Pemodelan Jumlah Uang yang Beredar Menggunakan Regresi Komponen Utama
Money Supply Modelling Using Principal Component Regression
Desi Yuniarti
Program Studi Statistika FMIPA Universitas Mulawaraman
Abstract
One of the assumptions that must be met in the OLS is no multicollinearity problem. Multicollinearity showed no association between the independent variables in the regression. In essence, the existence of multicollinearity still produce the BLUE estimator, but the cause of a variant of the model has a standard error of the parameter that also goes up or expand. Principal component regression is one method that can be used in overcoming the multicollinearity problem. In this study determined regression model to the data the money supply (in billion dollars) from January 2008 until July 2011. A problem with multicollinearity in the regression model, led to the use of principal component regression methods to overcome these problems. Based on the analysis found that the principal component regression model to the data the money supply from January 2008 until July 2011 is
ܻ = 2.046.909 − 59.188,9ܺଵ+ 68.937,66ܺଶ+ 66.709,372ܺଷ+ 68.798,392ܺସ− 44.147,956ܺହ
Keywords : linear multiple regression, multicollinearity, principal component regression, money supply and its change of affecting factors
PENDAHULUAN
Regresi linear berganda merupakan salah
satu metode analisis yang paling sering
digunakan. Regresi ini bermanfaat untuk melihat hubungan antara suatu variabel dependen dengan satu atau lebih variabel independen. Selain itu, regresi juga dapat digunakan untuk mengestimasi nilai variabel dependen berdasarkan nilai satu atau lebih variabel independen tersebut, juga sebagai kontrol (Ryan, 1997). Dalam mengestimasi parameter regresi linear berganda, digunakan
metode kuadrat terkecil (Ordinary Least
Square/OLS). Metode ini mencari nilai residual
sekecil mungkin dengan cara meminimumkan
jumlah kuadrat residualnya dan dibangun
menggunakan asumsi-asumsi, antara lain adalah hubungan antara variabel dependen dan variabel independen adalah linear dalam parameter,
variabel independen adalah variabel tidak
stokastik yang nilainya tetap, rata-rata dari residual adalah nol, varian dari residual adalah
sama (homoskedastisitas), tidak ada serial
korelasi, tidak terdapat multikolinearitas dan residual berdistribusi normal. Dengan asumsi-asumsi tersebut pada suatu model regresi linear, metode OLS akan menghasilkan estimator yang tidak bias, linear dan mempunyai varian yang minimum (Best Linear Unbiased Estimators = BLUE) (Widarjono, 2009).
Salah satu asumsi yang harus dipenuhi dalam
OLS adalah tidak terdapat masalah
multikolinearitas. Multikolinearitas menunjukkan adanya hubungan antara variabel independen dalam satu regresi. Pada dasarnya, adanya multikolinearitas masih menghasilkan estimator yang BLUE, tetapi menyebabkan suatu model
mempunyai varian yang besar sehingga standard
error dari parameter juga naik atau membesar.
Multikolinearitas merupakan masalah yang paling sering ditemui dalam model
ekonometrika karena pada dasarnya variabel-variabel ekonomi saling terkait. Misalnya fungsi produksi yang menggambarkan hubungan teknis antara input dengan output dalam proses produksi. Secara umum, output merupakan fungsi dari modal dan tenaga kerja. Sedangkan, penggunaan tenaga kerja dan modal sendiri sangatlah terkait, yaitu dalam proses produksi apabila modal yang digunakan besar, tenaga kerja yang dibutuhkan juga besar. Adanya korelasi di antara input ini
menyebabkan terjadinya multikolinearitas
(Setiawan dan Kusrini, 2010).
Banyak cara dapat dilakukan untuk
mengatasi kasus multikolinearitas dalam model regresi, antara lain adalah penggabungan data
cross section dan data time series, mengeluarkan
satu variabel atau lebih, transformasi variabel, penambahan data baru, regresi komponen utama (Principal Component Regression), regresi Ridge, regresi kuadrat terkecil parsial (Partial Least
Squares regression), regresi dengan pendekatan
bayes, dan regresi Kontinum (Setiawan dan Kusrini, 2010).
Pada penelitian ini akan ditentukan model regresi berganda untuk data jumlah uang yang beredar (dalam miliar rupiah) dari bulan Januari 2008 sampai dengan bulan Juli 2011. Adanya masalah multikolinearitas pada model regresi,
menyebabkan penggunaan metode regresi
komponen utama dalam mengatasi masalah tersebut.
REGRESI LINEAR BERGANDA
Model regresi untuk variabel dependen
ܻ dan ܭ variabel independen ܺଵ, ܺଶ, … , ܺ
ditulis sebagai berikut (Gujarati, 2004) :
ܻ= ߚ+ ߚଵܺଵ+ ߚଶܺଶ+ ⋯ + ߚܺ+ ݑ (1)
݆= 1,2,3, … , ݊
dengan ߚ adalah intersep, ߚଵ, ߚଶ, … , ߚ
adalah
slope koefisien, uj merupakan error, dan indeks
j = observasi ke-j. Model (1) ini dapat disajikan
dalam bentuk matriks berikut (Gujarati, 2004) :
ܡ = ܆ + ܝ (2) dengan : ܡ×ଵ= ൦ ܻଵ ܻଶ ⋮ ܻ ൪, ܆×(ାଵ)= ൦ 1 1 ⋮ 1 ܺଵଵ ܺଵଶ ⋮ ܺଵ ܺଶଵ ܺଶଶ ⋮ ܺଶ ⋯ ⋯ ⋮ … ܺଵ ܺଶ ⋮ ܺ ൪, (ାଵ)×ଵ= ൦ ߚ ߚଵ ⋮ ߚ ൪, ܝ×ଵ= ൦ ݑଵ ݑଶ ⋮ ݑ ൪
Asumsi model regresi linear klasik yang harus
dipenuhi adalah ܝ×ଵ~ܫܫܦܰ(0, ߪଶ۷) dengan I
adalah matriks identitas berukuran݊ × ݊ .
Estimasi OLS dari diperoleh dengan
meminimumkan ܝᇱܝ dengan cara menentukan
turunan ܝᇱܝ terhadap ᇱ kemudian
disamadengankan 0. Sehingga estimator OLS untuk model (2) adalah (Gujarati, 2004) :
= (܆ᇱ܆)ିଵ܆ᇱܡ asalkan invers ܆ᇱ܆ ada.
Vektor ini memenuhi sifat linear, tidak bias, dan
memiliki varians yang minimum (Best Linear
Unbiased Estimator = BLUE) (Gujarati, 2004).
Pengujian Signifikansi Parameter Model Regresi
Pengujian signifikansi parameter ini
dilakukan untuk mengetahui apakah parameter
yang terdapat dalam model regresi telah
menunjukkan hubungan yang tepat antara
variabel-variabel independen dengan variabel dependen. Uji ini merupakan salah satu cara mengevaluasi seberapa baik model regresi yang telah diperoleh. Pengujian dilakukan dalam dua tahap pengujian signifikansi parameter regresi, yaitu pengujian secara serentak dan pengujian secara parsial.
1. Uji Simultan
Uji simultan digunakan untuk mengevaluasi pengaruh semua variabel independen terhadap variabel dependen. Hipotesis uji serentak adalah :
ܪ ∶ ߚଵ= ߚଶ= ⋯ = ߚ = 0
ܪଵ ∶ minimal terdapat satu ߚ≠ 0, k = 1, 2, …,K.
Tolak ܪ diambil jika nilai ܨ௧௨> ܨ௧
dengan ܨ௧= ܨ(ିଵ,ି; ఈ)dimana n adalah
jumlah observasi (Draper & Smith, 1992).
2. Uji Parsial
Uji parsial ini digunakan untuk
membuktikan apakah variabel independen secara individu pengaruhi variabel dependen.
Hipotesis uji parsial adalah :
ܪ∶ ߚ= 0
ܪଵ∶ ߚ≠ 0, k = 1, 2, 3, …, K.
Statistik uji yang digunakan adalah : ݐ௧௨=௦൫ఉఉೖ
ೖ൯
Tolak ܪ jika nilai หݐ௧௨ห> ݐቀഀ
మ,ିቁ dan
disimpulkan bahwa ߚ≠ 0, k = 1, 2, 3, …, K ,
artinya variabel prediktor ܺ berpengaruh
signifikan terhadap variabel dependen ܻ (Draper
& Smith, 1992).
Asumsi Klasik Model Regresi Berganda
Estimasi parameter suatu model regresi dapat ditentukan dengan metode OLS. Metode OLS dibangun dengan menggunakan beberapa asumsi antara lain adalah tidak terdapat masalah
multikolinearitas, tidak terdapat
heteroskedastisitas, tidak terjadi autokorelasi, dan
error berdistribusi normal.
1. Multikolinearitas
Hubungan linear antara beberapa atau semua variabel independen di dalam model regresi disebut multikolinearitas. Salah satu asumsi model regresi linear klasik adalah bahwa tidak terdapat multikolinearitas di antara variabel-variabel independen yang masuk dalam model (Gujarati, 2004). Salah satu indikator yang dapat digunakan dalam mendeteksi multikolinearitas adalah nilai VIF yang lebih dari 10 (Widarjono, 2009).
Konsekuensi multikolinearitas dalam model regresi adalah :
1. Meskipun estimasi OLS mungkin bisa
diperoleh, nilai standar error cenderung besar dengan meningkatnya tingkat korelasi antara variabel.
2. Karena besarnya standar error, maka
interval kepercayaan untuk parameter
populasi cenderung lebih besar.
3. Akibat 2, dalam kasus multikolinearitas yang
tinggi, probabilitas untuk menerima
hipotesis yang salah (yaitu kesalahan tipe II) meningkat.
4. Pengestimasian koefisien regresi adalah
mungkin tetapi estimasi dan standar error-nya menjadi sangat sensitif terhadap sedikit perubahan dalam data.
5. Jika multikolinearitas tinggi, R2 yang
diperoleh mungkin tinggi tetapi tidak satu pun atau sangat sedikit koefisien yang
diduga signifikan secara Statistik (Gujarati, 2004).
Menurut Ryan (1997), multikolinearitas dapat menyebabkan tanda koefisien menjadi
salah, yaitu tanda dariߚመberbeda dari tanda ݎ.
Salah satu cara mengatasi multikolinearitas adalah dengan regresi komponen utama (Principal
Component Regression, PCR). Regresi komponen
utama merupakan analisis statistika yang
bertujuan untuk membentuk variabel baru
(komponen utama) yang merupakan kombinasi linear dari variabel asal sedemikian hingga varians komponen utama menjadi maksimum dan antar komponen utama tidak saling berkorelasi (Sharma, 1996).
Diberikan matriks kovarians dari vektor
random ܠᇱ= [ܺ
ଵ, ܺଶ, … , ܺ]. Jika memiliki
pasangan nilai eigen dan vektor eigen
(ߣଵ, ܍ଵ), (ߣଶ, ܍ଶ), … , (ߣ, ܍) dimana ߣଵ≥ ߣଶ≥
⋯ ≥ ߣ≥ 0 maka komponen utama ke-j
diberikan sebagai berikut (Johnson & Wichern, 2002) : ܻ= ܍ᇱܠ = ݁ଵܺଵ+ ݁ଶܺଶ+ ⋯ + ݁ܺ, (3) ݆= 1, 2, … , ݊ dengan ݒܽݎ൫ܻ൯= ܍ᇱ܍= ߣ, ݆= 1, 2, … , ݊ ܿݒ൫ܻ, ܻ௦൯= ܍ᇱ܍௦= 0, ݆= 1, 2, … , ݊
yang berarti bahwa komponen utama tidak saling berkorelasi dan memiliki varians yang sama
dengan nilai eigen dari.
Total varians populasi dari komponen utama (3) adalah (Johnson & Wichern, 2002) :
ߪଵଵ+ ߪଶଶ+ ⋯ + ߪ= ݒܽݎ൫ܺ൯ ୀଵ = ߣଵ+ ߣଶ+ ⋯ + ߣ = ݒܽݎ൫ܻ൯ ୀଵ
Jadi, proporsi total varians karena (dijelaskan oleh) komponen utama ke-j adalah :
ఒೕ
ఒభାఒమା⋯ାఒ, ݆= 1, 2, … , ݊
Jika sebagian besar (lebih dari 80%) dari proporsi total varians untuk p dapat dikaitkan dengan satu, dua atau tiga komponen, maka komponen ini dapat mengganti K variabel asal tanpa kehilangan banyak informasi (Johnson & Wichern, 2002). Menurut Draper & Smith (1992), biasanya tidak
semua komponen utama ܻ yang digunakan,
melainkan mengikuti suatu aturan seleksi tertentu yaitu dengan mengambil nilai eigen yang lebih besar dari 1 atau dengan mengambil komponen-komponen hingga sejumlah tertentu proporsi varians yang cukup besar (75% atau lebih) telah
terjelaskan, dengan kata lain dipilih k
penyumbang terbesar yang menghasilkan
∑ೖೕసభఒೕ
∑ೕసభఒೕ> 0,75.
2. Heteroskedastisitas
Salah satu asumsi penting dari model regresi linear adalah bahwa error yang muncul dalam fungsi regresi populasi adalah homoskedastik, yaitu mempunyai varians yang sama (Gujarati, 2004). Dengan menggunakan lambang,
ܧ൫ݑଶ൯= ߪଶ, ݆= 1, 2, … , ݊
Pelanggaran atas asumsi ini disebut
heteroskedastisitas, yaitu varians error tidak sama, dengan menggunakan lambang (Gujarati, 2004) :
ܧ൫ݑଶ൯= ߪଶ, ݆= 1, 2, … , ݊
Menurut Gujarati (2004), beberapa alasan
terjadinya heteroskedastisitas adalah : (1)
Mengikuti error-learning models, karena proses belajar, kesalahan-kesalahan yang terjadi pun semakin lama semakin kecil, (2) Dengan
peningkatan dalam teknik pengumpulan data, ߪଶ,
݆= 1, 2, … , ݊ akan menurun.
Konsekuensi jika pada model memenuhi semua asumsi kecuali homoskedastisitas adalah estimator OLS tetap tak bias dan konsisten tetapi estimator tadi tidak lagi efisien baik dalam sampel kecil maupun besar yang berakibat interval kepercayaan menjadi semakin lebar dan pengujian signifikansi menjadi kurang kuat. Oleh karena itu, tindakan perbaikan diperlukan yaitu dengan metode Weighted Least Squares (WLS) (Gujarati, 2004).
Terdapat beberapa metode yang dapat
digunakan untuk mendeteksi adanya
heteroskedastisitas, antara lain melalui pengujian Glejser. Uji Glejser dilakukan dengan cara
meregresikan nilai absolut residualݑdari regresi
OLS terhadap variabel X (Gujarati, 2004). Hipotesis uji Glejser adalah :
ܪ∶ ߪଵଶ= ߪଶଶ= ⋯ = ߪଶ= ߪଶ
ܪଵ∶ minimal terdapat satu ߪଶ≠ ߪ௦ଶ,
݆= 1, 2, … , ݊ ; ݏ= 1, 2, … , ݊
Tolak ܪ jika
หݐ
௧௨ห> ݐ
ቀഀమ,ିቁ atau jika
p-value <ߙ. Jika ܪditolak untuk masing-masing
parameter maka dapat disimpulkan bahwa terjadi masalah heteroskedastisitas pada model yang dihasilkan.
3. Autokorelasi
Istilah autokorelasi dapat didefinisikan
sebagai korelasi antara anggota serangkaian observasi yang diurutkan menurut waktu (seperti dalam data time series) atau ruang (seperti dalam data cross-section). Dalam model regresi linear klasik, diasumsikan bahwa autokorelasi seperti itu
tidak terdapat dalam error ݑ, hal ini dapat
dilambangkan sebagai (Gujarati, 2004) :
ܧ൫ݑݑ௦൯= 0 untuk ݆≠ ݏ.
Jika dilakukan penerapan OLS dalam situasi autokorelasi, konsekuensi yang dapat terjadi adalah sebagai berikut (Gujarati, 2004) :
1. Estimasi yang diperoleh tidak bias dan konsisten tetapi tidak efisien, sehingga interval kepercayaannya menjadi lebar dan pengujian signifikansi menjadi kurang kuat.
2. Jika tidak diperhatikan batas masalah
autokorelasi sama sekali dan tetap
diterapkan prosedur OLS, konsekuensinya akan menjadi lebih serius karena :
a. Varians residualߪොଶakan mengestimasi
terlalu rendah (underestimate) ߪଶ
sebenarnya.
b. Bahkan jika ߪଶtidak diestimasi terlalu
rendah, varians dan standar error estimator OLS akan mengestimasi varians dan standar error sebenarnya terlalu rendah.
c. Pengujian signifikansi t dan F tidak lagi
menjadi sah, dan jika diterapkan akan memberikan kesimpulan yang salah tentang signifikansi koefisien regresi yang diduga.
3. Meskipun estimator OLS tak bias, namun
menjadi sensitif terhadap fluktuasi
penyampelan.
Pengujian untuk mengetahui ada tidaknya masalah autokorelasi dapat dengan menggunakan metode Durbin-Watson. Metode Durbin-Watson merupakan metode yang paling banyak digunakan untuk mendeteksi masalah autokorelasi. Hipotesis yang digunakan dalam uji Durbin-Watson adalah sebagai berikut (Gujarati, 2004) :
ܪ∶ ߩ = 0
ܪଵ∶ ߩ ≠ 0
Statistik d dari uji Durbin-Watson ditetapkan sebagai berikut : ݀ =∑ ൫ݑො− ݑොିଵ൯ ଶ ୀଶ ∑ୀଵݑොଶ
denganݑොadalah residual metode OLS.
Statistik d merupakan rasio dari jumlah kuadrat selisih dalam residual yang berturutan terhadap residual sum square (RSS). Keuntungan dari statistik d adalah statistik ini didasarkan pada residual yang diestimasi, yang secara rutin dihitung dalam analisis regresi.
Keputusan hasil uji Durbin-Watson diambil dengan membandingkan nilai Durbin-Watson
hitung (݀௧௨) dengan nilai batas atas (upper
bound) dUdan nilai batas bawah (lower bound) dL,
dari tabel Durbin-Watson berdasarkan jumlah observasi (n) dan banyaknya variabel independen (K), yaitu :
a. Jika 0 < ݀௧௨ < ݀ maka ܪ ditolak
terdapat autokorelasi positif.
b. Jika ݀≤ ݀௧௨≤ ݀ merupakan daerah
keragu-raguan sehingga tidak ada keputusan. c. Jika ݀ ≤ ݀௧௨≤ 4 − ݀ maka ܪ
gagal ditolak yang berarti tidak ada autokorelasi positif/negatif.
d. Jika 4 − ݀ ≤ ݀௧௨ ≤ 4 − ݀ maka
tidak ada keputusan karena merupakan daerah keragu-raguan.
e. Jika 4 − ݀≤ ݀௧௨≤ 4 maka ܪ
ditolak yang berarti terdapat autokorelasi negatif.
4. Normalitas
Regresi linear klasik mengasumsikan bahwa
tiap errorݑdidistribusikan secara normal dengan
rata-rata ܧ൫ݑ൯= 0, varians ܧ൫ݑଶ൯= ߪଶ, dan
ܧ൫ݑݑ௦൯= 0 untuk ݆≠ ݏ (Gujarati, 2004).
Asumsi ini secara singkat ditulis :ݑ~ܰ(0, ߪଶ)
Menurut Gujarati (2004), dengan asumsi
kenormalan, estimator OLS mempunyai sifat tidak bias, efisien dan konsisten. Selain itu, distribusi probabilitas estimator OLS dengan
mudah diperoleh, karena merupakan sifat
distribusi normal bahwa setiap fungsi linear dari variabel-variabel yang didistribusikan secara normal dengan sendirinya didistribusikan secara normal.
Salah satu metode untuk mendeteksi
masalah normalitas adalah dengan uji Kolmogorof Smirnov (K-S). Hipotesis uji K-S sebagai berikut :
ܪ∶ error berdistribusi normal
ܪଵ∶ error tidak berdistribusi normal.
Keputusan tolak ܪ diambil jika p-value < ߙ,
yang berarti bahwa error tidak berdistribusi normal.
DEFINISI UANG DAN UANG BEREDAR
Uang diciptakan dalam perekonomian
dengan tujuan untuk melancarkan kegiatan tukar menukar dan perdagangan. Uang didefinisikan
sebagai benda-benda yang disetujui oleh
masyarakat sebagai alat perantaraan untuk mengadakan tukar menukar atau perdagangan. Pada masa lalu, emas dan perak merupakan dua
benda yang digunakan dalam kegiatan
perdagangan di berbagai negara. Namun,
kemajuan ekonomi dunia yang bertambah pesat sejak terjadinya Revolusi Industri di
negara-negara maju menyebabkan perdagangan
berkembang dengan sangat pesat sekali. Uang emas dan perak tidak dapat ditambah secepat seperti perkembangan perdagangan yang telah berlaku tersebut. Sebagai akibatnya, banyak negara menggantikan uang emas dan perak dengan uang kertas sebagai alat tukar menukar. Pada masa ini, uang kertas dan uang bank atau uang giral, yaitu uang yang diciptakan oleh bank-bank umum atau bank-bank perdagangan, adalah alat tukar menukar yang utama di semua negara di dunia (Sukirno, 2011).
Terdapat perbedaan antara mata uang dalam peredaran dan uang beredar. Mata uang dalam peredaran adalah seluruh jumlah mata uang yang
telah dikeluarkan dan diedarkan oleh bank sentral. Mata uang tersebut terdiri dari dua jenis, yaitu uang logam dan uang kertas. Dengan demikian uang dalam peredaran adalah sama dengan uang kartal. Sedangkan uang beredar adalah semua jenis uang yang berada di dalam perekonomian, yaitu jumlah dari mata uang dalam peredaran ditambah dengan uang giral dalam bank-bank umum (Sukirno, 2011).
Dalam Sukirno (2011) dijelaskan bahwa
pengertian uang beredar atau money supply perlu dibedakan pula menjadi dua pengertian, yaitu pengertian yang terbatas dan pengertian yang luas. Dalam pengertian yang terbatas, uang beredar adalah mata uang dalam peredaran ditambah
dengan uang giral yang dimiliki oleh
perseorangan-perseorangan,
perusahaan-perusahaan, dan badan-badan pemerintah. Dalam pengertian yang luas uang beredar meliputi : (i) mata uang dalam peredaran, (ii) uang giral dan (iii) uang kuasi. Uang kuasi terdiri dari deposito berjangka, tabungan, dan rekening (tabungan) valuta asing milik swasta domestik. Uang bereadar menurut pengertian yang luas ini dinamakan juga sebagai likuiditas perekonomian atau M2. Pengertian uang sempit dari uang beredar selalu disingkat dengan M1.
METODOLOGI PENELITIAN
Data yang digunakan dalam penelitian ini adalah data uang beredar dan faktor-faktor yang mempengaruhinya yang merupakan data sekunder
diambil dari situs Bank Indonesia www.bi.go.id.
Data berbentuk data bulanan (dalam miliar rupiah) dari bulan Januari 2008 sampai dengan bulan Juli 2011. Berdasarkan BPS (2011) dipilih variabel dependen (Y) adalah jumlah uang beredar dalam arti luas atau likuiditas perekonomian, yaitu kewajiban sistem moneter yang terdiri atas uang kartal, uang giral, uang kuasi dan surat berharga selain saham. Sedangkan variabel dependen terdiri atas tagihan bersih kepada Pemerintah
Pusat (X1), aktiva luar negeri bersih (X2), tagihan
kepada perusahaan bukan keuangan BUMN (X3),
tagihan pada sektor swasta (X4), dan aktiva
lainnya bersih termasuk derivatif keuangan (X5).
Selanjutnya dilakukan analisis regresi berganda dalam memodelkan jumlah uang beredar. Adanya masalah multikolinearitas diatasi dengan analisis komponen utama sehingga diperoleh model regresi komponen utama untuk data uang beredar. Analisis dilakukan dengan bantuan software MINITAB 14.0.
ANALISIS DAN PEMBAHASAN
Untuk melakukan pemodelan terhadap
jumlah uang beredar, metode yang digunakan adalah regresi linear berganda. Sedangkan untuk mengestimasi parameter-parameternya digunakan metode ordinary least square (OLS).
Model Regresi Linear Berganda
Pengestimasian model regresi berganda untuk jumlah uang beredar dilakukan dengan bantuan MINITAB 14. Berdasarkan hasil analisis diperoleh model regresi berganda untuk data uang beredar Januari 2008-Juli 2011 adalah sebagai berikut :
ܻ= 62747 + 0,881ܺଵ+ 0,581ܺଶ+ 2,94ܺଷ+
0,785ܺସ+ 0,224ܺହ (4)
Model (4) memiliki nilai R2 sebesar 0,994
yang berarti bahwa 99,4% variasi variabel Y
dapat dijelaskan variabel-variabel X1, X2, X3, X4,
dan X5. Sedangkan sisanya yaitu 0,6% dijelaskan
oleh variabel-variabel lain yang tidak dimasukkan
dalam model. Dengan nilai R2 yang mendekati 1,
maka dapat dikatakan bahwa model (4)
merupakan model regresi yang baik dalam menjelaskan jumlah uang yang beredar.
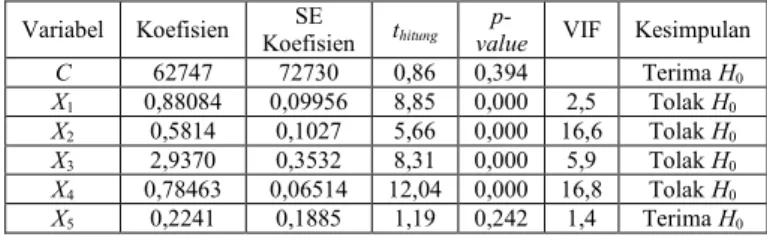
Selanjutnya dilakukan pengujian signifikansi parameter regresi, yaitu pengujian secara simultan dan pengujian secara parsial.Berdasarkan Tabel 1,
diperoleh bahwa nilai ܨு௧௨= 1263,06 >
ܨ௧= ܨ(ହ,ଷ)= 2,47 sehingga melalui
pengujian secara simultan dapat disimpulkan
bahwa terdapat minimal satu parameterߚ,
݆= 1,2, . . ,5, yang berpengaruh secara signifikan terhadap variabel dependen. Kemudian untuk mengetahui parameter yang secara individu signifikan terhadap variabel dependen, dilakukan pengujian secara parsial. Berdasarkan Tabel 2,
diperoleh bahwa tagihan bersih kepada
Pemerintah Pusat (X1), aktiva luar negeri bersih
(X2), tagihan kepada perusahaan bukan keuangan
BUMN (X3), dan tagihan pada sektor swasta (X4)
berpengaruh secara signifikan. Tabel 1. Analisis Variansi
Sumber Variansi df
Sum Of
Square Mean Square Fhitung p-value
Regresi 5 3,382E+12 6,76552E+11 1263,06 0,000 Residual 37 19818816708 535643695
Total 42 3,40258E+12
Tabel 2. Pengujian Parsial Model Regresi Linear Berganda
Variabel Koefisien KoefisienSE thitung valuep- VIF Kesimpulan
C 62747 72730 0,86 0,394 Terima H0 X1 0,88084 0,09956 8,85 0,000 2,5 Tolak H0 X2 0,5814 0,1027 5,66 0,000 16,6 Tolak H0 X3 2,9370 0,3532 8,31 0,000 5,9 Tolak H0 X4 0,78463 0,06514 12,04 0,000 16,8 Tolak H0 X5 0,2241 0,1885 1,19 0,242 1,4 Terima H0 Pendeteksian Multikolinearitas
Pada Tabel 2 terlihat bahwa terjadi kasus multikolinearitas karena nilai VIF untuk variabel
X2 dan X4 lebih besar daripada 10.
Multikolinearitas pada model (4) dapat diatasi dengan Regresi Komponen Utama (Principal
Component Regression/PCR). PCR dilakukan
dengan pendekatan matriks korelasi dan
berdasarkan nilai eigen matriks korelasi, diambil 1
komponen utama (PC1) dengan bobot
ditunjukkan pada Tabel 3.
Tabel 3. Bobot Variabel dalam PC1
Variabel PC1 X1 0,425 X2 -0,495 X3 -0,479 X4 -0,494 X5 0,317
Untuk mendapatkan model regresi dilakukan regresi antara variabel Y dengan PC1, sehingga diperoleh estimasi model PCR untuk PC1 adalah :
ܻ = 2046909 − 139268ܲܥ1 (5)
Model (5) memiliki nilai R2= 0,911 yang berarti
bahwa variasi variabel Y dapat dijelaskan oleh
PC1 sebesar 91,1% sedangkan sisanya, yaitu
8,9% dijelaskan oleh komponen utama lainnya yang tidak dimasukkan ke dalam model.
Selanjutnya melalui pengujian signifikansi terhadap model (5) dapat disimpulkan bahwa komponen utama PC1 berpengaruh secara signifikan terhadap variabel Y.
Pengujian Heteroskedastisitas
Uji heteroskedastisitas dilakukan untuk mengetahui homogenitas varians residual dari model (5). Pengujian dilakukan melalui uji Glejser, yaitu dengan cara meregresikan nilai mutlak residual terhadap komponen utama PC1. Jika variabel PC1 berpengaruh secara signifikan
maka disimpulkan terdapat kasus
heteroskedastisitas.
Berdasarkan hasil pengujian, diperoleh bahwa ݐ௧௨= 0,61 < |ݐ௧| = 2,00 maka H0 gagal
ditolak. Sehingga dapat disimpulkan bahwa varians residual homogen atau tidak terjadi heteroskedastisitas.
Uji Independen
Uji ini dilakukan untuk mendeteksi ada tidaknya masalah autokorelasi. Dengan nilai
Durbin Watson atau ݀௧௨ model (5) sebesar
1,66310, nilai ݀= 1,2642 dan ݀ = 1,78,
maka tidak ada keputusan yang dapat diambil karena model (5) terletak di daerah keragu-raguan. Sehingga tidak dapat dikatakan bahwa model (5) memiliki masalah autokorelasi. Namun menurut Widarjono (2009), jika ada autokorelasi dalam regresi maka estimator yang diperoleh masih linier dan tidak bias, hanya saja estimator ini tidak mempunyai varian yang minimum lagi.
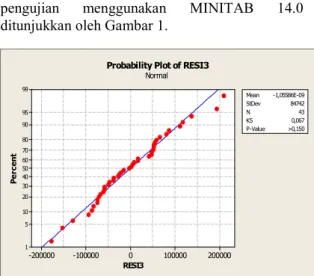
Uji Normalitas
Pengujian normalitas untuk model (5) dilakukan dengan uji Kolmogorof Smirnov. Hasil
pengujian menggunakan MINITAB 14.0
ditunjukkan oleh Gambar 1.
RESI3 P e rc en t 200000 100000 0 -100000 -200000 99 95 90 80 70 60 50 40 30 20 10 5 1 Mean >0,150 -1,05586E-09 StDev 84742 N 43 KS 0,067 P-Value Probability Plot of RESI3
Normal
Gambar 1. Hasil Uji Normalitas Kolmogorov Smirnov
Berdasarkan hasil pengujian tersebut diperoleh
nilai p-value lebih besar daripada ߙ = 0,05,
sehingga ܪ gagal ditolak dan dapat disimpulkan
bahwa error berdistribusi normal.
Model Regresi Komponen Utama
Berdasarkan model (5) dan nilai bobot variabel pada Tabel 3, maka dapat dibentuk model PCR untuk data jumlah uang beredar bulan Januari 2008 sampai dengan bulan Juli 2011, yaitu :
ܻ = 2.046.909 − 59.188,9ܺଵ+ 68.937,66ܺଶ+
66.709,372ܺଷ+ 68.798,392ܺସ+
−44.147,956ܺହ (6)
Selanjutnya, model PCR (6) dapat
diinterpretasikan bahwa dengan asumsi variabel lainnya tetap, maka untuk setiap kenaikan 1 Miliar rupiah dari tagihan bersih kepada
Pemerintah Pusat (X1) maka jumlah uang yang
beredar akan berkurang sebesar 59.188,9 Miliar rupiah, bertambahnya masing-masing 1 Miliar
rupiah dari aktiva luar negeri bersih (X2), tagihan
kepada perusahaan bukan keuangan BUMN (X3),
tagihan pada sektor swasta (X4) maka secara
berturut-turut akan meningkatkan jumlah uang
beredar sebesar 68.937,66 Miliar rupiah,
66.709,372 Miliar rupiah, dan 68.798,392 Miliar rupiah, selanjutnya bertambahnya aktiva lainnya
bersih termasuk derivatif keuangan (X5) sebesar 1
Miliar rupiah akan menurunkan jumlah uang yang beredar sebesar 44.147,956 Miliar rupiah.
KESIMPULAN
Berdasarkan hasil analisis terhadap data jumlah uang beredar bulan Januari 2008 sampai dengan bulan Juli 2011, diperoleh model regresi komponen utama untuk data tersebut adalah sebagai berikut :
66.709,372ܺଷ+ 68.798,392ܺସ+
−44.147,956ܺହ
Dengan nilai R2= 0,911 yang cukup tinggi,
hasil pengujian parameter yang signifikan, dan telah memenuhi asumsi-asumsi pada model regresi linear klasik, maka dapat disimpulkan bahwa model ini cukup baik dalam menerangkan jumlah uang yang beredar.
DAFTAR PUSTAKA
Draper N. dan Smith H. (1992), “Analisis Regresi
Terapan”, edisi kedua, PT. Gramedia, Jakarta.
Gujarati, D. (2004), “Basic Econometrics”, 4th
edition, McGraw-Hill, New York.
Johnson, R. A. and Wichern, D. W. (2002),
“Applied Multivariate Statistical Analysis”, 5th
edition, Prentice-Hall, Inc., Upper Saddle River, New York.
Ryan, T. P. (1997), “Modern Regression
Methods”, John Wiley & Sons, Inc., USA.
Setiawan dan Kusrini, D. E. (2010),
“Ekonometrika”, ANDI, Yogyakarta.
Sharma, S. (1996), “Applied Multivariate
Techniques”, John Wiley & Sons, Inc., USA.
Sukirno, S. (2011), “Makroekonomi : Teori
Pengantar”, Edisi ketiga, PT Raja Grafindo
Persada, Jakarta.
Widarjono, (2009), “Ekonometrika. Teori dan
Aplikasi untuk Ekonomi dan Bisnis”,