PERINGKASAN ARTIKEL ILMIAH BAHASA INDONESIA BERBASIS RHETORICAL ROLE MENGGUNAKAN
SUPPORT VECTOR MACHINE
SKRIPSI
SILVIA MAWARNI 151402097
PROGRAM STUDI S1 TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
MEDAN 2021
PERINGKASAN ARTIKEL ILMIAH BAHASA INDONESIA BERBASIS RHETORICAL ROLE MENGGUNAKAN
SUPPORT VECTOR MACHINE
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah Sarjana Teknologi Informasi
SILVIA MAWARNI 151402097
PROGRAM STUDI S1 TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
MEDAN 2021
i
PERSETUJUAN
Judul : PERINGKASAN ARTIKEL ILMIAH BAHASA
INDONESIA BERBASIS RHETORICAL ROLE MENGGUNAKAN SUPPORT VECTOR MACHINE
Kategori : SKRIPSI
Nama : SILVIA MAWARNI
Nomor Induk Mahasiswa : 151402097
Program Studi : TEKNOLOGI INFORMASI
Fakultas : ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Indra Aulia S.TI., M.Kom. Dr. Erna Budhiarti Nababan M.IT.
NIP.199005302017041001 NIP. 196210262017042001
Diketahui/disetujui oleh
Program Studi S1 Teknologi Informasi Ketua,
Romi Fadillah Rahmat B.Comp.Sc., M.Sc NIP.198603032010121004
PERNYATAAN
PERINGKASAN ARTIKEL ILMIAH BAHASA INDONESIA BERBASIS RHETORICAL ROLE MENGGUNAKAN
SUPPORT VECTOR MACHINE
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil karya saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing telah disebutkan sumbernya.
Medan, Juni 2021
SILVIA MAWARNI 151402097
iii
UCAPAN TERIMA KASIH
Puji dan syukur penulis sampaikan ke hadirat Allah Subhanallahu wa Ta’ala yang telah memberikan rahmat dan ridho-Nya sehingga penulis dapat menyelesaikan skripsi ini untuk memperoleh gelar Sarjana Komputer pada Program Studi S1 Teknologi Informasi Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara. Skripsi ini penulis persembahkan untuk ibunda penulis, R. Marpaung, yang semasa hidupnya dengan sabar dan penuh kasih sayang membesarkan dan membimbing penulis dan kedua adik penulis. Semoga setelah ini penulis dapat melangkah lebih jauh untuk membuat beliau bangga. Skripsi ini sangat berarti bagi penulis karena dukungan, doa, dan bantuan dari berbagai pihak, oleh karena itu dalam kesempatan ini penulis ingin mengucapkan terima kasih sebesar-besarnya kepada:
1. Ibunda penulis, R. Marpaung, yang walaupun tidak sempat melihat penulis mengerjakan skripsi ini akan selalu penulis rasakan hangat dukungannya lewat kenangan-kenangan yang ditinggalkan. Ayah penulis, R. Thahir, yang senantiasa mendoakan, mendukung, serta dengan sabar memberikan ruang bagi penulis untuk menyelesaikan skripsi ini tanpa desakan. Adik-adik penulis, Irvan dan Alvian, yang selalu menghibur penulis serta menjadi teman yang baik bagi penulis selama pengerjaan skripsi ini.
2. Tobio, kucing penulis yang suatu hari muncul dan menjadi dorongan bagi penulis untuk kembali menata hidup di tengah pandemi yang sedang dilalui serta senantiasa menghibur penulis.
3. Ibu Dr. Erna Budhiarti Nababan, M.IT. selaku dosen pembimbing pertama dan Bapak Indra Aulia S.TI., M.Kom. selaku dosen pembimbing kedua yang telah memberikan dukungan, bimbingan, dan saran yang membangun dan bermanfaat dalam proses pengerjaan skripsi ini.
4. Bapak Ainul Hizriadi, S.Kom, M.Sc. dan Bapak Dani Gunawan, ST., MT. selaku dosen penguji pertama dan kedua yang telah memberikan saran dan kritik yang membangun dan bermanfaat dalam penyelesaian skripsi ini.
5. Segenap dosen, seluruh staff akademik, staff keamanan, dan staff kebersihan Teknologi Informasi USU yang selalu membantu memberikan ilmu pengetahuan
dan/atau fasilitas yang menunjang proses perkuliahan dan penyelesaian skripsi penulis.
6. Para pencarikeramaian (Annadya, Adina, Ayu, Melissa, Noudika, Shifani, dan Yesi) yaitu sahabat-sahabat penulis yang senantiasa menemani penulis semasa perkuliahan dan menjadikan waktu yang penulis lalui bersama mereka menjadi waktu yang membahagiakan penulis. Wacana (Dhany, Faris, Faris Z., Hadyurrahman, Indirwan, Luhur, Ravie, Rhama, Riyandi, dan Tata) teman-teman penulis yang sangat menghibur penulis dan menjadi teman yang baik bagi penulis.
7. Yesi Angrainy Sihombing, S.Kom. dan Bang M. Faris Pratama, S.Kom yang senantiasa menanyakan kabar, mendengarkan keluh kesah penulis, dan memberikan dukungan semangat yang terasa sungguh hangat dan sangat berarti bagi penulis.
8. Kak Nadya Maysyarah, S.Kom., Bang Ibnu Habibie, S.Kom., dan Bang Fachrin Aulia Nasution, S.Kom. yang telah memberikan dukungan, ilmu, serta menjadi inspirasi dan contoh yang baik bagi penulis selama masa perkuliahan hingga kini.
9. Bang Isa Dadi, S.Kom, Bang Ridho Fariha, S.Kom., Faris Zharfan Alif, S.Kom., M.
Arka Kharisma, S.Kom., dan Firza Rinandha, S.Kom., yang tanpa pamrih senantiasa bersedia menjawab berbagai pertanyaan teknis maupun non-teknis terkait skripsi penulis yang sangat membantu penulis.
10. Sahabat-sahabat penulis semasa SMA, Miranda, Azrina, dan Diva yang telah menghilangkan lelah dan penat penulis dalam sekali temu pada suatu hari itu di tengah pengerjaan skripsi ini, semoga kita dapat segera bertemu lagi.
11. Teman-teman Teknologi Informasi USU yang telah mengisi hari-hari penulis selama masa studi dan pengerjaan skripsi ini dengan kenangan yang baik.
Semoga Allah Subhanallahu wa Ta’ala melimpahkan nikmat dan karunia-Nya kepada semua pihak yang telah memberikan bantuan, perhatian, serta dukungan kepada penulis dalam menyelesaikan skripsi ini.
Medan, Juni 2021
Penulis
v
ABSTRAK
Pengindeks jurnal ilmiah memudahkan para pembaca atau peneliti dalam mencari berbagai artikel ilmiah untuk dijadikan referensi atau sekadar menambah ilmu pengetahuan. Namun, dihadapkan dengan banyaknya pilihan juga dapat menimbulkan kesulitan dalam memilih artikel sesuai preferensi karena banyaknya artikel yang membahas topik serupa dengan rincian yang cukup berbeda. Beberapa abstrak jurnal yang memperlihatkan isi artikel secara ringkas pun tidak tersedia dalam format yang seragam sehingga informasi yang tersedia dalam suatu abstrak tidak ditemukan dalam abstrak lainnya. Hal ini menjadi masalah saat membandingkan artikel ilmiah dan memilah publikasi yang sesuai dengan preferensi. Penelitian ini mengklasifikasikan kalimat-kalimat dalam artikel ilmiah berbahasa Indonesia berdasarkan perannya (rhetorical roles) kemudian menyusun ringkasan terstruktur berdasarkan hasil klasifikasi tersebut. Dengan ini paragraf yang dihasilkan tidak hanya ringkas, tetapi juga rinci dan terstruktur. Metode klasifikasi yang digunakan adalah Support Vector Machine (SVM). Kemudian TextRank digunakan untuk memeringkatkan kalimat- kalimat hingga akhirnya tersusun menjadi ringkasan dalam bentuk abstrak. Klasifikasi biner kalimat dengan SVM untuk memilih kalimat penting menghasilkan nilai rata-rata akurasi sebesar 85.26%, precision 71.5%, recall 46.1%, dan F1-score sebesar 54.6%.
Pelabelan rhetorical roles kalimat dengan SVM menghasilkan rata-rata akurasi sebesar 65.87%. Hasil akhir sistem kemudian dievaluasi dengan pertanyaan. Karena beberapa faktor, masih banyak kalimat-kalimat dalam ringkasan akhir yang tidak relevan atau berhubungan dengan rhetorical role yang diberikan.
Kata kunci: peringkasan teks, klasifikasi kalimat, pemeringkatan kalimat, support vector machine, textrank
SUMMARIZATION OF INDONESIAN SCIENTIFIC ARTICLES BASED ON RHETORICAL ROLES USING SUPPORT VECTOR MACHINE
ABSTRACT
Scientific journal indexers make it easier for readers or researchers to find various scientific articles to be used as references or simply to improve one’s knowledge.
However, being faced with a large number of choices can also make selecting articles according to preference more complicated since many articles cover similar topics with quite different details. Some journal abstracts are not available in a consistent format so the information available in an abstract might not be found in others. Problems might arise when comparing scientific articles and sorting out publications according to preference. This study classifies sentences in Indonesian scientific articles based on their rhetorical roles, then compiles a structured summary based on the classification results. Thus, the resulting paragraph is not only concise, but also detailed and structured. The classification method used is the Support Vector Machine (SVM), then TextRank is used to rank sentences before compiled into a summary in abstract form.
Binary classification with SVM to select important sentences resulted in an average accuracy of 85.26%, 71.5% precision, 46.1% recall, and an F1-score of 54.6%.
Rhetorical role labelling of the sentences with SVM resulted in an average accuracy of 65.87%. The final results of the system are then evaluated with questions regarding its relevance to the assigned rhetorical role. Due to several factors, there are still sentences in the final summary that are not relevant or related to the assigned rhetorical role.
Keywords: text summarization, sentence classification, sentence ranking, support vector machine, textrank
vii
DAFTAR ISI
Hal.
PERSETUJUAN i
PERNYATAAN ii
UCAPAN TERIMA KASIH iii
ABSTRAK v
ABSTRACT vi
DAFTAR ISI vii
DAFTAR TABEL x
DAFTAR GAMBAR xi
BAB 1 PENDAHULUAN 1
1.1. Latar Belakang 1
1.2. Rumusan Masalah 3
1.3. Batasan Masalah 3
1.4. Tujuan Penelitian 3
1.5. Manfaat Penelitian 3
1.6. Metodologi Penelitian 4
1.7. Sistematika Penulisan 5
BAB 2 LANDASAN TEORI 6
2.1. Artikel Ilmiah 6
2.2. Ringkasan 6
2.3. Rhetorical Roles Classification 7
2.4. Support Vector Machine 7
2.5. TF-IDF 10
2.6. Textrank 11
2.7. Penelitian Terdahulu 12
BAB 3 ANALISIS DAN RANCANGAN 16
3.1. Data yang Digunakan 16
3.2. Arsitektur Umum 16
3.2.1. Input 17
3.2.2. Persiapan Data 17
3.2.3. Preprocessing 19
3.2.4. Klasifikasi Kalimat 20
3.2.5. Pelabelan Rhetorical Role Kalimat 21
3.2.6. Pemeringkatan dan Penyusunan Kalimat 22
3.2.7. Keluaran 23
3.3. Perancangan Antarmuka 24
3.3.1. Rancangan Tampilan Halaman Beranda 24
3.3.2. Rancangan Tampilan Halaman Ringkasan 25
3.4. Metode Evaluasi 26
BAB 4 IMPLEMENTASI DAN PEMBAHASAN 28
4.1. Implementasi Sistem 28
4.2. Implementasi Perancangan Antarmuka 28
4.2.1. Tampilan Halaman Beranda 28
4.2.2. Tampilan Halaman Ringkasan 29
4.3. Pengujian Sistem 31
4.3.1. Data 31
4.3.2. Klasifikasi Kalimat 33
4.3.3. Pelabelan Rhetorical Role Kalimat 35
ix
4.3.4. Pemeringkatan Kalimat 37
4.3.5. Hasil 40
BAB 5 KESIMPULAN DAN SARAN 45
5.1. Kesimpulan 45
5.2. Saran 46
DAFTAR PUSTAKA 47
DAFTAR TABEL
.
Hal.
Tabel 2.1. Penelitian Terdahulu 13
Tabel 3.1. Contoh Hasil Pemeringkatan dengan Textrank 22
Tabel 4.1. Distribusi Label Data Latih 31
Tabel 4.2. Distribusi Label Data Uji 31
Tabel 4.3. Rincian Hasil Klasifikasi untuk Klasifikasi Kalimat 34 Tabel 4.4. Nilai akurasi klasifikasi dengan parameter-parameter yang
dicoba
35
Tabel 4.5. Distribusi Hasil Pelabelan Kalimat 36
Tabel 4.6. Hasil Pemeringkatan Kalimat Dokumen No. 17 37 Tabel 4.7. Hasil Evaluasi Ringkasan dengan Pertanyaan Pelabelan 41
xi
DAFTAR GAMBAR
Hal.
Gambar 2.1. Linear Support Vector Machine 7
Gambar 3.1. Arsitektur Umum 17
Gambar 3.2. Contoh Konversi File PDF ke .txt 18
Gambar 3.3. Data dalam Format CSV 18
Gambar 3.4. Contoh Kalimat dan Pelabelannya 19
Gambar 3.5. Kalimat Orisinal dan Kalimat Setelah Pembersihan 20 Gambar 3.6. Contoh Kalimat dan Label Biner Summary-worthy 21 Gambar 3.7 Dataframe Berisi Contoh Hasil Pelabelan Kalimat 21
Gambar 3.8. Contoh Keluaran Akhir 23
Gambar 3.9. Rancangan Tampilan Halaman Beranda 24
Gambar 3.10. Rancangan Tampilan Halaman Ringkasan/Hasil 25
Gambar 4.1. Tampilan Halaman Beranda 28
Gambar 4.2. Tampilan Halaman Ringkasan Bagian Keluaran Akhir / Ringkasan
29 Gambar 4.3. Tampilan Halaman Ringkasan Bagian Sentence Removal 30 Gambar 4.4. Tampilan Halaman Ringkasan Bagian Sentence Labelling 30
Gambar 4.5. Beberapa kalimat hasil pembersihan 32
Gambar 4.6. Contoh kalimat serupa yang tersaring difflib 40
Gambar 4.7. Hasil Ringkasan Dokumen No. 12 42
Gambar 4.8. Hasil Ringkasan Dokumen No. 17 43
Gambar 4.9. Hasil Ringkasan Dokumen No. 19 44
Gambar 4.10. Hasil Ringkasan Dokumen No. 5 44
BAB 1 PENDAHULUAN
1.1. Latar Belakang
Dengan bantuan teknologi dan media pengindeks, kini publikasi jurnal yang dapat diakses masyarakat terus bertambah. Dengan akses ini, lebih banyak rujukan atau ide- ide yang dapat dikumpulkan sehingga semakin memacu munculnya penelitian- penelitian baru. Dalam laporan STM (2018) tercatat bahwa hingga pertengahan tahun 2018 terdapat sekitar 33.100 jurnal ilmiah dalam bahasa Inggris yang secara kolektif menerbitkan lebih dari 3 juta artikel dalam setahun. Di Indonesia, situs Garuda (Garba Rujukan Digital) mengindeks 128.409 artikel ilmiah diterbitkan pada tahun 2018.
Hingga September 2019, situs Garuda telah mengindeks 890,726 artikel ilmiah. Angka publikasi artikel ilmiah terus tumbuh seiring berjalannya waktu sehingga dibutuhkan alat bantu yang mampu memudahkan proses penelusuran informasi dari artikel-artikel ilmiah tersebut.
Di antara ragam cara memudahkan penelusuran informasi artikel ilmiah adalah lewat peringkasan. Salah satu penelitian terdahulu mengenai peringkasan artikel ilmiah adalah penelitian oleh (Luhn, 1958) dengan premis frekuensi kata tertentu dalam sebuah artikel menunjukkan relevansinya. (Kupiec, Pedersen, & Chen, 1995) membuat peringkasan dengan menentukan kelayakan kalimat yang akan diekstraksi menggunakan klasifikasi Naive-Bayes. (Qazvinian & Radev, 2008) meneliti peringkasan artikel ilmiah berbasis sitasi dengan memanfaatkan artikel-artikel ilmiah lain yang mengutip artikel yang akan diringkas.
Pada akhirnya, target peringkasan selain menghasilkan teks yang lebih ringkas adalah menghasilkan teks yang dapat memberikan informasi yang cukup dalam jumlah kalimat yang terbatas. Untuk mencapai target tersebut, salah satu solusi yang diusulkan adalah dengan klasifikasi rhetorical role (Blais et al., 2007; Liakata et al., 2013; Teufel
& Moens, 2002). Ketika konteks kalimat-kalimat dalam artikel ilmiah telah diketahui
2
maka akan lebih mudah memilih campuran kalimat yang tepat untuk digunakan sebagai hasil ringkasan. Misalnya seperti pada penelitian (Teufel & Moens, 2002) kalimat- kalimat dalam artikel ilmiah diklasifikasikan ke dalam tujuh kategori, yaitu Aim, Textual, Own, Background, Contrast, Basis, dan Other. (Liakata et al., 2012) mengklasifikasikan ke dalam sebelas kategori: Background (BAC), Hypothesis (HYP), Motivation (MOT), Goal (GOA), Object (OBJ), Method (MET), Model (MOD), Experiment (EXP), Observation (OBS), Result (RES) dan Conclusion (CON), menggunakan SVM dan CRF. Strategi tersebut telah digunakan dalam beberapa penelitian peringkasan dengan alur yang bervariasi. (Atkinson & Munoz, 2013) menentukan rhetorical role kalimat-kalimat sebelum memilih kalimat yang cocok untuk menjadi kandidat kalimat dalam ringkasan. (Teufel & Moens, 1999) menyeleksi kalimat-kalimat penting sebelum mengklasifikasi untuk meminimalisir jumlah kalimat yang harus diklasifikasi. Dalam hal ini, penulis ingin mengimplementasikan pendekatan yang serupa dengan penelitian Teufel & Moens yang telah disebutkan di atas.
Klasifikasi kalimat sesuai rhetorical role-nya dapat dilakukan dengan menggunakan algoritma SVM. Beberapa penelitian terkait telah dilakukan sebelumnya.
(Khodra et al., 2011) menemukan bahwa SVM dan Logistic memberikan hasil terbaik.
(Khodra et al., 2012; Widyantoro et al., 2013) juga menyimpulkan SVM memberikan performa terbaik dengan one-against-all SVM classifier.
Kemudian metode Textrank digunakan untuk memilih kalimat di peringkat teratas dari masing-masing kategori untuk menghasilkan paragraf ringkasan. (Gulden et al., 2019) meringkas deskripsi uji klinis dengan beberapa algoritma peringkasan teks dan menemukan bahwa Textrank menunjukkan kinerja terbaik. (Wang et al., 2020) memanfaatkan Textrank yang kemudian dikombinasikan Seq2Seq untuk menghasilkan paragraf pendahuluan untuk makalah ilmiah karena Textrank tidak membutuhkan intervensi manual atau data latih.
Pemaparan di atas menjadi latar belakang judul skripsi “Peringkasan Artikel Ilmiah Bahasa Indonesia Berbasis Rhetorical Roles Menggunakan Support Vector Machine”.
Hasil yang diharapkan dari penelitian ini adalah sebuah sistem peringkas artikel ilmiah yang mampu menghasilkan ringkasan yang terstruktur untuk membantu pembaca mengetahui isi suatu artikel ilmiah secara singkat atau membantu pembaca dalam memilih artikel ilmiah yang ingin dipelajari lebih lanjut.
1.2. Rumusan Masalah
Angka publikasi artikel ilmiah terus tumbuh seiring berjalannya waktu, sementara pembaca memiliki waktu yang terbatas untuk membaca keseluruhan artikel dan memilih artikel ilmiah yang sesuai preferensinya. Abstrak pun memiliki struktur yang beragam dan terkadang memiliki porsi yang tidak proporsional, misalnya lebih banyak menggambarkan masalah daripada deskripsi metode. Oleh karena itu, dibutuhkan sistem yang membantu menyeragamkan proses penelusuran informasi dari artikel- artikel ilmiah tersebut.
1.3. Batasan Masalah
Untuk menghindari perluasan dan penyimpangan yang tidak diperlukan dalam penelitian ini, maka penulis membuat batasan sebagai berikut:
a. Artikel ilmiah yang digunakan adalah artikel jurnal ilmiah yang menggunakan Bahasa Indonesia yang sesuai dengan kaidah-kaidah Bahasa Indonesia.
b. Artikel ilmiah yang digunakan adalah artikel ilmiah bidang teknologi informasi dan ilmu komputer
c. Tidak menangani tabel, persamaan, gambar, dan sitasi.
1.4. Tujuan Penelitian
Tujuan utama penelitian ini adalah menghasilkan sistem peringkasan artikel ilmiah yang menghasilkan ringkasan terstruktur yang mendukung serta meningkatkan keinformatifan abstrak sehingga proses penelusuran informasi artikel ilmiah menjadi lebih mudah.
1.5. Manfaat Penelitian
Penelitian ini diharapkan mampu meningkatkan keinformatifan abstrak dengan cakupan ringkasannya yang lebih luas namun terfokus. Penelitian ini juga diharapkan mampu menyingkat waktu yang diperlukan untuk menelusuri informasi dari suatu artikel ilmiah ke artikel ilmiah lainnya dengan ringkasan yang terstruktur dan seragam.
4
1.6. Metodologi Penelitian
Tahapan-tahapan yang dilakukan dalam penelitian ini adalah sebagai berikut:
1. Studi Literatur
Studi literatur dilakukan dengan mencari dan mengumpulkan bahan referensi serta mempelajari jurnal, buku, dan situs yang berkaitan dengan peringkasan teks, metode-metode klasifikasi kalimat, dan pemeringkatan teks.
2. Analisis Permasalahan
Analisis permasalahan dari informasi yang diperoleh dari berbagai sumber pada tahapan studi literatur untuk memilih metode yang tepat untuk menyelesaikan permasalahan yang diangkat, dalam hal ini algoritma-algoritma yang terpilih adalah SVM dan TextRank.
3. Pengumpulan Data
Pengumpulan data diperlukan untuk dijadikan data latih dan data uji sistem. Data penelitian ini bersumber dari situs Garba Rujukan Digital (Garuda), yaitu sebuah situs pengindeks publikasi ilmiah di Indonesia yang dikelola oleh Kementerian Riset, Teknologi, dan Pendidikan Tinggi.
4. Perancangan Sistem
Antarmuka dan arsitektur umum dirancang berdasarkan analisis permasalahan yang telah dilakukan sebelumnya untuk dijadikan acuan agar memudahkan tahap implementasi.
5. Implementasi
Pada tahap ini rancangan sistem yang telah disusun sebelumnya diimplementasikan ke dalam kode menggunakan bahasa pemrograman Python.
6. Pengujian
Hasil implementasi rancangan peringkas otomatis pada tahap sebelumnya diuji untuk mengukur kinerja algoritma yang digunakan dan memastikan sistem telah berjalan sesuai dengan yang diharapkan.
7. Dokumentasi dan Penyusunan Laporan
Pada tahap ini dilakukan dokumentasi dan penyusunan laporan hasil implementasi SVM dan TextRank untuk peringkasan artikel ilmiah berbahasa Indonesia yang telah dilakukan.
1.7. Sistematika Penulisan
Sistematika penulisan skripsi ini dibagi menjadi beberapa bagian sebagai berikut:
Bab 1: Pendahuluan
Bagian ini membahas latar belakang pemilihan judul skripsi ini, batasan permasalahan, tujuan penelitian, manfaat penelitian, metodologi penelitian, dan sistematika penulisan.
Bab 2: Landasan Teori
Dalam bab ini dibahas teori-teori seperti metode klasifikasi kalimat, dalam dan metode penyusunan kalimat menjadi paragraf yang digunakan untuk memahami permasalahan dan solusi yang diangkat dalam penelitian ini.
Bab 3: Analisis dan Perancangan
Analisis metode dan perancangan arsitektur umum untuk menghasilkan peringkas otomatis artikel ilmiah teknologi informasi berbahasa Indonesia yang menjadi pembahasan dalam penelitian ini akan dibahas dengan rinci dalam bab ini.
Bab 4: Implementasi dan Pengujian
Bab ini berisi dokumentasi pengimplementasian sistem seperti gambaran antarmuka sistem yang dibuat dan perwujudan dari perancangan yang dibahas dalam bab sebelumnya. Bab ini juga memaparkan hasil pengujian sistem yang telah dibangun.
Bab 5: Kesimpulan dan Saran
Bab ini merangkum kesimpulan yang didapatkan dari hasil penelitian serta menjabarkan beberapa saran pengembangan yang dapat dijadikan sebagai referensi untuk penelitian lebih lanjut terkait peringkasan artikel ilmiah.
BAB 2
LANDASAN TEORI
2.1. Artikel Ilmiah
Artikel ilmiah merupakan suatu jenis tulisan ilmiah yang berdasarkan suatu observasi dan dipublikasikan dalam jurnal ilmiah. Umumnya artikel ilmiah ditulis oleh para profesor, peneliti, dan mahasiswa. Kata-kata yang digunakan cenderung dalam artikel ilmiah cenderung bersifat teknis.
Artikel ilmiah diharuskan mengikuti standar jurnal yang memuatnya. Pada umumnya, suatu artikel ilmiah memiliki bagian-bagian berikut: judul, abstrak, pendahuluan, landasan teori, karya terkait, teknik yang digunakan, analisis data, hasil observasi, kesimpulan, dan referensi.
2.2. Ringkasan
Ringkasan dapat diartikan sebagai teks yang dihasilkan dari satu teks atau lebih, yang menguraikan informasi penting dari teks aslinya secara lebih singkat dan tidak lebih panjang dari setengah teks aslinya (Radev, Hovy, & McKeown, 2002).
(Radev et al., 2002) menyebutkan beberapa istilah dalam peringkasan: ekstraksi dalam mengidentifikasi bagian-bagian penting dari teks dan menghasilkannya kata demi kata; abstraksi bertujuan untuk menguraikan informasi penting dengan cara baru;
fusion menggabungkan bagian-bagian yang diekstraksi secara koheren; dan kompresi bertujuan untuk membuang bagian teks yang tidak penting.
Pada awal perkembangan peringkasan otomatis, (Luhn, 1958) mengemukakan bahwa banyaknya suatu kata muncul dalam suatu teks dapat menjadi ukuran signifikansinya. Kemudian seiring berjalannya waktu, penelitian-penelitian lainnya dilakukan dengan memanfaatkan pembelajaran mesin. Seperti yang dilakukan Kupiec et al. (1995) yaitu mengklasifikasi kata-kata yang cocok untuk dimuat dalam ringkasan menggunakan Bayesian classifier. Metode tersebut mampu belajar dari data. Kini,
metode peringkasan otomatis dilakukan menggunakan neural networks hingga metode deep natural language analysis.
2.3. Rhetorical Roles Classification
Peran suatu kalimat dalam tulisan telah diteliti proses klasifikasinya beberapa kali dengan sebutan yang beragam, misalnya Rhetorical Status atau Discourse Structure.
Klasifikasi ini bermanfaat untuk menciptakan ringkasan yang lebih fleksibel (tailored summary) dan untuk merangkum banyak aspek penting dari berkas yang diringkas sesuai dengan standar yang telah ditetapkan. Standar yang dimaksud adalah template atau annotation scheme untuk peran kalimat. Untuk artikel ilmiah, beberapa skema anotasi yang sering dirujuk adalah skema anotasi oleh Teufel et al. (1999) yang terdiri atas Background, Other, Own, Aim, Textual, Contrast, dan Basis, kemudian CoreSC (Liakata et al., 2013) terdiri atas Background, Hypothesis, Motivation, Goal, Object, Method, Model, Experiment, Observation, Result, dan Conclusion.
2.4. Support Vector Machine
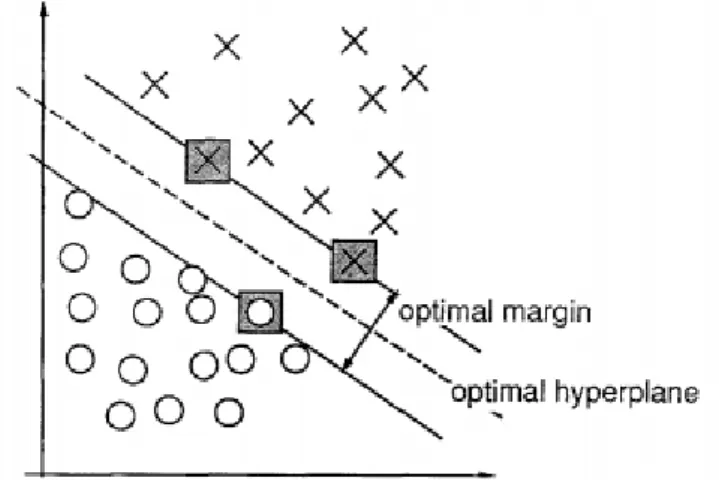
Support Vector Machine (SVM) adalah salah satu algoritma supervised dalam pembelajaran mesin yang digunakan untuk menyelesaikan permasalahan klasifikasi (Support Vector Classification) atau regresi (Support Vector Regression). Saat pertama kali diciptakan, algoritma ini diperuntukkan untuk permasalahan klasifikasi biner linear (Cortes & Vapnik, 1995). Ide awalnya adalah memetakan vektor masukan ke dalam suatu ruang fitur berdimensi tinggi lewat pemetaan non-linear. Dalam ruang tersebut kemudian dibangun suatu permukaan keputusan linear (hyperplane) dengan kriteria- kriteria yang memberikan jaringan tersebut kemampuan generalisasi yang tinggi (Cortes & Vapnik, 1995). Ide tersebut digambarkan dalam Gambar 2.1.
Gambar 2.1. Linear Support Vector Machine (Cortes & Vapnik, 1995)
8
Model SVM perlu kemampuan generalisasi yang tinggi agar tetap dapat memetakan data-data masukan yang baru dengan baik. Hal tersebut, seperti yang disebutkan di atas, dicapai dengan membangun hyperplane yang optimal. Hyperplane yang optimal adalah hyperplane dengan jarak maksimal antara titik-titik data dari dua kelas yang menjadi target klasifikasi atau hyperplane dengan margin maksimum. Titik-titik data yang terletak paling dekat dengan hyperplane itulah yang kemudian disebut dengan support vectors.
Anggaplah tiap titik data direpresentasikan sebagai (xi, yi) dimana xi merupakan titik data, dan yi merupakan label kelas dengan nilai +1 atau -1. Maka hyperplane didefinisikan dengan persamaan (1).
0
w b
xi (2.1)
Dimana w adalah vektor beban atau dalam visualisasinya merupakan area tegak lurus terhadap ketiga hyperplanes, x adalah vektor input, dan b adalah bias. Tujuannya adalah untuk menemukan hyperplane dimana tidak ada titik data yang terletak di antara xi wb1 yang merupakan definisi garis hyperplane pembatas kelas positif dan xi wb1 yang merupakan definisi garis hyperplane pembatas kelas negatif.
Maka titik-titik data diklasifikasikan dengan persamaan (2.2) dan (2.3).
1
w b
xi untuk yi 1 (2.2)
1
w b
xi untuk yi 1 (2.3)
Tujuan utama SVM adalah memaksimalkan margin pemisah antara data kelas positif dan kelas negatif atau mengoptimalkan hyperplane. Lebar margin pemisah tersebut didefinisikan dengan persamaan (2.4).
lebar margin=
||
||
2
w (2.4)
W adalah vektor yang tegak lurus dengan decision boundary. Memaksimalkan
margin sama dengan memaksimalkan
||
||
2
w . Maka nilai margin yang optimal dapat dirumuskan dengan menggunakan persamaan (2.5) dengan mengacu pada persamaan optimasi konstrain (2.6).
(2.5)
n i
b wx
yi( i )1, 1,..., (2.6) Persamaan (2.5) merupakan masalah optimasi terkendala yang dapat dipecahkan menggunakan Lagrange multiplier (a) seperti terlihat dalam persamaan Lagrange berikut (2.7). Dengan menyelesaikan persamaan (2.7), maka akan ditemukanlah parameter-parameter yang menentukan solusi margin yang telah disebutkan. Parameter- parameter yang dimaksud adalah w, b, dan a.
L 21||w||2
iai(yi(wxi b)1) (2.7)Dari persamaan Lagrange tersebut kemudian ditemukan masalah dualnya di samping permasalahan utama yang telah tertulis dalam permasalahan (2.7) dimana alih- alih meminimalisir w dan b, a yang dimaksimalkan. Solusinya harus memenuhi kedua relasi seperti yang dituliskan dalam persamaan (2.8)
l
i
i i
iy x
a w
1
,
l
i i iy a
1
0 (2.8)
Sehingga permasalahan dualnya dapat dituliskan sebagai persamaan (2.9).
(2.9)
Setelah menemukan ai yang dapat digunakan untuk menemukan w dengan persamaan (2.10).
l
i
i i iy a
1
, x
w (2.10)
Kemudian, setelah mendapat nilai w, diketahui titik u dihitung berdasarkan fitur xi
maka tiap titik data uji dapat diklasifikasi dengan melihat fungsi sign dari persamaan (2.11):
b y
a b
x
f i
l
i
i
) (
) (
1
u x u
w i (2.11)
||2
2||
min 1 w
) 2 (
) 1 ( max
1 1
j i j i l
i j i l
i i i
D a a a a y y
L
x x
10
Teori-teori di atas berdasarkan asumsi titik-titik data terpisah secara sempurna.
Dalam kasus klasifikasi non-linear, vektor input akan dipetakan ke ruang vektor berdimensi lebih tinggi, lalu hyperplane akan dibangun di runag vektor yang baru tersebut hingga hyperplanes yang dibangun dipetakan kembali di ruang vektor awal.
Cara ini membutuhkan tenaga komputasi yang tinggi. Fungsi kernel dapat menyelesaikan permasalahan tersebut tanpa melakukan komputasi di ruang vektor berdimensi lebih tinggi tersebut.
Beberapa kernel yang umum digunakan adalah kernel linear yang didefinisikan dengan persamaan (2.12), polynomial yang didefinisikan dengan persamaan (2.13), dan radial-basis function (RBF) dengan persamaan (2.14).
u x u x
K( , ) T (2.12)
d
T u r
x u
x
K( , )(( ) ) (2.13)
|| ||2
exp ) ,
(x u x u
K (2.14)
Gamma mengacu pada jangkauan training instance tunggal. Jika rendah maka tiap training instance akan memiliki jangkauan yang jauh sehingga menghasilkan batasan keputusan yang mempertimbangkan titik-titik yang lebih jauh (high variance).
Sebaliknya nilai tinggi berarti jangkauan yang dekat, sehingga batas keputusan hanya bergantung pada titik-titik yang paling dekat dan mengabaikan titik yang lebih jauh (low variance).
Setelah SVM semakin dikembangkan, akhirnya SVM pun juga dapat digunakan untuk klasifikasi multiclass dengan metode one-vs-rest (ovr) dimana untuk tiap kelas N dibuatlah model klasifikasi biner N dan kemudian prediksi dibuat menggunakan model yang paling meyakinkan, atau one-vs-one (ovo) dimana untuk tiap kelas N dibuat model klasifikasi biner N*(N-1)/2 yang artinya dataset utama dibagi menjadi satu dataset untuk tiap kelas versus tiap kelas lainnya.
2.5. TF-IDF
TF-IDF (Term Frequency – Inverse Document Frequency) adalah metode yang umum digunakan untuk Text Mining dan Information Retrieval untuk menghitung bobot kata sekaligus menandakan nilai kepentingannya dalam dokumen dan korpus dengan
mengalikan nilai TF dan IDF. Term Frequency (TF) adalah frekuensi kemunculan suatu kata dalam kalimat dan Inverse Document Frequency (IDF) didefinisikan sebagai jumlah kalimat dalam suatu dokumen dibagi jumlah kalimat dimana suatu kata muncul minimal satu kali (N /dfi). Namun pada kasus ketika korpus besar, misalnya berisi 7000 kalimat, maka nilai IDF akan terlalu besar. Untuk menormalisasi hasil IDF, maka digunakan log IDF, sehingga IDF dapat didefinisikan dalam persamaan (2.15) dimana N adalah jumlah kalimat dalam suatu dokumen, dan dfiadalah jumlah kalimat simana kata i muncul setidaknya 1 kali. Dengan mengombinasikan konsep TF dan IDF akan memberikan stopwords bobot yang kecil dan bobot yang besar untuk kata-kata yang lebih informatif.
) log(
dfi
IDF N (2.15)
2.6. Textrank
Textrank merupakan salah satu algoritma unsupervised berbasis graf yang dapat digunakan untuk pemeringkatan kalimat hingga peringkasan ekstraktif. Algoritma ini bekerja seperti sistem rekomendasi dimana semakin banyak vertex yang mengarah ke suatu vertex maka akan semakin mengangkat nilai kepentingan vertex tersebut (Mihalcea & Tarau, 2004). Konsep ini diturunkan dari algoritma PageRank yang digunakan untuk pemeringkatan halaman web pada mesin pencari.
Dalam hal pemeringkatan kalimat, vertices pada graf yang dibangun merepresentasikan kalimat-kalimat dan edges merepresentasikan konten yang tumpang tindih dengan menghitung nilai kesamaan antara kalimat-kalimat yang ingin diurutkan nilai kepentingannya.
||
||
cos ||
B A
B A
(2.16)
( ) ( )
| ) (
|
* 1 ) 1 ( ) (
Vi
In
j j
j
i S V
V d Out
d V
S (2.17)
Dalam implementasinya, cosine similarity antara dua vektor yang didefinisikan dalam persamaan (2.16) dapat digunakan untuk menghitung edges. Kemudian bobot (S) vertex Vi dapat dihitung dengan persamaan (2.17) dimana d adalah faktor peredam jika
12
tidak ada hubungan mengarah keluar vertex. Out(Vj) adalah tautan keluar dari j dan In(Vi) adalah tautan yang masuk ke i.
2.7. Penelitian Terdahulu
Dari hasil studi literatur ditemukan beberapa penelitian terkait yang telah membahas klasifikasi konteks kalimat untuk menghasilkan ringkasan serta penelitian-penelitian terkait yang menggunakan algoritma SVM atau Textrank. (Atkinson & Munoz, 2013) meringkas dengan mengklasifikasi rhetorical roles menggunakan CRF dan menemukan bahwa modelnya mampu menangkap hubungan semantik dan rhetorical antar kalimat hingga menggabungkannya untuk menghasilkan ringkasan yang koheren.
(Liakata et al., 2013) membuat model untuk ringkasan artikel ilmiah dengan me- manfaatkan anotasi scientific discourse menggunakan CRF dan SVM. Hasil ringkasan dalam penelitian ini kemudian dievaluasi dengan question-answering. (Khodra et al., 2012) juga menggunakan SVM untuk peringkasan multi-dokumen dengan mengekstraksi Rhetorical Document Profile (RDP) dengan hasil nilai rata-rata performa ekstraksi RDP mencapai 94.6%. Penelitian lainnya menggunakan SVM sebagai salah satu metodenya untuk klasifikasi rhetorical roles (Widyantoro et al., 2013) pada artikel ilmiah ACL/ACR. Dengan memanfaatkan multi-classifier, dimana tiap rhetorical role diklasifikasi dengan classifier tertentu, ditemukan bahwa base classifier SVM, Logistics, dan RC termasuk dalam classifier dengan performa terbaik dalam multi-homogeneous classifier dengan nilai performa mulai dari 80.6% hingga 82.4%. (Cohan & Goharian, 2017) mengelompokkan konteks sitasi (hypothesis, method, results, implication, discussion, dan dataset used) menggunakan one-against- all SVM classifier. Kemudian dilanjutkan dengan tahap pemeringkatan dalam tiap grup untuk menghasilkan ringkasan.
Berkaitan dengan pemeringkatan kalimat dan algoritma peringkasan otomatis, (Gulden et al., 2019) melakukan peringkasan dokumen uji klinis menggunakan beberapa metode peringkasan ekstraktif dan menyimpulkan bahwa TextRank paling unggul dibandingkan metode lainnya termasuk Lexrank dengan nilai ROUGE-1 F1 sebesar 0.35, ROUGE-2 F1 0.17, dan ROUGE-L F1 0.3003. (Wang et al., 2020) menghasilkan bagian pendahuluan untuk makalah ilmiah secara otomatis dengan menggabungkan algoritma Textrank untuk memilih kalimat-kalimat kunci dari moves
dari CARS-GEN dan metode deep-learning Seq2Seq untuk menghasilkan output akhir yang koheren. (Wang et al., 2020) memilih Textrank karena dalam implementasinya tidak memerlukan intervensi manual ataupun pelabelan data tambahan.
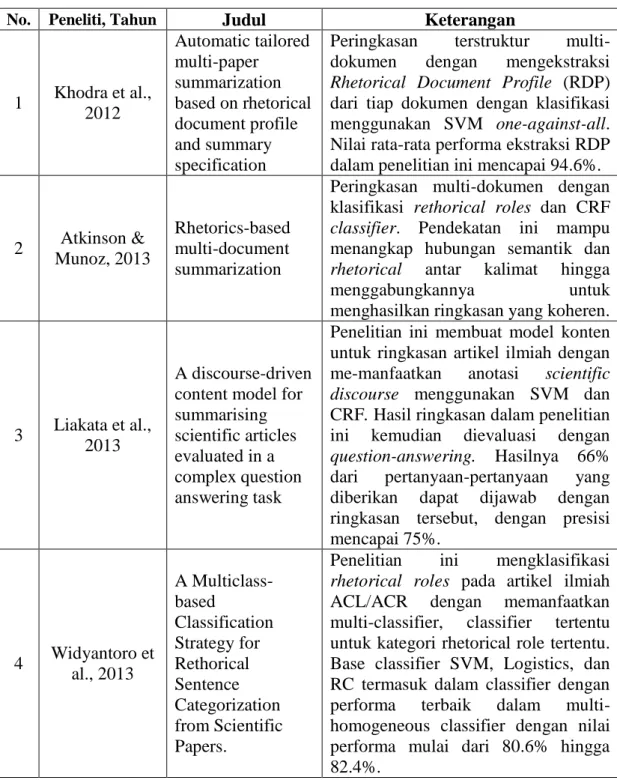
Tabel 2.1 Penelitian Terdahulu
No. Peneliti, Tahun Judul Keterangan
1 Khodra et al., 2012
Automatic tailored multi-paper
summarization based on rhetorical document profile and summary specification
Peringkasan terstruktur multi- dokumen dengan mengekstraksi Rhetorical Document Profile (RDP) dari tiap dokumen dengan klasifikasi menggunakan SVM one-against-all.
Nilai rata-rata performa ekstraksi RDP dalam penelitian ini mencapai 94.6%.
2 Atkinson &
Munoz, 2013
Rhetorics-based multi-document summarization
Peringkasan multi-dokumen dengan klasifikasi rethorical roles dan CRF classifier. Pendekatan ini mampu menangkap hubungan semantik dan rhetorical antar kalimat hingga
menggabungkannya untuk
menghasilkan ringkasan yang koheren.
3 Liakata et al., 2013
A discourse-driven content model for summarising scientific articles evaluated in a complex question answering task
Penelitian ini membuat model konten untuk ringkasan artikel ilmiah dengan me-manfaatkan anotasi scientific discourse menggunakan SVM dan CRF. Hasil ringkasan dalam penelitian ini kemudian dievaluasi dengan question-answering. Hasilnya 66%
dari pertanyaan-pertanyaan yang diberikan dapat dijawab dengan ringkasan tersebut, dengan presisi mencapai 75%.
4 Widyantoro et al., 2013
A Multiclass- based
Classification Strategy for Rethorical Sentence Categorization from Scientific Papers.
Penelitian ini mengklasifikasi rhetorical roles pada artikel ilmiah ACL/ACR dengan memanfaatkan multi-classifier, classifier tertentu untuk kategori rhetorical role tertentu.
Base classifier SVM, Logistics, dan RC termasuk dalam classifier dengan performa terbaik dalam multi- homogeneous classifier dengan nilai performa mulai dari 80.6% hingga 82.4%.
14
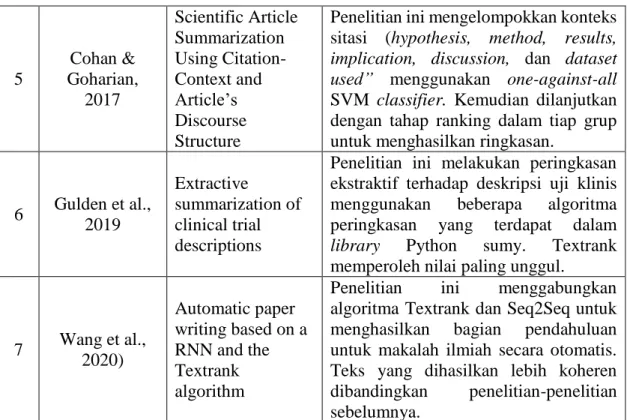
Tabel 2.1 Penelitian Terdahulu (lanjutan)
5
Cohan &
Goharian, 2017
Scientific Article Summarization Using Citation- Context and Article’s Discourse Structure
Penelitian ini mengelompokkan konteks sitasi (hypothesis, method, results, implication, discussion, dan dataset used” menggunakan one-against-all SVM classifier. Kemudian dilanjutkan dengan tahap ranking dalam tiap grup untuk menghasilkan ringkasan.
6 Gulden et al., 2019
Extractive
summarization of clinical trial descriptions
Penelitian ini melakukan peringkasan ekstraktif terhadap deskripsi uji klinis menggunakan beberapa algoritma peringkasan yang terdapat dalam library Python sumy. Textrank memperoleh nilai paling unggul.
7 Wang et al., 2020)
Automatic paper writing based on a RNN and the Textrank algorithm
Penelitian ini menggabungkan algoritma Textrank dan Seq2Seq untuk menghasilkan bagian pendahuluan untuk makalah ilmiah secara otomatis.
Teks yang dihasilkan lebih koheren dibandingkan penelitian-penelitian sebelumnya.
Penelitian yang akan dilakukan dalam tugas akhir ini berbeda dari penelitian- penelitian terdahulu yang telah disebutkan di atas dalam beberapa aspek. (Cohan &
Goharian, 2017) meneliti klasifikasi peran sitasi dan menggunakannya untuk menghasilkan ringkasan artikel yang direferensi. Sedangkan penelitian ini meneliti klasifikasi peran kalimat-kalimat dalam artikel itu sendiri.
(Liakata et al., 2013) meneliti pemodelan klasifikasi peran kalimat untuk dijadikan ringkasan yang kemudian dievaluasi dengan Question-Answering. Penelitiannya hanya fokus pada kalimat-kalimat yang diekstraksi dan tidak membahas penyusunan kalimat- kalimat tersebut hingga menjadi suatu paragraf yang terstruktur. Selain itu, penelitian ini tidak membahas secara rinci proses klasifikasinya, hanya fokus pada pemodelan dan karakteristik-karakteristik kalimat yang diekstraksi. Hal ini berbeda dengan penelitian ini yang akan melibatkan penyusunan kalimat dan pemeringkatan kalimat dengan Lexrank serta membahas metode klasifikasi peran kalimat menggunakan SVM dengan lebih rinci.
(Atkinson & Munoz, 2013) membahas peringkasan klasifikasi peran kalimat untuk peringkasan multi-dokumen yang berasal dari web menggunakan CRF dan kemudian menggunakannya untuk menyusun paragraf yang koheren, serupa dengan (Saravanan
et al., 2008). Tugas akhir ini juga membahas klasifikasi peran kalimat dan penyusunan paragraf yang terstruktur. Perbedaannya terletak pada jenis dokumen yang diteliti, yaitu dokumen tunggal artikel ilmiah berbahasa Indonesia, dan metode yang digunakan, yaitu SVM, mirip dengan (Khodra et al., 2012; Widyantoro et al., 2013). Namun, data yang digunakan dalam penelitian mereka adalah artikel ilmiah berbahasa Inggris.
BAB 3
ANALISIS DAN PERANCANGAN
3.1. Data yang Digunakan
Data yang digunakan dalam penelitian ini adalah artikel ilmiah teknologi informasi yang ditulis dalam bahasa Indonesia sebanyak 95 artikel. Artikel-artikel tersebut diambil dalam format PDF dari situs Garba Rujukan Digital (Garuda) yaitu sebuah situs pengindeks publikasi ilmiah di Indonesia yang dikelola oleh Kementerian Riset, Teknologi, dan Pendidikan Tinggi. Dokumen-dokumen PDF tersebut kemudian diubah menjadi dokumen txt dengan memanfaatkan library PDFMiner. Penelitian ini membagi artikel-artikel tersebut menjadi 76 artikel untuk data latih dan 19 artikel untuk data uji.
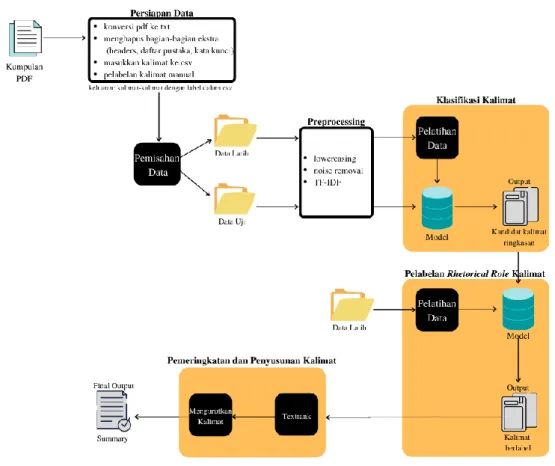
3.2. Arsitektur Umum
Sistem peringkasan ini dibangun atas tiga modul utama, yaitu sentence removal untuk memilih kandidat kalimat ringkasan, sentence labelling untuk memisahkan kalimat- kalimat sehingga dapat disusun secara terstruktur, dan sentence ranking untuk mengambil sebagian kecil kalimat yang telah melalui dua tahap sebelumnya sehingga keluaran sistem memenuhi kriteria abstrak yang hanya memuat 150 hingga 350 kata.
Sentence removal dilakukan lewat klasifikasi biner menggunakan metode Support Vector Machine (SVM). Kalimat-kalimat dipisahkan ke dalam kelas 0 jika tidak cocok dimasukkan ke dalam ringkasan dan kelas 1 jika cocok untuk dijadikan kandidat kalimat ringkasan. Dilanjutkan dengan sentence labelling lewat klasifikasi multiclass menggunakan SVM. Kalimat dipisahkan ke dalam beberapa kelas meniru sebagian skema anotasi Liakata et al. (2013), yaitu Background, Topic, Method, Dataset, Result, Conclusion, dan Suggestion. Pada bagian terakhir, yaitu sentence ranking menggunakan Textrank dan kemudian disusun sesuai urutan kemunculannya dalam artikel input.
Keluaran dari sistem ini berupa paragraf yang berisi kalimat berlabel seperti yang telah disebutkan. Gambaran keseluruhan rancangan sistem dapat dilihat pada Gambar 3.1.
3.2.1. Input
Data yang dikumpukan untuk penelitian ini berupa file PDF artikel ilmiah berbahasa Indonesia. File-file tersebut kemudian melalui proses persiapan data hingga menjadi beberapa file csv yang disimpan dalam sebuah folder. Pada sistem, file-file csv hasil konversi tersebut yang akan dipilih melalui file selector untuk dijadikan input.
3.2.2. Persiapan Data
Dalam persiapan data, tahap pertama setelah pengumpulan data adalah mengonversi file PDF yang telah dikumpulkan ke dalam format .txt seperti Gambar 3.2. dengan memanfaatkan library PDFMiner yang mampu memetakan teks dalam PDF berkolom lebih dari satu.
Setelah file telah berekstensi .txt, bagian-bagian seperti headers, daftar pustaka, dan kata kunci pada bagian abstrak dikumpulkan dengan regex lalu dihapus. Intervensi manual masih dibutuhkan untuk merapikan bagian-bagian yang tidak diproses
Gambar 3.1. Arsitektur Umum
18
sempurna oleh kode, seperti kata-kata yang bersambung tanpa spasi, kalimat yang seharusnya menjadi satu namun terpisah, dll.
Kalimat-kalimat yang telah diproses kemudian dipindahkan ke csv lewat program.
Header tiap kalimat juga disimpan di sebelah kolom kalimat karena akan berguna sebagai fitur dalam klasifikasi berikutnya. Setelah tahap tersebut barulah dilakukan pelabelan kalimat secara manual ke dalam kategori Background, Topic, Method, Dataset, Result, Conclusion, Suggestion, dan Others. Setelah pelabelan, dataset lengkapnya akan terlihat seperti Gambar 3.3.
Gambar 3.3. Data dalam Format CSV Gambar 3.2. Contoh Konversi File PDF ke .txt
Background adalah label untuk kalimat yang memaparkan latar belakang permasalahan penelitian. Topic adalah label untuk kalimat yang menerangkan penelitian apa yang diangkat dalam penelitian tersebut. Method memaparkan metode yang dgunakan. Dataset adalah label untuk kalimat yang menyebutkan dataset penelitian. Result memaparkan hasil. Conclusion berisi kesimpulan. Suggestion memaparkan saran. Others merupakan label yang diisi kalimat-kalimat yang akan disisihkan karena dianggap tidak cocok dijadikan kandidat ringkasan.
Gambar 3.4. Contoh Kalimat dan Pelabelannya
Kalimat-kalimat yang telah diberi label Rhetorical Role yang sesuai kemudian diberi label biner yang menandai apakah kalimat tersebut layak dijadikan kalimat ringkasan (label 1) atau tidak (label 0). Seperti terlihat pada Gambar 3.4., semua kalimat diberi nilai summary-worthy sebesar 1 selain yang berlabel OTHERS. Setelah proses pelabelan, 80% data disimpan sebagai data latih, kemudian 20% data digunakan untuk data uji.
3.2.3. Preprocessing
Setelah data dipisah menjadi data latih dan data uji, tiap data melewati tahap preprocessing yang terdiri atas lowercasing, noise removal, dan vektorisasi TF-IDF secara terpisah. Noise yang dimaksud dalam ini berupa angka romawi, angka, tanda baca, dan beberapa stopwords yang tidak digunakan dalam proses selanjutnya.
20
Setelah kalimat-kalimat telah dibersihkan hingga tampak seperti kalimat-kalimat pada kolom sentence_x pada Gambar 3.5., data akan masuk ke Pipeline dimana data akan dihitung bobotnya dengan TF-IDF vectorizer. Kolom yang akan diproses adalah kolom kalimat serta kolom heading. Proses ini menghasilkan matriks vektor bobot yang kemudian digunakan untuk klasifikasi.
3.2.4. Klasifikasi Kalimat
Tahap berikutnya dalam pipeline adalah klasifikasi biner dengan algoritma Support Vector Machine untuk memisahkan kalimat ke dalam dua kelas, yaitu kelas 1 untuk kalimat-kalimat yang berpotensi menjadi bahas ringkasan dan kelas 0 untuk kalimat- kalimat yang akan disisihkan. Contoh kalimat dan label biner yang menentukan kalimat yang disimpan atau dihapus ditunjukkan pada Gambar 3.6.
Gambar 3.5. Kalimat Orisinal dan Kalimat Setelah Pembersihan
Gambar 3.6. Contoh Kalimat dan Label Biner Summary-worthy 3.2.5. Pelabelan Rhetorical Role Kalimat
Setelah program berhasil memilih kalimat-kalimat yang diinginkan untuk hasil ringkasan, kalimat-kalimat tersebut melalui klasifikasi kedua yang akan menghasilkan label-label rhetorical roles tiap kalimat. Klasifikasi multiclass ini dilakukan dengan Support Vector Machine (SVM) one-vs-rest. Model untuk klasifikasi ini dibangun dari dataset untuk klasifikasi sebelumnya yang telah dimodifikasi untuk hanya mengambil kalimat-kalimat yang summary-worthy-nya berlabel 1. Contoh hasil pelabelan kalimat dapat dilihat pada Gambar 3.7.
Gambar 3.7. Dataframe Berisi Contoh Hasil Pelabelan Kalimat
22
3.2.6. Pemeringkatan dan Penyusunan Kalimat
Walaupun banyak kalimat yang sudah disisihkan pada tahap klasifikasi pertama (klasifikasi biner kalimat), hasil ringkasan hingga tahap ini masih terlalu panjang untuk ditampilkan sebagai hasil akhir. Oleh karena itu, pada tahap ini kalimat-kalimat dari tiap kategori rhetorical roles dipangkas lagi hingga hanya tersisa 150 – 350 total kata saja. Pemangkasan paragraf ini dilakukan dengan Textrank dan difflib.
Langkah ini diawali dengan tokenisasi kalimat menjadi kata-kata. Lalu hitung cosine similarity untuk membangun matriks kesamaan yang kemudian akan berperan sebagai adjacency matrix untuk grafik kesamaan dimana kalimat sebagai vertices, dan nilai kesamaan sebagai edges. Dari graf yang telah dibuat, hitung nilai Pagerank dengan fungsi pagerank() dari library networkx dan urutkan dari nilai tertinggi hingga terendah.
Beberapa kalimat teratas dari hasil pemeringkatan Textrank pada tiap kategori diambil kemudian diurutkan sesuai kemunculan untuk menghasilkan ringkasan akhir.
Jika jumlah kalimat dalam suatu kategori berjumlah sama dengan atau lebih dari 10, Tabel 3.1. Contoh Hasil Pemeringkatan dengan Textrank
maka diambil 40% kalimat teratas. Jika jumlah kalimat dalam suatu kategori berjumlah sama dengan atau lebih dari 10, maka diambil 50% kalimat teratas. Sisa kalimat-kalimat yang mirip namun tidak tersaring oleh Textrank akan dibuang oleh fungsi get_close_matches() dari difflib, sebuah library python yang dapat digunakan untuk membandingkan rangkaian kalimat.
3.2.7. Keluaran
Hasil dari sistem ini berupa ringkasan artikel ilmiah dengan kisaran kata sebanyak 100- 350 kata yang ditandai dengan kategori rhetorical role masing-masing dan ditampilkan di halaman ringkasan dengan format seperti terlihat pada Gambar 3.8.
Gambar 3.8. Contoh Keluaran Akhir
24
3.3. Perancangan Antarmuka
3.3.1. Rancangan Tampilan Halaman Beranda
Gambar 3.9. Rancangan Tampilan Halaman Beranda
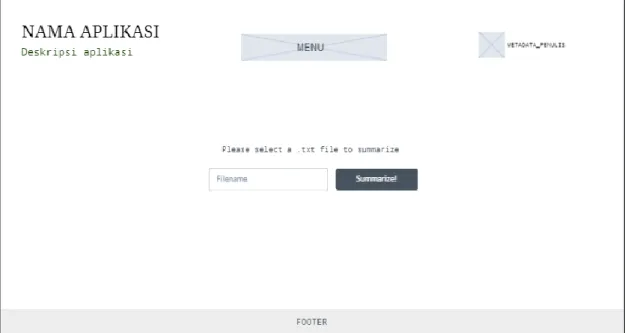
Pada rancangan halaman beranda yang dapat dilihat pada Gambar 3.9. pengguna mengunggah file yang ingin diringkas. Di bagian atas terdapat header yang berisi nama aplikasi, deskripsi singkat aplikasi, menu, dan nama, NIM, jurusan, dan universitas penulis. Di bagian bawah terdapat footer yang akan diisi dengan “Skripsi” dan judul skripsi. Pada bagian utama terdapat file selector untuk mengambil file yang ingin diringkas serta tombol submit untuk memicu pemrosesan. Pemilihan file dibatasi hanya untuk file berekstensi csv saja.
3.3.2. Rancangan Tampilan Halaman Ringkasan
Gambar 3.10. Rancangan Tampilan Halaman Ringkasan/Hasil
Gambar 3.10. menunjukkan rancangan tampilan halaman dimana pengguna akan diarahkan setelah unggahan file diproses. Tata letak komponen-komponennya serupa dengan rancangan tampilan halaman beranda, hanya saja pada bagian utama rancangan tampilan hasil terdapat area yang akan memperlihatkan hasil ringkasan yang dipisahkan dengan rhetorical role-nya. Misalnya, “TOPIC: Pada penelitian ini akan dibuat peringkas artikel ilmiah menggunakan metode SVM dan Textrank.” Di bagian atas area paragraf ringkasan terdapat nama file yang sedang diringkas. Di sebelah kanan kotak ringkasan terdapat div yang menunjukkan banyaknya kata yang terkandung dalam hasil ringkasan serta navigasi untuk mengarahkan pengguna ke bawah halaman dimana terdapat tabel-tabel hasil klasifikasi yang merupakan dataframe data uji yang diambil dari sistem peringkasan. Di atas tabel-tabel klasifikasi terpampang angka akurasi klasifikasi.
26
3.4. Metode Evaluasi
Untuk menilai kinerja sistem yang telah dibuat, metode evaluasi perlu diaplikasikan pada tiap modul yang terdapat dalam sistem. Bagian klasifikasi biner dievaluasi dengan menghitung rata-rata nilai akurasi, presisi, recall, dan F1-score. Klasifikasi multiclass akan dilihat nilai rata-rata akurasinya.
Nilai akurasi adalah perbandingan hasil klasifikasi yang benar dengan total percobaan klasifikasi. Presisi adalah perbandingan hasil klasifikasi kelas target (positif) yang benar (True Positive) dengan jumlah seluruh klasifikasi positif (True Positive + False Positive). Recall adalah perbandingan hasil True Positive dengan False Negative.
F1-Score dihitung dengan memanfaatkan nilai Recall dan Precision.
Hasil akhir ringkasan akan dievaluasi dengan menjawab pertanyaan-pertanyaan yang menjadi pertanyaan dasar saat melakukan pelabelan manual untuk melihat apakah tiap rhetorical role yang ditampilkan telah memuat kalimat-kalimat dengan informasi yang sesuai. Tiap bagian yang ditampilkan akan diberi nilai -1 jika informasi yang dimuat tidak relevan dengan kategorinya, 0 jika kategori tidak memuat kalimat apapun, 0.5 terdapat kalimat yang tidak relevan di antara kalimat yang relevan dalam suatu kategori atau jika kalimat-kalimatnya tidak cukup menjawab pertanyaan, dan nilai 1 jika seluruh kalimat yang dimuat relevan dengan kategori yang memuatnya.
Pertanyaan-pertanyaan yang digunakan untuk mengevaluasi tiap kategori dalam hasil akhir adalah: 1. Masalah apakah yang melatarbelakangi penelitian ini?
(BACKGROUND) 2. Hal apakah yang dibahas/apa yang dilakukan? (TOPIC) 3. Metode apakah yang digunakan/tahapan-tahapan apa yang dilakukan? (METHOD) 4. Dataset apakah yang digunakan? (DATASET) 5. Hasil apakah yang didapatkan? (RESULT) 6.
Kesimpulan apakah yang dapat diambil/penemuan apa yang didapat dari penelitian ini?
(CONCLUSION). 7. Saran apakah yang diberikan untuk penelitian lebih lanjut?
(SUGGESTION).
Pertanyaan-pertanyaan tersebut disusun berdasarkan pengamatan struktur abstrak artikel ilmiah pada umumnya dan bacaan mengenai bagian-bagian yang mungkin terdapat dalam suatu abstrak. Seperti dalam tulisan oleh Andrade (2011), latar belakang (background) sesuai dengan namanya menunjukkan latar belakang penelitian dan mengarahkan pembaca ke deskripsi metode yang digunakan dalam penelitian. TOPIC
terdapat pada sebagian besar abstrak memaparkan deskripsi penelitian yang dilakukan.
METHOD harus berisi informasi yang cukup untuk memungkinkan pembaca memahami apa yang dilakukan dan bagaimana caranya (Andrade, 2011). Pada rancangan ringkasan akhir dalam penelitian ini, bagian tentang apa yang dilakukan dalam suatu penelitian telah dimuat dalam TOPIC sehingga METHOD akan lebih fokus pada bagaimana topik penelitian dilakukan atau metode apa yang digunakan untuk menyelesaikan masalah yang menjadi topik penelitian. DATASET hanya membahas data yang digunakan dalam penelitian sehingga pertanyaan yang dihasilkan untuk mengevaluasinya cukup menanyakan dataset apa yang digunakan dalam penelitian.
RESULT berisi temuan yang didapatkan dari penelitian yang dilakukan (Andrade, 2011). Pada CONCLUSION umumnya berisi pesan terpenting yang didapat dari penelitian yang dilakukan dan umumnya berkaitan dengan pengukuran hasil utama dan dapat juga berisi penemuan tak terduga atau pendapat mengenai implikasi teoritis atau praktis dari hasil yang didapatkan (Andrade, 2011). Untuk mengurangi ambiguitas dari label RESULT dan CONCLUSION maka pertanyaan disusun dengan menuliskan ‘hasil yang didapatkan’ untuk label RESULT dan ‘penemuan yang didapat’ untuk CONCLUSION sehingga didapatkan pertanyaan akhir seperti yang telah dituliskan dalam paragraf di atas. SUGGESTION hanya memaparkan saran yang diberikan dalam suatu artikel ilmiah sehingga pertanyaan untuk mengevaluasinya cukup menanyakan saran apa yang diberikan untuk penelitian lebih lanjut.
BAB 4
IMPLEMENTASI DAN PEMBAHASAN
4.1. Implementasi Sistem
4.1.1. Spesifikasi Perangkat Keras dan Perangkat Lunak yang Digunakan
Berikut adalah spesifikasi perangkat keras dan perangkat lunak yang digunakan dalam penelitian ini:
1. Processor Intel® Core™ i5-7200U CPU @ 2.50GHz 2.71GHz 2. Memori RAM 4.00 GB
3. Sistem operasi Ubuntu 20.04.2 LTS 4. Visual Studio Code
5. Bahasa pemrograman Python
6. Library NLTK, Pandas, scikit-learn, PDFMiner, dan NetworkX.
4.2. Implementasi Perancangan Antarmuka 4.2.1. Tampilan Halaman Beranda
Gambar 4.1. Tampilan Halaman Beranda
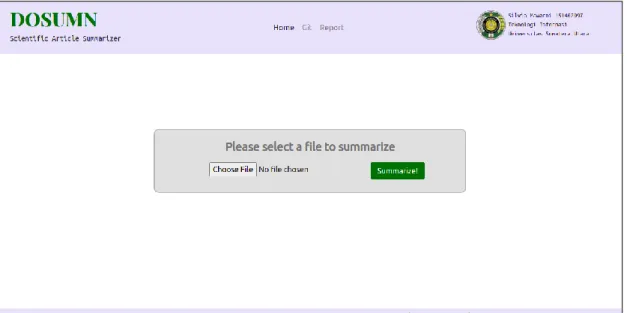
Tata letak halaman dalam sistem ini terbagi atas header, isi, dan footer. Header berisi nama aplikasi, menu, dan nama penulis. Tautan Home pada menu merujuk ke halaman beranda dan akan berguna di halaman ringkasan ketika pengguna ingin kembali meringkas halaman lain. Footer hanya ditampilkan pada halaman beranda saja. Pada bagian isi halaman beranda pengguna dapat mengunggah file artikel ilmiah berformat .csv yang ingin diringkas melalui file selector dan memprosesnya dengan menekan tombol bertuliskan “Summarize!” Tombol tersebut akan membawa pengguna ke halaman ringkasan/hasil yang akan dibahas pada bagian 4.2.2.
4.2.2. Tampilan Halaman Ringkasan
Gambar 4.2. Tampilan Halaman Ringkasan Bagian Keluaran Akhir / Ringkasan Di halaman ini hasil ringkasan ditampilkan di dalam sebuah div. Tiap bagian dipisahkan dengan heading yang bertuliskan rhetorical role-nya seperti yang terlihat pada Gambar 4.2. Di samping div ringkasan terdapat jumlah kata yang dimuat dalam hasil ringkasan beserta navigasi sederhana yang mengarahkan pengguna ke hasil klasifikasi pada tahap sentence removal dan sentence labelling.
Bagian sentence removal seperti yang ditampilkan Gambar 4.3. terletak tepat di bawah bagian ringkasan. Bagian ini menampilkan angka akurasi klasifikasi biner yang dilakukan sistem untuk mengeliminasi sebagian besar kalimat yang tidak diperlukan.
Di bawah angka akurasi ditampilkan dataframe yang berisi kalimat-kalimat yang
30
diklasifikasi yang telah melalui proses pembersihan, heading kalimat yang diklasifikasi, label rhetorical role, label biner yang diberi manual, serta label biner hasil prediksi.
Gambar 4.3. Tampilan Halaman Ringkasan Bagian Sentence Removal
Gambar 4.4. menampilkan angka akurasi serta tabel yang berisi dataframe dari proses Sentence Labelling yang terletak tepat di bawah bagian Sentence Removal. Tabel Sentence Labelling menampilkan kalimat orisinal yang belum melalui proses pembersihan yang dilabeli dengan sentence_ori, kalimat yang sudah melalui pembersihan dilabeli dengan sentence_x, heading kalimat, label yang diberi manual dalam kolom expected, serta label hasil prediksi pada kolom predicted.
Gambar 4.4. Tampilan Halaman Ringkasan Bagian Sentence Labelling
4.3. Pengujian Sistem 4.3.1. Data
Sebelum melalui proses klasifikasi, data yaitu 95 artikel ilmiah teknologi informasi berbahasa Indonesia sudah dibagi menjadi data latih dan data uji. Data latih dalam penelitian ini menggunakan 76 artikel ilmiah dengan total 10.622 kalimat dengan distribusi label rhetorical role seperti terlihat pada Tabel 4.1.
Tabel 4.1. Distribusi Label Data Latih
Label Jumlah Kalimat
Background 360
Topic 196
Method 499
Dataset 133
Result 470
Conclusion 304
Suggestion 101
Others 8558
Tabel 4.2. Distribusi Label Data Uji
Label Jumlah Kalimat
Background 129
Topic 43
Method 127
Dataset 44
Result 122
Conclusion 87
Suggestion 23
Others 2335
32
Sisanya sebanyak 19 artikel dengan total 2910 kalimat disimpan sebagai data uji.
Distribusi label yang diberikan secara manual untuk data uji dapat dilihat pada Tabel 4.2. Rata-rata tiap artikel berisi 153 kalimat.
Kalimat-kalimat dalam tiap artikel diubah menjadi huruf kecil (lowercasing), lalu seluruh tanda baca pada kalimat dihapus, diikuti dengan penghapusan angka dengan regex (r'\w*\d+\w*') dan penghapusan kata-kata yang dianggap sebagai noise.
Penelitian ini tidak serta-merta menghapus seluruh stopwords seperti yang terkandung dalam library yang ada. Noise yang dihapus hanya 'i', 'ii', 'iii', 'iv', 'v', 'vi', 'tabel', 'gambar', 'yang', 'dan', 'atau'. Seperti terlihat pada Gambar 4.5., kalimat-kalimat di bagian kanan tidak lagi mengandung angka, tanda baca, atau kata-kata yang termasuk dalam noise yang telah ditentukan.
Gambar 4.5. Beberapa kalimat hasil pembersihan (kiri: kalimat asli, kanan: kalimat telah diolah)
4.3.2. Klasifikasi Kalimat
Klasifikasi biner menggunakan SVM ini bertujuan untuk memilih kumpulan kalimat yang dihapus atau kumpulan kalimat yang dapat digunakan dalam ringkasan. Fitur yang digunakan adalah bobot kalimat dan bobot heading kalimat. Bobot didapatkan dengan TF-IDF vectorizer dengan kisaran n-gram [1,2] untuk kolom kalimat.
Seperti terlihat pada Tabel 4.2., dua percobaan parameter telah dilakukan dan akhirnya digunakan kernel RBF dengan nilai C sebesar 100. Karena distribusi data yang tidak seimbang, ditambahkan pula parameter class_weight='balanced' untuk menyeimbangkannya.
Tabel 4.2. Nilai akurasi klasifikasi dengan parameter yang berbeda Dokumen
No.
Kernel = linear, C = 10
Kernel = rbf, C = 100
Selisih akurasi
1 79.5 86.96 4.06
2 87.43 88.57 9.07
3 85.95 89.26 1.83
4 90.26 89.6 3.65
5 73.44 82.8 -7.46
6 86.46 88.5 15.06
7 79.56 88.4 1.94
8 81.98 83.78 4.22
9 61.76 65.4 -16.58
10 78.29 75.19 13.43
11 91.06 91.06 12.77
12 93.2 94.56 3.5
13 86.7 83.8 -9.4
14 89.36 82.98 -3.72
15 82.69 82.69 -6.67
16 82.2 82.2 -0.49
17 80.53 87.6 5.4
18 82.8 85.07 4.54
19 81.82 90.26 7.46
Rata-rata 82.89421053 85.19368421
34
Dengan parameter tetap yang telah dipilih, didapatkan rata-rata nilai akurasi sebesar 0.853, presisi 0.72, recall 0.46, dan F1-score 0.55 dengan rincian hasil seperti yang terpapar dalam Tabel 4.3. Nilai presisi yang cukup tinggi berarti model ini telah dapat memberikan hasil yang relevan dengan cukup baik (hasil True Positive tinggi, False Positive rendah). Namun nilai recall di bawah 0.5 menandakan tingkat False Negative yang masih lebih tinggi daripada True Positive.
Tabel 4.3. Rincian Hasil Klasifikasi untuk Klasifikasi Kalimat No.
Dokumen Accuracy Precision Recall F1-Score
1 0.87 0.42 0.26 0.32
2 0.89 0.76 0.58 0.66
3 0.89 0.57 0.29 0.38
4 0.9 0.84 0.55 0.67
5 0.83 0.82 0.25 0.39
6 0.89 1 0.37 0.54
7 0.88 0.7 0.53 0.6
8 0.84 0.75 0.46 0.57
9 0.65 0.58 0.37 0.45
10 0.75 0.41 0.44 0.43
11 0.91 0.58 0.54 0.56
12 0.95 0.88 0.71 0.79
13 0.84 1 0.3 0.46
14 0.83 0.55 0.63 0.59
15 0.83 0.68 0.52 0.59
16 0.82 0.57 0.35 0.43
17 0.88 0.89 0.59 0.71
18 0.85 0.85 0.44 0.58
19 0.9 0.74 0.58 0.65
Rata-rata 0.853 0.72 0.46 0.55
Rata-rata kalimat yang diambil dari proses ini berjumlah 19 kalimat dari rata-rata jumlah kalimat dalam dokumen sebanyak 153. Sehingga proses ini dapat memangkas 84% keseluruhan dokumen.