A STUDY ON THE DEVELOPMENT OF STUDENTS’ SYNTACTIC RECOGNITION OF ENGLISH DERIVATIONAL SUFFIXES IN
SENIOR HIGH SCHOOL
A THESIS
Presented as Partial Fulfillment of the Requirements to Obtain the Sarjana Pendidikan Degree
in English Language Education
By
Yohanes Sapta Nugraha Student Number: 011214065
ENGLISH LANGUAGE EDUCATION STUDY PROGRAM DEPARTMENT OF LANGUAGE AND ARTS EDUCATION FACULTY OF TEACHERS TRAINING AND EDUCATION
SANATA DHARMA UNIVERSITY YOGYAKARTA
A Thesis on
A STUDY ON THE DEVELOPMENT OF STUDENTS’ SYNTACTIC RECOGNITION OF ENGLISH DERIVATIONAL SUFFIXES IN
SENIOR HIGH SCHOOL
By
Yohanes Sapta Nugraha
Student Number: 011214065
Approved by
Sponsor
Drs. F.X. Mukarto, M.S., Ph.D. Yogyakarta, 10 January 2007
A Thesis on
A STUDY ON THE DEVELOPMENT OF STUDENTS’ SYNTACTIC RECOGNITION OF ENGLISH DERIVATIONAL SUFFIXES IN
SENIOR HIGH SCHOOL
By
Yohanes Sapta Nugraha Student Number: 011214065
Defended before the Board of Examiners on 23 January 2007
Board of Examiners
Chairperson : A. Hardi Prasetyo, S.Pd., M.A. ________
Secretary : Drs. P.G. Purba, M.Pd. ________
Member : Drs. F.X. Mukarto, M.S., Ph.D. ________
Member : Drs. J.B. Gunawan, M.A. ________
Member : A. Hardi Prasetyo, S.Pd., M.A. ________
Yogyakarta, 23 January 2006
Faculty of Teachers Training and Education
Sanata Dharma University
Dean,
Drs. Tarsisius Sarkim, M.Ed., Ph.D.
STATEMENT OF WORK ORIGINALITY
I honestly declare that this thesis which I wrote does not contain the works or part of
the works of other people, except those cited in the quotations and bibliography, as a
scientific paper should.
Yogyakarta, 10 January 2007
The researcher,
Yohanes Sapta Nugraha
God didn’t promise day without
pain
Laughter without sorrow
Sun without rain
But……
He did promise strength
for the day
Comfort for the tears, and
Light for your way
(Anonymous)
I dedicate this thesis to:
My
Jesus
My greatest
father
in heaven and
beloved
mother
My
brothers
and
sisters
My inspiration
Andriana
ACKNOWLEDGEMENTS
I dedicate my greatest and deepest gratitude to Jesus and Mother Mary for the
greatest love and strength during the completion of my thesis, now and forever.
I would like to thank:
1. Mr. Mukarto,my sponsor for his kindness and great patience in guiding me from
the very beginning until the completion of my thesis.
2. Ms. Rorik for her precious time and invaluable suggestion during the finishing of
my thesis.
3. Mr. Purba and his family, I thank them for the opportunity they have opened to
learn more the meaning of life and how to love others.
4. Sr. Maria Stella, PIJ, the head master of Sang Timur Senior High School for the permission in gathering my data, Bu Yovita and all Sang Timur English teachers who helped me in administrating the test and students in class X1-2, XIIPA-IPS and XIIIPA-IPS for becoming my respondents.
5. Th. Nangsir, my beloved father in heaven who gave me the chance to see the
world and C. Djumijati, my lovely mother for her endless love and each drop of her sweat and tears in raising me up.
6. My Brothers and Sisters who encouraged me to finish this thesis. Pak Lik and
Bu Lik Marjuki, who allowed me to live in the peaceful boarding house for 3 years. Mas Mothik and Mas Bowo for the time we share together.
7. Tanti Andriana, my greatest inspiration for the smiles, love, happiness, tears and lovely times so that we could reach our dreams.
8. My Special Friends, Lingga, Son, Broom, Tony, Hening, Asti , Pom-pom, Prima, DC, Inoel, Susan, Dina-solo, and Ya2 for the beautiful moments during
our study in PBI.
9. My Colleagues, Widi and Sito, Gelar and Diah, Puput, Rendy’02, Dina’98, Marta’00 and Onggo’99 for the ideas, supports and prayers that they have given
to me.
10.My Friends in ‘Kisgont’, Ki-ki, Sodiq, Pak Yoyok-Shita and Mas Rindi who always remind me to finish my thesis.
11.All PBI Lectures, who gave me precious knowledge during my study, Mbk Dani and Tari, and all librarian staffs in Sanata Dharma University for the
services.
12.All the people whose names could not be mentioned one by one for their help and
supports in finishing my thesis. May God bless you all.
Sapta
TABLE OF CONTENTS
TITLE PAGE ... i
PAGE OF APPROVAL ... ii
BOARD OF EXAMINERS ... iii
STATEMENT OF WORK ORIGINALITY ... iv
PAGE OF DEDICATION ... v
ACKNOWLEDGEMENTS ... vi
TABLE OF CONTENTS ... viii
LIST OF TABLES ... xi
LIST OF FIGURES ... xii
ABSTRACT ... xiv
ABSTRAK... xv
CHAPTHER I: INTRODUCTION ... 1
A. Background ... 2
B. Problem Identification ... 3
C. Problem Limitation ... 4
D. Problem Formulations ... 5
E. Objectives ... 5
F. Benefits ... 6
G. Definitions of Terms ... 6
H. Assumptions ... 7
CHAPTER II: LITERATURE REVIEW ... 8
A. Theoretical Description ... 8
1. Morpheme and Its Studies ... 8
2. Knowledge of Word ... 10
3. Lexical Development ... 17
4. Model of Vocabulary Acquisition ... 19
5. Vocabulary Learning ... 22
6. Lexical Mapping ... 24
7. Derivational Knowledge ... 24
B. Theoretical Framework ... 26
CHAPTER III: RESEARCH METHOD ... 29
A. Research Design ... 29
B. Instruments ... 30
C. Pilot Testing ... 32
D. Main Study ... 33
1. Subjects ... 34
2. Data collection ... 35
3. Scoring ... 35
4. Tabulation ... 35
5. Data Analysis ... 37
CHAPTER IV:ANALYSIS RESULTS ... 38
A. Data presentation ... 38
1. Scores of the First Year Students ... 38
2. Scores of the Second Year Students ... 38
3. Scores of the Third Year Students ... 39
4. Mean, Median and Mode ... 39
B. Results of Data Analysis ... 39
1. ANOVA ... 40
2. Students’ Syntactic Recognition of English Derivational Suffixes ... 41
C. Discussion ... 42
CHAPTER IV: CONCLUSION AND SUGGESTIONS ... 46
A. Conclusion ... 46
B. Suggestions ... 47
1. Suggestion for Senior High School Students ... 47
2. Suggestion for the English Teachers of Senior High School 48 3. Suggestion for Other Researchers ... 48
BIBLIOGRAPHY ... 50
APPENDICES ... 53
Appendix A. Surat Ijin Penelitian ... 53
Appendix B. Surat Keterangan ... 54
Appendix C. The First 2000 Words of English ... 55
Appendix D. Daftar Kosa Kata SMU ... 56
Appendix E. Checklist Test ... 65
Appendix F. Scores of the First, Second and Third Year Students ... 67
Appendix G. Interview Transcript ... 70
Appendix H. Output of SPSS Computations ... 87
LIST OF TABLES
Table 2.1: Some English Derivational Suffixes ... 25
Table 3.1: Checklist Test ... 31
Table 3.2: Matrix of Test Items ... 33
Table 3.3: Length of Study ... 34
Table 3.4: Scores Tabulation ... 36
Table 4.1: Frequencies Statistic ... 39
Table 4.2: Result of ANOVA ... 40
Table 4.3: Multiple Comparison ... 41
Table 4.4: Means Growth ... 41
LIST OF FIGURES
Figure 2.1: Initial Stage of Lexical Development in L2 ... 18
Figure 2.2: L1 Lemma Mediation Stage Lexical Development in L2 ... 18
Figure 2.3: L2 Integration Stage ... 19
Figure 2.4: Model of Vocabulary Acquisition ... 20
Figure 4.1: Mean Score of the First, Second and Third Year Students ... 42
ABSTRACT
Nugraha, Yohanes Sapta. (2007). A Study on the Development of Students’ Syntactic Recognition of English Derivational Suffixes in Senior High School
Yogyakarta: English Language Study Program, Sanata Dharma University.
Since communicative English language teaching becomes the primary concern, vocabulary learning tends to be ignored. Most of the English teachers of senior high school conduct teaching and learning vocabulary incidentally. They believe that through listening, speaking, reading, and writing activity vocabulary can be individually learnt by the learners. This condition causes other aspects of vocabulary knowledge tend to be discounted. Those aspects are word structure or morphology, syntactic category, relation with other words, such as synonymy, antonymy, and hyponymy.
This study was intended to investigate the development of students’ syntactic recognition of derivational suffixes of English words in Sang Timur Senior High school. Two research problems would be answered in this study i.e. 1) Are there any significant differences between first year, second year and third year students in their syntactic recognition of derivational suffixes of English words? 2) What are the developmental patterns of syntactic recognition of derivational suffixes of English words?
Cross-sectional design which was also a type of survey study was applied in order to answer the research problems. The main data were gathered using “Checklist” test which analyzed using One-way ANNOVA. The computations were done by SPSS 11.00 for windows release. The subjects of this study were 150 students of Sang Timur Senior High School. In order to have deeper explorations to the phenomena; simple informal interview was carried out.
The results of data analysis showed that there were significant differences between the first year, second year and third year students in their syntactic recognition of derivational suffixes of English words. The computation of multiple comparison indicated that the difference between the groups was not actually identical. On the other hand, it was found that the means growth of the students’ syntactic recognition of derivational suffixes of English words indicated positive growth. In other words, students’ syntactic recognition of derivational suffixes of English words increased in line with the length of their study in the senior high school.
ABSTRAK
Nugraha, Yohanes Sapta. (2007). A Study on the Development of Students’ Syntactic Recognition of Derivational Suffixes of English Words in Sang Timur
Senior High School Yogyakarta. Yogyakarta: English Language Study Program,
Sanata Dharma University.
Semenjak pengajaran bahasa Inggris berbasis komunikatif menjadi perhatian utama, pengetahuan vocabulary cenderung terabaikan. Sebagian besar guru-guru bahasa Inggris di sekolah menengah atas menyelenggarakan kegiatan belajar dan mengajar vocabulary sambil lalu. Mereka percaya bahwa melalui kegiatan menyimak, berbicara, membaca dan menulis vocabulary dapat dipelajari oleh siswa secara perseorangan. Konsisi seperti ini menyebabkan aspek-aspek pengetahuan yang lain tentang vocabulary tidak diperitungkan. Aspek-aspek tersebut adalah struktur kata atau morfologi, kategori (kelas) kata, hubungan dengan kata-kata lain seperti misalnya; sinonim, antonim, dan hiponim.
Penelitian ini bertujuan untuk mengetahui perkembangan siswa dalam pengenalan kategori (kelas) kata-kata turunan berbahasa Inggris yang berakhiran di SMA Sang Timur Yogyakarta. Dua permasalahan akan dipecahkan dalam penelitan ini, yakni 1) Adakah perbedaan yang berarti pada pengenalan siswa tahun pertama, kedua, dan ketiga terhadap kategori (kelas) kata-kata turunan berbahasa Inggris yang berakhiran? 2) Seperti apakah pola perkembangan pengenalan turunan berbahasa Inggris yang berakhiran?
Studi cross-sectional yang juga merupakan salah satu tipe studi survei diterapkan untuk menjawab dua permasalahan dalam penelitian ini. Data utama dikumpulkan dengan menggunakan “Checklist Test” yang diteliti dengan ANOVA satu arah. Seluruh penghitungan dikerjakan dengan SPSS 11.0. Subyek penelitian ini adalah 150 siswa di SMA Sang Timur. Dalam rangka mengexplorasi lebih mendalam terhadap fenomena yang terjadi dilakukan wawancara sederhana.
Hasil analisis data menunjukkan bahwa ada perbedaan yang berarti antara siswa tahun pertama, kedua adan ketiga pada pengenalan kategori (kelas) kata-kata turunan berbahasa Inggris yang berakhiran. Pada penghitungan multiple comparison menunjukkan bahwa perbedaan antar grup tidak benar-benar identik. Di sisi lain, ditemukan bahwa pertumbuhan pengenalan siswa terhadap kategori (kelas) kata-kata turunan berbahasa Inggris yang berakhiran menujukan pertumbuhan yang positif. Dengan kata lain pengenalan siswa terhadap kategori (kelas) kata-kata turunan berbahasa Inggris yang berakhiran meningkat sejajar dengan lamanya mereka belajar di SMA.
CHAPTER I INTRODUCTION
A. Background
The 2004 Competence Based Curriculum (Diknas, 2003: 14) explains that in
the context of education, English functions as medium to communicate in order to
access information. In accordance with this condition, it is proposed that there are
three scopes of English language learning of Senior High School in Indonesia. They
are language skills (listening, speaking, reading and writing), language competences
(Actional Competence, Linguistic Competence, Sociocultural Competence, Strategic
Competence and Discourse Competence) and positive development towards English
as a means of communication.
Discourse competence is the target competence of this curriculum. It can only
be achieved if students possess the supporting competences. Therefore, students are
supposed to have Actional Competence, Linguistic Competence, Sociocultural
Competence and Strategic Competence first in order to achieve the target
competence. Linguistic Competence then, is issued in order to conduct this research.
In this case, linguistic competence refers to the ability to understand and apply
aspects of syntax, vocabulary, phonology and spelling in a text correctly (Diknas,
2003: 47).
There are also the other aspects of language such as meaning of word or
semantic and morphology which are related to vocabulary. Zimmerman (in Coady &
Huckin; 1997: 5) remarks that vocabulary is the central of language and words are of
crucial importance to the typical language learner. Hence, vocabulary becomes the
central point in language learning. Learners will be deeply concerned in vocabulary
mastery of the language which is learned. For them, vocabulary mastery is a
compulsory aspect.
On the other hand, there are four skills in English i.e. listening, speaking,
reading and writing. Since the vocabulary is the central of language learning, learners
have to pay attention more on vocabulary mastery before they learn those four skills.
Here, vocabulary is the starting point before they achieve those four skills.
Furthermore, possessed sufficient vocabulary mastery is a part of Second Language
Acquisition.
Meanwhile, morphology deals with the understanding of word structure.
Further, it is related to aspects of vocabulary such as part of speech or syntactic
category (whether a word is noun, verb, adjective or adverb), inflection
(go-went-gone-going, book-books, child-children, long-longer-longest, etc.), derivation
(nation-national-nationality, like-dislike, interpret-misinterpret, etc.).
Knowledge of derivational affixes holds the important role in enriching
students’ vocabulary mastery. As stated by Mochizuki and Aizawa (1998: 291)
that:
“Affix knowledge is considered to be an important aspect in vocabulary knowledge. It helps the learners read material containing unfamiliar words and expand their vocabulary, especially their knowledge of derivates.”
Therefore, it is important for the learners to attend to that knowledge. Syntactic
recognition or recognizing syntactic category of a word becomes part of vocabulary
condition, derivational suffixes contribute large effects on the changes of syntactic
category of a word.
On one side, vocabulary mastery for senior high school students holds the
important roles in increasing their reading comprehension. Mochizuki and Aizawa
(1998: 291) argue that affix knowledge plays an important part in reading and
vocabulary development. It can be inferred from here that affix knowledge allow the
language learner develop their vocabulary mastery.
Furthermore, this knowledge influences on the development of learners’
vocabulary size. By mastering the derivational knowledge, Second or Foreign
Language learners can enlarge their vocabulary size. Then, their reading
comprehension will increase due to large number of vocabulary size.
Understandably, when students know the word employ they are also supposed to be
able to recognize the words family of it such as employment, unemployment,
employing.
Since there are many studies work on vocabulary development and focus
their subject on several vocabularies use and usage, the development of syntactic
recognition of the derivational suffixes of senior high school students is issued in
order to enlarge the vocabulary studies concerning affixations, especially
derivational suffixes.
B.
Problem Identification
According to O’Grady and Dobrovolsky (1996: 144) derivation forms a
addition of an affix. They add that derivation is the process by which a new word is
built from a base, usually through the addition of an affix. Other words, derivational
knowledge deals with the English words formation. This study intends to observe
students’ syntactic recognition of derivational suffixes of English words.
On the other hand, derivational knowledge means the ability in deriving
words uses derivational affixes. Derivational affixes consist of two major elements.
They are prefix and suffix. The proposed study will focus on students’ ability in
recognizing part of speech of derived words. Furthermore, this study intends to
search on the development of the syntactic recognition of derivational suffixes of
English words which can be achieved by Sang Timur Senior High School students
during their studies in the different duration.
Since vocabulary knowledge holds the significant role in the second and
foreign language acquisition process, it is very important to do this research.
Possessed derivational knowledge allows language learners to have maximum effort
in enriching their vocabulary size. Finally, mastering a large vocabulary size will
guarantee a better reading comprehension.
C. Problem Limitation
This study is closely related to English word formation, especially word
formation through the addition of derivational suffixes. The study also compares first
year, second year and third year of Senior High School students’ ability in
recognizing the syntactic categories of new words after the addition of derivational
English words concerning the length of their study during school time.
On the other hand this study is intended to investigate the developmental
patterns of students’ syntactic recognition of English derivational suffixes. Therefore,
this study will investigate whether the patterns of that the patterns are stable,
increased or even decreased.
D. Problem Formulations
1. Are there any significant differences between first year, second year and
third year students in their syntactic recognition of English derivational
suffixes?
2. What are the developmental patterns of syntactic recognition of English
derivational suffixes?
E. Objectives
This study will answer the questions which are stated in the problem
formulation. Conducting survey by means of one checklist-test of derivational
suffixes in the same time to the subjects of this study, the researcher will obtain the
data to be processed in order to answer the problem formulation above. The study
intends to find out whether there are significant differences in syntactic recognition
of English derivational suffixes between the first, second and third year of Senior
High School students or not. Then, the study is attempted to figure out the
developmental patterns of their syntactic recognition of derivational suffixes of
F. Benefits
Knowing the development of syntactic recognition of the derivational
suffixes helps students to read reading material containing unfamiliar words. In this
case, while facing the unfamiliar words the students also enrich their vocabulary size.
A good reading comprehension must be supported by sufficient vocabulary size.
Under this circumstance, the study gives perspective of the necessities to
the teachers that vocabulary learning need to be given considerable portion during
teaching-learning activities.
G. Definitions of Terms
There are some terms which are used in this study. They are terms of
development, derivation and Sang Timur Senior High School Students.
1. Development
As stated in Colins Cobuild English Dictionary (2001: 418) development means: (1)
the gradual growth or formation of something, (2) the growth of something such as
business or an industry (3) … The word development in this research is generated
from the second meaning of the above definition.
2. Pattern
In Colins Cobuild English Dictionary, (1) a pattern is the repeated or regular way in
which something happen or is done, (2) a pattern is an arrangement of lines or shape
especially a design in which the same shape is repeated at regular over a surface, and
(3) a pattern is a diagram or shape that you can use as a guide when you are making
study is defined as diagram or shape showing the growth of students’ syntactic
recognition of derivational suffixes of English words.
3. Derivation
As defined by O’Grady and Dobrovolsky (1989) that derivation is the process by
which a new word is built from a base, usually through the addition of affix.
H. Assumptions
Several aspects are not always able to be verified in this study, but they
influence on the precondition of the subject of the study. Therefore, they are assumed
that:
1. The subjects of this research have experienced learning English since Junior
High School, therefore all of them already have language input which is
relatively equal each of others before entering to Senior High School.
2. The subjects of this research sample are willing to answer the ‘checklist’ test
CHAPTER II LITERATURE REVIEW
This chapter is aimed to describe related theories in order to fulfill theoretical
truth demands of an educational research. Those related theories are the theoretical
base upon which the study outlined in Chapter I was laid down. There are two major
areas of concerns which are considered in this chapter. They are theoretical
description and theoretical framework.
The first part of theoretical description is concerned with discussion on the
nature of derivational knowledge. Second part, the discussion is about the
development of syntactic recognition of derivational suffixes in Sang Timur Senior
high School.
The theoretical framework concerns with the frame theory of the
development of syntactic recognition of derivational suffixes in Sang Timur Senior
High School and the hypothesis.
A. Theoretical Description 1. Morpheme and Its Studies
a. Morpheme knowledge
Kolln (1990: 258) defines morpheme as a combination of sounds that has
meaning, for some people sound is like the definition of word. Many morphemes are,
in fact, a complete word; such as develop, act and happy.
These words consist of single morpheme. Kolln also argues that morpheme
and syllable are not synonymous; in fact, many two-syllable words in English that
are single morpheme: carrot, jolly, merit, able. In contrast, many two-morpheme
words are single syllables: acts, walked, dog’s, swims. Fromkin and Rodman (1996:
114) add that morpheme may be defined as the minimal linguistic sign, a
grammatical unit in which there is an arbitrary union of a sound and a meaning.
Therefore, morpheme is the smallest component of word which contributes
its meaning. Radford, Atkinson, Britain, Clahsen and Spancer (1990: 162) state that a
morpheme which can also stand alone as a word is called free morpheme. In contrast,
a morpheme which cannot stand alone to convey its meaning is called bound
morpheme. For example; the word reader consists of a morpheme –er attached to a
word read. In this word, the word read is a free and suffix –er is a bound morpheme.
In addition, the words are made of morphemes, the minimal meaningful
linguistic unit that contains no smaller meaningful linguistics unit (Anglin, 1993 via
Long and Rule, 2004: 42). Long and Rule also propose that there are five major types
of words: root words, inflected words, derived words literal compounds, and idioms.
Those five types of words except idioms use morphological analysis to break words
into suffixes, prefixes, and root.
b. Natural order and sequence of L2 morpheme acquisition
Dulay and Burt (1973; 1974c) as cited in Ellis (1994: 91) find that the
acquisition order for group English morphemes remained the same irrespective of the
orders of groups are strikingly similar, 85% errors are developmental. This finding is
also confirmed by Bailey, Madden, and Krashen (1974). They investigate 73 adults
aged 17-55 years; classified as Spanish and non-Spanish-speaking members that
separates in 8 ESL classes.
From the above studies then it can be inferred that natural order of acquisition
in ESL learners is irrespective of age (Goldschneider and DeKeyser, 2001). On the
other hand Ellis and Laporte (1997: 64) as quoted by Goldschneider and DeKeyser
(2001) believe that the order acquisition can be explained by interaction between the
characteristic of the elements to be acquired and general cognitive principles of
inductive learning. The significance of this findings are intended to show that age of
language learners does not refer to the natural order and sequence of their second
language morpheme acquisition.
2. Knowledge of Word
a. Word
Bloomfield as cited from Poole (1999: 10) considers that a word to be a
minimum free form, a word, then, is a free form which does not consist entirely of
(two or more) lesser free forms; in brief a word is a minimum free form. Carter
(1998: 5) defines that a word is the minimum meaningful unit of language. On the
other hand, Poole further argues that linguists devised the terms lexeme or lexical
item to denote an item of vocabulary with a single referent. It can be inferred that a
word has relation with its reference. Second language learners may be sufficient to
Word is familiar but eludes precise definition (Taylor and Taylor, 1990)
as quoted from Susilo (2001: 10). In some purposes linguists or dictionary treat
words differently. Carroll et. all. (1971) as cited from Nation (1990) distinguish
words entirely on the basis of form. Word form for some extent may become
significant determination; for example: in the grammatical structure, word forms deal
with units that are part of grammatical patterns. In that case, a word can be the
subject of a sentence, the head of a modification structure, a structural signal in the
form of a function word, etc. (Lado 1984). These all are concern with form of word.
Clearly, Laufer (1997) as quoted from Mukarto (1999: 31) proposes some aspects or
features of word that learners need to attend to:
1. Word structure or morphology, i.e. the basic free morpheme and its derivational and, if any, inflectional morpheme.
2. Syntactic category, e.g. whether a word is a noun, an adjective or a verb; a verb in English may be mapped in to an adjective in Indonesia.
3. Relation with other words such as synonymy, hyponymy,
antonymy, and common collocation and registers.
b. The aspects are involved in knowing a word
A language learner needs to understand that knowing a word is not merely
able to show the equal meaning in his or her language. Richards (1976) via Read
(2000: 25) has outlined eight assumptions which cover various aspects which are
involved in knowing a word:
1. The vocabulary knowledge of native speakers continues to expand in
adult life, in contrast to the relative stability of their grammatical
2. Knowing a word means knowing the degree of probability of
encountering that word in speech or print. For many words, we also know
the sort of words most likely to be found associated with the word.
3. Knowing a word implies knowing the limitation on the use of word
according to variations of function and situation.
4. Knowing a word means knowing the syntactic behavior associated with
word.
5. Knowing a word entails knowledge of the underlying form of a word and
the derivation that can be made from it.
6. Knowing a word entails knowledge of network of associations between
that word and other words in the language.
7. Knowing a word means knowing the semantic value of a word.
8. Knowing a word means knowing many of the different meanings
associated with a word.
(Richards, 1976: 83)
The study confirms and modifies the fifth assumption. It deals with investigating
Senior High School Students’ ability on the syntactic recognition of derivational
suffixes of English words. Furthermore, this study also investigates the
developmental patterns of syntactic recognition of English derivational suffixes.
Meanwhile, Cronbach (1942) distinguishes five aspects of lexical knowledge:
generalization (knowing the definition), application (knowledge about how to use),
breadth of meaning (knowing the different senses of word), precisions of meaning
to use the word productively) (as cited from Bogaards, 2000: 491). On the other
hand, Cruse (1986) via Bogaards (2000: 492)prefers to use the concept of lexical
unit which is assumed to be the union of one stable meaning and a well-defined
meaning. In accordance with this concept Bogaards proposes six aspects that may be
learned about lexical unit in L2 as he assumes that L2 learners need to learn lexical
units not only “words”:
1. form: Learners have to get acquainted with the written and/or the spoken
form of the unit. Knowing that a given form does indeed belonging to a
given language seems to be a first stage of knowledge.
2. meaning: Knowledge of the semantic side of a lexical unit may come in
different shape. One can have a vague notion, e.g. that haematin has
something to do with the blood or that a beech is some kind of tree.
3. morphology: Lexical units have their own conditions on derivation and
compounding. Gracefully and graciously have relationships to two
different units which shared the form grace. Even when morphological
mechanisms of the L2 are well understood, many of actual relationships
have to be learned one by one (see also Bogaards 1994: 53-7). Especially
for productive it is difficult for L2 learners to know whether a given form
is possible and in what sense it may be used.
4. syntax: A learner who knows the rule of syntax may make many mistakes
by not applying the right rules to the lexical units. This applies especially
to verbs and, to lesser degrees, to adjectives. Learners have to find out
verb in a given sense, or which prepositions have to be used with a verb
or an adjective in some specific sense, e.g. with a particular lexical unit.
5. collocates: Whereas some lexical units, like very or red seem to be
useable with a great number of other elements of a given category, others
have a very restricted realm of use. Most of the collocations that seem so
natural to native speakers make for great trouble for L2.
6. discourse: In what types of discourse and to what effect can lexical units
like furthermore, moreover and what is more be used? Which lexical
units are to be avoided when speaking to someone belonging to another
ethnic group or when writing a letter of application? Knowledge of style,
register and appropriateness of particular senses of a same grammar is
notoriously difficult for L2 learners.
Nation (1990) as quoted in Susilo (2001: 12) has stated that a word is to be
learned or even acquired for receptive (listening and reading) and productive use
(speaking and writing).
1. Receptive (Passive) Knowledge
Nation (1990) also argues that knowing a word entails being able to
recognize it when it is heard (what does it sound like?) or when it is seen (what does
it look like?). This includes being able to distinguish it from words with similar form
and being able to judge if the word sounds right or wrong. Receptive knowledge of a
word reflects on having expectation of what grammatical pattern of the word will
occur in. Knowing the verbs suggest involves the expectation that an object
involves that it will not usually occur in the plural form.
Furthermore, according to Nation (1990) knowing a word means knowing its
form (spoken and written), its position (grammatical patterns, collocations), its
function (frequency, appropriateness), and its meaning (concept and associations) as
cited in Laufer and Paribhakt (1998: 367).
2. Productive Knowledge
Productive knowledge is the extension of receptive knowledge (Nation,
1990). In this scope, knowing a word means knowing how to pronounce, how to
write and spell it, how to use it in correct grammatical patterns along with the words
it usually collocates with. Productive knowledge represents not using the word too
often if it is a low-frequency word, and using it in suitable situation. Further, this
knowledge also involves using the word to stand for meaning it represents and
being able to think of suitable substitutes for the word if there are any. On the other
hand, Lado (1984) as quoted in Susilo (2001: 14) mentions that an active
vocabulary means that unit can be “recalled” almost instantaneously, put into sound
through articulation of its phonemes, placed in its proper stress and intonation
frame, into its proper structural positions and functions with its inflectional and
derivational affixes in accord with the context.
Most writers have assumed that passive vocabulary is larger than active
(Aitchison, 1989; Chanell, 1988; Laufer, 1998) as quoted from Laufer and Paribakht
(1998: 369). They add that even tough no one has conclusively demonstrated how
much larger it is or whether growth in passive vocabulary automatically growth in
c. Morphological processes of a word
According to Quirk and Greenbaum (1973: 430), the chief processes of
English word-formation by which the base may be modified are:
1. Affixation: (a) adding a prefix to the base, with or without a change of word-class (b) adding a suffix to the base, with or without a change of word-class
2. Conversion, i.e. assigning the base to a different word-class without changing its form (zero affixation)
3. Compounding, i.e. adding one base to another.
They add that once a base has undergone a rule of word-formation, the derived word
itself may become the base for another derivation. In line with those processes,
Fromkin and Rodman (1996: 117) have stated that rules which relate to the formation
of word and how morphemes combine to form new words called morphological
rules.
The significance of this theory is to show that the study relates to English
word formation. It employs one process out of three processes as mentioned
previously i.e. affixation.
On the other hand, Radford, Atkinson, Britain, Clahsen, Spencer (1999: 166)
explain lexeme as the more abstract term than term of ‘word’. They describe that cat
and cats are the singular and plurals of one lexeme CAT; two ‘word forms’ of one
lexeme. They claim that the singular and plural forms of a lexeme are the examples
of inflections; CAT inflects for the plural by taking the suffix –s.
On the other respect, they discuss the existence of the word read and reader
in accordance with the lexeme/word form distinction. They notice because of the
Of course, each of them (reader and read) has a number of word forms: reader and
readers in the case of READER, and reads, reading and read (/rεd/) in the case of
READ. Moreover, the new lexeme is of a different syntactic category from that of
original lexeme (a verb become a noun). They claim that the creation of a lexeme is
the province of derivational morphology (or ‘derivation’). They also notice while adverbs (ADV) are often derived from adjectives by suffixation of –ly (bad~ bad-ly,
noisy ~ noisi-ly, etc.). The other three categories (N, A, and A) can, however, readily
be derived from each other. They add that preposition (P) does not participate in
derivation in English (or most other languages for that matter).
3. Lexical development
Jiang (2000:50) compares the task of vocabulary acquisition in L1 and L2.
Task of vocabulary acquisition in L1 lexical development is to understand and
acquire the meanings as well as others properties of words. L1 lexical development
semantic properties even become the parameter in understanding the meaning of a
word. It can be inferred that lexical development in L2 consists of two aspects,
representations and processing.
Jiang (2000: 52) also suggests that there are three stages of the lexical
development in Second Language (L2). The first is the initial stage where L2
learners focus their attention on the formal features of word such i.e. spelling and
pronunciation. In this sense, lexical item acquired by the learners is considered
lexical item without lemma. Each lexical entry or vocabulary contains lexeme and
word meanings and part of speech while lexeme contains morphological and formal
specification such as phonological and orthographical. Carter (1998: 46) adds that
lemmatization problem concerns the information that sometimes two lexical items
are different in their meaning but have the same word-formation. Lemma (semantic
and syntactic specification) of L2 learners is gained through the First Language (L1)
lemma information. Figure 2.1 gives the simple illustration of the initial stage of
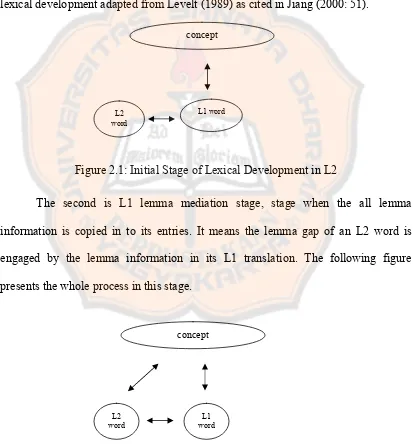
lexical development adapted from Levelt (1989) as cited in Jiang (2000: 51).
concept
L1 word L2
word
Figure 2.1: Initial Stage of Lexical Development in L2
The second is L1 lemma mediation stage, stage when the all lemma
information is copied in to its entries. It means the lemma gap of an L2 word is
engaged by the lemma information in its L1 translation. The following figure
presents the whole process in this stage.
concept
L2 word
L1 word
The third is L2 integration stage. It is the stage when semantic, syntactic and
morphological specifications of L2 word are extracted from exposure and use and
integrated into the lexical entry. At this stage, L1 and L2 will be similar each of other
in terms of both representations and processing. The next is figure 2.3 which
illustrates L2 integration stage.
concept
L1 word
Figure 2.3: L2 integration stage
Practically, when learners overtake the second stage or lemma mediation
stage, they may have difficulties of releases the L1 lemma information connection to
L2 lexeme. Furthermore, such condition stimulates fossilization; learners’ lexical
development stagnates in this stage. According to Ellis (1994) even large extensive
exposure of vocabulary acquisition L2 will strengthen connection of L1 lemma
information to L2 target word.
4. Model of Vocabulary Acquisition
A model may be defined as a description of a process or an operation
(Mukarto, 1999: 30). Mukarto adds a model specifies how the process works and
the process that we want to account for. The basic model adopted to account the
process of L2 vocabulary acquisition is adopted from Ellis (1997).
INPUT INTAKE LEXICON OUTPUT
Figure 2.4: Model of Vocabulary Acquisition
This model shows that learners are exposed to language input, in the spoken
or written forms or both. Commonly, in the foreign language context, learners are
more likely exposed to written forms rather than spoken one. Information contained
in the lexical items or words are attended and taken-in to short-term memory. The
attended properties may be the words forms (spelling, intonation, stress), and the
word meaning(s). Other word properties may not be attended. This attended
properties or information are called intake. Next some of the intake is stored in the
long-term memory as part of lexicon. The process that is responsible for creating
intake and the lexicon occurs within the “black box” of the learners’ mind. Finally
the lexicon is manipulated or used by the learners in learning language (Ellis, 1997:
35).
In detail, there are three crucial stages in the vocabulary acquisition
illustrated by this model. The first stage is from input to intake which is the first
stage of vocabulary mapping. As mentioned before, learners need to attend to other
aspects or features of word such as syntactic category, i.e. whether a word is a noun
or verb, an adjective or adverb. Once again, a verb in English may be mapped into an
one of language input. This stage corresponds to the initial stage of lexical
development in L2 (Levelt, 1989) where learners can temporarily consider the other
features or aspects of L2 word equivalent to those of the L1 word.
Furthermore Jiang (2000: 51) explains that in receptive use of language, the
recognition of a L2 word activates its L1 equivalent translation, whose semantic,
syntactic and morphological information then become available and assist
comprehension. Syntactic information deals with class of a word, whether second
language learners know that it is a noun, a verb, an adjective or an adverb. He
continues while in productive L2 use, the pre-verbal message first activates the L1
words whose semantic specifications match the message fragments. The L1 words
then activate the corresponding L2 words through the lexical link between L1 and
L2.
The second crucial is from intake to lexicon, from the short-term to the
long-term memory. It is the stage that delong-termines how much of the intake will be
incorporated. Learner will continually construct and adjust the vocabulary mapping
or network when entering this stage. According to Ellis (1997), the process takes
place in the black box, meaning that little is known of what happens here.
The third stage is the use of lexicon by the L2 learners. Melka (1997) as
quoted in Mukarto (1999: 32) states the word use can be of two natures: receptive
(for recognition, understanding, or interpretation) and productive (to express
oneself). In the case of receptive nature of language use, this study is aimed to
investigate the development of syntactic recognition of derivational suffixes. It can
5. Vocabulary Learning
According to Decarrico (2001: 286); there are two ways in learning
vocabulary i.e. explicit and implicit learning. In explicit vocabulary learning students
engage in activities that focus attention on vocabulary. Hence, foreign or second
language learners are exposed to systematic vocabulary learning process. Nation
(1990) adds that in systemic process or direct process, the learners do exercises and
activities that focus their attention on vocabulary. The exercises include
word-building exercises, guessing words from context when it is done in class exercise,
learning words in lists, and vocabulary games.
In accordance with systemic process, Read (2000: 40) states some findings:
1. Words belonging to different word classes vary according to how
difficult they are learnt. Rodgers (1969) finds that nouns are easiest to
learn, following by adjectives; on the other hand, verbs and adverbs
are the most difficult. Ellis and Beaton (1993b) confirm that nouns are
easier than verbs, because learners can for mental images ot them
more readily.
2. Mnemonic techniques are very effective methods for gaining Initial
knowledge of words meaning in a second language (Cohen, 1987).It
involves teaching learners to form vivid mental images which link the
meanings of an L2 word and in an L1 word that has similar sound.
3. In order to retrieve L2 from memory – rather than just recognizing
them when presented – learners need to say the word to them as they
learn it (Ellis and Beaton, 1993a).
4. Words which are heard to pronounce are learned more slowly than
ones are that to do not have significant pronunciation difficulty
(Rodgers, 1969)
5. Learners at a low level of language learning store vocabulary
according to the sound of words, whereas at more advanced level
words are stored according to meaning (Henning, 1973)
6. Lists of words which are strongly associated with each other – like
opposites (rich, poor) or word sets (shirt, jacket, sweater) – are
significantly more difficult to learn than list of un related words,
because of the cross – association that among the related words (Higa,
1963)
7. More generally, learners commonly confuse L2 words which look and
sound alike (Laufer, 1997b)
Regarding to Read’s findings, explicit learning prospects situation where vocabulary
is learned separately.
On the other side, implicit vocabulary learning means learning that occurs
when the mind is focused elsewhere, such as on understanding a text or using
language for communicative purposes (Deccarrio, 2001: 289). In this respect,
Decarrio uses the term incidental learning instead of implicit. He adds that just as
important for incidental learning. Furthermore, Gass (1999: 322) proposes three
conditions where words are more likely to be learned incidentally; (a) there are
recognized cognates between the native and the target languages, (b) there is
significant L2 exposure (cf. Nagy, Herman, and Anderson, 1985), or (c) other L2
related words are known.
6. Lexical Mapping
Mukarto (1999:28) argues that vocabulary (in this study known as lexical
entry) mapping refers to a learning strategy used by language learners to identify and
specify lexical properties and eventually incorporate them into their existing lexical
system or networks of the lexical properties. On the other hand, lexical properties
include among others, the phonological, morphological, syntactic, semantic, and
pragmatic aspect of the lexical items. Swan’s (1997) as quoted in Mukarto (1999)
claims that foreign language learners in Indonesia mapping second language
vocabulary onto mother tongue is a basic and indispensable learning strategy seems
to be a general phenomenon.
It can be inferred from the above theory that while identifying and specifying
a word, foreign or second language learners have their first effort of recognizing
lexical properties of that word i.e. syntactic categories (whether the word is noun,
verb, adjective or adverb) of that word may become one of their recognition.
7. Derivational knowledge
and/or category distinct which its base through the addition of an affix. He adds that
once formed, derived words become independent lexical items that receive their own
entry in speaker’s mental dictionary. On the other hand, these derivational affixes is
one of the processes in words formation. Knowing words formation involves the
understanding of words as one part of language elements or sometimes called
linguistic knowledge.
Derivational knowledge also reflects on affix acquisition. There are two terms
relate to affixation. Firstly, term of suffix, known as an affix that comes at the end of
word. Secondly, term of prefix, known as an affix that comes in the beginning of
word. It is already mentioned that the result of derivative affixes is a new word
which has different lexical categories from its base. The table below provides
derivates affixes and the changes of its lexical categories (O’Grady, 1996):
Affix Change Example
Suffixes
-able V
→
A fix-able, do-able, understand-able-(at)ion V
→
N realiz-ation, assert-ion, protect-ion-er V
→
N teach-er, work-er-ing1 V
→
N the shoot-ing, the danc-ing-ing2 V
→
A the sleep-ing giant, a blaz-ing fire-ive V
→
A assert-ive, impress-ive, restrict-ive-al V
→
N refusal, disposal-ment V
→
N adjour-ment, treat-ment, amze-ment-ful N
→
A faith-ful, hope-ful, dread-ful-(i)al N
→
A president-ial, nation-al, medic-al-(i)an1 N
→
A Arab-ian, Singapore-an, Mali-an-(i)an2 N
→
A Einstein-ian, Newton-ian, Chomsky-anAffix Change Example
-ize N
→
V hospital-ize, crystal-ize-less N
→
A penni-less, brain-less-ous N
→
A poison-ous, lecher-ous-ate A
→
V activ-ate, captiv-ate-en A
→
V dead-en, black-en, hard-en-ity A
→
N stupid-ity, prior-ity-ize2 A
→
V modern-ize, familiar-ize-ly A
→
Adv quiet-ly, slow-ly, careful-ly-ness A
→
N happi-ness, sad-nessPrefixes
anti- N
→
N anti-abortion, anti-pollutionde- V
→
V de-active, de-mystifydis- V
→
V dis-continue, dis-obeyex- N
→
N ex-president, ex-wife, ex-friendin- A
→
A in-competent, in-completemis- V
→
V mis-identify, mis-placeun1- A
→
A un-happy, un-fair, un-intelligentun2- V
→
V un-tie, un-lock, un-dore- V
→
V re-think, re-do, re-stateTable 2.1 Some English Derivational Affixes
Hence, the understanding of derivational knowledge does not only applying the affix
to form a new word from its base but also knowing the changes of its syntactic
category.
B. Theoretical Framework
Since meaning becomes the primary concern in learning vocabulary (words)
tends to be ignored. Wilkins (1972) as quoted in Susilo (2000: 29) states: “ … while
without grammar very little can be conveyed, without vocabulary nothing can be
conveyed”. It cannot be avoided that vocabulary learning is a central knowledge for
second or foreign language learners. Here, a word is a means to convey one meaning.
While learning meaning of a word, its syntactic category is interrelated each of other.
In order to be able to use a word properly, understanding only the meaning is not
enough. Therefore, knowing the syntactic category of that word is needed to
determine which grammar must be used in a proper sentence both oral and written
context. In such affixation is really influential in changing the syntactic category of a
word.
On the other hand, reading skill becomes the significant skill for Senior High
School Students to absorb much information during their learning. Meanwhile,
Susilo (2001:30) underlines that vocabulary size is found to be a good predictor of
reading comprehension and to correlate with writing quality. Understandably,
vocabulary enrichment may become an entry point for the Senior High School
Students to cover vocabulary size needed for their minimal comprehension. Laufer
(1992) as quoted from Susilo (2001:16) suggests a threshold of 3,000 word families
(5,000 lexical items) must be mastered for ‘minimal comprehension’ and 5,000 word
families (8,000 lexical items) for reading for pleasure (Hirsh and Nation, 1992).
Once more affixation is valuable in order to achieve that threshold of vocabulary
mastery.
In accordance with this condition, affix knowledge is issued to conduct an
suffixes of English words. Here, there are two aspects of affix i.e. prefixes and
suffixes. Both can also be classified as inflectional prefixes/suffixes and derivational
prefixes/suffixes. Because of the limitation of time, this study is only focused on
derivational suffixes. Students’ syntactic recognition of derivational suffixes
employs the ability to recognize the changes of syntactic category of a new word
after the addition a derivational suffix to its base.
Since the study is aimed to investigate the development of syntactic
recognition of derivational suffixes, therefore, it is included a study on receptive
knowledge of vocabulary. Hence, the study investigates whether there are any
significant differences between first, second, and third year of Sang Timur Senior
High School students in their syntactic recognition of derivational suffixes of English
words. Moreover, this study also tries to find out the developmental patterns of the
syntactic recognition of derivational suffixes of English words in Sang Timur Senior
High School.
Based on the discussion above, it is hypothesized that there are significant
differences between first year, second year and third year students in their syntactic
recognition of English derivational suffixes in Sang Timur Senior High School.
Pattern of the development of students’ syntactic recognition of English derivational
suffixes indicates the positive growth. It means that the syntactic recognition of
derivational suffixes of English word increase in accordance with the duration of
CHAPTER III RESEARCH METHOD
This chapter presents discussions about (1) research design, (2) instrument,
(3) pilot testing, (4) main study. Subject, data collection, scoring, tabulation and data
analysis will be discussed in the main study.
A. Research Design
This study was cross-sectional design. Wiersma (1995: 175) argues that
cross-sectional design involves data collection at one point in time from a sample or
from more than one sample representing two or more populations. He also states that
this design was also a type of survey design. Ary, Jacobs, and Razavieh (1990: 67)
define survey as a research method which is conducted to collect information about
characteristics of a population by examining a sample of that group. On the other
hand, they also argued that there was a major disadvantage of cross-sectional design
i.e. the possibilities difference between samples seriously bias the result. This
designs, however, was usually possible to investigate large number of samples.
Hence, this method is extensive and cross-sectional, dealing with a relatively large
number of cases at a particular time.
Knowing the feature of the data presentation, however, this study used mix
procedures to answer research question. The data from quantitative procedures
would be the starting point to answer research questions. Then the qualitative
procedures were intended to find out data which were used to analyze the
phenomena occurred.
Since it was not feasible to survey the entire population (all classes in Sang
Timur Senior High School), the selection of some samples of different year were
taken to represent the whole population.
B. Instruments
In order to answer the research questions the researcher used direct
observation by means of “checklist” test. Hopkins (1976: 82) argues that a checklist
has two major contributions to observation: (1) it is an efficient (time-wise) method
of recording, and (2) the data are objective. This checklist consisted of list of which
words came from derivational suffixes that had to be classified by the students based
on their lexical category. A simple recorded interview was also conducted in this
study. It was aimed to investigate the phenomena occurred after the survey research.
The words of the “checklist” included samples of words from A Vocabulary
List adapted from: The Thousand Word Little Language, The Second Thousand
Word List, Word Power 3000 ( Purba, 1996), Daftar Kosakata SMU taken from the
2004 CBC and students’ hand book entitled English for a Better Life (Yuliani and
Permatay, 2005). The last source was aimed to confirm that some words in the
“checklist” were the samples of words from their handbook which were regularly
read by the students. The main consideration in compiling the words for the checklist
was The First 1000 Words of the General Service List (Nation’s Appendix,
2002:54-55).
on the mentioned sources. Firstly, the word list of the sources provided highly
frequency items. Therefore the words in the “checklist” were compiled from the
sample of words from the sources mentioned above. Secondly, there was a list of
words in the 2004 CBC that was supposed to be taught by Senior High School
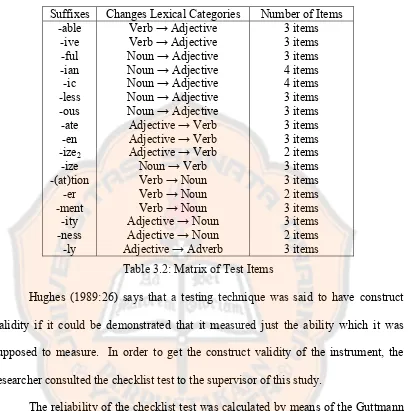
teachers of first year students. The form of that “checklist” could be seen below.
Mark (√) the following words, whether they are noun, adjective, verb or adverb. One word may have more than one lexical category.
No Words Noun Adjective Verb Adverb
1 Ability
2 Activate
3 Aggressive
4 Agreement
5 Assertive
6 …
Table 3.1: Checklist Test
The complete “Checklist” test will be presented in the appendices.
As defined by Read (2000: 86), second language learners generally know a
lot fewer words in target language than native speakers do. It could be inferred that
Senior High School students were only accustomed to highly frequency item of
words.
Considering this condition the study proposed some criteria in determining
which words were included in the checklist. First, the headword was the sample of
Senior High School in Indonesia has implemented this curriculum as the main
guideline of educational system this study included the sample of words from the
2004 CBC word list. Second, the vocabulary item in the “checklist” was the example
of words in the 1st 2000 thousand words of English taken from Nation (2002: 54-57).
C. Pilot Testing
Pilot study was done to find out whether this study is feasible and whether it
is worthwhile to continue. Previously, the study proposed 53 derived words
constructing the test. Six respondents were chosen as the pilot project of this study (2
respondents of each class in Senior High School students). The result of the pilot
testing indicated that there were significant differences between the first, second and
third year students in their syntactic recognition of derivational suffixes of English
words.
Through some steps of corrections, it was found that the checklist contained
three words which came from conversion (control, study, work). This study was only
focused to the investigation on English derivational suffixes. Therefore, those three
words were excluded from the list. Automatically, the maximum score of this
checklist test was 50.
On the other hand, Hopkins (1976: 99) argued that the most important
property of any measuring instrument is the validity. In order to have content validity
the researcher provided the matrix of the checklist test that was used in the study.
Matrix of Test Items
Suffixes Changes Lexical Categories Number of Items -able -ive -ful -ian -ic -less -ous -ate -en -ize2 -ize -(at)tion -er -ment -ity -ness -ly
Verb → Adjective Verb → Adjective Noun → Adjective Noun → Adjective Noun → Adjective Noun → Adjective Noun → Adjective Adjective → Verb Adjective → Verb Adjective → Verb
Noun → Verb Verb → Noun Verb → Noun Verb → Noun Adjective → Noun Adjective → Noun Adjective → Adverb
3 items 3 items 3 items 4 items 4 items 3 items 3 items 3 items 3 items 2 items 3 items 3 items 2 items 3 items 3 items 2 items 3 items
Table 3.2: Matrix of Test Items
Hughes (1989:26) says that a testing technique was said to have construct
validity if it could be demonstrated that it measured just the ability which it was
supposed to measure. In order to get the construct validity of the instrument, the
researcher consulted the checklist test to the supervisor of this study.
The reliability of the checklist test was calculated by means of the Guttmann
Split-Half method presented in SPSS 11.0 for windows. The range of reliability
coefficient is from o to 1. From the calculation it was found that reliability
coefficient (rxx) was 0,7341. This coefficient reliability was approaching +1. Hence,
it could be considered that this checklist test was reliable.
D. Main Study
study, data collection, scoring, tabulation and data analysis.
1. Subjects
The subjects of this study were class X1,2 (as the sample of the first year
students), XIIPA-IPS (as the sample of the second year students) and XIIIPA-IPS (as the
sample of the third year students) of Sang Timur Senior High School. Since it would
not be feasible to observe and study the entire population, samples were selected
with the assumption that those samples would be really representative enough to
study the development of syntactic recognition of derivational suffixes of English
words in this senior high school.
Ary et all. (1990) said that there are two major types of sampling procedures,
they were probability and non probability. They added that when probability
sampling was used, inferential statistic enabled researchers to estimate the extent to
which the findings based on the sample were likely to differ from they would have
found by studying the whole population. In line with the probability procedures, this
study used cluster sampling in order to get the representative sample. Three classes
of different year were used to represent the whole population in Sang Timur Senior
High School: X (1,2), XI (IPA-IPS) and XII (IPA-IPS). They have different length of study
in the Senior High School. Table 3.2 below showed the length of the study.
Classes Length of Study
X1,2 1 year of study
XIIPA-IPS 2 years of study
XIIIPA-IPS 3 years of study
2. Data collection
The data collection was conducted in order to answer the research problem.
The test was conducted relatively in the same time, it was on the third week of
October (October10-15, 2005) the researcher administrated the test in Sang Timur. It
is a private senior high school which is located on Jalan Batikan 7, Yogyakarta. The
students were asked to do the fifty items in 15-20 minutes. It was administrated
during the class hours.
At the first, there were 153 sheets of the “Checklists” (50 sheets of first year
students, 51 sheets of second year students and 52 sheets of third year students).
Since the sample needed in each class was only 50 students, while there were 51
students of second year and 52 students of third year, the researcher selected the
sample from both classes randomly in order to obtain the intended number of
respondents, 50 students in each class.
3. Scoring
The scoring was in terms of correct (1 point) or incorrect/ blank (0 point). An
item of word classification was considered correct when it was classified correctly.
For example, if a student classified the word ability as a noun, he would get 1 point.
As had been mentioned before that the maximum score of this test was 50.
4. Tabulation
The gathered data then was presented in a table which was consisted of 4
second was for frequency, third for percent and fourth for cumulative percent. The
complete gathered data will be presented in the appendices. Table 3.4 showed the
intended table.
Score Frequency Percent Cumulative Percent
1.00
Total 50 1
Table 3.4: Scores Tabulation
5. Data analysis
The gathered data was analyzed in order to answer the research problem. The
intended data were gathered from the students’ performance on classifying words
available on the “Checklist”. As stated previously the classification of the words was
done based on the lexical category of each word.
In order to answer the first research problem the researcher uses One-Way
ANOVA for independent sample. This test was used for comparing two or more
independent variable in this study was set at three different level, first year, second
year, and third year student of Sang Timur. Since the study was aimed to test the
hypothesis of significant difference, the F ratio became the statistical test.
nce groupvaria Mswithin
nce groupvaria Msbetween
F
− − =
CHAPTER IV ANALYSIS RESULTS
This chapter discusses data presentation, results of data analysis and
discussion.
A. Data presentation
This study intended to investigate three groups of students in Sang Timur
Senior High School. The grouping was determined by the year of student’s
admission. Therefore the results of data collections were provided group by group.
1. Scores of the First Year Students
This was the first group in the study named first year students, consisted of
two classes X1 and X2. There were 50 students included in this group to represent the
first year population. The highest and the lowest score obtained by the first year
student were 28 and 4. The highest score was obtained by two students from the
maximum total score 50. (see Appendix E)
2. Scores of the Second Year Students
Class XIIPA and XIIPS were the second group representing the population of
the Second Year Students. There were 50 students involved in this group with the
highest and the lowest scores of the second year students were 44 and 5. Both the
highest and the lowest scores from the maximum total score 50 in this group were
obtained by one student. (see Appendix E)
3. Scores of the third Year Students
There were 50 students involved in this group representing the population of
the third year students. It consisted of students from Class XIIIPA and XIIIPS –1. The
highest and the lowest scores of the third year students were 48 and 11. The highest
score in this group was obtained by one student while the lowest score obtained by
two student from the maximum total score 50. (see Appendix E)
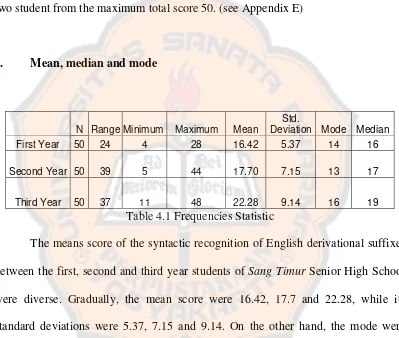
4. Mean, median and mode
N Range Minimum Maximum Mean Std.
Deviation Mode Median First Year 50 24 4 28 16.42 5.37 14 16
Second Year 50 39 5 44 17.70 7.15 13 17
Third Year 50 37 11 48 22.28 9.14 16 19
Table 4.1 Frequencies Statistic
The means score of the syntactic recognition of English derivational suffixes
between the first, second and third year students of Sang Timur Senior High School
were diverse. Gradually, the mean score were 16.42, 17.7 and 22.28, while its
standard deviations were 5.37, 7.15 and 9.14. On the other h