BAB II
TINJAUAN TEORITIS
2.1 DATA MINING
Data mining terdiri dari berbagai metode. Berbagai metode mempunyai tujuan yang berbeda, masing-masing menawarkan metode yang memiliki kelebihan dan kekurangan. Namun, penambangan data metode yang umum digunakan untuk review ini adalah kategori klasifikasi sebagai teknik prediksi. Dalam data mining, klasifikasi adalah salah satu tugas yang paling penting. Tujuan klasifikasi adalah untuk membangun sebuah classifier yang didasarkan pada beberapa kasus dengan beberapa atribut untuk menggambarkan benda atau satu atribut untuk menggambarkan kelompok objek. Kemudian, classifier digunakan untuk memprediksi kelompok atribut kasus baru dari domain yang didasarkan pada nilai-nilai lain atribut. Metode yang umum digunakan untuk tugas-tugas klasifikasi data mining dapat diklasifikasikan menjadi kelompok sebagai berikut:
- Decision Tree (Han, 2001)
- Support Vector Machine - Genetic Algorithm - Fuzzy Sets
- Neural Network - Rough Sets
Metode data mining diambil dari berbagai literatur, termasuk penambangan data dan pembelajaran mesin, psikometri dan bidang statistik, informasi visualisasi, dan pemodelan komputasi. Han dan Kamber (2001) mengkategorikan pekerjaan dalam data mining ke dalam kategori sebagai berikut:
• Statistik dan visualisasi
• P
-
enambangan web
- Penambangan aturan asosiai dan penambangan pola sekuensial - Penambangan teks
Istilah Knowlegde Discovery Database (KDD) dan Data Mining sering digunakan secara bergantian. KDD adalah proses untuk mengubah data low-level menjadi pengetahuan tingkat tinggi. Oleh karena itu, KDD mengacu pada trivial ekstraksi informasi implisit, yang sebelumnya tidak dikenal dan berpotensi berguna dari data dalam database. Sedangkan penambangan data dan KDD sering diperlakukan sebagai kata-kata yang sama tetapi dalam data mining yang sebenarnya merupakan langkah penting dalam KDD proses. (Gupta et al., 2011)
Proses knowledge discovery dalam Database terdiri dari beberapa langkah terkemuka dari koleksi data mentah ke beberapa bentuk pengetahuan baru. (Osmar, 2011) Proses iteratif terdiri dari langkah-langkah berikut
(1)
:
Data cleaning (pencucian data): juga dikenal sebagai pembersihan data itu adalah fase di mana kebisingan data dan data yang tidak relevan dikeluarkan dari koleksi (2)
. Data integration (integrasi data): pada tahap ini, sumber data yang sering heterogen, dapat dikombinasikan dalam sumber umum
(3)
.
Data selection (pemilihan data): pada langkah ini, data yang relevan untuk dianalisis dipilih untuk diambil dari koleksi data
(4)
.
Data transformasi: juga dikenal sebagai konsolidasi data, itu adalah tahap di mana data yang dipilih diubah menjadi bentuk yang sesuai untuk prosedur pertambangan (5)
. Data mining: itu adalah langkah penting di mana teknik pintar diterapkan untuk mengekstrak pola berpotensi berguna
(6)
.
Evaluasi Pola: langkah ini, benar-benar pola yang menarik mewakili pengetahuan diidentifikasi berdasarkan pada langkah-langkah yang diberikan
(7)
.
Representasi Pengetahuan: adalah fase terakhir di mana pengetahuan ditemukan adalah visual diwakili kepada pengguna. Dalam langkah ini teknik visualisasi yang digunakan untuk membantu pengguna memahami dan menafsirkan data hasil pertambangan.
2.2 METODE KLASIFIKASI
Klasifikasi data yang paling umum diterapkan dalam teknik mining, yang mengolah satu set pra-diklasifikasikan contoh untuk mengembangkan model yang dapat mengklasifikasikan populasi pada umumnya. Penipuan deteksi dan creditrisk aplikasi sangat cocok untuk jenis analisis. Pendekatan ini sering menggunakan pohon keputusan atau algoritma klasifikasi berbasis jaringan saraf tiruan. Proses klasifikasi data melibatkan belajar dan klasifikasi. Dalam Pembelajaran data pelatihan dianalisis dengan algoritma klasifikasi. Dalam klasifikasi data uji digunakan untuk memperkirakan ketepatan aturan klasifikasi. Jika ketepatan akan diterima aturan dapat diterapkan pada tupel data baru. Untuk aplikasi deteksi penipuan, ini akan termasuk catatan lengkap dari kedua kegiatan penipuan dan berlaku ditentukan berdasarkan catatan-oleh-record. Algoritma classifier-pelatihan menggunakan contoh-contoh ini pra-diklasifikasikan untuk menentukan set parameter diperlukan untuk diskriminasi yang tepat. Algoritma ini kemudian encode parameter ini ke dalam model yang disebut classifier. (Bharati, 2006)
Jenis-jenis model klasifikasi:
Classification by decision tree induction Bayesian Classification
Neural Networks
Support Vector Machines (SVM) Classification Based on Associations 2.2.1 Klasifikasi oleh Induksi
Induksi
Pohon Keputusan
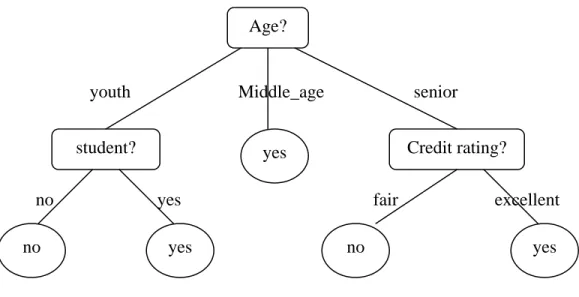
pohon keputusan adalah pembelajaran pohon keputusan dari kelas tupel pelatihan berlabel. Sebuah pohon keputusan adalah diagram alir seperti struktur pohon, di mana setiap node internal (nonleaf node) menunjukkan tes pada atribut, setiap cabang merupakan hasil tes dan setiap node daun (atau node terminal) memegang label kelas. Simpul yang paling atas dalam pohon adalah node root (Han, 2006).
Gambar 2.1 Konsep pohon keputusan untuk membeli komputer (Han, 2006)
Sebuah jenis pohon keputusan ditunjukkan dalam gambar 2.1 yang merupakan konsep membeli komputer, yaitu, untuk memprediksi apakah semua pelanggan di toko elektronik cenderung untuk membeli komputer. Simpul dalam ditandai dengan empat persegi panjang dan node daun dinotasikan dengan oval. Beberapa algoritma pohon keputusan hanya menghasilkan pohon biner (di mana setiap cabang simpul dalam untuk dua simpul lain dengan tepat) sedangkan yang lain dapat menghasilkan pohon non biner.
2.3 MACHINE LEARNING
Machine learning adalah bagian dari kecerdasan buatan yang menjelaskan bagaimana membuat program atau mesin pembelajaran. Dalam Data Mining, machine learning sering digunakan untuk prediksi atau klasifikasi, dengan machine learning komputer membuat suatu prediksi dan kemudian pembelajaran (Dunham, 2003).
Age?
Credit rating? student? yes
no yes no yes
youth Middle_age senior
2.4 SUPPORT VECTOR MACHINE (SVM)
Support Vector Machines (SVM) adalah satu kumpulan teknik klasifikasi dan regresi, yang merupakan pengembangan algoritma non-linear dan dikembangkan di Rusia pada tahun enam puluhan. Seperti yang telah diuraikan, SVM dapat digunakan baik untuk klasifikasi atau regresi, yang membatasi perhatian untuk sisa pekerjaan ini. Dalam berikut ini, ikhtisar singkat teori di balik menggunakan SVM untuk estimasi fungsi, memperkenalkan pada saat yang sama dan waktu yang paling relevan pengertian dan parameter, dengan khusus memperhatikan parameter yang dampaknya diselidiki di kemudian hari. Dalam arti, ikhtisar ini untuk memahami kinerja bagian evaluasi, tetapi untuk cakupan yang lebih menyeluruh dari SVM merujuk pada survei pembaca yang sangat baik.
SVM
(Bermolen, 2008) adalah suatu algoritma yang mencoba menemukan pemisah linear (hyper-plane) antara titik data dari dua kelas dalam ruang multidimensi. SVM cocok untuk berurusan dengan interaksi antara fitur dan fitur berlebihan. (Gupta et al., 2011)
2.5 SUPPORT VECTOR REGRESSION (SVR)
SVR merupakan penerapan support vector machine (SVM) untuk kasus regresi. Dalam kasus regresi output berupa bilangan riil atau kontinue. SVR merupakan metode yang dapat mengatasi overfitting, sehingga akan menghasilkan performansi yang bagus (Smola dan Scholkopf, 2004).
Misalnya ada λ set data training, (xj.,yj
N x
x x
x={ 1, 2, 3 }⊆ℜ
) dimana j = 1,2,… λ dengan input dan output yang bersangkutan y={yi,...,yλ}⊆ℜ. Dengan SVR, akan ditemukan suatu fungsi f(x) yang mempunyai deviasi paling besar ε dari target aktual yi
Misalnya kita mempunyai fungsi berikut sebagai garis regresi
untuk semua data training. Maka dengan SVR, manakala ε sama dengan 0 akan didapatkan regresi yang sempurna.
b x w x
dimana φ(x) menunjukkan suatu titik didalam feature space F hasil pemetaan x di dalam input space. Koefisien w dan b diestimasi dengan cara meminimalkan fungsi resiko (risk function) yang didefinisikan dalam persamaan (2)
( )
(
)
∑
= ∈ + λ λ 1 2 , 1 2 1 min i i i f x y L C w (2) Subject to( )
( )
ε λ ϕ ε ϕ ,..., 2 , 1 , = ≤ + − ≤ − − i b y x w b x w y i i i i Dimana( )
( )
( )
− − − ≥ = lain yang untuk x f y x f y x f y L i i i i i i , 0 0 ) , ( ε ε (3)Faktor w 2 dinamakan reguralisasi. Meminimalkan w2 akan membuat suatu fungsi setipis mungkin, sehingga bisa mengontrol kapasitas fungsi. Faktor kedua dalam fungsi tujuan adalah kesalahan empirik (empirical error) yang diukur dengan ε -insensitive loss function. Menggunakan ide ε-insensitive loss function harus meminimalkan norm dari w agar mendapatkan generalisasi yang baik untuk fungsi regresi f. Karena itu perlu menyelesaikan problem optimasi berikut:
2 2 1 min w (4) Subject to
( )
( )
ε λ ϕ ε ϕ ,..., 2 , 1 , = ≤ + − ≤ − − i b y x w b x w y i i i iAsumsikan bahwa ada suatu fungsi f yang dapat mengaproksimasi semua titik
(
xi,yi)
dengan presisi ε. Dalam kasus ini diasumsikan bahwa semua titik ada dalam 2 1 0 2 2 x)) b (b (y ) yˆ (y e + − = − =∑
∑
∑
rentang f ±ε (feasible). Dalam hal ketidaklayakan (infeasible), dimana mungkin ada beberapa titik yang mungkin keluar dari rentang f ±ε , bisa ditambahkan variabel slack
ξ, ξ* untuk mengatasi masalah pembatas yang tidak layak (infeasible constraint) dalam
problem optimasi. Selanjutnya problem optimasi di atas bisa diformulasikan sebagai berikut:
(
)
∑
= + λ ξ ξ λ 1 * 2 , 1 2 1 min i i i C w (5) Subject to( )
( )
0 , ,..., 2 , 1 , ,..., 2 , 1 , * * ≥ = ≤∈ − + − = ≤∈ − − − i i i i i i i T i i b y x w i b x w y ξ ξ λ ξ ϕ λ ξ ϕKonstanta C>0 menentukan tawar menawar (trade off) antara ketipisan fungsi f dan batas
atas deviasi lebih dari ε masih ditoleransi. Semua deviasi lebih besar daripada ε akan
dikenakan pinalty sebesar C. Dalam SVR, ε ekuivalen dengan akurasi dari aproksimasi
terhadap data training. Nilai ε yang kecil terkait dengan nilai yang tinggi pada variabel slack ξi(*) dan akurasi aproksimasi yang tinggi. Sebaliknya, nilai yang tinggi untuk ε berkaitan dengan nilai ξi(*) yang kecil dan aproksimasi yang rendah. Menurut persamaan (5) nilai yang tinggi untuk variabel slack akan membuat kesalahan empirik mempunyai pengaruh yang besar terhadap faktor regulasi. Dalam SVR, support vector adalah data training yang terletak pada dan diluar batas f dari fungsi keputusan, karena itu jumlah support vector menurun dengan naiknya ε.
Dalam formulasi dual, problem optimisasi dari SVR adalah sebagai berikut:
(
)
(
)
(
)
∑
∑
∑∑
= = = = + ∈ − − + − − − λ λ λ λ α α α α α α α α 1 1 * * * 1 1 * , 2 1 max i i i i i i i j i j j i j i i y x x K (6) Subject to(
)
λ α λ α α α λ ,..., 2 , 1 , 0 ,..., 2 , 1 , 0 0 * 1 * = ≤ ≤ = ≤ ≤ = −∑
= i C i C i i i i iDimana C didefinisikan oleh user, K xi,xj adalah dot-product kernel yang didefinisikan sebagai K xi,xj =ϕT
( )
xi ϕ( )
xj . Dengan menggunakan langrange multiplier dan kondisi optimalitas, fungsi regresi secara eksplisit dirumuskan sebagai berikut:( )
x(
)
K(
x x)
b f i i i i − + =∑
= λ α α 1 * , (7) 2.6 POHON KEPUTUSANSebuah model pohon keputusan terdiri dari satu set aturan untuk membagi suatu populasi heterogen besar menjadi lebih kecil, kelompok yang lebih homogen dengan memperhatikan suatu variabel target tertentu (Larose, 2005).
Sebuah pohon keputusan adalah pohon di mana setiap simpul non-terminal merupakan tes atau keputusan pada item data dipertimbangkan. Pilihan cabang tertentu tergantung pada hasil tes. Untuk mengklasifikasikan item data tertentu, Mulai dari akar simpul dan mengikuti asersi bawah sampai mencapai node terminal (atau daun). Sebuah keputusan dibuat ketika terminal node didekati. Pohon Keputusan juga dapat diartikan sebagai bentuk khusus dari suatu set aturan, yang ditandai oleh organisasi hirarkis mereka aturan
Banyak algoritma dikembangkan untuk melakukan membuat pohon keputusan, diantaranya ID3, CART dan C4.5. Algoritma C4.5 merupakan pengembangan dari algoritma ID3 (Larose, 2005).
(Gupta et al., 2011).
Secara umum algoritma C4.5 untuk membangun pohon keputusan adalah sebagai berikut (Craw, 2005):
a. Pilih atribut sebagai root
c. Bagi kasus dalam cabang
d. Ulangi proses untuk masing-masing cabang sampai semua kasus pada cabang memiliki kelas yang sama.
CART (Classification and Regression Tree) adalah algoritma data-eksplorasi dan prediksi mirip dengan C4.5, yang merupakan algoritma konstruksi pohon (Breiman et al. 1984). Klasifikasi dan pohon regresi, pada entropi informasi, memperkenalkan ukuran node yang dibuang. Hal ini digunakan pada berbagai masalah yang berbeda, seperti deteksi klorin dari data yang terdapat dalam spektrum massa. Meskipun pohon keputusan mungkin bukan metode terbaik untuk akurasi klasifikasi. Menggunakan lingkaran sebagai node keputusan dan sebuah persegi sebagai node terminal. Setiap node keputusan mempunyai kondisi yang diwakili oleh fungsi F, dan parameter adalah titik pemecahan atribut split. Setiap node terminal memiliki label kelas C, nilai yang mewakili sebuah kelas. Hal ini jelas bahwa adalah mudah digunakan pohon keputusan untuk menafsirkan pohon aturan, dari analisa yang bisa kita lakukan, dan mudah untuk menafsirkan representasi dari pemetaan input-output nonlinier.
Pada setiap node dari pohon, C4.5 memilih satu atribut data yang paling efektif membagi himpunan dari sampel ke subset diperkaya dalam satu kelas atau yang lain. Kriteria adalah keuntungan informasi dinormalisasi (perbedaan entropi) yang hasil dari pemilihan atribut untuk membelah data. Atribut dengan information gain tertinggi dinormalisasi dipilih untuk membuat keputusan. Algoritma C4.5 kemudian recurses pada sublists lebih kecil. Algoritma ini memiliki beberapa kasus dasar. Semua sampel dalam daftar ini termasuk ke dalam kelas yang sama. Ketika ini terjadi, itu hanya menciptakan node daun untuk pohon mengatakan keputusan untuk memilih kelas tersebut. Tidak ada fitur yang memberikan keuntungan informasi. Dalam hal ini, keputusan C4.5 menciptakan node lebih tinggi pohon dengan menggunakan nilai yang diharapkan dari kelas. Instance dari kelas sebelumnya-tak terlihat yang dihadapi. Sekali lagi, keputusan C4.5 menciptakan node lebih tinggi pohon menggunakan nilai yang diharapkan (Quinlan, 1993).