All sources 49 Internet sources 41 Own documents 8 [0] https://archive.org/stream/arxiv-1303.3964/1303.3964_djvu.txt
14.1% 60 matches
[1] https://arxiv.org/pdf/1303.3964.pdf 13.0% 52 matches
[2] "CR-INT110-Semantic interpretation ...ot; dated 2017-10-09 6.2% 26 matches
[3]
https://link.springer.com/chapter/10.1007/978-3-319-05476-6_9 10.7% 40 matches
1 documents with identical matches
[5] https://mafiadoc.com/keyword-extraction-...723dd05e32a77ea.html 6.0% 26 matches
[6] https://archive.org/stream/arxiv-1212.4702/1212.4702_djvu.txt 5.8% 22 matches
[7] https://archive.org/stream/arxiv-1212.3023/1212.3023_djvu.txt 5.3% 23 matches
[8] https://archive.org/stream/arxiv-1207.3583/1207.3583_djvu.txt 4.1% 16 matches
[9] eprints.binadarma.ac.id/2778/1/ICIBA2016-13-086-091-Nasution-SocialNetworkMining.pdf 3.4% 15 matches
[10] https://arxiv.org/pdf/1604.06976.pdf 3.2% 15 matches
[11] www.academia.edu/3144197/Simple_Search_Engine_Model_Adaptive_Properties_for_Doubleton 3.2% 10 matches
[12] dl.acm.org/citation.cfm?id=2961663 3.3% 11 matches
[13] https://link.springer.com/content/pdf/10.1007/978-3-319-05476-6_9.pdf 2.2% 10 matches
[14] www.academia.edu/3144214/Simple_Search_Engine_Model_Adaptive_Properties 1.5% 5 matches
[15] https://www.researchgate.net/publication...for_the_Social_Actor 1.7% 4 matches
[16] "CR-INT136-Social network extractio...ot; dated 2017-10-09 1.8% 11 matches
[17] https://link.springer.com/chapter/10.1007/978-3-319-67621-0_20 1.8% 8 matches
[18] "CR-INT137-Enhancing to method for ...ot; dated 2017-10-09 1.5% 8 matches
[19] "CR-INT135-Information Retrieval on...ot; dated 2017-10-09 1.5% 9 matches
[20] iopscience.iop.org/article/10.1088/1742-6596/801/1/012020 1.5% 7 matches
[21] https://www.researchgate.net/profile/Sha...tion-perspective.pdf 1.1% 5 matches
[22] https://www.researchgate.net/publication/234059964_Knowledge_Sharing_A_Model 1.2% 2 matches
[23] iopscience.iop.org/article/10.1088/1742-6596/801/1/012022 1.2% 6 matches
[24] "3028-3639-1-RV.pdf" dated 2017-10-30 1.2% 6 matches
[25] www.springer.com/cda/content/document/cda_downloaddocument/typeinst.pdf
33.6%
Results of plagiarism analysis from 2017-12-28 15:20 UTC
New Method for Extracting Keyword for the Social Actor.pdf
[25] www.springer.com/cda/content/document/cda_downloaddocument/typeinst.pdf 0.9% 2 matches
[26] https://www.overleaf.com/latex/templates/springer-book-chapter/hrdcrfynnzjn 0.9% 2 matches
[27] "3472-4529-1-SM.pdf" dated 2017-10-30 1.1% 6 matches
[28] www.academia.edu/3144207/Keyword_Extraction_for_Identifying_Social_Actors 0.7% 4 matches
[29] https://www.coursehero.com/file/9686843/typeinst/ 0.7% 2 matches
[30] https://www.researchgate.net/profile/Mahyuddin_Nasution 0.7% 2 matches
[31] https://link.springer.com/chapter/10.1007/978-3-642-54105-6_9 0.7% 4 matches
[32] https://vdocuments.site/vision-systems-segmentation-and-pattern-recognition.html 0.3% 3 matches
[33] dl.acm.org/citation.cfm?id=2130616 0.6% 2 matches
[34]
https://archive.org/details/arxiv-1212.4702 0.4% 1 matches
1 documents with identical matches
[36] www.finedictionary.com/semantic relation.html 0.3% 1 matches
[37] "ICTS_2017_paper_18.pdf" dated 2017-09-24 0.3% 1 matches
[38] https://ai.arizona.edu/research/isi 0.3% 1 matches
[39] https://rd.springer.com/content/pdf/10.1007/978-3-319-05476-6_9.pdf 0.2% 1 matches
[40] doi.acm.org/10.1145/215206.215383 0.4% 1 matches
[41] https://www.researchgate.net/publication...n_Positive_Documents 0.2% 1 matches
[42] https://link.springer.com/chapter/10.1007/978-3-642-32112-2_48 0.3% 1 matches
[43] ieeexplore.ieee.org/xpl/conhome.jsp?punumber=1001810 0.3% 1 matches
[44]
hinet.lindayi.me/paper.php?id=220711 0.4% 1 matches
1 documents with identical matches
[46] doi.acm.org/10.1145/138859.138867 0.4% 1 matches
[47] ingenst.academia.edu/MahyuddinKMNasution 0.2% 1 matches
[48] https://link.springer.com/chapter/10.1007/978-3-319-22053-6_43 0.3% 1 matches
[49]
www.refdoc.fr/Detailnotice?cpsidt=17135176 0.3% 1 matches
1 documents with identical matches
[51] "1733-1956-1-RV.pdf" dated 2017-09-26 0.1% 1 matches
10 pages, 5254 words
The document contains a suspicious mixture of alphabets. This could be an attempt of cheating.
PlagLevel: selected / overall
133 matches from 53 sources, of which 45 are online sources.
Settings
Data policy: Compare with web sources, Check against my documents, Check against my documents in the organization repository, Check against organization repository, Check against the Plagiarism Prevention Pool
Sensitivity: Medium
Bibliography: Consider text
Citation detection: Reduce PlagLevel
--New
New Metho
Metho d
d for
for Extracting
Extracting Keyw
Keyword
ord
[33]for
for the
the So
So cial
cial Actor
Actor
[12]
Mahyuddin K.M.Nasution
Information Technology Department
Fakultas Ilmu Komputer dan Teknologi Informasi (Fasilkom-TI) and
Centre of Information System
Universitas Sumatera Utara, Medan20155 USU, Sumatera Utara, Indonesia
[email protected], [email protected]
[3] Abstrac
Abstract.t. In this paper we study the relationship between query and
search engine by exploring some properties and also applying their
tionsto extract keyword for any social actor by proposing new method.
The proposed approach based on considering the result of search engine [3]
[3]
in the singleton and doubleton.In this paper, we develop a novel method for extracting keyword automatically from Web with mirror shade
con-[3]
cept (M2M).Results show the potential of the proposed approach, in experiment we get that the performance (recall and precision) of
worddepend on both weights (singleton andtfidf)and the distance of them.
[3] Keywords:
Keywords: singleton, doubleton, searh engine, query, information retrieval.
1
1
In
Intr
tro
oduction
duction
In the search space with a large repository such as Web, it is difficult to obtain
accurate information about any social actor or social agent, that is endowed as an human agency which means recognising individually the attempt to grips the
challenge for changing world around the agent to a good world. In this case, there are major obstacles that often accompanies the search engine capabilities
such as ambiguity [2] and bias [5]. Therefore, it is always necessary corresponding
[51]
keywords to pry information out of the heaps of data or documents in Web.In
this paper we propose a newmethod for generating and selecting automatically
the keyword for someone as an social actor in Web based on the principles of
information retrieval (IR) and model of search engine.
[25]
Please note that the LNCS Editorial assumes that all authors have used the west-[25]
ern naming convention, with given names preceding surnames.This determines the
structure of the names in the running heads and the author index.
N.T. Nguyen et al. (Eds.): ACIIDS 2014, Part I, LNAI 8397, pp. 83–92, 2014.
c
[3]
84 M.K.M. Nasution
2
2
Problem
Problem Definition
Definition
We define some terminologies and the properties of a model of search engine [13,14,15,19].
event (singleton space of event) of web pages that contain an occurrence of
tx∈ωx
is a set of singleton search term of search engine.A doubleton search term isD = {{tx, y t
[2]
}:tx, y ∈ Σt}and its vector space denoted by Ωx∩Ωy is
a double search engine event(doubleton space of event) ofwebpages that
conditions we obtain another properties. Those properties are as follows.
New Method for Extracting Keyword for the Social Actor 85
starting from Eq.(7), based on Eq. (5) and then P1, i.e.,
|Ωx∩Ωy|=|Ωx|+|Ωy|+|Ωx∩Ωy| (8)
and we know that|Ωx|=|Ωx∩Ωx|and|Ωy|=|Ωy∩Ωy|, hen q. 8)t e E ( b
|Ωx∩Ωy|=|Ωx∩Ωy|+|Ωx∩Ωx|+|Ωy∩Ωy| (9)
As information of any social actor the singleton and the doubleton are the
basic of some properties of search engine statistically that related to the actor
social. However, either a singleton or a doubleton depend on formulating a query, [13]
i.e. where and how the keyword there:Some of techniques for mining keyword
from information sources have been proposed, for example is to estimate
sifiers for labelling some messages by using simple [1] and more sophisticated [32]
[3,4] approaches.For features extractionseveral methods have been developed
[7]. Some of them are the substring search method [20], model and prototype
system [8], by using peer clustering [11], co-occurrence analysis [9], by using
[6]
ical chains [6], based on PageRank [21], laten sematic analysis [10], etc.In this case, thesingleton [16] and the doubleton [17] are the necessary condition for
gaining the information of social actor from Web because both singleton and doubleton contain bias and ambiguity, while other purpose requires a sufficient
condition [18] so that the major obstacles can be reduced or eliminated. Some
of the following formulas will be evidence against some of the approaches and
[0]
86 M.K.M.Nasution
3
3
The
The Prop
Prop osed
osed Approach
Approach
If the singleton is accompanied by a summary of the Web, then involvement
of the singleton and doubleton in thecomputation generates descriptions (as
keyword candidates) of an social actor as follows.
De
We construct a relationship of actors-snippets-wordsbased on frequency of [0]
words inWeb pages as environments of an social actor as follows.
[0]
De
Definitioninition 2.2. A relationship betweenso cial actors, web snipp ets and words is
[0]
j are the weights of
word.
Statistically, the task of relationship in Definition 2 is simply to gather and record information about words, features, and web pages where term weights
reflect the relative importance of words in web pages. One of the most common
type used in older retrieval models is known astf.idfweighting [12] whereby we
can generate the vectorνfor each word/termw, and then this information is used
for recognizing the different social actors in web pages based on clustering all
words by using one of similarity measurements such as using Jaccard coeficient
j c=|Ωa∩Ωb| |/(Ωa|+|Ωb| Ωa∩−Ωb |
[0]
|).For this purpose, we definethe words
undirected graphG= V ,E) to describe the relations between words( [12].
[11]
The micro-cluster is denoted byG
[1]
=V ,E ,ww, , , f.ρ α
A micro-cluster is maximal cliquesub graph oft
[0]
o where the node represents
[0]
wordhasthe highest score in document. However,the collection ofmentioned
[0]
words do not exactly refer to the same social actors.To group the words into [0]
the appropriated cluster, we construct the trees of words.This based on an assumption that the words are that appear in same domains having closest
[0]
New Method for Extracting Keyword for the Social Actor 87
[11]
De
Definitioninition 4.4. A reeT is an optimal micro-clustert if and only ifT is a
sub-graph of micro cluster G, and is denoted by T = V
T, T,wwET,f, , ,ραhere w
VT ⊆V E, T ⊂E, ndwwT⊆wwa.
In building the optimal micro-cluster, we save the strongest relations in T
[1]
between a word and another inG untilT has no cycle [0]. We introduce an in-
trusive word about the social actor,and there are at least one word of optimal
micro-cluster has strongest relation with the intrusive word, and an optimal
[0]
micro-cluster is a group of words refer to that social actor. However, the
[0]
lapkeyword also exists in the same list. We definea strategy to selectrelevant
[0]
wordsamong all list candidates.In this case, there are a few potentialwords as keyword candidates.
We also can generate for example another vectors fromΩ
[0]
because off−1g is also one-one function, this means thatV
T ⊆V hasssT as a
Lemma 2 declared that the words appeared frequently in certain snippets but
rarely in the remaining of snippets are that words strongly associated with one
of social actors only. Ifνx≥νythen|Ωx∩Ωa| . ≥ .Ωy≥∩Ω.a|. |therwise, O
the words that do not appear frequently in Web pages except on only an social actor, then the words are strongly associated with that social actor. The last
88 M.K.M. Nasution
of P1 and Theorem 1, we obtain
|Ωx∩Ωa| Ωy∩Ω≤a| |
Lemma 3 explains that distance between an social actor ta and candidate wo rds tx and ty can be used to select an appropriate keyword, or if μx ≥μy
Proposition 1.1. If the internval [0,1] divided by straight line into two ar eas:
[0,1 2)and [
1
2,1], then there are six p atterns of conditions satisfying the relation
b
Proof. Let us summarise the conditions of relation amongνandμinto (i)ν≥μ
and (ii)ν μ, and based on the conditionν≥μfrom Lemma 2 and Lemma 3
we can determine the value in{TRUE,FALSE}for relation patterns betweenν
andμ: 1) fν≥μ,( henI ν≥ 1 t
2 (FALSE). Thus, there are
only six patterns with TRUE value.
We can sort the candidate words by using six patterns of conditions for
fying Proposition 1, and the selected word as keyword is a candidate word with
New Method for Extracting Keyword for the Social Actor 89
Theore
Theore mm 2.2. e tL T is an optimal micro-cluster containing the keyword
candi-dates, then the suitable keyword is a keyword candidate with the highest value of
vector space ofp(a, S, w) and lowest value of mirror shade, where the distance b
Lemma 3 the mentioned word has a lowest value of mirror shade in [0,1], i.e.,
2, and with max-min values:
gives the maximum value, i.e.,δ= 1. It means that there is a keyword candidate in wwT as an optimal keyword, where ν = maxa lue andv μ= mina lue, orv
ν−μ=max−minvalues.
Three values of each wordw∈wwdetermine a relationship betweenwwand any social actor. The last theorem expresses that the suitable keyword will provide to
a query the enriched information with semantic relations of their contents, and
this give more effectiveness retrieval of information. The effectiveness of using
keywords dependent the query levels generally based onδx . δ.yif and only. iftxis suitable top keyword. This is an algorithm by using the micro-cluster and
the mirror-shade (therefore we called it as MM method (M2M)) for generating
keyword as follows.
generate(keyword) [9]
INPUT :Aset of social actors [16]
OUTPUT : keyword(s)of each social actor
STEPS : forseperatingTbe trees.
7.[7]Select a cluster from trees ofTby using a predefined stable attribute.
90 M.K.M. Nasution
[5] Fig.
Fig. 1.1.The optimal micro-cluster
4
4
Exp
Exp eriment
eriment
Let us consider information context of social actors that includes all relevant
re-[5]
lationshipswith their interaction history, where Yahoo!search engines fall short of utilizing any specific information, especially micro-cluster information, and
[7]
just therefore we use full text index search in web snippets.In experiment, we
use maximum of 500 web snippets for search termta representing an actor, and
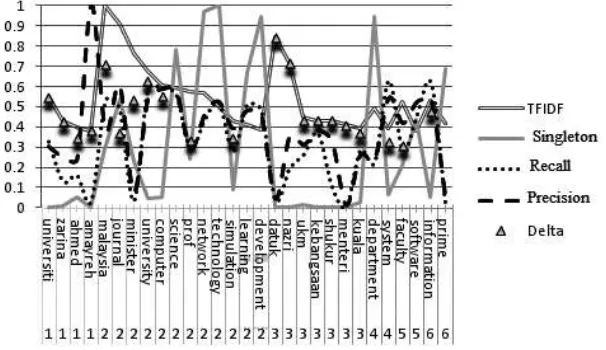
we consider words where the TF.IDF value .0[5]3×highest value of TF.[5]IDF, or
[5]
maximum number is 30 words.For example, Fig.1is a set of 30 words from web
[5]
snippets foran actor = ”Abdullah Mohd Zin”.We test for 143 names, and we
obtain 8 (5.[5]59%) actors without a cluster of candidate words, 14 (9.[5]09%) actors
[5]
with only one cluster, and 122 (85.[5]32%) persons have two or more keywords.In
[5]
a case of”Abdulah Mohd Zin”we have trees of wordsas micro clusters of words.
We can arrange the keyword candidates individualaccording to their
proxim-[5]
[5]
ity to the stable attribute”academic”, i.e.a set of words in SK = {sciences, faculty, associate, economic, prof, environment, career, journal, network, univer-sity,report, relationship, context,...}.[SK ndδ5maximum exactly determine thata ]
[5]
[5]
”network”be a keyword for actor”Abdullah Mohd Zin” as an academic (not
a politician).In this case, first keyword is ”computer”, while second keyword is
”university”, and for dataset of ”Abdullah Mohd Zin” with 143 files we obtain
New Method for Extracting Keyword for the Social Actor 91
[6]
Fig.
Fig. 2.2.Recall and precision of the optimal micro-cluster
5
5
Conclusion
Conclusion
and F
and
Future
uture W
Work
ork
Studying to properties of relation between query and search engine gave the
semantic meaning to the social actors.One of them is to provide keyword for
any social actor or the clue about the social actor. The mirror-shade approach
played a role to select top keyword from summary of web pages about the actor.
Our near future work is toexperimentand look intoIR performance.
[8]
Referen
References
ces
[3]
1. Abu-Nimeh, S., Nappa, D., Wang, X., Nair, S.:A comparison of machine
learn-[3]
ingtechniques for phising detection.In:Proceedings of the Anti-Phising Working Groups 2nd Annual eCrime Researhers Summit, pp.60–69 (2007)
[3]
2. Adriani, M.:Using statistical term similarity for sense disambiguation in
cross-[3]
language information retrieval.Information Retrieval 2, 69–80 (2000)
[3]
3. Bergholz, A., Chang, J.-H., Paass, G., Reichartz, F., Strobel, S.:Improved phishing
[3]
detection using model-based features.In:Proceedings of Fifth Conference on Email and Anti-Spam (2008)
4. Bergholz, A., Beer, J.D., Glahn, S., Moens, M.-F., Paass, G., Strobel, S.:[ New3]
[3]
filteringapproaches for phishing email.Journal of Computer Security (2009)
[3]
5. Buckley, C., Dimmick, D., Soboroff, I., Voorhees, E.:Bias and the limits of pooling
[3]
for large collections. Information Retrieval 10, 491–508 (2007)
6. Ercan, G., Cicekli, I.:[3]Using lexical chains for keyword extraction. [3]Information
Processing and Management 43, 1705–1714 (2007)
7. Fette, I., Sadeh, N., Tomasic, A.:[3]Learning to detect phising emails. In:[3]ACM
Proceedings of the 16th International Conference on World Wide Web, pp.
92 M.K.M. Nasution
[3]
8. HaCohen-Kerner, Y.: Automatic extraction of keywords froom abstracts. In:
Palade, V., Howlett, R.J., Jain, L. (eds.) KES 2003. LNCS, vol. 2773, pp. 843–849. Springer, Heidelberg (2003)
[3]
9. Kim, B.-M., Li, Q., Lee, K., Kang, B.-Y.:Extraction of representative keywords
considering co-occurrence in positive documents.In: Wang, L., Jin, Y. (eds.) FSKD 2005. LNCS (LNAI), vol. 3614, pp. 752–761. Springer, Heidelberg (2005)
10. L'Huillier, G., Hevia, A., Weber, R., R´ıos, S.: Laten semantic analysis and
key-[3]
word extraction for phising classification. In:IEEE International Conference on
Intelligence and Security Informatics (ISI), Vancouver, BC, Canada, pp.129–131 (2010)
[3]
11. Liang, B., Tang, J., Li, J., Wang, K.-H.:Keyword extraction based peer clustering.
In: Jin, H., Pan, Y., Xiao, N., Sun, J. (eds.) GCC 2004. LNCS, vol. 3251, pp. 827–830. Springer, Heidelberg (2004)
[3]
12. Nasution, M.K.M., Noah, S.A.:Superficialmethod for extracting social network for
academic using web snippets.In: Yu, J., Greco, S., Lingras, P., Wang, G., Skowron, A. (eds.) RSKT 2010. LNCS (LNAI), vol. 6401, pp. 483–490. Springer, Heidelberg (2010)
[2]
13. Nasution, M.K.M., Noah, S.A.M.:Extraction of academic social network from
line database. In: Noah, S.A.M., et al. (eds.[3)]IEEE Proceeding of 2011
tionalConference on Semantic Technology and Information Retrieval, Putrajaya, Malaysia, pp.64–69. IEEE (2011)
[0]
14. Nasution, M.K.M., Noah, S.A.M., Saad, S.: Social network extraction:Superficial
[3]
method and information retrieval.In:Proceeding of International Conference on Informatics for Development (ICID 2011), pp.c2-110-c2-115 (2011)
[3]
15. Nasution, M.K.M., Noah, S.A.M.: Information Retrieval Model:A Social Network
[12]
Extraction Perspective.In: IEEE Proc.of CAMP 2012 (2012) [0]
16. Nasution, M.K.M.:Simple search engine model:Adaptive properties. Cornell
Uni-versity Library (arXiv:1212.3906v1) (2012) [0]
17. Nasution, M.K.M.: Simple search engine model:Adaptive properties for doubleton.
Cornell University Library (arXiv:1212.4702v1) (2012) [2]
18. Nasution, M.K.M.: Simple search engine model: Selective properties. Cornell Uni-versity Library (arXiv:1303.3964v1) (2012)
[3]
19. Nasution, M.K.M. (Mahyuddin):Kaedah dangkal bagi pengekstrakan rangkaian
sosial akademik dari Web, Ph.D.[12Dissertation, Universiti Kebangsaan Malaysia] (2013) (in Malay)
[3]
20. Okada, M., Ando, K., Le, S.S., Hayashi, Y., Aoe, J.-I.:An efficientsubstring search
method by using delayed keyword extraction.Information Processing and Manage-ment 37, 741–761 (2001)
[3]
21. Wang, J., Liu, J., Wang, C.:Keyword extraction based on PageRank.In: Zhou,
![Fig. 1.Fig.1.[5] The optimal micro-cluster](https://thumb-ap.123doks.com/thumbv2/123dok/3908414.1860394/11.595.173.417.160.358/fig-fig-the-optimal-micro-cluster.webp)