PERBANDINGAN SOM DAN LVQ PADA IDENTIFIKASI
CITRA WAJAH DENGAN WAVELET SEBAGAI
EKSTRAKSI CIRI
SYEIVA NURUL DESYLVIA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2013
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Perbandingan SOM dan LVQ pada Identifikasi Citra Wajah dengan Wavelet sebagai Ekstraksi Ciri adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Desember 2013 Syeiva Nurul Desylvia NIM G64114005
ABSTRAK
SYEIVA NURUL DESYLVIA. Perbandingan SOM dan LVQ pada Identifikasi Citra Wajah dengan Wavelet sebagai Ekstraksi Ciri. Dibimbing oleh AGUS BUONO.
Pengenalan wajah merupakan salah satu topik penelitian menantang di bidang ilmu komputer karena wajah manusia sulit dimodelkan. Penelitian ini mengajukan metode SOM dan LVQ sebagai pengenal wajah tampak depan. Tujuan penelitian ini adalah membandingkan LVQ dan SOM berdasarkan akurasi identifikasi. Citra sebanyak 400 dari 20 individu berbeda yang masing-masing berukuran 180 x 200 pixels digunakan sebagai data percobaan. Sumber data dari University of Essex, UK. Coefficient approximation pada Haar Wavelet level 6 digunakan sebagai ciri yang akan diklasifikasi dan dikluster. K-fold cross validation dengan fold 10 digunakan untuk membagi data latih dengan data uji. Percobaan terbagi menjadi 3 set, yaitu percobaan menggunakan model SOM, LVQ, dan LVQ inisialisasi SOM. Akurasi tertinggi yang dihasilkan SOM sebesar 97.8947% dan akurasi tertinggi yang dihasilkan LVQ dan LVQ inisialisasi SOM sebesar 100%. Berdasarkan hasil akurasi, LVQ terbukti lebih baik dari pada SOM dalam hal pengenalan wajah tampak depan. Penelitian ini perlu dikembangkan agar model dapat mengenali wajah dengan berbagai pose dan ekspresi yang berubah-ubah.
Kata kunci: Haar Wavelet, K-fold cross validation, Learning Vector Quantization (LVQ), pengenalan wajah, Self Organizing Map (SOM)
ABSTRACT
SYEIVA NURUL DESYLVIA. Comparison of SOM and LVQ for Facial Image Identification with Wavelet as Feature Extraction. Supervised by AGUS BUONO. Face recognition is one of challenging research topics in computer science because human face is difficult to be modelled. In this research, SOM and LVQ are proposed for frontal face recognition. The purpose is to compare LVQ and SOM based on identification accuracy. Training uses 400 images from 20 different individuals, and the dimension is 180 x 200 pixels. The data are retrieved from University of Essex, UK. Coefficient approximation at Haar wavelet level 6 is used as feature for classification and clustering process. K-fold cross validation with 10-fold is used to divide training and testing data. The experiment is divided into 3 sets, i.e., the experiment using SOM, LVQ, and LVQ initialized by SOM. The highest accuracy achieved by SOM is 97.8974%, while both LVQ and LVQ initialized by SOM achieve 100% accuracy. Based on the accuracy, LVQ proves to be better than SOM for frontal face recognition. This research needs to be improved in order to recognize various poses and changing expressions.
Keywords: frontal face recognition, Haar wavelet, K-fold cross validation, Learning Vector Quantization (LVQ), Self Organizing Map (SOM)
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
PERBANDINGAN SOM DAN LVQ PADA IDENTIFIKASI
CITRA WAJAH DENGAN WAVELET SEBAGAI
EKSTRAKSI CIRI
SYEIVA NURUL DESYLVIA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2013
Penguji: 1 Aziz Kustiyo, SSi MKom
Judul Skripsi : Perbandingan SOM dan LVQ pada Identifikasi Citra Wajah dengan Wavelet sebagai Ekstraksi Ciri
Nama : Syeiva Nurul Desylvia NIM : G64114005
Disetujui oleh
Dr Ir Agus Buono, MSi MKom Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
Judul Skripsi: Perbandingan SOM dan LVQ pada Identifikasi Citra Wajah dengan Wavelet sebagai Ekstraksi Ciri
ama : Syeiva Nurul Desylvia 1M : G64114005
Disetujui oleh
Dr Ir tr-..:"'''-'U'uono MSi MKom Pembimbing
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga skripsi ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan April 2013 ini ialah pengenalan wajah, dengan judul Perbandingan SOM dan LVQ pada Identifikasi Citra Wajah dengan Wavelet sebagai Ekstraksi Ciri.
Terima kasih penulis ucapkan kepada:
1 Bapak Dr Ir Agus Buono, MSi MKom selaku pembimbing.
2 Bapak Aziz Kustiyo, SSi MKom dan Bapak Endang Purnama Giri, SKom MKom selaku penguji.
3 Bapak Ahmad Ridha, SKom MS dan Bapak Auzi Asfarian, SKomp atas pengecekan dan saran terkait abstrak dan penulisan skripsi.
4 Ayah, ibu, adik, serta seluruh keluarga, atas segala doa dan kasih sayangnya. 5 Teman-teman satu bimbingan dan teman-teman Alih Jenis Ilmu Komputer
IPB angkatan 6.
Semoga karya ilmiah ini bermanfaat.
Bogor, Desember 2013 Syeiva Nurul Desylvia
DAFTAR ISI
DAFTAR TABEL viii
DAFTAR GAMBAR viii
DAFTAR LAMPIRAN viii
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 2
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 2
METODE 2 Lingkungan Pengembangan 3 Kerangka Pemikiran 5 Studi Pustaka 5 Pengumpulan Data 5 Praproses 5 Pembagian Data 6
Pelatihan dan Pengujian 6
Evaluasi 9
HASIL DAN PEMBAHASAN 10
Praproses 10
Pembagian Data 10
Pelatihan dan Pengujian 11
Evaluasi 11
KESIMPULAN DAN SARAN 12
Kesimpulan 12
Saran 13
DAFTAR PUSTAKA 13
DAFTAR TABEL
1 Simbol yang digunakan pada algoritme LVQ 10
2 Parameter percobaan 11
DAFTAR GAMBAR
1 Tahapan penelitian 3
2 Metode penelitian secara lebih mendetail 4
3 Ilustrasi K-fold cross validation 7
4 Topologi SOM dan LVQ (Fausett 1994) 8
5 Ilustrasi ketetanggaan SOM di bidang hexagonal (Yang et al. 2012) 8 6 Ilustrasi cara kerja LVQ. (a) bobot mendekati X (data), (b) bobot
menjauhi X (data) 9
7 Persentase hasil percobaan 12
DAFTAR LAMPIRAN
1 Beberapa data yang digunakan pada penelitian 14
2 Contoh perhitungan LVQ (Fausset 1994) 15
3 Hasil percobaan 17
4 Sebagian data kelas 17 dan kelas 19 18
1
PENDAHULUAN
Latar Belakang
Pengenalan wajah merupakan salah satu penelitian canggih di bidang komputer dan sangat menantang untuk dikembangkan menggunakan komputer karena wajah manusia sulit dimodelkan. Hal ini disebabkan wajah manusia tergantung dari kondisi usia, pencahayaan, lokasi, orientasi, pose, ekspresi wajah, dan faktor lainnya. Di sisi lain, pengenalan wajah merupakan salah satu teknik biometric yang masih berkembang karena aplikasinya yang banyak digunakan, seperti image tagging dan surveillance camera. Perkembangan penelitian pada bidang pengenalan wajah ini memicu banyak metode baru atau perbaikan metode lama yang diajukan peneliti.
Salah satu penelitian pada bidang pengenalan wajah, yaitu Face Recognition with Learning-based Descriptor (Cao et al. 2010) yang menggunakan teknik learning-based encoding method berdasarkan unsupervised learning pada data latih dikombinasikan dengan Principal Component Analysis (PCA). Selain itu, pose adaptive matching method diajukan juga untuk menangani variasi pose pada dunia nyata. Akurasi terbaik didapatkan pada data Labeled Face in The Wild (LFW) sebesar 84.45%.
Penelitian lainnya adalah Bypassing Synthesis: PLS for Face Recognition with Pose, Low-Resolution and Sketch (Sharma dan Jacobs 2011) yang menggunakan Partial Least Squares (PLS) untuk penyeleksian fitur pada CMU PIE data set. Akurasi yang didapatkan sebesar 90.12%.
Penelitian selanjutnya ialah Hierarchical Ensemble of Global and Local Classifiers for Face Recognition (Su et al. 2009) yang memadukan ekstraksi ciri global menggunakan Fourier Transform dan ekstraksi ciri local menggunakan Gabor Wavelet. Fisher’s Linear Discriminant (FLD) diaplikasikan secara terpisah pada Fourier features dan Gabor features. Data yang digunakan pada penelitian adalah FERET dan Face Recognition Grand Challenge (FRGC) versi 2.0. Akurasi tertinggi sebesar 99.9% untuk recognition rate didapatkan dari pengujian menggunakan data FERET.
Learning Vector Quantization (LVQ) merupakan salah satu metode untuk pengenalan wajah seperti yang dilakukan Bashyal dan Venayagamoorthy (2008) pada penelitian Recognition of Facial Expressions Using Gabor Wavelets and Learning Vector Quantization. Penelitian tersebut menggunakan LVQ versi 1 (LVQ1) untuk klasifikasi 7 ekspresi wajah manusia (neutral, happy, sad, surprise, anger, disgust, fear) dengan ekstraksi fitur menggunakan Gabor Wavelet. Data yang digunakan, yaitu Japanese Female Facial Expression (JAFFE). Akurasi tertinggi yang dihasilkan sebesar 90.22%.
Pada penelitian Bashyal dan Venayagamoorthy (2008), LVQ1 dapat menghasilkan akurasi yang baik untuk mengenali 7 ekspresi wajah manusia dibandingkan dengan Multi Layer Perceptron (MLP). Akurasi yang dihasilkan tersebut mendasari hipotesis bahwa LVQ memungkinkan untuk menghasilkan akurasi tinggi jika digunakan sebagai classifier pada data frontal face.
Berdasarkan hipotesis tersebut, pada penelitian ini, metode LVQ diajukan sebagai classifier pada data frontal face yang diunduh dari University of Essex,
2
UK. Self Organizing Map (SOM) diajukan juga untuk inisialisasi vektor bobot pada LVQ. Selain itu, SOM juga akan dibandingkan dengan LVQ terkait hasil akurasi yang dihasilkan.
Untuk ekstraksi ciri pada setiap citra wajah, Haar Wavelet diajukan karena menghasilkan akurasi yang baik, yaitu 98.1% dibandingkan akurasi yang dihasilkan Principal Component Analysis (PCA) sebesar 91.2% pada penelitian Gumus et al. (2010) yang berjudul Evaluation of Face Recognition Techniques Using PCA, Wavelets, and SVM. Pada penelitian tersebut, kombinasi Haar Wavelet level 4 dan Support Vector Machine (SVM) menghasilkan akurasi yang lebih tinggi 6.9% dibandingkan kombinasi PCA dan SVM pada data ORL.
Perumusan Masalah
Perumusan masalah dalam penelitian ini adalah bagaimana memodelkan sistem pengenalan wajah tampak depan menggunakan jaringan syaraf tiruan SOM dan LVQ.
Tujuan Penelitian
Tujuan dari penelitian ini adalah:
1 Memodelkan SOM dan LVQ untuk mengenali wajah tampak depan dari setiap orang yang berbeda.
2 Menghasilkan akurasi perbandingan 3 model percobaan (SOM, LVQ, LVQ inisialisasi SOM) menggunakan data wajah tampak depan.
Manfaat Penelitian
Penelitian ini diharapkan dapat menghasilkan model pengenalan wajah yang menggunakan jaringan syaraf tiruan SOM dan LVQ agar dapat membantu peran manusia dalam hal mengenali wajah pada sistem online maupun offline.
Ruang Lingkup Penelitian
Ruang lingkup pada penelitian ini antara lain:
1 Pose wajah yang digunakan adalah tampak depan / frontal face.
2 Tidak ada perubahan gaya rambut, penggunaan kacamata, atau janggut pada setiap individu.
METODE
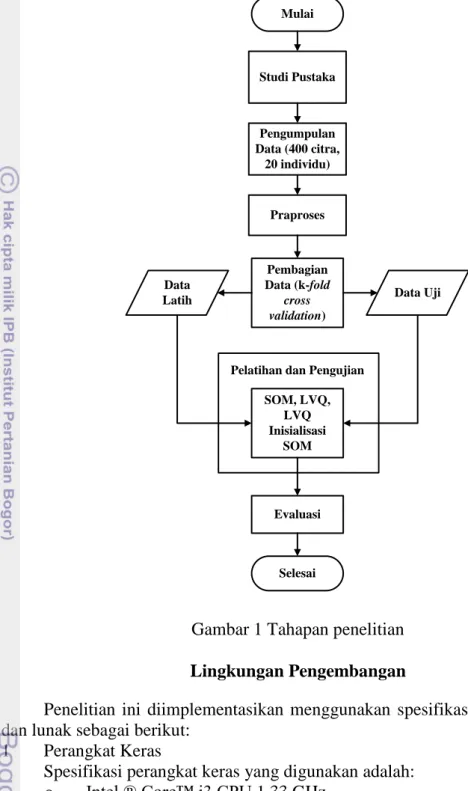
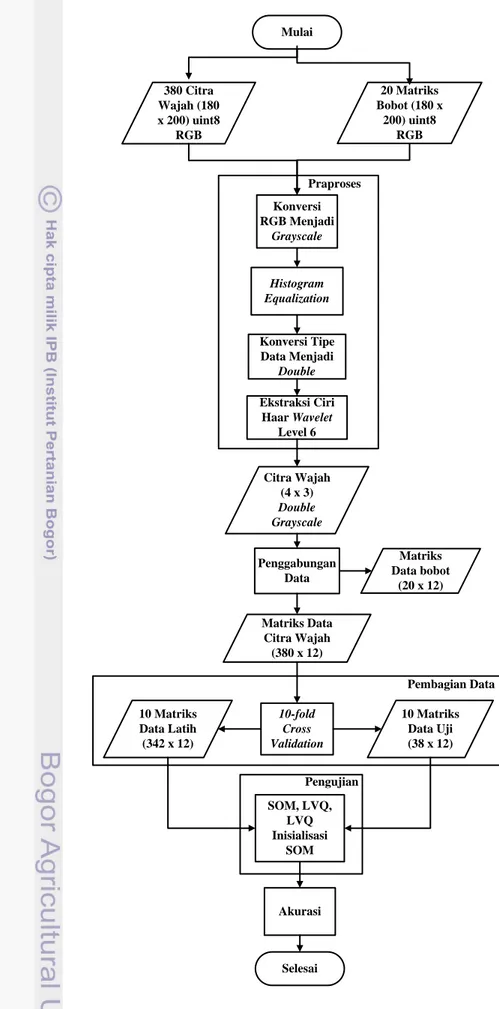
Penelitian ini terbagi menjadi beberapa tahapan proses. Gambar 1 menunjukan tahapan proses tersebut dan Gambar 2 menunjukan tahapan penelitian secara lebih detail.
3
Lingkungan Pengembangan
Penelitian ini diimplementasikan menggunakan spesifikasi perangkat keras dan lunak sebagai berikut:
1 Perangkat Keras
Spesifikasi perangkat keras yang digunakan adalah: o Intel ® Core™ i3 CPU 1.33 GHz.
o Memori 2 GB. o Harddisk 360 GB. o Keyboard dan mouse. o Monitor.
2 Perangkat Lunak
o Sistem operasi Windows 8.1 Pro 32 bit. o Matlab 7.7.0 (R2008b). Mulai Pengumpulan Data (400 citra, 20 individu) Praproses Pembagian Data (k-fold cross validation) Data
Latih Data Uji
SOM, LVQ, LVQ Inisialisasi SOM Evaluasi Selesai Pelatihan dan Pengujian
Studi Pustaka
4 Mulai 10-fold Cross Validation 10 Matriks Data Latih (342 x 12) 10 Matriks Data Uji (38 x 12) Matriks Data Citra Wajah (380 x 12) 380 Citra Wajah (180 x 200) uint8 RGB Konversi RGB Menjadi Grayscale Histogram Equalization Konversi Tipe Data Menjadi Double Ekstraksi Ciri Haar Wavelet Level 6 Citra Wajah (4 x 3) Double Grayscale Penggabungan Data Akurasi Selesai Praproses Pembagian Data Pengujian SOM, LVQ, LVQ Inisialisasi SOM 20 Matriks Bobot (180 x 200) uint8 RGB Matriks Data bobot (20 x 12)
5
Kerangka Pemikiran
Penelitian ini dikembangkan dengan metode yang dibagi menjadi beberapa tahap, yaitu studi pustaka, pengumpulan data, praproses, pembagian data (K-fold cross validation), pelatihan dan pengujian, dan evaluasi.
Studi Pustaka
Pada tahap ini, kegiatan yang dilakukan adalah mempelajari dan mengumpulkan pustaka yang berkaitan dengan penelitian. Hal-hal yang dipelajari, yaitu penggunaan dan teori Haar Wavelet, Self Organizing Map, dan Learning Vector Quantization. Selain itu, metode yang terkait pengenalan wajah juga dipelajari dan dilakukan analisis jika metode tersebut bisa diterapkan pada penelitian ini atau tidak. Buku dan paper penelitian merupakan sumber utama pada tahap ini.
Pengumpulan Data
Data pada penelitian ini diunduh dari University of Essex, UK. Individu yang digunakan sebanyak 20 individu (10 wanita dan 10 pria) dengan masing-masing 20 citra wajah tampak depan. Total data sebanyak 400. Beberapa individu menggunakan kacamata dan berjanggut untuk keseluruhan data pada kelas tersebut (20 citra). Usia setiap individu umumnya berkisar 18 sampai dengan 20 tahun, akan tetapi ada beberapa individu yang berusia lebih tua. Dimensi setiap citra adalah 180 x 200 pixels dengan format 24 bit color JPEG. Lampiran 1 menyajikan perwakilan data dari setiap kelas yang digunakan.
Praproses
Pada tahap ini, citra yang pada mulanya 24 bit RGB diubah menjadi grayscale. Citra yang direpresentasikan dalam model warna RGB terdiri atas 3 komponen citra yang masing-masing mewakili warna primer. Warna primer tersebut, yaitu Red, Green, dan Blue (RGB). Model ini berdasarkan sistem koordinat Cartesian. Banyaknya bits yang digunakan untuk merepresentasikan setiap pixel dalam ruang RGB disebut pixel depth (Gonzalez dan Woods 2007).
Langkah berikutnya, yaitu Histogram Equalization. Pada langkah ini, citra baru dihasilkan dengan cara memetakan setiap pixel pada citra masukan dengan intensitas r ke dalam pixel dengan level s yang sesuai. Persamaan yang digunakan pada Histogram Equalization ialah
r(r )
n
MN adalah jumlah pixel di dalam citra, n adalah jumlah pixel yang memiliki intensitas r , dan L adalah jumlah level intensitas pada citra (256 untuk citra 8 bit). Pemetaan ( ) terhadap r umumnya disebut histogram. Bentuk diskret dari persamaan sebelumnya, yaitu
6
s (r ) L ∑ r(r) L
∑ n L
r atau the transformation (mapping) pada persamaan tersebut adalah Histogram Equalization atau Histogram Linearization Transformation (Gonzalez dan Woods 2007).
Setelah citra diubah ke grayscale dan dilakukan teknik Histogram Equalization, Haar Wavelet digunakan untuk ekstraksi ciri dan reduksi dimensi untuk setiap citra. Wavelet yang digunakan untuk ekstraksi ciri dan reduksi dimensi pada citra terdiri atas beberapa konsep pendukung. Konsep-konsep tersebut disebut multiresolution analysis. Konsep pertama, yaitu image pyramid. Suatu image pyramid adalah koleksi resolusi citra yang menurun tersusun dalam bentuk seperti piramida. Semakin tinggi suatu image pyramid, ukuran dan resolusi citra menurun. Perkiraan citra dengan resolusi rendah disebut apex, sedangkan level dasar dari piramida merupakan representasi resolusi tinggi dari citra yang akan diproses. Level dasar J berukuran atau N x N, dalam hal ini lo , level apex 0 berukuran 1 x 1 dan level umum j berukuran ( ).
Konsep berikutnya, yaitu subband coding. Di dalam subband coding, dekomposisi dilakukan pada citra sehingga menghasilkan suatu kumpulan bandlimited component yang disebut subband. Subband yang dihasilkan adalah perkiraan (approximation), horizontal detail, vertical detail, dan diagonal detail. Ukuran dari setiap subband 2 kali lebih kecil ketimbang ukuran citra yang sebenarnya (citra masukan yang digunakan untuk proses). Konsep terakhir adalah Haar transform. Haar transform dapat diekspresikan menggunakan persamaan
F adalah matriks citra N x N, H adalah matriks N x N Haar transform. Berdasarkan Haar basis function, matriks Haar adalah
√ [ - ].
Kombinasi dari ketiga konsep tersebut (image pyramid, subband coding, dan Haar transform) disebut discrete wavelet transform (Gonzalez dan Woods 2007).
Pembagian Data
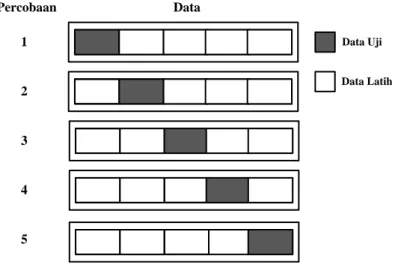
Untuk pembagian data uji dan data latih, digunakan metode K-fold cross validation. Pada metode ini, sample data dibagi menjadi beberapa subsample. Saat proses pelatihan, setiap subsample dijadikan data uji dan k-1 subsample lainnya dijadikan data latih. Proses ini berjalan sebanyak k iterasi. Pada penelitian ini, k yang digunakan sebesar 10 (10-fold). Gambar 3 menampilkan ilustrasi penggunakan K-fold dengan 5 fold.
Pelatihan dan Pengujian
Pada tahap ini, jaringan syaraf tiruan Self Organizing Map (SOM) dan Learning Vector Quantization (LVQ) digunakan untuk pelatihan dan pengujian.
7
jumlah neuron input yang digunakan sama dengan jumlah field matriks data yang dihasilkan dari tahap praproses dan jumlah neuron output sama dengan jumlah individu yang digunakan.
Pada mulanya, SOM dikembangkan untuk visualisasi relasi nonlinear pada data multi dimensi (Kohonen 2001). Ide dasar dari algoritme SOM adalah setiap input data item akan memilih model yang paling sesuai dengan item tersebut dan ketetanggaan unit-unit cluster akan dimodifikasi untuk menghasilkan tingkat kecocokan yang lebih baik. SOM membangun model sehingga model yang lebih mirip akan diasosiasikan dengan nodes yang lebih dekat, sedangkan model yang kurang mirip akan dijauhkan secara bertahap (Kohonen 2013).
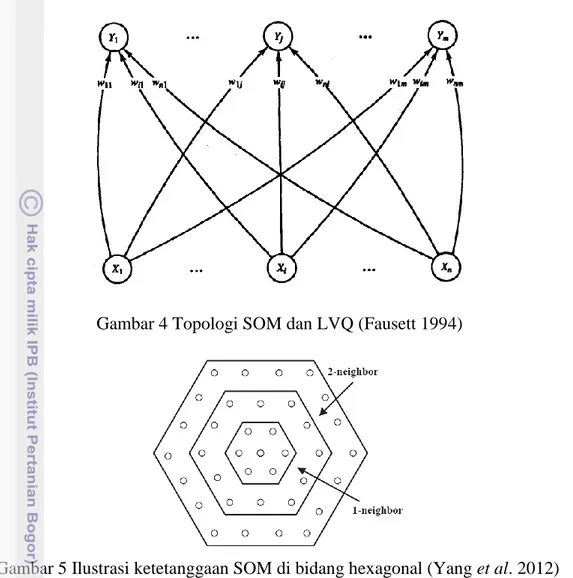
Selama proses self organizing, unit cluster yang vektor bobotnya paling dekat dengan vektor masukan (biasanya menggunakan fungsi jarak Euclidean) dipilih sebagai pemenang (winner). Unit pemenang (winner unit) dan unit tetangganya (unit tetangga secara bentuk topologi) membarui bobot mereka. Vektor bobot dari unit tetangga secara umum tidak dekat dengan vektor masukan. Arsitektur SOM ditunjukan pada Gambar 4 dan ketetanggaan SOM di bidang hexagonal ditampilkan pada Gambar 5.
Berikut algoritme SOM:
1 Tentukan bobot wi . Tentukan parameter topologi tetangga. Tentukan parameter learning rate.
2 Selama kondisi berhenti belum terpenuhi, lakukan langkah 3 - 9. 3 Untuk setiap vektor masukan x, lakukan langkah 4 - 6.
4 Untuk setiap j, lakukan perhitungan:
( ) ∑ wi i
i
5 Temukan indeks J sehingga D(J) bernilai minimum.
6 Untuk semua unit j di dalam topologi tetangga J yang sudah ditentukan dan untuk semua i:
wi (new) wi ( l ) [ i wi l ]
7 Update learning rate.
8 Kurangi radius topologi tetangga pada waktu yang spesifik. 9 Cek kondisi berhenti (Fausett 1994).
Percobaan Data 1 2 3 4 5 Data Uji Data Latih
8
Salah satu cara paling sederhana untuk inisialisasi vektor bobot pada SOM adalah dengan menggunakan random vector. Pada aplikasinya, inisialisasi menggunakan random vector akan memperlambat konvergensi algoritme dibandingkan dengan inisialisasi yang sudah melalui metode tertentu, misalkan linear initialization (Kohonen 2013). Pada penelitian ini, perwakilan data dari setiap class akan digunakan sebagai inisialisasi bobot pada SOM.
LVQ pada mulanya dikembangkan untuk statistical pattern recognition terutama pada data stochastic berdimensi tinggi dengan noise yang banyak (Kohonen 2001). Setiap unit keluaran pada LVQ merepresentasikan class atau kategori. Vektor bobot yang merepresentasikan setiap class sering kali disebut vektor reference atau codebook. Arsitektur LVQ pada dasarnya sama dengan SOM (ditunjukan pada Gambar 4) namun tidak ada struktur topologi ketetanggan pada unit keluaran dan setiap unit keluaran mewakili jumlah class yang ada. Algoritme LVQ, yaitu:
1 Tentukan vektor referensi. Tentukan learning rate, ( ). 2 Selama kondisi berhenti belum terpenuhi, lakukan langkah 3-6. 3 Untuk setiap vektor masukan x, lakukan langkah 4-5.
4 Temukan J sehingga ‖ -w‖ bernilai minimum. 5 Update nilai w sesuai ketentuan berikut:
Jika T = ,
Gambar 4 Topologi SOM dan LVQ (Fausett 1994)
9
w(new) w( l ) [ - w l ] Jika T ≠ ,
w(new) w( l ) [ w l ] 6 Kurangi learning rate.
7 Cek kondisi berhenti (Fausett 1994).
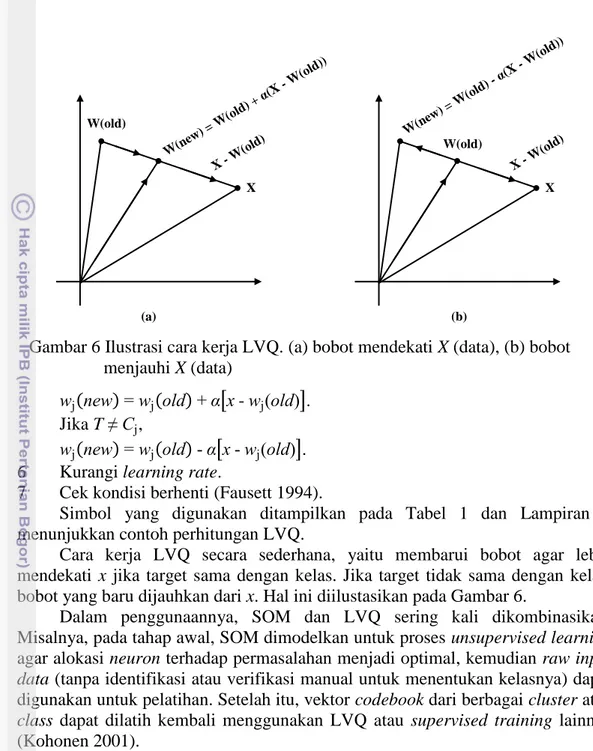
Simbol yang digunakan ditampilkan pada Tabel 1 dan Lampiran 2 menunjukkan contoh perhitungan LVQ.
Cara kerja LVQ secara sederhana, yaitu membarui bobot agar lebih mendekati x jika target sama dengan kelas. Jika target tidak sama dengan kelas, bobot yang baru dijauhkan dari x. Hal ini diilustasikan pada Gambar 6.
Dalam penggunaannya, SOM dan LVQ sering kali dikombinasikan. Misalnya, pada tahap awal, SOM dimodelkan untuk proses unsupervised learning agar alokasi neuron terhadap permasalahan menjadi optimal, kemudian raw input data (tanpa identifikasi atau verifikasi manual untuk menentukan kelasnya) dapat digunakan untuk pelatihan. Setelah itu, vektor codebook dari berbagai cluster atau class dapat dilatih kembali menggunakan LVQ atau supervised training lainnya (Kohonen 2001).
Evaluasi
Evaluasi merupakan tahap terakhir pada metode untuk menentukan jika proses pengenalan sudah tepat atau belum. Hasil dari tahap ini, yaitu akurasi yang didapat dengan cara,
∑
∑
Akurasi tersebut akan dirata-ratakan untuk setiap fold ke-i (i
W(old) W(ne w) = W(ol d) - α (X - W (old)) X X - W (old) (a) W(old) W(ne w) = W(ol d) + α (X - W (old)) X X - W (old) (b)
Gambar 6 Ilustrasi cara kerja LVQ. (a) bobot mendekati X (data), (b) bobot menjauhi X (data)
10
HASIL DAN PEMBAHASAN
Praproses
Setiap data wajah diubah formatnya dari RGB menjadi grayscale agar memudahkan proses ekstraksi ciri. Kemudian, histogram equalization dilakukan pada data untuk meratakan tingkat intensitas warna yang dilanjutkan dengan mengubah tipe data menjadi double. Perubahan tipe ini dikarenakan tipe double lebih mudah untuk komputasi.
Langkah selanjutnya, yaitu ekstraksi ciri menggunakan Haar Wavelet. Pada penelitian ini, digunakan level dekomposisi sebesar 6 yang akan menghasilkan citra hasil dekomposisi dengan dimensi 4 x 3 (12 fitur penciri) dari dimensi awal sebesar 180 x 200. Proses ini dilakukan untuk semua data. Hasil dari proses ini, yaitu matriks data sebesar 380 x 12, matriks bobot sebesar 20 x 12, dan matriks class sebesar 380 x 1, sedangkan 20 citra sisanya (1 citra untuk setiap kelas) digunakan untuk inisialisasi bobot SOM.
Pembagian Data
Setelah proses ekstraksi ciri, proses pembagian data dilakukan menggunakan metode k-fold cross validation. Data class digunakan sebagai masukan pada fungsi k-fold cross validation untuk diambil indeks datanya. Selanjutnya, data matriks wajah dipisahkan untuk data latih dan data uji berdasarkan indeks tersebut. Proses ini dilakukan sebanyak jumlah fold yang dalam penelitian ini sebanyak 10-fold. Hasil tahap pembagian data ini, yaitu 10 matriks data latih yang masing-masing berukuran 342 x 12 dan 10 matriks data uji yang masing-masing berukuran 38 x 12.
Data yang digunakan untuk inisialisasi bobot SOM dipisahkan dari data pelatihan, kemudian tahap praproses dilakukan seperti pada data utama. Matriks bobot digabungkan secara terpisah dari matriks data. Data class dipisahkan menjadi class data latih dan class data uji untuk proses pengujian. Data class tersebut dipisahkan sesuai dengan data latih dan data uji yang dihasilkan pada setiap fold. Class data latih digunakan untuk pelatihan menggunakan SOM dan LVQ. Class data uji digunakan untuk komputasi akurasi.
Tabel 1 Simbol yang digunakan pada algoritme LVQ
Simbol Makna
x Vektor masukan (training vector), x1 xi x.
T Kategori yang benar atau class untuk vektor masukan.
w Vektor bobot untuk unit keluaran ke-j (w wi w)
Kategori atau class yang direpresentasikan oleh unit keluaran ke-j.
‖ w‖ Jarak Euclidean di antara vektor masukan dan vektor bobot untuk unit keluaran ke-j.
11
Pelatihan dan Pengujian
Pada penelitian ini ada 3 model yang akan dibandingkan, yaitu model SOM, LVQ, dan LVQ inisialisasi SOM. Percobaan diulang sebanyak 3 kali karena fungsi k-fold yang digunakan menghasilkan indeks data secara acak. Ulangan ini dilakukan untuk menguji jika akurasi yang dihasilkan sudah stabil atau belum. Data yang digunakan untuk proses pelatihan dan pengujian merupakan data hasil k-fold cross validation. Pada tahap ini, pemanggilan SOM dan LVQ dilakukan sebanyak k kali sesuai jumlah fold (10 kali pada penelitian ini). Hasil dari SOM dan LVQ dibandingkan dengan setiap class pada data uji untuk perhitungan akurasi. Parameter yang perlu diperhatikan pada SOM dan LVQ adalah jumlah neuron input, jumlah neuron output, jumlah vektor masukan, jumlah epoch, nilai learning rate, dan nilai penurunan learning rate. Jumlah neuron input disesuaikan dengan jumlah fitur penciri yang dihasilkan oleh Haar Wavelet, yaitu 12 penciri. Neuron output ditentukan berdasarkan jumlah kelas yang digunakan, yaitu 20 kelas.
Pada penelitian ini, learning rate ditentukan akan berakhir pada nilai 0.01 untuk setiap nilai epoch yang ditetapkan. Penurunan learning rate dihitung menggunakan prinsip deret geometri agar bernilai 0.01 pada iterasi epoch terakhir. Learning rate sebagai suku pertama deret geometri dan 0.01 sebagai suku terakhir, sedangkan penurunan learning rate sebagai rasio. Rasio inilah yang perlu didapatkan menggunakan rumus deret geometri. Perbandingan nilai parameter SOM dan LVQ ditunjukan pada Tabel 1.
Lampiran 3 menyajikan hasil pengujian menggunakan SOM, LVQ, dan LVQ inisialisasi SOM dan Gambar 7 menampilkan grafik persentase rata-rata akurasi yang dihasilkan.
Evaluasi
Dari hasil pengujian, dapat diamati bahwa hasil akurasi menggunakan LVQ lebih baik dari pada SOM. Pada kolom akurasi SOM, rata-rata akurasi tertinggi sebesar 97.8% di ulangan ke-3. Pada kolom akurasi LVQ, rata-rata akurasi tertinggi sebesar 100.0% di ulangan ke-2 dan ke-3. Hasil pengujian LVQ inisialisasi SOM sama dengan hasil pengujian menggunakan LVQ. Hal ini berarti inisialisasi SOM pada percobaan ini tidak mempengaruhi LVQ karena permasalahan yang dihadapi cukup sederhana.
Untuk ulangan pertama, fold ke-2 menghasilkan akurasi yang sama pada 3 set percobaan, yaitu 97.3%. Hal ini menarik diamati karena baik LVQ maupun
Tabel 2 Parameter percobaan
SOM LVQ
Neuron Input 12 Neuron Input 12
Neuron Output 20 Neuron Output 20
Vektor Masukan 342 Vektor Masukan 342
Epoch 150 Epoch 150
Learning Rate 0.6 Learning Rate 0.3 Penurunan Learning Rate 0.973 Penurunan Learning Rate 0.977
12
LVQ inisialisasi SOM tidak dapat memperbaiki kesalahan klasifikasi atau clustering yang diujikan sebelumnya. Citra wajah yang membuat kesalahan tersebut, yaitu citra ke-3 pada kelas 19. Saat pengujian citra ini selalu terdeteksi sebagai citra kelas 17. Data kelas 17, yaitu wanita berambut panjang, dahi cukup lebar, dan berkacamata, sedangkan data kelas 19 adalah wanita berambut panjang, dahi cukup lebar namun tidak berkacamata. Beberapa citra kelas 17 dan kelas 19 ditunjukkan pada Lampiran 4.
Individu kelas 17 dan kelas 19 pada data yang digunakan mirip satu sama lain. LVQ dan LVQ inisialisasi SOM hanya tertukar 1 kali antara kelas 17 dan kelas 19, sedangkan SOM tertukar beberapa kali. Kesalahan clustering SOM ditunjukkan pada Lampiran 5.
KESIMPULAN DAN SARAN
Kesimpulan
Penelitian ini telah berhasil mengenali wajah tampak depan menggunakan SOM dan LVQ. Dari perbandingan 3 set percobaan, percobaan menggunakan LVQ dan LVQ inisialisasi SOM menghasilkan rata-rata akurasi tertinggi, yaitu 100.0% pada ulangan ke-2 dan ke-3, sedangkan rata-rata akurasi tertinggi yang dihasilkan SOM sebesar 97.8% pada ulangan ke-3. SOM tidak mempu membedakan kedua individu yang mirip sebaik LVQ dan LVQ inisialisasi SOM karena SOM lebih sering tertukar antara individu yang mirip.
Berdasarkan hasil percobaan ini, model LVQ lebih baik dari pada SOM dalam hal mengenali individu dan membedakan individu yang mirip. Hal ini karena LVQ mendekatkan vektor bobot dengan jarak minimum pada data jika target sama dengan kelas dan menjauhkannya jika sebaliknya, sedangkan SOM hanya membarui bobot saja tanpa menjauhkan atau mendekatkan bobot pada data.
Gambar 7 Persentase hasil percobaan 95.2 96.3 97.8 99.7 99.7 100 100 100 100 91 92 93 94 95 96 97 98 99 100
Ulangan 1 Ulangan 2 Ulangan 3
R at a -rat a A k urasi ( %)
13
Saran
Saran untuk pengembangan selanjutnya, yaitu:
1 Menggunakan ekstraksi fitur yang lebih peka terhadap data individu yang mirip terutama untuk model SOM.
2 Menambah fitur crop pada wajah sehingga bagian citra lain selain bagian wajah tidak ikut diekstraksi ciri. Hal ini memungkinkan peningkatan akurasi untuk membedakan citra yang mirip pada kelas yang berbeda.
3 Model LVQ dan LVQ inisialisasi SOM yang digunakan pada penelitian ini sudah menghasilkan akurasi yang baik untuk mengenali wajah tampak depan akan tetapi perlu dicobakan pada data dengan berbagai pose dan ekspresi, juga data yang terdistorsi noise.
DAFTAR PUSTAKA
Bashyal S, Venayagamoorthy GK. 2008. Recognition of facial expressions using Gabor Wavelets and Learning Vector Quantization. Eng Appl Artif Intel. 21(7):1056-1064.doi: 10.1016/j.engappai.2007.11.010.
Cao Z, Yin Q, Tang X, Sun J. 2010. Face recognition with learning based descriptor. Di dalam: The Twenty Third IEEE Conference on Computer Vision and Pattern Recognition; 2010 Jun 13-18; San Francisco, United States. Los Alamitos (US): IEEE Computer Society. hlm 2707-2714.
Fausett L. 1994. Fundamentals of Neural Networks: Architectures, Algorithms, and Applications. New Jersey (US): Prentice Hall.
Gonzalez RC, Woods RE. 2007. Digital Image Procesing. Ed ke-3. New Jersey (US): Prentice Hall.
Gumus E, Kilic N, Sertbas A, Ucan ON. 2010. Evaluation of face recognition techniques using PCA, wavelets and SVM. Expert Syst Appl. 37(2010):6404-6408.doi:10.1016/j.eswa.2010.02.079.
Kohonen T. 2001. Self-Organizing Maps. Ed ke-3. Berlin (DE): Springer.
Kohonen T. 2013. Essentials of the self-organizing map. Neural Networks. 37(2013):52-65.doi:10.1016/j.neunet.2012.09.018.
Sharma A, Jacobs DW. 2011. Bypassing synthesis PLS for face recognition with pose, low resolution and sketch. Di dalam: IEEE Computer Vision and Pattern Recognition (CVPR) 2011; 2011 Jun 21-23; Colorado, United States. Los Alamitos (US): IEEE Computer Society. hlm 593-600.
Su Y, Shan S, Chen X, Gao W. 2009. Hierarchical ensemble of global and local classifiers for face recognition. IEEE T Image Process. 18(8):1885-1896.doi:10.1109/TIP.2009.202173.
Yang L, Ouyang Z, Shi Y. A modified clustering method based on self-organizing maps and its applications. Procedia Computer Science. 9(2012):1371-1379.doi: 10.1016/j.procs.2012.04.151.
14
15 Lampiran 2 Contoh perhitungan LVQ (Fausset 1994)
Pada contoh ini, digunakan 2 referensi vektor. Vektor berikut merepresentasikan dua kelas, 1 dan 2:
Vektor Kelas ( ) 1 ( ) 2 ( ) 2 ( ) 1 ( ) 2
Untuk inisialisasi vektor referensi, digunakan 2 baris pertama pada vektor yang masing-masing mewakili kelas 1 dan 2. Sehingga, unit keluaran pertama merepresentasikan kelas 1 dan unit keluaran kedua untuk kelas 2 (secara simbolis = 1 dan = 2). Vektor yang digunakan untuk pelatihan, yaitu (0,0,1,1), (1,0,0,0), dan (0,1,1,0).
Perhitungan hanya dilakukan 1 iterasi (1 epoch) saja, yaitu: 1 Inisialisasi bobot:
w1 = (1,1,0,0)
w2 = (0,0,0,1)
Inisialisasi learning rate: = 0.1
2 Untuk input vektor x = (0,0,1,1) dan T = 2 lakukan:
o Perhitungan jarak terdekat yang dalam contoh ini menggunakan jarak Euclidean.
d1 = √ - - - - √
d2 = √ - - - - √
o Karena x lebih dekat ke w2, J = 2 dan = 2. Target sama dengan
kelas.
o Update w2 sebagai berikut:
w2 = (0,0,0,1) + 0.1[ (0,0,1,1) - (0,0,0,1) ] = (0,0,0.1,1)
3 Untuk input vektor x = (1,0,0,0) dan T = 1 lakukan:
o Perhitungan jarak terdekat menggunakan jarak Euclidean. d1 = √ - - - - √
d2 = √ - - - - √
o Karena x lebih dekat ke w1, J = 1 dan = 1. Target sama dengan
kelas.
16
w1 = (1,1,0,0) + 0.1[ (1,0,0,0) - (1,1,0,0) ] = (1,0.9,0,0)
4 Untuk input vektor x = (0,1,1,0) dan T = 2 lakukan:
o Perhitungan jarak terdekat menggunakan jarak Euclidean. d1 = √ - - - - √
d2 = √ - - - - √
o Karena x lebih dekat ke w1, J = 1 dan = 1. T = 2 namun = 1.
Target tidak sama dengan kelas. o Update w1 sebagai berikut:
w1 = (1,0.9,0,0) - 0.1[ (0,1,1,0) - (1,0.9,0,0) ] = (1.1,0.89,-0.1,0)
Bobot setelah 1 iterasi adalah: w1 = (1.1,0.89,-0.1,0)
17 Lampiran 3 Hasil percobaan
Ulangan Iterasi / Fold Akurasi SOM Akurasi LVQ Akurasi LVQ Inisialisasi SOM 1 1 89.4737% 100.0000% 100.0000% 2 97.3684% 97.3684% 97.3684% 3 94.7368% 100.0000% 100.0000% 4 100.0000% 100.0000% 100.0000% 5 100.0000% 100.0000% 100.0000% 6 89.4737% 100.0000% 100.0000% 7 92.1053% 100.0000% 100.0000% 8 100.0000% 100.0000% 100.0000% 9 100.0000% 100.0000% 100.0000% 10 89.4737% 100.0000% 100.0000% Rata - rata 95.2632% 99.7368% 99.7368% 2 1 94.7368% 100.0000% 100.0000% 2 100.0000% 100.0000% 100.0000% 3 97.3684% 100.0000% 100.0000% 4 89.4737% 100.0000% 100.0000% 5 92.1053% 100.0000% 100.0000% 6 100.0000% 100.0000% 100.0000% 7 100.0000% 100.0000% 100.0000% 8 100.0000% 100.0000% 100.0000% 9 100.0000% 100.0000% 100.0000% 10 89.4737% 100.0000% 100.0000% Rata - rata 96.3158% 100.0000% 100.0000% 3 1 100.0000% 100.0000% 100.0000% 2 100.0000% 100.0000% 100.0000% 3 92.1053% 100.0000% 100.0000% 4 97.3684% 100.0000% 100.0000% 5 100.0000% 100.0000% 100.0000% 6 94.7368% 100.0000% 100.0000% 7 100.0000% 100.0000% 100.0000% 8 100.0000% 100.0000% 100.0000% 9 94.7368% 100.0000% 100.0000% 10 100.0000% 100.0000% 100.0000% Rata - rata 97.8947% 100.0000% 100.0000%
18
19
Lampiran 5 Tabel kesalahan SOM
Ulangan Fold ID File Kelas Seharusnya Kelas yang dikenali
1 1 8 17 19 18 17 19 13 19 17 19 19 17 2 3 19 17 3 9 17 19 7 19 17 6 1 17 19 4 17 19 10 19 17 18 19 17 7 10 17 19 11 17 19 6 19 17 10 6 17 19 16 17 19 12 19 17 14 19 17 2 1 9 17 19 15 19 17 3 10 19 17 4 1 17 19 17 17 19 1 19 17 12 19 17 5 15 17 19 11 19 17 18 19 17 10 4 17 19 6 17 19 3 19 17 7 19 17 3 3 13 17 19 17 17 19 12 19 17 4 11 17 19 6 14 19 17 19 19 17 9 9 17 19 16 19 17
20
RIWAYAT HIDUP
Penulis dilahirkan di Sumedang pada tanggal 2 Desember 1989 dari pasangan Mohamad Yunus dan Neni Wartini. Penulis merupakan anak pertama dari 2 bersaudara.
Tahun 2007 penulis lulus dari SMA Negeri 3 Sukabumi dan pada tahun yang sama penulis masuk Institut Pertanian Bogor (IPB) Program Diploma pada Program Keahlian Teknik Komputer. Tahun 2009 penulis mengikuti lomba Ganesha Line Follower Robot (Galelobot) 2009 di Institut Teknologi Bandung. Penulis lulus pada tahun 2010 dan bekerja selama 10 bulan di PT Pusat Media Indonesia.
Pada tahun 2011, penulis melanjutkan studi ke Program S1 Ilmu Komputer Alih Jenis, Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor. Tahun 2013 penulis mengikuti lomba Pagelaran Mahasiswa Nasional Bidang Teknologi Informasti (Gemastik) 6 bidang data mining di Institut Teknologi Bandung dan masuk kategori 6 besar.