TUGAS AKHIR –SM141501
IMPLEMENTASI EXTREME LEARNING MACHINE UNTUK
PENGENALAN OBJEK CITRA DIGITAL
ZULFA AFIQ FIKRIYA NRP 1213 100 066 Dosen Pembimbing
Prof. Dr. Mohammad Isa Irawan, MT Drs. Soetrisno, MI.Komp
JURUSAN MATEMATIKA
Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Teknologi Sepuluh Nopember
FINAL PROJECT –SM141501
IMPLEMENTATION OF EXTREME LEARNING MACHINE
FOR OBJECT RECOGNITION OF DIGITAL IMAGES
ZULFA AFIQ FIKRIYANRP 1213 100 066 Supervisors
Prof. Dr. Mohammad Isa Irawan, MT Drs. Soetrisno, MI.Komp
DEPARTMENT OF MATHEMATICS
Faculty of Mathematics and Natural Science Sepuluh Nopember Institute of Technology Surabaya 2017
vii
IMPLEMENTASI EXTREME LEARNING MACHINE UNTUK PENGENALAN OBJEK CITRA DIGITAL Nama : Zulfa Afiq Fikriya
NRP : 1213100066
Jurusan : Matematika
Dosen Pembimbing : 1. Prof. Dr. M. Isa Irawan, MT
2. Drs. Soetrisno, MI.Komp
ABSTRAKPengenalan citra digital merupakan bagian yang sangat penting dalam computer vision yang menerapkan pattern
recognition. Pengenalan citra digital bertujuan untuk
menduplikasi kemampuan manusia dalam memahami informasi citra sehingga komputer dapat mengenali objek pada citra selayaknya manusia. Salah satu metode pattern
recognition adalah Extreme Learning Machine (ELM). Extreme Learning Machine merupakan jaringan syaraf tiruan feedforward dengan satu hidden layer atau lebih dikenal
dengan istilah single hidden layer feedforward neural networks (SLFNs). Extreme Learning Machine untuk pengenalan objek citra digital pada Tugas Akhir ini terdiri dari 2500 node pada
input layer, 1250 node pada hidden layer, dan 3 node pada output layer. Dataset dikelompokkan berdasarkan ukuran objek
dalam citra. Hasil uji coba dan evaluasi model dengan data
testing menghasilkan tingkat akurasi sebesar 57,33% pada citra
dengan objek berukuran kecil, 81,33% pada citra dengan objek berukuran sedang, dan 74,67% pada citra dengan objek berukuran besar.
Kata Kunci : Pengenalan Objek, Machine Learning, Extreme Learning Machine
viii
ix
IMPLEMENTATION OF EXTREME LEARNING MACHINE FOR OBJECT RECOGNITION OF
DIGITAL IMAGES Name of Student : Zulfa Afiq Fikriya
NRP : 1213100066
Department : Mathematics
Supervisors : 1. Prof. Dr. M. Isa Irawan, MT 2. Drs. Soetrisno, MI.Komp ABSTRACT
The recognition of digital images is a very important part in computer vision which applying pattern recognition. The recognition of digital images aims to duplicate the human ability to understand the image information so that the computer can recognize objects in an image like human. One of the methods of machine learning to solve this problem is Extreme Learning Machine (ELM). Extreme Learning Machine is a feedforward neural network with one hidden layer or better known as a single hidden layer feedforward neural networks (SLFNs). Extreme Learning Machine for object recognition of digital images in this Final Project consists of 2500 nodes in the input layer, 1250 nodes in the hidden layer, and 3 nodes in the output layer. Datasets are grouped based on the size of objects in the image. The results of trials and evaluation with the testing data reached accuracy rate of 57,33% in the image with small object, 81,33% in the image with medium object, and 74,67% in the image with large object.
Keywords : Object Recognition, Machine Learning, Extreme Learning Machine
x
xi
KATA PENGANTAR
Assalamu’alaikum Wr. Wb.
Segala puji dan syukur bagi Allah SWT yang memiliki apa yang ada di langit dan di bumi atas segala rahmat dan karunia-Nya, sehingga penulis dapat menyelesaikan Tugas Akhir yang berjudul
“IMPLEMENTASI EXTREME LEARNING
MACHINE UNTUK PENGENALAN OBJEK CITRA DIGITAL”
sebagai salah satu syarat kelulusan Program Sarjana Jurusan Matematika FMIPA Institut Teknologi Sepuluh Nopember (ITS) Surabaya.
Dalam menyelesaikan Tugas Akhir ini, penulis telah banyak mendapat bantuan serta masukan dari berbagai pihak. Oleh karena itu, dalam kesempatan ini penulis menyampaikan terima kasih kepada:
1. Keluarga tercinta yang senantiasa memberikan dukungan dan doa dengan ikhlas.
2. Bapak Prof. Dr. Mohammad Isa Irawan, MT dan Bapak Drs. Soetrisno, MI.Komp selaku Dosen Pembimbing Tugas Akhir yang telah banyak memberikan bimbingan, arahan serta motivasi sehingga Tugas Akhir ini dapat terselesaikan.
3. Bapak Dr. Imam Mukhlash, S.Si, MT selaku Ketua Jurusan Matematika ITS.
4. Bapak Drs. Iis Herisman, M.Si selaku Dosen Wali yang telah memberikan arahan akademik selama penulis menempuh pendidikan di Jurusan Matematika ITS.
xii
M.Si selaku Dosen Penguji yang telah memberikan saran demi perbaikan Tugas Akhir ini.
6. Bapak Dr. Didik Khusnul Arif, S.Si, M.Si selaku Ketua Program Studi S1 Jurusan Matematika ITS.
7. Seluruh jajaran dosen dan staf Jurusan Matematika ITS. 8. Teman-teman Jurusan Matematika ITS angkatan 2013
yang saling mendukung dan memotivasi.
9. Semua pihak yang tidak bisa penulis sebutkan satu-persatu, terima kasih telah membantu sampai terselesaikannya Tugas Akhir ini.
Apabila dalam Tugas Akhir ini ada kekurangan, penulis mengharapkan kritik dan saran dari pembaca. Semoga Tugas Akhir ini dapat bermanfaat bagi semua pihak.
Wassalamu’alaikum Wr. Wb.
Surabaya, 14 Januari 2017 Penulis
xiii DAFTAR ISI HALAMAN JUDUL……….i LEMBAR PENGESAHAN………..v ABSTRAK……….vii ABSTRACT………....ix KATA PENGANTAR……….xi DAFTAR ISI……….xiii DAFTAR GAMBAR………..….xvii DAFTAR TABEL……….xix BAB I PENDAHULUAN………..………....…..1 1.1 Latar Belakang…………...………...………1 1.2 Rumusan Masalah……..…...………...…….3 1.3 Batasan Masalah…….………...…….3 1.4 Tujuan………...………..3 1.5 Manfaat………...………3
1.6 Sistematika Penulisan Tugas Akhir………….…….4
BAB II TINJAUAN PUSTAKA……….………..7
2.1 Penelitian Terdahulu………..………...7
2.2 Citra Digital……..……….9
2.2.1 Pencuplikan Citra dan Kuantisasi Derajat Keabuan………...………..……….10
2.2.2 Citra Berwarna dan Citra Grayscale……....13
2.3 Deteksi Tepi Canny……….………14
2.4 Machine Learning………..…..15
2.4.1 Jaringan Syaraf Tiruan………16
2.5 Extreme Learning Machine……..………20
2.6 Moore-Penrose Generalized Inverse…………..….23
BAB III METODOLOGI PENELITIAN………..25
3.1 Diagram Metodologi………25
3.2 Studi Literatur………..26
3.3 Pengumpulan Data………...26
3.4 Perancangan Sistem……….26
xiv
3.8 Penulisan Laporan Tugas Akhir………..30
BAB IV PERANCANGAN SISTEM………31
4.1 Pengumpulan Dataset………..31
4.2 Praproses Data……….31
4.3 Desain Arsitektur Extreme Learning Machine……33
4.4 Pemodelan Extreme Learning Machine….…….…33
4.4.1 Input Layer………34 4.4.2 Hidden Layer……….35 4.4.3 Output Layer………..36 4.5 Gambaran Sistem………...….…….…36 4.5.1 Proses Training……….………36 4.5.2 Proses Testing………....40
BAB V IMPLEMENTASI SISTEM………43
5.1 Lingkungan Hardware dan Software…...…………43
5.2 Implementasi User Interface………...…....……….43
5.3 Implementasi Praproses Data………….……..……44
5.4 Implementasi Model Extreme Learning Machine....49
5.4.1 Proses Training……….49
5.4.2 Proses Testing………...51
5.6 Implementasi Perhitungan Pseudo Inverse………...45
BAB VI UJI COBA DAN EVALUASI SISTEM…………...53
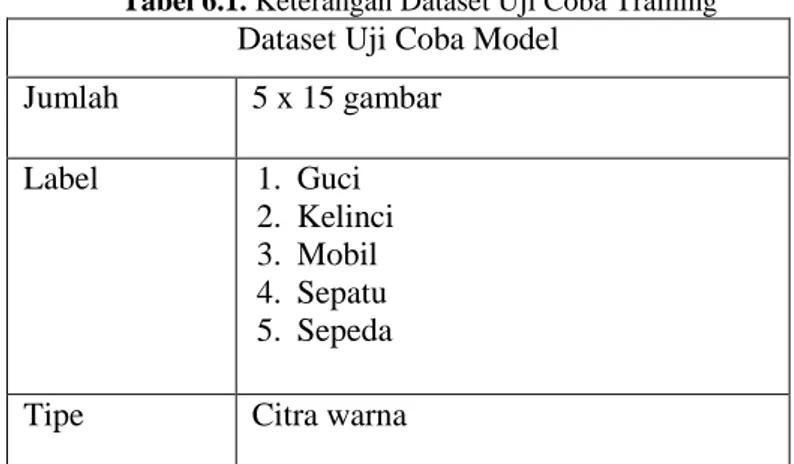
6.1 Dataset Uji Coba Training…………...…………....53
6.2 Uji Coba Model………56
6.3 Uji Coba 1 ………59
6.3.1 Uji Coba pada Citra dengan Objek Berukuran Kecil………..…..60
6.3.2 Uji Coba pada Citra dengan Objek Berukuran Sedang……….………..…..60
6.3.3 Uji Coba pada Citra dengan Objek Berukuran Besar………..…..61
6.4 Uji Coba 2 ………61
6.4.1 Uji Coba pada Citra dengan Objek Berukuran Kecil………..…..62
xv
6.4.2 Uji Coba pada Citra dengan Objek Berukuran
Sedang……….………..…..62
6.4.3 Uji Coba pada Citra dengan Objek Berukuran Besar………..…..63
6.5 Uji Coba 3 ………63
6.5.1 Uji Coba pada Citra dengan Objek Berukuran Kecil………..…..64
6.5.2 Uji Coba pada Citra dengan Objek Berukuran Sedang……….………..…..64
6.5.3 Uji Coba pada Citra dengan Objek Berukuran Besar………..…..65
BAB VII KESIMPULAN DAN SARAN………...67
7.1 Kesimpulan………..67 7.2 Saran……….68 DAFTAR PUSTAKA………69 LAMPIRAN A……….…..71 LAMPIRAN B………...75 LAMPIRAN C………...79 BIODATA PENULIS………83
xvi
xvii
DAFTAR GAMBAR
Gambar 2.1. Representasi Citra Digital dalam Koordinat
(x,y)……….12
Gambar 2.2. Proses sampling dan kuantisasi. (a) Citra Digital, (b) Citra Digital Disampling Menjadi 14 Baris dan 12 Kolom, (c) Citra Digital Hasil Sampling Berukuran 14 x 12 Piksel…………12
Gambar 2.3. Sel Syaraf (Neuron)………..17
Gambar 2.4. Feedforward Neural Network………...18
Gambar 2.5. Recurrent Neural Network………19
Gambar 2.6. Algoritma Extreme Learning Machine……….22
Gambar 3.1. Diagram Alir Metodologi Penelitian…………25
Gambar 3.2. Diagram Alir Proses Training………...28
Gambar 3.3. Diagram Alir Proses Testing………...29
Gambar 4.1. Diagram Blok Proses Pengenalan Objek dalam Citra………...32
Gambar 5.1. Desain User Interface Pengenalan Objek Citra Digital………..44
Gambar 5.2. (a) Citra Input, (b) Citra Hasil Deteksi Tepi...45
Gambar 5.3. Citra dengan Bounding Box……….…….……47
Gambar 5.4. Citra Hasil Cropping………..………...47
Gambar 5.5. Citra Grayscale………...48
Gambar 5.6. Citra Berukuran 50 x 50 Piksel……….48
Gambar 6.1. Tampilan User Interface………...56
Gambar 6.2. Uji Coba pada Citra Mobil dengan Ukuran Kecil………57
Gambar 6.3. Uji Coba pada Citra Guci dengan Ukuran Sedang……….………58
Gambar 6.4. Uji Coba pada Citra Kelinci dengan Ukuran Besar………58
Gambar 6.5. Uji Coba pada Citra Sepeda dengan Ukuran Kecil………59
xix
DAFTAR TABEL
Tabel 4.1. Representasi Label Nama Objek dalam Matriks t….………..…37 Tabel 4.2. Contoh Data Training….……….………37 Tabel 5.1. Spesifikasi Hardware dan Software….…………37 Tabel 6.1. Keterangan Dataset Uji Coba Training………...53 Tabel 6.2. Hasil Praproses Data……….………...54 Tabel 6.3. Perhitungan Tingkat Akurasi Model pada Citra
dengan Objek Berukuran Kecil pada Uji Coba 1 ………..…...60 Tabel 6.4. Perhitungan Tingkat Akurasi Model pada Citra
dengan Objek Berukuran Sedang pada Uji Coba 1 ………..………..61 Tabel 6.5. Perhitungan Tingkat Akurasi Model pada Citra
dengan Objek Berukuran Besar pada Uji Coba 1 ………..…...61 Tabel 6.6. Perhitungan Tingkat Akurasi Model pada Citra
dengan Objek Berukuran Kecil pada Uji Coba 2 ………..……..62 Tabel 6.7. Perhitungan Tingkat Akurasi Model pada Citra
dengan Objek Berukuran Sedang pada Uji Coba 2 ………..…...63 Tabel 6.8. Perhitungan Tingkat Akurasi Model pada Citra
dengan Objek Berukuran Besar pada Uji Coba 2 ………..……..63 Tabel 6.9. Perhitungan Tingkat Akurasi Model pada Citra
dengan Objek Berukuran Kecil pada Uji Coba 3 ………..…...64 Tabel 6.10. Perhitungan Tingkat Akurasi Model pada Citra
dengan Objek Berukuran Sedang pada Uji Coba 3 ………..…...65
xx
………..…...65 Tabel 6.12. Perbandingan Keseluruhan Akurasi………...66
1
BAB I PENDAHULUAN
Pada bab ini dijelaskan hal-hal yang melatarbelakangi munculnya permasalahan yang dibahas dalam Tugas Akhir ini. Kemudian permasalahan tersebut disusun ke dalam suatu rumusan masalah. Selanjutnya dijabarkan juga batasan masalah untuk mendapatkan tujuan yang diinginkan serta manfaat yang dapat diperoleh. Adapun sistematika penulisan Tugas Akhir ini akan diuraikan di bagian akhir bab ini.
1.1 Latar Belakang
Perkembangan teknologi informasi yang sangat cepat di tengah masyarakat membuat data atau informasi tidak hanya disajikan dalam bentuk teks, tetapi juga dapat berupa gambar, audio, dan video. Keempat macam data atau informasi ini sering disebut multimedia. Era teknologi informasi saat ini tidak dapat dipisahkan dari multimedia. Saat ini orang tidak hanya dapat mengirim pesan dalam bentuk teks, tetapi juga dapat mengirim pesan berupa gambar maupun video. Citra (image), istilah lain untuk gambar, merupakan salah satu komponen multimedia yang berperan sangat penting sebagai bentuk informasi visual. Sebuah gambar dapat memberikan informasi yang lebih banyak dari pada informasi tersebut disajikan dalam bentuk kata-kata.
Istilah pengolahan citra digital secara umum didefinisikan sebagai pemroresan citra dua dimensi dengan komputer. Pada awalnya pengolahan citra ini dilakukan untuk memperbaiki kualitas citra sehingga dapat lebih mudah diinterpretasikan oleh mata manusia, namun dengan berkembangnya dunia komputasi dan dengan semakin meningkatnya kapasitas dan kecepatan proses komputer maka muncullah ilmu-ilmu komputasi yang memungkinkan komputer dapat mengambil informasi dari suatu citra untuk keperluan pengenalan objek secara otomatis. Pengolahan citra digital ini sangat erat
kaitannya dengan ilmu pengenalan pola (pattern recognition) yang umumnya bertujuan untuk mengenali suatu objek dengan cara mengekstrak informasi penting yang terdapat pada suatu citra. Pengenalan pola bisa didefinisikan sebagai cabang kecerdasan yang menitikberatkan pada metode pengklasifikasian objek ke dalam kelas-kelas untuk menyelesaikan masalah tertentu.
Pengenalan citra digital merupakan salah satu masalah dalam computer vision khususnya pattern recognition dan
machine learning. Machine learning adalah salah satu disiplin
ilmu dari computer science yang mempelajari bagaimana membuat komputer atau mesin mempunyai suatu kecerdasan. Agar mempunyai suatu kecerdasan, komputer atau mesin harus dapat belajar. Dengan kata lain machine learning adalah suatu bidang keilmuan yang berisi tentang pembelajaran komputer atau mesin untuk menjadi cerdas.
Pada tahun 2016 telah dilakukan penelitian oleh I Wayan Suartika, dkk mengenai salah satu metode machine learning yaitu Convolutional Neural Network (CNN) yang digunakan untuk klasifikasi citra objek. CNN adalah pengembangan dari
Multilayer Perceptron yang didesain untuk mengolah data dua
dimensi. Hasil uji coba dari klasifikasi objek citra dengan CNN ini menghasilkan tingkat akurasi sebesar 20%-50% [1]. Metode lain dari machine learning yang dapat mengatasi permasalahan ini adalah Extreme Learning Machine (ELM) dengan tingkat akurasi yang lebih baik [2].
Berdasarkan kelebihan ELM tersebut, dapat diambil kesimpulan bahwa ELM memiliki kemampuan klasifikasi yang diperuntukkan untuk data gambar. Oleh karena itu, pada Tugas Akhir ini akan digunakan Extreme Learning Machine untuk pengenalan objek citra digital.
3
1.2 Rumusan Masalah
Rumusan masalah dari Tugas Akhir ini adalah bagaimana mengimplementasikan Extreme Learning Machine untuk pengenalan objek citra digital.
1.3 Batasan Masalah
Permasalahan dalam dunia nyata sangatlah luas oleh karena itu diberikan suatu batasan masalah pada Tugas Akhir ini antara lain:
1. Objek yang akan dikenali dalam citra adalah dalam keadaan utuh atau tidak terpotong.
2. Dalam 1 citra terdapat 1 objek.
3. Objek yang akan dikenali dalam citra dibatasi pada bagian depan dengan toleransi sebesar 45°.
4. Objek yang akan dikenali adalah guci, kelinci, mobil, sepatu, dan sepeda.
5. Jumlah maksimal data training adalah 100.
1.4 Tujuan
Tujuan dari penelitian Tugas Akhir ini adalah mengimplementasikan dan mengetahui kapabilitas metode
Extreme Learning Machine untuk pengenalan objek citra
digital.
1.5 Manfaat
Manfaat yang diperoleh dari Tugas Akhir ini antara lain: 1. Membantu memberikan solusi dalam masalah computer
vision khususnya dalam hal pengenalan objek dalam citra.
2. Dapat digunakan dalam dunia robotika sehingga robot dapat mengenali objek-objek yang berbeda untuk tujuan tertentu dengan asumsi telah dilakukan training pada dataset.
3. Dapat digunakan dalam dunia industri untuk mengenali produk-produk yang berbeda dengan tujuan memeriksa kualitas dari produk tertentu.
1.6 Sistematika Penulisan Tugas Akhir
Sistematika penulisan didalam Tugas Akhir ini adalah sebagai berikut:
1. BAB I PENDAHULUAN
Bab ini menjelaskan tentang latar belakang pembuatan Tugas Akhir, rumusan dan batasan permasalahan yang dihadapi dalam penelitian Tugas Akhir, tujuan dan manfaat pembuatan Tugas Akhir serta sistematika penulisan Tugas Akhir.
2. BAB II TINJAUAN PUSTAKA
Bab ini berisi teori dasar yang mendukung dalam Tugas Akhir ini, antara lain penelitian terdahulu, citra digital, deteksi tepi Canny, machine learning, Extreme Learning
Machine, dan Moore-Penrose generalized inverse.
3. BAB III METODOLOGI PENELITIAN
Bab ini menjelaskan tahap pengerjaan dalam menyelesaikan Tugas Akhir yang terdiri dari studi literatur, pengumpulan data, perancangan sistem, implementasi sistem, pengujian dan evaluasi sistem, serta penarikan kesimpulan dan penulisan laporan Tugas Akhir.
4. BAB IV PERANCANGAN SISTEM
Bab ini menjelaskan tahap persiapan pengolahan data hingga proses konstruksi sistem menggunakan metode
Extreme Learning Machine sebagai acuan dalam
implementasi sistem.
5. BAB V IMPLEMENTASI SISTEM
Bab ini membahas proses implementasi dengan menggunakan bahasa pemograman Java berdasarkan rancangan sistem yang telah dibuat pada bab sebelumnya.
5
6. BAB VI UJI COBA DAN EVALUASI SISTEM Bab ini membahas tahap-tahap uji coba berdasarkan implementasi sistem yang telah dibuat beserta pengujian kinerja sistem.
7. BAB VII KESIMPULAN DAN SARAN
Bab ini berisi kesimpulan Tugas Akhir yang diperoleh dari bab uji coba dan evaluasi sistem serta saran untuk pengembangan penelitian selanjutnya.
7
BAB II
TINJAUAN PUSTAKA
Pada bab ini diuraikan mengenai dasar teori yang digunakan dalam penyusunan Tugas Akhir ini. Dasar teori yang dijelaskan dibagi menjadi beberapa sub bab yaitu penelitian terdahulu, citra digital, deteksi tepi Canny, machine
learning, Extreme Learning Machine, dan Moore-Penrose Generalized Inverse.
2.1 Penelitian Terdahulu
Pada tahun 2013 telah dilakukan penelitian yang berjudul
“Extreme Learning Machine for Classification of Brain Tumor in 3D MR Images” oleh S. N. Deepa dan B. Arunadevi. Pada
penelitian tersebut dibahas mengenai extreme machine
learning (ELM) yaitu suatu algoritma dalam machine learning
yang digunakan sebagai model klasifikasi pola menggunakan citra MRI 3D untuk mengidentifikasi kelainan jaringan dalam histologi otak. Terdapat empat kategori klasifikasi, yaitu substansi abu-abu, substansi putih, cairan serebrospinal, dan tumor. Pada penelitian ini terdapat tiga segmen dari model klasifikasi tumor pada citra MRI 3D otak, yaitu metode pengolahan citra yang difokuskan pada segmentasi dan ekstraksi fitur, subseleksi fitur untuk karakteristik spektral dan intensitas dengan algoritma genetika, dan terakhir menggunakan ELM untuk model klasifikasi citra tumor. Hasil penelitian ini menunjukkan bahwa klasifikasi menggunakan ELM memiliki tingkat akurasi, sensitivitas, dan spesifisitas sebesar 93.20%, 91.6%, dan 97.98% [3].
Selanjutnya pada tahun 2015, telah dilakukan penelitian oleh Muhammad Athoillah dkk yang diberi judul “Support
Vector Machine with Multiple Kernel Learning for Image Retrieval”. Pada penelitian tersebut dibangun model klasifikasi
dengan algoritma SVM yang dimodifikasi dengan multiple
Supprot Vector Machine (SVM) adalah salah satu teknik yang
dapat menyelesaikan masalah klasifikasi dengan baik. Tetapi, SVM hanya dapat melakukan klasifikasi untuk data yang terpisah secara linear. Untuk mengklasifikasi data yang tidak terpisah secara linear, algoritma ini harus dimodifikasi dengan
kernel learning. Citra yang digunakan dalam penelitian ini
digolongkan ke dalam lima kategori. Hasil penelitian ini menunjukkan bahwa SVM dengan multi kernel learning memiliki akurasi yang baik dan waktu komputasi yang singkat. Hasil ini juga dibandingkan dengan ketika menggunakan single
kernel Polynomial dan RBF kernel. Hasilnya menunjukkan
bahwa RBF kernel tidak sesuai untuk masalah klasifikasi seperti ini yang ditandai dengan akurasi yang rendah dan lamanya waktu komputasi. Hal ini menunjukkan bahwa tidak setiap kernel sesuai untuk masalah klasifikasi [4].
Pada tahun 2016, I Wayan Suartika E. P dkk melakukan penelitian yang diberi judul “Klasifikasi Citra Menggunakan
Convolutional Neural Network (CNN) pada Caltech 101”.
Pada penelitian tersebut dibahas mengenai salah satu metode
machine learning yaitu CNN yang digunakan untuk klasifikasi
citra objek. CNN adalah pengembangan dari Multilayer
Perceptron (MLP) yang didesain untuk mengolah data dua
dimensi. CNN termasuk dalam deep neural network karena kedalaman jaringan yang tinggi dan banyak diaplikasikan pada data citra. Sebelum dilakukan klasifikasi, terlebih dahulu dilakukan praproses dengan metode wrapping dan cropping untuk memfokuskan objek yang akan diklasifikasi. Pada proses
wrapping, citra masukan dilakukan pengecekan terhadap edge
dari objek utama pada citra tersebut. Dari edge pada citra tersebut ditentukan edge maksimalnya sehingga saat hasil
cropping objek pada citra tersebut tetap utuh. Selanjutnya
dilakukan training menggunakan metode feedforward dan
backpropagation. Terakhir adalah melakukan tahap klasifikasi
menggunakan metode feedforward dengan bobot dan bias yang telah diperbarui. Hasil uji coba dari klasifikasi objek citra
9
dengan CNN menghasilkan tingkat akurasi sebesar 20%-50% [1].
Selanjutnya pada tahun yang sama, Shitong Wang dkk melakukan penelitian yang diberi judul “Feedforward Kernel
Neural Networks, Generalized Least Learning Machine, and Its Deep Learning with Application to Digital Image Classification”. Pada penelitian tersebut dilakukan klasifikasi
citra menggunakan deep FKNN dengan multi layer KPCA dan sebuah algoritma klasifikasi. FKNN terdiri dari input layer dengan input xi= [𝑥𝑖1, 𝑥𝑖2, . . . , 𝑥𝑖𝑛]𝑇𝜖𝑅𝑛, sejumlah L hidden layer di mana tiap node pada tiap hidden layer menggunakan
fungsi kernel dengan parameter yang berbeda sebagai fungsi aktivasinya, dan output layer di mana setiap output 𝑦 dari FKNN dapat dinyatakan sebagai kombinasi linear dari m fungsi aktivasi pada hidden layer terakhir dengan menggunakan bobot
output 𝛽𝑖 = [𝛽𝑖1, 𝛽𝑖2, . . . , 𝛽𝑖𝑚]𝑇. Algoritma klasifikasi yang
digunakan adalah SVM, KNN, dan Naïve bayes. Metode ini kemudian disebut sebagai deep learning framework (DLF). Hasil dari penelitian ini menunjukkan bahwa deep FKNN dengan DLF dapat meningkatkan performansi klasifikasi [5].
2.2 Citra Digital
Dalam pengolahan maupun pengenalan citra, masalah persepsi visual, yaitu apa yang dapat dilihat oleh mata manusia, mempunyai peranan penting. Penentuan apa yang dapat dilihat tidak hanya ditentukan oleh manusia itu sendiri. Mata merupakan bagian sistem visual manusia. Sistem visual ini sangat sulit dipelajari, terlebih jika ingin menyingkap proses yang melatarbelakangi timbulnya suatu persepsi, seperti pada peristiwa pengenalan (recognition).
Sesungguhnya citra merupakan suatu fungsi intensitas cahaya dalam bidang dua dimensi. Karena intensitas yang dimaksud berasal dari sumber cahaya, dan cahaya adalah suatu bentuk energi, maka berlaku keadaan di mana fungsi intensitas terletak di antara :
0 < 𝑓(𝑥, 𝑦) < ∞
Pada dasarnya, citra yang dilihat terdiri atas berkas-berkas cahaya yang dipantulkan oleh benda-benda di sekitarnya. Jadi secara alamiah, fungsi intensitas cahaya merupakan fungsi sumber cahaya yang menerangi objek, serta jumlah cahaya yang dipantulkan oleh objek, atau ditulis [6]:
𝑓(𝑥, 𝑦) = 𝑖(𝑥, 𝑦). 𝑟(𝑥, 𝑦) (2.1) di mana : 0 < 𝑖(𝑥, 𝑦) < ∞ (iluminasi sumber cahaya)
0 < 𝑟(𝑥, 𝑦) < 1 (koefisien pantul objek) Fungsi intensitas 𝑓 pada suatu titik (𝑥, 𝑦) disebut derajat keabuan atau gray level (l), dengan terletak di antara:
𝐿𝑚𝑖𝑛 ≤ 𝑙 ≤ 𝐿𝑚𝑎𝑥
Dengan demikian:
𝐿𝑚𝑖𝑛= 𝑖𝑚𝑖𝑛. 𝑟𝑚𝑖𝑛
𝐿𝑚𝑎𝑥= 𝑖𝑚𝑎𝑥. 𝑟𝑚𝑎𝑥
Selang (𝐿𝑚𝑖𝑛 , 𝐿𝑚𝑎𝑥) sering disebut sebagai skala keabuan.
Pada representasi suatu citra hitam putih secara numerik, biasanya selang digeser menjadi : (0, 𝐿), dengan 0 menyatakan hitam dan 𝐿 menyatakan putih. Semua bilangan yang terletak di antara 0 dan 𝐿 merupakan derajat keabuan.
2.2.1 Pencuplikan Citra dan Kuantisasi Derajat Keabuan
Suatu citra agar dapat direpresentasikan secara numerik, maka citra harus didigitalisasi, baik terhadap ruang (koordinat (𝑥, 𝑦)) maupun terhadap skala keabuannya (𝑓(𝑥, 𝑦)). Proses digitalisasi koordinat (𝑥, 𝑦) dikenal sebagai pencuplikan citra (image sampling), sedangkan proses digitalisasi skala keabuan (𝑓(𝑥, 𝑦)) disebut sebagai kuantisasi derajat keabuan (gray level
quantization).
Pencuplikan merupakan proses pengambilan informasi dari citra analog yang memiliki panjang dan lebar tertentu untuk membaginya ke beberapa blok kecil. Blok-blok tersebut disebut sebagai piksel. Kuantisasi adalah proses pemberian nilai derajat keabuan di setiap titik piksel yang merupakan
11
representasi dari warna asli dari citra analog dengan rentang nilai keabuan adalah 0 – 255. Hasil pencuplikan dan kuantisasi adalah sebuah matriks bilangan real.
Misalkan sebuah citra 𝑓(𝑥, 𝑦) dicuplik sehingga menghasilkan citra digital dengan M baris dan N kolom. Nilai dari koordinat (𝑥, 𝑦) sekarang menjadi kuantitas diskrit. Dengan demikian, nilai koordinat pada titik asal adalah (𝑥, 𝑦) = (0,0). Nilai koordinat berikutnya sepanjang baris pertama dari citra direpresentasikan sebagai (𝑥, 𝑦) = (0,1). Notasi (0,1) digunakan untuk menandakan sampel kedua sepanjang baris pertama. Representasi citra digital dalam koordinan (𝑥, 𝑦) dapat dilihat pada Gambar 2.1.
Sebuah citra kontinu ( 𝑓(𝑥, 𝑦)) akan didekati oleh cuplikan-cuplikan yang seragam jaraknya dalam bentuk matriks M x N di mana indeks baris dan kolomnya menyatakan suatu titik pada citra tersebut dan elemen matriksnya (yang disebut sebagai elemen gambar atau piksel) menyatakan tingkat keabuan pada titik tersebut. Untuk sebuah citra digital, setiap piksel memiliki nilai integer yakni gray level yang menunjukkan amplitudo atau intensitas dari piksel tersebut. Citra merupakan fungsi dua dimensi yang kedua variabelnya yaitu nilai amplitudo dan koordinatnya merupakan nilai integer Notasi matriks citra digital dapat dinyatakan sebagai berikut [7]: 𝑓(𝑥, 𝑦) = [ 𝑓(0, 0) ⋯ 𝑓(0, 𝑁 − 1) ⋮ ⋱ ⋮ 𝑓(𝑀 − 1, 0) ⋯ 𝑓(𝑀 − 1, 𝑁 − 1) ] (2.2)
Gambar 2.1. Representasi Citra Digital dalam Koordinat (x,y) [7]
Gambar 2.2. Proses sampling dan kuantisasi. (a) Citra Digital, (b) Citra Digital Disampling Menjadi 14 Baris dan 12 Kolom, (c) Citra Digital Hasil Sampling Berukuran 14 x 12 Piksel [7]
13
2.2.2 Citra Berwarna dan Citra Grayscale
Citra berwarna atau citra RGB (Red- Green-Blue) merupakan warna dasar yang dapat diterima oleh mata manusia. Setiap piksel pada citra warna mewakili warna yang merupakan kombinasi dari ketiga warna dasar RGB. Setiap titik pada citra warna membutuhkan data sebesar 3 byte. Setiap warna dasar memiliki intensitas tersendiri dengan nilai minimum nol (0) dan nilai maksimum 255 (8 bit). RGB didasarkan pada teori bahwa mata manusia peka terhadap panjang gelombang 630nm (merah), 530 nm (hijau), dan 450 nm (biru).
Citra grayscale merupakan citra digital yang hanya memiliki satu nilai kanal pada setiap pikselnya, artinya nilai dari Red = Green = Blue. Nilai-nilai tersebut digunakan untuk menunjukkan intensitas warna. Citra yang ditampilkan dari citra jenis ini terdiri atas warna abu-abu, bervariasi pada warna hitam pada bagian yang intensitas terlemah dan warna putih pada intensitas terkuat. Citra grayscale berbeda dengan citra ”hitam-putih”, dimana pada konteks komputer, citra hitam putih hanya terdiri atas 2 warna saja yaitu ”hitam” dan ”putih” saja. Pada citra grayscale warna bervariasi antara hitam dan putih, tetapi variasi warna diantaranya sangat banyak. Citra
grayscale seringkali merupakan perhitungan dari intensitas
cahaya pada setiap piksel pada spektrum elektromagnetik
single band. Citra grayscale disimpan dalam format 8 bit untuk
setiap sample piksel, yang memungkinkan sebanyak 256 intensitas. Untuk mengubah RGB menjadi grayscale menggunakan persamaan berikut ini:
𝑔𝑟𝑎𝑦 = 𝛼(𝑅𝑒𝑑) + 𝛽(𝐺𝑟𝑒𝑒𝑛) + 𝛾(𝐵𝑙𝑢𝑒), (2.3) dengan 𝛼 + 𝛽 + 𝛾 = 1
Pada dasarnya resolusi citra secara matematis direpresentasikan dengan matriks dimana setiap nilai elemen matriksnya merupakan nilai dari intensitas warna baik itu dalam RGB atau dalam grayscale.
2.3 Deteksi Tepi Canny
Salah satu algoritma deteksi tepi modern adalah deteksi tepi dengan menggunakan metode Canny. Deteksi tepi Canny ditemukan oleh Marr dan Hildreth yang meneliti pemodelan persepsi visual manusia. Deteksi tepi Canny dapat mendeteksi tepian yang sebenarnya dengan tingkat error yang minimum [8].
Berikut adalah langkah-langkah dalam melakukan deteksi tepi Canny:
1. Menghilangkan noise yang ada pada citra dengan mengimplementasikan filter Gaussian. Hasilnya citra akan tampak sedikit buram. Hal ini dimaksudkan untuk mendapatkan tepian citra yang sebenarnya. Bila tidak dilakukan maka garis-garis halus juga akan dideteksi sebagai tepian.
2. Melakukan deteksi tepi dengan salah satu operator deteksi tepi seperti Roberts, Prewitt, atau Sobel dengan melakukan pencarian secara horizontal (𝐺𝑥) dan secara vertikal (𝐺𝑦).
Hasil dari kedua operator digabungkan untuk mendapatkan hasil gabungan tepi horizontal dan vertikal dengan rumus :
|𝐺| = |𝐺𝑥| + |𝐺𝑦|
3. Menentukan arah tepian yang ditemukan dengan menggunakan rumus :
𝜃 = arctan (𝐺𝑦 𝐺𝑥
)
Selanjutnya membagi ke dalam 4 warna sehingga garis dengan arah yang berbeda memiliki warna yang berbeda. Pembagiannya adalah:
0° − 22,5° dan 157,7° − 180° berwarna kuning
22,5° − 67,5° berwarna hijau
67,5° − 157,5° berwarna merah
4. Memperkecil garis tepi yang muncul dengan menerapkan non maximum suppression sehingga menghasilkan garis tepian yang lebih ramping.
15
Ada beberapa kriteria pendeteksi tepian paling optimum yang dapat dipenuhi oleh algoritma Canny:
a. Mendeteksi dengan baik
Kemampuan untuk meletakkan dan menandai semua tepi yang ada sesuai dengan pemilihan parameter-parameter konvolusi yang dilakukan. Sekaligus juga memberikan fleksibilitas yang sangat tinggi dalam hal menentukan tingkat deteksi ketebalan tepi sesuai yang diinginkan.
b. Melokalisasi dengan baik
Dengan Canny dimungkinkan dihasilkan jarak yang minimum antara tepi yang terdeteksi dengan tepi yang asli.
c. Respon yang jelas
Hanya ada satu respon untuk setiap tepi. Sehingga mudah dideteksi dan tidak menimbulkan kerancuan pada pengolahan citra selanjutnya.
Pemilihan parameter deteksi tepi Canny sangat mempengaruhi hasil dari tepian yang dihasikan. Beberapa parameter tersebut antara lain:
Nilai standar deviasi Gaussian
Nilai ambang
2.4 Machine Learning
Learning mempunyai arti menambah pengetahuan,
memahami atau menguasai dengan belajar, mengikuti instruksi atau melalui pengalaman. Secara definisi, machine learning adalah cabang dari ilmu kecerdasan buatan yang berfokus pada pembangunan dan studi sebuah sistem agar mampu belajar dari data-data yang diperolehnya. Menurut Arthur Samuel, machine
learning adalah bidang studi yang memberikan kemampuan
program komputer untuk belajar tanpa secara eksplisit diprogram.
Untuk bisa mengaplikasikan teknik-teknik machine
machine learning tidak dapat bekerja. Data yang ada biasanya
dibagi menjadi dua, yaitu data training dan data testing. Data
training digunakan untuk melatih algoritma, sedangkan data testing digunakan untuk mengetahui performa algoritma yang
telah dilatih sebelumnya ketika menemukan data baru yang belum pernah dilihat.
Ada beberapa hal yang membuat machine learning menjadi penting, di antaranya yaitu [9]:
Beberapa tugas tidak dapat didefinisikan dengan baik kecuali dengan contoh. Kita mungkin dapat menentukan pasangan input dan output, tetapi bukan hubungan antara input dan output yang diinginkan. Kita ingin agar mesin dapat menyesuaikan struktur internal mereka untuk menghasilkan output yang benar untuk sejumlah besar sampel input.
Jumlah pengetahuan yang ada tentang tugas-tugas tertentu mungkin terlalu besar untuk diprogram secara eksplisit oleh manusia. Mesin yang belajar tentang pengetahuan ini mungkin secara bertahap bisa menangkap lebih banyak dari yang manusia ingin tuliskan.
Lingkungan yang berubah dari waktu ke waktu. Mesin yang dapat beradaptasi dengan perubahan lingkungan akan mengurangi kebutuhan untuk desain ulang.
2.4.1 Jaringan Syaraf Tiruan
Jaringan syaraf tiruan adalah salah satu cabang dari
machine learning. JST merupakan teknik yang digunakan
untuk membangun program yang cerdas dengan pemodelan yang mensimulasikan cara kerja jaringan syaraf pada otak manusia. Jadi, JST menggunakan konsep kerja dari syaraf otak manusia untuk menyelesaikan perhitungan pada komputer. JST menyerupai otak manusia dalam dua hal, yaitu:
17
2. Kekuatan hubungan antar sel syaraf (neuron) yang dikenal sebagai bobot-bobot sinaptik digunakan untuk menyimpan pengetahuan.
Seperti otak manusia, fungsi dari jaringan ditentukan oleh hubungan antar neuron. Hubungan antar neuron ini disebut bobot (weight). Untuk mendapatkan fungsi tertentu dapat dilakukan dengan pelatihan (training) dengan menyesuaikan nilai bobot dari masing-masing neuron. Satu sel syaraf terdiri dari tiga bagian, yaitu fungsi penjumlah (summing function), fungsi aktivasi (activation function), dan keluaran (output). Pada Gambar 2.3. dapat dilihat model dari sel syaraf (neuron) [10].
Gambar 2.3. Sel Syaraf (Neuron)
Pada umumnya, JST dilatih (trained) agar input mengarah ke target output yang spesifik. Jadi jaringan dilatih terus menerus hingga mencapai kondisi di mana input sesuai dengan target yang telah ditentukan. Pelatihan di mana setiap input diasosiasikan dengan target yang telah ditentukan disebut pelatihan terarah (supervised learning).
Secara umum, terdapat dua jenis arsitektur jaringan syaraf tiruan, yaitu:
1) Feedforward Neural Networks
Sebuah jaringan yang sederhana mempunyai struktur
feedforward di mana sinyal bergerak dari input kemudian
melewati lapisan tersembunyi dan akhirnya mencapai unit
output. Tipe jaringan feedforward mempunyai sel syaraf
yang tersusun dari beberapa lapisan. Lapisan input memberikan pelayanan dengan mengenalkan suatu nilai dari suatu variabel. Lapisan tersembunyi dan lapisan output sel syaraf terhubung satu sama lain dengan lapisan sebelumnya. Kemungkinan yang timbul adalah adanya hubungan dengan beberapa unit dari lapisan sebelumnya atau terhubung semuanya dengan baik. Pada Gambar 2.4. dapat dilihat arsitektur dari feedforward neural networks [10].
Gambar 2.4. Feedforward Neural Networks 2) Recurrent Neural Networks
Recurrent neural networks adalah jaringan yang
mempunyai minimal satu feedback loop. Sebagai contoh, suatu recurrent neural networks bisa terdiri dari satu lapisan neuron tunggal dengan masing-masing neuron memberikan kembali output-nya sebagai input pada semua neuron yang lain. Pada Gambar 2.5. dapat dilihat arsitektur dari Recurrent Neural Networks [10].
19
Gambar 2.5. Recurrent Neural Networks
Untuk mendapatkan tingkat kecerdasan yang diinginkan maka jaringan syaraf tiruan harus melalui proses pembelajaran. Pembelajaran (learning) adalah proses yang melibatkan serangkaian nilai input menjadi input jaringan secara berurutan dan bobot jaringan disesuaikan sehingga akan diperoleh nilai yang sama dengan nilai output-nya. Jaringan syaraf tiruan membagi metode belajar menjadi dua macam, yaitu :
1) Pembelajaran terawasi (supervised learning)
Metode belajar ini memerlukan pengawasan dari luar atau pelabelan data sampel yang digunakan dalam proses belajar. Jaringan belajar dari sekumpulan pola masukan dan keluaran sehingga pada saat pelatihan diperlukan pola yang terdiri dari vektor masukan dan vektor target yang diinginkan. Vektor masukan dimasukkan ke dalam jaringan yang kemudian menghasilkan vektor keluaran yang selanjutnya dibandingkan dengan vektor target. Selisih kedua vektor tersebut menghasilkan galat (error) yang digunakan sebagai dasar untuk mengubah matriks koneksi sedemikian rupa sehingga galat semakin mengecil pada siklus berikutnya.
2) Pembelajaran tak terawasi (unsupervised learning) Metode belajar ini menggunakan data yang tidak diberi label dan tidak memerlukan pengawasan dari luar. Data disajikan kepada JST dan membentuk kluster internal yang mereduksi data masukan ke dalam kategori klasifikasi tertentu. Tujuan dari pembelajaran ini adalah mengelompokkan unit-unit yang hampir sama dalam suatu area tertentu.
2.5 Extreme Learning Machine
Extreme Learning Machine merupakan metode pembelajaran baru dari jaringan syaraf tiruan. ELM merupakan jaringan syaraf tiruan feedforward dengan single hidden layer atau biasa disebut single hidden layer feedforward neural
networks (SLFNs). Metode pembelajaran ELM dibuat untuk
mengatasi kelemahan-kelemahan dari jaringan syaraf tiruan
feedforward terutama dalam hal learning speed [11]. Huang et
al mengemukakan dua alasan mengapa JST feedforward mempunyai learning speed rendah, yaitu:
1. Menggunakan slow gradient based learning algorithm untuk melakukan training.
2. Semua parameter pada jaringan ditentukan secara iterative dengan menggunakan metode pembelajaran tersebut. Pada pembelajaran dengan menggunakan conventional
gradient based learning algorithm seperti backpropagation
(BP), semua parameter pada JST feedforward harus ditentukan secara manual. Parameter yang dimaksud adalah input weight dan hidden bias. Parameter-parameter tersebut juga saling berhubungan antara layer yang satu dengan yang lain, sehingga membutuhkan learning speed yang lama dan sering terjebak pada local minima. Sedangkan pada ELM parameter-parameter seperti input weight dan hidden bias dipilih secara random, sehingga ELM memiliki learning speed yang cepat dan mampu menghasilkan good generalization performance.
21
Metode ELM mempunyai model matematis yang berbeda dari jaringan syaraf tiruan feedforward. Model matematis dari ELM lebih sederhana dan efektif. Untuk 𝑁 pasangan input dan target output yang berbeda (x𝑖, 𝑡𝑖), dengan x𝑖 =
[𝑥𝑖1, 𝑥𝑖2, . . . , 𝑥𝑖𝑛]𝑇 ∈ 𝑹𝑛 dan 𝑡𝑖 = [𝑡𝑖1, 𝑡𝑖2, . . . , 𝑡𝑖𝑚]𝑇 ∈ 𝑹𝑚,
standar SLFNs dengan jumlah hidden nodes sebanyak 𝑁̃ dan fungsi aktivasi 𝑔(𝑥) dapat dimodelkan secara matematis sebagai berikut [12]: ∑ 𝛽𝑖𝑔𝑖(𝑥𝑗) = 𝑁̃ 𝑖=1 ∑ 𝛽𝑖𝑔(𝑤𝑖 . x𝑗+ 𝑏𝑖) = 𝑜𝑗 𝑁̃ 𝑖=1 , 𝑗 = 1, 2, . . . , 𝑁 di mana
a. 𝑤𝑖 = [𝑤𝑖1, 𝑤𝑖2, . . . , 𝑤𝑖𝑛]𝑇 merupakan vektor bobot
yang menghubungkan hidden node ke-i dan input
nodes.
b. 𝛽𝑖 = [𝛽𝑖1, 𝛽𝑖2, . . . , 𝛽𝑖𝑚]𝑇 merupakan vektor bobot yang
menghubungkan hidden node ke-i dan output nodes. c. 𝑏𝑖 merupakan threshold dari hidden node ke-i
d.
𝑤
𝑖. x
𝑗 merupakan inner product dari 𝑤𝑖 danx
𝑗SLFNs standar dengan 𝑁̃ hidden nodes dan fungsi aktivasi 𝑔(𝑥) diasumsikan dapat memperkirakan 𝑁 sampel ini dengan tingkat error 0 yang artinya ∑𝑁𝑗=1‖𝑜𝑗− 𝑡𝑗‖ = 0,
sehingga terdapat 𝛽𝑖, 𝑤𝑖, dan 𝑏𝑖 sedemikian hingga [9]
∑ 𝛽𝑖𝑔(𝑤𝑖 . x𝑗+ 𝑏𝑖) = 𝑡𝑗 𝑁̃
𝑖=1
, 𝑗 = 1, 2, . . . , 𝑁
Persamaan di atas dapat dituliskan secara sederhana sebagai [12]: 𝐻𝛽 = 𝑇, di mana 𝐻 = [ 𝑔(𝑤1. x1+ 𝑏1) ⋯ 𝑔(𝑤𝑁̃. x1+ 𝑏𝑁̃) ⋮ ⋱ ⋮ 𝑔(𝑤1. x𝑁+ 𝑏1) ⋯ 𝑔(𝑤𝑁̃. x𝑁+ 𝑏𝑁̃) ], (2.4) (2.5) (2.6)
𝛽 = [ 𝛽1𝑇 ⋮ 𝛽𝑁̃𝑇 ] dan 𝑇 = [ 𝑡1𝑇 ⋮ 𝑡𝑁𝑇 ]
H pada persamaan di atas adalah matriks output hidden
layer dari jaringan syaraf. 𝑔(𝑤𝑖 . x𝑗+ 𝑏𝑖) menunjukkan output
dari hidden neuron yang berhubungan dengan input x𝑗. 𝛽
merupakan matriks dari bobot output dan 𝑇 matriks dari target. Pada ELM, input weight dan hidden bias ditentukan secara acak, sehingga bobot output yang berhubungan dengan hidden
layer dapat ditentukan dari Persamaan (2.5) [13]:
𝛽 = 𝐻
†𝑇
Algoritma Extreme Learning Machine (ELM) ditunjukkan pada Gambar 2.6. berikut [13].
Input : pola input x𝑗 dan pola target output
𝑡𝑗, 𝑗 = 1, 2, . . . , 𝑁
Output : bobot input 𝑤𝑖, bobot output 𝛽𝑖 dan bias
𝑏𝑖, 𝑖 = 1, 2, . .., 𝑁̃
Algoritma :
Langkah 1 : Tentukan fungsi aktivasi (𝑔(𝑥)) dan jumlah
hidden nodes (𝑁̃)
Langkah 2 : Tentukan secara acak nilai dari bobot input 𝑤𝑖
dan bias 𝑏𝑖, 𝑖 = 1, 2, . .., 𝑁̃
Langkah 3 : Hitung nilai matriks output 𝐻 pada hidden
layer
Langkah 4 : Hitung nilai bobot output 𝛽 dengan menggunakan 𝛽 = 𝐻†𝑇
Gambar 2.6. Algoritma Extreme Learning Machine
23
2.6 Moore-Penrose Generalized Inverse
Konsep invers matriks pada umumnya merupakan konsep invers matriks yang terbatas pada matriks persegi berordo 𝑛 𝑥 𝑛 dan non singular. Matriks yang berordo 𝑚 𝑥 𝑛 yang singular tidak mempunyai invers. Akan tetapi, terdapat matriks yang seolah-olah menjadi invers untuk matriks yang berordo 𝑚 𝑥 𝑛 yang singular. Matriks tersebut dinamakan
Moore-Penrose generalized inverse atau pseudoinverse yang
ditemukan oleh E.H. Moore pada tahun 1920 dan Roger penrose pada tahun 1955.
Definisi dari Moore-Penrose generalized inverse adalah sebagai berikut [14]:
Jika 𝐴 ∈ 𝑀𝑛,𝑚 maka terdapat 𝐴† ∈ 𝑀𝑚,𝑛 yang unik dan
memenuhi empat kondisi Penrose yaitu:
1.
𝐴𝐴
†𝐴 = 𝐴
2.
𝐴
†𝐴𝐴
†= 𝐴
†3.
𝐴
†𝐴 = (𝐴
†𝐴)
∗4.
𝐴𝐴
†= (𝐴𝐴
†)
∗25
BAB III
METODOLOGI PENELITIAN
Bab ini menjelaskan tentang tahap pengerjaan dalam menyelesaikan Tugas Akhir ini sehingga penelitian ini dapat dirancang sistematis dan diatur dengan sebaik-baiknya.
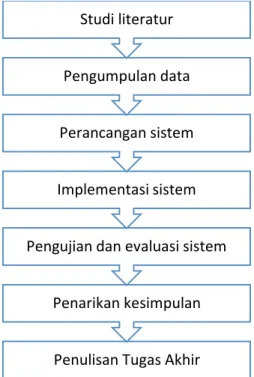
3.1 Diagram Metodologi
Gambaran tahap-tahap dalam penelitian pada Tugas Akhir ini disajikan sebagai diagram alir pada Gambar 3.1.
Gambar 3.1. Diagram Alir Metodologi Penelitian
Penulisan Tugas Akhir Penarikan kesimpulan Pengujian dan evaluasi sistem
Implementasi sistem Perancangan sistem Pengumpulan data
3.2 Studi Literatur
Pada tahap ini meliputi identifikasi permasalahan dan mencari referensi yang menunjang penelitian. Referensi yang dipakai adalah buku-buku literatur, jurnal ilmiah, tugas akhir atau thesis yang berkaitan dengan permasalahan, maupun artikel dari internet.
3.3 Pengumpulan Data
Pada tahap ini dilakukan pengumpulan citra digital yang mengandung objek-objek sesuai batasan masalah dan dibagi menjadi dua kelompok yaitu sebagai data training dan data
testing.
3.4 Perancangan Sistem
Pada tahap ini dilakukan perancangan desain arsitektur
Extreme Learning Machine dan pemodelan Extreme Learning Machine yang dijadikan acuan untuk implementasi sistem pada
Tugas Akhir ini.
3.5 Implementasi Sistem
Pada tahap ini dilakukan implementasi sistem dengan menggunakan perangkat lunak Netbeans IDE dengan bahasa pemrograman java dengan bantuan Library OpenCV dan JAMA (Java Matrix Package). Input sistem berupa citra sesuai batasan masalah. Output sistem berupa label nama objek dari hasil pengenalan. Sebelum diproses oleh ELM, citra input diolah di dalam praproses yaitu proses deteksi tepi dan
cropping untuk memfokuskan objek yang akan dikenali.
Setelah itu, citra dikonversi menjadi citra gray scale dan dilakukan resize untuk menyeragamkan ukuran citra. Kemudian dilakukan proses training dan dilanjutkan dengan proses testing.
27
3.6 Pengujian dan Evaluasi Sistem
Pada tahap ini dilakukan simulasi dengan menggunakan data yang telah diperoleh dan menguji output dari sistem apakah sudah sesuai dengan yang diharapkan. Dalam proses pengujian terdapat dua tahap, yaitu tahap training dan testing. Pada tahap training diperlukan input berupa citra dan label nama objek untuk memperoleh bobot dan bias. Kemudian dilakukan tahap testing menggunakan bobot yang diperoleh pada tahap training dengan input berupa citra dan akan memberikan output berupa label nama objek. Hasil keluaran tersebut kemudian akan dianalisis dengan perhitungan tingkat akurasi sebagai berikut:
𝐴𝐶 = 𝑛
𝑁𝑥100%
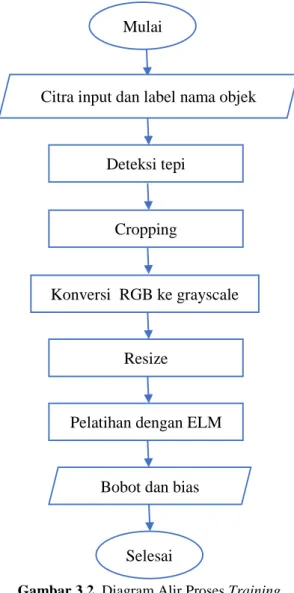
dengan 𝐴𝐶 adalah persentase akurasi, 𝑛 adalah jumlah kebenaran pengenalan objek pada citra, dan 𝑁 adalah jumlah citra pada proses pengenalan. Diagram alir proses training dan
testing dapat dilihat pada Gambar 3.2. dan Gambar 3.3.
Gambar 3.2. Diagram Alir Proses Training
Mulai
Citra input dan label nama objek
Deteksi tepi
Cropping
Konversi RGB ke grayscale
Resize
Pelatihan dengan ELM
Bobot dan bias
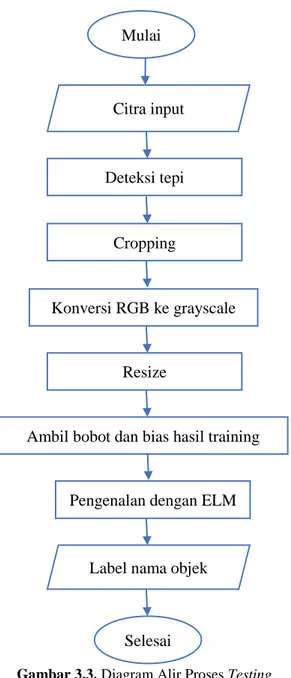
29
Gambar 3.3. Diagram Alir Proses Testing
Mulai Citra input Deteksi tepi Cropping Konversi RGB ke grayscale Resize
Ambil bobot dan bias hasil training
Label nama objek
Selesai
3.7 Penarikan Kesimpulan
Setelah sistem selesai diimplementasikan dan dilakukan pengujian serta evaluasi, maka tahap selanjutnya adalah penarikan kesimpulan dari keseluruhan tahap yang sudah dilakukan dan pemberian saran terkait kekurangan hasil penelitian untuk pengembangan pengenalan citra digital berikutnya.
3.8 Penulisan Laporan Tugas Akhir
Tahap akhir setelah semua tahap dijalankan adalah penulisan laporan Tugas Akhir. Konten laporan Tugas Akhir sesuai dengan hasil yang telah didapatkan dari proses awal pengumpulan data sampai dengan penarikan kesimpulan.
31
BAB IV
PERANCANGAN SISTEM
Bab ini menjelaskan rancangan desain sistem yang digunakan sebagai acuan untuk implementasi sistem. Desain sistem menggambarkan proses rancang bangun secara terperinci dari awal tahap pengumpulan data hingga proses konstruksi sistem menggunakan metode Extreme Learning
Machine, serta penjelasan mengenai cara untuk mendapatkan
data keluaran yang sesuai dengan tujuan dari penelitian Tugas Akhir ini.
4.1 Pengumpulan Dataset
Data yang dikumpulkan adalah data gambar yang di dalamnya terdapat satu objek dari kategori guci, kelinci, mobil, sepatu, dan sepeda. Data gambar tersebut adalah gambar yang berwarna dengan ukuran yang bervariasi. Data gambar ini nantinya akan dibagi ke dalam dua kelompok yaitu data
training dan data testing. 4.2 Praproses Data
Agar dapat diproses oleh Extreme Learning Machine, maka data citra yang telah dikumpulkan harus melalui praproses terlebih dahulu. Praproses ini terdiri dari proses deteksi tepi, cropping, konversi citra warna ke grayscale, dan penyeragaman ukuran citra. Algoritma deteksi tepi yang digunakan adalah metode Canny. Metode Canny ini digunakan karena metode ini memenuhi beberapa kriteria pendeteksian tepi yang optimum, antara lain :
memberikan fleksibilitas yang sangat tinggi dalam hal menentukan tingkat deteksi ketebalan tepi sesuai parameter-parameter yang dipilih.
dimungkinkan dihasilkan jarak yang minimum antara tepi yang terdeteksi dengan tepi yang asli.
hanya ada satu respon untuk setiap tepi.
Setelah dilakukan deteksi tepi kemudian masing-masing tepi yang terdeteksi akan diberikan bounding box. Luas masing-masing bounding box tersebut kemudian dihitung dan dicari bounding box dengan luas terbesar untuk dilakukan proses cropping. Selanjutnya citra berwarna yang telah melalui proses cropping akan dikonversi menjadi citra grayscale dan dilakukan penyeragaman ukuran citra yaitu menjadi 50x50 piksel. Tahap praproses ini diimplementasikan dengan menggunakan library OpenCV.
33
4.3 Desain Arsitektur Extreme Learning Machine
Extreme Learning Machine merupakan jaringan syaraf
tiruan feedforward dengan single hidden layer atau biasa disebut single hidden layer feedforward neural networks (SLFNs). ELM terdiri dari 3 layer, yaitu input layer, hidden
layer, dan output layer.
Input untuk jaringan berupa citra grayscale berukuran 50x50 piksel yang merupakan hasil dari praproses data. Jumlah node pada layer pertama sama dengan ukuran dari citra input yaitu 50x50 atau 2.500 node. Layer kedua merupakan hidden
layer yang memberikan hasil optimal dengan 1250 node. Hasil
keluaran dari hidden layer ini akan dimasukkan ke dalam layer terakhir yaitu output layer dan yang terdiri dari 3 buah node.
4.4 Pemodelan Extreme Learning Machine
ELM mempunyai model matematis yang berbeda dari jaringan syaraf tiruan feedforward. Model matematis dari ELM lebih sederhana dan efektif. Dengan 75 jumlah pasangan input dan target output yang berbeda (x𝑖, 𝑡𝑖), dengan x𝑖 =
[𝑥𝑖1, 𝑥𝑖2, . . . , 𝑥𝑖2500]𝑇 dan 𝑡𝑖 = [𝑡𝑖1, 𝑡𝑖2, 𝑡𝑖3]𝑇, jumlah hidden nodes sebanyak 1250 dan fungsi aktivasi 𝑔(𝑥) maka berdasarkan Persamaan (2.4) didapatkan model matematis ELM pada Tugas Akhir ini adalah sebagai berikut:
∑ 𝛽𝑖𝑔𝑖(x𝑗) = 1250 𝑖=1 ∑ 𝛽𝑖𝑔(𝑤𝑖 . x𝑗+ 𝑏𝑖) = 𝑜𝑗 1250 𝑖=1 , 𝑗 = 1, 2, . . . , 75 di mana
a. 𝑤𝑖 = [𝑤𝑖1, 𝑤𝑖2, . . . , 𝑤𝑖2500]𝑇 merupakan vektor bobot
yang menghubungkan hidden node ke-i dan input
nodes.
b. 𝛽𝑖 = [𝛽𝑖1, 𝛽𝑖2, 𝛽𝑖3]𝑇 merupakan vektor bobot yang
menghubungkan hidden node ke-i dan output nodes. c. 𝑏𝑖 merupakan bias dari hidden node ke-i
Konstruksi model Extreme Learning Machine pada Tugas Akhir ini mengacu pada desain arsitektur yang telah dibuat. Model berupa persamaan umum fungsi transfer antara layer satu dengan layer lainnya. Berikut penjabaran model pada setiap layer arsitektur jaringan.
4.4.1 Input Layer
Layer ini merupakan layer pertama pada jaringan. Layer
ini terdiri dari 50x50 atau 2.500 node sesuai dengan ukuran citra input yang merupakan hasil dari praproses data. Satu piksel pada citra input mewakili satu node pada lapisan ini.
Input layer dengan hidden layer dihubungkan oleh vektor
bobot 𝑤 yang nilainya ditentukan secara acak. Bias yang terhubung dengan node-node pada hidden layer juga ditentukan secara acak. Fungsi yang dipilih sebagai fungsi aktivasi pada layer ini adalah fungsi softsign yaitu [15]:
𝑓(𝑥) = 𝑥 1 + |𝑥|
Fungsi aktivasi ini memberikan batasan keluaran antara (-1,1). Berdasarkan Persamaan (4.1) dapat dirumuskan suatu fungsi umum sebagai berikut:
𝐻𝑖,𝑗= 𝑔(𝑤𝑖 . x𝑗+ 𝑏𝑖)
= 𝑤𝑖 . x𝑗+ 𝑏𝑖 1 + |𝑤𝑖 . x𝑗+ 𝑏𝑖|
Keterangan variabel dan indeks pada persamaan di atas adalah sebagai berikut:
𝐻 : matriks output pada hidden layer
𝑤 : vektor bobot yang menghubungkan hidden node dan input node.
x : matriks input
𝑏 : bias yang terhubung dengan hidden node 𝑖 : indeks jumlah node pada hidden layer 𝑗 : indeks jumlah citra input
𝑤. x : inner product dari 𝑤 dan x
(4.2) (4.1)
35
4.4.2 Hidden Layer
Layer ini merupakan layer kedua dari jaringan dan terdiri
dari 1250 buah node. Hidden layer dan output layer dihubungkan oleh vektor bobot β. Sehingga berdasarkan Persamaan (2.6) dengan 𝑁 = 75 dan 𝑁̃ = 1250 dapat dituliskan suatu persamaan sebagai berikut:
𝐻𝛽 = 𝑇, di mana
𝐻 = [
𝑔(𝑤
1.
x1+ 𝑏
1)
⋯
𝑔(𝑤
1250.
x1+ 𝑏
1250)
⋮
⋱
⋮
𝑔(𝑤
1.
x75+ 𝑏
1) ⋯ 𝑔(𝑤
1250.
x75+ 𝑏
1250)
],
𝛽 = [
𝛽
1𝑇⋮
𝛽
1250𝑇] dan 𝑇 = [
𝑡
1𝑇⋮
𝑡
75𝑇]
Keterangan variabel dan indeks pada persamaan di atas adalah sebagai berikut:
𝐻 : matriks output pada hidden layer
𝑤 : vektor bobot yang menghubungkan hidden node dan
input node.
x : matriks input
𝑏 : bias yang terhubung dengan hidden node 𝑤. x : inner product dari 𝑤 dan 𝑥
𝛽 : vektor bobot yang menghubungkan hidden node dan
output node.
𝑇 : matriks target
Sehingga bobot output yang berhubungan dengan hidden layer dapat ditentukan dari persamaan berikut:
𝛽 = 𝐻†𝑇
dengan 𝐻† merupakan Moore-Penrose generalized inverse dari 𝐻.
(4.3)
4.4.3 Output Layer
Setiap node yang ada di hidden layer dihubungkan dengan
output layer melalui vektor bobot 𝛽. Jumlah node pada output
layer disesuaikan dengan jumlah kelas dari objek yang akan
dikenali. Output layer pada Tugas Akhir ini terdiri dari 3 buah node dan hasil keluaran dari output layer ini mewakili kelas dari citra input. Nilai output dari layer ini dapat dihitung dengan Persamaan (4.3).
4.5 Gambaran Sistem
Proses berjalannya sistem secara umum terbagi menjadi dua tahap yaitu proses training dan testing. Pada proses
training memerlukan input berupa citra dan nama objek dalam
citra. Output dari proses training ini adalah bobot 𝑤 dan bias 𝑏 yang ditentukan secara acak serta bobot
𝛽
yang dihitung dengan menggunakan Persamaan (4.4). Bobot dan bias yang dihasilkan dari proses training ini akan digunakan untuk melakukan pengenalan objek pada proses testing. Prosestesting memerlukan input berupa citra dan akan memberikan
output berupa hasil pengenalan objek dalam citra. Berikut penjabaran proses berjalannya sistem pada tiap tahap.
4.5.1 Proses Training
Proses training memerlukan input berupa citra dan label nama objek dalam citra yang masing-masing akan mewakili matriks input x dan matriks target 𝑡. Sebelum diproses oleh ELM, citra input ini akan melewati tahap praproses sehingga menjadi citra grayscale berukuran 50x50 piksel. Nilai setiap piksel pada citra grayscale ini akan menjadi elemen dari matriks input x yang terdiri dari 2500 elemen. Label nama objek akan diubah menjadi matriks 𝑡 yang terdiri dari 3 elemen dengan nilai 1 atau -1. Representasi label nama objek dalam matriks 𝑡 dapat dilihat pada Tabel.4.1.
37
Tabel 4.1. Representasi Label Nama Objek dalam Matriks t
No Label Nama Objek Representasi dalam Matriks 𝑡
1 Guci [1, -1, -1]
2 Kelinci [-1, 1, -1]
3 Mobil [-1, -1, 1]
4 Sepatu [1, 1, -1]
5 Sepeda [1, -1, 1]
Data training pada Tugas Akhir ini terdiri dari 75 pasangan berbeda citra input dan label nama objek yang akan diubah ke dalam bentuk matriks input x dan matriks target 𝑡. Setelah seluruh data training ini diinputkan ke dalam sistem, kemudian bobot 𝑤 dan bias 𝑏 ditentukan dengan bilangan acak yang terletak pada selang (−1, 1) sehingga bisa didapatkan matriks 𝐻 dan 𝑇 pada Persamaan (4.3). Kemudian bobot 𝛽 dihitung dengan menggunakan Persamaan (4.4).
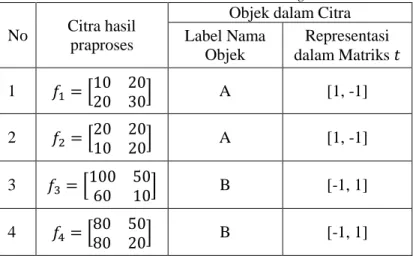
Berikut adalah contoh proses training dengan Extreme
Learning Machine:
Misal akan dilakukan proses training untuk pengenalan 2 jenis objek yaitu A dan B. Arsitektur Extreme Learning Machine yang digunakan terdiri dari 4 node pada input layer, 2 node pada hidden layer, dan 2 node pada output layer sehingga diperoleh x𝑖 = [𝑥𝑖1, 𝑥𝑖2, 𝑥𝑖3, 𝑥𝑖4]𝑇, 𝑡𝑖= [𝑡𝑖1, 𝑡𝑖2]𝑇, 𝑤𝑖 =
[𝑤𝑖1, 𝑤𝑖2, 𝑤𝑖3, 𝑤𝑖4]𝑇, dan 𝛽𝑖 = [𝛽𝑖1, 𝛽𝑖2]𝑇. Pada tahap
praproses akan dihasilkan citra grayscale dengan ukuran 2x2 piksel. Misal diberikan data training seperti pada Tabel 4.2. berikut.
Tabel 4.2. Contoh Data Training
No Citra hasil praproses
Objek dalam Citra Label Nama Objek Representasi dalam Matriks 𝑡 1 𝑓1= [10 2020 30] A [1, -1] 2 𝑓2= [20 2010 20] A [1, -1] 3 𝑓3= [100 5060 10] B [-1, 1] 4 𝑓4= [80 5080 20] B [-1, 1]
Dari data training ini didapatkan matriks input x1 = [10, 20, 20, 30]𝑇,
x2 = [20, 20, 10, 20]𝑇,
x3= [100, 50, 60, 10]𝑇,
x4= [80, 50, 80, 20]𝑇
dan matriks target
t1= [1, −1]𝑇,
t2= [1, −1]𝑇,
t3= [−1, 1]𝑇,
t4= [−1, 1]𝑇
Kemudian tentukan 𝑤1, 𝑤2, 𝑏1, dan 𝑏2 dengan bilangan
random yang terletak pada selang (-1, 1). Misal diperoleh w1= [0.5674, 0.8771, −0.5456, 0.1165]𝑇,
w2= [−0.9976, 0.7732, −0.2312, 0.1291]𝑇,
b1= 0.5512, dan b2= 0.4345
39
𝐻 =
[
𝑔(𝑤
1.
x1+ 𝑏
1) 𝑔(𝑤
2.
x1+ 𝑏
2)
𝑔(𝑤
1.
x2+ 𝑏
1) 𝑔(𝑤
2.
x2+ 𝑏
2)
𝑔(𝑤
1.
x3+ 𝑏
1) 𝑔(𝑤
2.
x3+ 𝑏
2)
𝑔(𝑤
1.
x4+ 𝑏
1) 𝑔(𝑤
2.
x4+ 𝑏
2)]
=
[
𝑤1 . x1+ 𝑏1 1 +|
𝑤1 . x1+ 𝑏1|
𝑤2 . x1+ 𝑏2 1 +|
𝑤2 . x1+ 𝑏2|
𝑤1 . x2+ 𝑏1 1 +|
𝑤1 . x2+ 𝑏1|
𝑤2 . x2+ 𝑏2 1 +|
𝑤2 . x2+ 𝑏2|
𝑤1 . x3+ 𝑏1 1 +|
𝑤1 . x3+ 𝑏1|
𝑤2 . x3+ 𝑏2 1 +|
𝑤2 . x3+ 𝑏2|
𝑤1 . x4+ 𝑏1 1 +|
𝑤1 . x4+ 𝑏1|
𝑤2 . x4+ 𝑏2 1 +|
𝑤2 . x4+ 𝑏2|]
= [
0.9492
0.8380
0.9634
−0.7909
0.9858
−0.9856
0.9798
−0.9826
]
Kemudian dihitung 𝐻† yang merupakan Moore-Penrose
generalized inverse dari 𝐻 dan didapatkan:
𝐻†= [
0.5415
0.1895
0.1552
0.1536
0.5720 −0.1319 −0.2115 −0.2115
]Setelah itu dihitung bobot 𝛽 dengan menggunakan Persamaan (4.4) sehingga diperoleh:
𝛽 = [
0.4221 −0.4221
4.5.2 Proses Testing
Setelah dilakukan training, maka selanjutnya akan dilakukan testing dengan bobot dan bias yang dihasilkan dari proses training. Proses testing memerlukan input berupa citra dan akan memberikan output berupa hasil pengenalan objek dalam citra. Sebelum dilakukan pengenalan oleh ELM, citra input harus melalui tahap praproses sehingga dihasilkan citra
grayscale berukuran 50x50 piksel. Persamaan yang digunakan
untuk menghitung nilai matriks output adalah: 𝑜 = ∑ 𝛽𝑖𝑔(𝑤𝑖 . x + 𝑏𝑖)
1250
𝑖=1
Matriks x terdiri dari 2500 elemen yang nilainya diperoleh dari nilai setiap piksel citra hasil praproses. Matriks output 𝑜 terdiri dari 3 elemen dan akan digunakan untuk menentukan label nama objek dalam citra. Untuk setiap 𝑜𝑖 ∈ 𝑜, jika 𝑜𝑖 ≥ 0 maka
𝑜𝑖 = 1 dan jika 𝑜𝑖 < 0 maka 𝑜𝑖 = −1. Hasil pengenalan objek
dalam citra akan ditentukan dari Tabel 4.1. dengan melihat label nama objek yang bersesuaian dengan matriks 𝑜.
Berikut adalah contoh pengenalan objek citra digital dengan Extreme Learning Machine:
Misal diberikan citra grayscale berukuran 2x2 piksel 𝑓 = [20 20
20 30] yang merupakan hasil dari tahap praproses. Dari citra tersebut didapatkan matriks x = [20, 20, 20, 30]𝑇.
Dengan menggunakan bobot dan bias yang telah didapatkan pada contoh proses training, maka dapat dihitung matriks output 𝑜 sebagai berikut:
𝑜 = ∑ 𝛽𝑖𝑔(𝑤𝑖 . x + 𝑏𝑖) 2 𝑖=1 = 𝛽1𝑔(𝑤1 . x + 𝑏1) + 𝛽2𝑔(𝑤2 . x + 𝑏2) = [0.4033, −0.4033] + [−0.7274, 0.7274] = [−0.3241, 0.3241]
41
Karena −0.3241 < 0 dan 0.3241 > 0 maka didapatkan matriks 𝑜 = [−1,1]. Berdasarkan pada Tabel 4.2., matriks [−1,1] merupakan representasi dari label nama objek B sehingga citra 𝑓 dikenali sebagai B.
43
BAB V
IMPLEMENTASI SISTEM
Pada bab ini, dibahas mengenai langkah-langkah dalam pengimplemetasian sistem berdasarkan desain sistem yang telah dirancang.
5.1 Lingkungan Hardware dan Software
Lingkungan perancangan sistem dibangun dari dua lingkungan yaitu lingkungan software dan lingkungan
hardware. Spesifikasi lingkungan perancangan sistem secara
lengkap dapat dilihat pada Tabel 5.1.
Tabel 5.1. Spesifikasi Hardware dan Software
Lingkungan Spesifikasi
Hardware Processor Intel® Core™
i3-2367M CPU @
1.40GHz (4 CPUs), ~1.4GHz
RAM 4 GB
Software Sistem Operasi Windows 10 Pro 64-bit
Tools NetBeans IDE 8.0.2
5.2 Implementasi User Interface
Desain user interface pengenalan objek citra digital ini dapat dilihat pada Gambar 5.1. Pada desain user interface ini terdapat menu select image, preprocessing, testing, clear, dan
exit. File yang digunakan sebagai masukan dalam Tugas Akhir
ini adalah file yang berekstensi jpg, jpeg, png, atau bmp yang diambil langsung dari direktori komputer.