhubungan dengan database yang dilakukan dengan cara memberikan command (khususnya command SQL) kepada DBMS (Connolly, 2005, p17). User berinteraksi dengan database melalui program aplikasi yang digunakan untuk membuat dan me-maintain database dan menghasilkan informasi.
2.4. Data Warehouse
2.4.1. Definisi Data Warehouse
Menurut Connolly (2005, pp1151-1152), data warehousing adalah kumpulan data yang bersifat subject oriented, integrated, time-variant, dan non-volatile yang mendukung proses pengambilan keputusan bagi pihak manajemen. Sedangkan, menurut Inmon (2005, p29), sebuah data warehouse adalah kumpulan data yang mendukung manajemen pengambilan keputusan yang bersifat subject-oriented, integrated, nonvolatile dan time-variant. Tujuan
akhir data warehousing adalah mengintegrasikan data yang terdapat pada seluruh perusahaan ke dalam satu tempat penyimpanan di mana user dapat dengan mudah melakukan query, membuat laporan, dan melakukan analisis. 2.4.2. Karakteristik Data Warehouse
1. Subject Oriented
Menurut Inmon (2005, pp29-33), secara klasik sistem operasi diorganisasikan seputar aplikasi fungsional dari perusahaan. Untuk perusahaan asuransi, aplikasinya dapat berupa auto, health, life dan casuality. Area subyek utama perusahaan asuransi dapat berupa customer, policy, premium, dan claim. Setiap tipe perusahaan memiliki subyek dengan keunikan tersendiri. Menurut Connolly (2005, pp1151-1152), subject Oriented berarti data warehouse disusun berdasarkan subjek-subjek penting pada perusahaan.
2. Integrated
Menurut Inmon (2005, pp29-33), data diambil dari banyak sumber berbeda kemudian dimasukkan ke dalam data warehouse. Selama data diambil data tersebut diubah, dilakukan format kembali, diurutkan, dan diringkas. Hasilnya, data terletak dalam data warehouse yang memiliki satu pandangan, yaitu sebagai data yang tergabung. Menurut Connolly (2005, pp1151-1152), integrated berarti data dalam data warehouse berasal dari berbagai data dalam sistem aplikasi perusahaan.
3. Nonvolatile
Menurut Inmon (2005, pp29-33), data pada data warehouse di-load dan diakses tetapi tidak update. Ketika data pada data warehouse
di-load, data di-load di dalam sebuah snapshot (static format). Ketika terjadi perubahan selanjutnya, snapshot record yang baru ditulis. Menurut Connolly (2005, pp1151-1152), non-volatile berarti data dalam data warehouse diperoleh dari database operasional dan tidak dapat diubah. 4. Time Variant
Menurut Inmon (2005, pp29-33), time-variant menyatakan bahwa setiap unit data dalam data warehouse adalah akurat. Dalam beberapa kasus, record ditandai. Dalam kasus lain, sebuah record memiliki tanggal transaksi. Tetapi pada setiap kasus, ada beberapa bentuk penanda waktu untuk menunjukkan bahwa record itu akurat. Menurut Connolly (2005, pp1151-1152), time-variant berarti data dalam data warehouse hanya akurat pada periode waktu tertentu.
2.4.3. Arsitektur Data Warehouse
Arsitektur Data Warehouse menggunakan dimensionality modeling. Dimensionality modeling adalah teknik desain data secara logic yang bertujuan untuk merepresentasikan data dalam bentuk yang memungkinkan performance akses yang tinggi (Connolly, 2005, p1183). Star schema merupakan suatu struktur data secara logic yang memiliki sebuah tabel fakta di tengah dan dikelilingi oleh tabel dimensi yang berisi data referensi dari tabel fakta (yang dapat didenormalisasi) (Connolly, 2005, p1183). Snowflake schema adalah variasi dari star schema di mana tabel dimensi berisi data yang sudah dinormalisasi. Snowflake schema memungkinkan tabel dimensi untuk memiliki tabel referensi yang lain (Connolly, 2005, p1184). Starflake schema merupakan
suatu struktur gabungan dari star schema dan snowflake schema (Connolly, 2005, p1185).
2.4.4. Hubungan Data Warehouse dan OLTP
Menurut Connolly (2005, p1153), OLTP dan data warehouse memiliki karakteristik yang berbeda dan dibuat untuk tujuan yang berbeda. Walaupun demikian, keduanya memiliki hubungan yang erat di mana data yang disimpan dalam data warehouse berasal dari OLTP. Namun demikian, sebelum data OLTP diekstrak ke dalam data warehouse, data tersebut harus melalui proses cleaning data terlebih dahulu. Hal ini karena data yang disimpan dalam OLTP tidak konsisten, terfragmentasi, dan mudah berubah. OLTP juga menyimpan data yang bersifat duplikat.
Tabel 2.1. Perbedaan antara Sistem OLTP dan Sistem Data Warehouse Sumber : Connolly (2005, p1153)
Sistem OLTP Sistem data warehouse
Menyimpan data operasional perusahaan Menyimpan data historis perusahaan Menyimpan data yang detail Menyimpan highly summarized data Data bersifat dinamis (sering berubah) Data bersifat statis (tidak berubah)
Proses dilakukan berulang Proses ad hoc, tidak terstruktur, dan heuristic.
Application oriented Subject oriented
Pola penggunaan yang dapat diprediksi Pola penggunaan yang tidak dapat diprediksi
Dibuat dengan tujuan untuk membantu dan mempermudah transaksi
Dibuat dengan tujuan untuk kepentingan analisis
Mendukung pengambilan keputusan harian
Mendukung pengambilan keputusan strategis
Digunakan oleh operational user dalam jumlah yang besar
Digunakan oleh managerial user yang jumlahnya relatif sedikit
Perusahaan dapat memiliki sejumlah OLTP untuk setiap proses bisnis
Perusahaan umumnya hanya memiliki satu buah data warehouse
2.5. Data Mining
2.5.1. Definisi Data Mining
Menurut Connolly (2005, p1233), data mining adalah proses menghasilkan informasi yang tidak diketahui sebelumnya dari suatu database yang besar, yang kemudian digunakan dalam proses pengambilan keputusan bisnis. Sedangkan, menurut Tang (2005, p2), data mining merupakan kegiatan menganalisis data dan menemukan pola tersembunyi secara otomatis atau semiotomatis.
Data dalam jumlah besar telah dikumpulkan dan disimpan dalam database dari software bisnis, seperti aplikasi keuangan, Enterprise Resource Management (ERP), Customer Relationship Management (CRM), dan web log. Kumpulan data dalam jumlah besar membuat organisasi memiliki data dalam jumlah banyak, namun tanpa adanya pengolahan data, data tersebut belum dapat menghasilkan informasi ataupun knowlegde yang berguna. Oleh karena
itu, data mining diperlukan untuk menemukan pola-pola dari data yang ada, meningkatkan nilai intrinsik data, dan mengubah data menjadi knowledge (Tang, 2005, p2).
2.5.2. Masalah Bisnis untuk Data Mining
Beberapa jenis masalah yang dapat dipecahkan dengan menggunakan data mining menurut Tang (2005, p5) :
• Churn analysis
Industri telekomunikasi, perbankan, dan asuransi menghadapi persaingan yang ketat saat ini. Setiap pelanggan mobile phone rata-rata menghabiskan lebih dari 200 dolar dana pemasaran perusahaan telepon. Setiap bisnis tentu ingin mendapatkan pelanggan sebanyak mungkin dan Churn analysis dapat membantu manajer pemasaran untuk memahami alasan mengenai loyalitas pelanggan.
• Cross-selling
Cross-selling merupakan suatu tantangan bisnis bagi retailer. Retailer dan online retailer menggunakan fitur ini untuk meningkatkan penjualannya. Sebagai contoh, ketika terjadi pembelian buku pada Amazon.com atau Barnes and Noble.com, website tersebut akan memberikan rekomendasi mengenai buku-buku yang berhubungan dengan buku yang dipilih di mana rekomendasi ini diperoleh dari analisis data mining.
• Fraud detection
Setiap harinya perusahaan asuransi melakukan proses pemeriksaan terhadap ribuan klaim, sehingga sulit bagi perusahaan untuk menyelidiki
lebih lanjut mengenai klaim-klaim tersebut. Dalam hal ini teknik data mining dapat membantu mengidentifikasi penyimpangan pada klaim yang ada.
• Risk management
Dalam memutuskan diterima tidaknya permintaan peminjaman dari pelanggan dan menilai tingkat resiko yang ditimbulkan dari peminjaman tersebut, teknik data mining dapat digunakan untuk membantu dalam penyelesaian masalah tersebut.
• Customer segmentation
Teknik data mining dapat membantu manajer pemasaran dalam memahami profil pelanggan yang bertujuan untuk pengambilan keputusan yang bersifat strategis yang mendukung pemasaran produk.
• Targeted ads
Teknik data mining dapat digunakan untuk mendapatkan sesuatu yang digemari oleh customer dan menawarkannya kepada customer. Sebagai contohnya adalah menelusuri pola urutan klik pada halaman web pembelian online yang diakses oleh customer.
• Sales forecast
Teknik data mining dapat digunakan untuk melakukan prediksi. 2.5.3. Kegiatan dalam Data Mining
Menurut Tang (2005, pp6-10), kegiatan data mining dikelompokkan menjadi:
• Classification
Klasifikasi merupakan salah satu kegiatan data mining yang paling banyak digunakan. Masalah bisnis, seperti churn analysis, risk management, dan ad targeting dapat ditangani dengan klasifikasi. Klasifikasi merupakan tindakan dalam menentukan apakah suatu data termasuk ke dalam kategori tertentu atau tidak berdasarkan atribut class (atribut yang diprediksi) yang dimiliki. Algoritma klasifikasi meliputi decision tree, neural network, dan Naïve Bayes.
• Clustering
Clustering disebut juga pengelompokan. Clustering membagi data menjadi kelompok-kelompok tertentu berdasarkan kumpulan atribut yang dimiliki. Data-data dengan nilai atribut yang sama akan masuk ke dalam kelompok yang sama. Algoritma yang digunakan untuk clustering adalah clustering.
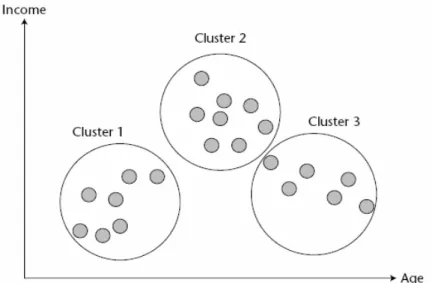
Gambar 2.1. Clustering Sumber : Tang (2005, p7)
Gambar 2.1 menggambarkan suatu dataset pelanggan sederhana yang memiliki dua atribut, yaitu usia dan pendapatan. Cluster 1 terdiri dari populasi yang usianya lebih muda dengan tingkat pendapatan yang rendah. Cluster 2 terdiri dari pelanggan paruh baya dengan tingkat pendapatan yang lebih tinggi. Cluster 3 terdiri dari kelompok yang usianya lebih tua dengan tingkat pendapatan yang relatif rendah.
• Association
Asosiasi merupakan kegiatan data mining yang juga banyak digunakan. Asosiasi disebut juga market basket analysis. Tujuan asosiasi adalah mengidentifikasi kumpulan item yang sering terjual bersama dalam suatu transaksi (frequent item sets) dan aturan-aturan untuk cross-selling. Dalam asosiasi, satu produk atau kumpulan beberapa produk dianggap sebagai satu item. Algoritma yang dapat digunakan dalam asosiasi meliputi Association Rules dan Decision Tree.
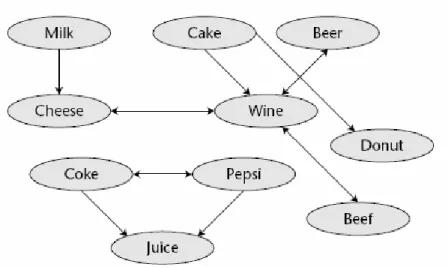
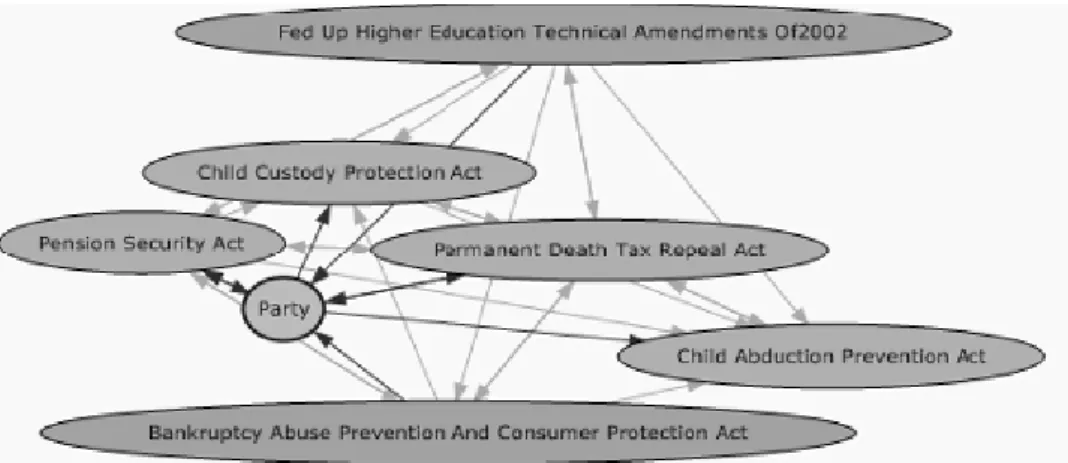
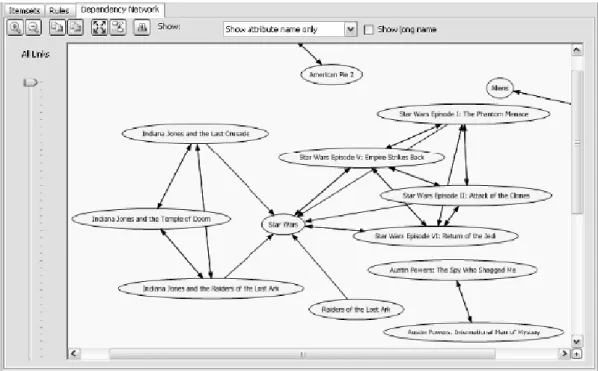
Gambar 2.2. Asosiasi Produk Sumber : Tang (2005, p9)
Gambar 2.2 menunjukkan pola asosiasi produk. Node dalam gambar menggambarkan produk, tanda panah menggambarkan hubungan antarproduk, dan arah tanda panah menggambarkan arah prediksi. Sebagai contoh, panah dari Milk ke Cheese menandakan bahwa siapapun yang membeli Milk memiliki kemungkinan untuk membeli Cheese juga.
• Regression
Kegiatan regresi sama dengan klasifikasi. Perbedaan utamanya adalah atribut yang diprediksi merupakan bilangan continuous. Linear regression dan logistic regression merupakan contoh metode regresi yang banyak digunakan. Contoh teknik regresi lainnya adalah regression tree dan neural networks. Kegiatan regresi dapat memecahkan banyak masalah bisnis. Contohnya, untuk memprediksi metode distribusi, volume distribusi, atau memprediksi kecepatan angin berdasarkan temperatur, tekanan air, dan kelembaban.
• Forecasting
Forecasting merupakan kegiatan data mining yang penting. Forecasting menggunakan time series dataset sebagai input. Time series data merupakan data yang berurutan dan berkelanjutan. Teknik forecasting berhubungan dengan tren umum dan periode waktu. Teknik time series yang paling populer adalah ARIMA (AutoRegressive Integrated Moving Average).
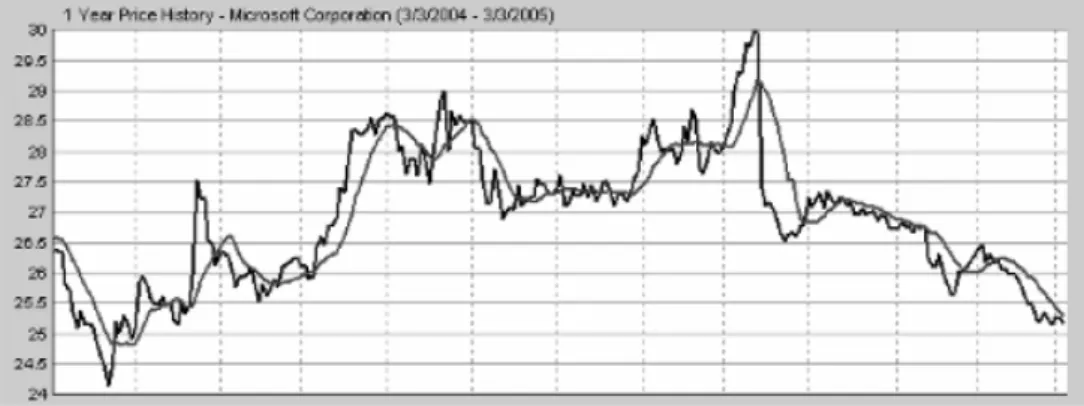
Gambar 2.3. Time Series Sumber : Tang (2005, p9)
Gambar 2.3 terdiri dari 2 kurva. Kurva garis yang solid merupakan time series data sebenarnya dari nilai stok Microsoft, sedangkan kurva titik-titik merupakan model time series dari teknik forecasting dari perubahan nilai rata-rata.
2.5.4. Algoritma Data Mining • Algoritma Naive Bayes
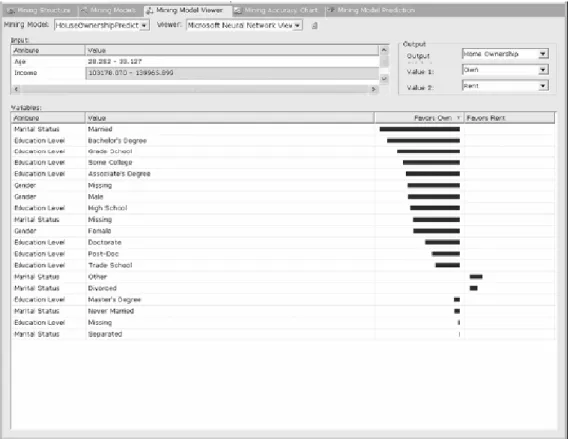
Menurut Tang (2005, p132), algoritma Naïve Bayes dapat digunakan untuk membuat model yang menyediakan kemampuan prediksi dan juga menyediakan metode baru untuk menyelidiki data. Algoritma ini belajar dari fakta dengan menghitung hubungan antara variabel yang menarik dengan seluruh variabel lainnya. Berikut adalah contoh laporan dari algoritma Naive Bayes :
Gambar 2.4. Contoh Laporan Algoritma Naive Bayes Sumber : Tang (2005, p141)
• Algoritma Decision Tree
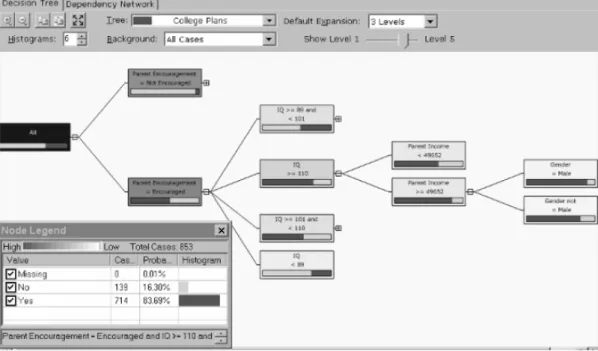
Menurut Tang (2005, pp145-146), data mining untuk Decision Tree yang paling banyak digunakan adalah classification. Prinsipnya adalah memecah data secara rekursif ke dalam bagian-bagian di mana bagian itu terdiri kurang lebih status target variabel yang sama. Decision Tree terbentuk setelah proses rekursif selesai. Ada 3 keuntungan menggunakan data mining, antara lain cepat, setiap cabang membentuk aturan, dan prediksi lebih efisien. Microsoft Decision Tree adalah perpaduan algoritma Decision Tree dengan penelitian Microsoft. Ini mendukung kegiatan classification dan regression. Berdasarkan pengaturan parameter, hasil pohon bisa berbeda tergantung pada pemecahan ujung dan bentuk pohon. Berikut adalah contoh laporan dari algoritma Decision Tree :
Gambar 2.5. Contoh Laporan Algoritma Decision Tree Sumber : Tang (2005, p164)
• Algoritma Time Series
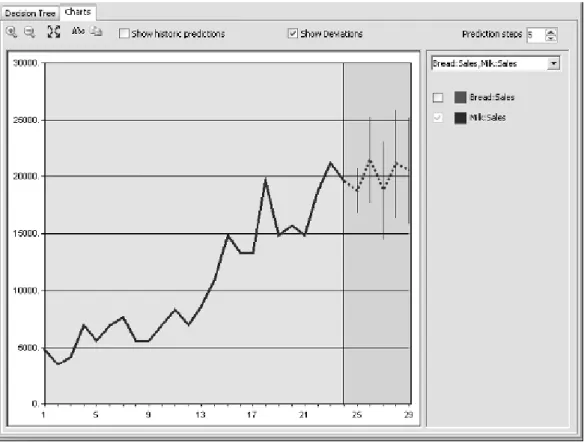
Menurut Tang (2005, p170), algoritma Time Series terdiri dari data yang dikumpulkan melalui bertambahnya waktu. Banyak variabel yang berubah seiring dengan waktu. Urutan nilai variabel membentuk Time Series. Peningkatan waktu dalam Time Series bisa discrete atau continuous. Tujuan utama dari mengumpulkan data berdasarkan urutan waktu adalah untuk meramalkan atau membuat perkiraan nilai yang akan datang. Berikut adalah contoh laporan dari algoritma Time Series :
Gambar 2.6. Contoh Laporan Algoritma Time Series Sumber : Tang (2005, p185)
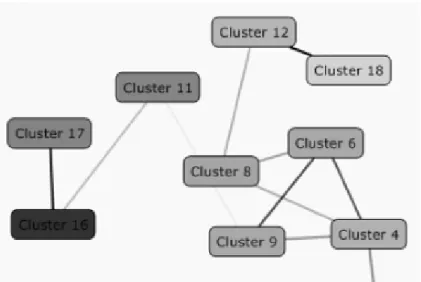
• Algoritma Clustering
Menurut Tang (2005, p188), algoritma Clustering menemukan kelompok alami di dalam data ketika pengelompokan tidak jelas. Dengan kata lain, menemukan variabel tersembunyi yang disusun secara akurat. Clustering bisa digunakan untuk mengetahui lebih banyak tentang pelanggan. Kemampuan menentukan dan mengidentifikasi segmen pasar merupakan alat yang sangat berguna untuk mengembangkan bisnis. Berikut adalah contoh laporan dari algoritma Clustering :
Gambar 2.7. Contoh Laporan Algoritma Clustering 1 Sumber : Tang (2005, p205)
Gambar 2.8. Contoh Laporan Algoritma Clustering 2 Sumber : Tang (2005, p206)
• Algoritma Association Rules
Menurut Tang (2005, p230), dengan menggunakan algoritma Association Rules, analisis shopping chart pelanggan dapat mempelajari produk apa yang umumnya dibeli secara bersama. Association rules mencari kumpulan item paling banyak. Ada 2 langkah dalam algoritma ini, yaitu tahap Calculation Intensive untuk menemukan kumpulan item yang paling banyak. Dan tahap berikutnya adalah menghasilkan aturan kumpulan berdasarkan kumpulan item yang paling banyak. Langkah ini lebih cepat dari pada langkah pertama. Berikut adalah contoh laporan dari algoritma Association Rules :
Gambar 2.9. Contoh Laporan Algoritma Association Rules Sumber : Tang (2005, p245)
• Algoritma Neural Network
Menurut Tang (2005, pp247-248), Neural Network pada dasarnya mengacu pada classification dan regression. Seperti Decision Tree, Neural Network bisa menemukan hubungan yang tidak sesuai diantara attribute masukan dan attribute prediksi. Kekurangannya, biasanya diperlukan pembelajaran lebih dalam menggunakan Neural Network daripada menggunakan Decision Tree dan Naïve Bayes. Neural Network mendukung hasil discrete dan continuous. Neural Network terdiri dari sekumpulan node dan bagian yang membentuk sebuah jaringan. Berikut adalah contoh laporan dari algoritma Neural Network :
Gambar 2.10. Contoh Laporan Algoritma Time Series Sumber : Tang (2005, p264)
2.5.5. Aliran Data
Gambar 2.11. Aliran Data Sumber : Tang (2005, p12)
Gambar 2.11 menggambarkan aliran data pada aplikasi data mining. Aplikasi bisnis menyimpan data transaksi dalam sebuah database Online Transaction Processing (OLTP). Data OLTP kemudian diekstrak, diubah, dan diisi ke dalam data warehouse. Setelah itu OLAP cubes dapat dibuat dari data warehouse.
Pada umumnya data mining diaplikasikan pada data warehouse yang sudah mengalami proses data cleaning dan transformation. Pola yang ditemukan pada model data mining nantinya akan diberikan kepada manajer pemasaran melalui laporan-laporan yang dihasilkan. Biasanya perusahaan kecil tidak memiliki data warehouse. Oleh karena itu, data mining dilakukan secara langsung pada tabel-tabel OLTP.
Prediksi dapat dilakukan secara langsung mengakses data mining melalui Web aplikasi. Dalam cross-selling, begitu pelanggan Web memasukkan
produk ke dalam shopping chart, query prediksi data mining langsung dijalankan untuk mendapatkan daftar rekomendasi produk berdasarkan association analysis.
Data mining juga dapat diaplikasikan untuk menganalisis OLAP cubes. Cube adalah database multidimensi yang memiliki banyak dimensi dan measures. Teknik data mining dapat digunakan untuk menemukan pola-pola yang tersembunyi dalam suatu cube. Sebagai contoh, algoritma asosiasi dapat diaplikasikan pada cube penjualan untuk menganalisis pola pembelian pelanggan pada daerah dan periode waktu tertentu. Teknik data mining juga dapat diaplikasikan untuk memprediksi measures, sebagai contohnya : besar penjualan dan keuntungan toko. Contoh lainnya ialah clustering. Data mining dapat mengelompokkan pelanggan berdasarkan properti dan measure dimensi. Data mining tidak hanya dapat menemukan pola dalam cube, tetapi juga menyusun ulang desain cube berdasarkan hasil model data mining. (Tang, 2005, pp11-12).
2.5.6. Data Mining Project Cycle
Menurut Tang (2005, pp13-17), langkah-langkah proyek data mining meliputi:
1. Data Collection
Data mengenai aktivitas bisnis disimpan dalam berbagai sistem dalam perusahaan. Sebagai contoh: Microsoft memiliki ratusan database OLTP dan lebih dari 70 data warehouse. Langkah pertama dalam data mining adalah mengambil data yang diperlukan dan menyimpannya ke dalam suatu database atau suatu data mart di mana analisis data akan
dilakukan. Data dalam data warehouse belum cukup untuk keperluan data mining, sehingga data masih dikumpulkan dari sumber lainnya.
2. Data Cleaning dan Transformation
Tujuan Data Cleaning adalah untuk membuang informasi yang tidak berhubungan dari dataset. Tujuan transformasi data adalah untuk mengubah data sumber ke dalam bentuk format yang berbeda sesuai dengan nilai dan tipe data yang ada. Ada beberapa teknik yang dapat digunakan dalam Data Cleaning dan Transformation, antara lain:
Data type transform
Merupakan transformasi data yang paling mudah. Contohnya adalah mengubah tipe data Boolean menjadi integer. Alasan transformasi ini adalah adanya beberapa algoritma data mining yang berfungsi lebih baik pada data integer, sedangkan algoritma yang lain berfungsi lebih baik pada data Boolean.
Continuous column transform
Transformasi data berfungsi untuk membagi data continuous ke dalam kelompok-kelompok tertentu. Selain mengelompokkan, teknik seperti normalisasi juga biasanya digunakan untuk mengubah data continuous. Normalisasi mengubah semua nilai numerik menjadi angka antara 0 dan 1 (atau -1 sampai 1) agar angka-angka yang besar tidak menominasi angka-angka yang lebih kecil selama proses analisis. Grouping
Biasanya terdapat banyak nilai yang berbeda pada kolom diskrit sehingga diperlukan pengelompokan pada kolom ini ke dalam beberapa
kelompok untuk mengurangi kompleksitas model. Pengelompokan ini membuat model lebih mudah diinterpretasikan.
Aggregation
Misalkan terdapat sebuah tabel berisi catatan detail mengenai panggilan telepon (Call Detail Record/CDR) untuk setiap pelanggan, dan akan dilakukan pengelompokan pelanggan berdasarkan penggunaan telepon perbulannya. Karena informasi CDR terlalu detail untuk model, maka perlu dilakukan agregasi untuk seluruh panggilan menjadi beberapa atribut, seperti jumlah total panggilan dan rata-rata durasi panggilan. Atribut inilah yang akan digunakan dalam model. Missing value handling
Ada beberapa penyebab hilangnya data. Sebagai contoh, tabel demografis pelanggan dapat memiliki kolom umur, tetapi pelanggan tidak selalu memberitahukan umurnya pada saat pendaftaran. Contoh lainnya adalah terdapat tabel nilai penutupan harian bursa saham MSFT dan bursa saham tutup setiap akhir minggu sehingga akan ada nilai null pada tanggal-tanggal tersebut dalam tabel.
Ada beberapa cara untuk mengatasi masalah ini. Kita dapat mengganti nilai yang hilang dengan nilai yang paling umum (tetap). Jika kita tidak mengetahui umur pelanggan, kita dapat menggantinya dengan umur rata-rata semua pelanggan. Jika suatu record memiliki banyak nilai yang hilang, maka dapat dihapus. Untuk kasus yang lebih tinggi tingkatannya, dapat dibuat mining model dengan menggunakan data yang lengkap, dan kemudian menggunakan model untuk
memprediksikan nilai yang paling mendekati nilai dari tiap missing case.
Removing outliers
Outlier merupakan data abnormal dalam sebuah dataset. Data abnormal akan mempengaruhi kulitas model. Outliers dapat dibuang berdasarkan kumpulan atribut. Algoritma clustering dapat digunakan untuk mengelompokkan outliers ke dalam beberapa cluster berbeda. 3. Model Building
Setelah memahami kegiatan dalam proses data mining, akan lebih mudah untuk menentukan algoritma yang tepat, tetapi akan sulit untuk menentukan algoritma data mining yang cocok sebelum dilakukan training model. Tingkat akurasi algoritma tergantung pada data, seperti jumlah status atribut prediksi, distribusi nilai tiap atribut, hubungan antar atribut, dan lainnya. Sebagai contoh, jika hubungan di antara semua atribut input dan atribut yg diprediksi sama, algoritma decision tree merupakan pilihan yang baik. Jika hubungan antar atribut lebih rumit, algoritma neural network adalah pilihan yang tepat.
Cara yang tepat adalah membuat berbagai model dengan menggunakan algoritma yang berbeda kemudian membandingkan akurasi tiap model dengan menggunakan tool, seperti lift chart. Untuk algoritma yang sama, perlu dibangun beberapa model menggunakan parameter setting yang berbeda untuk menemukan akurasi model yang terbaik.
4. Model Assessment
Terdapat beberapa tools yang digunakan untuk menilai model dan yang paling sering digunakan adalah lift chart. Lift chart menggunakan model yang sudah di-training untuk memprediksikan nilai testing dataset. Berdasarkan nilai dan kemungkinan yang diprediksi, model digambarkan dalam bentuk grafik.
5. Reporting
Reporting merupakan langkah penyajian hasil penemuan dari proses data mining. Data mining tools memiliki fasilitas laporan yang memungkinkan user untuk membuat laporan dari model data mining dalam bentuk tekstual atau grafik. Ada dua tipe laporan, yaitu laporan tentang penemuan (pola) dan laporan tentang prediksi atau ramalan.
6. Prediction (Scoring)
Tujuan akhir data mining adalah mengunakan model untuk melakukan prediksi. Prediksi disebut juga scoring dalam istilah data mining. Untuk melakukan prediksi, diperlukan trained model dan sekumpulan data baru.
7. Application Integration
Memasukkan data mining ke dalam aplikasi bisnis berarti menerapkan intelligence pada bisnis. Menggabungkan fasilitas data mining, terutama prediksi secara real time ke dalam aplikasi merupakan salah satu langkah penting dalam proyek data mining.
8. Model Management
Pada sebagian besar analisis bisnis, model yang telah dibuat harus dilakukan training ulang. Contohnya pada toko buku online di mana setiap harinya terbit buku baru. Seperti data lainnya, mining model juga memiliki masalah keamanan sehingga perlu adanya pengaturan hak akses untuk masing-masing user.
2.5.7. Hubungan Data Mining dengan Data Warehouse
Menurut Connolly (2005, p1233), informasi yang banyak dan kompleks dalam data warehouse menyebabkan data warehouse sulit mengidentifikasi tren dan hubungan antar datanya dengan menggunakan query yang sederhana dan reporting tools. Data mining merupakan cara terbaik untuk menemukan tren dan pola yang ada dalam data warehouse. Data mining dapat menemukan informasi yang tidak dapat dihasilkan secara efektif dengan menggunakan query dan laporan. Walaupun demikian, data mining dan data warehouse tetap berhubungan.
Menurut Connolly (2005, p1242), salah satu halangan organisasi dalam mengembangkan data mining adalah menemukan data yang tepat untuk digunakan dalam data mining. Data mining memerlukan data sumber yang tunggal, clean, terintegrasi, dan konsisten. Berikut adalah alasan mengapa data warehouse digunakan untuk menyediakan data untuk data mining:
Konsistensi dan kualitas data merupakan prasyarat dalam data mining untuk menjamin keakuratan model prediksi, dan data warehouse dibuat dari data yang clean dan konsisten.
Jika data yang digunakan berasal dari banyak sumber maka akan mempermudah dalam mencari hubungan antar data, dan data warehouse berisi data yang berasal dari sejumlah sumber.
Memilih subset yang relevan dari records dan fields untuk data mining memerlukan query yang digunakan dalam data warehouse.
Penelusuran yang dilakukan pada uncovered pattern dapat digunakan agar hasil data mining dapat dimanfaatkan secara maksimal. Data warehouse dapat berhubungan dengan data source untuk mendukung hal ini.
2.6. Web – Based
Web-Based Application merupakan sebuah aplikasi yang memanfaatkan teknologi World Wide Web sebagai interface-nya, yang berarti data yang diinginkan dapat diakses dan diubah dengan menggunakan sebuah Web Browser. Ini sangat menguntungkan sebuah perusahaan karena aplikasi ini dapat dijalankan pada semua komputer yang memiliki Web Browser di dalamnya.
Beberapa keuntungan dari Web-Based Applications diantaranya: 1. Data dapat diakses kapan dan dari mana saja,
2. Mudah dipakai, pemakai cukup melakukan point & click,
3. Perusahaan tidak harus membeli program pengakses karena browser umumnya tersedia secara gratis di Internet. Contoh browser yang gratis adalah Mozilla, Netscape, dan Opera.