SURAT PERNYATAAN PUBLIKASI KARYA ILMIAH
Yang bertanda tangan di bawah ini :
Nama : Irwansyah
NIM : 311410587
Program Pendidikan : Strata Satu
Program Studi : Teknik Informatika
Dengan ini memberikan izin kepada pihak Sekolah Tinggi Teknologi Pelita Bangsa Hak Bebas Royalti Non-Eklusif atas karya ilmiah penulis yang berjudul “ Prediksi Penjualan Produk Dengan Menggunakan Metode Data Mining Dengan Algoritma C 4.5”.
Pihak STT Pelita Bangsa berhak menyimpan, mengelola dan mendistribusikan atau mempublikasikan di internet atau media lain untuk kepentingan akademis tanpa perlu meminta izin daari saya selama tetap mencantumkan nama saya sebagai penulis atau pencipta karya ilmiah.
Saya bersedia menanggung secara pribadi, tanpa melibatkan pihak STT PELITA BANGSA, segala bentuk tuntutan hukum yang timbul atas pelanggaran hak cipta dalam karya ilmiiah saya ini.
Demikian pernyataan ini saya buat dengan sebenarnya.
Cikarang, 14 Nonvember 2018
Yang menyatakan Irwansyah
ABSTRAK
CV. DHARMA BHAKTI, merupakan perusahan yang bergerak dalam bidang jasa distributor dan suplayers drum logam dan plastik untuk komoditi perusahan penghasil bahan bakar minyak yang beralamat di Jl. Raya Warung Satu Kecamatan Sukatani, Kabupaten Bekasi. Perusahaan ini didirikan pada tahun 2000 dibawah pimpinan Bapak Andry Hermawan. CV. DHARMA BHAKTI didirikan karena perusahaan bahan bakar minyak sangat banyak membutuhkan drum dan tempat wadah yang lain nya. Oleh karena itu produksi pembuatan drum didirikan. Hal ini kemudian menyebabkan pembentukan badan usaha dari CV. DHARMA BHAKTI. Sejak saat itu, CV. DHARMA BHAKTI bertekad untuk terus mengembangkan produk mereka agar menjadi perusahaan yang bisa berkembang baik dan maju di industri Indonesia.
Pengembangan produk telah menciptakan hasil yaitu drum logam 200 liter dan drum plastik 150 liter untuk jalur distribusi Pertamina dan perusahaan lain nya. Produk drum yang di hasilkan berguana untuk ukm atau industri lain. Produk dari perusahaan ini digunakan untuk kimia industry, tempat air dan bahan bakar (pertalite,solar,pertamak dan oli). Produk ini sangat tebal dan kuat sekali sehingga bisa digunakan dalam jangka waktu lama.
ABSTRACT
CV. DHARMA BHAKTI, is a company engaged in the services of metal drum and plastic suplayers and distributors for the commodity of oil-producing companies located at Jl. Raya Warung Satu, Sukatani District, Bekasi Regency. The company was founded in 2000 under the leadership of Mr. Andry Hermawan. CV. DHARMA BHAKTI was founded because oil companies needed very much drums and other containers. Therefore the production of drum making was established. This then led to the formation of a business entity from CV. DHARMA BHAKTI. Since then, CV. DHARMA BHAKTI is determined to continue to develop their products agar menjadi perusahaan yang bisa berkembang baik dan maju di industri Indonesia.
The product development has created a result of a 200-liter metal drum and a 150-liter plastic drum for Pertamina's distribution lines and other companies. Drum products that are produced are widely used for SMEs or other industries. Products from this company are used for industrial chemistry, places for water and fuel (pertalite, diesel, pertamak and oil). This product is very thick and very strong so that it can be used for a long time.
KATA PENGANTAR
Puji syukur penulis panjatkan ke hadiran Allah SWT. yang telah melimpahkan segala rahmat dan hidayah-Nya, sehingga tersusunlah Skripsi yang berjudul “PREDIKSI PENJUALAN PRODUK CV. DHARMA BHAKTI MENGGUNAKAN METODE DATA MINING DENGAN ALGORITMA C 4.5”.
Skripsi tersusun dalam rangka melengkapi salah satu persyaratan dalam rangka menempuh ujian akhir untuk memperoleh gelar Sarjana Komputer (S.Kom.) pada Program Studi Teknik Informatika di Sekolah Tinggi Teknologi Pelita Bangsa.
Penulis sungguh sangat menyadari, bahwa penulisan Skripsi ini tidak akan terwujud tanpa adanya dukungan dan bantuan dari berbagai pihak. Sudah selayaknya, dalam kesempatan ini penulis menghaturkan penghargaan dan ucapan terima kasih yang sebesar-besarnya kepada:
a. Bapak Dr. Ir. Suprianto, M.P selaku Ketua STT Pelita Bangsa
b. Bapak Muhammad Fatchan, S.Kom, M.Kom selaku Ketua Program Studi Teknik Informatika STT Pelita Bangsa.
c. Bapak Yoga, S.Kom, M.Kom selaku Pembimbing Utama yang telah banyak memberikan arahan dan bimbingan kepada penulis dalam penyusunan Skripsi ini. d. Seluruh Dosen STT Pelita Bangsa yang telah membekali penulis dengan wawasan
e. Seluruh staf STT Pelita Bangsa yang telah memberikan pelayanan terbaiknya kepada penulis selama perjalanan studi jenjang Strata 1.
f. Rekan-rekan mahasiswa STT Pelita Bangsa, khususnya angkatan 2014, yang telah banyak memberikan inspirasi dan semangat kepada penulis untuk dapat menyelesaikan studi jenjang Strata 1.
g. Ibu dan Ayah tercinta yang senantiasa mendo’akan dan memberikan semangat dalam perjalanan studi Strata 1 maupun dalam kehidupan penulis.
h. Tiara Zukriah tercinta yang senantiasa mendo’akan dan memberikan semangat dalam perjalanan studi Strata 1 maupun dalam kehidupan penulis.
Akhir kata, penulis mohon maaf atas kekeliruan dan kesalahan yang terdapat dalam Skripsi ini dan berharap semoga Skripsi ini dapat memberikan manfaat bagi khasanah pengetahuan Teknologi Informasi di lingkungan STT Pelita Bangsa khususnya dan Indonesia pada umumnya.
Bekasi, November 2018
DAFTAR ISI
COVER
LEMBAR PENGESAHAN………...i
LEMBAR PERSETUJUAN...………....……...ii
SURAT PERNYATAAN KEASLIAN………..iii
SURAT PERNYATAAN PUBLIKASI KARYA ILMIAH………....iv
ABSTRAK………....v
ABSTRACT……….………i
KATA PENGANTAR ………...vii
DAFTAR ISI ……….viii
DAFTAR GAMBAR ... ix
DAFTAR TABEL ... .x
BAB I PENDAHULUAN ... 1
1.1 Latar Belakang Masalah ... 1
1.2 Identifikasi Masalah ... 2
1.3 Rumusan Masalah ... 2
1.4 Batasan Masalah ... 3
1.6 Manfaat ... 3
1.7 Sistematika Penulisan……….4
BAB II LANDASAN TEORI ... 6
2.1 Definisi Prediksi ... 6
2.2 Penjualan ... 7
2.2.1 Definisi Penjualan ... 7
2.2.2 Telemarketing ... 8
2.3 Data Mining ... .9
2.3.1 Definisi Data Mining………..9
2.3.2 Tahapan DataMining………10 2.3.3 Klasifikasi………...12 2.3.4 Prediksi………...………...12 2.3.5 AplikasiRapidMiner………...13 2.4 AlgoritmaC4.514 2.4.1 DefinisiAlgoritma C 4.514 2.5 Split Validation ……….…..16 2.6 Confusion Matrix………....16 2.7 Penelitian Terdahulu………18
BAB III METEDOLOGI PENELITIAN ………...21
3.1.1 Sejarah Perusahaan……….21
3.1.2 Visi Dan Misi………..22
3.1.3 Struktur Organisasi Dan Fungs………...23
3.1.4 KerangkaPemikiran………24
3.2 Tahapan Penelitian………..25
3.3 Pengumpulan Data……….26
3.4 Pra Proses Data (Pre-Processing Data)………...27
3.4.1 Tahapan-tahapan Pra Proses Data………27
3.5 Transformation………29
3.6 Pemodelan………...30
3.7 Split Validation ………...…………35
BAB IV HASIL DAN PEMBAHASAN ……….36
4.1 Hasil………...36
4.1.1 Jumlah Kasus Data Keseluruhan……….36
4.1.2 Hasil Process Validation………42
4.1.3 Akurasi Prediksi………...48
4.1.4 Akurasi Precision Dan Recall………..51
4.2 Analisa Hasil Pengujian……….51
5.2 Saran………...54
DAFTAR PUSTAKA LAMPIRAN-LAMPIRAN
DAFTAR GAMBAR
Gambar 2.1 Tahapan Data Mining………... ...11
Gambar 3.1 Struktur Organisasi……….…...23
Gambar 3.2 Tahapan Penelitian ……….…..25
Gambar 3.3 Gambar Barang Jadi CV. DHARMA BHAKTI...26
Gambar 3.4 Dataset Yang Sudah Dicleaning...29
Gambar 4.1 Tampilan Awal RapidaMiner………35
Gambar 4.2 Tampilan Menu Utama Sebelum Proses...36
Gambar 4.3 Tampilan Menu Utama New Proses…………...36
Gambar 4.4 Tampilan Process Read Excel……….………37
Gambar 4.5 Data Import Wizard………..………37
Gambar 4.6 Data Training………....38
Gambar 4.7 Hasil keputusan sebagai label……….…………...38
Gambar 4.8 Tampilan Process Data Training...39
Gambar 4.9 Tampilan Process Validation………...39
Gambar 4.10 Tampilan Sub Process Validation………...40
Gambar 4.12 Hasil pengukuran Data Precision……….……….…42
Gambar 4.13 Hasil pengukuran Recall Data………..….42
Gambar 4.14 Kurva ROC AUC (optimistic)………...…………...….43
Gambar 4.15 Performace Vector………...…...45
Gambar 4.16 Decision Tree atau Pohon Keputusan………...45
Gambar 4.17 Proses Training dan Testing………...47
Gambar 4.18 Hasil Akurasi data Testing………....48
DAFTAR TABEL
Tabel 2.1 Confusion Matrix………17
Tabel 3.1 Kerangka Pemikiran………...24
Tabel 3.2 Seleksi Atribut Yang Digunakan ...27
Tabel 3.3 Hasil Transformasi ………30
Tabel 3.4 Data Training ……….…………32
Tabel 3.5 Data Testing………..……….…………33
BAB I
PENDAHULUAN
1.1 Latar Belakang Masalah
Pada saat ini perkembangan informasi telah berkembang dengan sangat pesat, oleh karena itu sudah banyak pula perusahaan-perusahaan atau instansi-instansi yang menggunakan sistem informasi untuk meningkatkan usahanya.
Cara untuk memudahkan suatu perusahaan ialah dengan cara membuat analisa ataun prediksi penjualan dengan Sitem Informasi. Merupakan sesuatu yang menunjukan hasil pengolahan data organisasi dan berguna kepada orang yang menerimanya. Sedangkan Analiasa dan Prediksi dapat didefinisikan Suatu cara tertentu untuk memudahkan organisasi bisnis dengan cara yang menguntungkan.
Dan syarat untuk membuat Analisa atau Prediksi dengan sistem informasi yaitu adanya kecepatan dan keakuratan untuk memperoleh informasi yang dibutuhkan. Komputer adalah suatu alat yang dapat menyimpan data, mengolah data, dan memberikan informasi yang diinginkan secara tepat dan akurat yang berguna bagi perusahaan untuk kemajuan usahanya.
Pada CV. DHARMA BAKTI , Prediksi penjualan produk secara sistematis belum bisa digunakan. Hal ini dapat dikatakan kurang efektif dan efisien, dikarenakan sulit untuk memprediksi dan menghitung banyaknya jenis barang yang ada, banyaknya jumlah barang, maupun besarnya jumlah penjualan barang. Banyaknya jumlah barang
yang dijual dan tingkat keramaian pembeli dapat mengakibatkan CV. DHARMA BAKTI mengalami kesulitan untuk mengelola dan menghitung prediksi penjualan secara cepat dan efisien. Dalam melaksanakan penelitian ini, mahasiswa/si diharapkan mampu untuk lebih jeli dalam melihat kesempatan agar dapat bersaing langsung di dunia kerja. Dengan berbekal ilmu yang didapatkan di bangku kuliah baik teori maupun praktek diharapkan dapat membantu mahasiswa dalam melaksanakan tugas kerja secara real dan profesional serta dapat mempermudah proses produksi perusahaan dengan membuat sistem atau analisa yang mampu dibuat oleh mahasiswa.
1.2 Identifikasi Masalah
Berdasarkan latar belakang masalah diatas dapat diidentifikasikan bahwa masalah yang muncul yaitu Belum bisa memprediksi penjualan produk barang membuat sulitnya perusahaan untuk meningkatkan produktivitas pengenalan dan penjualan produk. Maka dari itu perusahaan juga dituntut harus bisa membuat atau mengembangkan sebuah sistem informasi yang nanti nya akan bermanfaat untuk meningkatkan produk yang di buat oleh perusahaan tersebut.
1.3 Rumusan Masalah
Dilihat dari latar belakang tersebut di atas dapat kita ambil suatu permasalahan yaitu:
1. Bagaimana untuk bisa memprediksi penjualan produk barang pada CV. DHARMA BHAKTI dengan menggunakan metode data mining dengan algoritma C4.5?
1.4 Batasan Masalah
Dalam penulisan laporan penelitian ini penulis membatasi masalah hanya meliputi tugas-tugas yang diberikan oleh pembimbing skripsi di perusahaan CV. DHARMA BAKTI yaitu “Prediksi penjualan produk dengan menggunakan metode data mining dengan algoritma C 4.5 ”.
1.5 Tujuan Penelitian
Adapun Tujuan penelitian ini adalah :
1. Untuk memprediksi penjualan produk CV. DHARMA BHAKTI dengan menggunakan metode data mining algoritma C 4.5.
2. Untuk memudahkan prediksi penjualan produk CV. DHARMA BHAKTI secara baik dan aktual.
1.6 Manfaat
Manfaat yang di peroleh dari penellitian ini adalah :
1. Untuk Akademik
Penelitian ini dapat memberikan informasi bagi peneliti atau calon peneliti lain untuk menerapkannya kedalam sistem yang lebih luas dan lebih kompleks atau
sebagai bahan acuan yang dapat dikembangkan bagi kemungkinan pengembang konsep dan materi lebih lanjut serta dapat melengkapi referensi pustaka akademik.
2. Untuk Perusahaan
Mempermudah pihak perusahaan dalam mengmbil keputusan untuk bisa memprediksi penjualan barang secara akurat dan juga bisa merencanakan produksi untuk bulan atau bahkan tahun yang akan datang sesuai order dari perusahaan lain.
3. Untuk Penulis
Penulis dapat mengaplikasikan ilmu dan keterampilan yang diperoleh selama diperkuliahan, dan untuk memenuhi salah satu syarat kelulusan Stara Satu (S1) Program Studi Teknik Informatika Sekolah Tinggi Teknologi (STT) Pelita Bangsa Bekasi.
1.7 Sistematika Penulisan
Sistematika penulisan yang digunakan dalam laporan ini adalah sebagai berikut :
Merupakan bab pendahuluan yang akan menguraikan mengenai umum, maksud dan tujuan , metode pengumpulan data, ruang lingkup, disertai sistematika penulisan.
BAB II LANDASAN TEORI
Merupakan bab yang berisikan definisi dari judul, penelitian terdahulu, contoh contoh dan teori yang mendukung objek penelitian.
BAB III METEDOLOGI PENELITIAN
Merupakan tinjauan lembaga secara umum, tinjauan lembaga yang di dalamnya mencakup penyajian profil, sejarah lembaga, struktur organisasi dan fungsi, prosedur sistem akutansi berjalan, diagram alir data ( DAD ) sistem akutansi berjalan, spesifikasi berjalan diantaranya spesifikasi bentuk dokumen masukan, spesifikasi bentuk dokumen keluaran.
BAB IV HASIL DAN PEMBAHASAN
Pada bab terakhir ini disajikan kesimpulan dan saran saran yang penulis angkat berdasarkan pembahasan pada bab – bab sebelumnya.
BAB II
LANDASAN TEORI
2.1 Definisi Prediksi
Prediksi adalah proses peramalan kejadian yang akan datang berdasarkan parameter tertentu untuk mengurangi ketidakpastian dalam suatu kondisi serta membat suatu tolak ukur untuk memperkirakan kejadian yang akan datang berdasarkan pola yang telah terjadi di masa lampau (Khoirunnisa, 2016).
Peramalan merupakan bagian awal dari suatu proses pengembalian suatu keputusan. Sebelum melakukan peramalan harus diketahui terlebih dahulu apa sebenarnya persoalan dalam pengambilan keputusan. Peramalan adalah pemikiran terhadap besaran, misalnya permintaan terhadap satu atau beberapa produk pada periode yang akan datang. Pada hakikatnya peramalan hanya merupakan suatu perkiraan (guess), tetapi dengan menggunakan teknik-teknik tertentu, maka peramalan menjadi lebih sekedar perkiraan. Peramalan dapat dikatakan perkiraan yang ilmiah (educated guess). Setiap pengambilan keputusan yang menyangkut keadaan dimasa yang akan datang, maka pasti ada peramalan yang melandasi pengambilan keputusan tersebut. Forecasting atau peramalan adalah suatu usaha untuk meramalkan keadaan di masa mendatang melalui pengujian keadaan di masa lalu. Dalam kehidupan sosial segala sesuatu itu tidak pasti, sukar untuk diperkirakan secara tepat. Forecast yang dibuat selalu diupayakan agar dapat meminimumkan pengaruh ketidakpastian ini
terhadap perusahaan. Dengan kata lain forecasting bertujuan mendapatkan forecast yang bisa meminimumkan kesalahan meramal (forecast error) yang biasanya diukur dengan Mean Squared Error (MSE), Mean Absolute Error (MAE) dan ssebagainya (Weneda, 2015).
Menurut Nasution dalam (Purwanto, 2012), Peramalan adalah proses untuk memperkirakan berapa kebutuhan dimasa yang akan datang yang meliputi kebutuhan dalam ukuran kuantitas, kualitas, waktu dan lokasi yang dibutuhkan dalam rangka memenuhi permintaan barang ataupun jasa.
Prediksi hampir sama dengan klasifikasi dan estimasi, kecuali bahwa dalam prediksi nilai dari hasil akan ada di masa mendatang. Beberapa metode dan teknik yang digunakan dalam klasifikasi dan estimasi dapat pula digunakan (untuk keadaan yang tepat) untuk prediksi (Gunadi, 2012).
2.2 Penjualan
2.2.1 Definisi Penjualan
Penjualan adalah interaksi antara individu saling bertemu muka yang ditujukan untuk menciptakan, memperbaiki, menguasai atau mempertahankan hubungan pertukaran sehingga menguntungkan bagi pihak lain. Penjualan dapat diartikan juga sebagai usaha yang dilakukan manusia untuk menyampaikan barang bagi mereka yang memerlukan dengan imbalan uang menurut harga yang telah ditentukan atas persetujuan bersama (Weneda, 2015).
Penjualan merupakan salah satu indikator paling penting dalam sebuah perusahaan, bila tingkat penjualan yang dihasilkan oleh perusahaan tersebut besar, maka laba yang dihasilkan perusahaan itu pun akan besar pula sehingga perusahaan dapat bertahan dalam persaingan bisnis dan bisa mengembangkan usahanya. Prediksi penjualan sales forecasting adalah salah satu cara yang efektif untuk dapat meningkatkan laba perusahaan. Data dan informasi penjualan sangat penting bagi perusahaan untuk merencanakan penjualan yang akan datang, misalnya: data pelanggan, jumlah kendaraan, harga mobil, suku cadang, jenis kendaraan dan yang tidak kalah pentingnya adalah kebijakan pemerintah dalam memberikan pajak kendaraan serta subsidi bahan bakar kendaraan (Purwanto, 2012).
Menurut Ronny dalam (Purwanto, 2012). Pengertian penjualan ialah penjualan ialah proses sosial manaherial dimana individu dan kelompok mendapatkan apa yang mereka butuhkan dan inginkan, menciptakan, menawarkan dan mempertukarkan produk yang bernilai dengan pihak lain.
2.2.2 Telemarketing
Telemarketing berasal dari kata Tele dan Marketing. Tele artinya jauh, marketing artinya aktifitas pemasaran secara garis besarnya Marketing merupakan sebuah kegiatan sosial dan sebuah pengaturan yang dilakukan oleh individu ataupun kelompok yang bertujuan untuk mendapatkan apa yang mereka inginkan dengan jalan membuat sebuah produk dan menukarkannya dengan besaran nominal tertentu kepada pihak lainnya (Kotler & Keller, 2009). agar kegiatan marketing bisa berjalan dengan
baik, maka dibutuhkan strategi marketing yang baik pula. Strategi marketing merupakan sekumpulan rancangan dan juga rencana yang sengaja dibuat oleh perusahaan demi tercapainya kegiatan marketing yang efektif dan efisien sehingga perusahaan dapat lebih mudah mencapai tujuannya. Dalam dunia marketing dikenal beberapa strategi marketing, seperti salah satunya adalah strategi marketing 4P yaitu Place, Product, Price, dan Promotion (Waringin, 2008).
2.3 Data Mining
2.3.1 Definisi Data Mining
Data mining, sering juga disebut sebagai knowledge discovery in database (KDD) adalah kegiatan yang meliputi pengumpulan, pemakaian data, historis untuk menemukan keteraturan, pola atau hubungan dalam set data berukuran besar . knowledge discovery in database (KDD) pada intinya adalah proses menemukan pengetahuan yang bermanfaat dari kumpulan data. A. Berstein dkk. juga mendefinisikan knowledge discovery in database (KDD) sebagai hasil proses penjelajahan yang melibatkan penerapan berbagai Prosedur algoritma untuk memanipulasi data, membangun model dari data, dan memanipulasi model .
Menurut Turban dalam bukunya yang berjudul ”Decision Support Systems and Intelligent Systems”, data mining adalah suatu istilah yang digunakan untuk menguraikan penemuan pengetahuan di dalam basis data. Data mining adalah proses yang menggunakan teknik statistik, matematika, kecerdasan buatan, dan machine
learning untuk mengekstraksi dan mengidentifikasi informasi yang bermanfaat dan pengetahuan yang terkait dari berbagai basis data besar (Elisa , 2018 ).
Menurut Witten dan Frank dalam (Mujab, 2013), Data Mining (DM) adalah teknologi BI yang menggunakan model data driven untuk mengekstrak pengetahuan yang berguna (misalnya pola) dari data yang kompleks dan luas (Witten dan Frank, 2005).
Metodologi ini mendefinisikan urutan prosesnya menjadi enam fase, yang memungkinkan pelaksanaan pembangunan model DM untuk digunakan dalam lingkungan yang nyata, membantu untuk mendukung keputusan bisnis. Beberapa metode pada Data Mining yang terkait dalam penelitian strategi pemasaran langsung antara lain NB (Naïve Bayes) dan Decision Trees (Mujab, 2013).
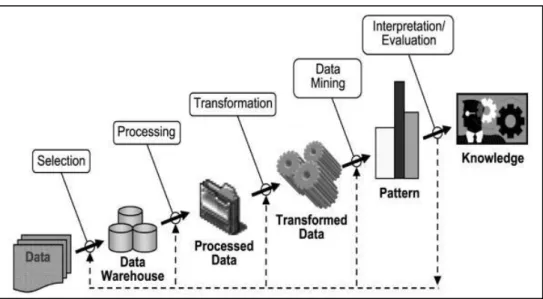
2.3.2 Tahapan Data Mining
Data mining sebenarnya merupakan salah satu bagian proses Knowledge Discovery in Database (KDD) yang bertugas untuk mengekstrak pola atau model dari data dengan menggunakan suatu algoritma yang spesifik(Sembiring, 2016 ). Adapun proses KDD sebagai berikut :
1. Data Selection : pemilihan data dari sekumpulan data operasional perlu dilakukan sebelum tahap penggalian informasi dalam KDD dimulai.
2. Preprocessing : sebelum proses data mining dapat dilaksanakan, perlu dilakukan proses cleaning dengan tujuan untuk membuang duplikasi data, memeriksa data yang inkonsisten, dan memperbaiki kesalahan pada data, seperti kesalahan cetak
(tipografi). Juga dilakukan proses enrichment, yaitu proses “memperkaya” data yang sudah ada dengan data atau informasi lain yang relevan dan diperlukan untuk KDD, seperti data atau informasi eksternal.
3. Transformation : yaitu proses coding pada data yang telah dipilih, sehingga data tersebut sesuai untuk proses data mining. Proses coding dalam KDD merupakan proses kreatif dan sangat tergantung pada jenis atau pola informasi yang akan dicari dalam database.
4. Data mining : proses mencari pola atau informasi menarik dalam data terpilih dengan menggunakan teknik atau metode tertentu.
5. Interpretation / Evaluation : pola informasi yang dihasilkan dari proses data mining perlu ditampilkan dalam bentuk yang mudah dimengerti oleh pihak yang berkepentingan. Tahap ini mencakup pemeriksaan apakah pola atau informasi yang ditemukan bertentangan dengan fakta atau hipotesa yang ada sebelumnya atau tidak.
Data mining juga dapat diartikan sebagai pengekstrakan informasi baru yang diambil dari bongkahan data besar yang membantu dalam pengambilan keputusan. Tahapan-tahapan pada data mining dapat digambarkan seperti gambar
Gambar 2.1 Tahapan Data Mining
Sumber : (Sembiring, 2016).
2.3.3 Klasifikasi
Menurut Tan dalam (Elisa, 2018) klasifikasi adalah proses untuk menyatakan suatu objek ke salah satu kategori yang sudah didefinisikan sebelumnya. Klasifikasi juga bisa didefinisikan sebagai proses pembelajaran fungsi target (model klasifikasi) yg memetakan setiap sekumpulan atribut x (input) ke salah satu klas y yang didefinisikan sebelumnya.
Lebih lanjut, input didefinisikan sebagai sekumpulan record (training set), dan setiap record terdiri atas sekumpulan atribut, salah satu atribut adalah klas. Adapun model klasifikasi digunakan untuk antara lain :
a. Pemodelan Deskriptif sebagai perangkat penggambaran untuk membedakan objek-objek dari klas berbeda.
b. Pemodelan Prediktif digunakan untuk memprediksi label klas untuk record yang tidak diketahui atau tidak dikenal.
2.3.4 Prediksi
Prediksi adalah proses peramalan kejadian yang akan datang berdasarkan parameter tertentu untuk mengurangi ketidakpastian dalam suatu kondisi serta membat suatu tolak ukur untuk memperkirakan kejadian yang akan datang berdasarkan pola yang telah terjadi di masa lampau (Khoirunisa, 2016).
Prediksi hampir sama dengan klasifikasi dan estimasi, kecuali bahwa dalam prediksi nilai dari hasil akan ada di masa mendatang. Beberapa metode dan teknik yang digunakan dalam klasifikasi dan estimasi dapat pula digunakan (untuk keadaan yang tepat) untuk prediksi.peramalan kejadian yang akan datang berdasarkan parameter tertentu untuk mengurangi ketidakpastian dalam suatu kondisi serta membat suatu tolak ukur untuk memperkirakan kejadian (Gunadi, 2012)
2.3.5 Aplkasi RapidMiner
RapidMiner sebelumnya dikenal sebagai YALE ( Yet Another Learning Environment), dikembangkan mulai tahun 2001. RapidMiner dan plugin yang sekarang menyediakan lebih dari 400 belajar dan preproceesing operator dan kombinasi yang tak terhitung jumlahnya. Oleh karena itu , RapidMiner adalah
pelengkap pengetahuan penemuan Suite yang dapat digunakan untuk semua tugas data mining. Diantara fitur baru adalah ruang kerja untuk proyek yang berbeda dengan meningkatkan visualisasi dari kritreria kinerja seperti kurva ROC rata rata atau plot 3D dari matriks. RapidMiner adalah aplikasi data mining yang tidak perlu dipertanyakan lagi dan berbasis sistem open-source dunia yang terkemuka dan ternama. Tersedia sebagai aplikasi yang berdiri sendiri untuk analisis data dan sebagai mesin data mining untuk integrasi kedalam produk sendiri. Ribuan pengguna aplikasi RapidMiner di lebih dari 40 negara memberikan pengguna mereka keunggulan yang kompetitif (SENTIKA, 2018).
RapidMiner merupakan perangkat lunak yang bersifat terbuka ( open source ). RapidMiner adalah sebuah solusi untuk melakukan analisis terhadap data mining, text mining dan analisis prediksi. RapidMiner menggunakan berbagai teknik deskriptif dan prediksi dalam memberikan wawasan kepada pengguna sehingga dapat membuat keputusan yang paling baik. RapidMiner memiliki kurang lebih 500 operator data mining, termasuk operator untuk input, output, data preprocessing dan visualisasi. RapidMiner merupakan software yang berdiri sendiri untuk analisis data dan sebagai mesin data mining yang dapat diintegrasikan pada produknya sendiri. RapidMiner ditulis dengan menggunakan Bahasa java sehingga dapat bekerja di semua sistem operasi (Zack, 2015).
2.4 Algoritma C 4.5
2.4.1 Definisi Algoritma C 4.5
Algoritma C4.5 yaitu sebuah algoritma yang digunakan untuk membangun decision tree (pengambilan keputusan). Algoritma C.45 adalah salah satu algoritma induksi pohon keputusan yaitu ID3 (Iterative Dichotomiser 3). ID3 dikembangkan oleh J. Ross Quinlan. Dalam prosedur algoritma ID3, input berupa sampel training, label training dan atribut. Algoritma C4.5 merupakan pengembangan dari ID3. Beberapa pengembangan yang dilakukan pada C4.5 adalah sebagai antara lain bisa mengatasi missing value, bisa mengatasi continu data, dan pruning (Elisa, 2018).
Sebuah objek yang diklasifikasikan dalam pohon harus dites nilai Entropy nya. Entropy adalah ukuran dari teori informasi yang dapat mengetahui karakteristik dari impuryt dan homogenity dari kumpulan data. Dari nilai Entropy tersebut kemudian dihitung nilai information gain (IG) masing-masing atribut. Entropy (S) merupakan jumlah bit yang diperkirakan dibutuhkan untuk dapat mengekstrak suatu kelas (+ atau -) dari sejumlah data acak pada ruang sampel. Entropy dapat dikatakan sebagai kebutuhan bit untuk menyatakan suatu kelas. Semakin kecil nilai Entropy maka akan semakin Entropy digunakan dalam mengekstrak suatu kelas. Entropy digunakan untuk mengukur ketidakaslian .
Untuk memilih atribut akar, didasarkan pada nilai gain tertinggi dari atribut-atribut yang ada. Untuk menghitung gain digunakan rumus seperti yang tertera dalam persamaan berikut.
Di mana :
S : himpunan kasus
A : atribut
N : jumlah partisi atribut A
|Si| : jumlah kasus pada partisi ke-i
|S| : jumlah kasus dalam S
Sementara itu, perhitungan nilai entropi dapat dilihat pada persamaan 2 berikut.
Di mana :
S : himpunan kasus
N : jumlah partisi S pi : proporsi dari Si terhadap S
Secara umum algoritma C4.5 untuk membangun pohon keputusan adalah sebagai berikut :
a. Pilih atribut sebagai akar.
b. Buat cabang untuk tiap-tiap nilai. c. Bagi kasus dalam cabang.
d. Ulangi proses untuk setiap cabang sampai semua kasus pada cabang memiliki kelas yang sama.
2.5 Split Validation
Split Validation merupakan teknik validasi yang membagi data menjadi dua bagian secara acak, sebagian data training dan sebagian data testing. Data yang sudah disiapkan untuk klasifikasi dibagi menjadi dua untuk data training dan data testing menggunakan teknik sampling random sistematik (Systematic Random Sampling). Cara penggunaan teknik sampling random sistematik ini perandoman atau pengundian hanya dilakukan satu kali, yakni ketika menentukan unsur pertama dari sampling yang akan diambil. Penentuan unsur sampling selanjutnya ditempuh dengan cara memanfaatkan interval sampel (Elisa, 2018).
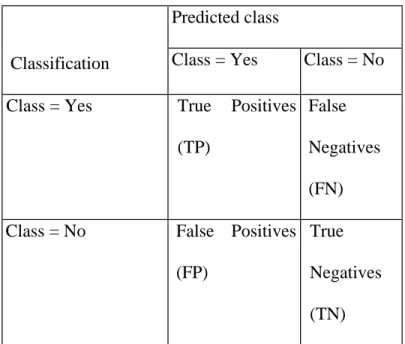
2.6 Confusion Matrix
Confusion Matrix adalah tools yang digunakan untuk mengevaluasi model klasifikasi yang digunakan untuk memperkirakan objek yang benar dan yang salah. Hasil prediksi akan dibandingkan dengan kelas asli dari data tersebut. Confusin Matrix mengevaluasi kinerja mdel berdasarkan pada kemampuan akurasi prediktif suatu model. Akurasi prediktif merupakan parameter yang mengukur ketepatan aturan klasifikasi yang dihasilkan dalam mengklasifikasikan test set berdasarkan atribut yang ada ke dalam kelasnya (Khoirunisa, 2016)
Tabel 2.1 Confusion Matrix
Classification
Predicted class
Class = Yes Class = No Class = Yes True Positives
(TP)
False Negatives (FN) Class = No False Positives
(FP)
True Negatives (TN)
True Positives adalah jumlah data yang diklasifikasikan Yes dan diprediksi Yes dengan benar. False Positives adalah jumlah data yang diklasifikasikan No dan diprediksi Yes. False Negatives adalah jumlah data yang diklasifikasikan Yes dan
diprediksi No. True Negatives adalah jumlah data yang diklasifikasikan No dan diprediksi No dengan benar.
2.7 Penelitian Terdahulu
Beberapa penelitian mengenai prediksi penjualan produk ataupun yang mendekati penelitian tersebut adalah sebagai berikut :
1. Prediksi Penjualan Barang Pada Alfamart Rembang Menggunakan Expotensial Smothing (Weneda, 2014). Prediksi jumlah penjualan merupakan faktor penting yang menentukan kelancaran usaha suatu perusahaan diantaranya yaitu Alfamart Rembang. Permasalahan yang umum dihadapi oleh Alfamart Rembang adalah bagaimana memprediksi atau meramalkan penjualan barang di masa mendatang berdasarkan data penjualan sebelumnya. Selama ini Alfamart Rembang secara tidak langsung selalu memprediksi penjualan yang akan datang. Akan tetapi prediksi ini selalu kurang tepat karena hanya melihat perkiraan berdasarkan penjualan yang telah terjadi. Pencatatan dan prediksi di Alfamart Rembang masih dilakukan secara manual dengan menambahkan 10 % dari target penjualan pada bulan sebelumnya. Metode prediksi yang digunakan dalam penelitian ini adalah metode exponential smoothing dengan nilai α = 0.5, α = 0.7 dan α = 0.9. Penelitian ini menghasilkan implementasi metode exponential smoothing dapat diterapkan pada sistem prediksi penjualan barang pada Alfamart Rembang dengan melakukan prediksi penjualan per bulan (1 bulan) dan hasil yang mendekati dengan penjualan barang pada
Alfamart Rembang dengan nilai α = 0.9 dengan total nilai MSE yaitu 1.202.405.414.267.760.
2. Prediksi Penjualan di Perusahaan Ritel dengan Metode Peramalan Hirarki Berdasarkan Model Variasi Kalender (Khoirunisa, 2016). Data penjualan perusahaan ritel Amigo Group mengindikasikan setiap tahun cenderung terjadi peningkatan di semua toko khususnya produk pakaian saat menjelang Idul Fitri. Idul Fitri terjadi mengikuti kalender hijriyah, inilah yang memunculkan adanya indikasi kasus efek variasi kalender. Tujuan dari penelitian ini yaitu meramalkan penjualan produk di tujuh toko dengan metode peramalan time series hirarki. Peramalan time series hirarki dilakukan dengan tiga pendekatan yaitu bottom-up, top-down proporsi histori, dan top-down proporsi peramalan. Nilai MAPE Simetri out-sample setiap pendekatan peramalan hirarki dibandingkan untuk mendapatkan model terbaik. Hasil dari penelitian menunjukkan bahwa level 0 hem panjang dewasa pria, celana panjang jeans dewasa pria, dan jaket dewasa pria model terbaik yaitu bottom-up. Level 0 produk rok dewasa wanita dan celana panjang wanita model terbaik yaitu top-down. Level 1 hem panjang dewasa pria model terbaik yaitu top down proporsi histori dengan rata-rata proporsi dari rata-rata data asli tahun 2002-2011. Produk celana panjang jeans dewasa pria, rok dewasa wanita dan celana panjang wanita model terbaik yaitu top down proporsi histori dengan proporsi , sedangkan ntuk level 1 produk jaket dewasa pria model terbaik yaitu bottom-up.
3. Prediksi Penjualan Mobil Menggunakan Jaringan Syaraf Tiruan dan Certainty Factor (Purwanto, 2016). Prediksi penjualan adalah salah satu cara untuk meningkatkan laba perusahaan, peramalan diperlukan untuk menyetarakan antara perbedaan waktu yang sekarang dan yang akan datang terhadap kebutuhan, Jaringan Syaraf Tiruan (JST) dapat mengaplikasikan dengan baik metode peramalan. Pendekatan peramalan kuantitatif dengan metode times series akan menentukan nilai data masukan dari sekumpulan data serial atau berkala dari transaksi pada suatu jangka waktu tertentu. Data dibagi menjadi data pelatihan, pengujian dan validasi. Proses peramalan menggunakan metode certainty factor (CFf) sebagai nilai pembanding pada bobot koreksi yang telah di latih dalam jaringan backpropagation untuk prediksi yang optimal. Simulasi program peramalan penjualan mobil honda tahun 2015 dengan variabel input data penjualan daerah 30,000 unit, penjualalan dealer 25.000, penjualan tunai 25.000, CF = 0.5 dan kredit 19.000 menghasilkan ramalan penjualan sebanyak 29579 unit dengan target error 4,205 %.
BAB III
METODOLOGI PENELITIAN
Metodologi penelitian adalah pembahasan mengenai proses-proses yang ada pada kerangka kerja penelitian dalam mengklasifikasikan barang jadi menggunakan algoritma C4.5 sehingga dapat diketahui hasil klasifikasi dengan baik.
3.1 Objek Penelitian
3.1.1 Sejarah Perusahaan
CV. DHARMA BHAKTI, merupakan perusahan yang bergerak dalam bidang jasa distributor dan suplayers drum logam dan plastik untuk komoditi perusahan penghasil bahan bakar minyak yang beralamat di Jl. Raya Warung Satu Kecamatan Sukatani, Kabupaten Bekasi. Perusahaan ini didirikan pada tahun 2000 dibawah pimpinan Bapak Andry Hermawan. CV. DHARMA BHAKTI didirikan karena perusahaan bahan bakar minyak sangat banyak membutuhkan drum dan tempat wadah yang lain nya. Oleh karena itu produksi pembuatan drum didirikan. Hal ini kemudian menyebabkan pembentukan badan usaha dari CV. DHARMA BHAKTI. Sejak saat itu, CV. DHARMA BHAKTI bertekad untuk terus mengembangkan produk mereka.
Pengembangan produk telah menciptakan hasil yaitu drum logam 200 liter dan drum plastik 150 liter untuk jalur distribusi Pertamina dan perusahaan lain nya.
Produk drum yang di hasilkan berguana untuk ukm atau industri lain. Produk dari perusahaan ini digunakan untuk kimia industry, tempat air dan bahan bakar (pertalite,solar,pertamak dan oli). Produk ini sangat tebal dan kuat sekali sehingga bisa digunakan dalam jangka waktu lama.
3.1.2 Visi dan Misi
Visi CV. DHARMA BHAKTI
Dengan kemampuan sumber daya yang dimiliki menjadikan CV. DHARMA BHAKTI sebagai perusahaan yang terkemuka dalam industri logam terkemuka.
Misi CV. DHARMA BAHAKTI
1. Menghasilkan produk yang berkualitas melalui teknologi yang mutakhir dan rekayasa yang mengutamakan faktor keamanan dan keselamatan baik pada saat produksi maupun terpasang di lapangan.
2. Menghasilkan produk yang berkualitas melalui pembinaan dan pemberdayaan kemampuan sumber daya manusia yang sehat dan sumber daya alat yang memadai serta kondisi lingkungan kerja yang dinamis atas dasar keselamatan dan kesehata kerja karyawan.
3. Menghasilkan produk yang berkualitas melalui peningkatan keunggulan kompetitif yang disertai dengan inovasi berkelanjutan sesuai dengan kebutuhan pasar.
3.1.3 Struktur Organisasi
Organisasi merupakan alat atau wadah yang digunakan oleh perusahaan guna merealisir tujuan yang telah digariskan. Tujuan utama dalam pembentukan struktur organisasi adalah untuk mengkoordinasikan semua kegiatan, baik secara fisik maupun non fisik yang diarahkan pada pencapaian tujuan.
Anggota prod 1 - Riza Ariawan - Dita Dwi Prasetyo
Anggoa prod 2 - Inu Anjar - Ari kustiawan - Aji Santoso Direktur Andry. H HHermawan Wakil Direktur Opan Temmy Purchasing Dhani ssSasSaputra Foreman Rustam Amirudin Leader Prod 1 Salim Janu Priatmojo Leader Prod 2 Rahmat Adm & Gudang Rahman Finance
3.1.4 Kerangka Pemikiran
Berikut gambaran keseluruhan penelitian dalam bentuk diagram kerangka pemikiran yang berguna sebagai pedoman atau acuhan penelitian ini sehingga dapat dilakukan secara konsisten.
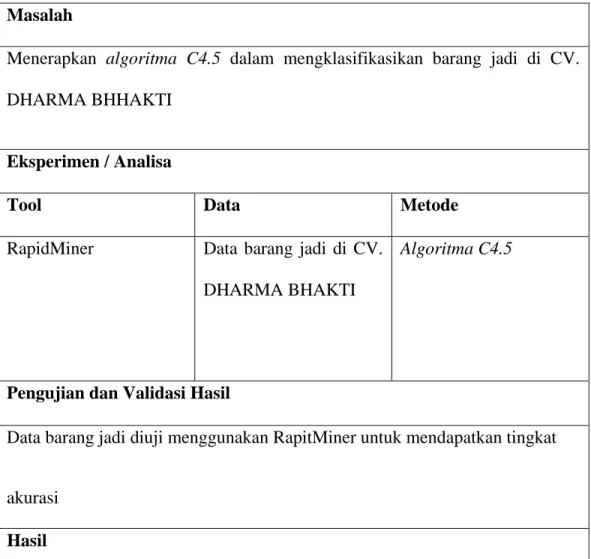
Tabel 3.1 Kerangka pemikiran Masalah
Menerapkan algoritma C4.5 dalam mengklasifikasikan barang jadi di CV. DHARMA BHHAKTI
Eksperimen / Analisa
Tool Data Metode
RapidMiner Data barang jadi di CV. DHARMA BHAKTI
Algoritma C4.5
Pengujian dan Validasi Hasil
Data barang jadi diuji menggunakan RapitMiner untuk mendapatkan tingkat
akurasi Hasil
Rekomendasi hasil klasifikasi dan prediksi barang jadi di CV. DHARMA BHAKTI
3.2 Tahapan Penelitian
Penelitian merupakan rangkaian kegiatan ilmiah. Langkah awal yang harus dilakukan sebelum memulai penelitian adalah studi literatur untuk menentukan data mining guna mengolah data dan penentuan alternatif solusi. Kemudian dilakukan pencarian dan pengumpulan data berkaitan dengan masalah yang akan diteliti. Secara umum proses-proses tahapan yang dilakukan dalam pelaksanaan penelitian ini adalah :
Gambar 3.2. Tahapan Penelitian
1. Studi literatur dilakukan dengan membaca dan memahami teori dari buku atau jurnal yang relevan bertujuan untuk mendapatkan teori-teori tentang permasalahan yang telah dirumuskan. Teori ini dapat dijadikan pedoman untuk mendapatkan solusi.
Studi Literatur
Pengumpulan
Data Pra Proses Data
Proses Data Mining
2. Pengumpulan data mentah didapat dari data barang jadi yang ada pada PT. Dantosan Precon Perkasa. Tahapan ini menerangkan tentang darimana sumber data dalam penelitian ini didapatkan dan menemukan informasi yang bisa digunakan untuk penelitian.
3. Pra proses data mining, meliputi data cleaning pembersihan data yang di dalamnya terdapat atribut kosong maupun tidak lengkap, data integration atau pengubahan data menjadi format yang sesuai untuk digunakan dalam proses data mining, dan task relevan data sejalan dengan data integration yang memilih atribut yang relevan dengan rumusan masalah.
4. Proses data mining. Data yang telah didapatkan kemudian diolah dengan proses data mining dimana pengolahan ini menggunakan algoritma C4.5 hasil pengujian akan di validasi dan kemudian di evaluasi. Penjelasan mengenai hal ini akan di paparkan pada BAB IV.
3.3 Pengumpulan Data
Data yang diperlukan dalam penelitian ini diperoleh dari CV. DHARMA BHAKTI berupa data barang jadi pada bulan desember tahun 2017 sebanyak 100 data. Selain berisi data barang, didalamnya juga terdapat beberapa atribut data yang menunjang atau mempengaruhi proses data mining klasifikasi dan prediksi menggunakan algoritma C4.5. Berikut adalah data barang jadi pada CV. DHARMA BHAKTI.
Gambar 3.3. Data Barang Jadi CV. DHARMA BHAKTI.
3.4 Pra Proses Data (Pre-Processing Data)
Data mentah yang telah diperoleh tidak serta merta dapat langsung diolah. Agar dapat diolah menggunakan metode klasifikasi C4.5 diperlukan pra proses data guna memperoleh atribut dan tipe data yang cocok dan berguna untuk diolah dalam proses data mining.
3.4.1 Tahapan-tahapan Pra Proses Data
a. Task Relevan Data
Task Relevan Data adalah melakukan seleksi data yang memiliki atribut yang relevan. Dengan melakukan seleksi data akan membantu tahapan proses data mining dalam menemukan pola yang berguna. Oleh karena itu tidak
semua atribut dapat digunakan, hanya atribut yang dianggap peneliti berguna dan sebarannya tidak terlalu acak.
Dibawah ini adalah tabel atribut yang akan digunakan dan tidak digunakan.
Tabel 3.2 Seleksi Atribut yang Digunakan
No. Nama Atribut Keterangan
1. Area Produksi Digunakan
2. Tgl Produksi Tidak Digunakan
3. No Produksi Tidak Digunakan
4. Tgl LPH Tidak Digunakan
5. No LPH Tidak Digunakan
6. Kod Barang Tidak Digunakan
7. Kode Panel Tidak Digunakan
8. Ukuran Tidak Digunakan
9. Tonase Tidak Digunakan
10. Qty Produksi Tidak Digunakan
11. Tgl BASTPr Tidak Digunakan
12. Kondisi barang baik Digunakan
13. Kondisi barang repair Tidak Digunakan
15. Umur Barang Digunakan
16. Status Barang Digunakan
17. Agregat Digunakan
18. Hasil Digunakan
b. Pembersihan Data (Data Cleaning)
Pada proses ini akan dilakukan pembersihan data untuk membuang data yang missing value yaitu data yang tidak konsisten dan juga memperbaiki data yang rusak. Proses pembersihan data dilakukan untuk memastikan bahwa data yang telah dipilih layak untuk dilakukan proses permodelan. Pemilihan atribut / variable tersebut dengan mempertimbangkan tujuan penulisan, sehingga akan diperoleh beberapa atribut / variabel yang akan digunakan untuk menjadi masukan atau
variabel input.
Dari data 100 record dengan 18 atribut hanya diambil 6 atribut saja, yaitu
Area produksi, Kondisi barang baik, Umur barang, Status barang, Agregat dan hasil. Pemilihan data seleksi yang nantinya akan digunakan dalam proses data mining menggunakan tool yaitu dengan tool Ms.Excel.
Gambar 3.4. Dataset Yang Sudah Dicleaning
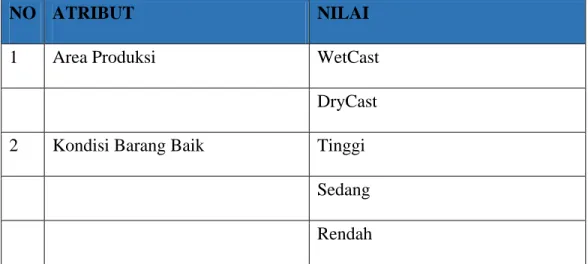
3.5 Transformation
Setelah data sudah dipilih maka akan dilakukan tahapan untuk melakukan transformasi terhadap atribut, transformasi akan dilakukan untuk memodifikasi sumber data ke format berbeda yang dapat diterima oleh proses data mining pada tahap selanjutnya. Transformasi nilai-nilai dari atribut juga perlu dilakukan karena jangkauan nilai terlalu lebar, sehingga dapat mengakibatkan proses pengenalan pola
data dan pembentukan pohon keputusan menjadi lama. Berikut adalah hasil dari trasnformasi atribut :
Tabel 3.3 Hasil Transformasi
NO ATRIBUT NILAI
1 Area Produksi WetCast
DryCast
2 Kondisi Barang Baik Tinggi
Sedang
Rendah
3.6 Pemodelan
Metode yang akan digunakan dalam penelitian ini adalah Algoritma C4.5.
Berikut ini tahapan proses pemodelan dalam penelitian ini:
1. Choosing the appropriate Data Mining taks
Pada tahap ini memilih jenis data mining yang digunakan untuk mengolah data barang jadi berdasarkan departemen maka dipilih jenis data mining yang akan digunakan adalah klasifikasi.
2. Choosing the Data Mining Algorithm
Setelah pemilihan jenis data mining yang akan digunakan yaitu klasifikasi, maka selanjutnya menentukan algoritma klasifikasi yang akan digunakan. Pada penelitian ini algoritma yang dipilih adalah Algoritma C4.5.
3. Employing the Data Mining Algorithm
Tahapan ini dilakukan untuk pengolahan data dengan algoritma yang telah dipilih yaitu dengan menggunakan Algoritma C4.5.
4. Evaluation
Dalam tahap ini dilakukan evaluasi dan menafsirkan pola yang didapatkan dari hasil algoritma yang dipakai untuk mengetahui aturan, kehandalan, dan lainlain. Evaluasi dilakukan dengan menerapkan pola yang didapat dari proses sebelumya terhadap data testing yang disediakan. Evaluasi dilakukan dengan confusion matrix dan kurva ROC.
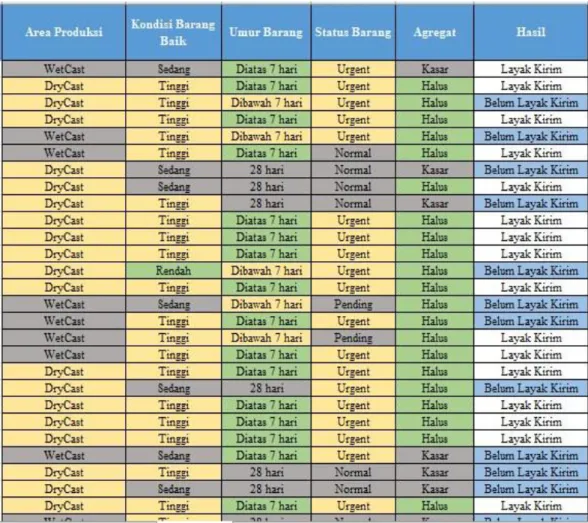
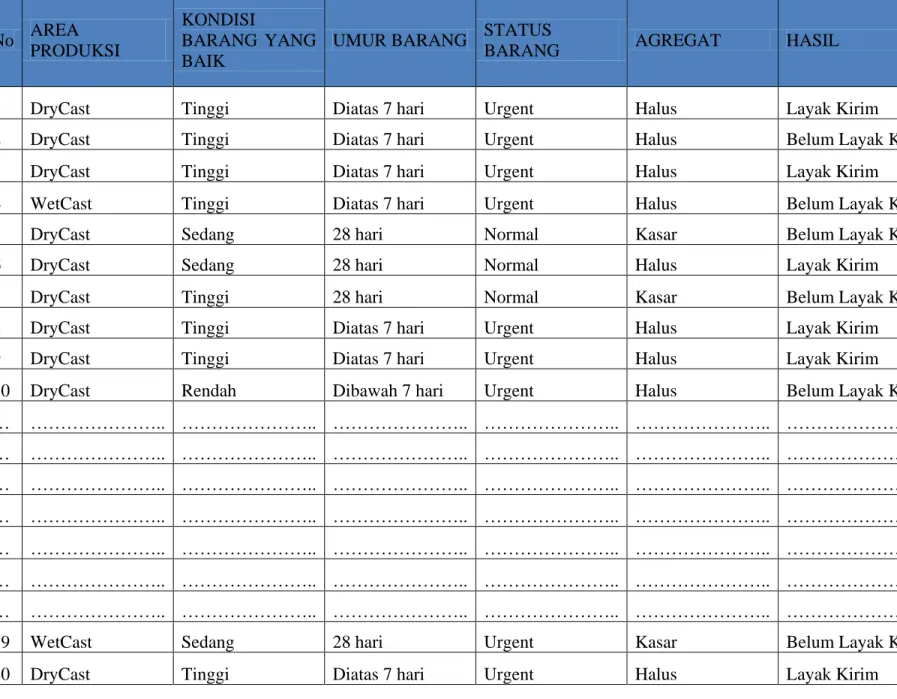
Tabel 3.4 Data Training No AREA PRODUKSI KONDISI BARANG YANG BAIK
UMUR BARANG STATUS
BARANG AGREGAT HASIL
1 DryCast Tinggi Diatas 7 hari Urgent Halus Layak Kirim
2 DryCast Tinggi Diatas 7 hari Urgent Halus Belum Layak Kirim
3 DryCast Tinggi Diatas 7 hari Urgent Halus Layak Kirim
4 WetCast Tinggi Diatas 7 hari Urgent Halus Belum Layak Kirim
5 DryCast Sedang 28 hari Normal Kasar Belum Layak Kirim
6 DryCast Sedang 28 hari Normal Halus Layak Kirim
7 DryCast Tinggi 28 hari Normal Kasar Belum Layak Kirim
8 DryCast Tinggi Diatas 7 hari Urgent Halus Layak Kirim
9 DryCast Tinggi Diatas 7 hari Urgent Halus Layak Kirim
10 DryCast Rendah Dibawah 7 hari Urgent Halus Belum Layak Kirim
… ……….. ……….. ……….. ……….. ……….. ……….. … ……….. ……….. ……….. ……….. ……….. ……….. … ……….. ……….. ……….. ……….. ……….. ……….. … ……….. ……….. ……….. ……….. ……….. ……….. … ……….. ……….. ……….. ……….. ……….. ……….. … ……….. ……….. ……….. ……….. ……….. ……….. … ……….. ……….. ……….. ……….. ……….. ………..
79 WetCast Sedang 28 hari Urgent Kasar Belum Layak Kirim
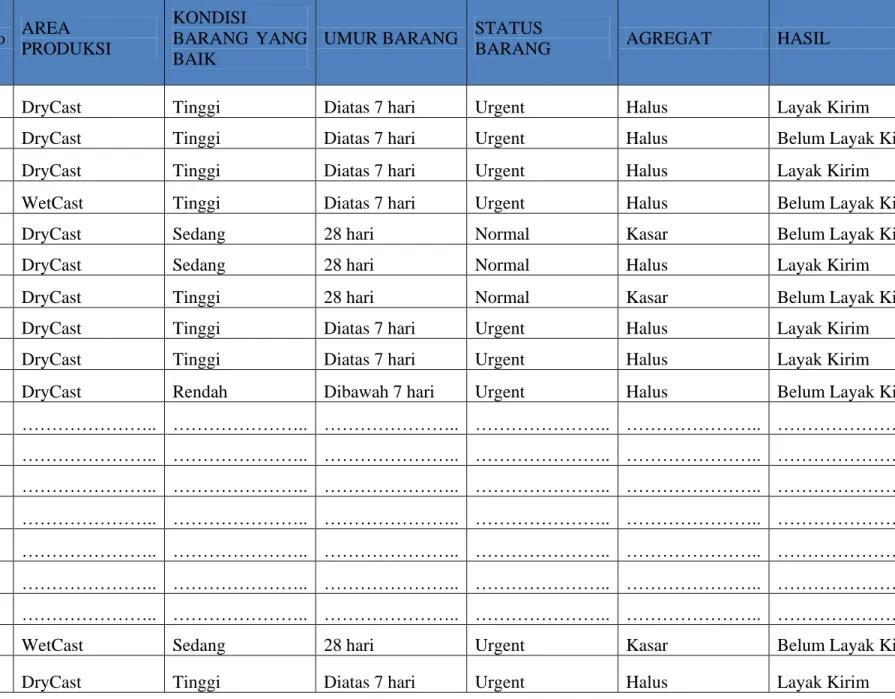
Tabel 3.5 Data Testing No AREA PRODUKSI KONDISI BARANG YANG BAIK
UMUR BARANG STATUS
BARANG AGREGAT HASIL
1 DryCast Tinggi Diatas 7 hari Urgent Halus Layak Kirim
2 DryCast Tinggi Diatas 7 hari Urgent Halus Belum Layak Kirim
3 DryCast Tinggi Diatas 7 hari Urgent Halus Layak Kirim
4 WetCast Tinggi Diatas 7 hari Urgent Halus Belum Layak Kirim
5 DryCast Sedang 28 hari Normal Kasar Belum Layak Kirim
6 DryCast Sedang 28 hari Normal Halus Layak Kirim
7 DryCast Tinggi 28 hari Normal Kasar Belum Layak Kirim
8 DryCast Tinggi Diatas 7 hari Urgent Halus Layak Kirim
9 DryCast Tinggi Diatas 7 hari Urgent Halus Layak Kirim
10 DryCast Rendah Dibawah 7 hari Urgent Halus Belum Layak Kirim
… ……….. ……….. ……….. ……….. ……….. ……….. … ……….. ……….. ……….. ……….. ……….. ……….. … ……….. ……….. ……….. ……….. ……….. ……….. … ……….. ……….. ……….. ……….. ……….. ……….. … ……….. ……….. ……….. ……….. ……….. ……….. … ……….. ……….. ……….. ……….. ……….. ……….. … ……….. ……….. ……….. ……….. ……….. ………..
79 WetCast Sedang 28 hari Urgent Kasar Belum Layak Kirim
3.6.1 PENYELESAIAIN DENGAN RUMUS AL GORITMA C.45
Dimana log2 pi bisa diartikan sbb:
Entrophy (total) = (-(7/14)*(ln(7/14)/ln(2))+ (-(5/14)*(ln(5/14)/ln(2)) = 0,979869
Entrophy ( kondisi barang ) = (-(5/8)*(ln(5/8)/ln(2))+ (-(3/8)*(ln(3/8)/ln(2)) = 0,979869
Dst
Kunci pencarian entrophy
- Jika diantara kolom “Ya” atau “Tidak” ada yang bernilai 0 (nol) maka entrophy-nya di pastikan juga bernilai 0 (nol)
- Jika kolom “Ya” dan “Tidak” mempunyai nilai yang sama maka entrophy-nya di pastikan juga bernilai 1 (satu)
Gain (kondisi barang ) = 0,979869 – ( ( (8/12) * 0,979869 ) + ( (4/12) * 1 ) ) = 0,010246 Gain (Hasil ) = 0,979869 – ( ( (8/12) * 0,811278 ) + ( (3/12) * 0, 918296 ) + ( (1/12) * 0 ) ) = 0,209443 3.7 Split Validation
Split Validation merupakan teknik validasi yang membagi data menjadi dua bagian secara acak, sebagian data training dan sebagian data testing. Data yang sudah disiapkan untuk klasifikasi dibagi menjadi dua untuk data training dan data testing menggunakan teknik sampling random sistematik (Systematic Random Sampling). Cara penggunaan teknik sampling random sistematik ini perandoman atau pengundian hanya dilakukan satu kali, yakni ketika menentukan unsur pertama dari sampling yang akan diambil. Penentuan unsur sampling selanjutnya ditempuh dengan cara memanfaatkan interval sampel.
Interval sampel atau juga disebut sampling rasio diperoleh dengan cara membagi ukuran populasi dengan ukuran sampel yang dikehendaki (N/n). Hasil perhitungan untuk mengambil data testing adalah sebagai berikut :
Jumlah populasi (N) = 100
Jumlah sampel (n) = 20
Pembagian data menjadi data training dan data testing pada penelitian ini menggunakan split ratio 80% untuk data training dan 20 % untuk data testing.
BAB IV
HASIL DAN PEMBAHASAN
4.1 Hasil
4.1.1 Jumlah Kasus Data Keseluruhan, Data Training dan Data Testing
Data keseluruhan yang digunakan pada penelitian ini sejumlah 100 kasus, kemudian dilakukan pembagian data menjadi data training sebanyak 80 kasus dan data testing sebanyak 20 kasus. Metode yang digunakan adalah klasifikasi dengan algoritma C4.5. Berikut penerapan algoritma C4.5 memakai tool RapidMiner.
1. Langkah awal pada yaitu membuka aplikasi RapidMiner akan muncul loading
tampilan awal seperti berikut :
Gambar 4.1 Tampilan awal RapidMiner
Gambar 4.2 Tampilan Menu Utama Sebelum Proses
Setelah muncul tampilan menu utama, tekan New Process untuk memulai proses pengolahan data.
Gambar 4.3 Tampilan Utama New Process
Setelah muncul tampilan process selanjutnya pada menu operator cari Read Excel dan pilih hingga muncul kotak Read Excel pada process.
Gambar 4.4 Tampilan Process Read Excel
Kemudian klik Import Configuration Wizard untuk mengambil data barang jadi dengan format data excel yang terdapat pada komputer.
Gambar 4.5 Data Import Wizard
2. Mengolah data training
Menyiapkan data training dari data barang jadi. Pada data import wizard pilih dataset pada komputer lalu klik data training kemudian next.
Gambar 4.6 Data Training Kemudian klik next.
Gambar 4.7 Hasil keputusan sebagai label
Pilih hasil keputusan sebagai Polinominal dan label, sedangkan yang lainnya sebagai Polinominal dan Atribut. Setelah itu klik Finish.
Gambar 4.8 Tampilan Process Data Training
Klik di process, lalu klik Menu Edit pilih Insert Building Block kemudian pilih Nominal Cross Validation lalu klik OK.
Gambar 4.9 Tampilan Process Validation
Setelah muncul Validation pada Process, geser Validation ke kanan lalu sambungkan kabel Input ke Read Excel satu kabel, Read Excel ke Validation satu kabel dan Validation ke res empat kabel. Kemudian klik Run.
Sebelum klik Run perlu diketahui didalam Validation tedapat sub proses yang tediri dari beberapa operator yang nantinya akan menampilkan hasil akurasi dan hasil klasifikasi data dari data training yang sebelumnya sudah kita import, pada kolom parameter terdapat number of folds yang artinya validation akan membagi dataset menjadi 1-10 data akan digunakan menjadi testing dan 9-10 lainnya akan digunakan menjadi training.
Gambar 4.10 Tampilan Sub Process Validation
Pada sub proses training terdapat Decision Tree yaitu salah satu metode Clasification yang nantinya dapat diketahui atribut yang paling berpengaruh dalam pembuatan decision tree dan pada sub proses testing terdapat Apply Model dan Performance proses ini nantinya dapat mengetahui akurasi data yang diperoleh.
4.1.2 Hasil Process Validation
Gambar 4.11 Hasil pengukuran Data Accuracy Training
Hasil pengukuran data accuracy yang diperoleh dari data training mencapai 81.25% dengan +/-11.52% (mikro: 81.25%). Dari data tersebut diketahui prediksi layak Kirim dengan true layak Kirim mencapai 47 barang dan true Belum Layak Kirim sebanyak 9 barang, dengan pencapaian class precision 88.68%. Sedangkan untuk prediksi Belum Layak Kirim dengan true layak Kirim sebanyak 6 barang dan untuk true Belum Layak Kirim mencapai 18 barang dengan pencapaian class precision 66.67%. Untuk class recall dengan true layak Kirim mencapai 83.93% sedangkan untuk class recall dengan true Belum Layak Kirim mencapai 75.00%.
Gambar 4.12 Hasil Pengukuran Data Precision
Hasil pengukuran data precision yang diperoleh dari data training mencapai
64.17% dengan +/-21.10% (mikro: 66.67%) dengan positive class “Belum Layak
Kirim”. Dari data tersebut diketahui prediksi Layak Kirim dengan true Layak Kirim
mencapai 47 barang dan true Belum Layak Kirim sebanyak 9 Barang, dengan pencapaian class precision 88.68%. Sedangkan untuk prediksi Belum Layak Kirim dengan true Layak Kirim sebanyak 6 barang dan untuk true Belum Layak Kirim mencapai 18 barang dengan pencapaian class precision 66.67%. Untuk class recall dengan true Layak Kirim mencapai 83.93% sedangkan untuk class recall dengan true Belum layak Kirim mencapai 75.00%.
Gambar 4.13 Hasil pengukuran Recall Data
Hasil pengukuran recall data yang diperoleh dari data training mencapai 71.67% dengan +/-23.63% (mikro: 75.00%) dengan positive class “Belum Layak kirim”. Dari data tersebut diketahui prediksi layak kirim dengan true layak kirim mencapai 47 barang dan true belum layak sebanyak 9 barang, dengan pencapaian class precision 88.68%. Sedangkan untuk prediksi belum layak kirim dengan true layak kirim sebanyak 6 barang dan untuk true belum layak kirim mencapai 18 barang dengan pencapaian class precision 66.67%. Untuk class recall dengan true layak kirim mencapai 83.93% sedangkan untuk class recall dengan true belum layak kirim mencapai 75.00%.
Gambar 4.14 Kurva ROC AUC (optimistic)
Hasil perhitungan divisualisaikan dengan kurva ROC (Receiver Operating Characteristic) atau AUC (Area Under Curve) optimistic. ROC memiliki tingkat diagnose yaitu :
1. Akurasi bernilai 0.90 – 1.00 = excellent classification
2. Akurasi bernilai 0.80 – 0.90 = good classification
3. Akurasi bernilai 0.70 – 0.80 = fair classification
4. Akurasi bernilai 0.60 – 0.70 = poor classification
Nilai dari kurva ROC (Receiver Operating Characteristic) diketahui dari AUC (Area Under Curve) optimistic dengan hasil sebesar 0.913 dengan +/-0.087 (mikro:
0.913) serta dengan positive class “Belum Layak kirim”, itu berarti hasil klasifikasi penelitian ini masuk kedalam tingkat diagnose excellent classification.
Untuk mengetahui Performace Vector yang diperoleh adalah sebagai
berikut :
Gambar 4.15 Performace Vector
Pembentukan pola-pola dengan perhitungan, maka diperoleh decision tree untuk mengklasifikasi barang jadi sebagai berikut :
Gambar 4.16 Decision Tree atau Pohon Keputusan
Berdasarkan decision tree maka diperoleh rule untuk klasifikasi barang jadi sebagai berikut :
Tabel 4.1 Rule Decision Tree
Rule Keterangan Rule
R1 Jika agregat “kasar” maka “belum layak kirim”
R2 Jika agregat “halus” dan umur barang “28 hari” maka “layak kirim” R3 Jika agregat “halus” dan umur barang “diatas 7 hari” maka “layak
R4 Jika agregat “halus” dan umur barang “dibawah 7 hari” dan area produksi “drycast” dan kondisi barang baik “rendah” maka “belum layak kirim”
R5 Jika agregat “halus” dan umur barang “dibawah 7 hari” dan area produksi “drycast” dan kondisi barang baik “sedang” maka “layak kirim”
R6 Jika agregat “halus” dan umur barang “dibawah 7 hari” dan area produksi “drycast” dan kondisi barang baik “tinggi” maka “Belum layak kirim”
R7 Jika agregat “halus” dan umur barang “dibawah 7 hari” dan area produksi “wetcast” dan kondisi barang baik “sedang” maka “belum layak kirim”
R8 Jika agregat “halus” dan umur barang “dibawah 7 hari” dan area produksi “wetcast” dan kondisi barang baik “tinggi” maka “layak kirim”
4.1.3 Akurasi Prediksi
Proses klasifikasi dengan RapidMiner menggunakan metode algoritma decision tree C4.5 pada data barang jadi ini untuk membandingkan data testing dengan data training yang sudah diketahui rule-rulenya sebelumnya. Berikut langkahnya:
Pada tampilan process masukan operator Read Excel masukan masingmasing data training dan data testing, selanjutnya masukan operator Decision Tree, Apply Model, dan Performance dan sambungkan kabel seperti gambar dibawah ini.
Gambar 4.17 Proses Training dan Testing
Dengan mengetahui jumlah data yang diklasifikasikan secara benar maka dapat diketahui akurasi hasil prediksi yaitu 70.00% dari hasil data testing.
Gambar 4.18 Hasil Akurasi data Testing
Hasil pengukuran data accuracy yang diperoleh dari data testing mencapai 70.00%.
Dari data tersebut diketahui prediksi layak kirim dengan true layak kirim mencapai 11 barang dan true belum layak kirim sebanyak 3 barang, dengan pencapaian class precision 78.57%. Sedangkan untuk prediksi belum layak kirim dengan true layak kirim sebanyak 3 barang dan untuk true belum layak kirim mencapai 3 barang dengan pencapaian class precision 50.00%. Untuk class recall dengan true layak kirim mencapai 78.57% sedangkan untuk class recall dengan true belum layak kirim mencapai 50.00%.
Hasil analisa data testing dengan data training pada RapidMiner dapat dilihat pada gambar di bawah ini.
Gambar 4.19 Hasil Prediksi RapidMiner
Hasil penerapan data testing terhadap data training sebagai berikut :
Jumlah data yang diprediksi benar : 14
Jumlah data yang diprediksi salah : 6
4.1.4 Akurasi Precision Dan Recall
Dari hasil pengujian dapat diketahui nilai precision, recall, dan accuracy untuk setiap percobaan. Perhitungan rata-rata dari semua percobaan menghasilkan nilai precision, recall, dan accuracy masing-masing 67%, 44%, dan 60% . Nilai precision tertinggi dari semua percobaan yaitu 83%, sedangkan nilai precision terendah dari semua percobaan yaitu 56%. Untuk Nilai recall tertinggi dari semua percobaan yaitu 50%, sedangkan nilai recall terendah dari semua percobaan yaitu 20%. Nilai accuracy tertinggi dari semua percobaan yaitu 70%, sedangkan nilai accuracy terendah dari semua percobaan yaitu 55%. Perbandingan nilai precision, recall, dan accuracy untuk setiap percobaan dapat divisualisasikan dalam bentuk grafik seperti pada Gambar 11. Dari grafik tersebut dapat dilihat bahwa besar kecilnya jumlah data latih tidak selalu berbanding lurus dengan nilai precision, recall, dan accuracy dari data uji.
4.2 Analisa Hasil Pengujian
Untuk analisa hasil pengujian dapat di simpulkan Hasil pengukuran data accuracy yang diperoleh dari data testing mencapai 70.00%. Dari data tersebut diketahui prediksi layak kirim dengan true layak kirim mencapai 11 barang dan true belum layak kirim sebanyak 3 barang, dengan pencapaian class precision 78.57%. Sedangkan untuk prediksi belum layak kirim dengan true layak kirim sebanyak 3
barang dan untuk true belum layak kirim mencapai 3 barang dengan pencapaian class precision 50.00%. Untuk class recall dengan true layak kirim mencapai 78.57% sedangkan untuk class recall dengan true belum layak kirim mencapai 50.00%. Dari hasil pengujian dapat diketahui nilai precision, recall, dan accuracy untuk setiap percobaan. Perhitungan rata-rata dari semua percobaan menghasilkan nilai precision, recall, dan accuracy masing-masing 67%, 44%, dan 60% . Nilai precision tertinggi dari semua percobaan yaitu 83%, sedangkan nilai precision terendah dari semua percobaan yaitu 56%. Untuk Nilai recall tertinggi dari semua percobaan yaitu 50%, sedangkan nilai recall terendah dari semua percobaan yaitu 20%. Nilai accuracy tertinggi dari semua percobaan yaitu 70%, sedangkan nilai accuracy terendah dari semua percobaan yaitu 55%. Perbandingan nilai precision, recall, dan accuracy untuk setiap percobaan dapat divisualisasikan dalam bentuk grafik seperti pada Gambar 11. Dari grafik tersebut dapat dilihat bahwa besar kecilnya jumlah data latih tidak selalu berbanding lurus dengan nilai precision, recall, dan accuracy dari data uji. Dan hasil dari semua data yang diuji menggunakan rapidminer dapat disimpulkan bahawa hasil nya hampir di atas 50% prediksi barang jadi CV. DHARMA BHAKTI untuk layak kirim ke customer.
BAB V
KESIMPULAN DAN SARAN
5.1 Kesimpulan
Berdasarkan hasil penelitian yang penulis lakukan pada CV. DHARMA BHAKTI, maka penulis dapat menarik kesimpulan bahwa memprediksi penjualan data barang jadi dapat menentukan pengiriman barang dengan menggunakan metode Data Mining khususnya Algoritma C4.5.
1. Dari metode Decision Tree Algoritma C4.5 diketahui bahwa atribut agregat adalah atribut yang paling berpengaruh pada hasil klasifikasi dalam menentukan pengiriman.
2. Dari hasil perhitungan data training data barang jadi dengan algoritma C4.5 menghasilkan akurasi sebanyak 81.25% dan juga diperoleh pohon keputusan yang memiliki rule-rule didalamnya sehingga dapat dengan mudah mengambil keputusan dengan melihat rule yang sudah ada.
3. Berdasarkan Decision Tree Algoritma C4.5 diperoleh rule untuk mengklasifikasikan data barang jadi untuk menentukan pengiriman barang dengan dua kategori yaitu (LAYAK KIRIM) jika agregat halus, umur barang 28 hari, produksi drycast dan kondisi barang baik sedang. Sedangkan (BELUM LAYAK
KIRIM) jika agregat halus, umur barang dibawah 7 hari, area produksi drycast dan kondisi barang baik rendah.
5.2 Saran
Berdasarkan hasil penelitian dan pembahasan serta kesimpulan, maka berikut adalah beberapa saran untuk pengembangan skripsi ini.
1. Dalam menggunakan algoritma C4.5 untuk melakukan klasifikasi, harus dilakukan pemilihan variabel yang tepat agar hasil dari pohon keputusan lebih akurat. 2. Sebagai pendukung dan panutan dalam pengambilan keputusan pengiriman barang
ke customer di CV. DHARMA BHAKTI.
3. Selanjutnya penulis menyarankan agar dapat membandingkan metode pangambilan keputusan dengan metode Data Mining dengan metode lainnya.
DAFTAR PUSTAKA
Khoirunisa. (2016). Analisis Dan Implementasi Perbandingan Algoritma C 4.5 Dengan Naïve Bayes Untuk Prediksi Penawaran Produk.e-Proceeding of Engineering : Vol.3, No.3 December 2016 | Page 78.
Winata. (2017). Analisis Dan Prediksi Penjualan Produk Terlaris Distro “Root Shoes” Dengan Aplikasi Android. E comers html : Vol.4, No.27
Danar. (2016). Implementasi Metode Last Square Untuk Prediksi Penjualan Tahu Pong. Jurnal Ilmiah NERO Vol. 2, No.2
Wahyuni. (2017). Implrmntasi Rapidminer Dalam Menganalisa Data Mahasiswa Drop Out Vol. 10 No2 Desember 2017 ISSN : 1979-5408
Mujab. (2012). Pencarian Model Terbaik Antar Algoritma C4.5 Dan C4.5 Berbasis Particle Swarm Optimation Untuk Prediksi Prmosi Deposito. DATA MINING : Vol.76, No.04.
Fitriana. (2015). Penerapan Data Mining dalam Memprediksi Pembelian cat. Konferensi Nasional Sistem & Informatika 2015.
Gunadi. (2012). Penerapan Metode Data Mining Market Basket Analisis Terhadap Data Penjualan Prouk Buku Dengan Menggunakan Algotima Apriori Dan Frequent Pattrent Growth (FP-GROWTH) : Studi Kasus Percetakan PT. GRAMEDIA.Jurnal TELEMATIKA MKOM Vol.4 No.1.