12
BAB III
PELAKSANAAN KERJA MAGANG
3.1 Kedudukan dan Koordinasi
Gambar 3. 1 Struktur Organisasi Divisi Tech (SIRCLO,2019)
Dalam pelaksanaan kerja magang ini proyek yang dikerjakan berupa proyek secara tim dalam divisi teknologi dengan supervisi Bapak Wiguno selaku Head of Engineering yang memiliki struktur organisasi seperti pada Gambar 3.1 dan Bapak Andika Pramana selaku pembimbing lapangan dan team lead. Kedudukan selama berlangsungnya praktek kerja magang sebagai Back End Developer dalam proyek Scraper. Bapak Andika Pramana berperan memberikan koordinasi kepada tim untuk membagi tugas dari proses perancangan aplikasi, dan membantu memberikan solusi dari kendala proses pembuatan aplikasi. Karena project Scraper ini terbilang baru di SIRCLO sehingga proses yang berlangsung adalah melakukan riset tentang bahasa pemrograman, library, dan framework yang paling ideal untuk digunakan, hingga mencoba mengimplementasikannya dan selalu memberikan progress pekerjaan setiap harinya kepada tim.
13 3.2 Tugas yang Dilakukan
Selama pelaksanaan praktek kerja magang ini, tugas yang dilakukan adalah membuat aplikasi scraper untuk Shopee yang berguna untuk mengambil informasi dari Official Stores berserta semua produknya. Penulis bertugas untuk melakukan riset tentang bahasa pemrograman¸ library¸dan framework yang paling ideal untuk digunakan dalam proyek ini yang memenuhi standard yang dapat melakukan monitoring dalam mengerjakan tasks dan . Tim terdiri dari tiga orang, terdiri dari Bapak Andika sebagai team lead, Bapak Palito membuat scraper Tokopedia, dan penulis membuat scraper Shopee.
Repository yang digunakan ada satu yaitu untuk pengerjaan dari aplikasi scraper. Dalam Pengembangan aplikasi dibagi menjadi beberapa fase yaitu riset, pembuatan modul, staging, dan deployment. Namun, selama pelaksanaan praktek kerja magang hanya cukup menyelesaikan hingga fase staging. Tahapan yang dilakukan selama pelaksanaan kerja magang adalah sebagai berikut:
• Melakukan adaptasi dengan pemahaman tentang proyek yang akan dikerjakan baik dari segi fungsionalitas, cara kerja dan proses pemahaman proyek Scraper ini dibantu dengan penjelasan dari pembimbing lapangan.
• Melakukan riset mengenai bahasa pemrograrman, library, atau framework yang digunakan untuk proses Scraping yang memenuhi standard seperti dapat melakukan monitoring saat mengerjakan tasks, dan dapat dilakukan dalam proses paralel.
• Meeting dilakukan di saat beberapa step proses sudah tercapai, tetapi untuk tim internal dilakukan setiap hari untuk melaporkan progress proyek.
14
• Testing dan debugging untuk mencari kesalahan dalam proses pengembangan proyek Scraper dan perbaikan pada bagian yang bermasalah.
• Review untuk memeriksa dan memberikan masukan terhadap pekerjaan anggota tim lain dalam proyek menggunakan Phabricator.
3.3 Uraian Pelaksanaan Kerja Magang
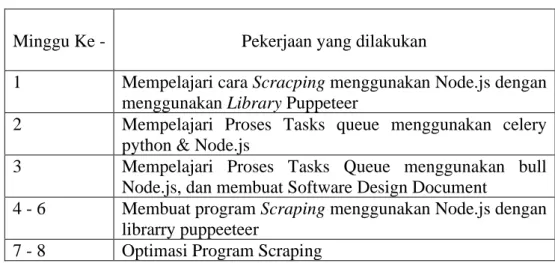
Pelaksanaan kerja magang terdapat rincian tugas seperti pada Tabel 3.1.
Tabel 3.1 Tabel Realisasi Kerja Magang
Minggu Ke - Pekerjaan yang dilakukan
1 Mempelajari cara Scracping menggunakan Node.js dengan menggunakan Library Puppeteer
2 Mempelajari Proses Tasks queue menggunakan celery python & Node.js
3 Mempelajari Proses Tasks Queue menggunakan bull Node.js, dan membuat Software Design Document
4 - 6 Membuat program Scraping menggunakan Node.js dengan librarry puppeeteer
7 - 8 Optimasi Program Scraping
Pada minggu pertama diawali dengan onboarding pengenalan lingkungan kantor serta pengenalan dengan rekan kerja yang akan berkoordinasi dan bekerja sama selama periode kerja magang. Kemudian mempersiapkan segala aplikasi yang digunakan SIRCLO untuk berkomunikasi seperti membuat akun di Phabricator, Slack, dan Workchat. Mulai diperkenalkan dengan proyek yang akan dikerjakan selama periode magang yaitu Scraper dengan menggunakan Puppeteer.
15 Pada minggu kedua melakukan riset mengenai bagaimana proses tasks queue yang terjadi pada celery python dan bagaimana diimplementasikan menggunakan Node.js. lalu dipresentasikan kepada supervisor.
Pada minggu ketiga melakukan riset tentang tasks queue yang terjad pada bull Node.js, dan cara monitoring tasks queue yang akan dikerjakan aplikasi. Lalu membuat sebuah software design document yang menjelaskan bagaimana alur, dan requirements dari aplikasi scraper.
Pada minggu keempat hingga keenam, tugas yang dilakukan adalah membuat aplikasi scraper secara menyeluruh yang mencangkup proses penyimpanan html dari suatu catalog dan produk toko, proses scraping secara lokal, hingga melakukan testing terhadap aplikasi, proses testing harus dilakukan berkali- kali karena dalam proses scraping banyak format dari html yang berbeda beda, bahkan mengubah kembali alur dari proses aplikasi demi mendapatkan proses yang stabil. Serta menentukan format dari hasil scraping.
Pada minggu ketujuh dan kedelapan, melakukan optimasi aplikasi dimana dioptimasi dari proses menyimpan html catalog dan produk suatu toko yang tidak tidak akan menyimpan gambar dari halaman website sehingga diharapkan proses akan berjalan lebih cepat dan stabil. Serta menerapkan puppeteer-cluster yang membuat proses scraping berjalan seacara paralel. Lalu mengirim hasil scraping ke Google Cloud Storage.
Dalam pelaksanaan kerja magang ini digunakan laptop pribadi Acer Aspire E5 471G dengan spesifikasi sebagai berikut.
1. Processor : Intel Core i5-4210U
16 2. VGA : Nvidia Geforce 820M 2GB
3. Sistem Operasi : Linux Ubuntu 20.04 4. Memori : 12 GB
5. Hardisk : 500 GB HDD
Adapun software (perangkat lunak) dan tools yang digunakan selama pelaksanaan kerja magang adalah sebagai berikut.
• Visual Studio Code: Text Editor untuk mengkoding menyelesaikan tugas yang diberikan.
• Phabricator: Sebagai sarana pengelolaan proses pengembangngan proyek, sebagai sarana pertukaran, review source code.
• Google Chrome: Web browser yang digunakan untuk melakukan proses scraping.
3.3.1 Perancangan
Proses perancangan aplikasi scraper dilakukan dengan menggunakan diagram flowchart yang terdiri dari sembilan proses umum yaitu:
1. Proses keseluruhan program scraper.
2. konfigurasi web browser.
3. Proses mengambil list link Official Stores.
4. Proses Mengambil Catalog dan produk dari Official Stores.
5. Flowchart fungsi get_product().
6. Proses Scraping data dan produk toko.
7. Proses scrapeProduct
17 8. Proses scrapeBrand
9. Proses Upload data JSON ke Google Cloud Storage
A. Flowchart
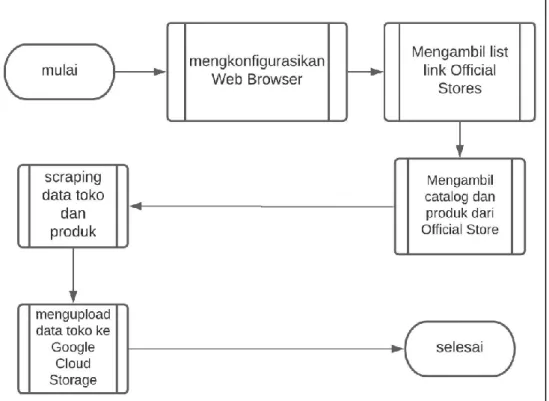
Program scraper mempunyai alur kerja umum yang mempunyai beberapa proses utama yang ditunjukan pada Gambar 3.2.
Gambar 3.2 Flowchart keseluruhan program Scraper
Pada Gambar 3.2 merupakan alur keseluruhan dari program scraper, dimulai dari mengkonfigurasi Web Browser yang akan dipakai dalam proses scraping, mengambil semua link official stores dari Shopee Mall yang kurang lebih berjumlah 3255 official stores yang bergabung dengan Shopee, Mengambil catalog dan produk dari setiap official store yang bermaksud menyimpan halaman toko yang menampilkan list dari produk dan halaman setiap produk ke dalam bentuk
18 Hypertext Markup Language (HTML), Scraping data toko dan produk adalah proses pengambilan data menggunakan file HTML yang telah disimpan diproses sebelumnya dan dibuka di Web Browser secara lokal atau tidak memerlukan jaringan internet karena filenya telah disimpan lalu data yang telah diambil akan disimpan secara lokal dalam format JavaScript Object Notation (JSON) sesuai jumlah toko, dan terakhir mengupload data toko yang telah disimpan dalam bentuk JSON ke Google Cloud Storage (GCS).
Gambar 3.3 Flowchart Proses konfigurasi web browser
Proses mengkonfigurasi Web Browser merupakan tahap membuat Web Browser dengan konfigurasi yang diinginkan dengan menggunakan library puppeteer dapat membuat browser dengan banyak konfigurasi dalam program scraper browser dikonfigurasi dengan 3 parameter yaitu headless, devtools, dan args:[‘—no-sandbox’].
19 1. Headless adalah fitur dari puppeteer yang berfungsi untuk menjalankan web browser secara background process yang berarti saat proses web browser berjalan tidak akan muncul dilayar komputer tetapi tetap berjalan di background process maka dibuat menjadi true agar berjalan di background process.
2. Parameter kedua devtools berfungsi untuk mengijinkan web browser menggunakan tools untuk mengedit sebuah website atau mendiagnosa masalah pada website seperti menggunakan inspect element.
3. Parameter ketiga args:[‘—no-sandbox’], sandbox yang dimaksud adalah untuk melindungi environment dari konten website mencurigakan seperti google chrome yang menggunakan beberapa lapis dari sandbox, karena program scraper sudah jelas ingin mengakses Shopee maka sandbox tidak perlu digunakan.
Variabel page adalah variabel yang digunakan untuk membuat semua page atau tab dalam sebuah website dengan menggunkan fungsi dari puppeteer yaitu browser.newPage(), page.setDefaultNavigationTimeOut(15000) digunakan untuk membuat website menunggu load navigasi hingga 15 detik, dan yang terakhir page.setCacheEnable(false) membuat page tidak menggunakan cache, dengan konfigurasi web browser ini akan digunakan oleh program scraper.
20 Gambar 3.4 Flowchart dari Proses Mengambil list link Official Stores
Pada proses pengambilan dari semua link Official Stores program scraper yang masih dalam proses staging maka tidak perlu mengambil semua Official Stores yang dipunyai oleh Shopee, maka kita membutuhkan nilai dari jumlah toko yang diinginkan, maka variabel filecontents akan membaca semua data yang telah dikonfigurasi di file application.dev.uml, adapun isi file yang dipakai dapat dilihat di Gambar 3.5.
21
Gambar 3.5 Isi Konfigurasi dalam file application.dev.yml
Tahap selanjutnya pada proses pengambilan semua link Official Stores harus meyimpan variabel filecontents ke variabel content, lalu pada variabel max_os akan langsung membaca bagian variabel content dengan indeks [‘max_os’][‘Shopee’] jika dilihat pada Gambar 3.5 berarti nilai datanya adalah 10.
Dengan menggunakan browser dan tab yang telah dikonfigurasi pada Gambar 3.2 akan mengakses website dari dari Shopee mall menggunakan fungsi puppeter yaitu page.goto(), setelah berhasil membuka halaman website yang diinginkan maka untuk mendapatkan semua link dari Official Stores dibutuhkan suatu proses pengulangan yang menggunakan variabel max_os sebagai batas jumlah toko yang ingin diambil, dalam proses pengulanngan yang dilakukan ada proses pengambilan data link toko yang akan ditambahkan ke variabel results setiap kali proses pengulangan berlangsung, jika jumlah toko yang diambil sudah sesuai dengan nilai dari variabel max_os maka pengulangan akan berhenti, maka proses pada
22 pengambilan list link Official Stores sudah selesai dan akan memberikan return value variabel results agar dapat digunakan diproses selanjutnya.
Gambar 3.6 Flowchart Mengambil Catalog dan produk dari Official Stores
Pada tahap mengambil Catalog dan produk dari Official Stores data result yang dilakukan pada proses pengambilan list link Offcial Stores dimasukkan ke dalam variabel data_os, lalu membuat tab browser baru karena proses scraping
23 akan menggunakan 2 tabs yang berbeda, tahap selanjutnya membuat inisialisasi variabel urutan yang nilainya akan dibuat dalam proses pengulangan sesuai dengan jumlah link toko yang telah diambil. Setelah variabel urutan terisi, maka akan menggunakan fungsi shuffle untuk mengacak isi nilai dari varibel urutan. Variabel urutan berguna sebagai urutan proses pencarian data toko, nilainya diacak karena program scraper harus sebisa mungkin mempunyai tingkah laku selayaknya manusia yang mencari toko secara acak.
Lalu pada proses selanjutnya akan melakukan proses pengulangan sesusai jumlah data, tab akan membuka link yang telah diambil dengan indeks menggunakan variabel urutan sehingga akan menggunakan link toko secara acak, halaman pertama yang diakses adalah halaman catalog yang berisi beberapa informasi dari toko¸ maka halaman tersebut akan disimpan dalam bentuk HTML dengan menggunakan nama toko sebagai nama file, dan nama file tersebut akan di push ke variabel info_brands, karena dihalaman catalog mempunyai beberapa produk yang harus di scraping juga maka dalam proses pengulangan ini akan memanggil fungsi get_product() yang akan menyimpan semua halaman produk toko dan akan mengembalikan variabel yang menyimpan nama file html dari produk toko. Sesudah mengujungi semua halaman catalog maka pengulangan akan terhenti dan proses ini akan mengembalikan nilai info_link, urutan, dan data os agar dapat dipakai untuk proses selanjutnya.
24
Gambar 3.7 Flowchart fungsi get_product()
Proses get_product() adalah proses yang menerima link catalog toko yang diberikan dari proses sebelumnya, saat membuka link pada tab page variabel length akan diisi nilai dari jumlah produk yang terdapat pada halaman catalog. Variabel length akan digunakan kembali diproses pengulangan untuk mendapatkan setiap link produk yang ada di halaman catalog ke variabel link_produk. Proses selanjutnya demi membuat program yang mempunyai tingkah laku seperti manusia
25 membutuhkan variabel yang diacak yaitu variabel urutan, lalu tahap terakhir yaitu proses pengulangan sesuai jumlah produk dalam suatu catalog, saat membuka website produk dengan indeks urutan maka variabel nama_barang akan menyimpan nama produk lalu akan menyimpan halaman website produk dalam bentuk HTML dengan format nama file sesuai dengan nama produk. Selanjutnya fungsi get_product akan mengembalikan variabel nama_barang agar dapat dipakai proses sebelumnya.
Gambar 3.8 Flowchart Proses scraping data dan produk toko
Pada proses scraping data dan produk toko terdapat pengulangan sesusai dengan jumlah toko yang telah disimpan kedalam bentul HTML. Dalam proses pengulangan akan menggunakan 2 fungsi untuk scrapeProduct(info_link, i) adalah
26 proses scraping yang dilakukan secara paralel dimana parameter pertama adalah info_link yang memiliki informasi tentang produk-produk dari toko, dan i adalah indeks yang berguna untuk mengeluarkan semua data info_link. Sedangkan untuk fungsi scrapeBrand(info_link, i, page, urutan , data_os) digunakan untuk mendapatkan informasi-informasi dari toko, pada parameter pertama adalah variabel info_link yang memuat data dari halaman produk, untuk mendapatkan informasi toko tetap menggunakan halaman produk karena dihalaman produk ada beberapa informasi yang tidak ada dihalaman catalog, parameter kedua i sebagai indeks dari urutan toko yang mau discrape, parameter ketiga adalah page yaitu tab dari web yang akan dipakai, parameter keempat adalah variabel urutan yang akan dipakai sebagai indeks dari parameter kelima yaitu data_os, karena hasil dari data toko harus ada url dari toko yang terdapat pada variabel data_os yang memiliki indeks variabel urutan.
Tahap selanjutnya varibel product_list dan Brand akan digabungkan menjadi variabel brand_info, selanjutnya menginisialisasi variabel data yang menggunakan fungsi JSON.stringfy() untuk membuat data dalam susunan JSON, hingga membuat file dalam format JSON menggunakan variabel data, belanjut dalam proses pengulangan hingga semua data selesai di-scrape.
27 Gambar 3.9 Flowchart proses scrapeProduct
Pada proses scrapeProduct diawali dengan proses yang sama seperti pada Gambar 3.4 yang membaca file application.dev.uml yang kali ini akan membaca nilai dari total proses yang akan diparalelkan. Selanjutnya membuat variabel cluster yang memiliki nilai dari fungsi dari library puppeteer-cluster untuk membuat sebuah proses paralel dengan menggunakan nilai total_process untuk jumlah dari proses yang akan dijalankan, dan monitor menjadi true yang berfungsi akan memunculkan log dari proses pengerjaan scraping. Lalu terdapat proses pengulangan yang akan membuat variabel file_name dan folder_path yang
28 digunakan untuk membuat sebuah link dari file HTML yang telah disimpan pada tahap-tahap sebelumnya dan menjadi nlai dari variabel products_offline.
Dalam proses paralel ini menerapkan konsep tasks queue sehinga dalam proses pengulangan ini menggunakan fungsi cluster.queue(products_offline), berarti variabel products_offline yang memiliki nilai link dari produk akan masuk kedalam list antrian dalam proses. Saat sudah ada job yang akan dilakukan maka puppeteer-cluster akan mengeksekusi variabel products_offline yang merupakan link dari produk lalu hasilnya akan ditampung di varibel products. Setelah proses paralel selesai maka akan ditampil di variabel semua_product, dan proses ini akan mengembalikan variabel semua_product agar dapat digunakan proses selanjutnya.
Gambar 3.10 Flowchart proses scrapeBrand
29 Pada tahap scrapeBrand diawali dengan proses inisialisasi variabel file_name dan folder_path sama seperti tahap prosese scrapeProduct yang membedakannya adalah pada proses ini membutuhkan variabel brand_offline yang menampung nilai dari link halaman catalog toko. Demi mendapatkan informasi yang lengkap maka proses pengambilan data toko dilakukan sebanyak dua kali yaitu membuka halaman produk, lalu membuka halaman catalog karena ada beberapa informasi toko yang tidak terdapat pada halaman catalog tetapi ada di halaman produk.
Sehingga pertama kali akan membuka tab page dengan membuka link products_offline yang akan mendapatkan informasi seperti alamat, total produk, waktu pertama kali toko bergabung dengan Shopee, dan frekuensi membalas pesan ke pelanggan. Setelah data dari halaman produk didapatkan maka akan dimasukan ke dalam variabel address, tahap terakhir adalah membuka halaman catalog sehingga mendapatkan data nama, rating, dan jumlah pengikut dari toko. Data dari halaman catalog akan disimpan ke variabel Brand, maka variabel address akan disatukan kedalam variabel Brand, dan fungsi scrapeBrand akan mengembalikan variabel Brand yang akan digunakan pada tahap Gambat 3.8. Sesudah mendapatkan semua data dan dijadikan kedalam bentuk JSON maka akan di upload ke Google Cloud Storage, dengan proses yang dapat dilihat pada Gambar 3.11.
30
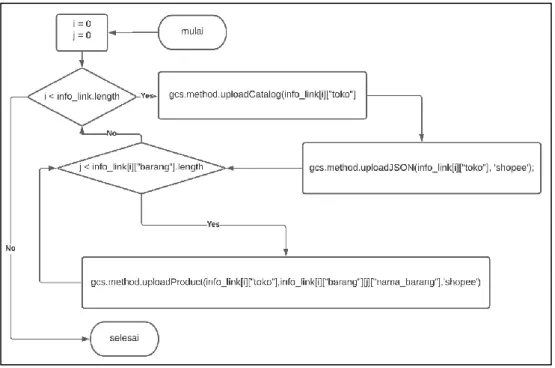
Gambar 3. 11 Flowchart proses Upload Data JSON ke Google Cloud Storage
Pada proses meng-upload data ke Google Cloud Storage, hanya memerlukan link atau path dari file JSON dan HTML yang telah disimpan. Dalam proses ini ada 2 proses pengulangan, yang pertama melakukan proses pengulangan sesuai jumlah toko yang ada, yang kedua melakukan pengulanngan sesuai jumlah produk dari toko yang diinginkan, sehingga pada proses pengulangan pertama akan mengupload file JSON dan halaman catalog dari toko, setelah berhasil mengupload file JSON dan catalog dari toko maka akan masuk ke proses pengulangan kedua yang akan mengupload semua halaman produk dari toko, jika sudah selesai akan kembali kepengulangan pertama hingga berhasil mengupload informasi semua toko. Adapun fitur yang tak tergambarkan di flowchart yaitu fitur retry yang digunakan di setiap proses pengulangan ada fitur retry yang berguna saat aplikasi mengalami eror maka proses akan diulangi kembali.
31
3.3.2 Implementasi Aplikasi
Program scraper sebelumnya ingin menggunakan docker agar dapat dijalankan di semua perangkat dengan berbagai operating system, tetapi saat proses implementasi ada beberapa masalah dengan Node.js terutama dengan puppeteer, sehingga cara menjalankan program yang akan baru digunakan hanya dengan menggunakan command “npm install” untuk menginstall semua modul-modul yang dibutuhkan oleh program yang caranya dapat dilihat pada Gambar 3.12.
Gambar 3.12 Instalasi Aplikasi
Setelah menginstall semua modul, karena program yang dikerjakan adalah untuk Shopee, maka harus pindah ke directory Shopee dengan command “cd Shopee”, lalu untuk menjalankan program dengan command “node index.js” maka program akan bekerja, yang dapat dilihat pada Gambar 3.12.
Gambar 3.13 Menjalankan Program
32 Setelah aplikasi berhasil menyimpan semua halaman website menjadi bentuk HTML maka proses paralel akan langsung bekerja, seperti pada Gambar 3.14.
Gambar 3.14 Proses Paralel
Proses yang terjadi pada Gambar 3.14 adalah proses paralel yang menggunakan puppeteer-cluster dengan mode monitoring yang dapat dilihat dari waktu saat memulai hingga progress dari proses paralel, serta progress file yang harus dikerjakan, jumlah workers yang digunakan, total resource CPU dan memory yang digunakan, dan setiap pekerjaan setiap worker. Setelah proses scraping selesai, maka aplikasi akan menyimpan semua data dalam bentuk JSON, dengan format seperti pada Gambar 3.15.
33 Gambar 3.15 Data hasil Scraping dalam bentuk JSON
Setelah berhasil mendapatkan data dan membuat dalam bentuk JSON, maka tahap terakhir dari aplikasi adalah meng-upload data ke Google Cloud Storage, prosesnya terdapat pada Gambar 3.16 dengan menampilkan log dari proses yang dijalankan.
Gambar 3. 16 Proses Meng-upload data ke Google Cloud Storage
34 3.4 Kendala yang Ditemukan
Secara umum kendala-kendala yang ditemui adalah sebagai berikut.
• Pemilihan Bahasa pemrograman dan Library yang akan digunakan untuk program scraper, karena dalam proses kerja magang pihak perusahaan belum tahu untuk menggunakan bahasa dan library apa untuk diimplementasikan, sehingga meminta untuk mempelajari beberapa library seperti Celery Python, Node.js, Puppeteer, Puppeteer-cluster, dan Bull Node.js.
• Pengimplementasian pembelajaran sebelumnya, yang sering membuat banyak perubahan karena ternyata library yang dipilih kurang revelan untuk digunakan, seperti contoh dalam proses paralel sebelumnya ingin menggunakan celery python, tetapi dalam proses scraping menggunakan Node.js, sehingga saat menjalankan program celery python akan dihubungkan dengan Node.js. Yang menjadi kendala adalah disaat Node.js sedang bekerja celery python tidak dapat memonitor pekerjana dari Node.js.
• Membutuhkan koneksi internet yang stabil dan baik. Kebutuhan ini sangat dibutuhkan karena program hanya dapat berjalan jika ada koneksi yang cepat dan stabil.
• Membutuhkan banyak testing, karena program scraper melakukan Document Object Model (Model) dan dalam suatu website pasti mempunyai banyak tampilan yang berbeda-beda atau tidak terpikirkan oleh programmer.
• Sering mengubah struktur dari cara kerja program karena ingin mendapatkan hasil kerja yang optimal.
35 3.5 Solusi atas Kedala yang Ditemukan
Adapun solusi dari kendala yang ditemui adalah sebagai berikut.
• Inisiatif untuk memberikan progress belajar kepada supervisor, dan jika diperlukan menanyakan saran tahap apa lagi yang perlu dilakukan.
• Meluangkan waktu diluar jam kerja untuk melakukan testing program.
• Berkonsultasi kepada supervisor, senior, atau teman satu tim jika ada kendala dalam proses belajar atau implementasi.
• Mencoba menjalakankan program bersama-sama dengan satu tim dan memecahkan masalah bersama-sama.