16
BAB II
DASAR TEORI
Bab ini berisi penjelasan tentang beberapa teori dasar yang digunakan selama pelaksanaan Tugas Akhir. Pembahasan dilakukan terhadap kompilator, lexical analyzer, parser, code generator dan pembahasan singkat perbandingan bahasa C dan Pascal.
2.1 Kompilator
Kompilator adalah suatu program atau sekelompok program yang menerjemahkan kode dalam satu bahasa ke bahasa lainnya, pada umumnya adalah dari bahasa komputer tingkat tinggi diterjemahkan ke bahasa rakitan (assembly) [HOL92], kode dalam bahasa rakitan ini kemudian diproses oleh program lain yang disebut assembler, yang menerjemahkannya menjadi kode bahasa mesin. Meski demikian, adapula kompilator yang menerjemahkan kode dari bahasa tingkat tinggi langsung ke bahasa mesin (biner).
Kompilator adalah program yang rumit dan kompleks, karena terdiri dari banyak upa bagian dan proses. Masing-masing bagian dan proses ini disebut phases (fase), yang saling berkomunikasi satu sama lain, lewat temprorary file (berkas sementara). Kompilator pada umumnya memiliki empat fase, sebagaimana ditampilkan pada gambar II-1, yaitu : fase 1 (preprocessing), fase 2 (penganalisis leksikal, penganalisis sintaks, table simbol, pembangkitan kode/code generation), fase 3 (optimasi kode) dan fase 4 (back end) [HOL92]. Meski demikian, terdapat banyak sekali variasi pada pembagian fase ini. Ada kompilator yang tidak mempunyai preprocessor, sebagian yang lain langsung menerjemahkan kode bahasa rakitan pada fase 2, lainnya lagi tidak memiliki fase 4, dll.
Gambar II-1 Alur kerja kompilator empat fase [HOL92]
Fase 1 adalah preprocessing, berkaitan dengan membuang bagian-bagian yang tidak diperlukan dalam proses kompilasi, seperti komentar dalam kode, pengaturan eksekusi kompilator lewat line-control atau compiler directive, dll. Fase 2 adalah inti dari kompilator, karena didalamnya proses penerjemahan kode dilakukan. Proses utama dalam tugas akhir ini juga berkaitan erat dengan fase 2. Karena itu, penjelasan tentang fase 2 perlu dijabarkan secara lebih detil pada upa bab berikutnya. Fase 3 adalah optimasi, bertujuan meningkatkan kualitas
kode yang dihasilkan, kualitas dalam hal ini bisa berarti kecepatan eksekusi, manajemen memori, ukuran berkas keluaran, dll. Fase 4 (back end) adalah penerjemahan menjadi kode bahasa rakitan atau langsung menjadi bahasa mesin biner oleh program lain yang disebut assembler.
2.2 Penganalisis Leksikal / Lexical Analyzer
Penganalisis leksikal berfungsi memisahkan kode menjadi bagian-bagian yang bermakna dalam bahasa yang diolah kompilator, bagian-bagian ini disebut token. penganalisis leksikal bekerja langsung mengambil data dari berkas / stream, lalu memecahnya menjadi token-token. Misal, penganalisis leksikal bahasa C, akan mengambil token dari suatu berkas kode sumber berupa 'while', 'do', 'int', '_var', '<', '<=', dll. Token adalah rangkaian karakter yang membentuk simbol yang bermakna dalam suatu bahasa. Penganalisis leksikal bekerja bersama dengan penganalisis sintaks sebagai subrutin yang dipanggil oleh penganalisis sintaks. [AHO77]
2.3 Penganalisis Sintaks / Grammar
Penganalisis sintaks berfungsi memeriksa apakah kode sumber sesuai dengan tata bahasa yang digunakan. Misal: dalam bahasa C, token 'int' harus diikuti oleh suatu identifier pada kasus deklarasi identifier.
int john; int doe;
maka grammar yang dipakai oleh penganalisis sintaks adalah
<deklarasi-variabel> ::= <tipe-variabel> <identifier> ';' (*)
penganalisis sintaks berusaha mencocokkan <tipe-variabel> dengan token 'int' dan <identifier> dengan 'john' serta 'doe'. Notasi yang dipakai pada aturan (*) untuk menyatakan grammar seperti diatas disebut notasi BNF (Backus Naur Form), dan item yang dikurung dengan tanda < > disebut meta-variabel. Tiap kali penganalisis sintaks berusaha mencocokkan meta-variabel, penganalisis sintaks memanggil rutin penganalisis leksikal yang
akan mengembalikan token yang didapat dari input stream. Token ini kemudian dicocokkan apakah sesuai dengan aturan (*). Jika sesuai maka, penganalisis sintaks akan melakukan pemrosesan lebih lanjut sesuai dengan algoritma parsing yang dipakai. Jika tidak sesuai, penganalisis sintaks akan berusaha mencari aturan lain yang memungkinkan keadaan proses parsing saat ini cocok, dengan cara berkonsultasi menggunakan tabel parsing.
Ada dua macam tipe algoritma parsing yaitu : top-down dan bottom-up. Pendekatan top-down bekerja dengan menurunkan meta-variabel pada tiap aturan dalam grammar hingga ke level token. Sedangkan pendekatan bottom-up bekerja sebaliknya, dengan mereduksi token menjadi aturan-aturan dalam grammar, hingga ke accepting state.
2.3.1 Bottom-up Parser
Parser yang dihasilkan oleh yacc /bison termasuk jenis bottom-up parser, yaitu parser yang bekerja menggunakan push-down automaton untuk membangun pohon parsing dari bawah ke atas ( dari token direduksi menjadi rule ). Proses parsing dimulai dari simpul pohon paling bawah ( daun ) , dan ketika telah cukup mengumpulkan sejumlah simpul lain dalam satu level (maksudnya mencocoki satu aturan parsing yang ada dalam grammar), simpul-simpul ini kemudian disatukan dengan membuat satu simpul pada satu level diatasnya ( simpul akar / root ). Proses ini dinamakan sebagai reduksi.
Karena parser bottom-up adalah push-down automaton maka parser ini membutuhkan tabel state, yang menentukan arah proses berikutnya, dari suatu state. Dan juga membutuhkan suatu stack, untuk mencatat state saat ini berada. Dari sudut pandang stack, algoritma parsing bottom-up adalah sebagai berikut :
a. Jika puncak stack saat ini, mencocoki item bagian sebelah kanan suatu aturan produksi pada grammar, maka puncak stack ini harus di-pop, dan diganti ( push ) dengan item di sebelah kirinya ( proses reduksi ).
b. Jika tidak, lakukan push simbol yang saat ini dibaca oleh scanner ke stack, dan lakukan proses advance ( pembacaan token berikutnya pada stream oleh scanner ). Proses ini disebut shift.
simbol akhir yang diterima sebagai accepting state ), maka proses parsing telah selesai. Namun jika tidak, kembali ke langkah a. [HOL92]
2.3.2 Top-down parser
Prinsip kerja dari top-down parser berkebalikan dengan bottom-up parser. Pada parser tipe ini, aturan produksi pada grammar direduksi menjadi token, untuk kemudian dicocokkan dengan masukan. Dibandingkan dengan bottom-up parser, parser tipe ini kurang dalam segi performansi [HOL92]. Sebagaimana bottom-up parser, top-down parser menggunakan stack untuk operasinya, hanya saja parser tipe ini menggunakan metode rekursif dalam menurunkan grammar-nya. Top-down parser menggunakan prinsip recursive-descent parsing.
2.4 Pembangkitan
Kode
Proses pembangkitan kode dilakukan dengan menelusuri pohon sintaks hasil proses parsing. Pada bottom-up penganalisis sintaks, pembangkitan kode dilakukan dalam bentuk syntax directed translation, sebelum proses reduksi dilakukan. Hasil keluaran dari tahapan ini sangat bervariasi, bergantung dari kompilator. Beberapa kompilator multi fase menghasilkan intermediate language, sedangkan jenis lainnya langsung memproduksi kode biner.
Misal, kompilator mengevaluasi ekspresi : 1 + 2 * 3 + 4, asumsi grammar yang digunakan menganggap precedence dari operator kali '*' lebih tinggi dari operator tambah '+'. Maka pohon parsing-nya adalah sebagai berikut :
<+ , t0>
<+ , t0> <4 , t1>
<1 , t0> <* , t1>
<2 , t1> <3 , t2> Gambar II-2 Pohon Parsing
(ket : t0,t1 & t2 adalah variabel temporer yang disediakan kompilator, pada kompilator yang sebenarnya variabel temporer ini menyatakan register mesin atau runtime stack)
Maka kompilator akan menghasilkan kode intermediate language sebagai berikut :
t0 = 1 t1 = 2 t2 = 3 t1 *= t2 t0 += t1 t1 = 4 t0 += t1
Ada dua masalah utama yang harus diatasi saat pembangunan modul pembangkit kode: 1. mekanisme untuk mengalokasikan variabel temporer / sementara
2. menentukan nama dari variabel temporer yang menangani nilai suatu ekspresi yang telah dievaluasi sebagian, pada satu waktu tertentu. [HOL92]
2.5 Tabel
Simbol
Tabel simbol berfungsi menyimpan nama simbol (baik itu variabel, konstanta, prosedur atau fungsi) yang dipakai dalam program, serta menyimpan informasi penting menyangkut simbol tersebut, seperti tipe (untuk variabel), nomor baris tempat simbol dideklarasikan, dll. [AHO77]
Tabel simbol dipakai oleh komponen lain pada fase 2, misal oleh penganalisis sintaks atau lexical analyzer. Setiap kali penganalisis sintaks atau lexical analyzer menjumpai simbol, pengecekan dilakukan di tabel simbol, untuk mengecek apakah simbol telah dideklarasikan sebelumnya, apa tipe/jenisnya, dll. Dengan demikian, tabel simbol berfungsi sebagai database yang menyimpan informasi semua simbol yang muncul dalam kode program. Karena itu, tabel simbol sangat penting.
Karakteristik tabel simbol yang harus dipenuhi dalam implementasinya adalah A. cepat (semua data dimuat ke memori, bukan didalam berkas)
B. mudah digunakan, dikembangkan dan didaur ulang C. fleksibel
D. entri data yang duplikat harus dapat ditangani
E. mampu menghapus data-data yang tidak dipakai dengan cepat [HOL92] Ada beberapa alternatif implementasi tabel simbol, yaitu :
1. Stack : pencarian simbol bersifat linear dan tidak efisien, ukuran stack juga harus diketahui saat waktu kompilasi.
2. Pohon/Tree : pencarian bersifat linear dan penanganan collision (deklarasi simbol yang sama namun dalam scope yang berbeda) menjadi sulit.
3. Hash based : pencarian bersifat logaritmik dan hemat ruang memori. [HOL92]
Berikut beberapa item yang biasanya disimpan di dalam tabel simbol : 1. Nama identifier
2. Object time address : menunjukkan lokasi relatif variabel pada saat runtime. 3. tipe identifier
4. dimensi (pada referensi ke senarai) atau jumlah parameter untuk prosedur 5. nomor baris tempat variabel dideklarasikan
6. nomor baris tempat variabel digunakan [NAT07]
Misal : kode dibawah ini akan menghasilkan tabel simbol yang ditampilkan tabel II-1. Tabel simbol ini dihasilkan dengan menggunakan kakas dari sistem UNIX yaitu nm.
int i; char c; void foo( ); int bar( );
Tabel II-1 Contoh Tabel Simbol
Run time address tipe nama simbol nomor baris tempat
dideklarasikan
00000005 T bar 4
00000001 C c 2
00000000 T foo 3
2.6 C
dan
Pascal
C dan Pascal seringkali dibandingkan, mungkin karena berbagai latar belakang yang sama antara keduanya (waktu pertama muncul yang hampir bersamaan, tujuan dan pengaruh yang sama, serta sudut pandang dan pendekatan filosofis yang hampir sama). C dan Pascal sama-sama menjadi penerus dari seri bahasa ALGOL. [WIK07] C didesain sebagai bahasa aras rendah, bahasa yang didesain sebagai antar muka dengan sistem. Sedangkan Pascal memiliki latar belakang akademik dan pendidikan.
Namun perbedaan paling mencolok antara keduanya adalah dalam masalah alokasi memori untuk senarai dinamis. C memungkinkan pengguna untuk mengalokasikan ruang memori sebagai senarai secara bebas, sedangkan Pascal tidak demikian. Tabel II-2 menampilkan beberapa poin perbandingan C dan Pascal, yang diambil dari [WIK07]
Tabel II-2 Perbandingan C dan Pascal
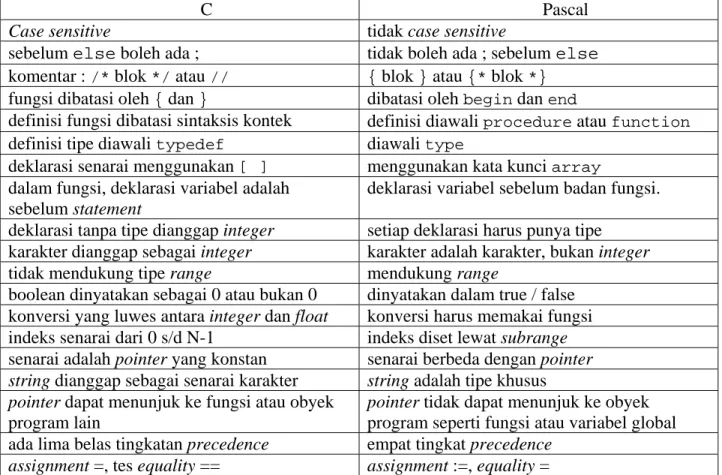
C Pascal
Case sensitive tidak case sensitive
sebelum else boleh ada ; tidak boleh ada ; sebelum else komentar : /* blok */ atau // { blok } atau {* blok *}
fungsi dibatasi oleh { dan } dibatasi oleh begin dan end
definisi fungsi dibatasi sintaksis kontek definisi diawali procedure atau function
definisi tipe diawali typedef diawali type
deklarasi senarai menggunakan [ ] menggunakan kata kunci array dalam fungsi, deklarasi variabel adalah
sebelum statement
deklarasi variabel sebelum badan fungsi. deklarasi tanpa tipe dianggap integer setiap deklarasi harus punya tipe
karakter dianggap sebagai integer karakter adalah karakter, bukan integer
tidak mendukung tipe range mendukung range
boolean dinyatakan sebagai 0 atau bukan 0 dinyatakan dalam true / false konversi yang luwes antara integer dan float konversi harus memakai fungsi indeks senarai dari 0 s/d N-1 indeks diset lewat subrange senarai adalah pointer yang konstan senarai berbeda dengan pointer string dianggap sebagai senarai karakter string adalah tipe khusus pointer dapat menunjuk ke fungsi atau obyek
program lain
pointer tidak dapat menunjuk ke obyek program seperti fungsi atau variabel global ada lima belas tingkatan precedence empat tingkat precedence
2.6.1 Struktur program
Struktur program dalam bahasa C terdiri dari satu blok prosedur utama yang disebut main( ), diikuti blok program yang diawali ‘{’ dan diakhiri ‘}’. Bagian lain hanyalah bersifat pendukung. Pada Pascal, program terdiri dari kata kunci program diikuti nama program, lalu dilanjutkan dengan blok utama yang dimulai dari begin dan diakhiri end. Perbandingan struktur program antara C dan Pascal ditampilkan pada tabel II-3.
Tabel II-3 Pebandingan Struktur Program
disini dideklarasikan variable, konstanta, fungsi dan identifier lainnya. Dan juga directive seperti include, dan line-control serta preprocessor lainnya.
program abc;
disini dideklarasikan variable, konstanta, fungsi dan identifier lainnya. Directive untuk include seperti pada C, digantikan oleh ‘use’, namun ini bukan fitur dari Pascal standar.
main() { // kode program } Begin { kode program} end.
Program dalam bahasa C terdiri dari paling tidak satu fungsi utama yang dieksekusi, yaitu fungsi main(). Fungsi terdiri dari deklarasi nama fungsi dan badan fungsi. Badan fungsi berisi rangkaian statement yang dilingkupi oleh tanda { dan }. Pada Pascal, fungsi main identik dengan blok program utama, seperti yang diilustrasikan diatas.
Kode program C dan Pascal terdiri dari serangkaian statement, yang selalu diakhiri tanda ‘;’ untuk memisahkan statement satu dengan lainnya. Satu atau lebih statement dapat digabung menjadi satu buah blok, yang dalam bahasa C dibatasi oleh tanda { dan } , sedangkan dalam Pascal, blok dibatasi oleh begin dan end.
2.6.2 Tipe String
Tipe String pada bahasa C sering disebut sebagai character string atau string constants yang diekspresikan sebagai rangkaian karakter dilingkupi oleh tanda petik ganda “ “. Dalam terminologi C, dikenal istilah escape sequence yaitu rangkaian karakter ‘\’ yang diterjemahkan sebagai nilai karakter khusus. Misal ‘\n’ adalah escape sequence newline, diterjemahkan oleh fungsi input output sebagai karakter ganti baris. Contoh escape sequence newline pada string
adalah “hello \n world”, yang jika dicetak ke output standar adalah hello
world
Pada Pascal string diapit oleh tanda ‘ (petik tunggal). Perbandingan penggunaan string pada C dan Pascal dapat dilihat pada tabel II-4.
Tabel II-4 String pada C dan Pascal
C Pascal char *s; s = “helloworld”; var s : string; s := ‘helloworld’; 2.6.3 Komentar
Komentar dibutuhkan untuk menjelaskan kode sumber program sehingga lebih mudah dibaca dan dimengerti. Komentar dalam C diawali dengan /* dan diakhiri dengan */ , semua karakter diantara keduanya diabaikan dari proses pengolahan oleh kompilator. Pada Pascal, komentar diapit oleh tanda { dan }.
2.6.4 Deklarasi
Deklarasi suatu variabel pada C terdiri dari nama tipe diikuti serangkaian nama variabel, misal
int i; float h;
Deklarasi pada C dilakukan pada awal blok program. int memiliki lebar 16-bit sedangkan float 32-bit. Selain int dan float, C menyediakan beberapa tipe dasar lain, yaitu :
char character-1 byte short short integer long long integer
double double-precision floating point
Pada Pascal, deklarasi variabel diawali menggunakan kata kunci var dan juga dilakukan di awal blok program. Tabel II-5 menampilkan perbandingan deklarasi variabel antara C dan
Pascal.
Tabel II-5 Deklarasi Variabel
Deklarasi pada C Deklarasi pada Pascal int x, y; main() { int z; } f ( ) { int a; } program decl; var x, y, z : integer; function f( ):integer; var a : integer; begin end; begin end. 2.6.5 Operator Assignment
Proses assignment dalam C menggunakan tanda ‘=’ sama dengan. Ekspresi disebelah kanan tanda ‘=’ memberikan nilai hasil evaluasi ekspresi, sedangkan simbol disebelah kiri tanda ‘=’ menampung nilai hasil evaluasi.
lower = 0; upper = 300;
Sedangkan pada Pascal, assignment dilakukan menggunakan tanda ‘:=’ lower := 0;
upper := 300;
2.6.6 Standar Input Output
Bahasa C tidak memiliki sistem input dan output yang built-in, namun lebih disediakan dalam bentuk pustaka standar, berbeda dengan Pascal yang telah menyediakan fungsi IO secara built-in sebagai bagian dari kompilator. Fungsi untuk menulis ke standar output pada C adalah printf, yang menuliskan data ke standar output dengan format tertentu. Pada Pascal, fungsi cetak ke layar adalah write. Untuk fungsi membaca input, C memiliki banyak varian fungsi / pustaka standar. Misal getc, scanf, fscanf, sscanf, vscanf dan vsscanf. Pada Pascal standar, input umumnya cukup ditangani dengan fungsi read. Perbandingan fungsi input dan output antara C dan Pascal dapat dilihat pada tabel II-6.
Tabel II-6 Input dan Output
C Pascal printf(“data1=%d data2=%f”,i, h ); write(‘data1=‘, i , ‘data2=’, h );
c = getch( ); readln( c );
2.6.7 Statement for
for digunakan sebagai salah satu looping dari tiga jenis looping di C. for memiliki tiga upabagian ( di luar badan pengulangan ) yang semuanya bersifat optional; bagian pertama untuk inisialisasi, bagian kedua untuk evaluasi apakah looping diteruskan atau tidak, dan bagian ketiga untuk stepping. for harus diikuti oleh badan pengulangan berupa paling tidak satu statement atau satu blok.
for pada Pascal memiliki format yang berbeda dengan C, karena menggunakan keyword bantu lain yaitu to atau downto dan do. Perbandingan pengulangan for antara C dan Pascal dapat dilihat pada Tabel II-7.
Tabel II-7 Pengulangan for
C Pascal for( f = 0 ; f < 300 ; f = f + 1 )
{
// kode diulang tiga ratus kali }
for f = 1 to 300 do begin
{ kode diulang tiga ratus kali } end;
for f = 300 downto 1 do begin
{ kode diulang tiga ratus kali } end;
2.6.8 Macro
Bahasa C menyediakan fasilitas macro sebagai bagian dari preprocessor ( program yang dipanggil kompilator C untuk memproses semua bagian kode yang diawali tanda ‘#’ ). Semua macro pada kode akan diganti dengan kode asli pada saat pemrosesan awal oleh preprocessor. Macro pada C menggunakan preprocessor define, diikuti nama macro lalu spasi atau tab dan terakhir diikuti kode pengganti. Bahasa Pascal tidak menyediakan fasilitas macro.
Perbandingan kode sebelum dan setelah preprocessing ( pemrosesan kode oleh preprocessor ) dapat dilihat pada tabel II-8.
Tabel II-8 Efek preprocessing
sebelum preprocessing setelah preprocessing #define LOWER 0
#define UPPER 300 #define STEP 10 main()
{
for ( f = LOWER ; f < UPPER ; f = f + STEP ) ; } main() { for( f = 0 ; f < 300 ;f = f + 10 ) ; } 2.6.9 Senarai
Senarai adalah serangkaian obyek yang memiliki tipe sama, yang terurut kontigu di memori. Senarai diakses dengan menggunakan indeks yang berupa integer (pada bahasa C elemen senarai dimulai dari nol, sedangkan pada Pascal elemen diakses tergantung bagaimana senarai dideklarasikan). Senarai dideklarasikan secara konstan ( jumlah elemennya tetap, tidak dapat diubah-ubah ). Pada bahasa C, senarai dideklarasikan dengan menggunakan tanda siku [ ] pada akhir nama identifier. Sedangkan pada Pascal, senarai dideklarasikan dengan kata kunci array. Perbandingan senarai antara C dan Pascal dapat dilihat Tabel II-9.
Tabel II-9 Penggunaan Senarai pada C dan Pascal
C Pascal int a[ 10 ]; // array integer
dengan 10 elemen. a[ 0 ] = 1; // elemen pertama a[ 9 ] = 2; // elemen terakhir var a :array [ 1 .. 10 ] of integer; b :array [ -1 .. 8 ] of integer; a[ 1 ] : = 3; a[ 10 ] := 4; b[-1] := 5; b[ 8 ] := 6;
2.6.10 Subrutin
Subrutin adalah bagian dari program yang merepresentasikan sejumlah operasi yang sering dilakukan selama program dieksekusi, sehingga daripada ditulis berulang-ulang, akan lebih efisien ditulis sebagai suatu subrutin. Biasanya, subrutin menerima parameter input saat dipanggil, dan mengembalikan nilai sebagai hasil operasi eksekusi badan subrutin. Pada C, subrutin dikenal sebagai function, sedangkan pada Pascal ada dua jenis subrutin, yaitu procedure dan function (procedure tidak mengembalikan nilai). Berikut adalah format subrutin pada C
tipe-kembalian nama-fungsi( deklarasi parameter, jika ada ) {
deklarasi statement }
Perbandingan subrutin antara C dan Pascal dapat dilihat pada tabel II-10. Tabel II-10 Subrutin pada C dan Pascal
C Pascal int twice( int i )
{
return i * 2; }
function twice( i : integer ) : integer;
begin
twice := i * 2; end;
2.7 Kakas
Parser Generator dan Scanner Generator
Sebagaimana dijelaskan diawal, dua dari komponen kompilator adalah parser dan scanner. Seringkali, proses pembuatan scanner dan parser menjadi rumit dan berisiko terhadap munculnya error. Pada parser, kesalahan seringkali berasal dari desain grammar dari perancang bahasa, misal kesalahan penanganan rekursif, kesalahan penanganan konflik antara reduce dan shift, kesalahan pemilihan operator precedence, dll. Sedangkan pada scanner, kesalahan biasanya muncul dari sistem IO dan buffering.
Salah satu solusi untuk permasalahan ini diawali oleh para ilmuwan peneliti dari AT & T Bell Laboratory, yaitu dengan membuat program yang menghasilkan parser dan scanner, secara otomatis. Dasar pemikirian dari scanner generator diusulkan oleh Ken Thompson, yang terkenal sebagai prinsip Thompson Construction. Ide dasarnya adalah mengubah ekspresi reguler menjadi
NFA ( Nondeterministic Finite Automata ), selanjutnya NFA digunakan oleh scanner generator untuk menerjemahkan input string, apakah sesuai dengan pola ekspresi reguler atau tidak. Pada beberapa kasus, NFA dapat diubah menjadi DFA ( Deterministic Finite Automata ). Scanner generator mengimplementasikan scanner yang dihasilkan sebagai mesin otomata dalam struktur data berupa tabel. Semakin banyak pola input string yang harus dikenali oleh scanner, makin besar ukuran tabel. Optimasi yang dilakukan adalah melakukan minimasi ukuran tabel dengan beberapa metode yang sudah dikenal baik, misal dengan menghapus baris atau kolom yang redundan atau melakukan kompresi tabel. [HOL92]
Sedangkan parser generator, ide utamanya adalah membuat parser secara otomatis dari spesifikasi grammar yang diberikan kepada program. Karena setiap parser LALR membutuhkan state tabel, parser generator harus menyediakan state table ke dalam parser yang dihasilkan. Dalam proses men-generate parser, parser generator juga membangun tabel simbol internal, yang diperlukan untuk menyimpan data-data tentang grammar dan simbol non-terminal. [HOL92]
Setelah state table selesai dibuat sesuai dengan spesifikasi grammar, parser generator akan mengenali sejumlah masalah yang mungkin muncul, biasanya berkaitan dengan spesifikasi grammar yang ambigu. Pada tahap ini, grammar yang diberikan kepada parser generator harus menyediakan operator precedence atau mekanisme lain yang memungkinkan masalah ambiguitas dapat diatasi. Parser generator juga menyediakan fasilitas error recovery, yaitu kemampuan untuk sejauh mana kesalahan gramatikal pada kode sumber yang di-parsing dapat diatasi, dan memberikan pesan error yang cukup informatif kepada user tentang kesalahan gramatikal apa yang terjadi.
![Gambar II-1 Alur kerja kompilator empat fase [HOL92]](https://thumb-ap.123doks.com/thumbv2/123dok/2079270.3531102/2.918.163.619.124.857/gambar-ii-alur-kerja-kompilator-empat-fase-hol.webp)