PENGENALAN WAJAH DENGAN CITRA PELATIHAN
TUNGGAL MENGGUNAKAN ALGORITME VFI5 BERBASIS
HISTOGRAM
ESTI ARYANI PURWANINGRUM
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
PENGENALAN WAJAH DENGAN CITRA PELATIHAN
TUNGGAL MENGGUNAKAN ALGORITME VFI5 BERBASIS
HISTOGRAM
ESTI ARYANI PURWANINGRUM
Skripsi
Sebagai salah satu syarat untuk memperoleh
Gelar Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRACT
ESTI ARYANI PURWANINGRUM. Face Recognition with Single Image Training Using VFI5 Algorithm based on image histogram. Supervised by AZIZ KUSTIYO.
Face recognition is one of the biometric methods which is frequently used. One of the approach in face recognition is view based (photometric) approach which represents the information of the image pixels. In this research, information from the image pixels represented using the image histogram. According to Gonzales (2002), histogram are the basis for numerous spatial domain processing techniques. Histogram is used as input to Voting Feature Intervals 5 (VFI5) algorithm. Range of image histogram is 0-255 divided into several intervals. Afterwards, on training stage will be determined the vote value from single training image per person that will be used in the classification stage. The recognition rate is reached 96.3%.
Keywords : Face recognition, Voting Feature Intervals 5 (VFI5), single training image, image histogram.
Judul : Pengenalan Wajah dengan Citra Pelatihan Tunggal Menggunakan Algoritme VFI5 Berbasis Histogram
Nama : Esti Aryani Purwaningrum NRP : G64052450
Menyetujui, Pembimbing
Aziz Kustiyo, S.Si., M.Kom. NIP 197007191998021001
Mengetahui,
Dekan Fakultas Matematika Dan Ilmu Pengetahuan Alam Institut Pertanian Bogor
Dr. drh. Hasim, DEA NIP 196103281986011002
PRAKATA
Syukur alhamdulillah penulis panjatkan kepada Allah SWT atas segala nikmat, rahmat, dan karunia-Nya sehingga penulis dapat menyelesaikan tulisan ini. Shalawat dan salam pada junjungan kita Nabi Muhammad SAW serta keluarga dan sahabatnya. Terima kasih penulis ucapkan kepada Ayah dan Ibu penulis, Bapak Narsono dan Ibu Parilah, serta adik-adik penulis, Nana dan Dede, atas doa, semangat, dan dukungannya pada penulis sampai detik ini. Dukungan mereka membuat penulis semakin termotivasi untuk menyelesaikan penelitian ini.
Terima kasih juga penulis sampaikan kepada bapak Aziz Kustiyo S.Si., M.Kom. selaku pembimbing skripsi atas bimbingan yang diberikan kepada penulis selama lebih kurang enam bulan penelitian. Banyak pelajaran berharga yang penulis dapatkan selama penelitian ini. Terselesaikannya tulisan ini juga tidak lepas dari saran dan kritik yang membangun dari para penguji. Terima kasih penulis sampaikan kepada bapak Firman Ardiansyah S.Kom., M.Si. dan bapak Endang Purnama Giri S.Kom., M.Kom. selaku dosen penguji. Kepada ibu Sri Nurdiati, bapak Hari Agung, mba Rahma, pak Sholeh, pak Pendi, dan mas Irvan terima kasih atas bantuannya sampai tulisan ini dapat terselesaikan.
Kepada Mas Habibi dan keluarga, penulis menyampaikan terima kasih atas semangat, doa, dan motivasinya yang selalu mengingatkan penulis untuk tetap berusaha lebih giat lagi. Dan tak lupa kepada teman-teman satu bimbingan, Novi, Furqon, dan Fathoni, yang telah berjuang bersama-sama dan saling membantu satu sama lain. Terima kasih juga penulis ucapkan pada Listia, Cira, Mega, Fitri, dan teman-teman seperjuangan di Ilmu Komputer IPB angkatan 42 yang tidak bisa penulis sebutkan satu persatu. Teman-teman di Wisma Mega, mba Ririn, mba Mona, Reni, Mila, Eno, Mpit, dan Della, terima kasih telah menemani, mendengar keluh kesah, dan memberikan saran kepada penulis. Kepada bu Dwina, test team leader di tempat penulis bekerja, terima kasih atas keringanan-keringanan yang diberikan sehingga penulis dapat menyelesaikan tulisan ini. Kemudian kepada pak Broto, bu Wuri, mba Inggi, mba Ellvi, Haikal, kak Baskoro, dan teman satu ruangan kerja, terima kasih atas doa dan dukungannya selama ini.
Bogor, Juli 2009
RIWAYAT HIDUP
Penulis anak pertama dari tiga bersaudara putri pasangan ayahanda Narsono dan ibunda Parilah. Penulis dilahirkan pada tanggal 13 September 1987 di Banyumas. Pada tahun 2005 penulis menyelesaikan Sekolah Menengah Atas (SMA) di SMA Negeri Banyumas kemudian diterima di Institut Pertanian Bogor lewat jalur Undangan Seleksi Masuk IPB (USMI). Penulis sangat menggemari sesuatu yang berhubungan dengan exact oleh karena itu penulis memilih mayor Ilmu Komputer.
Penulis menjadi anggota PASKIBRA kecamatan Banyumas periode 2002-2004 dan PASKIBRA IPB pada tahun 2005. Pada periode tahun 2006/2007 penulis aktif dalam kegiatan HIMALKOM sebagai staf divisi Programming. Pada Juli-Agustus 2008 penulis melaksanakan kegiatan Praktik Kerja Lapangan di Pertamina Pusat. Mulai 10 Maret 2009, penulis bekerja di Aero Systems Indonesia sebagai software tester.
v
DAFTAR ISI
Halaman DAFTAR TABEL ... vi DAFTAR GAMBAR ... vi DAFTAR LAMPIRAN ... vi PENDAHULUAN ... 1 Latar Belakang ... 1 Tujuan Penelitian ... 1Ruang Lingkup Penelitian ... 1
TINJAUAN PUSTAKA ... 2
Representasi Citra Digital ... 2
Ukuran statistik bagi data ... 2
Histogram... 2
Klasifikasi ... 3
Citra pelatihan tunggal (Single training image)... 3
Voting Feature Intervals (VFI5) ... 3
Penerapan VFI5 berdasarkan histogram ... 4
METODE PENELITIAN ... 5
Data ... 5
Histogram citra ... 6
Data latih dan data uji ... 6
Algoritme VFI5 ... 6
Menghitung akurasi ... 6
HASIL DAN PEMBAHASAN... 6
Percobaan 1 ... 7
Percobaan 2 ... 7
Percobaan 3 ... 8
Menentukan jumlah interval yang baik untuk pengenalan ... 9
Menentukan citra pelatihan yang handal ... 9
KESIMPULAN DAN SARAN... 11
Kesimpulan ... 11
Saran ... 11
DAFTAR PUSTAKA ... 11
vi
DAFTAR TABEL
Halaman
1 Jumlah piksel pada setiap interval data latih ... 5
2 Vote yang diperoleh ... 5
3 Klasifikasi data uji... 5
4 Hasil percobaan dengan citra pertama (c1) sebagai data latih ... 7
5 Hasil percobaan dengan citra kedua(c2) sebagai data latih ... 7
6 Rata-rata nilai akurasi ... 8
7 Nilai rata-rata pengenalan citra dengan jumlah interval 128 untuk setiap data latih ... 8
8 Perbandingan nilai rata-rata akurasi ... 8
9 Statistik nilai rata-rata akurasi seluruh percobaan terhadap jumlah interval ... 9
10 Statistik nilai rata-rata seluruh percobaan terhadap citra pelatihan pada jumlah interval 64 ... 10
11 Statistik nilai rata-rata seluruh percobaan terhadap citra pelatihan pada jumlah interval 128 ... 10
12 Statistik nilai rata-rata seluruh percobaan terhadap citra pelatihan pada jumlah interval 256 ... 10
13 Rekapitulasi hasil percobaan ... 10
DAFTAR GAMBAR
Halaman 1 Fungsi koordinat sebagai representasi cita digital ... 22 Dua wajah yang berbeda dan histogramnya ... 2
3 Algoritme pelatihan pada VFI5 ... 4
4 Algoritme klasifikasi pada VFI5 ... 4
5 Penerapan VFI5 berdasarkan histogram ... 5
6 Tahapan Penelitian ... 6
7 Grafik nilai akurasi rata-rata pengenalan wajah berdasarkan jumlah citra perorang ... 7
DAFTAR LAMPIRAN
Halaman 1 Data yang digunakan ... 142 Nilai akurasi hasil percobaan dengan sepuluh kelas ... 21
3 Tabel pengenalan citra dengan menghilangkan kelas yang paling sedikit dikenali ... 22
4 Tabel nilai akurasi percobaan dengan menghilangkan kelas yang dikenali dengan baik ... 23
5 Nilai akurasi dengan menghilangkan kelas 1, 2, 5, 7, 9, dan 10 ... 24
6 Statistik nilai rata-rata hasil seluruh percobaan terhadap jumlah interval ... 26
PENDAHULUAN
Latar Belakang
Pengenalan wajah merupakan salah satu metode biometrik untuk mengidentifikasi karakteristik dengan menggunakan fitur pada wajah (Karande & Talbar 2008). Penelitian dalam bidang ini telah dilakukan lebih dari 30 tahun sebagai buktinya teknik pengenalan wajah sudah semakin berkembang. Banyak aplikasi pengenalan wajah komersial yang digunakan untuk identifikasi penjahat, sistem keamanan, pemrosesan film, dan lain-lain.
Terdapat dua pendekatan utama untuk pengenalan wajah yaitu pendekatan geometris (feature based) dan pendekatan fotometrik (view based). Pendekatan geometris adalah pendekatan dengan mengekstraksi dan menghubungkan fitur berasal dari komponen citra wajah seperti mata, hidung, dan mulut. Pendekatan fotometrik adalah pendekatan dengan merepresentasikan informasi dari piksel citra. Dalam merepresentasikan citra tersebut ada beberapa metode yang dapat digunakan seperti Principal Component Analysis (PCA), Linear Discriminant Analysis (LDA), Independent Component Analysis (ICA), dan lain-lain (Karande & Talbar 2008).
Penelitian ini menggunakan pendekatan kedua yaitu dengan menggunakan algoritme Voting Feature Interval (VFI5). VFI5 merupakan suatu algoritme yang merepresentasikan deskripsi sebuah konsep oleh sekumpulan interval dari nilai-nilai fitur. VFI5 mempunyai tingkat akurasi yang lebih tinggi jika dibandingkan dengan algoritme nearest-neighbor. Kedua algoritme ini telah diuji dengan menambahkan fitur yang tidak relevan dimana penambahan fitur yang tidak relevan pada algoritme VFI5 memperlihatkan jumlah pengurangan akurasi yang sangat kecil (Guvenir 1998).
Penggunaan algoritme VFI5 selama ini menggunakan data numerik. Akurasi yang diperoleh pada penelitian VFI5 menggunakan data numerik sangat bagus. Menurut Apniasari (2007) akurasi VFI5 100% untuk identifikasi penyakit demam berdarah sedangkan akurasi dengan model ANFIS adalah 86,67%. Kemudian menurut Sulistyo (2007) pada penelitiannya yang berjudul Pengaruh Inclomplete Data Terhadap Akurasi VFI5, tingkat akurasi pada data ordinal sebesar 96.38%. Selain menggunakan data numerik penelitian menggunakan VFI5 juga telah dilakukan pada data citra oleh Pramitasari
(2009) yaitu Pengenalan Wajah dengan Praproses Transformasi Wavelet. Hasil yang diperoleh sebesar 90% pada level 2. Dengan pertimbangan hasil akurasi yang tinggi pada data numerik dan data citra pada penelitian Pramitasari, maka diharapkan akan tinggi pula pengenalan menggunakan VFI5 berbasis histogram dan citra pelatihan tunggal.
Menurut Gonzales (2002), histogram digunakan sebagai dasar dari banyak teknik pemrosesan domain spasial. Histogram merepresentasikan derajat keabuan sebuah citra. Histogram sebuah citra grayscale, berkisar pada interval 0-255. Nilai interval inilah yang nantinya akan dijadikan fitur pada algoritme VFI5.
Terdapat dua tipe data latih yang digunakan dalam pengenalan wajah berdasarkan jumlah data per orangnya. Data latih yang digunakan dapat berjumlah banyak (lebih dari satu) atau hanya ada satu (tunggal) untuk setiap orangnya. Penggunaan citra tunggal sebagai data latih telah dilakukan pada beberapa penelitian, salah satunnya oleh Majumdar dan Ward (2008). Dalam penerapannya, citra tunggal untuk setiap orang digunakan untuk mengenali wajah pada kamera pengintai, identifikasi kartu SIM atau passport (Tan, Chen, Zhou, dan Zhang 2006).
Tujuan Penelitian
Penelitian ini bertujuan:
1 Mengetahui akurasi pengenalan wajah dengan citra pelatihan tunggal menggunakan algoritme VFI5 berbasis histogram.
2 Mengetahui pengaruh panjang selang nilai keabuan yang digunakan sebagai fitur pada algoritme VFI5.
Ruang Lingkup Penelitian
Ruang lingkup pada penelitian ini adalah pengenalan citra wajah berdasarkan tingkat keabuan. Data citra yang digunakan berupa sepuluh citra berbeda pada sepuluh orang yang berbeda. Beberapa citra diambil pada waktu yang berbeda, variasi pencahayaan yang rendah, ekpresi wajah yang berbeda (membuka/menutup mata, tersenyum atau tidah tersenyum), dan penggunaan kacamata atau tidak. Seluruh citra diambil dengan latar belakang berwarna gelap yang seragam.
2
TINJAUAN PUSTAKA Representasi Citra Digital
Citra digital adalah citra yang dilakukan diskritisasi koordinat spasial (sampling) dan diskritisasi tingkat kecemerlangannya/keabuan (kuantisasi). Citra digital merupakan suatu matriks yang indeks baris dan kolomnya menyatakan suatu titik pada citra tersebut. Citra mempunyai elemen matriks yang disebut sebagai elemen gambar / piksel / picture element / pels yang menyatakan tingkat keabuan pada titik tersebut. Fungsi koordinat berukuran M × N merepresentasikan fungsi . Variabel M adalah baris dan variabel N adalah kolom sebagaimana ditunjukkan pada Gambar 1.
Gambar 1 Fungsi koordinat sebagai representasi cita digital
Citra mempunyai derajat keabuan berformat 8-bit dan 256 intensitas warna yang berkisar pada nilai 0 sampai 255. Nilai 0 menunjukan tingkat paling hitam dan 255 menunjukkan nilai paling putih (Gonzales 2002).
Ukuran statistik bagi data
Beberapa macam ukuran statistik digunakan untuk meringkaskan dan menjelaskan data. Ukuran tersebut adalah ukuran pemusatan dan keragaman. Secara bersama, kedua ukuran tersebut sangat berguna dalam menjelaskan sebaran yang menyusun data.
Ukuran pemusatan
Mendefinisikan ukuran numerik yang menjelaskan ciri-ciri penting sangat berguna untuk meyelidiki segugus data kuantitatif. Salah satu caranya adalah dengan menghitung nilai rata-rata. Rata-rata menunjukkan ukuran pusat jika data diurutkan dari kecil ke besar atau sebaliknya. Ukuran pemusatan yang sering digunakan adalah nilai tengah (rata-rata), median, dan modus.
Nilai tengah adalah ukuran lokasi yang paling umum digunakan dalam statistika. Salah satu kekurangan dari nilai ini adalah sangat terpengaruh dengan nilai pencilan. Berbeda dengan nilai tengah, median tidak terpengaruh dengan adanya pencilan. Median ditentukan dengan mengambil nilai tengah dari segugus data yang telah diurutkan. Jika jumlah data ganjil maka nilai yang diambil adalah yang
tepat ditengah namun jika jumlah data genap maka median adalah rata-rata dari kedua bilangan yang ditengah. Modus adalah data yang paling sering muncul. Modus adalah ukuran pemusatan yang jarang sekali digunakan.
Ukuran keragaman
Ukuran statistik yang paling penting untuk mengukur nilai keragaman adalah ragam. Ragam untk sebuah contoh acak x1, x2,…, xn
didefinisikan sebagai
Untuk memperoleh ukuran keragaman yang sesuai dengan satuan nilai asalnya maka digunakan nilai simpangan baku (standar deviasi). Simpangan baku dilambangankan dengan s didefinisikan sebagai akar dari ragam (Walpole 1995).
Histogram
Histogram dari sebuah citra digital dengan derajat keabuan antara [0, L-1] adalah fungsi diskret , dimana adalah derajat keabuan ke-k dan adalah jumlah piksel pada citra yang mempunyai derajat keabuan dengan k = 0, 1, 2, 3, …, L-1. Untuk menormalisasi histogram dapat dilakukan dengan membagi setiap nilai dengan total piksel pada citra dengan jumlah setiap komponen hasil normalisasi tersebut sama dengan 1. Histogram merupakan dasar dari banyak teknik pemrosesan domain spasial. Histogram dapat digunakan untuk memperbaiki citra, kompresi dan segmentasi citra (Gonzales 2002). Contoh citra dan histogramnya disajikan pada Gambar 2.
Gambar 2 Dua wajah yang berbeda dan histogramnya
3 Penelitian yang berkaitan dengan
penggunaan histogram sebagai dasar klasifikasi citra antara lain oleh Gibson & Gaydecki (1996) yang menggunakan histogram citra dalam pengenalan objek suatu organel dalam sebuah citra histologikal dengan menggunakan histogram matching serta Chunhong & Zhe (2001) yang menawarkan suatu metode berbasis pada fitur dari histogram citra menggunakan fuzzy ARTMAP neural network untuk mengklasifikasi citra.
Klasifikasi
Klasifikasi adalah serangkaian proses untuk menemukan model yang merepresentasikan dan membedakan kelas-kelas data. Dengan adanya klasifikasi diharapkan dapat memprediksi kelas dari data atau objek dengan menggunakan model yang sudah dibuat (Han & Kember 2001). Klasifikasi juga merupakan tahapan kedua pada algoritme VFI5.
Citra pelatihan tunggal (Single training
image)
Banyak algoritme pengenalan citra yang menggunakan mekanisme pembelajaran. Mekanisme ini membutuhkan sejumlah citra pelatihan yang cukup banyak. Algoritme – algoritme tersebut akan menurun akurasi pengenalannya jika menggunakan citra pelatihan tunggal (Tan, Chen, Zhou, dan Zhang 2006). Permasalahan ini diatasi dengan beberapa cara, yaitu
1 membuat citra pelatihan semu yang berasal dari citra tunggal telah dilakukan oleh Beymer dan Poggio (1995),
2 melokalisasi citra pelatihan telah dilakukan oleh Chen, Liu, and Zhou (2004),
3 probabilistic matching pada artikel yang ditulis oleh Martinez (2003),
4 dan neural network pada artikel yang ditulis oleh Tan X. et al.(2005).
Voting Feature Intervals (VFI5)
VFI5 adalah algoritme pengklasifikasian yang merepresentasikan deskripsi sebuah konsep dari sekumpulan interval nilai-nilai fitur. Pengklasifikasian instance baru berdasarkan voting pada klasifikasi yang dibuat oleh nilai tiap-tiap fitur secara terpisah. VFI5 merupakan algoritme klasifikasi yang bersifat non-incremental dan supervised (Güvenir et al. 1998). Algoritme VFI5 membuat interval yang berupa range atau point interval untuk setiap
fitur. Range interval terdiri atas nilai-nilai antara dua end point yang berdekatan namun tidak termasuk kedua end point tersebut.
Algoritme VFI5 cukup kokoh (robust) terhadap fitur yang tidak relevan namun mampu menghasilkan hasil yang baik pada real-world datasets yang ada. VFI5 mampu menghilangskan pengaruh yang kurang menguntungkan dari fitur yang tidak relevan dengan mekanisme voting-nya (Güvenir et al. 1998).
Algoritme VFI5 terdiri atas dua tahap yaitu: 1. Pelatihan
Hal pertama yang dilakukan pada proses pelatihan adalah menemukan end point setiap fitur f pada kelas data c. End point untuk fitur linear adalah nilai minimum dan maksimum dari suatu fitur. Sedangkan end point untuk struktur nominal adalah semua nilai yang berbeda yang ada pada fitur kelas yang sedang diamati. End point untuk setiap fitur f akan dimasukkan ke dalam array EndPoint[f]. Jika fitur adalah fitur linear maka akan dibentuk dua interval yaitu point interval yang terdiri dar semua nilai end point yang diperoleh dan range interval yang terdiri dari nila-nilai diantar dua end point yang berdekatan dan tidak termasik end point tersebut. Jika fitur adalah fitur nominal maka akan dibentuk point interval saja.
Batas bawah pada interval adalah -∞ sedangkan batas atas interval adalah +∞. Jumlah maksimum end point pada fitur linear adalah 2k sedangkan jumlah maksimum intervalnya adalah 4k+1, dengan k adalah jumlah kelas yang diamati. Selanjutnya jumlah instance pelatihan setiap kelas c dengan fitur f untuk setiap interval dihitung dan direpresentasikan sebagai interval_count[f,i,c]. Untuk setiap instance pelatihan, dicari interval i dimana nilai fitur f dari instance pelatihan e (ef) tersebut jatuh. Jika interval i adalah point
interval dan nilai ef sama dengan batas bawah
interval tersebut (sama dengan batas atas point interval) maka jumlah kelas instance pada interval i ditambah dengan 1. Jika interval i adalah range interval dan nilai ef jatuh pada
interval tersebut maka jumlah kelas instance ef
pada interval i ditambah 0.5. Hasil proses tersebut merupakan jumlah vote kelas c pada interval i. Algoritme VFI5 pada tahap pelatihan disajikan pada Gambar 3.
Gambar 3 Algoritme pelatihan pada VFI5
Gambar 4 Algoritme klasifikasi pada VFI5
2. Klasifikasi
Klasifikasi diawali dengan inisialisasi vote dengan nilai nol untuk setiap kelasnya. Untuk setiap fitur f, dicari interval i dimana ef jatuh,
dengan ef adalah nilai fitur f untuk instance tes
e. Jika nilai ef tidak diketahui maka fitur
tersebut tidak diikiusertakan dalam proses klasifikasi. Interval yang ditemukan dapat menyimpan instance dari beberapa kelas. Kelas-kelas direpresentasikan dengan nilai vote. Untuk setiap kelas c, fitur f memberikan vote yang sama dengan interval_vote[f, i, c]. Setiap feture f mengumpulkan vote-nya kemudian dijumlahkan untuk mendapatkan totalvote vector. Kelas dengan jumlah vote paling tinggi akan diprediksi sebagai kelas dari
instance e. Algoritme pada tahapan klasifikasi dalam VFI5 disajikan pada Gambar 4.
Penerapan VFI5 berdasarkan histogram
Penerapan VFI5 berdasarkan histogram adalah penggunaan nilai pada histogram sebagai fitur. Dari histogram citra yang berkisar antara 0-255 akan dibagi menjadi beberapa interval kemudian dihitung jumlah piksel yang mempunyai derajat keabuan pada interval tertentu. Interval-interval tersebut yang akan dijadikan fitur pada algoritme VFI5.
Pada tahapan pelatihan dilakukan normalisasi dengan merasiokan jumlah piksel setiap citra data latih dengan jumlah piksel Classify(e);/*e:example to be classfy*/
begin
for each class c vote[c] = 0 for each feature f
for each class c
feature_vote[f,c] = 0 /*vote of feature f for class c*/ if ef value is known
i = find_interval(f, ef) for each class c
feature_vote[f, c] = interval_vote[f, I, c]
vote[c] = vote [c] + feature_vote[f, c]*weight[f]; return the class c with highest vote[c];
end
train(TrainingSet) begin
for each feature f for each class c
EndPoints[f] = EndPoints[f]U find_end_points(TrainingSet,f,c); sort(endPoints[f]);
if f is linear
foreach end point p in EndPoints[f] form a poin interval from end poin p
form a range interval between p and the next endpoint p else /*if is normal*/
each distinc point in EndPoints[f] forms a point interval for each interval I on feature dimension f
for each class c
interval_count[f,I,c] = 0 count_instances(f,,TrainingSets);
for each interval I on feature dimension f for each class c
interval_vote[f,I,c] = interval_count[f,I,c]/class_count [c] normalize interval_vote[f,I,c]
/*such that interval_vote[f,I,c] = 1*/ end
5 citra seluruh data latih pada setiap intervalnya.
Nilai tersebut disebut vote untuk citra pada masing-masing kelasnya. Untuk lebih jelasnya akan diuraikan pada Tabel 1 dan Tabel 2. Dalam hal ini citra 1 dan citra 2 adalah citra dengan kelas yang berbeda karena data latih yang digunakan pada setiap kelasnya adalah data tunggal.
Tabel 1 Jumlah piksel pada setiap interval data latih
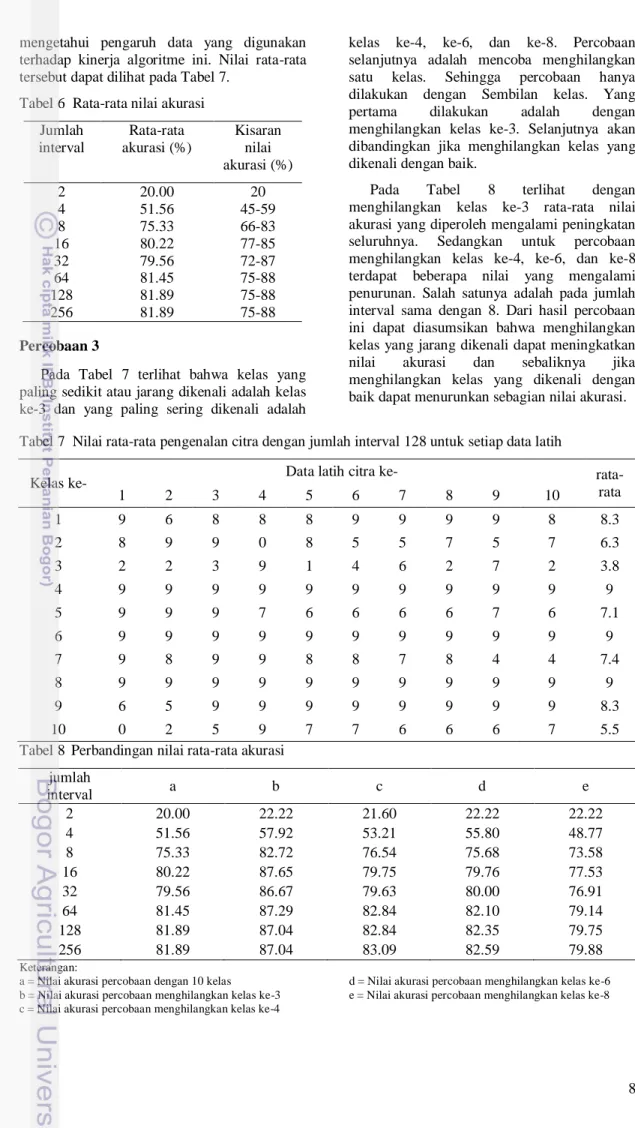
citra 1 citra 2 interval 1 a c interval 2 b d Pada tahap klasifikasi seluruh vote yang dihasilkan akan dikalikan dengan jumlah piksel pada citra uji. Misalkan, jumlah piksel citra uji pada interval 1 dan interval 2 berturut-turut f dan g. Maka hasil perkalian antar vote dengan jumlah piksel citra uji diilustrasikan pada Tabel 3.
Gambar 5 Penerapan VFI5 berdasarkan histogram
Tabel 2 Vote yang diperoleh
citra 1 citra 2 interval 1
interval 2
Tabel 3 Klasifikasi data uji
citra 1 citra 2 interval 1
interval 2
Jumlah h I Hasil perkalian dijumlahkan untuk setiap kelasnya kemudian dicari nilai yang paling besar. Nilai yang terbesar itulah yang menentukan citra tersebut diklasifikasikan ke kelas yang mana. Jika h lebih besar dari i maka citra uji tersebut diklasifikasikan pada kelas yang pertama (citra 1). Alur dari algoritme ini dapat dilihat pada Gambar 5.
METODE PENELITIAN
Penelitian ini dilakukan dengan beberapa tahapan proses. Mulai dari mempersiapkan data sampai dengan memperoleh nilai akurasi. Tahapan-tahapan tersebut disajikan secara lengkap pada Gambar 6.
Data
Data yang digunakan dalam penelitian ini adalah data sekunder dari Olivetti Research Laboratory dan dapat diperoleh dari url http://www.cl.cam.ac.uk/Research/DTG/attarch ive/pub/data/att_faces.zip. Data berupa 100 citra wajah, terdiri atas 10 wajah yang berbeda dengan 10 eskpresi yang berbeda pula. Data pada penelitian ini adalah data citra yang berformat pgm. Beberapa citra diambil pada waktu yang berbeda, variasi pencahayaan yang rendah, ekpresi wajah yang berbeda (membuka/menutup mata, tersenyum atau tidah tersenyum), dan penggunaan kacamata atau tidak. Seluruh citra diambil dengan latar belakang berwarna gelap yang seragam. Data tersebut akan dijadikan data latih dan data uji.
6 Gambar 6 Tahapan Penelitian
Histogram citra
Histogram dari sebuah citra digital dengan derajat keabuan antara [0, L-1] adalah fungsi diskret . adalah derajat keabuan ke-k dan adalah jumlah piksel pada citra yang mempunyai derajat keabuan dengan k = 0, 1, 2, 3, …, L-1. Tahapan ini adalah tahapan dimana data citra yang digunakan dihitung histogram citranya.
Data latih dan data uji
Dari histogram citra yang diperoleh, data citra dibagi menjadi data latih dan data uji. Data latih adalah data yang akan digunakan dalam tahap pelatihan. Dalam penelitian ini data latih yang digunakan adalah citra tunggal. Data uji adalah data yang digunakan untuk menguji pada tahap klasifikasi. Perbandingan antara data latih dan data uji adalah 1:9.
Algoritme VFI5
Seperti yang sudah dijelaskan sebelumnya, algoritme VFI5 terdiri atas dua tahap yaitu pelatihan dan klasifikasi. Input dari algoritme VFI5 ini adalah jumlah piksel pada setiap derajat keabuan yang diperoleh dari histogram citra. Nilai tersebut akan dibagi menjadi beberapa interval. Interval yang digunakan bervariasi untuk mengetahui pengaruh panjang interval terhadap hasil akurasi. Dalam penelitian ini interval yang digunakan 2, 4, 8,
16, 32, 64, 128,dan 256. Pemilihan nilai tersebut dimaksudkan untuk memudahkan dalam pembagian data.
Pada tahap pelatihan dihitung nilai vote tiap intervalnya untuk data latih pada masing-masing kelas. Nilai tersebut diperoleh dengan merasiokan jumlah piksel setiap citra data latih dengan jumlah piksel citra seluruh data latih pada setiap intervalnya. Dalam proses pelatihan, nilai histogram yang digunakan sebagai data latih hanya satu per orang.
Tahap klasifikasi dimulai dengan menghitung jumlah piksel yang mempunyai derajat keabuan sama pada data uji untuk masing-masing kelasnya. Kemudian mengalikan frekuensi tersebut dengan vote yang diperoleh pada tahap pelatihan. Setelah itu hasil perkalian dijumlahkan untuk masing-masing citra dan akan diperoleh hasil klasifikasi citra tersebut terhadap kelas yang ada. Hasil klasifikasi diambil dari nilai yang terbesar.
Menghitung akurasi
Tingkat akurasi yang diperoleh dihitung pada tahapan ini. Tingkat akurasi diperoleh dengan perhitungan:
Nilai akurasi digunakan untuk mengetahui kinerja dari suatu algoritme pengenalan. Nilai akurasi yang tinggi menandakan algoritme tersebut baik dalam mengenali.
HASIL DAN PEMBAHASAN
Salah satu tantangan utama dalam pengenalan wajah adalah bagaimana mengumpulkan sampel. Sampel yang baik adalah sampel yang bisa merepresentasikan seluruh data dengan baik. Sampel selanjutnya akan disebut data latih. Penelitian ini dimulai dengan pengumpulan data. Data yang digunakan adalah 10 wajah orang yang berbeda yang selanjutnya disebut kelas dengan 10 ekspresi berbeda pula untuk setiap orangnya selanjutnya disebut c1,c2,…,c10. Data yang
digunakan adalah data sekunder yang berasal dari Olivetti Research Laboratory. Data yang digunakan dan histogramnya disajikan pada Lampiran 1. Citra grayscale tersebut berformat pgm dan berukuran 92 × 112.
Citra grayscale memiliki derajat keabuan berkisar antar 0-255. Untuk mengetahui jumlah piksel pada masing-masing derajat keabuan
7 direpresentasikan dengan histogram. Perlakuan
pertama terhadap data-data penelitian ini adalah menghitung histogramnya. Kemudian dari interval antara 0-255 akan dibagi menjadi interval-interval bagian yang lebih kecil. Jumlah interval yang dipilih pada penelitian ini adalah 2, 4, 8, 16, 32, 64, 128, dan 256. Pemilihan interval-interval tersebut untuk memudahkan dalam pembagiannya.
Percobaan 1
Percobaan pertama kali yang dilakukan adalah dengan menggunakan citra pertama pada masing-masing orang sebagai data latih. Data uji yang digunakan adalah sembilan citra sisanya. Hasil yang diperoleh bisa dilihat pada Tabel 4. Pada Tabel 4 terlihat bahwa semakin banyak jumlah interval, nilai akurasi yang diperoleh semakin tinggi. Mulai dari jumlah interval 8, nilai akurasi lebih dari 75% sedangkan pada jumlah interval 2 dan 4 nilai akurasinya berkisar antara 20% hingga 60% Tabel 4 Hasil percobaan dengan citra pertama
(c1) sebagai data latih
Jumlah interval Akurasi ( % ) 2 20.00 4 58.89 8 75.56 16 77.78 32 75.56 64 76.67 128 77.78 258 77.78 .
Gambar 7 Grafik nilai akurasi rata-rata pengenalan wajah berdasarkan jumlah citra perorang (sumber: Tan, Chen, Zhou, dan Zhang 2006 )
Pada Tabel 4 juga dapat dilihat bahwa nilai akurasi terendah sebesar 20% dan tertinggi sebesar 77,78%. Nilai akurasi tersebut cukup baik karena menurut Tan, Chen, Zhou, dan
Zhang (2006), jika menggunakan single image untuk setiap orangnya maka nilai akurasi rata-rata jatuh menjadi 65%, mengalami penurunan 30% dari 95%. Lebih jelasnya bisa dilihat pada Gambar 7.
Untuk lebih meyakinkan nilai akurasi yang diperoleh, maka dilakukan pergantian data yang dijadikan data latih. Percobaan selanjutnya adalah mengubah data latih yang digunakan.
Percobaan 2
Percobaan ini terdiri dari beberapa sub percobaan. Data latih pada percobaan sebelumnya menggunakan c1 diubah
menggunakan c2, c3 dan seterusnya. Percobaan
ini bertujuan untuk mengetahui apakah algoritme pengenalan ini bekerja berdasarkan data yang digunakan. Hasil yang diperoleh pada percobaan dengan c2 sebagai data latih
dapat dilihat pada Tabel 5 dan rekapitulasinya dapat dilihat pada Lampiran 2.
Tabel 5 Hasil percobaan dengan citra kedua(c2) sebagai data latih
Jumlah interval Akurasi ( % ) 2 20.00 4 54.44 8 66.67 16 77.78 32 72.22 64 75.56 128 75.56 258 75.56
Pada Lampiran 2 terdapat grafik yang menunjukkan semakin banyak jumlah interval maka nilai akurasi yang diperoleh semakin tinggi.
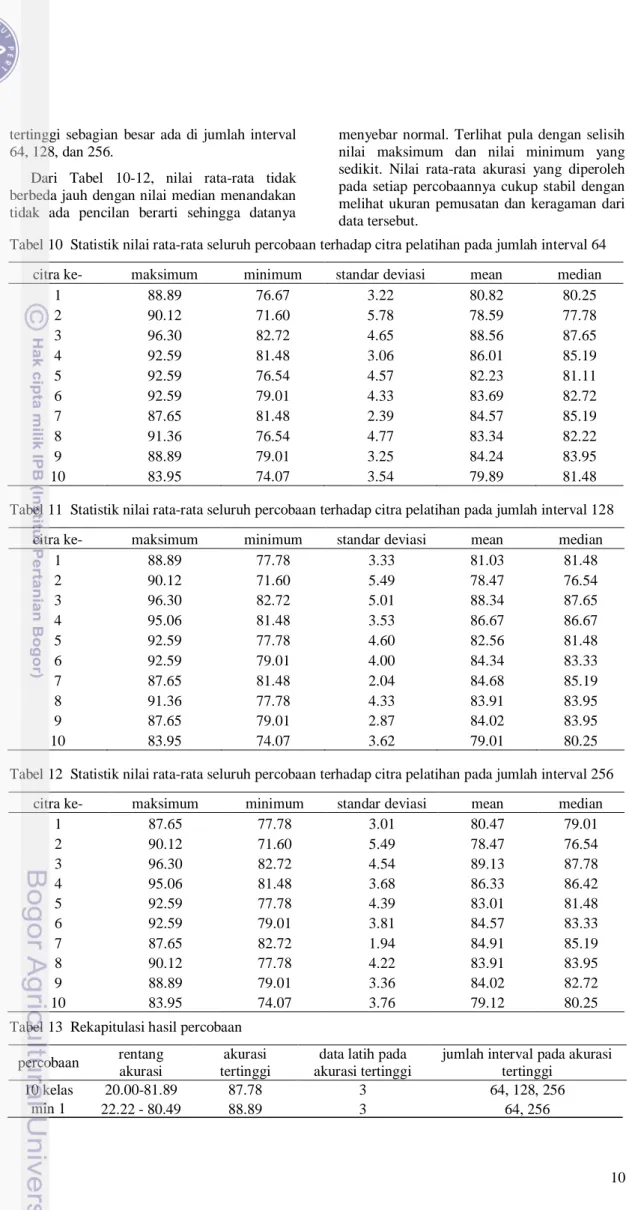
Berikut ini akan disajikan hasil rata-rata dan range keseluruhan nilai akurasi yang diperoleh dari percobaan 1 dan percobaan 2 pada setiap intervalnya dengan berbagai data latih. Nilai rata-rata dan kisarannya dapat dilihat pada Tabel 6. Dari Tabel 6 diperoleh kisaran nilai akurasi secara keseluruhan pada jumlah interval 2 dan 4 adalah 20% hingga 59% sedangkan jumlah interval 8 hingga 256 nilai akurasinya berkisar antara 66% s.d 88%. Selain itu dapat dilihat juga jumlah interval terkecil yang mempunyai rata-rata akurasi terbesar adalah 128. Oleh karena itu pada jumlah interval 128, dicek berapa jumlah kelas yang benar dan berapa yang salah diklasifikasikan. Hal ini dilakukan untuk
8 mengetahui pengaruh data yang digunakan
terhadap kinerja algoritme ini. Nilai rata-rata tersebut dapat dilihat pada Tabel 7.
Tabel 6 Rata-rata nilai akurasi Jumlah interval Rata-rata akurasi (%) Kisaran nilai akurasi (%) 2 20.00 20 4 51.56 45-59 8 75.33 66-83 16 80.22 77-85 32 79.56 72-87 64 81.45 75-88 128 81.89 75-88 256 81.89 75-88 Percobaan 3
Pada Tabel 7 terlihat bahwa kelas yang paling sedikit atau jarang dikenali adalah kelas ke-3 dan yang paling sering dikenali adalah
kelas ke-4, ke-6, dan ke-8. Percobaan selanjutnya adalah mencoba menghilangkan satu kelas. Sehingga percobaan hanya dilakukan dengan Sembilan kelas. Yang pertama dilakukan adalah dengan menghilangkan kelas ke-3. Selanjutnya akan dibandingkan jika menghilangkan kelas yang dikenali dengan baik.
Pada Tabel 8 terlihat dengan menghilangkan kelas ke-3 rata-rata nilai akurasi yang diperoleh mengalami peningkatan seluruhnya. Sedangkan untuk percobaan menghilangkan kelas ke-4, ke-6, dan ke-8 terdapat beberapa nilai yang mengalami penurunan. Salah satunya adalah pada jumlah interval sama dengan 8. Dari hasil percobaan ini dapat diasumsikan bahwa menghilangkan kelas yang jarang dikenali dapat meningkatkan nilai akurasi dan sebaliknya jika menghilangkan kelas yang dikenali dengan baik dapat menurunkan sebagian nilai akurasi.
Tabel 7 Nilai rata-rata pengenalan citra dengan jumlah interval 128 untuk setiap data latih
Kelas ke- Data latih citra ke- rata-rata 1 2 3 4 5 6 7 8 9 10 1 9 6 8 8 8 9 9 9 9 8 8.3 2 8 9 9 0 8 5 5 7 5 7 6.3 3 2 2 3 9 1 4 6 2 7 2 3.8 4 9 9 9 9 9 9 9 9 9 9 9 5 9 9 9 7 6 6 6 6 7 6 7.1 6 9 9 9 9 9 9 9 9 9 9 9 7 9 8 9 9 8 8 7 8 4 4 7.4 8 9 9 9 9 9 9 9 9 9 9 9 9 6 5 9 9 9 9 9 9 9 9 8.3 10 0 2 5 9 7 7 6 6 6 7 5.5 Tabel 8 Perbandingan nilai rata-rata akurasi
jumlah interval a b c d e 2 20.00 22.22 21.60 22.22 22.22 4 51.56 57.92 53.21 55.80 48.77 8 75.33 82.72 76.54 75.68 73.58 16 80.22 87.65 79.75 79.76 77.53 32 79.56 86.67 79.63 80.00 76.91 64 81.45 87.29 82.84 82.10 79.14 128 81.89 87.04 82.84 82.35 79.75 256 81.89 87.04 83.09 82.59 79.88 Keterangan:
a = Nilai akurasi percobaan dengan 10 kelas d = Nilai akurasi percobaan menghilangkan kelas ke-6 b = Nilai akurasi percobaan menghilangkan kelas ke-3 e = Nilai akurasi percobaan menghilangkan kelas ke-8 c = Nilai akurasi percobaan menghilangkan kelas ke-4
9 Tabel 9 Statistik nilai rata-rata akurasi seluruh percobaan terhadap jumlah interval
interval maksimum minimum Standar deviasi Rata-rata median 2 22.22 20 0.6767 21.96 22.22 4 57.92 48.77 3.3885 53.97 53.46 8 82.72 73.58 2.7626 76.95 76.54 16 87.65 77.53 3.0071 81.04 80.22 32 86.79 76.91 3.1456 80.96 80 64 89.88 79.14 3.0424 83.20 82.22 128 90.25 79.75 2.9889 83.30 82.35 256 90.12 79.88 2.9197 83.39 82.59
Hasil selengkapnya untuk percobaan menghilangkan kelas ke-3 dapat dilihat pada Lampiran 3 dan menghilangkan kelas yang dikenali dengan baik dapat dilihat pada Lampiran 4.
Walaupun terdapat perubahan nilai akurasi ketika menghilangkan sebuah kelas namun perubahan itu tidaklah terlalu signifikan karena masih dalam kisaran yang sama. Pada percobaan menghilangkan kelas-kelas yang lain yaitu kelas 1, 2, 5, 7, 9, dan 10 juga memberikan hasil dengan kisaran yang tidak jauh berbeda. Hasil dari percobaan-percobaan tersebut dapat dilihat pada Lampiran 5.
Dari keseluruhan percobaan menggunakan sembilan kelas, terdapat satu percobaan yang terbaik diantara percobaan yang lain. Percobaan tersebut adalah percobaan dengan menghilangkan kelas ke-2. Percobaan ini dikatakan terbaik dari yang lain karena kisaran nilai rata-rata yang diperoleh relatif lebih tinggi dariapa percobaan yang lain. Nilai rata-rata yang diperoleh berkisar antara 22,22% hingga 90,25%. Nilai tersebut bisa dilihat pada Lampiran 5.
Menentukan jumlah interval yang baik untuk pengenalan
Terdapat delapan variasi jumlah interval yang digunakan dalam penelitian ini. Akan ditentukan jumlah interval berapakah yang ideal untuk pengenalan agar akurasi yang diperoleh cukup baik. Dalam menentukan jumlah interval tersebut digunakan nilai statistik dari rata-rata akurasi pada setiap percobaan yang telah dilakukan. Nilai-nilai statistik yang dimaksud disajikan pada Tabel 10 dan selengkapnya pada Lampiran 6.
Tabel 9 adalah nilai statistik dari percobaan dengan menggunakan 10 kelas, percobaan menghilangkan kelas ke 1 hingga kelas ke 10. Pada Tabel 9 diperoleh nilai rata-rata pada jumlah interval 64, 128, dan 256 tidak jauh
berbeda dibandingkan dengan jumlah interval yang lainnya. Nilai maksimum, minimum, dan nilai median dari ketiga selang tersebut juga tidak jauh berbeda selisihnya. Jika melihat nilai standar deviasinya relatif lebih kecil dibandingkan jumlah interval 32. Nilai standar deviasi yang kecil menunjukkan keragaman yang kecil pula. Dengan kata lain semakin kecil nilai standar deviasi maka nilainya akan semakin mendekati seragam. Pada jumlah interval selain 64, 128, dan 256, nilai standar deviasinya memang ada yang lebih kecil lagi namun nilai rata-ratanya juga kecil. Sehingga jumlah interval yang disarankan untuk digunakan dalam pengenalan citra adalah jumlah interval 64, 128, dan 256.
Menentukan citra pelatihan yang handal
Citra pelatihan yang handal adalah citra yang bisa mewakili citra yang lainnya. Sehingga ketika dilakukan pengenalan maka sebagian besar citra uji dapat dikenali dengan baik. Jika sebelumnya menggunakan nilai statistik terhadap jumlah interval, kali ini menggunakan nilai statistik terhadap citra pelatihan yang digunakan. Nilai statistik yang akan digunakan untuk menentukan citra pelatihan yang handal diperoleh dari pada jumlah interval yang disarankan. Nilai-nilai tersebut disajikan pada Tabel 10, Tabel 11, dan Tabel 12 sedangkan untuk statistik selengkapnya disajikan pada Lampiran 7.
Dari Tabel 10, Tabel 11, dan Tabel 12 diperoleh nilai maksimum, minimum, dan rata-rata tertinggi dicapai ketika menggunakan citra pelatihan ke-3. Sehingga dapat dikatakan citra ke-3 relatif lebih handal untuk dijadikan citra pelatihan dibandingkan citra yang lain. diteliti lagi dari seluruh percobaan yang dirangkum pada Tabel 13, nilai akurasi tertinggi hampir pada setiap percobaan diperoleh dengan menggunakan citra pelatihan ke-3. Begitu juga untuk jumlah interval yang nilai akurasinya
10 tertinggi sebagian besar ada di jumlah interval
64, 128, dan 256.
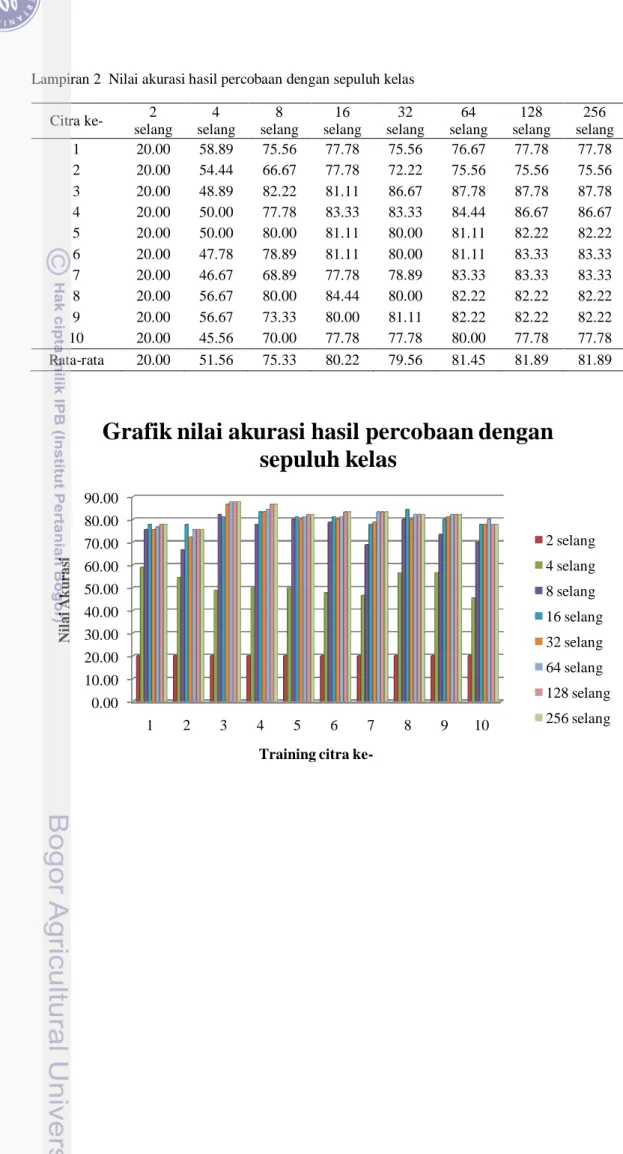
Dari Tabel 10-12, nilai rata-rata tidak berbeda jauh dengan nilai median menandakan tidak ada pencilan berarti sehingga datanya
menyebar normal. Terlihat pula dengan selisih nilai maksimum dan nilai minimum yang sedikit. Nilai rata-rata akurasi yang diperoleh pada setiap percobaannya cukup stabil dengan melihat ukuran pemusatan dan keragaman dari data tersebut.
Tabel 10 Statistik nilai rata-rata seluruh percobaan terhadap citra pelatihan pada jumlah interval 64
citra ke- maksimum minimum standar deviasi mean median 1 88.89 76.67 3.22 80.82 80.25 2 90.12 71.60 5.78 78.59 77.78 3 96.30 82.72 4.65 88.56 87.65 4 92.59 81.48 3.06 86.01 85.19 5 92.59 76.54 4.57 82.23 81.11 6 92.59 79.01 4.33 83.69 82.72 7 87.65 81.48 2.39 84.57 85.19 8 91.36 76.54 4.77 83.34 82.22 9 88.89 79.01 3.25 84.24 83.95 10 83.95 74.07 3.54 79.89 81.48
Tabel 11 Statistik nilai rata-rata seluruh percobaan terhadap citra pelatihan pada jumlah interval 128
citra ke- maksimum minimum standar deviasi mean median 1 88.89 77.78 3.33 81.03 81.48 2 90.12 71.60 5.49 78.47 76.54 3 96.30 82.72 5.01 88.34 87.65 4 95.06 81.48 3.53 86.67 86.67 5 92.59 77.78 4.60 82.56 81.48 6 92.59 79.01 4.00 84.34 83.33 7 87.65 81.48 2.04 84.68 85.19 8 91.36 77.78 4.33 83.91 83.95 9 87.65 79.01 2.87 84.02 83.95 10 83.95 74.07 3.62 79.01 80.25
Tabel 12 Statistik nilai rata-rata seluruh percobaan terhadap citra pelatihan pada jumlah interval 256
citra ke- maksimum minimum standar deviasi mean median 1 87.65 77.78 3.01 80.47 79.01 2 90.12 71.60 5.49 78.47 76.54 3 96.30 82.72 4.54 89.13 87.78 4 95.06 81.48 3.68 86.33 86.42 5 92.59 77.78 4.39 83.01 81.48 6 92.59 79.01 3.81 84.57 83.33 7 87.65 82.72 1.94 84.91 85.19 8 90.12 77.78 4.22 83.91 83.95 9 88.89 79.01 3.36 84.02 82.72 10 83.95 74.07 3.76 79.12 80.25 Tabel 13 Rekapitulasi hasil percobaan
percobaan rentang akurasi
akurasi tertinggi
data latih pada akurasi tertinggi
jumlah interval pada akurasi tertinggi
10 kelas 20.00-81.89 87.78 3 64, 128, 256 min 1 22.22 - 80.49 88.89 3 64, 256
11 Lanjutan percobaan rentang akurasi akurasi tertinggi
data latih pada akurasi tertinggi
jumlah interval pada akurasi tertinggi min 2 22.22 - 90.25 96.30 3 32, 64, 128, 256 min 3 22.22 - 87.29 96.30 3 32, 64, 128, 256 min 4 21.60 - 83.90 88.89 3 256 min 5 22.22 - 83.95 93.83 3 128, 256 min 6 22.22 - 82.59 88.89 3 64, 128, 256 min 7 22.22 - 82.10 88.89 9 64, 256 min 8 22.22 - 79.88 87.65 3 256 min 9 22.22 - 82.47 88.89 4 16 min 10 22.22 - 83.93 87.65 4 32, 64, 128, 256 min 10 22.22 - 83.93 87.65 7 64, 128, 256 min 10 22.22 - 83.93 87.65 8 64, 128, 256 Keterangan:
10 kelas : percobaan dengan menggunakan 10 kelas min i : percobaan menghilangkan kelas ke-i i : 1, 2, …, 10
Nilai akurasi tertinggi (lihat Tabel 13) yang peroleh pada penelitian ini cukup baik karena menurut Tan, Chen, Zhou, dan Zhang (2006) nilai akurasi akan menurun sebesar 30% jika menggunakan citra pelatihan tunggal. Dari 95% menurun menjadi 65%. Dibandingkan dengan penelitian sejenis, algoritme ini mempunyai beberapa kelebihan antara lain:
Jika citra diputar maka histogram citra akan sama seperti citra yang tidak diputar. Hal itu dikarenakan histogram citra tidak tergantung pada letak dari suatu piksel namun hanya pada derajat keabuannya. Dan input dari algoritme ini adalah nilai histogram citra. Berbeda dengan penelitian yang dilakukan Pramitasari, input yang digunakan adalah nilai piksel.
Bertambahnya ukuran citra tidak menambah fitur yang digunakan sebagai input algoritme VFI5 karena input yang digunakan pada penelitian ini adalah banyaknya interval yang digunakan.
KESIMPULAN DAN SARAN Kesimpulan
Dari penelitian ini didapatkan beberapa kesimpulan. Pertama, nilai akurasi yang dihasilkan dari pengenalan wajah dengan citra pelatihan tunggal menggunakan algoritme VFI5 berbasis histogram baik. Dengan nilai tertinggi pada percobaan menggunakan 10 kelas mencapai 87,78% dan untuk percobaan menggunakan sembilan kelas mencapai 96,3%. Dari keseluruhan hasil percobaan terlihat semakin banyak jumlah interval yang
digunakan maka nilai akurasinya semakin tinggi. Selain itu, didapatkan pula interval yang disarankan pada percobaan ini adalah interval adalah 64, 128, dan 256. Dan data yang relatif lebih handal untuk dijadikan data latih adalah citra ke-3.
Saran
Beberapa hal yang dapat dilakukan pada penelitian selanjutnya adalah dengan memproses data terlebih dahulu dengan menormalisasi intensitas atau tingkat keabuan data sehingga diharapkan dapat mengoptimalkan pengenalan. Selain itu perlu dilakukan penelitian dengan menggunakan teknik perata-rataan citra (image averaging) dan penambahan noise. Percobaan dengan memilih citra yang semuanya baik dikenali sebagai data latih juga perlu dilakukan selanjutnya. Misalkan, dengan melihat Tabel 7 dilakukan percobaan dengan menggunakan kombinasi data latih c1, c3, c4, c3,c3, c3, c3, c3,
c3, danc4. Percobaan yang menggunakan citra
pertama untuk kelas pertama, citra ketiga pada kelas kedua, dan seterusnya.
DAFTAR PUSTAKA
Apniasari AI. 2007. Diagnosis Penyakit Demam Berdarah dengan Menggunakan Voting Feature Intervals 5 [Skripsi]. Bogor: Departemen Ilmu Komputer, FMIPA, Institut Pertanian Bogor.
Beymer D and Poggio T. 1995. Face Recognition from One Example View,Science, 272(5250)
12 Chen SC, Liu J, and Zhou ZH. 2004. Making
FLDA applicable to face recognition with one sample per person. Pattern Recognition, 37(7) 1553-1555.
Chunhong J & Zhe C. 2001.Histogram-based image classification using fuzzy ARTMAP neural network. Proc. SPIE, Vol. 4555, 51 (2001); DOI:10.1117/12.441672
Gibson, D & Gaydecki PA.1996. The application of local grey level histograms to organelle classification in histological images.Computers in Biology and Medicine Volume 26, Issue 4, Page 329-337.
Gonzales, RC & RE Woods. 2002. Digital Image Processing. 2nd Edition. New Jersey: Prentice Hall.
Güvenir et al.1998. Learning Differential Diagnosis of Erythemato-squamous Diseases Using Voting Feature Intervals. Ankara: Departement of Computer Engineering and Information Science, Bilkent University.
Han J, Kember.2001.Data Mining Concept & Techniques.USA:Academic Press.
Karande KJ & Talbar SN. 2008. Face Recognition under Variation of Pose and Illumination using Independent Component Analysis.India: ICGST-GVIP.
Majumdar A & Ward RK.2008.Single Image Per Person Face Recognition with Image Synthesized by non-linear Approximation.IEEE 978-1-4244-1764-3/08
Martinez AM. 2003. Recognizing Expression Variant Faces from a Single Sample Image per Class, Proceedings of IEEE Computer Vision and Pattern Recognition (CVPR), 353-358.
Pramitasari N. 2009. Pengenalan citra wajah menggunakan algoritme VFI5 dengan praproses Transformasi Wavelet [Skripsi]. Bogor: Departemen Ilmu Komputer, FMIPA, Institut Pertanian Bogor.
Sulistyo AP. 2007. Pengaruh Incomplete Data Terhadap Akurasi Voting Feature Intervals-5 (VFIIntervals-5) [Skripsi]. Bogor: Departemen Ilmu Komputer, FMIPA, Institut Pertanian Bogor.
Tan X et al. 2005. Recognizing partially occluded, expression variant faces from single training image per person with SOM
and soft kNN ensemble. IEEE Transactions on Neural Networks, 16(4) 875-886. Walpole RE. 1995. Pengantar Statistik Edisi
ke-3. Jakarta:PT. Gramedia Pustaka Utama. Tan X, Chen S, Zhou ZH, dan Zhang F.
2006.“Face recognition from a single image per person: A survey”, Pattern Recognition, Vol. 39 (9), pp. 1725-1745.
14 Lampiran 1 Data yang digunakan
1. Orang Pertama
15 Lampiran 1 (lanjutan)
16 Lampiran 1 (lanjutan)
4. Orang Keempat
17 Lampiran 1 (lanjutan)
18 Lampiran 1 (lanjutan)
7. Orang Ketujuh
19 Lampiran 1 (lanjutan)
20 Lampiran 1 (lanjutan)
21 Lampiran 2 Nilai akurasi hasil percobaan dengan sepuluh kelas
Citra ke- 2 selang 4 selang 8 selang 16 selang 32 selang 64 selang 128 selang 256 selang 1 20.00 58.89 75.56 77.78 75.56 76.67 77.78 77.78 2 20.00 54.44 66.67 77.78 72.22 75.56 75.56 75.56 3 20.00 48.89 82.22 81.11 86.67 87.78 87.78 87.78 4 20.00 50.00 77.78 83.33 83.33 84.44 86.67 86.67 5 20.00 50.00 80.00 81.11 80.00 81.11 82.22 82.22 6 20.00 47.78 78.89 81.11 80.00 81.11 83.33 83.33 7 20.00 46.67 68.89 77.78 78.89 83.33 83.33 83.33 8 20.00 56.67 80.00 84.44 80.00 82.22 82.22 82.22 9 20.00 56.67 73.33 80.00 81.11 82.22 82.22 82.22 10 20.00 45.56 70.00 77.78 77.78 80.00 77.78 77.78 Rata-rata 20.00 51.56 75.33 80.22 79.56 81.45 81.89 81.89 0.00 10.00 20.00 30.00 40.00 50.00 60.00 70.00 80.00 90.00 1 2 3 4 5 6 7 8 9 10 N il ai A k u r as i
Training citra
ke-Grafik nilai akurasi hasil percobaan dengan
sepuluh kelas
2 selang 4 selang 8 selang 16 selang 32 selang 64 selang 128 selang 256 selang22 Lampiran 3 Tabel pengenalan citra dengan menghilangkan kelas yang paling sedikit dikenali
data latih citra ke- jumlah interval 2 selang 4 selang 8 selang 16 selang 32 selang 64 selang 128 selang 256 selang 1 22.22 64.2 85.19 86.41 83.95 82.72 82.72 82.72 2 22.22 56.79 72.83 82.72 82.72 85.19 83.95 83.95 3 22.22 55.56 90.12 90.12 96.30 96.30 96.3 96.30 4 22.22 50.62 77.78 83.95 85.19 85.19 85.19 85.19 5 22.22 55.56 87.65 87.65 90.12 92.59 92.59 92.59 6 22.22 64.32 88.89 91.36 90.12 88.89 88.89 88.89 7 22.22 55.56 77.78 86.42 83.95 85.19 85.19 85.19 8 22.22 64.2 86.42 92.59 88.89 91.36 90.12 90.12 9 22.22 61.73 82.72 86.42 83.95 82.72 82.72 82.72 10 22.22 50.62 77.78 88.89 81.48 82.72 82.72 82.72 rata-rata 22.22 57.916 82.716 87.653 86.667 87.287 87.039 87.039
23 Lampiran 4 Tabel nilai akurasi percobaan dengan menghilangkan kelas yang dikenali dengan baik
Menghilangkan kelas ke-4
citra ke- Jumlah interval 2 selang 4 selang 8 selang 16 selang 32 selang 64 selang 128 selang 256 selang 1 22.22 64.20 75.31 77.78 79.01 81.48 81.48 79.01 2 22.22 51.85 71.61 80.25 77.78 85.18 83.95 83.95 3 22.22 55.56 77.78 80.25 81.48 87.65 87.65 88.89 4 22.22 41.97 77.78 81.48 82.72 83.95 83.95 82.72 5 22.22 55.56 80.25 80.25 79.01 80.25 80.25 81.48 6 22.22 56.79 79.01 79.01 77.78 80.25 80.25 82.72 7 16.04 49.38 70.37 79.01 76.54 81.48 82.72 82.72 8 22.22 55.56 77.78 81.48 79.01 80.25 80.25 81.48 9 22.22 51.85 79.01 80.25 82.72 86.41 86.41 86.41 10 22.22 49.38 76.54 77.78 80.25 81.48 81.48 81.48 rata-rata 21.60 53.21 76.54 79.75 79.63 82.84 82.84 83.09
Menghilangkan kelas ke-6
citra ke- Jumlah interval 2 selang 4 selang 8 selang 16 selang 32 selang 64 selang 128 selang 256 selang 1 22.22 60.49 75.31 79.01 77.78 81.48 81.48 81.48 2 22.22 62.96 69.14 71.64 70.37 72.84 72.84 72.84 3 22.22 60.49 80.25 81.48 82.72 85.19 82.72 83.95 4 22.22 55.56 82.72 83.95 86.42 88.89 88.89 88.89 5 22.22 53.09 79.01 82.72 79.01 79.01 80.25 80.25 6 22.22 46.91 75.31 81.48 77.78 80.25 82.72 82.72 7 22.22 48.15 69.14 75.31 79.01 85.19 85.19 86.42 8 22.22 56.79 79.01 82.72 81.48 81.48 83.95 83.95 9 22.22 59.26 76.54 81.48 83.95 85.19 85.19 85.19 10 22.22 54.32 70.37 77.78 81.48 81.48 80.25 80.25 rata-rata 22.22 55.80 75.68 79.76 80.00 82.10 82.35 82.59
Menghilangkan kelas ke-8
citra ke- Jumlah interval 2 selang 4 selang 8 selang 16 selang 32 selang 64 selang 128 selang 256 selang 1 22.22 64.20 79.01 76.54 74.07 79.01 79.01 79.01 2 22.22 45.68 66.67 75.31 72.84 75.31 76.54 76.54 3 22.22 49.38 77.78 81.48 81.48 85.19 83.95 87.65 4 22.22 49.38 75.31 80.25 79.01 81.48 81.48 81.48 5 22.22 48.15 76.54 80.25 77.78 76.54 77.78 77.78 6 22.22 44.44 75.31 79.01 77.78 80.25 81.48 81.48 7 22.22 40.74 66.67 74.07 76.54 81.48 82.72 82.72 8 22.22 51.85 79.01 77.78 79.01 77.78 79.01 77.78 9 22.22 54.32 72.84 77.78 76.54 80.25 81.48 80.25 10 22.22 39.51 66.67 72.84 74.07 74.07 74.07 74.07 rata-rata 22.22 48.77 73.58 77.53 76.91 79.14 79.75 79.88
24 Lampiran 5 Nilai akurasi dengan menghilangkan kelas 1, 2, 5, 7, 9, dan 10
Menghilangkan kelas ke-1
citra ke- Jumlah interval 2 selang 4 selang 8 selang 16 selang 32 selang 64 selang 128 selang 256 selang 1 22.22 70.37 77.78 76.54 79.01 80.25 82.72 80.25 2 22.22 58.02 71.60 76.54 75.31 77.78 76.54 76.54 3 22.22 55.56 79.01 80.25 80.25 88.89 87.65 88.89 4 22.22 54.32 80.25 82.72 82.72 83.95 83.95 83.95 5 22.22 58.02 80.25 81.48 79.01 80.25 80.25 80.25 6 22.22 54.32 74.07 79.01 76.54 79.01 79.01 79.01 7 22.22 51.85 65.43 75.31 75.31 81.48 81.48 82.72 8 22.22 64.20 76.54 79.01 79.01 76.54 77.78 77.78 9 22.22 62.96 74.07 75.31 76.54 79.01 79.01 79.01 10 22.22 46.91 65.43 76.54 76.54 77.78 76.54 76.54 rata-rata 22.22 57.65 74.44 78.27 78.02 80.49 80.49 80.49 Menghilangkan kelas ke-2
citra ke- Jumlah interval 2 selang 4 selang 8 selang 16 selang 32 selang 64 selang 128 selang 256 selang 1 22.22 66.67 85.19 85.19 88.89 88.89 88.89 87.65 2 22.22 61.73 76.54 86.42 87.65 90.12 90.12 90.12 3 22.22 55.56 83.95 87.65 96.30 96.30 96.30 96.30 4 22.22 48.15 85.19 91.36 92.59 92.59 95.06 95.06 5 22.22 55.56 82.72 88.89 87.65 88.89 90.12 90.12 6 22.22 59.26 83.95 83.95 81.48 92.59 92.59 92.59 7 22.22 55.56 75.31 79.01 82.72 86.42 86.42 86.42 8 22.22 58.02 76.54 81.48 83.95 90.12 91.36 90.12 9 22.22 58.02 80.25 85.19 85.19 88.89 87.65 88.89 10 22.22 54.32 77.78 82.72 81.48 83.95 83.95 83.95 rata-rata 22.22 57.29 80.74 85.19 86.79 89.88 90.25 90.12 Menghilangkan kelas ke-5
citra ke- Jumlah interval 2 selang 4 selang 8 selang 16 selang 32 selang 64 selang 128 selang 256 selang 1 22.22 53.01 72.84 76.54 76.54 79.01 79.01 79.01 2 22.22 44.44 69.14 75.31 70.37 71.60 71.60 71.60 3 22.22 46.91 80.27 82.72 87.65 92.59 93.83 93.83 4 22.22 46.91 79.01 83.95 85.19 86.42 87.65 86.42 5 22.22 48.19 85.19 83.95 82.72 82.72 82.72 82.72 6 22.22 46.91 79.01 82.72 81.48 87.65 87.65 87.65 7 22.22 49.38 75.31 77.78 82.72 86.42 85.19 85.19 8 22.22 53.09 77.78 81.48 82.72 85.19 83.95 83.95 9 22.22 53.09 76.54 81.48 80.25 83.95 83.95 82.72 10 22.22 46.91 77.78 82.72 85.19 83.95 82.72 83.95 rata-rata 22.22 48.88 77.29 80.87 81.48 83.95 83.83 83.70
25 Lampiran 5 lanjutan
Menghilangkan kelas ke-7
citra ke- Jumlah interval 2 selang 4 selang 8 selang 16 selang 32 selang 64 selang 128 selang 256 selang 1 22.22 50.62 74.07 76.54 76.54 80.25 77.78 77.78 2 22.22 51.85 62.96 72.84 74.07 75.31 75.31 75.31 3 22.22 54.32 81.48 81.48 85.19 83.95 85.19 86.42 4 22.22 50.62 72.84 82.72 81.48 83.95 85.19 83.95 5 22.22 50.62 77.78 80.25 80.25 81.48 81.48 81.48 6 22.22 51.85 79.01 79.01 77.78 82.72 82.72 82.72 7 22.22 58.02 74.07 79.01 79.01 83.95 83.95 83.95 8 22.22 58.02 77.78 80.25 79.01 82.72 83.95 85.19 9 22.22 56.79 76.54 80.25 83.95 88.89 87.65 88.89 10 22.22 51.85 70.37 77.78 79.01 77.78 75.31 75.31 rata-rata 22.22 53.46 74.69 79.01 79.63 82.10 81.85 82.10 Menghilangkan kelas ke-9
citra ke- Jumlah interval 2 selang 4 selang 8 selang 16 selang 32 selang 64 selang 128 selang 256 selang 1 22.22 62.96 79.01 80.25 76.54 77.78 77.78 77.78 2 22.22 44.44 67.90 79.01 76.54 77.78 77.78 77.78 3 22.22 51.85 77.78 81.48 85.19 87.65 87.65 87.65 4 22.22 43.21 81.48 88.89 87.65 87.65 87.65 87.65 5 22.22 59.26 79.01 81.48 80.25 81.48 81.48 82.72 6 22.22 46.91 82.72 83.95 82.72 83.95 85.19 85.19 7 22.22 59.26 79.01 83.95 81.48 87.65 87.65 87.65 8 22.22 58.02 80.25 81.48 81.48 81.48 82.72 82.72 9 22.22 54.32 76.54 81.48 80.25 82.72 81.48 81.48 10 22.22 41.98 70.37 80.25 71.61 74.07 74.07 74.07 rata-rata 22.22 52.22 77.41 82.22 80.37 82.22 82.35 82.47 Menghilangkan kelas ke-10
citra ke- Jumlah interval 2 selang 4 selang 8 selang 16 selang 32 selang 64 selang 128 selang 256 selang 1 22.22 64.20 76.54 82.72 81.48 81.48 82.72 82.72 2 22.22 59.26 74.07 76.54 76.54 77.78 79.01 79.01 3 22.22 62.96 80.25 83.95 82.72 82.72 82.72 82.72 4 22.22 55.56 82.72 85.19 87.65 87.65 87.65 87.65 5 22.22 51.85 77.78 79.01 79.01 80.25 79.01 81.48 6 22.22 46.91 80.25 80.25 77.78 83.95 83.95 83.95 7 22.22 53.09 76.54 77.78 80.25 87.65 87.65 87.65 8 22.22 59.26 83.95 85.19 82.72 87.65 87.65 87.65 9 22.22 59.26 77.78 82.72 85.19 86.42 86.42 86.42 10 22.22 56.79 70.37 76.54 81.48 81.48 80.25 80.25 rata-rata 22.22 56.91 78.03 80.99 81.48 83.70 83.70 83.95
26 Lampiran 6 Statistik nilai rata-rata hasil seluruh percobaan terhadap jumlah interval
Jumlah interval
Percobaan Nilai statistik 10
kelas min 1 min 2 min 3 min 4 min 5 min 6 min 7 min 8 min 9 min
10 maks min std dev mean median 2 20 22.22 22.22 22.22 21.6 22.22 22.22 22.22 22.22 22.22 22.22 22.22 20 0.6767 21.96 22.22 4 51.56 57.65 57.29 57.92 53.21 48.88 55.8 53.46 48.77 52.22 56.91 57.92 48.77 3.3885 53.97 53.46 8 75.33 74.44 80.74 82.72 76.54 77.29 75.68 74.69 73.58 77.41 78.03 82.72 73.58 2.7626 76.95 76.54 16 80.22 78.27 85.19 87.65 79.75 80.87 79.76 79.01 77.53 82.22 80.99 87.65 77.53 3.0071 81.04 80.22 32 79.56 78.02 86.79 86.67 79.63 81.48 80 79.63 76.91 80.37 81.48 86.79 76.91 3.1456 80.96 80 64 81.45 80.49 89.88 87.29 82.84 83.95 82.1 82.1 79.14 82.22 83.7 89.88 79.14 3.0424 83.20 82.22 128 81.89 80.49 90.25 87.04 82.84 83.83 82.35 81.85 79.75 82.35 83.7 90.25 79.75 2.9889 83.30 82.35 256 81.89 80.49 90.12 87.04 83.09 83.7 82.59 82.1 79.88 82.47 83.95 90.12 79.88 2.9197 83.39 82.59 Keterangan:
10 kelas : Percobaan dengan menggunakan 10 kelas
Min i : Percobaan menghilangkan kelas ke-i, i = 1, 2, 3,…, 10 Maks : Nilai maksimum
Min : Nilai minimum Std dev : Nilai standar deviasi Mean : Nilai rata-rata Median : Nilai median
27 Lampiran 7 Statistik nilai rata-rata hasil seluruh percobaan terhadap citra pelatihan yang digunakan
Jumlah interval 64
citra ke-
Percobaan Nilai statistik
10
kelas min 1 min 2 min 3 min 4 min 5 min 6 min 7 min 8 min 9 min 10 maks min std dev mean median 1 76.67 80.25 88.89 82.72 81.48 79.01 81.48 80.25 79.01 77.78 81.48 88.89 76.67 3.220 80.82 80.25 2 75.56 77.78 90.12 85.19 85.18 71.60 72.84 75.31 75.31 77.78 77.78 90.12 71.60 5.784 78.59 77.78 3 87.78 88.89 96.30 96.30 87.65 92.59 85.19 83.95 85.19 87.65 82.72 96.30 82.72 4.653 88.56 87.65 4 84.44 83.95 92.59 85.19 83.95 86.42 88.89 83.95 81.48 87.65 87.65 92.59 81.48 3.058 86.01 85.19 5 81.11 80.25 88.89 92.59 80.25 82.72 79.01 81.48 76.54 81.48 80.25 92.59 76.54 4.570 82.23 81.11 6 81.11 79.01 92.59 88.89 80.25 87.65 80.25 82.72 80.25 83.95 83.95 92.59 79.01 4.325 83.69 82.72 7 83.33 81.48 86.42 85.19 81.48 86.42 85.19 83.95 81.48 87.65 87.65 87.65 81.48 2.390 84.57 85.19 8 82.22 76.54 90.12 91.36 80.25 85.19 81.48 82.72 77.78 81.48 87.65 91.36 76.54 4.770 83.34 82.22 9 82.22 79.01 88.89 82.72 86.41 83.95 85.19 88.89 80.25 82.72 86.42 88.89 79.01 3.251 84.24 83.95 10 80.00 77.78 83.95 82.72 81.48 83.95 81.48 77.78 74.07 74.07 81.48 83.95 74.07 3.539 79.89 81.48 Jumlah interval 128 citra ke-
Percobaan Nilai statistik
10
kelas min 1 min 2 min 3 min 4 min 5 min 6 min 7 min 8 min 9 min 10 maks min std dev mean median 1 77.78 82.72 88.89 82.72 81.48 79.01 81.48 77.78 79.01 77.78 82.72 88.89 77.78 3.326 81.03 81.48 2 75.56 76.54 90.12 83.95 83.95 71.60 72.84 75.31 76.54 77.78 79.01 90.12 71.60 5.490 78.47 76.54 3 87.78 87.65 96.30 96.30 87.65 93.83 82.72 85.19 83.95 87.65 82.72 96.30 82.72 5.010 88.34 87.65 4 86.67 83.95 95.06 85.19 83.95 87.65 88.89 85.19 81.48 87.65 87.65 95.06 81.48 3.526 86.67 86.67 5 82.22 80.25 90.12 92.59 80.25 82.72 80.25 81.48 77.78 81.48 79.01 92.59 77.78 4.601 82.56 81.48 6 83.33 79.01 92.59 88.89 80.25 87.65 82.72 82.72 81.48 85.19 83.95 92.59 79.01 4.002 84.34 83.33 7 83.33 81.48 86.42 85.19 82.72 85.19 85.19 83.95 82.72 87.65 87.65 87.65 81.48 2.043 84.68 85.19 8 82.22 77.78 91.36 90.12 80.25 83.95 83.95 83.95 79.01 82.72 87.65 91.36 77.78 4.328 83.91 83.95 9 82.22 79.01 87.65 82.72 86.41 83.95 85.19 87.65 81.48 81.48 86.42 87.65 79.01 2.866 84.02 83.95 10 77.78 76.54 83.95 82.72 81.48 82.72 80.25 75.31 74.07 74.07 80.25 83.95 74.07 3.622 79.01 80.25
28 Lampiran 7 lanjutan
Jumlah interval 256
citra ke-
Percobaan Nilai statistik
10
kelas min 1 min 2 min 3 min 4 min 5 min 6 min 7 min 8 min 9 min 10 maks min std dev mean median 1 77.78 80.25 87.65 82.72 79.01 79.01 81.48 77.78 79.01 77.78 82.72 87.65 77.78 3.014 80.47 79.01 2 75.56 76.54 90.12 83.95 83.95 71.60 72.84 75.31 76.54 77.78 79.01 90.12 71.60 5.490 78.47 76.54 3 87.78 88.89 96.30 96.30 88.89 93.83 83.95 86.42 87.65 87.65 82.72 96.30 82.72 4.544 89.13 87.78 4 86.67 83.95 95.06 85.19 82.72 86.42 88.89 83.95 81.48 87.65 87.65 95.06 81.48 3.682 86.33 86.42 5 82.22 80.25 90.12 92.59 81.48 82.72 80.25 81.48 77.78 82.72 81.48 92.59 77.78 4.390 83.01 81.48 6 83.33 79.01 92.59 88.89 82.72 87.65 82.72 82.72 81.48 85.19 83.95 92.59 79.01 3.814 84.57 83.33 7 83.33 82.72 86.42 85.19 82.72 85.19 86.42 83.95 82.72 87.65 87.65 87.65 82.72 1.937 84.91 85.19 8 82.22 77.78 90.12 90.12 81.48 83.95 83.95 85.19 77.78 82.72 87.65 90.12 77.78 4.220 83.91 83.95 9 82.22 79.01 88.89 82.72 86.41 82.72 85.19 88.89 80.25 81.48 86.42 88.89 79.01 3.356 84.02 82.72 10 77.78 76.54 83.95 82.72 81.48 83.95 80.25 75.31 74.07 74.07 80.25 83.95 74.07 3.765 79.12 80.25