PENERAPAN DATA MINING PADA CDR (CALL DETAILS
RECORDS) UNTUK MENGETAHUI PROFILE INTEREST
DARI PELANGGAN PT. XYZ
Joppy Justian
Lukas Siswanto Tanutama, Ir., MM
Laporan Teknis
Jakarta, 19/02/2014 Disetujui:
Pembimbing:
ABSTRACT
This thesis will discuss about the ways of processing calls data transaction (Call Details Records) from customer of PT. XYZ to get an idea of profile interest or user's or pattern of user's interest in making or receiving a call. The process will be done with the application of data mining on the call transaction data to obtain certain groups in accordance with the information obtained. Then in the end the previous data which not be understood by the companies, can become a useful information for the company and supporting in planning corporate strategy.
Keywords: Data mining, Call details records, Profile Interest
ABSTRAK
Penulisan dalam thesis ini akan membahas mengenai cara pengolahan pada data transaksi panggilan (Call details records) dari pelanggan PT XYZ untuk mendapatkan gambaran mengenai profile interest atau pola ketertarikan pengguna dalam melakukan atau menerima panggilan. Pengolahan akan dilakukan dengan penerapan data mining pada data transaksi panggilan sehingga didapatkan kelompok-kelompok tertentu sesuai dengan informasi yang ingin didapatkan. Kemudian pada akhirnya data-data yang sebelumnya tidak dimengerti oleh perusahaan tersebut dapat menjadi informasi yang berguna bagi perusahaan dan dapat menjadi pendukung dalam perencanaan strategi perusahaan..
PENDAHULUAN
PT XYZ merupakan sebuah perusahaan yang bergerak pada bidang telekomunikasi dengan memberikan beberapa pelayanan seperti panggilan telepon, SMS, dan layanan data. Dalam salah satu kegiatan usahanya, yaitu memberikan layanan panggilan telepon, PT XYZ melakukan penyimpanan mengenai data transaksi dari panggilan yang dilakukan. Oleh perusahaan data mengenai panggilan tersebut akan disimpan dalam sebuah penyimpanan dan data yang disimpan disebut sebagai Call Details Records(CDR). Seiring dengan banyaknya pelanggan, maka data yang dikumpulkan dari setiap transaksi pelanggan tentu akan menjadi semakin banyak.Dengan banyaknya data tersebut, terkadang perusahaan tidak mengetahui untuk apa data-data tersebut disimpan. Hal ini membuat kondisi yang disebut “data rich but information poor” (Han & Kamber, 2006) dimana banyaknya data yang terkumpul tanpa mengetahui informasi yang terdapat didalamnya, walaupun tanpa disadari mungkin saja dalam data tersebut terdapat informasi yang berguna bagi perusahaan. Salah satu informasi yang bisa didapat adalah profile interest dari pelanggan terhadap penggunaan jasa panggilan.
Profile interest merupakan gambaran dari pola dan ketertarikan para pelanggan dalam menggunakan layanan panggilan dengan berdasarkan parameter tertentu. Informasi tersebut dapat berfungsi sebagai pendukung dalam perencanaan strategi perusahaan. Contohnya adalah bagi pihak penjualan. Dengan menemukan pola panggilan pelanggan, maka hal tersebut dapat menjadi pendukung dalam strategi penjulaan. Salah satunya adalah sebagai pertimbangan dalam penentuan tarif serta pemberian layanan. Untuk mendapatkan profile interest tersebut, maka akan dilakukan penerapan data mining yang mengelompokan pengguna ke dalam kelompok-kelompok tertentu sesuai dengan informasi yang ingin didapatkan.
Tujuan
Mengetahui gambaran profile interest pelanggan dalam melakukan panggilan melalui pengolahan data transaksi panggilan (CDR) dengan menggunakan data mining.
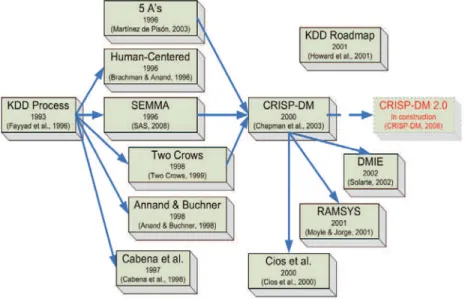
Secara singkat, data mining berarti menggali atau menemukan informasi dari sejumlah besar data (Han & Kamber, 2006). Dan secara luasnya, data mining adalah proses menemukan interesting knowledge dari sejumlah besar data yang tersimpan dalam database, data warehouse, atau media penyimpanan lainnya (Han & Kamber, 2006). Sedangkan berdasarkan Gartner Group (Larose, 2005), data mining adalah sebuah proses untuk menemukan hubungan, pola, dan tren dengan memilah-milah sejumlah besar data yang tersimpan dalam media penyimpanan, menggunakan teknologi pengenalan pola serta statistika dan matematika. Dalam melakukan data mining, terdapat beberapa metodologi yang digunakan. Metodologi atau model proses merupakan suatu rangkaian tugas yang harus dilakukan untuk mengembangkan elemen tertentu, serta unsur-unsur yang diproduksi dalam setiap tugas(output) dan dan unsur-unsur yang diperlukan untuk melakukan tugas(input). Dengan tujuan untuk membuat proses agar dapat berulang, dikendalikan, dan terukur (Marbán, Mariscal, & Segovia, 2009). Pada pengembangannya hingga sekarang ini, terjadi beberapa perkembangan terhadap metodologi dalam penerapan data mining. Berikut merupakan gambaran perkembangan metodologi data mining.
Gambar 1. Perkembangan Metodologi Data Mining (Marbán, Mariscal, & Segovia, 2009) Terdapat beberapa fungsi atau tugas dari data mining yang biasanya dikerjakan dalam proyek data mining. Fungsi tersebut antara lain (Larose, 2005) adalah description, estimation, prediction, classification, clustering, dan association.
Clustering merupakan proses pengelompokan sekumpulan objek fisik atau abstrak kedalam kelas dengan objek yang serupa (Han & Kamber, 2006). Sedangkan cluster merupakan koleksi objek data yang memiliki kesamaan satu sama lain dalam kelompok yang sama dan berbeda dengan objek di kelompok lain. Cluster analisis dapat diterapkan secara luas pada berbagai penggunaan, salah satunya dalam bisnis, clustering dapat membantu pemasaran dalam mengetahui pengelompokan bagi pelanggannya dan mengkarakterisasi kelompok pelanggannya berdasarkan pola belanjanya. Dalam melakukan clustering terdapat algoritma yang dapat diterapkan. Salah satunya adalah K-Means. Algoritma K-means adalah metode iteratif sederhana untuk melakukan partisi terhadap data yang diberikan ke dalam sejumlah penggunaan cluster tertentu (Wu, et al., 2008). Secara umum, langkah-langkah utama dari algoritma K-means adalah sebagai berikut:
• Pilih partisi awal pada cluster K, ulangi langkah 2 dan 3 sampai keanggotaan cluster telah stabil.
• Menghasilkan sebuah partisi baru dengan menetapkan kepada masing-masing pola terhadap pusat cluster terdekatnya.
• Menghitung pusat cluster yang baru.
Call Details Records
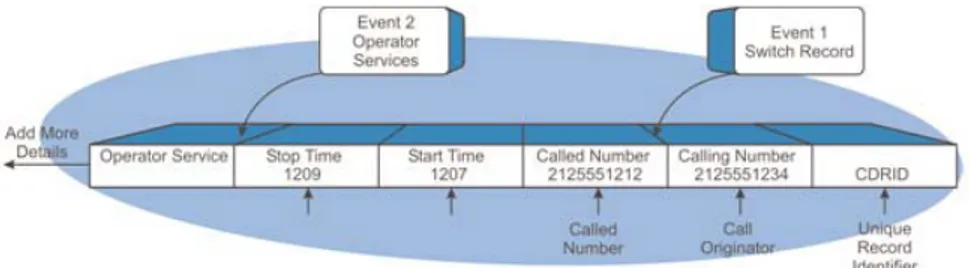
Call Details Records(CDR) menyimpan informasi yang memadai dan menggambarkan kegiatan panggilan dari setiap kegiatan panggilan yang terjadi (Folasade, 2011). Call Details Records(CDR) pada umumnya akan terdiri dari hal berikut (Ofrane & Lawrence, 2003): Nomor telepon asal dan tujuan panggilan, Tanggal dan waktu panggilan, serta durasi panggilan, Jenis panggilan dan perinciannya, Lokasi panggilan, dan Alasan kejadian perekaman. Dalam penerapannya Call Details Records(CDR) memiliki struktur dasar sebagai berikut:
Pada diagram diatas penggambaran dilakukan dengan referensi terhadap, Usage Detail Record(UDR). Hal ini dikarenakan tidak semua kejadian pada transaksi layanana selular merupakan transaksi panggilan, sehingga terdapat catatan yang dihasilkan pada jaringan yang disebut Usage Detail Record(UDR). Berdasarkan data pada Call Details Records(CDR), maka perilaku komunikasi dari pelanggan dapat digambarkan dengan ketertarikan pelanggan (profile interest) dalam panggilan. Dengan mendapatkan informasi pelanggan tersebut maka perusahaan dapat memahami kebutuhan pelanggan, sehingga penawaran khusus mengenai penggunaan panggilan dapat dibuat dan tarif dapat disesuaikan dengan perilaku pelanggan tersebut (Maedche, Hotho, & Wiese)
WEKA version 3.6.8
WEKA (Waikato Environment for Knowledge Learning) merupakan sebuah tools data mining yang dikembangkan untuk studi para akademisi oleh University of Waikato di Selandia Baru. WEKA dapat mendukung banyak tugas dengan data mining yang berbeda seperti data preprocessing, classification, clustering, regression, visualization dan lain sebagainya.
METODOLOGI
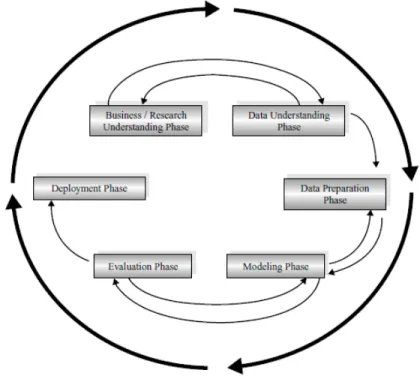
Metodologi data mining yang digunakan dalam proses data mining ini adalah Cross Industry Standard Process for Data Mining(CRISP-DM), yang membagi pengembangan data mining menjadi enam tahap dengan proses sebagai berikut:
Gambar 4. Tahapan Metodologi CRISP-DM (Larose, 2005)
Metodologi merupakan metodologi yang paling sering digunakan. Dimana berdasarkan pada Survey Penggunaan Metodologi Data Mining (Mariscal, Marban, & Fernandez, 2010), pada tahun 2002 jumlah pemilih CRISP-DM mencapai 51%, sedangkan pada tahun 2004 dan 2007 menurun menjadi 41%. Selain itu pada metodologi ini terdapat sebuah tahapan yaitu business undertanding, dimana pada tahapan ini akan diketahui pemahaman mengenai tujuan dari proyek data mining yang akan dilakukan serta kebutuhan dari perspektif bisnis. Dengan adanya tahap tersebut, maka metodologi memiliki pandangan terhadap bisnis yang bisa dihasilkan dari data mining.
Business Understanding
Pada tahap ini akan dilakukan pemahaman mengenai tujuan dari kegiatan data mining yang akan dilakukan serta kebutuhan dari perspektif bisnis.
Data Understanding
Data Understanding atau pemahaman data adalah tahapan dimana dilakukan pengumpulan terhadap data, kemudian mempelajari data tersebut dengan tujuan untuk mengenal data, dan melakukan identifikasi dari data.
Data Preparation
Pada tahapan data preparation ini akan mencakup semua kegiatan untuk mempersiapkan data yang akan dimasukkan ke dalam alat pemodelan, dimana data tersebut merupakan pengolahan dari data mentah awal. Dalam tahapan ini akan dilakukan penentuan Data sampling, lalu pemilihan data yang akan digunakan, kemudian memodifikasi sumber data ke format berbeda yang dapat diterima oleh proses data mining, dan dilakukan proses pembersihan data agar data siap untuk tahap modeling.
Modelling
Pada tahap ini akan dilakukan proses pengolahan data mining dengan menggunakan algoritma yang telah ditentukan sebelumnya.
Evaluation
Tahap evaluasi merupakan tahapan dimana dilakukan interpretasi terhadap hasil data mining yang telah dihasilkan pada tahapan sebelumnya.
Deployment
Pada tahapan deployment ini, akan dilakukan pembuatan laporan mengenai hasil dari kegiatan data mining yang dilakukan secara keseluruhan.
HASIL DAN PEMBAHASAN
Data sampel yang digunakan adalah data pada rentang waktu 7 hari, yaitu dimulai pada tanggal 2 oktober 2013-8 oktober 2013 dan dengan rentang waktu dari pukul 8.00 WIB sampai 16.00 WIB setiap harinya. Dan untuk atribut yang digunakan adalah
Begin Time
Tanggal dan waktu awal dalam transaksi Way
Arah panggilan/transaksi yang terjadi Conversation Time
Lamanya waktu percakapan yang terjadi pada setiap transaksi A-number
Nomor dari pihak pemanggil B-number
Nomor dari pihak yang dipanggil
Proses data mining yang digunakan adalah proses clustering. Hal ini dimaksudkan karena hasil yang diharapkan yaitu mendapatkan pola ketertarikan pelanggan (profile interest) dalam melakukan kegiatan panggilan serta mengelompokan pelanggan berdasarkan pada informasi yang terdapat pada aktivitas dari penggunaan panggilannya. Sehingga dengan membandingkan terhadap tujuan itu sendiri maka clustering merupakan metode data mining yang dinilai cocok untuk mendapatkan hasil yang diharapkan. Kemudian algoritma yang akan digunakan adalah algoritma K-means, karena seperti pada jurnal (Wu, et al., 2008), disebutkan bahwa algoritma K-means menempati posisi pertama untuk algoritma dalam metode clustering. Kemudian pada pengolahannya akan digunakan alat bantu yaitu WEKA.
Gambar 5 Alur Proses
Interest factor
Interest factor merupakan faktor yang menunjukan ketertarikan pelanggan dalam melakukan panggilan. Untuk mendapatkan hal ini, perlu diketahui calling pattern dari pelanggan tersebut. Calling pattern pada penelitian mencakup gambaran pola pada outgoing connection interest, incoming connection interest, dan calling interest.
Outgoing connection interest
Outgoing connection merupakan panggilan keluar yang terjadi. Pelanggan PT XYZ memanggil nomor lain ketika melakukan panggilan. Berikut merupakan gambaran pada panggilan keluar yang didapat:
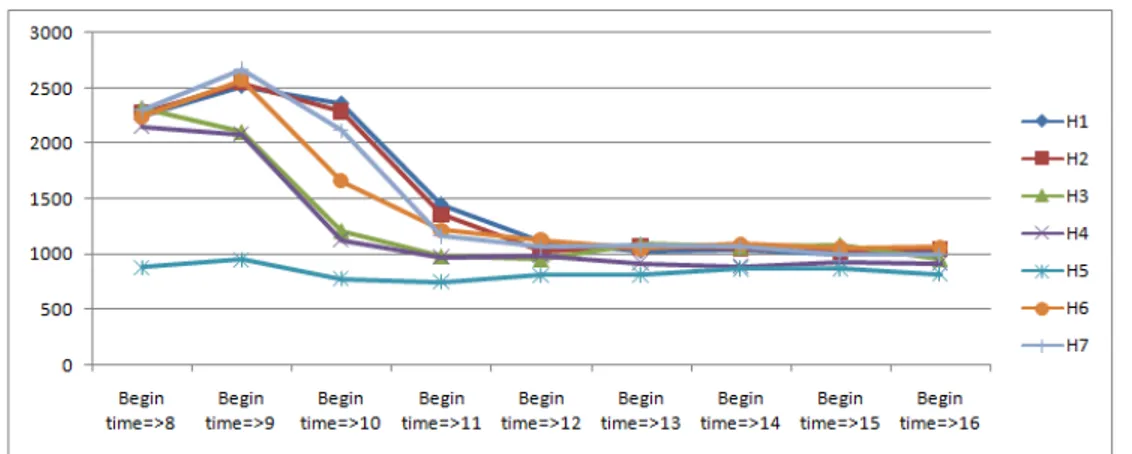
Gambar 6. Pergerakan percobaan panggilan keluar dengan percakapan setiap hari per cluster-nya
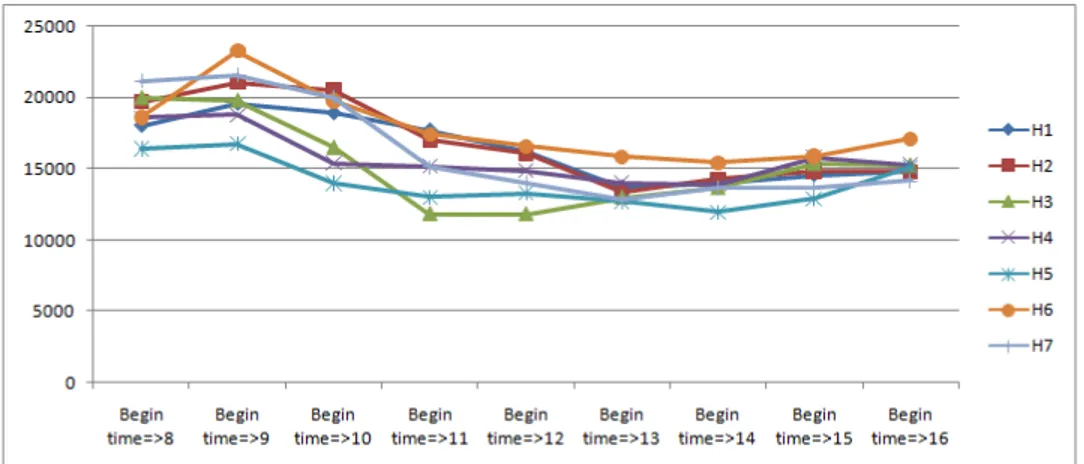
Gambar 7. Pergerakan percobaan panggilan keluar tanpa percakapan setiap hari per cluster-nya
Incoming connection interest
Incoming connection merupakan panggilan masuk yang terjadi, dimana pelanggan PT XYZ menerima panggilan dari nomor lain ketika terjadi panggilan. Berikut merupakan gambaran pada panggilan masuk yang didapat:
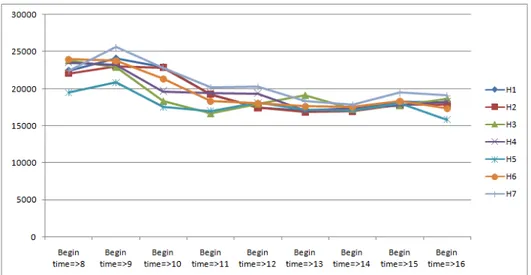
Gambar 8. Pergerakan percobaan panggilan masuk dengan percakapan setiap hari per cluster-nya
Gambar 9. Pergerakan percobaan panggilan masuk tanpa percakapan setiap hari per cluster-nya.
Pada interest factor, dari pengelompokan outgoing connection yang menghasilkan percakapan, didapatkan pola panggilan yang mengalami kenaikan pada jam 8.00 sampai jam 10.00, kemudian terus menurun hingga cenderung stabil pada jam 12.00 sampai dengan jam 16.59. Dari grafik tersebut, bisa diketahui ketertarikan pelanggan dalam melakukan panggilan keluar yang menghasilkan percakapan berjumlah tinggi ketika jam 8.00 sampai 10.00. Begitu pula dengan pengelompokan incoming connection yang menghasilkan percakapan, dengan berdasarkan pada gambar 4.18 didapatkan pola yang tidak jauh berbeda dari pola pada outgoing connection dimana naik ketika jam 8.00 sampai 10.00, lalu turun hingga cenderung stabil pada jam 12.00 sampai jam 16.59. Untuk panggilan yang tidak berhasil(gagal), maka dari hasil yang didapat diketahui bahwa untuk incoming dan outgoing connection pada jenis panggilan ini memiliki pola yang sama. Pola digambarkan dengan puncak tertinggi pada jam 9.00 dan kemudian turun serta cenderung stabil pada jam 11.00 keatas. Dari hasil pembahasan pola ini, dapat disimpulkan bahwa banyak panggilan yang gagal terjadi ketika jam 9.00 dan kemudian tingkat kegagalan panggilan cenderung menurun hingga akhir data
Calling Interest
Calling interest merupakan gambaran dari tujuan panggilan pelanggan operator atau dari mana pelanggan menerima panggilan. Hasil dari pengelompokan ini akan menggambarkan bagaimana bentuk panggilan yang terjadi pada pelanggan PT XYZ. Berikut merupakan hasil yang didapat:
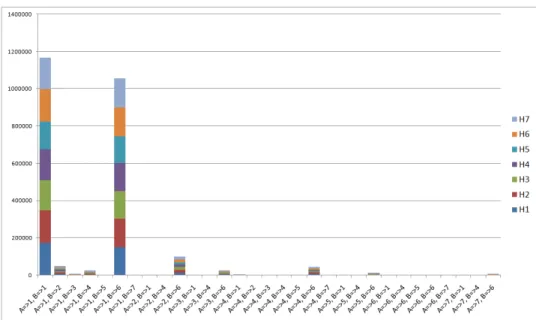
Gambar 10. Diagram calling interest pelanggan berdasarkan cluster yang dihasilkan. Pada calling interest, diketahui bahwa pola terbanyak pelanggan dalam melakukan panggilan adalah dari GSM X menuju GSM X, yang berarti adalah panggilan antar sesama GSM dari operator PT XYZ. Dimana rata-rata perharinya panggilan antar GSM X tersebut mendapatkan total 46,43% dari keseluruhan hari pada sampel data.
Holding Time
Holding time akan menggambarkan mengenai pola lama percakapan. Lamanya percakapan akan digolongkan menjadi 3 cluster yaitu:
• Kelompok dengan percakapan 1-60 detik(1 menit),
• Kelompok dengan percakapan 61-180 detik(1 sampai 3 menit), dan
• Kelompok dengan percakapan lebih dari 3 menit.
Sama seperti pada interest factor, penghitungan holding time akan dibagi menjadi 2 bagian, yaitu untuk incoming connection dan outgoing connection. Berikut merupakan hasil yang didapatkan:
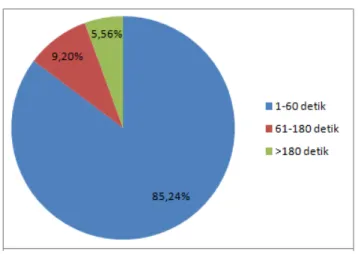
Gambar 11. Persentase panggilan keluar dengan berdasarkan kelompok lama panggilan
Gambar 12. Persentase panggilan masuk dengan berdasarkan kelompok lama panggilan Dari hasil tersebut diketahui kelompok tertinggi pada outgoing connection adalah kelompok pertama yaitu kelompok lama percakapan dibawah 1 menit. Kelompok tersebut mendapatkan persentase 85,24% lalu berikutnya adalah kelompok kedua dengan 9,2% dan terakhir adalah kelompok ketiga dengan 5,56%. Hasil tidak jauh berbeda juga terdapat pada panggilan incoming, dimana kelompok pertama mendapatkan 86,34% lalu berikutnya 10,40% untuk kelompok kedua dan terakhir 3,26% untuk kelompok ketiga. Sehingga dari hasil tersebut dapat disimpulkan bahwa dari seluruh panggilan baik itu incoming atau outgoing connection, panggilan paling banyak adalah panggilan dengan lama percakapan kurang dari 1 menit.
KESIMPULAN
Dari penerapan data mining yang dilakukan, diketahui bahwa profile interest pelanggan yang didapat adalah sebagai berikut:
a. Melakukan atau menerima panggilan dengan jumlah panggilan yang tinggi pada jam 8.00 sampai 10.00, kemudian turun hingga cenderung stabil mulai jam 12.00. b. Bagi pengguna GSM X akan cenderung lebih melakukan panggilan kepada sesama
pengguna GSM X, dan
c. Pelanggan yang melakukan panggilan sebagian besar hanya membutuhkan waktu percakapan kurang dari 1 menit.
Hasil profile interest dapat memberikan informasi bagi perusahaan serta dalam pengambilan keputusan atau menentukan strategi pemasaran seperti:
• Dengan berdasarkan analisa diketahui waktu telepon ternyata sebagian besar adalah kurang dari 1 menit sehingga bisa diberikan promosi untuk panggilan dengan waktu lebih dari 1 menit. Dengan pemanfaatan tarif tersebut diharapkan dapat menambah pendapatan perusahaan, karena dengan strategi tersebut selain dapat meningkatkan penggunaan telepon di bawah 1 menit, juga bisa menaikkan lama panggilan kelompok lainnya sehingga pendapatan bagi perusahaan pun meningkat. • Dengan berdasarkan jam panggilan, dimana waktu setelah jam 12.00 yang
cenderung stabil, maka bisa di lakukan promosi untuk melakukan panggilan pada rentang jam tersebut. Hal ini tentu menjadikan tambahan pengguna layanan panggilan yang kemudian memberikan tambahan pendapatan bagi perusahaan. • Dengan berdasarkan pada calling interest pelanggan dimana panggilan ke GSM
non-sesama terlihat sangat kecil, sehingga bisa dilakukan promosi tarif untuk panggilan keluar operator tersebut. Dengan promosi panggilan ke GSM non-sesama tersebut tentu dapat menjadikan nilai tambah bagi para pelanggan PT. XYZ. Sehingga dapat menambah ketertarikan pengguna untuk menjadi pelanggan PT. XYZ.
REFERENSI
Folasade, I. O. (2011). Computational Intelligence in Data Mining and Prospects in Telecommunication Industry. Journal of Emerging Trends in Engineering and Applied Sciences , Vol. 2, 601-605.
Han, J., & Kamber, M. (2006). Data Mining: Concepts and Techniques. San Francisco: Elsevier Inc.
Larose, D. T. (2005). Discovering Knowledge In Data An Introduction to Data Mining. New Jersey: John Wiley & Sons, Inc.
Marbán, Ó., Mariscal, G., & Segovia, J. (2009). A Data Mining & Knowledge Discovery Process Model, Data Mining and Knowledge Discovery in Real Life Applications. InTech.
Mariscal, G., Marban, O., & Fernandez, C. (2010). A survey of data mining and knowledge discovery process models and methodologies. The Knowledge Engineering Review , Vol. 25, 137–166.
Ofrane, A., & Lawrence, H. (2003). Introduction To Telecom Billing Usage Events, Call Detail Records, and Bill Cycles. ALTHOS, Inc.
Wu, X., Kumar, V., Quinlan, J. R., Ghosh, J., Yang, Q., Motoda, H., et al. (2008). Top 10 algorithms in data mining. Knowledge Information System , Vol. 14, 1–37.
RIWAYAT PENULIS
Joppy justian, lahir di kota Tanjung Pandan pada 3 Oktober 1988. Penulis menamatkan pendidikan S1 di STMIK JIBES dalam bidang Sistem Komputer pada tahun 2010. Saat ini bekerja sebagai Lead Programmer di PT. Uni Tokopo Teknologi, Jakarta.