An Automatically Generated Evaluation Function
in General Game Playing
Karol Wal
ę
dzik and Jacek Ma
ń
dziuk
, Senior Member, IEEE
Abstract—General game-playing (GGP) competitions provide a framework for building multigame-playing agents. In this paper, we describe an attempt at the implementation of such an agent. It relies heavily on our knowledge-free method of automatic con-struction of an approximate state evaluation function, based on game rules only. This function is then employed by one of the two game tree search methods: MTD or guided upper confidence bounds applied to trees (GUCT), the latter being our proposal of an algorithm combining UCT with the usage of an evaluation func-tion. The performance of our agent is very satisfactory when com-pared to a baseline UCT implementation.
Index Terms—Autonomous game playing, evaluation function, general game playing (GGP), MTD, upper confidence bounds ap-plied to trees (UCT).
I. INTRODUCTION
G
AMES, some of them played by humans for thousands of years (GoandBackgammondate back to 1000–2000 BC), are a natural and interesting topic for AI and computational intelligence (CI) research. They provide well-defined environ-ments for devising and testing possibly sophisticated strategies. Most of them are not simple enough to be solved by brute-force algorithms, yet they are limited enough to allow concentration on the development of an intelligence algorithm, instead of han-dling environment complexities.Years of research into particular games has led to a situation in which the goal of significantly outplaying top human players has been achieved in almost all the popular games (Gobeing the most notable exception). Several moderately sophisticated games, most notablyCheckers, have been solved [23].
Yet, almost all of these successful applications involved no learning mechanisms whatsoever, relying instead on fast and heavily optimized search algorithms coupled with manually tuned game-specific heuristic state evaluation functions,
de-fined by human players with significant experience in a given game. None of the top programs is actually able to transfer its game-playing abilities to the domain of another game, no matter how similar to the one it was intended for.
In this paper, continuing our research presented in [28], we deal with the topic of constructing a multigame-playing agent, i.e., a program capable of playing a wide variety of games, in
Manuscript received August 22, 2012; revised December 28, 2012; accepted October 08, 2013. Date of publication October 22, 2013; date of current version September 11, 2014. This work was supported by the National Science Centre in Poland, based on the decision DEC-2012/07/B/ST6/01527.
The authors are with the Faculty of Mathematics and Information Sci-ence, Warsaw University of Technology, Warsaw 00-662, Poland (e-mail: [email protected]; [email protected]).
Digital Object Identifier 10.1109/TCIAIG.2013.2286825
our case defined by the game description language (GDL) part of the general game-playing (GGP) competition specification. The multitude of possible games prevents the introduction of any significant amount of external knowledge or preconceptions into the application. It is expected that it will rely on some kind of learning algorithm, allowing it to reason about the game and come up with a successful playing strategy based solely on the rules (and possibly on experience gathered during the play it-self).
Our GGP agent relies on a fully automatically generated state evaluation function. Its construction process interweaves two human-specific, cognitively inspired processes of generaliza-tion and specializageneraliza-tion for generating a pool of possible game state features. Those features are then combined into the final evaluation function, depending on the results of their statistical analysis. This function is then employed by one of the two game tree search algorithms. Thefirst one is a modification of the stan-dard MTD method. The second one, which we call guided upper confidence bounds applied to trees (GUCT) is our own proposal of an algorithm, combining typical UCT with an eval-uation function usage.
While the UCT algorithm itself can operate with no explicit evaluation function and some applications of it have proven suc-cessful in the context of multigame playing, we strongly believe that its quality can be improved by the introduction of a state evaluator. After all, game tree search algorithms combined with heuristic evaluation functions have remained the standard and most powerful approach to single game agent creation for years, and for good reason. An intelligent mix of both mentioned ap-proaches should lead to a best of both worlds solution.
Recent, limited use of evaluation functions in the context of GGP has probably been caused by the difficulties in their gener-ation for arbitrary games. In this paper, we prove, however, that this task is feasible, at least for some of the GGP games and, with further refinement, can form at least part of a successful GGP approach.
It is also worth noting that, as presented in Appendixes A and B, our approach generates evaluation functions in a form that can be relatively easily understood and analyzed by hu-mans. This, in effect, is an important step in the transition from a black-box UCT algorithm toward a white-box approach to multigame playing, in which an agent’s decisions can be ana-lyzed in order to further tweak its operation and improve playing strength.
The remainder of this paper is divided into several sections. In thefirst three, we briefly introduce the concept of GGP and the basic UCT and MTD algorithms. Afterwards, we describe in detail the process of building the state evaluation function
Fig. 1. CondensedTic-Tac-Toegame description in GDL [16].
and incorporating it into our solution; this includes the specifi -cation of the GUCT method. Finally, we present the promising results of several experiments we have performed, conclude our research, and provide suggestions for its further development.
II. GENERALGAMEPLAYING
GGP is one of the latest and currently most popular ap-proaches to multigame playing. It stems from Stanford Univer-sity (Stanford, CA, USA), where the annual GGP Competition [8], [10] was proposed for the first time. GGP agents are expected to be able to play a broad class of games whose rules can be expressed in GDL. Competitions typically encompass a number of varied games, including one-player puzzles, as well as multiplayer competitive and cooperative games. Some of the games are based on real-world ones while others are designed from scratch, specifically for the tournament.
GGP matches are coordinated by the so-called game server. First, it sends the rules of the game (in the form of a set of GDL statements) to all participants, then contestants (programs) are allotted a limited amount of time (typically from several seconds to several minutes, depending on the complexity of the game) to study the rules and devise a reasonable playing strategy. After-wards, the match is played with a time limit per move (typically of significantly less than 1 min).
Since games are not assigned names and their rules are pro-vided separately for each match, knowledge transfer between matches is severely limited. Additionally, a GGP agent knows nothing about its opponents and, therefore, cannot modify its strategy based on previous experience of the same opponent(s).
A. Game Description Language
GDL is a variant of Datalog which can, in principle, be used to define anyfinite, discrete, deterministic multiplayer or single-player game of complete information. In GDL, game states are represented by sets of facts. Logical inferences define the rules for computing the legal actions for all players, subsequent game states, termination conditions, andfinal scores. Yet, GDL re-mains fairly simple and requires only a handful of predefined relations:
role defining as a player;
stating that is true in the initial state of the game;
true stating that holds in the current game state; does stating that player performs move ; next stating that will be true in the next state
(reached after all actions defined by “does” relations are performed);
legal stating that it is legal in the current state for the player to perform move ;
goal stating that, should the current state be terminal, the score of player would be ; terminal stating that the current state is terminal.
An excerpt from a simple game (Tic-Tac-Toe) description can be seen in Fig. 1. First, it defines the players taking part in the game via “role” relation. Afterwards, the initial game state is described by means of a predefined predicate “init” and game-specific function “cell” defining the contents of each square of the game board. Rules for state transitions and moves legality follow. Finally, game termination conditions are defined, again based on a game-specific predicate “line.”
GDL makes use of an easy-to-parse prefix notation and relies heavily on the usage of game-specific predicates and variables (prefixed with “?”). We encourage interested readers to consult [16] for a more detailed description of GDL.
GDL, being a variant of Datalog, is easily translatable to Prolog (or any other logic programming language). In fact, this is exactly what we do in our implementation of a GGP agent, using Yap [30] as our main game engine.
Recently, some extensions to GDL have been proposed: GDL-II allows defining nondeterministic games and, fur-thermore, last year’s GGP tournament games included two additional predefined relations, allowing easier identification of all possible game-state description facts. All research pre-sented in this paper is, however, based on the original GDL specification.
III. GAMETREEANALYSIS
positions (game states) and arcs—possible transitions between states (i.e., players’ actions).
These trees are then analyzed by dedicated algorithms. Two of them are today dominant: alpha–beta pruning [12] (including its various modifications) and UCT [13]. They are both em-ployed by our GGP agent and described in Section III-A. For the sake of space saving, the description is brief. Consult the original papers for more information.
A. UCT
UCT is a simulation-based game tree analysis algorithm [13]. It has repeatedly proven to be relatively successful in the case of some very difficult games, including Go[6]. Many of the GGP tournament winners so far have relied heavily on the UCT algorithm [4], [20].
UCT is based on the UCB1 [1] algorithm for solving a -armed bandit problem. The -armed bandit problem deals with the issue of finding an optimal strategy for interacting with gambling machines (or, alternatively, one machine with play modes—arms). The rewards of each machine/arm are presumed to be nondeterministic but, nevertheless, stable (their distributions should not change in time) and pairwise independent.
The UCT algorithm assumes that the problem of choosing an action to perform in a given game state is actually equivalent to solving a -armed bandit problem. While this may not be strictly true, it is expected to be a sufficiently good approxima-tion.
UCT consists of performing multiple simulations of possible continuations of the game from the current state. Instead of per-forming fully random rollouts, as in the case of Monte Carlo sampling, it proposes a more intelligent approach to choosing continuations worth analyzing so that the obtained results are more meaningful.
In each state, following the principles of UCB1, UCT advises tofirst try each action once and then, whenever the same posi-tion is analyzed again, choose the move according to
(1)
where is a set of all actions possible in state ,
denotes the average result of playing action in state in the simulations performed so far, is the number of times state has been visited, and is the number of times action has been sampled in this state. Constant controls the bal-ance between exploration and exploitation, since the formula postulates choosing actions with the highest expected rewards, however, at the same time, avoiding repetitive sampling of only one action while others might yet prove more beneficial.
A direct implementation of the approach described above is, of course, infeasible due to memory limitations. With
suf-ficient time it would lead directly to storing the whole game tree in memory, which is impossible in the case of all but the simplest games. Therefore, each simulation actually consists of two phases: the strict UCT phase and the Monte Carlo (random
Fig. 2. Conceptual overview of a single simulation in the UCT algorithm [4].
rollout) phase (see Fig. 2). An in-memory game tree is built it-eratively, and in each simulated episode the UCT strategy is ap-plied only until the first not-yet-stored game state is reached. This state is then added to the in-memory game tree, itsfirst ac-tion to be tested is chosen, and a strictly random Monte Carlo rollout is performed further down the tree. No data are retained about the positions encountered during this phase of the simula-tion. All the nodes visited during the strict UCT phase have their and values incremented and their values updated with thefinal value of the rollout.
Additionally, as the game progresses, the part of the in-memory game tree not reachable from the current game state is discarded. In our implementation, in order to further optimize the algorithm, we make use of the fact that some states may be reached in several ways (by performing different move sequences) and, therefore, as mentioned earlier, the game should be represented as a directed acyclic graph rather than a tree. This does not, however, influence the basis of UCT algorithm operation.
With UCT analysis finished, choosing the next move is simply a matter offinding the action with the highest value in the current state.
B. MTD
MTD [21] (a member of the family of memory enhanced test driver algorithms) is one of the popular algorithms based on alpha–beta pruning [12].
Fig. 3. MTD algorithm for real-valued evaluation function [17].
value. A pseudocode for this algorithm is presented in Fig. 3. Our GGP agent employs an iterative-deepening version of the real-valued MTD method.
IV. EVALUATIONFUNCTION A. Evaluation Function Construction
Building an evaluation function for a GGP player is inher-ently different and much more difficult than building an eval-uation function for any single-game application. While in the latter case a lot is usually known about the game at hand (or can be deduced by the function developer), in the former case, one has to create an agent able to deal with a vast number of possible games that can be described in GDL. There is virtually no way of incorporating any domain-specific (game) knowledge directly into the program, and the evaluation function must be somehow autonomously generated, probably by an AI- or CI-based rou-tine.
Nevertheless, some researchers have attempted (with some success) to identify (within the game rules) concepts typical for many human-played games, such as boards and pieces [11], [14], [17], [18], [24]. While there is no GGP-inherent reason for this approach to work, many of the GGP games are naturally based on real-world human games and, therefore, these concepts are actually fairly abundant in many of them.
In our application, though, we decided to avoid any such preconceptions and employ a totally knowledge-free evaluation function generation approach, based solely on simulations and statistical analysis of a game description. Our evaluation func-tion is represented as a linear combinafunc-tion of features. Features are game-specific numerical values describing game positions. Typical feature examples would be checker or king counts in the game ofCheckersor the presence of a particular piece on a particular square inChess. While a set of features is not ex-pected to uniquely and fully describe a game state, it is exex-pected to provide enough information to judge the most likely outcome of the game with reasonable accuracy.
In order to build our evaluation function, we needed, there-fore, two mechanisms: one for generating the set of features to be incorporated into our function and another for assigning weights to them. The following sections describe the process in detail.
1) Features Identification: The first step of our algorithm consisted in generation of a (possibly huge) set of features that could be used for building evaluation function for the particular game at hand. While designing this process, we were inspired by
the general ideas and concepts presented in some of the earlier papers dealing with GGP [14], [24], [2].
In particular, Clune [2] provided the source of many of the concepts described below. He incorporates the ideas of extracting expressions from the game description and identi-fying function argument domains to generate more specialized features. He also introduces the concept of stability, albeit not calculated according to the same formula we use. On the other hand, the GGP agent presented in [2] does not employ a feature generalization phase or build compound features in a way present in our solution. Additionally, we do not attempt to impose any predefined interpretations to the expressions to build a simplified model of the game. Instead, we employ a custom algorithm to build an evaluation function directly from the generated expressions.
Features used by our agent are represented by expressions similar to those of a GDL description of the analyzed game. For instance, the expression(cell ?x ?y b)would represent the number of empty fields in the current position in a game of
Tic-Tac-Toe. In general, the value of a feature (in a particular game state) is calculated by identifying the number of possible combinations of values for variables of the expression, so that the resulting expression is true in a given state. In the case of features with constants only (and no variables), only two values would be possible: 0 and 1.
The initial set of features is extracted directly from the game rules. This set is expected to already be reasonable as the game description contains mainly expressions that have direct signif-icance either for further development of the game, or for its score. In both cases, they make good candidates for evaluation function components.
Still, we do not settle for this relatively small number of can-didate features and try to identify more of them. For this pur-pose, we employ two procedures, characteristic for human cog-nitive processes: generalization and specialization. We believe their combination should lead us to a better understanding of the game andfinding features possibly crucial for a success.
We start with generalization, which is a relatively straightfor-ward process. Namely, in each of the expressions identified so far, we replace constants with variables, generating all possible combinations of constants and variables. For instance, for an ex-pression of(cell 1 ? b), we would generate three new candidate features:(cell ? ? b),(cell 1 ? ?), and(cell ? ? ?). Obviously, we may arrive at a feature that is already in our population; it is then ignored as we do not need any repetitions.
The aim of the specialization phase is, as the name suggests, opposite to the generalization phase. We try to generate fea-tures that contain fewer variables than those found so far. For the feature(cell 1 1 ?)we would ideally like to generate three new expressions(cell 1 1 x),(cell 1 1 o), and(cell 1 1 b). This phase, however, requires a slightly more sophisticated algorithm than generalization. Theoretically, we could simply attempt to replace variables in all the features with all known constants, but it would lead to an explosion in the number of features that would be impossible to handle.
This method is not guaranteed to generate precise results but rather supersets of the actual domains. Still, it is capable of severely limiting the number of generated features. Basically, it consists in analyzing all inferences and, within each of them, identifying variables present in several predicates (or as several arguments of a single predicate). Whenever such a case is discovered, it is assumed that the parameters in question have identical domains. A simultaneous analysis of all constant occurrences allows a quick assignment of constants to all the shared domains found by the algorithm.
Still, in some cases, it is possible for the domain sizes to be prohibitively big, possibly leading to an explosion in the can-didate features count. Therefore, whenever a parameter’s do-main size exceeds a configured limit, it is ignored and takes no part in the specialization process. In all our experiments, this threshold was set to 30, which resulted in up to several thou-sands of candidate features in moderately sophisticated games (4343 inCheckers, being the greatest value in this category) and several dozens of thousands in extreme cases (such asChess
with 28 163 candidate features).
Finally, after the specialization phase is completed, even more features are generated by the process of combining ex-isting features. The only type of compound feature currently in use in our application is the difference of two similar features, where two simple features are considered similar if and only if they are based on the same predicate and its arguments differ in one position only, which in both instances contains a constant. An example of a pair of such similar features would be (cell ? ? x)and(cell ? ? o). A compound feature built of those two simple components would, therefore, calculate the difference in the count of and markers on the board.
2) Features Analysis: Since building evaluation function with the use of several thousands of features (many of them redundant or unimportant for thefinal score) is not feasible, the next step of our algorithm involves some statistical analysis of the features in order to allow selecting the most promising ones and assigning weights to them.
The assessment is made by means of random simulations. First, we generate a set of some number (typically 100) of random short game-state sequences that will form the basis for further analysis. Each sequence starts in a position generated by randomly making a number of moves from the initial position of the game. This initial depth is selected randomly for each sequence from an interval depending on the expected length of a game, also estimated by random simulations.
Each random-play-generated sequence consists of two tofive positions, either consecutive or almost consecutive (with a dis-tance of two or three plies). Once the sequences are generated, up to ten Monte Carlo rollouts are performed from each one’s last position. These allow an estimation of thefinal scores of all the players for each sequence.
The data obtained so far serves as the basis for calculating some typical statistics for all features. These include their av-erage values, avav-erage absolute values, variance, minimum and maximum values, etc. While thesefigures are useful for some minor optimizations of the algorithm, two statistics are crucial for the overall effectiveness of the features selection process: correlation of the feature’s value with the scores of each player,
and its stability. While the former is obvious (and calculated on the basis of random rollouts mentioned earlier), the latter re-quires some explanation.
Stability is intuitively defined as the ratio of the feature’s vari-ance across all game states to its average varivari-ance within a single game (or, in our case, game subsequence). More precisely, it is calculated according to
(2) where denotes the total variance of the feature (across all game states in our implementation: initial states of all generated sequences) and is the average variance within sequences. Continuing with theTic-Tac-Toegame example, we would ex-pect the feature(cell ? ? b)(the number of empty squares) to have a low stability value, since it changes with each and every ply. On the other hand, the feature(cell 2 2 x)( on the center square) would be characterized by relatively high stability, as its value changes at most once per game.
We expect more stable features to be better candidates for usage in the heuristic evaluation of game states. Low stability due to a high value would signal significant oscillations of the feature value between successive positions and, therefore, a strong horizon effect (and, as a consequence, low prognostic quality). Relatively low , on the other hand, is typical for features that remain constant or change slowly and are not useful for distinguishing between even significantly different states. Although some false negatives are in general possible, we try to avoid using features with a low stability value.
3) Evaluation Function Generation: Once the set of can-didate features is built and analyzed, it is time to define the evaluation function. As mentioned earlier, it is constructed as a linear combination of selected features. Two steps are required to create it: selection of the most promising features and as-signing weights to them.
At the moment, we employ a relatively simple strategy for realization of these tasks. Although simplistic, it turned out to be surprisingly robust, and so far preliminary attempts at using more advanced CI-based approaches have not proven to be su-perior.
The procedure relies on the statistics described in Section IV-A2, namely correlation with the expected score of the player and stability of the feature . The features are arranged in descending order according to the minimum absolute value of their score correlations and stability [i.e., ] and we choose thefirst 30 of them as components of the evaluation function. While those two values ( and ) are not directly comparable, they both fall in the same range and although in most cases absolute values of score correlations are lower than stability, both of them actually infl u-ence the choice. The formula cannot be simplified to only using one of them. The decision to have exactly 30 components in each evaluation function was based on a number of preliminary tests, which proved this size of the evaluation function to be quite robust across several test games.
of the resulting weight will always be the same as that of the correlation.
Additionally, each evaluation function contains a special con-stant component equal to the average score of a given role in a game. Its value is calculated based on the simulations per-formed during the features analysis phase. Its effect is a shift in the expected value of the evaluation function. In the case of a two-player competitive game, if all the other components eval-uate to 0, thereby indicating no bias toward any of the players, the evaluation value will be equal to the average score expected for the player. Since the generated weights of the components are relatively low, the value of the evaluation function should rarely fall out of the range of possible scores. Simple automatic scaling of the function wouldfix this problem, should the need arise, but it was not necessary in the case of any of the selected games.
4) Implementation: For the experiments described in this paper we used an implementation without any time limit for the evaluator generation. Two out of the three main parts of the algorithm can easily be parallelized, especially but not ex-clusively, in a shared-memory model employed in our solu-tion. The time-consuming generation of a pool of random game sequences can easily be divided into independent and parallel tasks while creating each of the sequences. Similarly, once this pool is prepared, statistic calculations for each of the features re-quire almost no cooperation at all and can safely be parallelized. Finally, while it would be possible to at least partially parallelize the feature generation phase, we decided instead to run it in a single dedicated thread while other processors were utilized for game sequence pool generation.
Overall, while obviously there is still place for optimization, we assess our solution’s speed as more than satisfactory. On the Intel Core i7 machine employed in our experiments, the whole evaluation function generation phase took from several seconds for a simple game (e.g.,Connect4), through up to half a minute for a moderately sophisticated one (Checkers being the slowest with results of 26–31s) and up to 2 min forChess. In other words, our approach could potentially operate within tournament-level time limits even on a single machine. Further optimization and implementation in a distributed environment is also possible so as to reduce time requirements.
B. MTD in GGP
In two-player turn-based adversarial games, the most typ-ical method of using a state evaluation function is employing it within the alpha–beta pruning algorithm or one of its
modi-fications, or in other algorithms based on it [such as MTD described in Section III-B].
GGP framework, however, is not limited to two-player games. While in this paper we restrict our experimentation to this category, we aim at designing a solution that would be applicable to any game that can be defined in GDL, including games with simultaneous moves and any finite number of players. While it is possible in such a case to perform a full
fixed-depth game tree analysis, it would be far too slow to be practical.
Therefore, we decided to employ one of several possible variations of the alpha–beta algorithm for multiplayer simul-taneous move games. Namely, we took a “paranoid” approach [25], which assumes that all other players form a coalition against us (aiming to minimize our final score) and in each state can decide their actions after our own move (i.e., with prior knowledge of our not-yet-performed move). This way we effectively transform the game into a two-player one with twice the depth of the original one. While this transformation is clearly not optimal for all games, it is relatively simple and reasonable for most of the multiplayer games encountered at GGP tournaments.
With the game transformed as described above, we actu-ally employ the time-constrained MTD instead of a plain alpha–beta pruning algorithm. While the alpha–beta algorithm can be parallelized with, in some cases, significant gains in efficiency, at the moment, we rely on its single-threaded imple-mentation. Again, wefind our solution speed to be acceptable. In entry and near-entry game positions, we manage to perform a search with a depth ranging from three to four moves inChess
to six moves in Checkers and Connect4, within a 10-s time limit.
C. Guided UCT
Arguably an important advantage of the UCT algorithm is that there is no need for an externally defined heuristic evalua-tion funcevalua-tion. Still, in many cases (e.g.,Go[7], Amazons [15],
Lines of Action[29], and GGP itself [4], [26]), it seems that the UCT can benefit from the introduction of some sort of an addi-tional, possibly game-specific, bias into the simulations. Below, we discuss several possibilities of combining the UCT with our automatically inferred game-specific state evaluation function into what we call GUCT algorithm. While there are publica-tions (e.g., the aforementioned [29]) that propose alternative so-lutions, we concentrate here on universal, generally effective ap-proaches that seem especially well suited for the GGP research framework.
We believe the evaluation function can be useful both in the strict UCT phase (while traversing the graph of pregenerated and stored game states) and during the Monte Carlo random roll-outs. It is also worth noting that once a state evaluation function is available, it is relatively easy to construct a state–action pair evaluation function . In our approach, we define its value to be the average value of across the set
of all states directly reachable from state by performing ac-tion (there may be more than one such state, because the state reached after performing may also depend on actions per-formed by other players), i.e.,
(3)
UCT tree. All actions possible in such a new state would start with some preset value of (proportional to the level of trust in the evaluation function) and values equal to . Afterwards, these values would be updated according to the standard UCT rules. This solution would make sure that some, potentially biased, assessment of the moves is available immediately and then gradually improved by averaging with, hopefully less biased, results of random rollouts. With time the influence of the heuristic evaluation function would gradually diminish.
2) Evaluation Function for Move Ordering: In the case of less trust in the quality of the function, another, less inva-sive, approach could be used. In a typical UCT implementa-tion, whenever a new node is added to the tree, its actions are tested in the simulations performed in random order. When time runs out, there will obviously be game states left with some ac-tions not played even once. It would, hence, be advantageous to start testing from the most promising actions, and the evaluation function could help achieve this goal by means of ordering the moves according to their expected quality. An analogous move ordering scheme, albeit useful for different reasons, is often em-ployed in alpha–beta algorithm implementations, e.g., by means of a history heuristic [22]. Incidentally, this last concept has also proven useful in the context of a UCT algorithm and GGP agent [4].
3) Evaluation Function in Random Rollouts: Alternatively, the heuristic evaluation function can also be weaved into the Monte Carlo rollout phase of the UCT algorithm. Following the ideas presented, in a slightly different context, in [4], the random selection of actions to perform can be replaced by one in which each move’s selection probability depends in some way on its evaluation by the function. The actual selection would usually be implemented by means of either Gibbs distribution or -greedy policy.
4) Evaluation Function as Rollouts Cutoff: While we per-formed some initial experiments with the approaches presented above, so far we have achieved the best results with yet another method of introducing an evaluation function into the Monte Carlo phase of the UCT routine. Namely, in each node encoun-tered in the fully random simulations, we introduced a rela-tively minor (0.1 in the current experiments) probability of stop-ping the rollout there and using the heuristic evaluation func-tion’s value as the rollout’s return value. In effect, the longer the rollout, the higher the chance it will be stopped and replaced by the value of the evaluation function in the last node reached. The potential advantages of this approach are twofold. First, there is a high chance we will cut short any long and time-consuming simulation, resulting in time saving that will allow us to perform more simulations than would be otherwise possible. Second, the evaluation function will typically be applied to states at least several moves down the game tree from the last in-memory game tree position. It is reasonable to assume that the closer to the end of the game that the state is, the easier it is to esti-mate thefinal score and, hence, the more reliable the evaluation function’s value.
As afinal note, it should be stressed that the aforementioned four strategies can be safely mixed with one another. Still, after
some initial testing, we decided to use only the last one in the experiments described herein.
V. EXPERIMENTS
In order to verify the quality of both the mechanism for auto-matic generation of the evaluation function and our search algo-rithm, we organized several tournaments, comparing our GGP agents [the UCT and MTD based ones] with the one based on a plain UCT algorithm, as well as with each other.
At this stage of research, we decided to limit the experiments to various two-player games. We relied on the definitions avail-able on the Dresden GGP Server [9], selecting 13 games based on real-world ones for the ease of intuitive assessment of their complexity level and identification of their pertinent features. After performing a set of simple experiments, we chosefive of those for further analysis, each for a reason:
1) Chessas the most sophisticated of all the games consid-ered;
2) Checkersas a moderately sophisticated game in which our agent is very successful;
3) Connect4 and Connect5 as games in which our agent achieves mixed results;
4) Othelloas the game in which our agent fares worst of all the 13 games tested.
Apart from minor changes forced by the limitations of GDL (such as the inability to efficiently define a draw by the threefold repetition rule in Chess), those games closely resemble their original counterparts. This is the exception ofConnect5which, contrary to its name suggesting some modification ofConnect4, is simply a small-board variant ofGomoku.
In most of the tournaments described in Sections V-A–V-C), more than 1000 matches were played for each of thefive afore-mentioned games. The actual number of matches depended on the stability of results obtained. In general, we would not stop an experiment until a standard mean error of at most six per-centage points (i.e., 3% of the range of possible values) was achieved for each of the tested time limits. In effect, the av-erage standard error of the presented results does not exceed 5 percentage points (pp) for any of the games and typically stays significantly below 4 pp. Since our test regime caused the exper-iments to be extremely time consuming (they spanned several months of usage of three tofive machines) and we are not, at this point, interested in analysis of minute score differences, we feel that the data accuracy is satisfactory for our needs.
A. Guided UCT Versus Plain UCT
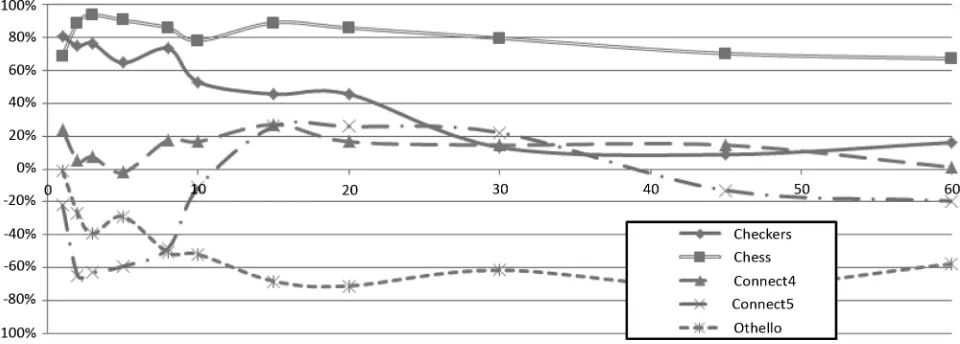
Fig. 4. GUCT versus plain UCT tournament results (in percent). The -axis denotes time limits per move (in seconds).
Fig. 4 presents the results for the GUCT agent in each game for each time limit. It is apparent that the GUCT agent deci-sively loses to UCT in one game (Othello), slightly loses in another one (Connect5), and outperforms plain UCT in the re-maining three—most notably inChess, being the game with the highest branching factor among all the games tested and diffi -cult to sample conclusively by the plain UCT algorithm. As far asChessis concerned, one can also easily observe a relatively low score for the time limit of 1 s per move. This stems from the fact that it is hard for any of the players to achieve a reasonable level of play with such a strict time regime and, therefore, more games actually end in draws.
The results forCheckers(another game for which an effective evaluation function must have been generated), besides showing a high level of play of the GUCT agent, also make an interesting dependency visible. It seems that with the increase in thinking time for the players, the advantage of GUCT over UCT dimin-ishes.
In order to verify that this is not a statistical flux, we per-formed a limited number of additional tests with higher time limits. The net result is that with higher time limits, both players begin to play more and more similarly. This effect is to be expected, since a greater number of simulations naturally im-proves the UCT method’s efficiency and weakens the total
in-fluence of the evaluation function in GUCT. The same effect may not be so visible for other games (with the exception of
Othello) because the effect can manifest itself at different move time limits and/or can be dampened by other effects.
In the case ofConnect4, our agent still clearly outperforms plain UCT, however, with a much lower margin than inChess
orCheckers. At the same time,Connect5turns out to be a some-what more difficult game for GUCT. Additionally, in this case, a very interesting dependence of the score values on time limits can be observed: the GUCT agent’s score is very low for short times and then raises significantly only to oscillate above and below the zero point depending on the time limit. At this point, we are not able to provide a full explanation of this behavior. We speculate that it is caused by an intricate interplay between the effects of random simulations and a less-than-ideal but useful evaluation function, both assessing similar states differently and
urging the agent to employ different playing strategies. This may lead to confused decisions depending on the strength of influence of each of the two components.
Finally, after some inconclusive results with extremely low time limits (probably due to the plain UCT’s inability to come up with any reasonable strategy with very low simulation counts), our GUCT agent decisively loses to plain UCT inOthellowith higher thinking times per move. It is obvious that our method fails to properly identify the key positional factors inOthello
to generate at least a reasonable positional strategy. Remember, however, thatOthellohas been included in our experiment pre-cisely because of how difficult it was for our agent.
B. Alpha–Beta Pruning Versus Plain UCT
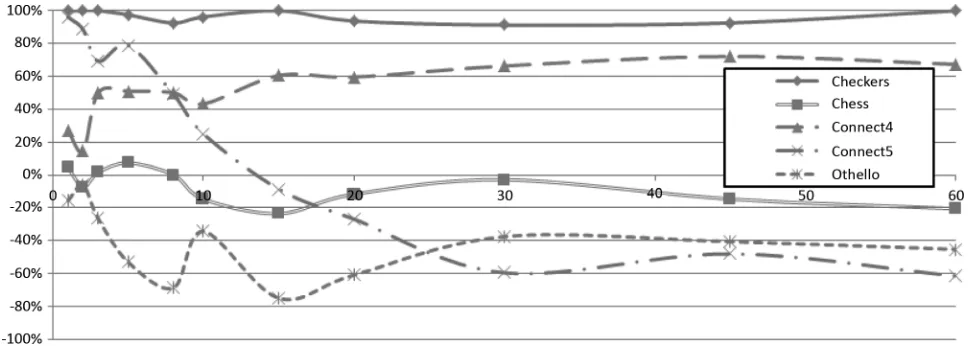
In the second test, we analogically assessed the efficiency of our MTD -based player by pitting it against the plain UCT agent. This time, however, another factor had to be considered. While our UCT implementation was multithreaded and capable of making good use of all eight (virtual) cores of our test ma-chine, MTD was implemented in its basic single-threaded form. Therefore, we decided to actually perform two separate experiments. In thefirst one, the MTD player would face a single-threaded version of the UCT agent. This comparison would be fair in that both players would have exactly the same processing power at their disposal. In the second one, we would use a typical, multithreaded implementation of UCT, conceptu-ally similar to the one presented in [3]. Considering the fact that UCT can be parallelized much more easily and possibly with much higher gains than alpha–beta pruning algorithms, we ex-pected thefirst experiment to slightly favor the MTD method and the second one—the UCT algorithm.
The results of the tournaments are presented in Figs. 5 and 6, which make several interesting observations possible. First, for games with moderately sophisticated rules, limited branching factors and reasonable automatically generated evaluation func-tions (as proven by the previous experiment), MTD seems to fare much better than GUCT did in the previous tests, even facing a multithreaded implementation of UCT.
Fig. 5. MTD versus single-threaded plain UCT tournament results (in percent). The -axis denotes time limits per move (in seconds).
Fig. 6. MTD versus multithreaded plain UCT tournament results (in percent). The -axis denotes time limits per move (in seconds).
multithreaded UCT. It seems that a relatively high branching factor and high cost of generating successive game states are the two major factors here. Additionally, in Fig. 5, it can be observed that, with low time limits per move (up to 10 s), all
Chessgames repeatedly end in draws, again with none of the players being able to devise a winning strategy within such a limited time. It seems that while the inferred evaluation func-tion is strong enough to significantly improve the playing level with reasonable-depth searches, it is not sufficient to guide the player on its own (with dramatically limited search time). Such an effect could be expected even with simpler, manually
de-finedChess position evaluators. Our agent simply requires a play clock of more than 10 s to playChess-level games reason-ably. Fortunately, one can safely expect that any game of such complexity will be played with a reasonably high time limit per move.
While theOthelloscores have improved compared to thefirst tournament, the problem with generating an efficient evaluation function for this game is still visible.
As previously, the dependence between time limits and scores inConnect5remains the most specific one. With a strict time regime, the UCT algorithm’s level of play is clearly low enough for it to be easily defeated by an alpha–beta player, even with a
nonoptimal evaluation function. As time limits grow, however, the UCT algorithm quickly gains more than MTD (which still heavily relies on the evaluation function).
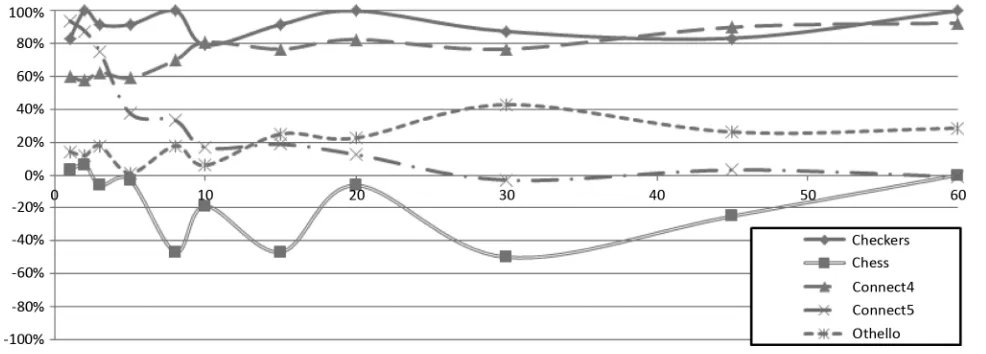
C. Alpha–Beta Pruning Versus Guided UCT
Finally, we decided to directly compare our two agents. The results, presented in Figs. 7 and 8, are in line with the previous experiments’ results. Alpha–beta pruning is a clear winner in the case ofCheckersandConnect4: moderately complicated games with, apparently, successful evaluation functions.Chess, on the other hand, is clearly better suited for the use of GUCT rather than MTD (at least in the case of the time limits tested, and high cost of state transition due to the GDL-based encoding of rules). In the case of Othello, a slightly better score from alpha–beta-based player should not be treated as significant due to a generally low level of play.Connect5scores, traditionally, depend significantly on the time limits. Strict time regimes lead to easy victories for the MTD method, while higher time limits make the chances more even.
D. Guided UCT Versus Null Heuristic
evalua-Fig. 7. MTD versus single-threaded GUCT tournament results (in percent). The -axis denotes time limits per move (in seconds).
Fig. 8. MTD versus multithreaded GUCT tournament results (in percent). The -axis denotes time limits per move (in seconds).
tion function, by simply assuming that they end in a draw. This has been proven in the context of GGP in [5]. While the afore-mentioned approach included initial analysis to intelligently de-cide which rollouts to stop early, it could be that a similar ef-fect may also be achieved for some games by our probabilistic cutoff algorithm. If this effect were dominant, the actual value of the evaluation function would not matter as long as it remained close to a draw value.
In order to verify if this is the case, we compared our evalu-ation functions with a null one which returns a draw for every game state. The results of such a comparison for several typical time limits are presented in Table I. Each value is based on at least 50 matches and the rules were identical to those in other tournaments: sides were swapped after each game, 1 point was awarded for a victory, 1 for a loss, and 0 for a draw. To com-pensate for differences in match counts, results in the table are presented as percentages (with 100% representing a GUCT vic-tory in every game, and 100% its loss in all matches). Based on these values, it can be safely stated that, with a single possible exception of theOthelloevaluator, our evaluation functions are actually useful and the results obtained in the previous experi-ments are not simply the effects of early cutoffs.
TABLE I
GUCT VERSUSGUCT WITHNULLHEURISTICTOURNAMENTRESULTS
(WITH95% CONFIDENCEBOUNDS)
E. Results Summary
We think that the results achieved so far are promising, doubly so considering the simplified way of choosing the evaluation function components and assigning weights to them. Our method is obviously not equally successful in all games, but that is only to be expected considering the broad range of games that can be defined in GDL.
Additionally, it is possible that it is not the game itself that is problematic for our solution but the specific way in which it was defined (the same game can be defined by different GDL descriptions).
The quality of the proposed players depends heavily on the amount of time available for each move. We performed tests with a range of limit values typical for the GGP tournaments held so far, thus proving the feasibility of employing the pro-posed solution in a tournament environment.
The relative quality of the two game tree search algorithms utilized in our application seems, additionally, to depend heavily on the specifics of the game played and, to some extent, the quality of the evaluation function. The alpha–beta pruning-based agent is generally better suited for games of moderate complexity (and, hence, a relatively lower cost of state expansions) and higher quality, more reliable evaluation functions. The GUCT algorithm has some potential to deal with more biased evaluation functions and definitely copes better with sophisticated games with higher branching factors and more expensive rules processing.
F. Sample Evaluation Functions
Evaluation functions differ significantly from match to match, since they are regenerated each time in a process based on a randomly selected set of sample game positions. Addi-tionally, the same value can often be calculated in multiple ways, e.g., the piece count difference can be represented by a single compound feature, separate features for each player with opposite weights, or a number of features calculating the piece count for each row of the chessboard.
Sample evaluation functions for Checkersand Othello are presented in Appendixes A and B. On a general note, we observe that the majority of the components of the evaluation function have proper (i.e., consistent with human intuition) signs, which means that advantageous features contribute positively whereas disadvantageous ones have a negative contribution to the overall position assessment.
In the case ofCheckers, note that in the notation used in this game definition,h1 is a playable position while a1 is not. It is clearly visible (and was discernible across all generated in-stances of the evaluation function) that the evaluators initially contain general material-based features: theirfirst two compo-nents calculate the differences in pieces and king counts of the players. This rule would hold true for almost all evaluation func-tion instances (in more than 80% of the analyzed cases). In rare exceptions, these components would typically be replaced by a functionally equivalent notation, e.g., counting pieces and kings separately for each player, summing pieces counts separately for each row, etc.
Further components form at least some attempt at positional assessment. For instance, the evaluators (especially thefirst one) apparently stress control of the h column, probably because pieces in these positions cannot be captured. At the same time, there is also a lot of noise in the formula. For instance, some of the compound expressions contain references to cellsa5andh2
which will always remain empty.
Building an evaluation function forOthelloproved to be a much more difficult task. These functions contain quite a lot of noise and apparently random components. Still, in most of them, at least some reasonable components are identifiable. Simple piece counts are often present but are known to be not very useful as part of an evaluator. The sample evaluation function presented herein clearly shows that our algorithm managed, at least to some extent, to identify the importance of board borders and corners; unfortunately, in this case, only for one side of the board.
The last component of each function represents the bias (au-tonomously developed by the method) whose role is to shift the average expected value of the evaluation function to the average expected value of the game.
VI. CONCLUSION ANDFUTURERESEARCH
We have described in detail our attempt at creating a GGP agent relying on an automatically inferred heuristic state evalu-ation function. We also offered two methods of employing this function in the context of GGP, based on two popular game tree search algorithms.
As stated earlier, we assess this attempt as successful, espe-cially considering that, at the moment, only very simple sta-tistical methods for building evaluation function from compo-nents generated by human-cognition-inspired processes of gen-eralization and specialization of the game rules are employed. Further improvements in this part of our application are one of our current research goals. One of the solutions we are consid-ering at the moment is to employ CI techniques for this task, in particular the layered learning method [19], [27]. We also plan to further tweak and improve the evaluation function during the game (i.e., in the playing phase of the match).
Additionally, our experiments show that the relative efficacy of the game tree analysis algorithms tested (MTD and GUCT) depends heavily on the characteristics of the game played. Devising a method for the automatic selection of one of the two approaches before the game begins (or perhaps even switching them while playing) is, therefore, another interesting research topic.
Finally, further analysis and a possible identification of the class of games for which our approach is not successful would probably allow methods to be designed for circumventing such problems and gaining a more even level of play across all games. Specifically, it can be clearly seen in the results presented that
Othello proved to be one such game and its deeper analysis should provide important insight into this issue.
APPENDIXA
SAMPLEAUTOMATICALLYINFERREDEVALUATIONFUNCTIONS FOR, RESPECTIVELY, WHITE ANDBLACKCHECKERSPLAYERS.
0,33*(cell(?, ?, wp)-cell(?, ?, bp)) + 0,11*(cell(?, ?, wk)-cell(?, ?, bk)) + 0,12*(cell(h, 3, bp)-cell(h, 5, bp)) + 0,12*(cell(h, ?, wp)-cell(h, ?, bk)) + 0,14*(cell(h, 3, wp)-cell(h, 3, bp)) + 0,12*cell(h, ?, wp) + 0,11*(cell(h, ?, wp)-cell(h, ?, bp)) + 0,065*cell(h, 5, b) + 0,065*(cell(a, 5, b)-cell(h, 5, b)) + 0,065*(cell(c, 5, b)-cell(h, 5, b)) + 0,065*(cell(e, 5, b)-cell(h, 5, b)) + 0,065*(cell(g, 5, b)-cell(h, 5, b)) + 0,065*(cell(h, 4, b)-cell(h, 5, b)) + 0,065*(cell(h, 5, b)-cell(h, 2, b)) + 0,065*(cell(h, 5, b)-cell(h, 6, b)) + 0,065*(cell(h, 5, b)-cell(h, 8, b)) + 0,1*(cell(?, 3, wp)-cell(?, 3, bp)) + 0,061*(cell(h, 3, b)-cell(h, 5, b)) + 0,053*(cell(h, 5, b)-cell(h, 5, bk)) + 0,13*cell(h, 3, bp) + 0,13*(cell(a, 3, bp)-cell(h, 3, bp)) + 0,13*(cell(c, 3, bp)-cell(h, 3, bp)) + 0,13*(cell(e, 3, bp)-cell(h, 3, bp)) + 0,13*(cell(g, 3, bp)-cell(h, 3, bp)) + 0,13*(cell(h, 1, bp)-cell(h, 3, bp)) + 0,13*(cell(h, 3, bp)-cell(h, 3, wk)) + 0,13*(cell(h, 3, bp)-cell(h, 4, bp)) + 0,13*(cell(h, 3, bp)-cell(h, 2, bp)) + 0,13*(cell(h, 3, bp)-cell(h, 6, bp)) + 0,13*(cell(h, 3, bp)-cell(h, 8, bp)) + 48*1 0,23*(cell(?, ?, wp)-cell(?, ?, bp)) + 0,12*(cell(?, ?, wk)-cell(?, ?, bk)) + 0,12*(cell(h, 5, bp)-cell(h, 7, bp)) + 0,13*(cell(b, 5, bp)-cell(h, 5, bp)) + 0,14*(cell(h, 3, bp)-cell(h, 5, bp)) + 0,067*(cell(c, 2, wp)-cell(c, 2, bk)) + 0,084*cell(c, 2, wp) + 0,084*(cell(b, 2, wp)-cell(c, 2, wp)) + 0,084*(cell(c, 1, wp)-cell(c, 2, wp)) + 0,084*(cell(c, 3, wp)-cell(c, 2, wp)) + 0,084*(cell(c, 5, wp)-cell(c, 2, wp)) + 0,084*(cell(c, 7, wp)-cell(c, 2, wp)) + 0,084*(cell(c, 2, wp)-cell(c, 2, wk)) + 0,084*(cell(c, 2, wp)-cell(c, 8, wp)) + 0,084*(cell(c, 2, wp)-cell(d, 2, wp)) + 0,084*(cell(c, 2, wp)-cell(f, 2, wp)) + 0,084*(cell(c, 2, wp)-cell(h, 2, wp)) + 0,16*(cell(a, 6, wp)-cell(a, 6, bp)) + 0,079*(cell(a, ?, wp)-cell(a, ?, bp)) + 0,094*(cell(h, 7, wp)-cell(h, 7, bp)) + 0,097*(cell(?, 6, wp)-cell(?, 6, bp)) + 0,06*(cell(f, 1, b)-cell(f, 1, bk)) + 0,072*(cell(a, 2, wp)-cell(c, 2, wp)) + 0,13*(cell(a, 6, bp)-cell(a, 6, wk)) + 0,074*(cell(h, 5, b)-cell(h, 7, b)) + 0,057*(cell(g, ?, wp)-cell(g, ?, bp)) + 0,073*(cell(g, ?, bp)-cell(g, ?, wk)) + 0,052*(cell(a, ?, wk)-cell(h, ?, wk)) + 0,053*(cell(d, ?, bk)-cell(g, ?, bk)) + 0,08*(cell(b, ?, bp)-cell(b, ?, wk)) + 59*1
APPENDIXB
SAMPLEAUTOMATICALLYINFERREDEVALUATION
FUNCTION FORBLACKOTHELLOPLAYER.
cell(x, y, z)denotes the fact that az-colored piece occupies square(x, y).
0,19 *cell(?, ?, red) 0,22 *cell(8, ?, red) 0,22 *cell(?, ?, ?) 0,08 *cell(8, 8, red) 0,76 *cell(?, 8, red) 0,19 *cell(8, ?, ?) 0,17 *cell(?, 8, ?) 0,067 *cell(8, 8, ?) 0,14 *(cell(8, ?, black)-cell(8, ?, red)) 0,052 *cell(4, ?, red) 0,067 *(cell(?, ?, black)-cell(?, ?, red)) 0,095 *cell(8, 4, red) 0,42 *cell(5, ?, red) 0,099*cell(8, 5, red) 0,11*cell(4, ?, ?) 0,14 *cell(?, 4, ?) 0,52 *cell(?, 4, red) 0,13*cell(?, 5, ?) 0,039*(cell(5, 8, black)-cell(5, 4, black)) 0,097 *(cell(8, ?, ?)-cell(5, ?, ?)) 0,047 *(cell(8, ?, red)-cell(5, ?, red)) 0,087 *(cell(5, 8, ?)-cell(5, 4, ?)) 0,087 *(cell(5, 8, ?)-cell(5, 5, ?)) 0,087 *cell(5, 8, ?) 0,035 *(cell(8, 5, red)-cell(5, 5, red)) 0,11 *cell(5, ?, ?) 0,085 *(cell(8, ?, ?)-cell(4, ?, ?)) 0,036 *cell(?, 5, red)
0,028*(cell(?, 8, black)-cell(?, 8, red)) 0,072 *(cell(?, 8, ?)-cell(?, 5, ?)) 49 *1
REFERENCES
[1] P. Auer, N. Cesa-Bianchi, and P. Fischer, “Finite-time analysis of the multiarmed bandit problem,”Mach. Learn., vol. 47, no. 2/3, pp. 235–256, 2002.
[2] J. Clune, “Heuristic evaluation functions for general game playing,” in
Proc. 22nd AAAI Conf. Artif. Intell., Vancouver, BC, Canada, 2007, pp. 1134–1139.
[3] M. Enzenberger and M. Muller, “A lock-free multithreaded Monte-Carlo tree search algorithm,” in Advances in Computer Games, ser. Lecture Notes in Computer Science. Berlin, Germany: Springer-Verlag, 2010, vol. 6048, pp. 14–20.
[4] H. Finnsson and Y. Bjornsson, “Simulation-based approach to general game playing,” inProc. 23rd AAAI Conf. Artif. Intell., Chicago, IL, USA, 2008, pp. 259–264.
[5] H. Finnsson, “Generalized Monte-Carlo tree search extensions for gen-eral game playing,” inProc. 26th AAAI Conf. Artif. Intell., 2012, pp. 1550–1556.
[6] S. Gelly and Y. Wang, “Exploration exploitation in Go: UCT for Monte-Carlo Go,” inProc. Conf. Neural Inf. Process Syst., 2006. [7] S. Gelly, Y. Wang, R. Munos, and O. Teytaud, “Modification of UCT
with patterns on Monte Carlo Go,” INRIA, Paris, France, Tech. Rep. 6062, 2006.
[8] Stanford University, “General game playing,” [Online]. Available: http://games.stanford.edu/.
[9] Dresden University of Technology, “General game playing,” [Online]. Available: http://www.general-game-playing.de/.
[10] M. Genesereth and N. Love, “General Game Playing: Overview of the AAAI Competition,” 2005 [Online]. Available: http://games.stanford. edu/competition/misc/aaai.pdf
[11] D. Kaiser, “The design and implementation of a successful general game playing agent,” inProc. FLAIRS Conf., 2007, pp. 110–115. [12] D. E. Knuth and R. W. Moore, “An analysis of alpha-beta algorithm,”
Artif. Intell., vol. 6, no. 4, pp. 293–326, 1975.
[13] L. Kocsis and C. Szepesvari, “Bandit based Monte-Carlo planning,” in
Proc. 17th Eur. Conf. Mach. Learn., 2006, pp. 282–293.
[14] G. Kuhlmann, K. Dresner, and P. Stone, “Automatic heuristic construc-tion in a complete general game player,” inProc. 21st AAAI Conf. Artif. Intell., Boston, MA, 2006, pp. 1457–1462.
[15] R. Lorentz, “Amazons discover Monte-Carlo,” in Computers and Games, ser. Lecture Notes in Computer Science, H. van den Herik, X. Xu, Z. Ma, and M. Wins, Eds. Berlin, Germany: Springer-Verlag, 2008, vol. 5131, pp. 13–24.
[16] N. Love, T. Hinrichs, D. Haley, E. Schkufza, and M. Genesereth, “General game playing: Game description language specifi ca-tion,” 2008 [Online]. Available: http://games.stanford.edu/lan-guage/spec/gdl_spec_2008_03.pdf,
[17] J. Mańdziuk, Knowledge-Free and Learning-Based Methods in Intel-ligent Game Playing, ser. Studies in Computational Intelligence. Berlin, Germany: Springer-Verlag, 2010, vol. 276.
[18] J. Mańdziuk and M.Świechowski, “Generic heuristic approach to gen-eral game playing,” inSOFSEM 2012: Theory and Practice of Com-puter Science, ser. Lecture Notes in Computer Science. Berlin, Ger-many: Springer-Verlag, 2012, vol. 7147, pp. 649–660.
[19] J. Mańdziuk, M. Kusiak, and K. Walędzik, “Evolutionary-based heuristic generators for checkers and give-away checkers,” Expert Syst., vol. 24, no. 4, pp. 189–211, 2007.
[20] J. Mehat and T. Cazenave, “Combining UCT and nested Monte Carlo search for single-player general game playing,”IEEE Trans. Comput. Intell. AI Games, vol. 2, no. 4, pp. 271–277, Dec. 2010.
[21] A. Plaat, J. Schaeffer, W. Pijls, and A. de Bruin, “Best-firstfixed-depth minimax algorithms,”Artif. Intell., vol. 87, no. 1–2, pp. 255–293, 1996. [22] J. Schaeffer, “The history heuristic,”Int. Comput. Chess Assoc. J., vol.
6, no. 3, pp. 16–19, 1983.
[23] J. Schaefferet al., “Checkers is solved,”Science, vol. 317, no. 5844, pp. 1518–1522, 2007.
[24] S. Schiffel and M. Thielscher, “Automatic construction of a heuristic search function for general game playing,” inProc. 7th IJCAI Int. Workshop Non-Monotonic Reason. Action Change, 2007.
[26] M.Świechowski and J. Mańdziuk, “Self-adaptation of playing strate-gies in general game playing,”IEEE Trans. Comput. Intell. AI Games, 2013, DOI: 10.1109/TCIAIG.2013.2275163.
[27] K. Walędzik and J. Mańdziuk, “TheLayered Learningmethod and its application to generation of evaluation functions for the game of Checkers,” in Parallel Problem Solving from Nature, PPSN XI, ser. Lecture Notes in Computer Science. Berlin, Germany: Springer-Verlag, 2010, vol. 6239, pp. 543–552.
[28] K. Walędzik and J. Mańdziuk, “Multigame playing by means of UCT enhanced with automatically generated evaluation functions,” in
Arti-ficial General Intelligence, ser. Lecture Notes in Computer Science. Berlin, Germany: Springer-Verlag, 2011, vol. 6830, pp. 327–332. [29] M. H. M. Winands, Y. Bjornsson, and J.-T. Saito, “Monte Carlo tree
search in lines of action,”IEEE Trans. Comput. Intell. AI Games, vol. 2, no. 4, pp. 239–250, Oct. 2010.
[30] YAP Prolog [Online]. Available: http://www.dcc.fc.up.pt/ vsc/Yap/
Karol Walędzik received M.Sc. degree (with honors) in computer science from Warsaw Univer-sity of Technology, Warsaw, Poland, in 2006 and the M.Sc. degree (with honors) in economics from Warsaw School of Economics, Warsaw, Poland, in 2008. He is currently working toward the Ph.D. degree at Warsaw University of Technology.
He is currently with Warsaw University of Technology, where he lectures in Windows pro-gramming and computational intelligence. While he is interested in various aspects of artificial and computational intelligence, his research currently concentrates on multigame playing, learning, and reasoning in dynamic environments and application of bandit algorithm.
Jacek Mańdziuk(M’05–SM’10) received the M.Sc. (honors) and Ph.D. degrees in applied mathematics from Warsaw University of Technology, Warsaw, Poland, in 1989 and 1993, respectively, and the D.Sc. degree in computer science from the Polish Academy of Sciences, Warsaw, Poland, in 2000.
He is a Professor of Computer Science and Head of Department of Artificial Intelligence and Computational Methods at Warsaw University of Technology, Warsaw, Poland. His current research interests include application of computational in-telligence methods to game playing, bioinformatics,financial modeling, and development of metaheuristic general-purpose humanlike learning methods. He is the author of two books, includingKnowledge-Free and Learning-Based Methods in Intelligent Game Playing(New York, NY, USA: Springer-Verlag, 2010) and a coauthor of one textbook and over 90 refereed papers.
Prof. Mańdziuk is an Associate Editor of the IEEE TRANSACTIONS ON
![Fig. 1. Condensed Tic-Tac-Toe game description in GDL [16].](https://thumb-ap.123doks.com/thumbv2/123dok/4037924.1981344/2.592.39.289.64.367/fig-condensed-tic-tac-toe-game-description-gdl.webp)
![Fig. 2. Conceptual overview of a single simulation in the UCT algorithm [4].](https://thumb-ap.123doks.com/thumbv2/123dok/4037924.1981344/3.592.332.522.65.287/fig-conceptual-overview-single-simulation-uct-algorithm.webp)
![Fig. 3. MTDalgorithm for real-valued evaluation function [17].](https://thumb-ap.123doks.com/thumbv2/123dok/4037924.1981344/4.592.67.262.66.157/fig-mtdalgorithm-for-real-valued-evaluation-function.webp)