Perangkat keras berupa Notebook: • Processor intel Core i3 2.20 GHz. • RAM kapasitas 2.0 GB.
• Harddisk Kapasitas 500 GB.
• Monitor pada resolusi 1366 x 768 piksel. • Merek Acer Aspire 4750.
Perangkat lunak berupa:
• Sistem operasi Microsoft Windows 7 Profesional.
• Aplikasi pemrograman Matlab 7.7.0.471 (R2008b).
HASIL DAN PEMBAHASAN
Segmentasi
Langkah pertama dalam sistem pengenalan iris mata ialah memisahkan daerah iris mata pada suatu citra mata. Hal ini disebabkan daerah iris mata dipengaruhi bulu mata dan kelopak mata. Proses segmentasi dilakukan dengan melakukan deteksi tepi Canny.
Tahap awal pada proses segmentasi ini ialah lokalisasi pupil dan lokalisasi iris. Untuk melakukan lokalikasasi pupil dilakukan deteksi tepi Canny. Pada deteksi tepi ini dilakukan pencarian tepi dari pupil dengan menggunakan nilai threshold tertentu. Hal ini disebabkan perbedaan tingkat kecerahan citra. Hasil deteksi tepi Canny dapat dilihat pada Gambar 2.
(a) (b)
Gambar 2 Hasil deteksi tepi Canny, (a) sebelum dilakukan segmentasi, (b) setelah dilakukan deteksi tepi Canny.
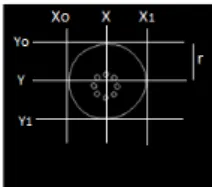
Setelah deteksi tepi, dilakukan pencarian titk pusat dari pupil. Proses ini dapat dilakukan dengan cara mencari nilai piksel 1 untuk memperoleh wilayah pupil terluas. Selanjutnya dilakukan pengecekan antara perpotongan garis horizontal dan vertikal. Setelah itu akan dilakukan pencarian jari-jari pupil dan akan didapatkan titik pusatnya. Ilustrasi pencarian titik pusat dan jari-jari pupil dapat dilihat pada Gambar 3.
Variabel Yo, Y1, Xo, dan X1 merupakan batas tepi dari wilayah pupil. Variabel Y didapat dari rata-rata penjumlahan Yo dan Y1, sedangkan variabel X merupakan nilai titik pusat dari pupil yang didapat dari rata-rata dari penjumlahan Xo dan X1. Jari-jari pupil didapatkan dari rata-rata selisih antara Yo dan Y1, dan Xo serta X1.
Gambar 3 Ilustrasi pencarian titik pusat dan jari-jari pupil.
Setelah didapatkan titik pusat dan jari-jari pupil, akan didapatkan wilayah collarette (lokalisasi iris). Wilayah ini didapatkan dengan menambahkan wilayah terluar pupil dengan 20 piksel. Ilustrasi wilayah collarette dapat dilihat pada Gambar 4.
Gambar 4 Ilustrasi wilayah collarette (iris). Histogram Citra
Hasil dari segmentasi yaitu daerah collarette akan diambil histogramnya. Histogram citra iris ini berada pada rentang 0-255, namun yang diambil ialah yang lebih besar dari 0. Hal ini disebabkan nilai piksel yang mengandung informasi pada citra hasil segmentasi adalah piksel yang bernilai lebih besar dari 0. Gambar 5 menunjukkan histogram dari hasil segmentasi citra.
(a) (b)
Gambar 5 Hasil histogram citra (a) citra hasil segmentasi, (b) histogramnya. Pelatihan dan Pengujian
Proses pelatihan dan pengujian dilakukan menggunakan algoritme k-nearest neighbor terhadap tiga subset yang saling lepas dari data
0 50 100 150 200 250 300 0 50 100 150 200 250
histogram iris mata kanan, iris mata kiri, dan gabungan keduanya sesuai dengan 3-cross fold validation. Untuk fold1, fold2, dan fold3 dilakukan pemilihan acak sebanyak 10 kali dengan menggunakan algoritme KNN sebagai algoritme klasifikasinya, dengan nilai k=1 dan k=3 untuk menentukan nilai k yang paling baik. Pembagian subset dapat dilihat pada Lampiran 5.
Pengenalan dengan Mata Kiri
Dari 90 data mata kiri, data dibagi menjadi 3 subset yang tiap subset berisi 3 data dari setiap kelas. Percobaan terus dilakukan hingga setiap subset pernah menjadi data uji. Setelah itu, dilakukan pemilihan acak untuk fold1, fold2, dan fold3 sebanyak 10 kali untuk menentukan nilai k yang menghasilkan nilai akurasi terbaik.
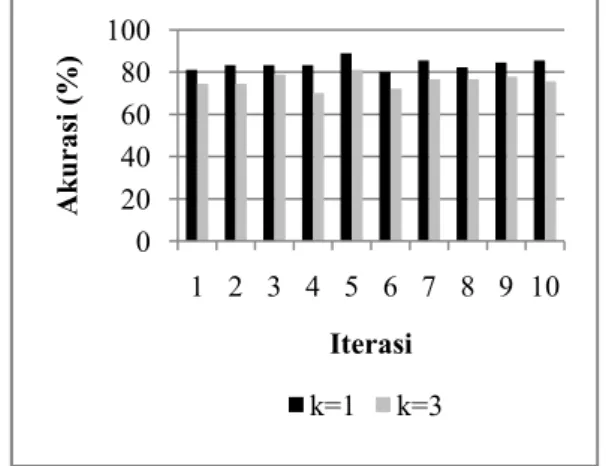
Gambar 6 Akurasi setiap iterasi pengenalan mata kiri.
Berdasarkan Gambar 6 dapat disimpulkan bahwa iterasi kedua memiliki hasil akurasi tertinggi yaitu sebesar 86.7% dengan k=1. Terlihat pula bahwa akurasi tertinggi tiap iterasi diperoleh pada k=1. Gambar 7 menunjukkan perbandingan akurasi nilai k pada pengenalan mata kiri.
Gambar 7 Akurasi nilai k pada pengenalan mata kiri.
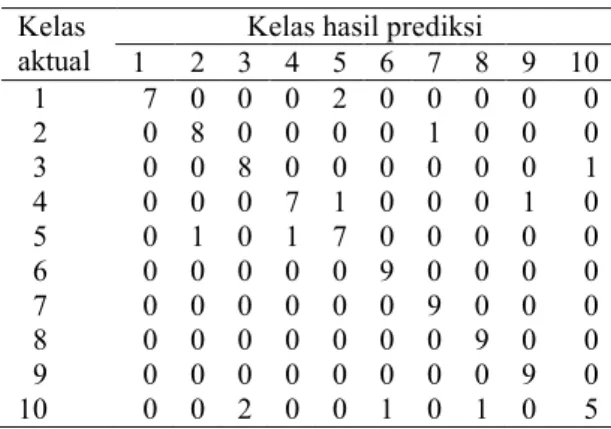
Dari Gambar 7 akurasi tertinggi sebesar 86.7% dengan k=1. Untuk mengetahui record yang salah diklasifikasikan dari iterasi kedua digunakan confusion matrix yang disajikan pada Tabel 1. Confusion matrix iterasi lainnya disajikan pada Lampiran 3.
Tabel 1 Confusion matrix pengenalan mata kiri iterasi kedua
Kelas aktual
Kelas hasil prediksi
1 2 3 4 5 6 7 8 9 10 1 7 0 0 0 2 0 0 0 0 0 2 0 8 0 0 0 0 1 0 0 0 3 0 0 8 0 0 0 0 0 0 1 4 0 0 0 7 1 0 0 0 1 0 5 0 1 0 1 7 0 0 0 0 0 6 0 0 0 0 0 9 0 0 0 0 7 0 0 0 0 0 0 9 0 0 0 8 0 0 0 0 0 0 0 9 0 0 9 0 0 0 0 0 0 0 0 9 0 10 0 0 2 0 0 1 0 1 0 5 Berdasarkan Tabel 1, terlihat bahwa kelas 10 merupakan kelas yang memiliki nilai akurasi yang paling kecil dibandingkan kelas yang lain setelah diklasifikasi. Hal ini dipengaruhi oleh nilai histogram dari data uji kelas tersebut memiliki nilai histogram yang lebih mendekati nilai histogram data latih kelas yang diidentifikasikan sebagai kelas yang salah. Tabel 2 Statistik nilai rata-rata dan standar
deviasi kelas 7 dan kelas 10
Data ke- Kelas 7 Kelas 10 Standar deviasi Rata-rata Standar deviasi Rata-rata 1 53.6 25.2 42.4 23.4 2 55.9 25.4 45.5 25.1 3 52.9 25.4 49.4 22.7 4 55.4 25.7 38.5 22.7 5 53.0 24.8 40.4 22.5 6 55.1 25.4 44.4 22.7 7 54.5 23.9 44.2 21.9 8 54.9 24.8 41.8 22.3 9 57.8 24.9 45.0 25.3 Standar deviasi 1.5 0.5 3.2 1.2
Pada Tabel 2 disajikan perbandingan nilai standar deviasi dan rata-rata kelas 10 dengan kelas 7. Dari Tabel 2, nilai rata-rata kelas 7 tidak berbeda jauh antar datanya, sedangkan untuk kelas 10 terdapat banyak perbedaan. Begitu juga dengan nilai standar deviasi dari data tersebut. Nilai rata-rata menunjukkan lebar dari histogram. Standar deviasi menunjukkan posisi dari histogram. Semakin berbeda nilai standar deviasinya, artinya datanya semakin 0 20 40 60 80 100 1 2 3 4 5 6 7 8 9 10 A k u r a si ( %) Iterasi k=1 k=3 0 20 40 60 80 100 k=1 k=3 A k u ra si ( %) Nilai k
beragam, sehingga akurasi klasifikasinya juga akan semakin kecil.
Pada Gambar 8 ditunjukkan ilustrasi histogram pada kelas 10 yang diklasifikasikan sebagai kelas 8 dan kelas 10 itu sendiri. Sementara itu, kelas yang tidak terklasifikasi dengan benar ditunjukkan pada Lampiran 4.
(a)
(b)
(c)
Gambar 8 Ilustrasi nilai histogram pada kelas yang dikenali kelas 10 (a) ilustrasi wilayah collarette kelas 10 yang dikenali sebagai kelas 8 dan histogramnya (b) ilustrasi wilayah collarette kelas 8 dan histogramnya (c) ilustrasi wilayah collarette kelas 10 dan histogramnya.
Dari pengenalan mata kiri dapat disimpulkan nilai k terbaik sebesar 1 dengan akurasi tertinggi 86.7%.
Pengenalan dengan Mata Kanan
Dari 90 data mata kanan, data dibagi menjadi 3 subset yang tiap subset berisi 3 data dari setiap kelas. Percobaan terus dilakukan hingga setiap subset pernah menjadi data uji. Setelah itu, dilakukan pemilihan acak untuk fold1, fold2, dan fold3 sebanyak 10 kali untuk menentukan nilai k yang menghasilkan nilai akurasi terbaik.
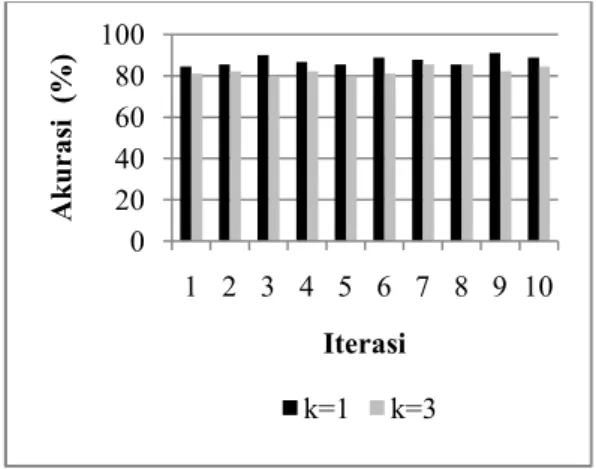
Berdasarkan Gambar 9 dapat disimpulkan bahwa iterasi kelima memiliki hasil akurasi tertinggi yaitu sebesar 88.9% dengan k=1.
Terlihat pula bahwa akurasi tertinggi tiap iterasi diperoleh pada k=1. Gambar 10 menunjukkan perbandingan akurasi nilai k pada pengenalan mata kanan.
Gambar 9 Akurasi setiap iterasi pengenalan mata kanan.
Dari Gambar 10 akurasi tertinggi sebesar 88.9% dengan k=1. Untuk mengetahui record yang salah diklasifikasikan pada iterasi kelima digunakan confusion matrix yang disajikan pada Tabel 3.
Gambar 10 Akurasi nilai k pada pengenalan mata kanan.
Tabel 3 Confusion matrix pengenalan mata kanan pada iterasi kelima
Kelas aktual
Kelas hasil prediksi
1 2 3 4 5 6 7 8 9 10 1 8 0 0 0 1 0 0 0 0 0 2 0 8 0 0 1 0 0 0 0 0 3 0 0 8 0 0 0 0 0 0 1 4 0 0 0 9 0 0 0 0 0 0 5 0 1 0 0 7 0 0 0 1 0 6 0 0 0 0 1 8 0 0 0 0 7 0 0 0 0 0 0 9 0 0 0 8 0 2 1 0 0 0 0 6 0 0 9 0 0 0 1 0 0 0 0 8 0 10 0 0 0 0 0 0 0 0 0 9 0 50 100 150 200 250 300 0 20 40 60 80 100 120 140 160 180 0 50 100 150 200 250 300 0 20 40 60 80 100 120 140 160 180 0 50 100 150 200 250 300 0 20 40 60 80 100 120 140 160 180 200 0 20 40 60 80 100 1 2 3 4 5 6 7 8 9 10 A k u ra si ( %) Iterasi k=1 k=3 0 20 40 60 80 100 k=1 k=3 A k u ra si ( %) Nilai k
Berdasarkan Tabel 3, terlihat bahwa kelas 5 dan kelas 8 merupakan kelas yang memiliki nilai akurasi yang paling kecil dibandingkan kelas yang lain setelah diklasifikasi. Hal ini dipengaruhi oleh nilai histogram dari data uji kelas tersebut memiliki nilai histogram yang lebih mendekati nilai histogram data latih kelas yang diidentifikasikan sebagai kelas yang salah.
Pada Gambar 11 ditunjukkan ilustrasi histogram pada kelas 8 yang diklasifikasikan sebagai kelas 2 dan kelas 8 itu sendiri.
(a)
(b)
(c)
Gambar 11 Ilustrasi nilai histogram pada kelas yang dikenali kelas 8 (a) ilustrasi wilayah collarette kelas 8 yang dikenali sebagai kelas 2 dan histogramnya (b) ilustrasi wilayah collarette kelas 2 dan histogramnya (c) ilustrasi wilayah collarette kelas 8 dan histogramnya.
Dari pengenalan mata kanan dapat disimpulkan nilai k terbaik sebesar 1 dengan akurasi tertinggi 88.9%. Pengenalan mata kanan lebih baik dibandingkan dengan pengenalan mata kiri untuk penelitian ini. Namun, nilai akurasi penelitian ini lebih kecil jika dibandingkan dengan penelitian Zaki (2011) yaitu 93.3%.
Pengenalan dengan Gabungan Mata Kiri dan Kanan
Dari data uji kanan dan data uji kiri, dihitung masing-masing jarak euclidean-nya, kemudian dibandingkan kedua nilai tersebut, lalu dicari nilai yang lebih kecil. Kelas hasil klasifikasi adalah kelas dari jarak euclidean-nya yang lebih kecil.
Gambar 12 Akurasi setiap iterasi pengenalan mata gabungan.
Gambar 13 Akurasi nilai k pada pengenalan mata gabungan.
Berdasarkan Gambar 12 dapat disimpulkan bahwa iterasi kesembilan memiliki hasil akurasi tertinggi yaitu sebesar 91.1% dengan k=1. Terlihat pula bahwa akurasi tertinggi tiap iterasi diperoleh pada k=1. Gambar 13 menunjukkan perbandingan akurasi nilai k pada pengenalan mata gabungan.
Dari Gambar 13 akurasi tertinggi sebesar 91.1% dengan k=1. Untuk mengetahui record yang salah diklasifikasikan pada iterasi kesembilan digunakan confusion matrix yang disajikan pada Tabel 4.
0 50 100 150 200 250 300 0 20 40 60 80 100 120 140 160 0 50 100 150 200 250 300 0 50 100 150 200 250 0 50 100 150 200 250 300 0 50 100 150 200 250 0 20 40 60 80 100 1 2 3 4 5 6 7 8 9 10 A k u ra si (%) Iterasi k=1 k=3 0 20 40 60 80 100 k=1 k=3 A k u ra si (%) Nilai k
Tabel 4 Confusion matrix pengenalan mata gabungan pada iterasi kesembilan Kelas
aktual
Kelas hasil prediksi
1 2 3 4 5 6 7 8 9 10 1 8 0 0 0 6 4 0 0 0 0 2 0 18 0 0 0 0 0 0 0 0 3 0 0 18 0 0 0 0 0 0 0 4 0 0 0 18 0 0 0 0 0 0 5 0 0 0 0 18 0 0 0 0 0 6 0 0 0 0 0 18 0 0 0 0 7 0 0 0 0 0 0 18 0 0 0 8 0 0 0 0 0 0 0 16 0 2 9 0 0 0 0 0 0 0 0 18 0 10 0 0 2 0 0 0 0 2 0 14 Berdasarkan Tabel 4, terlihat bahwa kelas 1 merupakan kelas yang memiliki nilai akurasi yang paling kecil dibandingkan kelas yang lain setelah diklasifikasi. Hal ini disebabkan pada data kelas 1 mata kiri iterasi kesembilan memiliki nilai jarak yang lebih kecil dibandingkan dengan nilai jarak data kelas 1 mata kanan iterasi kesembilan, sehingga ketika digabung akan dikenali sebagai kelas mata kiri yang memiliki nilai akurasi yang lebih kecil.
Hasil jarak euclidean diperlihatkan pada Tabel 5 dengan mengggunakan fold1 pada iterasi kesembilan dengan mengambil satu data tiap kelas data uji.
Tabel 5 Hasil jarak Euclidean pada iterasi kesembilan Kelas aktual Kelas kanan Jarak kanan Kelas kiri Jarak kiri Kelas gabung 1 2 399.6 6 243.7 6 2 2 147.9 2 129.5 2 3 3 115.8 10 156.9 3 4 4 145.6 4 192.3 4 5 5 204.4 5 251.1 5 6 6 189.4 6 141.9 6 7 7 216.3 7 113.9 7 8 8 183.4 8 132.9 8 9 9 190.5 9 273.3 9 10 10 192.8 10 120.8 10
Berdasarkan Tabel 5 terlihat bahwa meskipun terdapat kesalahan klasifikasi pada salah satu data mata kanan atau mata kiri sebelum digabung, namun setelah digabung terdapat peningkatan hasil klasifikasi, seperti pada data mata kiri kelas 3 yang diklasifikasikan sebagai kelas 10. Setelah digabung dengan data mata kanan, data tersebut dikenali sebagai kelas yang tepat. Untuk kasus kelas 1, baik pada mata kanan maupun mata kiri, keduanya tidak terklasifikasi sebagai kelas yang benar, sehingga meskipun data kelas 1 mata kiri
lebih kecil dibandingkan dengan mata kanan, data tetap dikenali sebagai kelas yang salah.
Pada Gambar 14 ditunjukkan grafik perbandingan nilai k pada rata-rata pengenalan mata kiri, kanan, dan gabungan. Dari grafik terlihat bahwa terdapat peningkatan akurasi setelah dilakukan penggabungan data latih. Nilai akurasi tertinggi pada tiap pengenalan terdapat pada k=1.
Gambar 14 Perbandingan nilai akurasi tiap pengenalan.
Gambar 15 Grafik perbandingan akurasi k=1 tiap iterasi.
Gambar 16 Grafik perbandingan akurasi k=3 tiap iterasi 0 20 40 60 80 100
kiri kanan gabungan
A k u ra si ( %) Pengenalan mata k=1 k=3 0 20 40 60 80 100 1 2 3 4 5 6 7 8 9 10 A k u ra si (%) Iterasi
kiri kanan gabungan
0 20 40 60 80 100 1 2 3 4 5 6 7 8 9 10 A k u ra si (%) Iterasi kiri kanan gabungan