Beginning
SQL Server
™
2005 Programming
Beginning
Beginning
SQL Server
™
2005 Programming
Beginning SQL Server
™2005 Programming
Copyright © 2006 by Wiley Publishing, Inc., Indianapolis, Indiana Published simultaneously in Canada
ISBN-13: 978-0-7645-8433-6 ISBN-10: 0-7645-8433-2
Manufactured in the United States of America 10 9 8 7 6 5 4 3 2 1
1MA/QT/QS/QW/IN
Library of Congress Cataloging-in-Publication Data: Available from publisher
No part of this publication may be reproduced, stored in a retrieval system or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, scanning or otherwise, except as permitted under Sec-tions 107 or 108 of the 1976 United States Copyright Act, without either the prior written permission of the Pub-lisher, or authorization through payment of the appropriate per-copy fee to the Copyright Clearance Center, 222 Rosewood Drive, Danvers, MA 01923, (978) 750-8400, fax (978) 646-8600. Requests to the Publisher for permis-sion should be addressed to the Legal Department, Wiley Publishing, Inc., 10475 Crosspoint Blvd., Indianapolis, IN 46256, (317) 572-3447, fax (317) 572-4355, or online at http://www.wiley.com/go/permissions.
LIMIT OF LIABILITY/DISCLAIMER OF WARRANTY: THE PUBLISHER AND THE AUTHOR MAKE NO REPRESENTATIONS OR WARRANTIES WITH RESPECT TO THE ACCURACY OR COMPLETENESS OF THE CONTENTS OF THIS WORK AND SPECIFICALLY DISCLAIM ALL WARRANTIES, INCLUDING WITHOUT LIMITATION WARRANTIES OF FITNESS FOR A PARTICULAR PURPOSE. NO WARRANTY MAY BE CREATED OR EXTENDED BY SALES OR PROMOTIONAL MATERIALS. THE ADVICE AND STRATEGIES CONTAINED HEREIN MAY NOT BE SUITABLE FOR EVERY SITUATION. THIS WORK IS SOLD WITH THE UNDERSTANDING THAT THE PUBLISHER IS NOT ENGAGED IN RENDERING LEGAL, ACCOUNTING, OR OTHER PROFESSIONAL SERVICES. IF PROFESSIONAL ASSISTANCE IS REQUIRED, THE SERVICES OF A COMPETENT PROFESSIONAL PERSON SHOULD BE SOUGHT. NEITHER THE PUBLISHER NOR THE AUTHOR SHALL BE LIABLE FOR DAMAGES ARISING HERE-FROM. THE FACT THAT AN ORGANIZATION OR WEBSITE IS REFERRED TO IN THIS WORK AS A CITATION AND/OR A POTENTIAL SOURCE OF FURTHER INFORMATION DOES NOT MEAN THAT THE AUTHOR OR THE PUBLISHER ENDORSES THE INFORMATION THE ORGANIZATION OR WEBSITE MAY PROVIDE OR RECOMMENDATIONS IT MAY MAKE. FURTHER, READERS SHOULD BE AWARE THAT INTERNET WEBSITES LISTED IN THIS WORK MAY HAVE CHANGED OR DISAP-PEARED BETWEEN WHEN THIS WORK WAS WRITTEN AND WHEN IT IS READ.
For general information on our other products and services please contact our Customer Care Department within the United States at (800) 762-2974, outside the United States at (317) 572-3993 or fax (317) 572-4002.
Trademarks:Wiley, the Wiley logo, Wrox, the Wrox logo, Programmer to Programmer, and related trade dress
Credits
Executive Editor
Robert Elliott
Development Editor
Adaobi Obi Tulton
Technical Editor
John Mueller
Production Editor
Pamela Hanley
Copy Editor
Nancy Rapoport
Editorial Manager
Mary Beth Wakefield
Production Manager
Tim Tate
Vice President and Executive Group Publisher
Richard Swadley
Vice President and Executive Publisher
Joseph B. Wikert
Project Coordinator
Kristie Rees
Quality Control Technician
Laura Albert Jessica Kramer
Graphics and Production Specialists
Carrie A. Foster Lauren Goddard Denny Hager Stephanie D. Jumper Barbara Moore Alicia South
Proofreading and Indexing
About the Author
Experiencing his first infection with computing fever in 1978, Robert Vieiraknew right away that this
was something “really cool.” In 1980 he began immersing himself into the computing world more fully — splitting time between building and repairing computer kits, and programming in Basic as well as Z80 and 6502 assembly. In 1983, he began studies for a degree in Computer Information Systems, but found the professional mainframe environment too rigid for his tastes, and dropped out in 1985 to pursue other interests. Later that year, he caught the “PC bug” and began the long road of programming in database languages from dBase to SQL Server. Rob completed a degree in Business Administration in 1990, and, since has typically worked in roles that allow him to combine his knowledge of business and computing. Beyond his Bachelor’s degree, he has been certified as a Certified Management Accountant as well as Microsoft Certified as a Solutions Developer (MCSD), Trainer (MCT), and Database
Administrator (MCDBA).
Rob is currently a Software Architect for WebTrends Corporation in Portland, Oregon.
Acknowledgments
Five years have gone by, and my how life has changed since the last time I wrote a title on SQL Server. So many people have affected my life in so many ways, and, as always, there are a ton of people to thank.
I’ll start with my kids, who somehow continue to be just wonderful even in the face of dad stressing out over this and that. Even as my youngest has asked me several times when I’m “going to be done with that book” (she is not pleased with how it takes up some of my play time), she has been tremendously patient with me all during the development of this book. My eldest just continues to amaze me in her maturity and her sensitivity to what doing a book like this requires (and, of course, what it means to her college education!). The thank yous definitely need to begin with those two.
You — the readers. You’ve written me mail and told me how I helped you out in some way. That was and continues to be the number one reason I find to strength to write another book. The continued sup-port of my Professional series titles has been amazing. We struck a chord — I’m glad. Here’s to hoping we help make your SQL Server experience a little less frustrating and a lot more successful.
I also want to pay special thanks to several people past and present. Some of these are at the old Wrox Press and have long since fallen out of contact, but they remain so much of who I am as I writer that I need to continue to remember them. Others are new players for me, but have added their own stamp to the mix — sometimes just by showing a little patience:
Kate Hall— Who, although she was probably ready to kill me by the end of each of my first two books,
somehow guided me through the edit process to build a better book each time. I have long since fallen out of touch with Kate, but she will always be the most special to me as someone who really helped shape my writing career. I will likely always hold this first “professional” dedication spot for you — wherever you are Kate, I hope you are doing splendidly.
Adaobi Obi Tulton— Who has had to put up with yet another trialing year in my life and what that has
sometimes meant to delivery schedules. If I ever make it rich, I may hire Adaobi as my spiritual guide. While she can be high stress about deadlines, she has a way of displaying a kind of “peace” in just about everything else I’ve seen her do — I need to learn that.
Dominic Shakeshaft— Who got me writing in the first place (then again, given some nights filled with writing instead of sleep lately, maybe it’s not thanks I owe him...).
Catherine Alexander— who played Kate’s more than able-bodied sidekick for my first title, and was
central to round two. Catherine was much like Kate in the sense she had a significant influence on the shape and success of my first two titles.
John Mueller — Who had the dubious job of finding my mistakes. I’ve done tech editing myself, and it’s
x
Acknowledgments
Contents
Acknowledgments
ix
Introduction
xxi
Chapter 1: RDBMS Basics: What Makes Up a SQL Server Database?
1
An Overview of Database Objects
2
The Database Object
2
The Transaction Log
6
The Most Basic Database Object: Table
6
Filegroups
8
Diagrams
8
Views
9
Stored Procedures
10
User-Defined Functions
10
Users and Roles
11
Rules
11
Defaults
11
User-Defined Data Types
11
Full-Text Catalogs
12
SQL Server Data Types
12
NULL Data
17
SQL Server Identifiers for Objects
17
What Gets Named?
17
Rules for Naming
18
Summary
18
Chapter 2: Tools of the Trade
19
Books Online
20
The SQL Server Configuration Manager
21
Service Management
22
Network Configuration
22
The Protocols
23
xii
Contents
The SQL Server Management Studio
28
Getting Started
28
Query Window
33
SQL Server Integration Services (SSIS)
38
Bulk Copy Program (bcp)
39
SQL Server Profiler
40
sqlcmd
40
Summary
40
Chapter 3: The Foundation Statements of T-SQL
41
Getting Started with a Basic SELECT Statement
42
The SELECT Statement and FROM Clause
42
The WHERE Clause
45
ORDER BY
49
Aggregating Data Using the GROUP BY Clause
52
Placing Conditions on Groups with the HAVING Clause
61
Outputting XML Using the FOR XML Clause
63
Making Use of Hints Using the OPTION Clause
63
The DISTINCT and ALL Predicates
64
Adding Data with the INSERT Statement
66
The INSERT INTO . . . SELECT Statement
70
Changing What You’ve Got with the UPDATE Statement
72
The DELETE Statement
75
Summary
77
Exercises
77
Chapter 4: JOINs
79
JOINs
79
INNER JOINs
81
How an INNER JOIN Is Like a WHERE Clause
85
OUTER JOINs
89
The Simple OUTER JOIN
90
Dealing with More Complex OUTER JOINs
95
Seeing Both Sides with FULL JOINs
99
CROSS JOINs
100
Exploring Alternative Syntax for Joins
102
An Alternative INNER JOIN
102
An Alternative OUTER JOIN
103
xiii
Contents
The UNION
104
Summary
109
Exercises
110
Chapter 5: Creating and Altering Tables
111
Object Names in SQL Server
111
Schema Name (aka Ownership)
112
The Database Name
114
Naming by Server
114
Reviewing the Defaults
114
The CREATE Statement
115
CREATE DATABASE
115
CREATE TABLE
121
The ALTER Statement
133
ALTER DATABASE
133
ALTER TABLE
137
The DROP Statement
140
Using the GUI Tool
142
Creating a Database Using the Management Studio
142
Backing into the Code: The Basics of Creating Scripts with the Management Studio
148
Summary
149
Exercises
149
Chapter 6: Constraints
151
Types of Constraints
152
Domain Constraints
152
Entity Constraints
153
Referential Integrity Constraints
154
Constraint Naming
154
Key Constraints
155
PRIMARY KEY Constraints
155
FOREIGN KEY Constraints
158
UNIQUE Constraints
169
CHECK Constraints
170
DEFAULT Constraints
171
Defining a DEFAULT Constraint in Your CREATE TABLE Statement
172
Adding a DEFAULT Constraint to an Existing Table
173
Disabling Constraints
173
xiv
Contents
Rules and Defaults — Cousins of Constraints
178
Rules
178
Defaults
180
Determining Which Tables and Datatypes Use a Given Rule or Default
181
Triggers for Data Integrity
181
Choosing What to Use
181
Summary
183
Chapter 7: Adding More to Our Queries
185
What Is a Subquery?
186
Building a Nested Subquery
186
Correlated Subqueries
190
How Correlated Subqueries Work
190
Correlated Subqueries in the WHERE Clause
190
Dealing with NULL Data — the ISNULL Function
194
Derived Tables
195
The EXISTS Operator
197
Using EXISTS in Other Ways
199
Mixing Datatypes: CAST and CONVERT
201
Performance Considerations
204
JOINs vs. Subqueries vs. ?
204
Summary
205
Exercises
206
Chapter 8: Being Normal: Normalization and Other Basic Design Issues
207
Tables
208
Keeping Your Data “Normal”
208
Before the Beginning
209
The First Normal Form
211
The Second Normal Form
214
The Third Normal Form
216
Other Normal Forms
218
Relationships
219
One-to-One
219
One-to-One or Many
221
Many-to-Many
223
Diagramming
227
Tables
230
Adding and Deleting Tables
230
xv
Contents
De-Normalization
241
Beyond Normalization
241
Keep It Simple
242
Choosing Datatypes
242
Err on the Side of Storing Things
242
Drawing Up a Quick Example
243
Creating the Database
243
Adding the Diagram and Our Initial Tables
244
Adding the Relationships
248
Adding Some Constraints
251
Summary
252
Exercises
252
Chapter 9: SQL Server Storage and Index Structures
255
SQL Server Storage
255
The Database
255
The Extent
256
The Page
256
Rows
257
Understanding Indexes
257
B-Trees
258
How Data Is Accessed in SQL Server
262
Creating, Altering, and Dropping Indexes
270
The CREATE INDEX Statement
270
Creating XML Indexes
276
Implied Indexes Created with Constraints
277
Choosing Wisely: Deciding What Index Goes Where and When
277
Selectivity
277
Watching Costs: When Less Is More
278
Choosing That Clustered Index
278
Column Order Matters
281
Dropping Indexes
281
Use the Database Engine Tuning Wizard
282
Maintaining Your Indexes
282
Fragmentation
282
Identifying Fragmentation vs. Likelihood of Page Splits
283
Summary
286
xvi
Contents
Chapter 10: Views
289
Simple Views
289
Views as Filters
293
More Complex Views
295
Using a View to Change Data — Before INSTEAD OF Triggers
298
Editing Views with T-SQL
301
Dropping Views
302
Creating and Editing Views in the Management Studio
302
Editing Views in the Management Studio
306
Auditing: Displaying Existing Code
306
Protecting Code: Encrypting Views
308
About Schema Binding
309
Making Your View Look Like a Table with VIEW_METADATA
310
Indexed (Materialized) Views
310
Summary
313
Exercises
314
Chapter 11: Writing Scripts and Batches
315
Script Basics
315
The USE Statement
316
Declaring Variables
317
Using @@IDENTITY
320
Using @@ROWCOUNT
324
Batches
325
Errors in Batches
327
When to Use Batches
327
SQLCMD
330
Dynamic SQL: Generating Your Code On-the-Fly with the EXEC Command
334
The Gotchas of EXEC
335
Summary
339
Exercises
340
Chapter 12: Stored Procedures
341
Creating the Sproc: Basic Syntax
342
An Example of a Basic Sproc
342
Changing Stored Procedures with ALTER
343
xvii
Contents
Parameterization
344
Declaring Parameters
344
Control-of-Flow Statements
349
The IF . . . ELSE Statement
349
The CASE Statement
360
Looping with the WHILE Statement
366
The WAITFOR Statement
367
TRY/CATCH Blocks
368
Confirming Success or Failure with Return Values
369
How to Use RETURN
369
Dealing with Errors
371
The Way We Were . . .
372
Handling Errors Before They Happen
378
Manually Raising Errors
381
Adding Your Own Custom Error Messages
385
What a Sproc Offers
388
Creating Callable Processes
389
Using Sprocs for Security
390
Sprocs and Performance
391
Extended Stored Procedures (XPs)
393
A Brief Look at Recursion
393
Debugging
396
Setting Up SQL Server for Debugging
396
Starting the Debugger
397
Parts of the Debugger
400
Using the Debugger Once It’s Started
402
.NET Assemblies
406
Summary
407
Exercises
407
Chapter 13: User Defined Functions
409
What a UDF Is
409
UDFs Returning a Scalar Value
410
UDFs That Return a Table
414
Understanding Determinism
421
Debugging User-Defined Functions
423
.NET in a Database World
423
Summary
424
xviii
Contents
Chapter 14: Transactions and Locks
425
Transactions
425
BEGIN TRAN
426
COMMIT TRAN
427
ROLLBACK TRAN
427
SAVE TRAN
427
How the SQL Server Log Works
428
Failure and Recovery
429
Implicit Transactions
431
Locks and Concurrency
431
What Problems Can Be Prevented by Locks
432
Lockable Resources
435
Lock Escalation and Lock Effects on Performance
435
Lock Modes
436
Lock Compatibility
438
Specifying a Specific Lock Type — Optimizer Hints
439
Setting the Isolation Level
440
Dealing with Deadlocks (aka “A 1205”)
442
How SQL Server Figures Out There’s a Deadlock
443
How Deadlock Victims Are Chosen
443
Avoiding Deadlocks
443
Summary
445
Chapter 15: Triggers
447
What Is a Trigger?
448
ON
449
WITH ENCRYPTION
450
The FOR|AFTER vs. the INSTEAD OF Clause
450
WITH APPEND
452
NOT FOR REPLICATION
453
AS
453
Using Triggers for Data Integrity Rules
453
Dealing with Requirements Sourced from Other Tables
454
Using Triggers to Check the Delta of an Update
455
Using Triggers for Custom Error Messages
457
Other Common Uses for Triggers
457
Other Trigger Issues
458
Triggers Can Be Nested
458
xix
Contents
Triggers Don’t Prevent Architecture Changes
458
Triggers Can Be Turned Off Without Being Removed
459
Trigger Firing Order
459
INSTEAD OF Triggers
461
Performance Considerations
462
Triggers Are Reactive Rather Than Proactive
462
Triggers Don’t Have Concurrency Issues with the Process That Fires Them
462
Using IF UPDATE() and COLUMNS_UPDATED
463
Keep It Short and Sweet
465
Don’t Forget Triggers When Choosing Indexes
465
Try Not to Roll Back Within Triggers
465
Dropping Triggers
466
Debugging Triggers
466
Summary
468
Chapter 16: A Brief XML Primer
469
XML Basics
470
Parts of an XML Document
471
Namespaces
479
Element Content
481
Being Valid vs. Being Well Formed — Schemas and DTDs
481
What SQL Server Brings to the Party
482
Retrieving Relational Data in XML Format
483
RAW
484
AUTO
486
EXPLICIT
487
PATH
503
OPENXML
508
A Brief Word on XSLT
514
Summary
516
Chapter 17: Reporting for Duty, Sir!: A Look At Reporting Services
517
Reporting Services 101
518
Building Simple Report Models
518
Data Source Views
523
Report Creation
529
Report Server Projects
532
Deploying the Report
537
xx
Contents
Chapter 18: Getting Integrated With Integration Services
539
Understanding the Problem
539
Using the Import/Export Wizard to Generate Basic Packages
540
Executing Packages
547
Using the Execute Package Utility
547
Executing Within the Business Intelligence Development Studio
549
Executing Within the Management Studio
549
Editing the Package
550
Summary
553
Chapter 19: Playing Administrator
555
Scheduling Jobs
556
Creating an Operator
557
Creating Jobs and Tasks
558
Backup and Recovery
567
Creating a Backup: a.k.a. “A Dump”
567
Recovery Models
570
Recovery
571
Index Maintenance
572
ALTER INDEX
573
Archiving Data
575
Summary
576
Exercises
576
Appendix A: Exercise Solutions
577
Appendix B: System Functions
587
Appendix C: Finding the Right Tool
639
Appendix
D: Very Simple Connectivity Examples
647
Appendix
E: Installing and Using the Samples
651
Introduction
What a long strange trip it’s been. When I first wrote Professional SQL Server 7.0 Programming in early 1999, the landscape of both books and the development world was much different than it is today. At the time, .NET was as yet unheard of, and while Visual Studio 98 ruled the day as the most popular devel-opment environment, Java was coming on strong and alternative develdevel-opment tools such as Delphi were still more competitive than they typically are today. The so-called “dot com” era was booming, and the use of database management systems (DBMS) such as SQL Server was growing.
There was, however a problem. While one could find quite a few books on SQL Server, they were all ori-ented towards the administrator. They spent tremendous amounts of time and energy on things that the average developer did not give a proverbial hoot about. Something had to give, and as my development editor and I pondered the needs of the world, we realized that we could not solve world hunger or arms proliferation ourselves, but we could solve the unrealized need for a new kind of SQL book — one aimed specifically at developers.
At the time, we wrote Professional SQL Server 7.0 Programming to be everything to everyone. It was a compendium. It started at the beginning, and progressed to a logical end. The result was a very, very large book that filled a void for a lot of people (hooray!).
SQL Server 2005 represents the 2ndmajor revision to SQL Server since that time, and, as we did the
plan-ning for this cycle of books, we realized that we once again had a problem — it was too big. The new features of SQL Server 2005 created a situation where there was simply too much content to squeeze into one book, and so we made the choice to split the old Professional series title into a Beginning and a more targeted Professional pair of titles. You are now holding the first half of that effort.
My hope is that you find something that covers all of the core elements of SQL Server with the same suc-cess that we had in the previous Professional SQL Server Programming titles. When we’re done, you should be set to be a highly functional SQL Server 2005 programmer, and, when you need it, be ready to move on to the more advanced Professional title.
Who This Book Is For
It is almost sad that the word “Beginner” is in the title of this book. Don’t get me wrong; if you are a beginner, then this title is for you. But it is designed to last you well beyond your beginning days. What is covered in this book is necessary for the beginner, but there is simply too much information for you to remember all of it all the time, and so it is laid out in a fashion that should make a solid review and ref-erence item even for the more intermediate, and, yes, even advanced user.
xxii
Introduction
For the intermediate user, you can probably skip perhaps as far as chapter 7 or 8 for starting. While I would still recommend scanning the prior chapters for holes in your skills or general review, you can probably skip ahead with little harm done and get to something that might be a bit more challenging for you.
Advanced users, in addition to utilizing this as an excellent reference resource, will probably want to focus on Chapter 12 and beyond. Virtually everything from that point forward should be of some inter-est (the new debugging, transactions, XML, Reporting Services and more!).
What This Book Covers
Well, if you’re read the title, you’re probably not shocked to hear that this book covers SQL Server 2005 with a definite bent towards the developer perspective.
SQL Server 2005 is the latest incarnation of a database management system that has now been around for what is slowly approaching two decades. It builds on the base redesign that was done to the product in version 7.0, and significantly enhances the compatibility and featureset surrounding XML, .NET, user defined datatypes as well as a number of extra services. This book focuses on core development needs of every developer regardless of skill level. The focus is highly orienting to just the 2005 version of the product, but there is regular mention of backward compatibility issues as they may affect your design and coding choices.
How This Book Is Structured
The book is designed to become progressively more advanced as you progress through it, but, from the very beginning, I’m assuming that you are already an experienced developer — just not necessarily with databases. In order to make it through this book you do need to already have understanding of programming basics such as variables, data types, and procedural programming. You do not have to have ever seen a query before in your life (though I suspect you have).
The focus of the book is highly developer-oriented. This means that we will, for the sake of both brevity and sanity, sometimes gloss over or totally ignore items that are more the purview of the database administrator than the developer. We will, however, remember administration issues as they either affect the developer or as they need to be thought of during the development process — we’ll also take a brief look at several administration related issues in Chapter 19.
The book makes a very concerted effort to be language independent in terms of your client side develop-ment. VB, C#, C++, Java and other languages are generally ignored (we focus on the server side of the equation) and treated equally where addressed.
xxiii
Introduction
What You Need to Use This Book
In order to make any real viable use of this book, you will need an installation of SQL Server. The book makes extensive use of the actual SQL Server 2005 management tools, so I highly recommend that you have a version that contains the full product rather than just using SQL Server Express. That said, the book is focused on the kind of scripting required for developers, so even SQL Server Express users should be able to get the lion’s share of learning out of most of the chapters.
A copy of Visual Studio is handy for working with this book, but most of the Visual Studio features needed are included in the Business Intelligence Studio that comes along with the SQL Server product.
Conventions
To help you get the most from the text and keep track of what’s happening, we’ve used a number of con-ventions throughout the book.
Try It Out
The Try It Outis an exercise you should work through, following the text in the book.
1.
They usually consist of a set of steps.2.
Each step has a number.3.
Follow the steps through with your copy of the database.How It Works
After each Try It Out, the code you’ve typed will be explained in detail.
Tips, hints, tricks, and asides to the current discussion are offset and placed in italics like this.
As for styles in the text:
❑ We highlightnew terms and important words when we introduce them.
❑ We show keyboard strokes like this: Ctrl+A.
❑ We show file names, URLs, and code within the text like so: persistence.properties.
❑ We present code in two different ways:
In code examples we highlight new and important code with a gray background. The gray highlighting is not used for code that’s less important in the present context, or has been shown before.
xxiv
Introduction
Source Code
As you work through the examples in this book, you may choose either to type in all the code manually or to use the source code files that accompany the book. All of the source code used in this book is avail-able for download at http://www.wrox.com. Once at the site, simply locate the book’s title (either by
using the Search box or by using one of the title lists) and click the Download Code link on the book’s detail page to obtain all the source code for the book.
Because many books have similar titles, you may find it easiest to search by ISBN; this book’s ISBN is 0-7645-8433-2 (changing to 978-0-7645-8433-6 as the new industry-wide 13-digit ISBN numbering system is phased in by January 2007).
Once you download the code, just decompress it with your favorite compression tool. Alternately, you can go to the main Wrox code download page at http://www.wrox.com/dynamic/books/ download.aspxto see the code available for this book and all other Wrox books.
Errata
We make every effort to ensure that there are no errors in the text or in the code. However, no one is per-fect, and mistakes do occur. If you find an error in one of our books, like a spelling mistake or faulty piece of code, we would be very grateful for your feedback. By sending in errata you may save another reader hours of frustration and at the same time you will be helping us provide even higher quality information.
To find the errata page for this book, go to http://www.wrox.comand locate the title using the Search box or one of the title lists. Then, on the book details page, click the Book Errata link. On this page you can view all errata that has been submitted for this book and posted by Wrox editors. A complete book list including links to each book’s errata is also available at www.wrox.com/misc-pages/booklist.shtml.
If you don’t spot “your” error on the Book Errata page, go to www.wrox.com/contact/techsupport .shtmland complete the form there to send us the error you have found. We’ll check the information and, if appropriate, post a message to the book’s errata page and fix the problem in subsequent editions of the book.
p2p.wrox.com
For author and peer discussion, join the P2P forums at p2p.wrox.com. The forums are a Web-based
xxv
Introduction
At http://p2p.wrox.comyou will find a number of different forums that will help you not only as you
read this book, but also as you develop your own applications. To join the forums, just follow these steps:
1.
Go to p2p.wrox.comand click the Register link.2.
Read the terms of use and click Agree.3.
Complete the required information to join as well as any optional information you wish to provide and click Submit.4.
You will receive an e-mail with information describing how to verify your account and complete the joining process.You can read messages in the forums without joining P2P but in order to post your own messages, you must join.
Once you join, you can post new messages and respond to messages other users post. You can read mes-sages at any time on the Web. If you would like to have new mesmes-sages from a particular forum e-mailed to you, click the Subscribe to this Forum icon by the forum name in the forum listing.
Beginning
1
RDBMS Basics: What Makes
Up a SQL Ser ver Database?
What makes up a database? Data for sure. (What use is a database that doesn’t store anything?) But a Relational Database Management System(RDBMS) is actually much more than data. Today’s
advanced RDBMSs not only store your data; they also manage that data for you, restricting what kind of data can go into the system, and also facilitating getting data out of the system. If all you want is to tuck the data away somewhere safe, you could use just about any data storage system. RDBMSs allow you to go beyond the storage of the data into the realm of defining what that data should look like, or the business rulesof the data.
Don’t confuse what I’m calling the “business rules of data” with the more generalized business rules that drive your entire system (for example, someone can’t see anything until they’ve logged on, or automatically adjusting the current period in an accounting system on the first of the month). Those types of rules can be enforced at virtually any level of the system. (These days, it’s usually in the middle or client tier of an n-tier system). Instead, what we’re talking about here are the business rules that specifically relate to the data. For example, you can’t have a sales order with a negative amount. With an RDBMS, we can incorporate these rules right into the integrity of the database itself.
This chapter provides an overview to the rest of the book. Everything discussed in this chapter will be covered again in later chapters, but this chapter is intended to provide you with a roadmap or plan to bear in mind as we progress through the book. Therefore, in this chapter, we will take a high-level look into:
❑ Database objects ❑ Data types
An Over view of Database Objects
An RDBMS such as SQL Server contains many objects. Object purists out there may quibble with
whether Microsoft’s choice of what to call an object (and what not to) actually meets the normal defini-tion of an object, but, for SQL Server’s purposes, the list of some of the more important database objects can be said to contain such things as:
The database itself Indexes The transaction log Assemblies
Tables Reports
Filegroups Full-text catalogs Diagrams User-defined data types
Views Roles
Stored procedures Users User Defined Functions
The Database Object
The database is effectively the highest-level object that you can refer to within a given SQL Server. (Technically speaking, the server itself can be considered to be an object, but not from any real “pro-gramming” perspective, so we’re not going there). Most, but not all, other objects in a SQL Server are children of the database object.
If you are familiar with old versions of SQL Server you may now be saying, “What? What happened to logins? What happened to Remote Servers and SQL Agent tasks?” SQL Server has several other objects (as listed previously) that exist in support of the database. With the exception of linked servers, and per-haps Integration Services packages, these are primarily the domain of the database administrator and as such, we generally don’t give them significant thought during the design and programming processes. (They are programmable via something called the SQL Management Objects (SMO), but that is far too special a case to concern ourselves with here.)
A database is typically a group that includes at least a set of table objects and, more often than not, other objects, such as stored procedures and views that pertain to the particular grouping of data stored in the database’s tables.
What types of tables do we store in just one database and what goes in a separate database? We’ll dis-cuss that in some detail later in the book, but for now we’ll take the simple approach of saying that any data that is generally thought of as belonging to just one system, or is significantly related will be stored in a single database. An RDBMS, such as SQL Server, may have multiple user databases on just one server, or it may have only one. How many can reside on one SQL Server depends on such factors as capacity (CPU power, disk I/O limitations, memory, etc.), autonomy (you want one person to have man-agement rights to the server this system is running on, and someone else to have admin rights to a dif-ferent server), or just how many databases your company or client has. Many servers have only one production database; others may have many. Also keep in mind that with any version of SQL Server you’re likely to find in production these days (SQL Server 2000 was already five years old by the time it
2
was replaced, so we’ll assume most shops have that or higher), we have the ability to have multiple instances of SQL Server — complete with separate logins and management rights — all on the same physical server.
I’m sure many of you are now asking: Can I have different versions of SQL Server on the same box — say, SQL Server 2000 and SQl Server 2005? The answer is, yes. You can mix SQL Server 2000 and 2005 on the same box. Personally, I am not at all trusting of this configuration, even for migration sce-narios, but, if you have the need, yes, it can be done.
When you first load SQL Server, you will start with four system databases:
❑ master ❑ model
❑ msdb
❑ tempdb
All of these need to be installed for your server to run properly. (Indeed, for some of them, it won’t run at all without them.) From there, things vary depending on which installation choices you made. Examples of some of the databases you may see include the following:
❑ AdventureWorks (the sample database)
❑ AdventureWorksDW (sample for use with Analysis Services)
In addition to the system installed examples, this book makes extensive use of the older samples. (See Appendix F — online for more info on how to get these installed.)
❑ pubs
❑ Northwind
During the design of this book, much debate was had over whether to use the newer examples or stick with the tried and true older examples. I’m going to be very up front that Microsoft was not very happy about my choice to retain the older examples, but I’m not making any apologies about it.
The newer AdventureWorks database is certainly a much more robust example, and does a great job of providing examples of just about every little twist and turn you can make use of in SQL Server 2005. There is, however, a problem with that — complexity. The AdventureWorks database is excessively com-plex for a training database. It takes features that are likely to be used only in exception cases and uses them as a dominant feature. I polled several friends who teach and/or write books on SQL Server, and all of them shared my opinion on this: Northwind and pubs, while overly simplistic in many ways, make it relatively easy to understand the basic concepts at work in SQL Server. I’d much rather get you to understand the basics and move forward than overwhelm you in the unnecessary complexity that is AdventureWorks.
The master Database
Every SQL Server, regardless of version or custom modifications, has the master database. This database holds a special set of tables (system tables) that keeps track of the system as a whole. For example, when you create a new database on the server, an entry is placed in the sysdatabases table in the master
3
database. All extended and system stored procedures, regardless of which database they are intended for use with, are stored in this database. Obviously, since almost everything that describes your server is stored in here, this database is critical to your system and cannot be deleted.
The system tables, including those found in the master database, can, in a pinch, be extremely useful. They can enable you to determine whether certain objects exist before you perform operations on them. For example, if you try to create an object that already exists in any particular database, you will get an error. If you want to force the issue, you could test to see whether the table already has an entry in the sysobjects table for that database. If it does, you would delete that object before re-creating it.
The model Database
The model database is aptly named, in the sense that it’s the model on which a copy can be based. The model database forms a template for any new database that you create. This means that you can, if you wish, alter the modeldatabase if you want to change what standard, newly created databases look like.
For example, you could add a set of audit tables that you include in every database you build. You could also include a few user groups that would be cloned into every new database that was created on the system. Note that since this database serves as the template for any other database, it’s a required database and must be left on the system; you cannot delete it.
There are several things to keep in mind when altering the model database. First, any database you cre-ate has to be at least as large as the model database. That means that if you alter the modeldatabase to
be 100MB in size, you can’t create a database smaller than 100MB. There are several other similar pitfalls. As such, for 90% of installations, I strongly recommend leaving this one alone.
The msdb Database
msdbis where the SQL Agent process stores any system tasks. If you schedule backups to run on a
database nightly, there is an entry in msdb. Schedule a stored procedure for one time execution, and yes,
it has an entry in msdb.
If you’re quite cavalier, you may be saying to yourself, “Cool, I can’t wait to mess around in there!” Don’t go there!Using the system tables in any form is fraught with peril. Microsoft has recommended against using the system tables for at least the last three versions of SQL Server. They make absolutely no guarantees about com-patibility in the master database between versions — indeed, they virtually guaran-tee that they will change. The worst offense comes when performing updates on objects in the master database. Trust me when I tell you that altering these tables in any way is asking for a SQL Server that no longer functions. Fortunately, several alternatives (for example, system functions, system stored procedures, and informa-tion_schema views) are available for retrieving much of the meta data that is stored in the system tables.
All that said, there are still times when nothing else will do. We will discuss a few situations where you can’t avoid using the system tables, but in general, you should consider them to be evil cannibals from another tribe and best left alone.
4
The tempdb Database
tempdbis one of the key working areas for your server. Whenever you issue a complex or large query
that SQL Server needs to build interim tables to solve, it does so in tempdb. Whenever you create a
tem-porary table of your own, it is created in tempdb, even though you think you’re creating it in the current
database. Whenever there is a need for data to be stored temporarily, it’s probably stored in tempdb. tempdbis very different from any other database. Not only are the objects within it temporary; the
database itself is temporary. It has the distinction of being the only database in your system that is com-pletely rebuilt from scratch every time you start your SQL Server.
AdventureWorks
SQL Server included samples long before this one came along. The old samples had their shortcomings though. For example, they contained a few poor design practices. (I’ll hold off the argument of whether AdventureWorks has the same issue or not. Let’s just say that AdventureWorks was, among other things, an attempt to address this problem.) In addition, they were simplistic and focused on demon-strating certain database concepts rather than on SQL Server as a product or even databases as a whole.
From the earliest stages of development of Yukon (the internal code name for what we know today as SQL Server 2005) Microsoft knew they wanted a far more robust sample database that would act as a sample for as much of the product as possible. AdventureWorks is the outcome of that effort. As much as you will hear me complain about its overly complex nature for the beginning user, it is a masterpiece in that it shows it alloff. Okay, so it’s not really everything, but it is a fairly complete sample, with more
realistic volumes of data, complex structures, and sections that show samples for the vast majority of product features. In this sense, it’s truly terrific.
I use it here and there — more as you get to some of the more advanced features of the product.
AdventureWorksDW
This is the Analysis Services sample. (The DW stands for Data Warehouse, which is the type of database over which most Analysis Services projects will be built.) Perhaps the greatest thing about it is that Microsoft had the foresight to tie the transaction database sample with the analysis sample, providing a whole set of samples that show the two of them working together.
Decision support databases are well outside the scope of this book, and you won’t be using this
database, but keep it in mind as you fire up Analysis Services and play around. Take a look at the differ-ences between the two databases. They are meant to serve the same fictional company, but they have dif-ferent purposes; learn from it.
Technically speaking, you can actually create objects yourself in tempdb– I strongly recommend against this practice. You can create temporary objects from within any database you have access to in your system – it will be stored in tempdb. Creating objects directly in tempdbgains you nothing, but adds the confusion of referring to things across databases. This is another of those, “Don’t go there!” kind of things.
5
The pubs Database
Ahhhh pubs! It’s almost like an old friend. pubsis now installed only as a separately downloaded
sam-ple from the Microsoft website and is available primarily to support training articles and books like this one. pubshas absolutely nothing to do with the operation of SQL Server. It’s merely there to provide a
consistent place for your training and experimentation. You make use of pubsoccasionally in this book. pubscan be installed, although it is a separate install, and deleted with no significant consequences.
The Northwind Database
If your past programming experience has involved Access or Visual Basic, = you are probably already somewhat familiar with the Northwinddatabase. Northwindwas new to SQL Server beginning in
ver-sion 7.0, but is being removed from the basic installation as of SQL Server 2005. Much like pubs, it must
be installed separately from the base SQL Server install. (Fortunately, it’s part of the same sample down-load and install). The Northwinddatabase serves as one of the major testing grounds for this book.
The Transaction Log
Believe it or not, the database file itself isn’t where most things happen. Although the data is certainly read in from there, any changes you make don’t initially go to the database itself. Instead, they are writ-ten serially to the transaction log. At some later point in time, the database is issued a checkpoint— it is at that point in time that all the changes in the log are propagated to the actual database file.
The database is in a random access arrangement, but the log is serial in nature. While the random nature of the database file allows for speedy access, the serial nature of the log allows things to be tracked in the proper order. The log accumulates changes that are deemed as having been committed, and then writes several of them to the physical database file(s) at a time.
We’ll take a much closer look at how things are logged in Chapter 14, “Transactions and Locks,” but for now, remember that the log is the first place on disk that the data goes, and it’s propagated to the actual database at a later time. You need both the database file and the transaction log to have a functional database.
The Most Basic Database Object: Table
Databases are made up of many things, but none are more central to the make-up of a database than tables. A table can be thought of as equating to an accountant’s ledger or an Excel spreadsheet. It is made up of what is called domaindata (columns) and entitydata (rows). The actual data for the database is stored in the tables.
Each table definition also contains the metadata(descriptive information about data) that describes the
nature of the data it is to contain. Each column has its own set of rules about what can be stored in that column. A violation of the rules of any one column can cause the system to reject an inserted row or an update to an existing row, or prevent the deletion of a row.
pubsand Northwindare only installed as part of a separate installation that can be downloaded from Microsoft. See Appendix F (online) for more information on how to get them installed on your practice system.
6
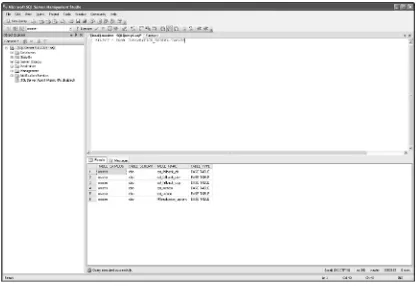
Let’s take a look at the publisherstable in the pubsdatabase. (The view presented in Figure 1-1 is
from the SQL Server Management Studio. This is a fundamental tool and we will look at how to make use of it in the next chapter.)
Figure 1-1
The table in Figure 1-1 is made up of five columns of data. The number of columns remains constant regardless of how much data (even zero) is in the table. Currently, the table has eight records. The num-ber of records will go up and down as we add or delete data, but the nature of the data in each record (or row) is described and restricted by the data typeof the column.
Indexes
An indexis an object that exists only within the framework of a particular table or view. An index works
much like the index does in the back of an encyclopedia; there is some sort of lookup (or “key”) value that is sorted in a particular way, and, once you have that, you are provided another key with which you can look up the actual information you were after.
An index provides us ways of speeding the lookup of our information. Indexes fall into two categories:
❑ Clustered— You can have only one of these per table. If an index is clustered, it means that the
table on which the clustered index is based is physically sorted according to that index. If you were indexing an encyclopedia, the clustered index would be the page numbers; the informa-tion in the encyclopedia is stored in the order of the page numbers.
❑ Non-clustered— You can have many of these for every table. This is more along the lines of
what you probably think of when you hear the word “index.” This kind of index points to some other value that will let you find the data. For our encyclopedia, this would be the keyword index at the back of the book.
I’m going to take this as my first opportunity to launch into a diatribe on the naming of objects. SQL Server has the ability to embed spaces in names and, in some cases, to use keywords as names. Resist the temptation to do this! Columns with embedded spaces in their name have nice headers when you make a SELECTstatement, but there are other ways to achieve the same result. Using embedded spaces and keywords for column names is literally begging for bugs, confusion, and other disasters. I’ll dis-cuss later why Microsoft has elected to allow this, but for now, just remember to asso-ciate embedded spaces or keywords in names with evil empires, torture, and certain death. (This won’t be the last time you hear from me on this one.)
7
Note that views that have indexes — or indexed views— must have at least one clustered index before it
can have any non-clustered indexes.
Triggers
Atriggeris an object that exists only within the framework of a table. Triggers are pieces of logical code that are automatically executed when certain things, such as inserts, updates, or deletes, happen to your table.
Triggers can be used for a great variety of things, but are mainly used for either copying data as it is entered or checking the update to make sure that it meets some criteria.
Constraints
Aconstraintis yet another object that exists only within the confines of a table. Constraints are much like
they sound; they confine the data in your table to meet certain conditions. Constraints, in a way, com-pete with triggers as possible solutions to data integrity issues. They are not, however, the same thing; each has its own distinct advantages.
Filegroups
By default, all your tables and everything else about your database (except the log) are stored in a single file. That file is a member of what’s called the primary filegroup. However, you are not stuck with this arrangement.
SQL Server allows you to define a little over 32,000 secondary files. (If you need more than that, perhaps it
isn’t SQL Server that has the problem.) These secondary files can be added to the primary filegroup or created as part of one or more secondary filegroups. While there is only one primary filegroup (and it is
actually called “Primary”), you can have up to 255 secondary filegroups. A secondary filegroup is cre-ated as an option to a CREATE DATABASEor ALTER DATABASEcommand.
Diagrams
We will discuss database diagramming in some detail when we discuss normalization and database design, but for now, suffice it to say that a database diagram is a visual representation of the database design, including the various tables, the column names in each table, and the relationships between tables. In your travels as a developer, you may have heard of an entity-relationshipdiagram — or ERD. In
an ERD the database is divided into two parts: entities (such as “supplier” and “product”) and relations (such as “supplies” and “purchases”).
Although they have been entirely redesigned with SQL Server 2005, the included database design tools remain a bit sparse. Indeed, the diagramming methodology the tools use doesn’t adhere to any of the accepted standards in ER diagramming.
Still, these diagramming tools really do provide all the “necessary” things; they are at least something of a start. See Appendix C for more on ERD and other tools.
Figure 1-2 is a diagram that shows some of the various tables in the AdventureWorks database. The dia-gram also (though it may be a bit subtle since this is new to you) describes many other properties about the database. Notice the tiny icons for keys and the infinity sign. These depict the nature of the relationship
8
between two tables. We’ll talk about relationships extensively in Chapters 7 and 8 and we’ll look further into diagrams later in the book.
Figure 1-2
Views
A view is something of a virtual table. A view, for the most part, is used just like a table, except that it doesn’t contain any data of its own. Instead, a view is merely a preplanned mapping and representation of the data stored in tables. The plan is stored in the database in the form of a query. This query calls for data from some, but not necessarily all, columns to be retrieved from one or more tables. The data retrieved may or may not (depending on the view definition) have to meet special criteria in order to be shown as data in that view.
9
Until SQL Server 2000, the primary purpose of views was to control what the user of the view saw. This has two major impacts: security and ease of use. With views you can control what the users see, so if there is a section of a table that should be accessed by only a few users (for example, salary details), you can create a view that includes only those columns to which everyone is allowed access. In addition, the view can be tailored so that the user doesn’t have to search through any unneeded information.
In addition to these most basic uses for view, we also have the ability to create what is called an indexed view. This is the same as any other view, except that we can now create an index against the view. This results in a couple of performance impacts (some positive, one negative):
❑ Views that reference multiple tables generally perform muchfaster with an indexed view
because the join between the tables is preconstructed.
❑ Aggregations performed in the view are precalculated and stored as part of the index; again,
this means that the aggregation is performed one time (when the row is inserted or updated), and then can be read directly from the index information.
❑ Inserts and deletes have higher overhead because the index on the view has to be updated
immediately; updates also have higher overhead if the key column of the index is affected by the update.
We will look into these performance issues more deeply in Chapter 10.
Stored Procedures
Stored procedures(or sprocs) are historically and, even in the .NET era, likely to continue to be the bread
and butter of programmatic functionality in SQL Server. Stored procedures are generally an ordered series of Transact-SQL (the language used to query Microsoft SQL Server) statements bundled up into a single logical unit. They allow for variables and parameters as well as selection and looping constructs. Sprocs offer several advantages over just sending individual statements to the server in the sense that they:
❑ Are referred to using short names, rather than a long string of text, therefore less network traffic
is required in order to run the code within the sproc.
❑ Are pre-optimized and precompiled, saving a small amount of time each time the sproc is run. ❑ Encapsulate a process, usually for security reasons or just to hide the complexity of the
database.
❑ Can be called from other sprocs, making them reusable in a somewhat limited sense.
In addition, you can utilize any .NET language to add program constructs, beyond those native to T-SQL, to your stored procedures.
User-Defined Functions
User Defined Functions(or UDFs) have a tremendous number of similarities to sprocs, except that they:
❑ Can return a value of most SQL Server data types. Excluded return types include text, ntext,
image, cursor, and timestamp.
❑ Can’t have “side effects.” Basically, they can’t do anything that reaches outside the scope of the
function, such as changing tables, sending e-mails, or making system or database parameter changes.
10
UDFs are similar to the functions that you would use in a standard programming language such as VB.NET or C++. You can pass more than one variable in, and get a value out. SQL Server’s UDFs vary from the functions found in many procedural languages; however, in that allvariables passed into the
function are passed in by value. If you’re familiar with passing in variables By Ref in VB, or passing in pointers in C++, sorry, there is no equivalent here. There is, however, some good news in that you can return a special data type called a table. We’ll examine the impact of this in Chapter 13.
Users and Roles
These two go hand in hand. Usersare pretty much the equivalent of logins. In short, this object
repre-sents an identifier for someone to login into the SQL Server. Anyone logging into SQL Server has to map (directly or indirectly depending on the security model in use) to a user. Users, in turn, belong to one or more roles. Rights to perform certain actions in SQL Server can then be granted directly to a user or to a role to which one or more users belong.
Rules
Rules and constraints provide restriction information about what can go into a table. If an updated or inserted record violates a rule, then that insertion or update will be rejected. In addition, a rule can be used to define a restriction on a user-defined data type. Unlike rules, constraints aren’t really objects unto themselves, but rather pieces of metadata describing a particular table.
Rules should be considered there for backward compatibility only and should be avoided in new development.
Defaults
There are two types of defaults. There is the default that is an object unto itself, and the default that is not really an object, but rather metadata describing a particular column in a table (in much the same way as we have constraints, which are objects, and rules, which are not objects but metadata). They both serve the same purpose. If, when inserting a record, you don’t provide the value of a column and that column has a default defined, a value will be inserted automatically as defined in the default. We will examine both types of defaults in Chapter 6.
User-Defined Data Types
User-defined data types are extensions to the system-defined data types. Beginning with this version of SQL Server, the possibilities here are almost endless. Although SQL Server 2000 and earlier had the idea of user-defined data types, they were really limited to different filtering of existing data types. With SQL Server 2005, you have the ability to bind .NET assemblies to your own data types, meaning you can have a data type that stores (within reason) about anything you can store in a .NET object.
Careful with this! The data type that you’re working with is pretty fundamental to your data and its storage. Although being able to define your own thing is very cool, recognize that it will almost cer-tainly come with a large performance cost. Consider it carefully, be sure it’s something you need, and then, as with everything like this, TEST, TEST, TEST!!!
11
Full-Text Catalogs
Full-text catalogs are mappings of data that speed the search for specific blocks of text within columns that have full-text searching enabled. Although these objects are tied at the hip to the tables and columns that they map, they are separate objects, and are therefore not automatically updated when changes hap-pen in the database.
SQL Ser ver Data Types
Now that you’re familiar with the base objects of a SQL Server database, let’s take a look at the options that SQL Server has for one of the fundamental items of any environment that handles data: data types. Note that, since this book is intended for developers, and that no developer could survive for 60 seconds without an understanding of data types, I’m going to assume that you already know how data types work, and just need to know the particulars of SQL Server data types.
SQL Server 2005 has the intrinsic data types shown in the following table:
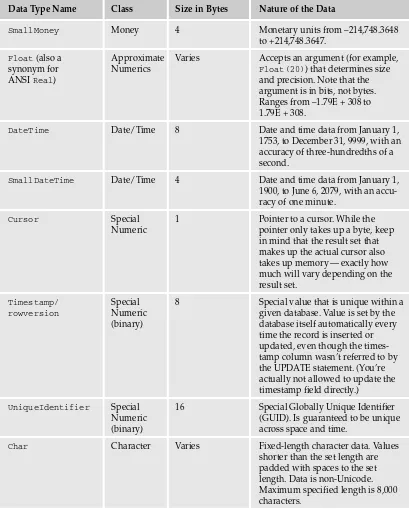
Data Type Name Class Size in Bytes Nature of the Data
Bit Integer 1 The size is somewhat misleading.
The first bitdata type in a table
takes up one byte; the next seven make use of the same byte. Allow-ing nulls causes an additional byte to be used.
Bigint Integer 8 This just deals with the fact that we
use larger and larger numbers on a more frequent basis. This one allows you to use whole numbers from –263to 263–1. That’s plus or
minus about 92 quintrillion.
Int Integer 4 Whole numbers from –2,147,483,648
to 2,147,483,647.
SmallInt Integer 2 Whole numbers from –32,768 to
32,767.
TinyInt Integer 1 Whole numbers from 0 to 255. Decimalor Numeric Decimal/ Varies Fixed precision and scale from
Numeric –1038–1 to 1038–1. The two names are
synonymous.
Money Money 8 Monetary units from –263to 263plus
precision to four decimal places. Note that this could be any mone-tary unit, not just dollars.
12
Data Type Name Class Size in Bytes Nature of the Data
SmallMoney Money 4 Monetary units from –214,748.3648
to +214,748.3647.
Float(also a Approximate Varies Accepts an argument (for example,
synonym for Numerics Float(20)) that determines size
ANSI Real) and precision. Note that the
argument is in bits, not bytes. Ranges from –1.79E + 308 to 1.79E + 308.
DateTime Date/Time 8 Date and time data from January 1,
1753, to December 31, 9999, with an accuracy of three-hundredths of a second.
SmallDateTime Date/Time 4 Date and time data from January 1,
1900, to June 6, 2079, with an accu-racy of one minute.
Cursor Special 1 Pointer to a cursor. While the
Numeric pointer only takes up a byte, keep in mind that the result set that makes up the actual cursor also takes up memory — exactly how much will vary depending on the result set.
Timestamp/ Special 8 Special value that is unique within a rowversion Numeric given database. Value is set by the
(binary) database itself automatically every time the record is inserted or updated, even though the times-tamp column wasn’t referred to by the UPDATE statement. (You’re actually not allowed to update the timestamp field directly.)
UniqueIdentifier Special 16 Special Globally Unique Identifier
Numeric (GUID). Is guaranteed to be unique (binary) across space and time.
Char Character Varies Fixed-length character data. Values
shorter than the set length are padded with spaces to the set length. Data is non-Unicode. Maximum specified length is 8,000 characters.
Table continued on following page